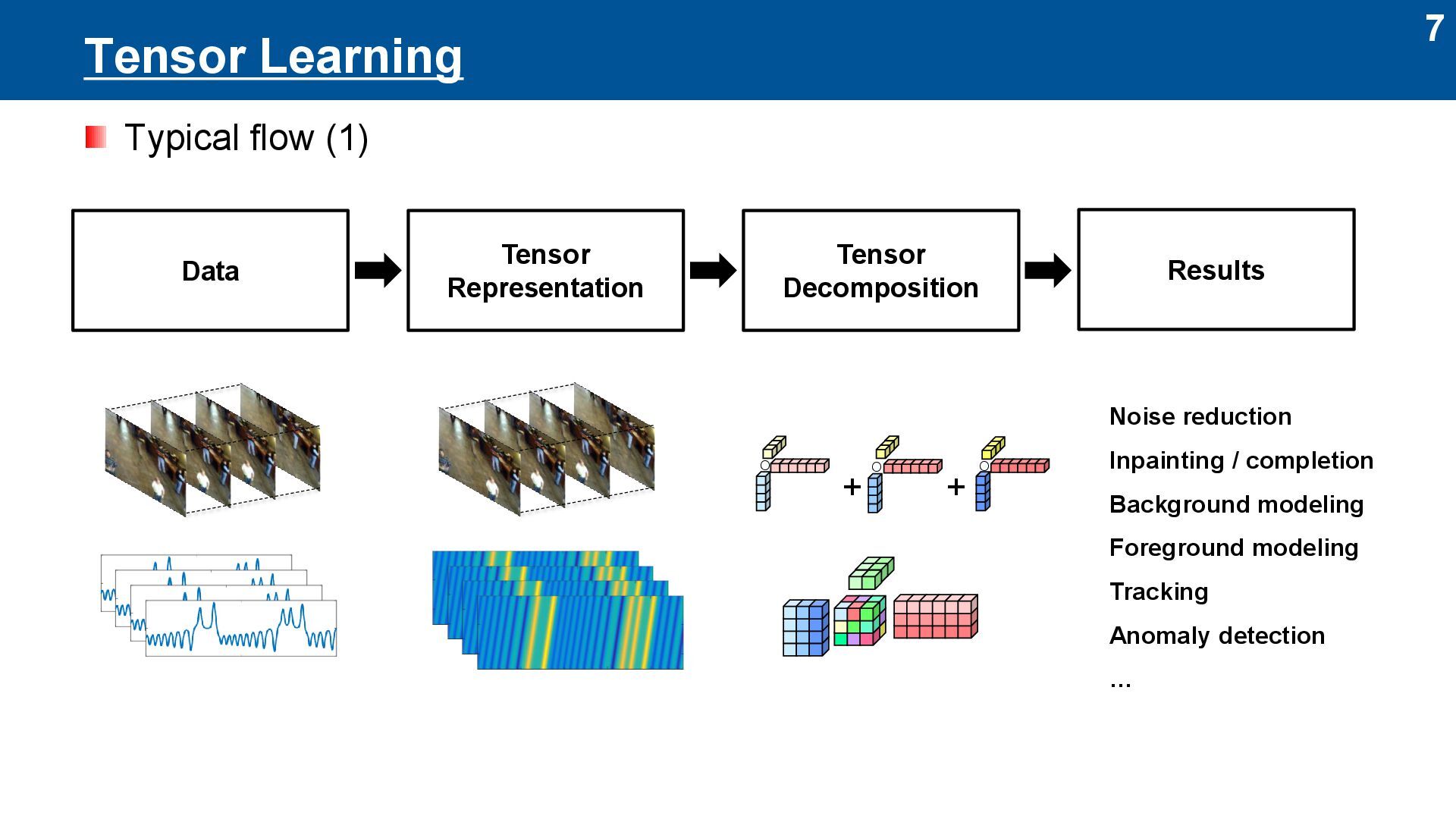
Learning Tatsuya Yokota Nagoya Institute of Technology / RIKEN AIP [AIP Progress Report Meeting Series] Workshop on Tensor Representation for Machine Learning
learning ⚫ [IEEE SPL, 2020] Matrix and Tensor Completion in Multiway Delay Embedded Space Using Tensor Train, with Application to Signal Reconstruction ⚫ [AAAI, 2020] Block Hankel Tensor ARIMA for Multiple Short Time Series Forecasting ⚫ [IEEE TNNLS, 2022] Manifold Modeling in Embedded Space: An Interpretable Alternative to Deep Image Prior ⚫ [CVPR, 2022] Fast Algorithm for Low-rank Tensor Completion in Delay-embedded Space ⚫ [IEEE Access, 2023] A New Model for Tensor Completion: Smooth Convolutional Tensor Factorization Sparse regularization in tensor learning ⚫ [SN Computer Science, 2022] Bayesian tensor completion and decomposition with automatic CP rank determination using MGP shrinkage prior ⚫ [IEEE CAI Workshop, 2024] Tensor Completion with Adaptive Block Multi-layer Sparsity-based CP Decomposition ⚫ [EUSIPCO, 2024] Adaptive Block Sparse Regularization under Arbitrary Linear Transform Algorithm development in tensor learning ⚫ [IEEE CAI Workshop, 2024] ADMM-MM Algorithm for General Tensor Decomposition ⚫ [Frontiers in Applied Mathematics and Statistics, 2025] Expectation-Maximization Alternating Least Squares for Tensor Network Logistic Regression Medical imaging using tensor learning ⚫ [ICCV, 2019] “Dynamic PET Image Reconstruction Using Nonnegative Matrix Factorization Incorporated with Deep Image Prior ⚫ [HPC Asia, 2024] "Efficient implementation and acceleration of DIP-NMF-MM algorithm for high-precision 4D PET image reconstruction“
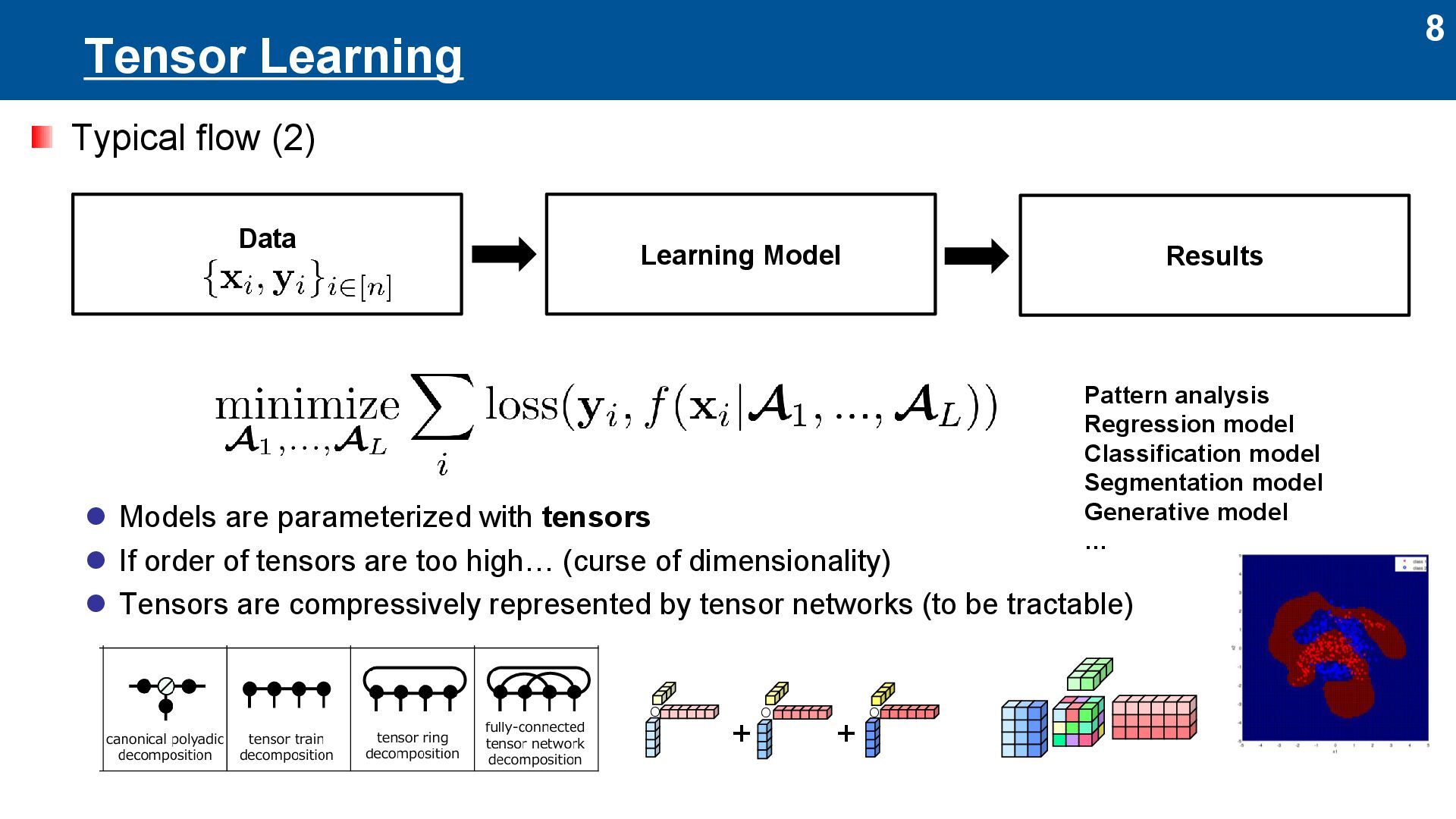
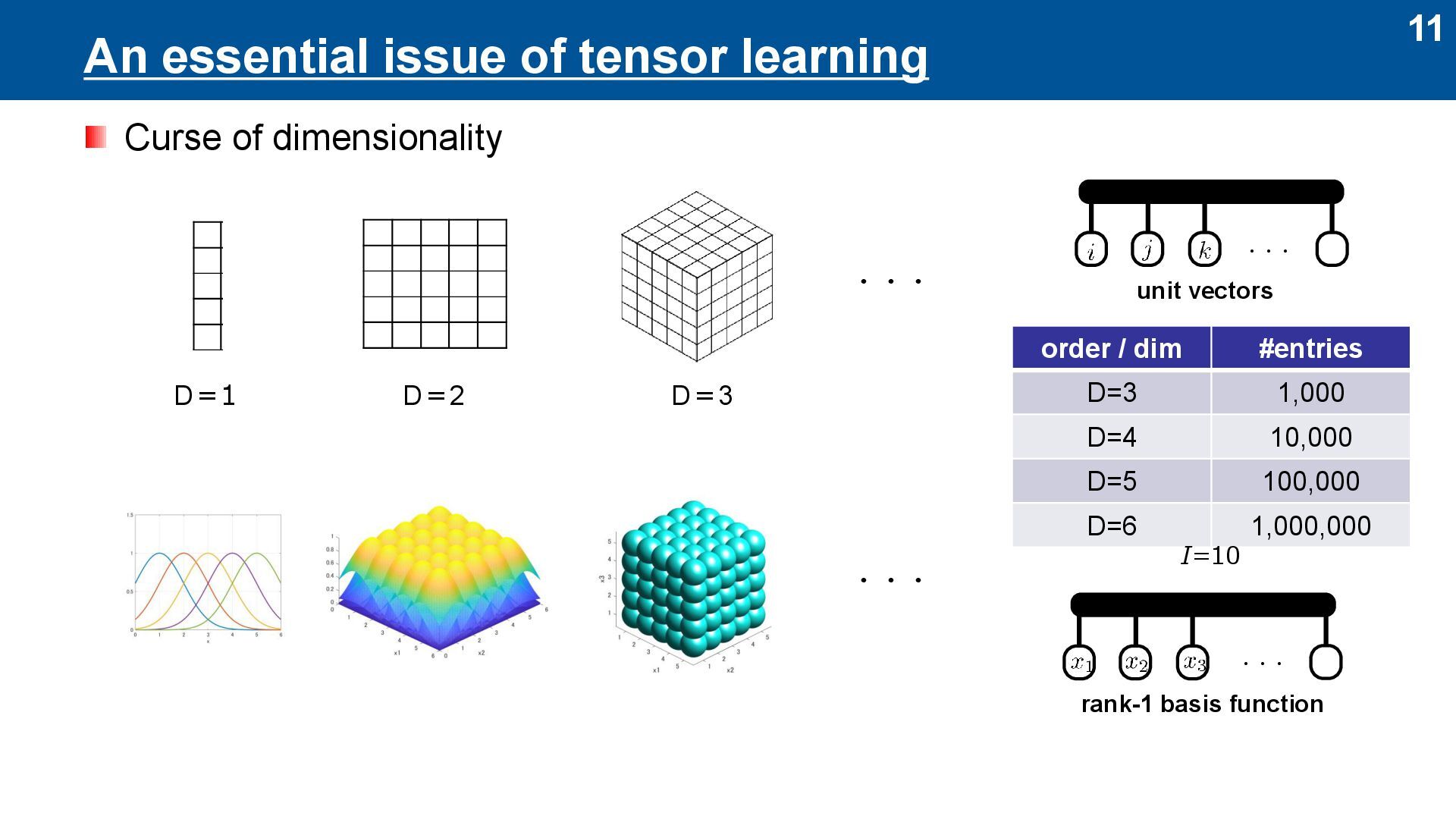
with tensors ⚫ If order of tensors are too high… (curse of dimensionality) ⚫ Tensors are compressively represented by tensor networks (to be tractable) Data Learning Model Results + + ◦ ◦ ◦ Pattern analysis Regression model Classification model Segmentation model Generative model …
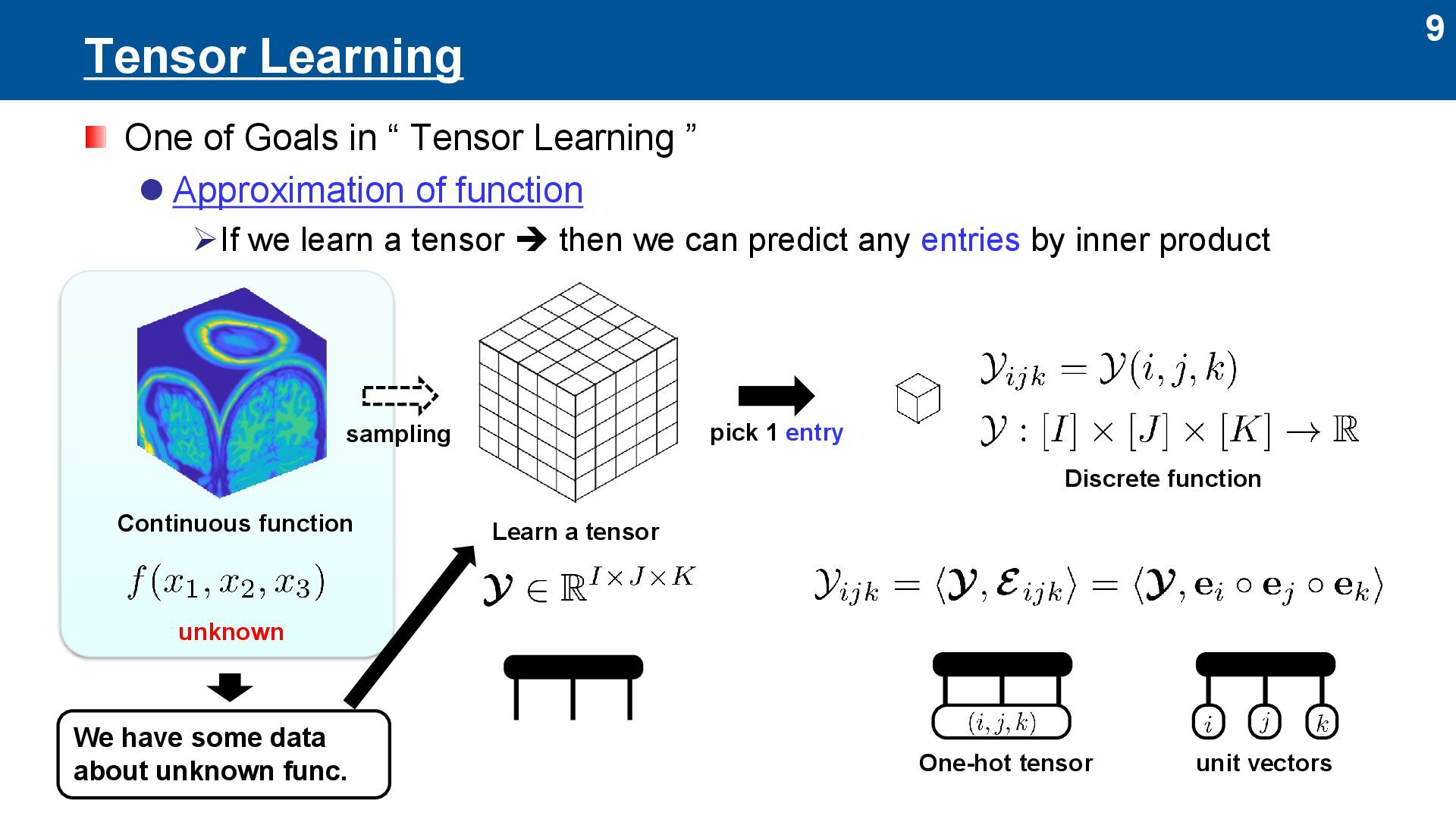
” ⚫ Approximation of function ➢If we learn a tensor ➔ then we can predict any entries by inner product sampling Continuous function Learn a tensor pick 1 entry One-hot tensor unit vectors unknown We have some data about unknown func. Discrete function
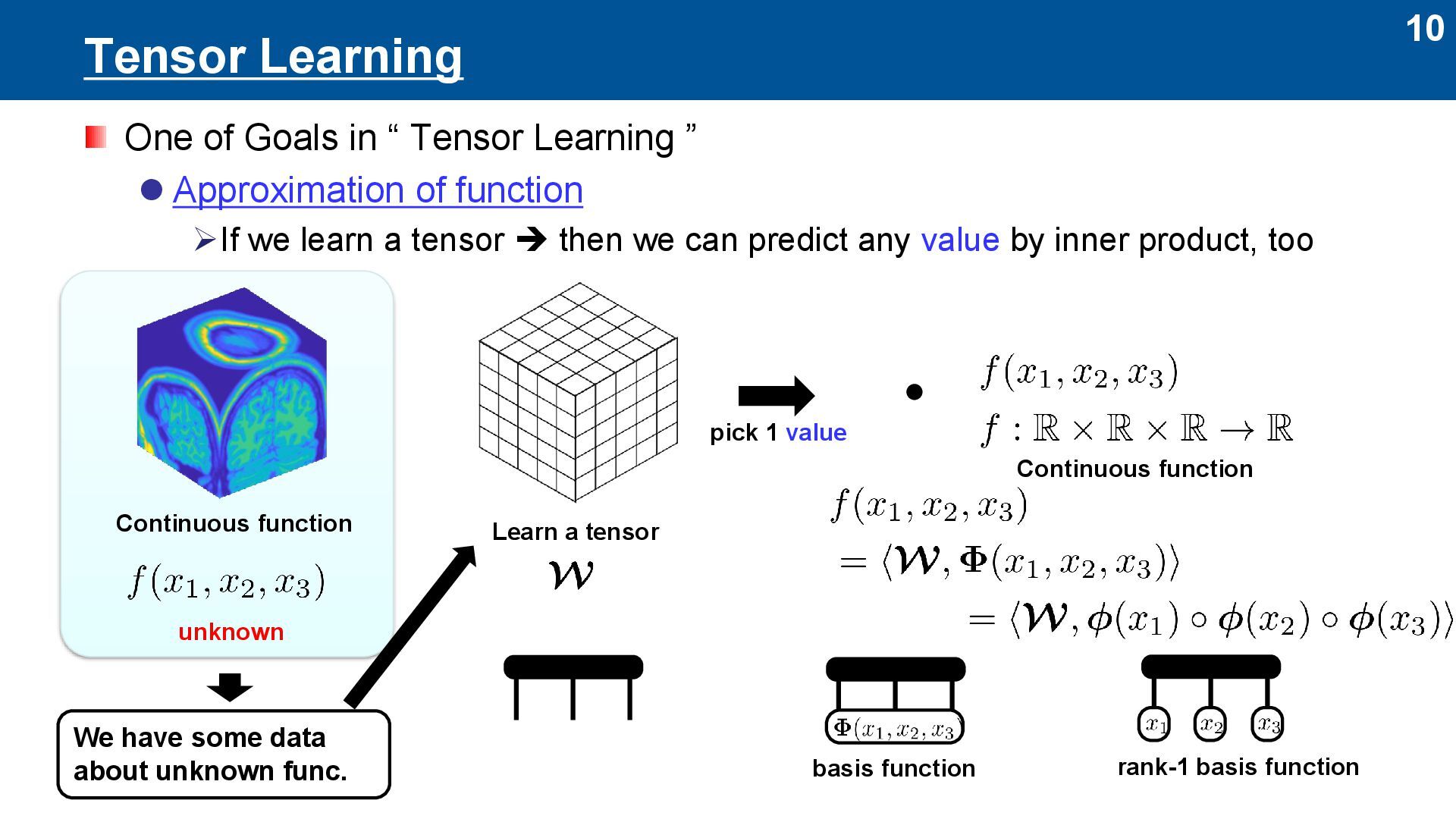
” ⚫ Approximation of function ➢If we learn a tensor ➔ then we can predict any value by inner product, too Continuous function Learn a tensor pick 1 value basis function rank-1 basis function unknown We have some data about unknown func. Continuous function
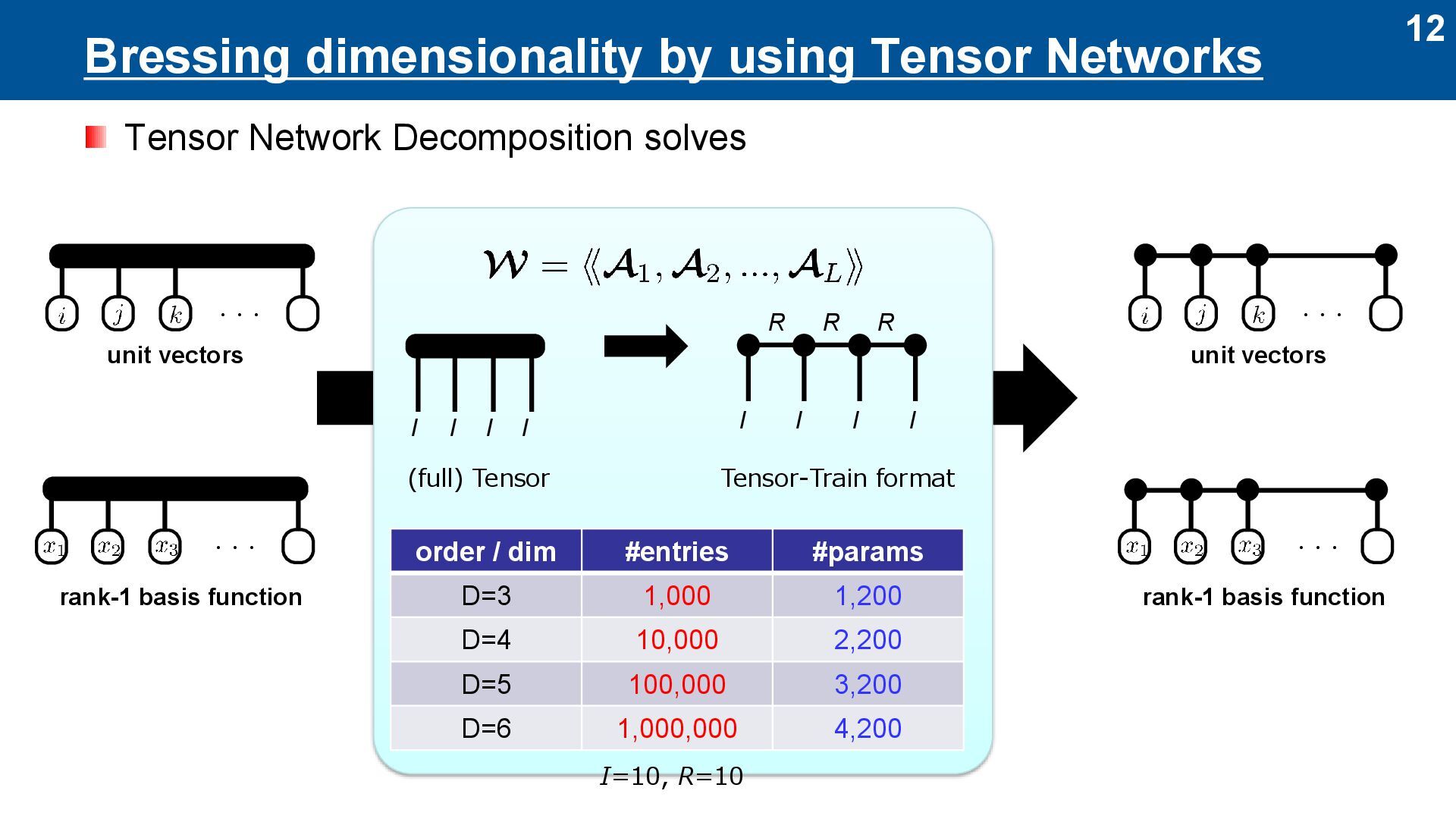
Decomposition solves rank-1 basis function unit vectors ・・・ ・・・ (full) Tensor Tensor-Train format I I I I I I I I R R R order / dim #entries #params D=3 1,000 1,200 D=4 10,000 2,200 D=5 100,000 3,200 D=6 1,000,000 4,200 rank-1 basis function unit vectors ・・・ I=10, R=10
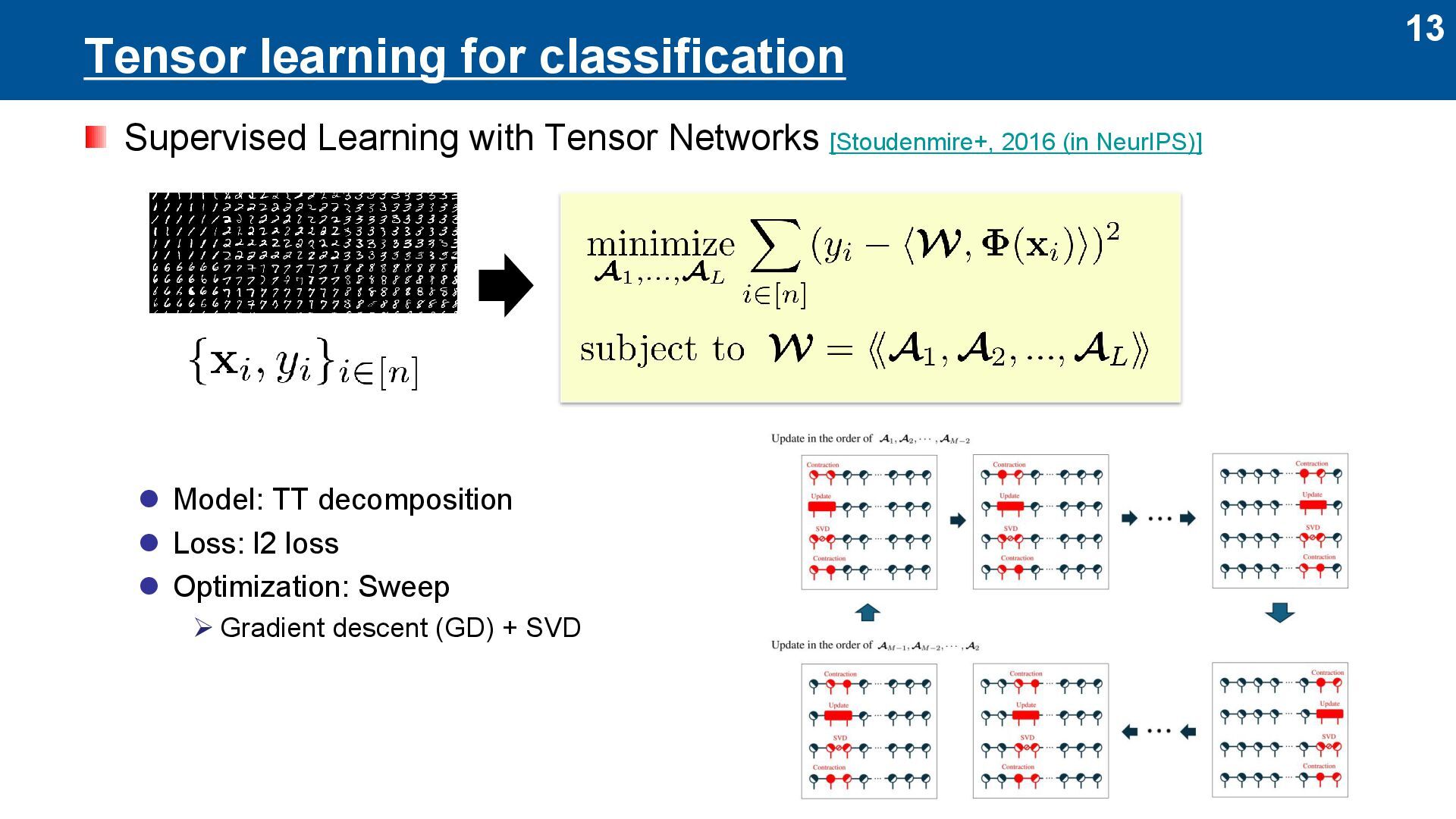
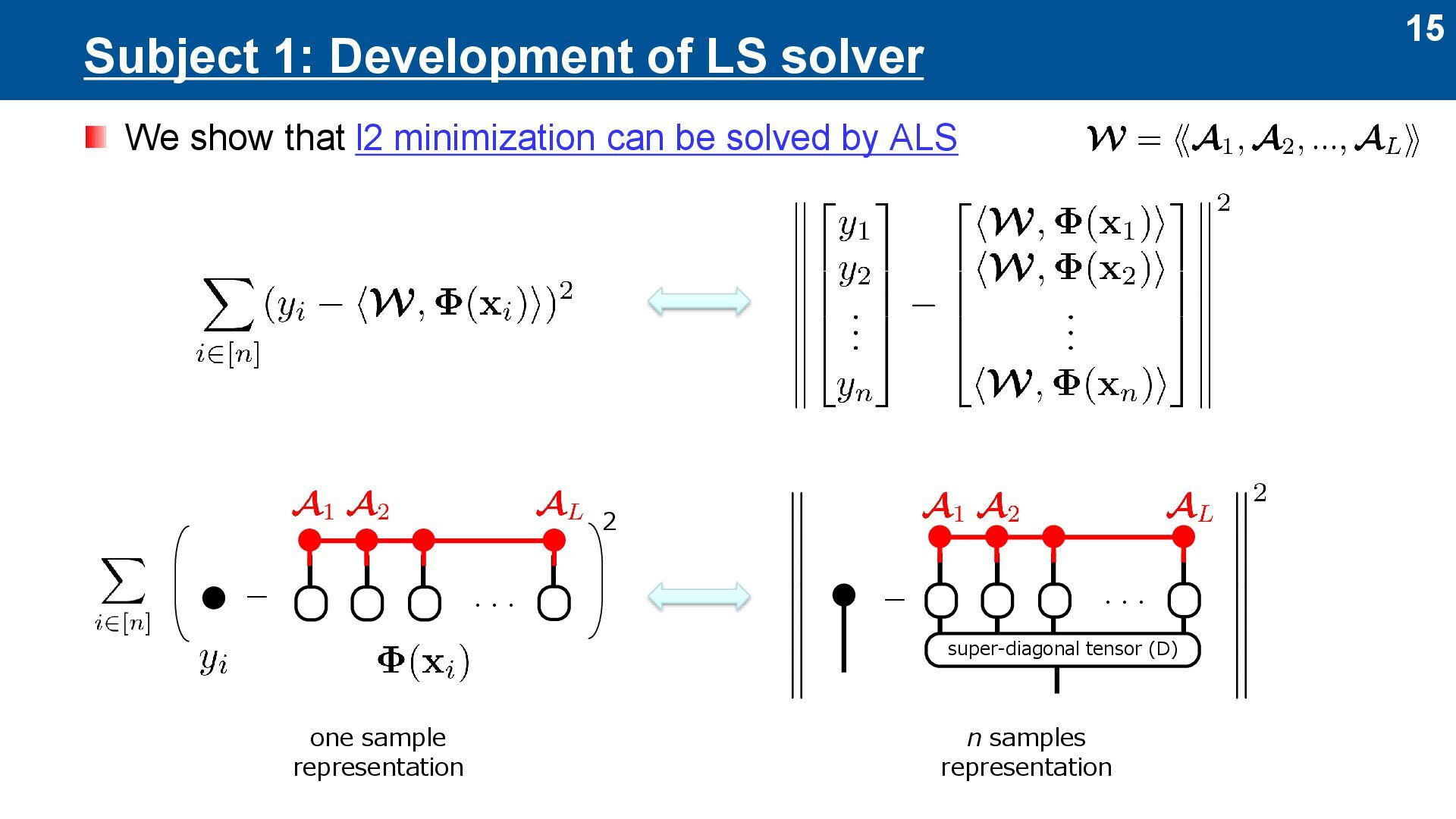
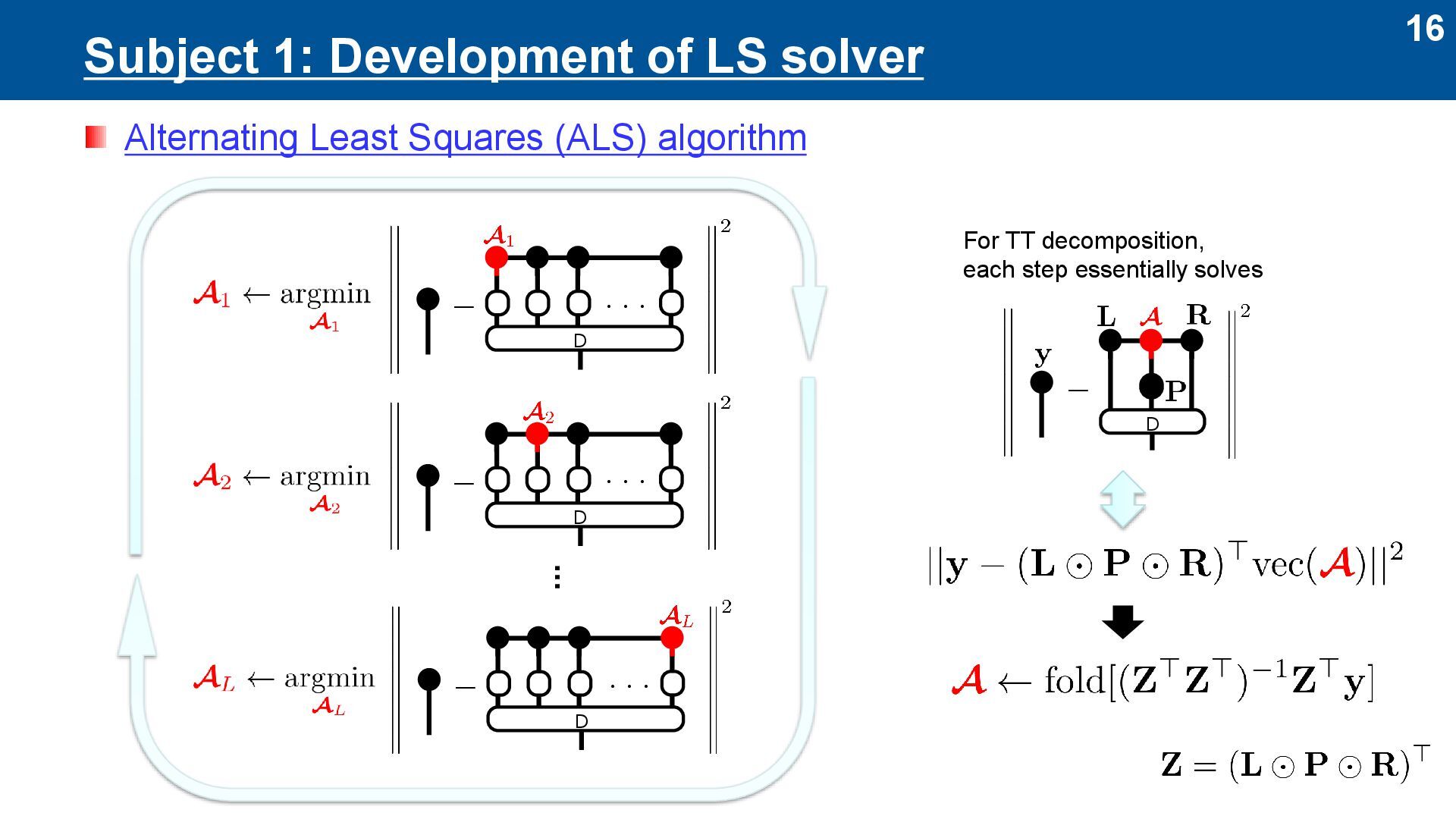
it as follows: ⚫ Model: TT decomposition ➔ other tensor networks ⚫ Loss: l2 loss ➔ other loss functions ⚫ Optimization: Sweep ➢ Gradient descent (GD) + SVD ➔ alternating least squares (ALS)
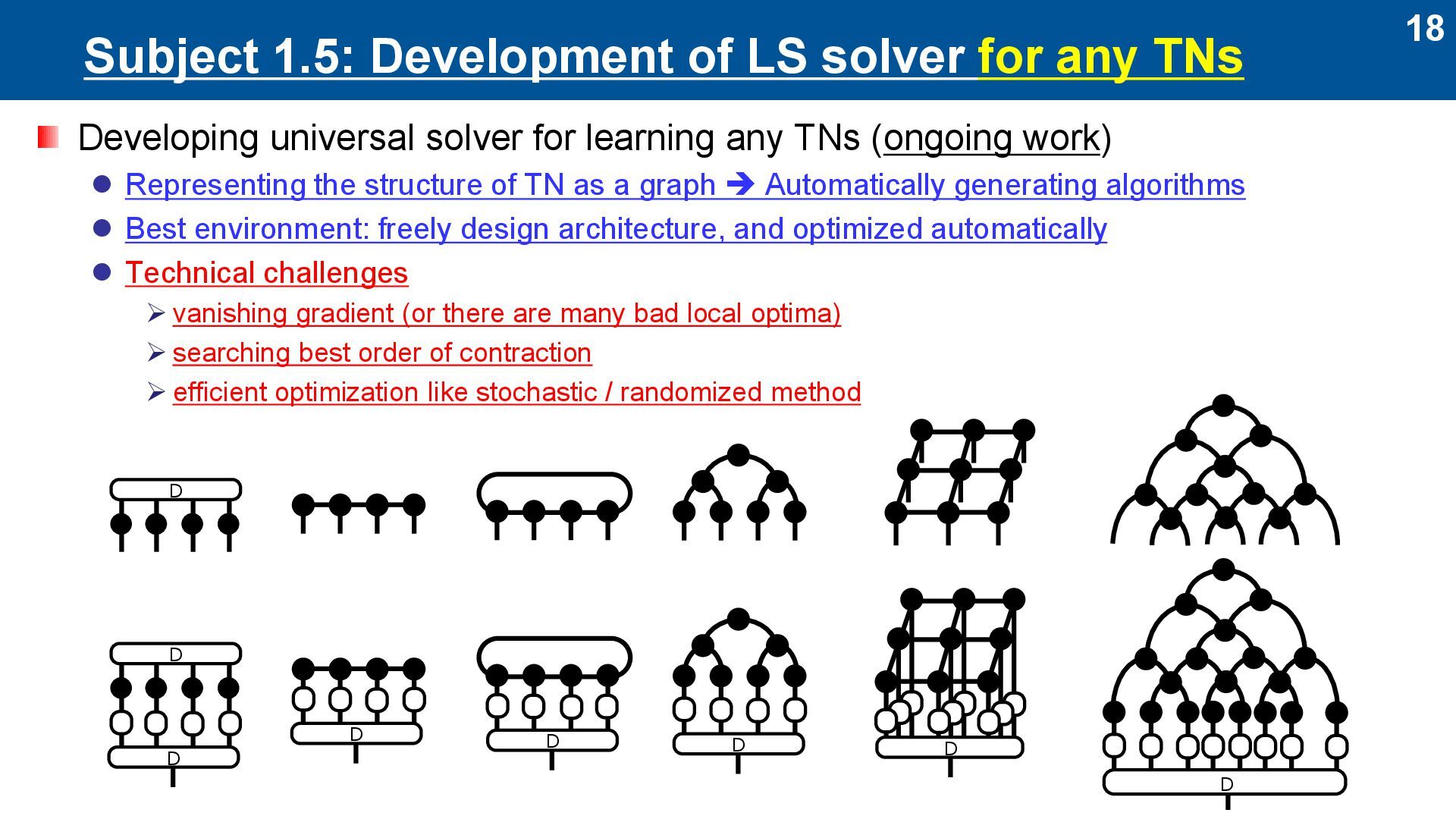
Developing universal solver for learning any TNs (ongoing work) ⚫ Representing the structure of TN as a graph ➔ Automatically generating algorithms ⚫ Best environment: freely design architecture, and optimized automatically ⚫ Technical challenges ➢ vanishing gradient (or there are many bad local optima) ➢ searching best order of contraction ➢ efficient optimization like stochastic / randomized method D D D D D D D D
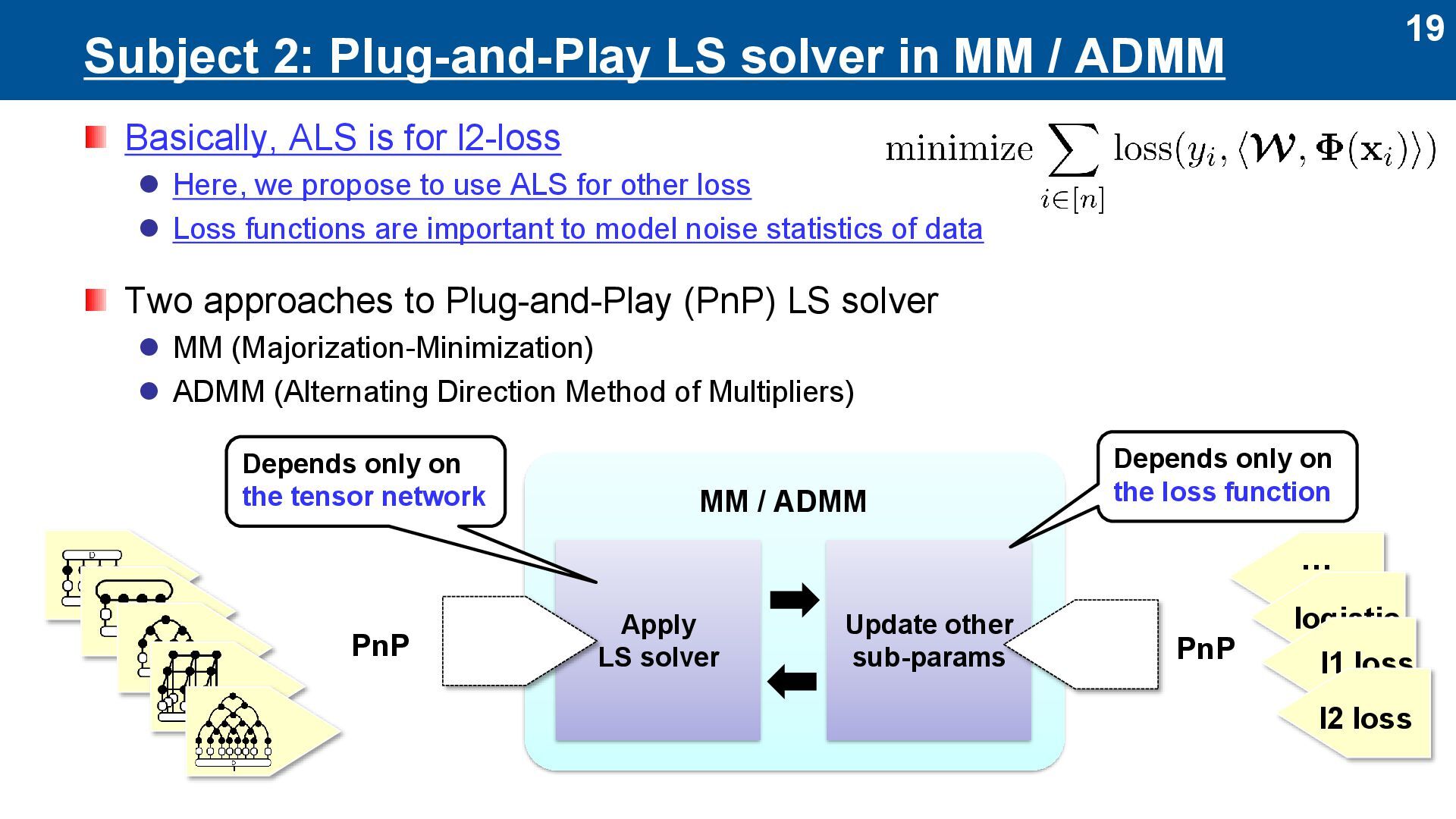
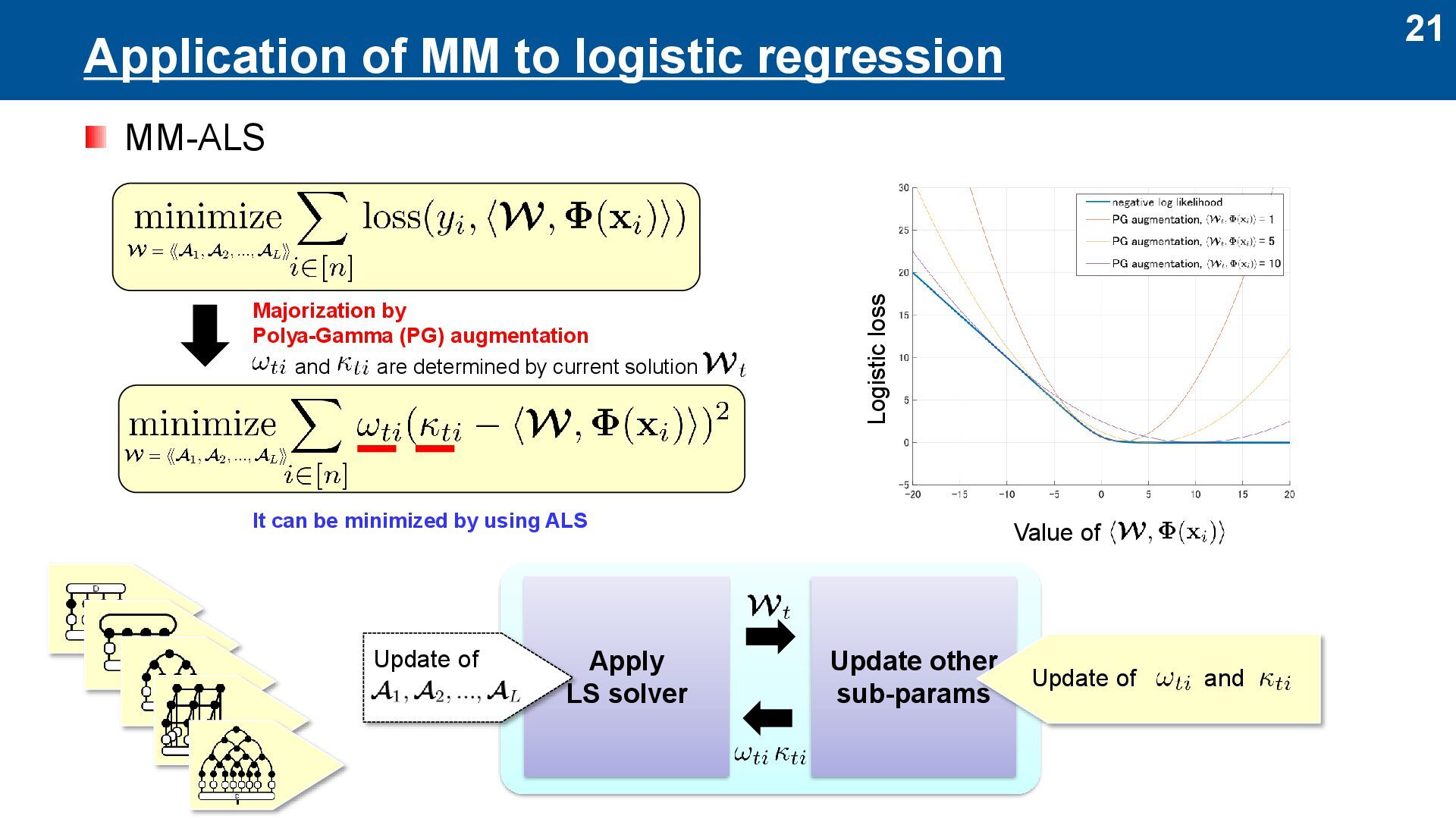
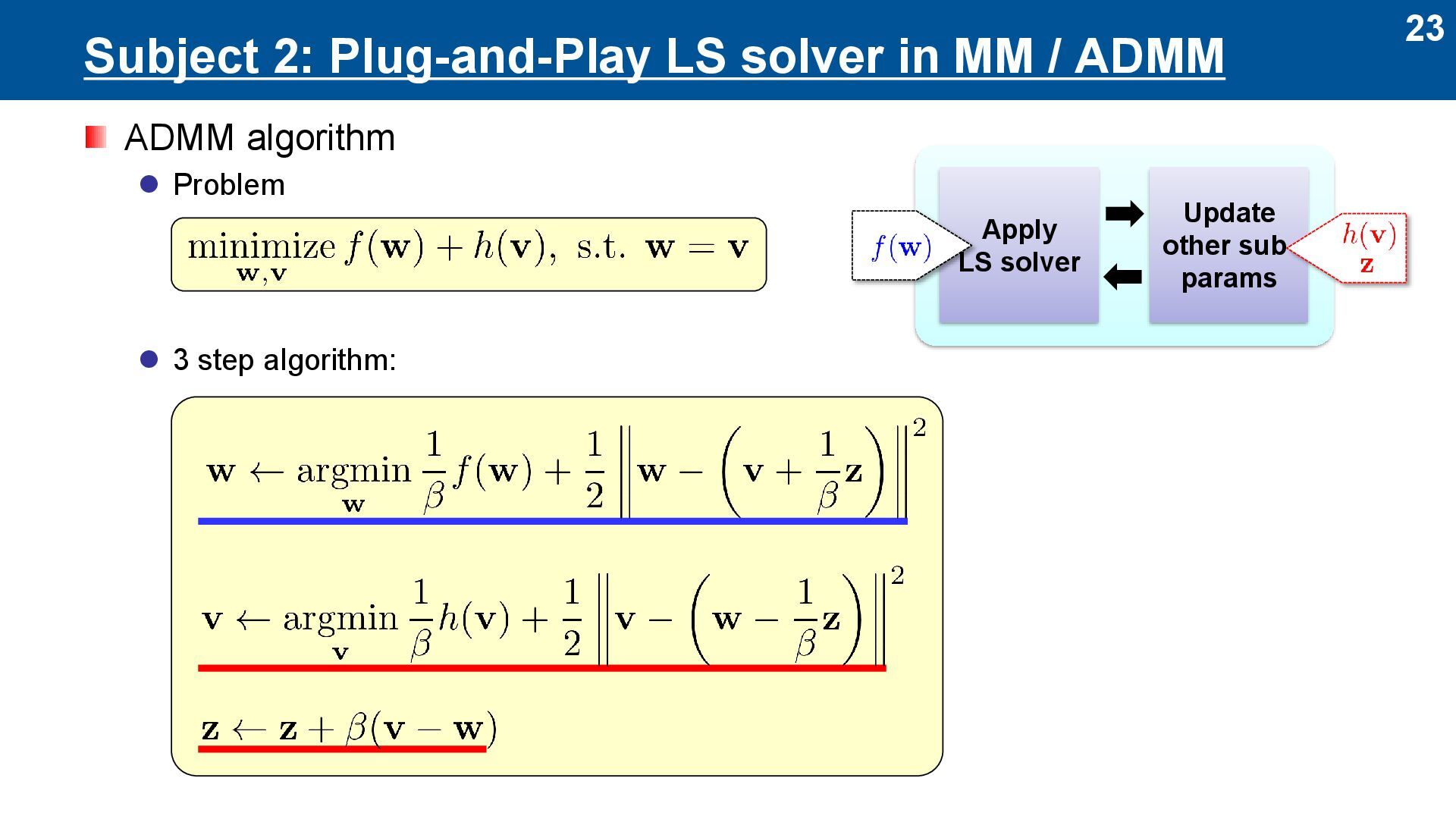
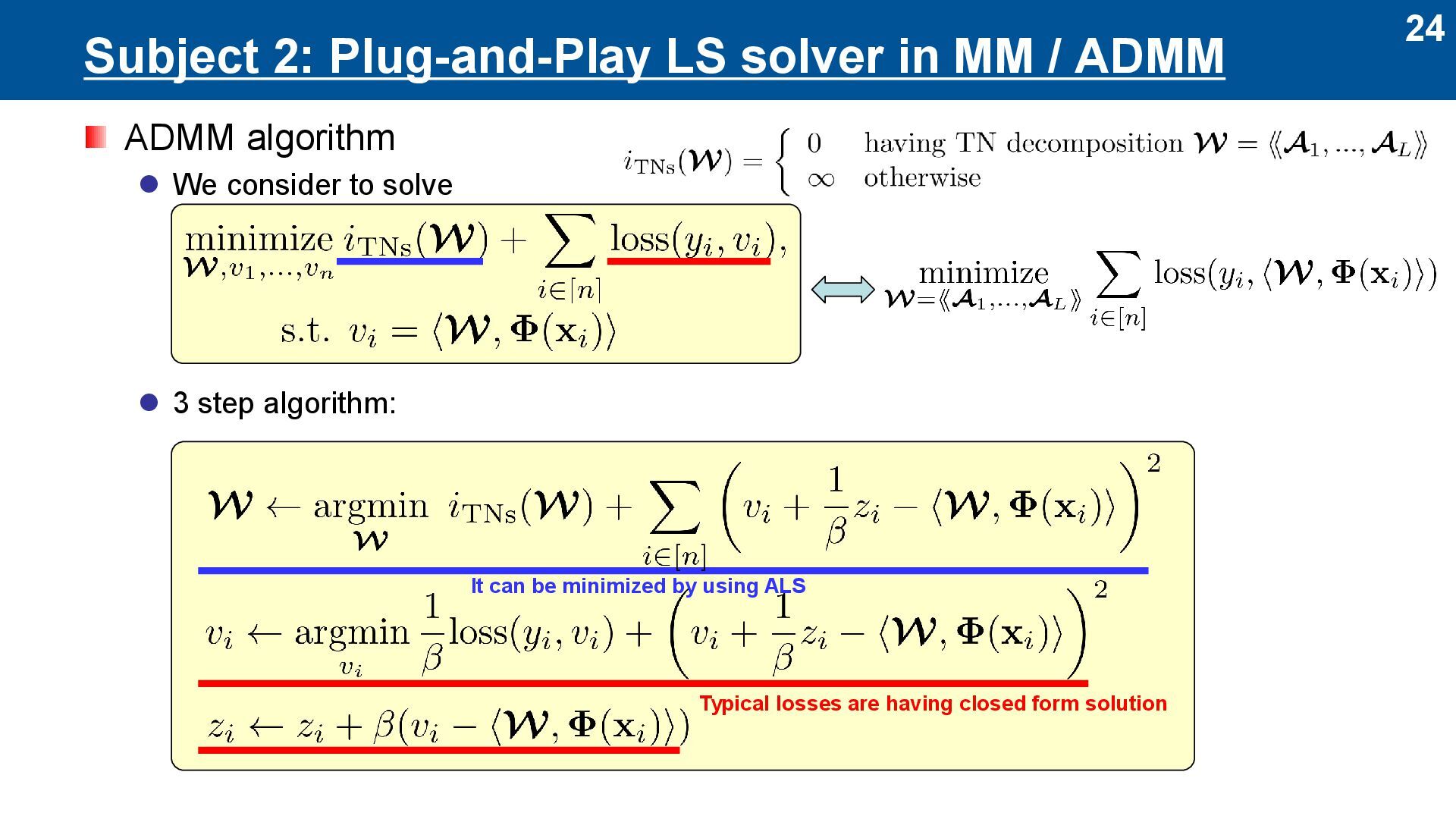
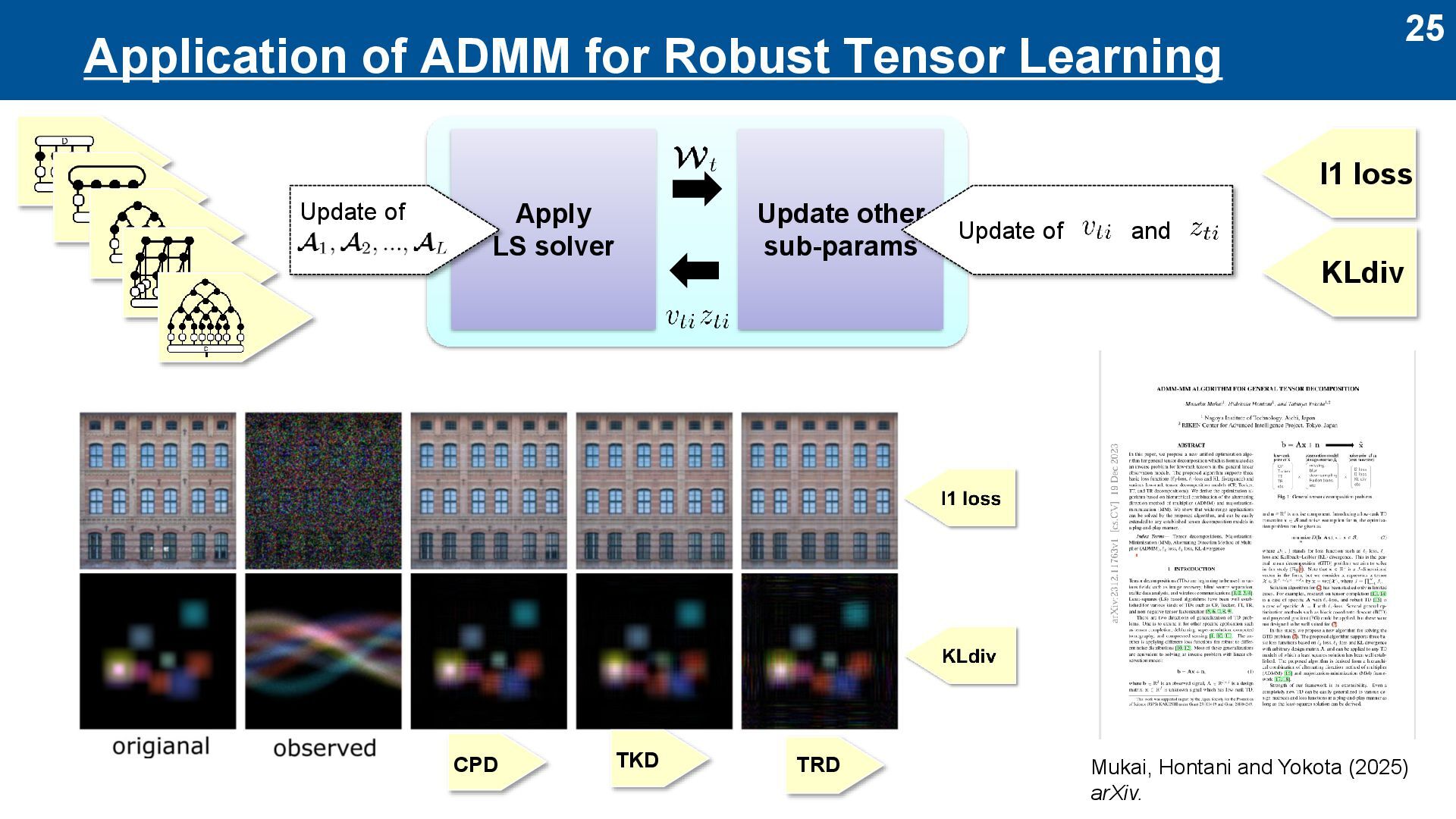
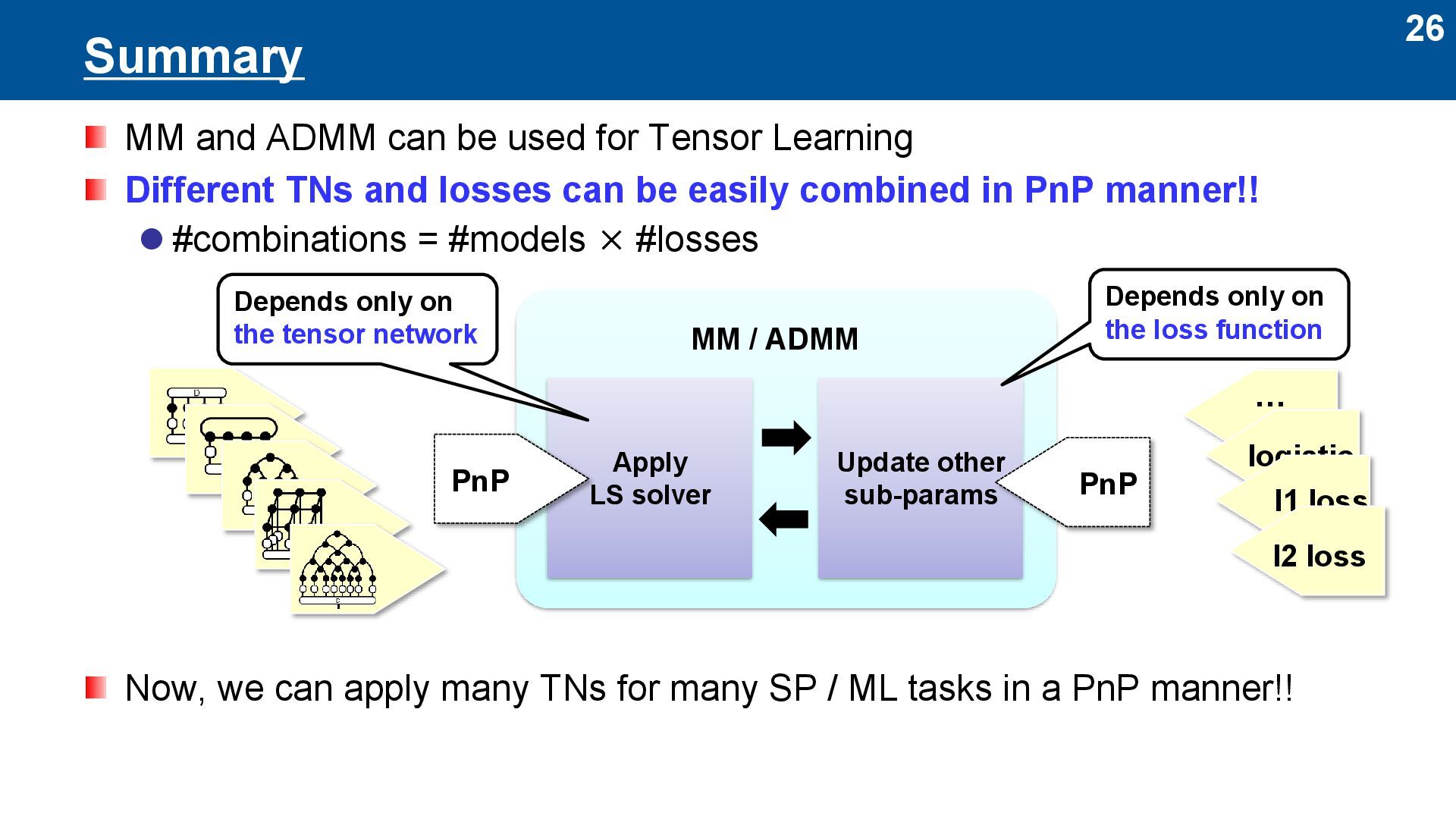
Basically, ALS is for l2-loss ⚫ Here, we propose to use ALS for other loss ⚫ Loss functions are important to model noise statistics of data Two approaches to Plug-and-Play (PnP) LS solver ⚫ MM (Majorization-Minimization) ⚫ ADMM (Alternating Direction Method of Multipliers) MM / ADMM Apply LS solver Update other sub-params Depends only on the loss function Depends only on the tensor network PnP … logistic l1 loss l2 loss PnP
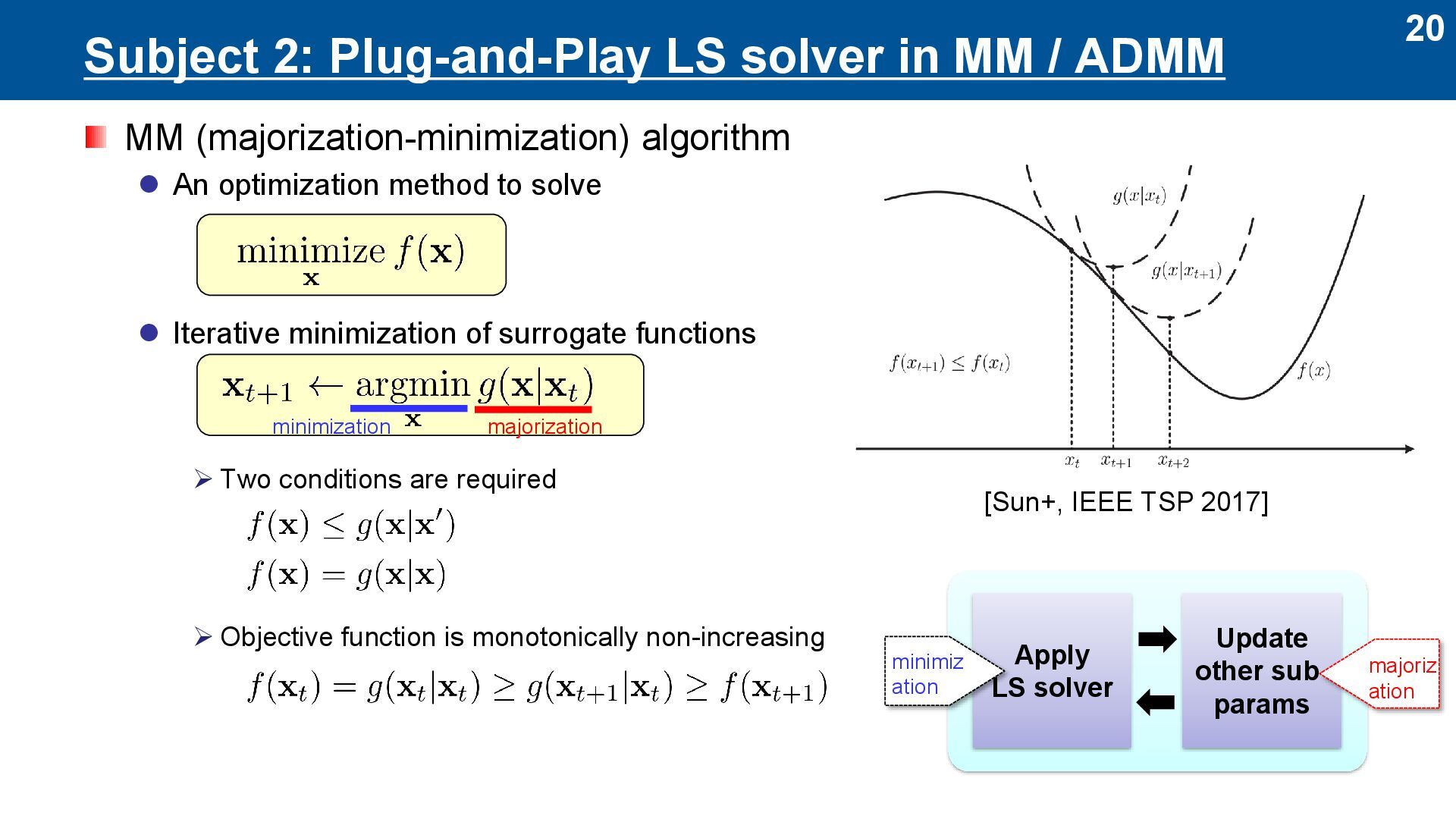
MM (majorization-minimization) algorithm ⚫ An optimization method to solve ⚫ Iterative minimization of surrogate functions ➢ Two conditions are required ➢ Objective function is monotonically non-increasing [Sun+, IEEE TSP 2017] Apply LS solver Update other sub- params majorization minimization majoriz ation minimiz ation
Polya-Gamma (PG) augmentation Logistic loss Value of and are determined by current solution It can be minimized by using ALS Apply LS solver Update other sub-params Update of and Update of
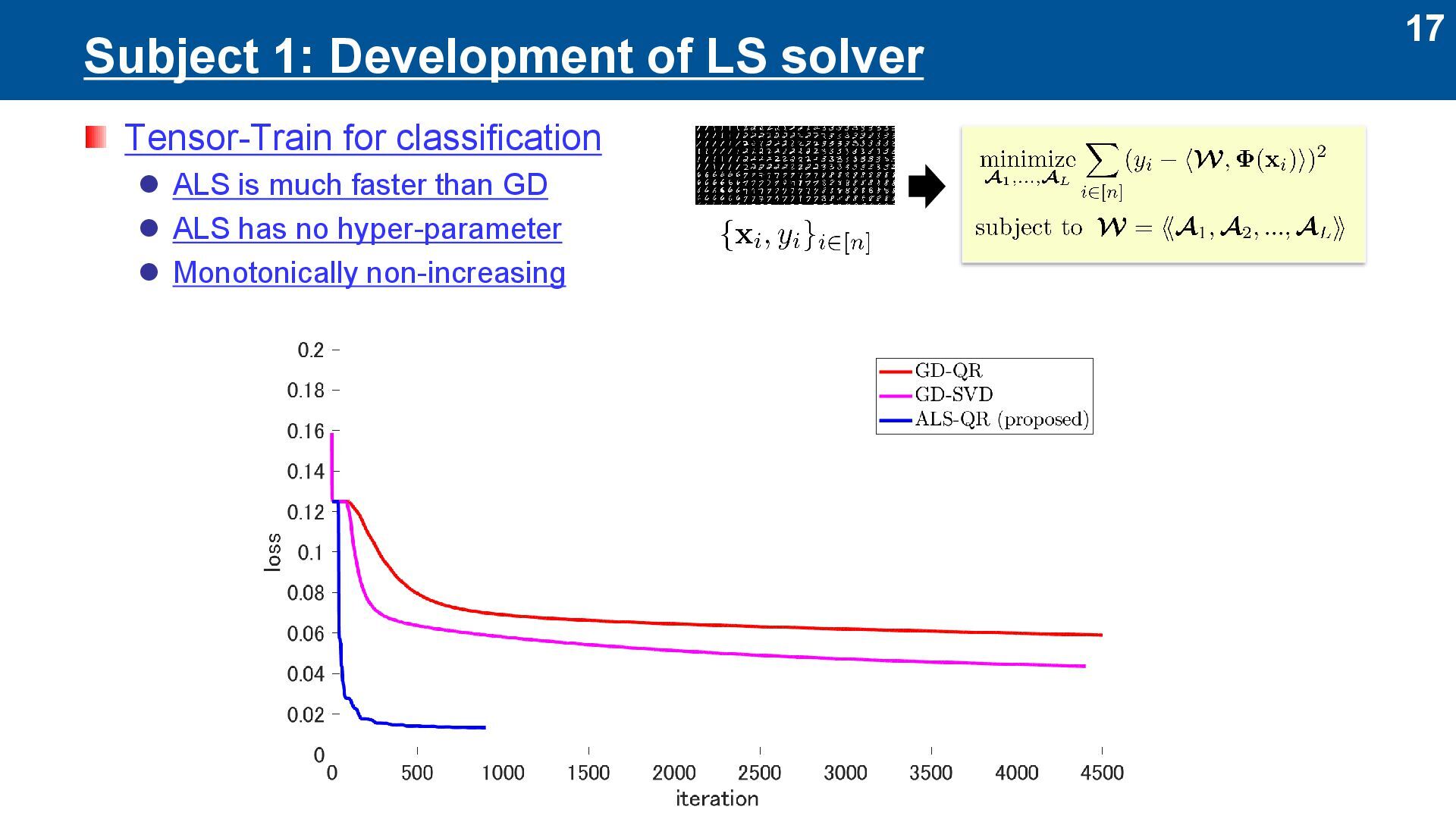
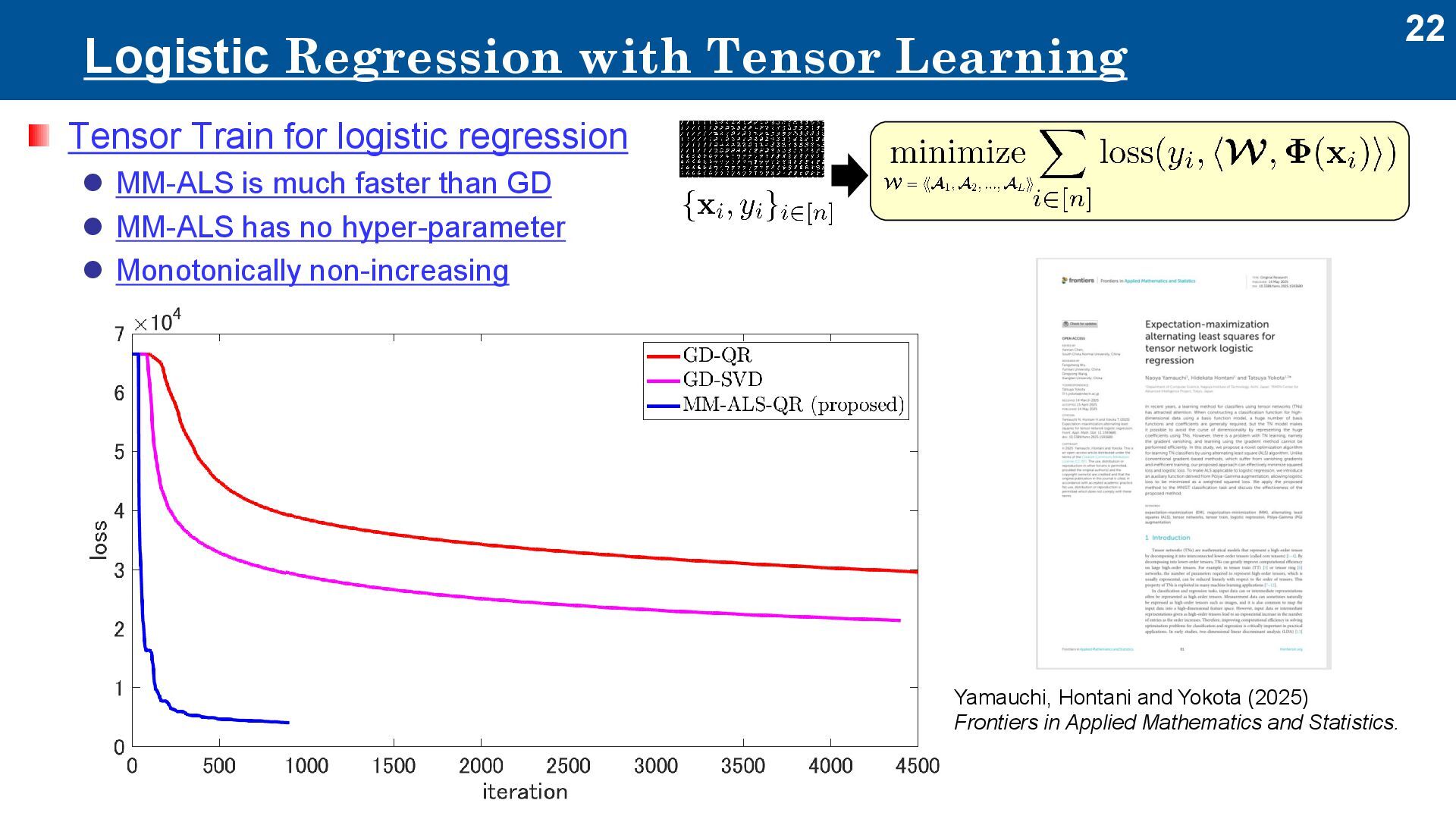
regression ⚫ MM-ALS is much faster than GD ⚫ MM-ALS has no hyper-parameter ⚫ Monotonically non-increasing Yamauchi, Hontani and Yokota (2025) Frontiers in Applied Mathematics and Statistics.
Learning Different TNs and losses can be easily combined in PnP manner!! ⚫ #combinations = #models × #losses Now, we can apply many TNs for many SP / ML tasks in a PnP manner!! MM / ADMM Apply LS solver Update other sub-params Depends only on the loss function Depends only on the tensor network PnP … logistic l1 loss l2 loss PnP
{kind=link}
{kind=link}
![4 Book 1 Tensors for Data Processing, Elsevier, 2021 [link]](https://files.speakerdeck.com/presentations/ae1c799e01d34d5dab8948d5a47fb37b/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}