Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Scaling your data infrastructure
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
barrachri
April 20, 2018
Technology
240
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Scaling your data infrastructure
Scaling your data infrastructure @ PyConNove
barrachri
April 20, 2018
More Decks by barrachri
See All by barrachri
Will Tech Save Us?
barrachri
0
120
How software can feed the World
barrachri
1
190
How to fight with yourself and win.
barrachri
0
350
Introduction to Statistics with Python
barrachri
0
460
EuroPython 2015 and the future
barrachri
2
130
Start with Flask
barrachri
3
200
Django & Docker
barrachri
6
1.1k
Other Decks in Technology
See All in Technology
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.4k
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
150
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
3.5k
知らん間に、回ってる
ming_ayami
0
360
初めてのDatabricks勉強会
taka_aki
2
250
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
620
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
100
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
380
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3k
Claude Codeとハーネスについて考えてみる
oikon48
18
8.9k
Featured
See All Featured
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Faster Mobile Websites
deanohume
310
32k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Believing is Seeing
oripsolob
1
170
Speed Design
sergeychernyshev
33
1.9k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
Code Reviewing Like a Champion
maltzj
528
40k
Typedesign – Prime Four
hannesfritz
42
3.1k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Transcript
Scaling your data infrastructure C H R I S T
I A N B A R R A @ P Y C O N N O V E
THE AGENDA 2 3 START THE DATA SCIENCE WORKFLOW SCALING
IS NOT JUST A MATTER OF MACHINE WHEN THE SIZE OF YOUR DATA MATTERS 1
THE AGENDA 4 5 CONTAINERIZED DATA SCIENCE CASSINY: PUT ALL
THE THINGS TOGETHER END
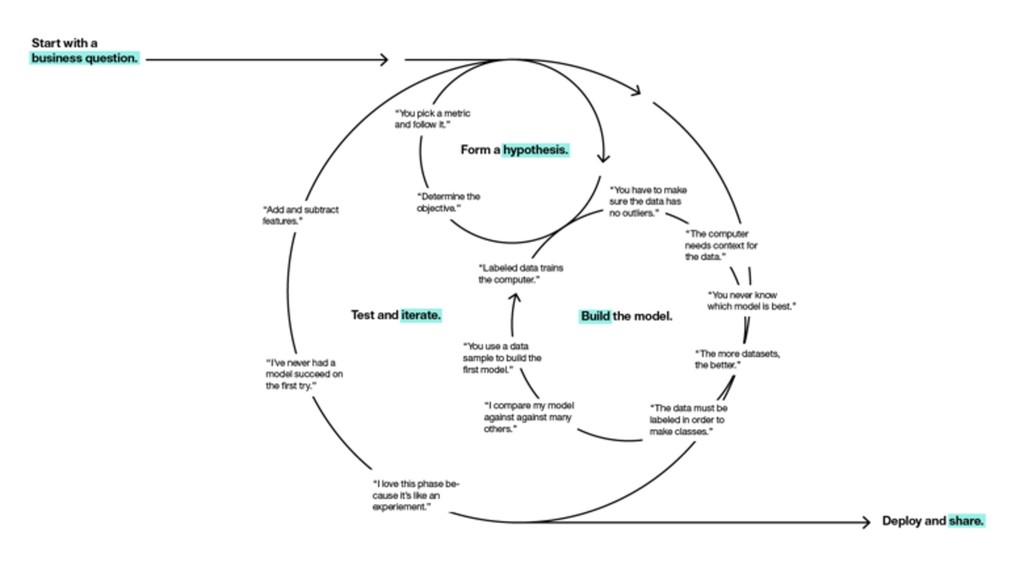
THE DATA SCIENCE WORKFLOW
HEXAGON PRESENTATION TEMPLATE
HOW YOU BUILD, ITERATE AND SHARE DEPENDS ON MANY THINGS
Your Users Your Product Your Team Your Company Your Tech Stack Your Domain
SCIKIT-LEARN DOCKER DATA SCIENCE TOOLBELT PANDAS JUPYTER RAY
SCALING IS NOT JUST A MATTER OF MACHINES
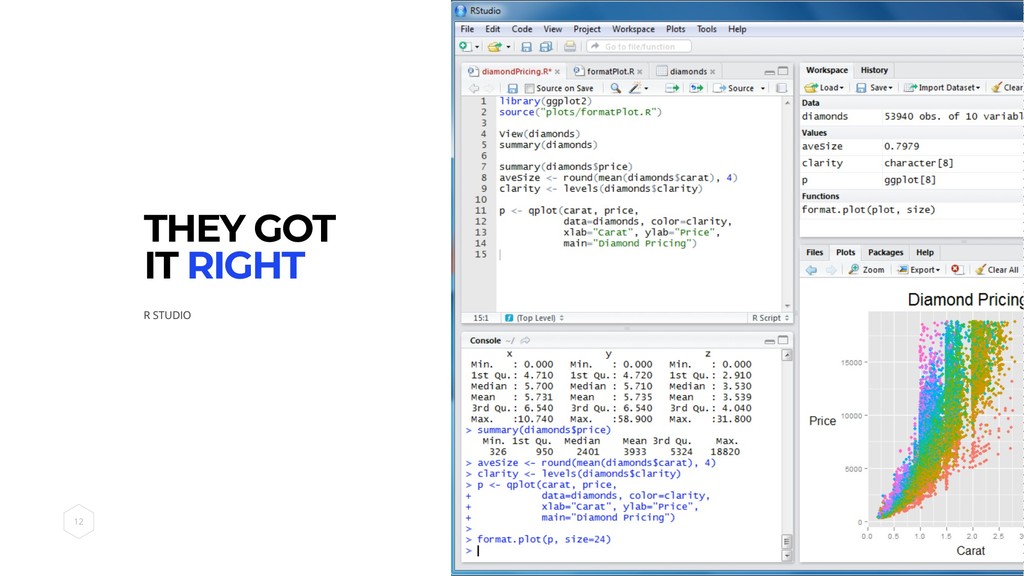
We all use it.
We really care about versioning. We have Untitled_1.ipynb, Untitled_2.ipynb and
Untitled_3.ipynb. HOMER SIMPSON C H I E F D A T A S C I E N T I S T D A T A B E E R I N C
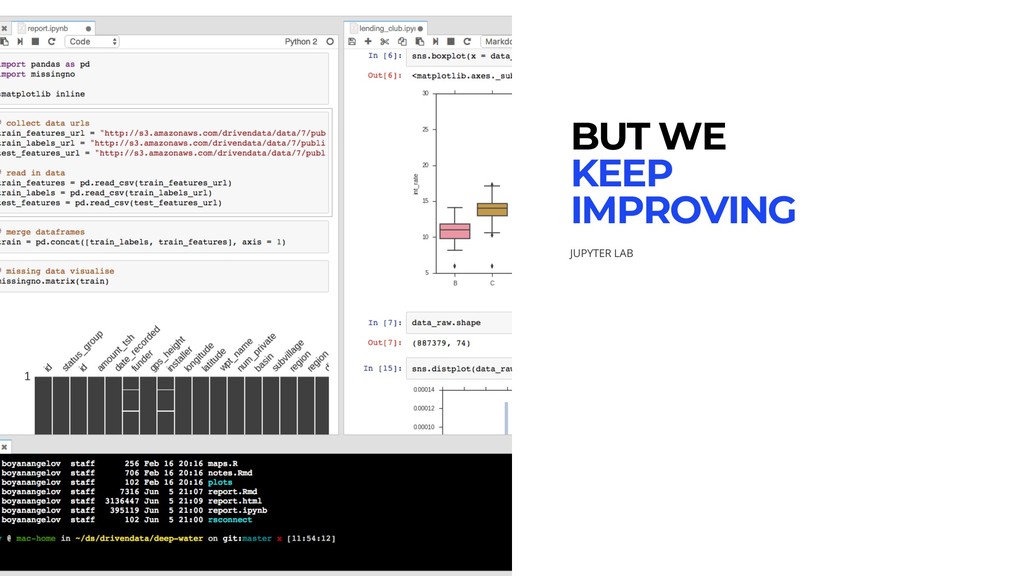
Since JSON is a plain text format, they can be
version-controlled and shared with colleagues. E X I P Y T H O N N O T E B O O K D O C U M E N T A T I O N
THEY GOT IT RIGHT
BUT WE KEEP IMPROVING
90% OF JUPITER IS MADE BY HYDROGEN
THE HARD THING ABOUT STORAGE
PARQUET P A R Q U E T + O
B J E C T S T O R A G E = YO U C A N Q U E R Y I T U S I N G S Q L PA N DA S H A S N AT I V E S U P P O R T F O R G E T A B O U T C S V
WHEN THE SIZE OF YOUR DATA MATTERS
IT’S TOO SLOW DOESN’T FIT IN YOUR RAM
CODE OPTIMIZATION APPROACH SCALING FROM DIFFERENT SIDES A BIGGER MACHINE
USE MULTIPLE CORES MORE MACHINES FRAMEWORKS: DASK RAY SPARK PANDAS: READ BY CHUNKS SCIKIT-LEARN: PARTIAL FIT
chunks & partial_fit 1 M A C H I N
E
Multiple machines. n M A C H I N E
S
I don’t want to use Spark/JVM, what do you have
for me? H A P P Y P Y T H O N U S E R
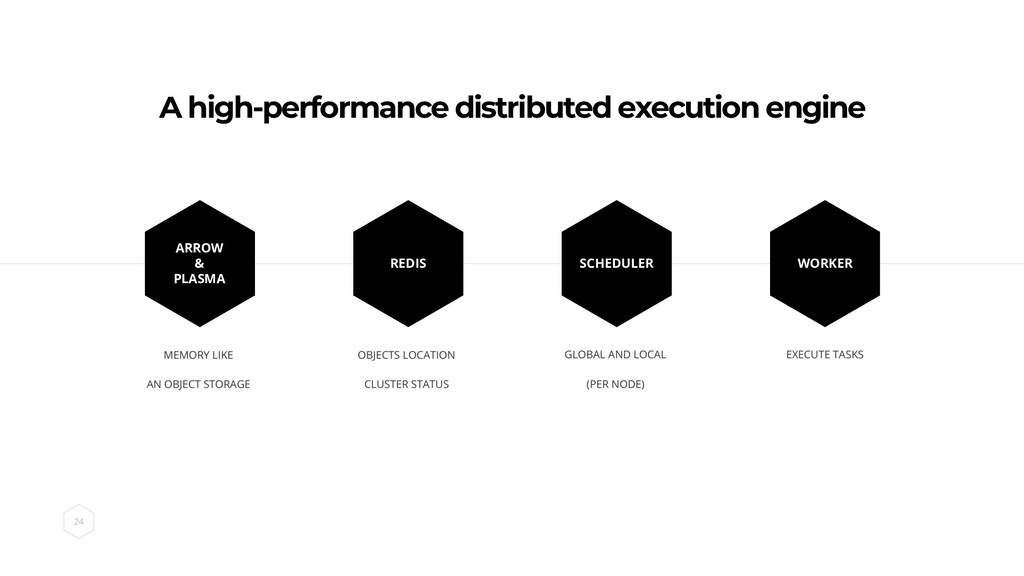
WHAT IS RAY?
A high-performance distributed execution engine REDIS SCHEDULER WORKER ARROW &
PLASMA
Use pandas through ray to query parquet files in an
object storage. W O R K I N P R O G R E S S
CONTAINERIZED DATA SCIENCE
If you trained a model with scikit-learn 0.18.1, will the
same model work with 0.19.1? P R O B L E M # 1
How do you share your models? P R O B
L E M # 2
How do you put your models in production? P R
O B L E M # 3
Containerize everything. T H E A N S W E
R
1. It’s damn easy to move things around 2. You
get versioning for free 3. Stack agnostic 4. Move Docker images around T O R E C A P
CASSINY: PUT ALL THE THINGS TOGETHER
CLEAR REQUIREMENTS CONTAINERIZED EASY OBJECT STORAGE JUPYTER + IPYTHON PLATFORM
AGNOSTIC
OPEN SOURCE
DEMO
TAKEAWAYS UNIFIED DATA WAREHOUSE KEEP YOUR CODE RUNNING ON ONE
MACHINE USE DOCKER TRY RAY BRING CI/CD TO YOUR DATASCIENCE WORKFLOW OBJECT STORAGE IS COOL DISTRIBUTED COMPUTING IS HARD I DIDN’T HAVE ANOTHER POINT
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}