" + it)) .doOnError(e -> e.printStackTrace()); } // ... Flux<Item> items = getFlux(); addLogging(items); items.subscribe(); 1. Will print both items and errors 2. Will only print items, not errors @bsideup
" + it)) .doOnError(e -> e.printStackTrace()); } // ... Flux<Item> items = getFlux(); addLogging(items); items.subscribe(); 1. Will print both items and errors 2. Will only print items, not errors 3. Will not print anything @bsideup
" + it)) .doOnError(e -> e.printStackTrace()); } // ... Flux<Item> items = getFlux(); addLogging(items); items.subscribe(); 1. Will print both items and errors 2. Will only print items, not errors 3. Will not print anything @bsideup
sub-stream, and join the current and the sub-stream. • concatMap - same as flatMap, but one-by-one • switchMap - same as concatMap, but will cancel the previous sub- stream when a new item arrives @bsideup
sub-stream, and join the current and the sub-stream. • concatMap - same as flatMap, but one-by-one • switchMap - same as concatMap, but will cancel the previous sub- stream when a new item arrives • flatMapSequential - same as flatMap, but preserves the order of sub- stream items according to the original stream’s order @bsideup
may sneak into your production system • Use https://github.com/reactor/BlockHound to detect them • Supports multiple frameworks (Reactor, RxJava, etc) • … and maybe even Kotlin: https://github.com/Kotlin/kotlinx.coroutines/issues/1031 • Use a dedicated pool for the necessary blocking calls, or schedule them on the Schedulers.boundedElastic() built-in pool if they happen rarely @bsideup
the provided callback when the send has been acknowledged.” - Javadoc java.lang.Error: Blocking call! java.lang.Object#wait at reactor.BlockHound$Builder.lambda$new$0(BlockHound.java:154) at reactor.BlockHound$Builder.lambda$install$8(BlockHound.java:254) at reactor.BlockHoundRuntime.checkBlocking(BlockHoundRuntime.java:43) at java.lang.Object.wait(Object.java) at org.apache.kafka.clients.Metadata.awaitUpdate(Metadata.java:181) at org.apache.kafka.clients.producer.KafkaProducer.waitOnMetadata(KafkaProducer.java:938) at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:823) at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:803) @bsideup
the provided callback when the send has been acknowledged.” - Javadoc java.lang.Error: Blocking call! java.lang.Object#wait at reactor.BlockHound$Builder.lambda$new$0(BlockHound.java:154) at reactor.BlockHound$Builder.lambda$install$8(BlockHound.java:254) at reactor.BlockHoundRuntime.checkBlocking(BlockHoundRuntime.java:43) at java.lang.Object.wait(Object.java) at org.apache.kafka.clients.Metadata.awaitUpdate(Metadata.java:181) at org.apache.kafka.clients.producer.KafkaProducer.waitOnMetadata(KafkaProducer.java:938) at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:823) at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:803) https://issues.apache.org/jira/browse/KAFKA-3539 @bsideup
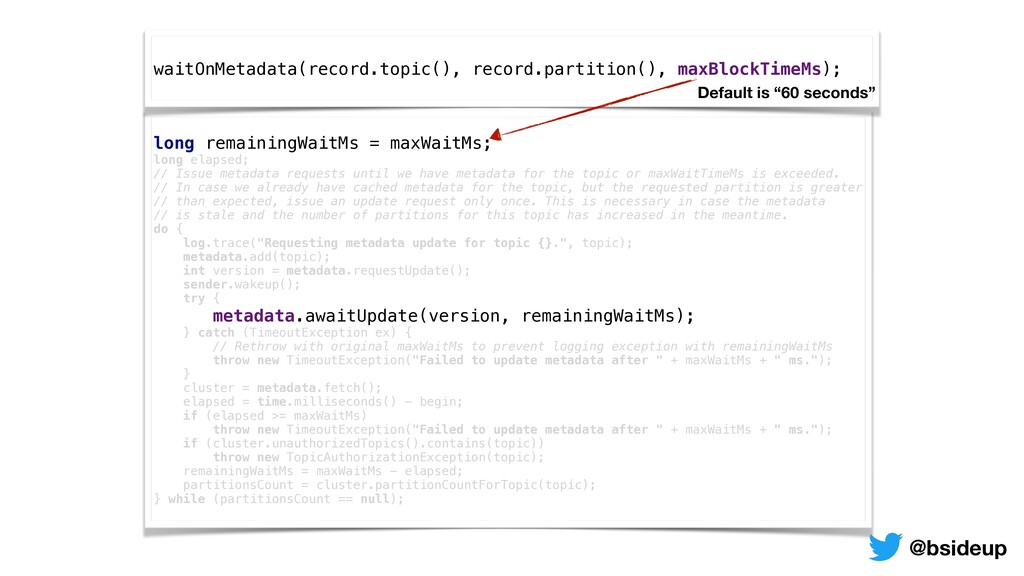
until we have metadata for the topic or maxWaitTimeMs is exceeded. // In case we already have cached metadata for the topic, but the requested partition is greater // than expected, issue an update request only once. This is necessary in case the metadata // is stale and the number of partitions for this topic has increased in the meantime. do { log.trace("Requesting metadata update for topic {}.", topic); metadata.add(topic); int version = metadata.requestUpdate(); sender.wakeup(); try { metadata.awaitUpdate(version, remainingWaitMs); } catch (TimeoutException ex) { // Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms."); } cluster = metadata.fetch(); elapsed = time.milliseconds() - begin; if (elapsed >= maxWaitMs) throw new TimeoutException("Failed to update metadata after " + maxWaitMs + " ms."); if (cluster.unauthorizedTopics().contains(topic)) throw new TopicAuthorizationException(topic); remainingWaitMs = maxWaitMs - elapsed; partitionsCount = cluster.partitionCountForTopic(topic); } while (partitionsCount == null); waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs); Default is “60 seconds” @bsideup
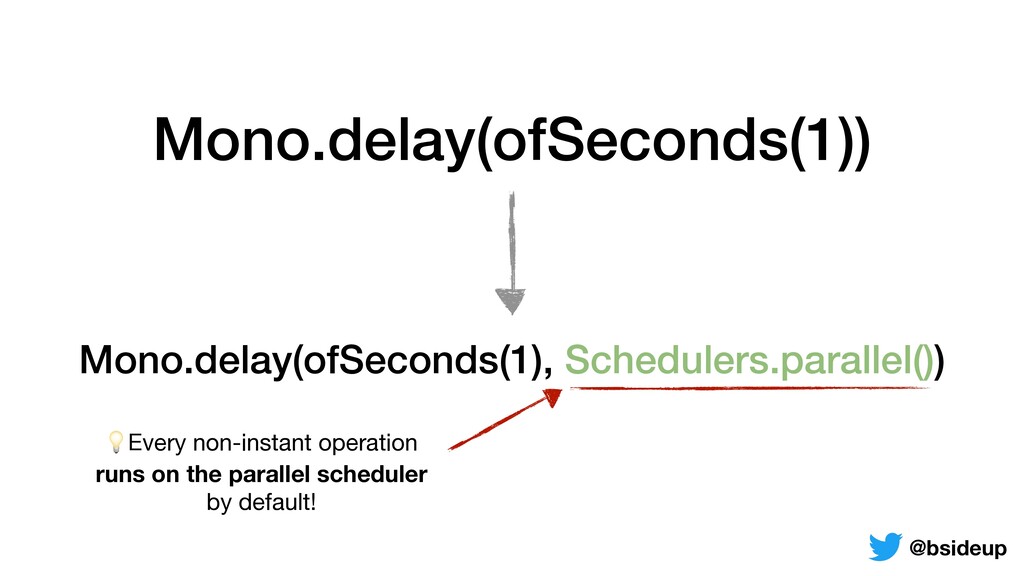
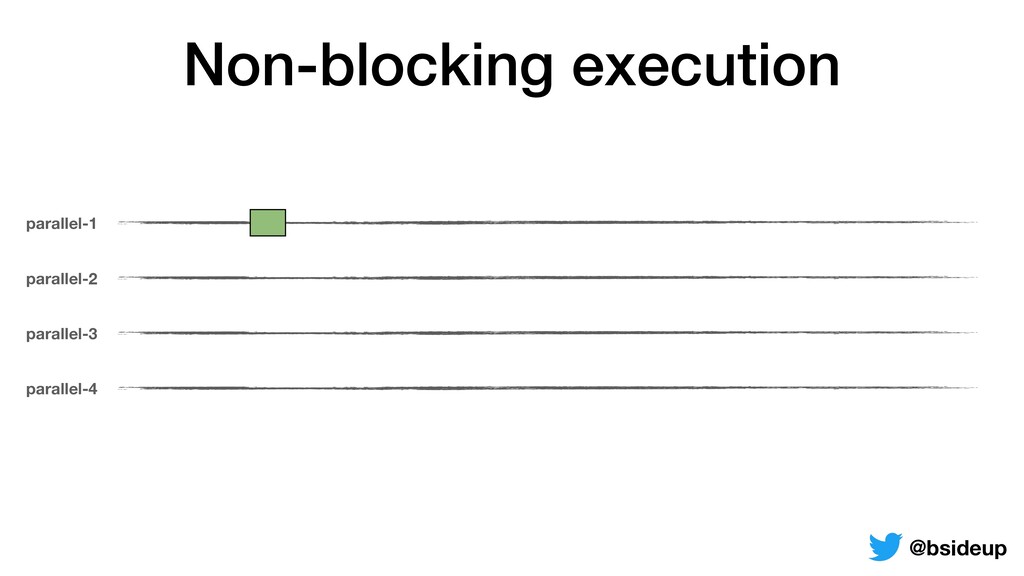
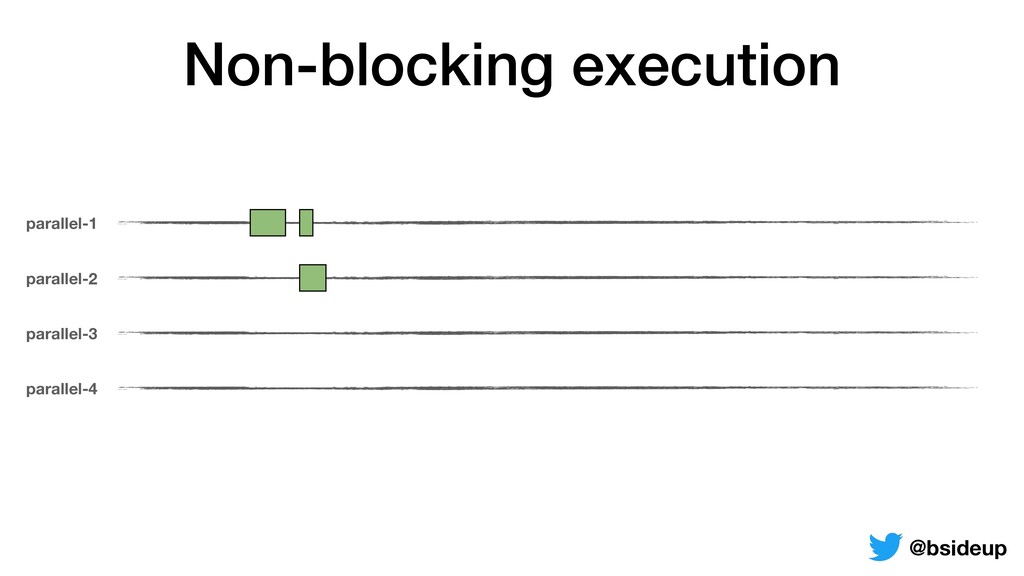
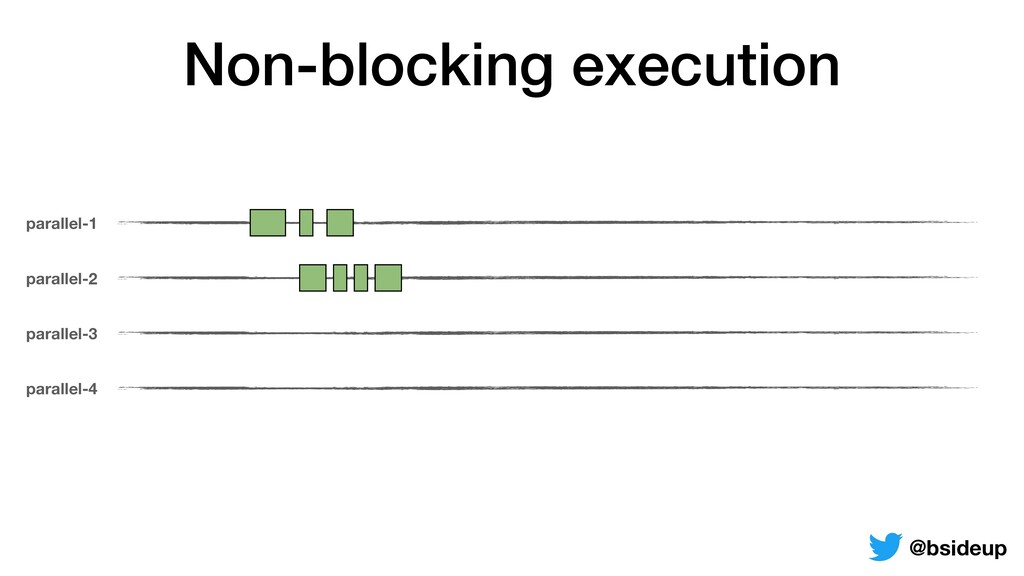
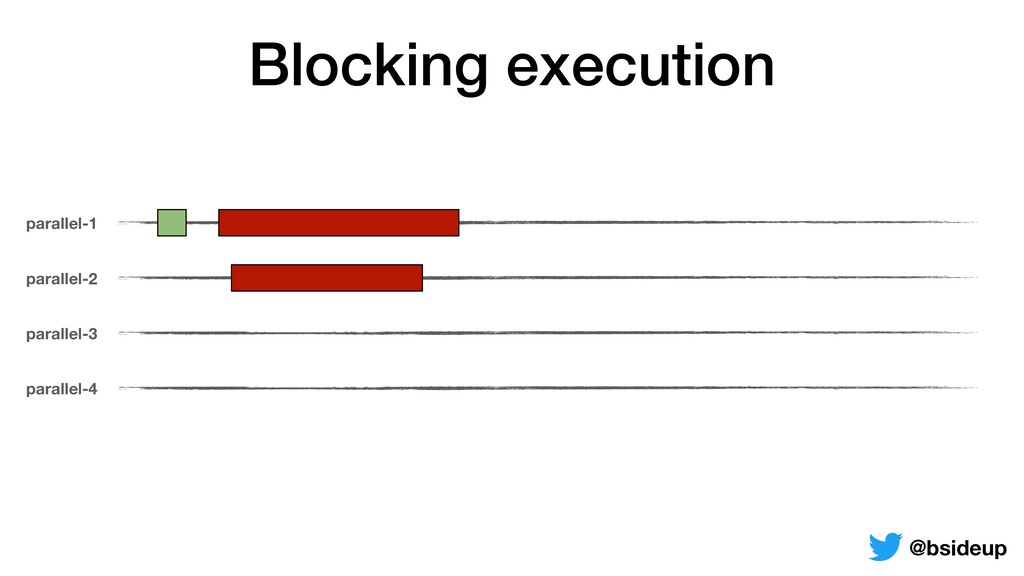
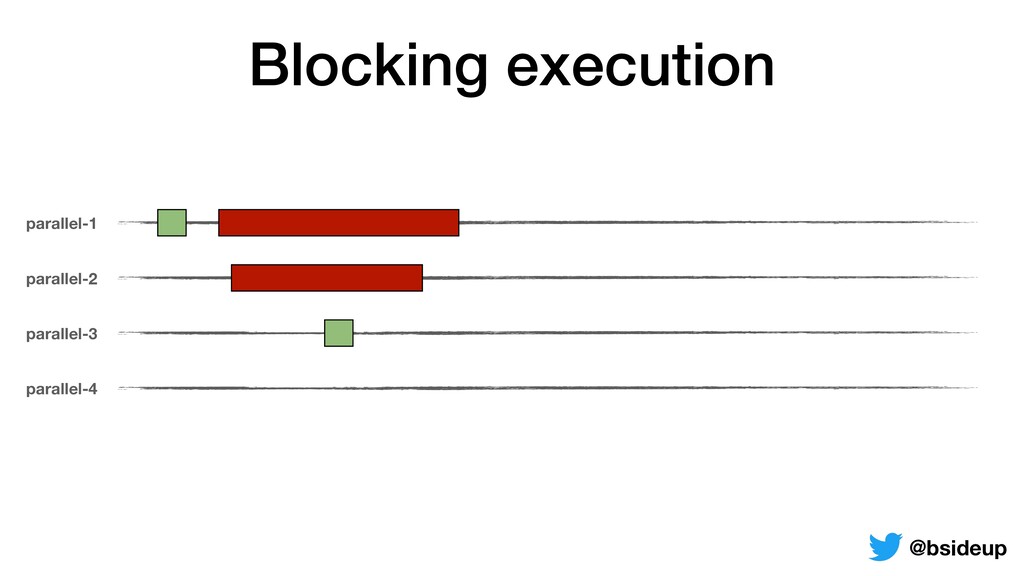
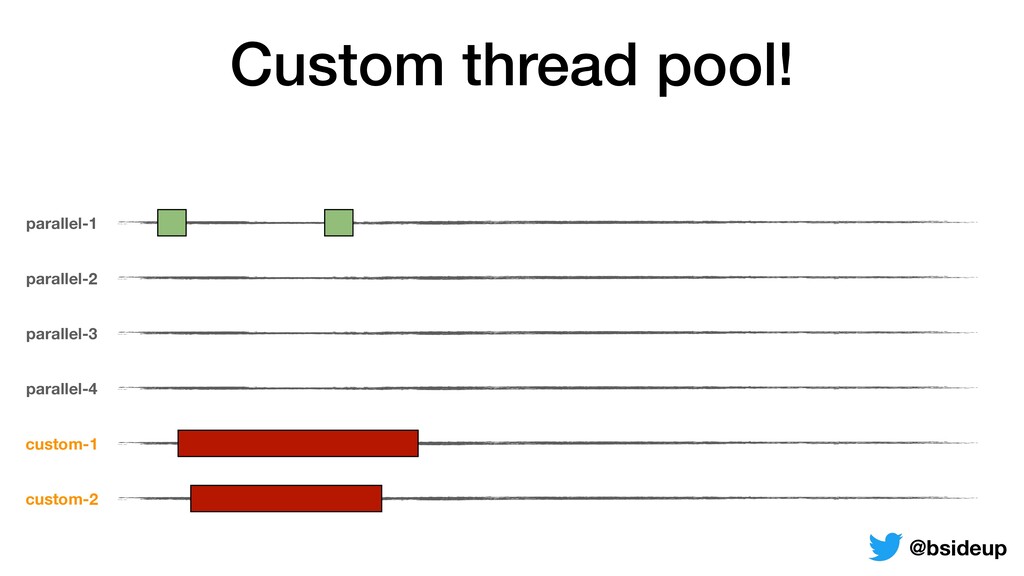
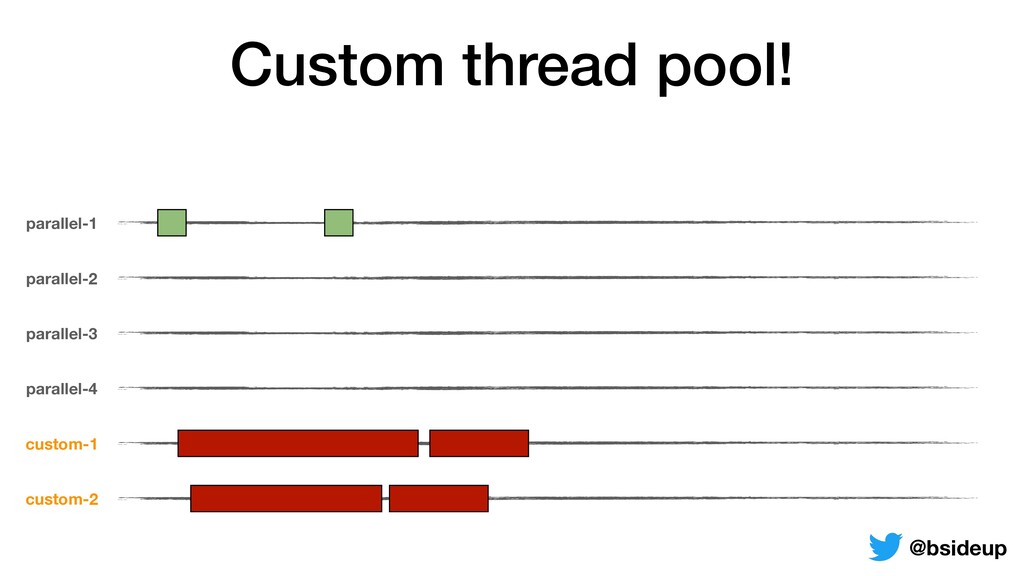
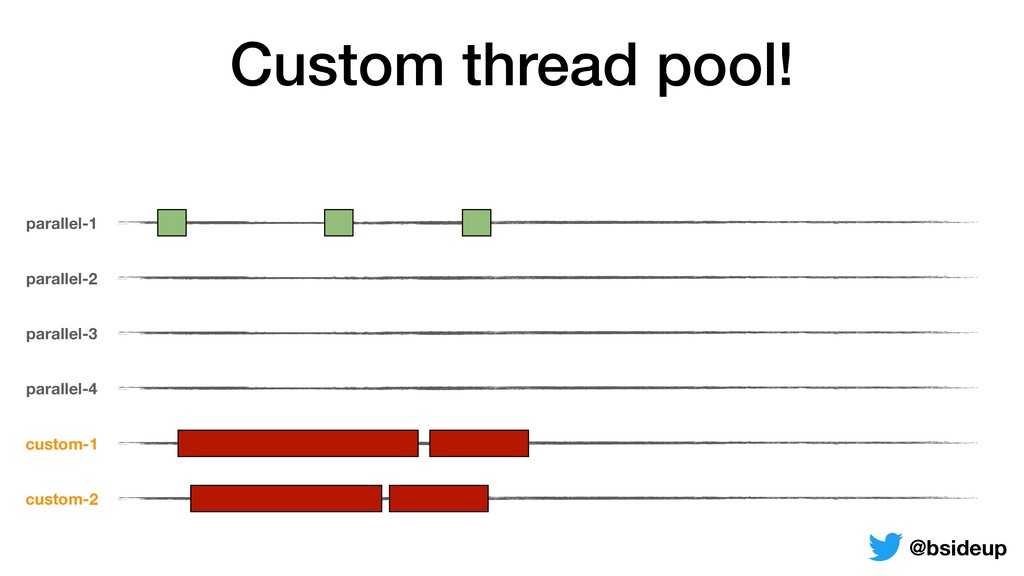
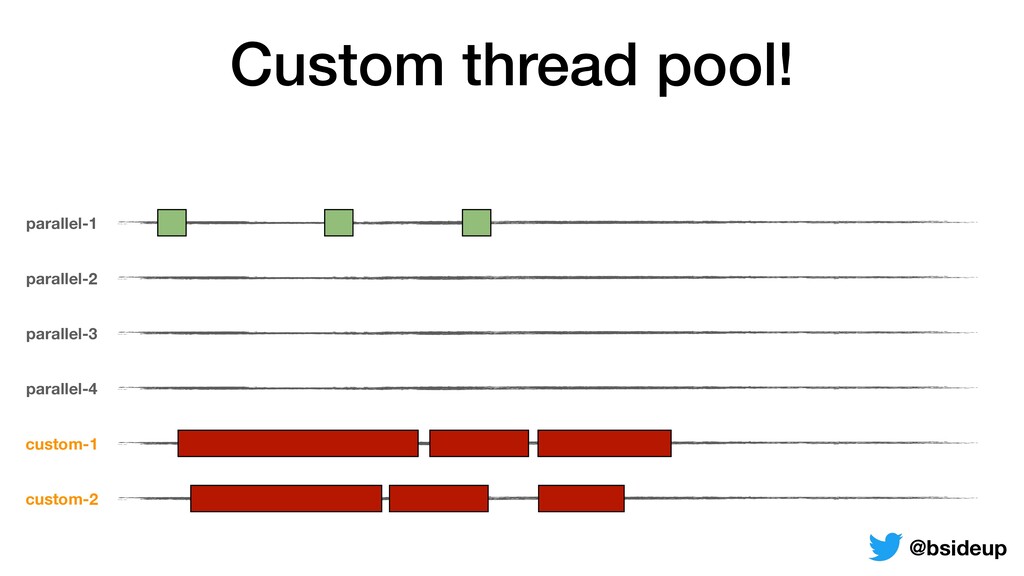
by multiple threads • Everything is non-blocking, an accepted request may be returned to the client from another thread • ThreadLocals must be propagated from one thread to another @bsideup
fail if no items emitted • .retry()/retryWithBackoff() - retry the subscription on failure • .repeatWhenEmpty() - repeat the subscription when it completes without values @bsideup
fail if no items emitted • .retry()/retryWithBackoff() - retry the subscription on failure • .repeatWhenEmpty() - repeat the subscription when it completes without values • .defaultIfEmpty() - fallback when empty @bsideup
fail if no items emitted • .retry()/retryWithBackoff() - retry the subscription on failure • .repeatWhenEmpty() - repeat the subscription when it completes without values • .defaultIfEmpty() - fallback when empty • .onErrorResume() - fallback on error @bsideup
Read about Hooks.onOperatorDebug()… • … but use reactor-tools’ ReactorDebugAgent (works in prod too) • https://spring.io/blog/2019/03/06/flight-of-the-flux-1-assembly-vs- subscription - great article from Simon Basle about the internals @bsideup
Think about the resiliency • Start gradually • Prepare for day 2 • Use it for heavy computations • Care about the threads • Block non-blocking threads • Use ThreadLocals • Be afraid of it ;) DO… DON’T… @bsideup
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}