Share
AcademiX が開催した 第2回 XAI勉強会 資料 トピック:線形モデルの説明可能性 日時:2023/08/13 参考図書:実践XAI[説明可能なAI] 機械学習の予測を説明するためのPythonコーディング
{kind=link}
![参考文献 • 実践XAI[説明可能なAI] 機械学習の予測を説明するための Pythonコーディング • コード :https://github.com/Apress/Practical-Explainable-AI-Using- Python/tree/main •](https://files.speakerdeck.com/presentations/4713c19ef27e4b0fa0b8187566e91fac/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SHAP値の具体例 • X軸:ある特徴量(Age)の値とその分布 • Y軸:目的変数Priceの値 • E[f(x)]:水平の点線はモデルの出力の 期待値(平均値) • E[Age]:Age特徴量の平均値](https://files.speakerdeck.com/presentations/4713c19ef27e4b0fa0b8187566e91fac/slide_16.jpg){kind=link}
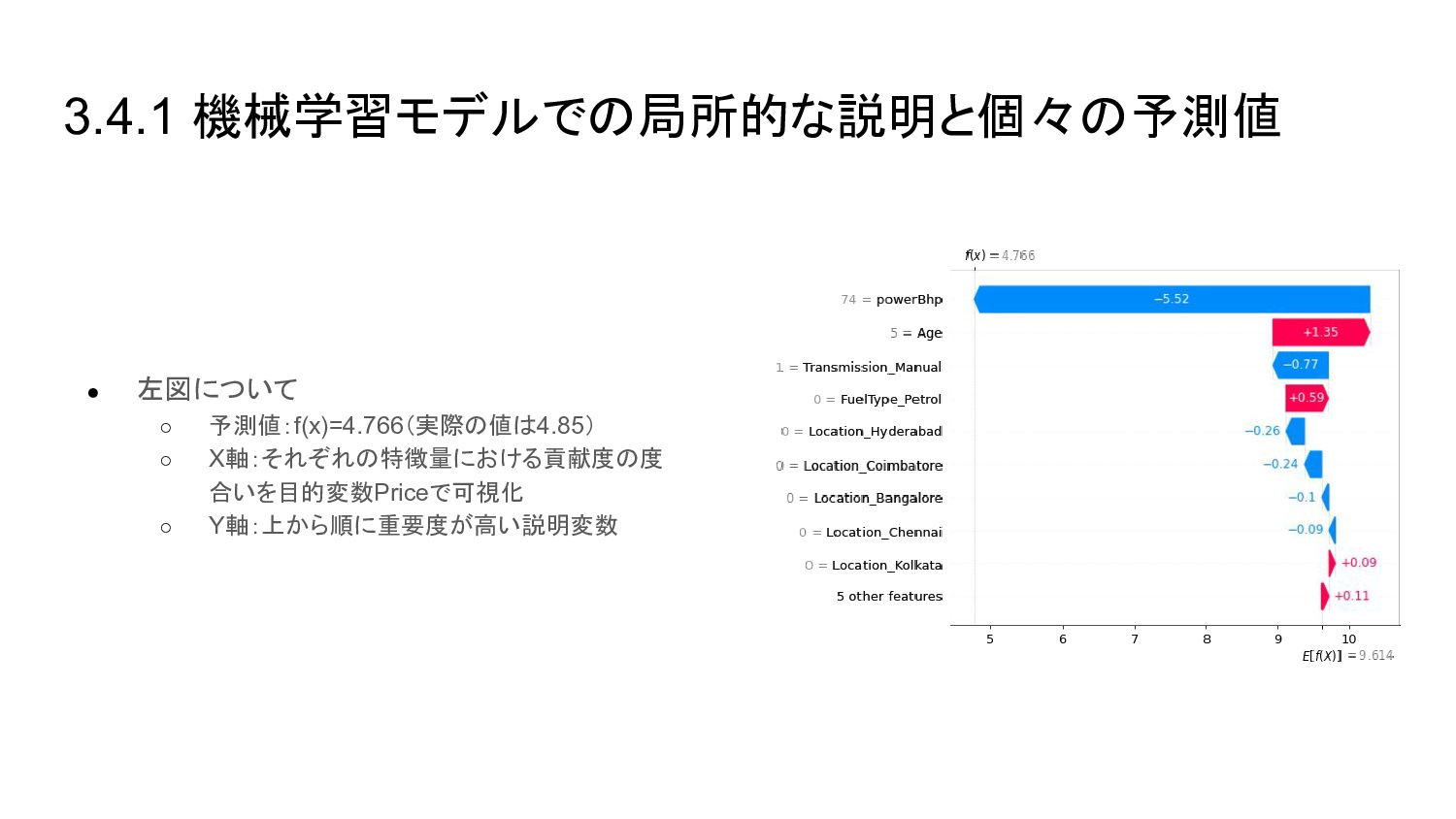{kind=link}
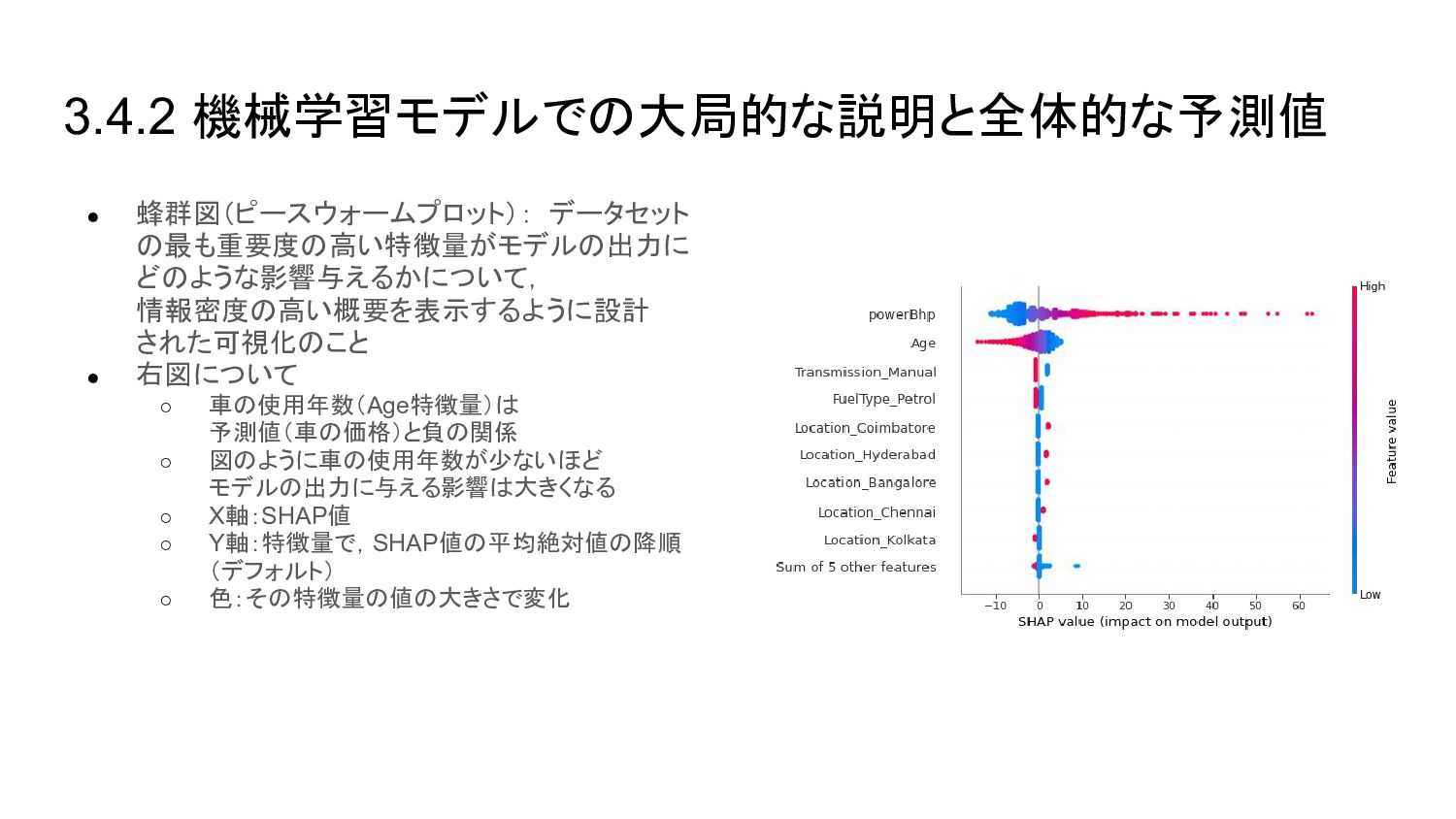{kind=link}
{kind=link}
{kind=link}
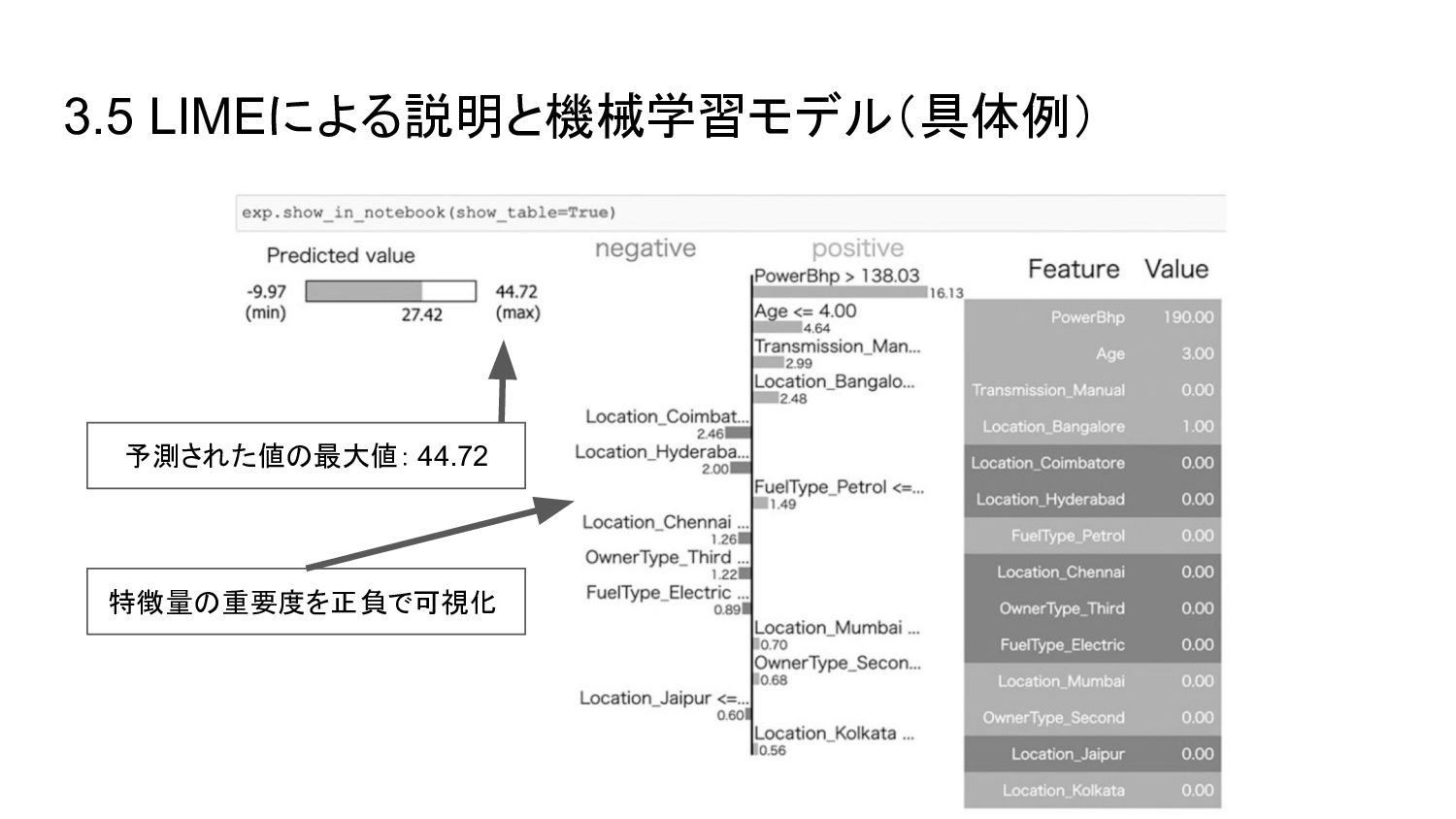{kind=link}
{kind=link}
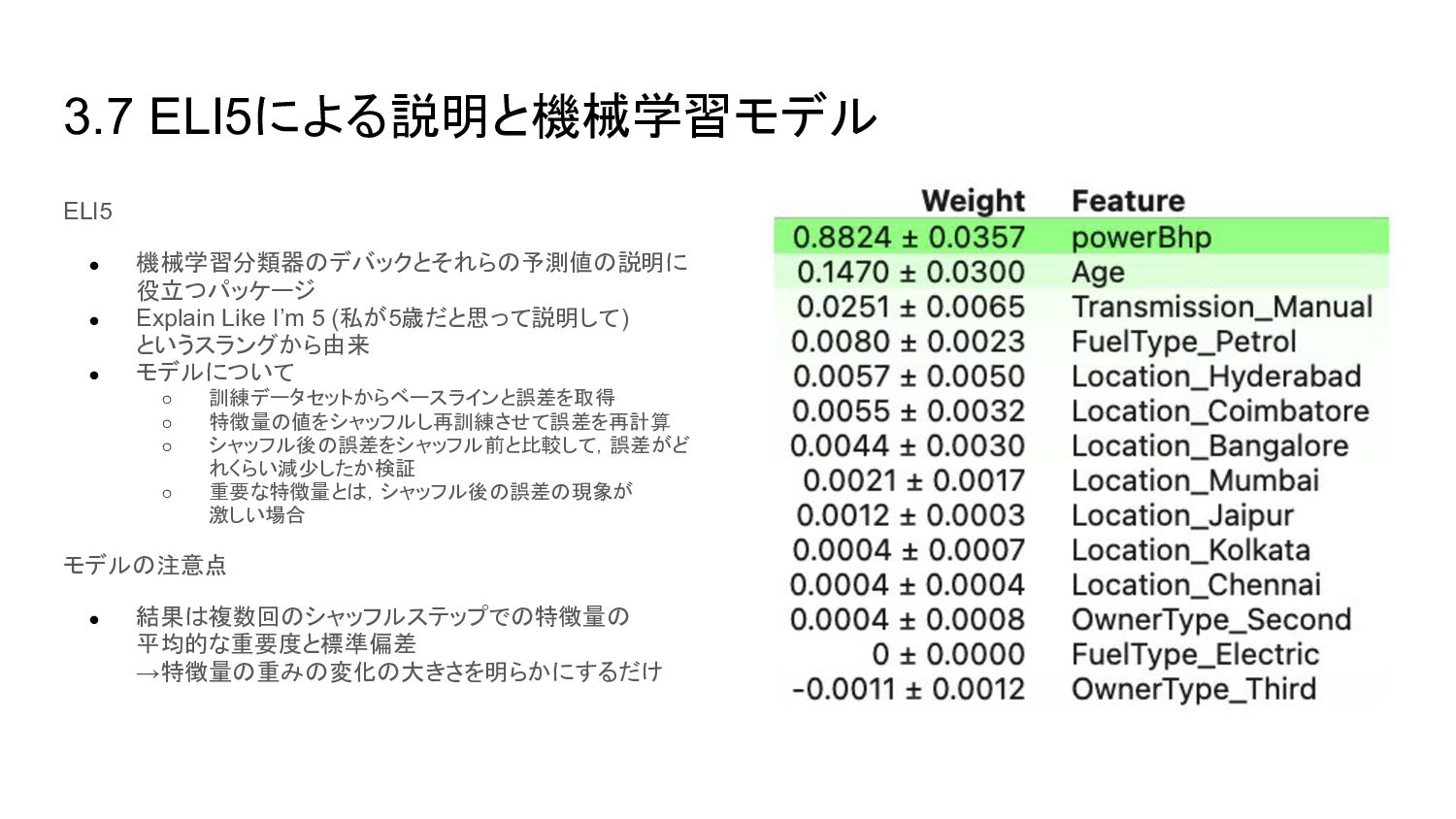{kind=link}
{kind=link}
{kind=link}
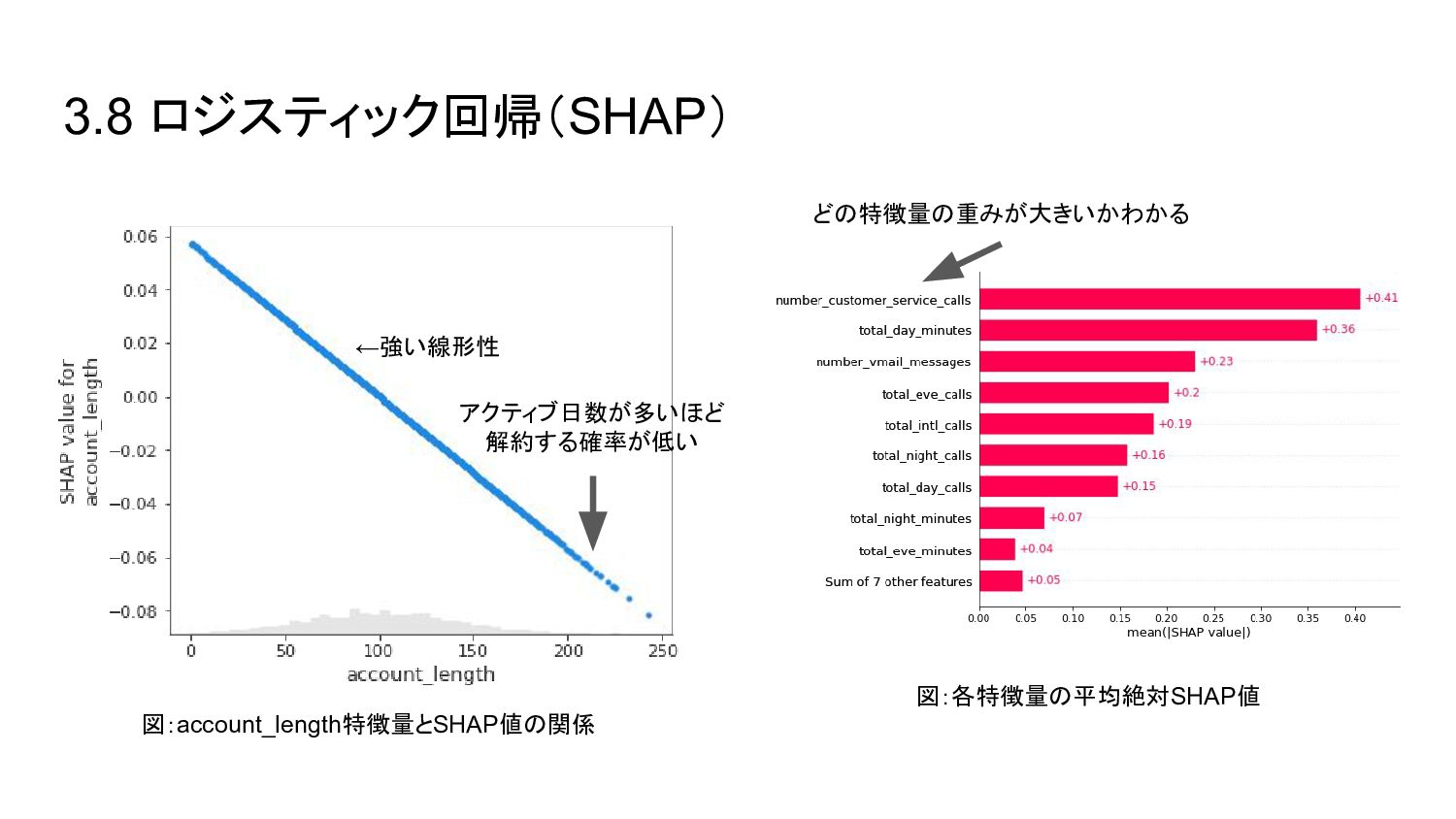{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}