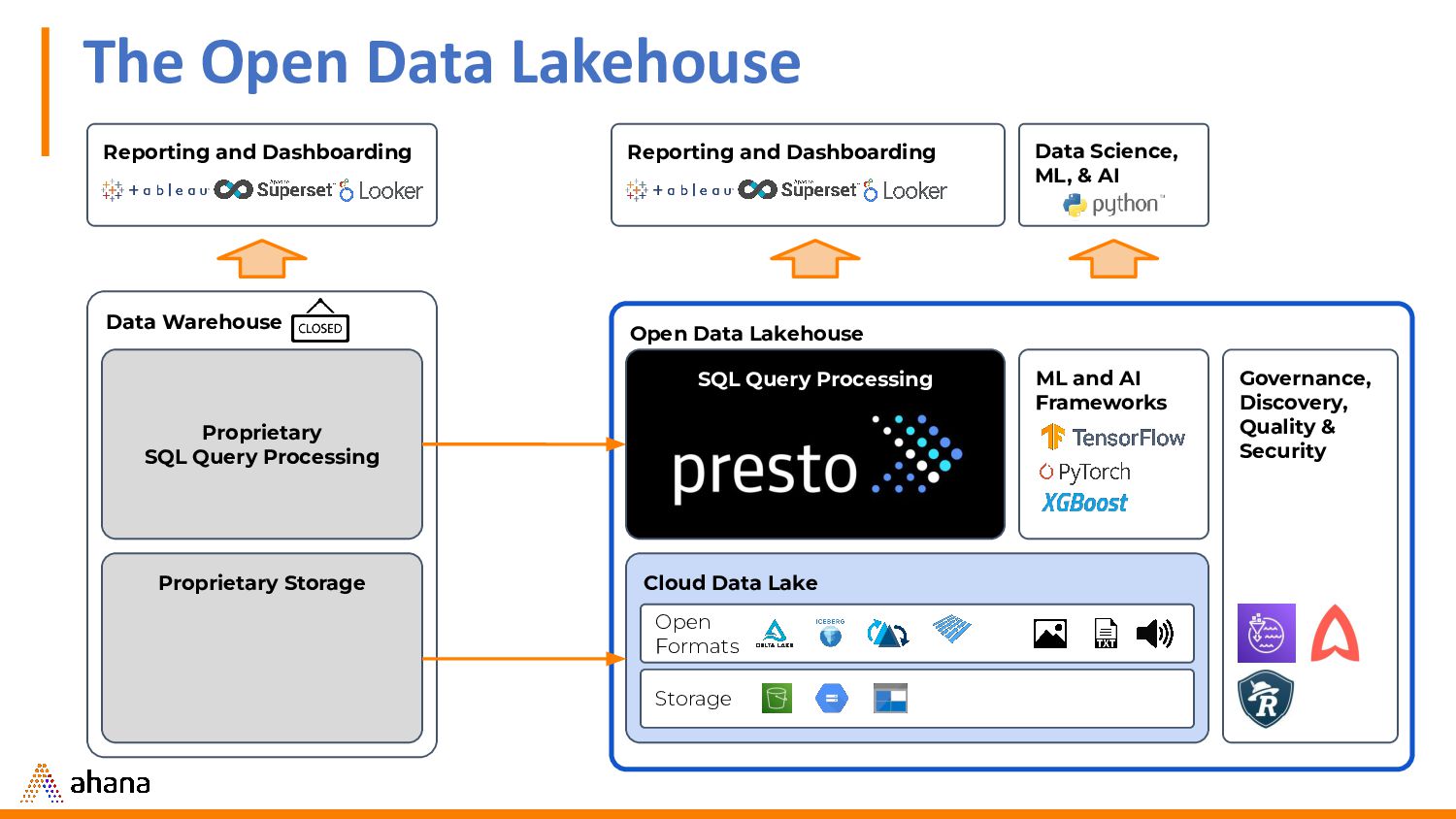
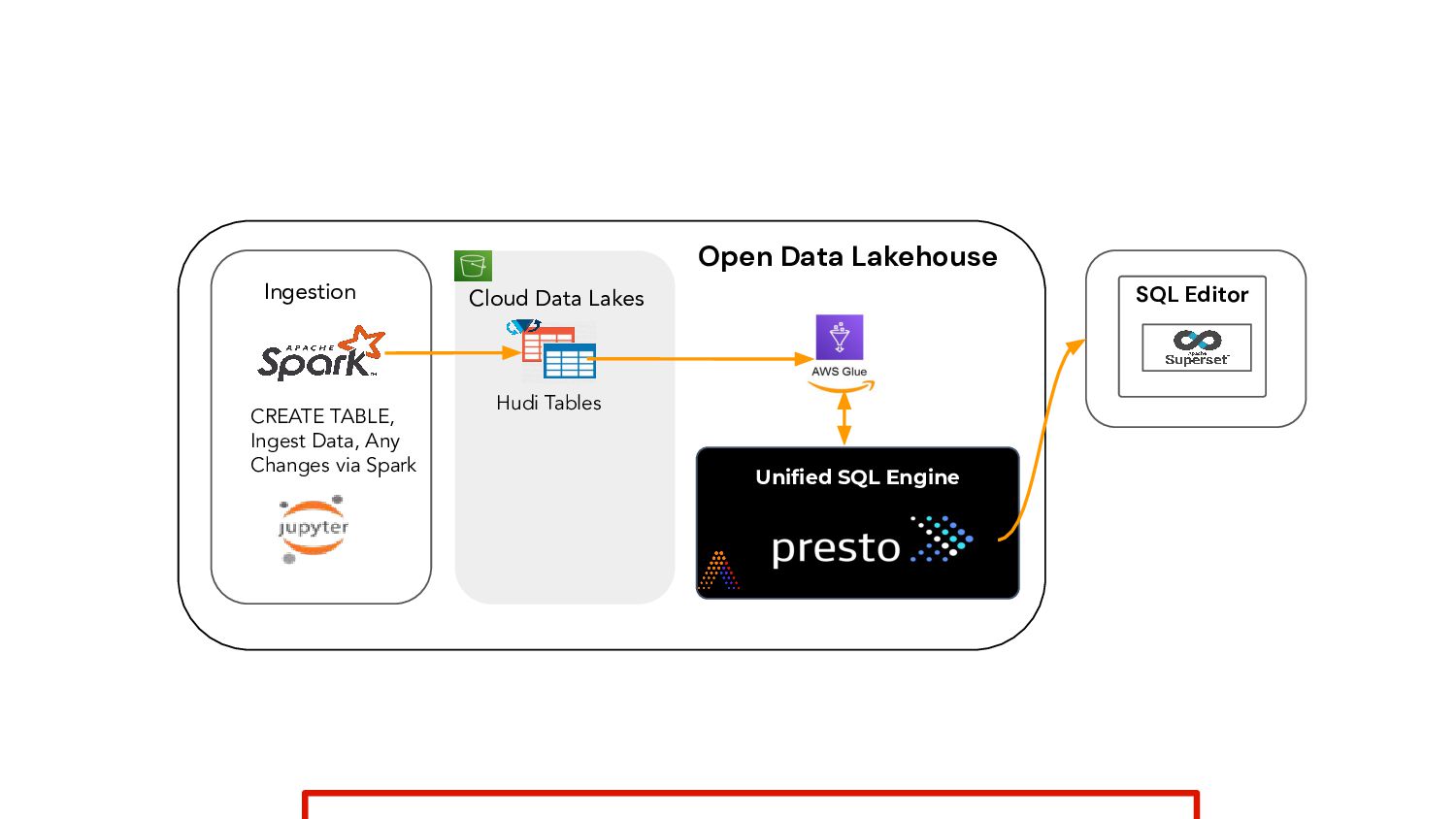
You may be familiar with the Data Lakehouse, an emerging architecture that brings the flexibility, scale and cost management benefits of the data lake together with the data management capabilities of the data warehouse. In this workshop, we’ll get hands-on building an Open Data Lakehouse – an approach that brings open technologies and formats to your lakehouse.
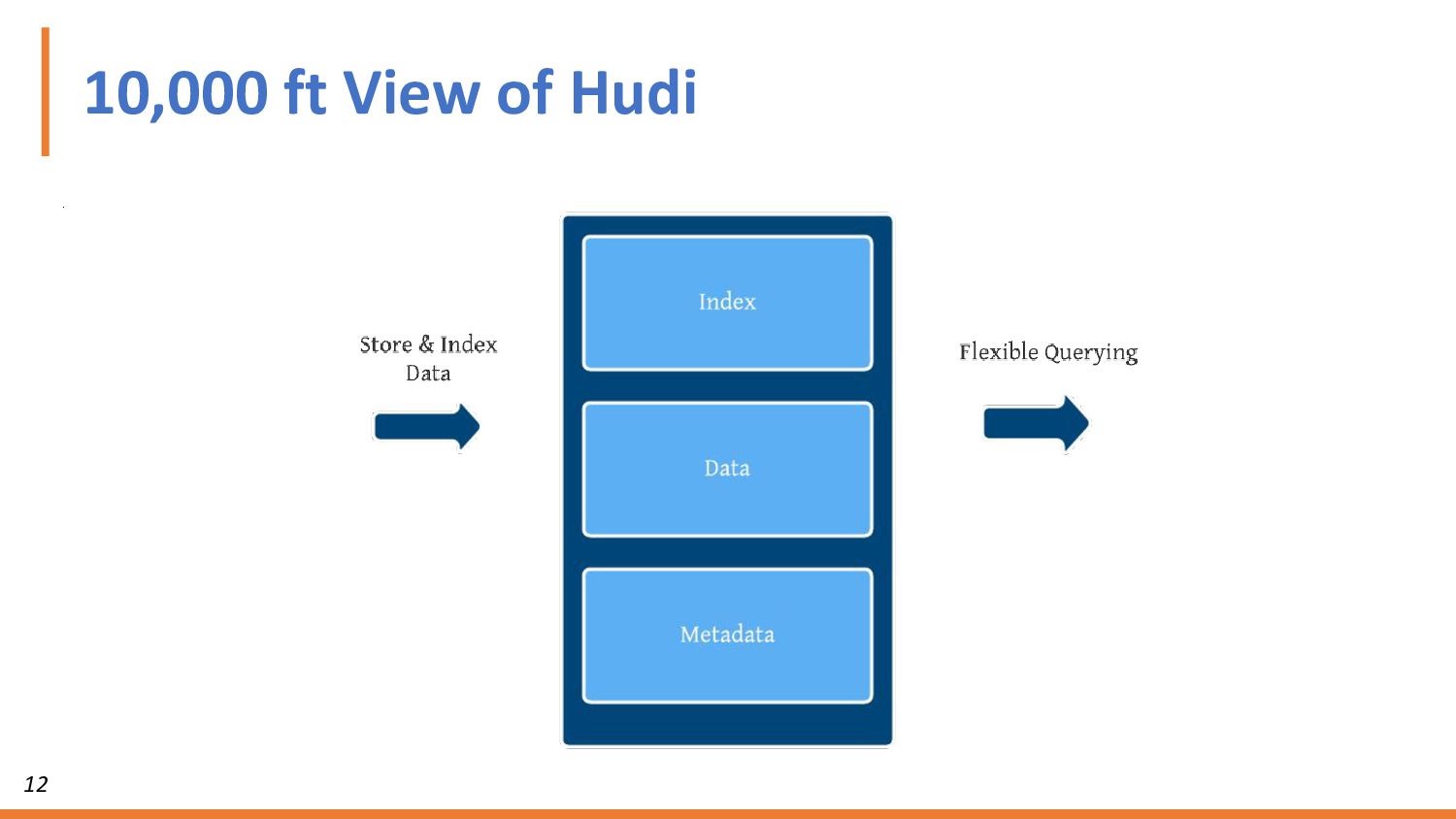
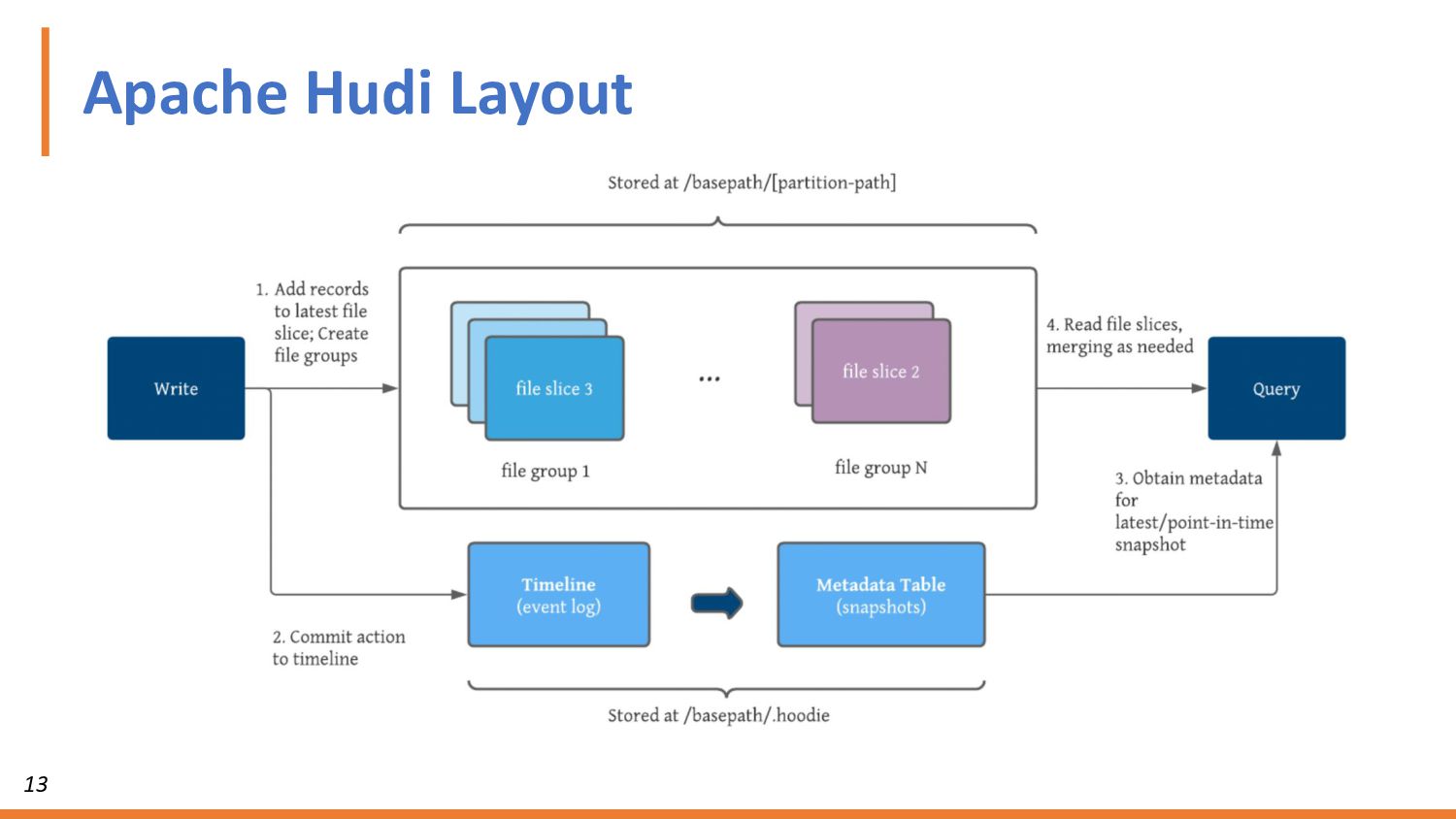
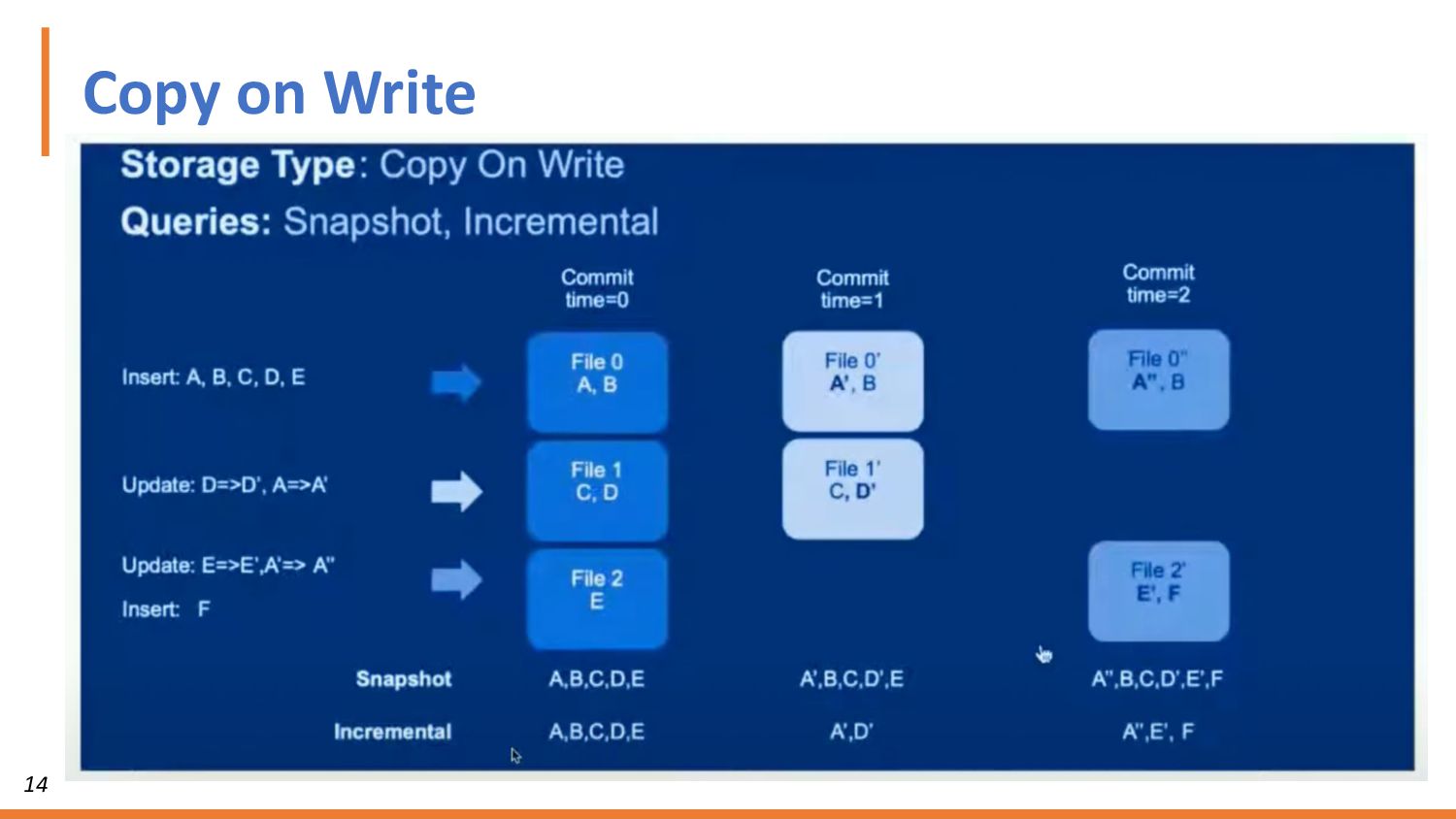
For the purpose of this workshop, we’ll use Presto for the open source SQL query engine, Apache Hudi for ACID transactions, and AWS S3 for the data lake. You’ll get hands-on with Presto and Hudi. We’ll show you how to deploy each, connect them, set up your Hudi tables for ACID transactions, and finally run queries on your S3 data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
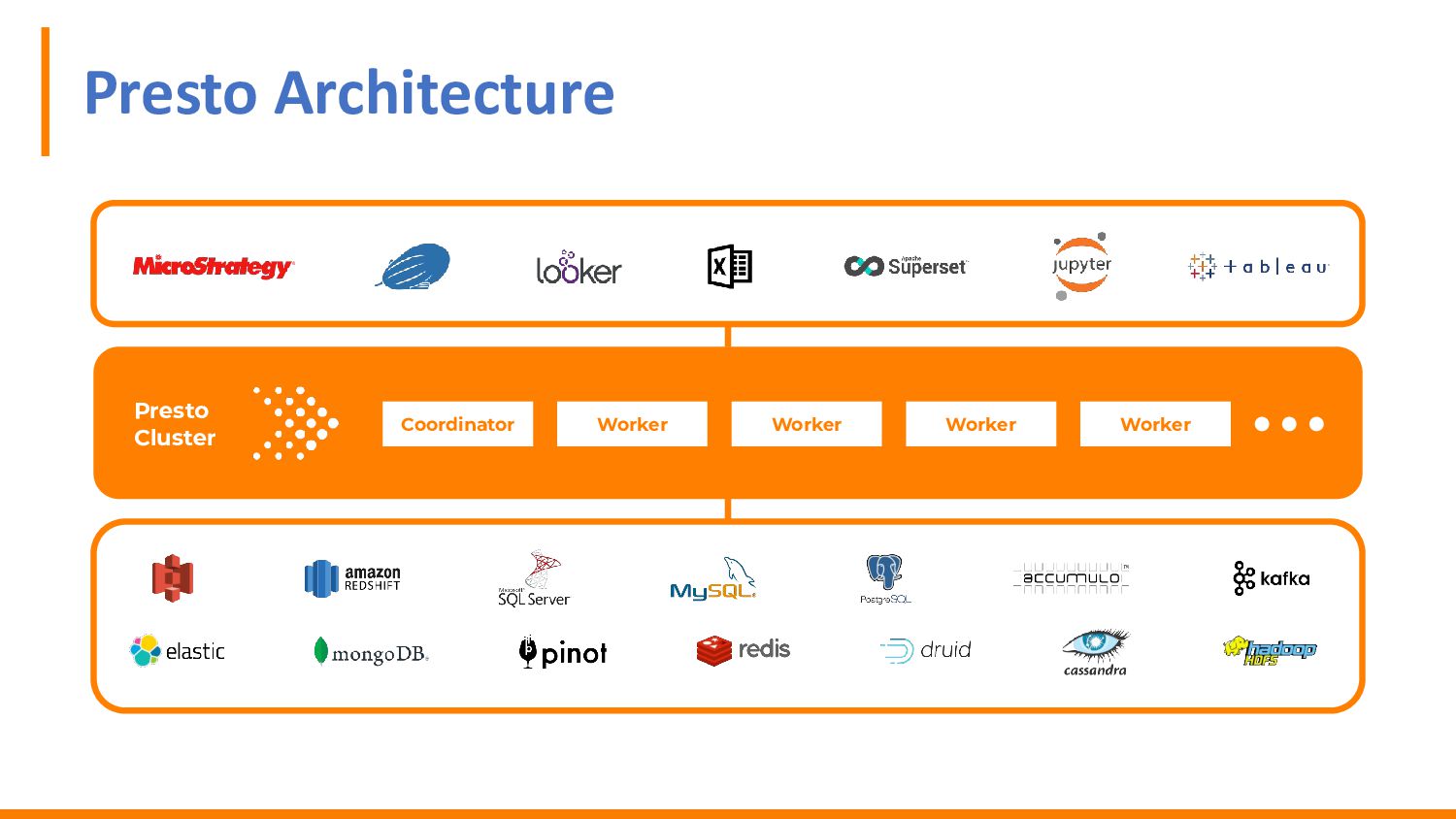{kind=link}
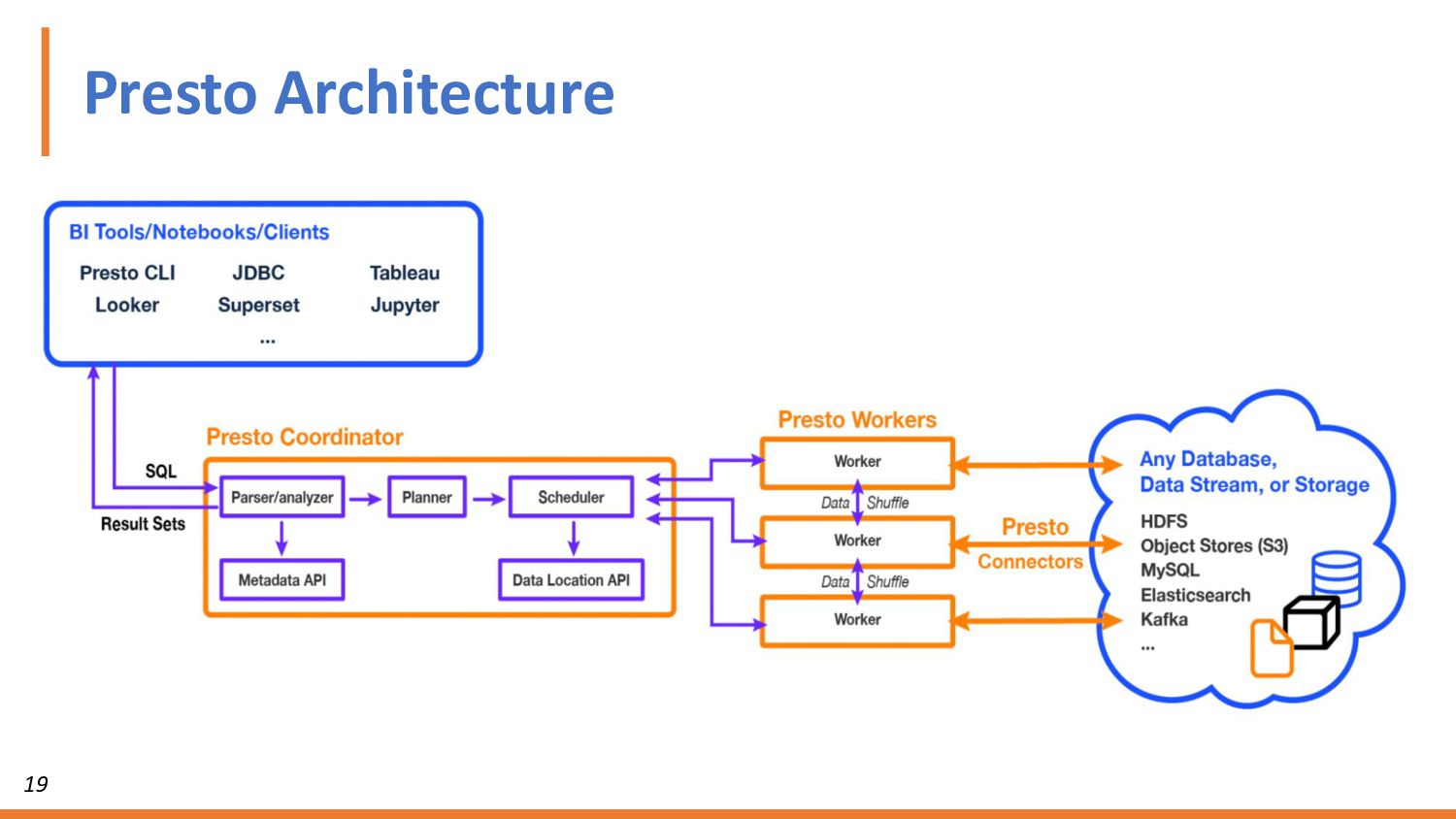{kind=link}
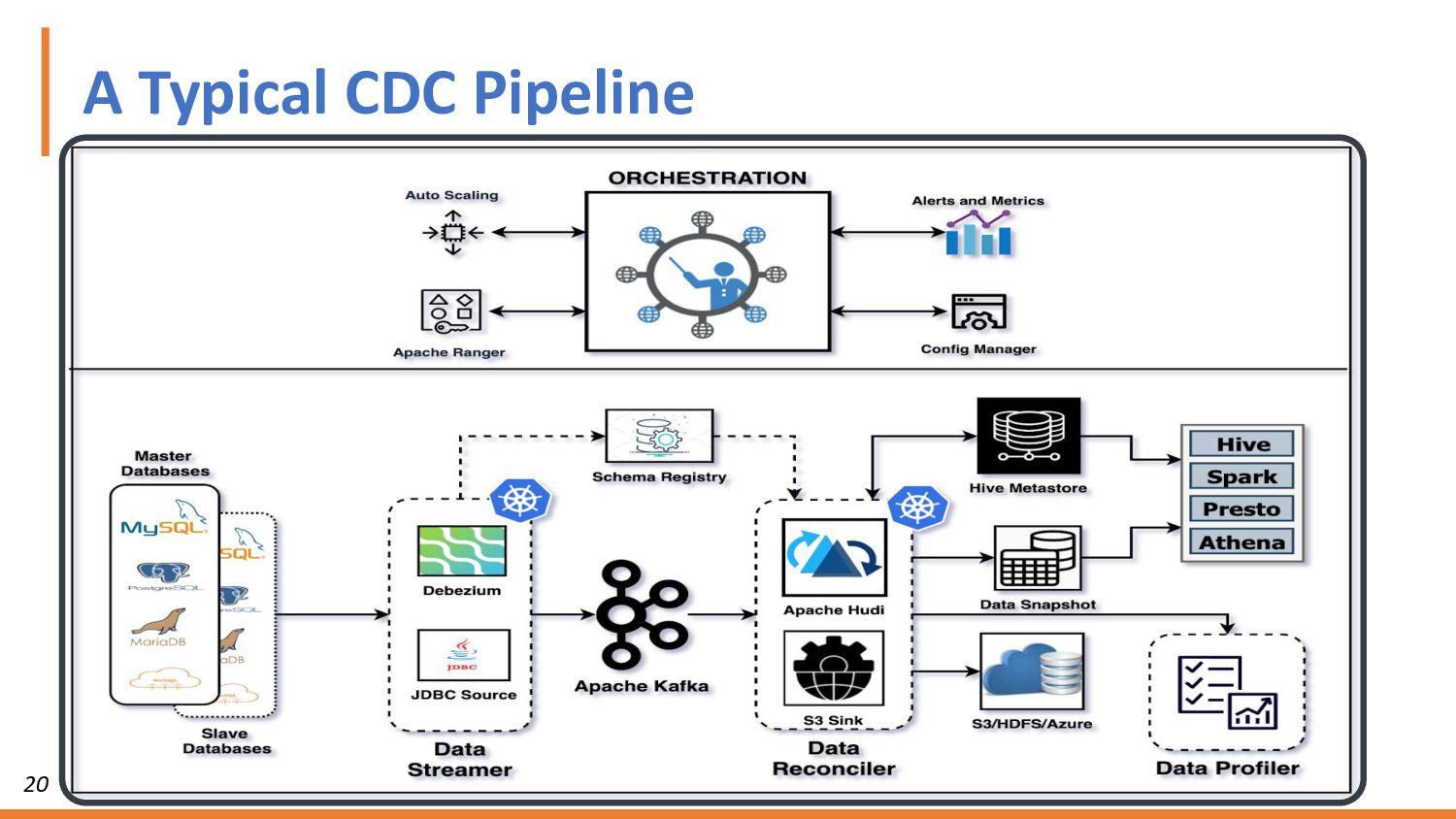{kind=link}
{kind=link}
{kind=link}
{kind=link}
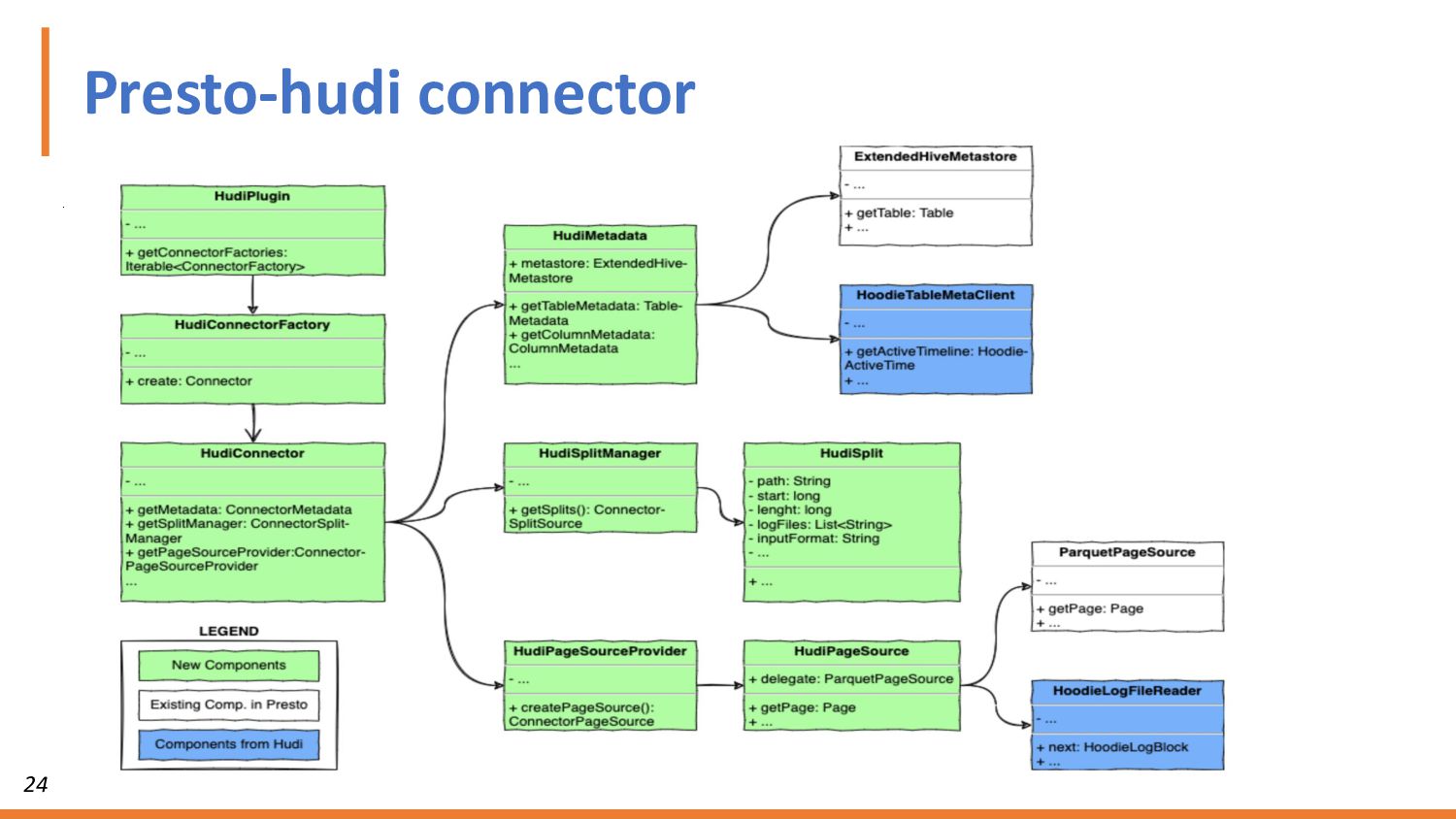{kind=link}
{kind=link}
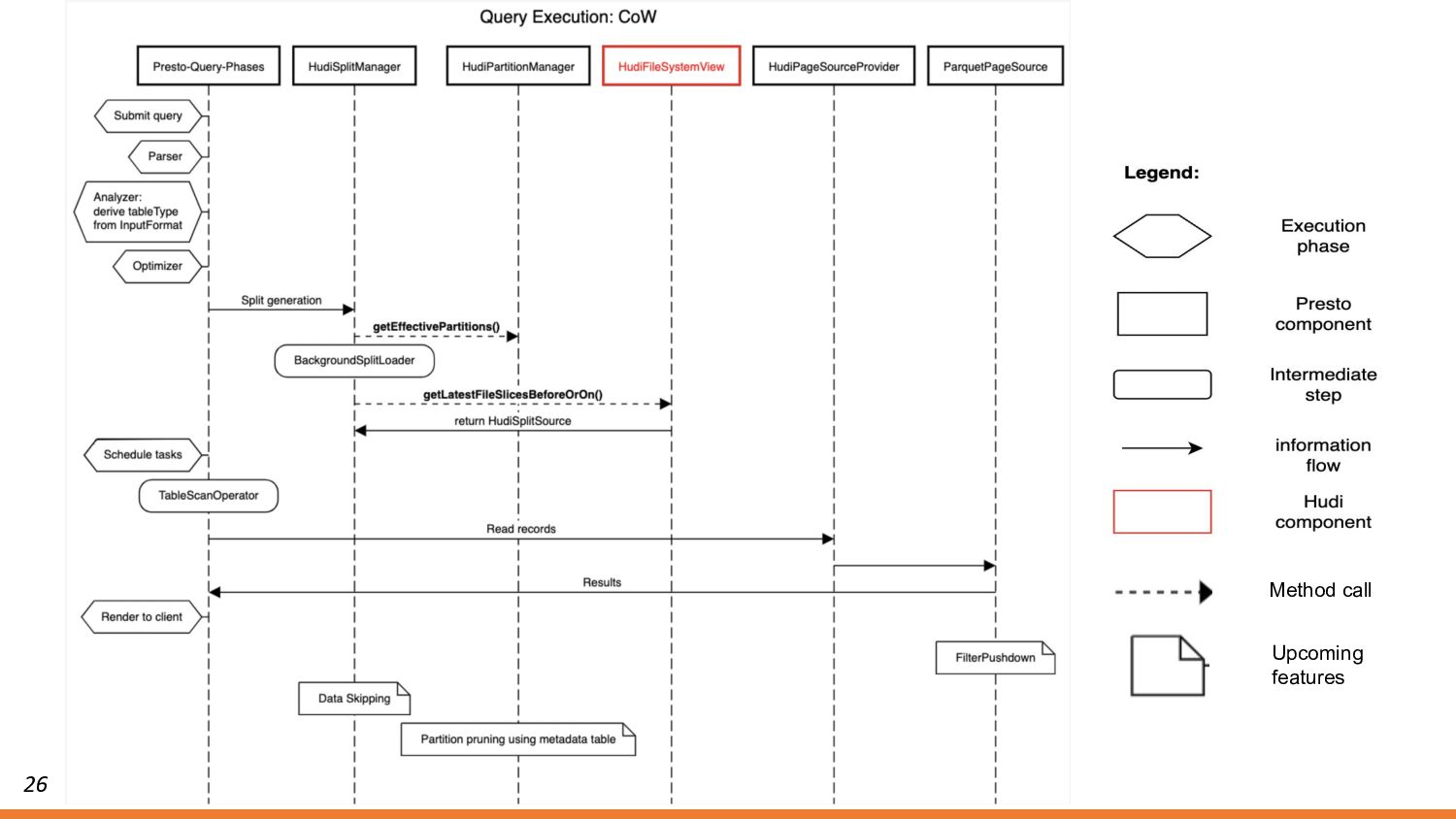{kind=link}
{kind=link}
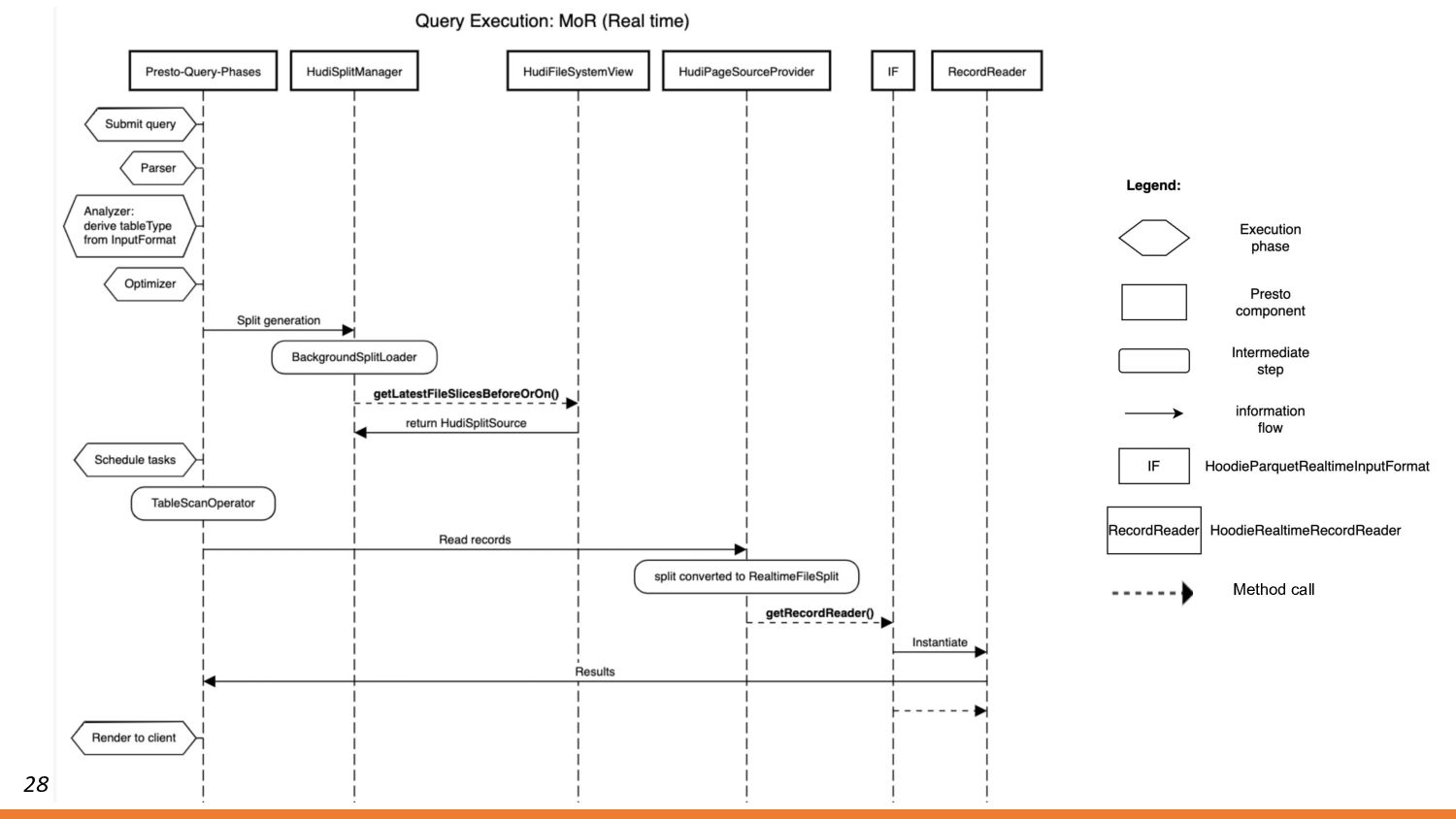{kind=link}
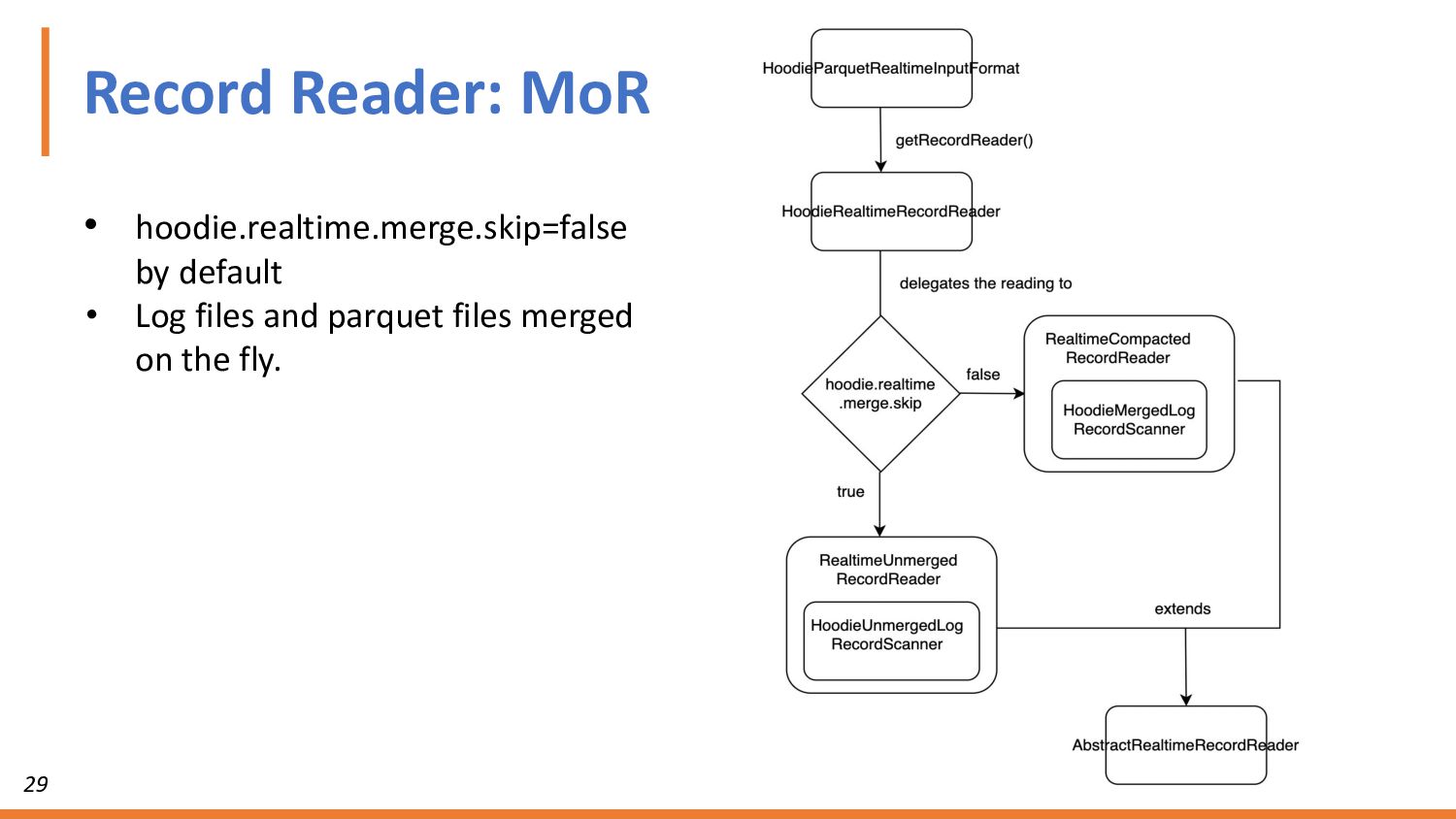{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
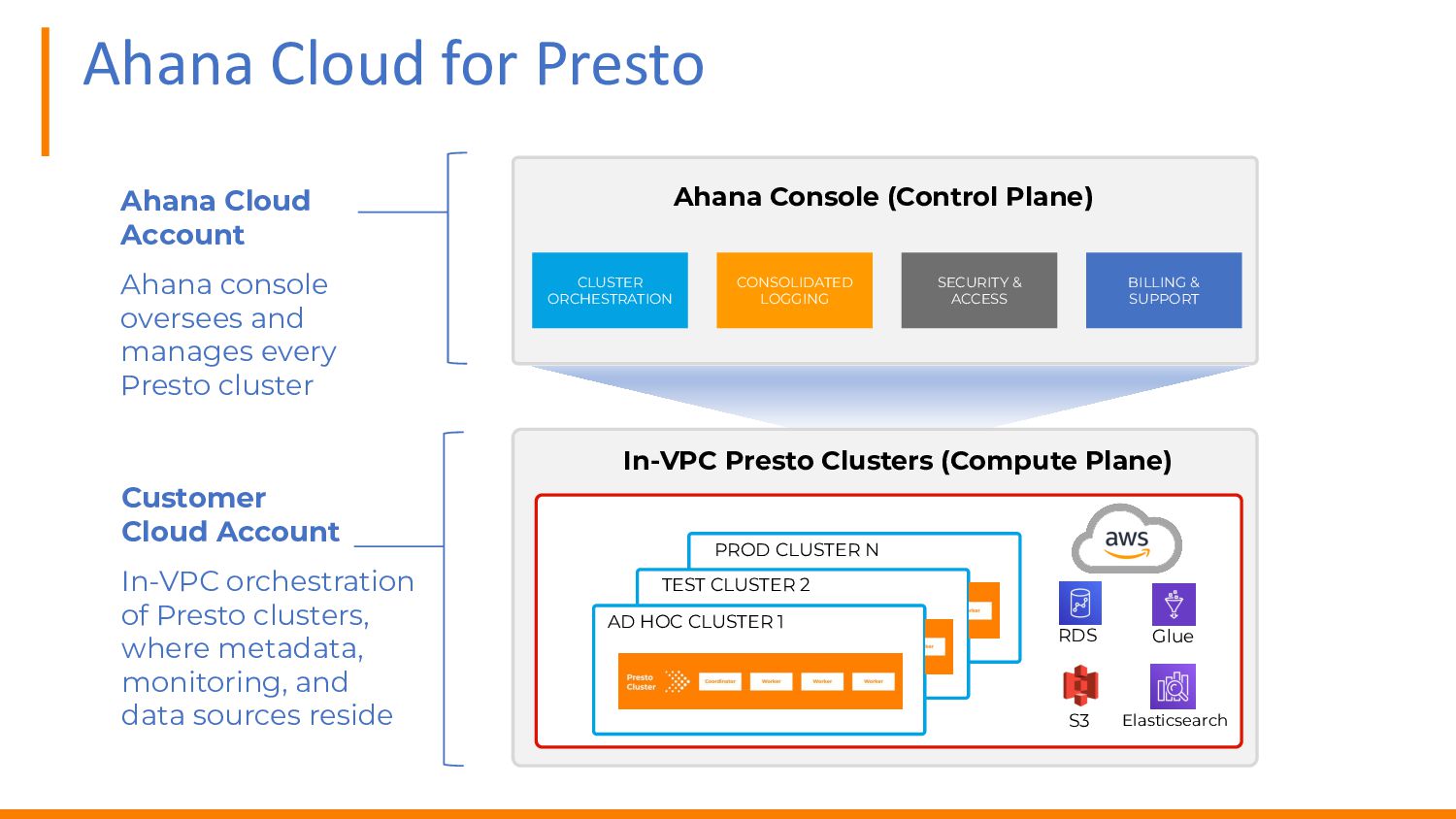{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}