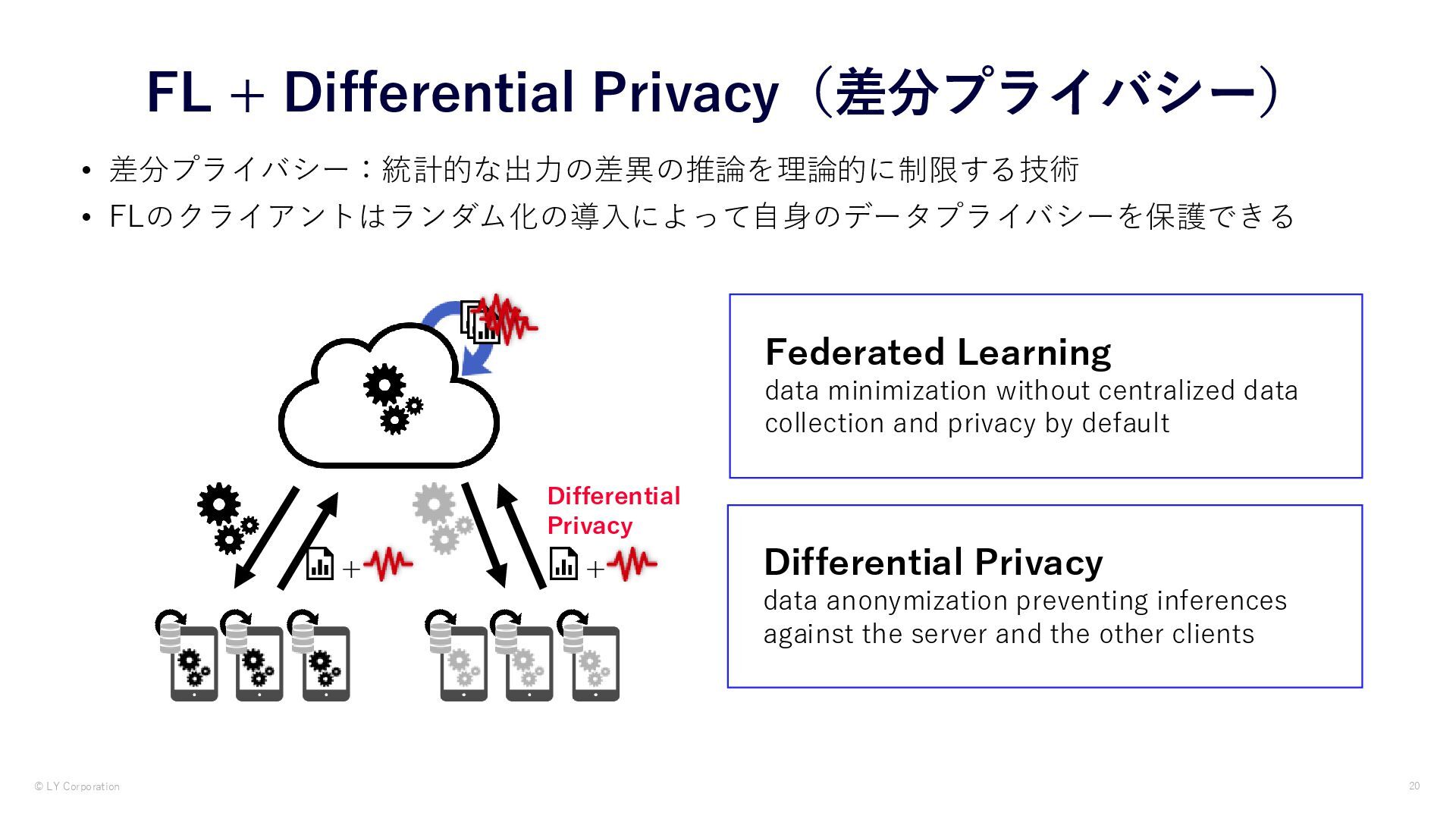
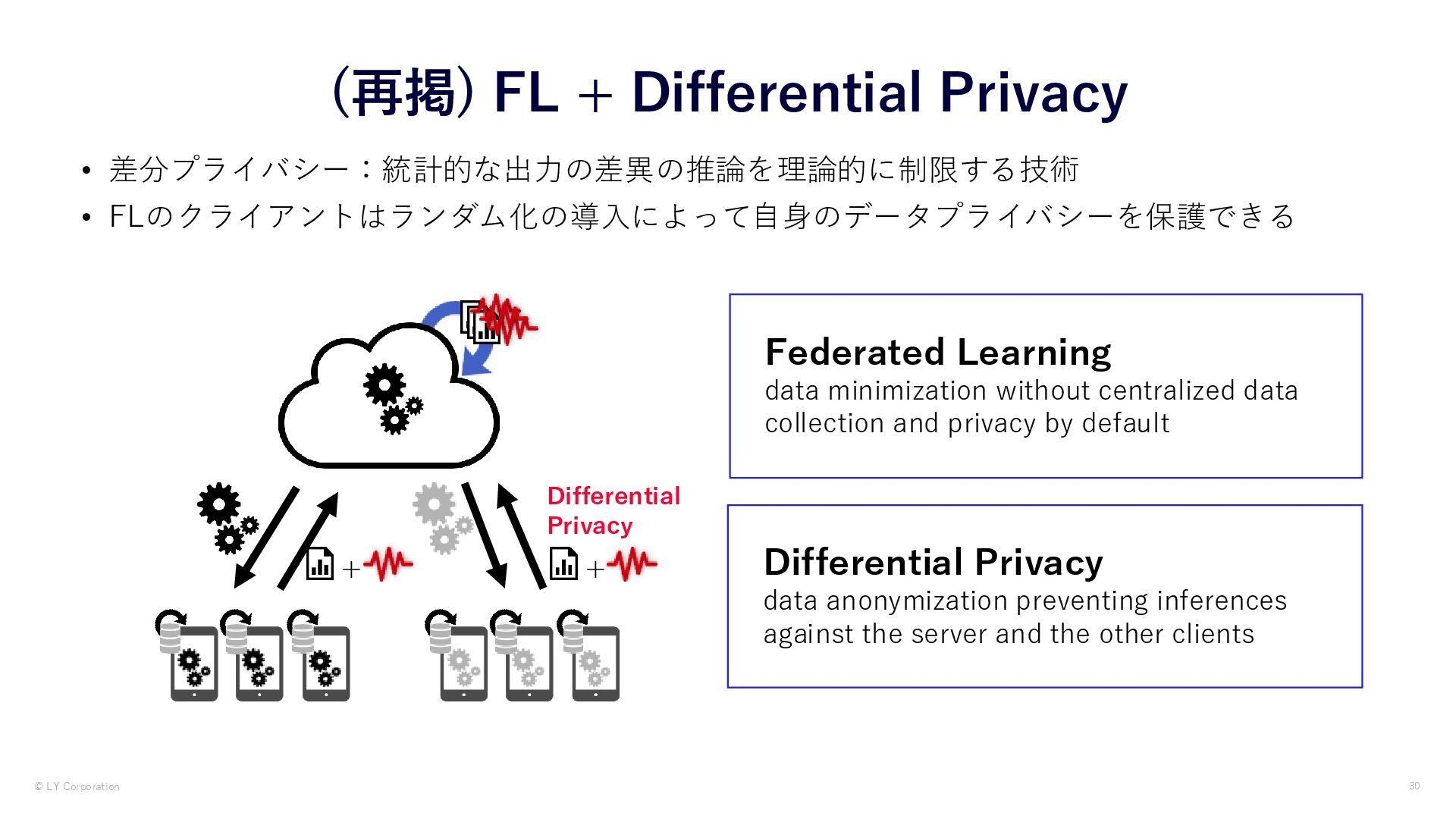
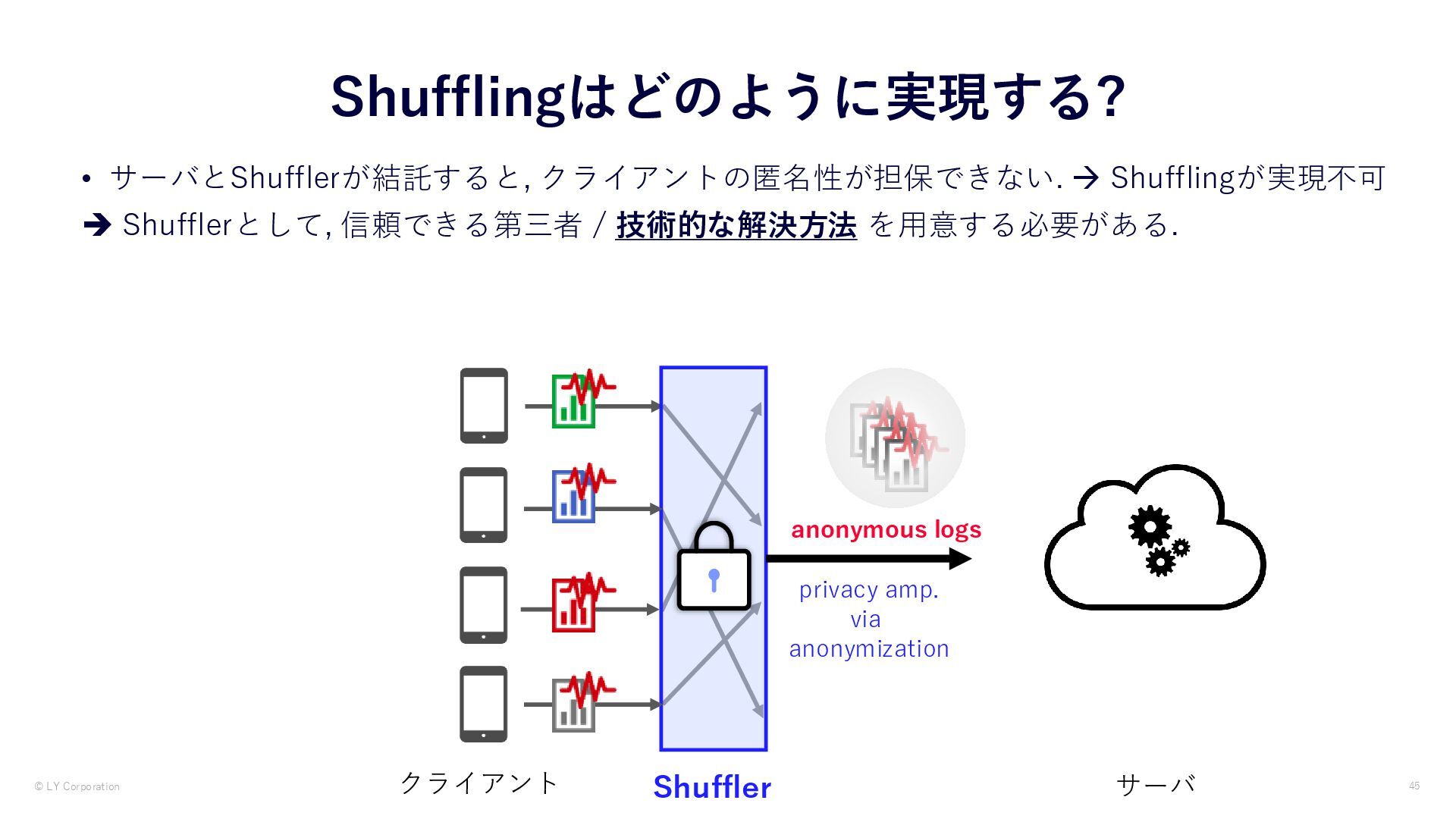
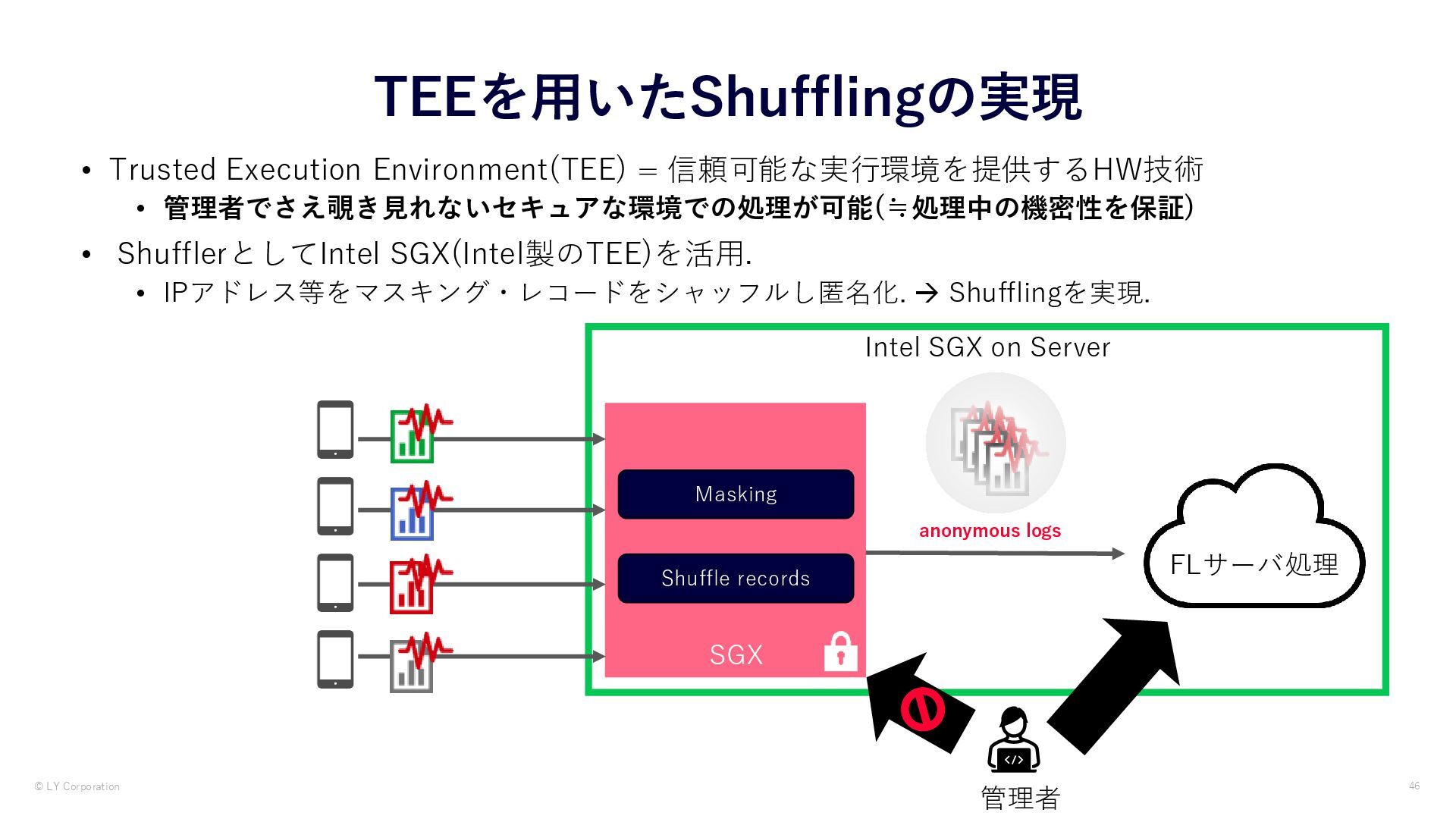
• FLのクライアントはランダム化の導入によって自身のデータプライバシーを保護できる Differential Privacy + + Federated Learning data minimization without centralized data collection and privacy by default Differential Privacy data anonymization preventing inferences against the server and the other clients
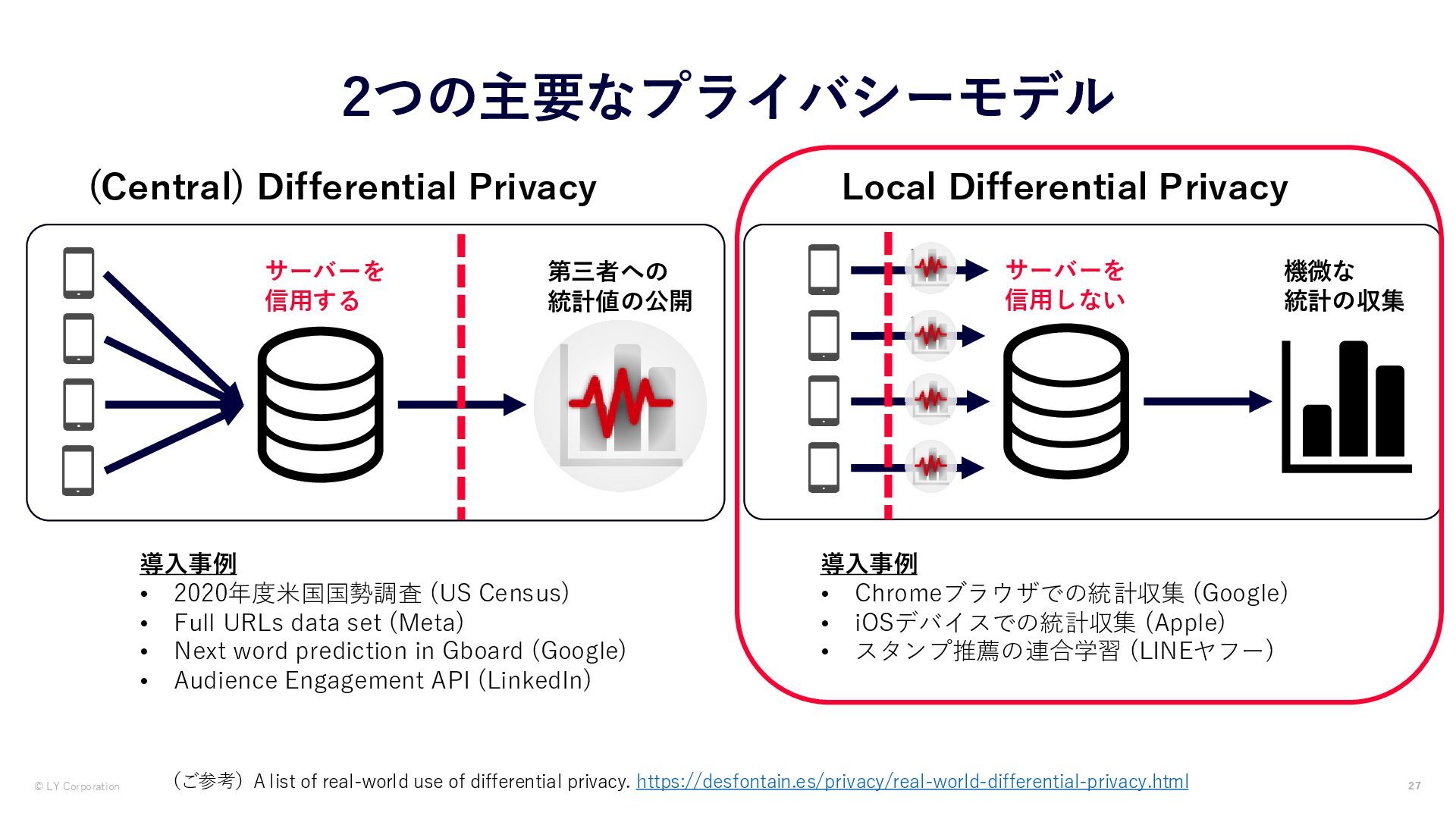
Privacy 第三者への 統計値の公開 機微な 統計の収集 サーバーを 信用しない サーバーを 信用する 導入事例 • Chromeブラウザでの統計収集 (Google) • iOSデバイスでの統計収集 (Apple) • スタンプ推薦の連合学習 (LINEヤフー) 導入事例 • 2020年度米国国勢調査 (US Census) • Full URLs data set (Meta) • Next word prediction in Gboard (Google) • Audience Engagement API (LinkedIn) (ご参考)A list of real-world use of differential privacy. https://desfontain.es/privacy/real-world-differential-privacy.html
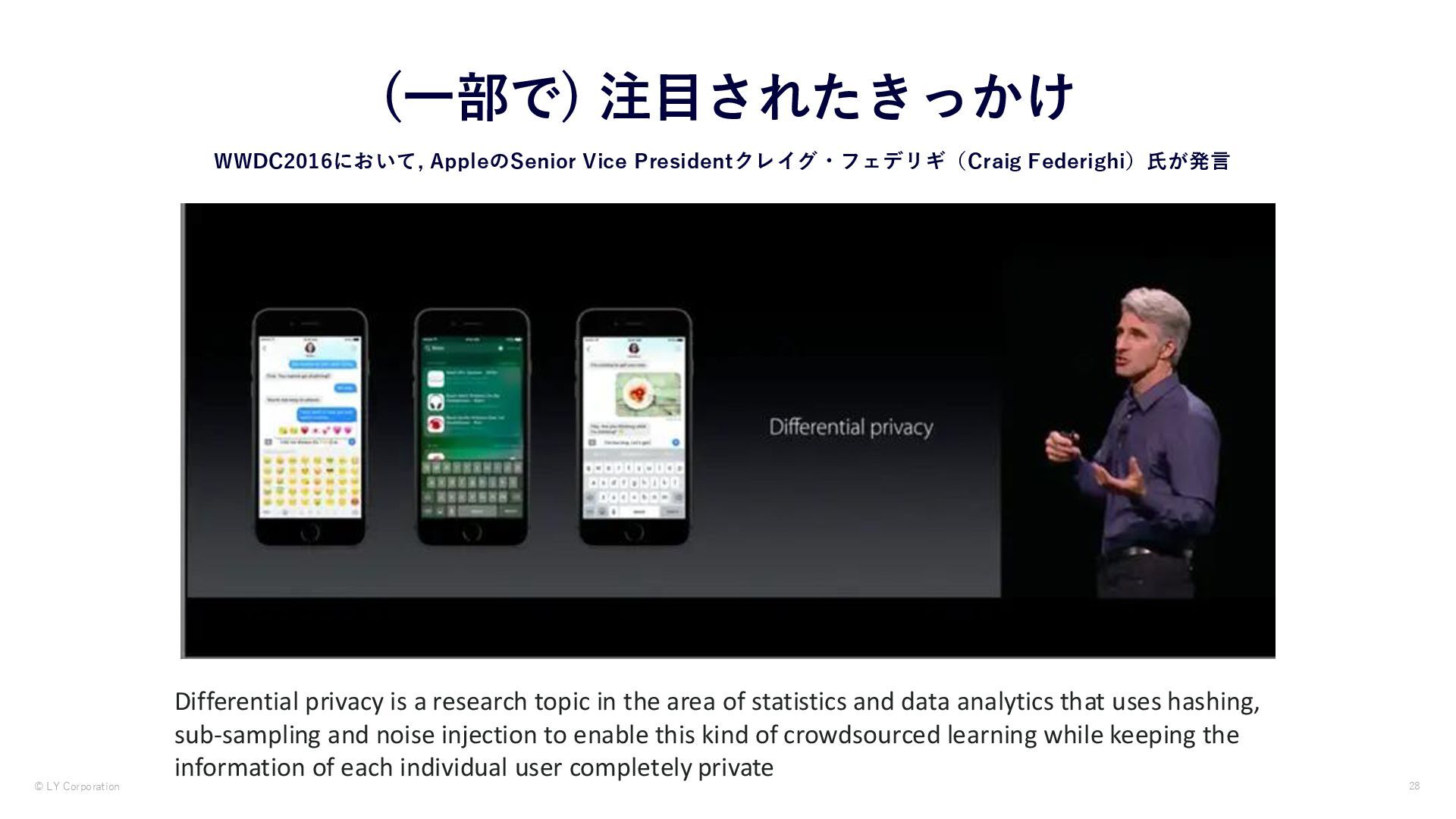
注目されたきっかけ Differential privacy is a research topic in the area of statistics and data analytics that uses hashing, sub-sampling and noise injection to enable this kind of crowdsourced learning while keeping the information of each individual user completely private
差分プライバシー:統計的な出力の差異の推論を理論的に制限する技術 • FLのクライアントはランダム化の導入によって自身のデータプライバシーを保護できる Differential Privacy + + Federated Learning data minimization without centralized data collection and privacy by default Differential Privacy data anonymization preventing inferences against the server and the other clients
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© LY Corporation 19 勾配から元の学習データを再構築する「勾配反転攻撃」がNeurIPS 2020で提案 勾配から元の学習データは再構築できる場合がある [Geiping+, NeurIPS2020] https://arxiv.org/abs/2003.14053](https://files.speakerdeck.com/presentations/5a2dca9448b44e8caa8fe870cd03ac7f/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
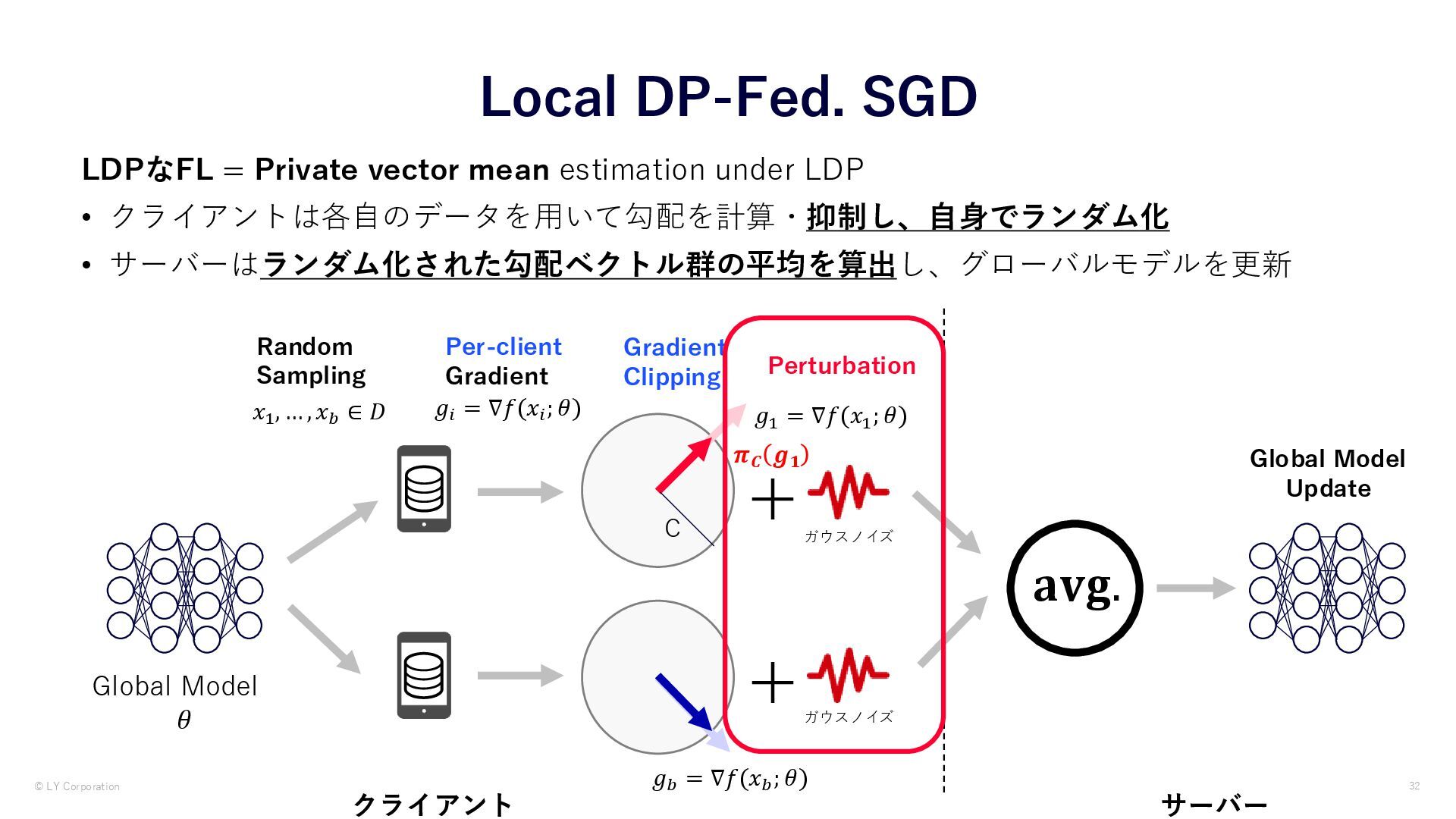{kind=link}
{kind=link}
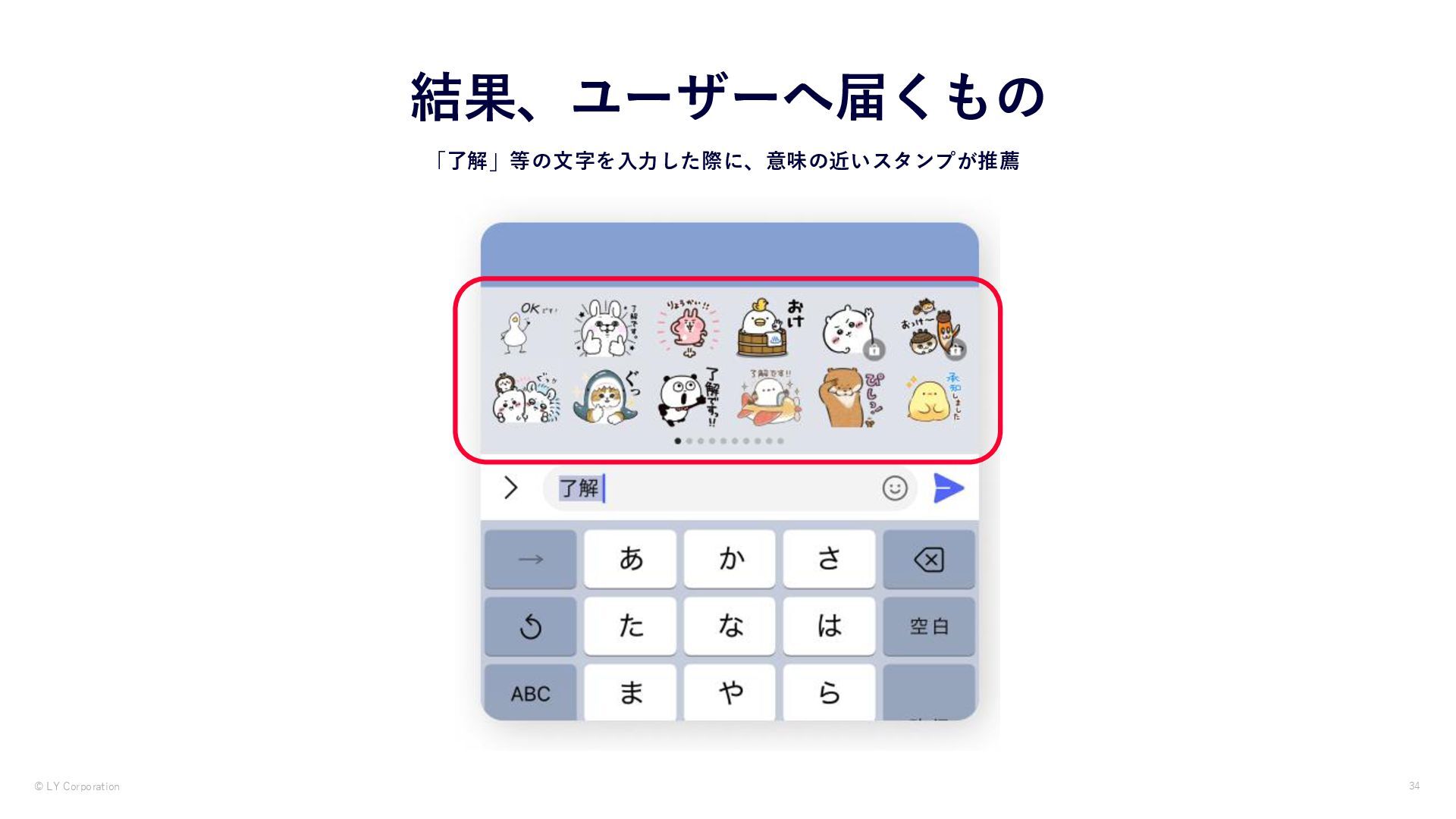{kind=link}
{kind=link}
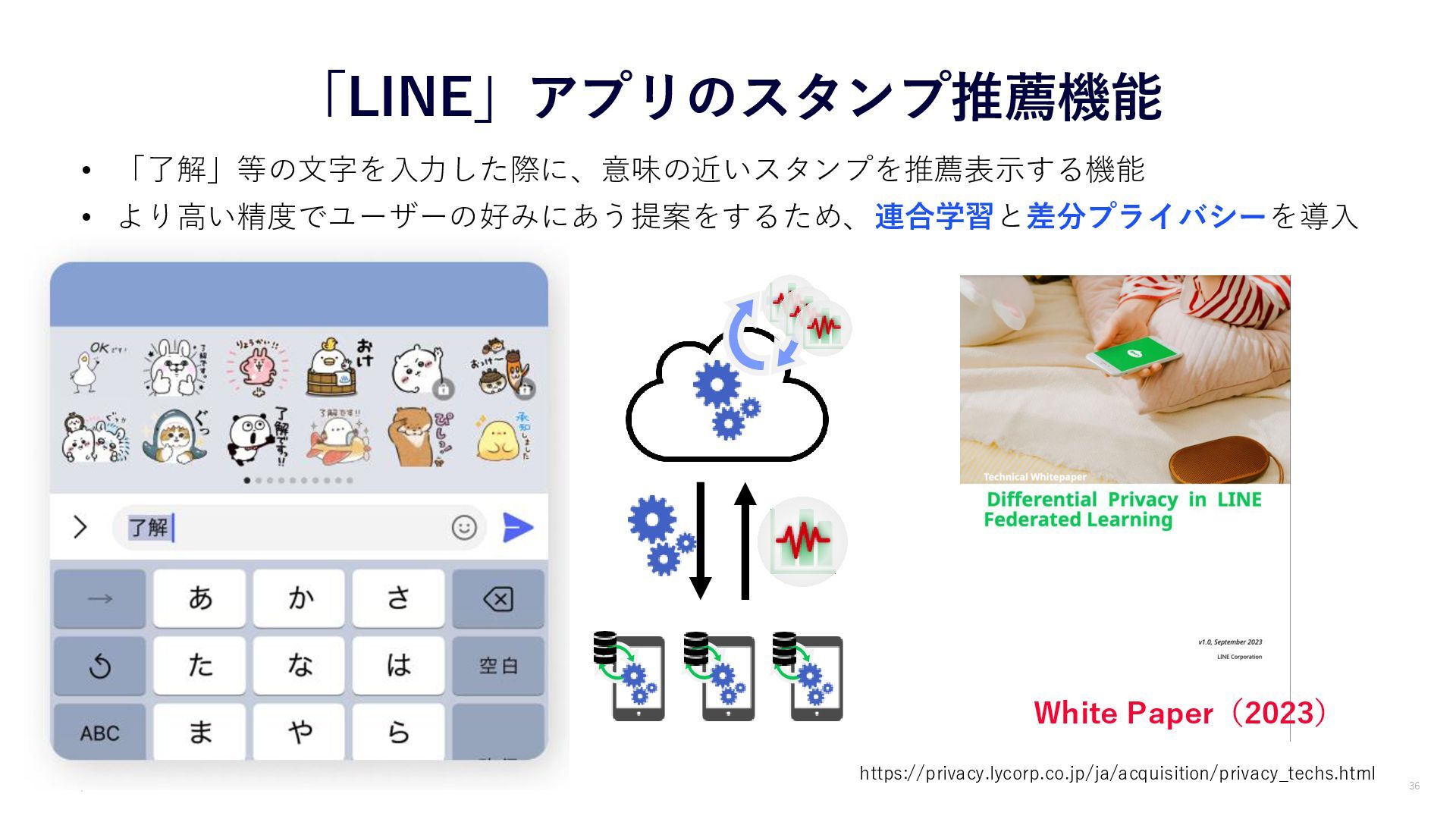{kind=link}
{kind=link}
{kind=link}
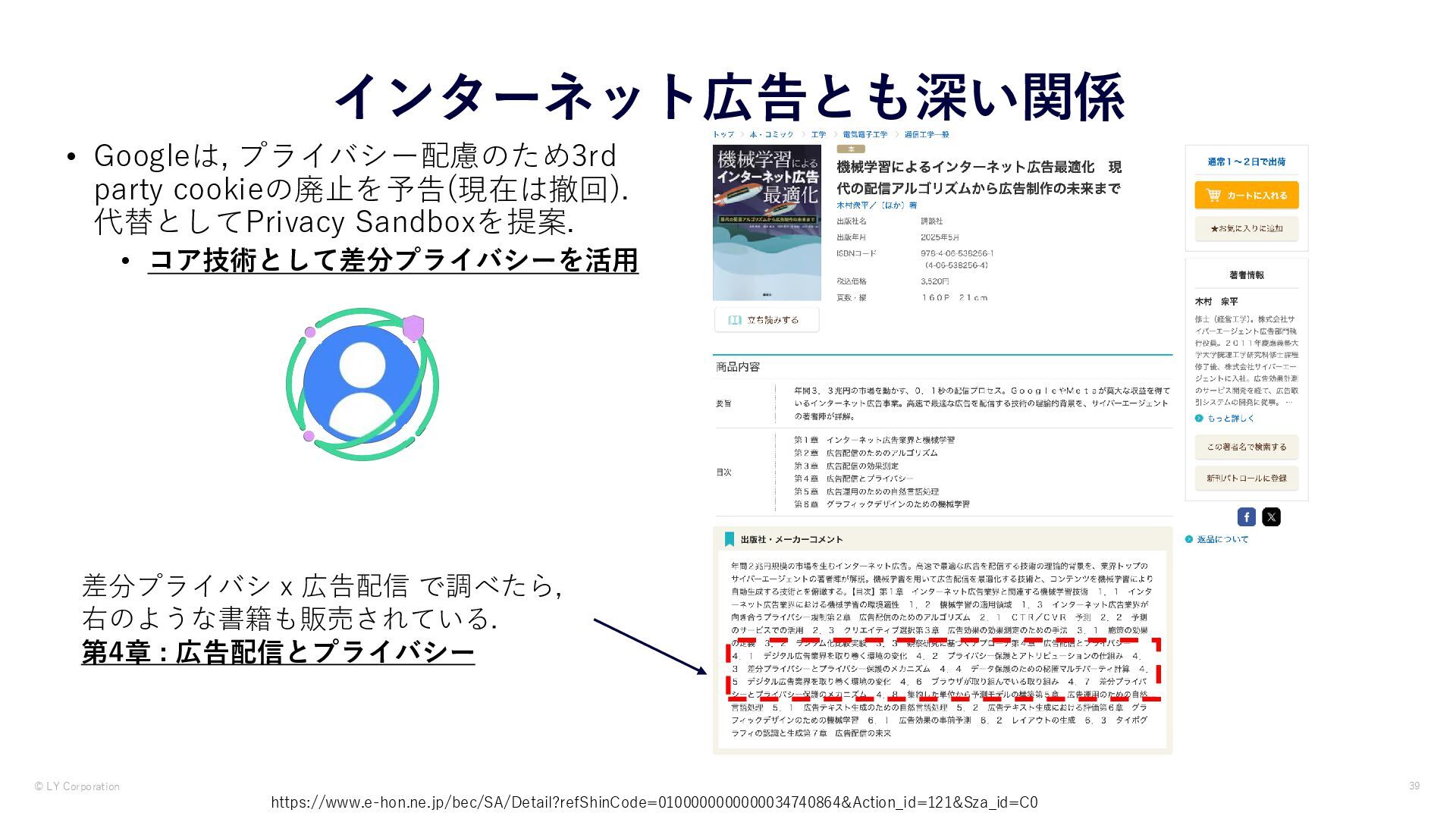{kind=link}
{kind=link}
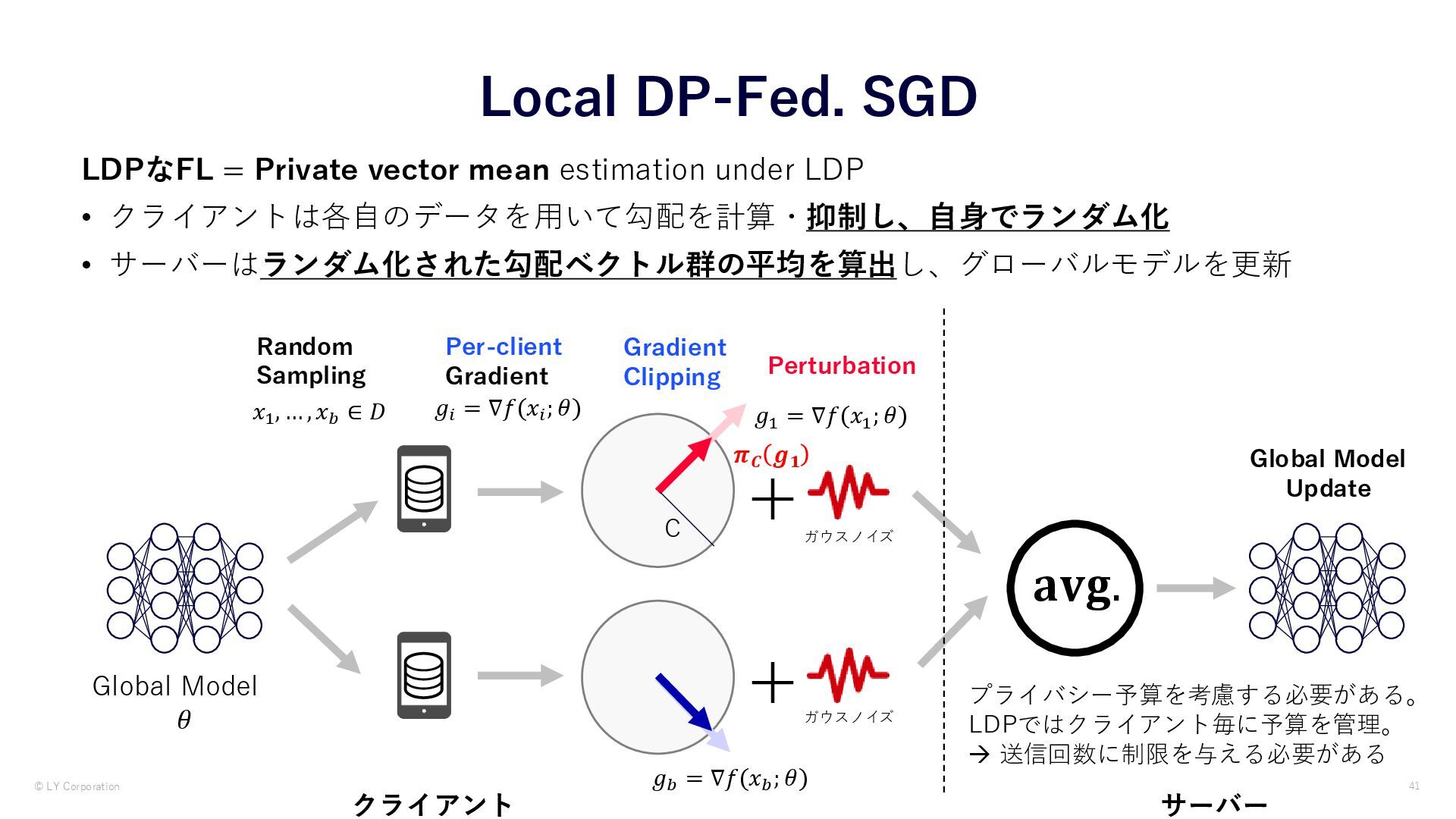{kind=link}
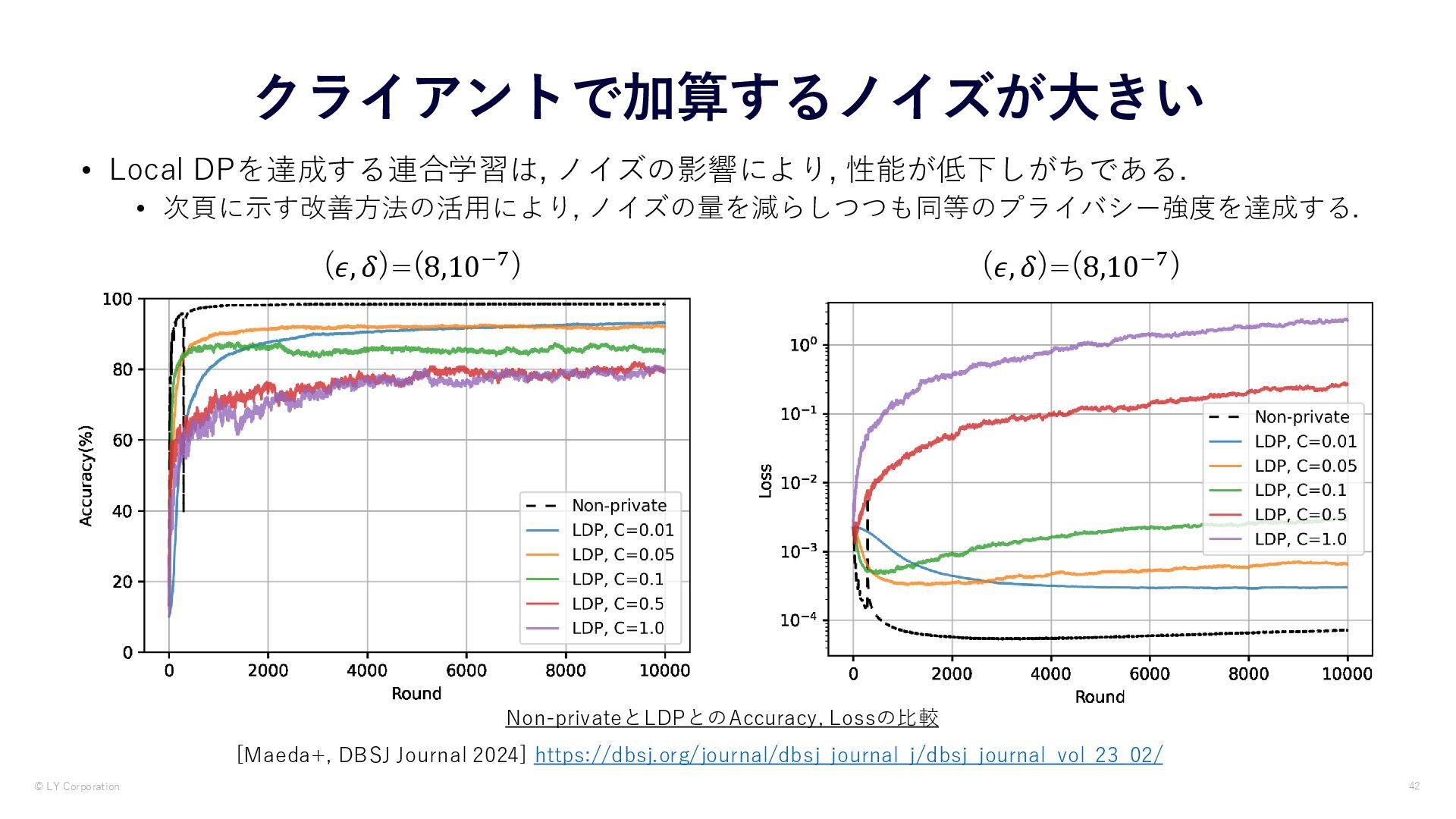{kind=link}
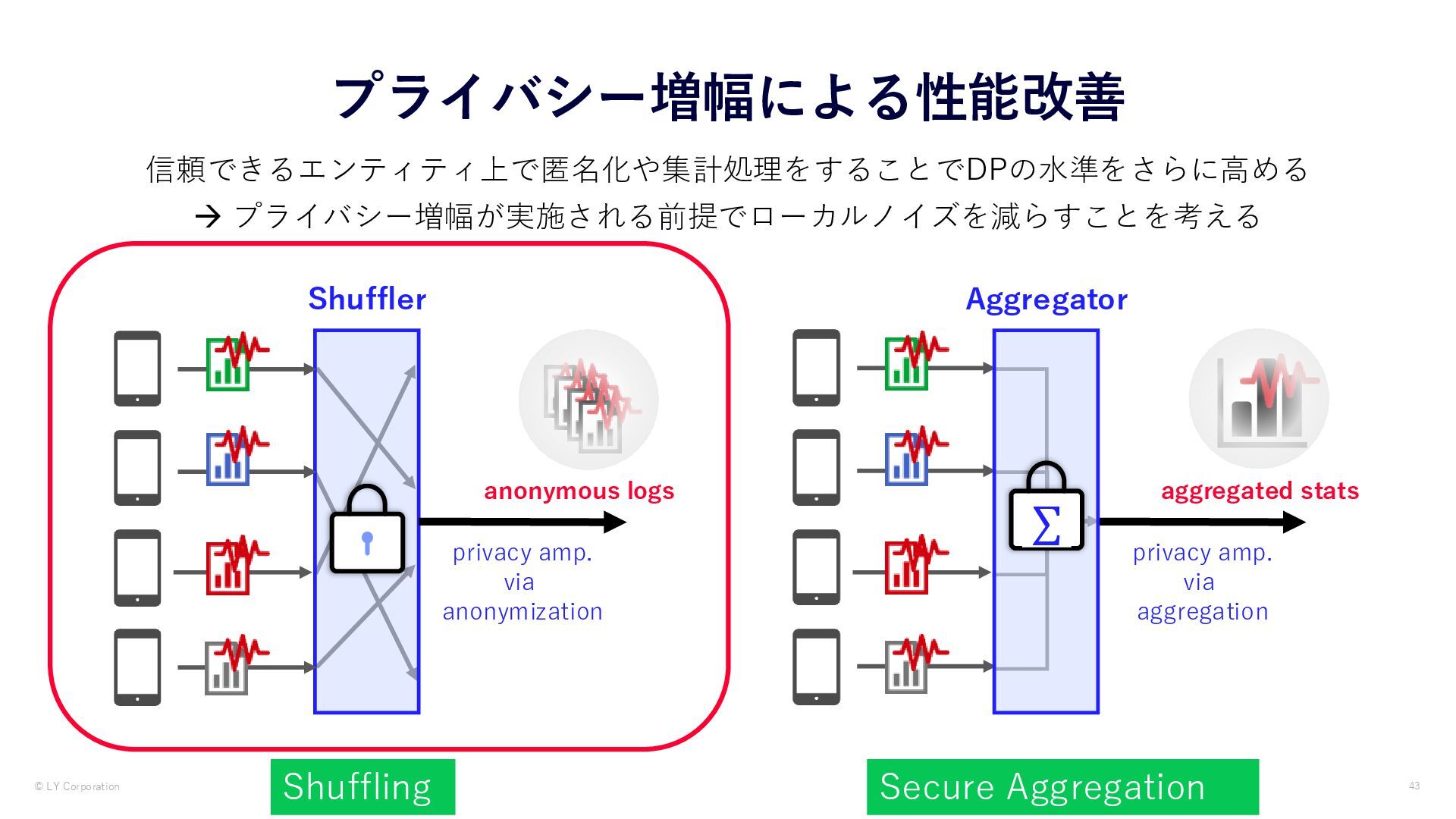{kind=link}
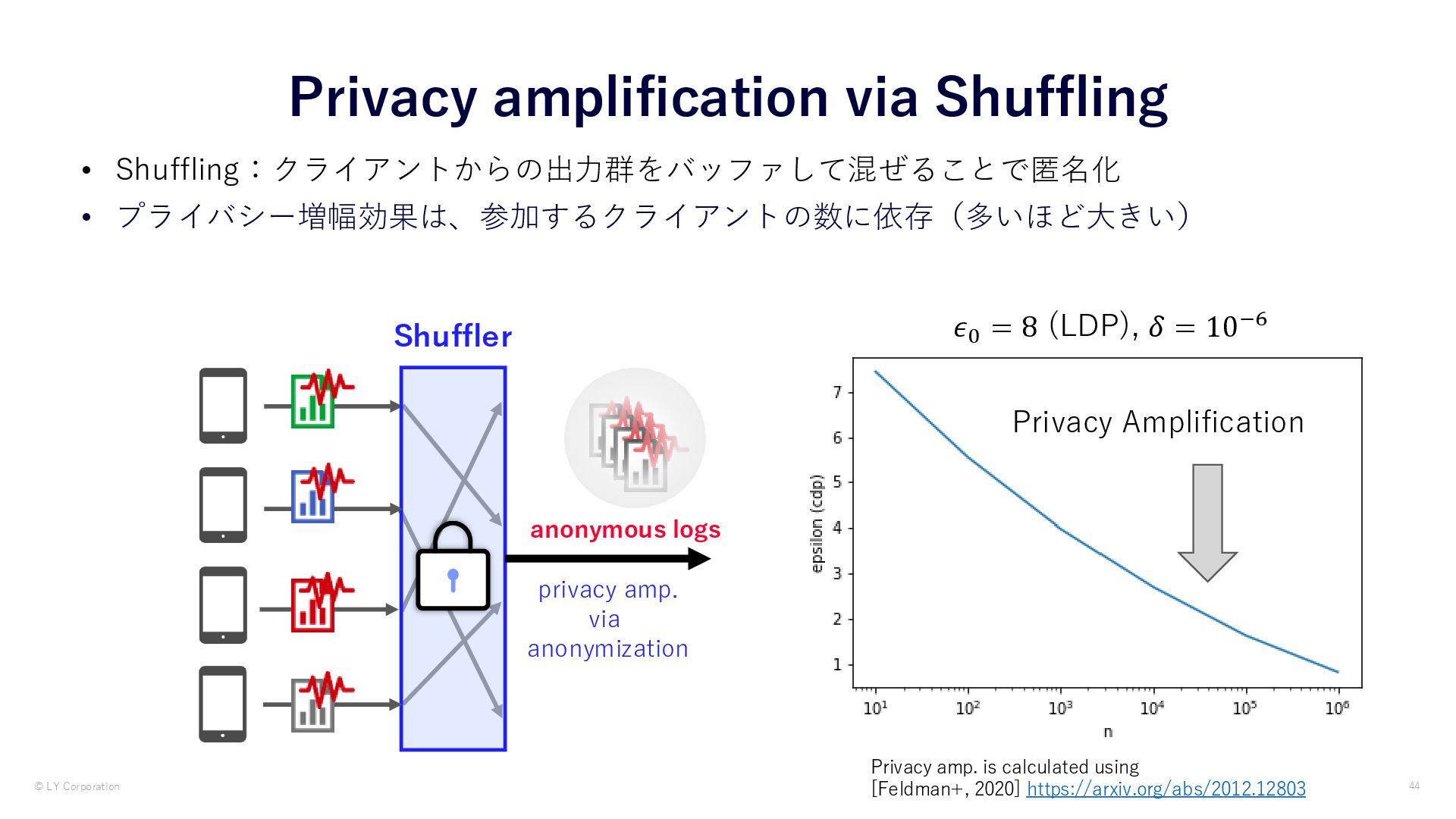{kind=link}
{kind=link}
{kind=link}