A.: METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments, in IEEvaluation@ACL, pp. 65–72 (2005) 2. [Vedantam+, CVPR15] Vedantam, R., Zitnick, L., and Parikh, D.: CIDEr: Consensus-based Image Description Evaluation, in CVPR, pp. 4566–4575 (2015) 3. [Anderson+, ECCV16] Anderson, P., Fernando, B., et al.: SPICE: Se- mantic Propositional Image Caption Evaluation, in ECCV, pp. 382–398 (2016) 4. [Wada+, CoNLL23] Wada, Y., Kaneda, K., and Sugiura, K.: JaSPICE: Automatic Evaluation Metric Using Predicate-Argument Structures for Image Captioning Models, in CoNLL (2023) 5. [Zhang+, ICLR20] Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., and Artzi, Y.: BERTScore: Evaluating Text Generation with BERT, in ICLR (2020) 6. [Devlin+, NACCL19] Devlin, J., et al.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL- HLT, pp. 4171–4186 (2019) 7. [Hessel+, EMNLP21] Hessel, J., et al.: CLIPScore: A Reference-free Evaluation Metric for Image Captioning, in EMNLP, pp. 7514–7528 (2021) 8. [Kim+, NeurIPS22] Kim, J.-H., Kim, Y., Lee, J., Yoo, K. M., and Lee, S.- W.: Mutual information divergence: A unified metric for multimodal generative models, NeurIPS, Vol. 35, pp. 35072–35086 (2022) 9. [Lee+, ACL21] Lee, H., Yoon, S., Dernoncourt, F., and Jung, K.: UMIC: An Unreferenced Metric for Image Captioning via Con- trastive Learning, in ACL, pp. 220–226 (2021) 10. [Sarto+, CVPR23] Sarto, S., Barraco, M., Cornia, M., Baraldi, L., and Cucchiara, R.: Positive-Augmented Contrastive Learning for Image and Video Captioning Evaluation, in CVPR, pp. 6914– 6924 (2023) 11. [Chen+, ECCV20] Chen, Y.-C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., Cheng, Y., and Liu, J.: UNITER: Universal image-text representation learning, in ECCV, pp. 104–120 (2020) 12. [Radford+, PMLR21] Radford, A., Kim, J. W., Hallacy, C., et al.: Learning transferable visual models from natural language supervi- sion, in ICML, pp. 8748–8763 (2021) 13. [Gao+, EMNLP21] Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In 737 EMNLP, pages 6894–6910, 2021. 14. [Rei+, EMNLP20] Rei, R., Stewart, C., Farinha, A. C., and Lavie, A.: COMET: A Neural Framework for MT Evaluation, in EMNLP, pp. 2685–2702 (2020) 15. [Sellam+, ACL20] Sellam, T., Das, D., and Parikh, A.: BLEURT: Learning Robust Metrics for Text Generation, in ACL, pp. 7881–7892 (2020) 参考⽂献
{kind=link}
{kind=link}
![- 4 - o METEOR [Banerjee+, ACL05] / CIDEr [Vedantam+,](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_2.jpg){kind=link}
![- 5 - o METEOR [Banerjee+, ACL05] / CIDEr [Vedantam+,](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_3.jpg){kind=link}
![- 6 - ⼿法 概要 BERTScore [Zhang+, ICLR20] BERT [Devlin+,](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_4.jpg){kind=link}
![- 7 - ⼿法 概要 BERTScore [Zhang+, ICLR20] BERT [Devlin+,](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_5.jpg){kind=link}
![- 8 - UMIC PAC-S ⼿法 概要 UMIC [Lee+, ACL21]](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_6.jpg){kind=link}
![- 9 - ⼿法 概要 UMIC [Lee+, ACL21] UNITER [Chen+,](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_7.jpg){kind=link}
![- 10 - o Polos [Wada+, CVPR24 (Highlight)] o 新規性](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_8.jpg){kind=link}
![- 11 - o Polos [Wada+, CVPR24 (Highlight)] o 新規性](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_9.jpg){kind=link}
![- 12 - o Polos [Wada+, CVPR24 (Highlight)] o 新規性](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_10.jpg){kind=link}
![- 13 - o Polos [Wada+, CVPR24 (Highlight)] o 新規性](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_11.jpg){kind=link}
![- 14 - o Polos [Wada+, CVPR24 (Highlight)] o 新規性](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_12.jpg){kind=link}
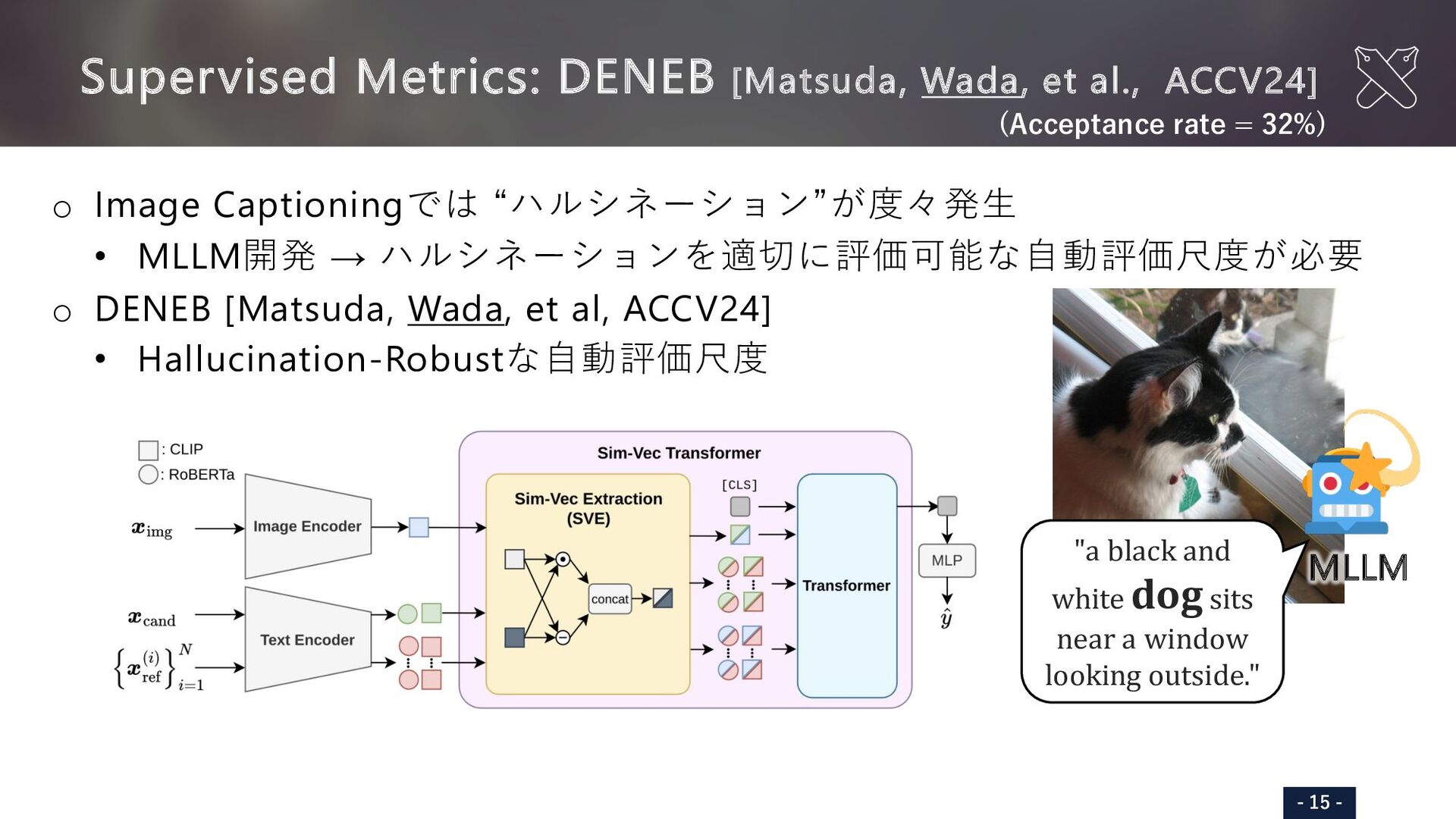{kind=link}
![- 16 - o DENEB [Matsuda, Wada, et al, ACCV24]](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_14.jpg){kind=link}
![- 17 - o 既存⼿法 [Wada+, CoNLL23] [Sarto+, CVPR23]の問題点 •](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_15.jpg){kind=link}
{kind=link}
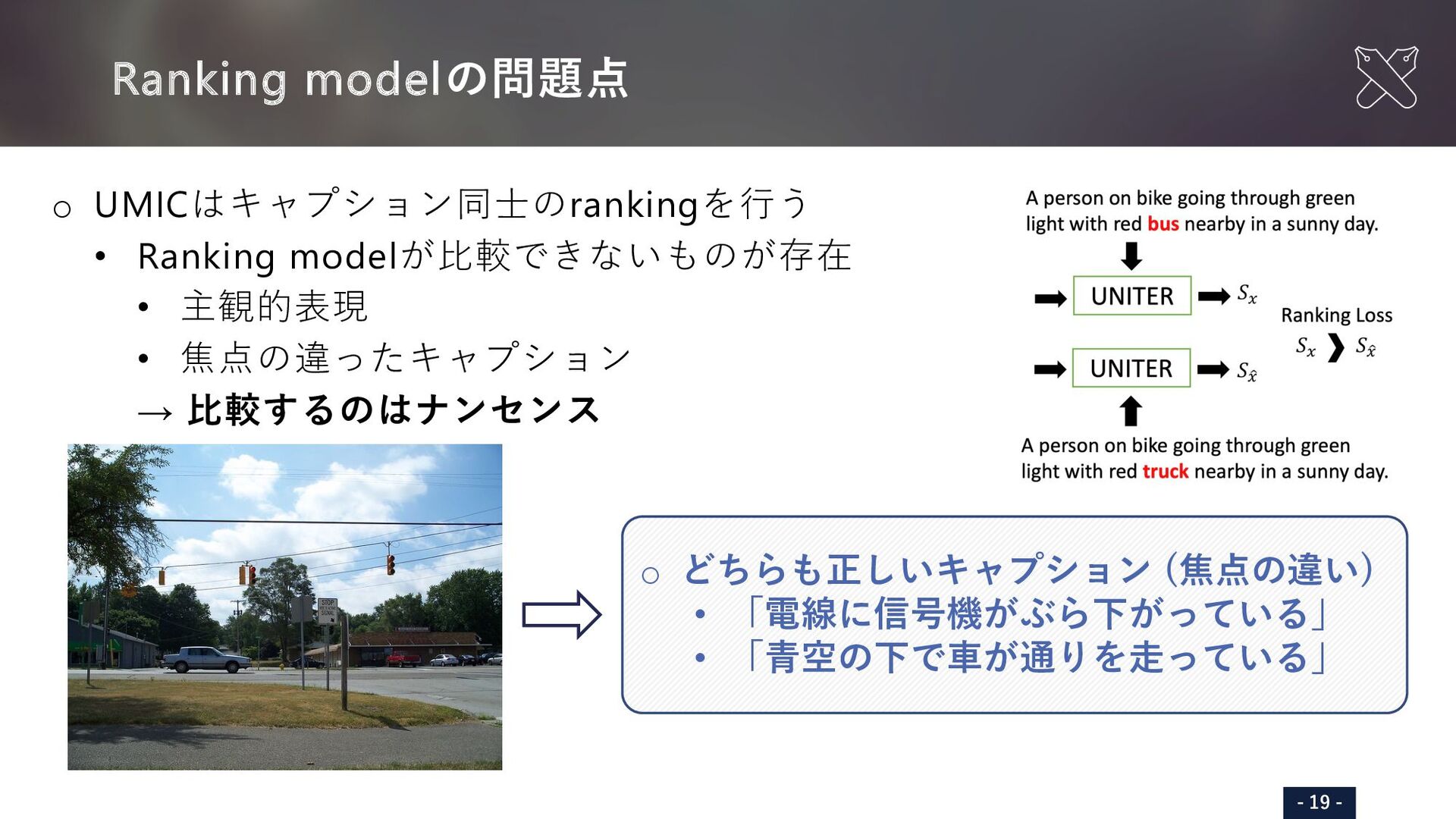{kind=link}
{kind=link}
![- 21 - o 画像キャプション⽣成: 画像を説明するキャプションを⽣成 • 視覚障害者の補助 [Gurari+, ECCV20]](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_19.jpg){kind=link}
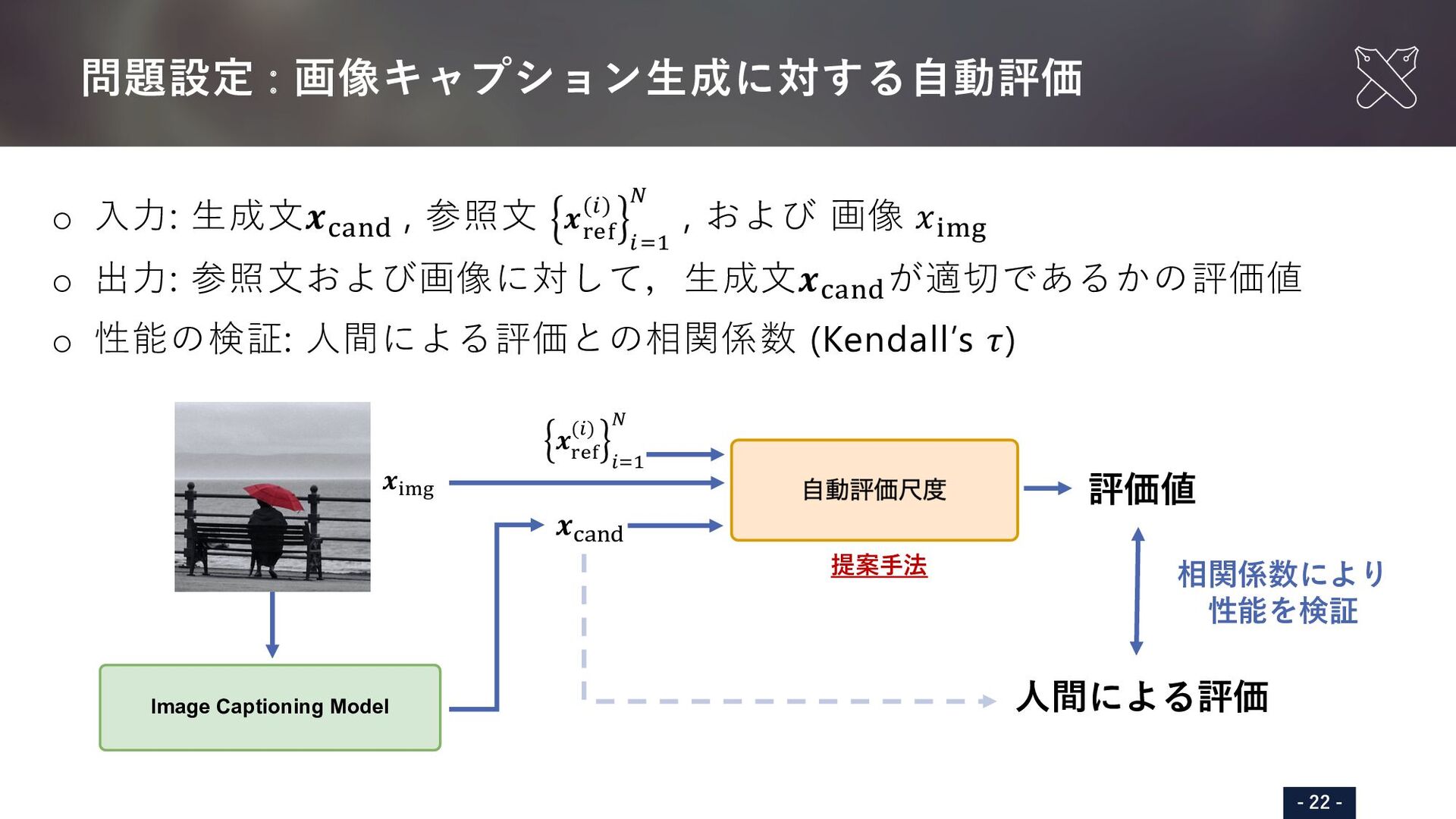{kind=link}
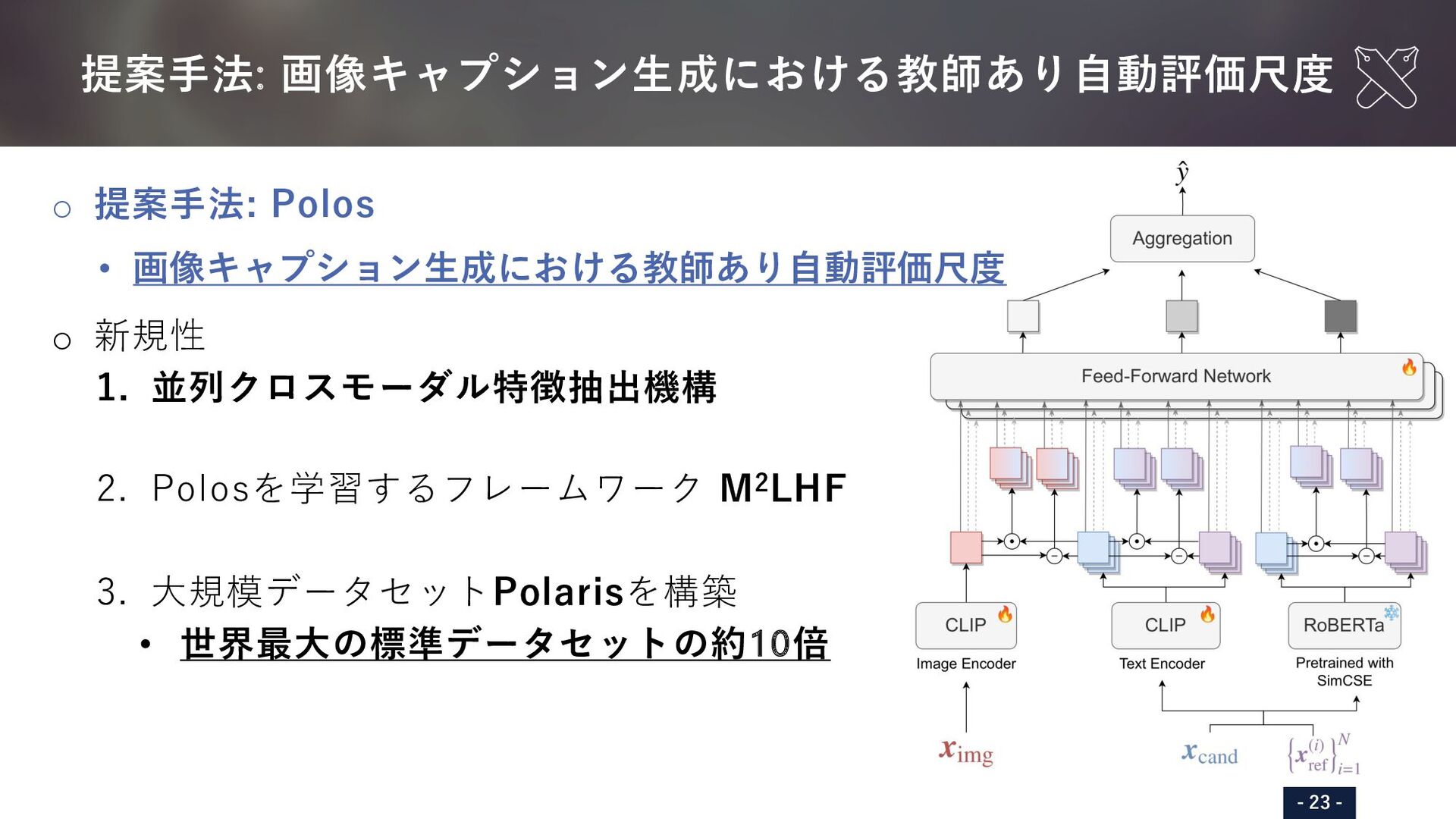{kind=link}
{kind=link}
{kind=link}
{kind=link}
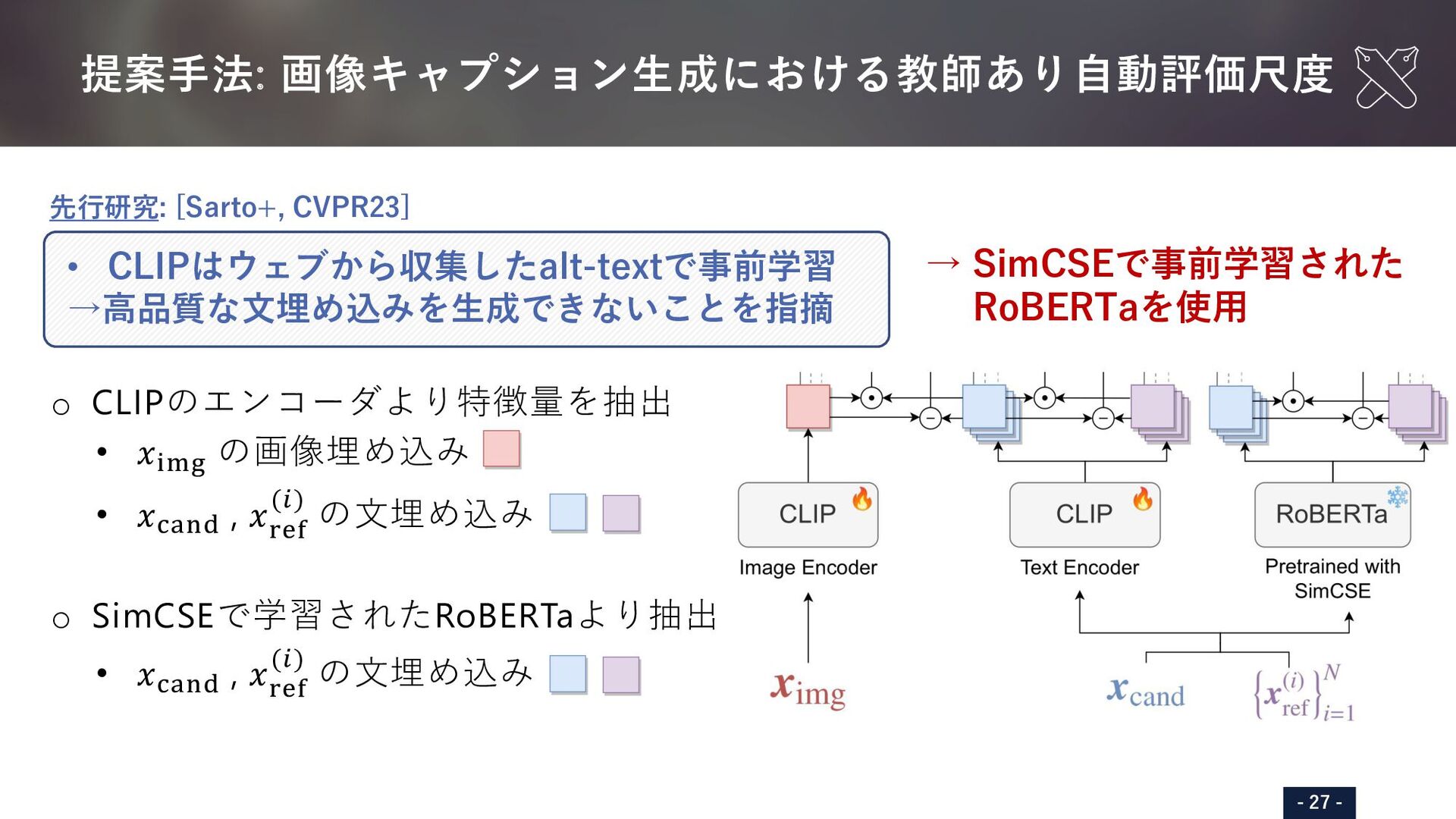{kind=link}
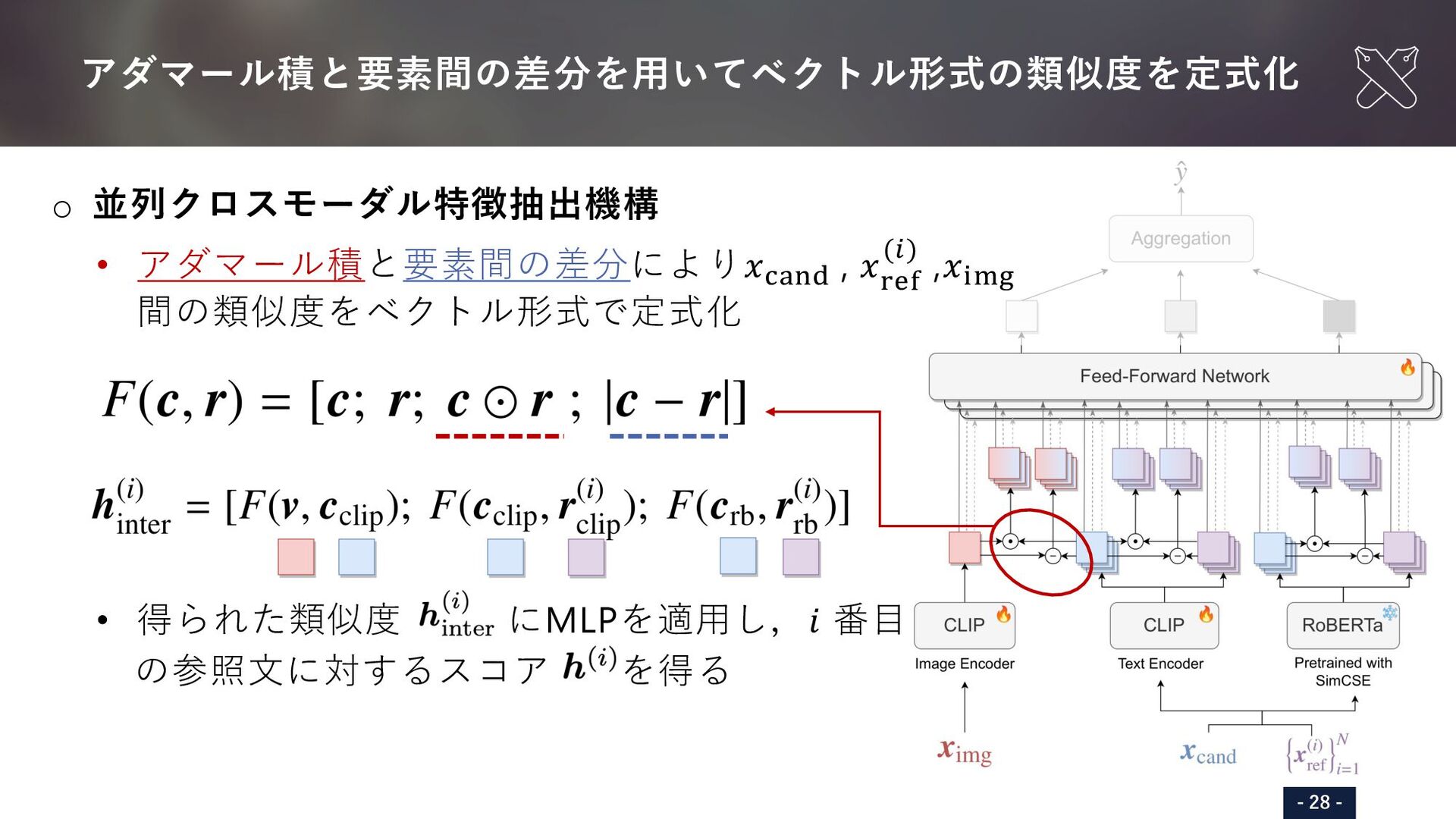{kind=link}
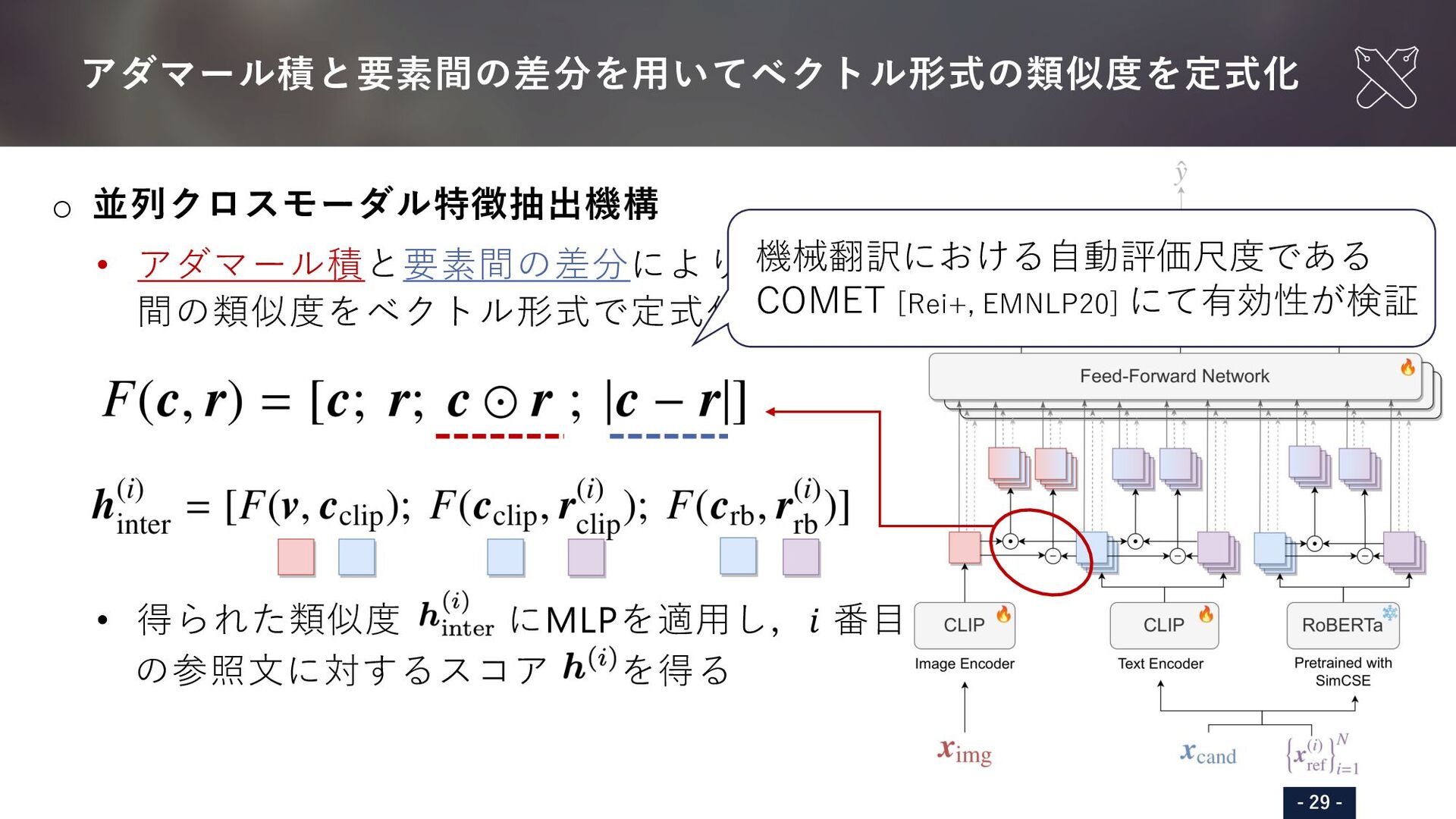{kind=link}
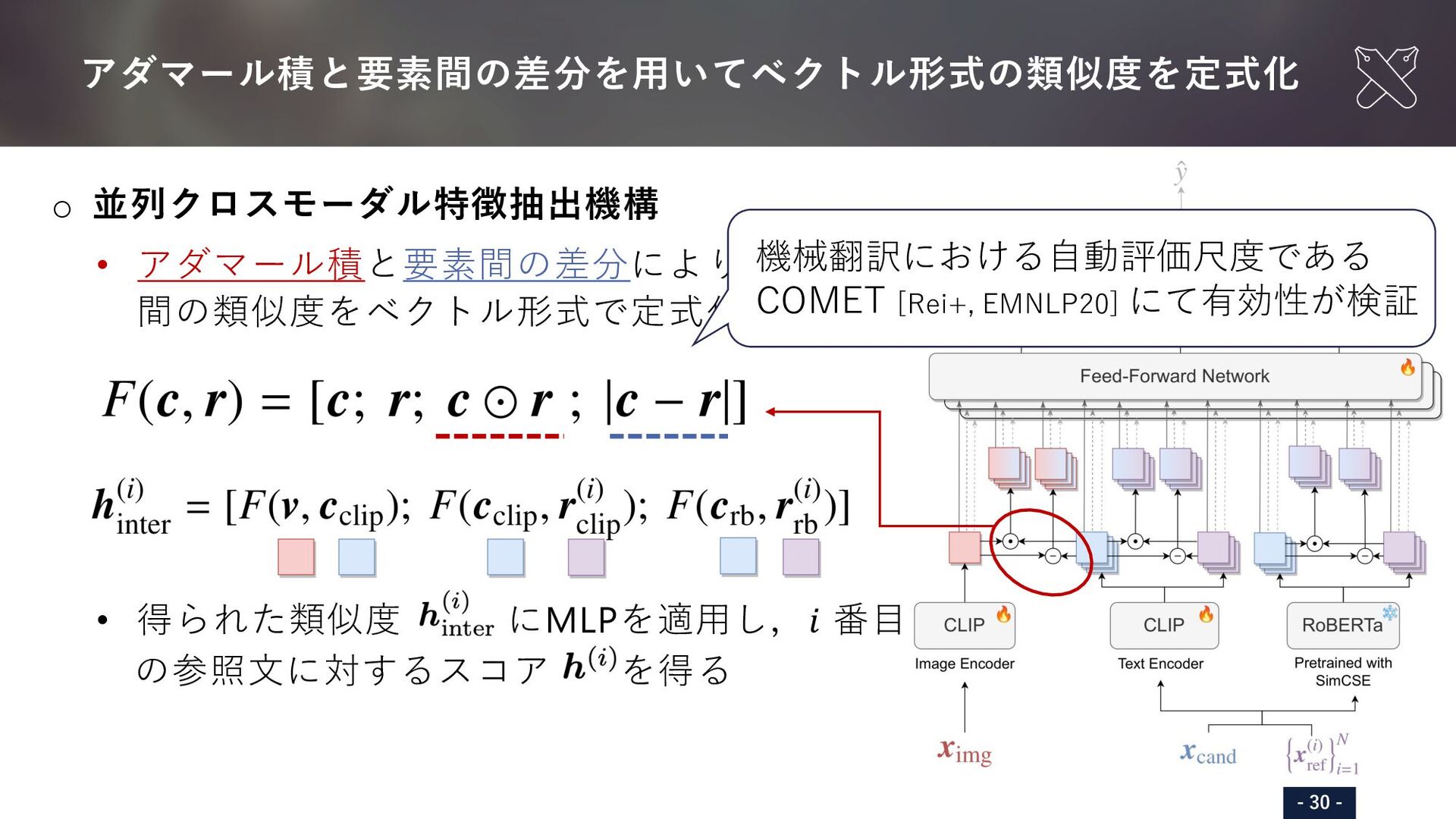{kind=link}
{kind=link}
{kind=link}
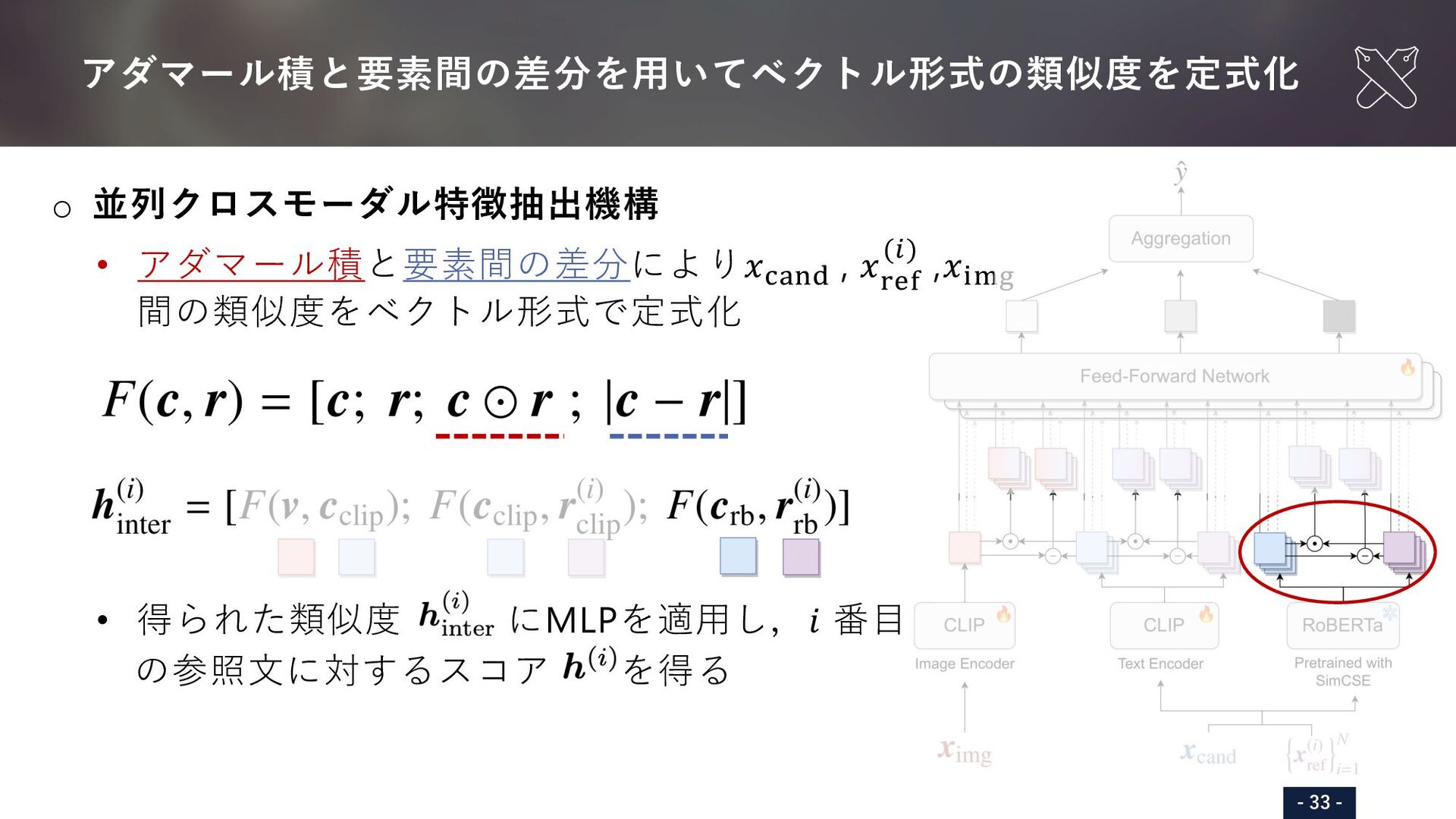{kind=link}
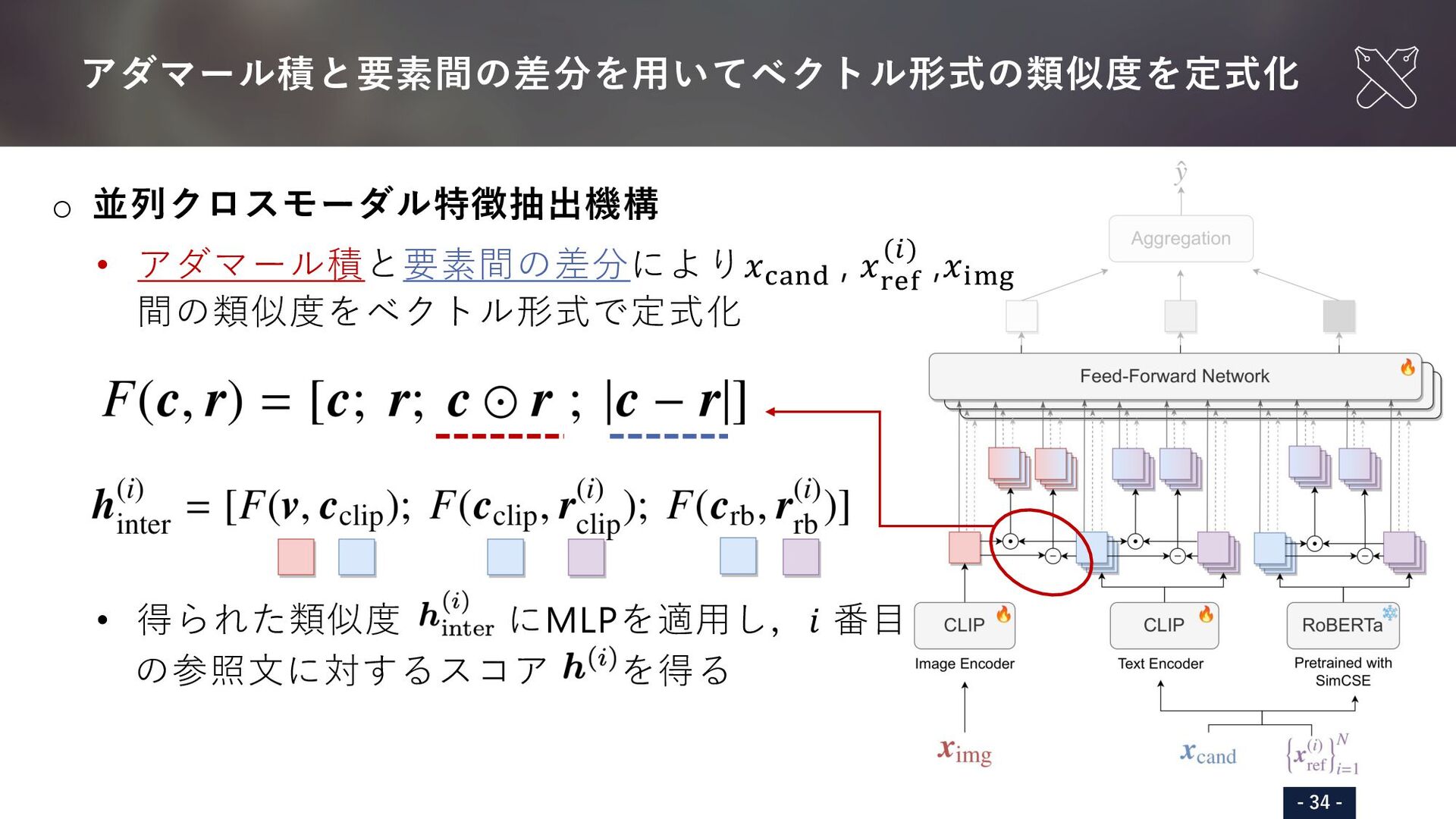{kind=link}
{kind=link}
{kind=link}
![o 18個の⾃動評価尺度・6個のベンチマークにおいて⽐較 (以下⼀部抜粋) J 現時点でのSOTA尺度 RefPAC-S [Sarto+, CVPR23] を上回る良好な結果 -](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
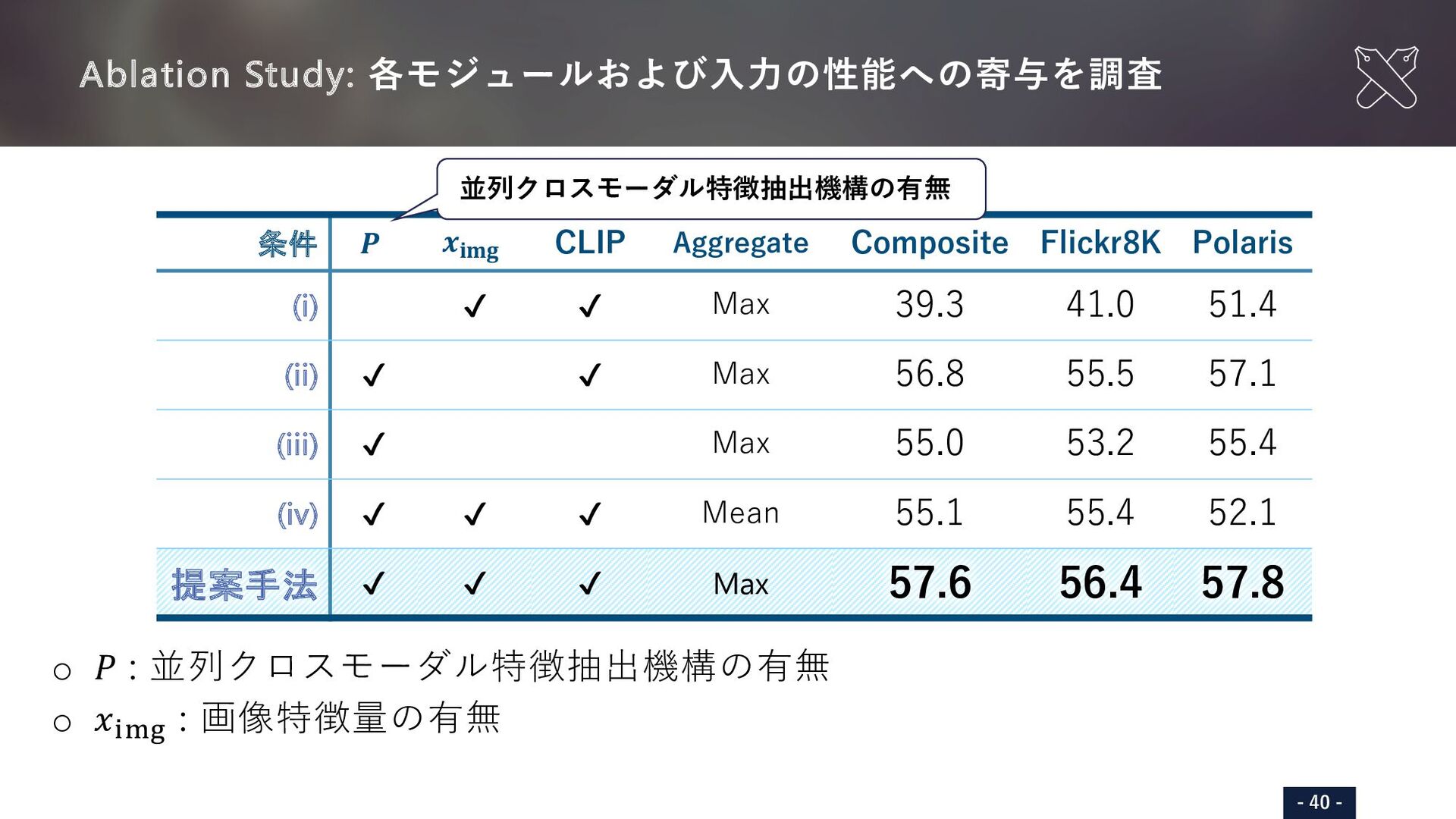{kind=link}
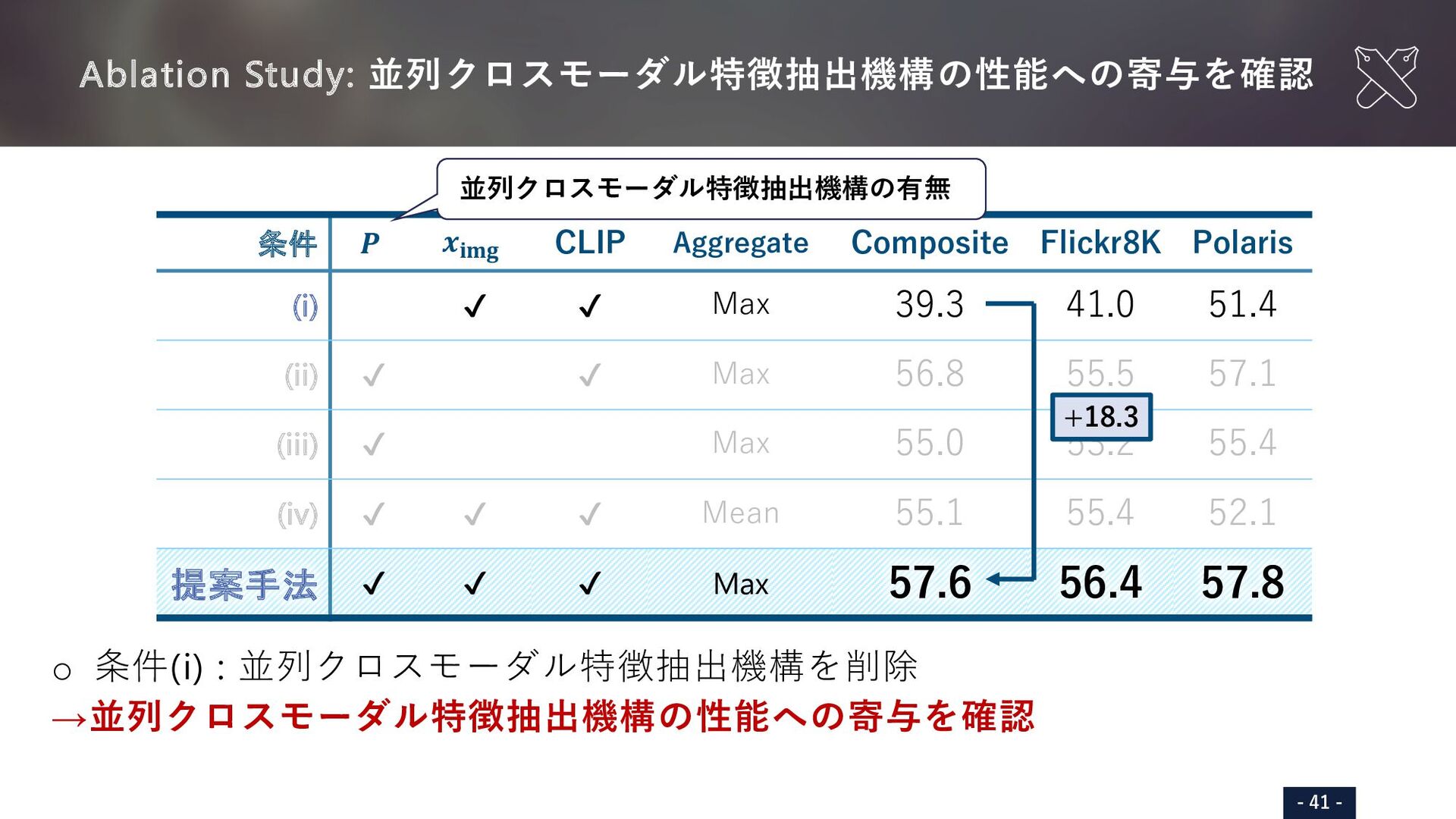{kind=link}
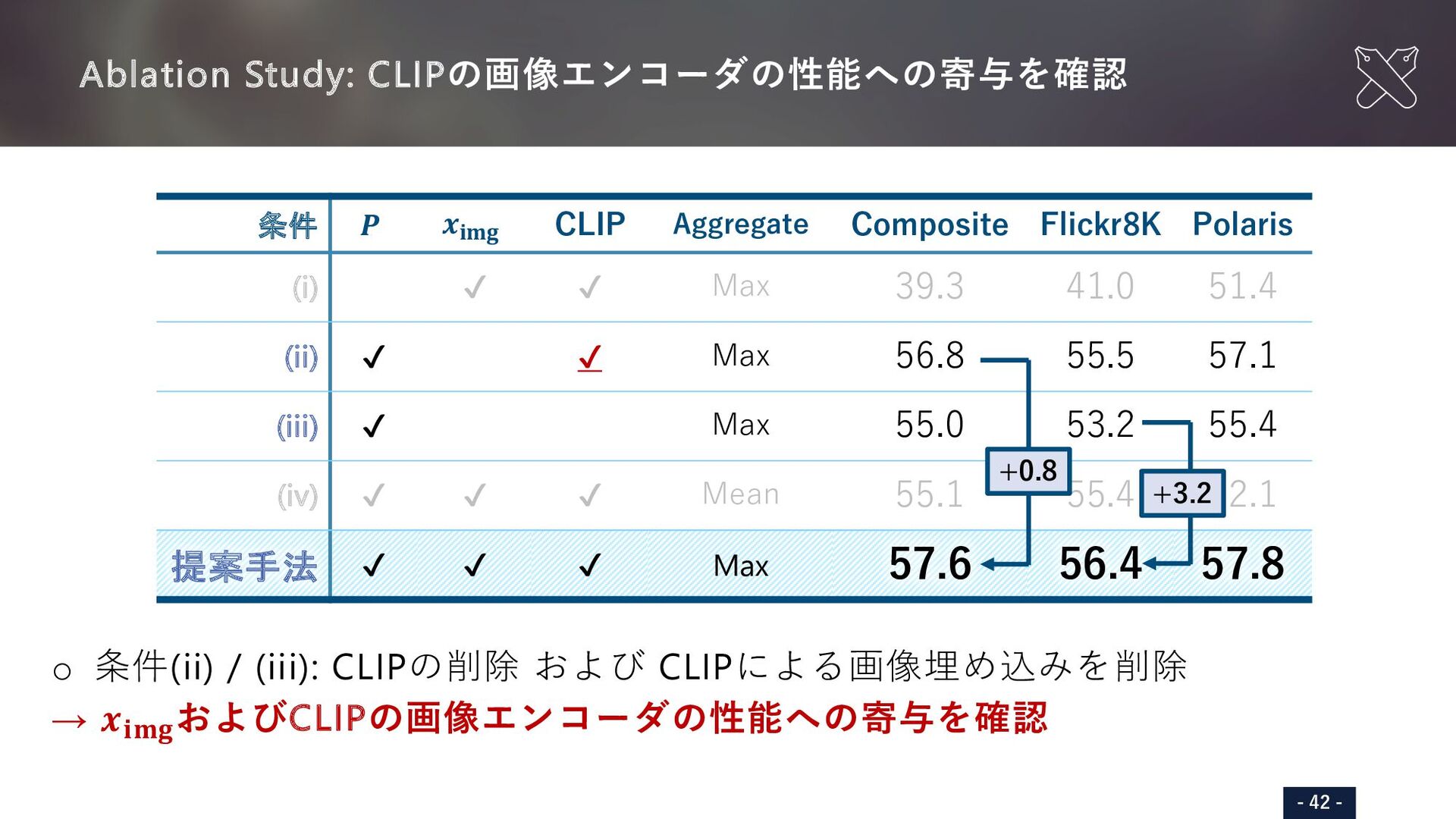{kind=link}
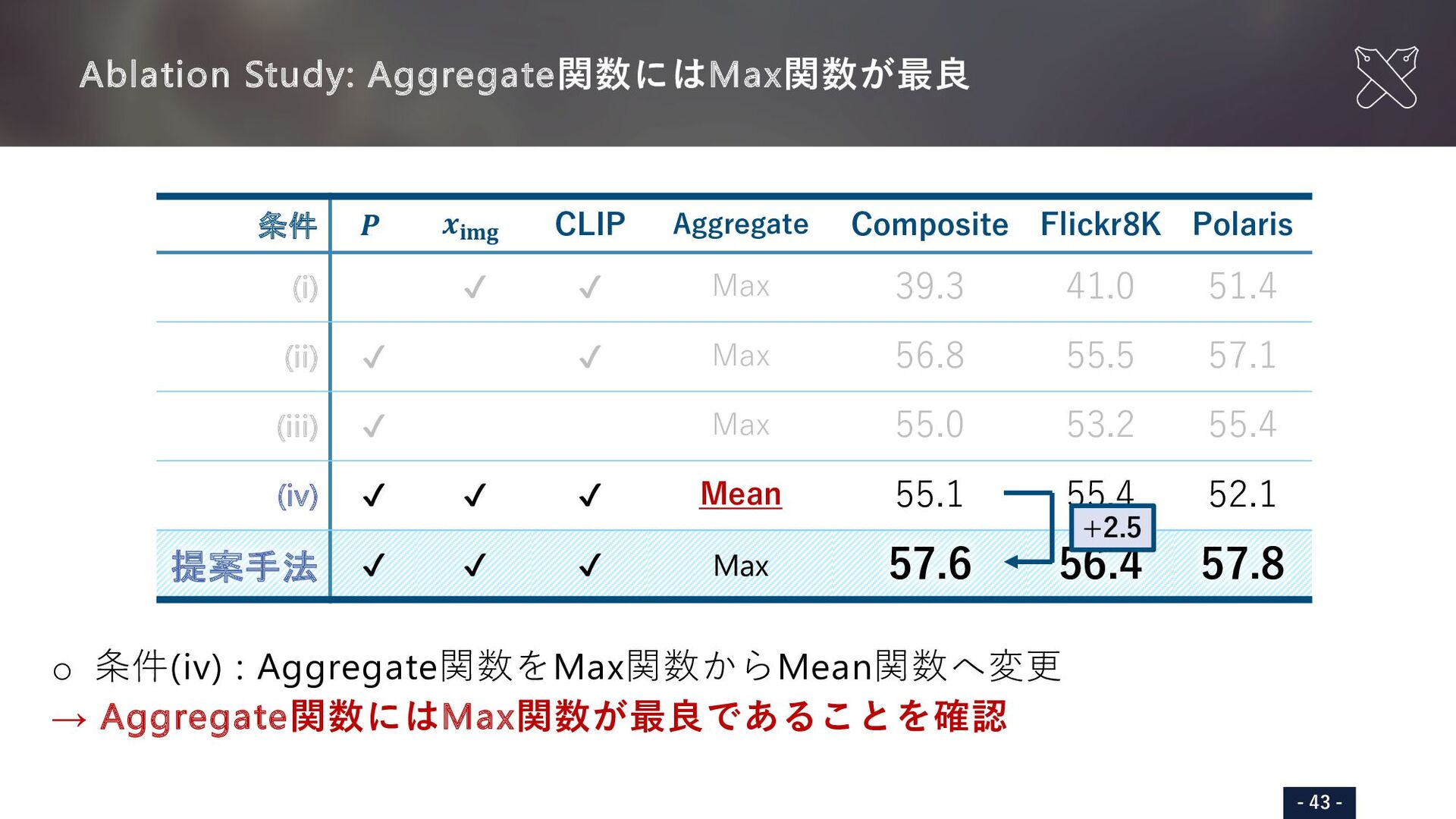{kind=link}
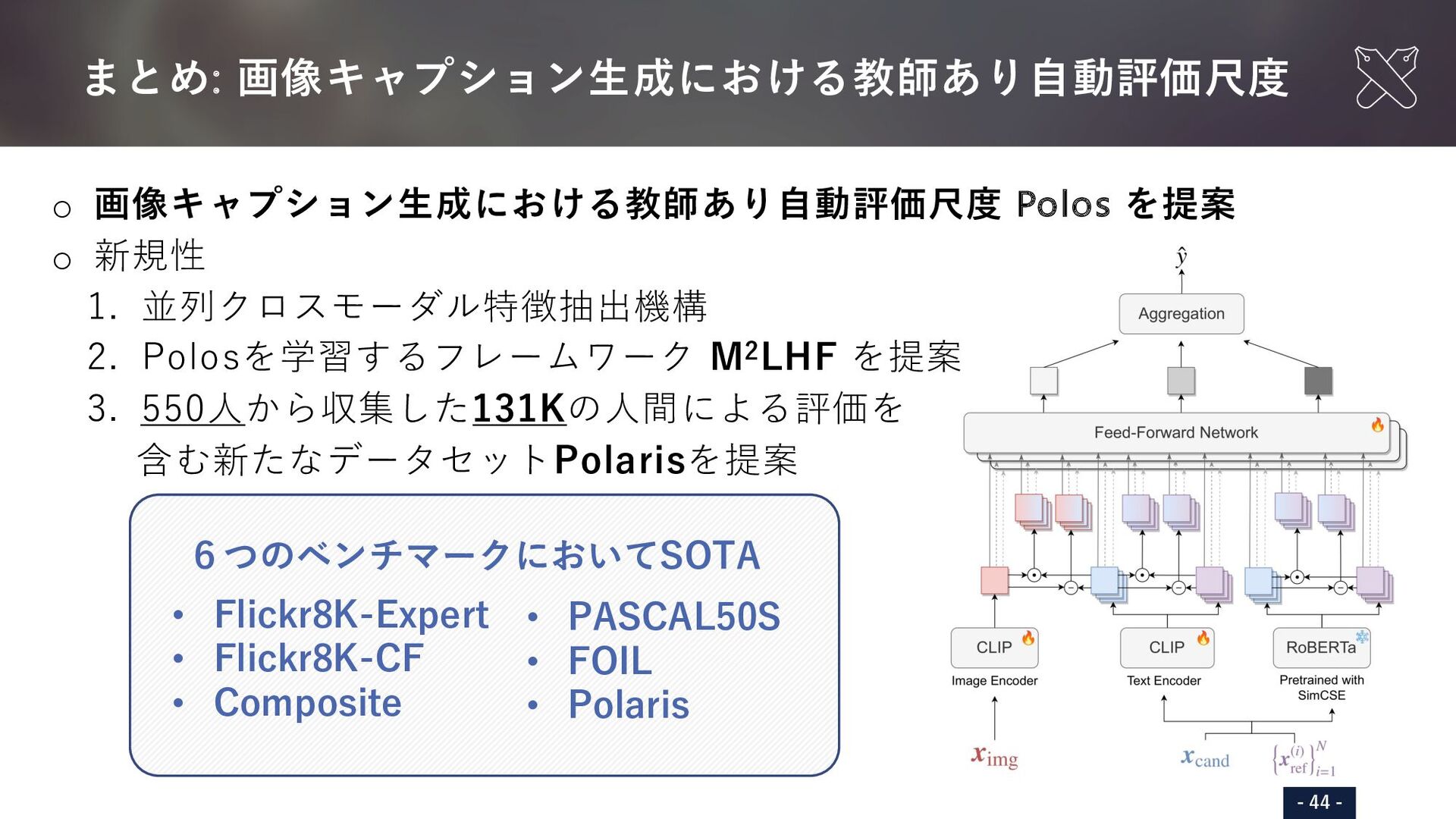{kind=link}
{kind=link}
![- 46 - 1. [Banerjee+, ACL05] Banerjee, S. and Lavie,](https://files.speakerdeck.com/presentations/7417875a118e45419ec71801db675ba0/slide_44.jpg){kind=link}