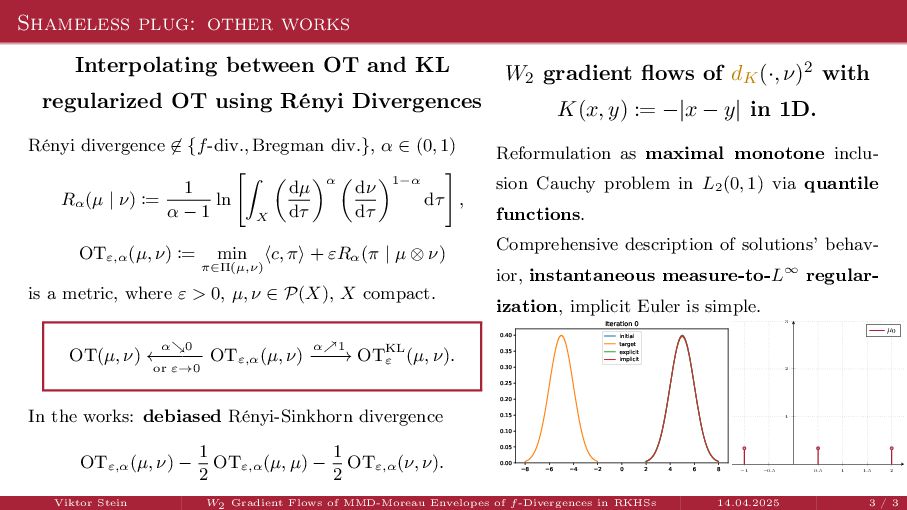
OT using Rényi Divergences Rényi divergence ̸∈ {f-div., Bregman div.}, α ∈ (0, 1) Rα (µ | ν) := 1 α − 1 ln X dµ dτ α dν dτ 1−α dτ , OTε,α (µ, ν) := min π∈Π(µ,ν) ⟨c, π⟩ + εRα (π | µ ⊗ ν) is a metric, where ε > 0, µ, ν ∈ P(X), X compact. OT(µ, ν) α↘0 ← − − − − or ε→0 OTε,α (µ, ν) α↗1 − − − → OTKL ε (µ, ν). In the works: debiased Rényi-Sinkhorn divergence OTε,α (µ, ν) − 1 2 OTε,α (µ, µ) − 1 2 OTε,α (ν, ν). W2 gradient flows of dK (·, ν)2 with K(x, y) := −|x − y| in 1D. Reformulation as maximal monotone inclu- sion Cauchy problem in L2 (0, 1) via quantile functions. Comprehensive description of solutions’ behav- ior, instantaneous measure-to-L∞ regular- ization, implicit Euler is simple. Viktor Stein W2 Gradient Flows of MMD-Moreau Envelopes of f-Divergences in RKHSs 14.04.2025 3 / 3 −1 −0.5 0.5 1 1.5 2 1 2 3 µ0 8 6 4 2 0 2 4 6 8 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 Iteration 0 initial target explicit implicit
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
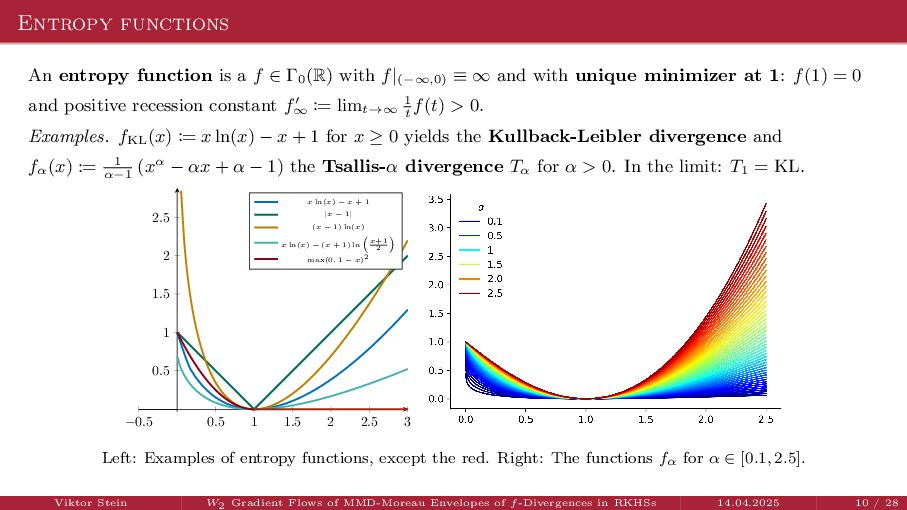{kind=link}
{kind=link}
{kind=link}
![Properties of Dλ f,ν [SNRS24] • Dual formulation Dλ f,ν](https://files.speakerdeck.com/presentations/f539c4f182c8420a81845e55f82077d6/slide_12.jpg){kind=link}
![Theorem. (Properties of Dλ f,ν) [SNRS24] • Asymptotic regimes: Mosco](https://files.speakerdeck.com/presentations/f539c4f182c8420a81845e55f82077d6/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Theorem (Regularized tight f-divergence [SNRS’25]) The function ˜ Gf,ν :](https://files.speakerdeck.com/presentations/f539c4f182c8420a81845e55f82077d6/slide_21.jpg){kind=link}
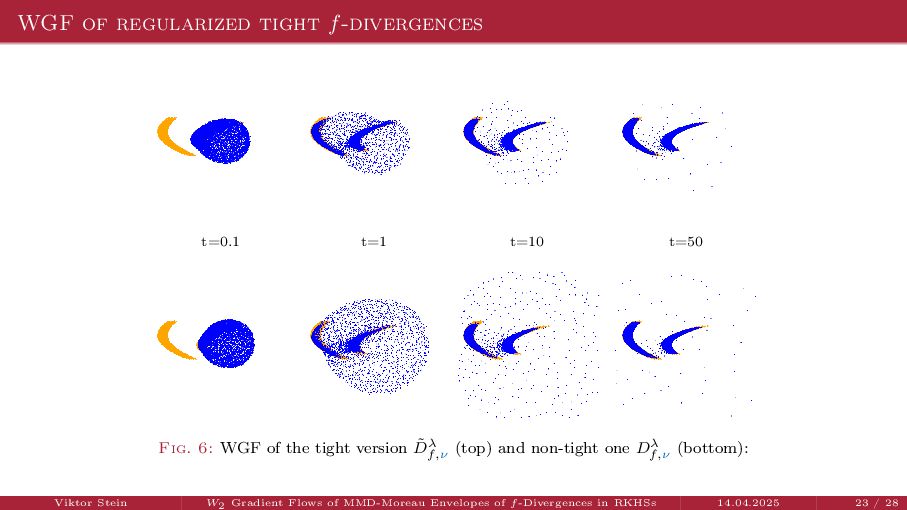{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References I [AGS08] Luigi Ambrosio, Nicola Gigli, and Giuseppe Savaré,](https://files.speakerdeck.com/presentations/f539c4f182c8420a81845e55f82077d6/slide_28.jpg){kind=link}
![References II [KYSZ23] H. Kremer, Nemmour Y., B. Schölkopf, and](https://files.speakerdeck.com/presentations/f539c4f182c8420a81845e55f82077d6/slide_29.jpg){kind=link}
{kind=link}