Share
BigQuery + dbt + Paradime.ioを中心としたデータ基盤で、データの民主化を実現するための6つのアクションプランと具体的な解決策を紹介します。
主な取り組み
定義・指標の統一 - 過去数値の確定化 dbt mesh構成 - 複数プロジェクト対応による疎結合化 CI/CDによる品質担保 - Column Lineage Diffで影響範囲を事前把握 データカタログ共有 - ThoughtSpot含む全ダッシュボードのリネージュ可視化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
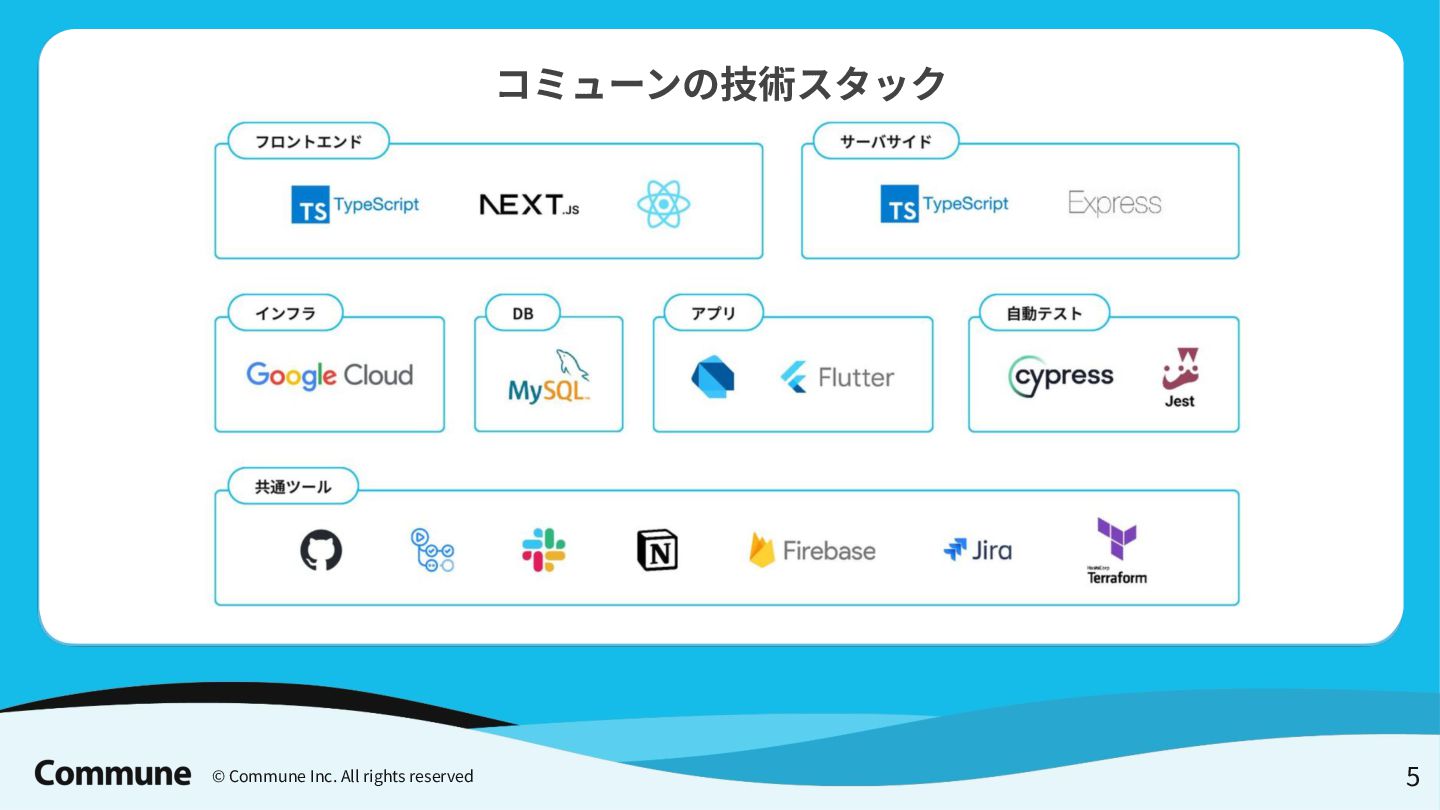{kind=link}
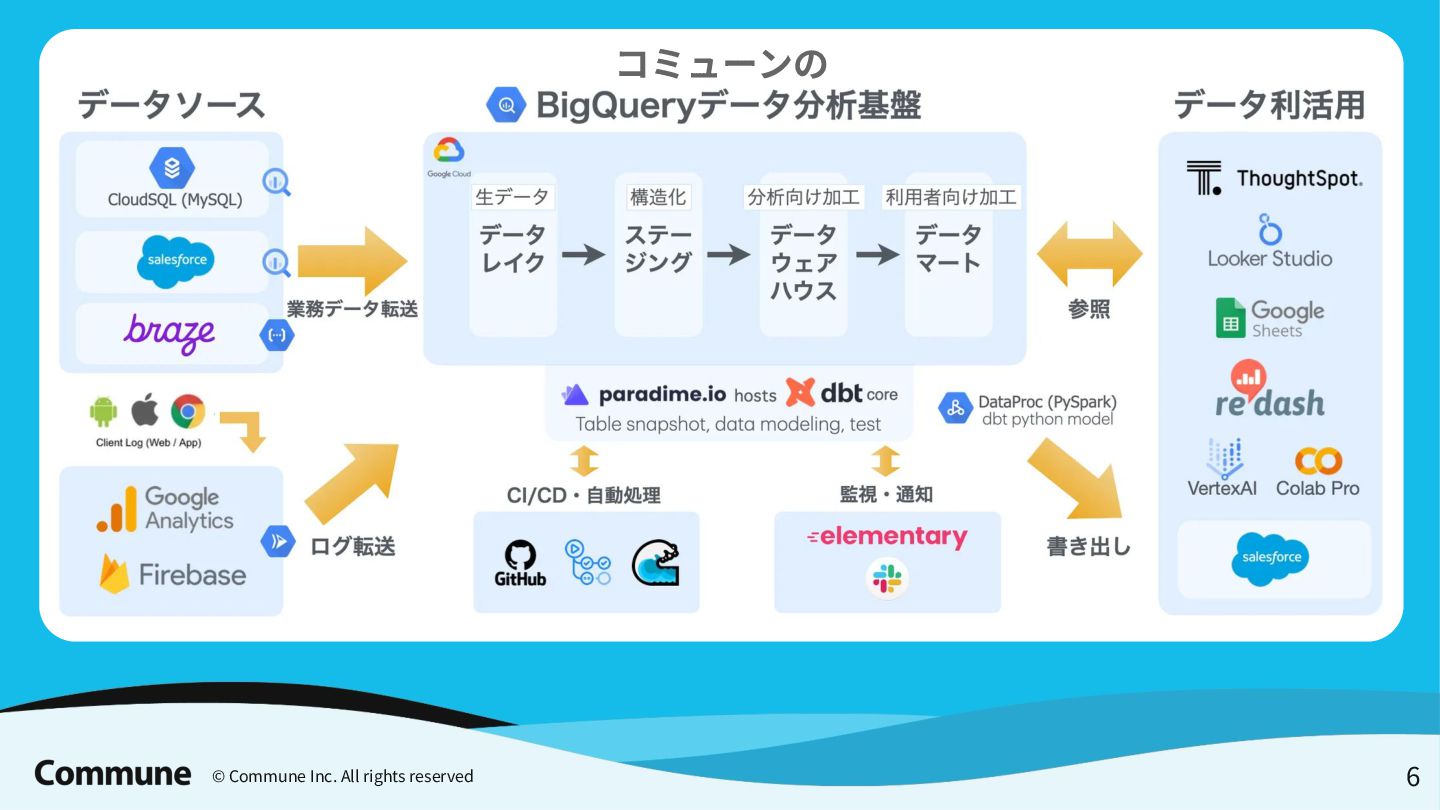{kind=link}
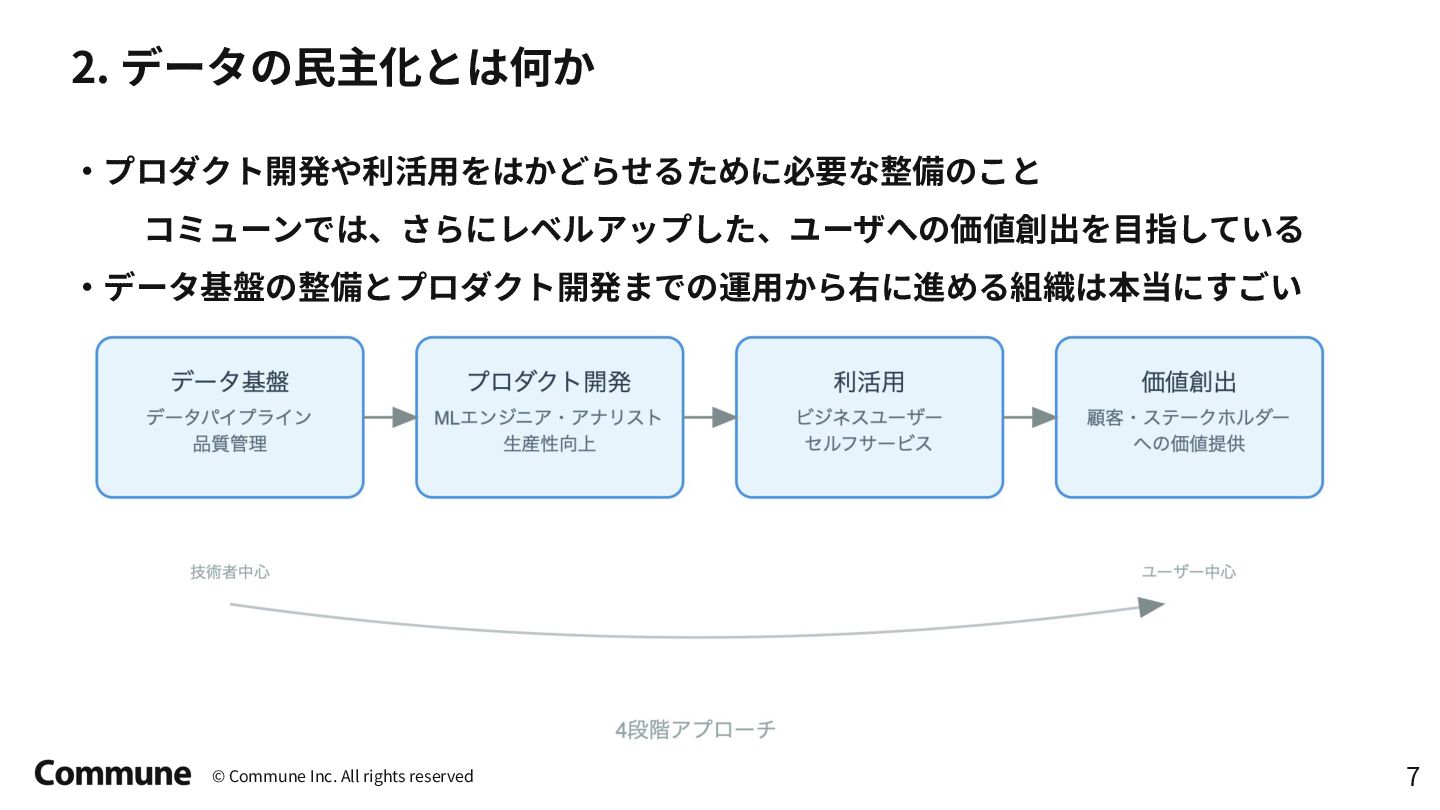{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
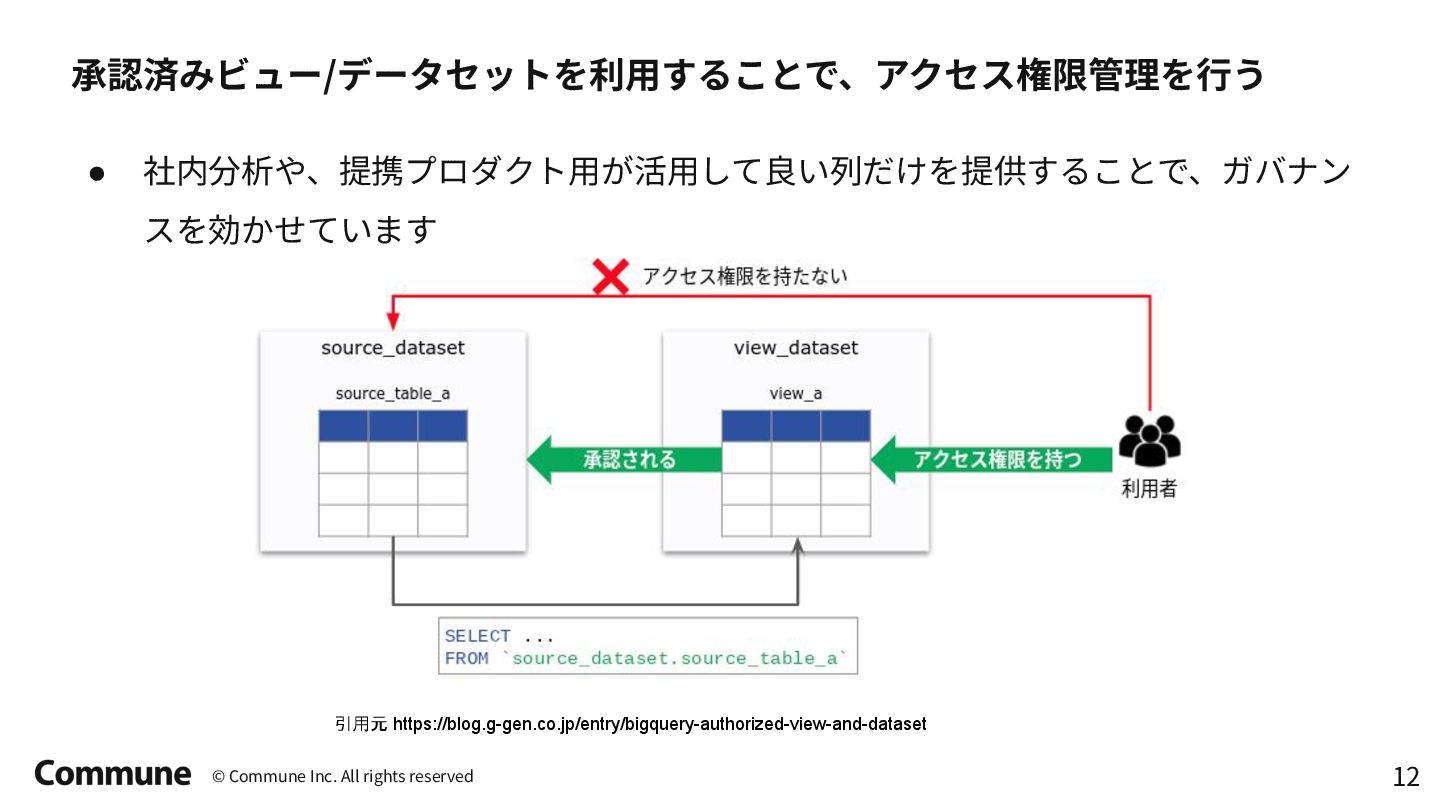{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
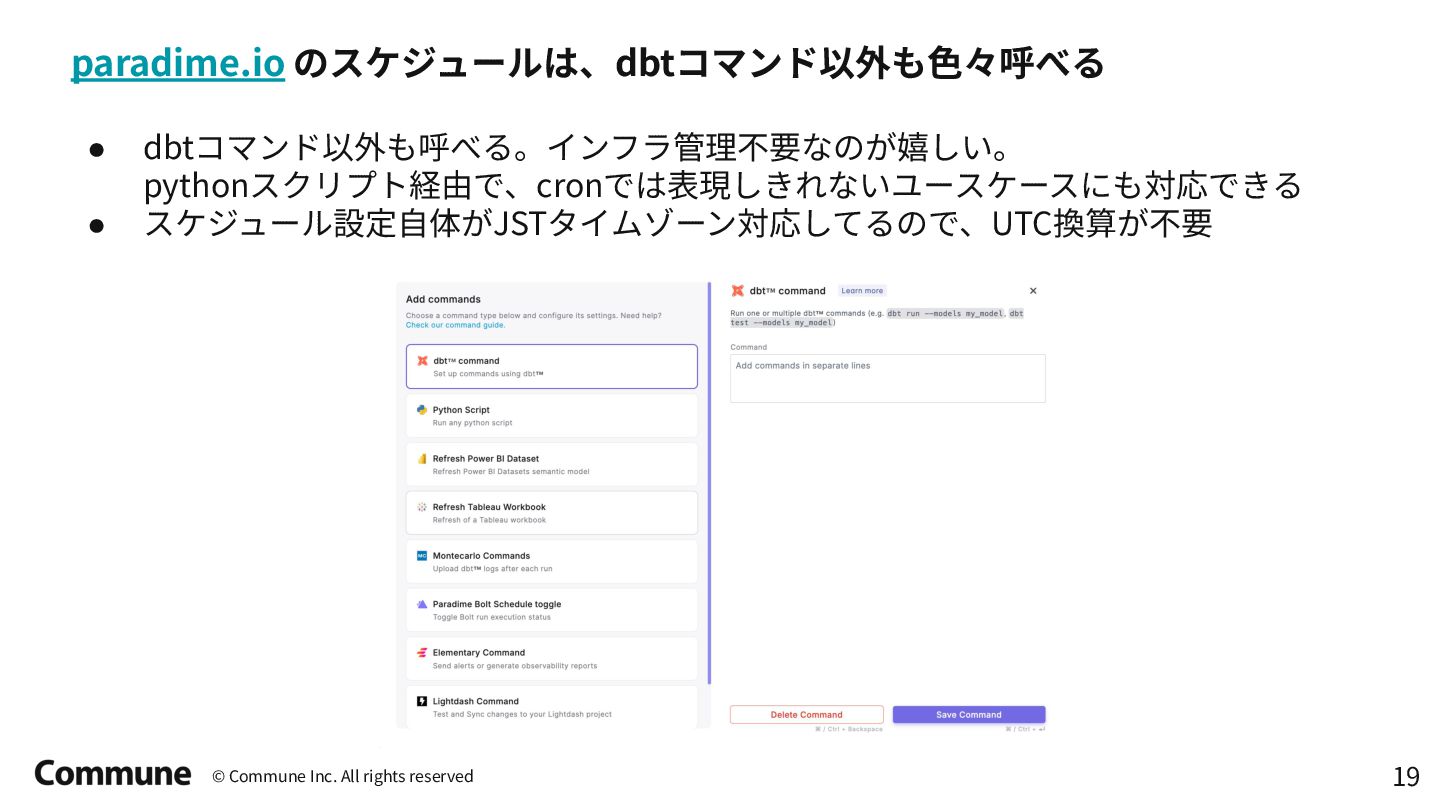{kind=link}
{kind=link}
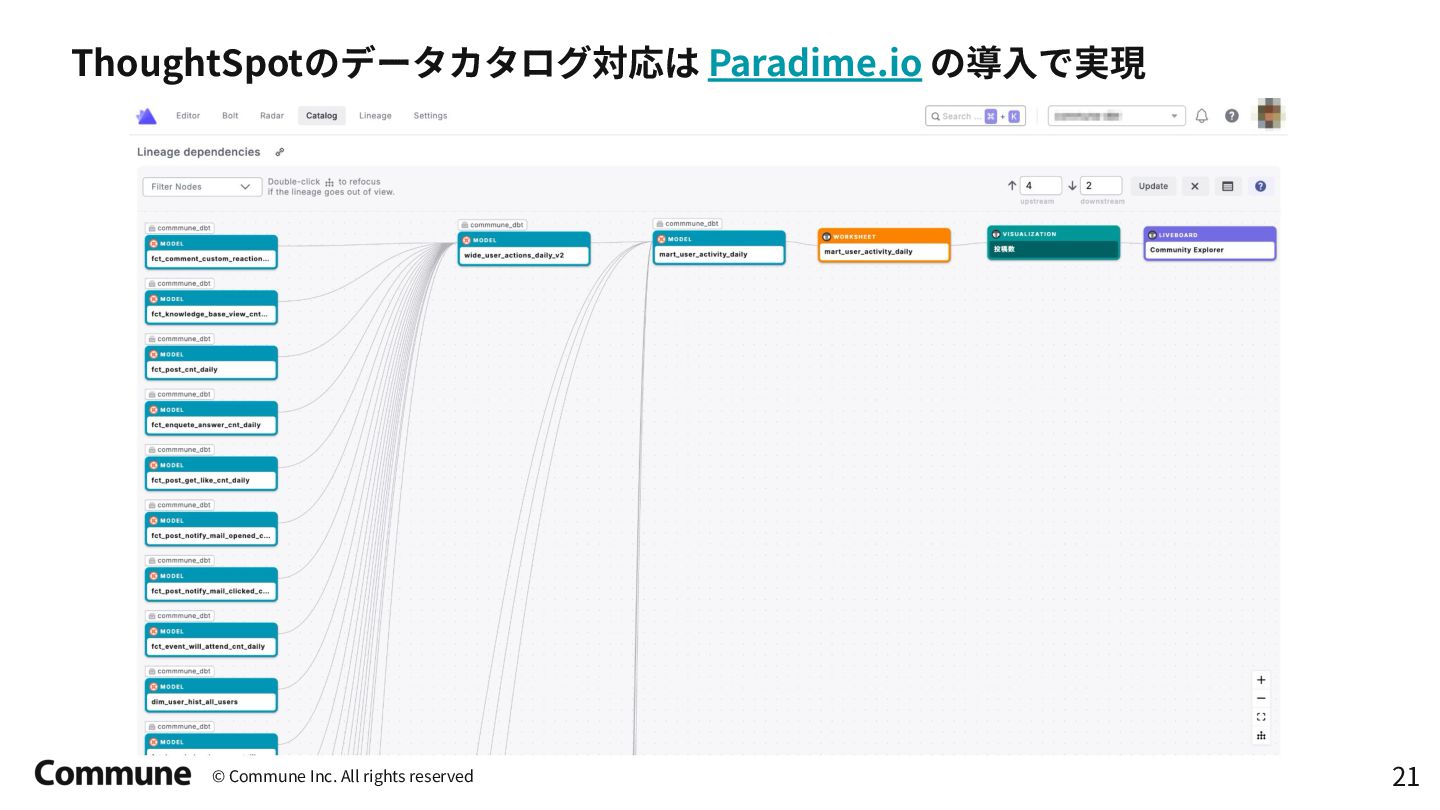{kind=link}
{kind=link}
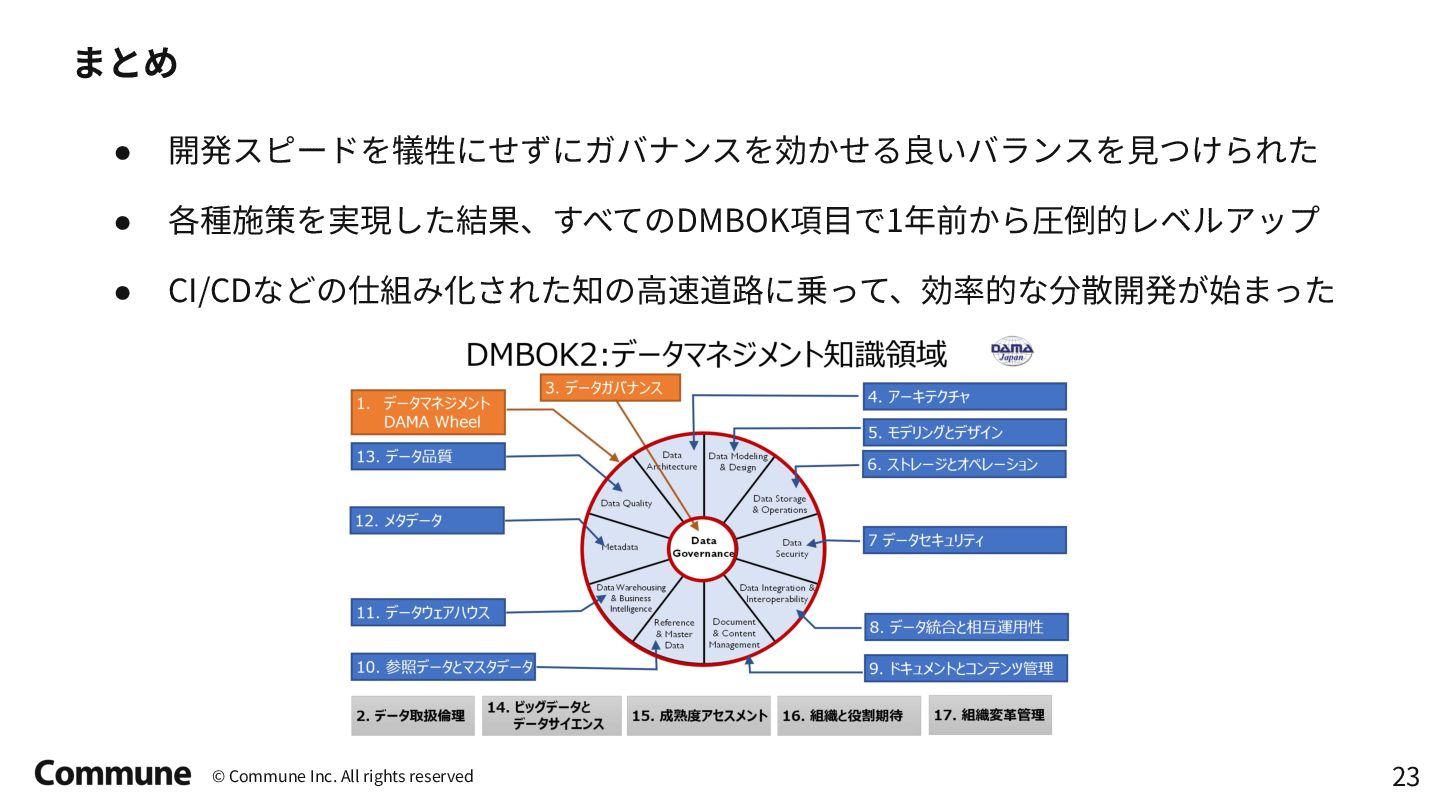{kind=link}
{kind=link}
{kind=link}
{kind=link}