island. Each company has a different schedule of departures. The first company departs every 100 days, the second every 120 days and the third every 150 days. What is the greatest positive integer $d$ for which it is true that there will be $d$ consecutive days without a flight from Dodola island, regardless of the departure times of the various airlines? 6
trained to output a chain of thought (CoT) enclosed in <think> tags at the beginning of its response. ◦ <think> CoT... </think> response… • For math problems, the model is trained to output the final answer in LaTeX format using \boxed{}. • The answer is often also output right before the closing </think> tag. ◦ <think> CoT...\boxed{answer} </think> response…\boxed{answer} 10
Hiroshi Yoshihara: Aillis Inc., The University of Tokyo ◦ Yuichi Inoue: Sakana AI Co, Ltd. ◦ Taiki Yamaguchi: Rist Inc. • Public LB 29/50 (7th) - Private LB 28/50 (9th) 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
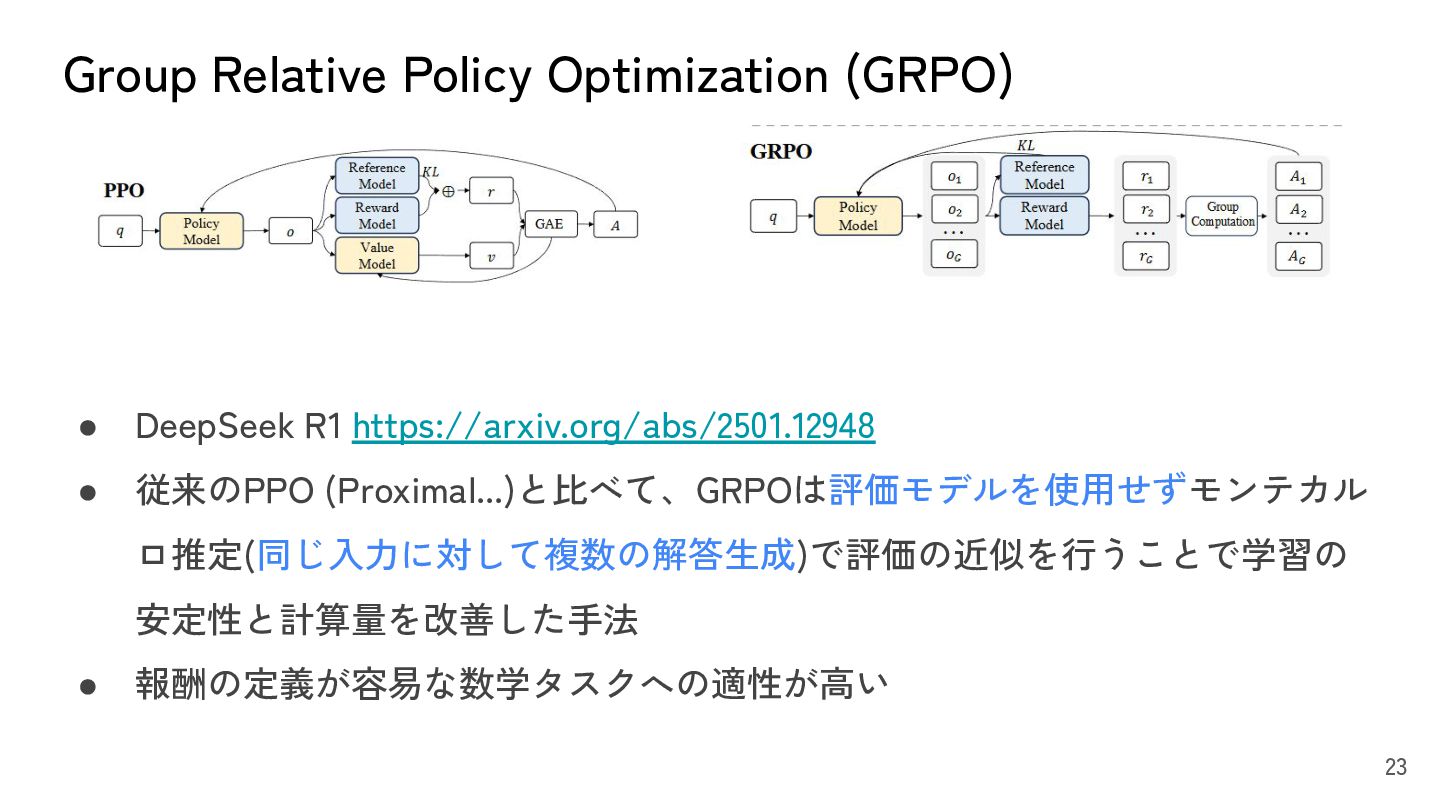{kind=link}
{kind=link}
{kind=link}
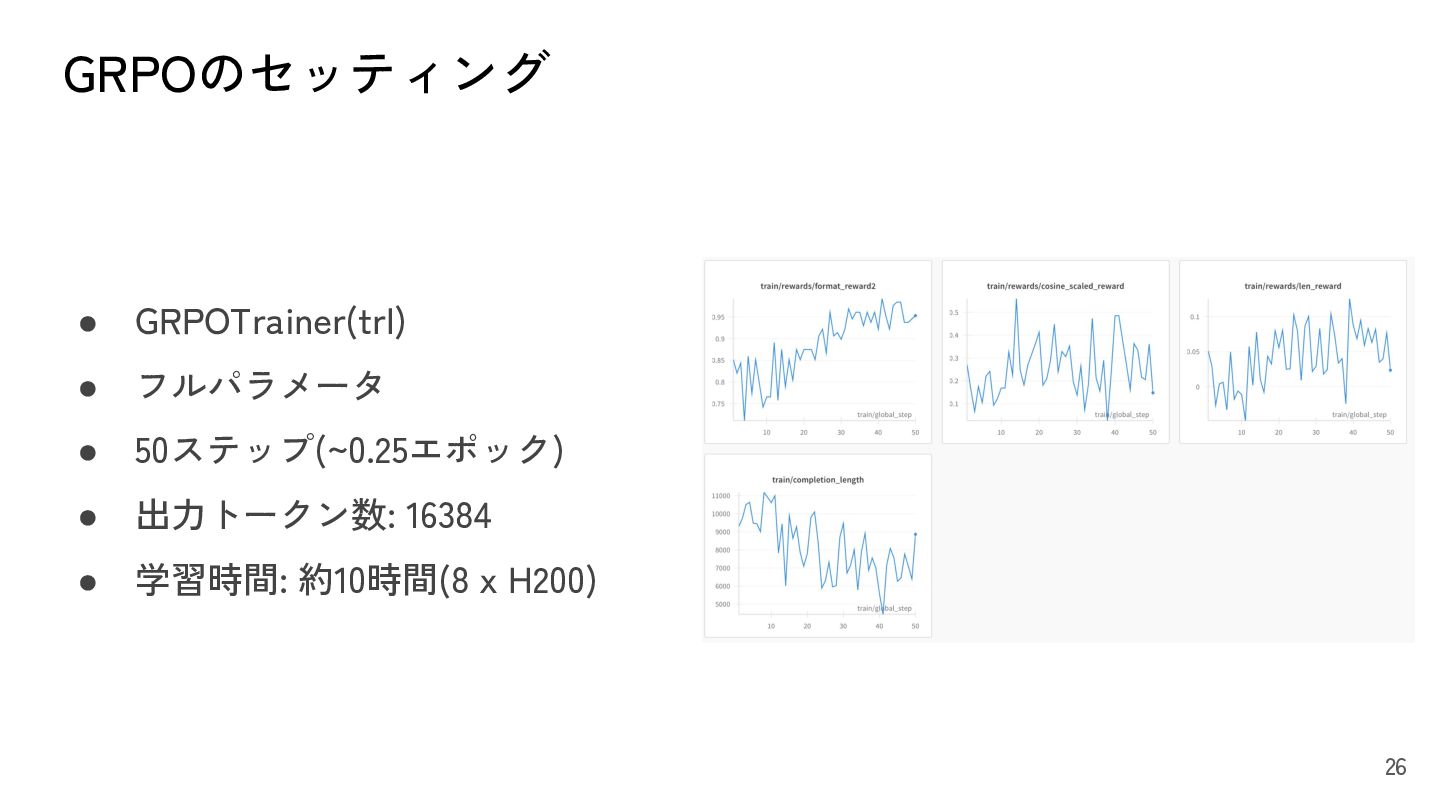{kind=link}
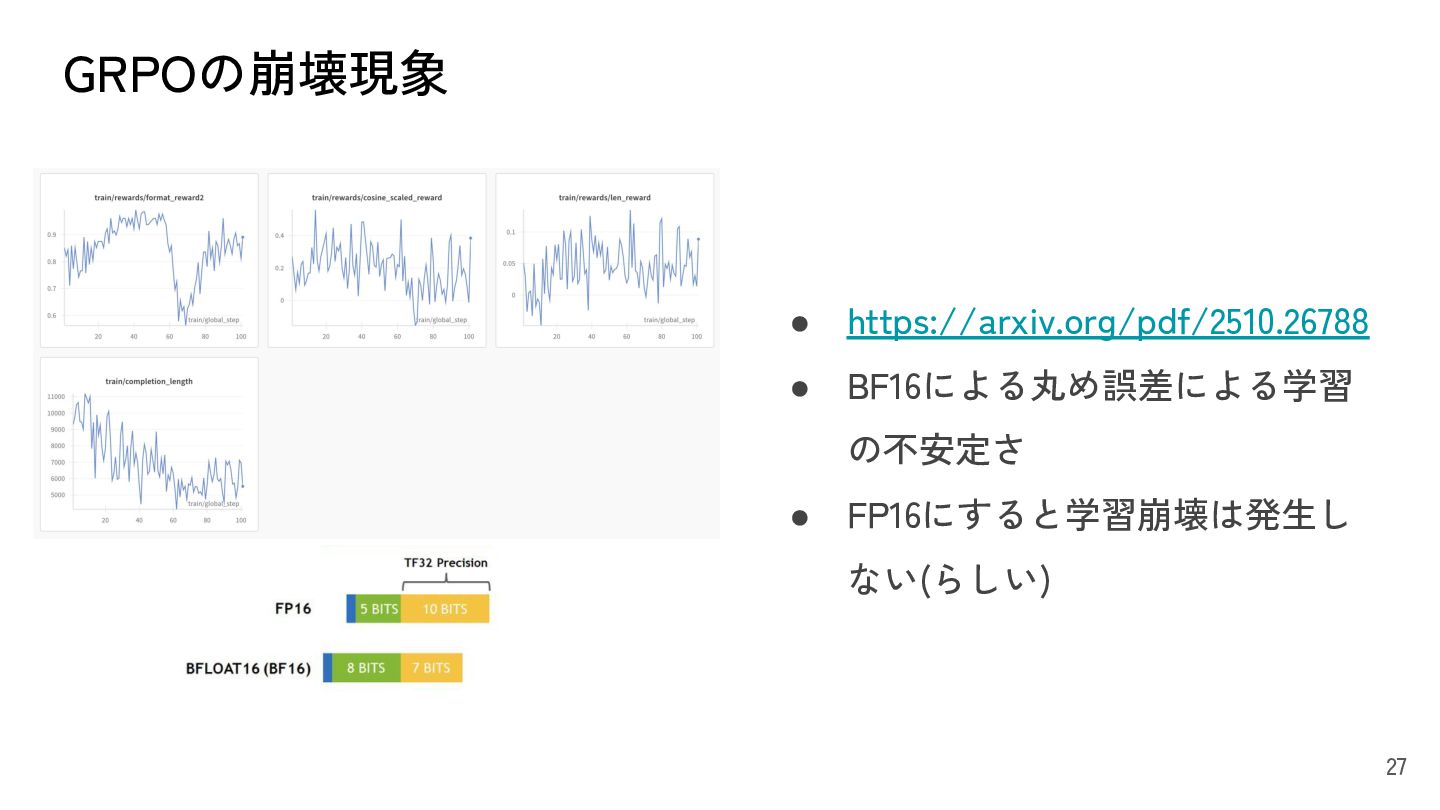{kind=link}
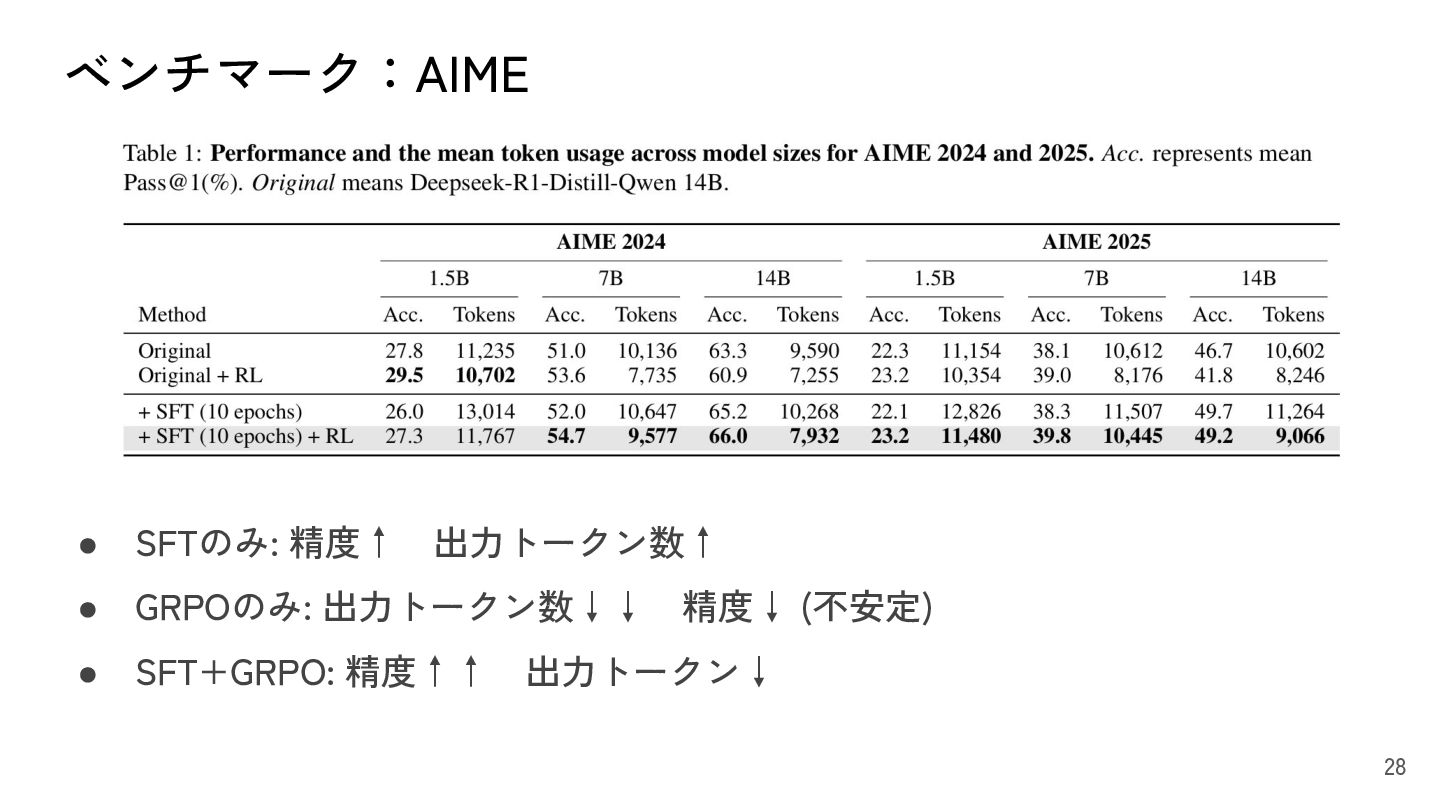{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}