Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文読み会 SNLP2025 Learning Dynamics of LLM Finetun...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
S
August 24, 2025
Research
470
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文読み会 SNLP2025 Learning Dynamics of LLM Finetuning. In: ICLR 2025
S
August 24, 2025
More Decks by S
See All by S
論文読み会 SNLP2024 Instruction-tuned Language Models are Better Knowledge Learners. In: ACL 2024
s_mizuki_nlp
1
620
埋め込み表現の意味適応による知識ベース語義曖昧性解消
s_mizuki_nlp
2
600
論文読み会 SNLP2018 Sequence to Action: End to End Semantic Graph Generation for Semantic Parsing
s_mizuki_nlp
0
130
論文読み会 SNLP2019 Ordered neurons: Integrating tree structures into recurrent neural networks
s_mizuki_nlp
0
140
論文読み会 SNLP2020 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
s_mizuki_nlp
0
200
論文読み会 SNLP2021 A Distributional Approach to Controlled Text Generation
s_mizuki_nlp
0
160
Other Decks in Research
See All in Research
NLP colloquium: AI Safety Survey
kanekomasahiro
0
820
Fukui Shibiten 39 - AI Art
butchi
0
140
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
150
Data Visualization Tools in the Age of AI
flekschas
0
170
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
360
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
110
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
570
Ankylosing Spondylitis
ankh2054
0
180
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
170
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
280
Featured
See All Featured
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Making the Leap to Tech Lead
cromwellryan
135
10k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
4 Signs Your Business is Dying
shpigford
187
22k
Side Projects
sachag
455
43k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
Practical Orchestrator
shlominoach
191
11k
Transcript
Learning Dynamics of LLM Finetuning. In: ICLR 2025 Yi Ren
and Danica J. Sutherland 第16回 最先端NLP勉強会 Hottolink/SciTokyo Okazaki Lab/AIST: Sakae Mizuki 2025-08-31 ※ スライド中の図表・数式は,断りのないかぎり本論文からの引用です ICLR2025 Outstanding Paper
概要 2
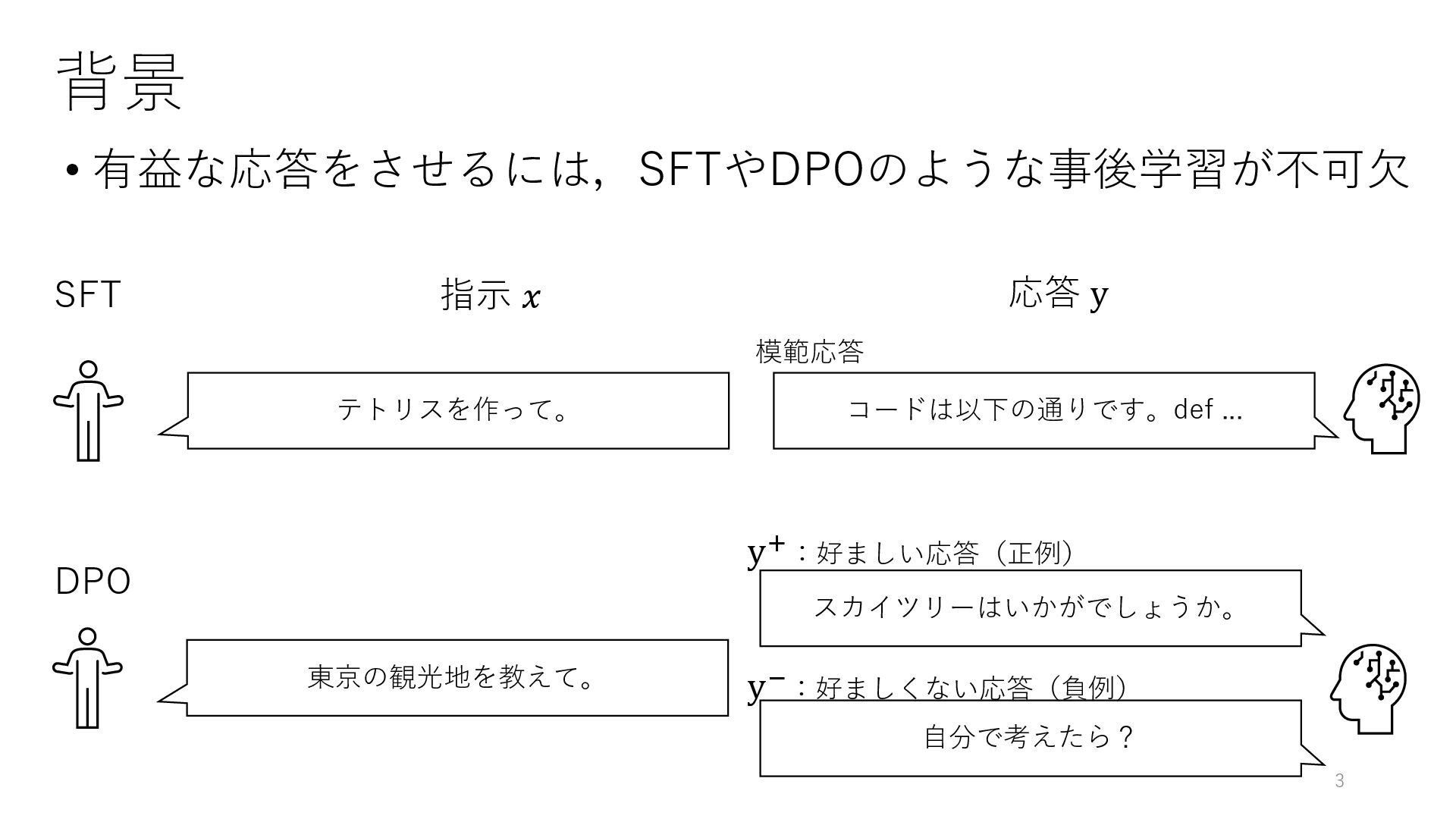
背景 • 有益な応答をさせるには,SFTやDPOのような事後学習が不可欠 3 SFT コードは以下の通りです。def ... 指示 𝑥 応答
y テトリスを作って。 DPO y+:好ましい応答(正例) 東京の観光地を教えて。 スカイツリーはいかがでしょうか。 自分で考えたら? y−:好ましくない応答(負例) 模範応答
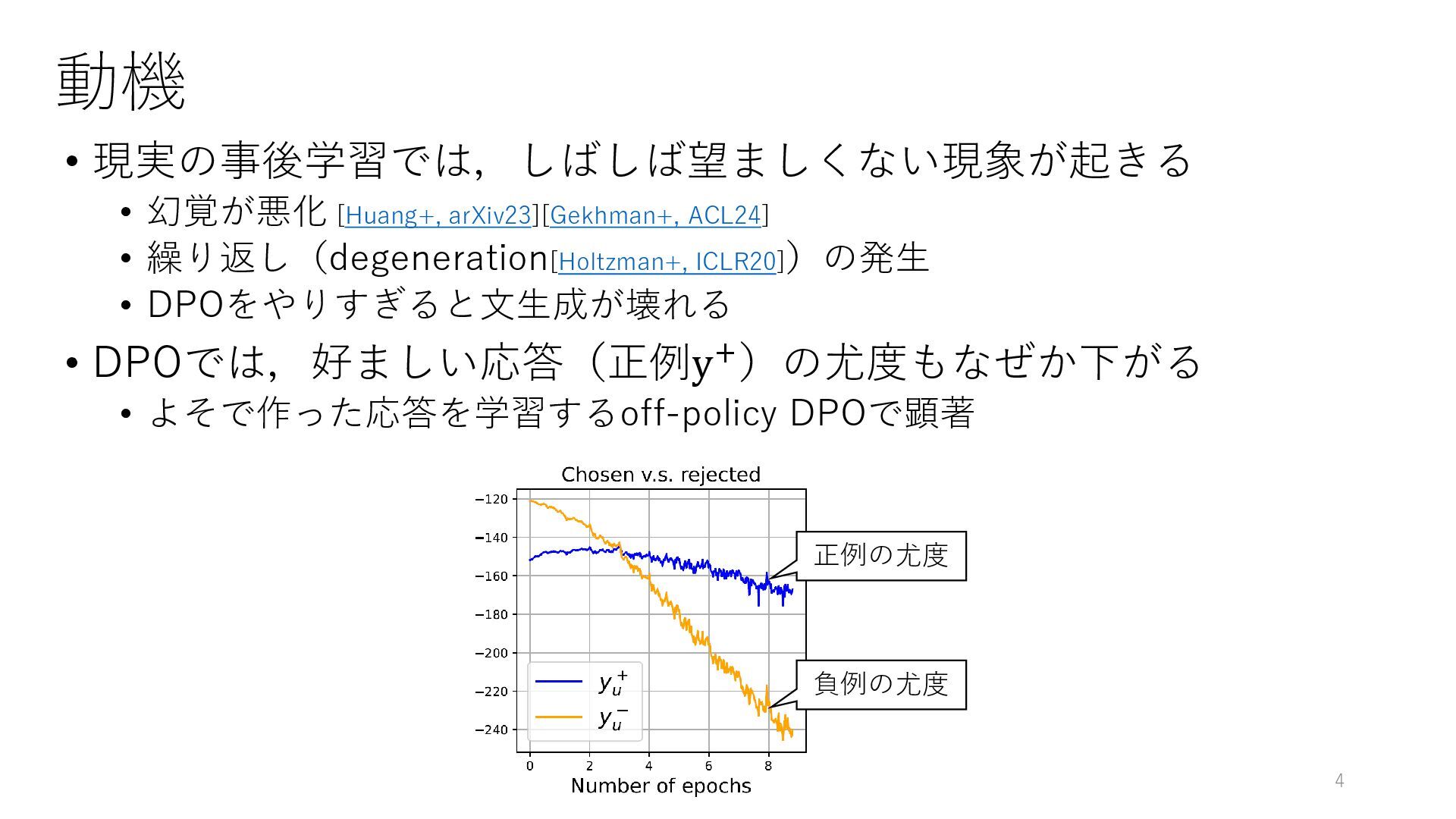
動機 Huang+, arXiv23 Gekhman+, ACL24 Holtzman+, ICLR20 • 現実の事後学習では,しばしば望ましくない現象が起きる •
幻覚が悪化 [Huang+, arXiv23][Gekhman+, ACL24] • 繰り返し(degeneration[Holtzman+, ICLR20])の発生 • DPOをやりすぎると文生成が壊れる • DPOでは,好ましい応答(正例y+)の尤度もなぜか下がる • よそで作った応答を学習するoff-policy DPOで顕著 4 正例の尤度 負例の尤度
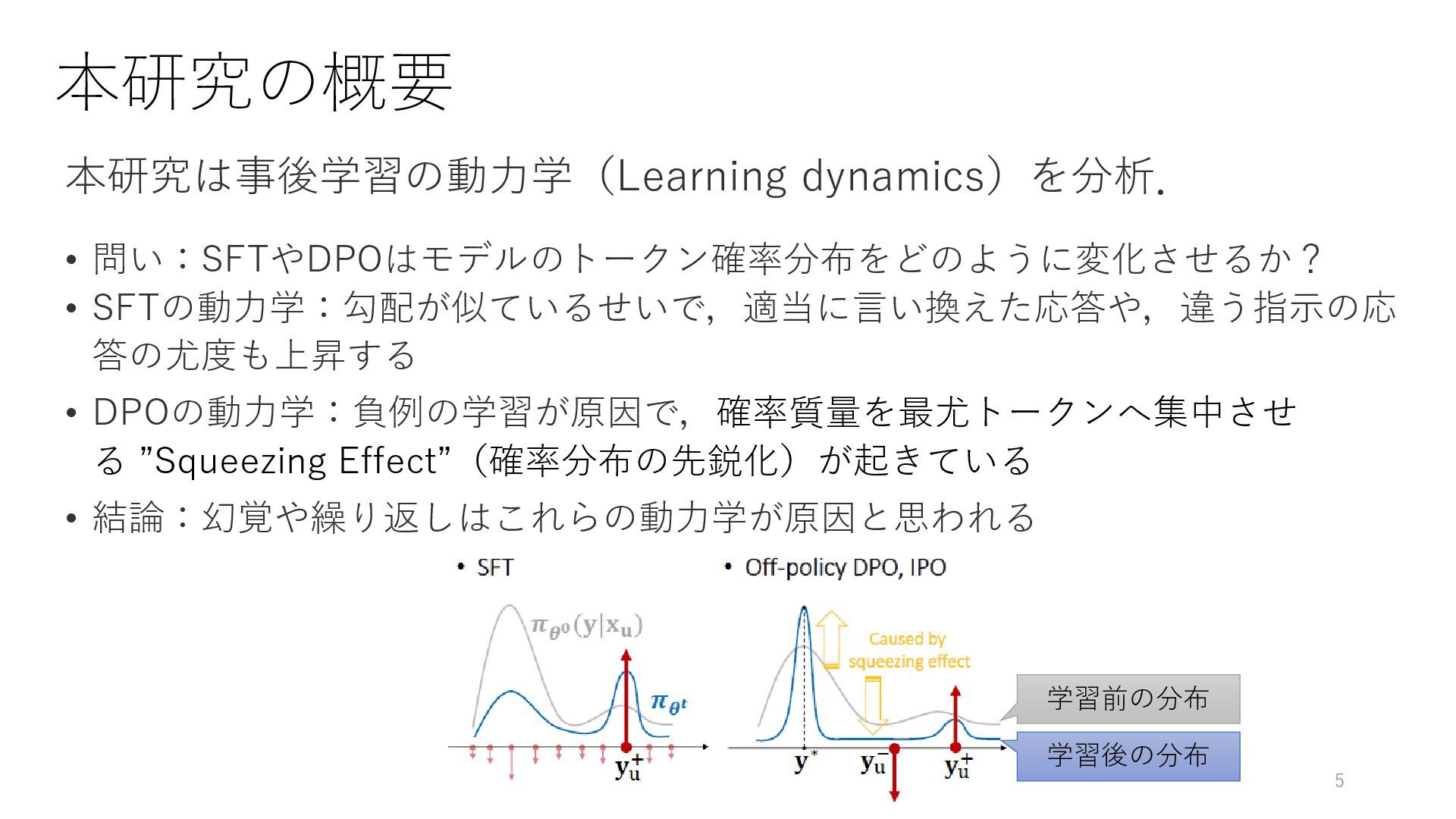
本研究の概要 本研究は事後学習の動力学(Learning dynamics)を分析. • 問い:SFTやDPOはモデルのトークン確率分布をどのように変化させるか? • SFTの動力学:勾配が似ているせいで,適当に言い換えた応答や,違う指示の応 答の尤度も上昇する • DPOの動力学:負例の学習が原因で,確率質量を最尤トークンへ集中させ
る ”Squeezing Effect”(確率分布の先鋭化)が起きている • 結論:幻覚や繰り返しはこれらの動力学が原因と思われる 5 学習前の分布 学習後の分布
分析 - SFTの動力学 6
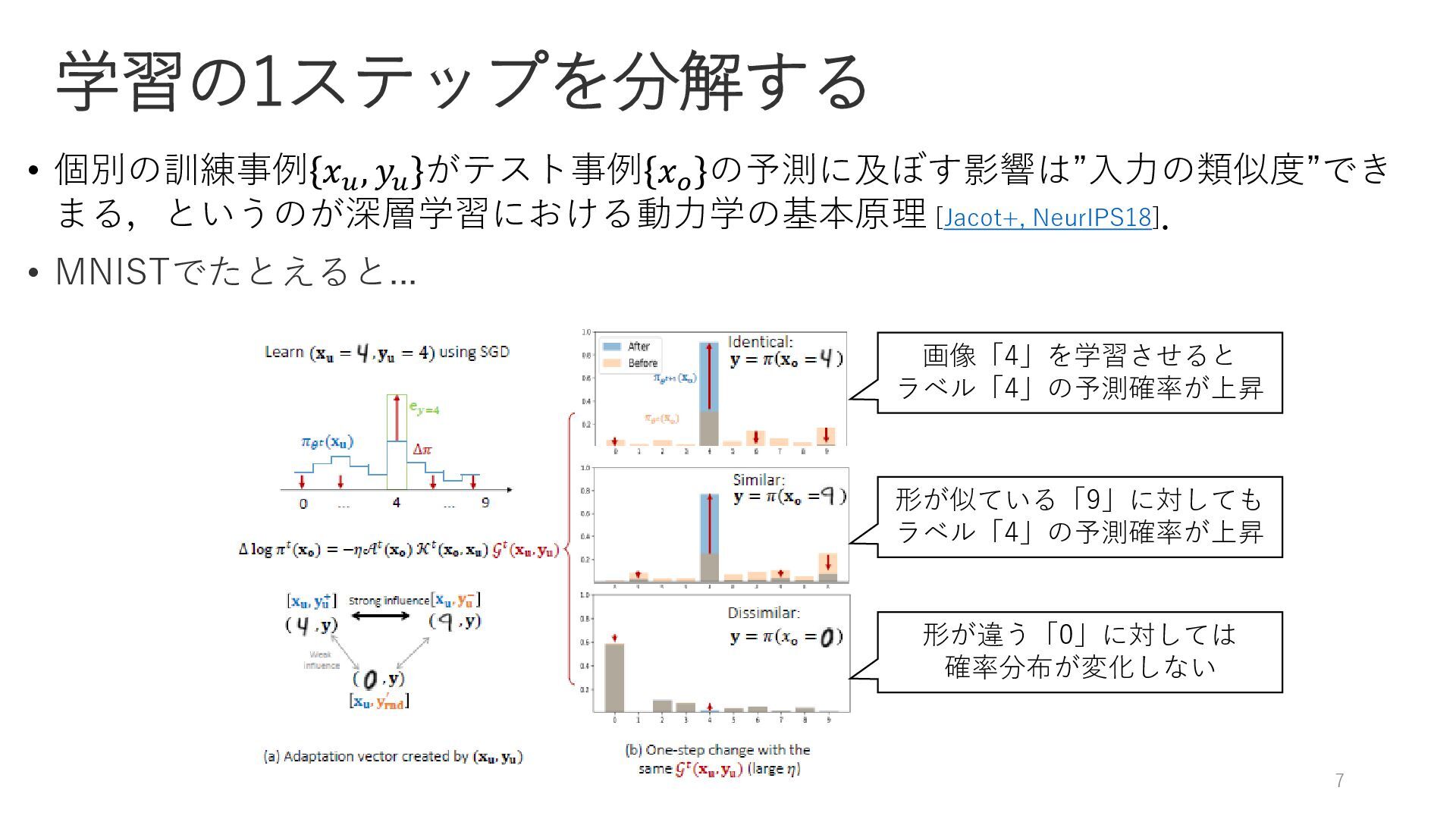
学習の1ステップを分解する Jacot+, NeurIPS18 • 個別の訓練事例 𝑥𝑢 , 𝑦𝑢 がテスト事例 𝑥𝑜
の予測に及ぼす影響は”入力の類似度”でき まる,というのが深層学習における動力学の基本原理 [Jacot+, NeurIPS18]. • MNISTでたとえると... 7 画像「4」を学習させると ラベル「4」の予測確率が上昇 形が似ている「9」に対しても ラベル「4」の予測確率が上昇 形が違う「0」に対しては 確率分布が変化しない
学習の1ステップを分解する • 次単語予測もMNISTと同じく多クラス分類深層学習なので,動力学はおなじ: 入力の類似度がトークン確率分布 𝜋 の変化を左右する.式で表すと… 8 G: Gradient 損失関数(クロスエントロ
ピー誤差)の勾配.予測と正 解の差で決まる. K: Neural Tangent Kernel 事例間の類似度.中間層zの 勾配で決まる. A: Adaptation Softmax層の勾配.現在の トークン確率分布で決まる. Δlog π トークン確率分布の変化. =
SFTの動力学 • SFTの動力学はトークンごとの動力学の総和になる.つまり トークン確率分布の変化=Softmax層の勾配×事例間の類似度×損失関数の勾配 という原理はかわらない. 9 SFTの場合 1トークンの場合 テスト事例の応答トークン数をM,訓練事例の応答トークン数をLとする
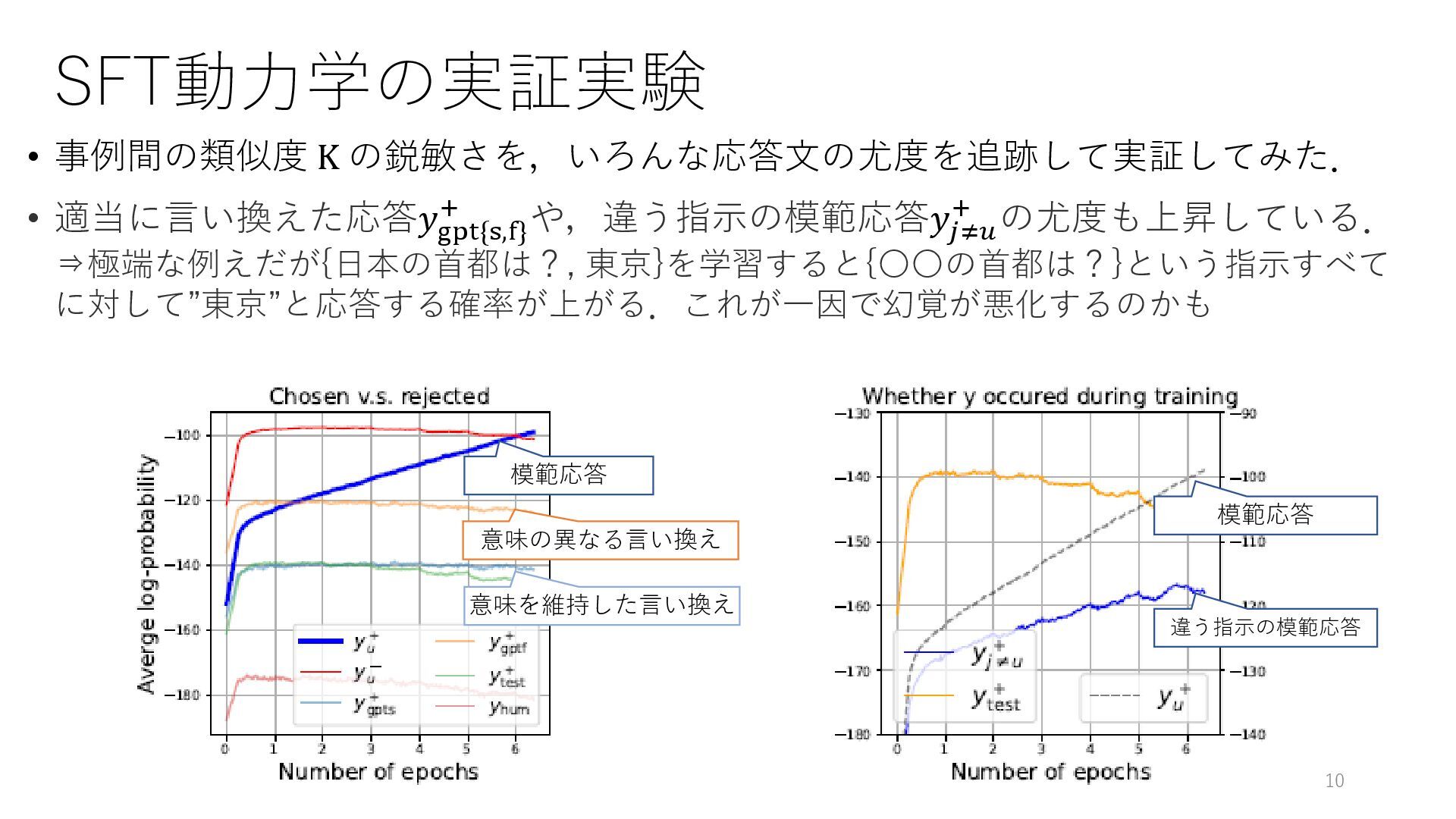
SFT動力学の実証実験 • 事例間の類似度 K の鋭敏さを,いろんな応答文の尤度を追跡して実証してみた. • 適当に言い換えた応答𝑦gpt{s,f} + や,違う指示の模範応答𝑦𝑗≠𝑢 +
の尤度も上昇している. ⇒極端な例えだが{日本の首都は?, 東京}を学習すると{〇〇の首都は?}という指示すべて に対して”東京”と応答する確率が上がる.これが一因で幻覚が悪化するのかも 10 模範応答 意味の異なる言い換え 意味を維持した言い換え 模範応答 違う指示の模範応答
分析 - DPOの動力学 11
DPOの動力学 • SFTに対して好ましくない応答(負例)の勾配を追加したのが,DPOの動力学: 負例の尤度を減らそうとする勾配の存在がDPOの特徴である. • 減らしたぶんの確率質量はどこに再分配されるのか?が,動力学を理解するカギ. 12 DPOの場合 SFTの場合 好ましい応答(正例)
𝑦+と好ましくない応答(負例) 𝑦−のペアに拡張 負例の尤度を減らす勾配
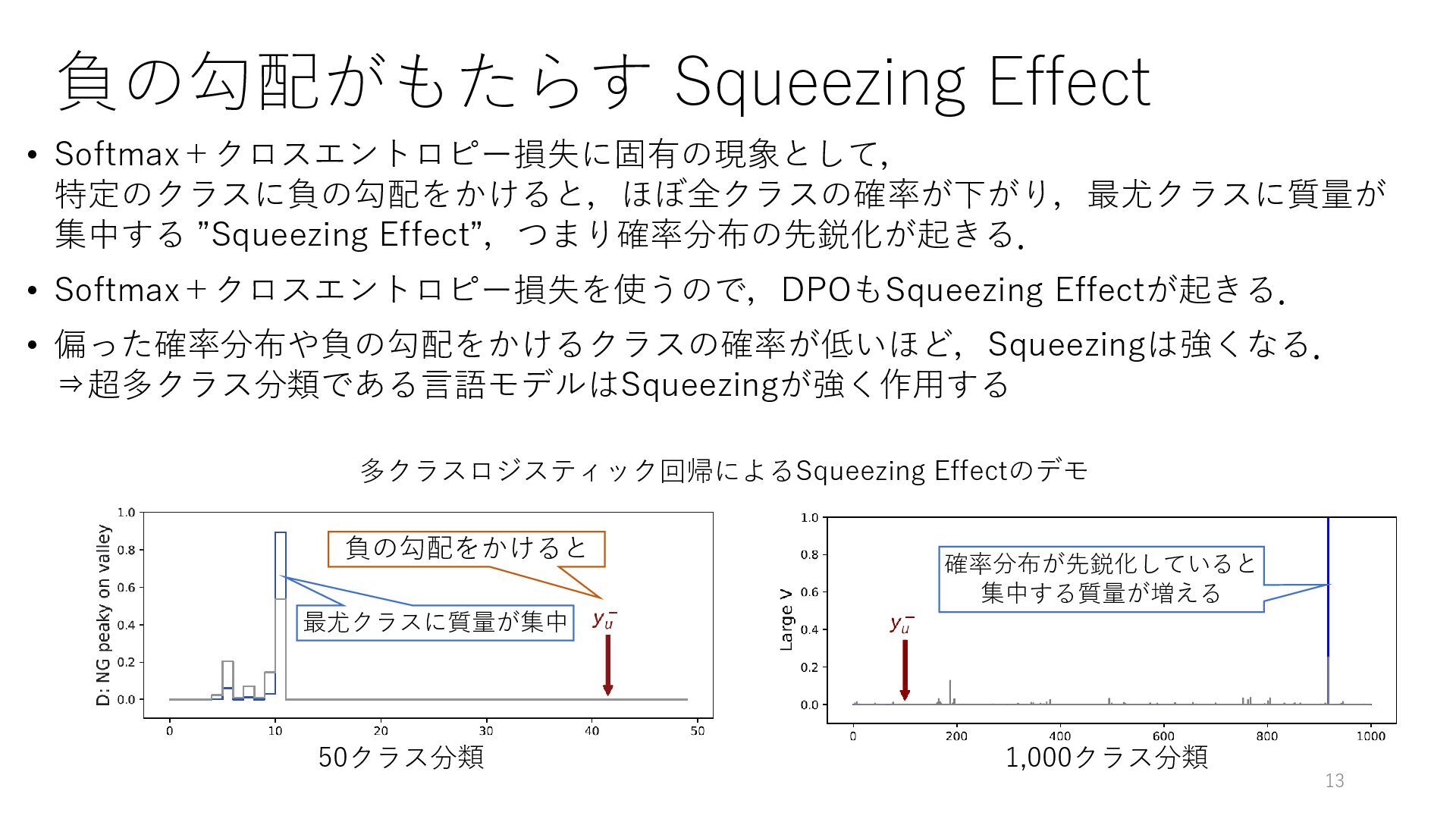
負の勾配がもたらす Squeezing Effect • Softmax+クロスエントロピー損失に固有の現象として, 特定のクラスに負の勾配をかけると,ほぼ全クラスの確率が下がり,最尤クラスに質量が 集中する ”Squeezing Effect”,つまり確率分布の先鋭化が起きる. •
Softmax+クロスエントロピー損失を使うので,DPOもSqueezing Effectが起きる. • 偏った確率分布や負の勾配をかけるクラスの確率が低いほど,Squeezingは強くなる. ⇒超多クラス分類である言語モデルはSqueezingが強く作用する 13 多クラスロジスティック回帰によるSqueezing Effectのデモ 負の勾配をかけると 最尤クラスに質量が集中 50クラス分類 1,000クラス分類 確率分布が先鋭化していると 集中する質量が増える
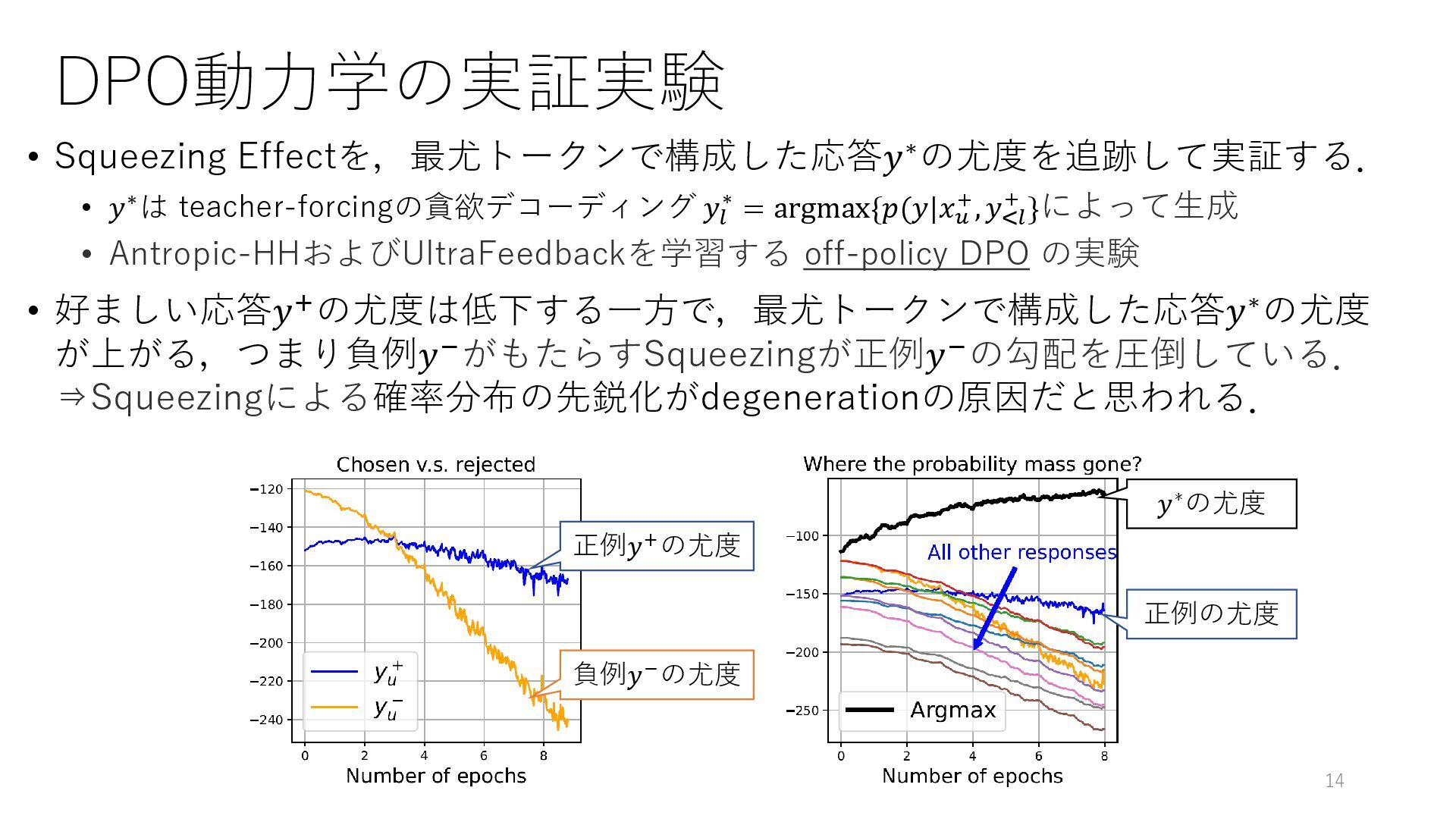
DPO動力学の実証実験 • Squeezing Effectを,最尤トークンで構成した応答𝑦∗の尤度を追跡して実証する. • 𝑦∗は teacher-forcingの貪欲デコーディング 𝑦𝑙 ∗ =
argmax𝑦 {𝑝(𝑦|𝑥+ , 𝑦<𝑙 + }によって生成 • Anthropic-HH-RLHFおよびUltraFeedbackを学習する off-policy DPO の実験 • 好ましい応答𝑦+の尤度は低下する一方で,最尤トークンで構成した応答𝑦∗の尤度 が上がる,つまり負例𝑦−がもたらすSqueezingが正例𝑦+の勾配を圧倒している. ⇒Squeezingによる確率分布の先鋭化がdegenerationの原因だと思われる. 14 正例𝑦+の尤度 負例𝑦−の尤度 𝑦∗の尤度 正例の尤度
DPO派生アルゴリズムを見直してみる • しばしば有効性が主張されるDPO派生アルゴリズム(SPIN [Chen+, ICML24], SPPO [Wu+, ICLR25], SLiC [Zhao+,
ICLR23] 等)は,Squeezingを弱める設計になっている • たとえばモデル自身の応答で学習するon-policy DPOは,尤度の高い”峰”に負の勾 配をかけるのでSqueezingが起きにくい. 15
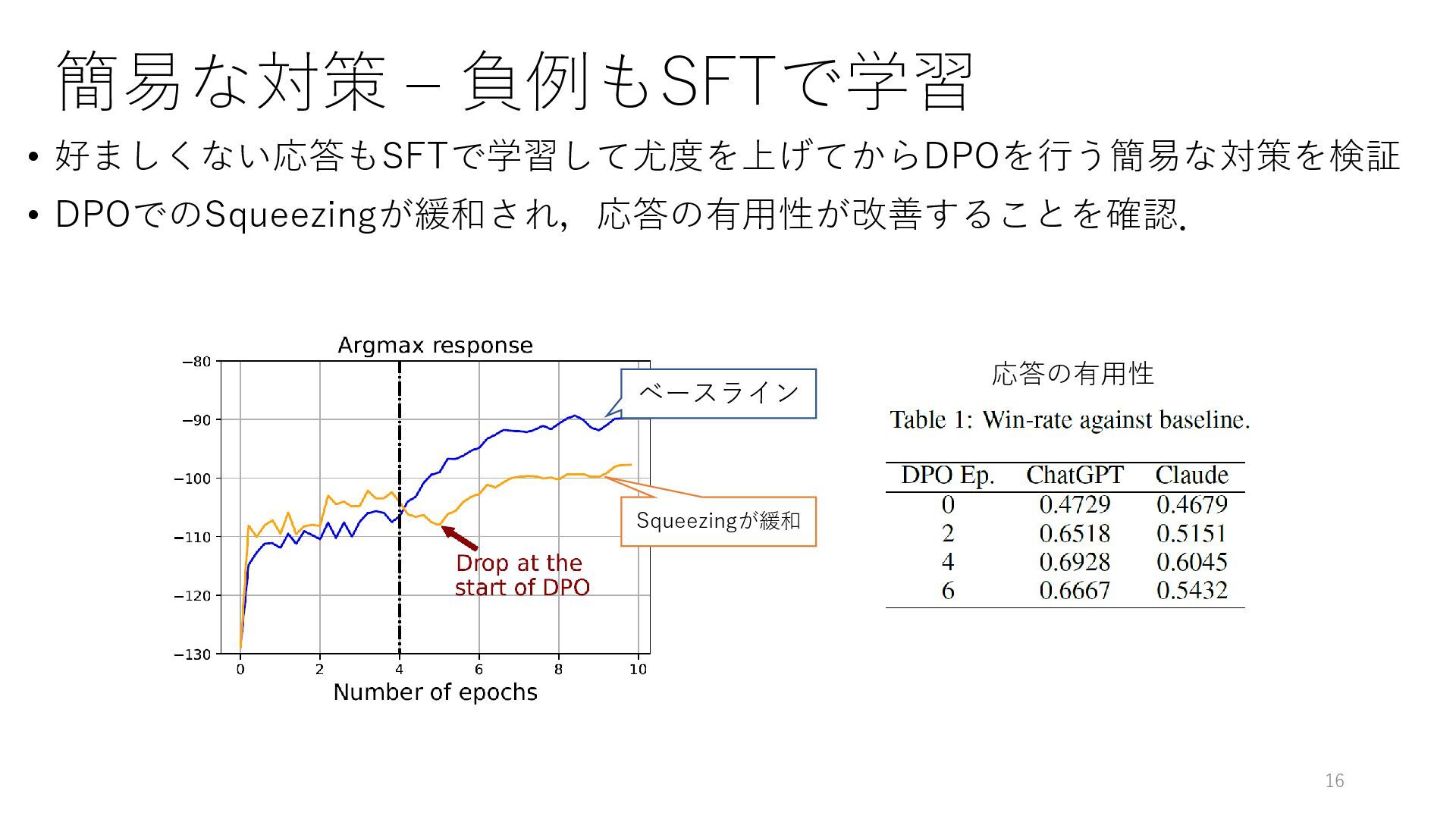
簡易な対策 – 負例もSFTで学習 • 好ましくない応答もSFTで学習して尤度を上げてからDPOを行う簡易な対策を検証 • DPOでのSqueezingが緩和され,応答の有用性が改善することを確認. 16 ベースライン Squeezingが緩和
応答の有用性
まとめと考察 17
まとめ 事後学習の動力学(Learning dynamics)を分析. • (Off-policy) DPOにおける性能劣化の謎を,確率分布の先鋭化を引き 起こす “Squeezing Effect” という現象で説明.
• DPOの学習しすぎや,尤度の低い応答に負の勾配をかけるのは要注意. • 実用上主流であるOn-policy DPOの分析が今後の研究課題. 18
読んだ理由・読んでみた感想 • 事後学習は予想外の結果が起きやすいので知見を得たかった • Squeezing Effectに限らず,確率分布を大きく変化させてしまう事後学習はたい てい失敗する印象がある. • 事前学習してない知識を教えると幻覚が悪化する [Gekhman+,
ACL24] • 低尤度の応答は選好順序の学習が困難 [Chen+, NeurIPS24] • 深い推論を模倣学習するとout-of-domainの性能が低下する [Huan+, arXiv25] • 同じモデル系列からの蒸留が効果的 [Zhang+, NAACL25] ... など • 推論型モデルではrepetitionが起きやすいのだが,GRPO損失の報酬標準化によっ て負の勾配が生じることが原因なのかも. • On-policy学習では文生成パラメータに注意するのがよさそう. • 動力学の定常性が担保できないOn-policy DPOの分析は容易ではないだろう. 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DPO派生アルゴリズムを見直してみる • しばしば有効性が主張されるDPO派生アルゴリズム(SPIN [Chen+, ICML24], SPPO [Wu+, ICLR25], SLiC [Zhao+,](https://files.speakerdeck.com/presentations/db28d272ee164bc6b503e19979d9d58c/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}