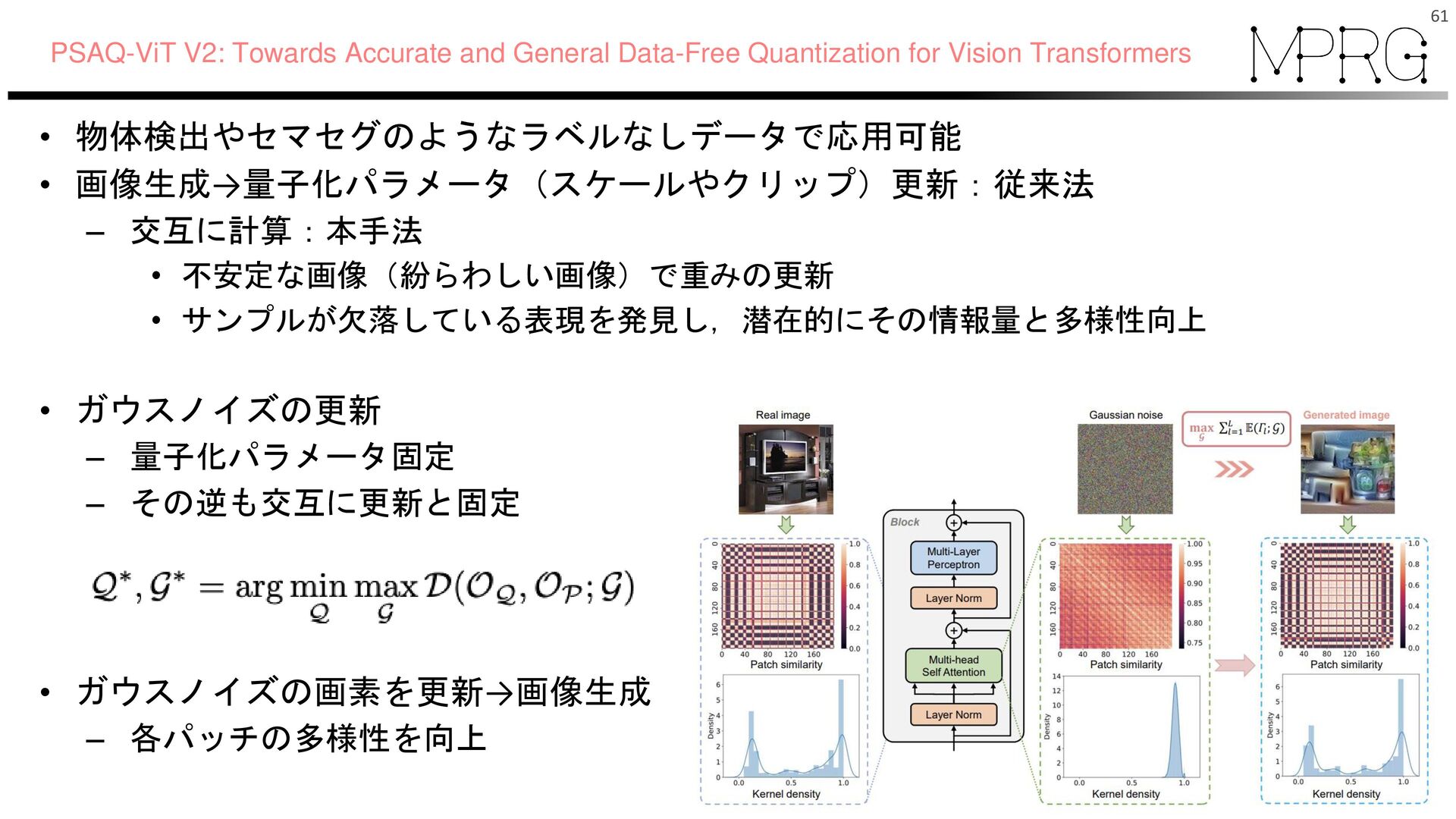
各パッチでコサイン類似度(パッチ類似度の計算) →エントロピー計算 →エントロピーが最大化を目指す – パッチ類似度の分布を滑らかにする • 分布の多様性向上 62 PSAQ-ViT V2: Towards Accurate and General Data-Free Quantization for Vision Transformers
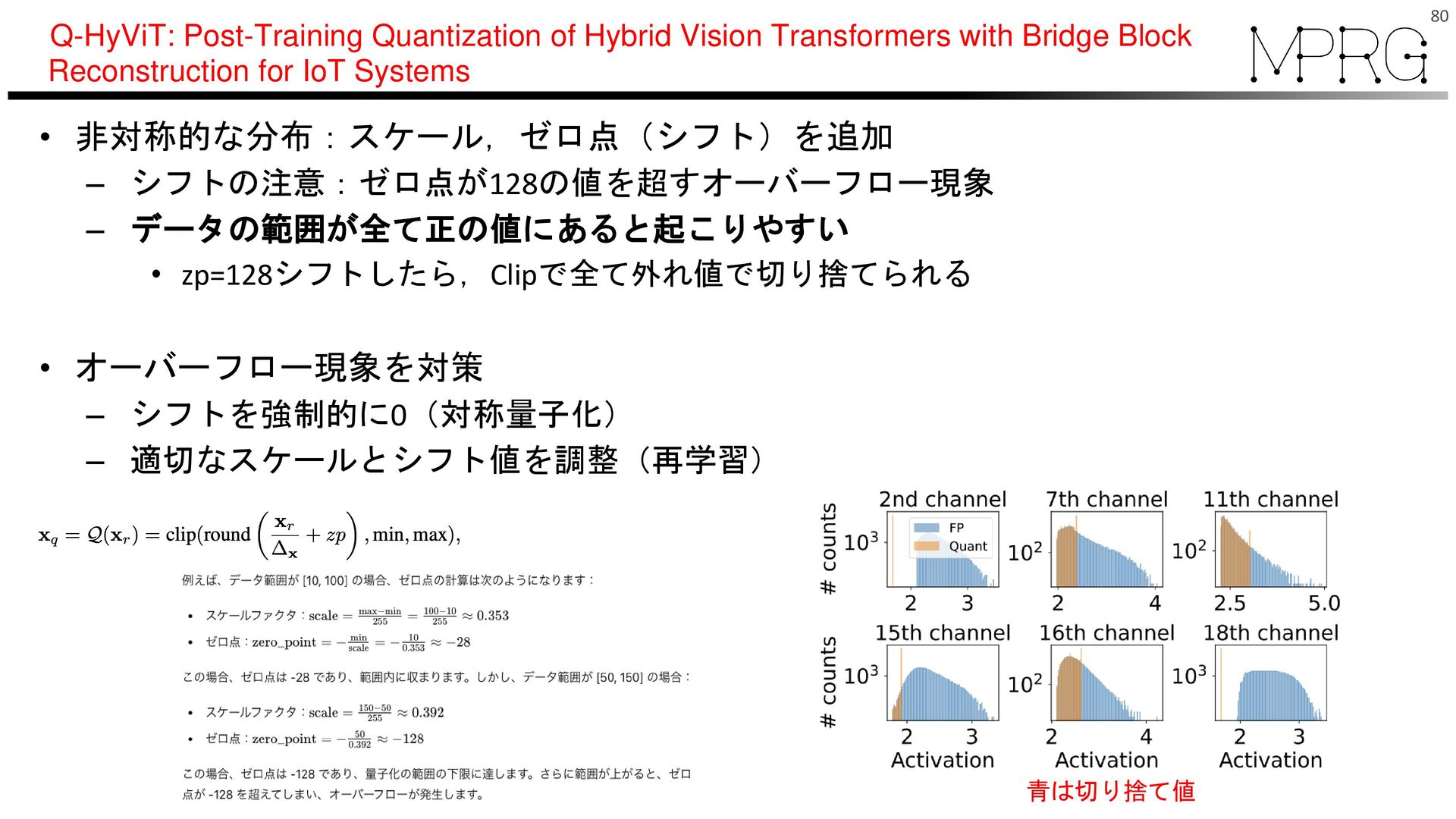
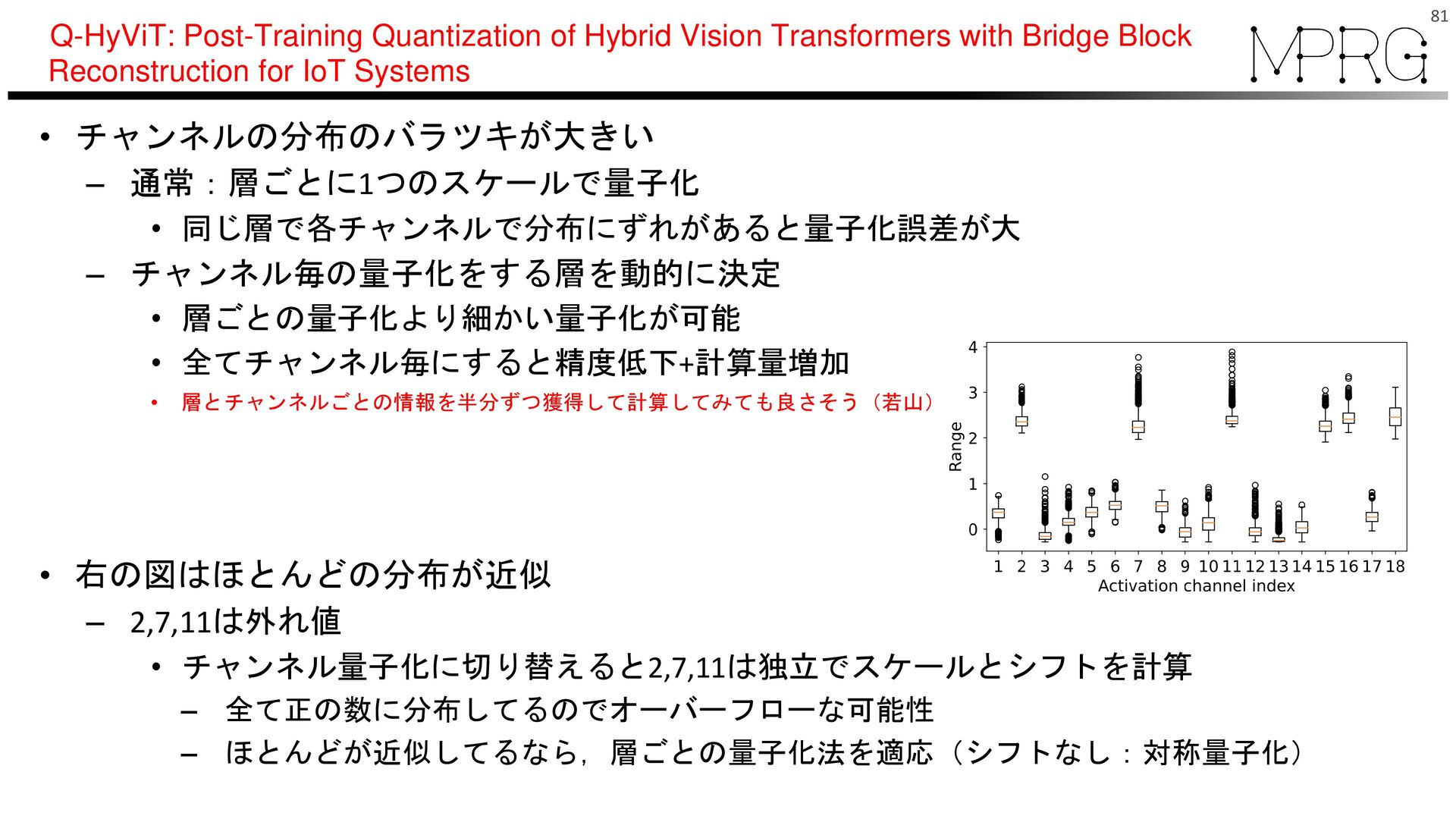
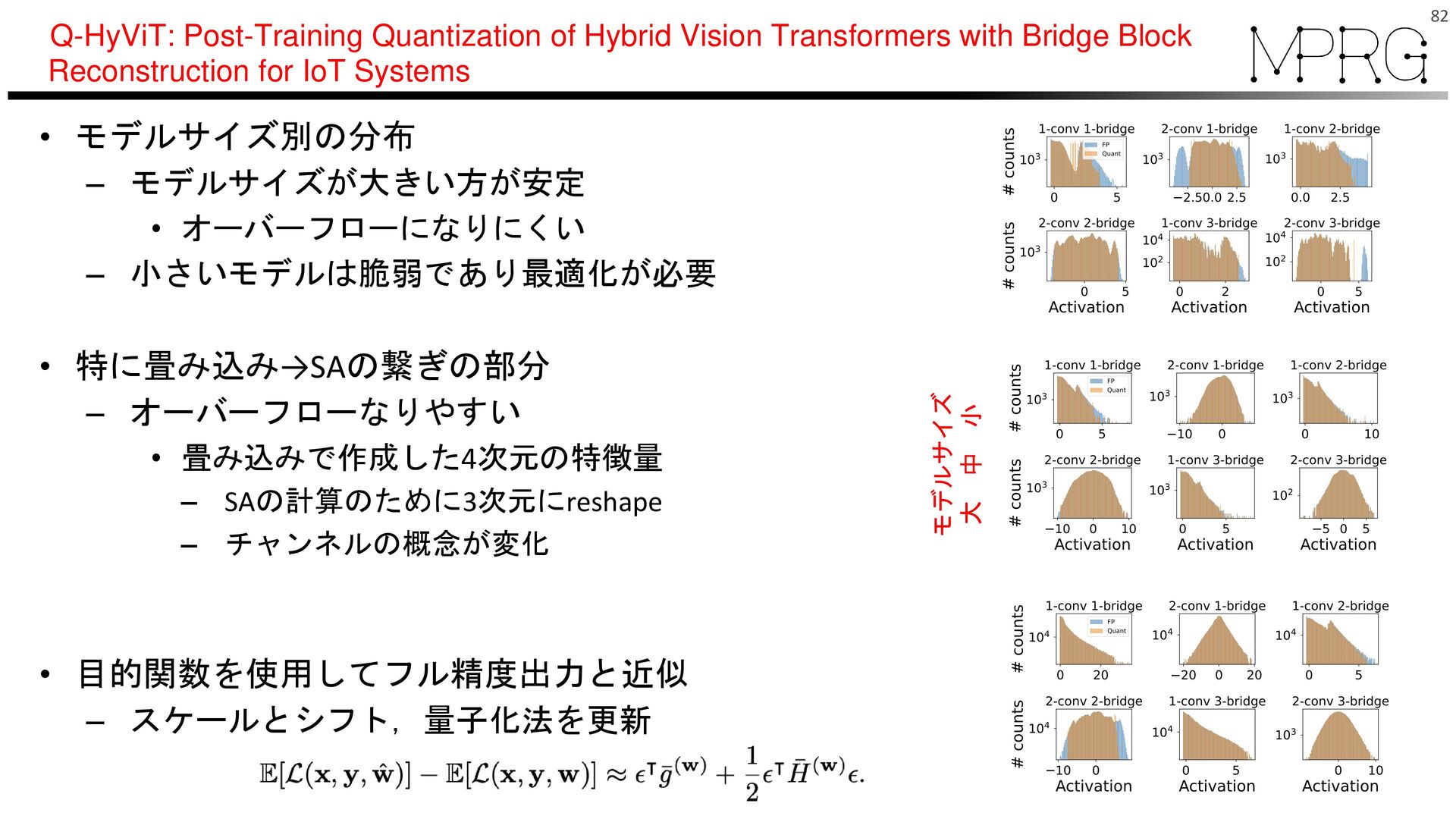
– シフトを強制的に0(対称量子化) – 適切なスケールとシフト値を調整(再学習) 80 青は切り捨て値 Q-HyViT: Post-Training Quantization of Hybrid Vision Transformers with Bridge Block Reconstruction for IoT Systems
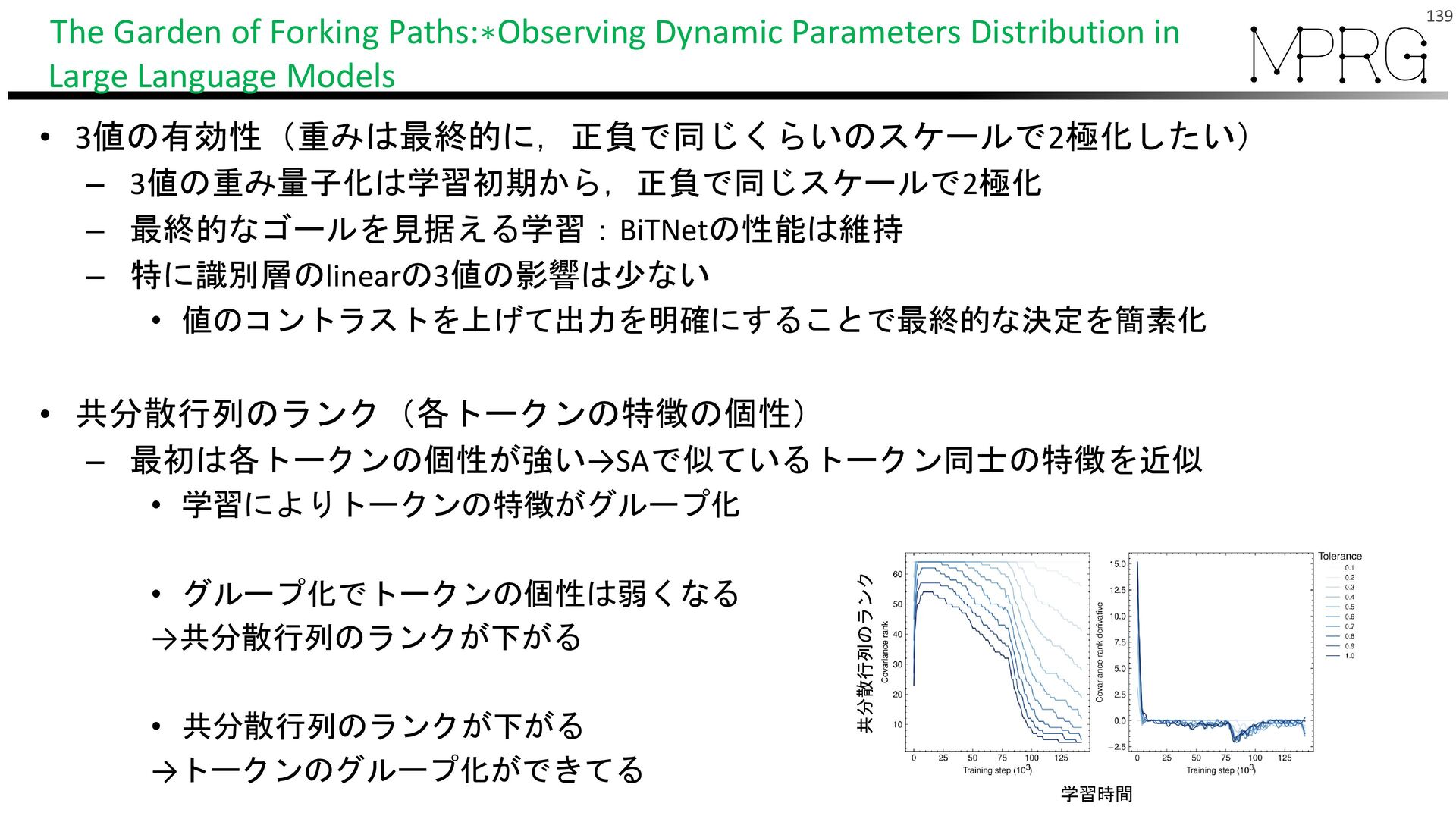
• 共分散行列のランク(各トークンの特徴の個性) – 最初は各トークンの個性が強い→SAで似ているトークン同士の特徴を近似 • 学習によりトークンの特徴がグループ化 • グループ化でトークンの個性は弱くなる →共分散行列のランクが下がる • 共分散行列のランクが下がる →トークンのグループ化ができてる 139 The Garden of Forking Paths:∗Observing Dynamic Parameters Distribution in Large Language Models 共分散行列のランク 学習時間
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
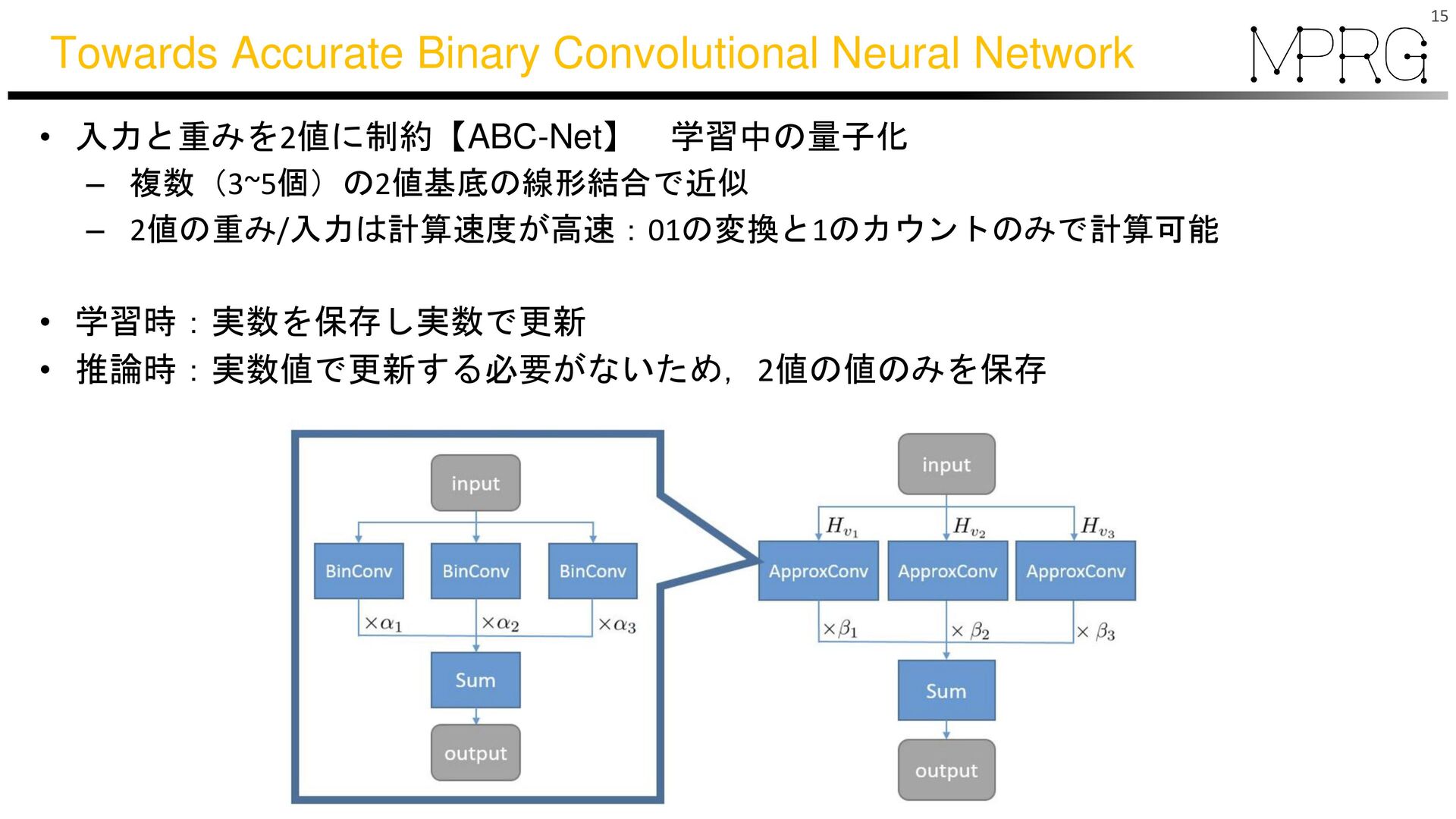{kind=link}
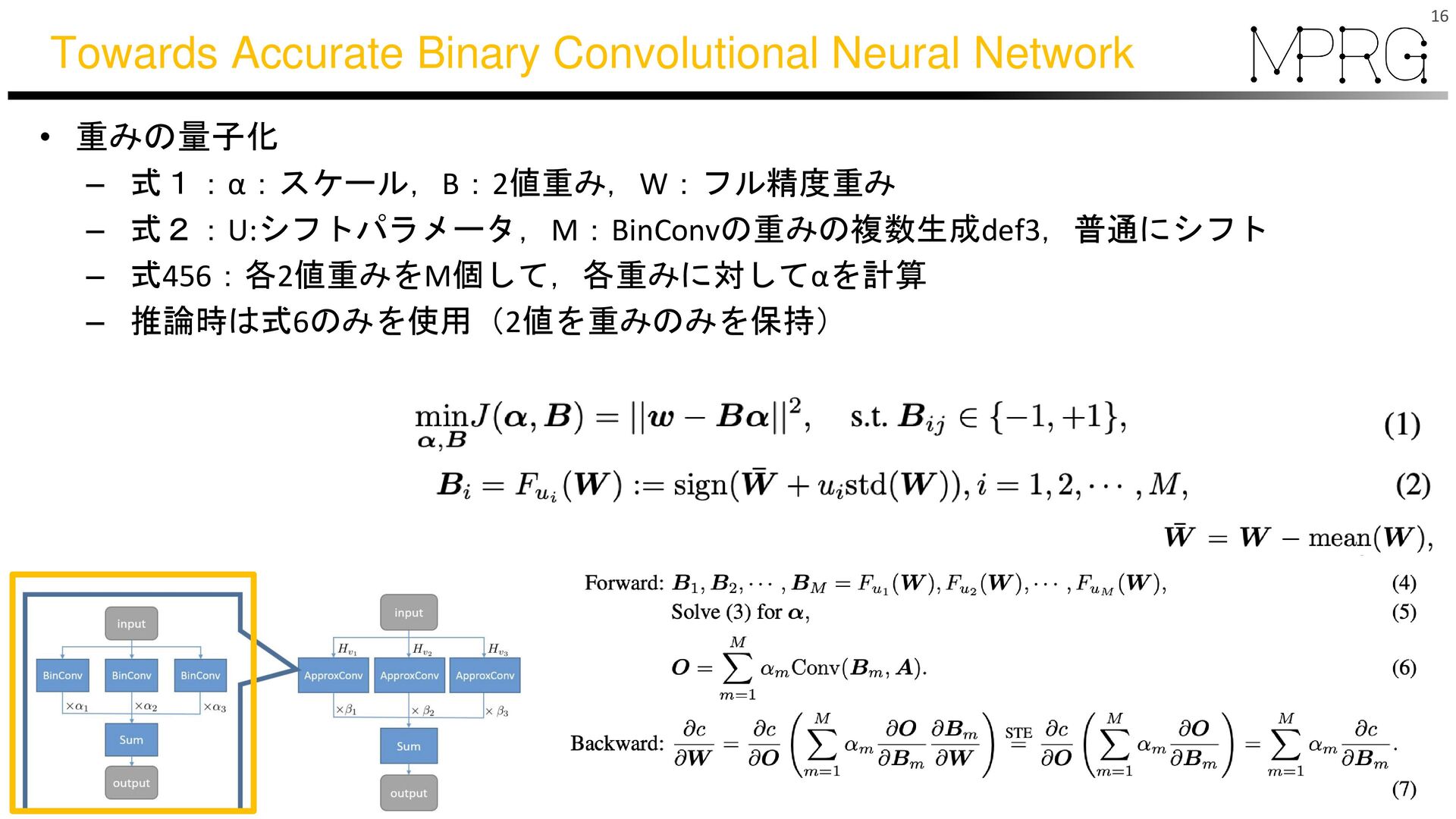{kind=link}
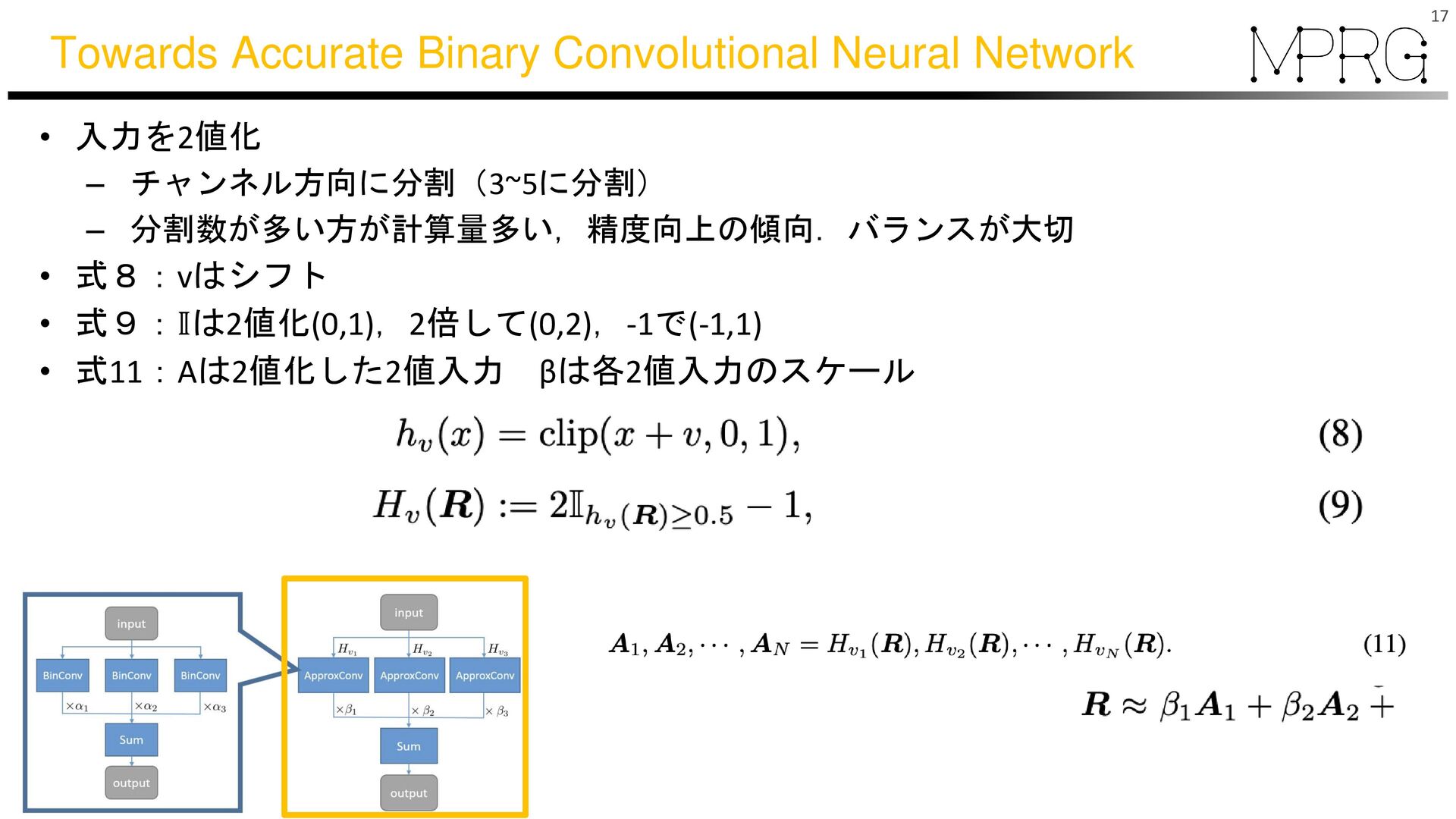{kind=link}
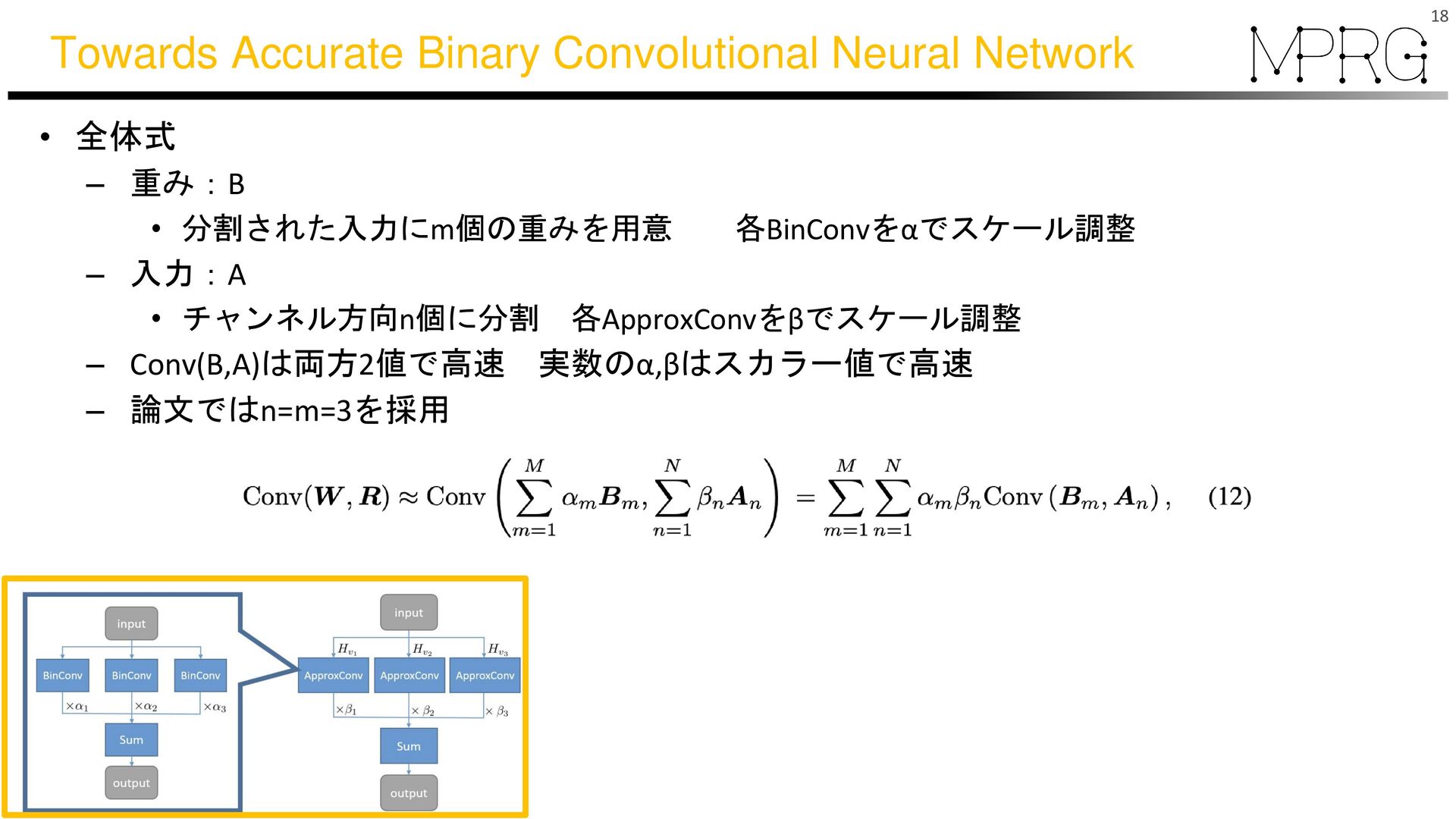{kind=link}
{kind=link}
{kind=link}
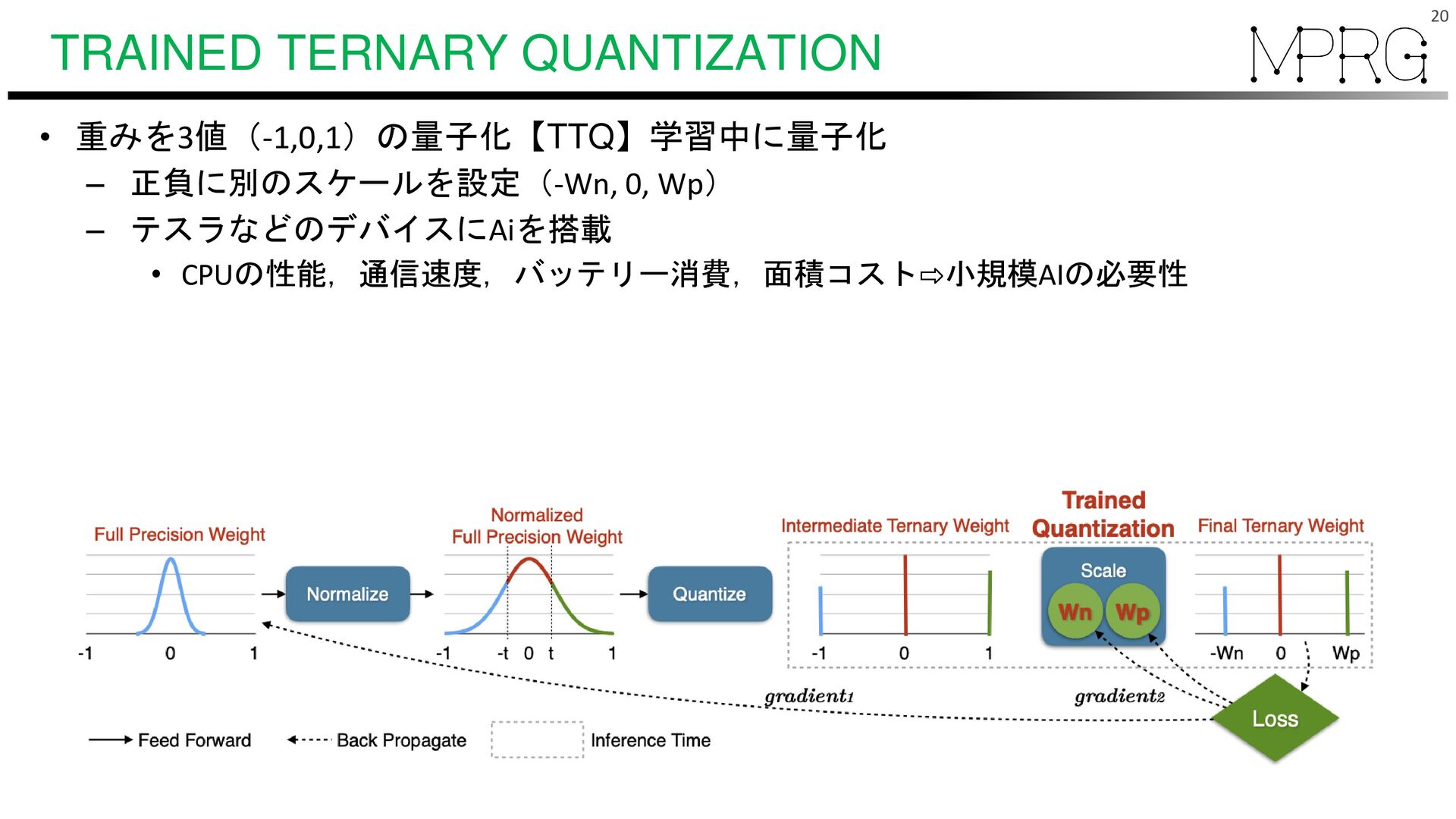
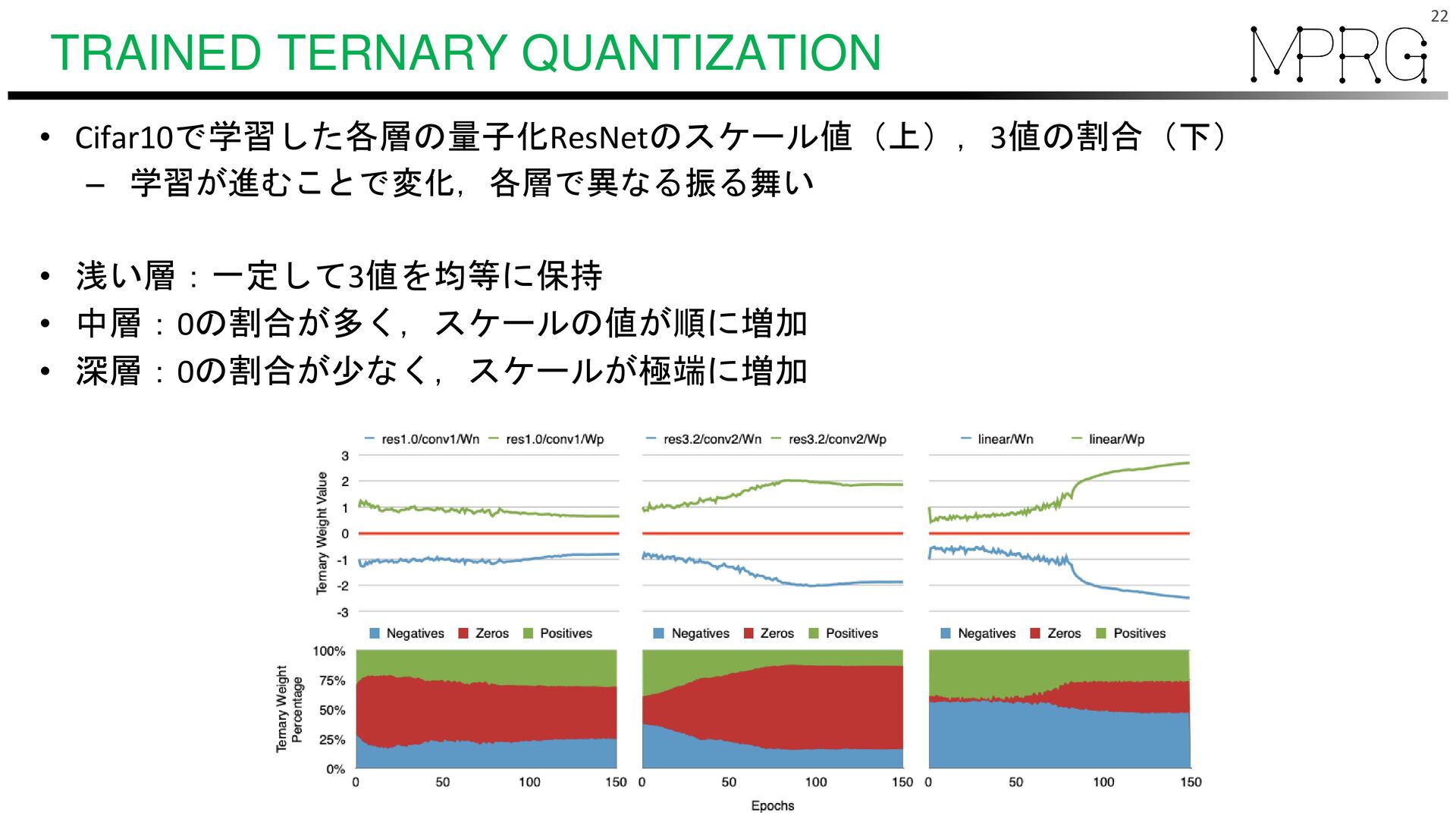
![TRAINED TERNARY QUANTIZATION • 各重みの最大値で割る⇨[-1,1]の範囲に正規化 • 閾値処理t(ハイパラ)で重みを[-1,0,1]に量子化 • スケール(WpとWn)でスケール •](https://files.speakerdeck.com/presentations/ae067b4761414c509b03d07a60f91eb6/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
![Ternary Neural Networks with Fine-Grained Quantization • 入力を8,4bitに重みを3値化[-a,0,+a] 【FGQ】学習後の量子化 –](https://files.speakerdeck.com/presentations/ae067b4761414c509b03d07a60f91eb6/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
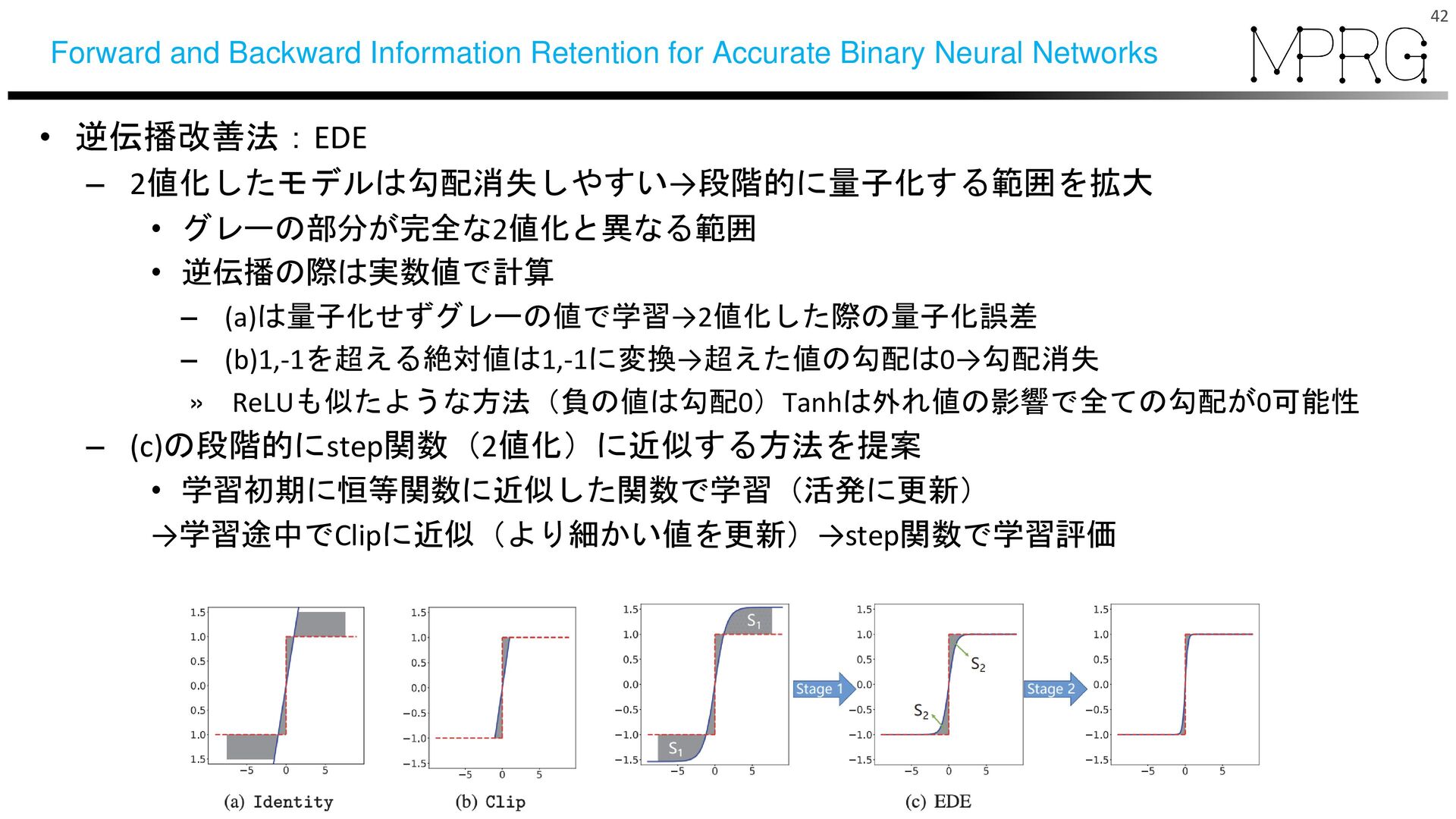{kind=link}
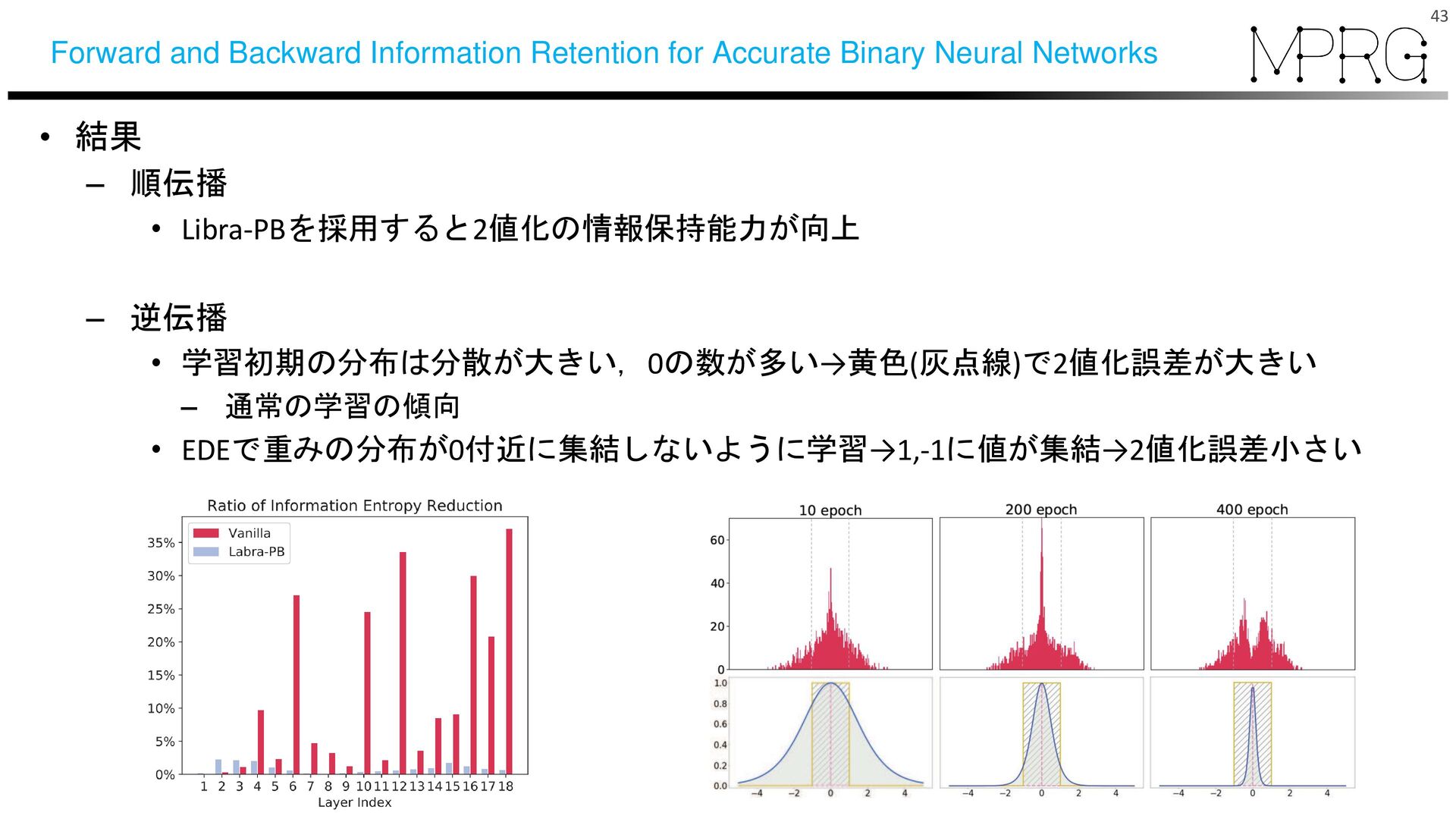{kind=link}
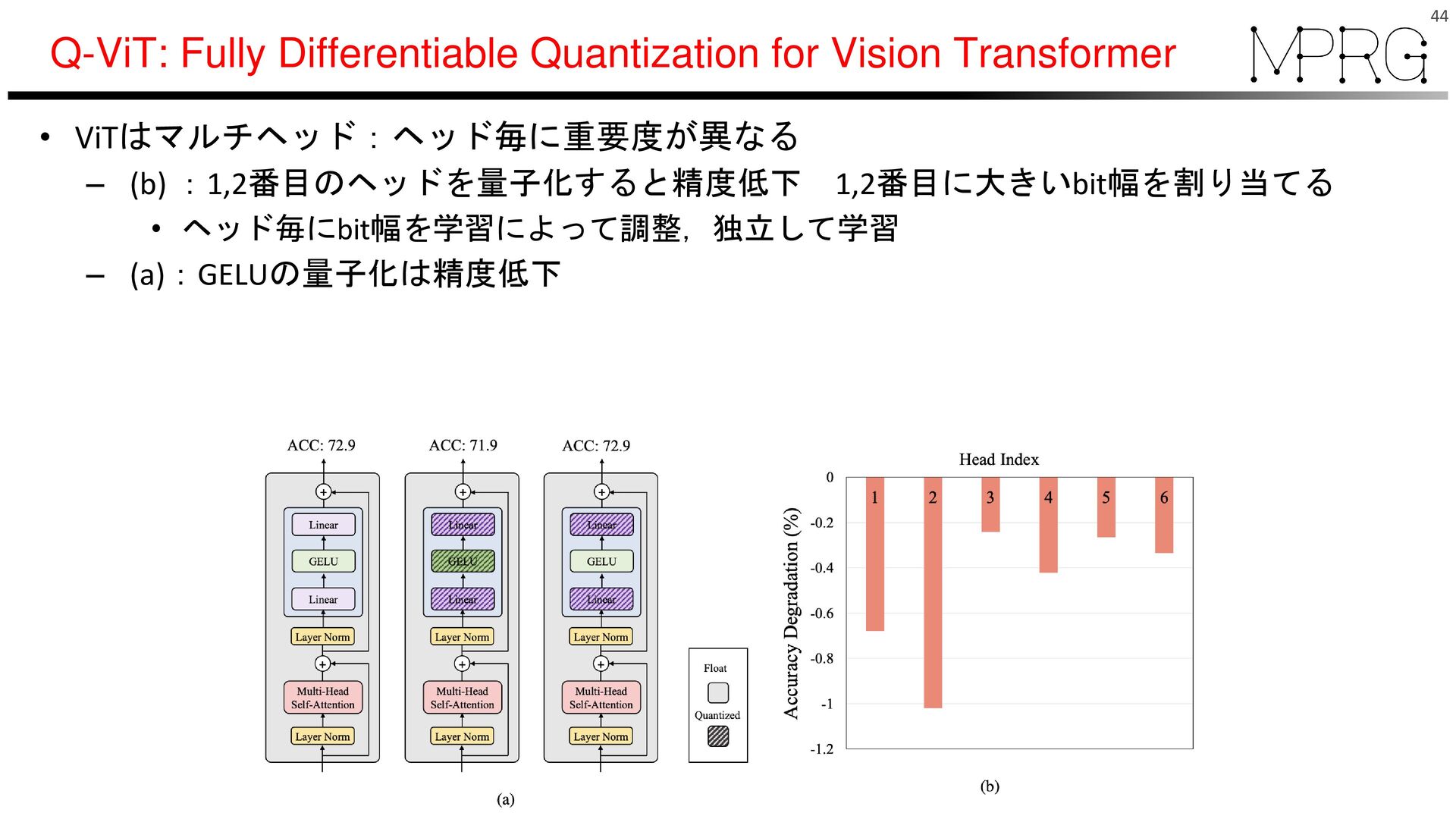{kind=link}
{kind=link}
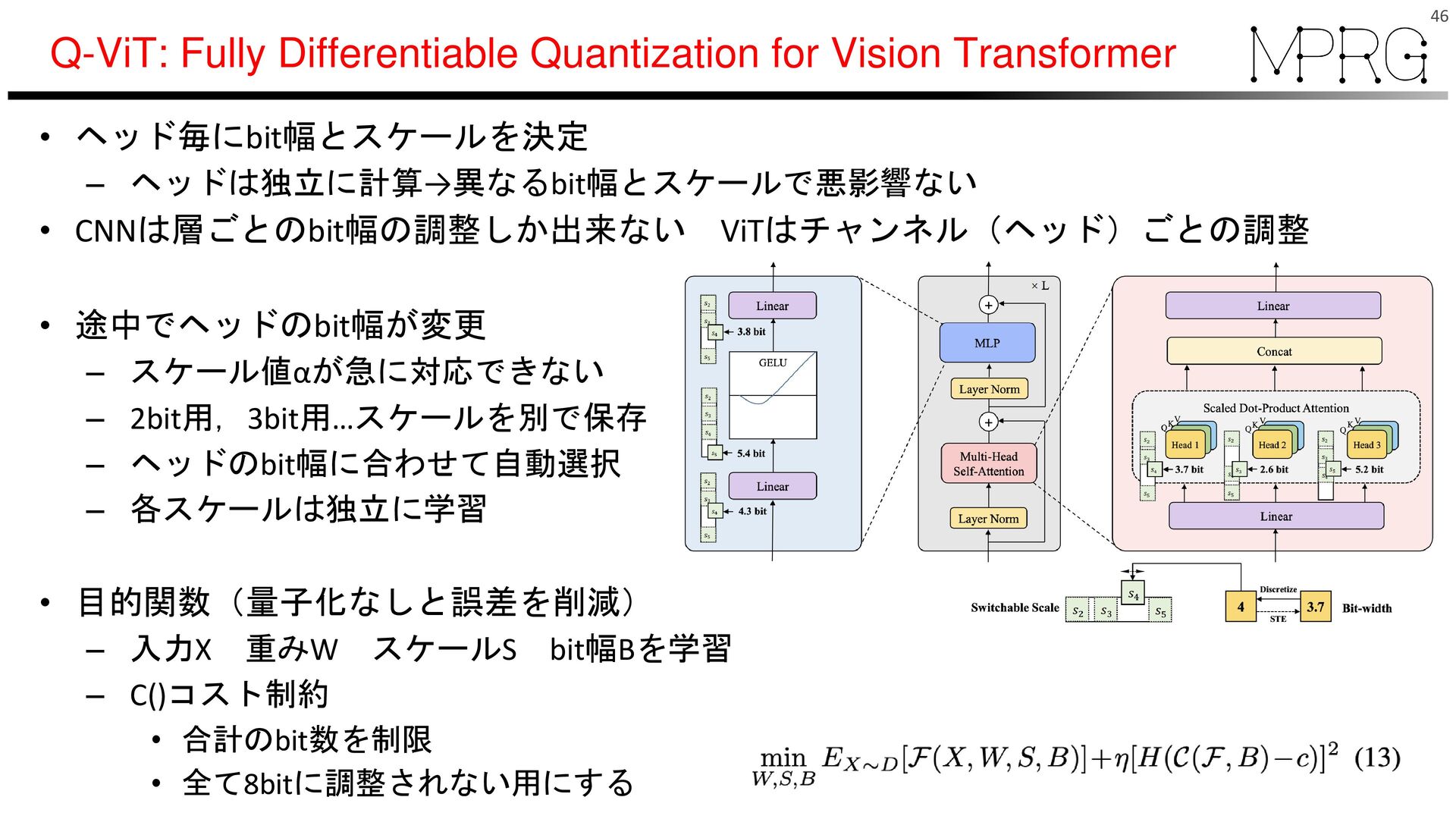{kind=link}
{kind=link}
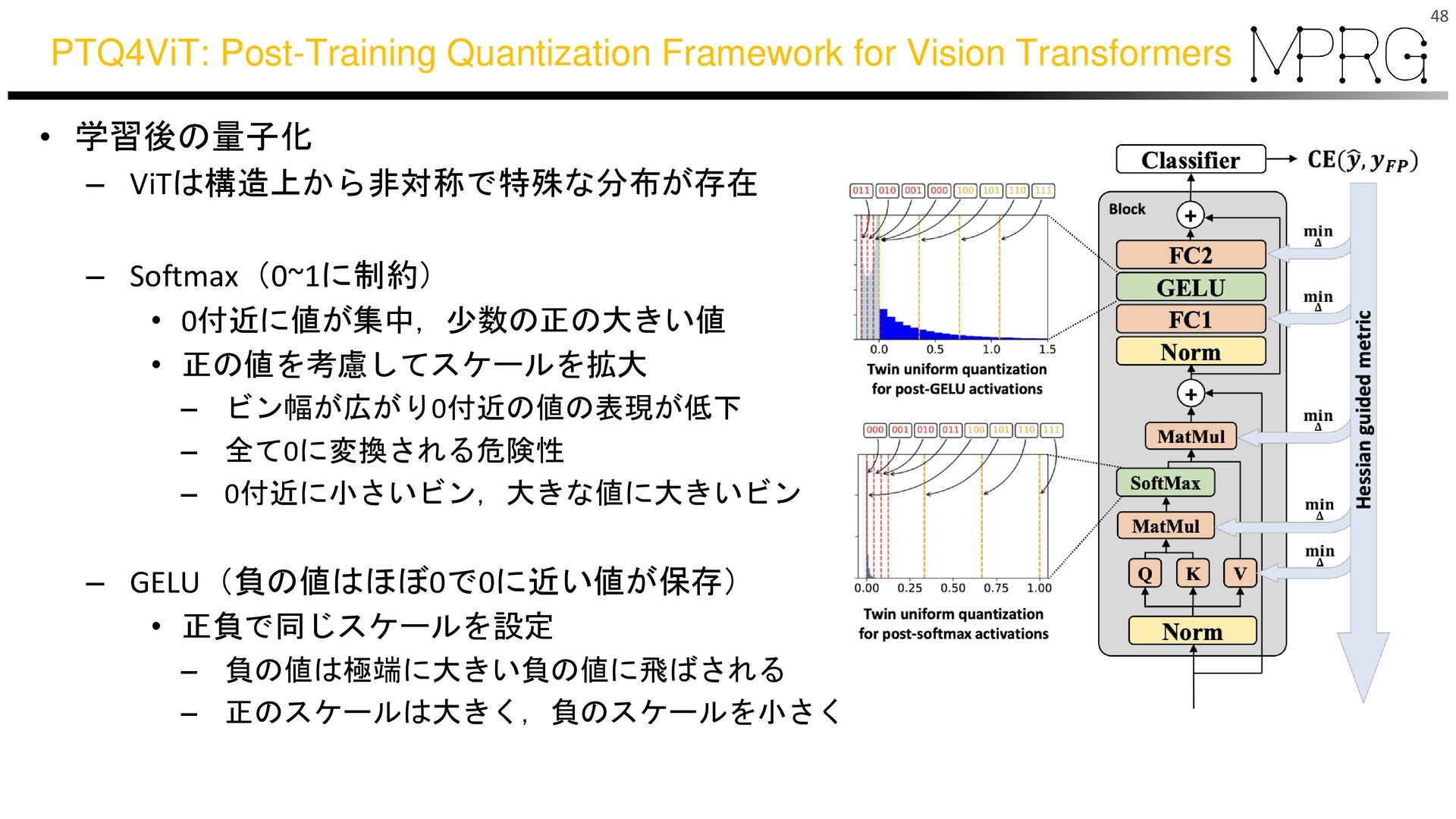{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
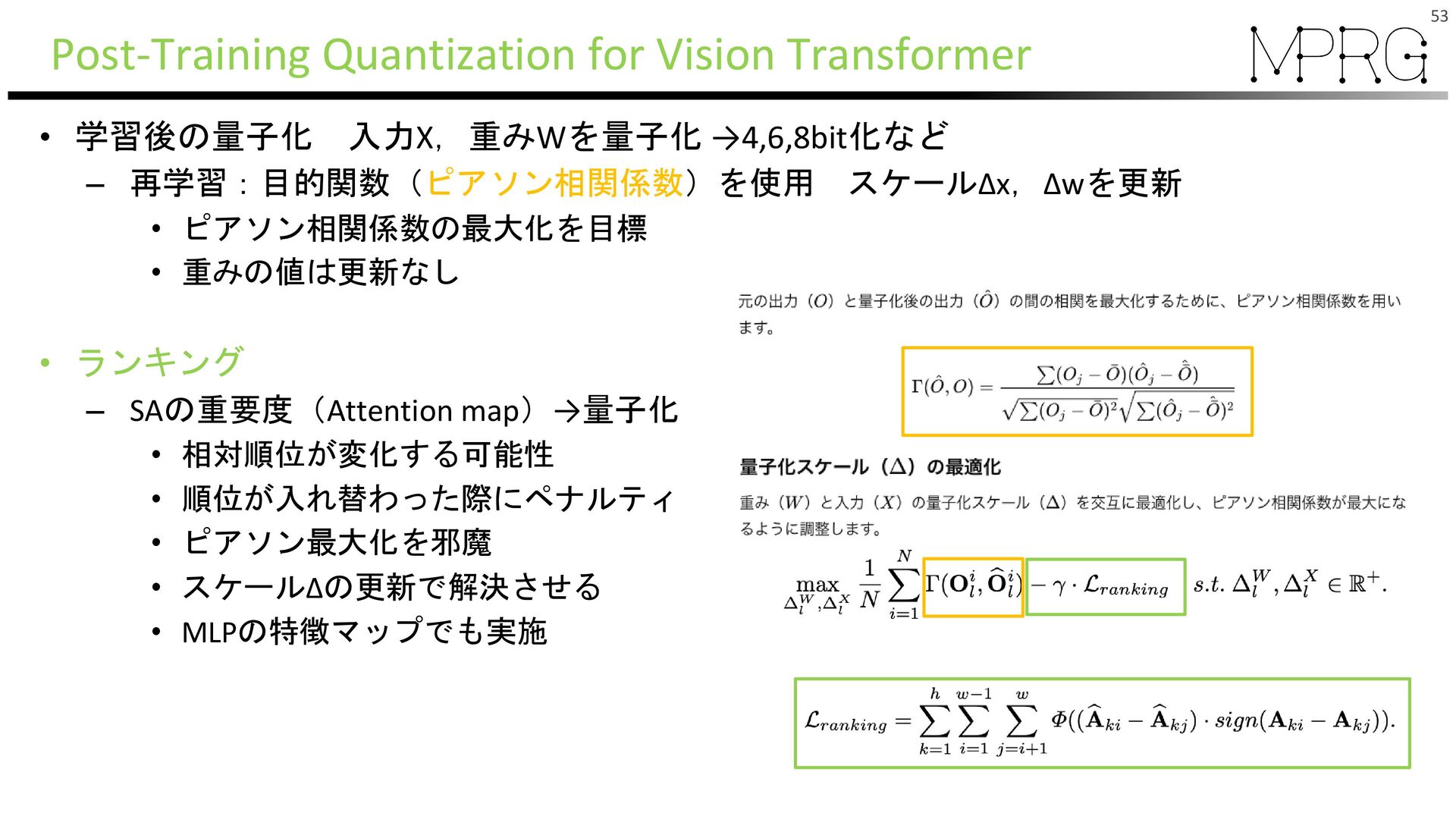{kind=link}
{kind=link}
{kind=link}
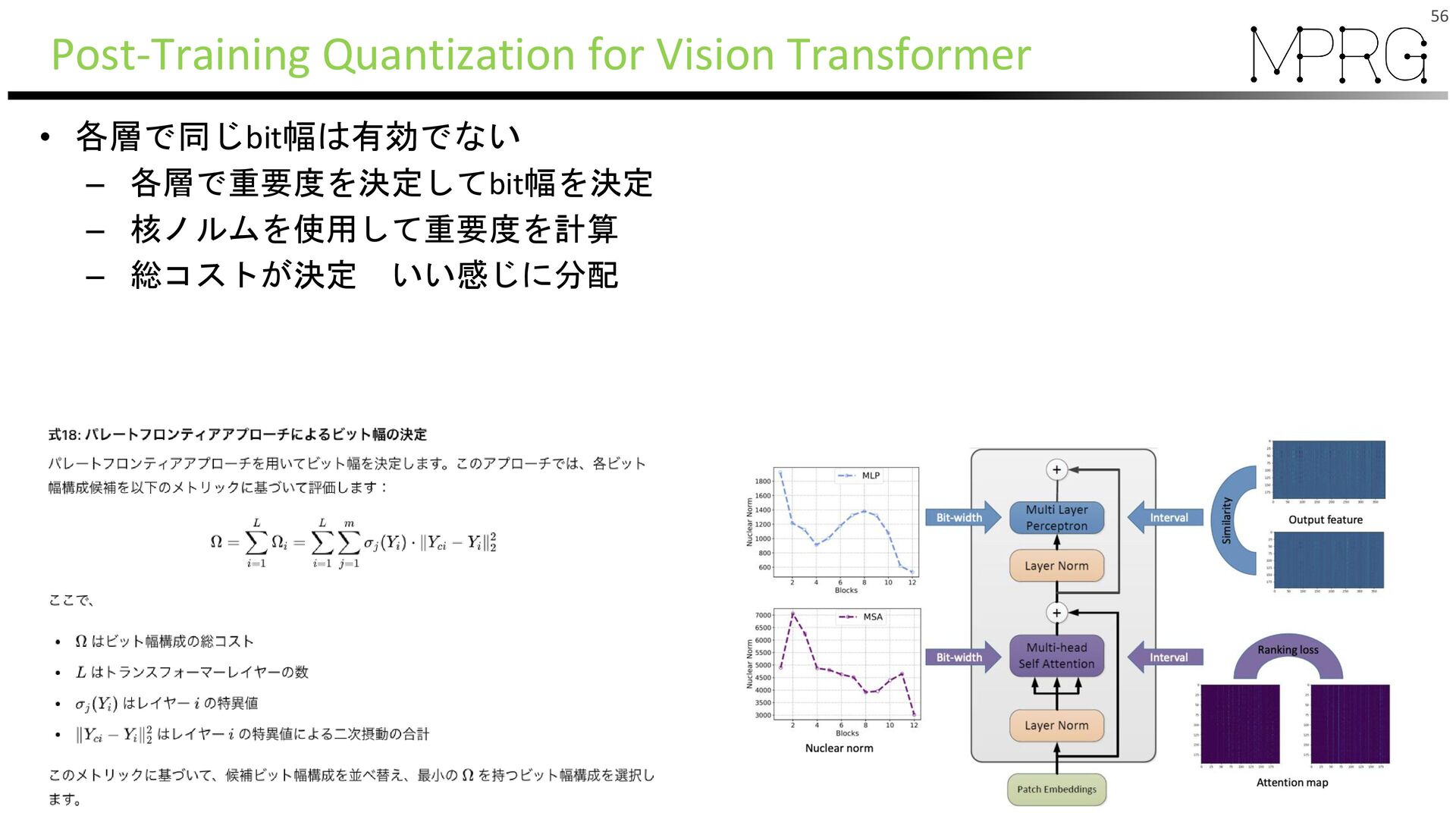{kind=link}
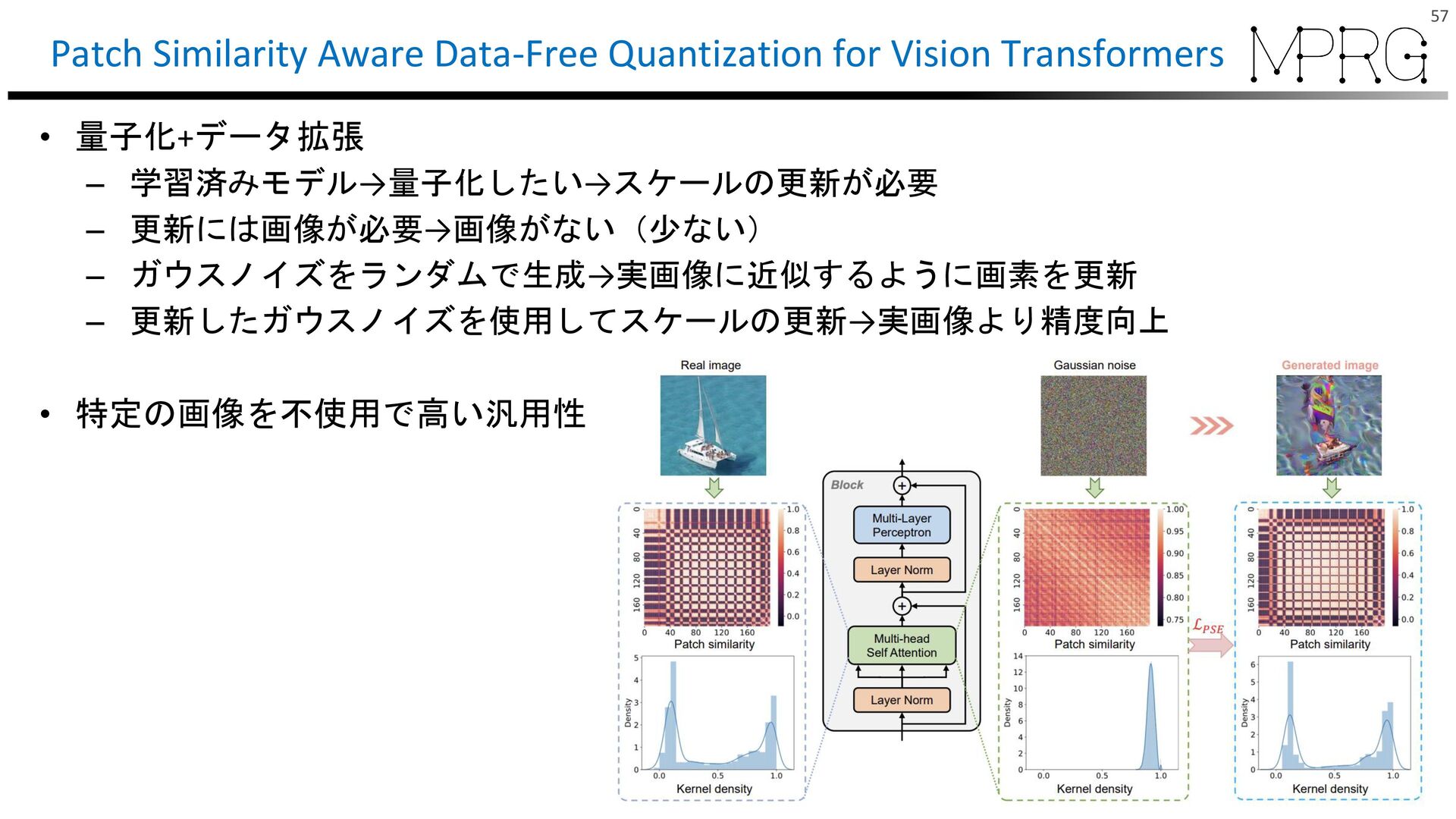{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• 学習可能なシフトとスケール • [-1~127]の分布→4bit[0~64] • シフトβ=1 – [-1~127]+1→[0~128] • スケールs=0.5](https://files.speakerdeck.com/presentations/ae067b4761414c509b03d07a60f91eb6/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
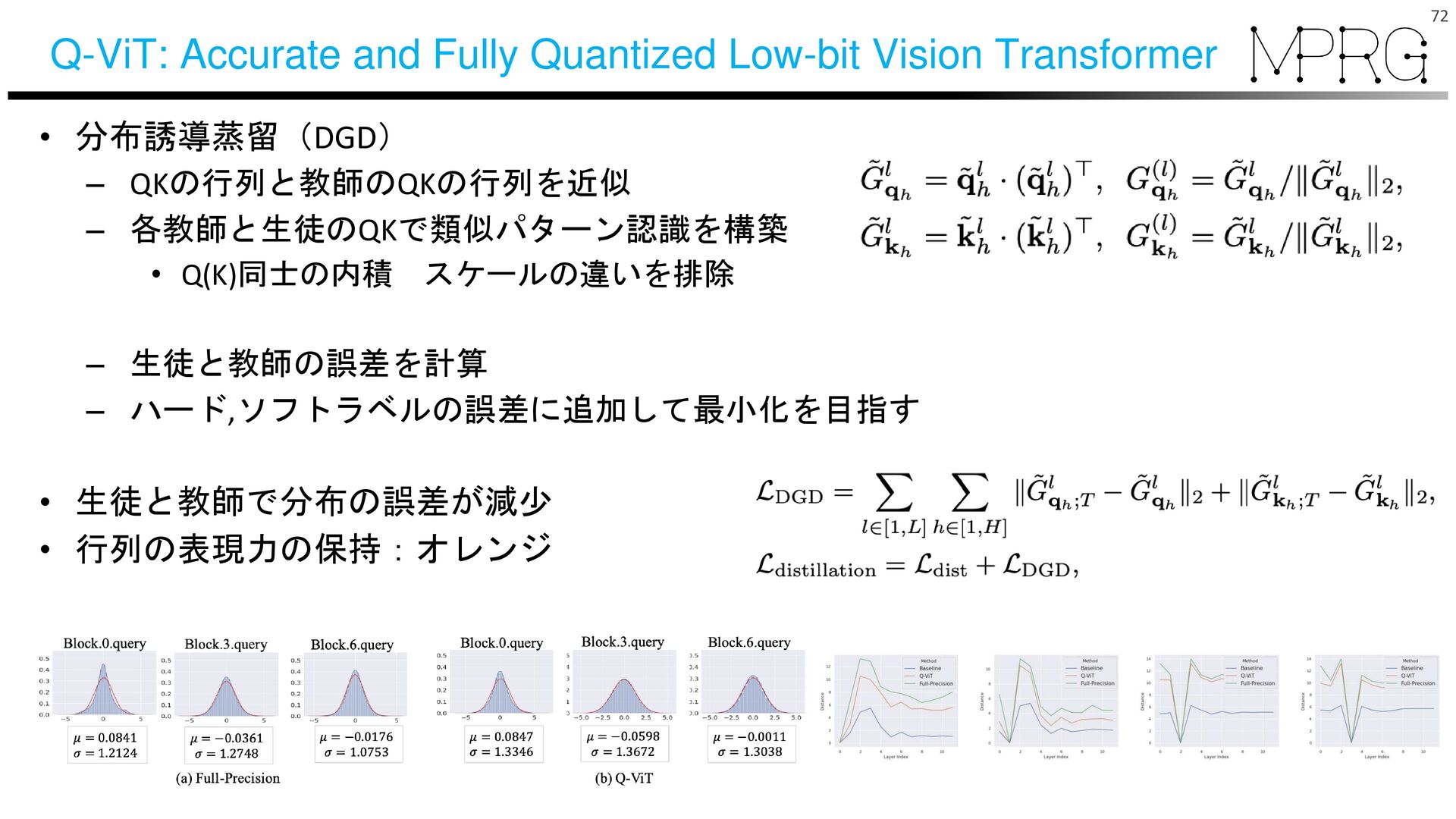{kind=link}
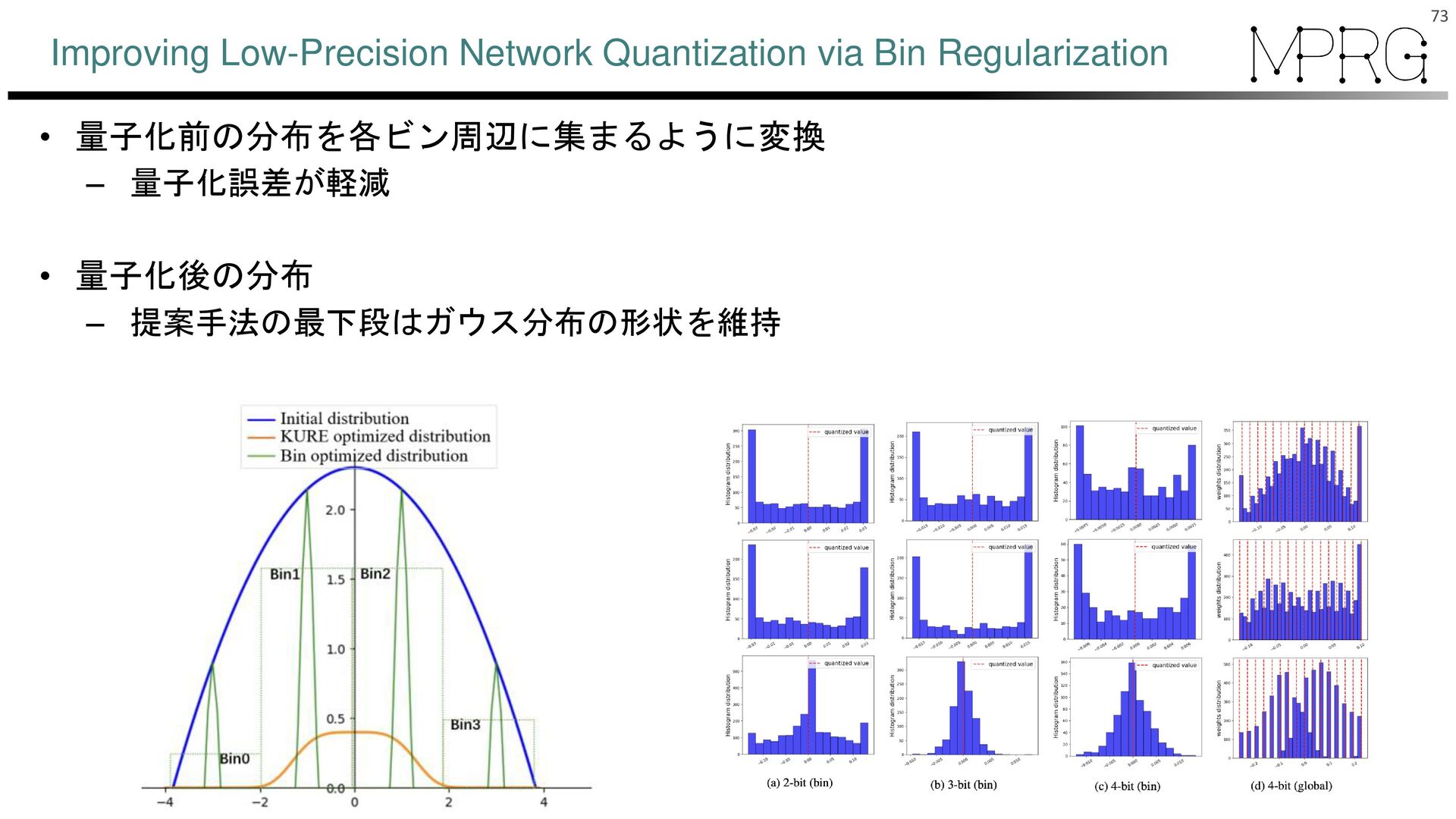{kind=link}
{kind=link}
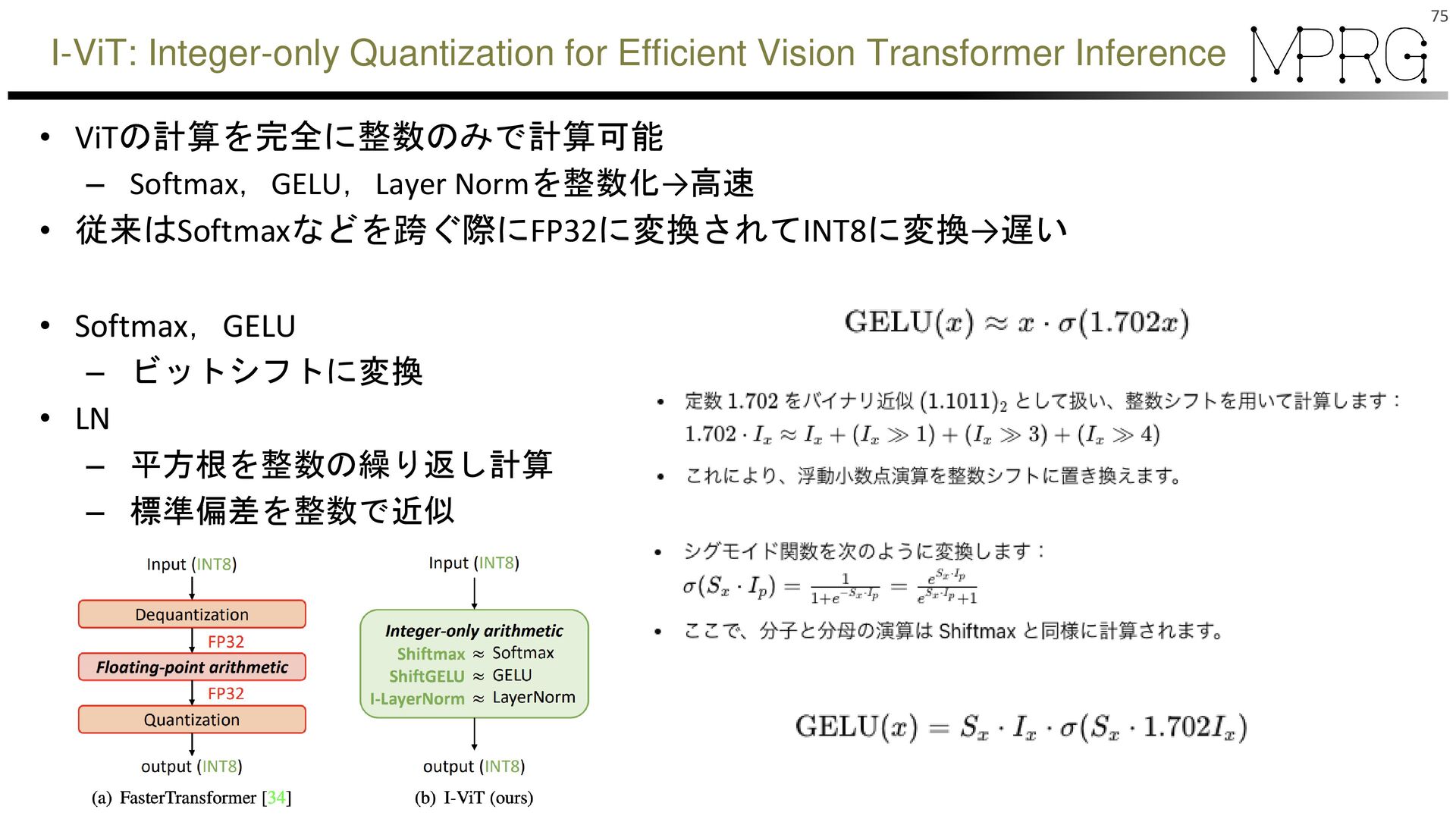{kind=link}
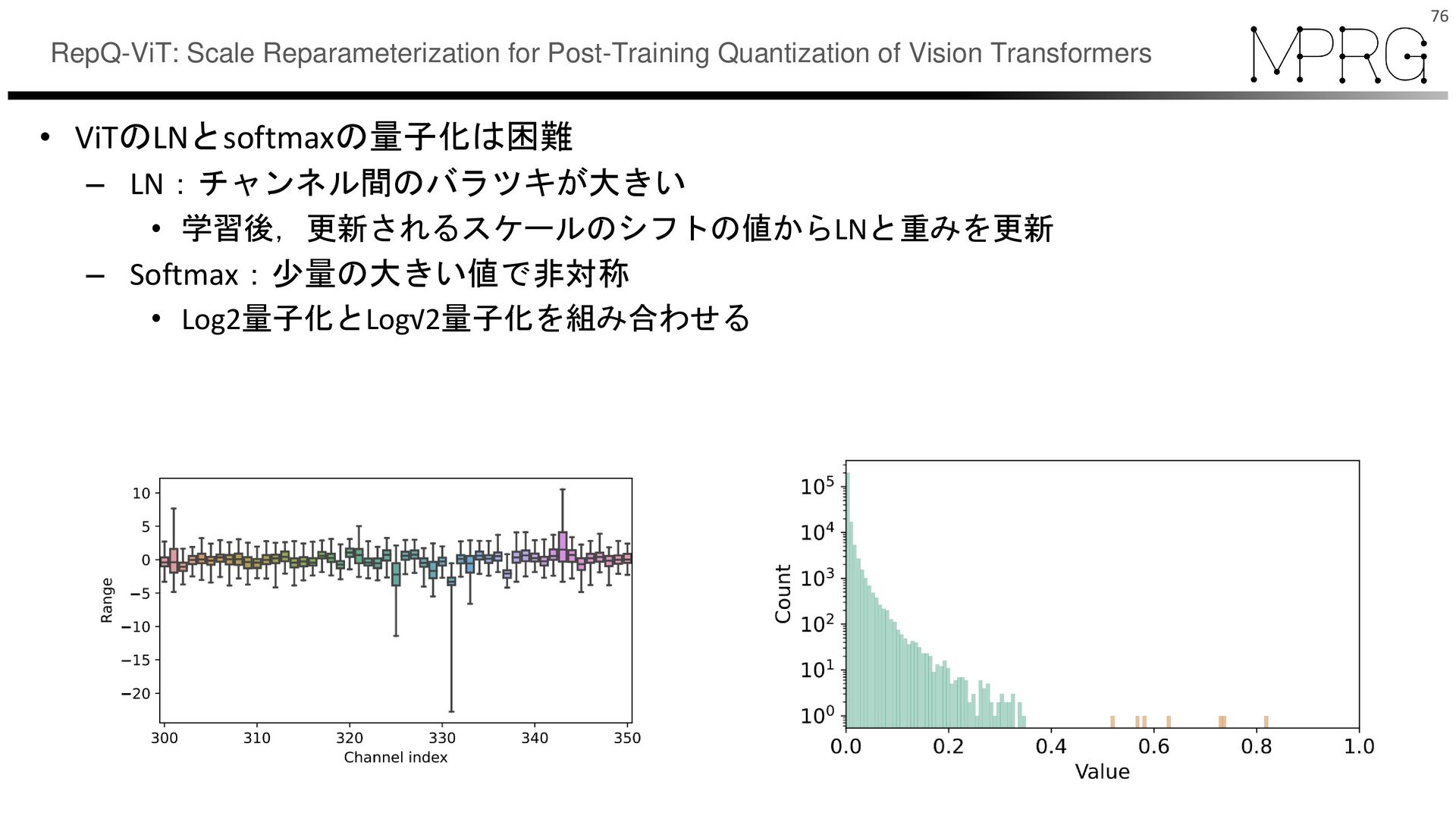{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
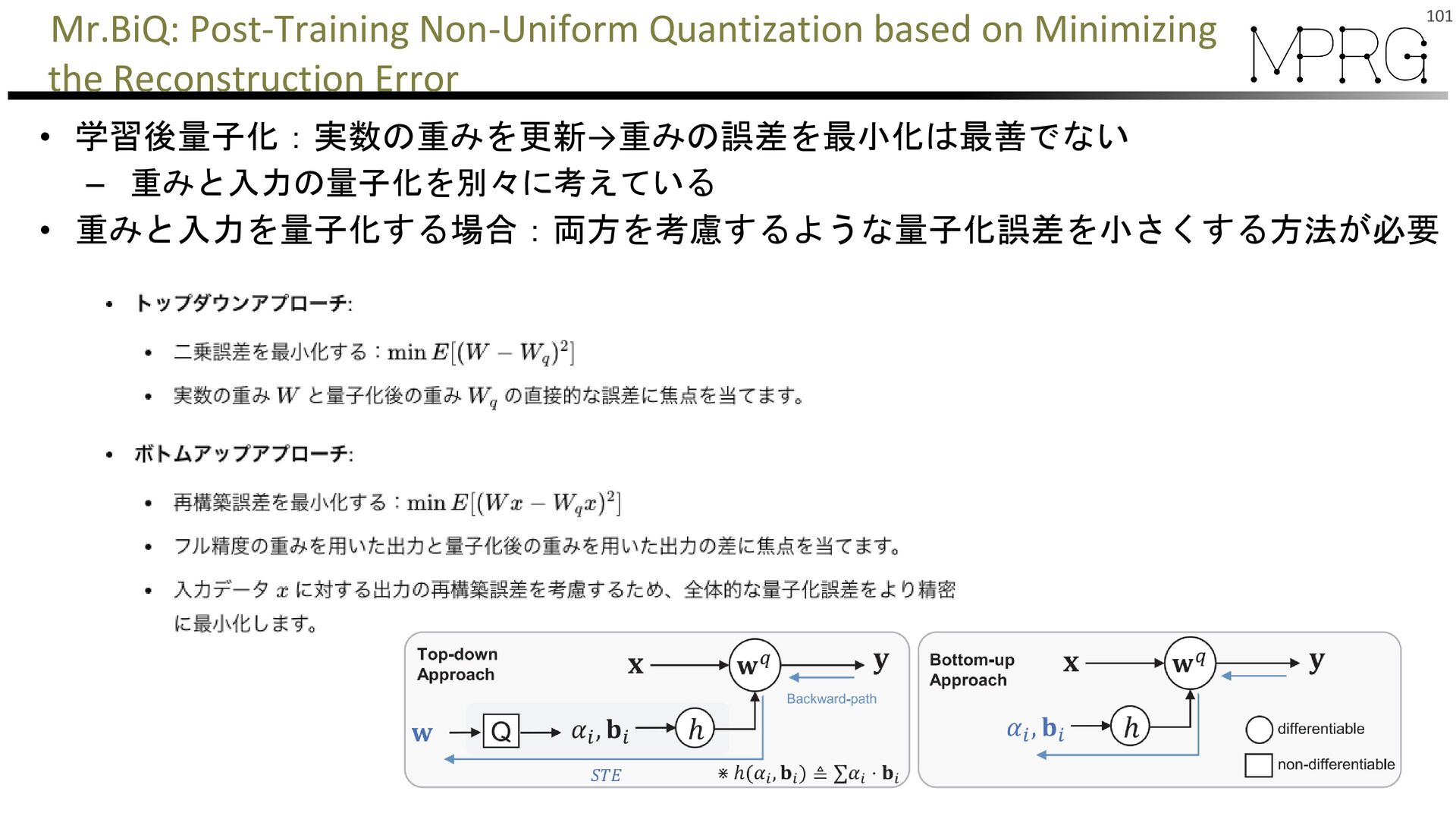{kind=link}
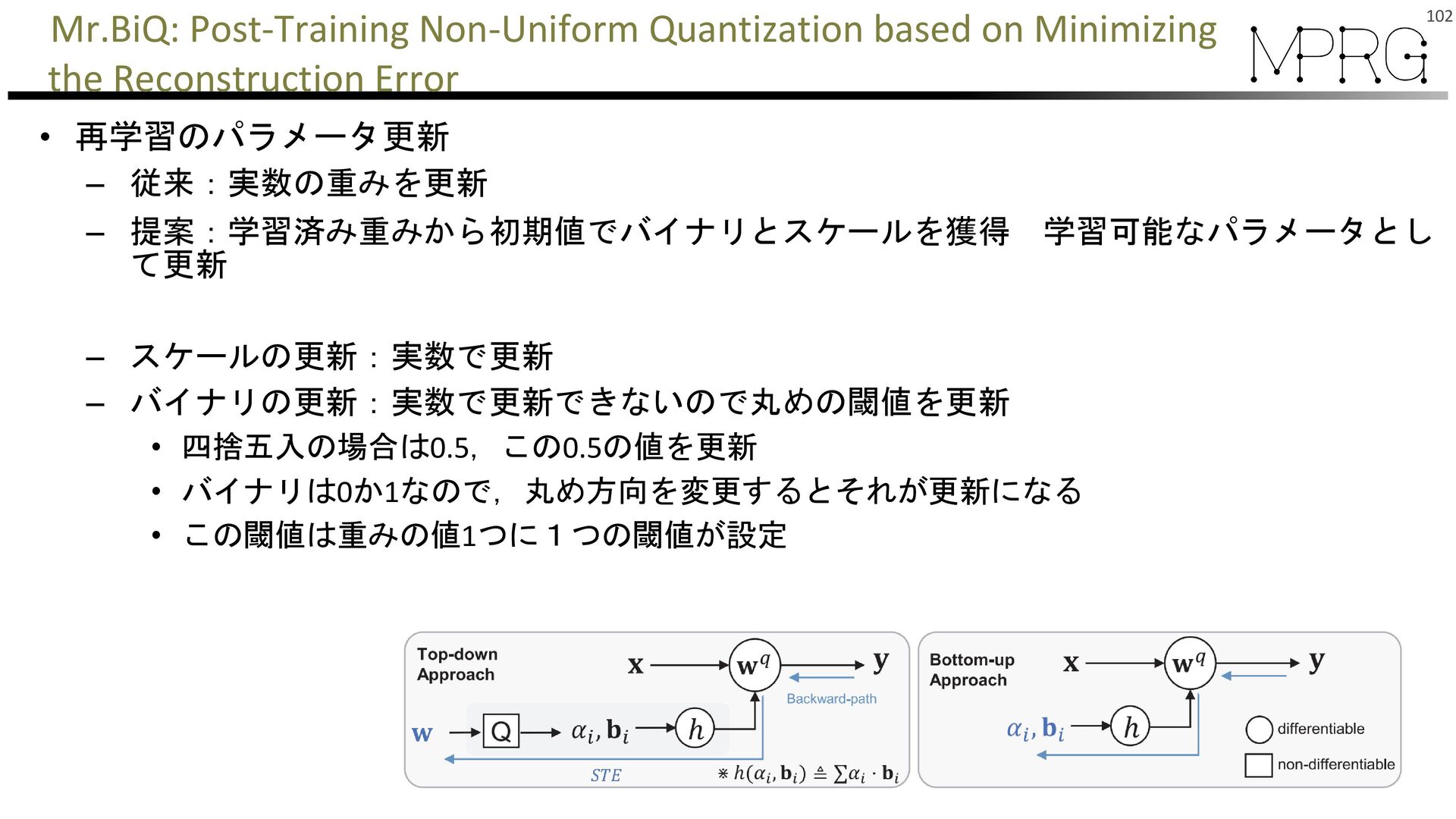{kind=link}
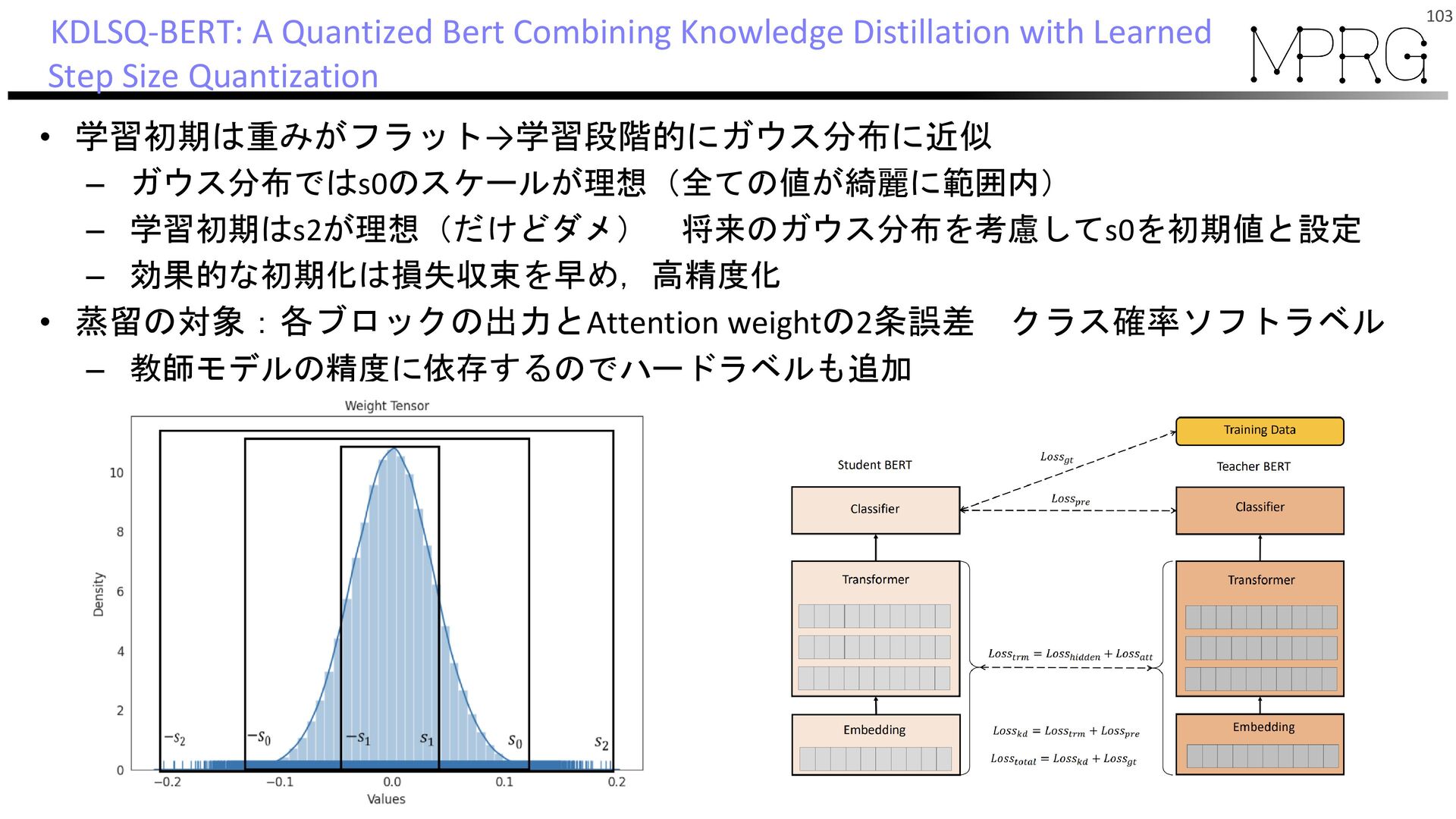{kind=link}
{kind=link}
![A White Paper on Neural Network Quantization[サーベイ] • 畳み込みの入力のチャンネル毎の量子化が困難 –](https://files.speakerdeck.com/presentations/ae067b4761414c509b03d07a60f91eb6/slide_104.jpg){kind=link}
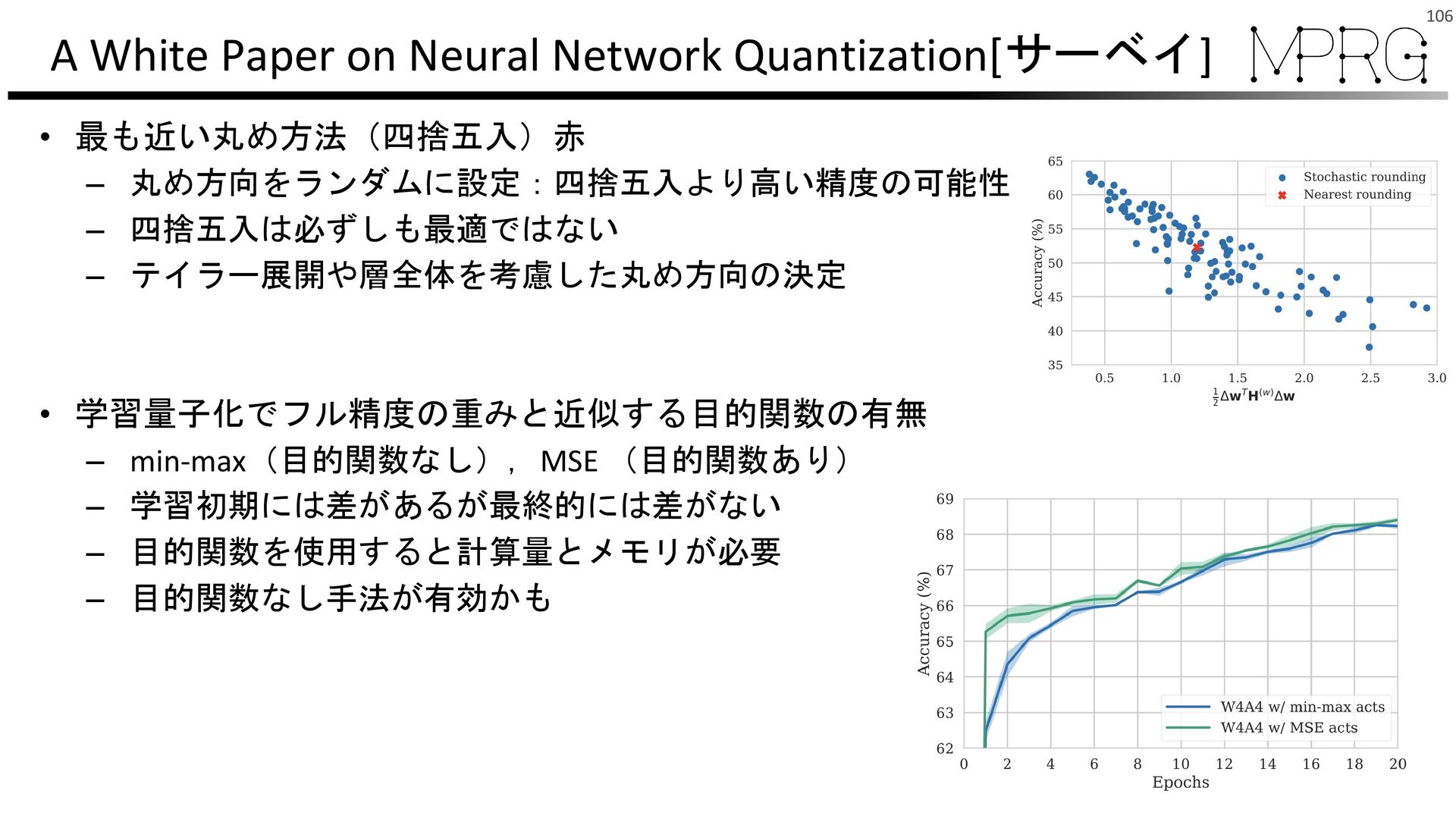{kind=link}
{kind=link}
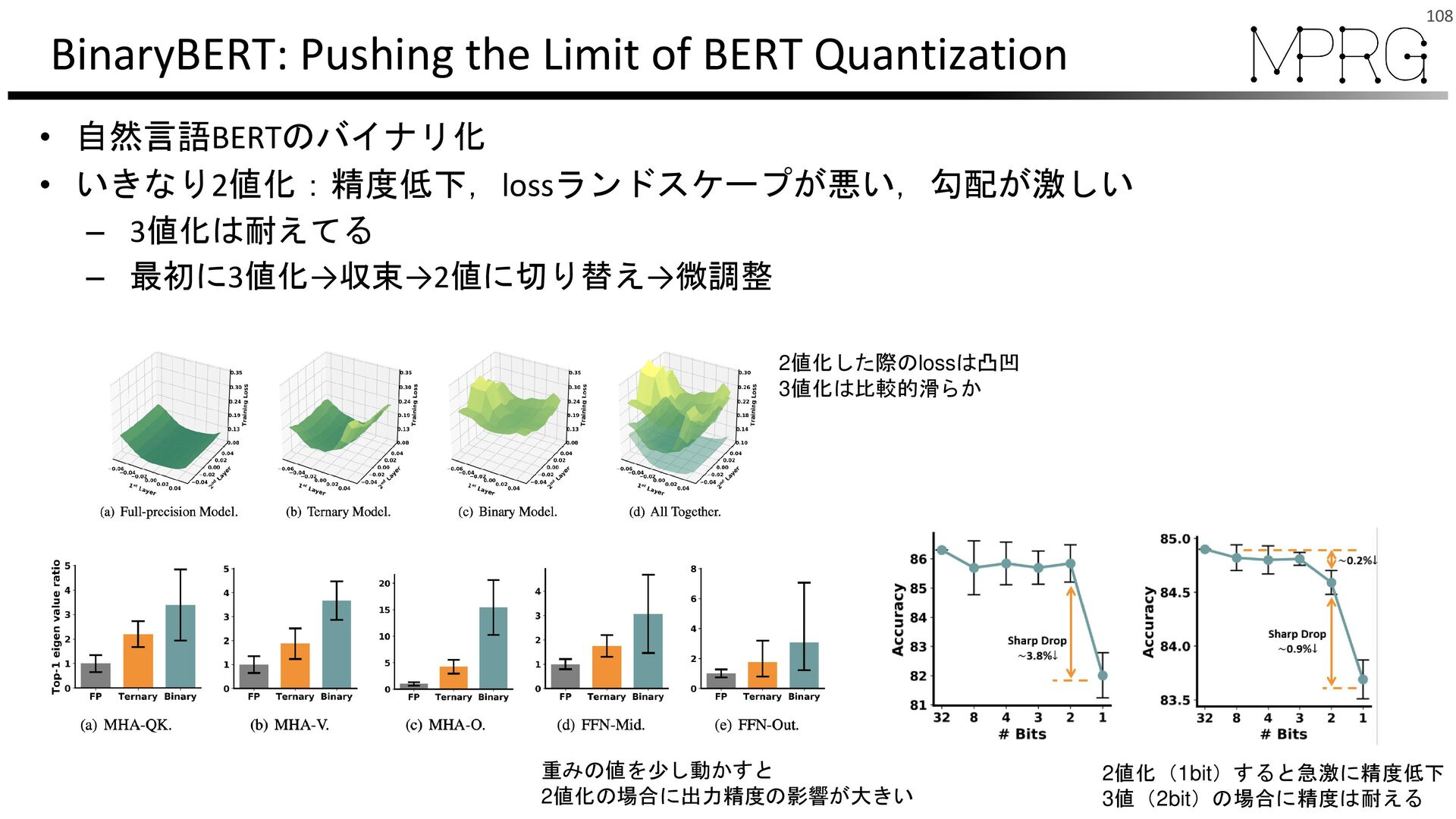{kind=link}
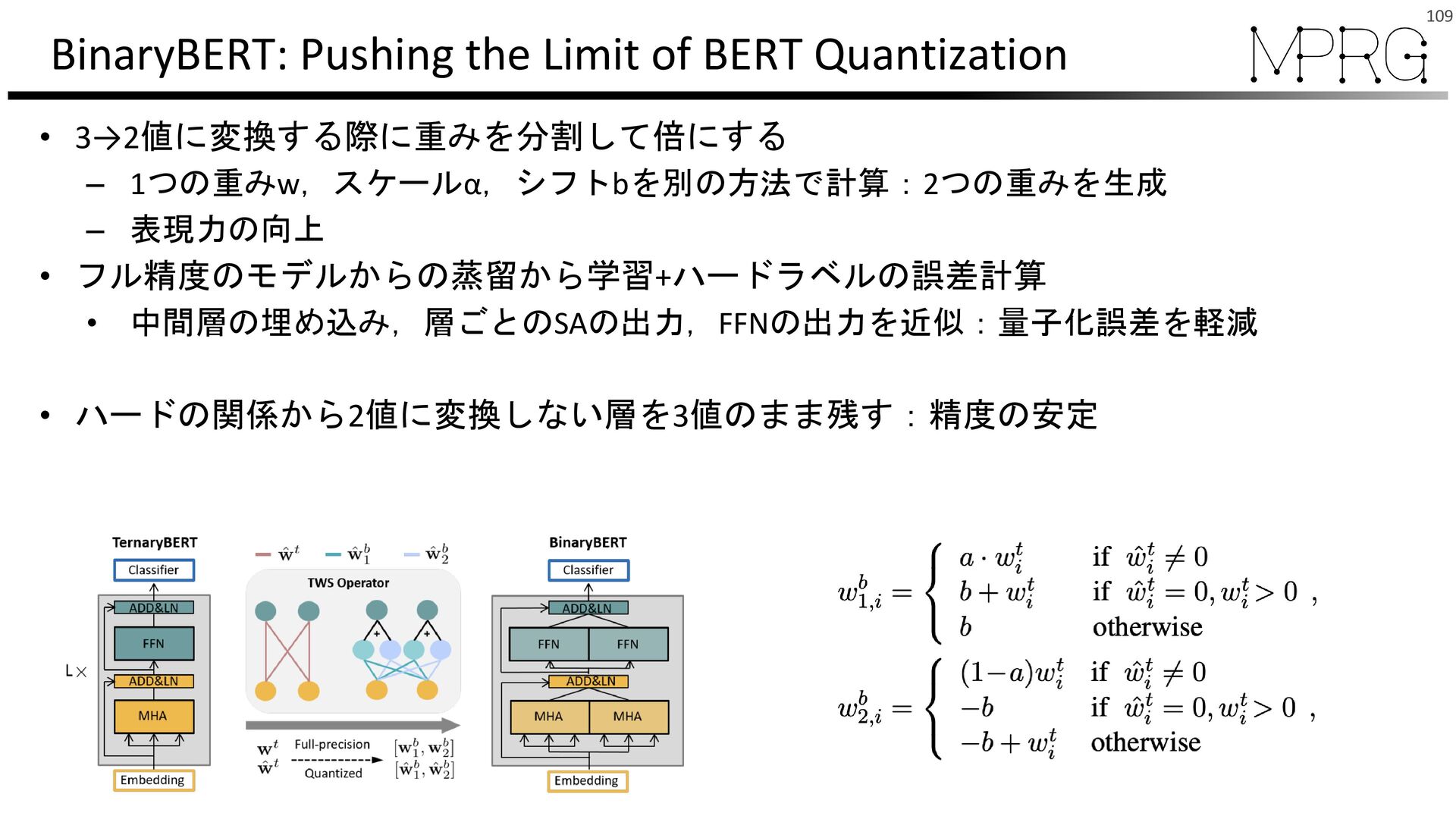{kind=link}
{kind=link}
![• 分布範囲の異なる同士で量子化:量子化誤差拡大 – 範囲が広い→ビンの間隔が広い:特定範囲に集中している場合に少ないビンの割り当て – 範囲が狭い→ビンの間隔が狭い:範囲外の値はClipで切り捨てられる • 外れ値が発生するのはごく僅か – [SEP]が外れ値になりやすい](https://files.speakerdeck.com/presentations/ae067b4761414c509b03d07a60f91eb6/slide_110.jpg){kind=link}
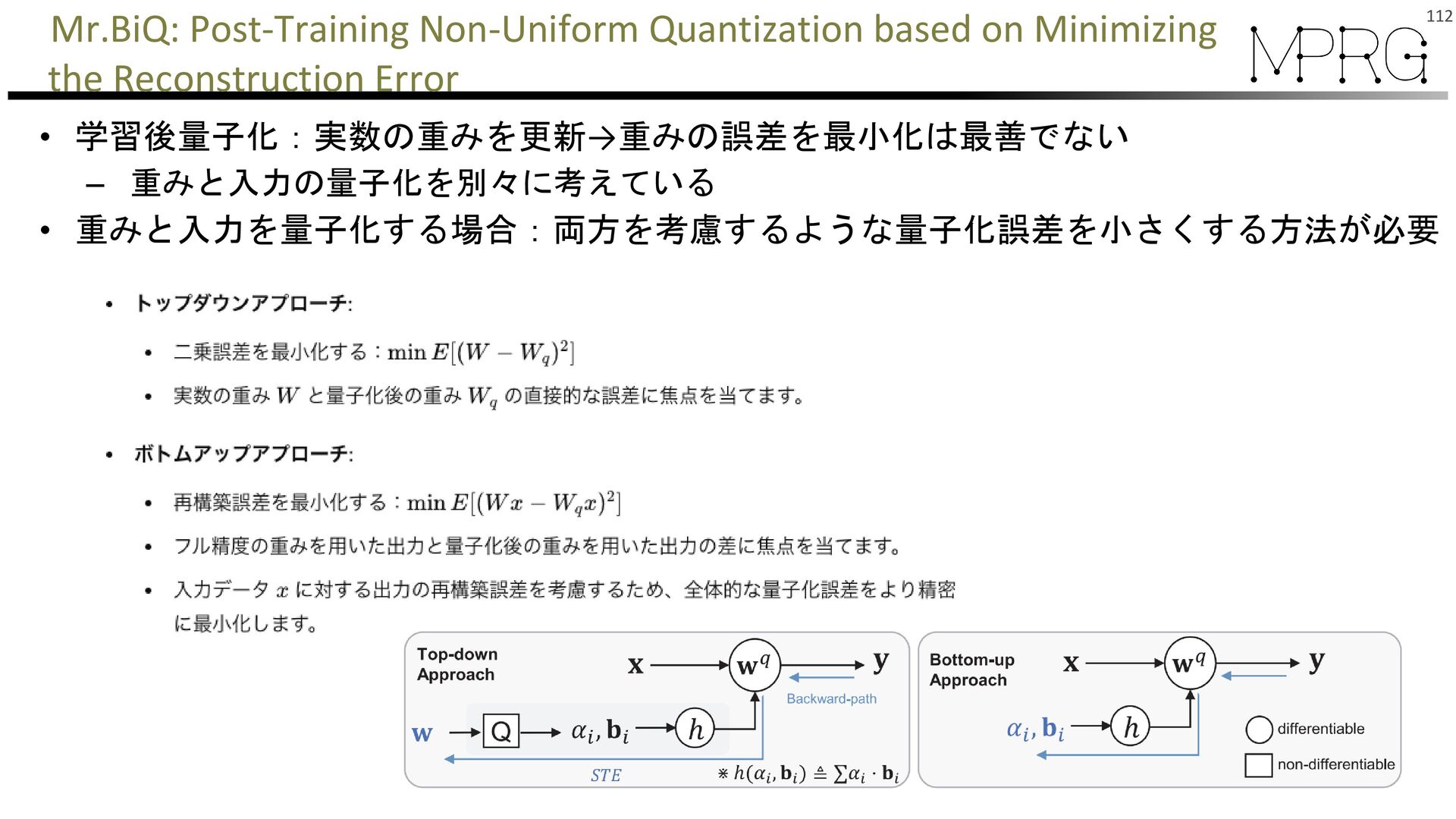{kind=link}
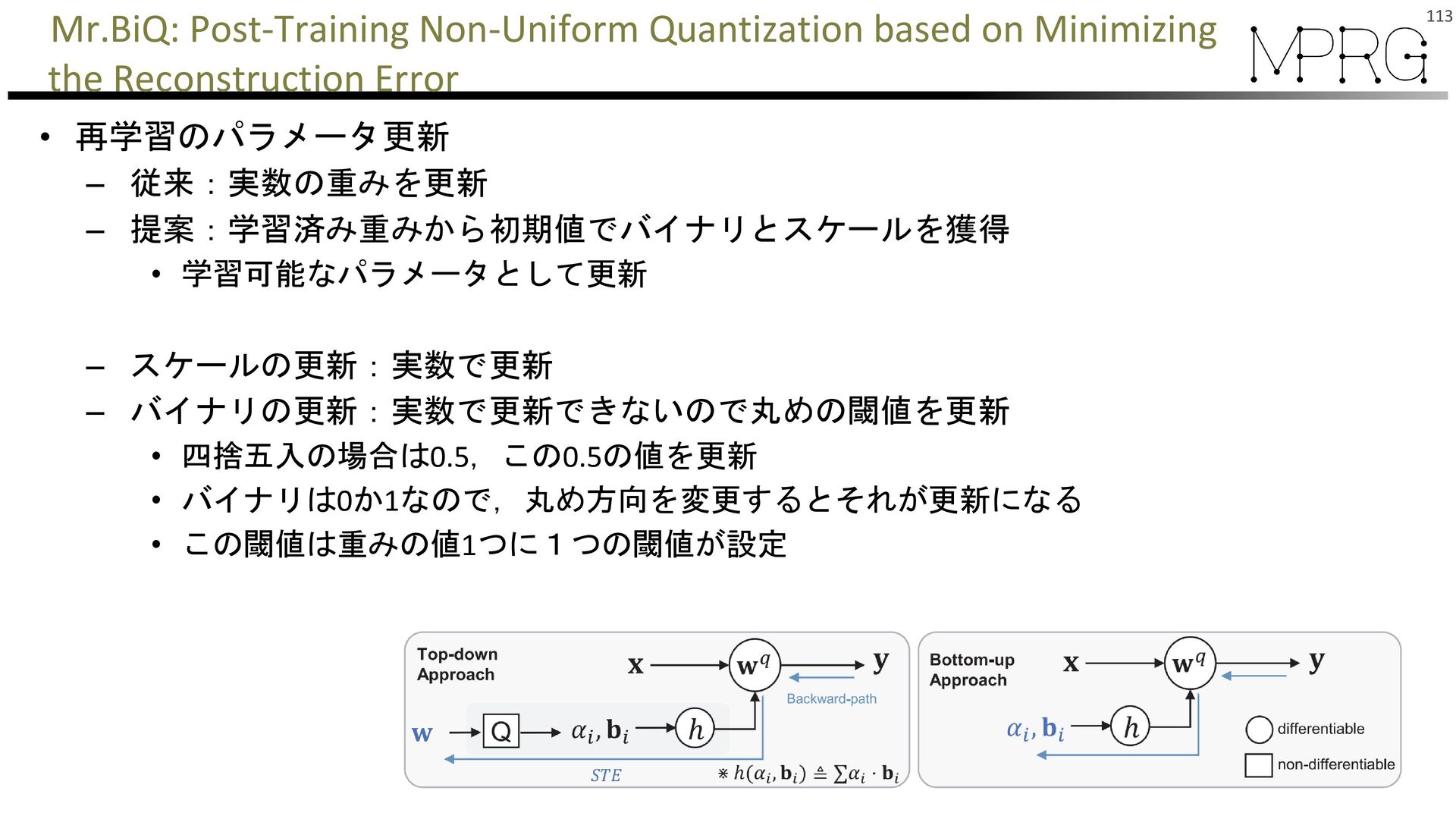{kind=link}
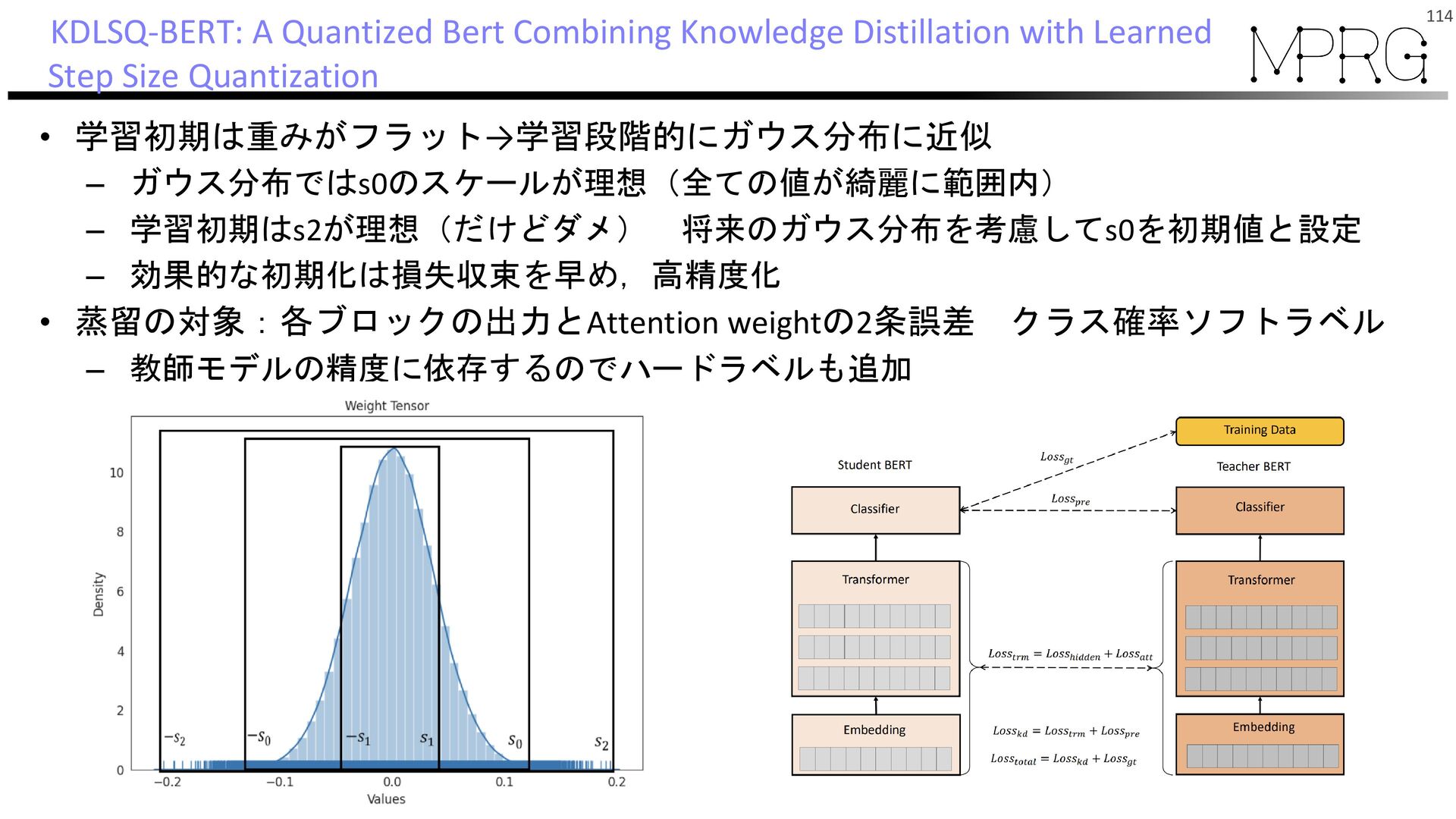{kind=link}
{kind=link}
![A White Paper on Neural Network Quantization[サーベイ] • 畳み込みの入力のチャンネル毎の量子化が困難 –](https://files.speakerdeck.com/presentations/ae067b4761414c509b03d07a60f91eb6/slide_115.jpg){kind=link}
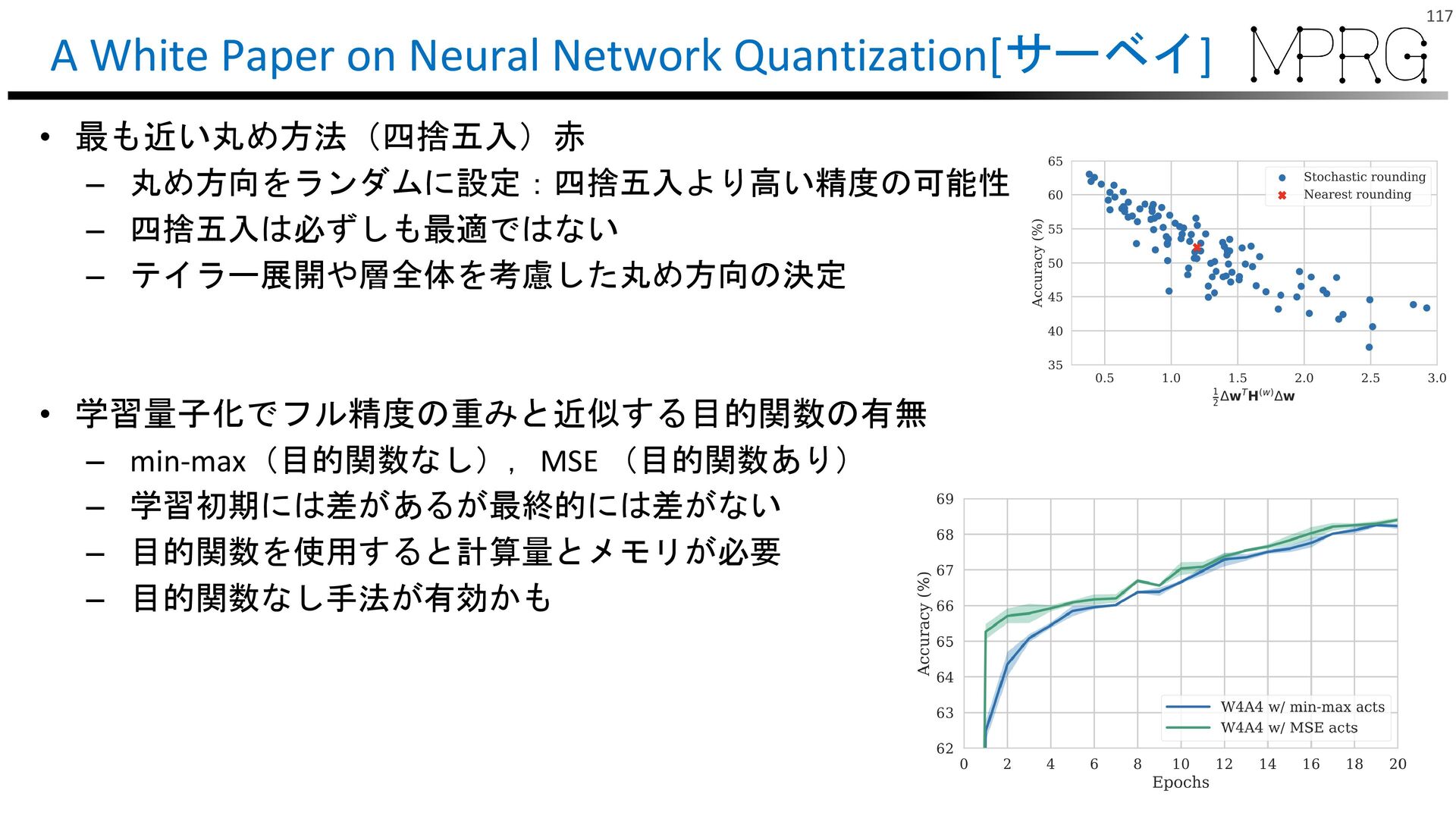{kind=link}
{kind=link}
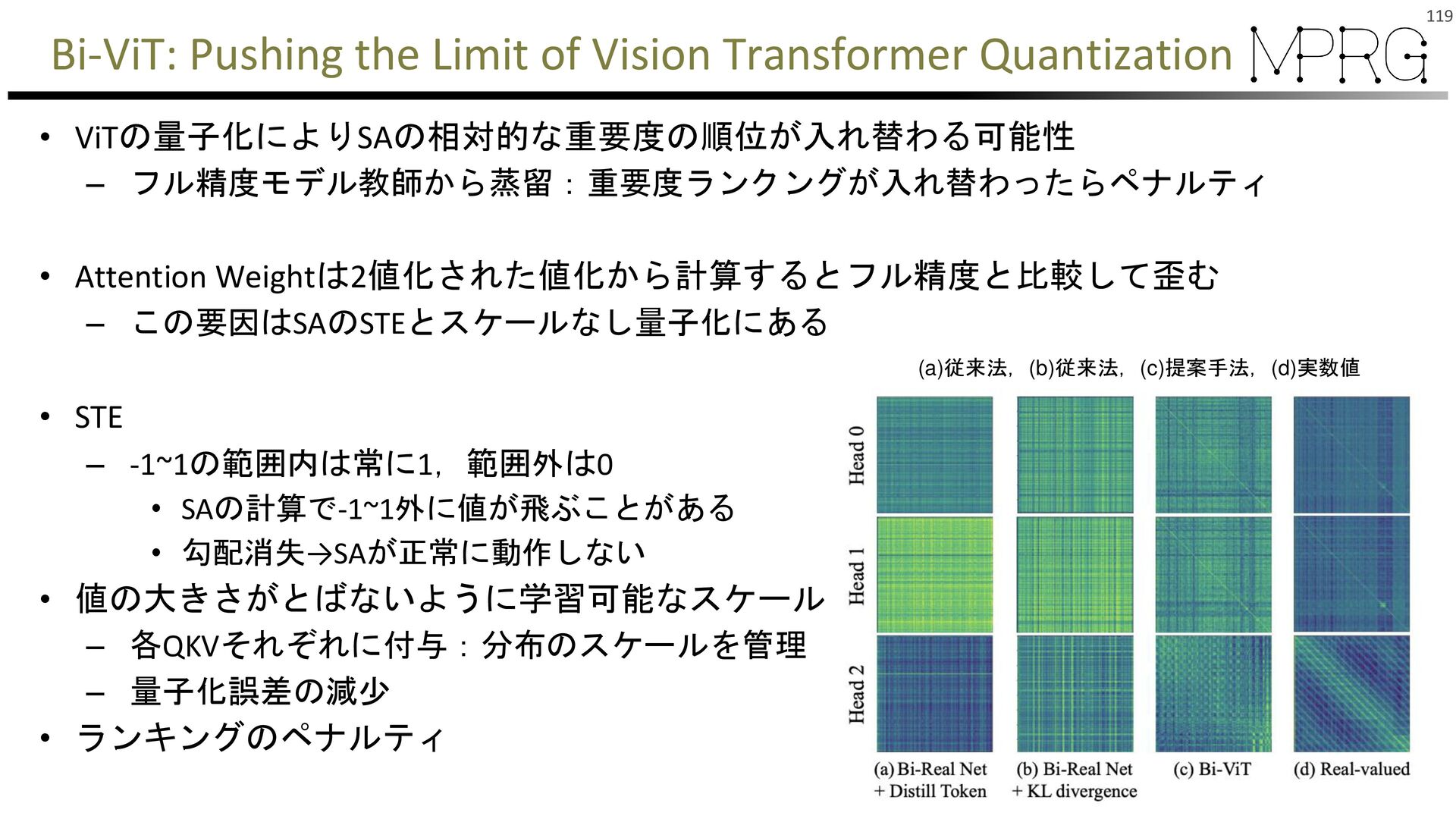{kind=link}
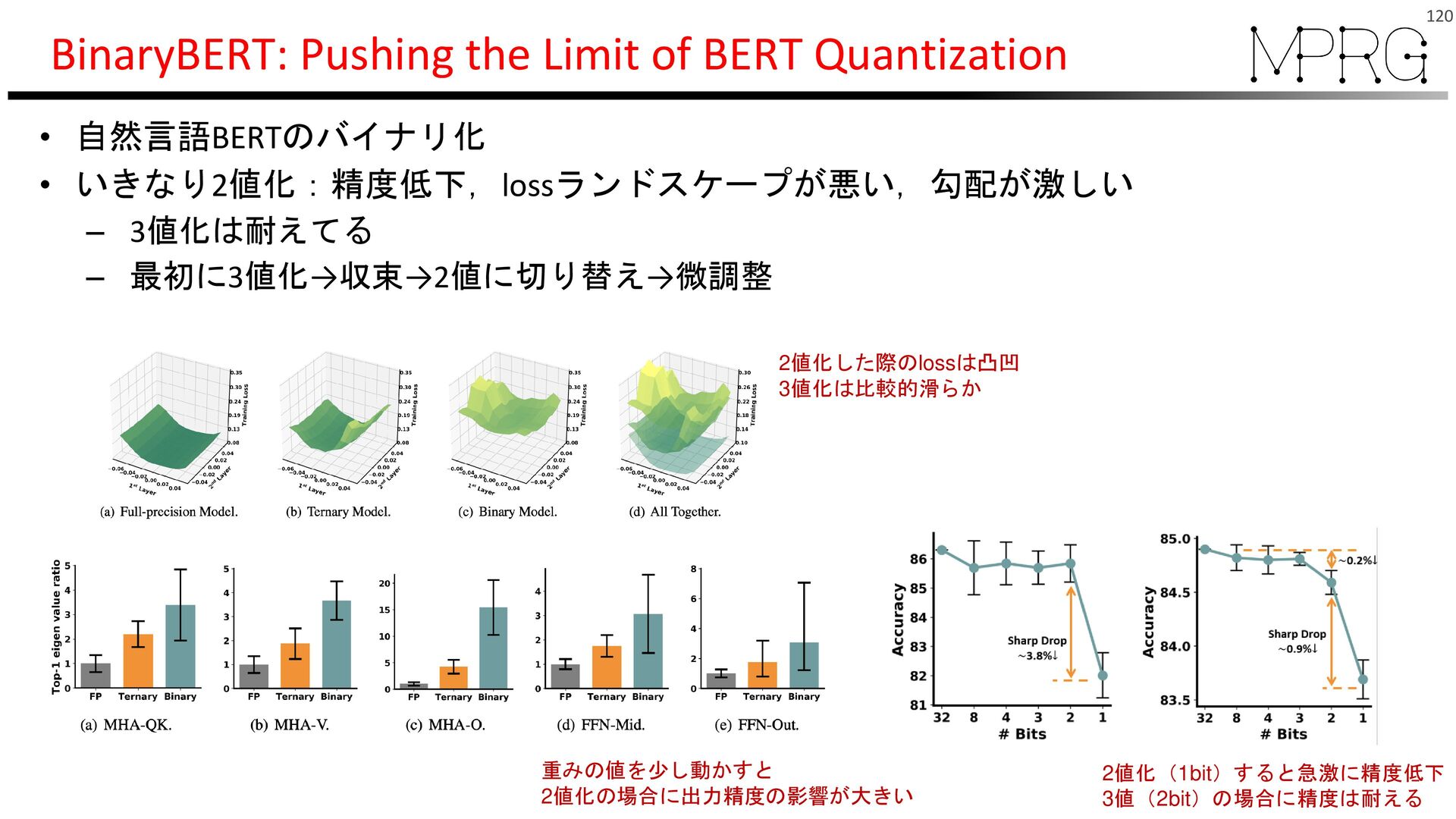{kind=link}
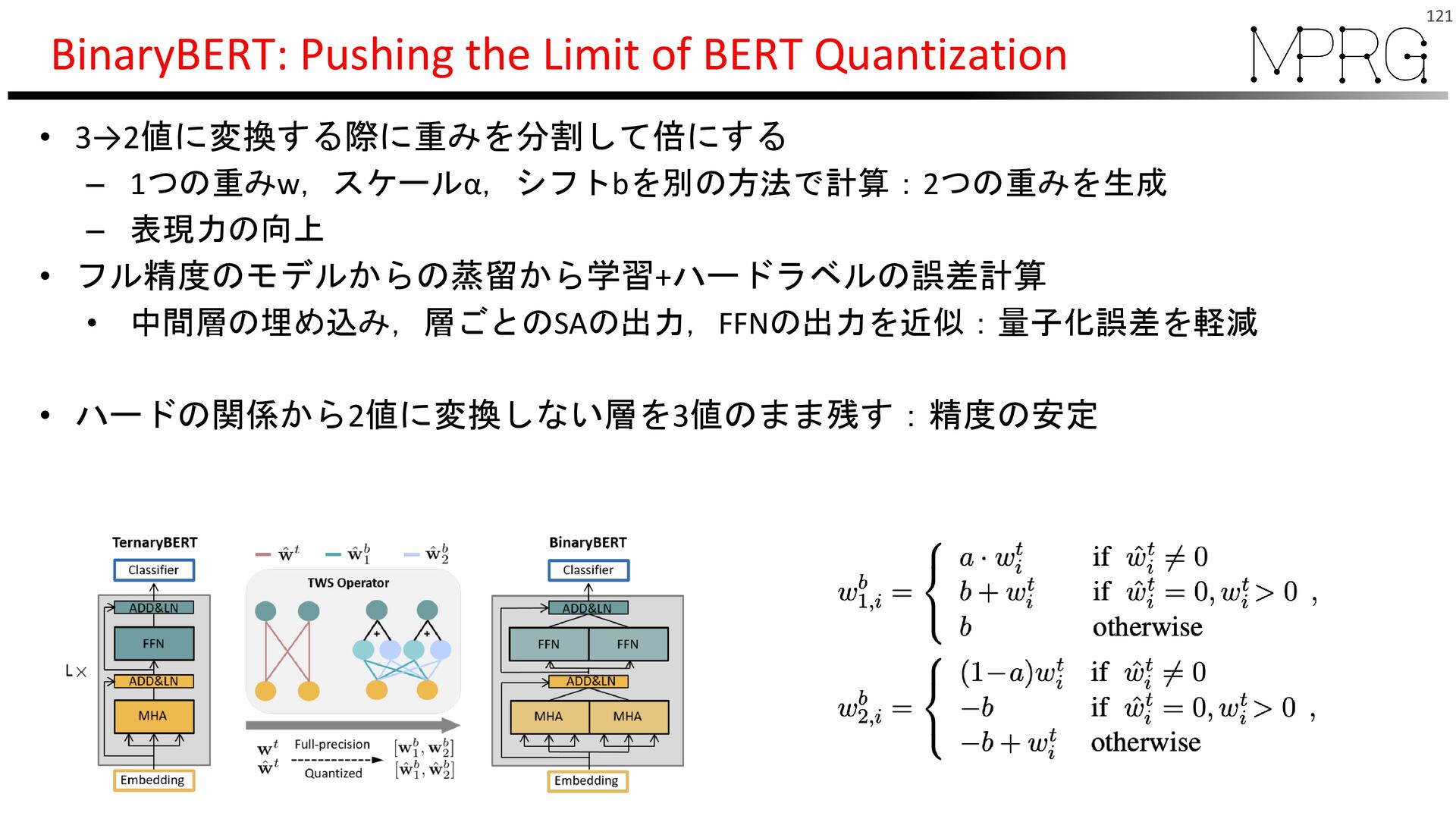{kind=link}
{kind=link}
![• 分布範囲の異なる同士で量子化:量子化誤差拡大 – 範囲が広い→ビンの間隔が広い:特定範囲に集中している場合に少ないビンの割り当て – 範囲が狭い→ビンの間隔が狭い:範囲外の値はClipで切り捨てられる • 外れ値が発生するのはごく僅か – [SEP]が外れ値になりやすい](https://files.speakerdeck.com/presentations/ae067b4761414c509b03d07a60f91eb6/slide_122.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
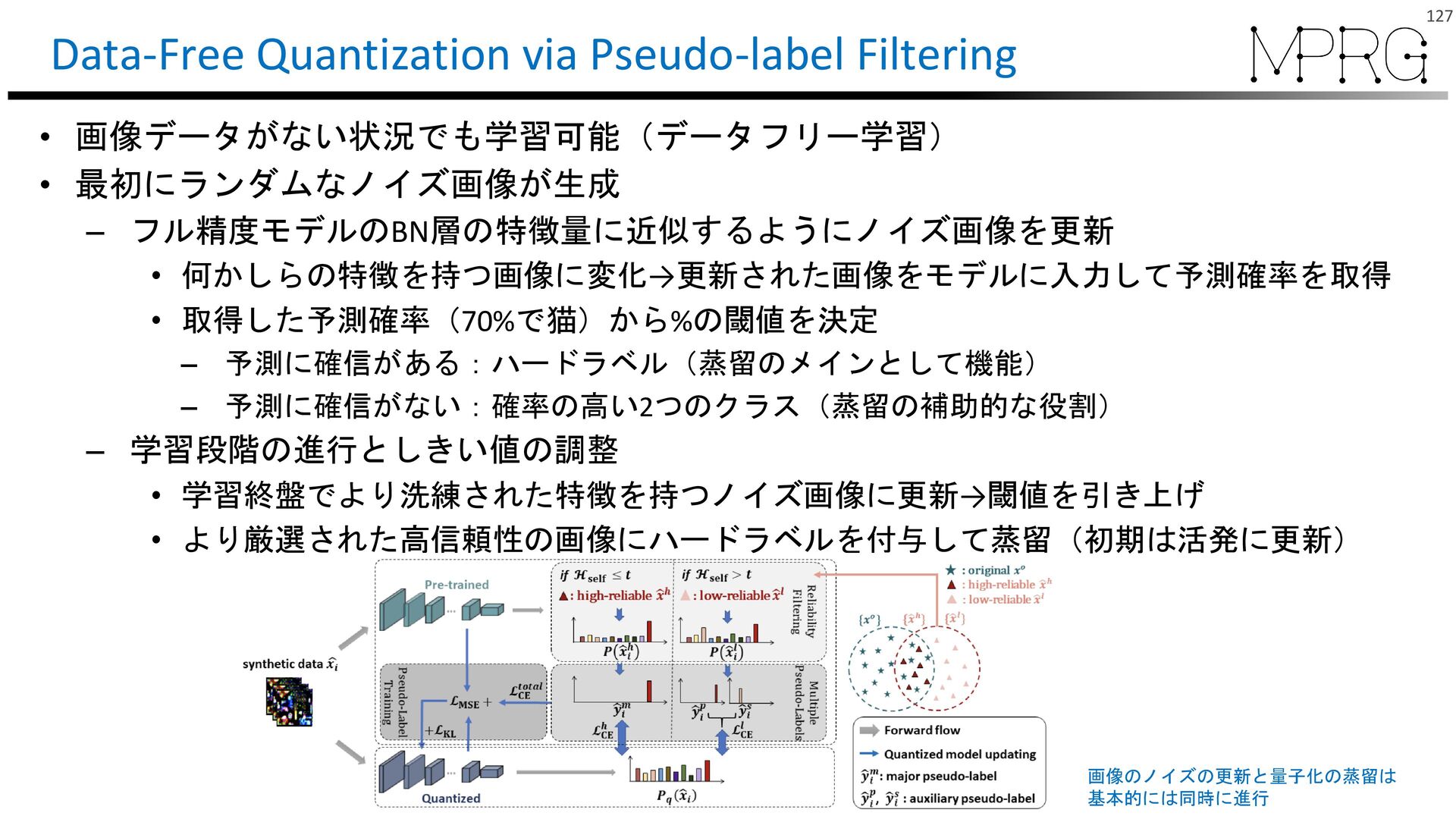{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
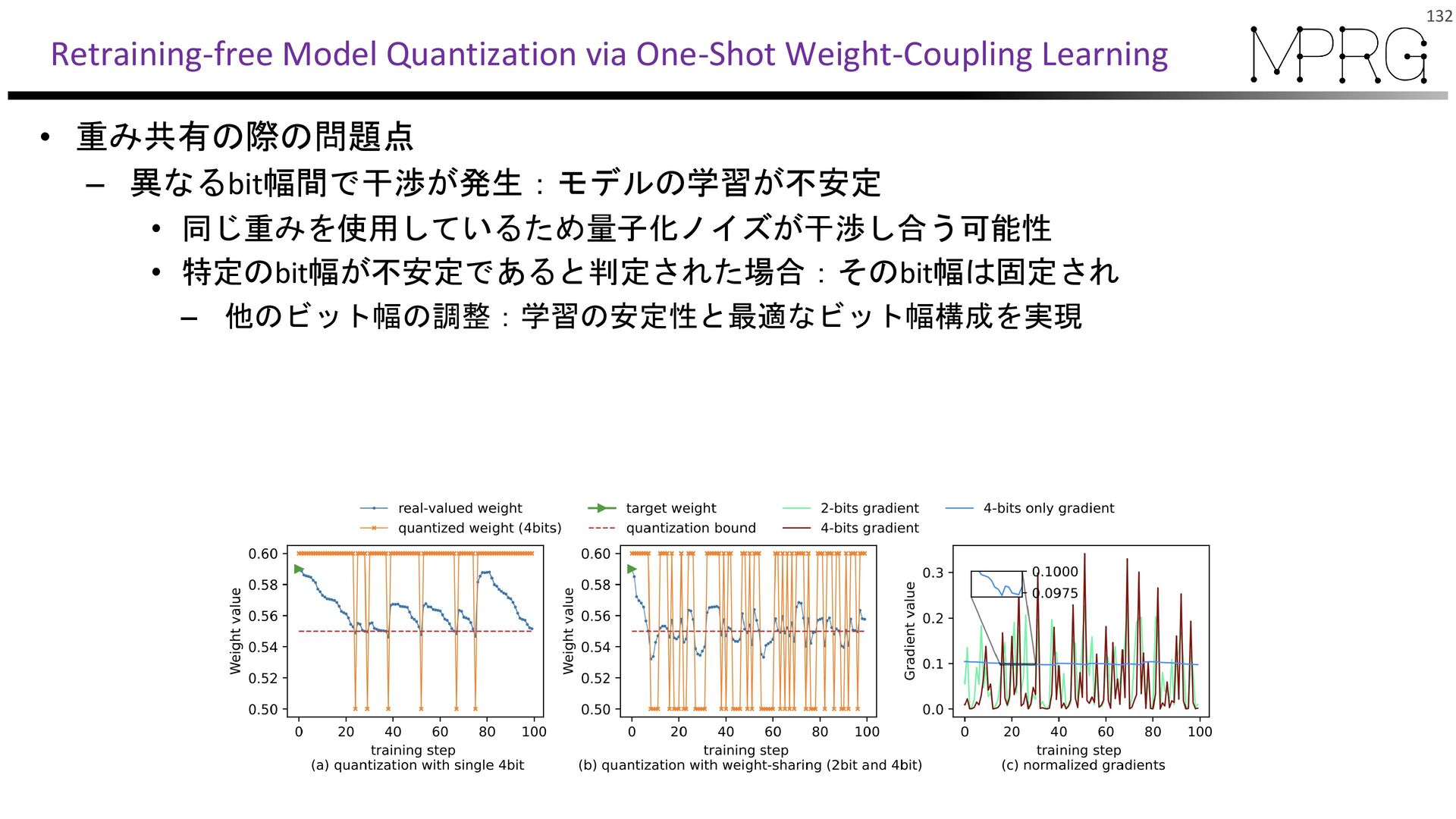{kind=link}
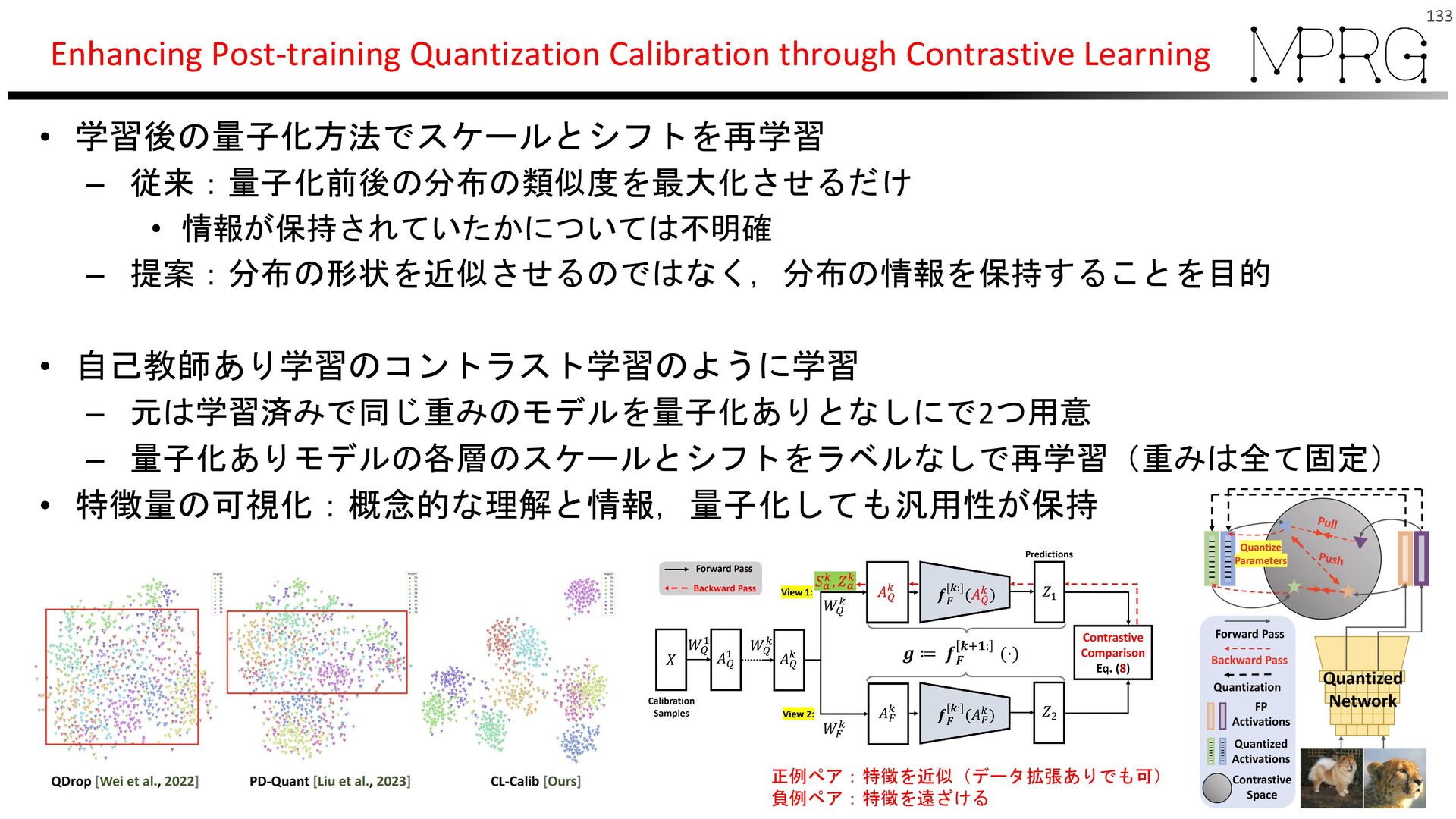{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
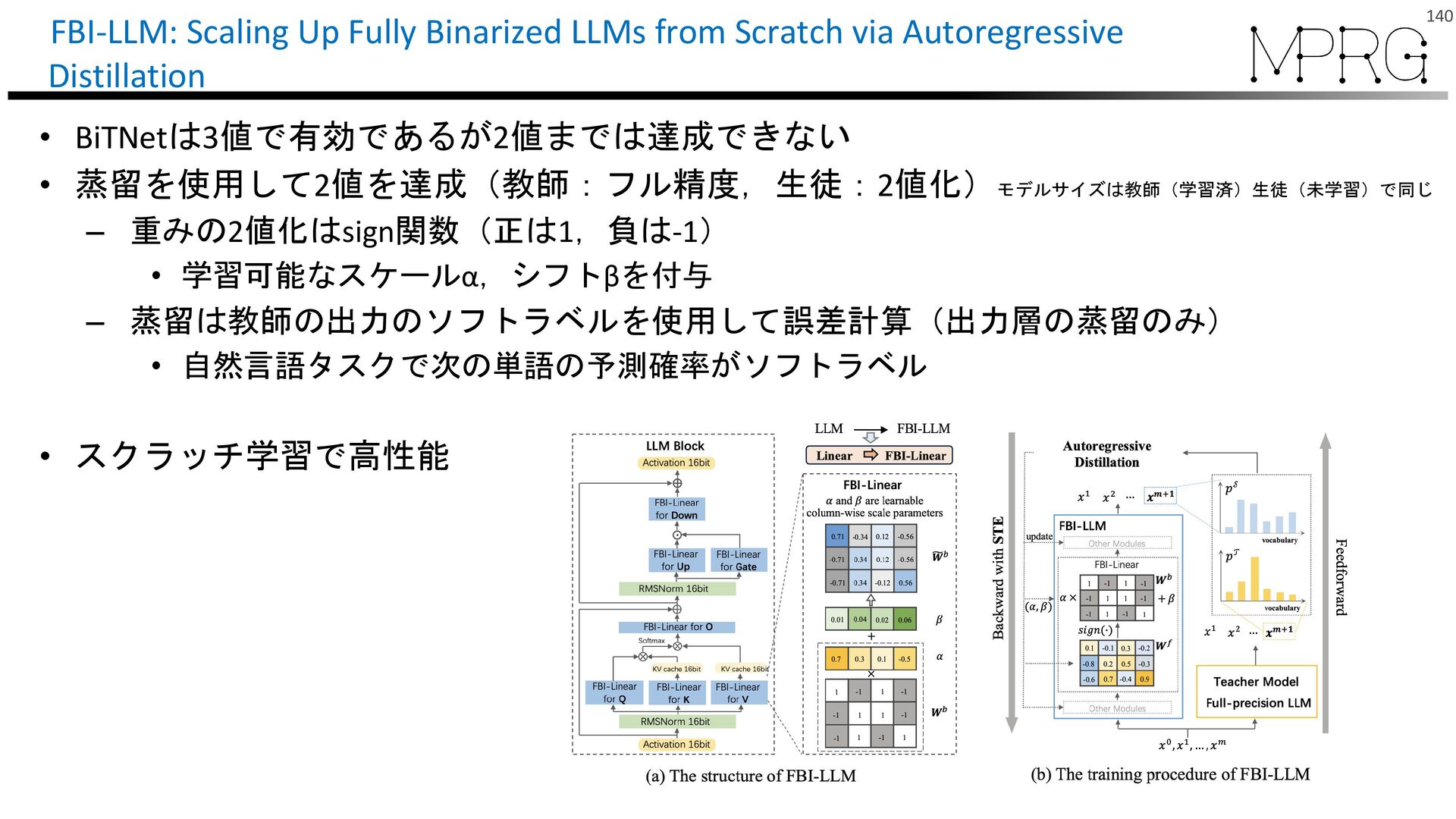{kind=link}
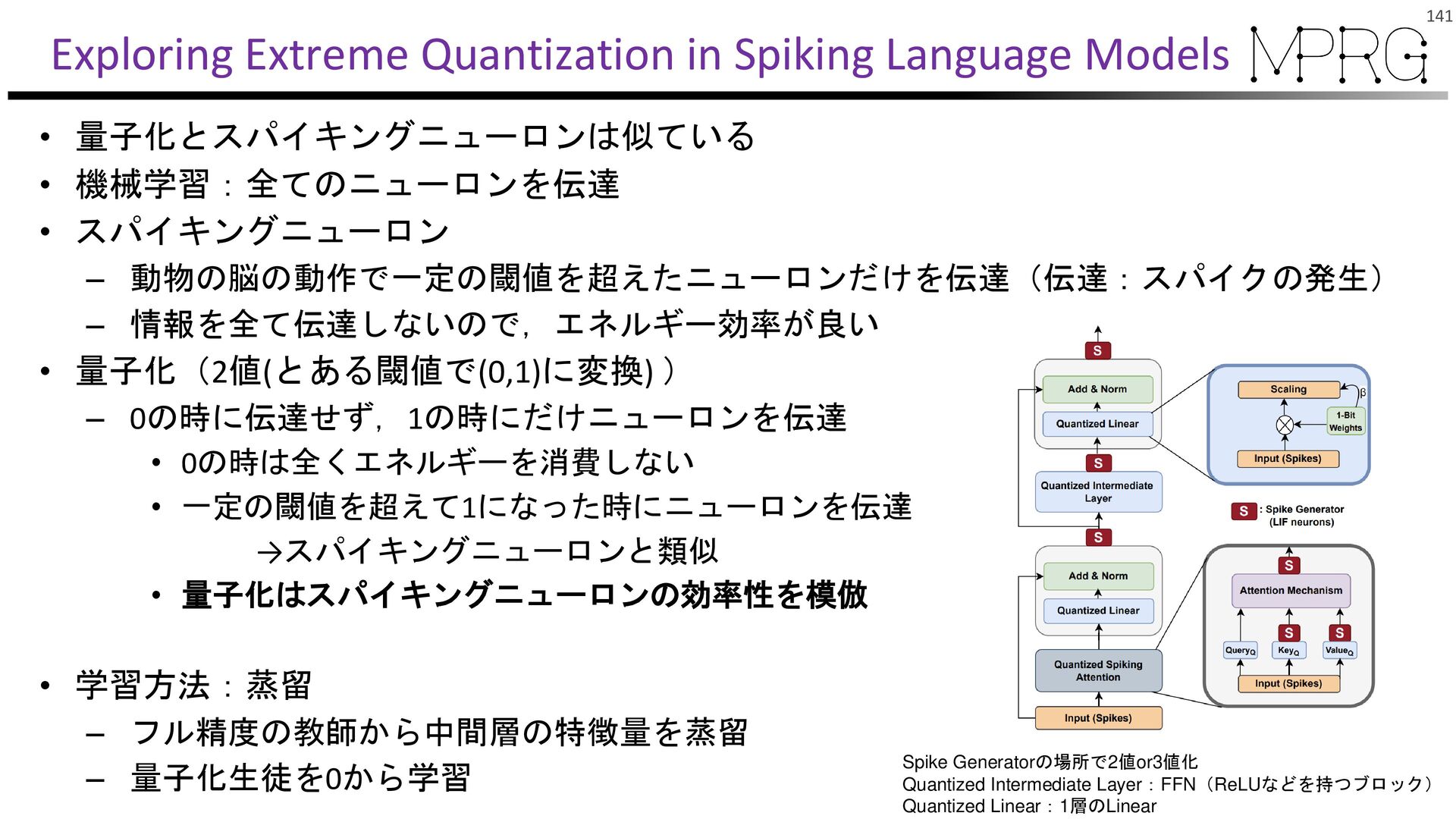{kind=link}
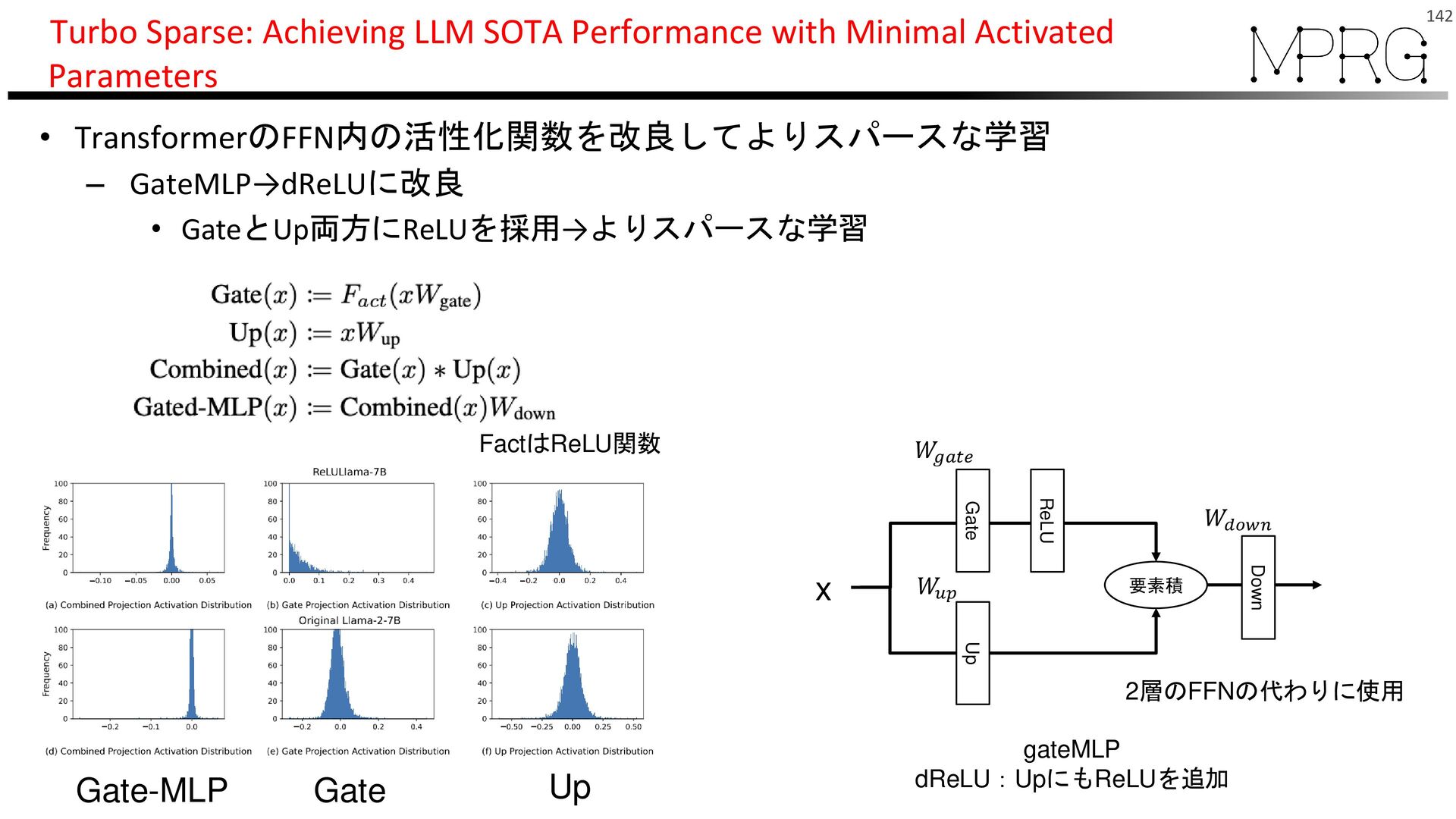{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
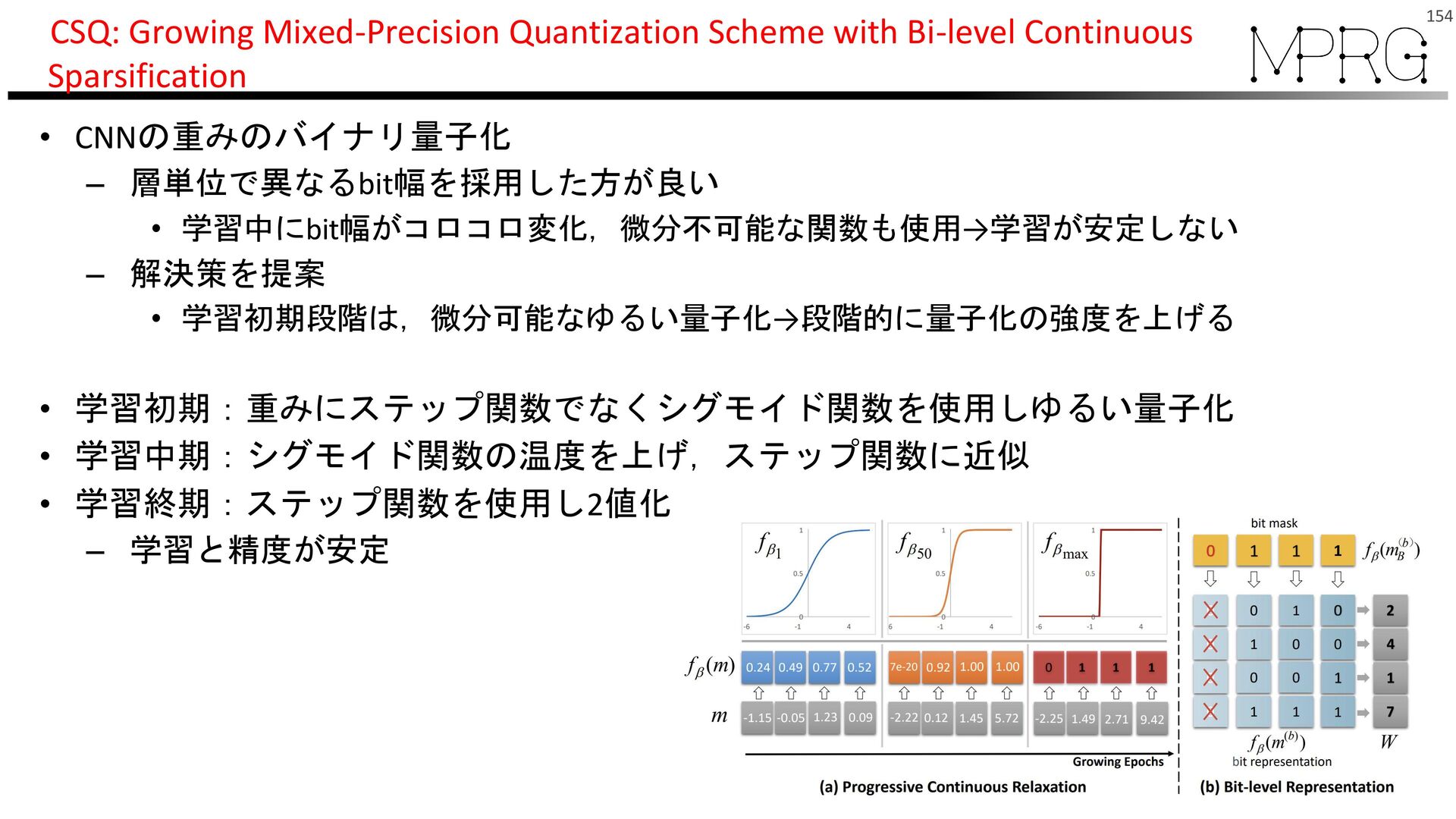
{kind=link}
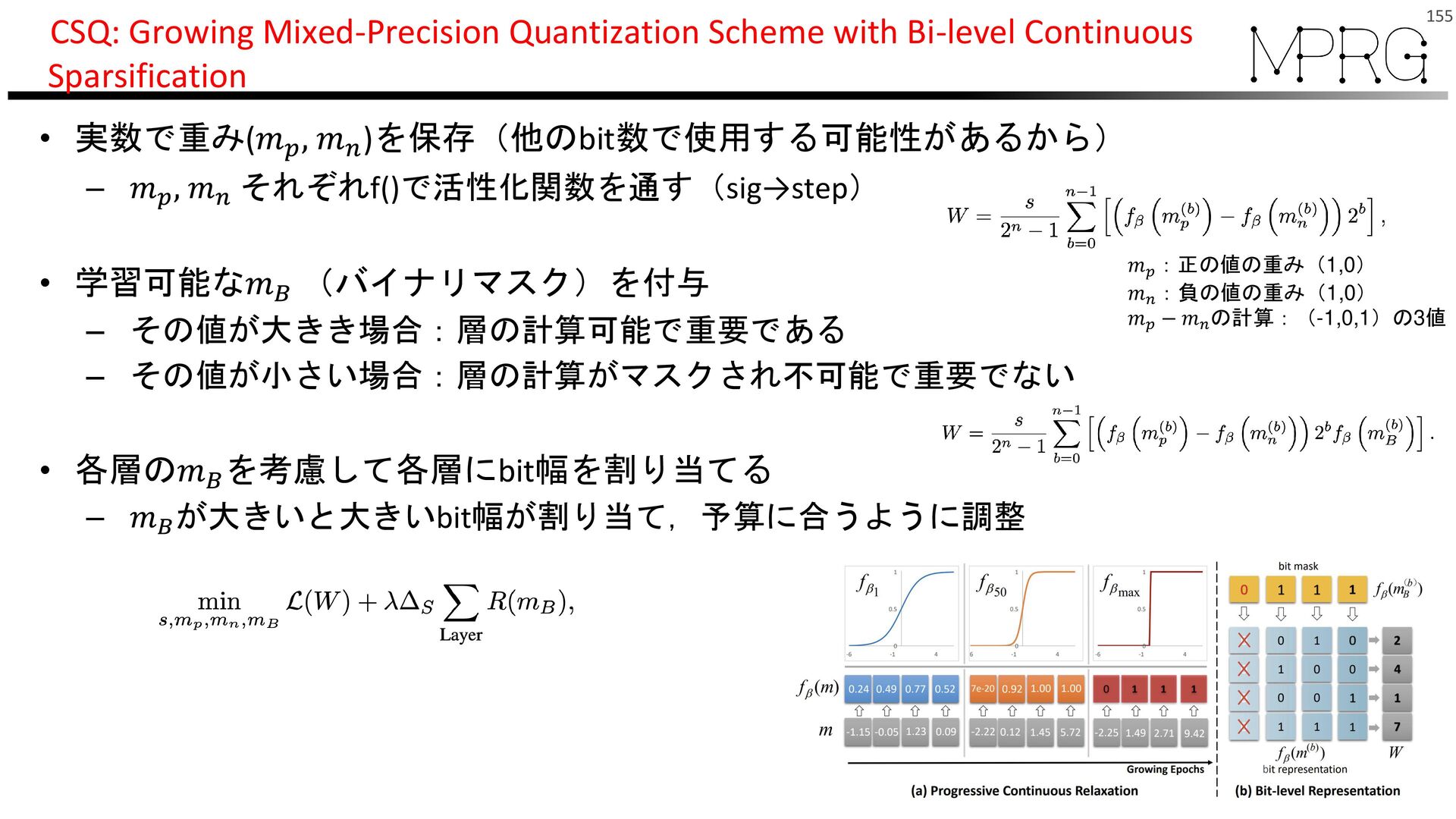
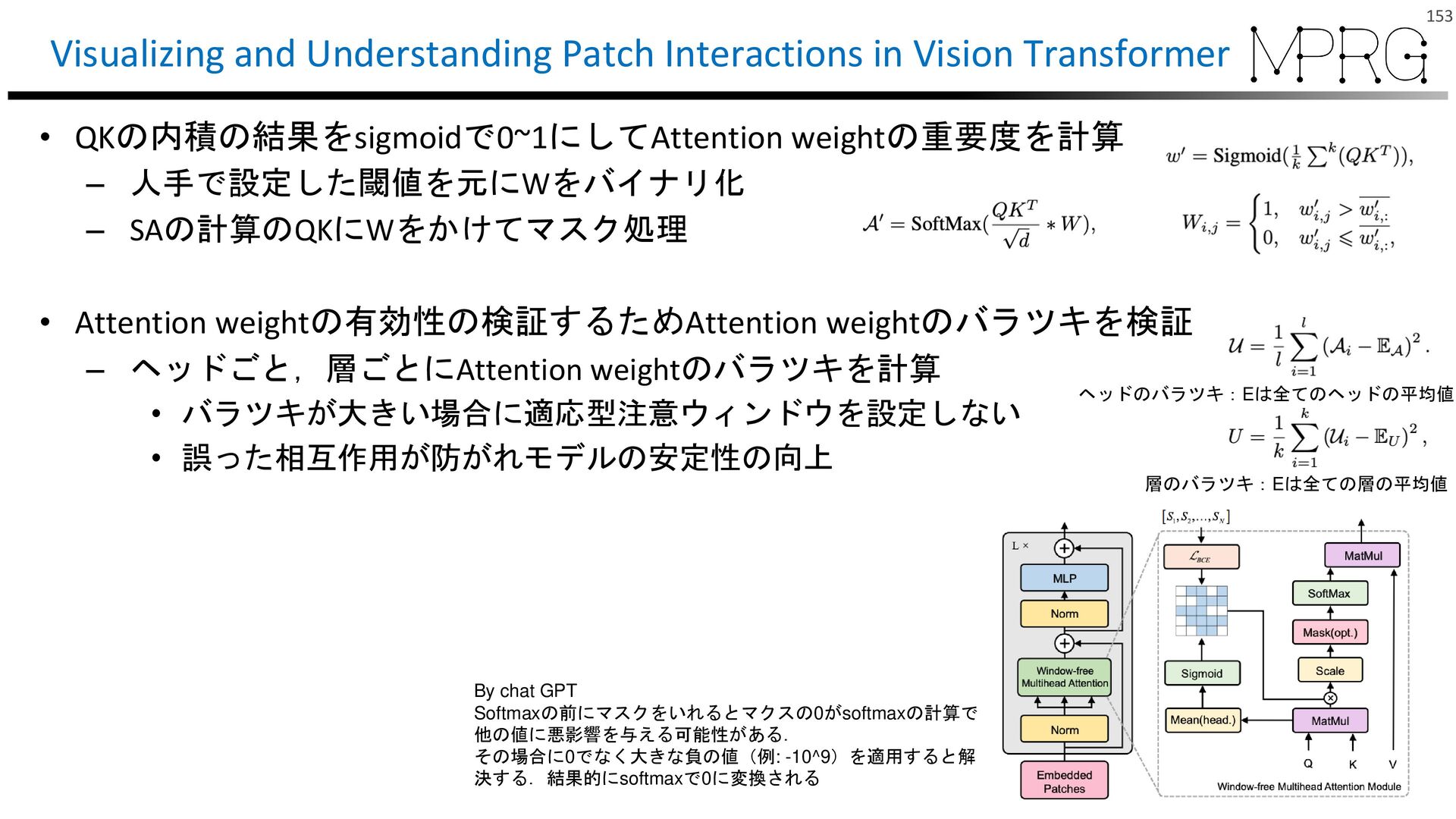{kind=link}
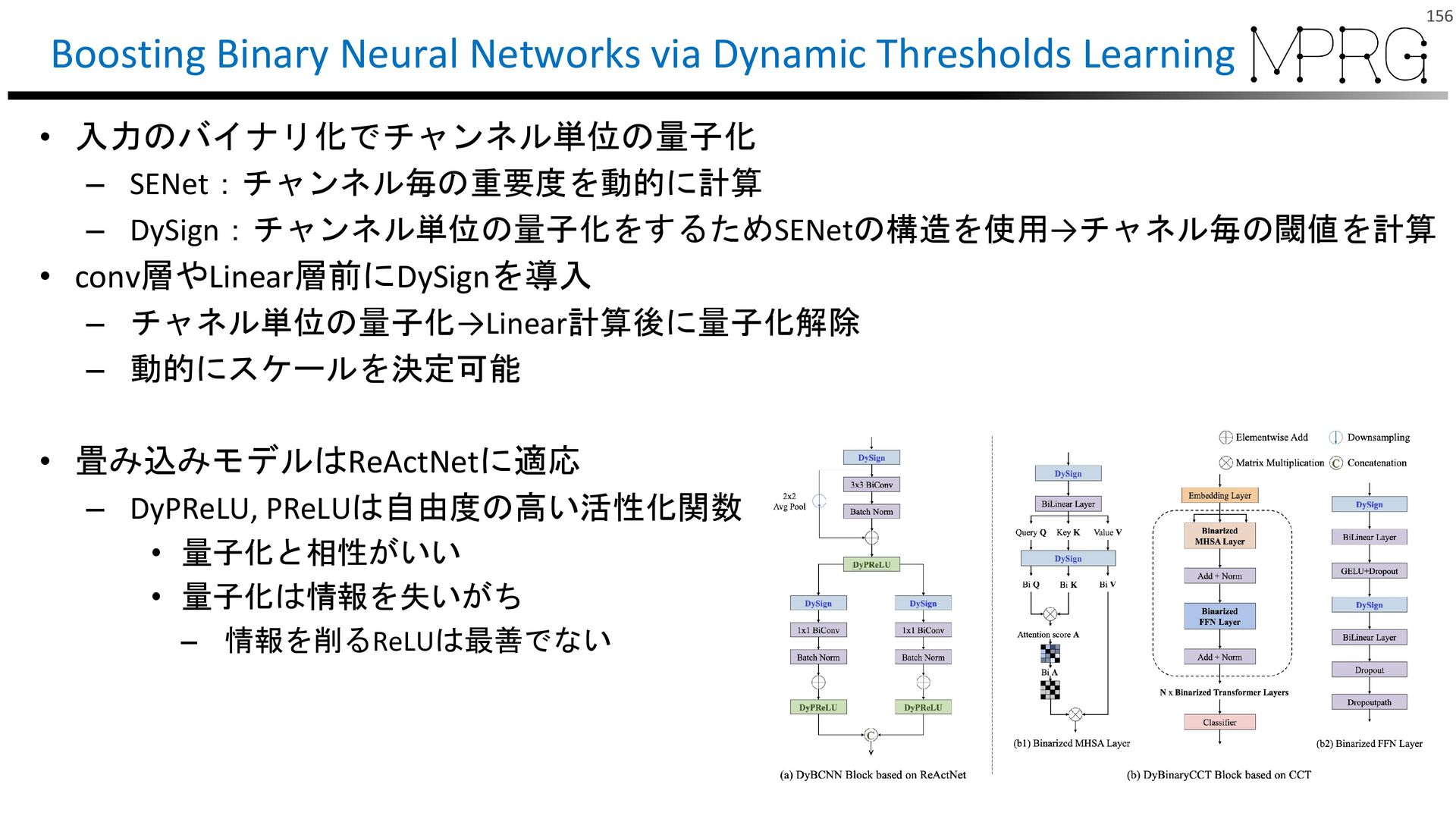
{kind=link}
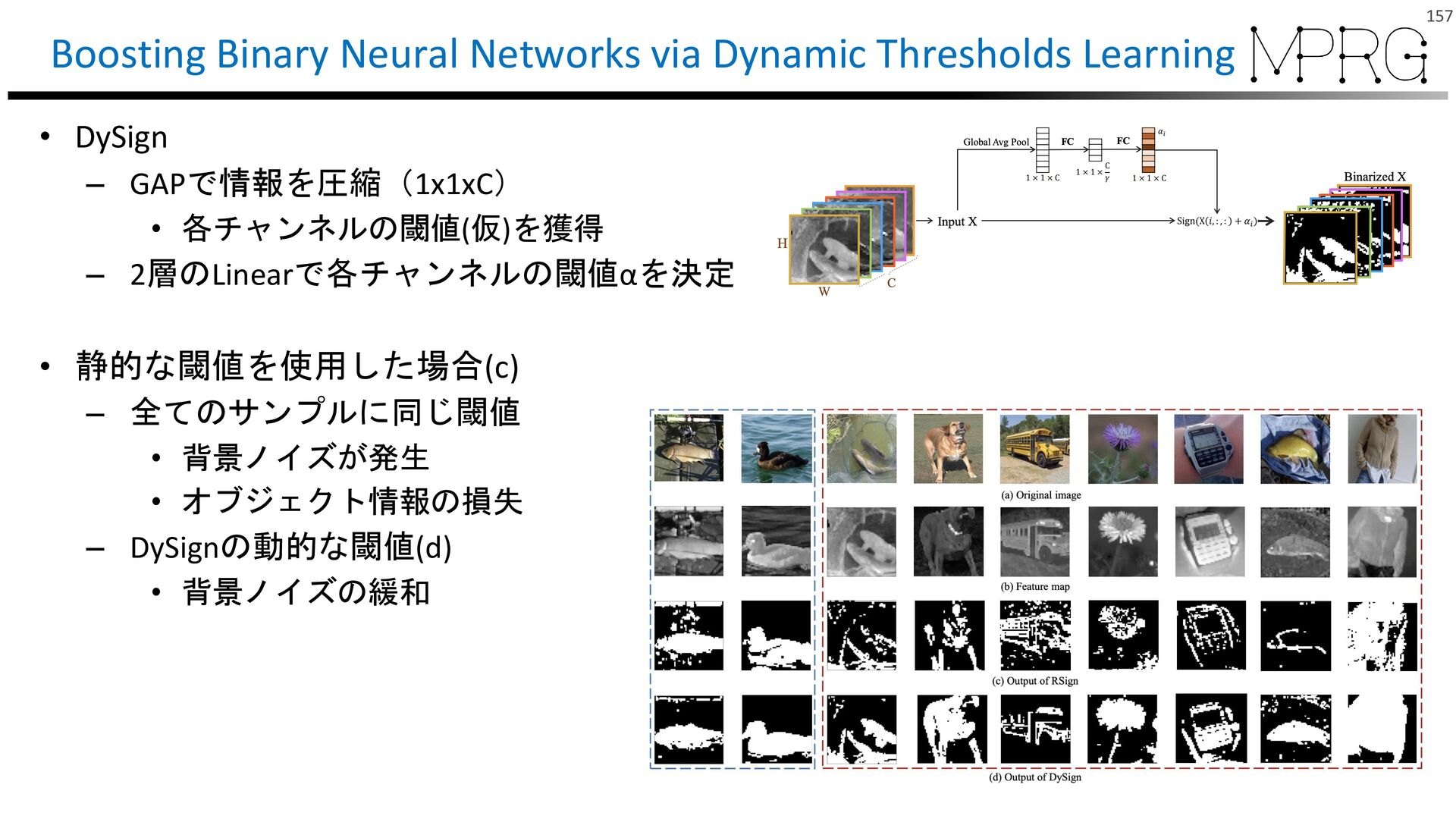
{kind=link}
{kind=link}
{kind=link}
{kind=link}