Talk abstract: In this talk, I would like to introduce this COLING-2022 paper. Besides the details of the work itself, I also want to discuss the stories behind the work. For example, how did the idea come out; how we developed the idea gradually; how we responded to the negative comments in the previous two submission rounds; etc. I also want to discuss with the audience how our work may be improved and look forward to new ideas.
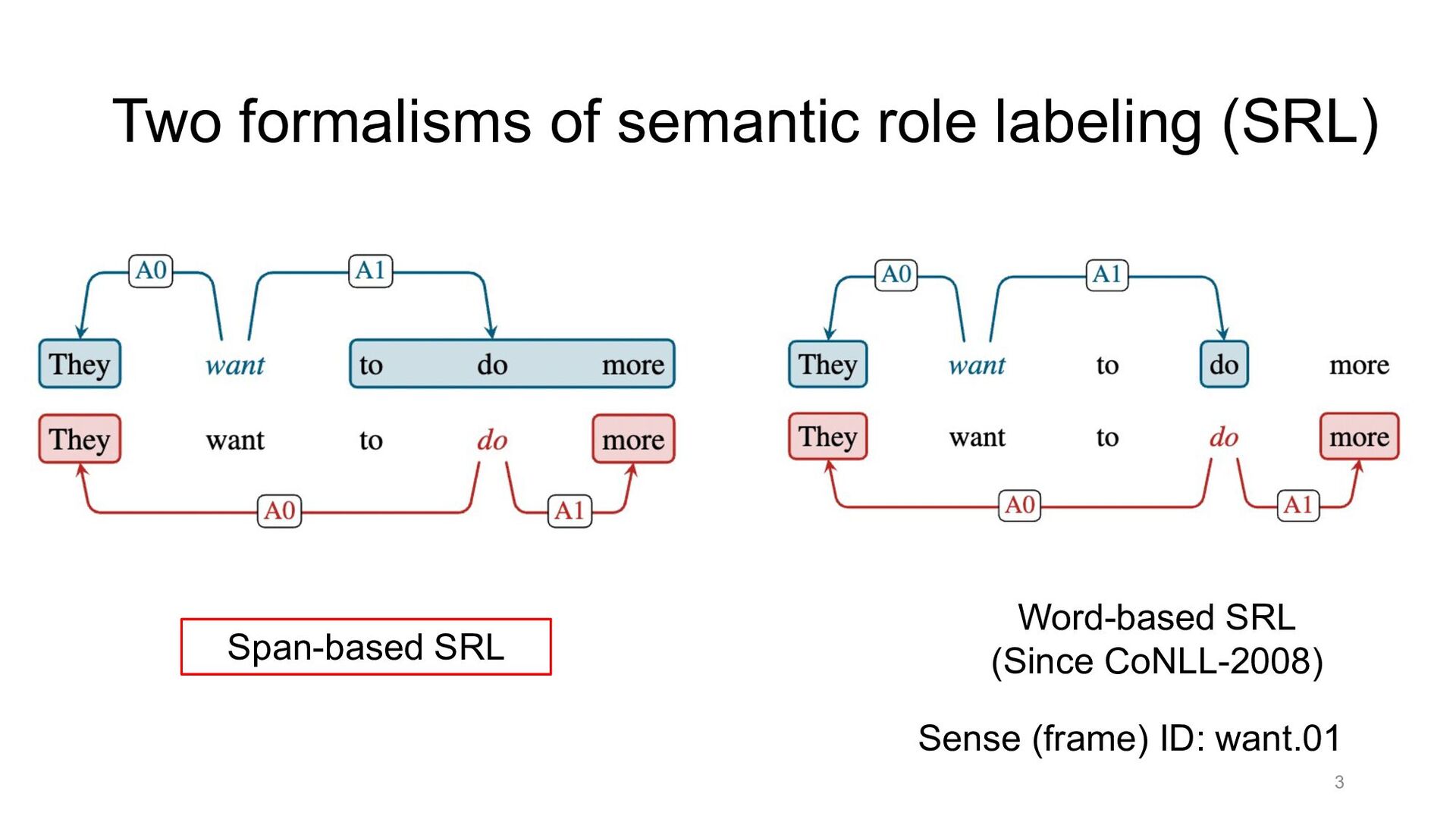
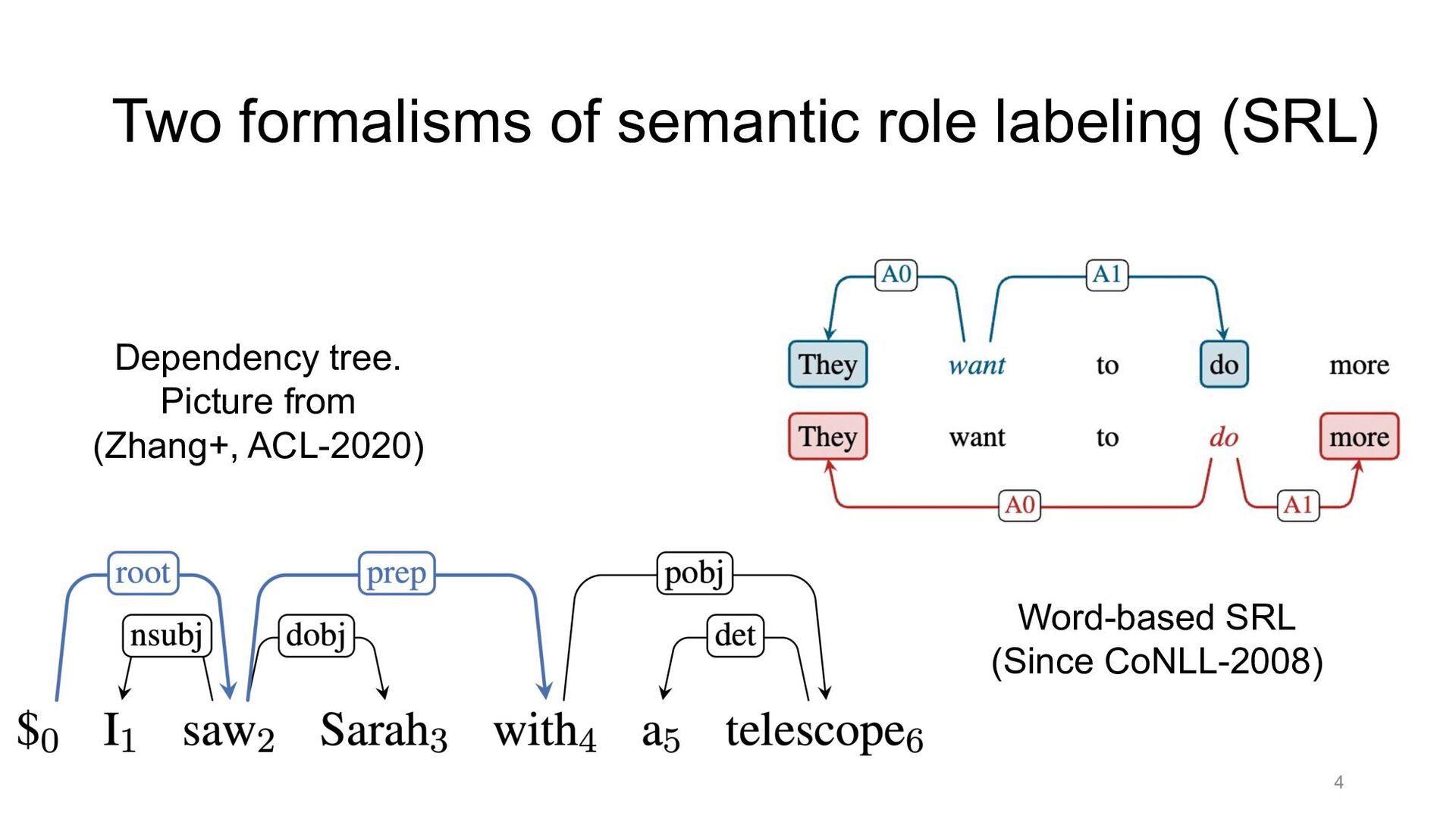
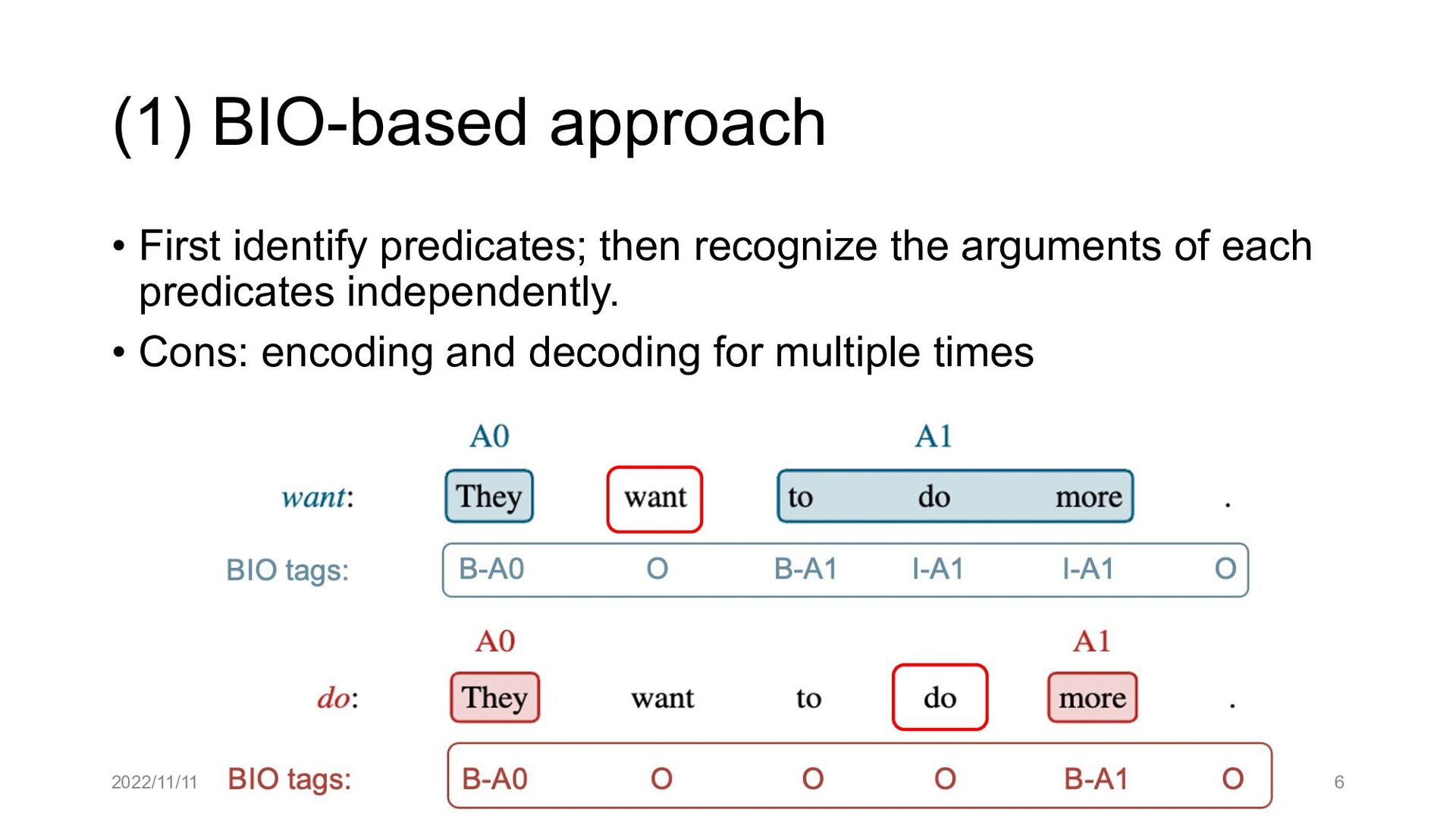
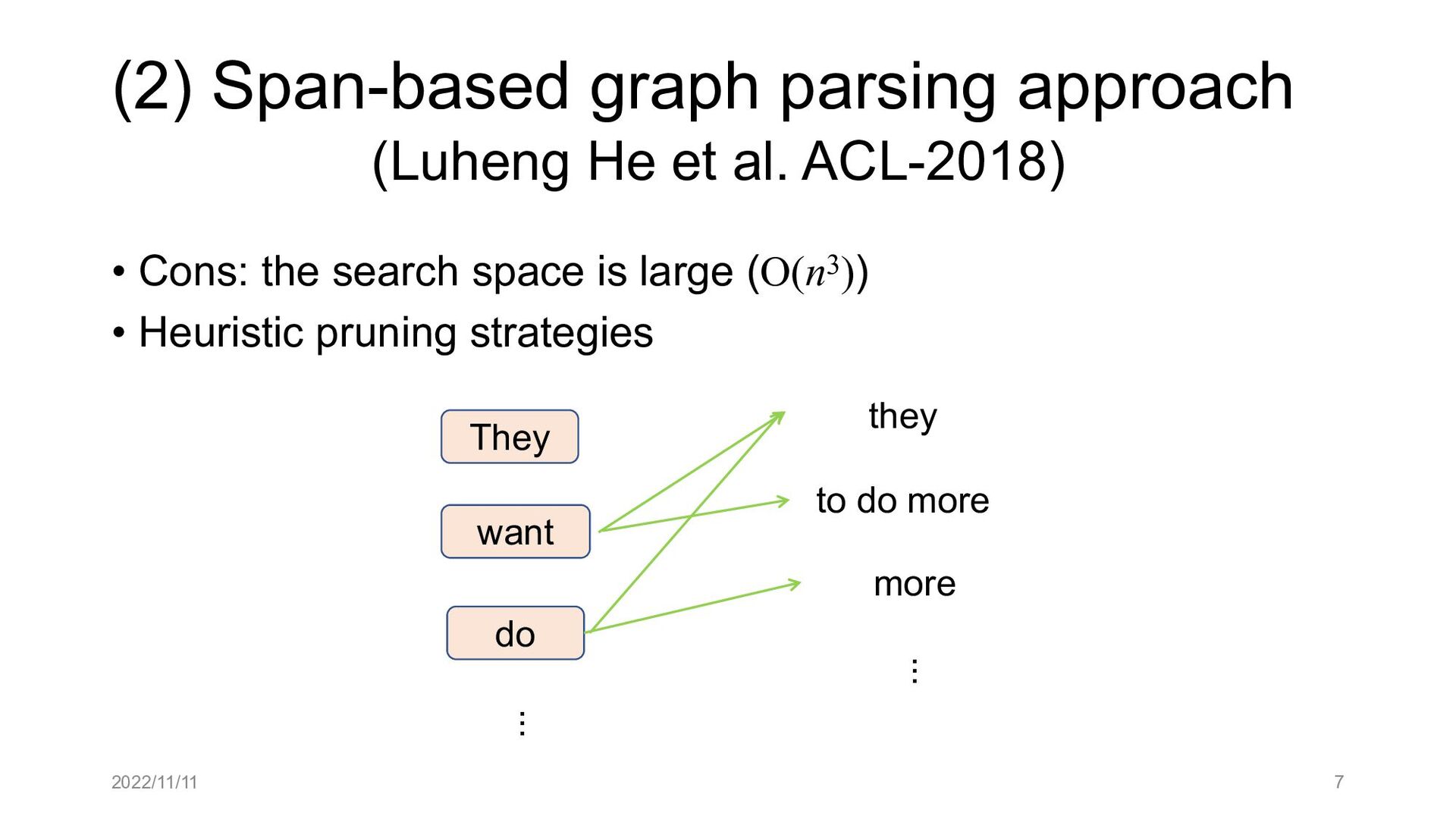
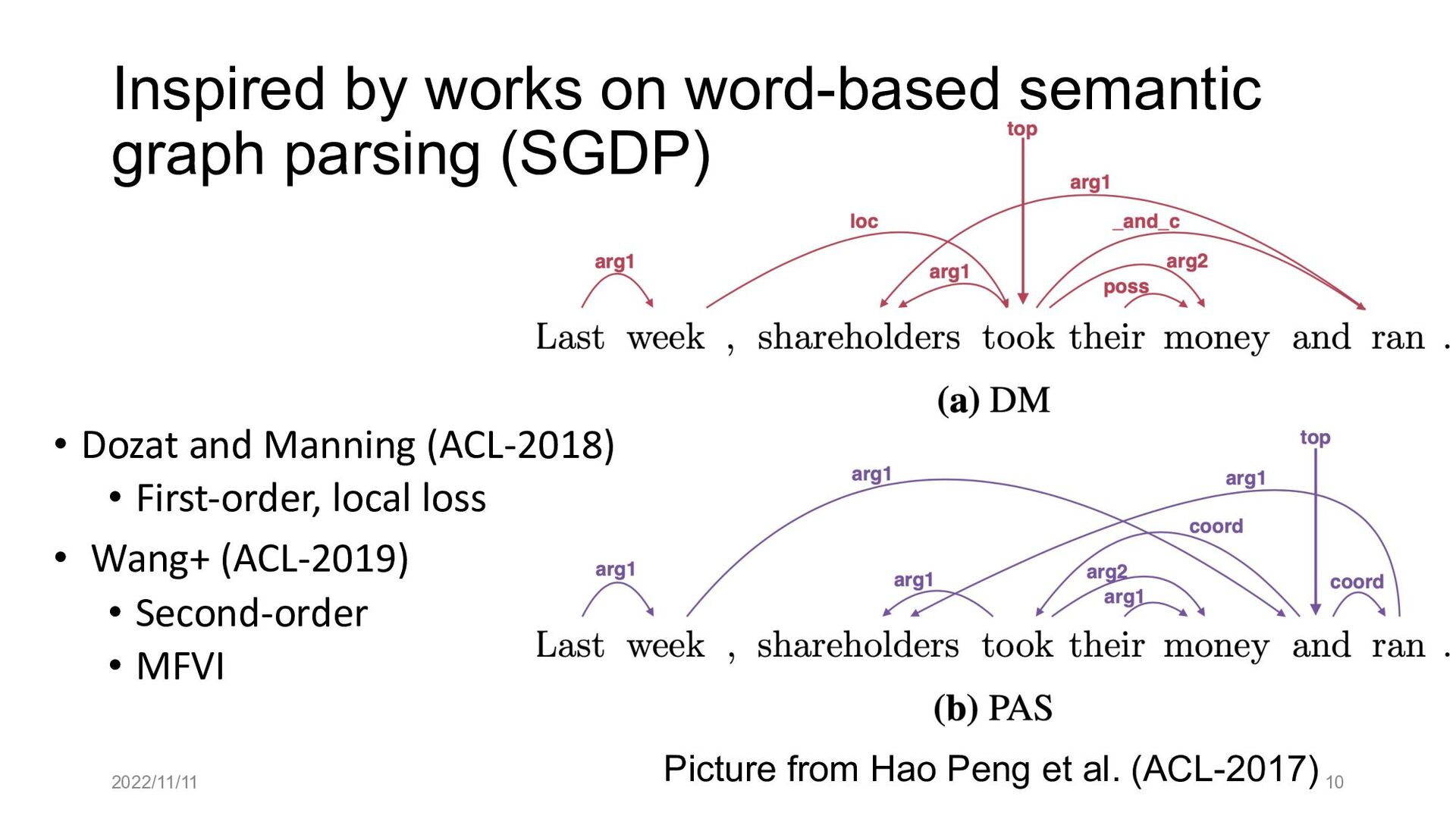
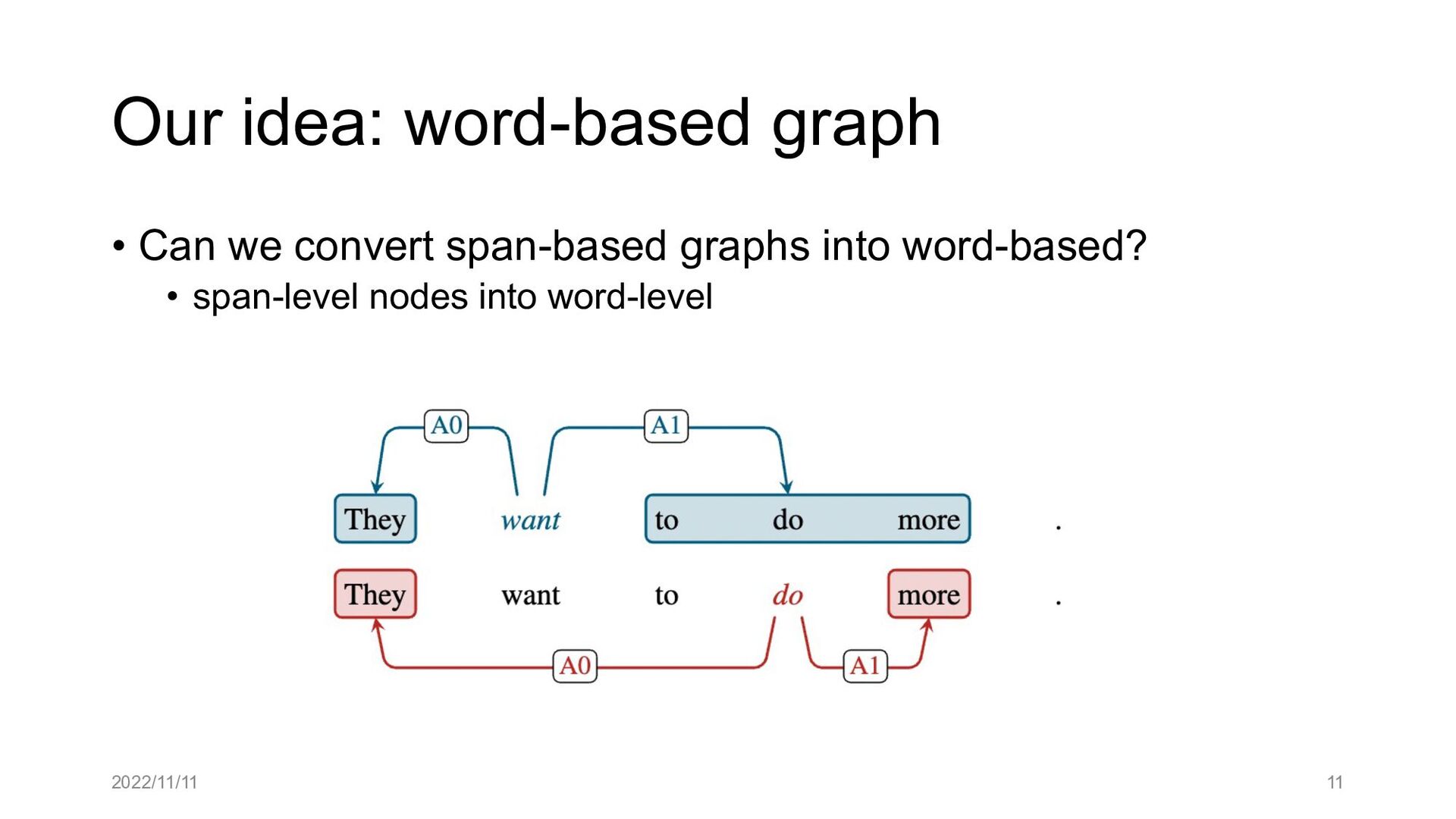
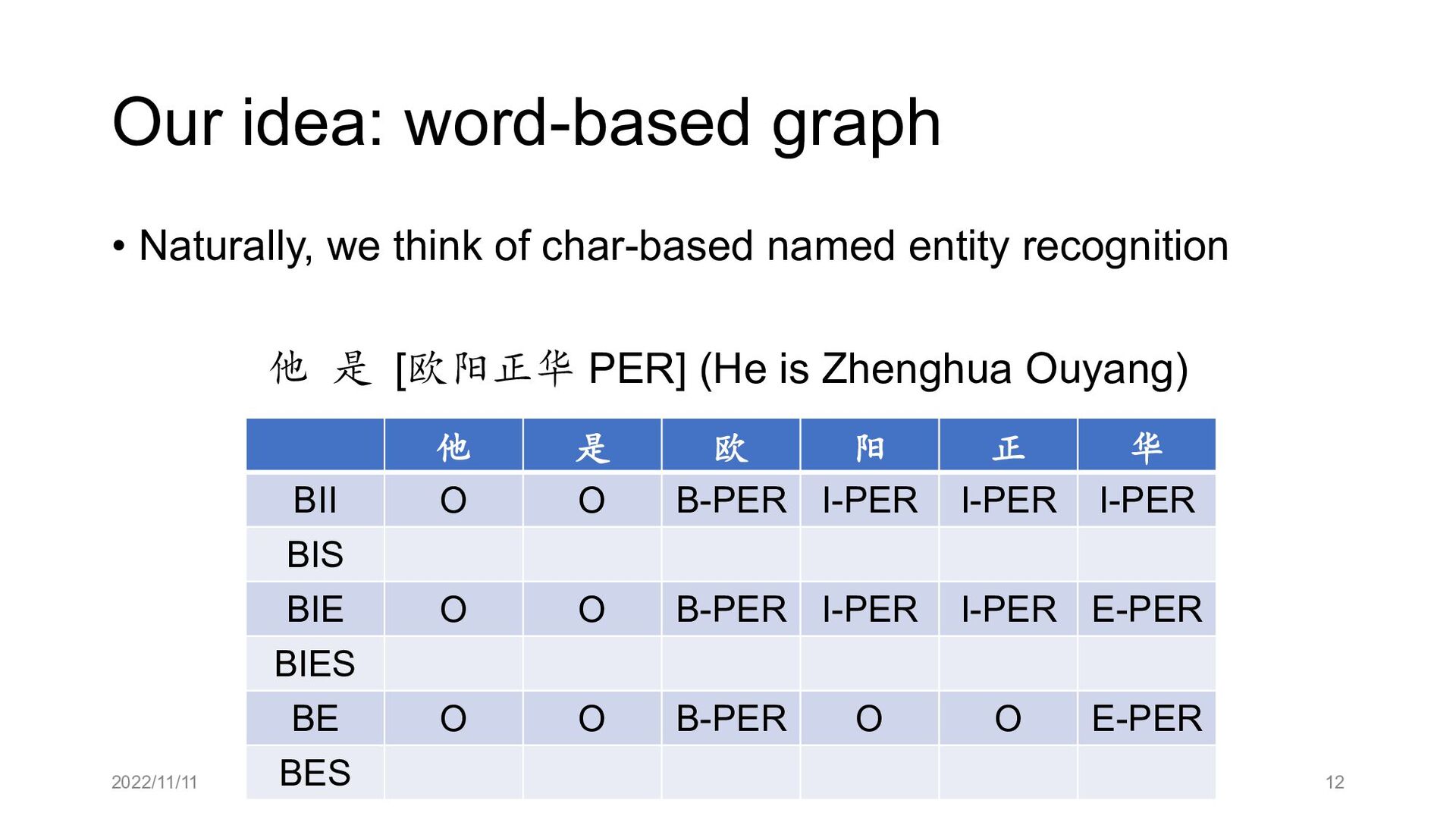
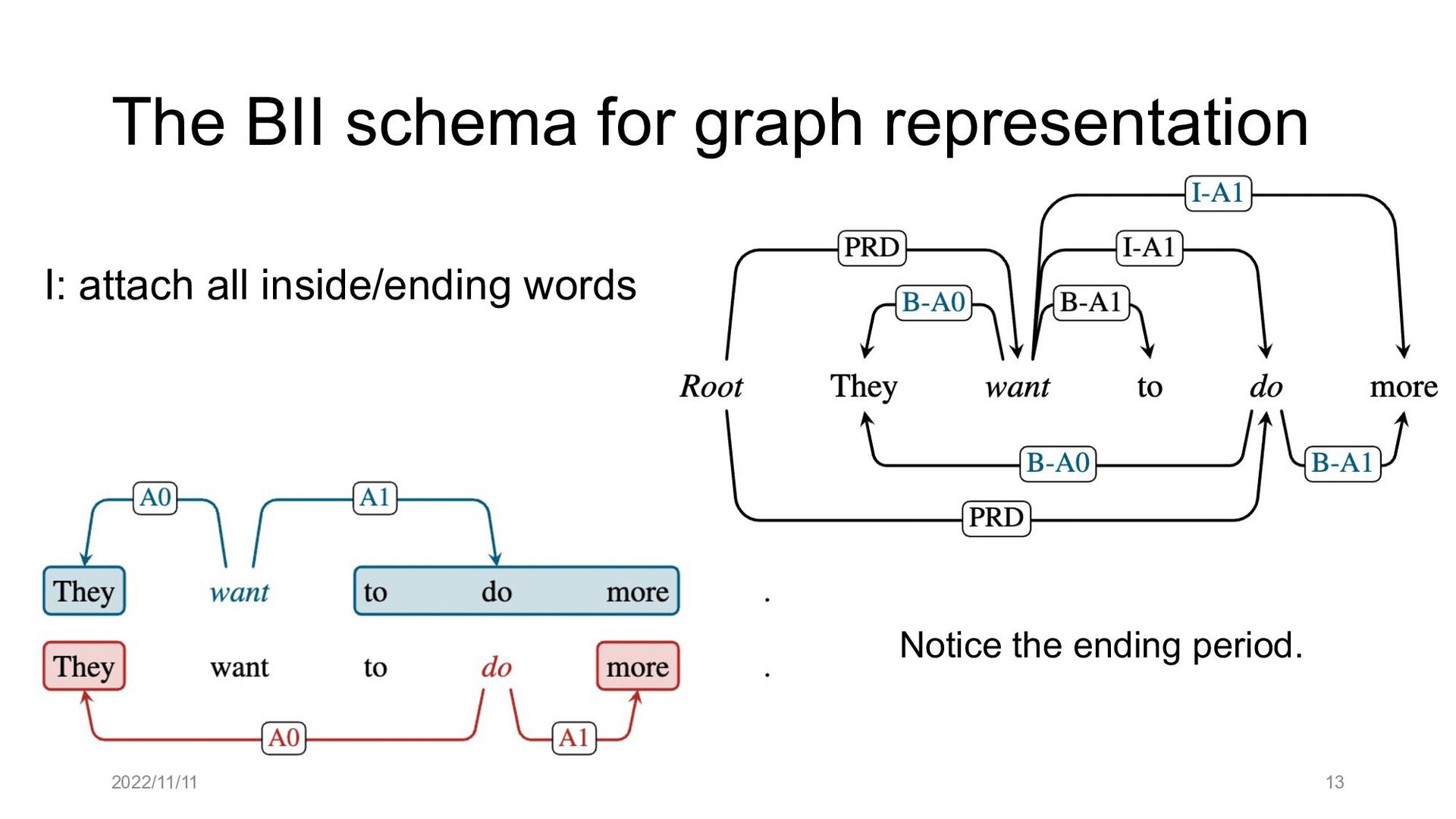
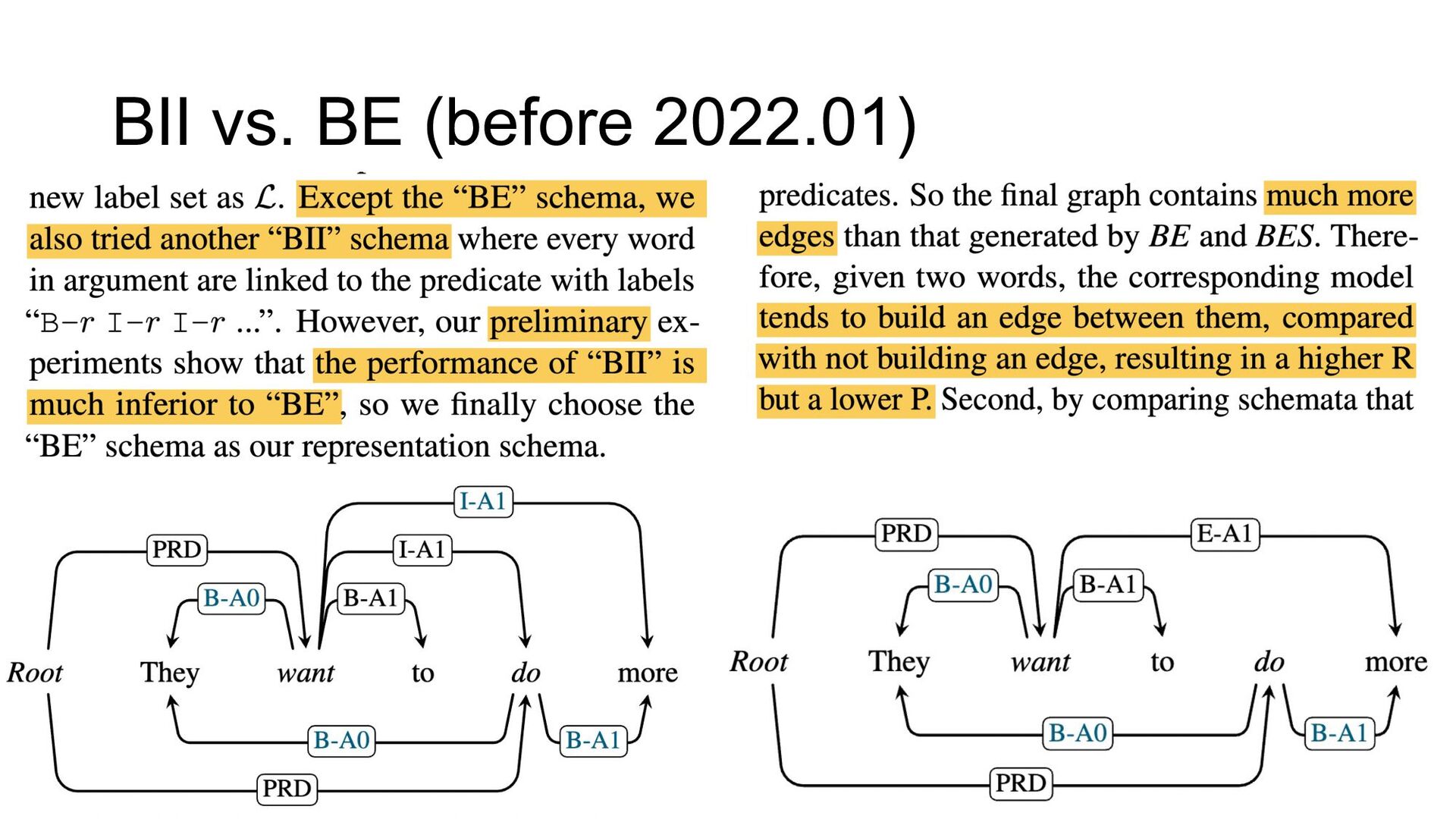
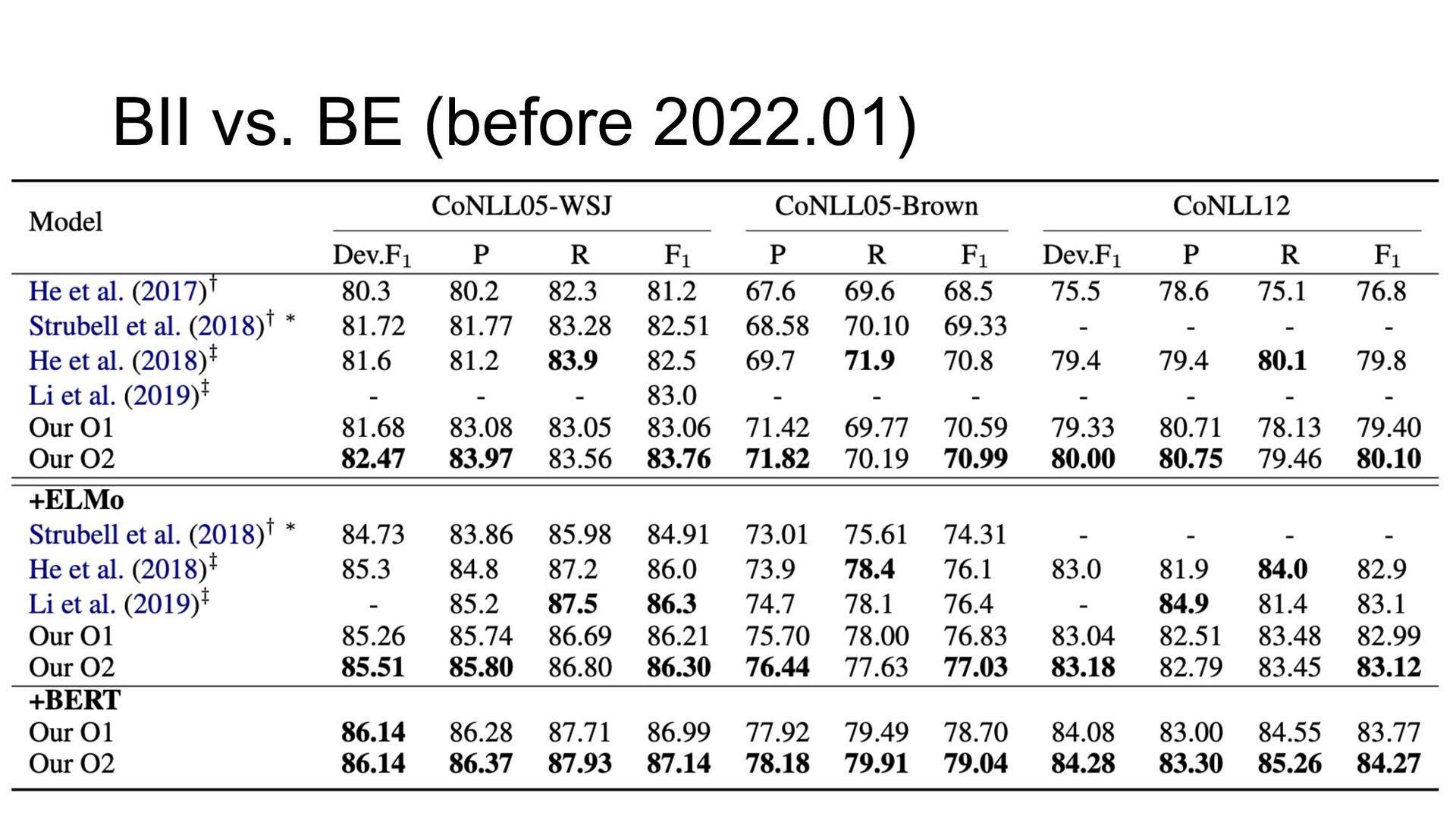
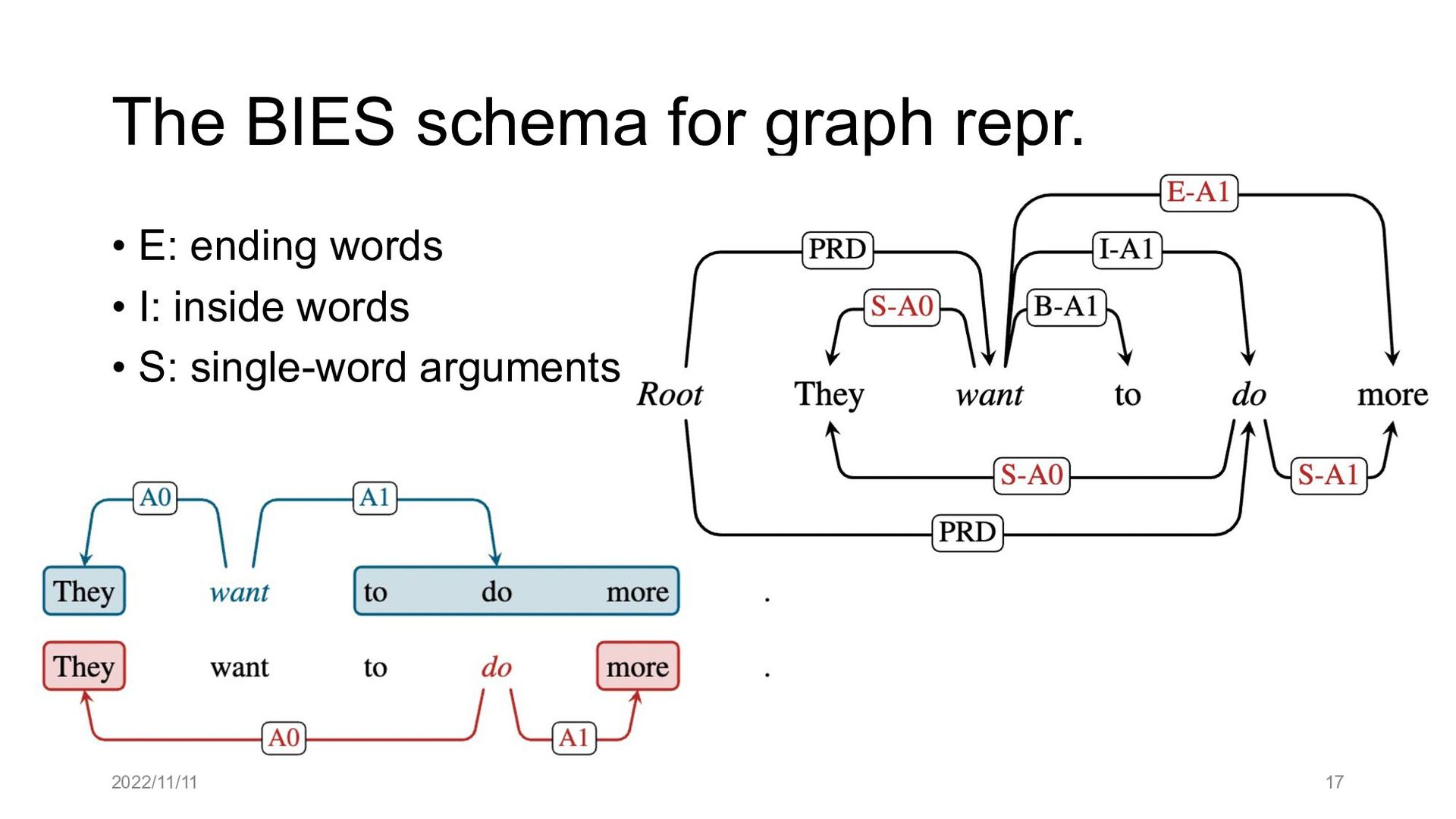
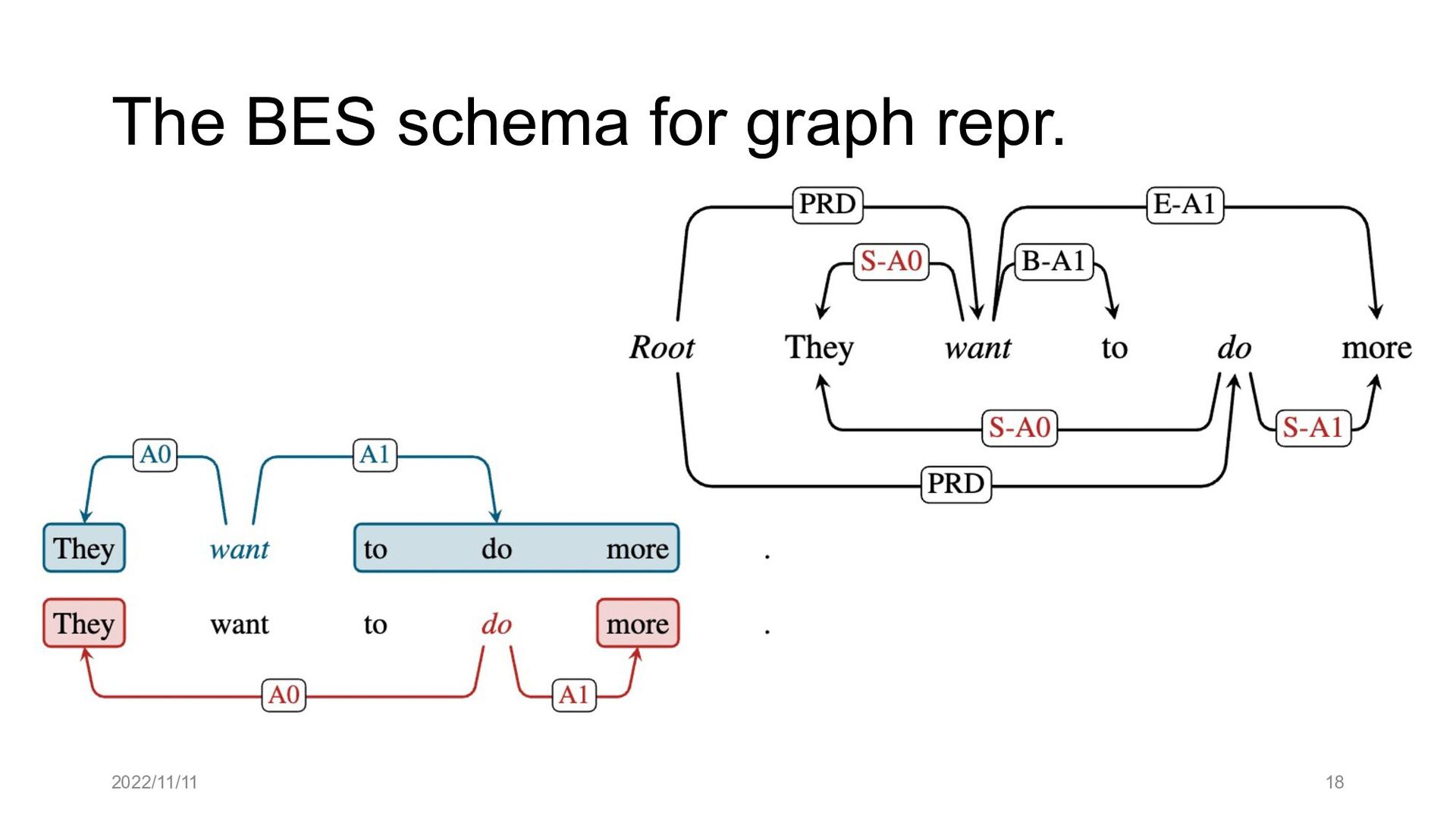
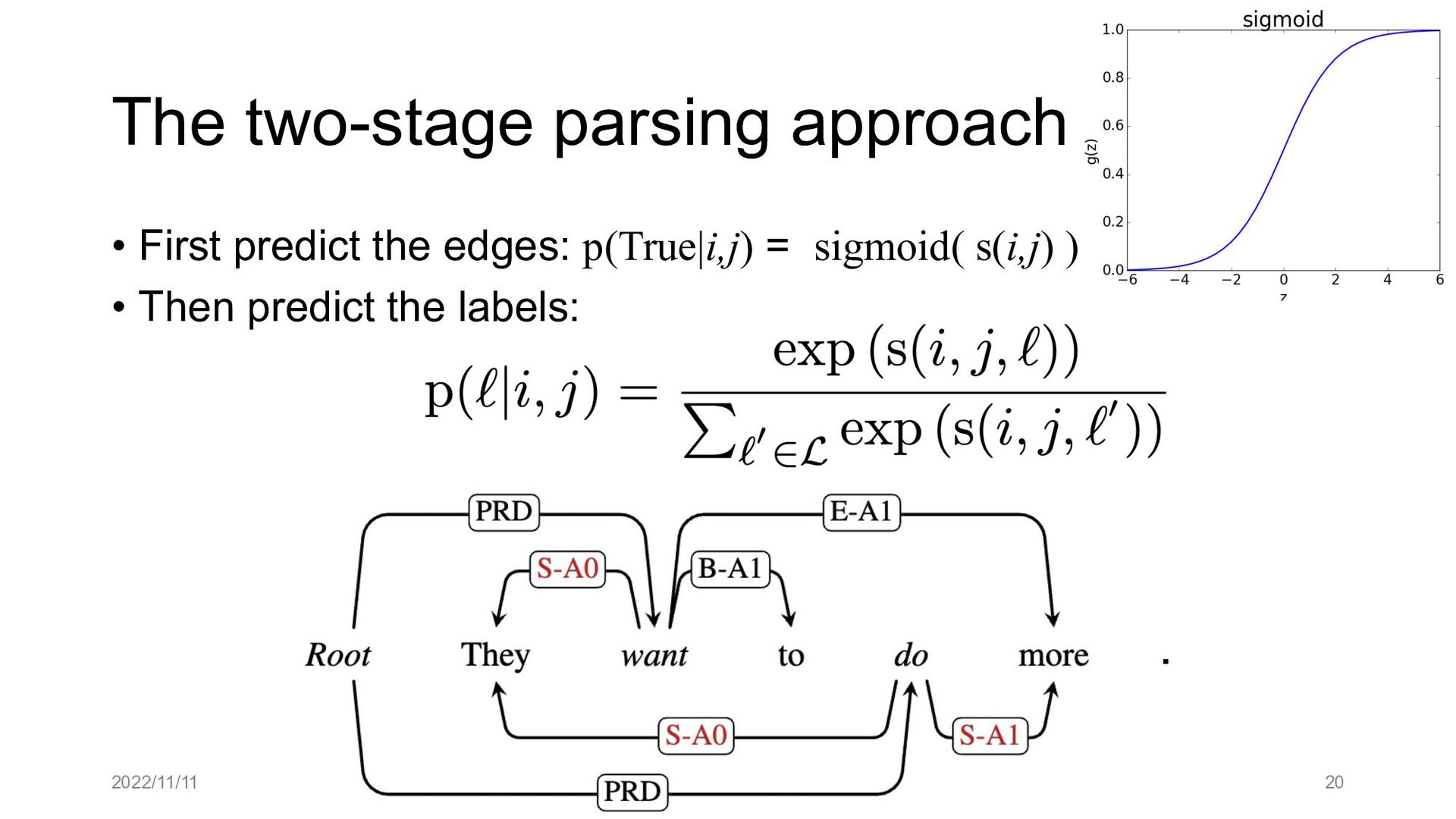
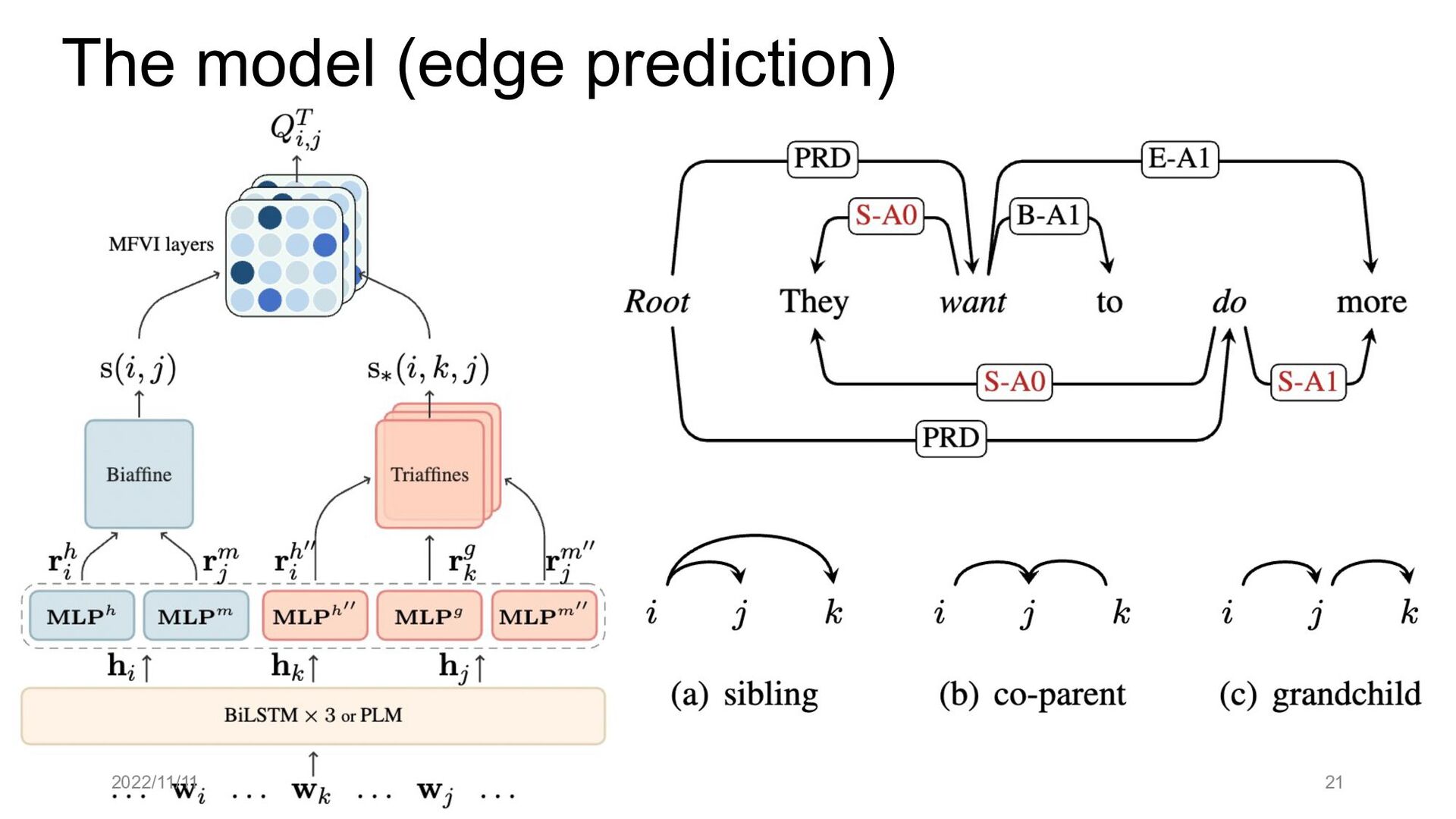
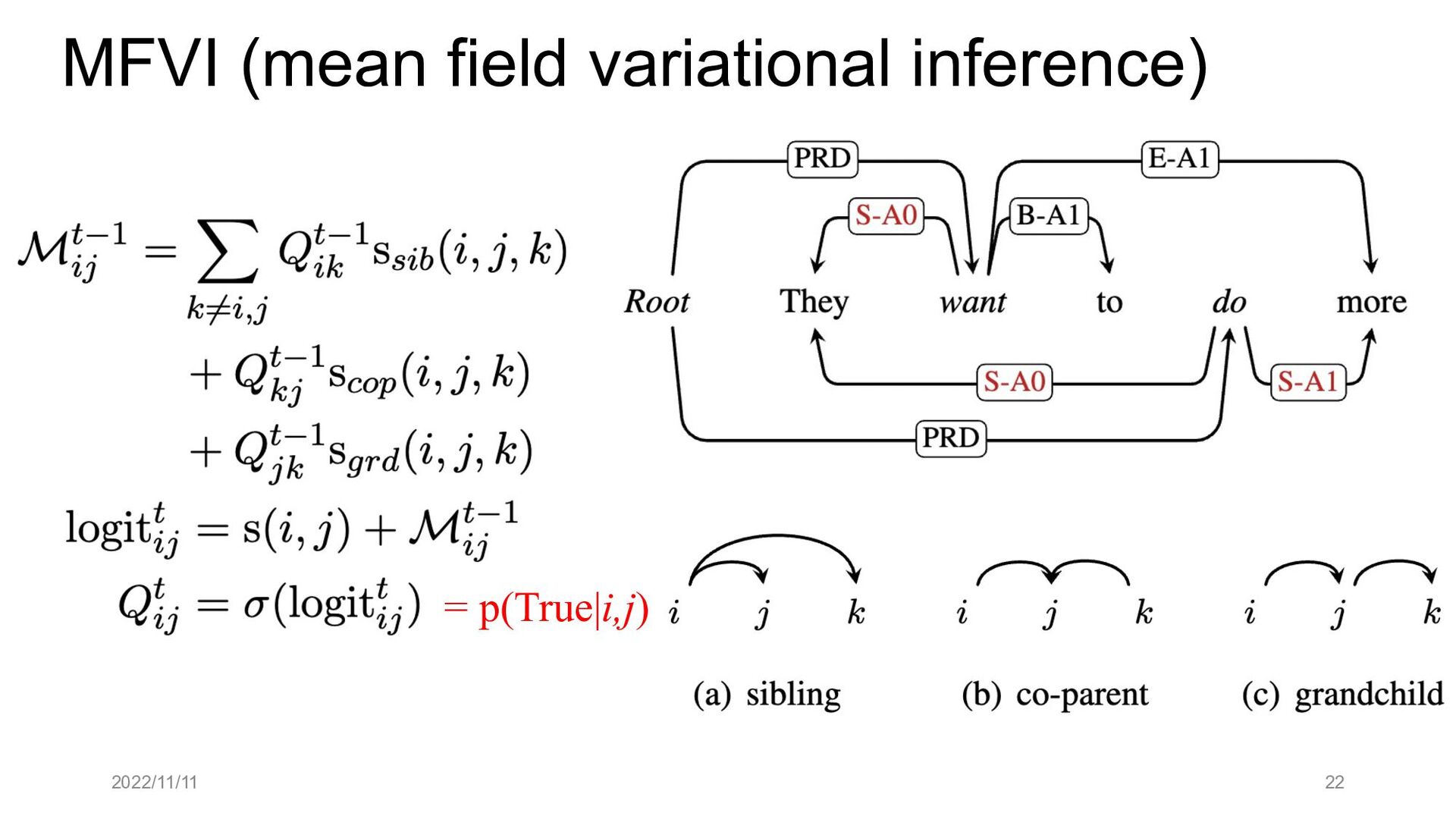
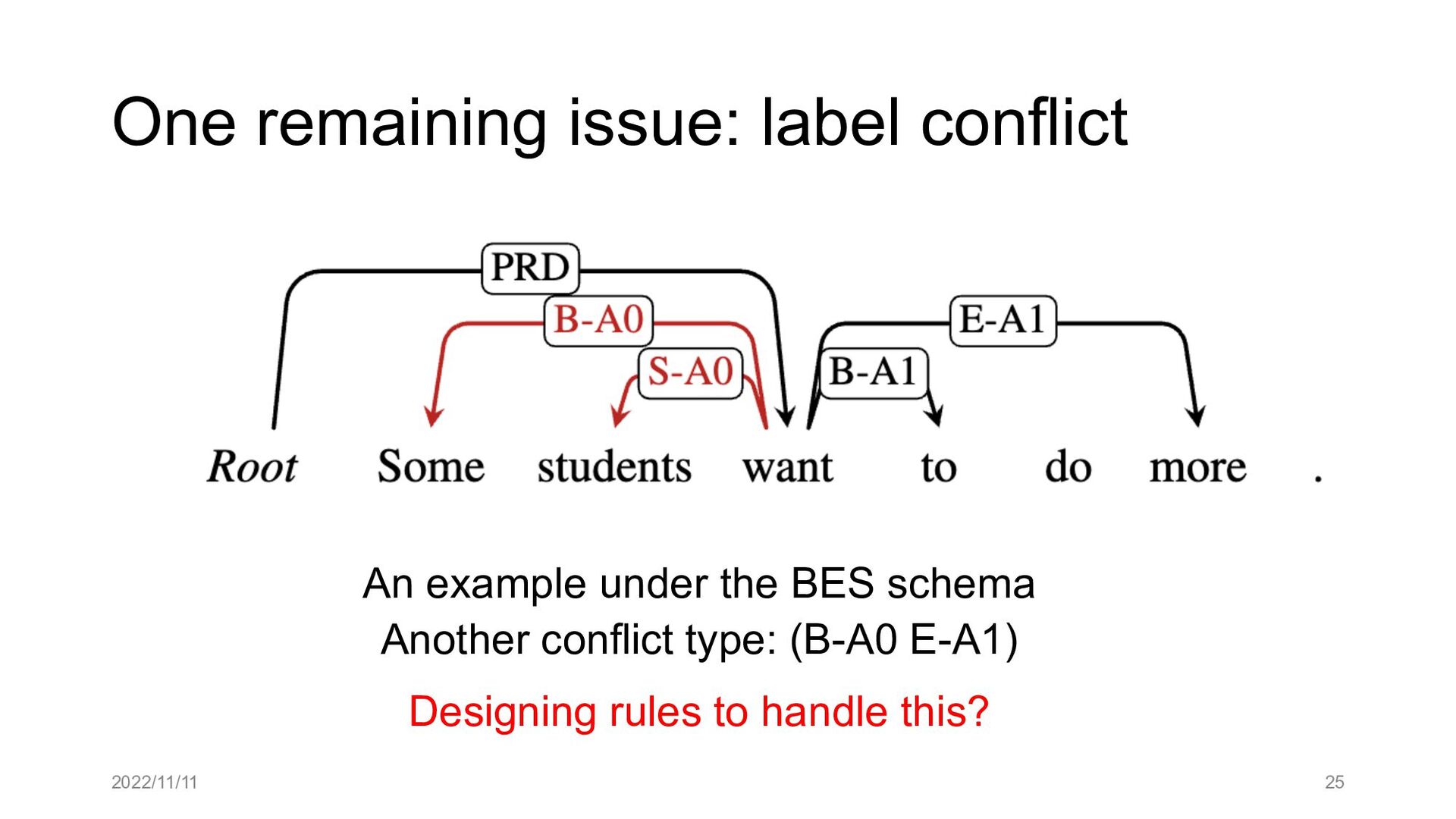
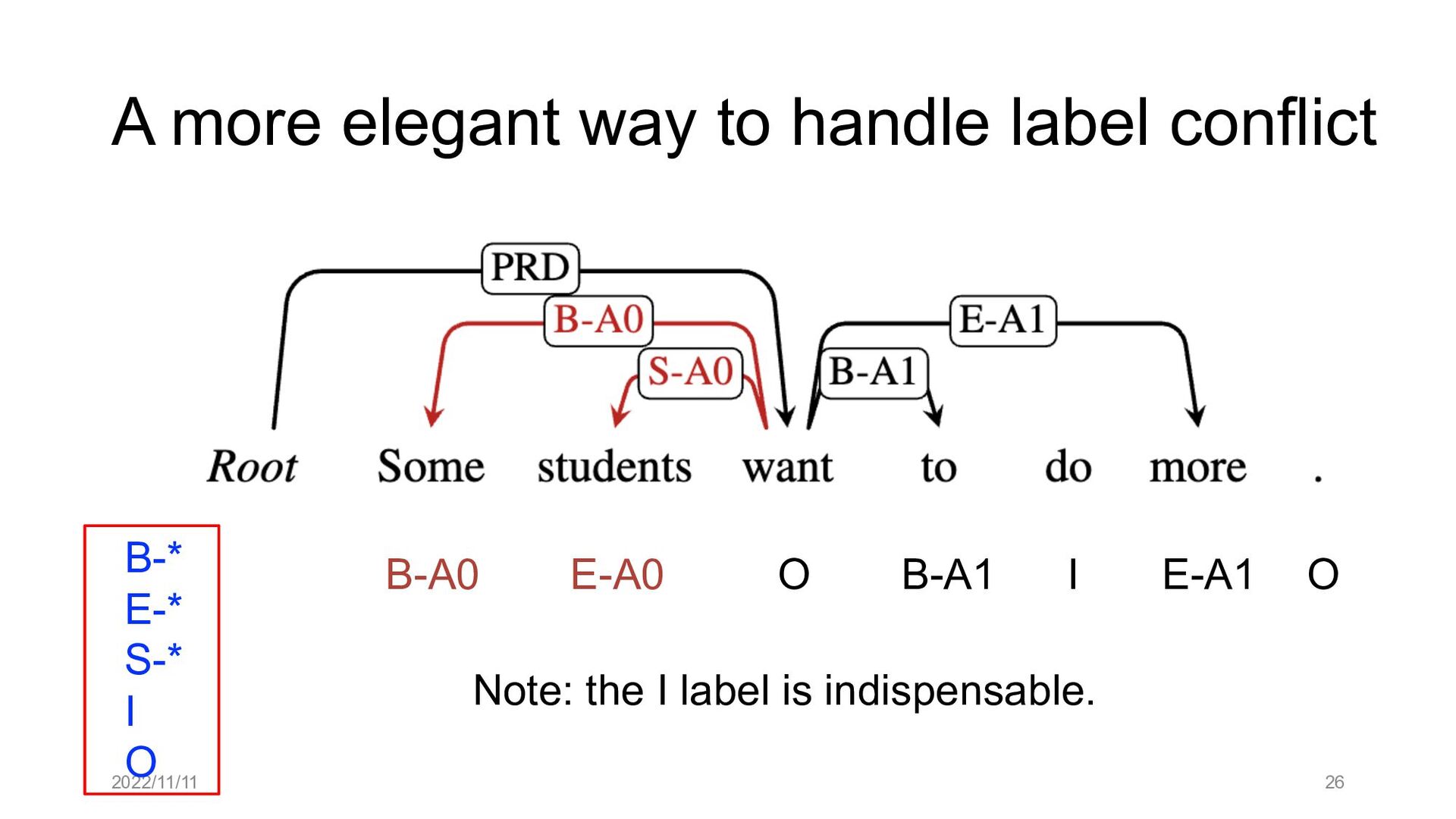
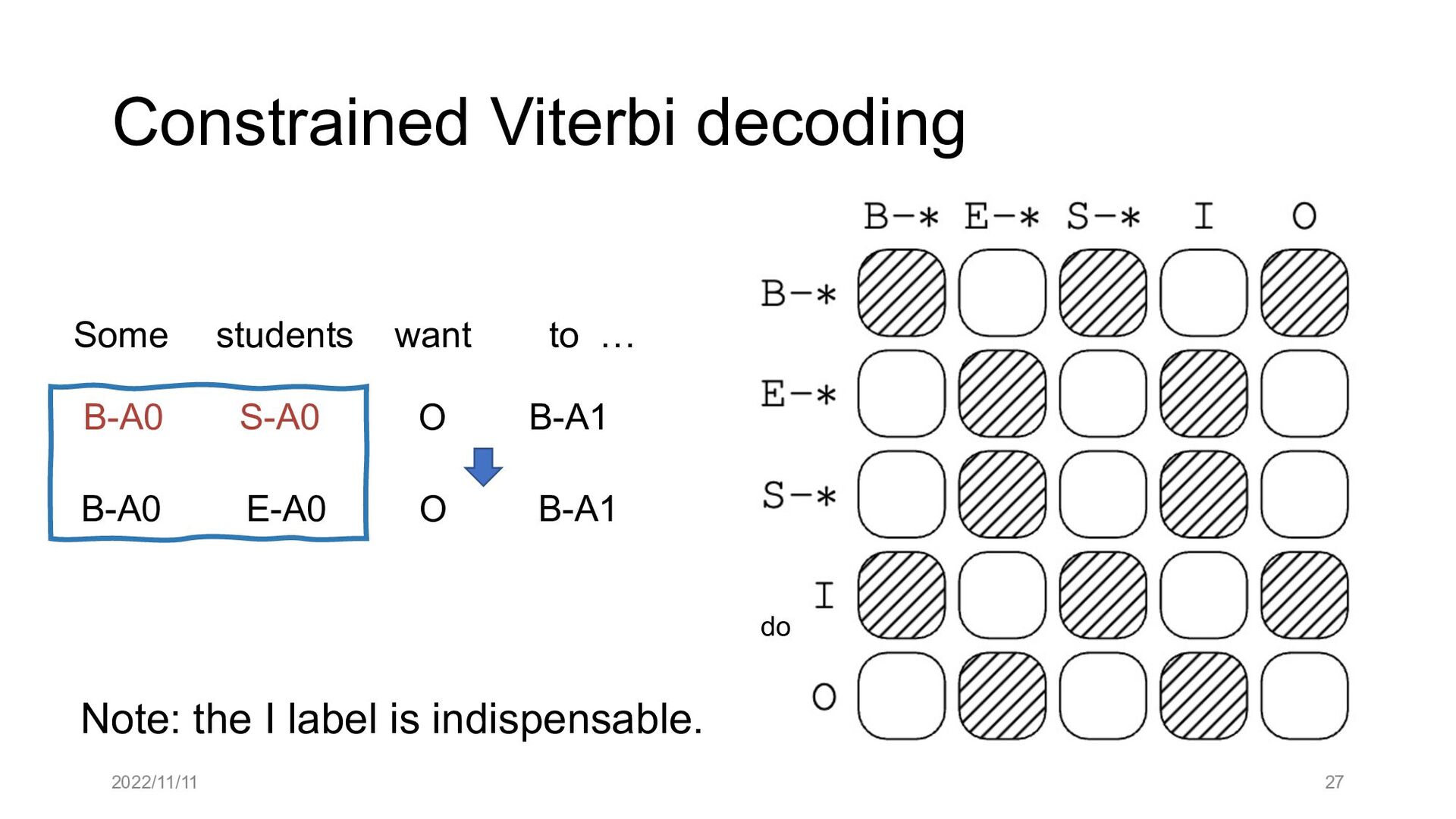
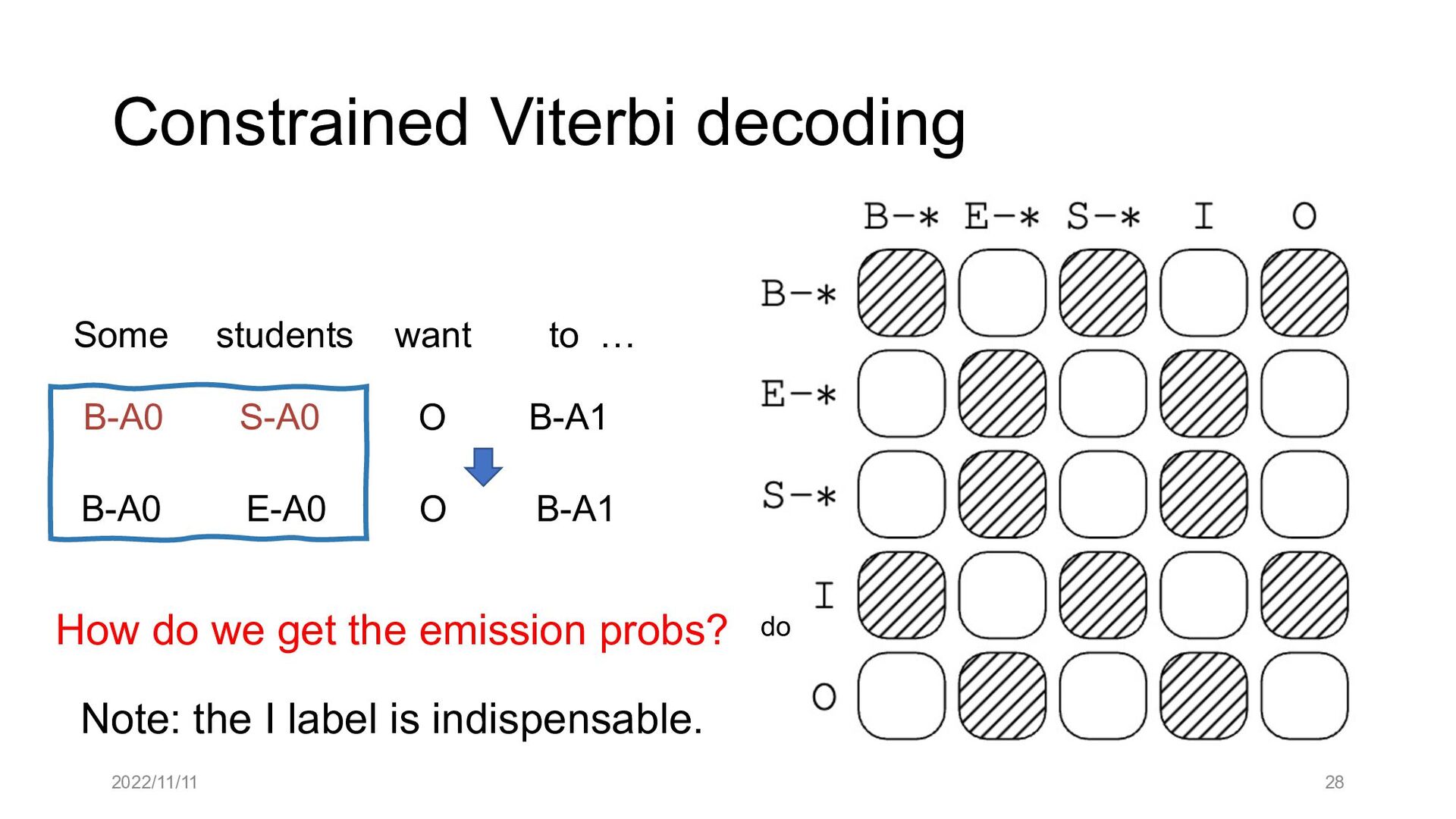
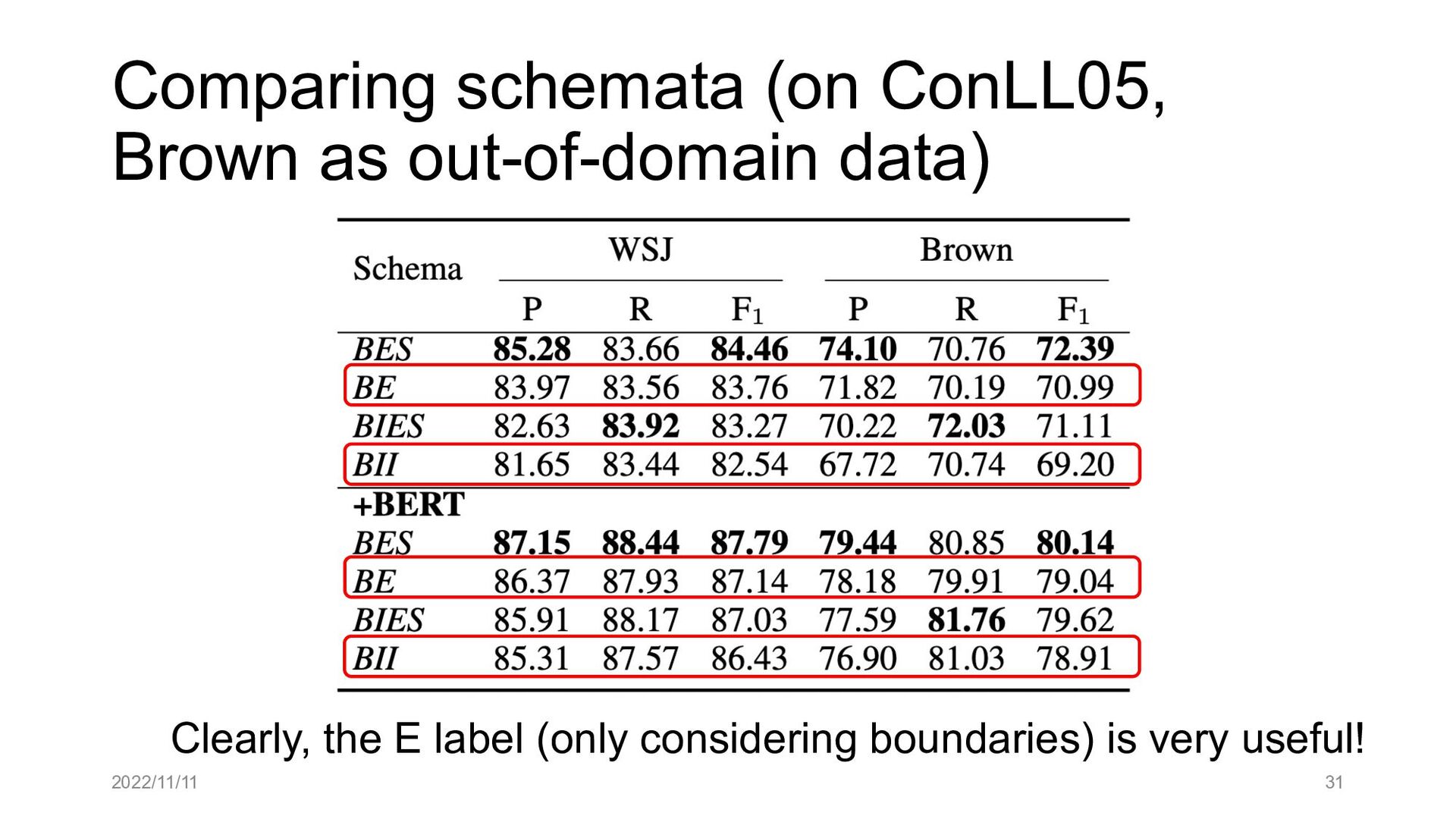
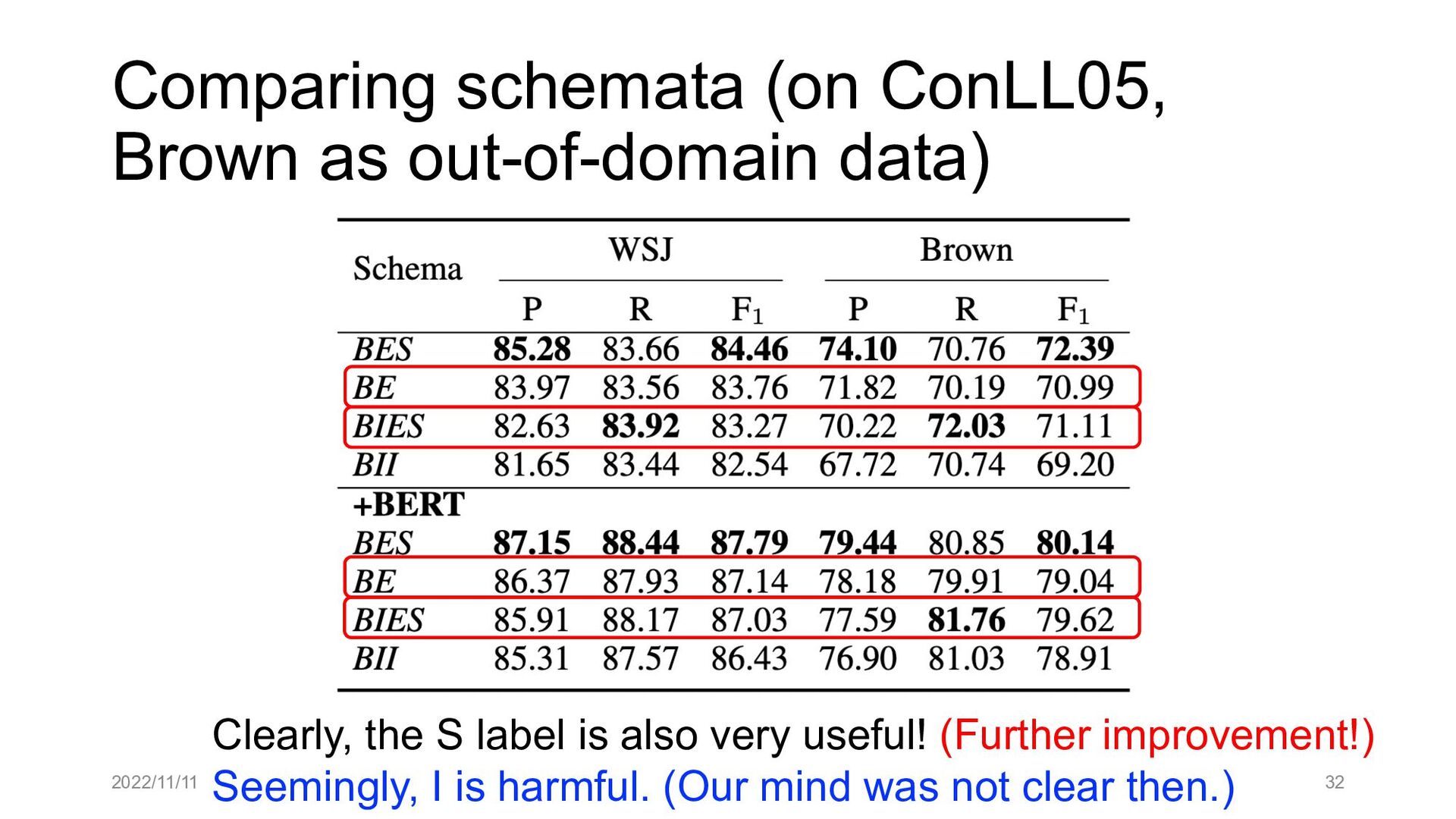
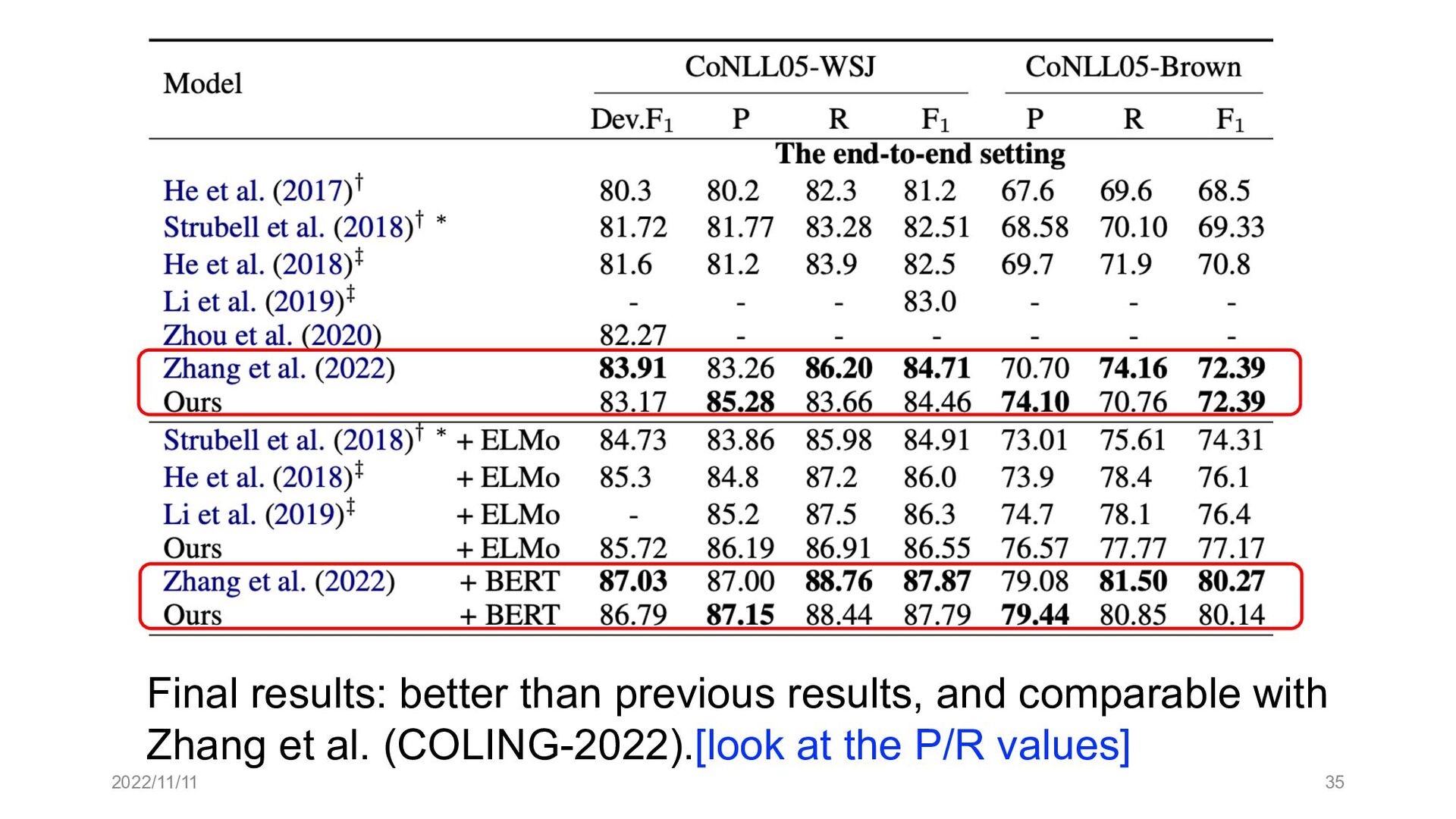
Paper abstract: This paper proposes to cast end-to-end span-based SRL as a word-based graph parsing task. The major challenge is how to represent spans at the word level. Borrowing ideas from research on Chinese word segmentation and named entity recognition, we propose and compare four different schemata of graph representation, i.e., BES, BE, BIES, and BII, among which we find that the BES schema performs the best. We further gain interesting insights through detailed analysis. Moreover, we propose a simple constrained Viterbi procedure to ensure the legality of the output graph according to the constraints of the SRL structure. We conduct experiments on two widely used benchmark datasets, i.e., CoNLL05 and CoNLL12. Results show that our word-based graph parsing approach achieves consistently better performance than previous results, under all settings of end-to-end and predicate-given, without and with pre-trained language models (PLMs). More importantly, our model can parse 669/252 sentences per second, without and with PLMs respectively.
Bio: Zhenghua Li is a full professor at Soochow University Suzhou, China. Zhenghua received the Bachelor, Master, and PhD degrees in computer science from Harbin Institute of Technology, Harbin, China, in 2006, 2008, and 2013, respectively. He joined Soochow University afterward. So far, he has published 40+ top-tier conference papers in the NLP/AI fields, including 9 ACL long papers, as the first author or the corresponding author. His NLPCC-2020 paper had won the best paper award; and his COLING-2022 paper had won the best long paper award. Besides writing papers, he has been actively participated in shared tasks and competitions and has won the first place for multiple times, including tasks on syntax parsing (CoNLL-2009), semantic parsing (SemEval-2019 UCCA), CoNLL-2019 EDS), and grammatical error correction (GEC) (CTC-2021, CGED-2021, WAIC-2022). Meanwhile, he has been highly interested in and constantly engaged in constructing high-quality datasets for research on syntactic parsing (CODT), semantic parsing (MuCPAD), text-to-SQL parsing (DuSQL, SeSQL), and GEC (MuGEC). He, as PI, has been granted three NSFC projects, and has been closely collaborated with Alibaba, Huawei, and Baidu during the past three years. As a graduate student supervisor, he has 3 students obtaining their PhD degree and about 15 students obtaining their Master degree. Two of them teach and do research in universities, and many work in top-tier IT companies in China.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}