Stein variational gradient descent (SVGD) is a kernel-based particle method for sampling from a target distribution, e.g., in generative modeling and Bayesian inference. SVGD does not require estimating the gradient of the log-density, which is called score estimation. In practice, SVGD can be slow compared to score-estimation based sampling algorithms. To design fast and efficient high-dimensional sampling algorithms, we introduce ASVGD, an accelerated SVGD, based on an accelerated gradient flow in a metric space of probability densities following Nesterov's method. We then derive a momentum-based discrete-time sampling algorithm, which evolves a set of particles deterministically. To stabilize the particles' momentum update, we also study a Wasserstein metric regularization. For the generalized bilinear kernel and the Gaussian kernel, toy numerical examples with varied target distributions demonstrate the effectiveness of ASVGD compared to SVGD and other popular sampling methods.
This is joint work with Wuchen Li (University of South Carolina)
Preprint: https://arxiv.org/abs/2503.23462
Code: https://github.com/ViktorAJStein/Accelerated_Stein_Variational_Gradient_Flows/tree/main
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
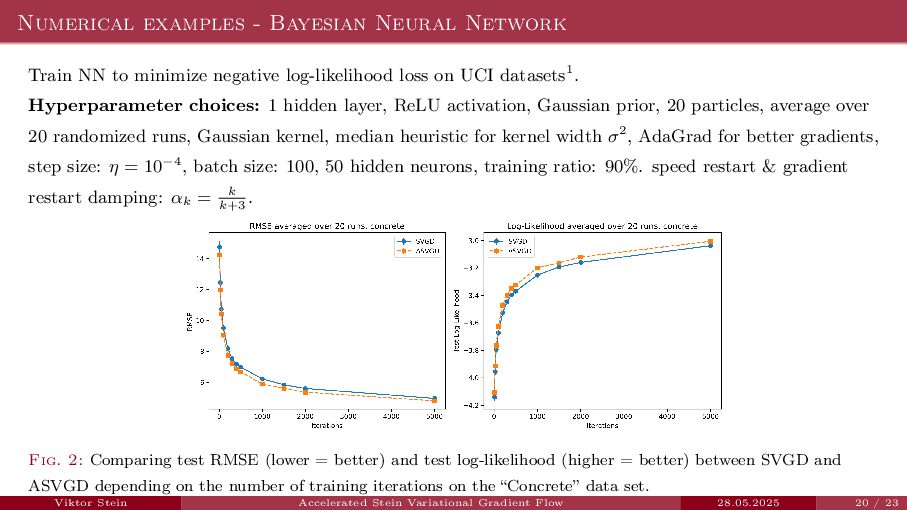{kind=link}
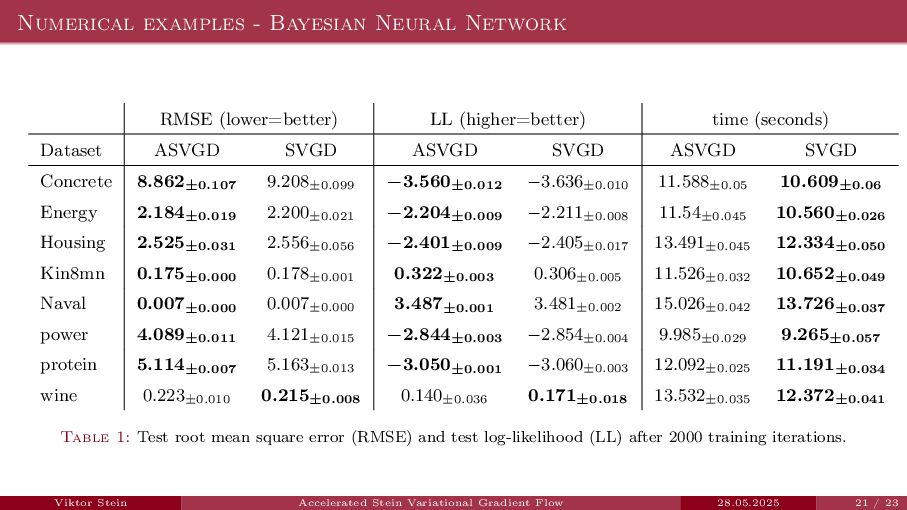{kind=link}
{kind=link}
{kind=link}
![References I [Goh17] Gabriel Goh, Why momentum really works, 2017.](https://files.speakerdeck.com/presentations/276bc18f9c5c464aac276e8fe9b6784e/slide_23.jpg){kind=link}
![References II [OC15] Brendan O’Donoghue and Emmanuel Candes, Adaptive restart](https://files.speakerdeck.com/presentations/276bc18f9c5c464aac276e8fe9b6784e/slide_24.jpg){kind=link}
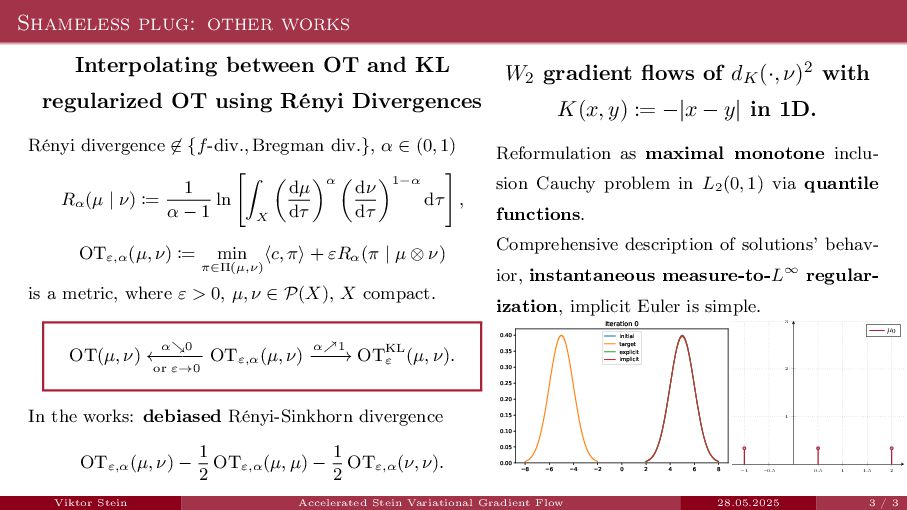{kind=link}