Slides from my May 2025 talk at Hive MCR in Manchester. I spoke about the technical SEO foundations of Googlebot crawling, some theories on different levels of crawl queues, and tips on maximising crawl efficiency.
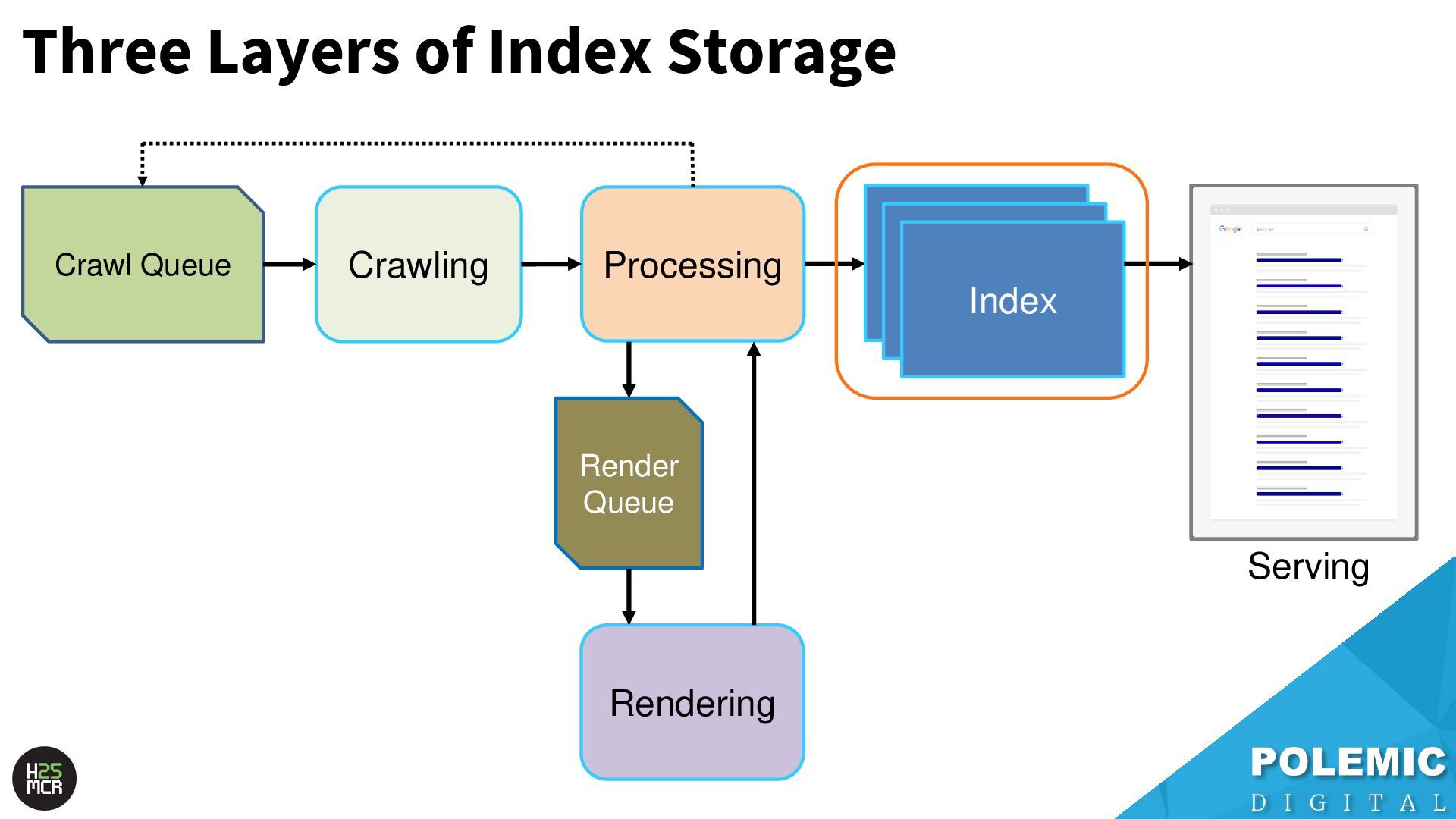
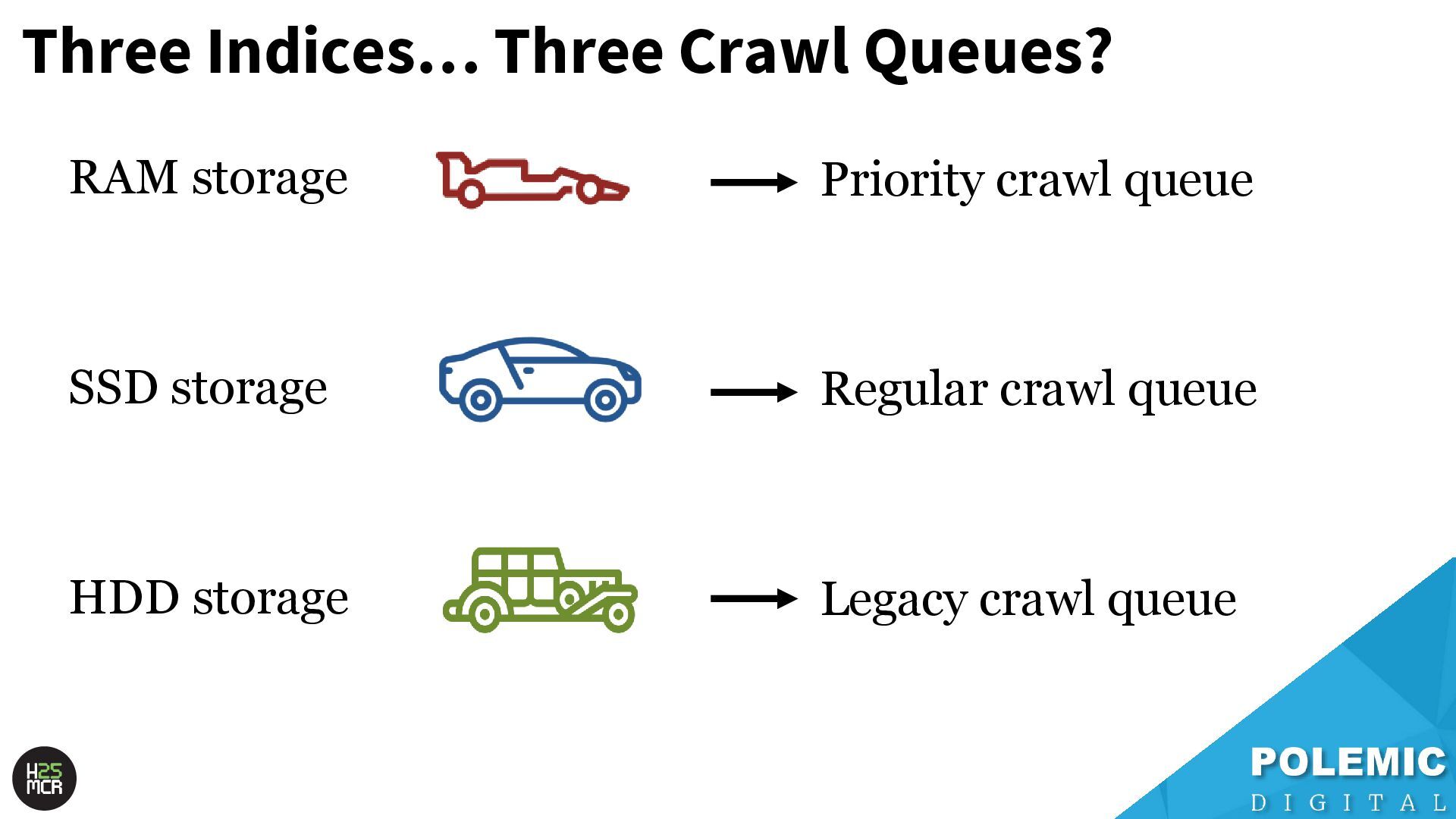
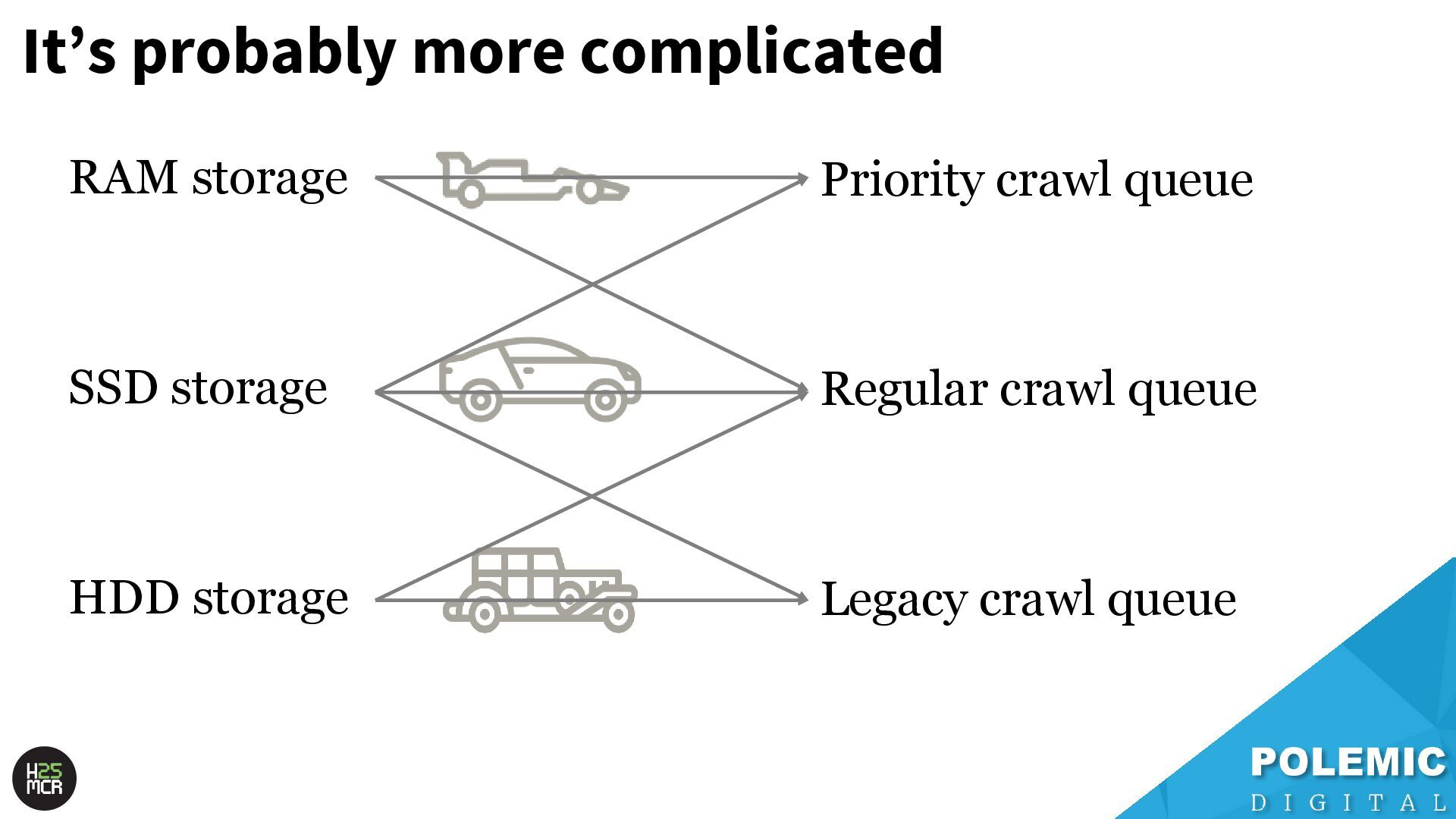
need to be served quickly and frequently ➢Includes news articles, popular content, high- traffic URLs 2. SSD storage; ➢Pages that are regularly served in SERPs but aren’t super popular 3. HDD storage; ➢Pages that are rarely (if ever) served in SERPs
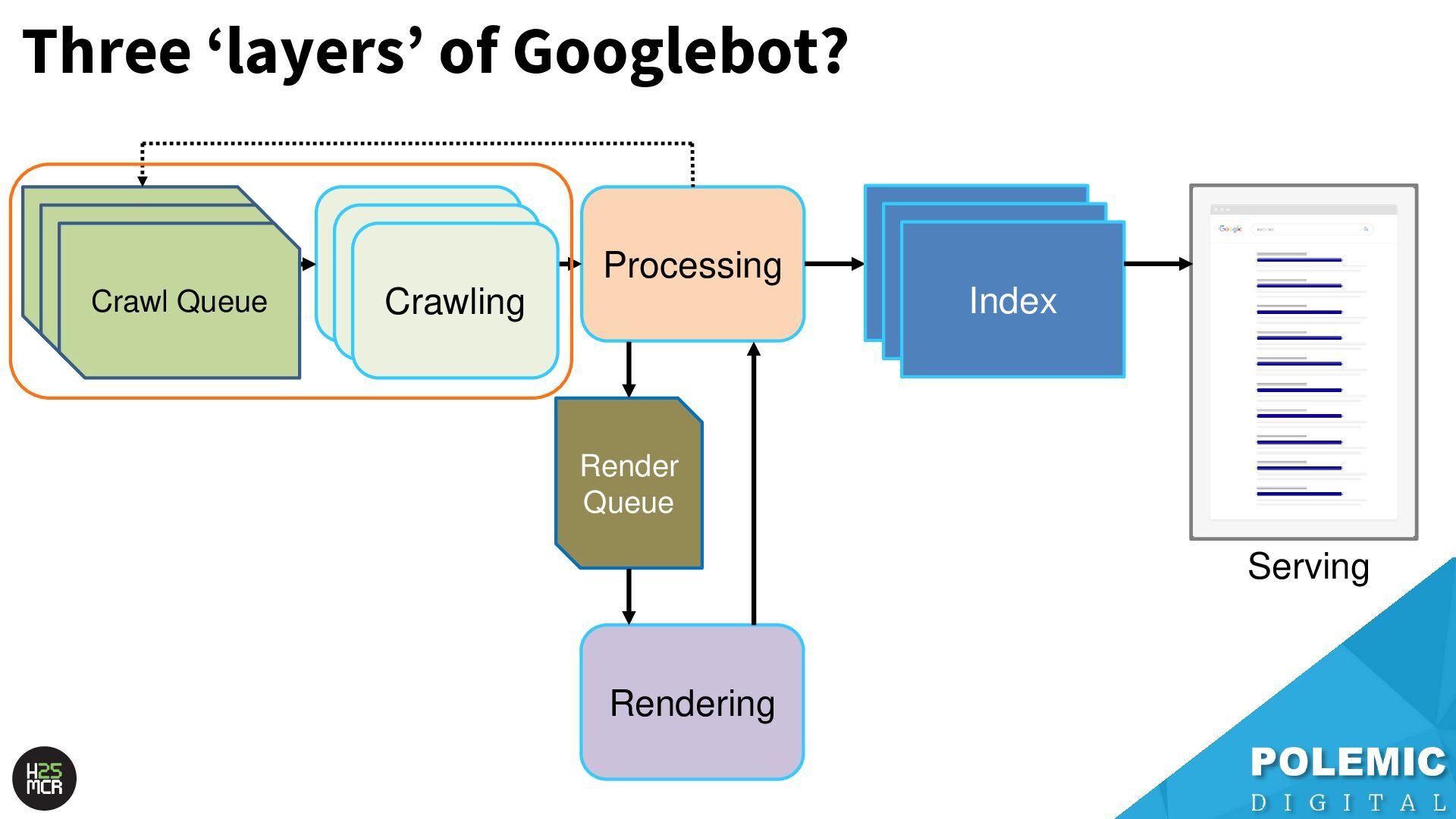
Webpages that have a high change frequency and/or are seen as highly authoritative News website homepages & key section pages Highly volatile classified portals (jobs, properties) Large volume ecommerce (Amazon, eBay, Etsy) • Main purpose = discovery of valuable new content; ➢ i.e., news articles, new product pages, new classified listings • Rarely re-crawls newly discovered URLs; ➢ New URLs can become VIPs over time
of the heavy lifting • Less frantic; ➢ More time for crawl selection, de-duplication, sanitisation of the crawl queue • Recrawls URLs first crawled by the Priority crawl queue; ➢ Checks for changes ➢ Updates relevant signals for next crawl prioritisation
URLs that have very little link value and/or are very rarely updated ➢ Recrawls URLs that serve 4XX errors; -Likely also occasionally checks old redirects
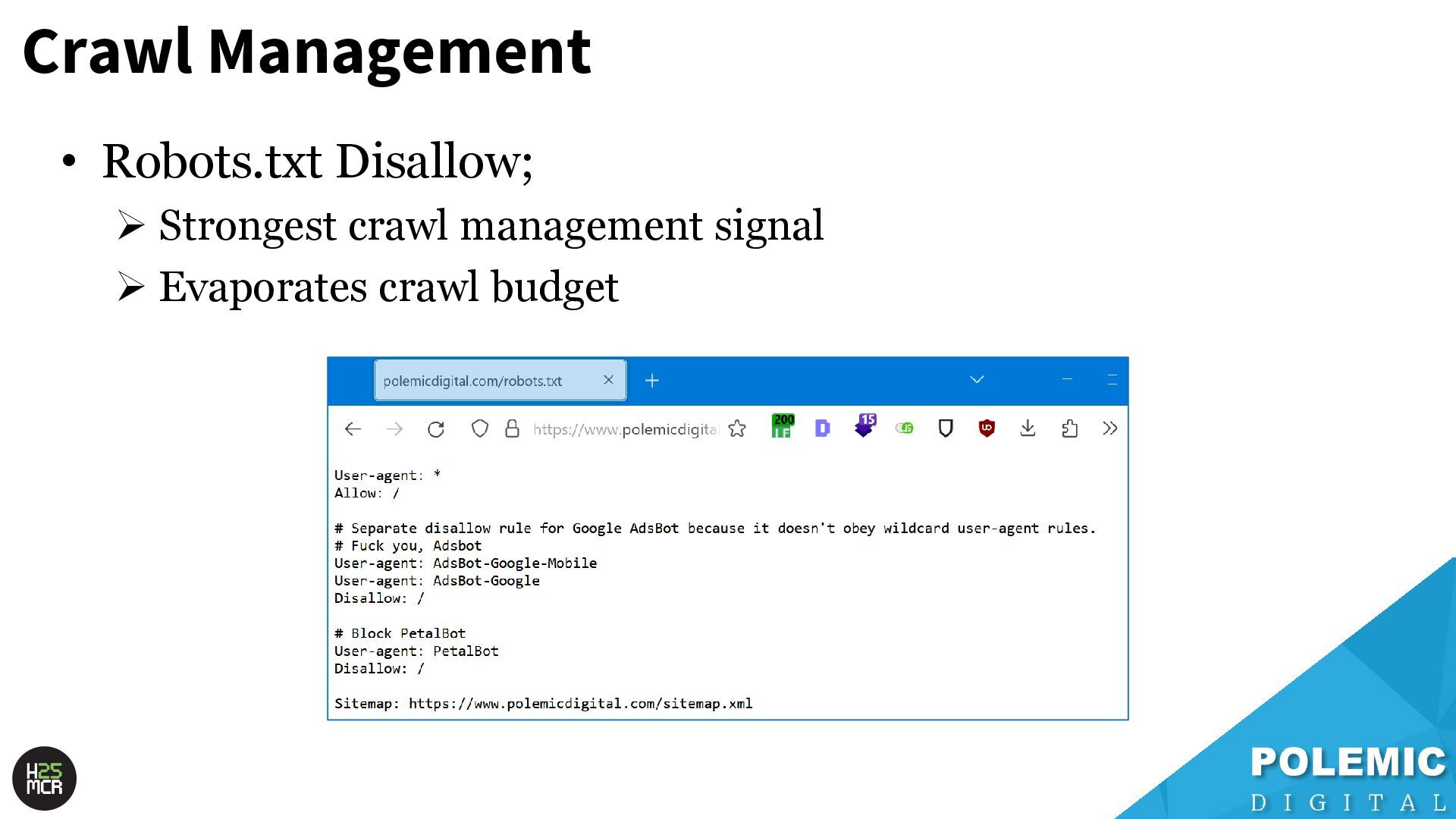
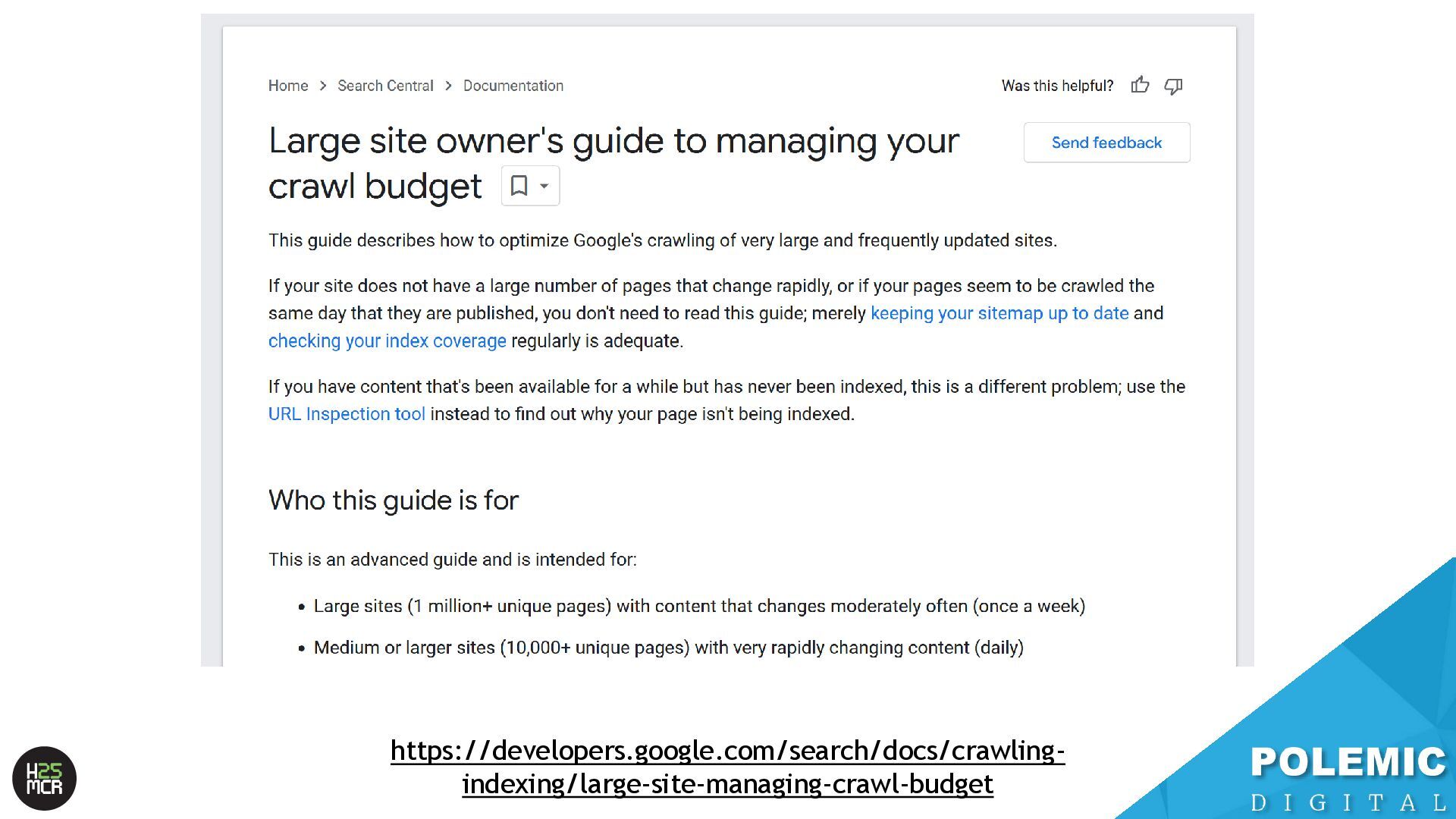
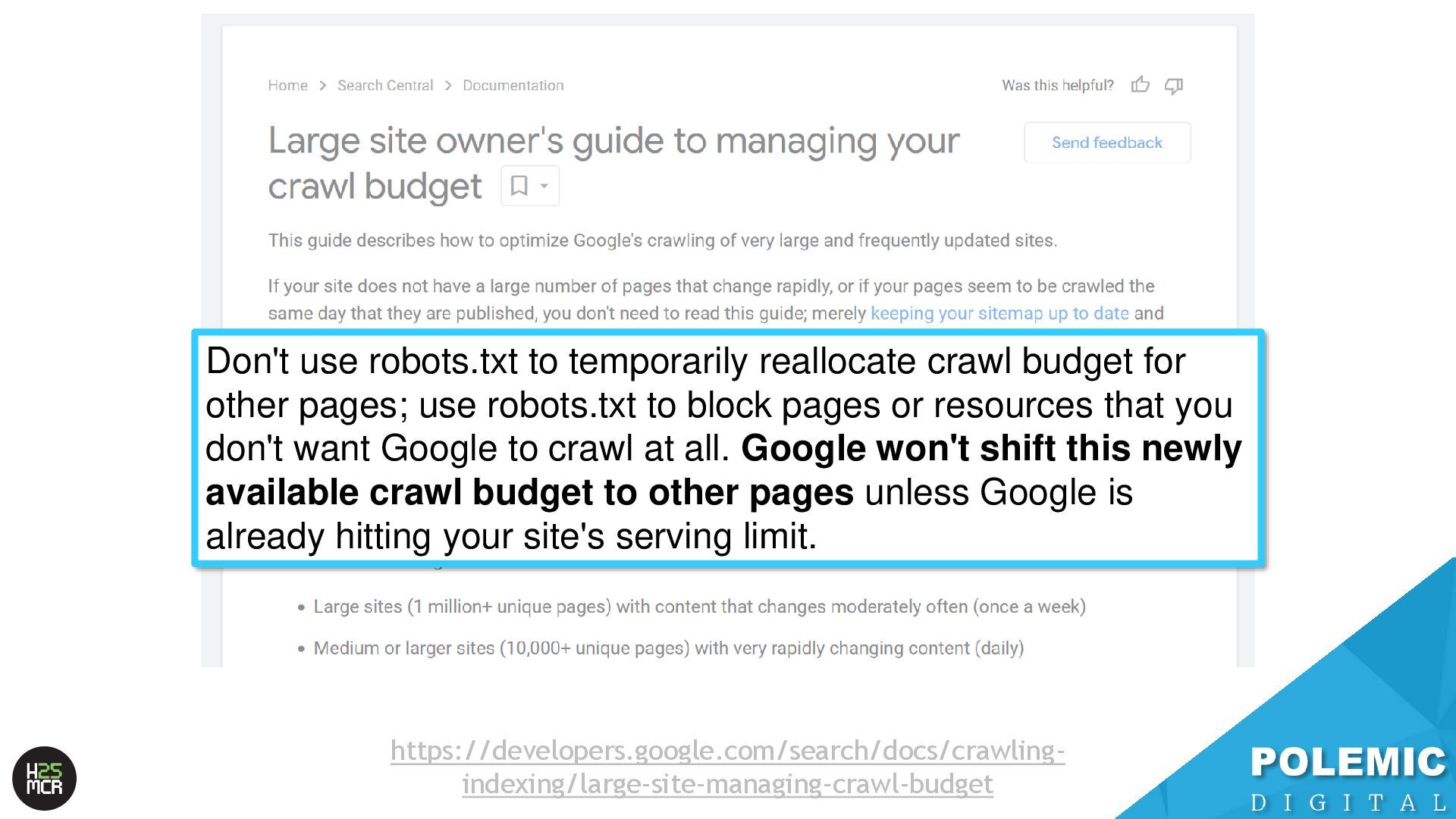
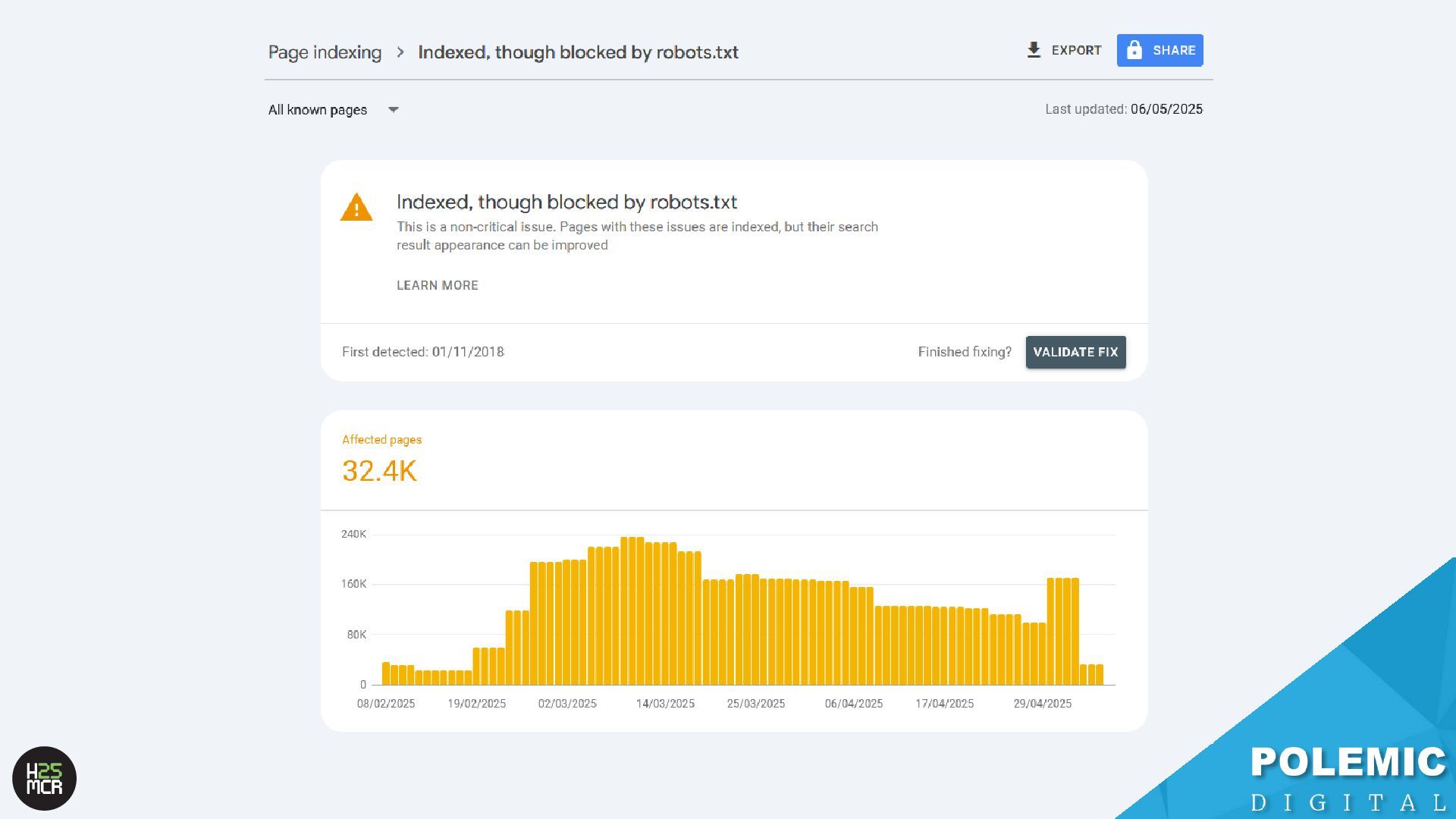
pages; use robots.txt to block pages or resources that you don't want Google to crawl at all. Google won't shift this newly available crawl budget to other pages unless Google is already hitting your site's serving limit. https://developers.google.com/search/docs/crawling- indexing/large-site-managing-crawl-budget
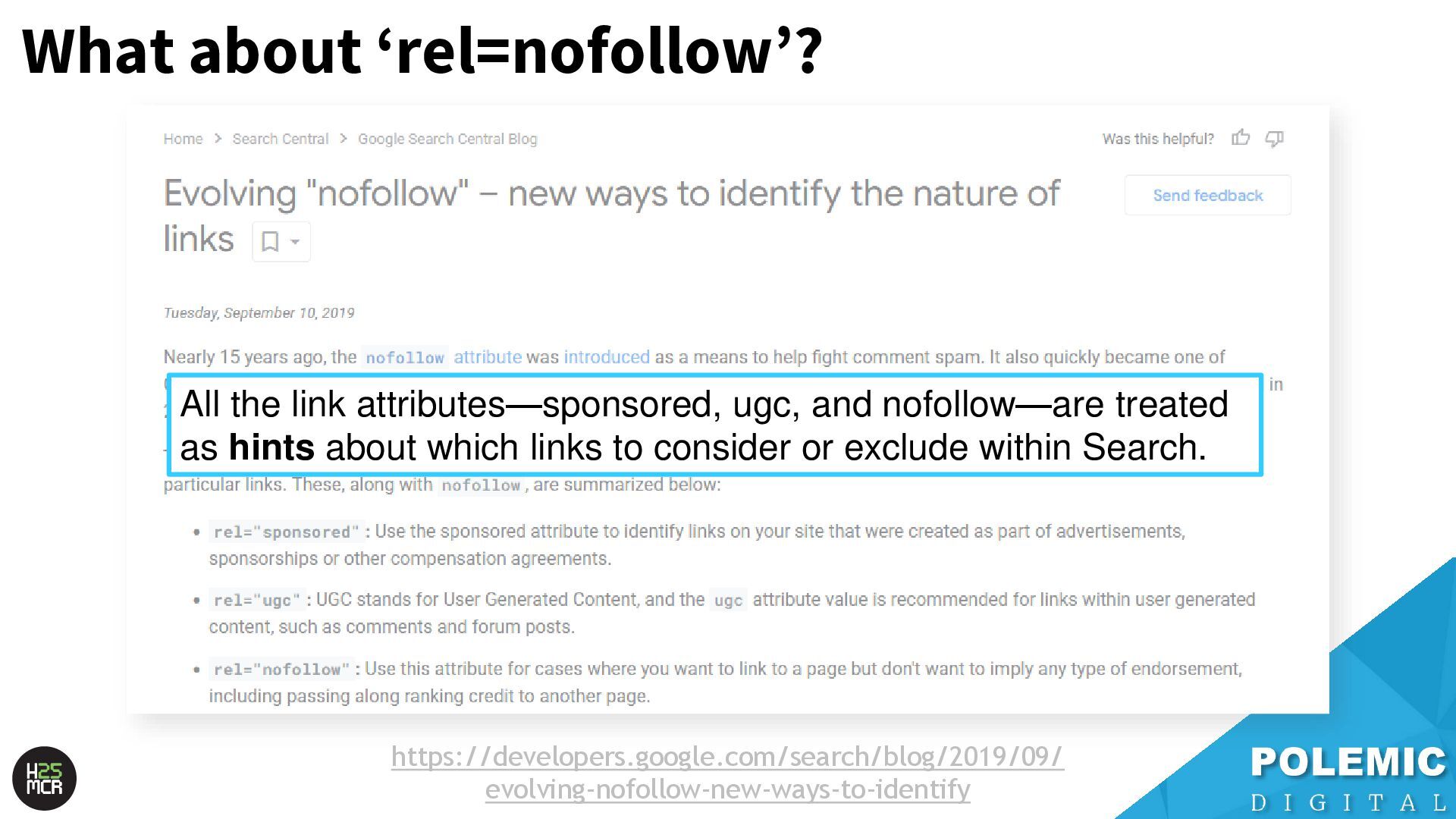
treated as hints about which links to consider or exclude within Search. https://developers.google.com/search/blog/2019/09/ evolving-nofollow-new-ways-to-identify
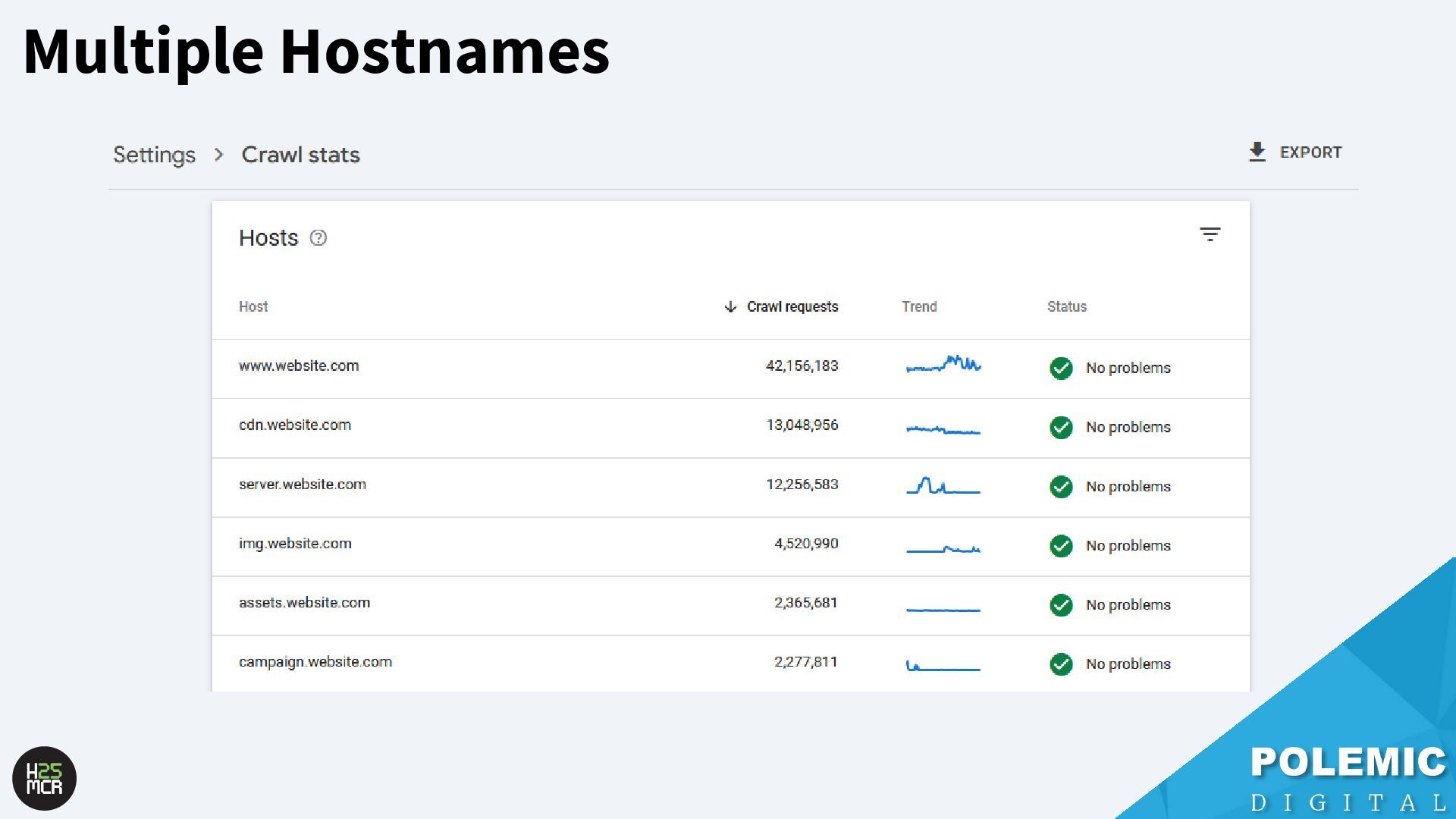
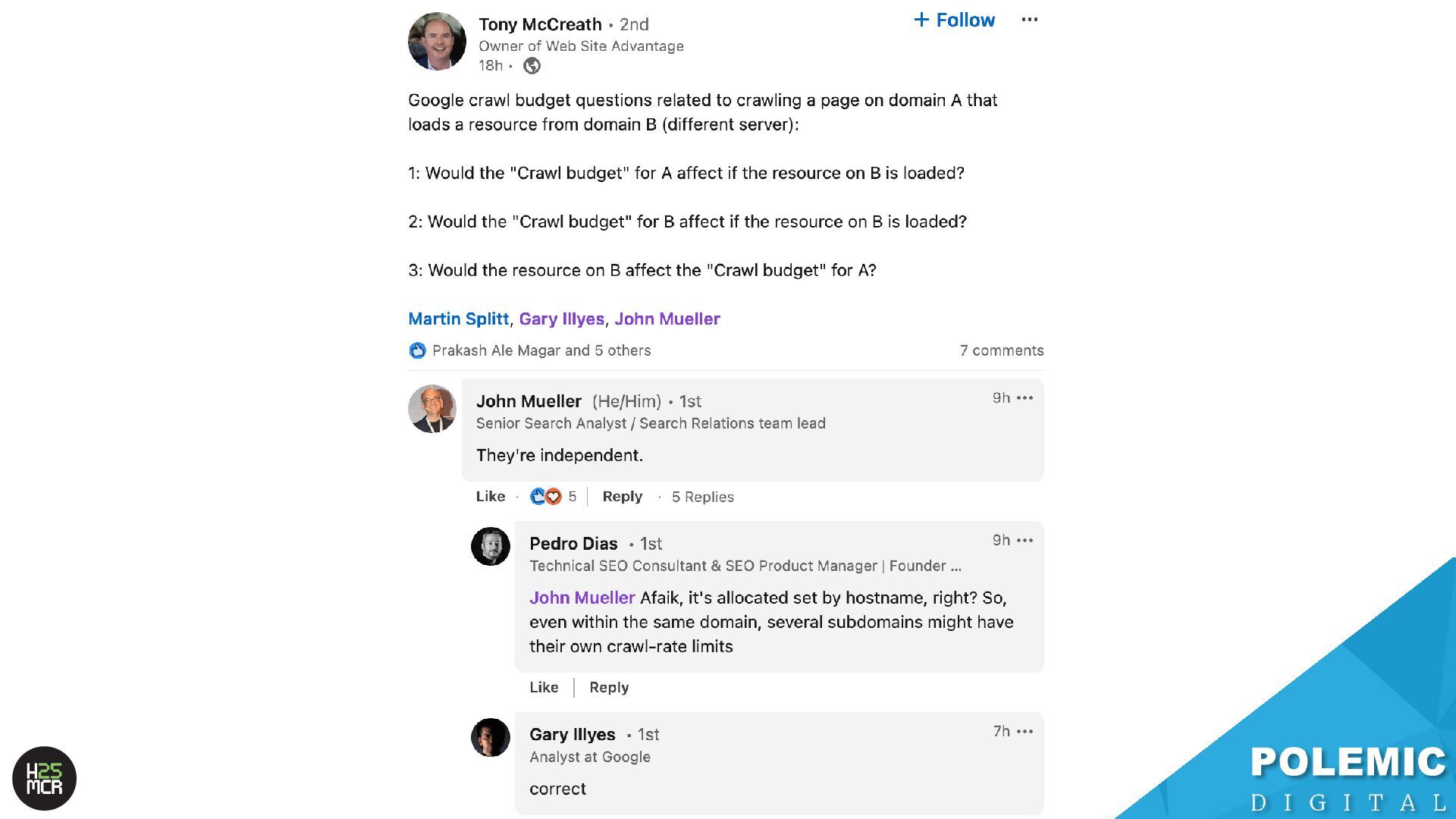
allocation of crawl budget; ➢ ‘www.website.com’ is independently crawled from ‘cdn.website.com’ • Offload page resources to a subdomain; ➢ Frees up crawl budget on your main domain
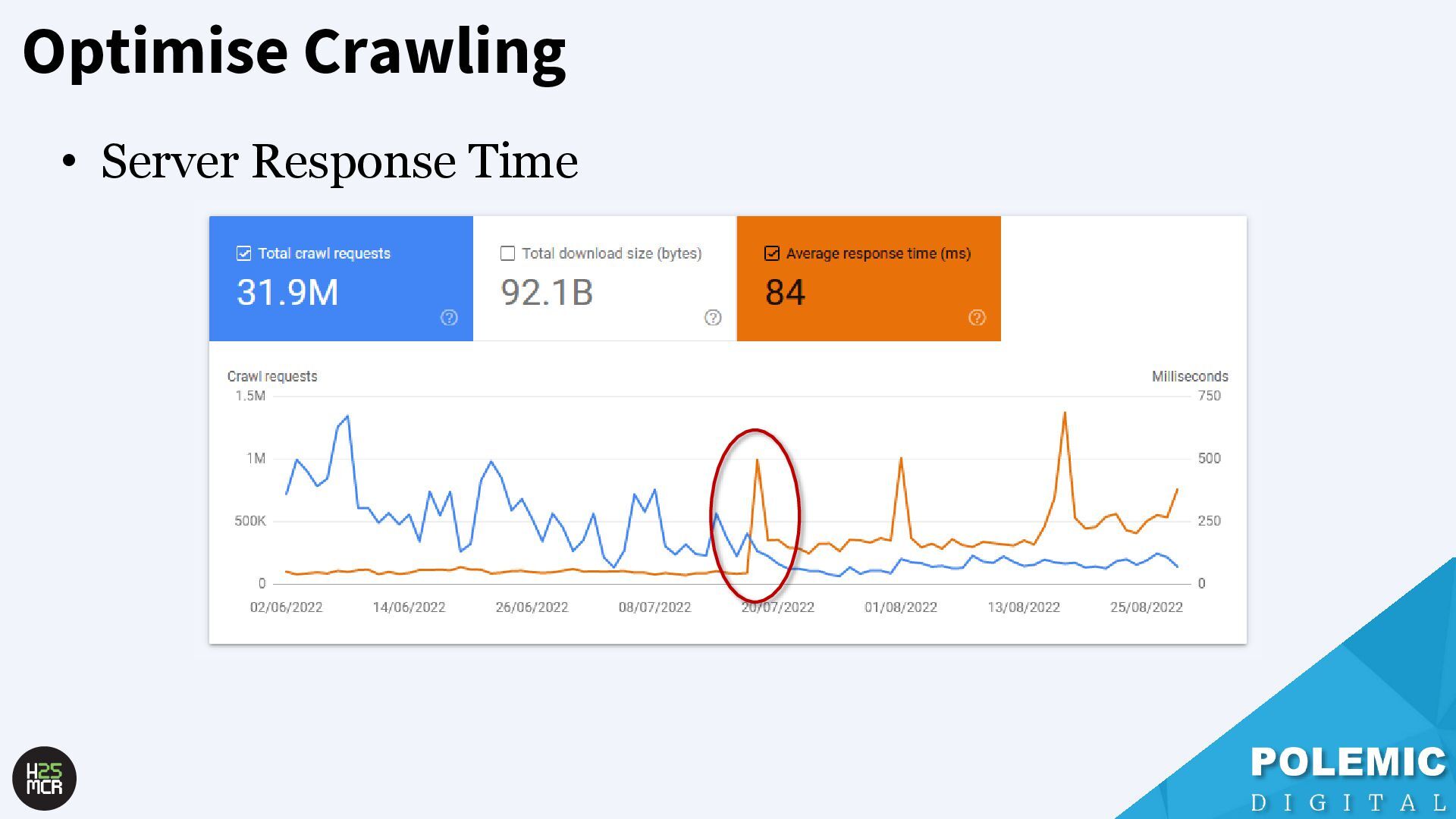
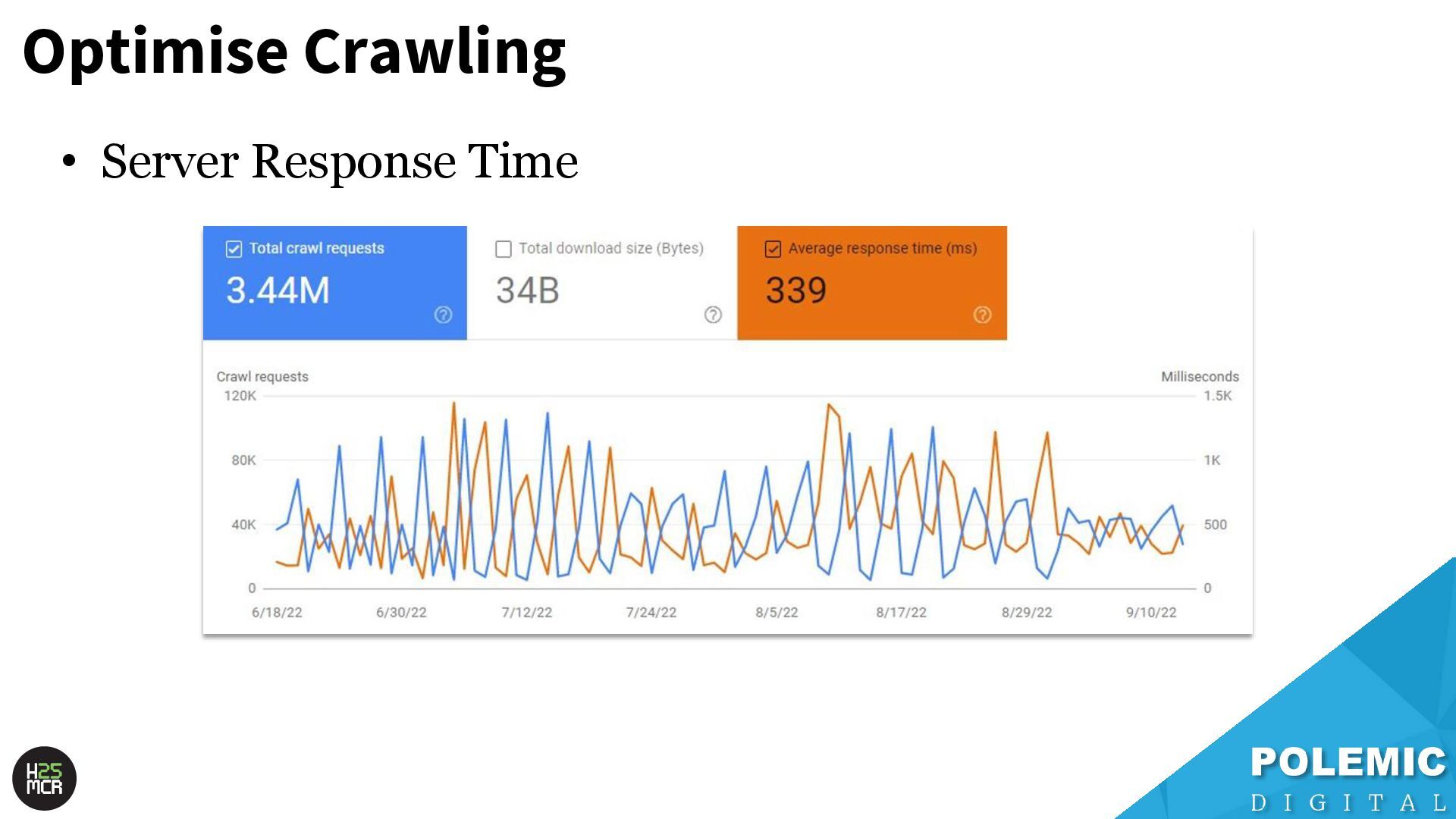
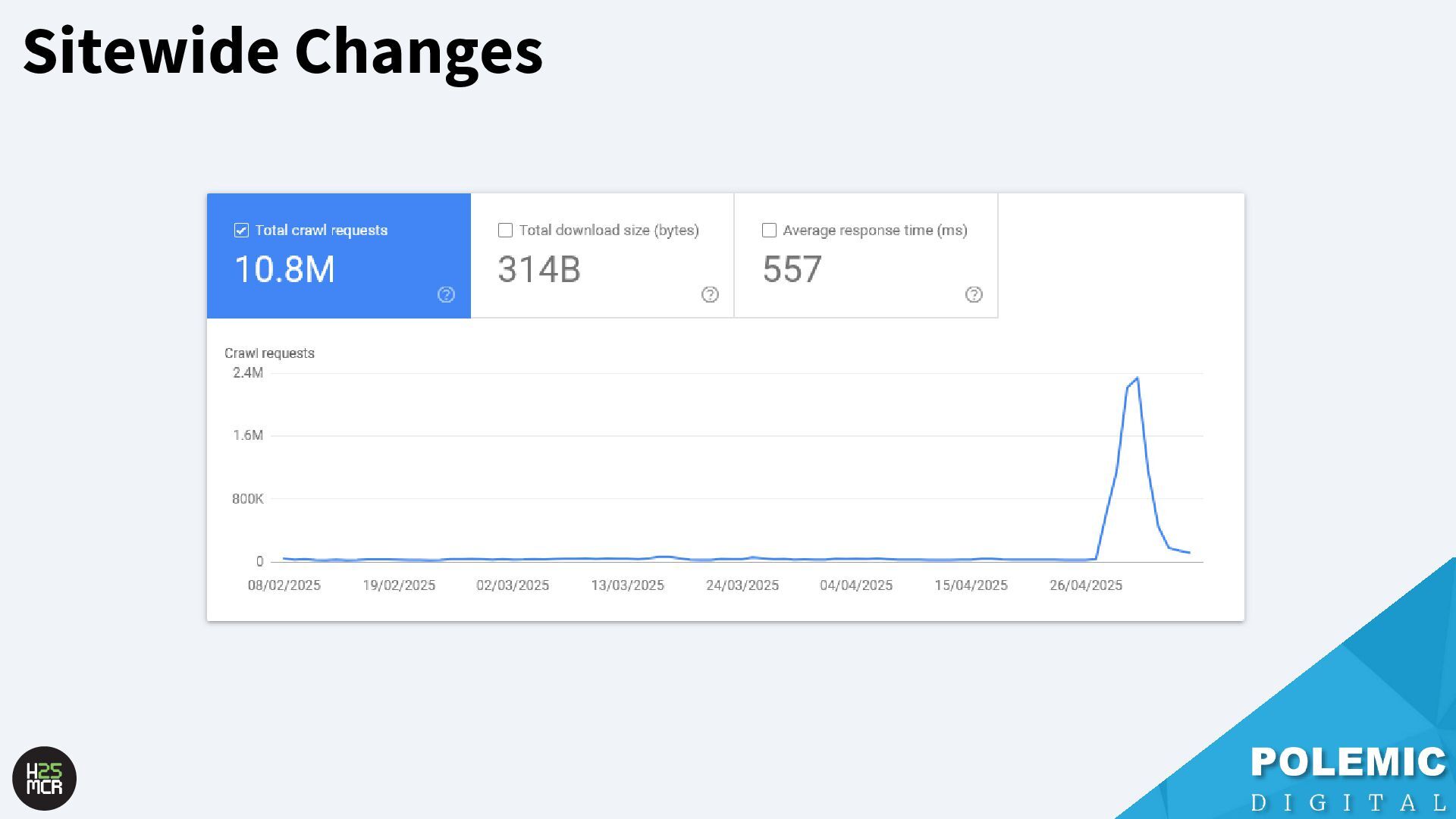
website; ➢ Crawl rate will temporarily be increased ➢ Ensures the changes are rapidly reflected in the index • Enable your hosting to handle increased crawl rate; ➢ Temporarily increase server capacity after a sitewide change ➢ Sitewide changes include: -Redesign -Site migrations -Large number of new URLs
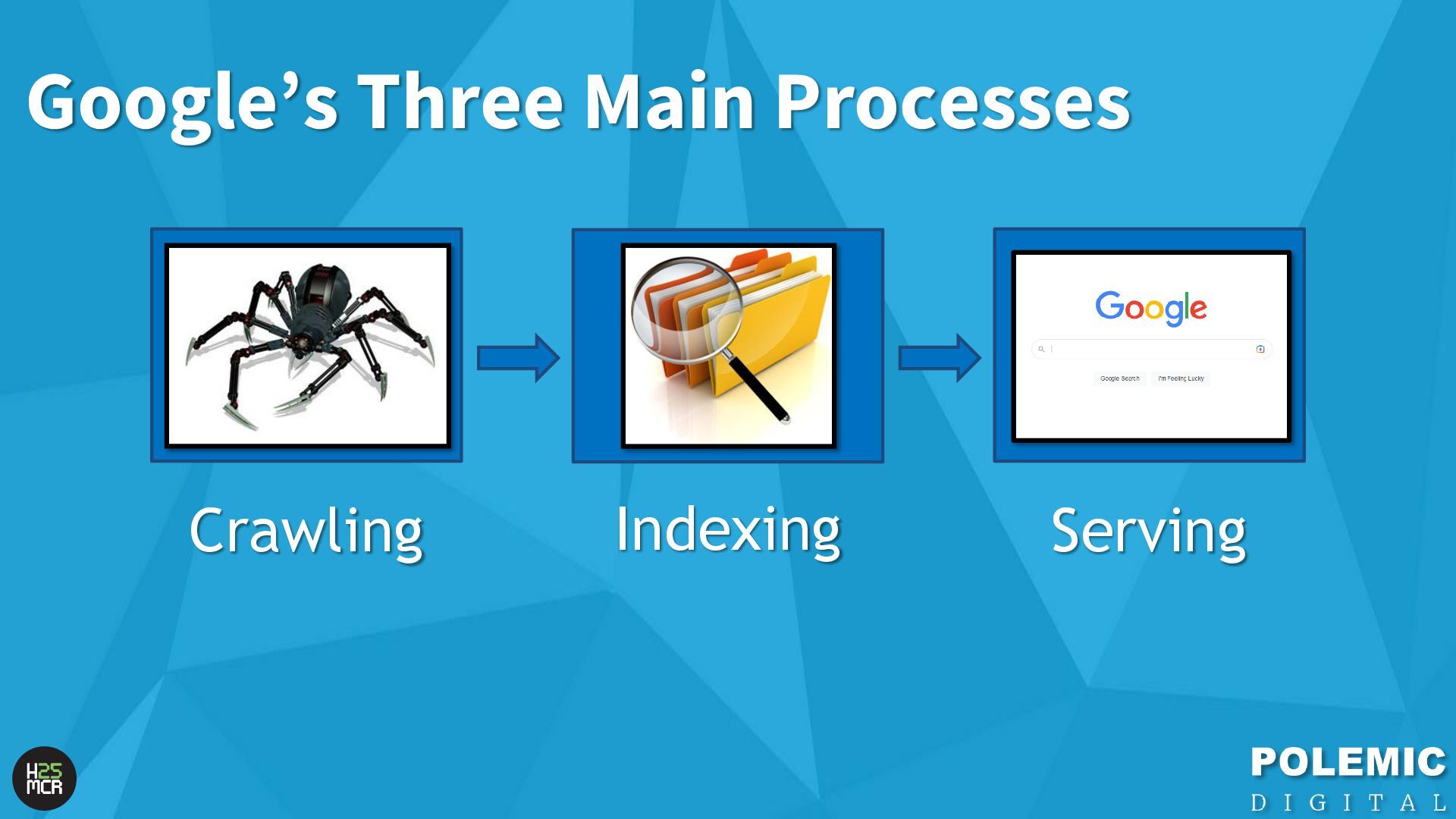
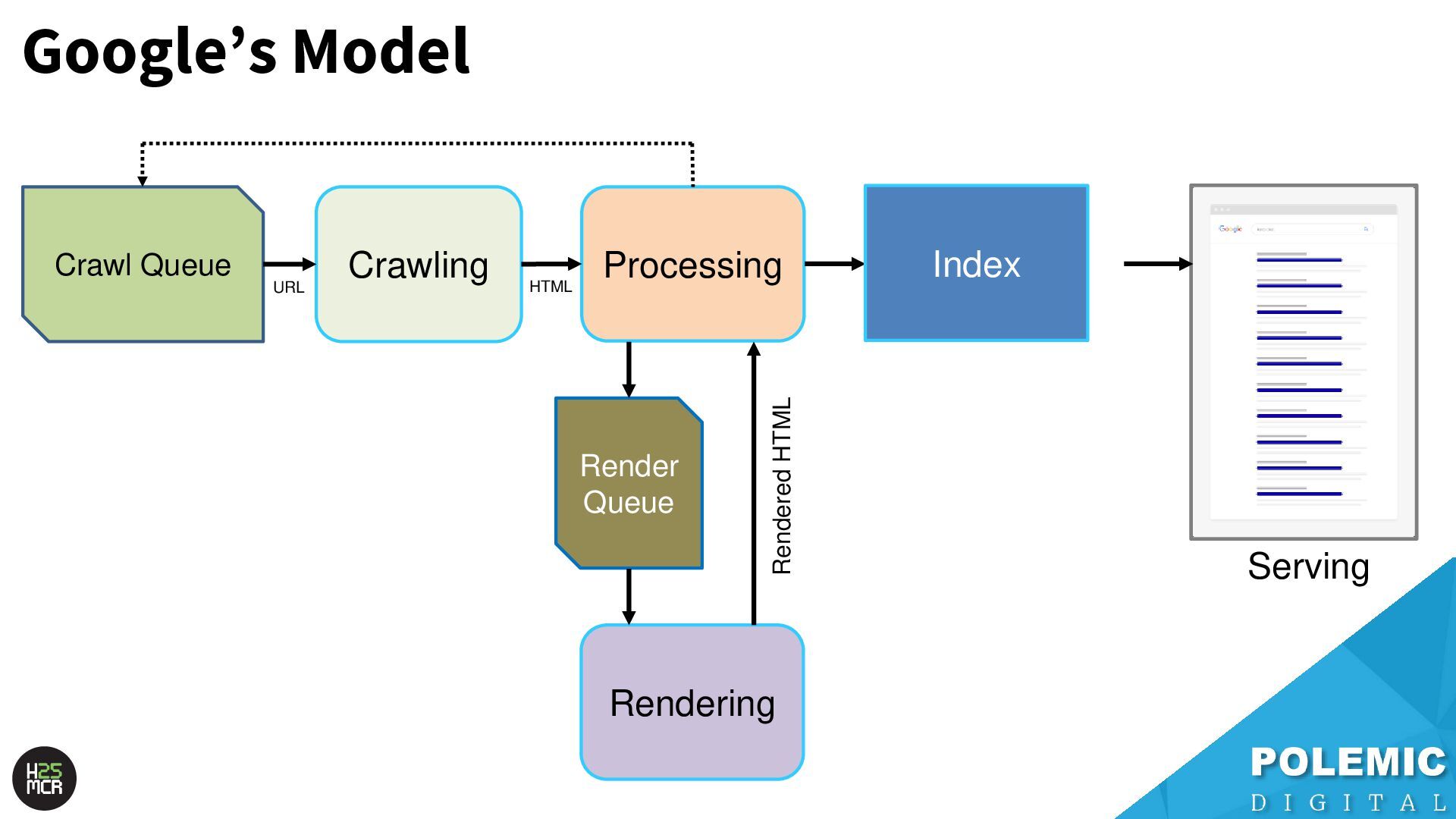
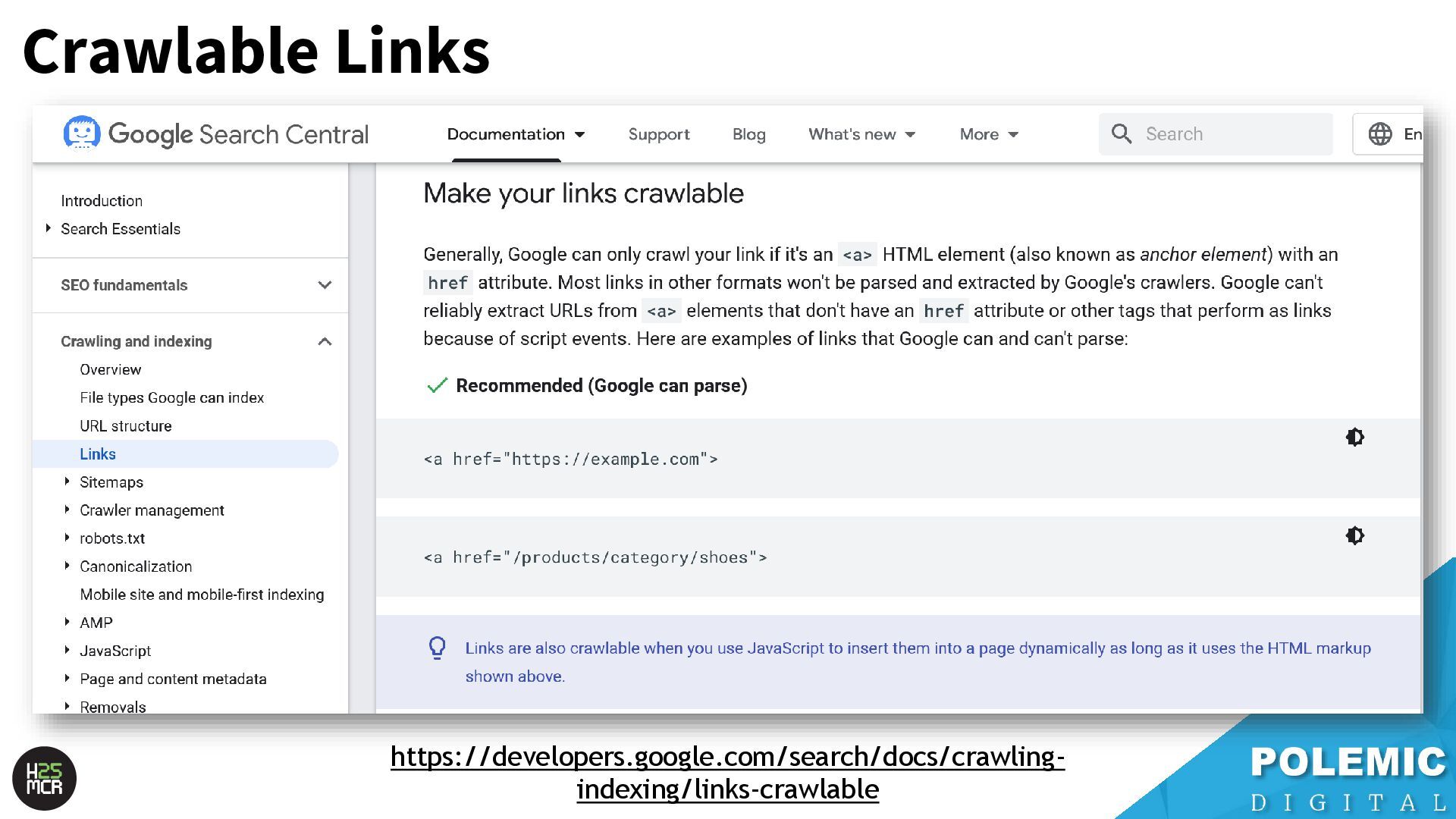
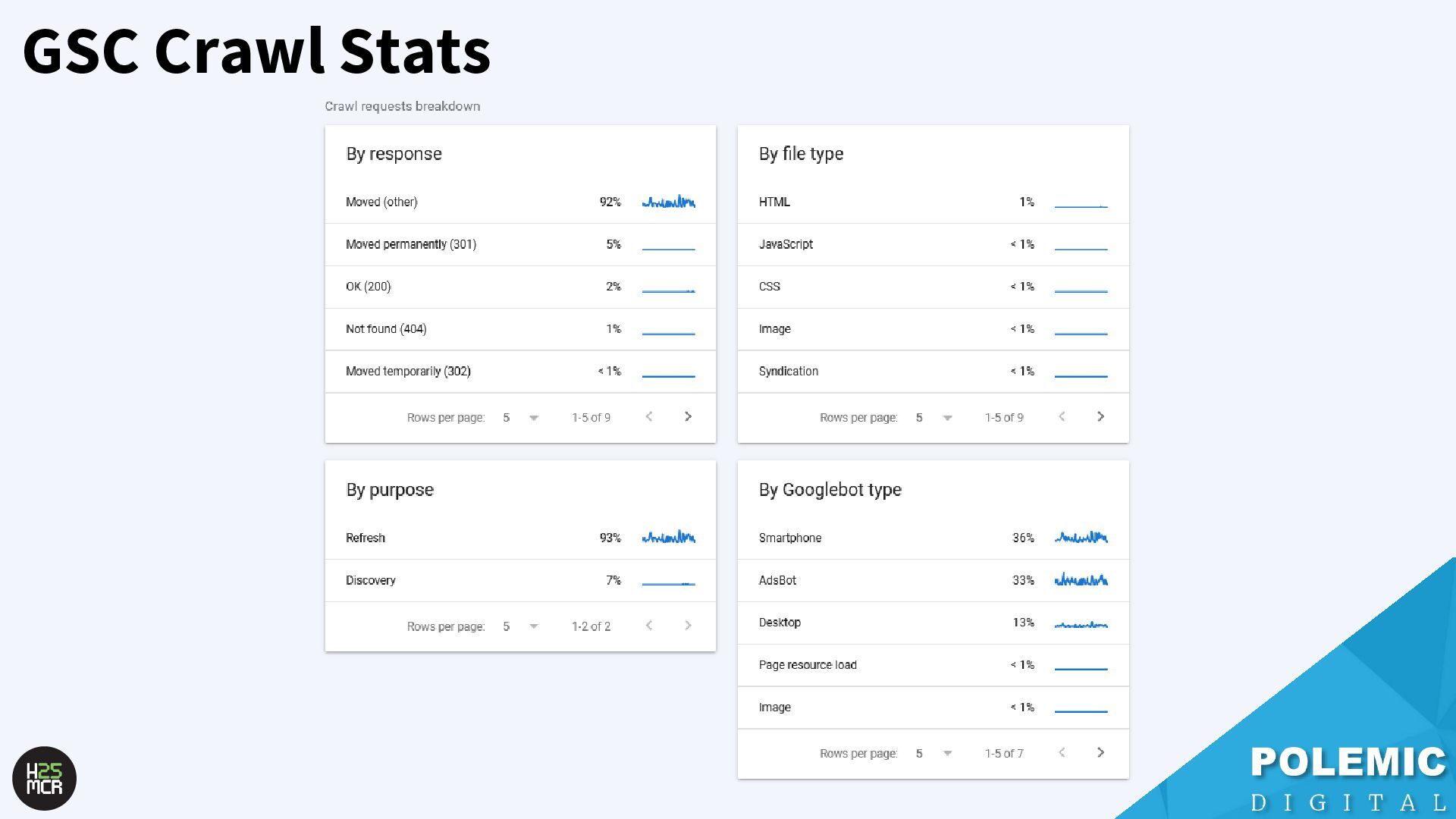
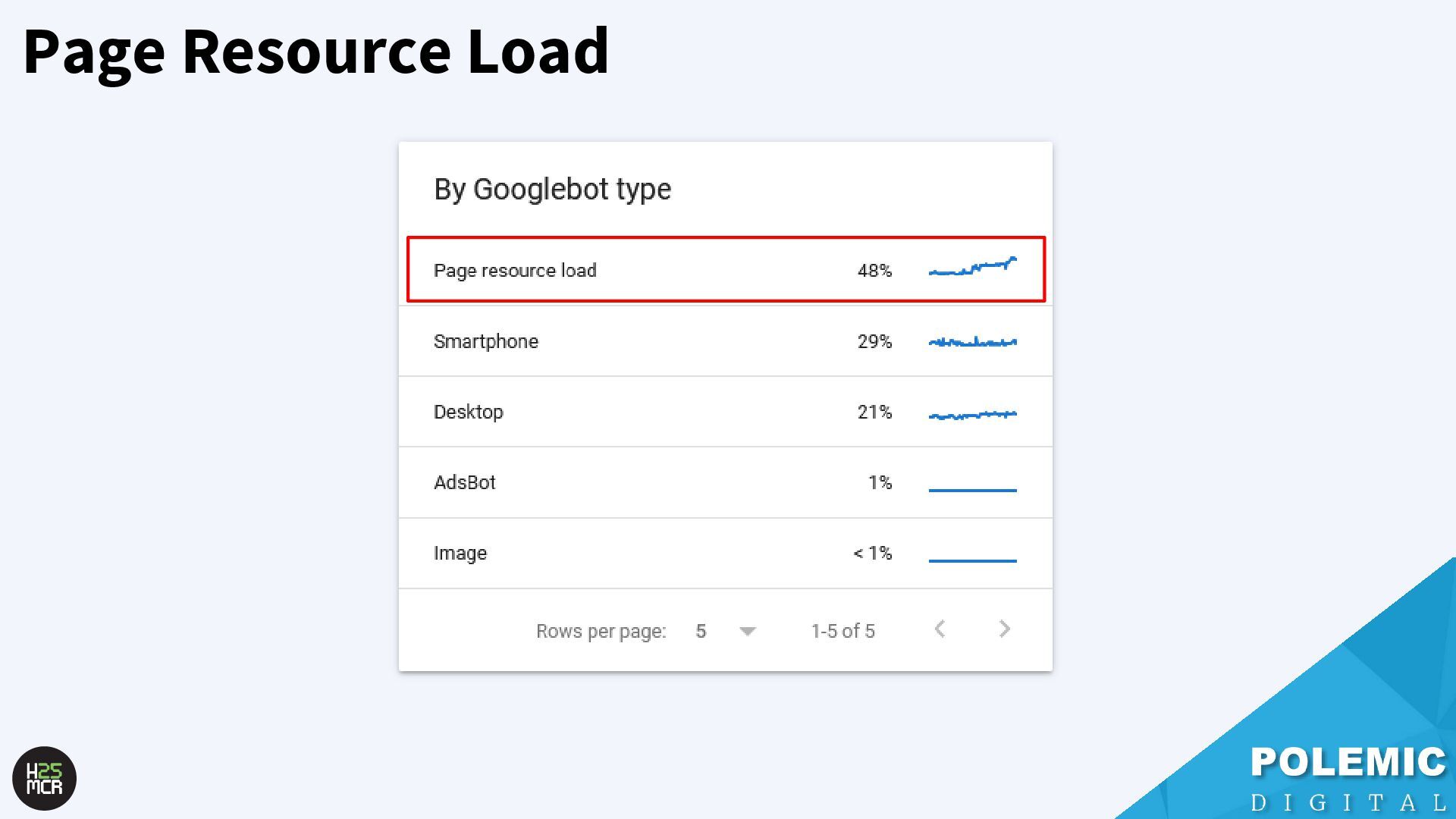
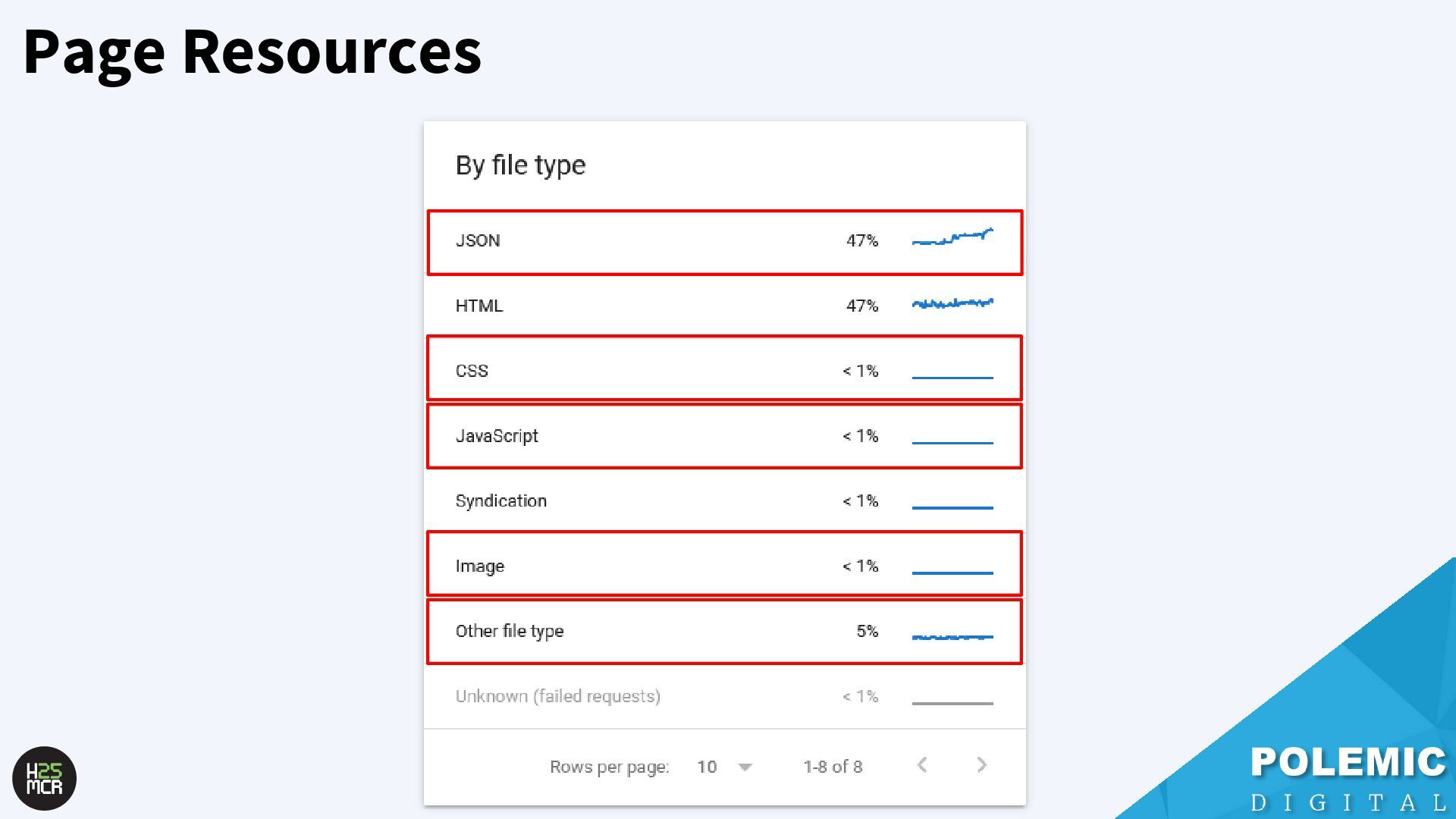
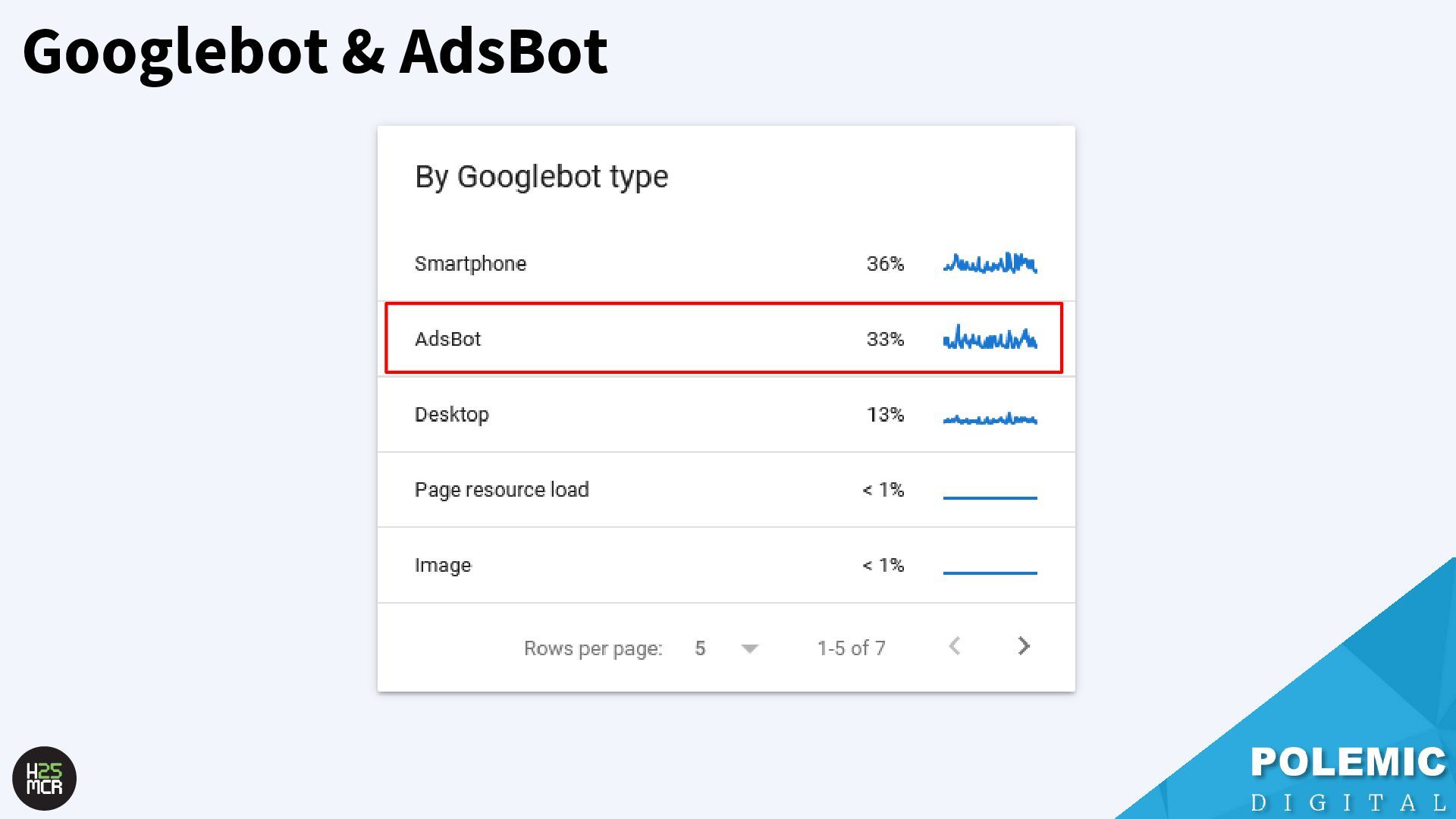
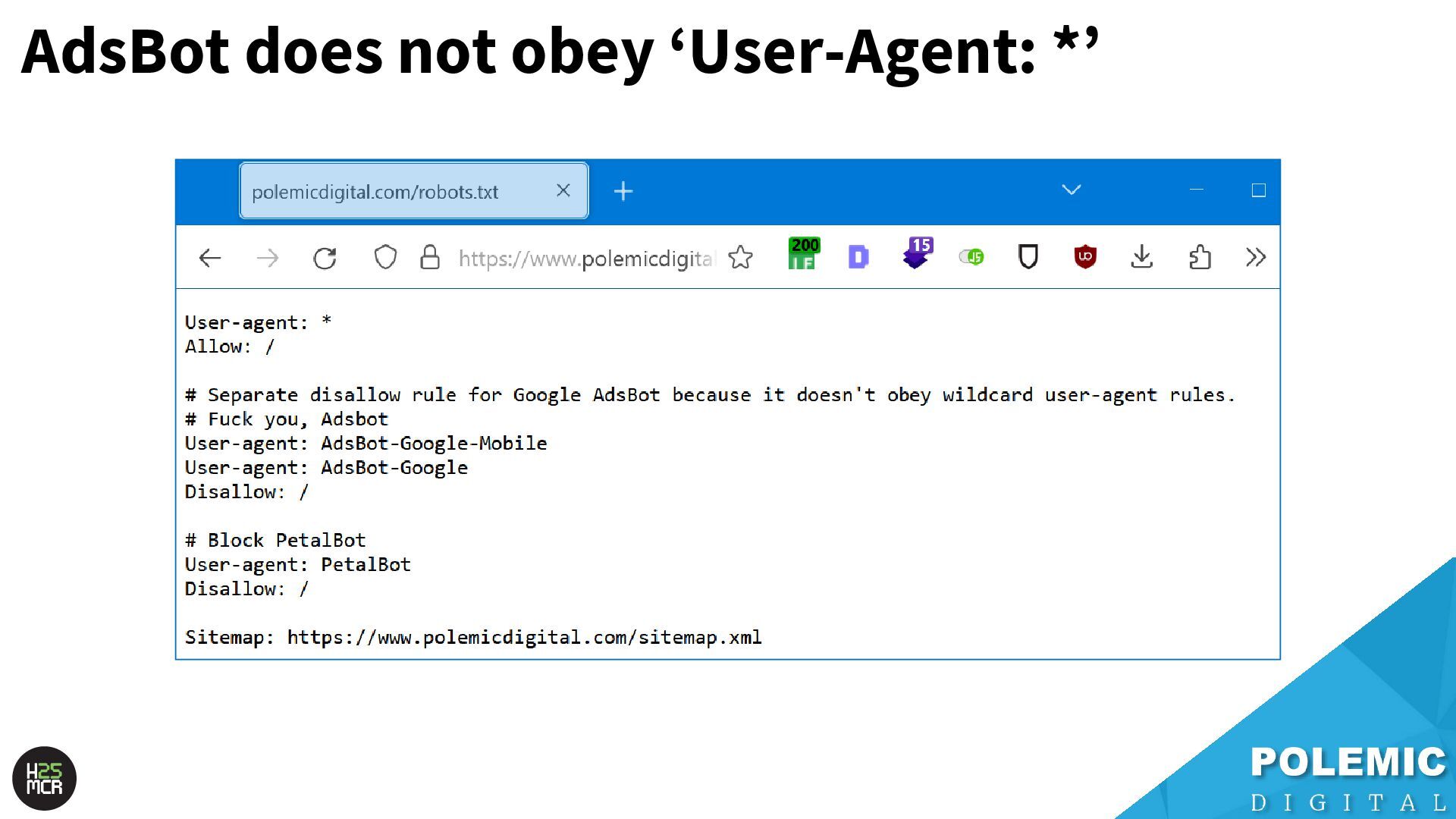
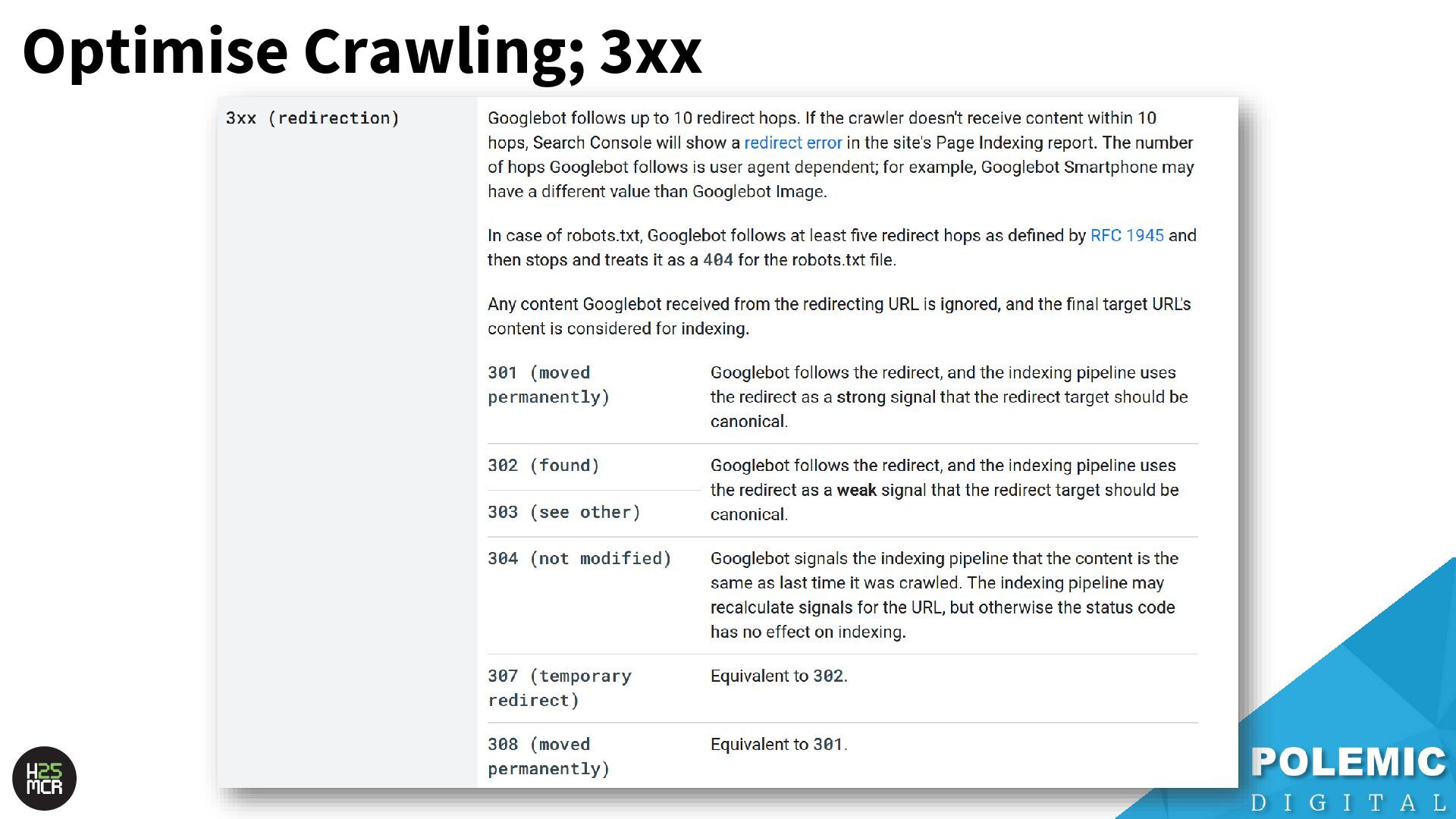
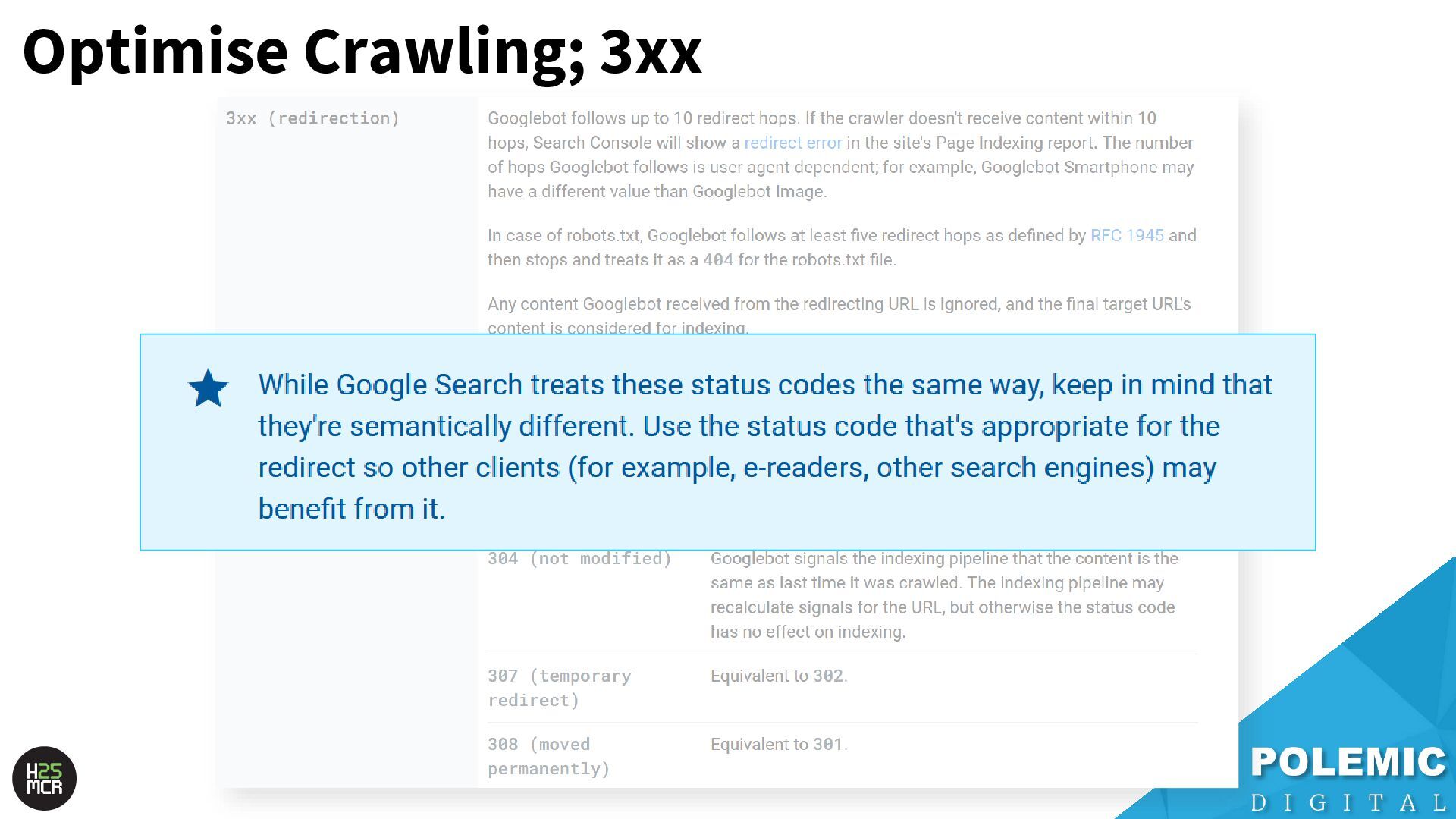
Googlebot; ➢ Not just HTML pages ➢ Reduce amount of HTTP requests per page • Link equity (PageRank) impacts crawling; ➢ More link value = more crawling ➢ Elevate key pages to VIPS • Each hostname has its own crawl budget; ➢ Offload resources to subdomains • AdsBot can use up crawl requests; ➢ Double-check your Google Ads campaigns • Serve correct HTTP status codes; ➢ Googlebot will adapt accordingly
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You [email protected] https://www.linkedin.com/in/barryadams/ https://www.SEOforGoogleNews.com/](https://files.speakerdeck.com/presentations/243b806103e944ae97e48a47ad003468/slide_46.jpg){kind=link}