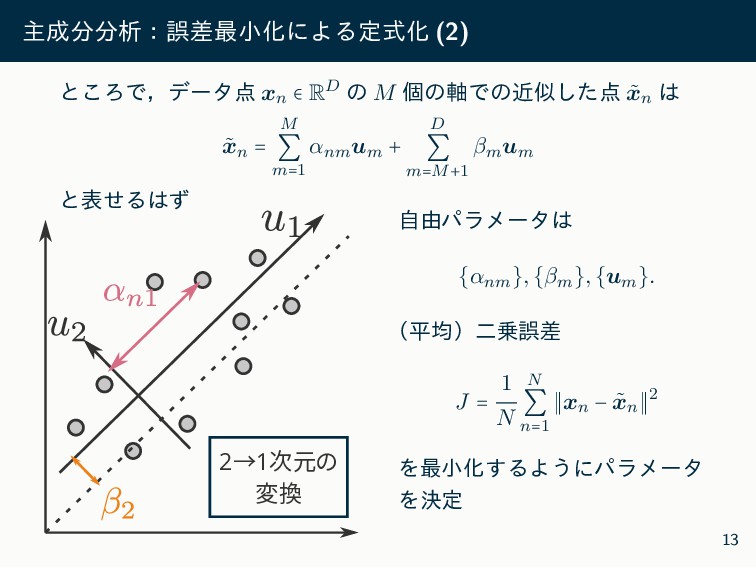
N N ∑ n=1 ∥xn − ˜ xn ∥2 = 1 N N ∑ n=1 [x⊺ n xn − 2x⊺ n ( M ∑ m=1 αnm um + D ∑ m=M+1 βm um ) + M ∑ m=1 α2 nm ] + M ∑ m=M+1 β2 m ͜ͷ J ʹରͯ͠ αnm,βm ʹؔ͢ΔҰ࣍ͷ࠷దੑ݅ΛͱΔɿ ∂J ∂αnm = 2 N (−x⊺ n um + αnm) = 0 ⇒ αnm = x⊺ n um ∂J ∂βm = − 2 N N ∑ n=1 x⊺ n um + 2βm = 0 ⇒ βm = ¯ x⊺um ͢ͳΘͪ ˜ xn = ∑M m=1 αnmum + ∑D m=M+1 βmum ˜ xn = M ∑ m=1 (x⊺ n um)um + D ∑ m=M+1 (¯ x⊺um)um 14
= V Σ⊺ɽ ֤͝ͱͷදݱʹ͢Δͱ x⊺ n um = σmvmn. PCA Ͱ u⊺ m xn = x⊺ n um σʔλ xn ͷ࣠ um ͷࣹӨͩͬͨ 4 ·ͨಛҟ σm ͕࣠ m ͷεέʔϧΛఆΊ͍ͯΔͷͰɼ V = (vmn) εέʔϧਖ਼نԽ͞ΕࣹͨӨઌͷσʔλදݱ 4p.8 ࢀর 20
⊺SBW )(W ⊺SW W )−1}. ͷ࠷େԽΛߟ͑Δɽͨͩࣗ͠༝Λམͱͨ͢Ίʹ W ⊺SW W = I ͷ੍Λ՝͢ɽ ͢Δͱ tr(⋅) ͷ W ⊺SW W ୯ҐߦྻʹͳΔͷͰɼओ Maximize tr(W ⊺SBW ) subject to I − W ⊺SW W = O ⎫ ⎪ ⎪ ⎬ ⎪ ⎪ ⎭ ͱͳΔɽLagrange ؔ ⟨⋅,⋅⟩ Λߦྻͷੵͱͯ͠ɼ L(W ,Λ) = tr(W ⊺SBW ) + ⟨Λ,I − W ⊺SW W ⟩. 41
Φ(xn)⟩2 ͕ max a1,...,aN 1 N N ∑ n=1 ⟨ N ∑ m=1 am ˜ Φ(xm), ˜ Φ(xn)⟩ 2 = 1 N N ∑ n=1 N ∑ m=1 (am⟨˜ Φ(xm), ˜ Φ(xn)⟩)2 ͱมܗͰ͖Δ͜ͱ͕Θ͔ͬͨɽ த৺ԽάϥϜߦྻ ˜ K ∈ RN×N Λ ˜ Knm = ⟨˜ Φ(xn), ˜ Φ(xm)⟩ ʹΑΓఆٛ͠ɼa = (an)N n=1 ͱ͢Δͱɼతؔ max a 1 N a⊺ ˜ K2a. 51
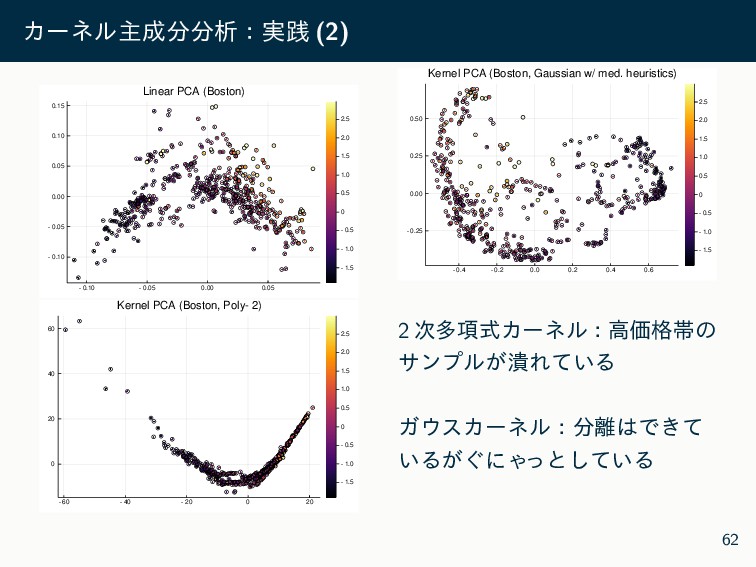
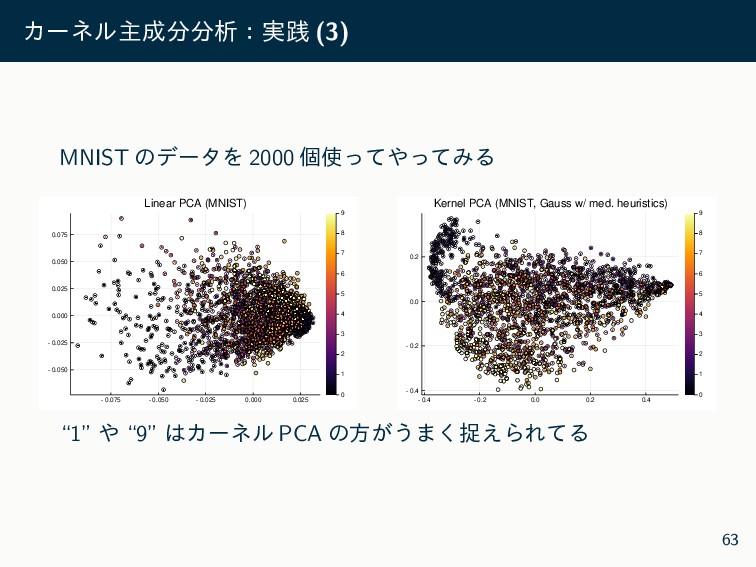
X ڭࢣͳ͠ͳͷͰύϥϝʔλΛ͏·ܾ͘ΊΔͷ݁ߏ͍͠ X ࣍ݩݮޙʹڭࢣ͋ΓֶशΛߦ͏ͳΒ CV ͕͑Δ X ΨεΧʔωϧͷύϥϝʔλΛܾΊΔ heuristics Λհ ҙ X ແͳͷઢܗ PCA X ඇઢܗ࣍ݩݮͷڧ͍ಈػ͕ͳ͚ΕɼύϥϝʔλϑϦʔ Ͱղऍ͍͢͠ઢܗ PCA Λ͏͖ʢචऀॴײʣ X աֶशʹؾΛ͚ͭΔ X ΨεΧʔωϧͳͲදݱྗ͕ߴ͗͢ΔͷͰɼͱ͘ʹߴ࣍ݩ σʔλʹରͯ͠ʮσʔλͷ͋Δͱ͜Ζ͔͠Λͨͳ͍ʯ Α͏ͳ͜ͱʹͳΓ͕ͪ 64
X., and Huang, T. (2007), “Trace Ratio vs. Ratio Trace for Dimensionality Reduction,” in 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN: IEEE, pp. 18. [2] Petersen, K., and M. S. Pedersen. (2012) “The matrix cookbook,” Version November 15 2012. [3] ਫ݈࣍. (2010) “Χʔωϧ๏ೖ -ਖ਼ఆΧʔωϧʹΑΔ σʔλղੳ-,” ேॻళ.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References i [1] Wang, H., Yan, S., Xu, D., Tang,](https://files.speakerdeck.com/presentations/882aac6a413e4ad8961771d0896ab32d/slide_68.jpg){kind=link}