Zhou, Fengwei Yu, Wei Wu, “Incorporating Convolution Designs into Visual Transformers ,” ; [arXiv:2103.11816 [cs.CV]]. 2. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. “An image is worth 16x16 words: Transformers for image recognition at scale,” ; [arXiv:2010.11929[cs.CV]]. 3. Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou. “Training data-efficient image transformers & distillation through attention,” ; [arXiv:2012.12877[cs.CV]]. 4. Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, Ruoming Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” ; [arXiv:2005.08100[eess.AS]]. 5. Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang, “CvT: Introducing Convolutions to Vision Transformers,” ; [arXiv:2103.15808[cs.CV]]. 6. Samira Abnar, Mostafa Dehghani, Willem Zuidema, “Transferring Inductive Biases through Knowledge Distillation,” ; [arXiv:2006.00555[cs.LG]]. 7. Hugo Touvron, Andrea Vedaldi, Matthijs Douze, Hervé Jégou, “Fixing the train-test resolution discrepancy,” ; [arXiv:1906.06423[cs.CV]]. 8. @takoroy, “【論⽂読解めも】Training data-efficient image transformers & distillation through attention,” https://zenn.dev/takoroy/scraps/ced7059a36d846 9. Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L. Yuille, Yuyin Zhou, “TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation,” [arXiv:2102.04306 [cs.CV]].
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
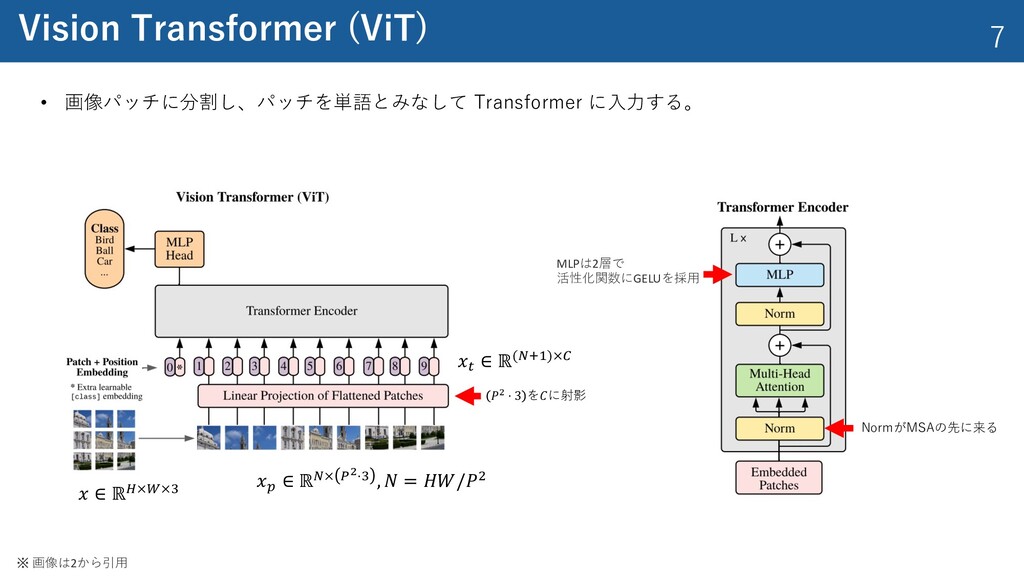{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
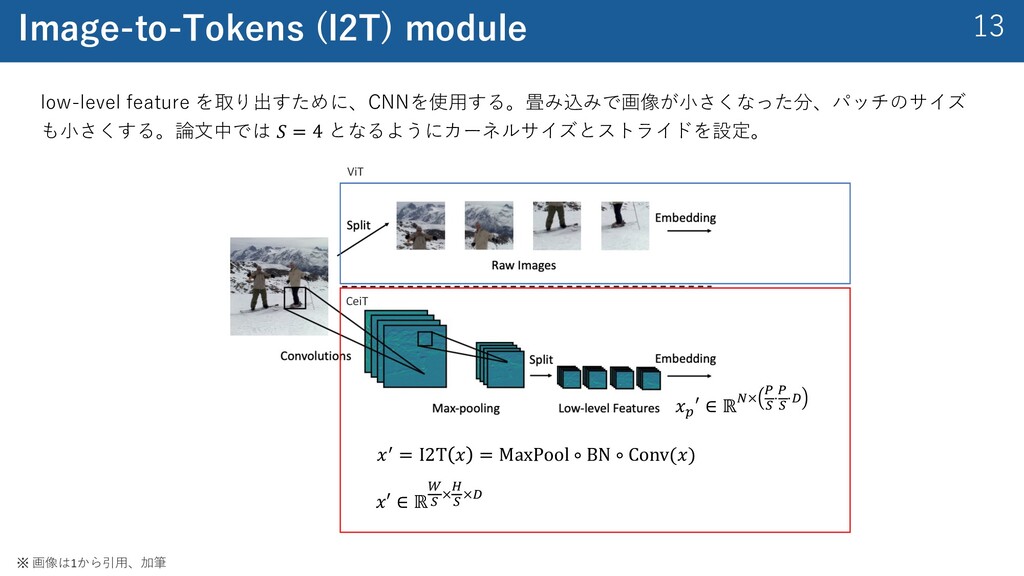{kind=link}
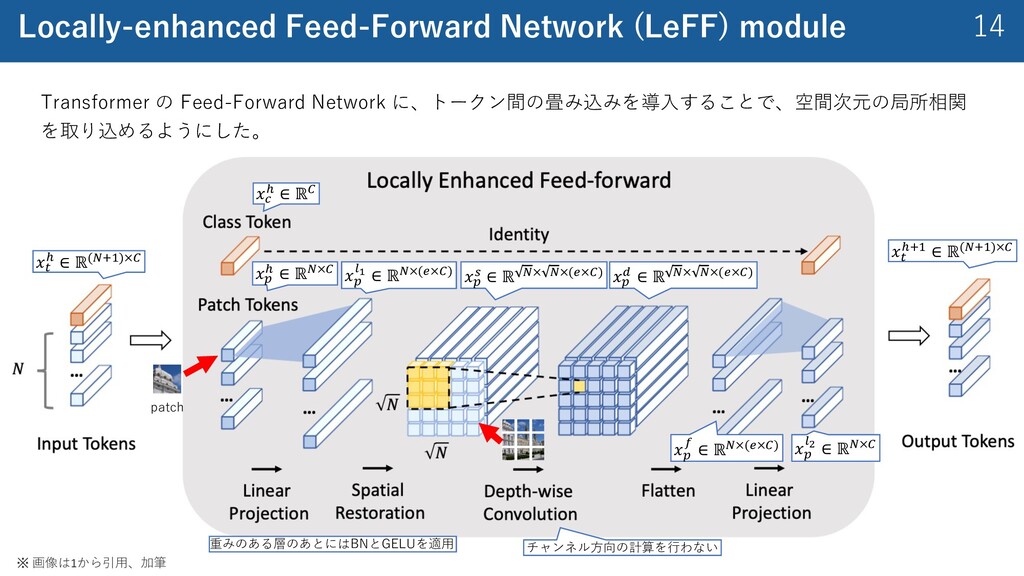{kind=link}
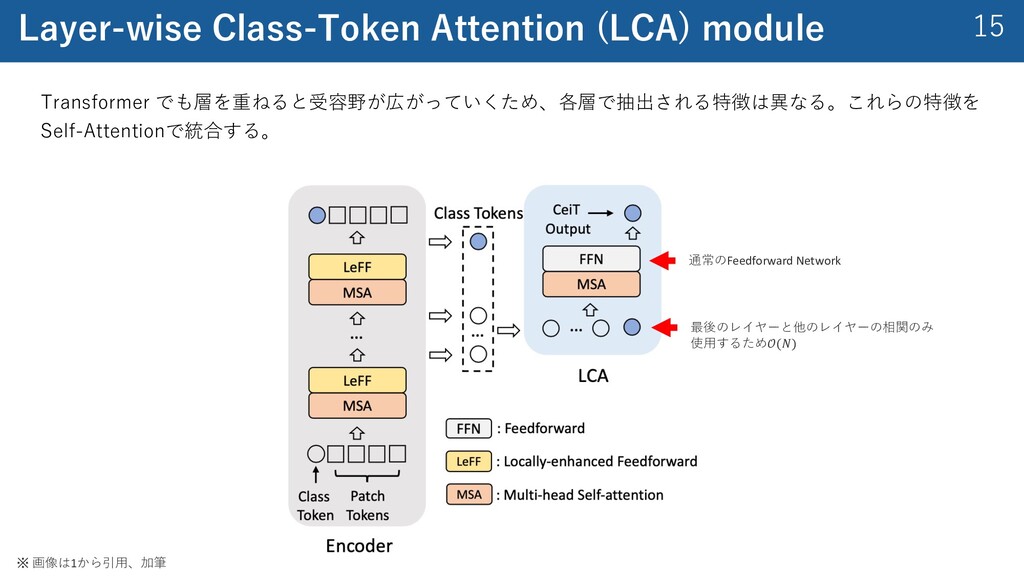{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
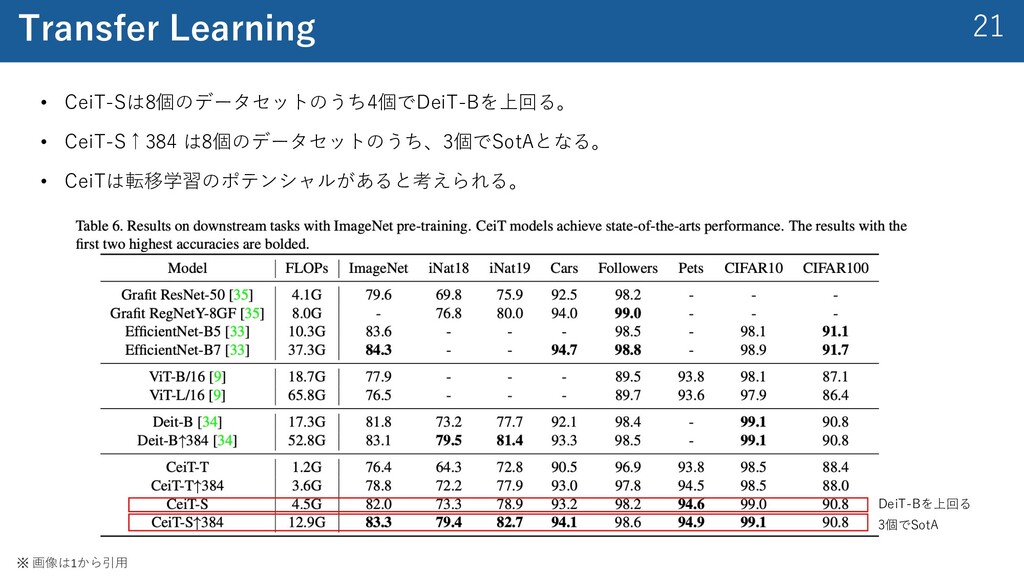{kind=link}
{kind=link}
{kind=link}
{kind=link}
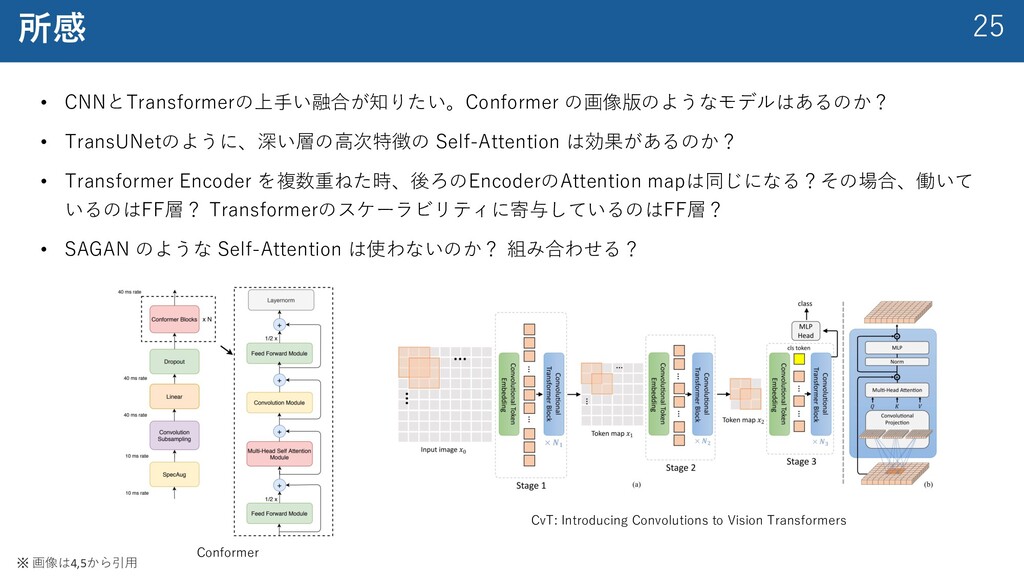{kind=link}
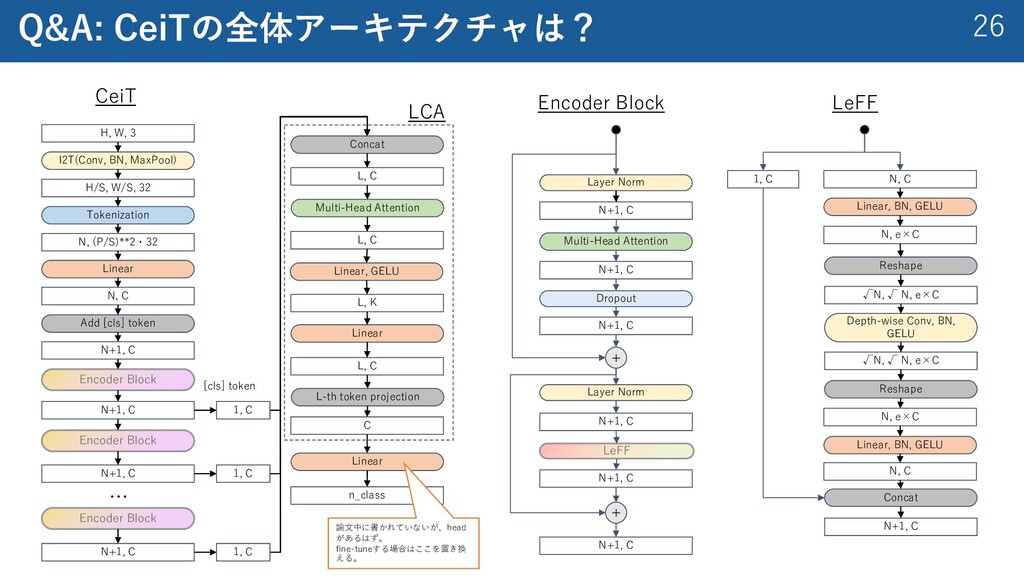{kind=link}
{kind=link}
{kind=link}
![29 Q&A: class tokenの意味は? • シンプルに、BERTの構造を踏襲していると考えられる。 • BERTでは、次の⽂が正しいか判定するタスクに使⽤されるトークンだった。 • [考察]](https://files.speakerdeck.com/presentations/3c1043bb26d94a99b08d095106654f8f/slide_28.jpg){kind=link}
{kind=link}