how well AI can acquire mathematical reasoning skills. • Problem difficulty: AIMO1 < AIME (domestic competition) < AIMO2 < IMO (international competition) • Each answer was a non-negative integer between 0 and 999. • Intermediate reasoning or proofs were not evaluated. Only the accuracy of the final numerical answer was considered. 5
island. Each company has a different schedule of departures. The first company departs every 100 days, the second every 120 days and the third every 150 days. What is the greatest positive integer $d$ for which it is true that there will be $d$ consecutive days without a flight from Dodola island, regardless of the departure times of the various airlines? 7
50 private LB problems • L4 x 4 Instance / 5 hours time limit • No official training data • One submission/day • Only one question was visible at a time ◦ No access to multiple questions simultaneously ◦ Impossible to return to previous questions • The order of questions was randomized for each submission (public LB only) 8
difficult than those in AIMO1 • In the beginning of AIMO2, open-source models on public LB: ◦ NuminaMath-7B (AIMO1 1st place) ~2/50 (cf. 29/50 in AIMO1) ◦ Qwen2.5-Math-72B-CoT ~5/50 ◦ Qwen2.5-Math-72B-TIR ~8/50 • Lack of deep (long) reasoning capability in LLMs 9
released during this competition. ◦ Nov 2024 Alibaba - QwQ-32B-Preview ◦ Jan 2025 DeepSeek - DeepSeek-R1 and distilled models • Long reasoners (w/o fine-tuning) on public LB: ◦ QwQ-32B-Preview ~18/50 ◦ R1-Distilled-Qwen-14B ~27/50 • Long reasoning capability significantly raised the competition baseline. 10
trained to output a chain of thought (CoT) enclosed in <think> tags at the beginning of its response. ◦ <think> CoT... </think> response… • For math problems, the model is trained to output the final answer in LaTeX format using \boxed{}. • The answer is often also output right before the closing </think> tag. ◦ <think> CoT...\boxed{answer} </think> response…\boxed{answer} 11
served on vLLM • Prompts: two different simple prompts mixed • Token budget: 12000 or 8000, dynamic scheduling based on time left • Answer processing: early-stop at </think> token, majority voting @ 32 • Public LB: 27/50 (results very unstable: score variance ~4) 12
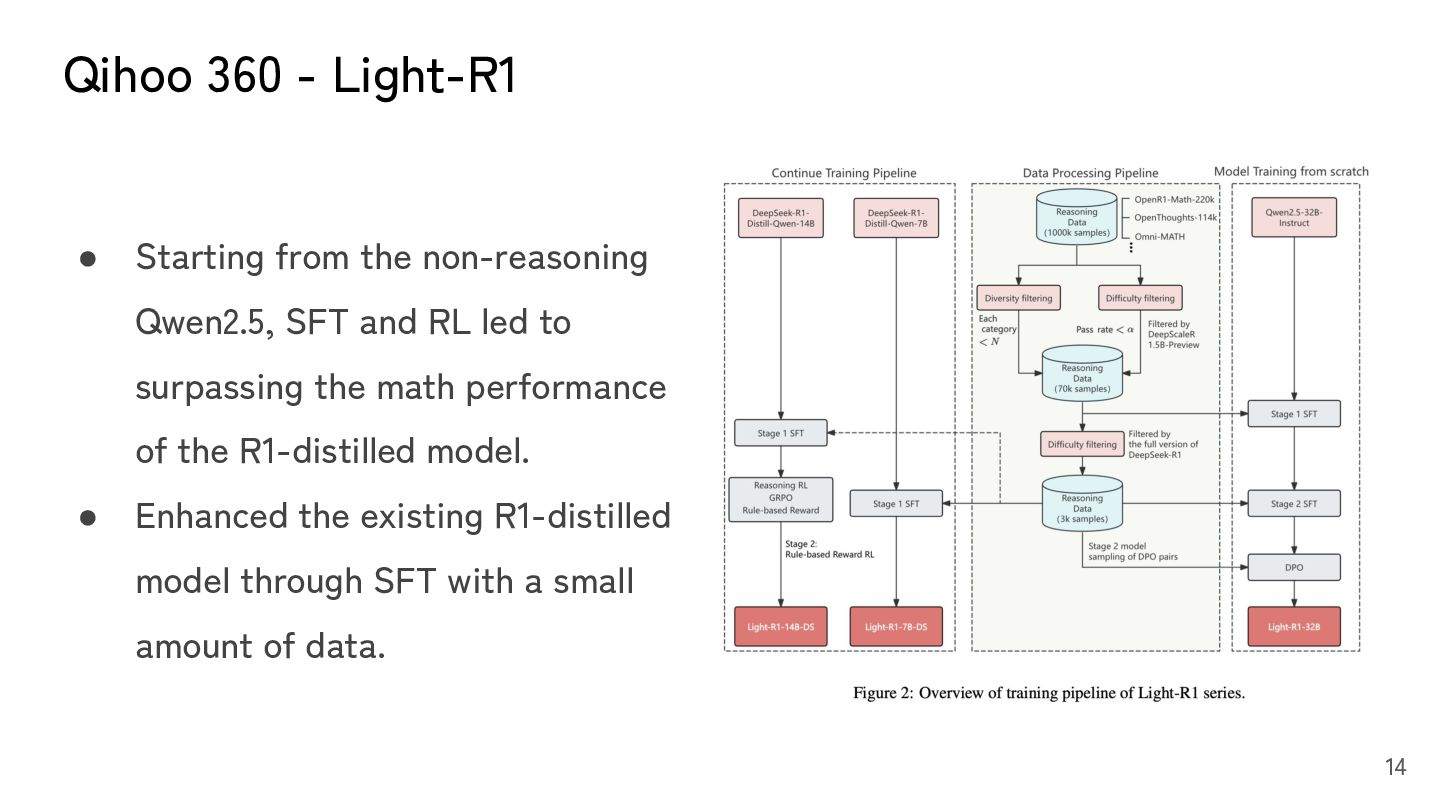
◦ e.g., Qihoo 360 - Light-R1 https://github.com/Qihoo360/Light-R1 • Strategy #2: Using TIR (Tool-Integrated Reasoning) capability ◦ TIR: Ask model to output code instead of direct answer ◦ TIR enables models to solve specific types of problems with brute force. ◦ R1-distilled-Qwen models inherit TIR capability from its base model, Qwen2.5. 13
SFT and RL led to surpassing the math performance of the R1-distilled model. • Enhanced the existing R1-distilled model through SFT with a small amount of data. 14
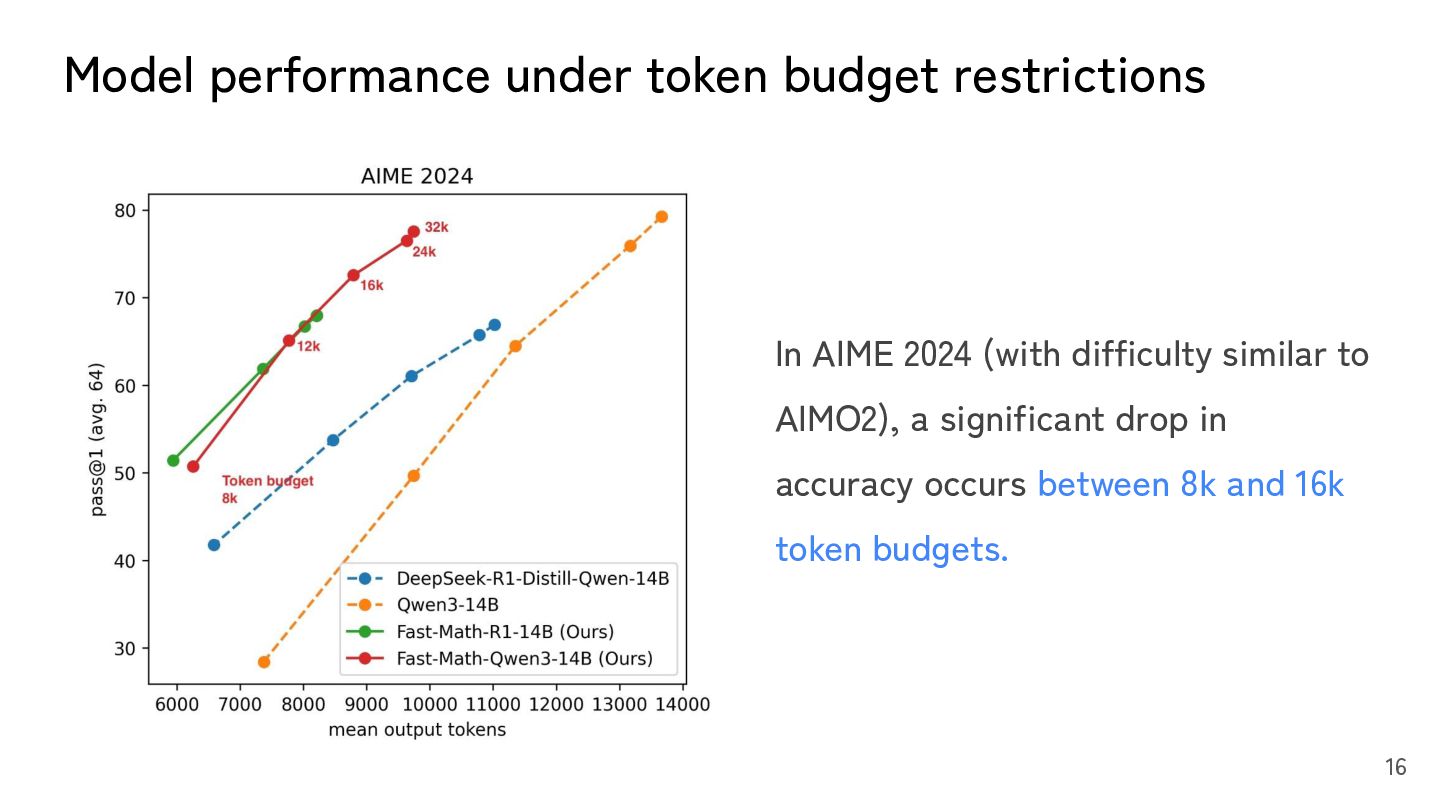
answers. ◦ Reasoning efficiency: the number of tokens required to reach a answer • Reported performance in papers and technical reports is typically based on generous token budgets (e.g., 32k tokens). • In the AIMO2 submission environment, token budgets were practically limited to 8k–16k, depending on the model size. • Many teams overlooked/underestimated this part. 15
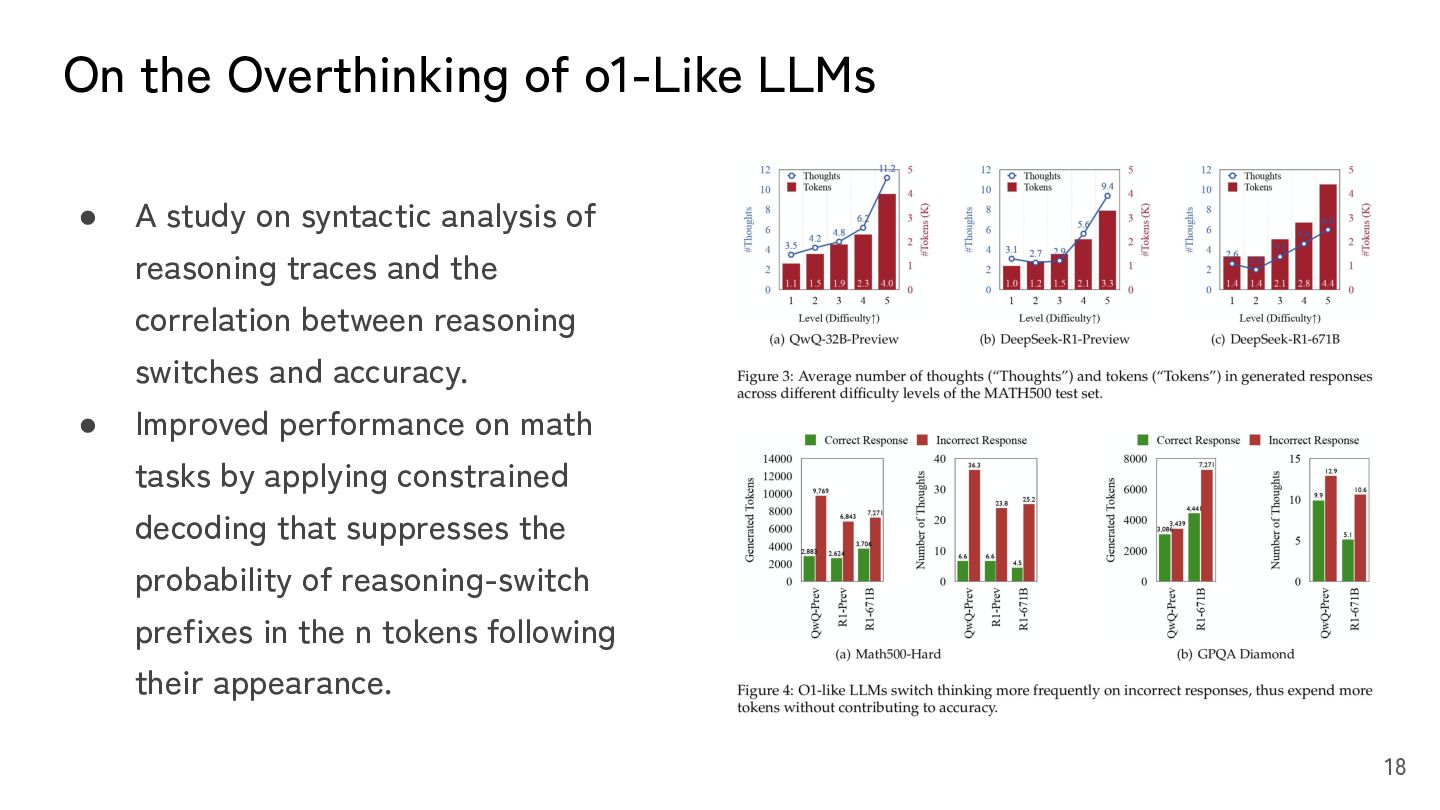
syntactic analysis of reasoning traces and the correlation between reasoning switches and accuracy. • Improved performance on math tasks by applying constrained decoding that suppresses the probability of reasoning-switch prefixes in the n tokens following their appearance. 18
#1 and #2: enhancing CoT / using TIR • Part II: Efficiency Optimization ◦ Strategy #4 and #5: accelerating inference / exploring quantization • Part III: Inference-Time Strategies ◦ Quite elaborate inference pipeline, but I will omit this part to focus on the model itself. 22
learning as a binary classification task, where the model is trained to assign higher likelihood to the preferred response over the less preferred one, based on comparisons. • Team imagination-research created DPO training pairs based on three criteria: answer correctness, response length, and pairwise similarity. 24
compared with vllm, can provide higher throughput and shorter model initialization time. • Using 4-bit AWQ weight / 8-bit KV cache quantization (W4KV8) enabled ~25% faster inference compared to W4KV16 quantization with no accuracy degradation. 25
team: Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, Igor Gitman • Public LB 32/50 (2nd) - Private LB 34/50 (1st) • "The training lasted 48 hours on 512 H100 (yes, 512!)" 26
#2: enhancing CoT / TIR • Inference Optimization ◦ Strategy #4 and #5: accelerating inference / exploring quantization ◦ This part handles fancy backend inference using TensorRT, but I will skip the details here. 27
DeepSeek-R1. • Created high-quality 15k math TIR dataset. • First stage: Qwen2.5-14B / SFT / 8 epochs / CoT dataset • Second stage: first-stage model / SFT / 400 steps / TIR dataset • Final model is a merged model: CoT * 0.3 + TIR * 0.7 • 512 x H100 x 48 hrs 28
TensorRT-LLM was used to. ReDrafter head was trained on a random subset of problems from OpenMathReasoning-1 dataset. • Inference speed on TensorRT-LLM: bf16 < int8 ~ fp8 < int4 < fp8 + Redrafter • Accuracy: int4 < all others 29
Hiroshi Yoshihara: Aillis Inc., The University of Tokyo ◦ Yuichi Inoue: Sakana AI Co, Ltd. ◦ Taiki Yamaguchi: Rist Inc. • Public LB 29/50 (7th) - Private LB 28/50 (9th) 31
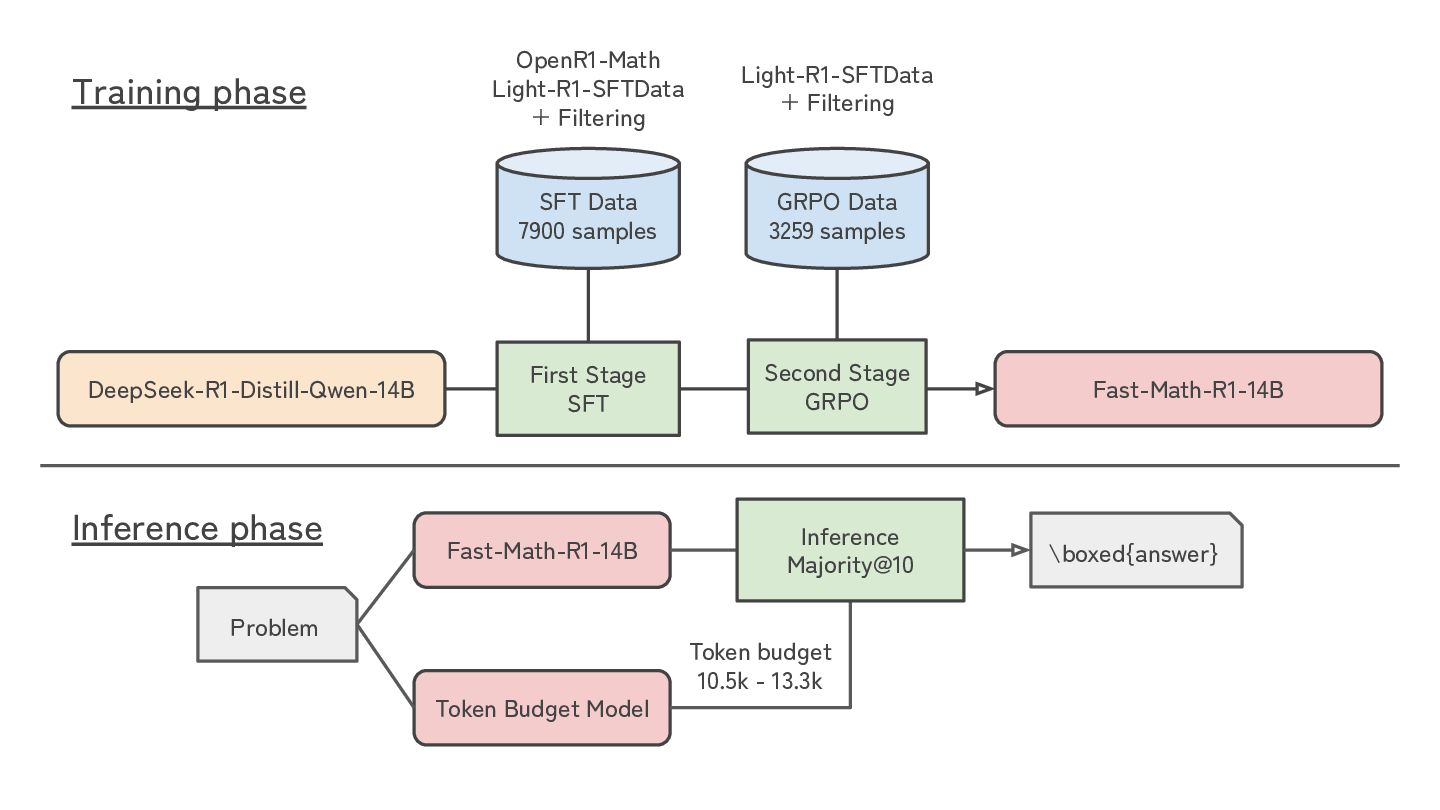
(low accuracy with R1) problems from the OpenR1-Math and Light-R1 second-stage datasets, and generated 7900 problem - R1 shortest correct trace pairs. • Quality of the dataset (difficulty, answer length, and diversity) was crucial in SFT. ◦ SFT on easy problems resulted in a model that quickly produces incorrect answers for difficult questions. 34
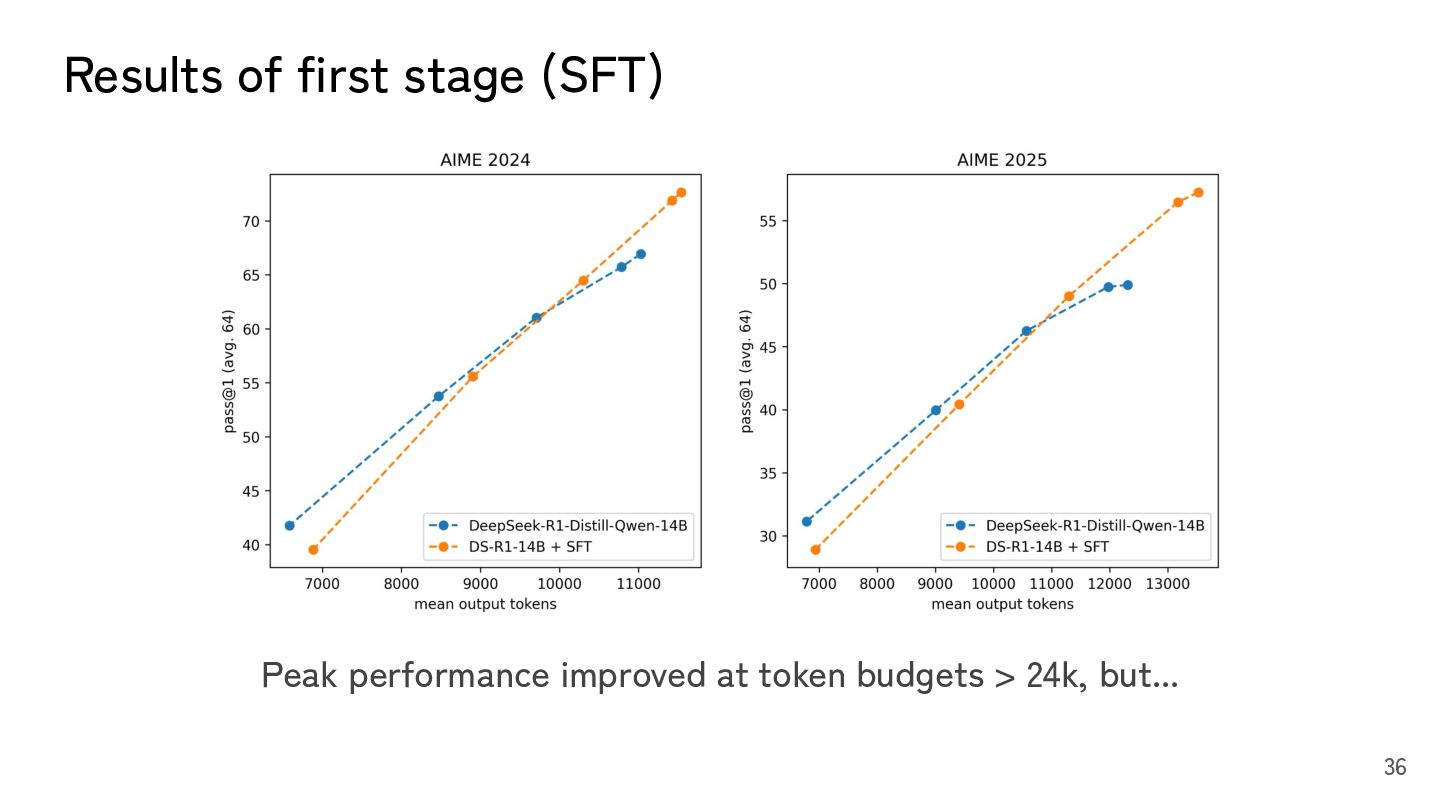
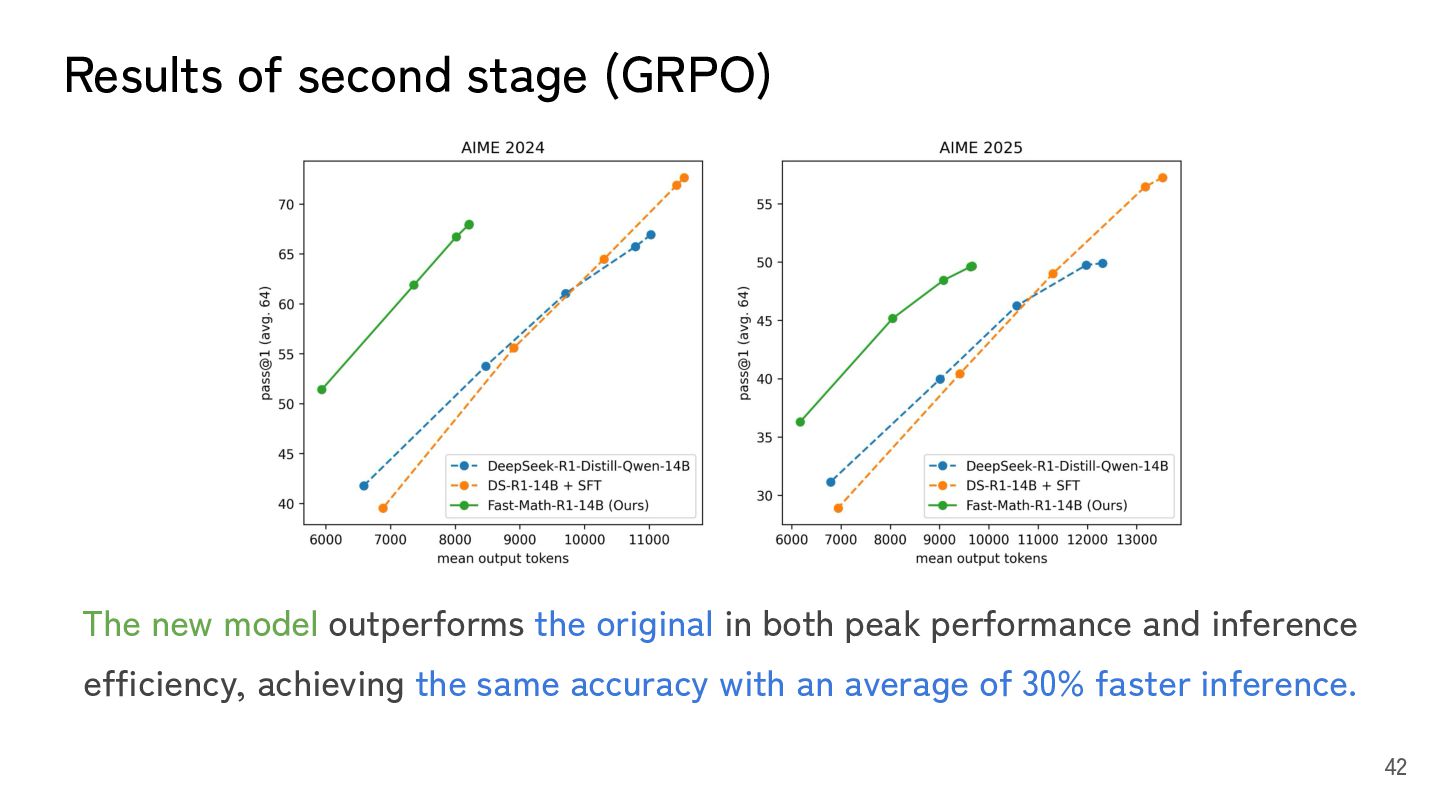
R1-distilled-Qwen 14B ~25/50 vs. SFT ~24/50 (worse!) • SFT does improve model performance when token budget is unlimited. • Under the constraints of this competition, it is necessary to improve efficiency while maintaining model accuracy. • R1's CoT is quite verbose. 37
in DeepSeek R1 https://arxiv.org/abs/2501.12948 • Unlike conventional PPO (Proximal...), GRPO removes value model and instead uses Monte Carlo estimation of expected rewards (by sampling multiple responses to the same question), reducing computation and improving training stability. • Well-suited for tasks like math problems, where rewards are easy to define. 38
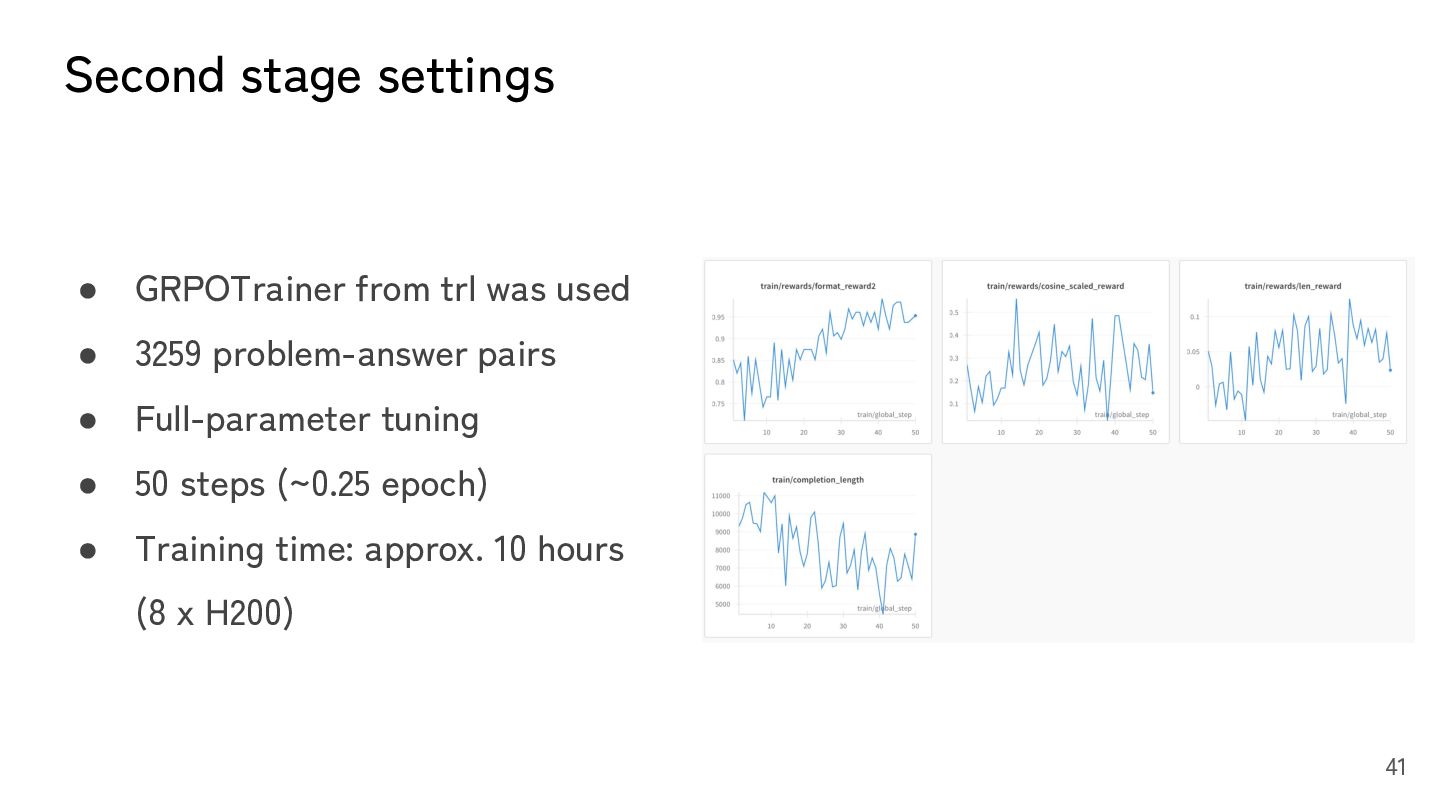
were extracted from the Light-R1 dataset and used for GRPO training. • Three types of reward functions were used: ◦ Format reward: in order to save output tokens, we forced the model to give an answer in the end of reasoning block before </think> by rewarding the pattern r"^.*?oxed{(.*?)}.*?</think>.*?$". Generation is stopped at </think> during inference. 39
of reward functions were used: ◦ Cosine reward: compared to a normal accuracy-based reward, cosine reward applies a continuous penalty to longer correct reasoning traces and shorter incorrect ones. ◦ Length reward: length-based rewards to discourage overthinking and promote token efficiency. https://arxiv.org/abs/2501.12599 ◦ Total reward = format reward + cosine reward + length reward 40
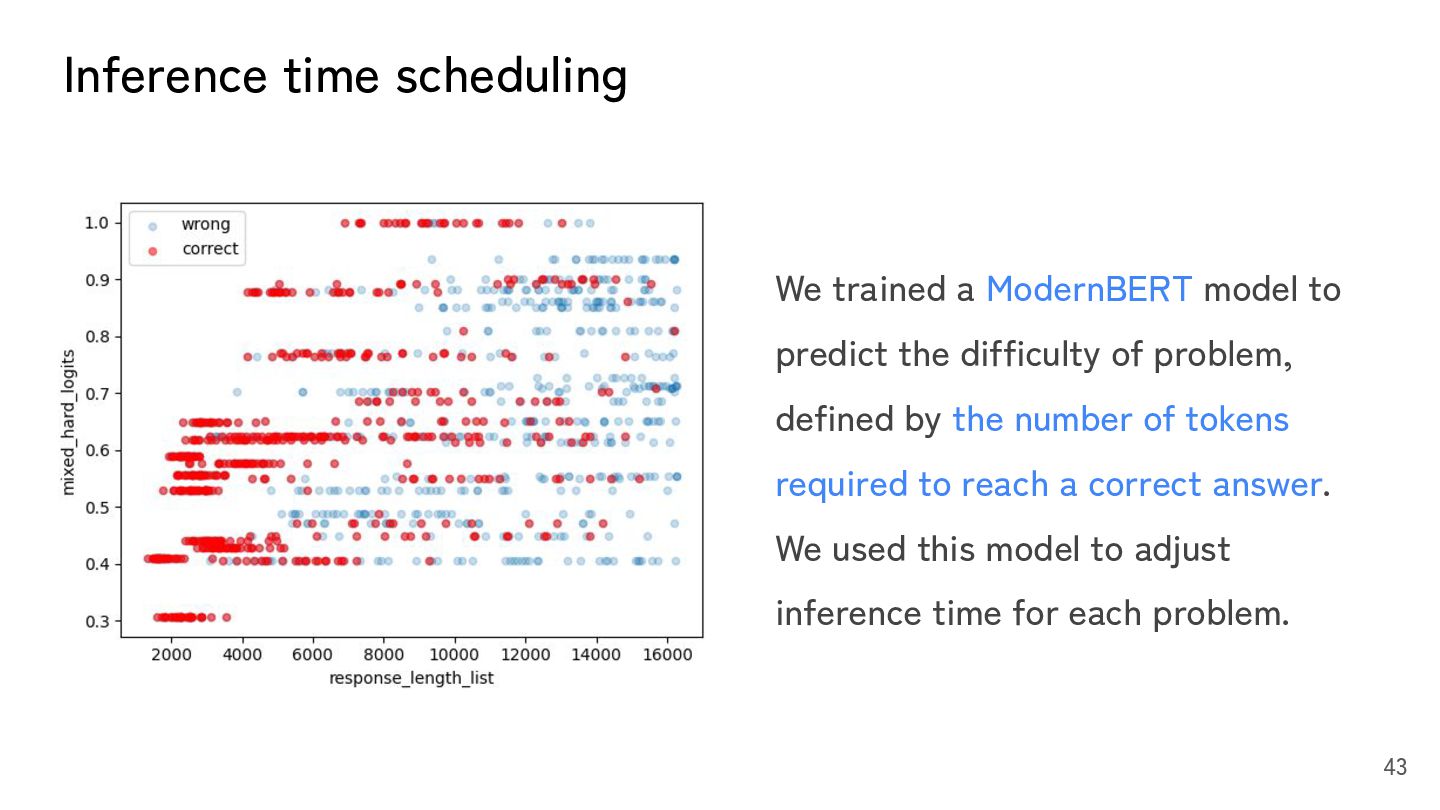
predict the difficulty of problem, defined by the number of tokens required to reach a correct answer. We used this model to adjust inference time for each problem.
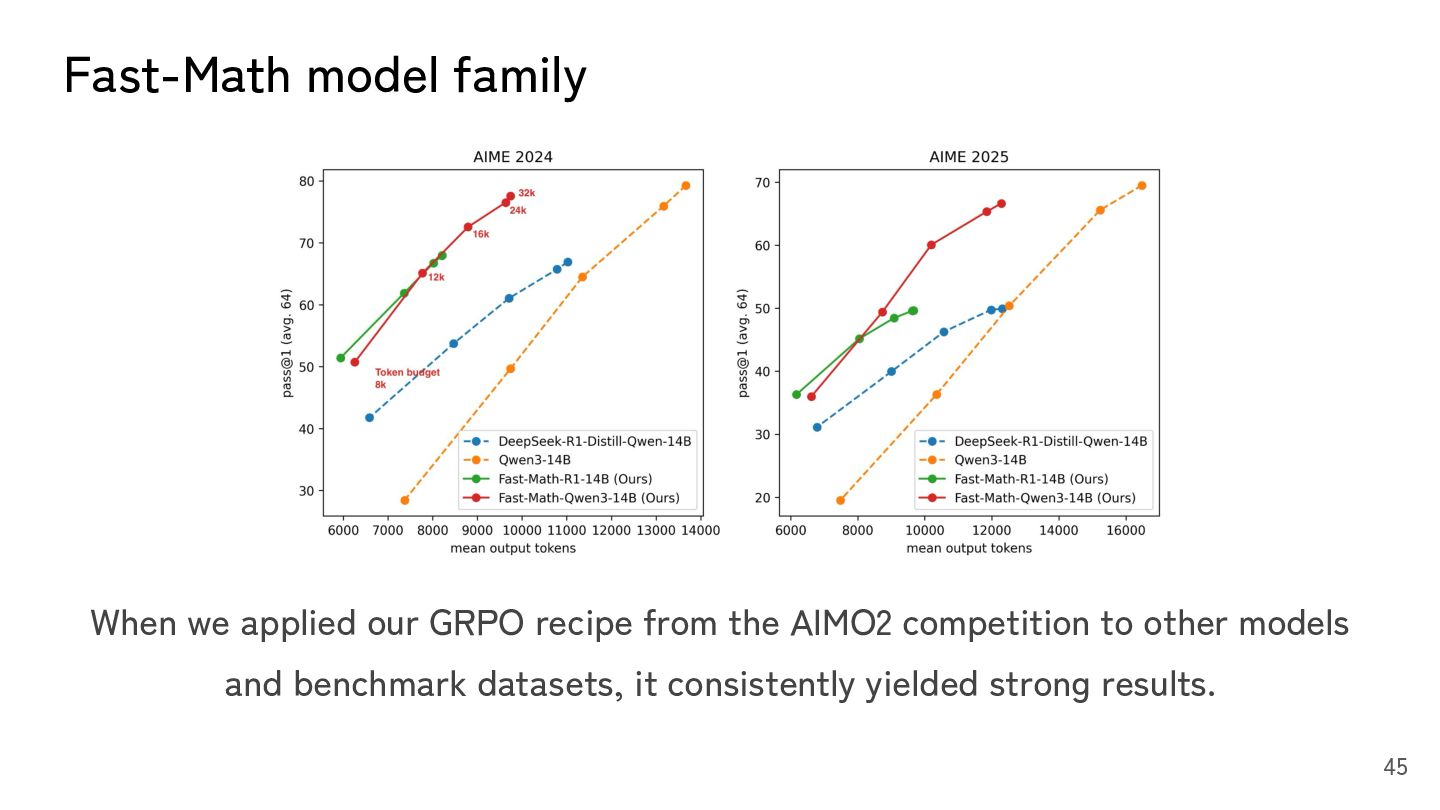
score from 25 to 29, and stabilized the score. • The score gap between us and top teams is likely the use of TIR. • SFT is good at adding new knowledge to the model and improve the peak performance. • GRPO is a powerful RL method for aligning how a model leverages its knowledge to specific goals, and is especially effective in tasks like math where rewards are easy to define. 44
datasets, code, and model weights used to train the Fast-Math models. ◦ Model weights (DeepSeek Qwen 2.5, NVIDIA OpenMath, Qwen3 variants) and datasets (Huggingface) ◦ Code (Github) • A paper detailing the technical methodology and ablation studies is currently in preparation. 47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}