- Training | Microsoft Learn https://learn.microsoft.com/en- us/training/modules/characterize-devops- continous-collaboration-improvement/3-explore- continuous-improvement
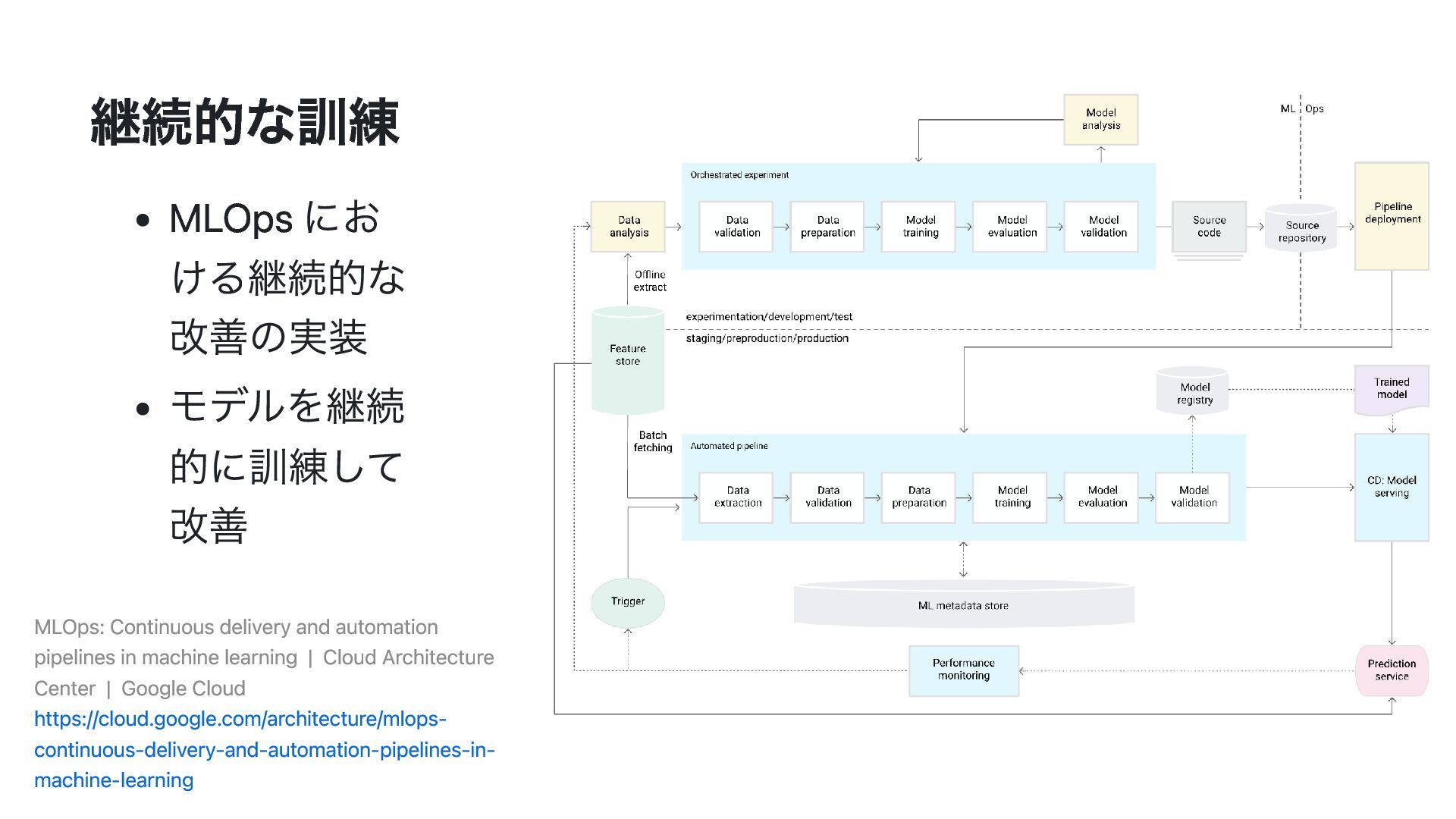
delivery and automation pipelines in machine learning | Cloud Architecture Center | Google Cloud https://cloud.google.com/architecture/mlops- continuous-delivery-and-automation-pipelines-in- machine-learning
with Human Preferences Criteria Drift LLM の出力に対する評価基準 が、評価を進めるにつれてユ ーザー自身によって変化また は洗練されていく [2404.12272] Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences https://arxiv.org/abs/2404.12272
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
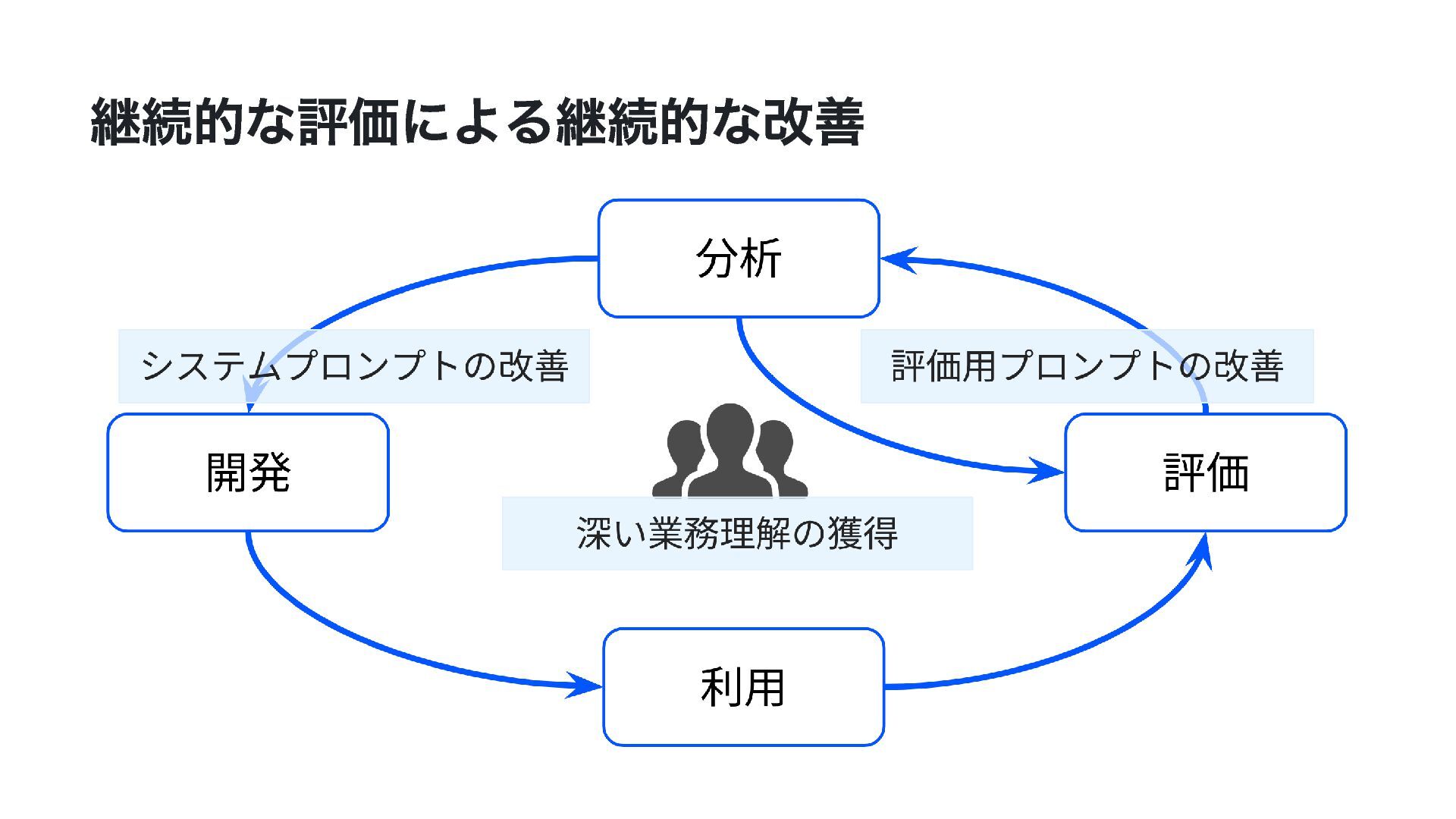{kind=link}
{kind=link}
{kind=link}
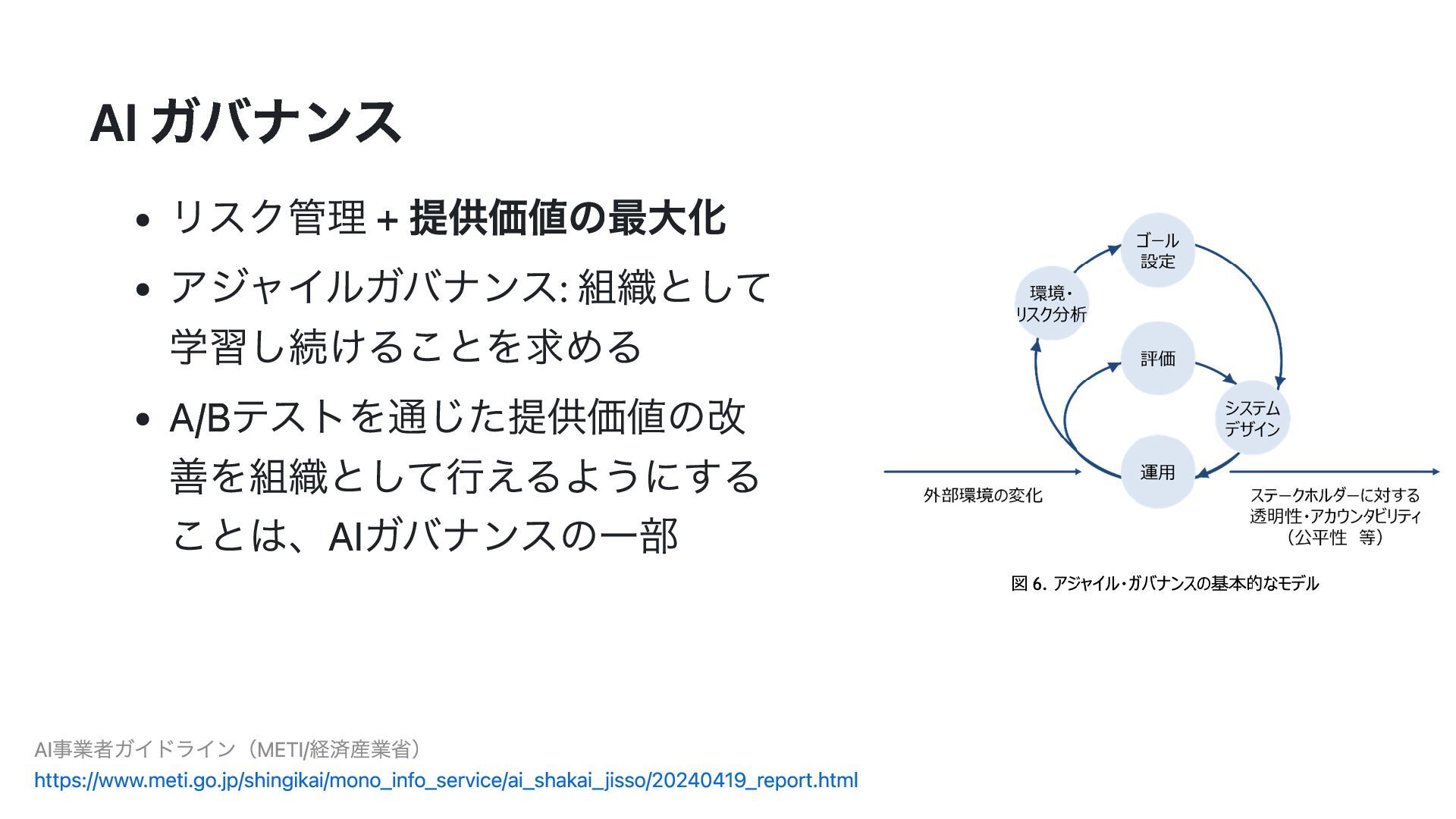{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}