Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Strands AgentsのEvaluatorをLangfuseにぶち込んでみた
Search
あんどお
December 20, 2025
Technology
0
160
Strands AgentsのEvaluatorをLangfuseにぶち込んでみた
2025/12/20@JAWS-UG Presents - AI Builders Day懇親会LT(5min)
あんどお
December 20, 2025
Tweet
Share
More Decks by あんどお
See All by あんどお
Agentの「今、何してる?」がわかる! AgentOpsのはじめ方
andoooooo_bb
0
15
Other Decks in Technology
See All in Technology
AIエージェント時代に備える AWS Organizations とアカウント設計
kossykinto
3
850
決済サービスを支えるElastic Cloud - Elastic Cloudの導入と推進、決済サービスのObservability
suzukij
2
620
ナレッジワーク IT情報系キャリア研究セッション資料(情報処理学会 第88回全国大会 )
kworkdev
PRO
0
170
Go標準パッケージのI/O処理をながめる
matumoto
0
160
OCI技術資料 : コンピュート・サービス 概要
ocise
4
54k
AIエージェント、 社内展開の前に知っておきたいこと
oracle4engineer
PRO
2
110
白金鉱業Meetup_Vol.22_Orbital Senseを支える衛星画像のマルチモーダルエンベディングと地理空間のあいまい検索技術
brainpadpr
2
290
身体を持ったパーソナルAIエージェントの 可能性を探る開発
yokomachi
1
110
Claude Code 2026年 最新アップデート
oikon48
11
8.7k
Claude Codeの進化と各機能の活かし方
oikon48
22
12k
作りっぱなしで終わらせない! 価値を出し続ける AI エージェントのための「信頼性」設計 / Designing Reliability for AI Agents that Deliver Continuous Value
aoto
PRO
2
280
実践 Datadog MCP Server
nulabinc
PRO
1
110
Featured
See All Featured
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.1k
Designing for humans not robots
tammielis
254
26k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
150
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
How Software Deployment tools have changed in the past 20 years
geshan
0
32k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
110
Paper Plane
katiecoart
PRO
0
48k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
1
1.4k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
130
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
270
Navigating Weather and Climate Data
rabernat
0
140
Transcript
Strands AgentsのEvaluatorを Langfuseにぶち込んでみた 2025/12/20 安藤 弘輝
2 © 2025 Leverages Co., Ltd. 自己紹介
自己紹介 安藤 弘輝 Hiroki Ando # 所属 システム本部 / テクノロジー戦略室
/ AI Agent開発チーム # 普段の業務内容 ・AI活用の推進 ・生成AIの評価基盤開発 ・生成AIを使ったサービスの開発 # 経歴等 ・通信キャリアで新規サービス企画・プロマネ ・ベンチャーで与信スコアリングモデルの開発 # 趣味や一言 脳筋としてトライアスロンやフルマラソンなどを通し、種々の限界に挑んでい ます。最近はハンターハンターを読んで念能力開発のヒントを探してます。 レバレジーズ株式会社
アジェンダ - 背景 - Strands AgentsのEvaluatorをLangfuseに入れてみた - まとめ
5 © 2025 Leverages Co., Ltd. 背景
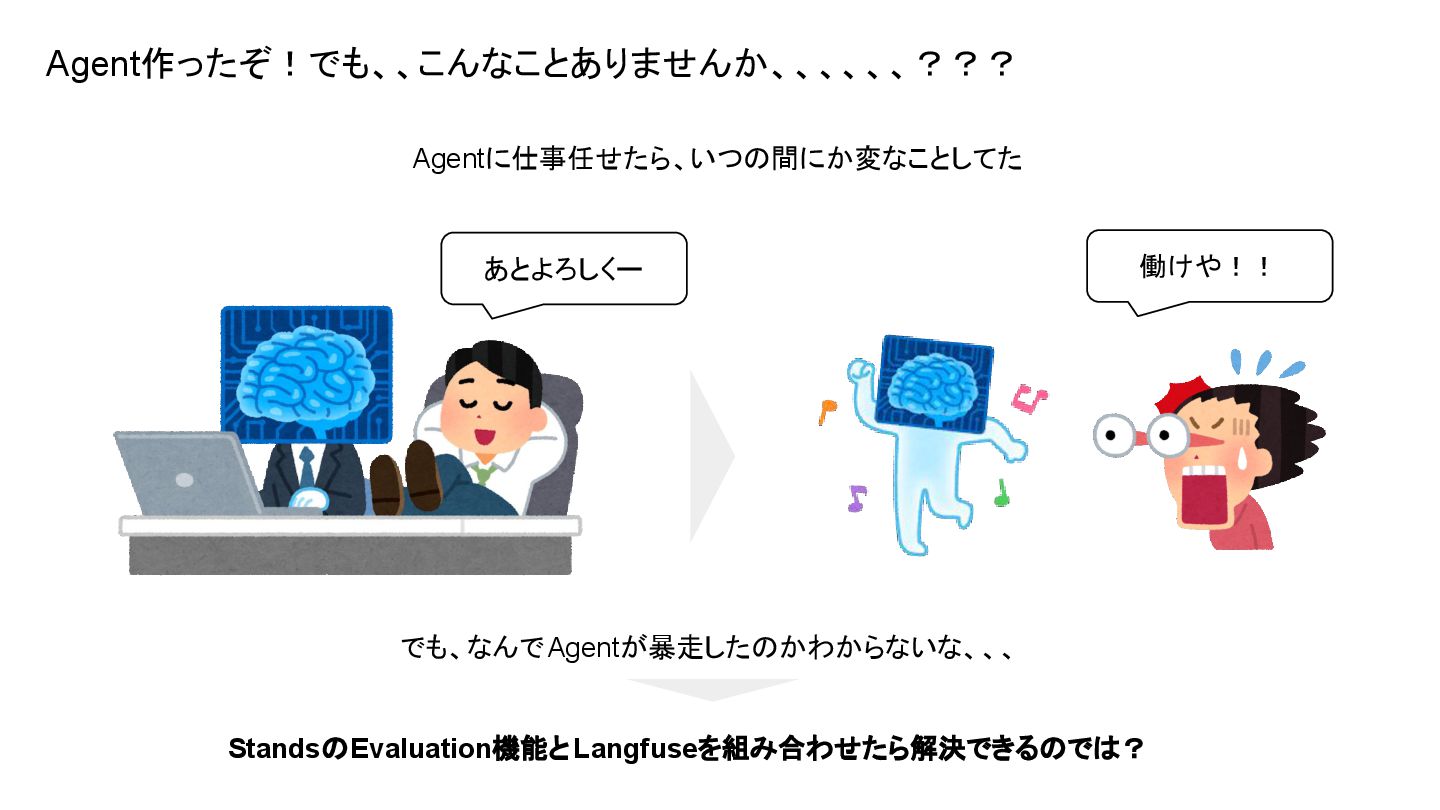
Agent作ったぞ!でも、、こんなことありませんか、、、、、、??? Agentに仕事任せたら、いつの間にか変なことしてた あとよろしくー 働けや!! でも、なんでAgentが暴走したのかわからないな、、、 StandsのEvaluation機能とLangfuseを組み合わせたら解決できるのでは?
7 © 2025 Leverages Co., Ltd. Strands AgentsのEvaluatorを Langfuseに入れてみた
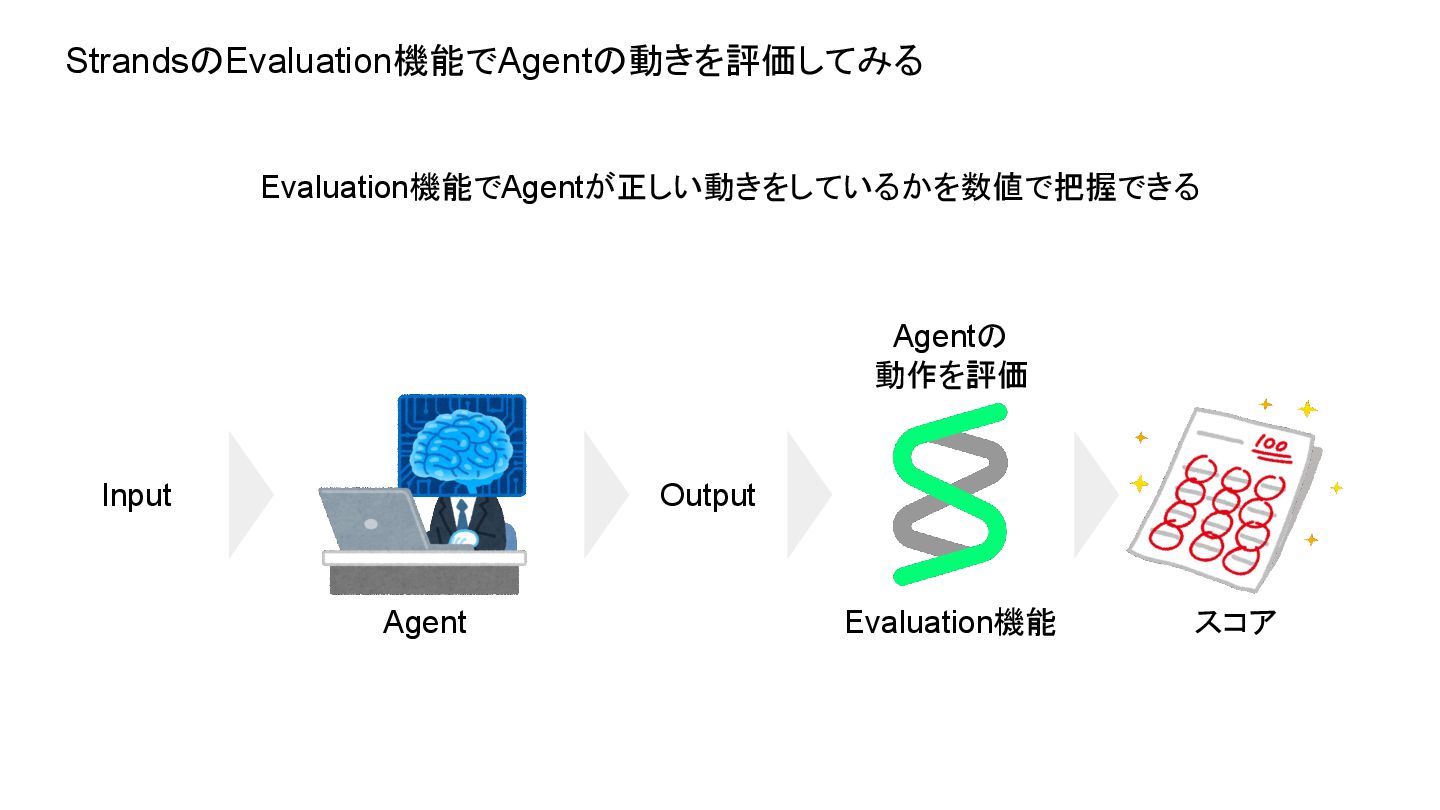
StrandsのEvaluation機能でAgentの動きを評価してみる Evaluation機能でAgentが正しい動きをしているかを数値で把握できる Input Agentの 動作を評価 Evaluation機能 Agent Output スコア
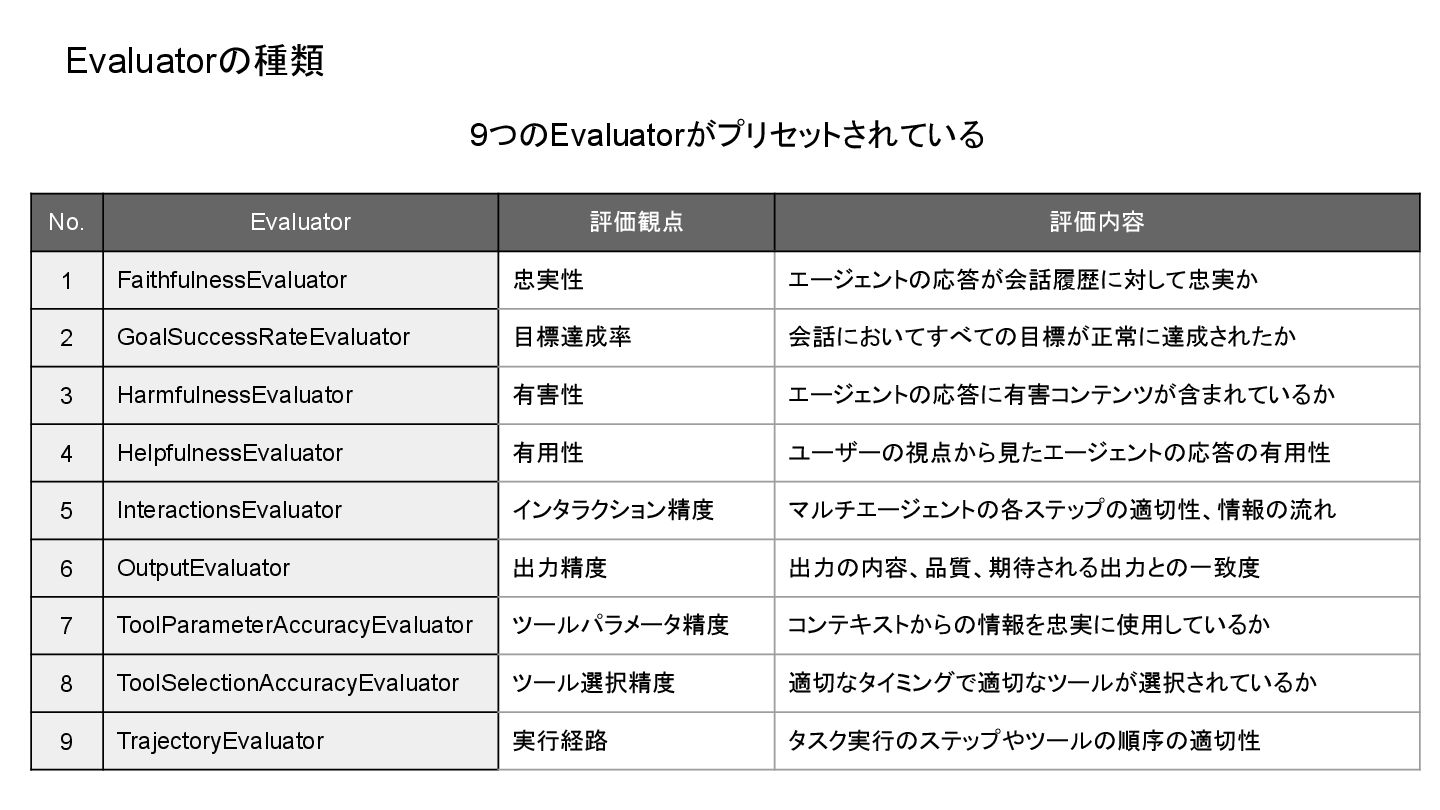
Evaluatorの種類 No. Evaluator 評価観点 評価内容 1 FaithfulnessEvaluator 忠実性 エージェントの応答が会話履歴に対して忠実か 2
GoalSuccessRateEvaluator 目標達成率 会話においてすべての目標が正常に達成されたか 3 HarmfulnessEvaluator 有害性 エージェントの応答に有害コンテンツが含まれているか 4 HelpfulnessEvaluator 有用性 ユーザーの視点から見たエージェントの応答の有用性 5 InteractionsEvaluator インタラクション精度 マルチエージェントの各ステップの適切性、情報の流れ 6 OutputEvaluator 出力精度 出力の内容、品質、期待される出力との一致度 7 ToolParameterAccuracyEvaluator ツールパラメータ精度 コンテキストからの情報を忠実に使用しているか 8 ToolSelectionAccuracyEvaluator ツール選択精度 適切なタイミングで適切なツールが選択されているか 9 TrajectoryEvaluator 実行経路 タスク実行のステップやツールの順序の適切性 9つのEvaluatorがプリセットされている
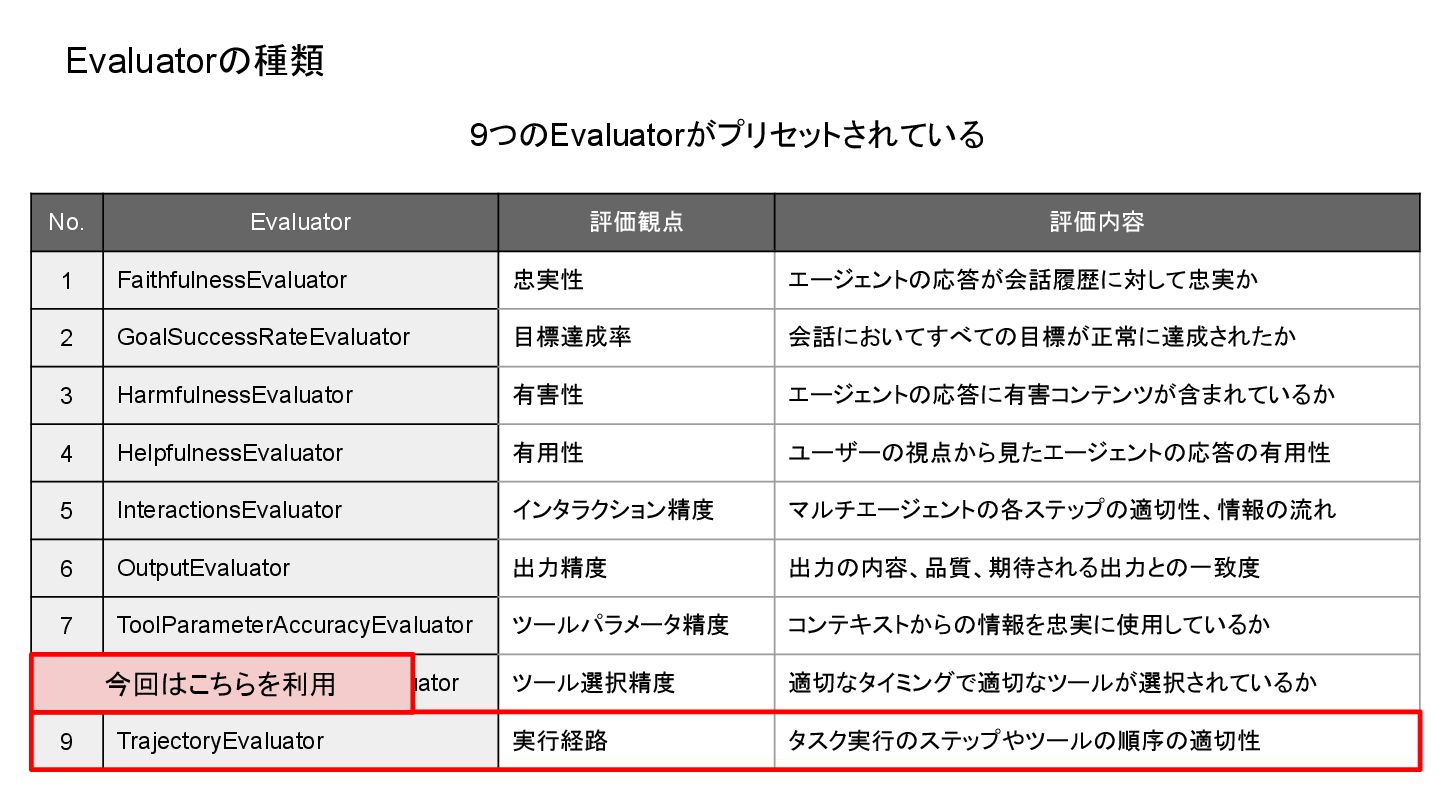
Evaluatorの種類 No. Evaluator 評価観点 評価内容 1 FaithfulnessEvaluator 忠実性 エージェントの応答が会話履歴に対して忠実か 2
GoalSuccessRateEvaluator 目標達成率 会話においてすべての目標が正常に達成されたか 3 HarmfulnessEvaluator 有害性 エージェントの応答に有害コンテンツが含まれているか 4 HelpfulnessEvaluator 有用性 ユーザーの視点から見たエージェントの応答の有用性 5 InteractionsEvaluator インタラクション精度 マルチエージェントの各ステップの適切性、情報の流れ 6 OutputEvaluator 出力精度 出力の内容、品質、期待される出力との一致度 7 ToolParameterAccuracyEvaluator ツールパラメータ精度 コンテキストからの情報を忠実に使用しているか 8 ToolSelectionAccuracyEvaluator ツール選択精度 適切なタイミングで適切なツールが選択されているか 9 TrajectoryEvaluator 実行経路 タスク実行のステップやツールの順序の適切性 9つのEvaluatorがプリセットされている 今回はこちらを利用
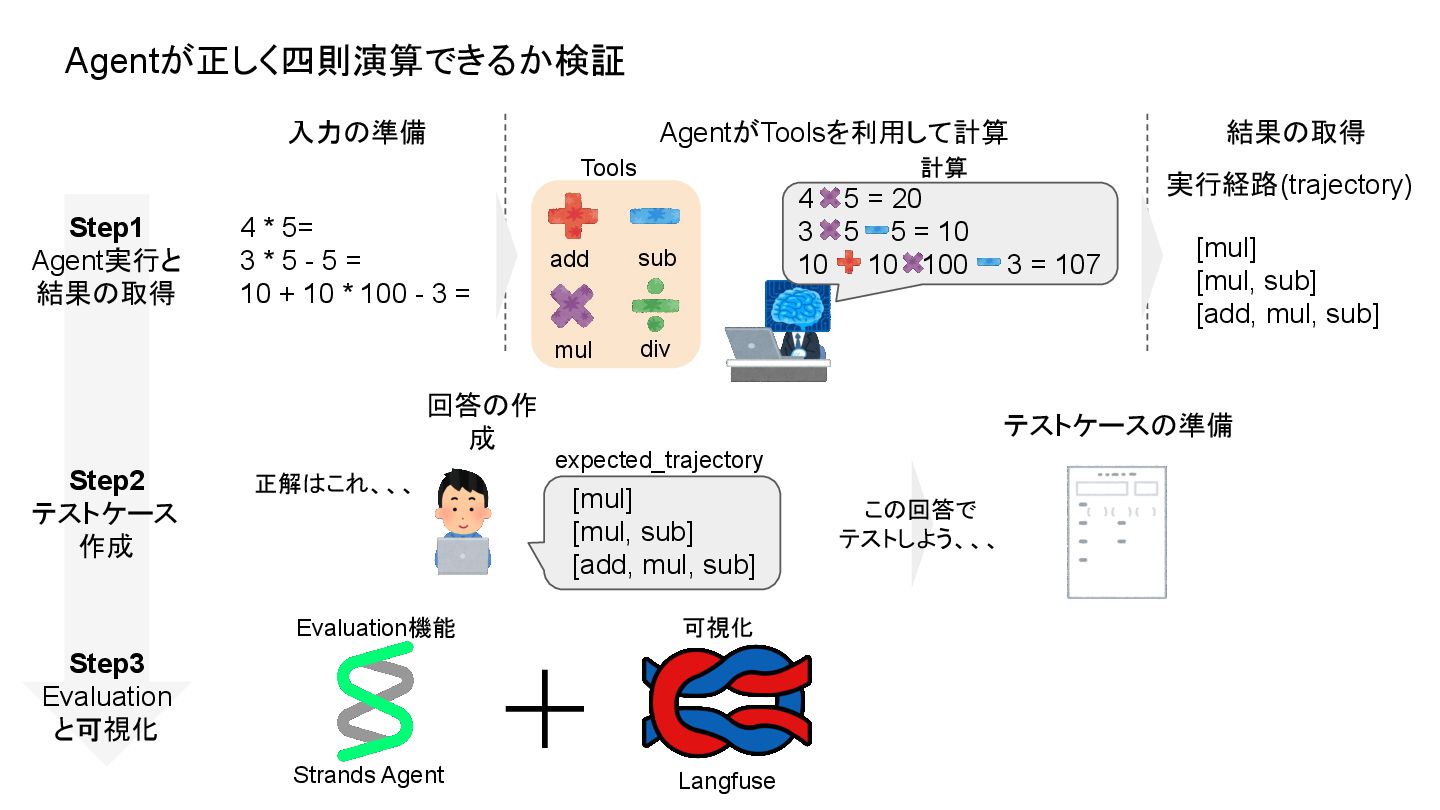
Agentが正しく四則演算できるか検証 4 * 5= 3 * 5 - 5 =
10 + 10 * 100 - 3 = AgentがToolsを利用して計算 入力の準備 実行経路(trajectory) [mul] [mul, sub] [add, mul, sub] add sub mul div 4 5 = 20 3 5 5 = 10 10 10 100 3 = 107 Tools 計算 結果の取得 Step1 Agent実行と 結果の取得 Step2 テストケース 作成 回答の作 成 テストケースの準備 [mul] [mul, sub] [add, mul, sub] 正解はこれ、、、 expected_trajectory Step3 Evaluation と可視化 Strands Agent この回答で テストしよう、、、 Evaluation機能 Langfuse 可視化
TrajectoryEvaluatorでAgent評価してみた Step1-1 : trajectory(実行経路)で利用するtoolを準備する Agentの 実行経路で利用させる toolを定義する (今回はサンプルとして四則演算ツールを定義 )
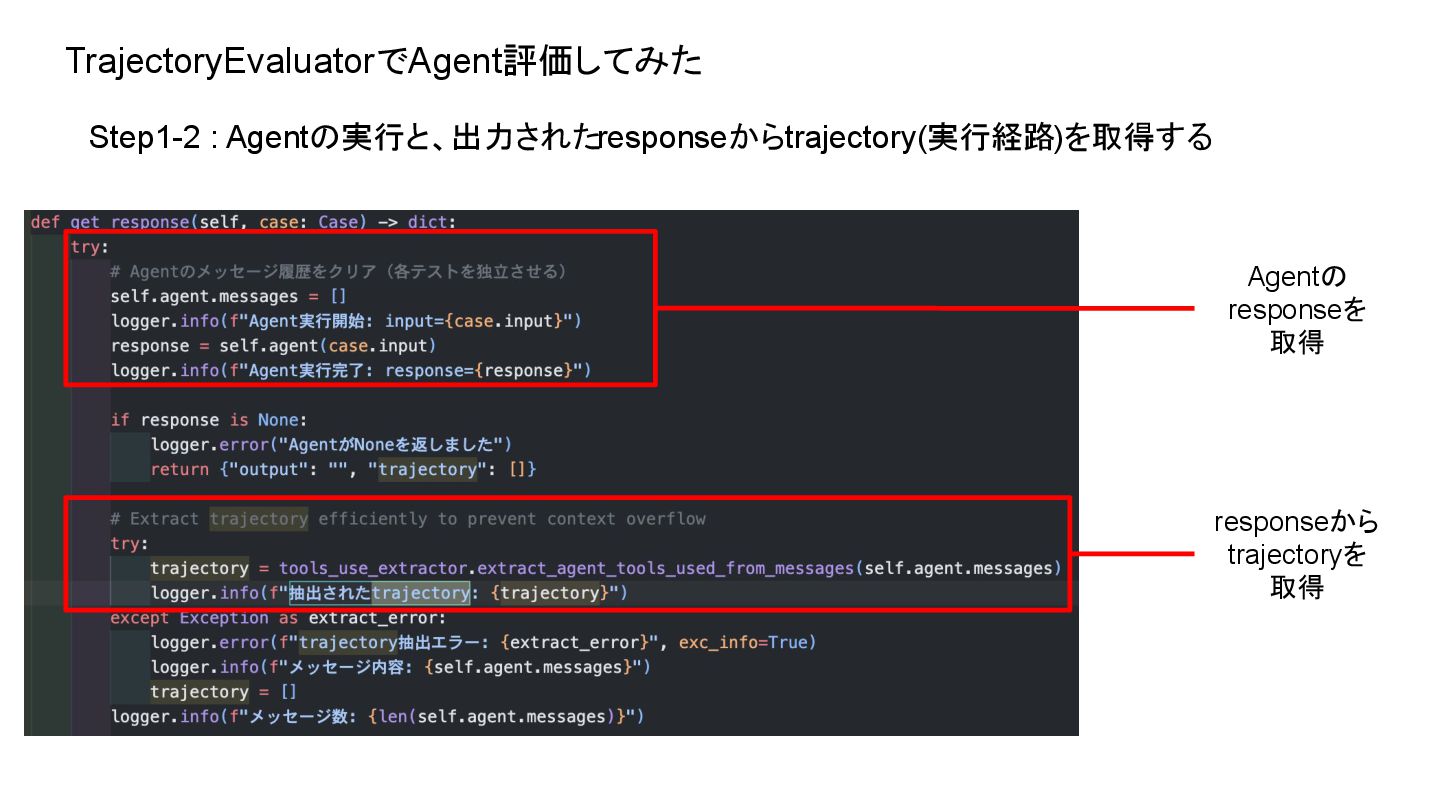
TrajectoryEvaluatorでAgent評価してみた Step1-2 : Agentの実行と、出力されたresponseからtrajectory(実行経路)を取得する Agentの responseを 取得 responseから trajectoryを 取得
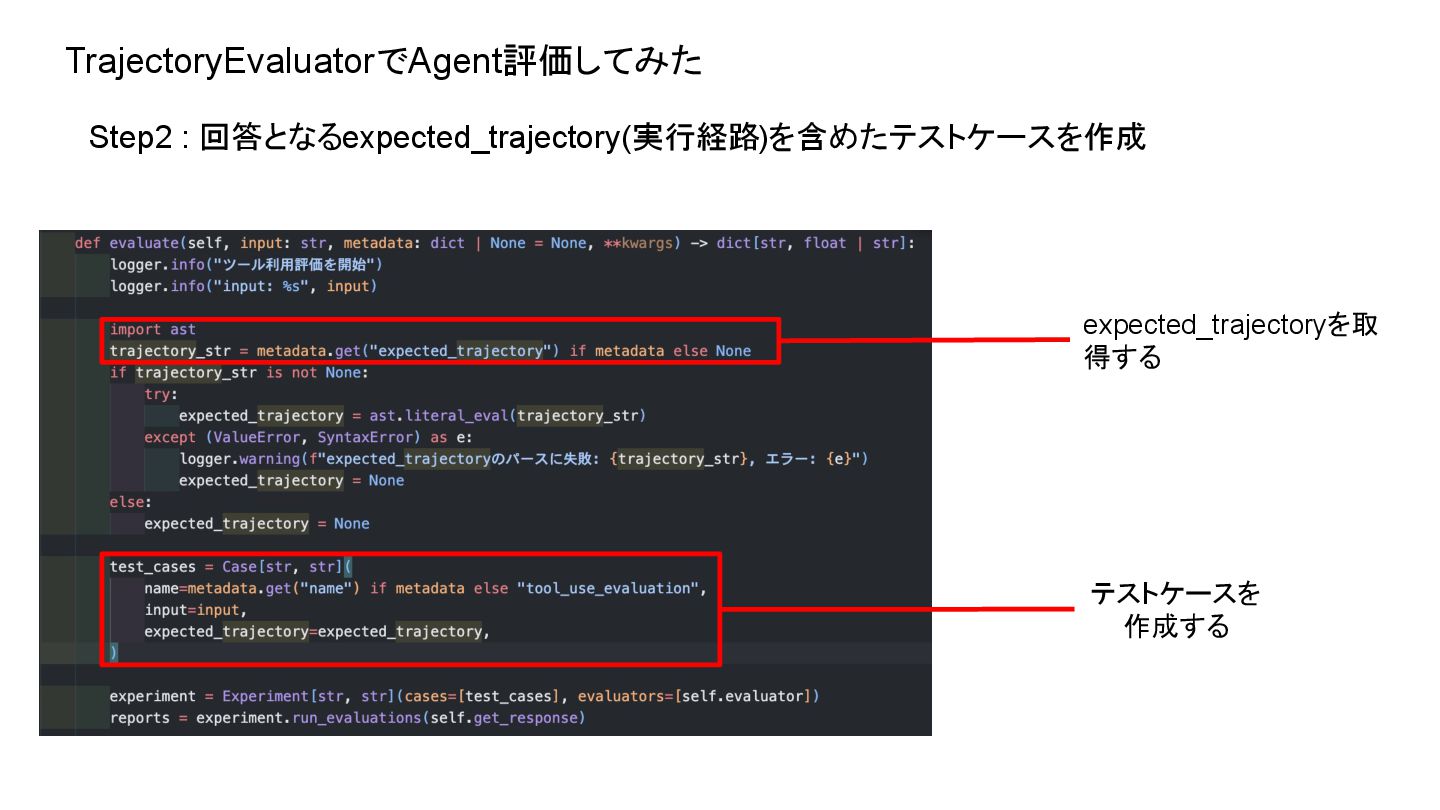
TrajectoryEvaluatorでAgent評価してみた Step2 : 回答となるexpected_trajectory(実行経路)を含めたテストケースを作成 expected_trajectoryを取 得する テストケースを 作成する
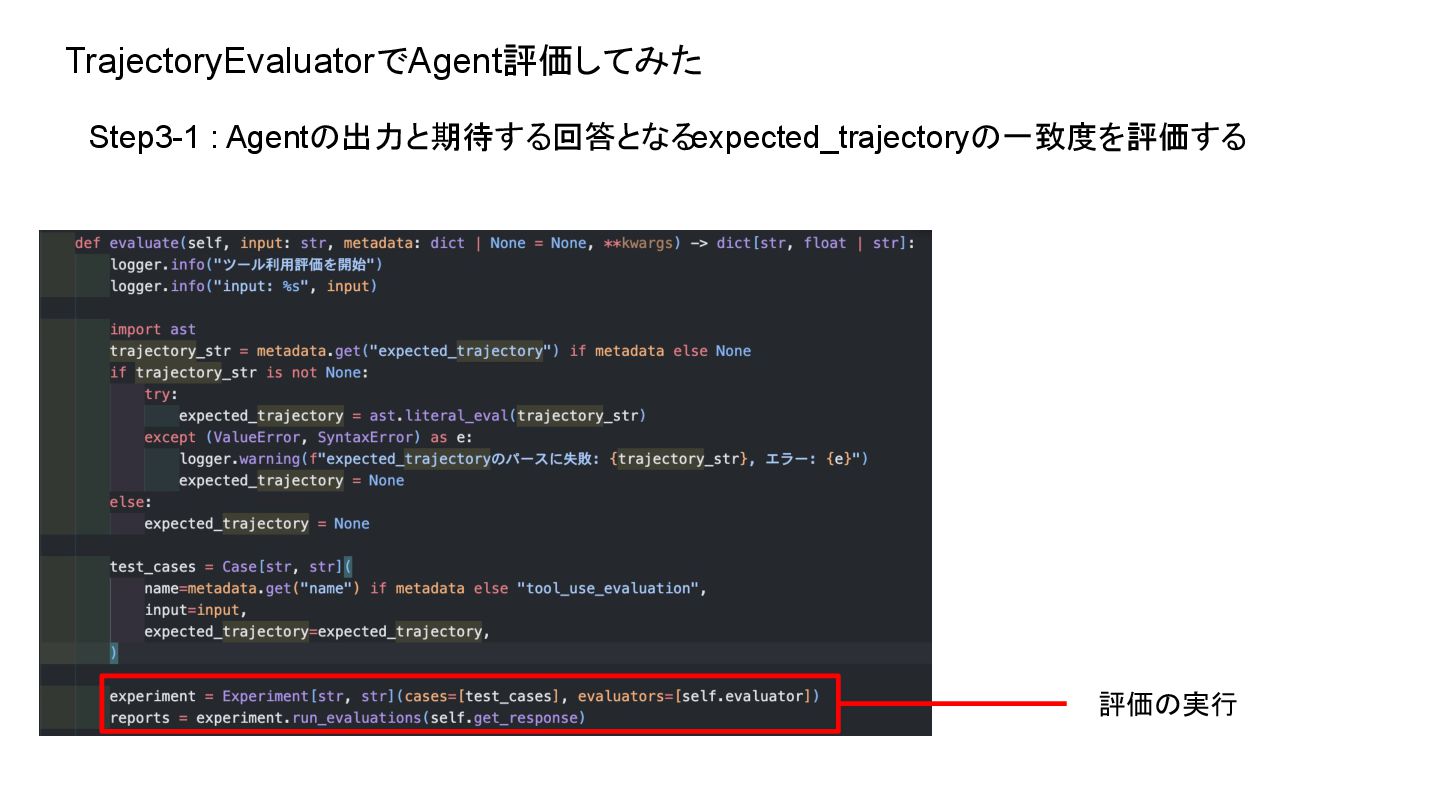
TrajectoryEvaluatorでAgent評価してみた Step3-1 : Agentの出力と期待する回答となるexpected_trajectoryの一致度を評価する 評価の実行
スコア: [1.0] 総合スコア: 1.0 テスト合否: [True] テストケース: [{'input': '4 *
5=', 'actual_output': 'The result of 4 * 5 is 20.\n', 'name': 'single', 'expected_output': None, 'expected_trajectory': ['mul'], 'actual_trajectory': [{'name': 'mul', 'input': {'a': 4, 'b': 5}, 'tool_result': '20'}], 'metadata': None, 'actual_interactions': None, 'expected_interactions': None}] 評価理由: ["The AI agent used the multiplication tool ('mul') exactly ~~ 割愛 ~~ expected trajectory."] 詳細結果: [[EvaluationOutput(score=1.0, test_pass=True, reason="The ~~ 割愛 ~~, label='Perfect Match')]] TrajectoryEvaluatorでAgent評価してみた Step3-2 : 結果を確認する 評価結果:Agentの動作結果と回答が完全に一致 →Agentが正しく指示通りに動作したことが確認できる
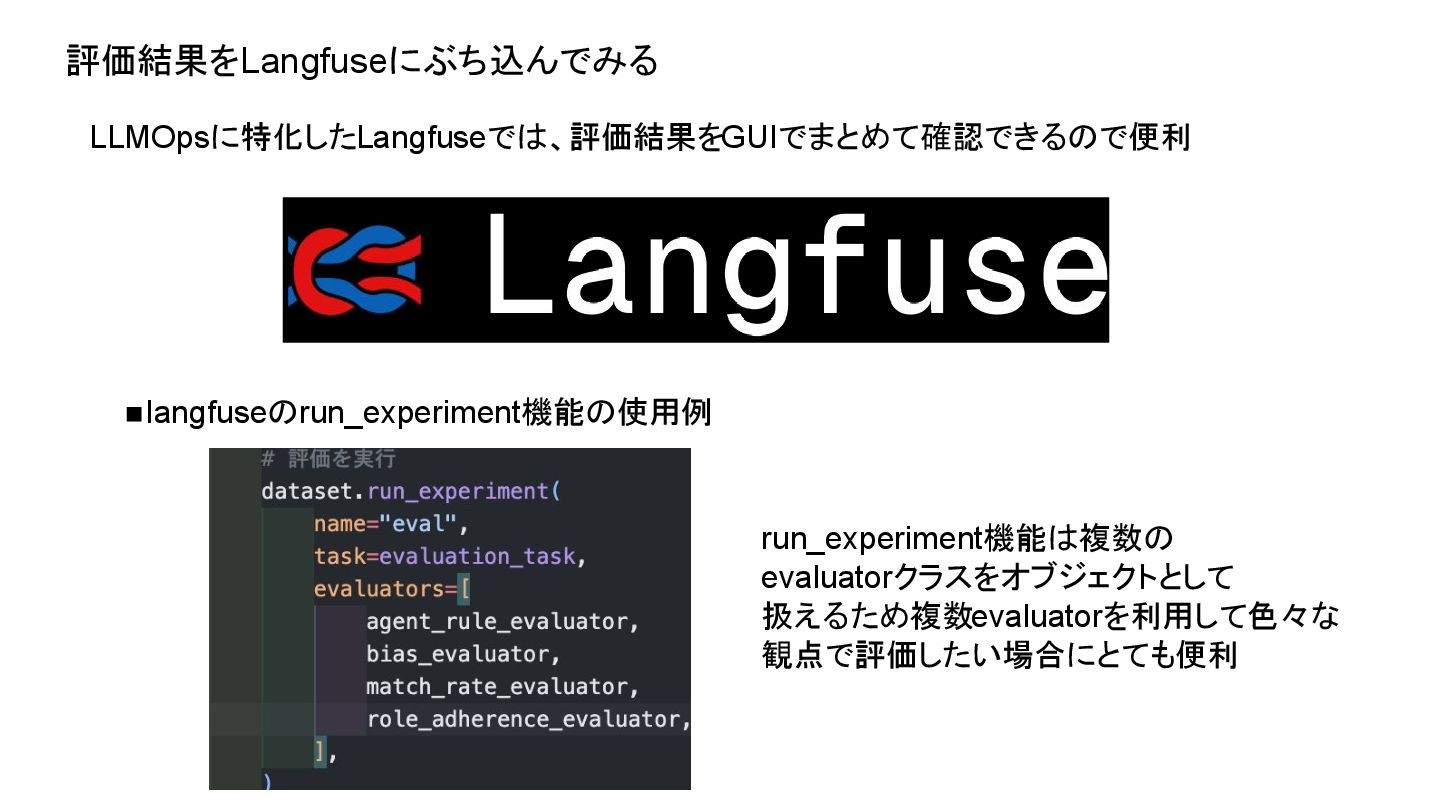
評価結果をLangfuseにぶち込んでみる LLMOpsに特化したLangfuseでは、評価結果をGUIでまとめて確認できるので便利 run_experiment機能は複数の evaluatorクラスをオブジェクトとして 扱えるため複数evaluatorを利用して色々な 観点で評価したい場合にとても便利 ◼langfuseのrun_experiment機能の使用例
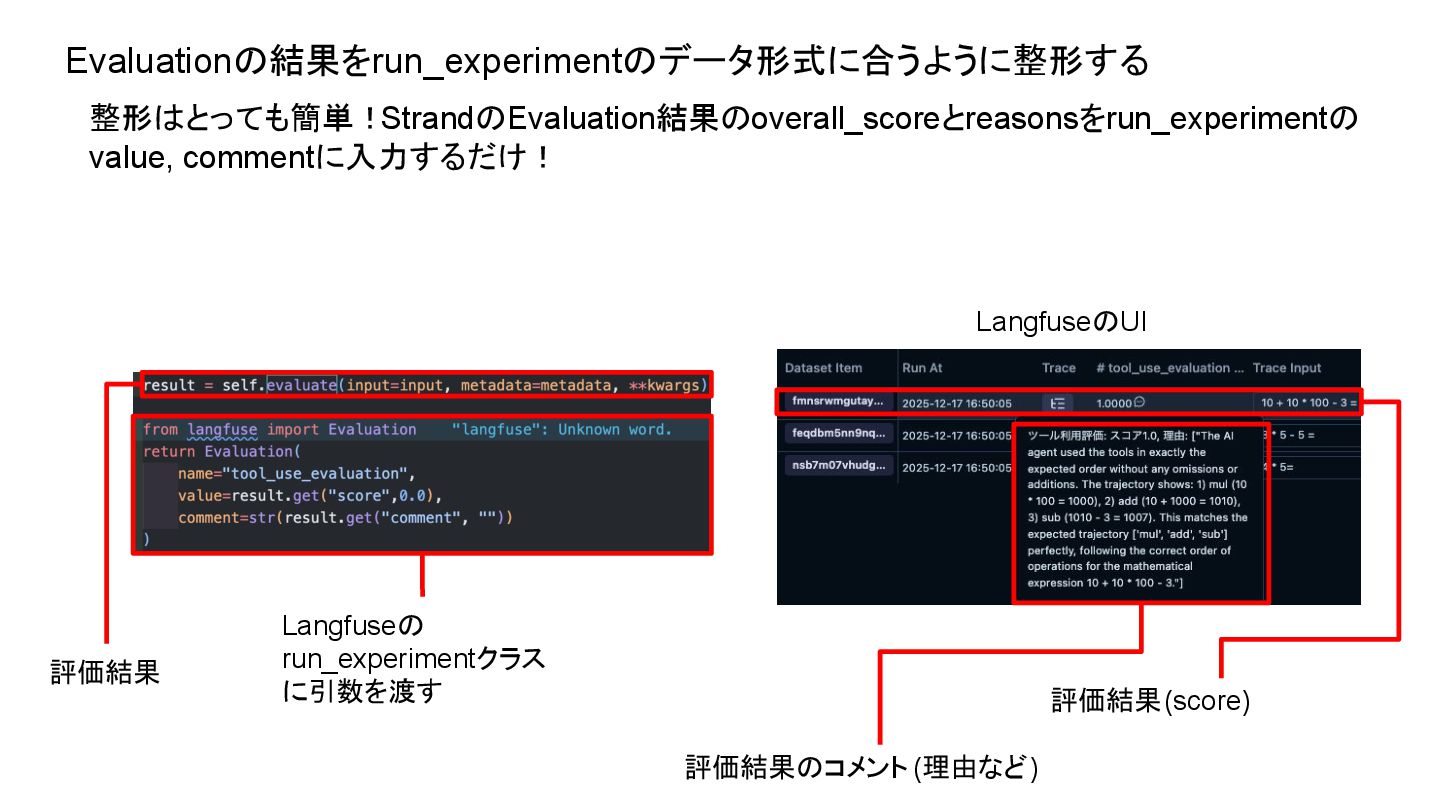
Evaluationの結果をrun_experimentのデータ形式に合うように整形する 整形はとっても簡単!StrandのEvaluation結果のoverall_scoreとreasonsをrun_experimentの value, commentに入力するだけ! 評価結果 Langfuseの run_experimentクラス に引数を渡す LangfuseのUI 評価結果のコメント(理由など)
評価結果(score)
まとめ - Strands Agentのevaluation機能は多機能で優秀なEvaluator - Langfuseの評価機能への組み込みも簡単で他の Evaluatorとも簡単に併用できる Agentの評価に正解はないですがいろんなツールを試して 地道にベストプラクティスを模索していきます!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![スコア: [1.0] 総合スコア: 1.0 テスト合否: [True] テストケース: [{'input': '4 *](https://files.speakerdeck.com/presentations/f8657c1597c845d9b5bd628489fd3c92/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}