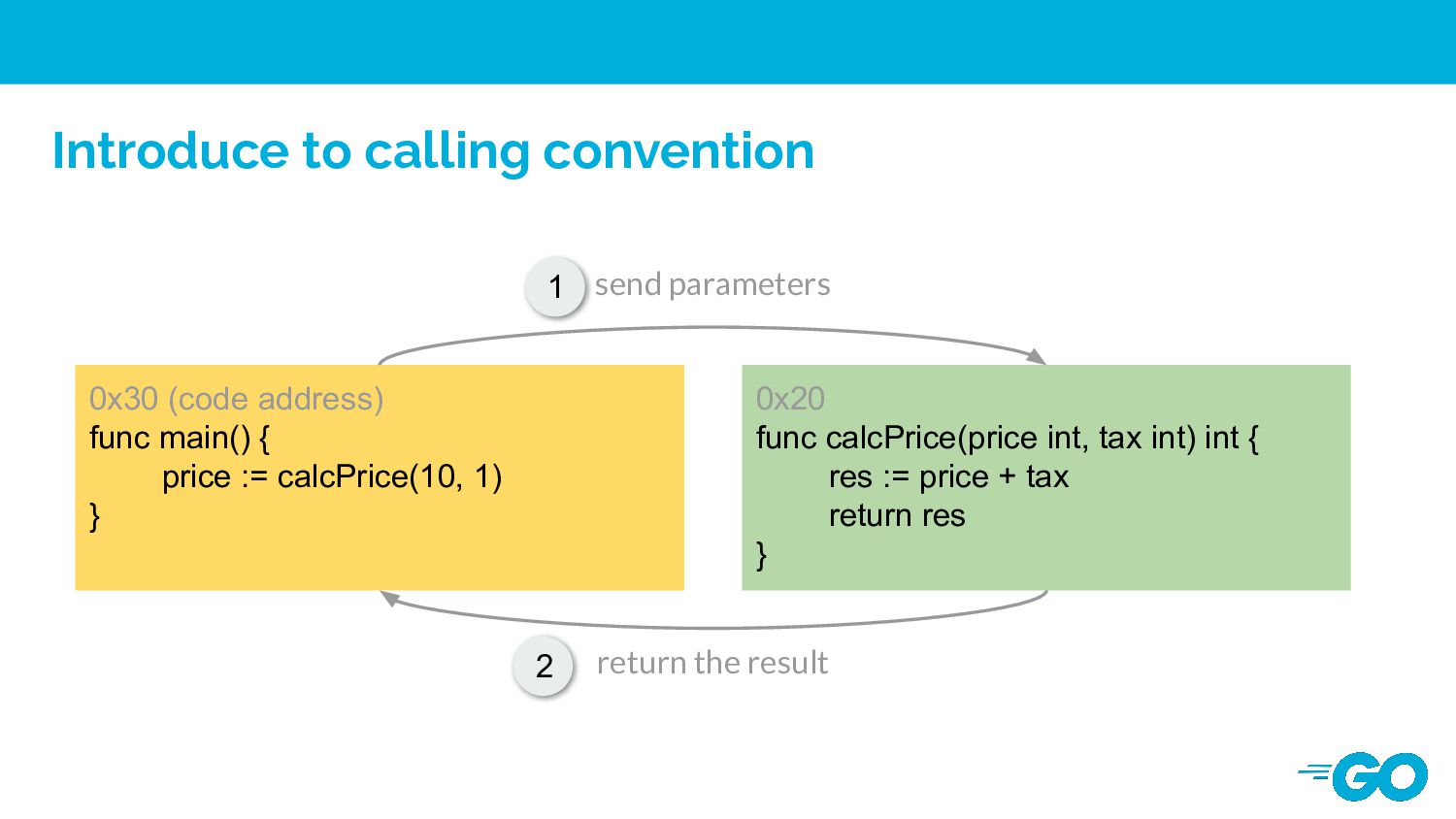
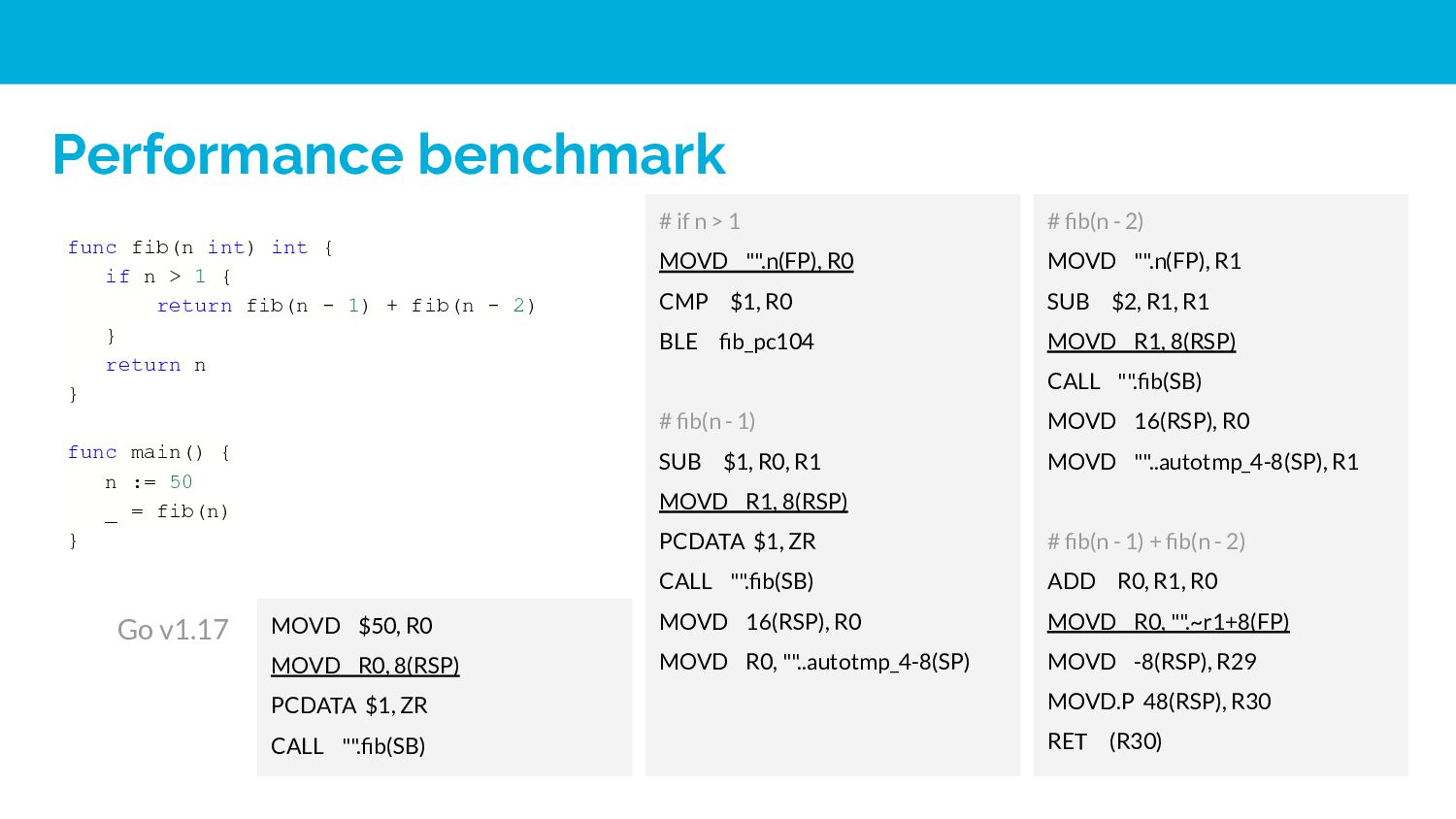
Application Binary Interface (ABI), it defines how subroutines receive parameters from their caller and how they return a result. https://en.wikipedia.org/wiki/Calling_convention
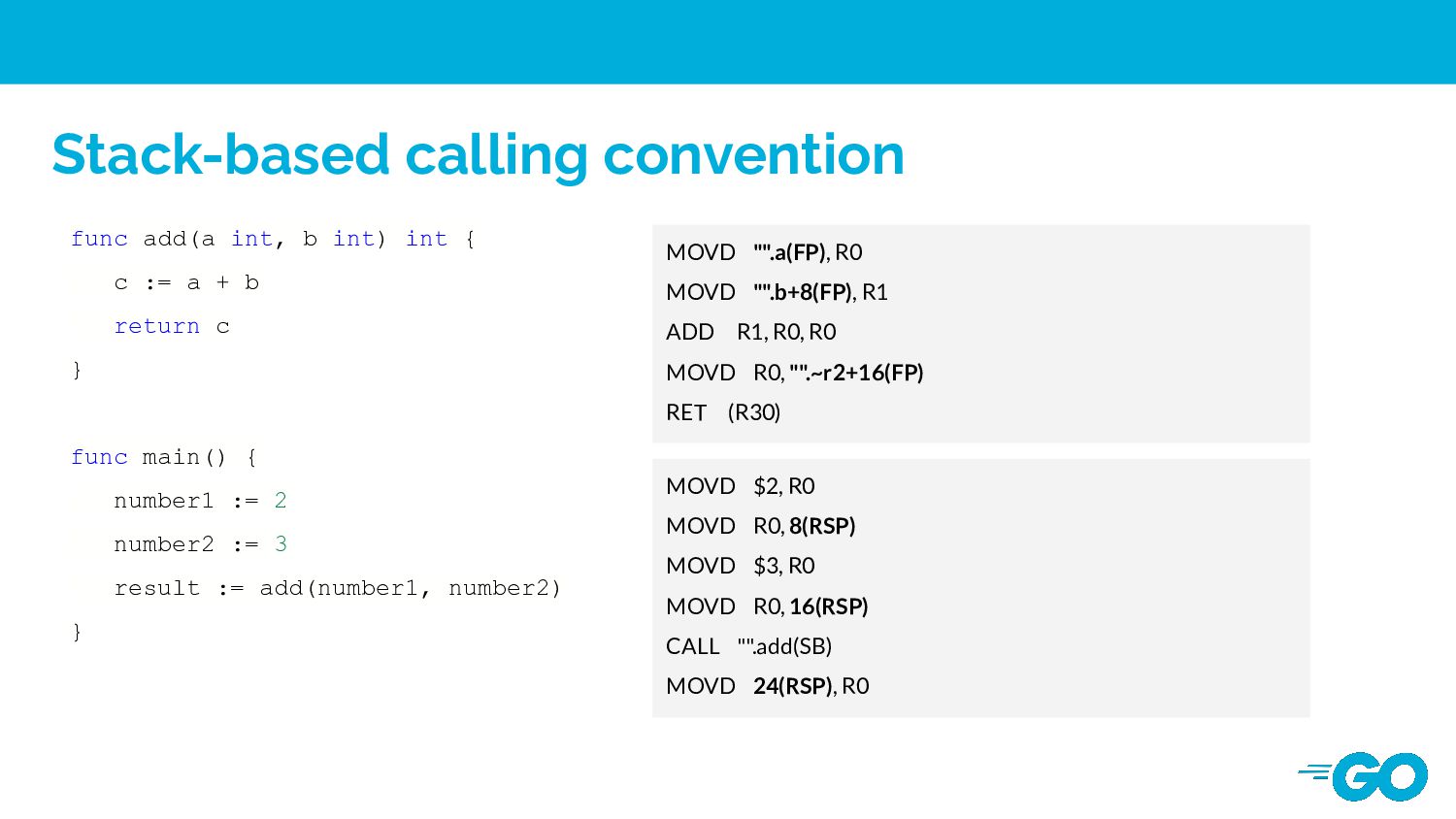
(go 1.15) Why Go use a stacked-based calling convention before go 1.17 1. All platforms can use essentially the same conventions 2. Simplify the implementation of loacal variable allocation 3. Simplify the stack tracing for garbage collection and stack growth Drawbacks It leaves a lot of performance on the table.
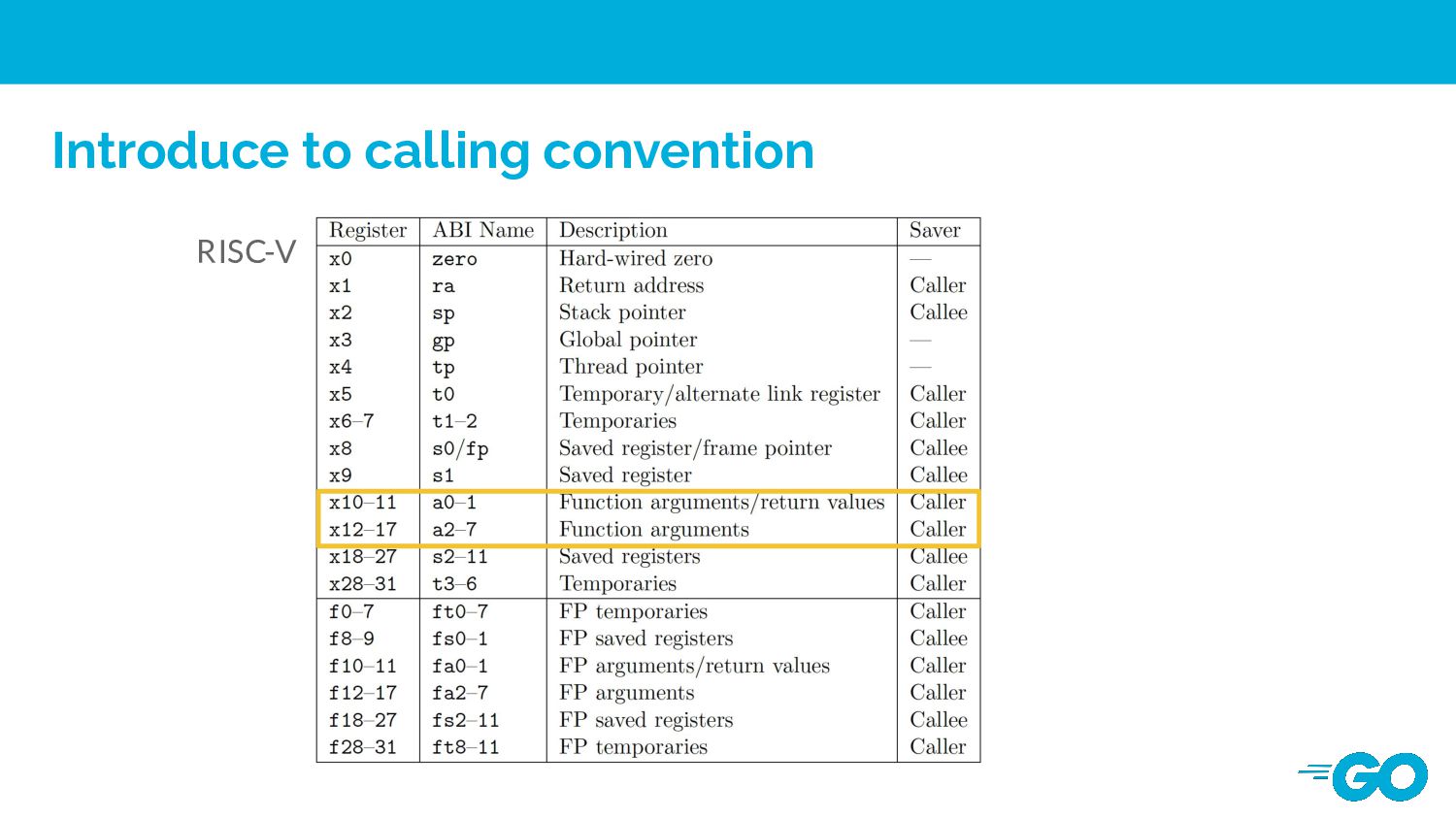
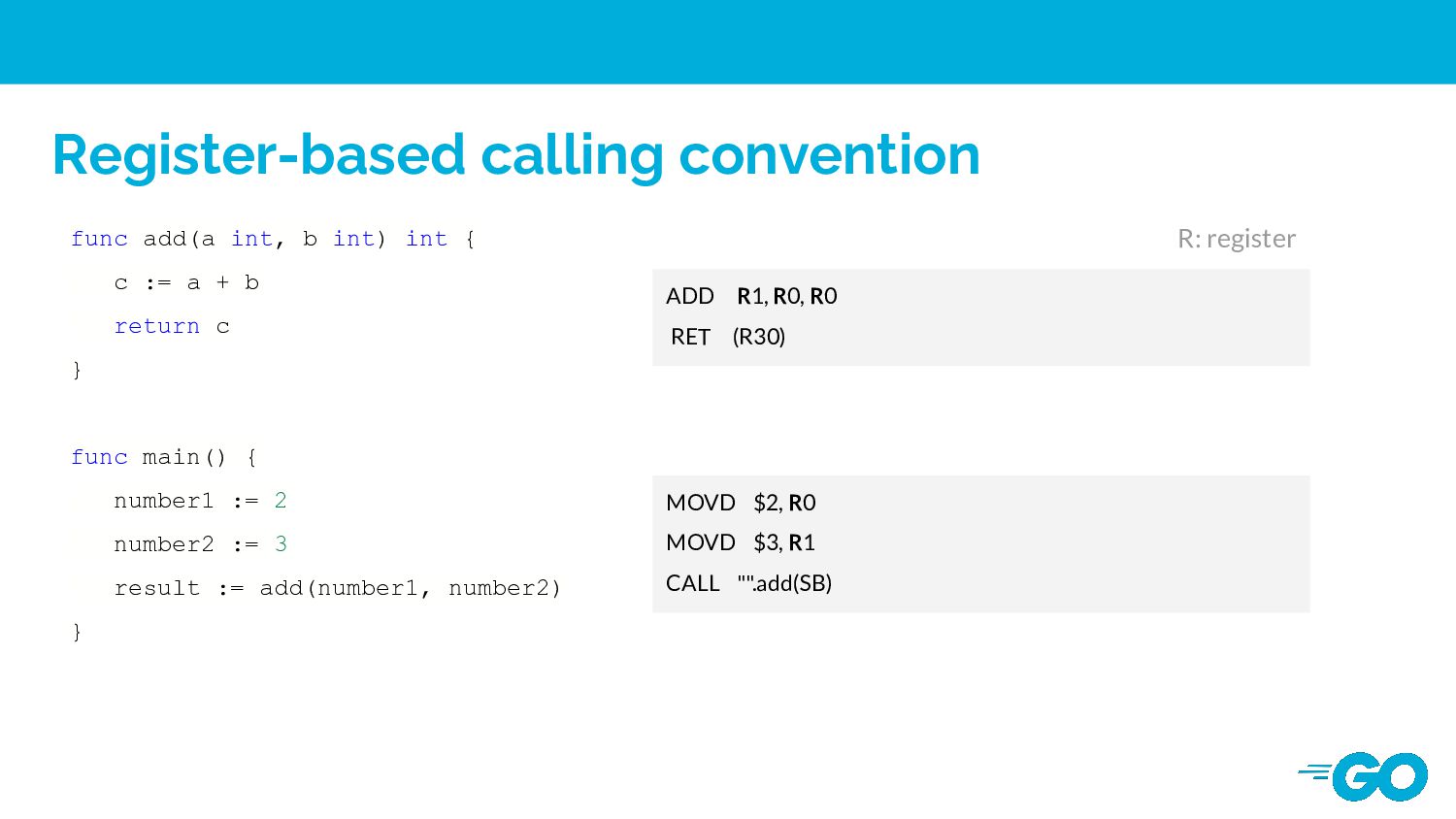
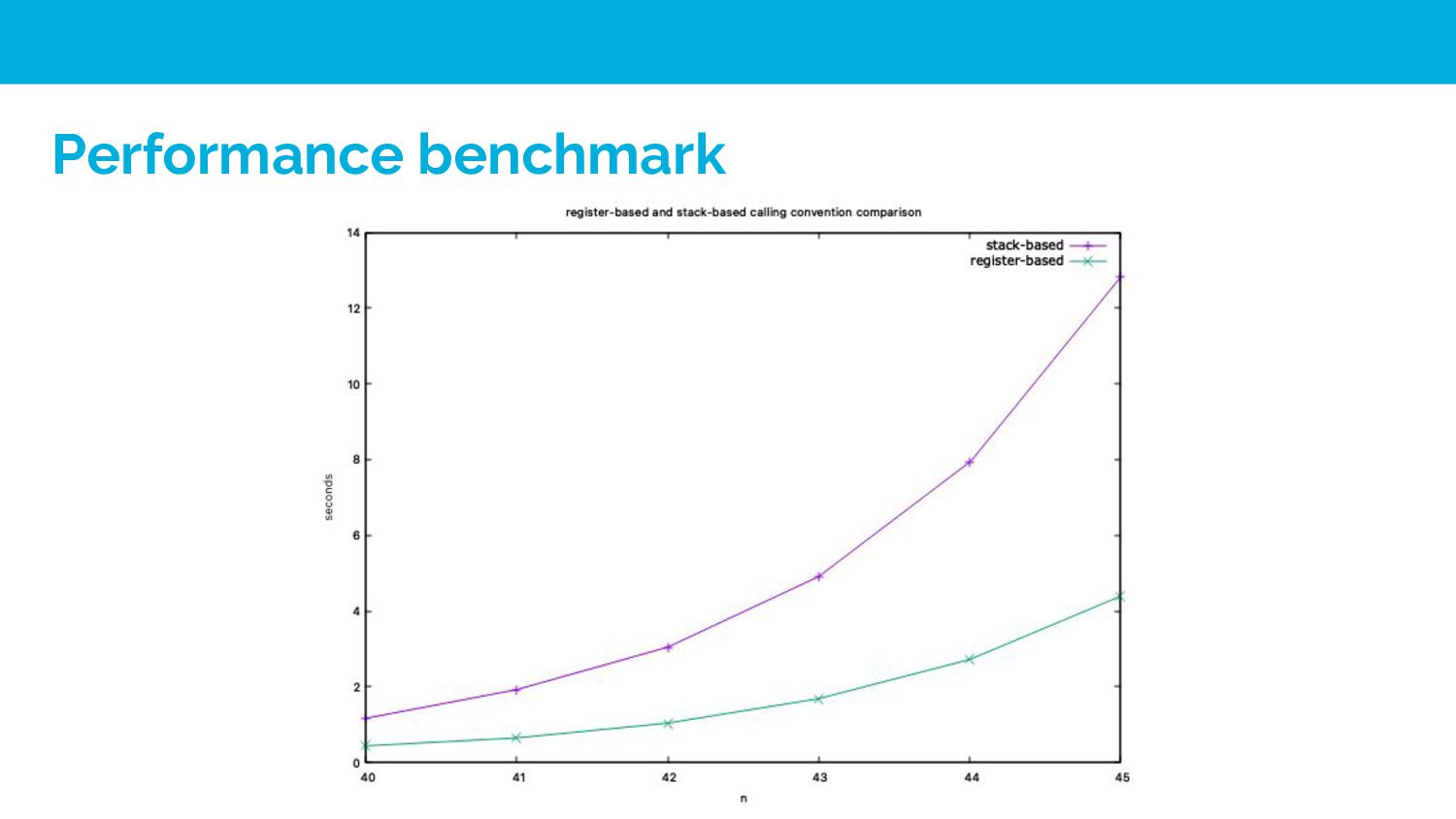
convention accessing arguments in registers is still roughly 40% faster than accessing arguments on the stack (main memory). Drawbacks 1. It would introduce additional compile time to allocate registers. 2. Increasing the design compelxity of compiler
64-bit Arm CPU performance improvements released in Go 1.18. Programs with an object-oriented design, recursion, or that have many function calls in their implementation will likely benefit more from the new register ABI calling convention. Making your Go workloads up to 20% faster with Go 1.18 and AWS Graviton
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}