Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Langfuseを活用したLLM評価について
Search
Yuto Toya
February 04, 2025
1
120
Langfuseを活用したLLM評価について
1月28日(火)に
Langfuse Night
で登壇した資料になります。
Yuto Toya
February 04, 2025
Tweet
Share
More Decks by Yuto Toya
See All by Yuto Toya
LangfuseとClickHouse で進化するLLMOps
toyayuto
3
1.6k
Langfuse ✖️ Clickhouse MCPサーバを活用した分析
toyayuto
0
75
Langfuseを活用して、評価用プロンプトを育てていく
toyayuto
0
220
Featured
See All Featured
The Pragmatic Product Professional
lauravandoore
36
6.9k
BBQ
matthewcrist
89
9.8k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
45
2.5k
Optimizing for Happiness
mojombo
379
70k
Designing Experiences People Love
moore
142
24k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
127
53k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
33
2.4k
Navigating Team Friction
lara
189
15k
Typedesign – Prime Four
hannesfritz
42
2.8k
For a Future-Friendly Web
brad_frost
180
9.9k
Being A Developer After 40
akosma
90
590k
Scaling GitHub
holman
463
140k
Transcript
Langfuse を活用した LLM Evaluation 解説 Yuto Toya ガオ株式会社
自己紹介
スピーカー 遠矢 侑音(Toya Yuto) ガオ株式会社 エンジニア
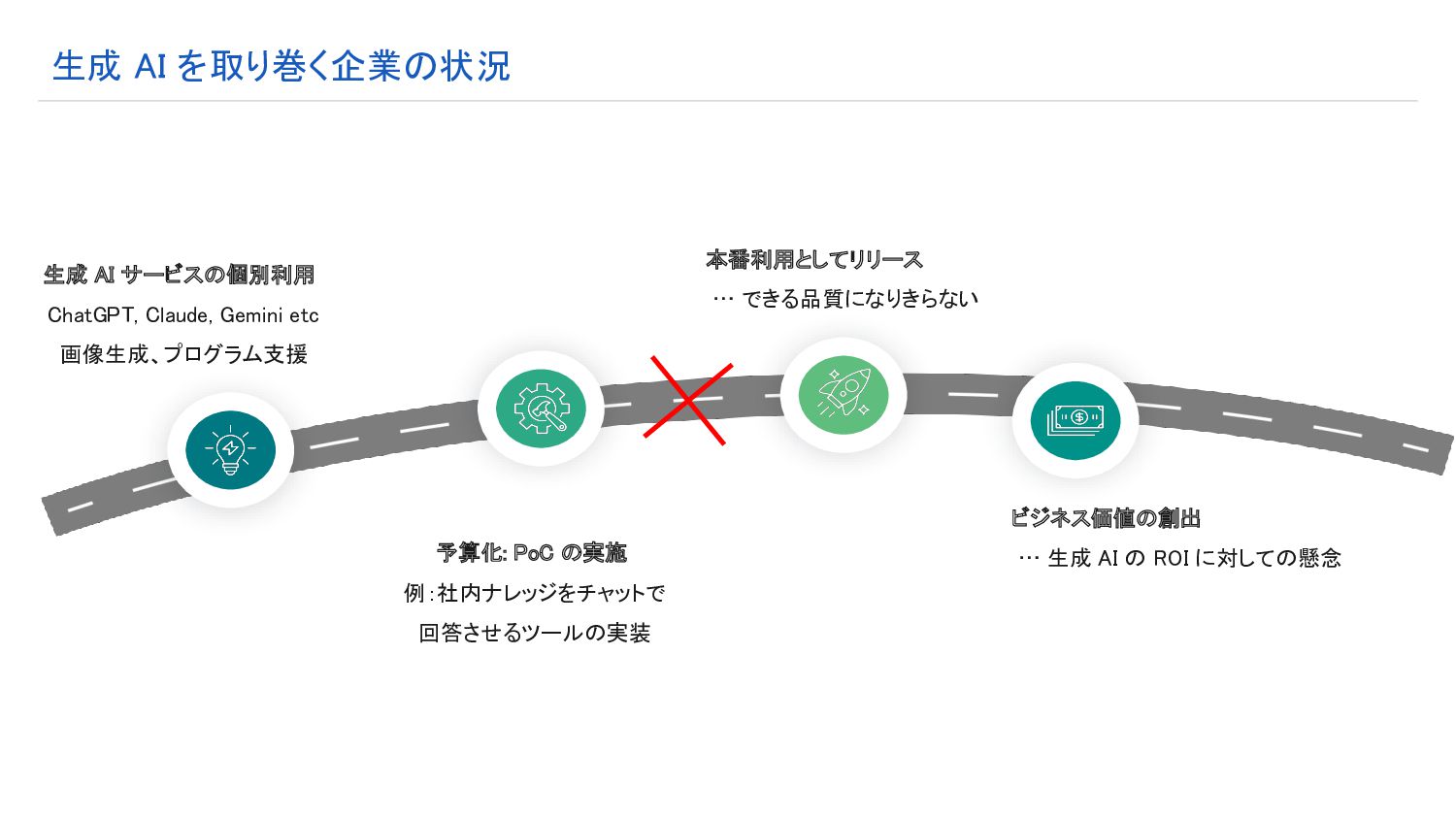
現状の LLM システム開発の課題
生成 AI サービスの個別利用 ChatGPT, Claude, Gemini etc 画像生成、プログラム支援
予算化: PoC の実施 例:社内ナレッジをチャットで 回答させるツールの実装 本番利用としてリリース … できる品質になりきらない ビジネス価値の創出 … 生成 AI の ROI に対しての懸念 生成 AI を取り巻く企業の状況
本題
LLM システムの評価はどのようにしてますか? 出力結果のみを 目視で確認 ユーザー フィードバック LLM as a Judge
RAGAS
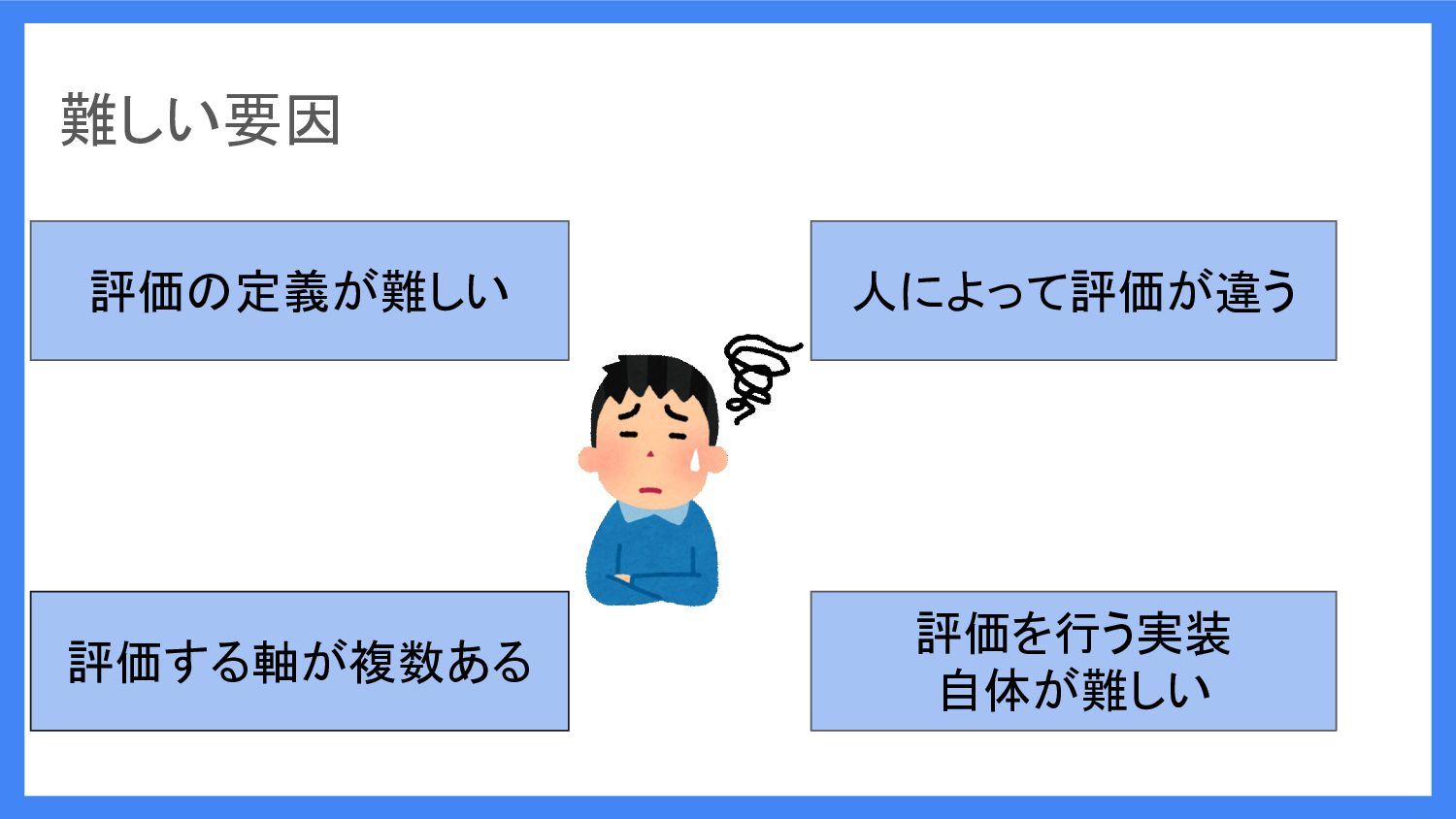
でも、LLM システムの評価って 難しくないですか ...
難しい要因 評価の定義が難しい 人によって評価が違う 評価を行う実装 自体が難しい 評価する軸が複数ある
Langfuse を使えば、これらの 難しい要因が改善できます!
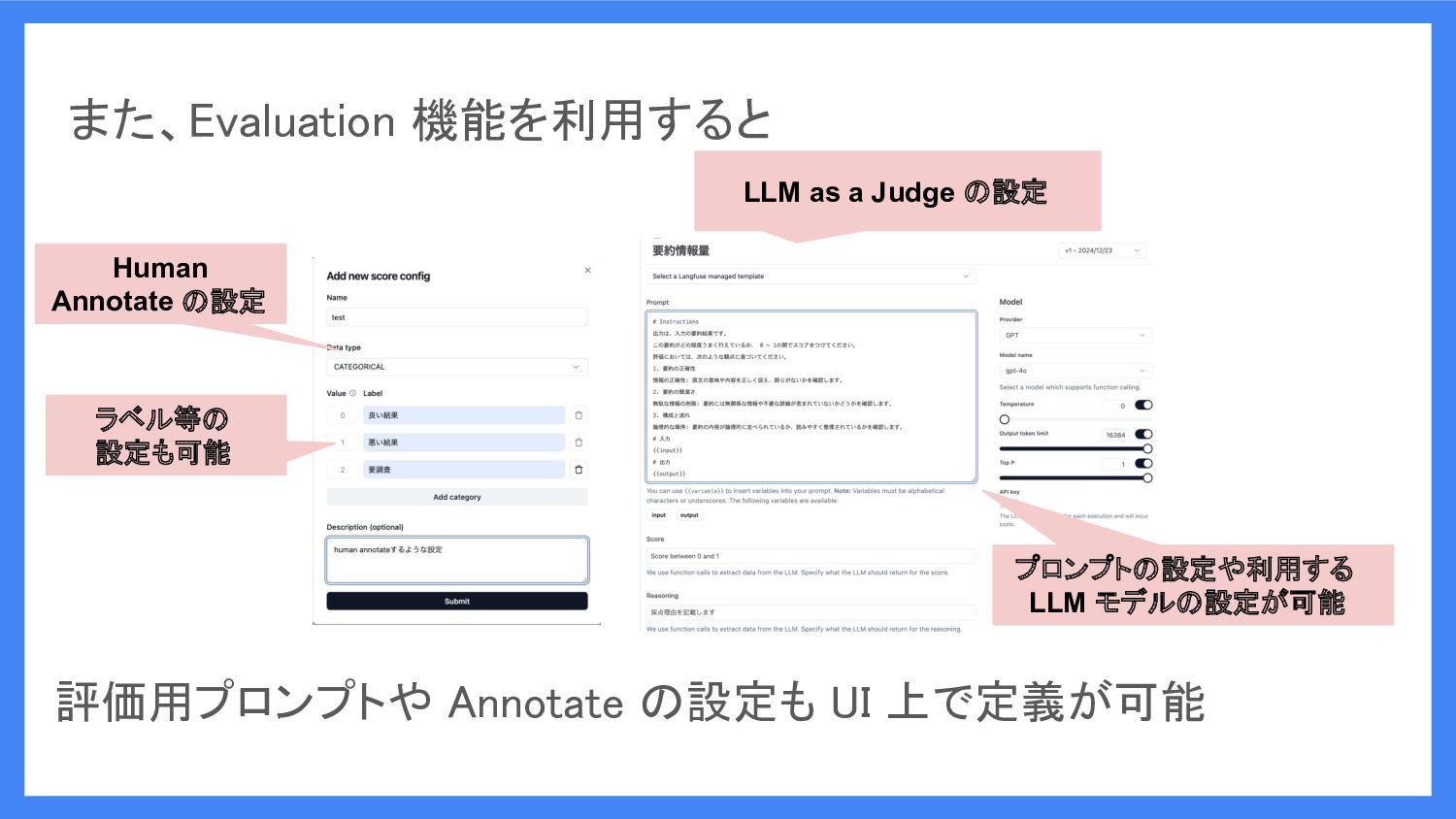
Human Annotate • 人間が手動でラベリングができるようになる • 開発者とは別のドメインエキスパートの人が評価する 場合などに有用 Evaluation
機能では以下の 2 つの設定が UI 上からできます LLM as a Judge • LLM が評価用プロンプトを元に評価を自動で行う • UI 上でトレースと紐付けが可能(ソースの修正なし) • 合間な表現に対して、点数をつけたりする時などに有用 ※ セルフホスティングの場合 Pro/Enterprise 版のみ利用可能
Langfuse の Evaluation 機能を利用すると 管理者側で Annotate することが可能 様々なステップに対して、人間の評価と
LLM as a Judge をそれぞれ UI 上で簡単に設定が可能 自動的にトレースやデータセットと紐づいた LLM as a Judge の設定を可能
Human Annotate の設定 プロンプトの設定や利用する LLM モデルの設定が可能 評価用プロンプトや Annotate の設定も
UI 上で定義が可能 また、Evaluation 機能を利用すると ラベル等の 設定も可能 LLM as a Judge の設定
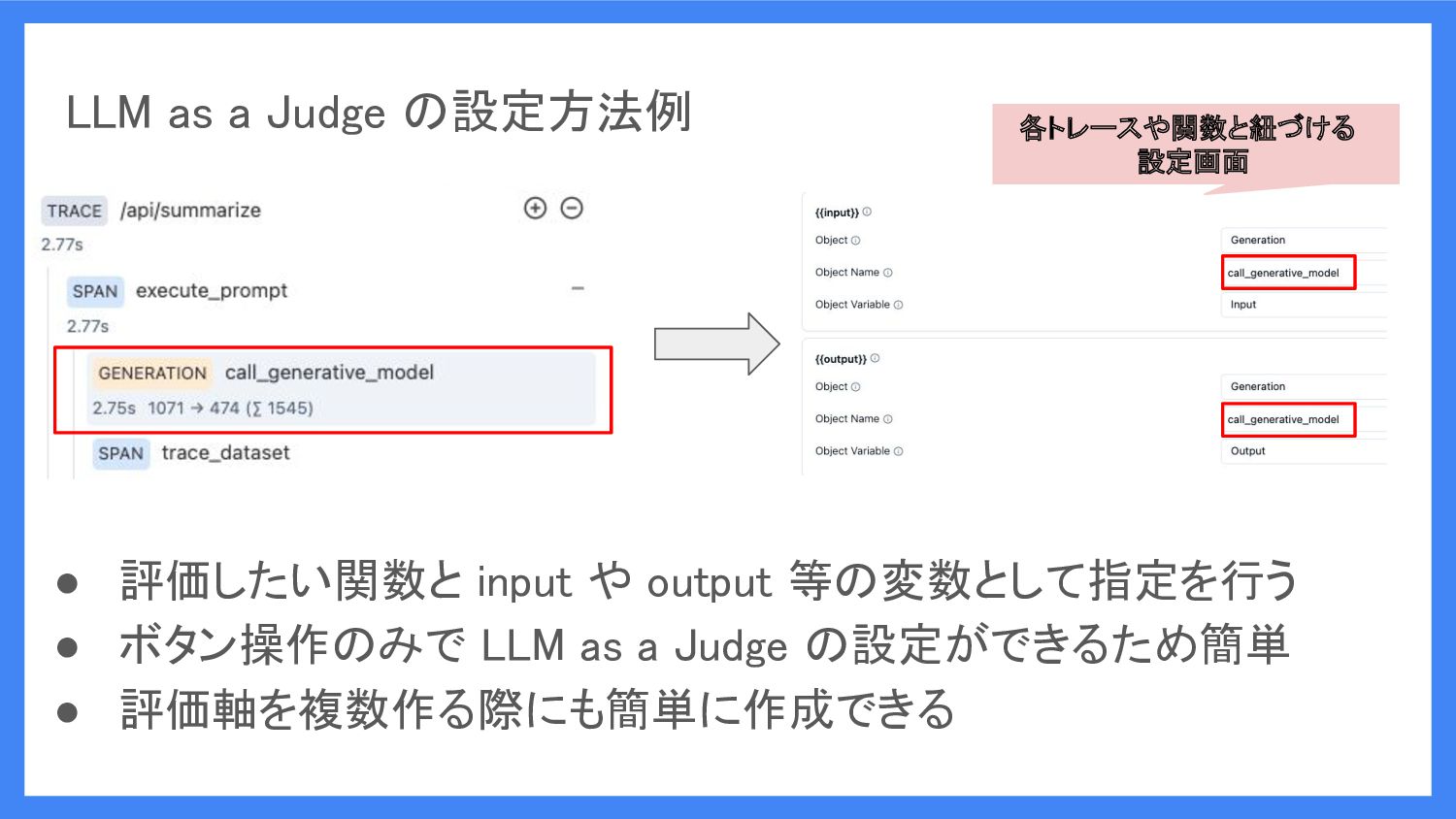
LLM as a Judge の設定方法例 • 評価したい関数と input や output
等の変数として指定を行う • ボタン操作のみで LLM as a Judge の設定ができるため簡単 • 評価軸を複数作る際にも簡単に作成できる 各トレースや関数と紐づける 設定画面
Langfuse を活用することで LLM システムの評価が 容易にできそう!
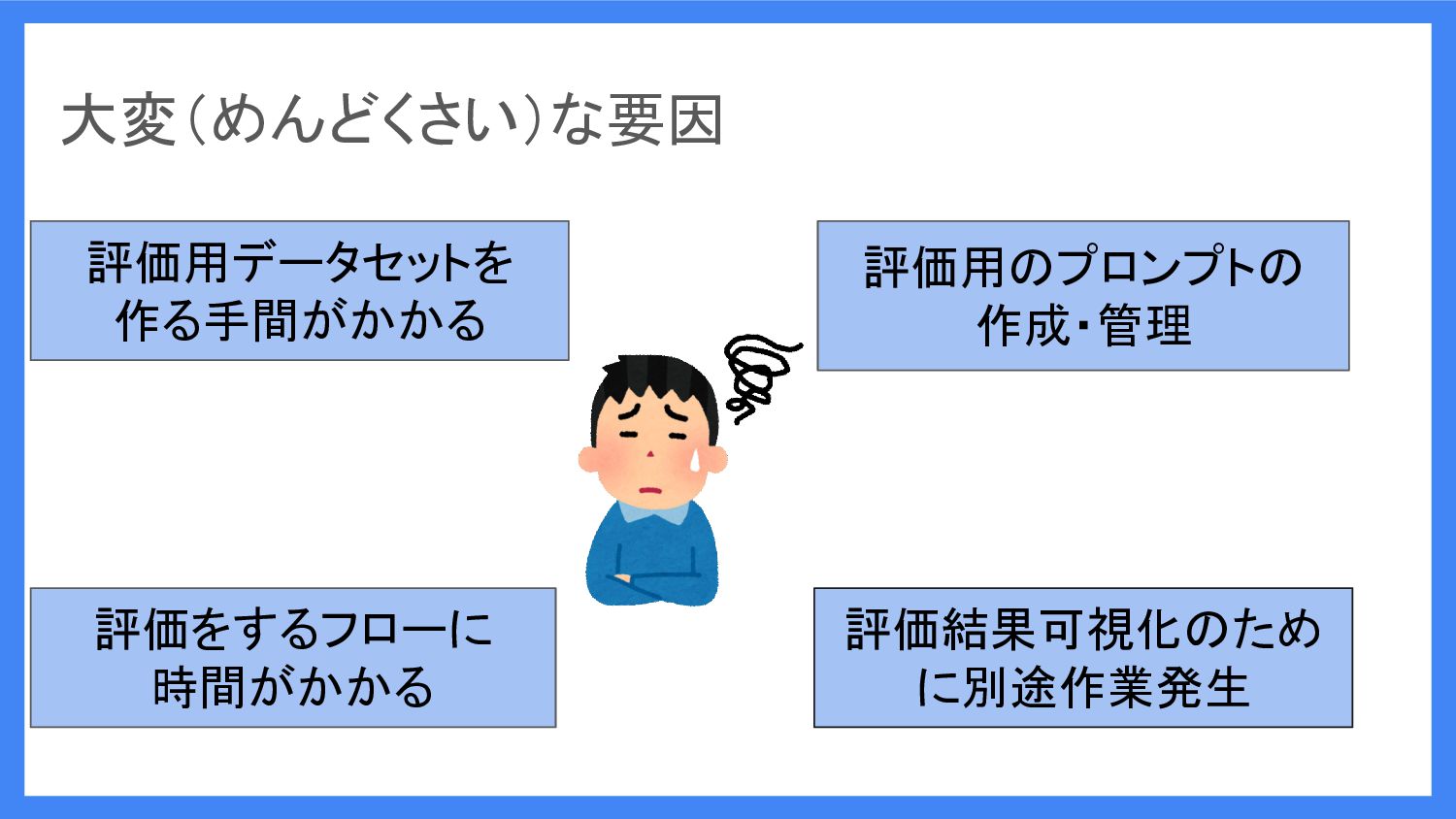
でも、LLM システムの評価は やること多くて 大変じゃないですか?
大変(めんどくさい)な要因 評価用データセットを 作る手間がかかる 評価用のプロンプトの 作成・管理 評価をするフローに 時間がかかる 評価結果可視化のため に別途作業発生
Langfuse を使えば、これらの 大変な要因が改善できます!
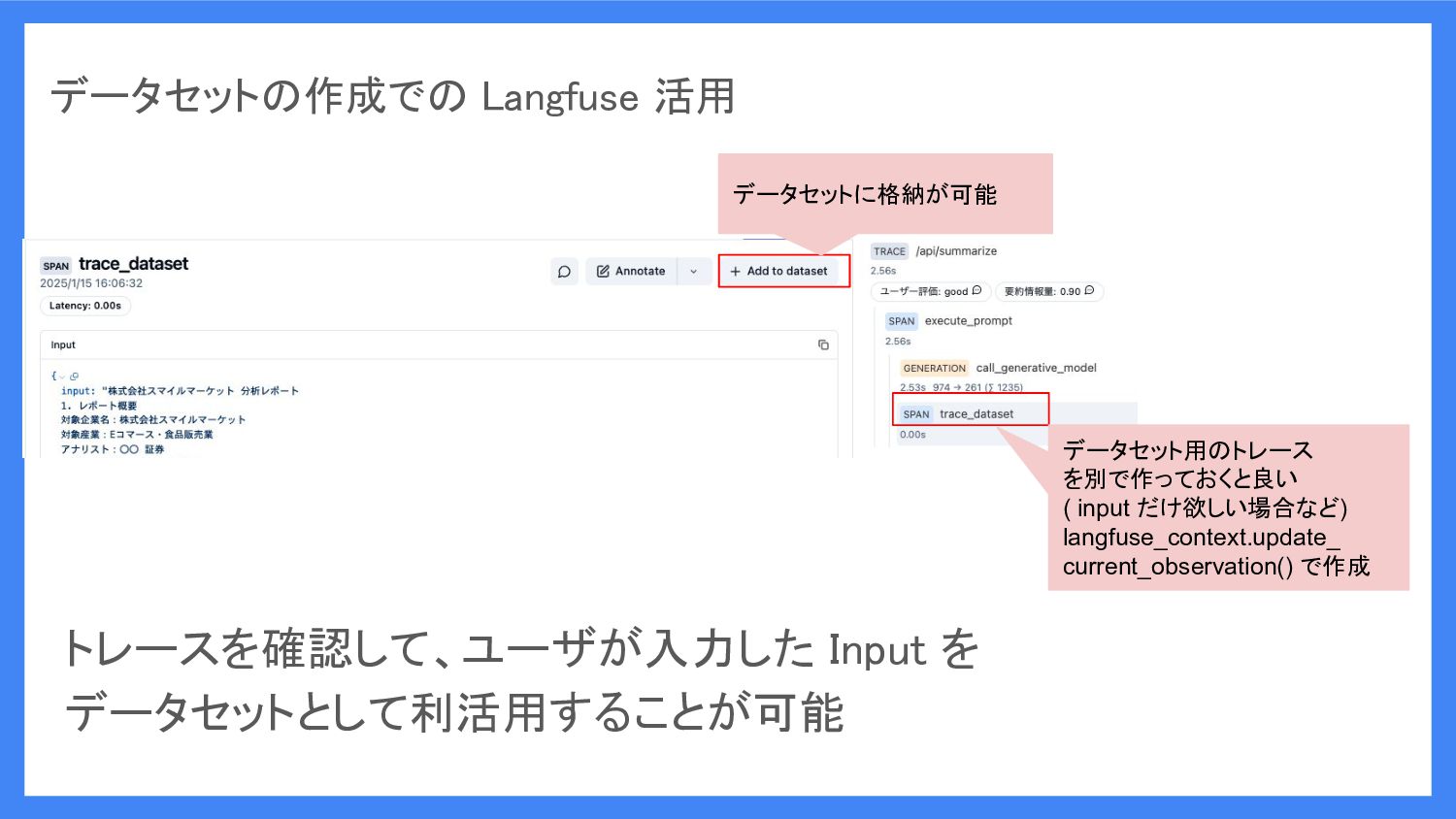
トレースを確認して、ユーザが入力した Input を データセットとして利活用することが可能 データセット用のトレース を別で作っておくと良い (
input だけ欲しい場合など) langfuse_context.update_ current_observation() で作成 データセットに格納が可能 データセットの作成での Langfuse 活用
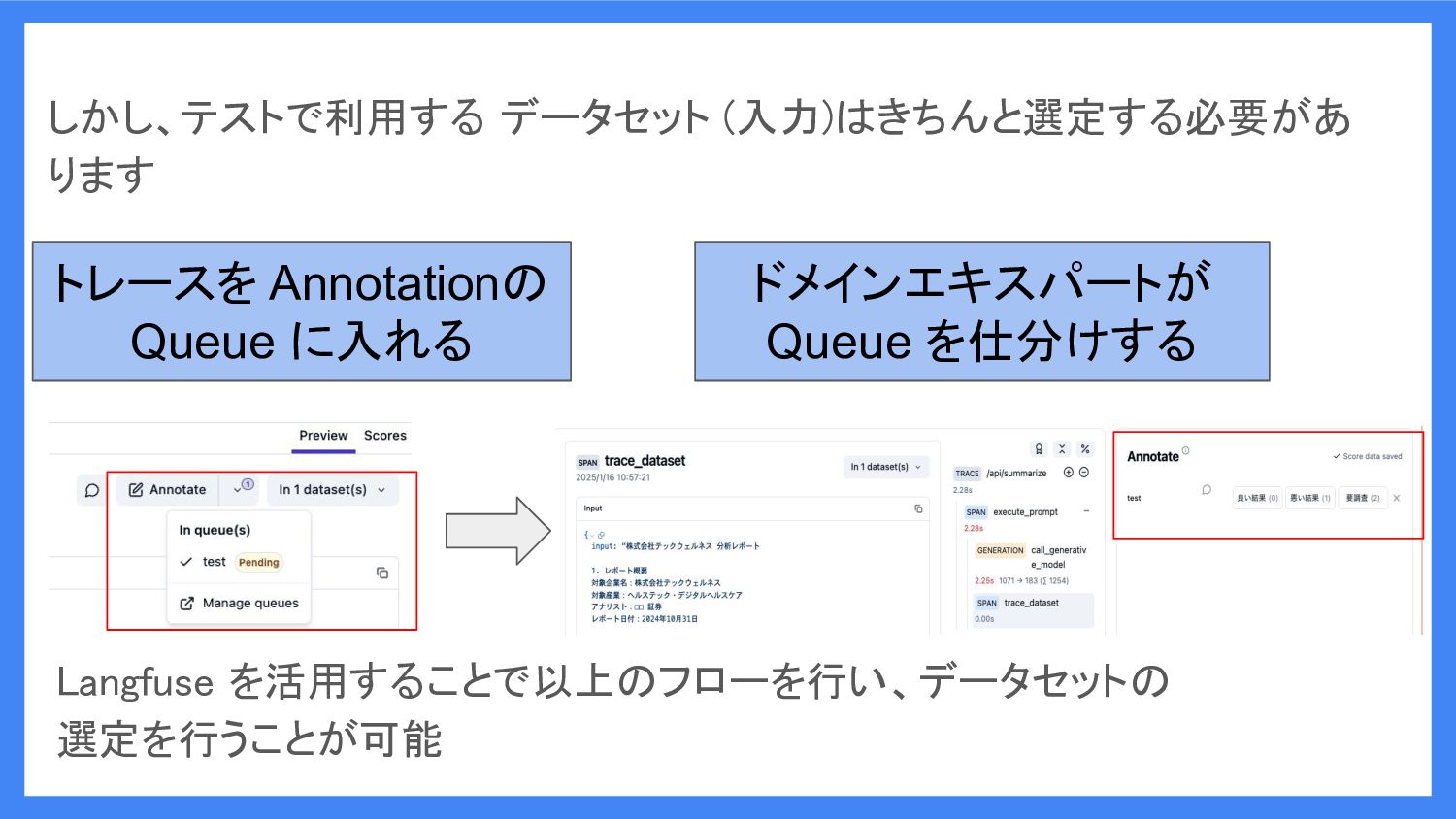
しかし、テストで利用する データセット (入力)はきちんと選定する必要があ ります トレースを Annotationの Queue に入れる ドメインエキスパートが Queue
を仕分けする Langfuse を活用することで以上のフローを行い、データセットの 選定を行うことが可能
また、データセットの選定に LLM as a Judge も活用が可能で す また、LLM as a
Judge には以下のような基準のテンプレートもある ので、簡単に評価用プロンプトの作成が可能です • Conciseness (簡潔性) • Context correctness (文脈の正確性 ) • Context relevance (文脈の関連性 ) • Correctness (正確性) • Hallucination (幻覚/誤作成) • Helpfulness (有用性)など 前述したような設定を行えば、トレースには自動で LLM as a judge でスコアが入るので、怪しい値があったらチェッ クして格納するような運用も可能です スコアを確認して データセット選定
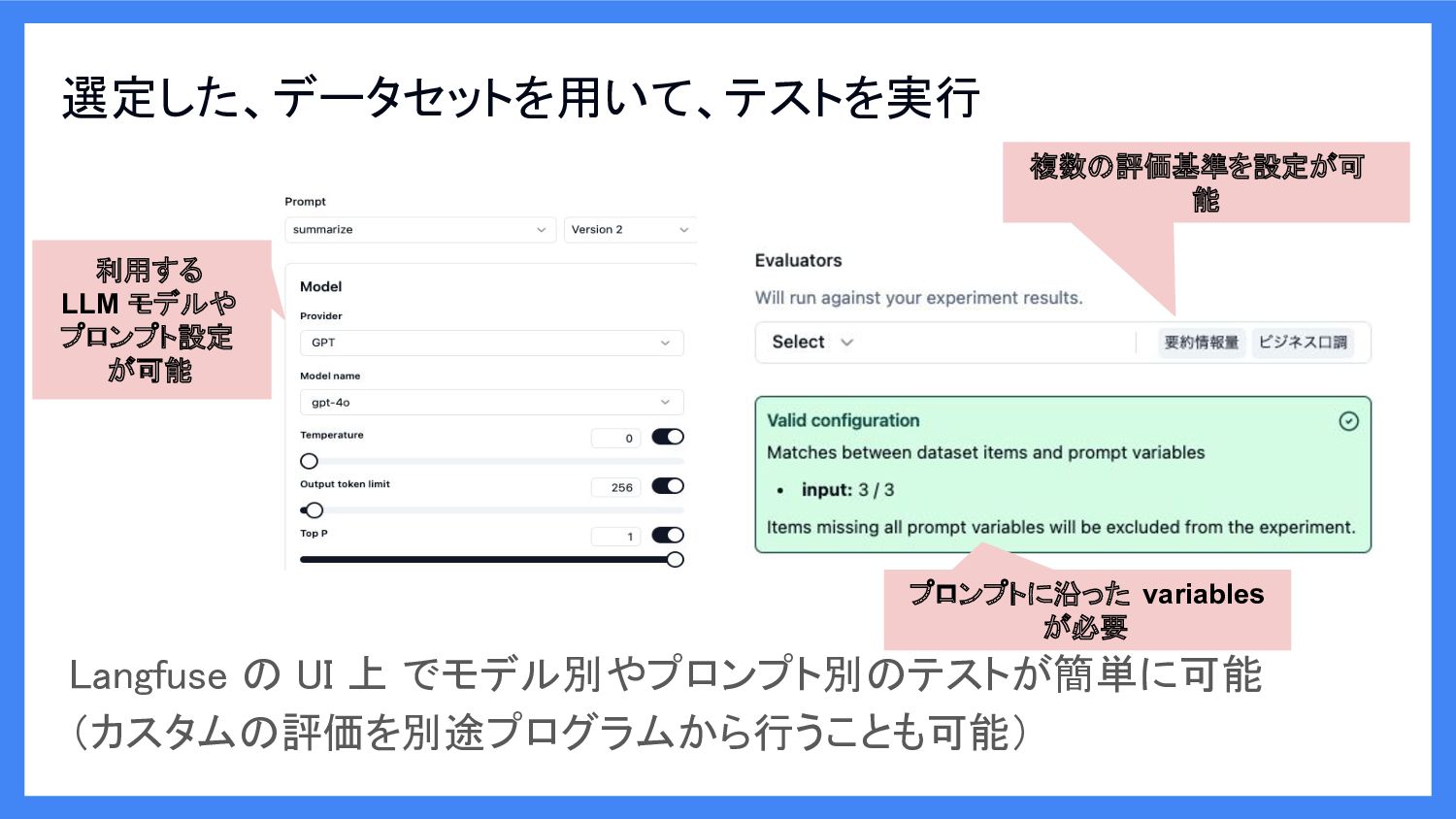
利用する LLM モデルや プロンプト設定 が可能 Langfuse の UI 上 でモデル別やプロンプト別のテストが簡単に可能
(カスタムの評価を別途プログラムから行うことも可能) 選定した、データセットを用いて、テストを実行 複数の評価基準を設定が可 能 プロンプトに沿った variables が必要
Input と OutPut、事前に設定 した LLM as a Judge の スコア等が可視化できる
テストした結果をきちんと可視化することも可能 LLM as a Judge のスコア 可視化した結果を確認して、システムの改善を行っていく
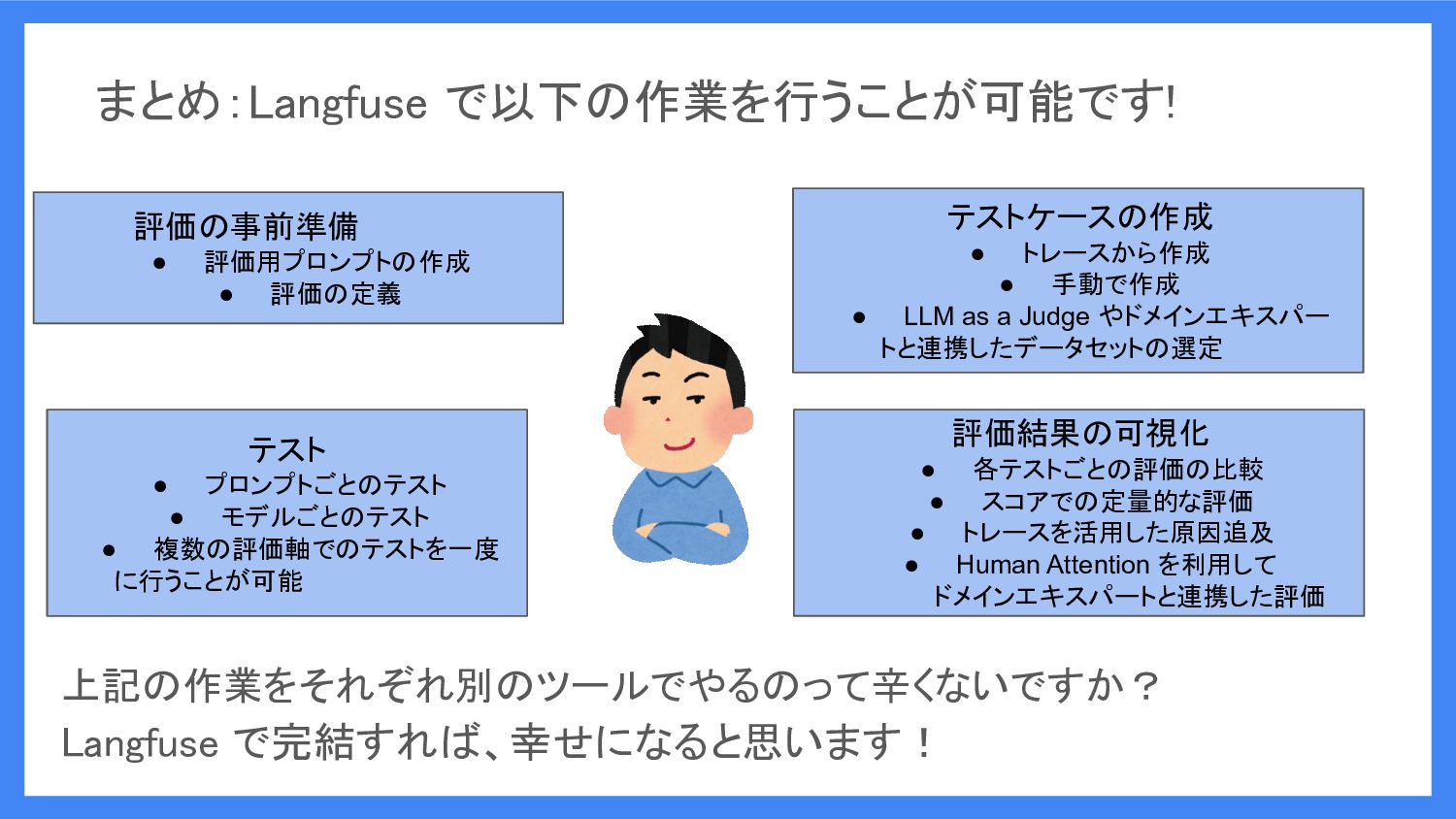
まとめ:Langfuse で以下の作業を行うことが可能です! テストケースの作成 • トレースから作成 • 手動で作成 •
LLM as a Judge やドメインエキスパー トと連携したデータセットの選定 テスト • プロンプトごとのテスト • モデルごとのテスト • 複数の評価軸でのテストを一度 に行うことが可能 評価の事前準備 • 評価用プロンプトの作成 • 評価の定義 評価結果の可視化 • 各テストごとの評価の比較 • スコアでの定量的な評価 • トレースを活用した原因追及 • Human Attention を利用して ドメインエキスパートと連携した評価 上記の作業をそれぞれ別のツールでやるのって辛くないですか? Langfuse で完結すれば、幸せになると思います!
最後に
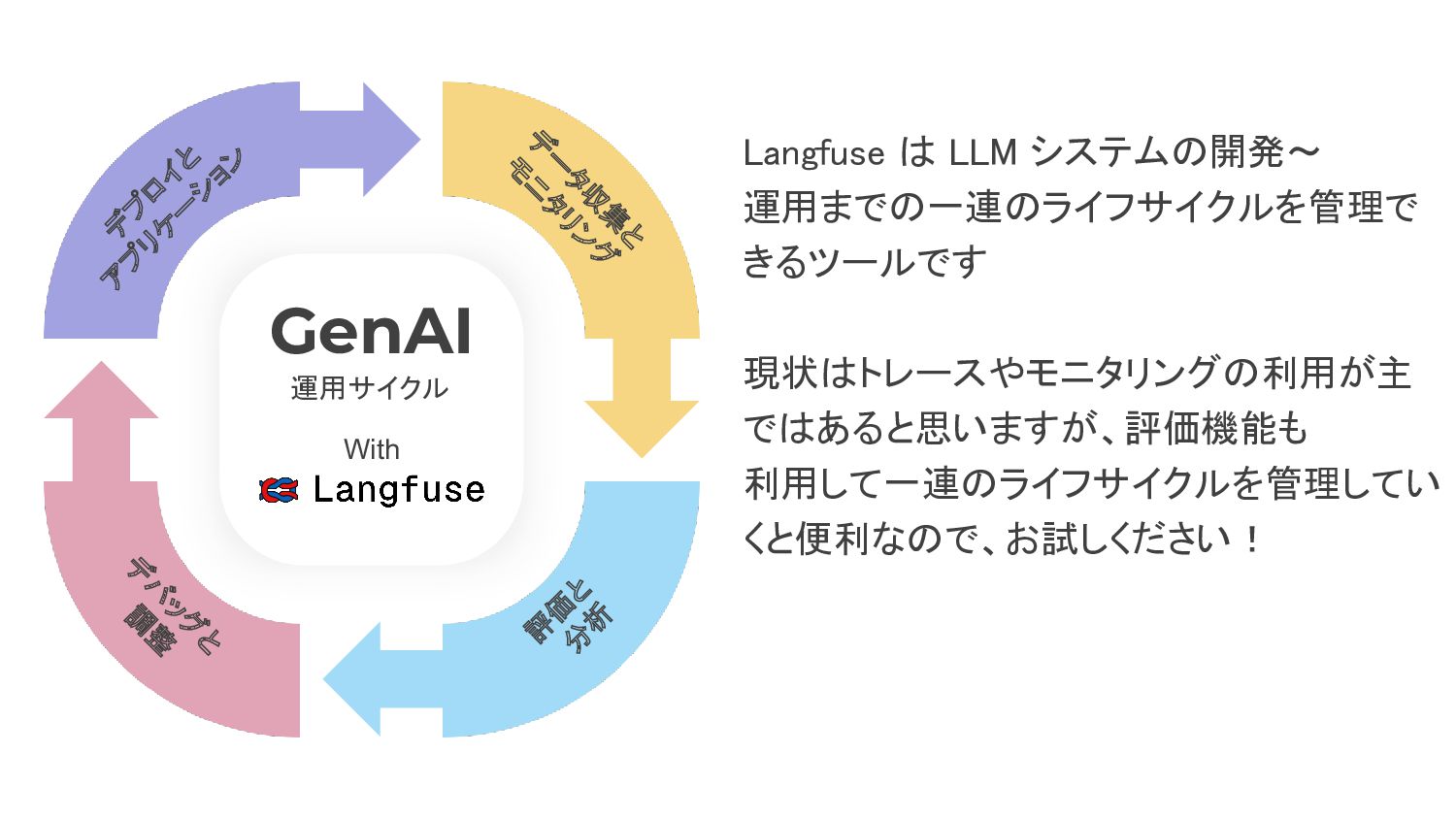
デ プ ロ イ と ア プ リ ケ ー
シ ョン デ ー タ 収 集 と モ ニ タ リ ン グ デ バ ッ グ と 調 整 評 価 と 分 析 GenAI 運用サイクル Langfuse は LLM システムの開発〜 運用までの一連のライフサイクルを管理で きるツールです 現状はトレースやモニタリングの利用が主 ではあると思いますが、評価機能も 利用して一連のライフサイクルを管理してい くと便利なので、お試しください! With
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}