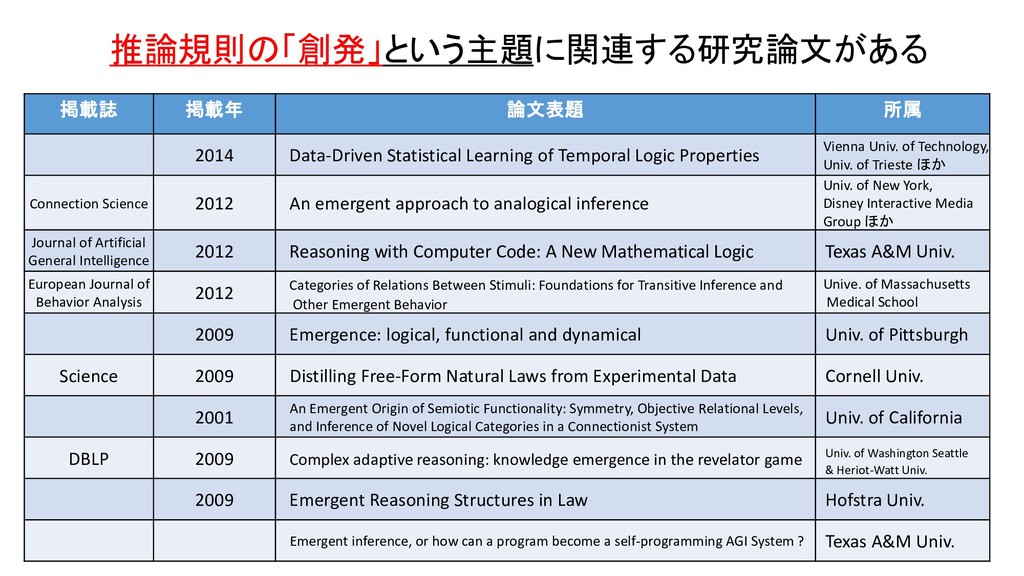
Causal Mathematical Logic as a guiding framework for the prediction of “Intelligence Signals” in brain simulations Open Univ. & Univ. of Houston Journal of Artificial General Intelligence 2013 Black-box Brain Experiments, Causal Mathematical Logic, and the Thermodynamics of Intelligence Univ. of Houston & Open Univ. Causal Logic Models Carnegie Mellon Univ. & Univ. of Pittsburgh Bounded Seed-AGI The Swiss AI Lab IDSIA ほか International Journal of Mathematics and Computational Sciences 2010 Coupled dynamics in host-guest comples systems duplicates emergent behavior in the brain Engineering and Technokogy 2009 A New Universal Model of Computation and its Contribution to Learning, Intelligence, Parallelism, Ontologies, Refactoring, and the Sharing of Resources Member of IEEE, AAAI, APS Conceptual Blending and Quest for the Holy Creative Process Univ. of Coimbra AISB Journal 2003 Optimality Principles for Conceptual Blending: A First Computational Approach Univ. de Coimbra (CISUC) Argument and Computation 2012 Rational argument, rational inference Cardiff Univ & University College London INTERDISCIPLINARIA 2004 Information and Inference as Combined Cognitive Processes Consejo Nacional de Investigacions Cientificas y Tecnicas 推論規則の「創発」という主題に関連する研究論文がある
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
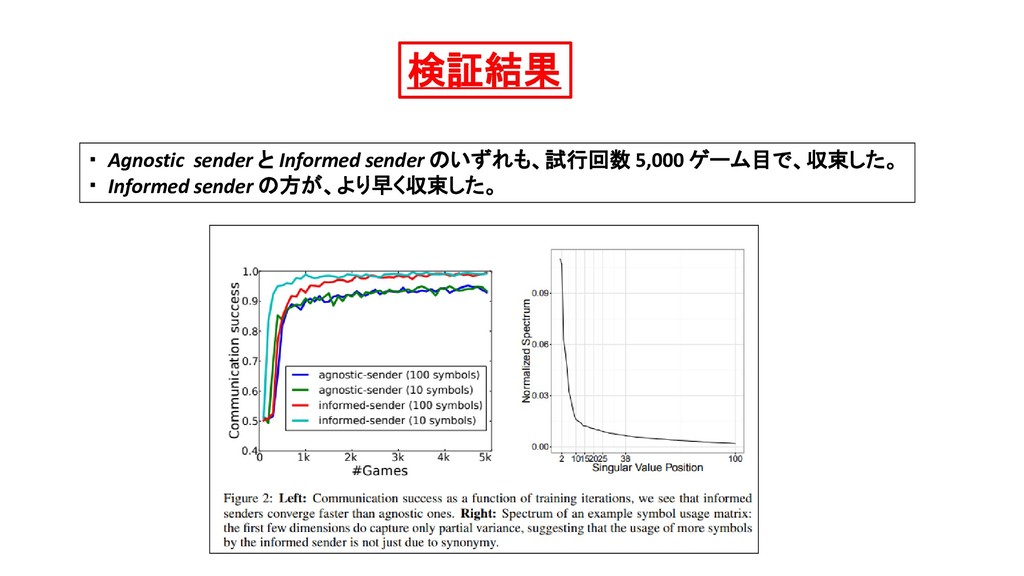{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
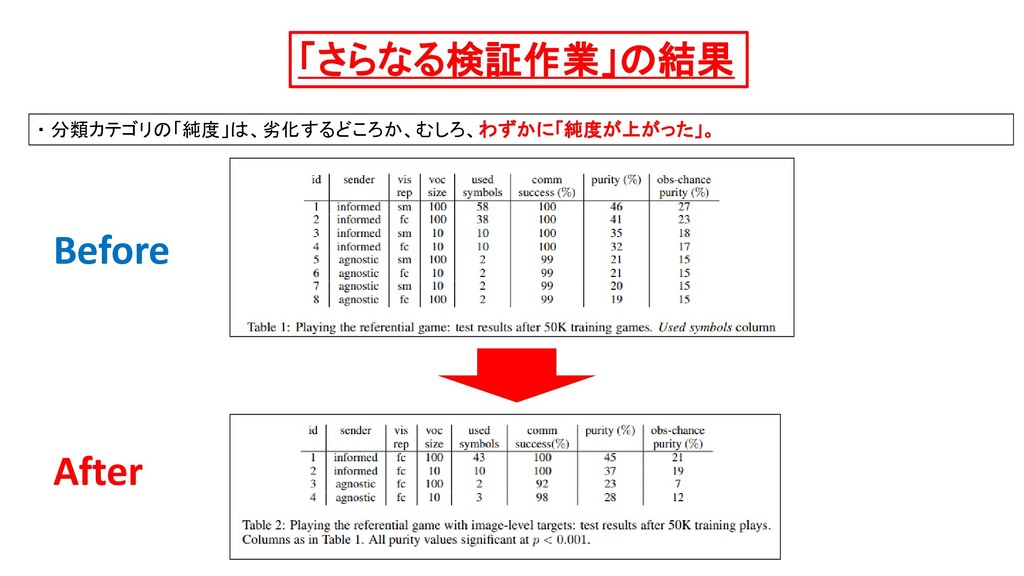{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![複数の文章・文書に散らばる断片的な知識の手がかりを、 互いに論理的につなぎあわせて論理推論する精度を競う 技術コンテスト 及び 研究用データセット [ACL 2018] Johannes Welbl et.al.,](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_186.jpg){kind=link}
![複数の文章・文書に散らばる断片的な知識の手がかりを、 互いに論理的につなぎあわせて論理推論する精度を競う 技術コンテスト 及び 研究用データセット [EMNLP 2005] Xiaoqiang Luo, On](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_187.jpg){kind=link}
{kind=link}
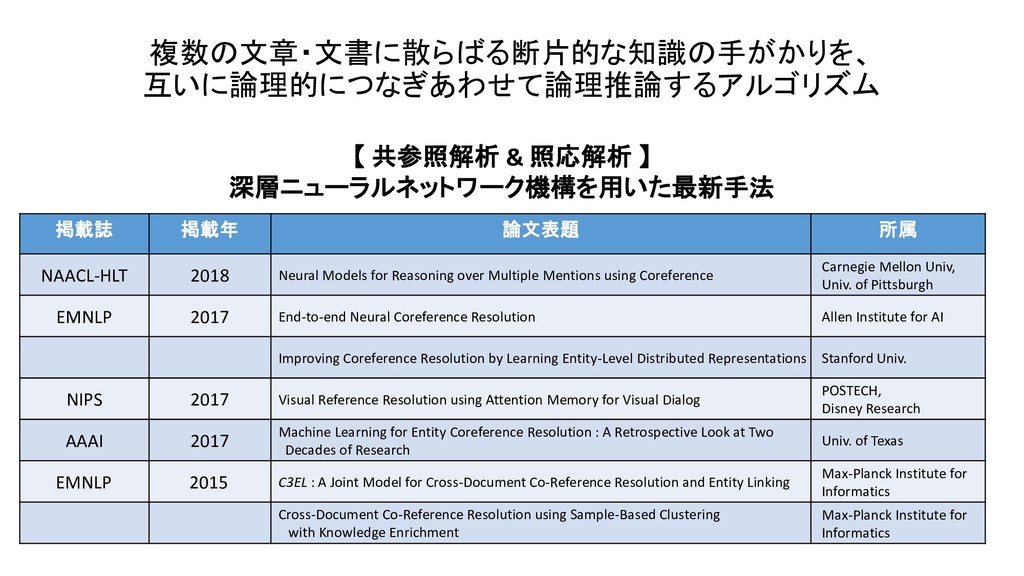{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Graph Network による物体や事物間の連関関係 の特徴表現獲得(学習)と転移学習の実現 [Arxiv. 2018] Peter W. Battaglia et.al,](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_193.jpg){kind=link}
![[Arxiv. 2018] Peter W. Battaglia et.al, Relational inductive biases, deep](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_194.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
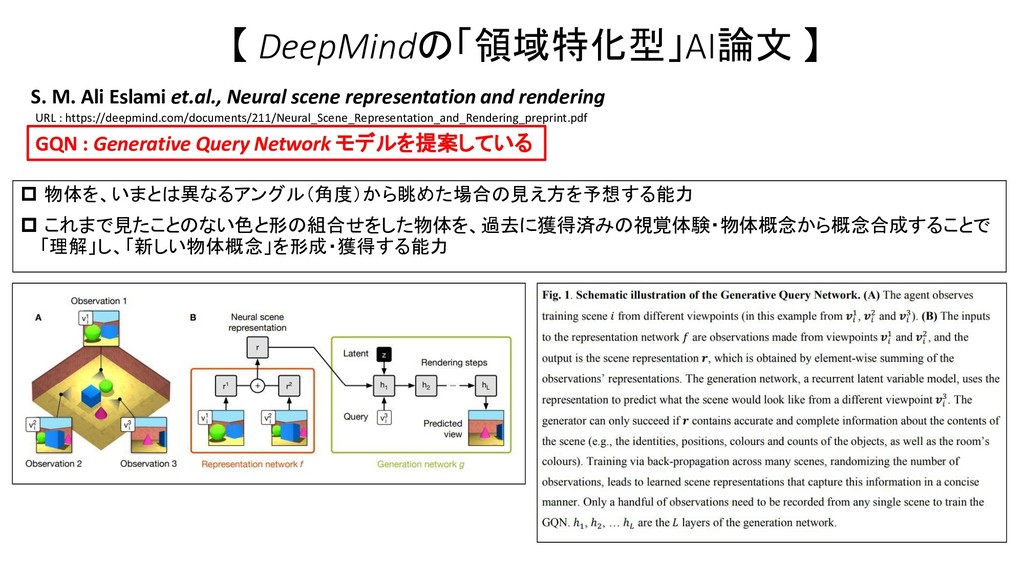{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Predictive Coding とは? 【 参考 】 [ ICLR 2017 ]](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_224.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DeepMind 社がとる進路の『予想』 アプローチ A. を取るのではないか? [ 「予想」の根拠 ] [ 根拠1]](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_241.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
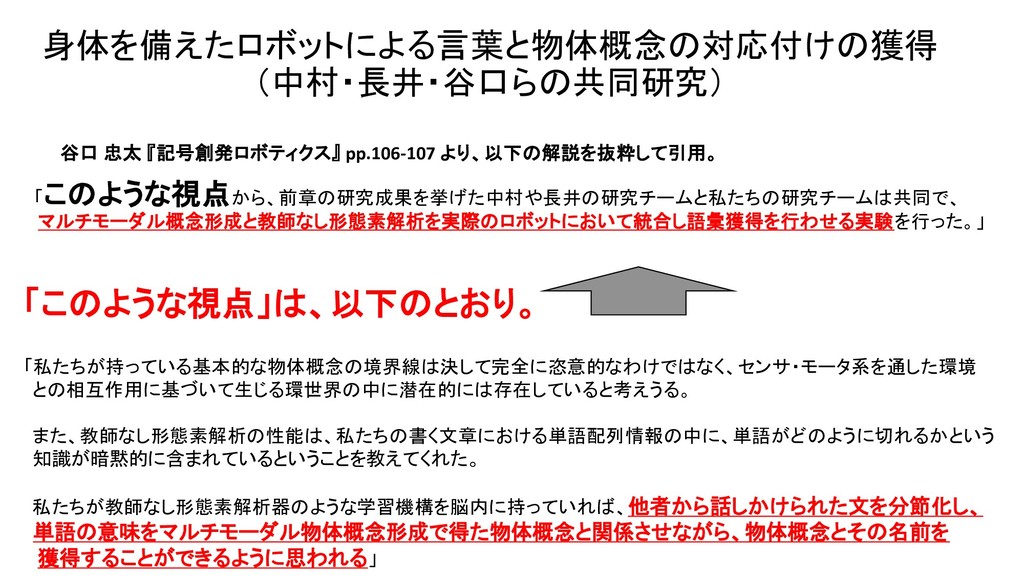{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
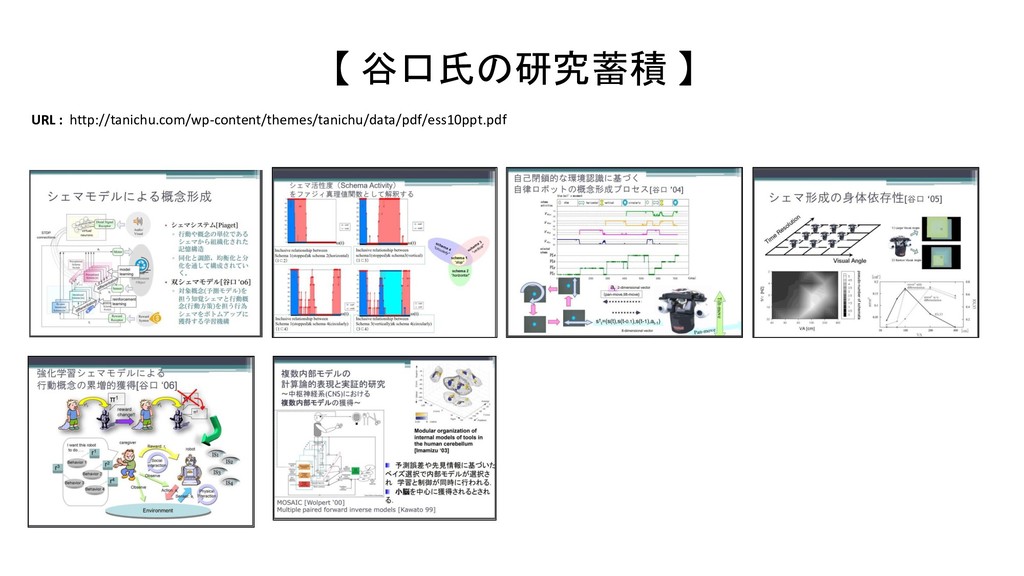{kind=link}
{kind=link}
{kind=link}
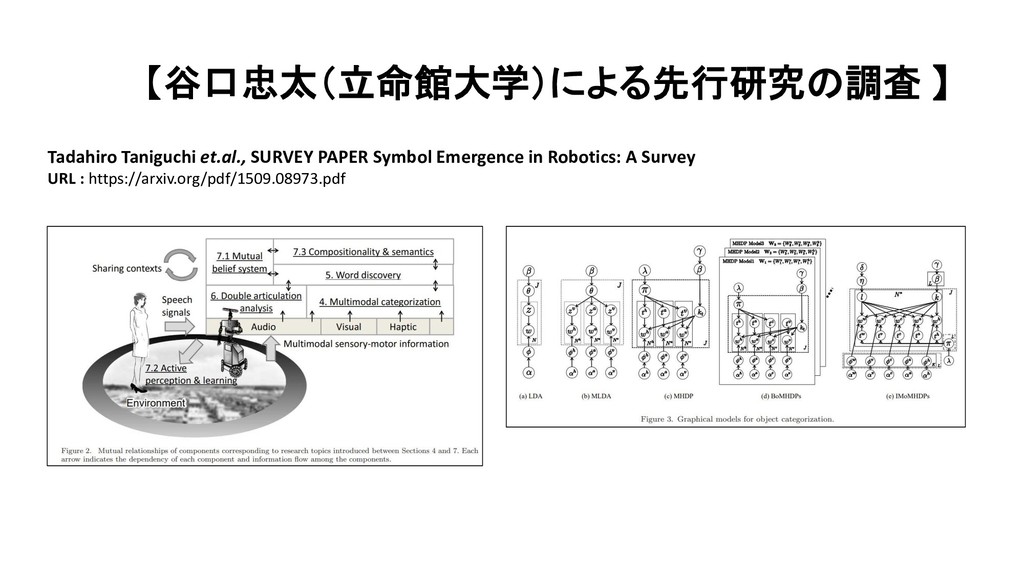{kind=link}
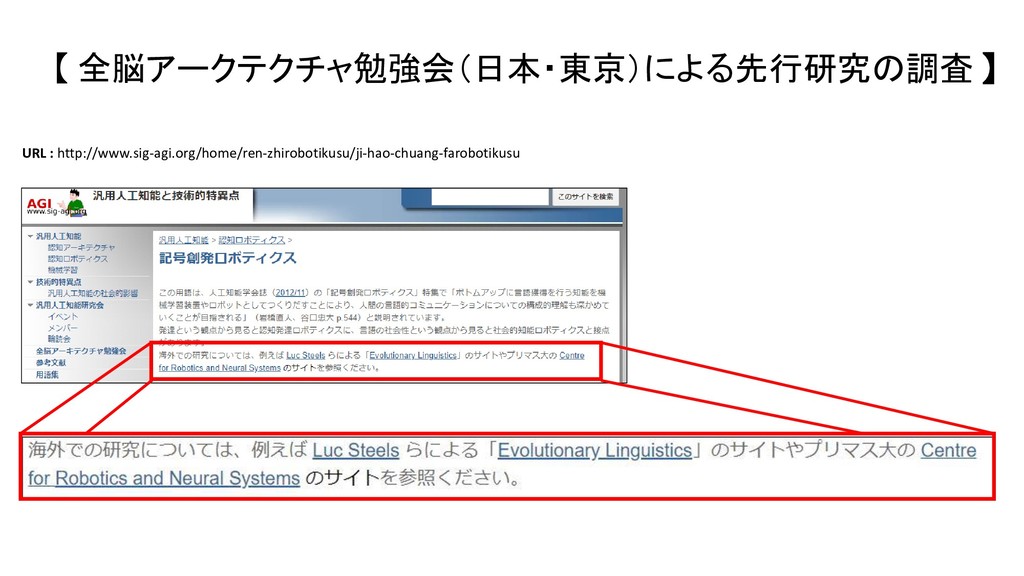{kind=link}
{kind=link}
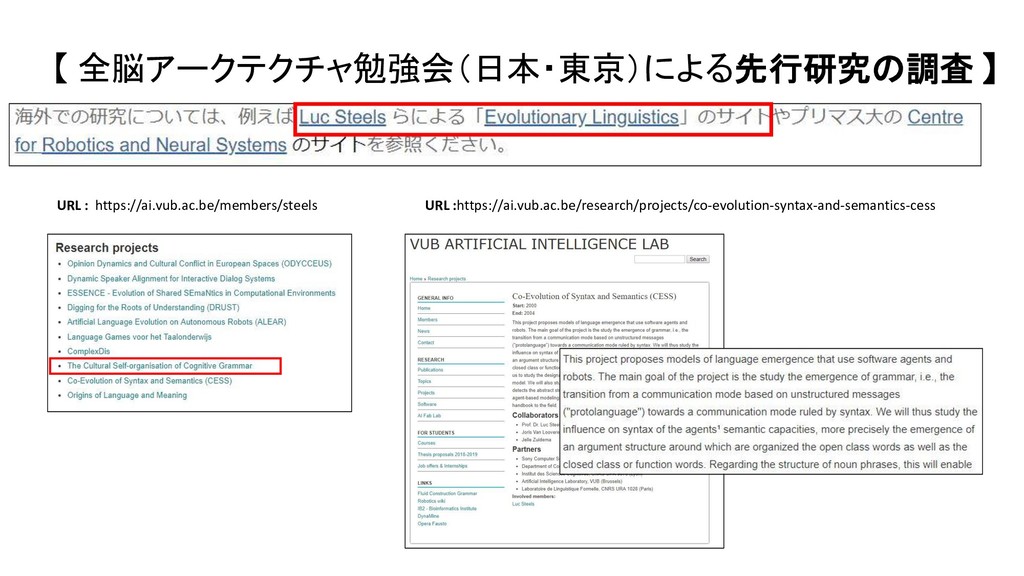{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
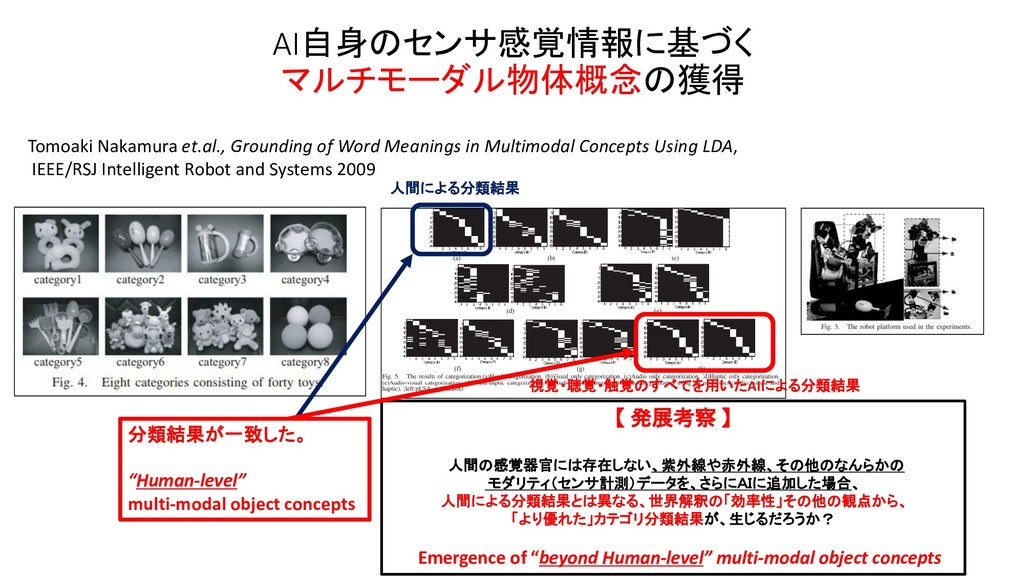
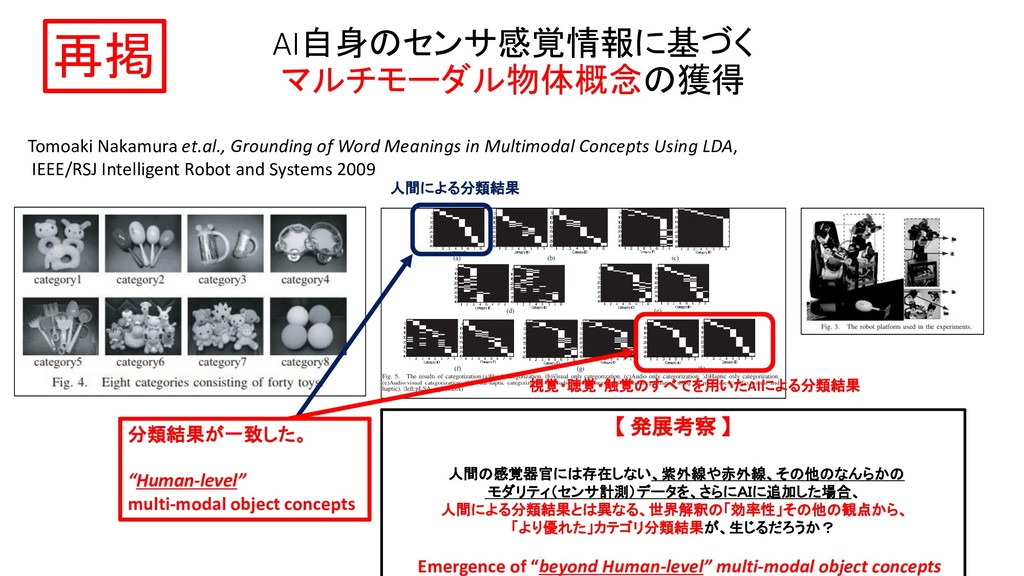
![中村研究室 [JSAI 2013] Muhammad Fadlilほか 「多層マルチモーダルLDAを用いた人の動きと物体の統合的概念の形成」 人工知能学会, 2013](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_319.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
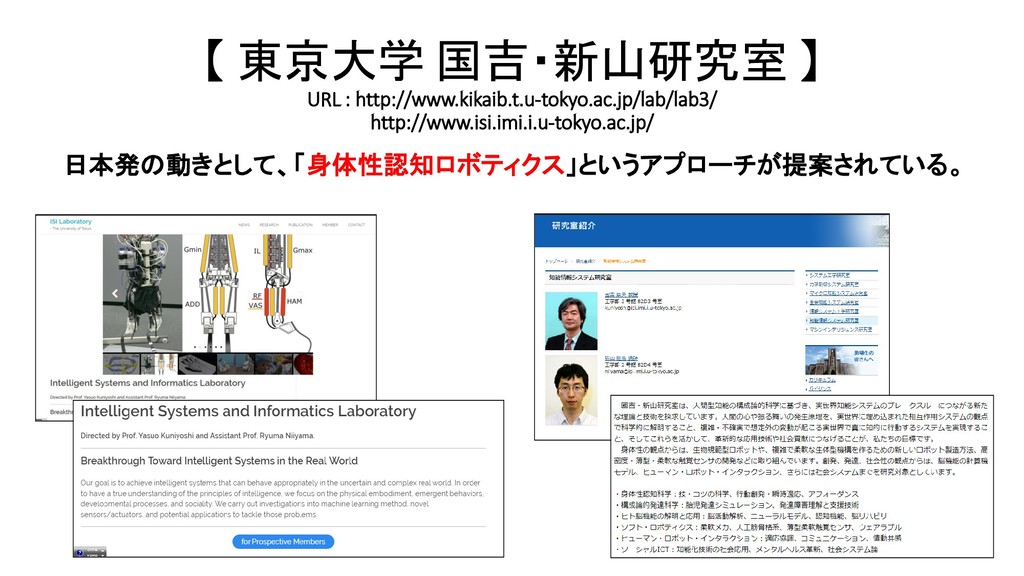{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
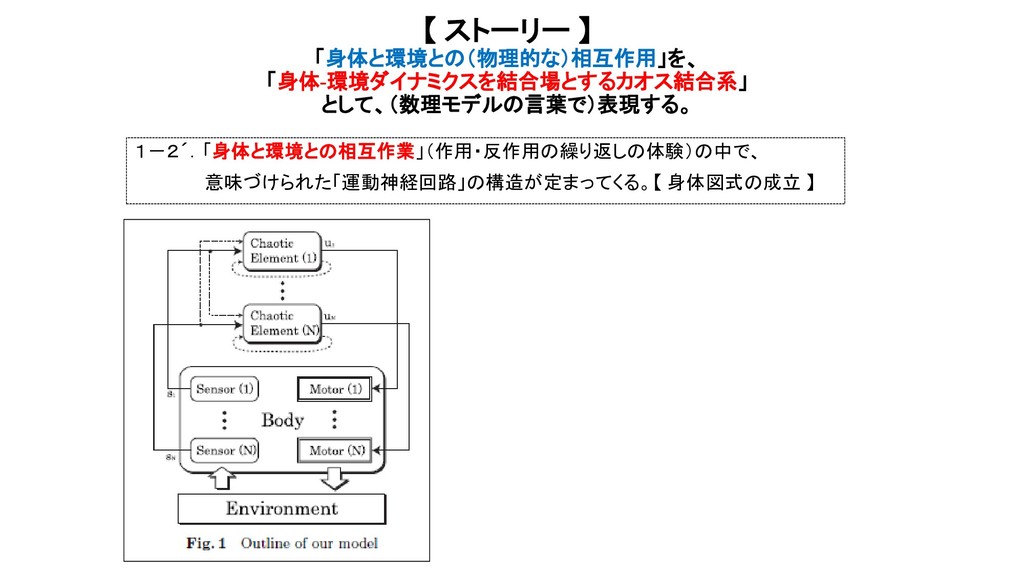{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
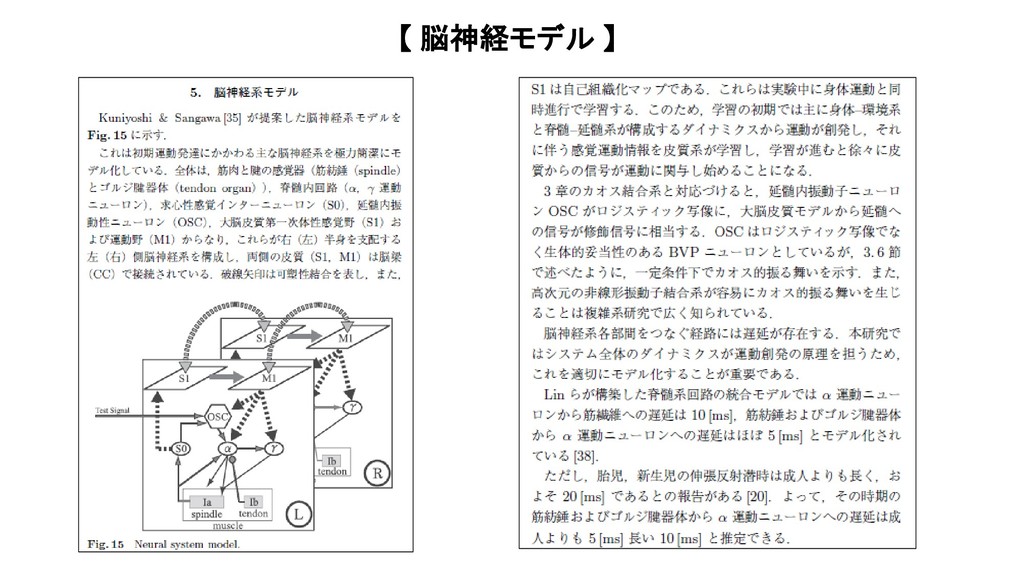{kind=link}
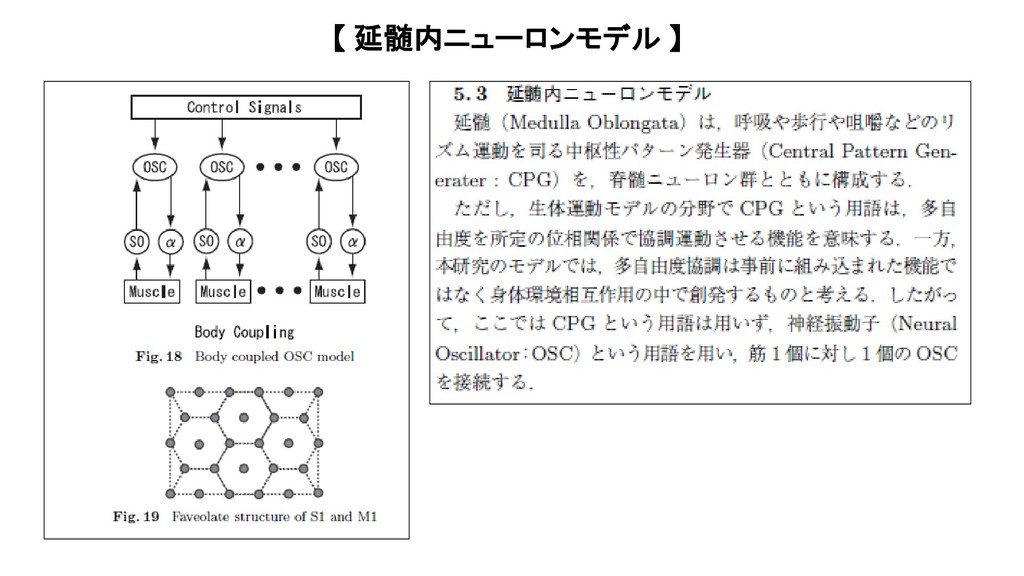{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
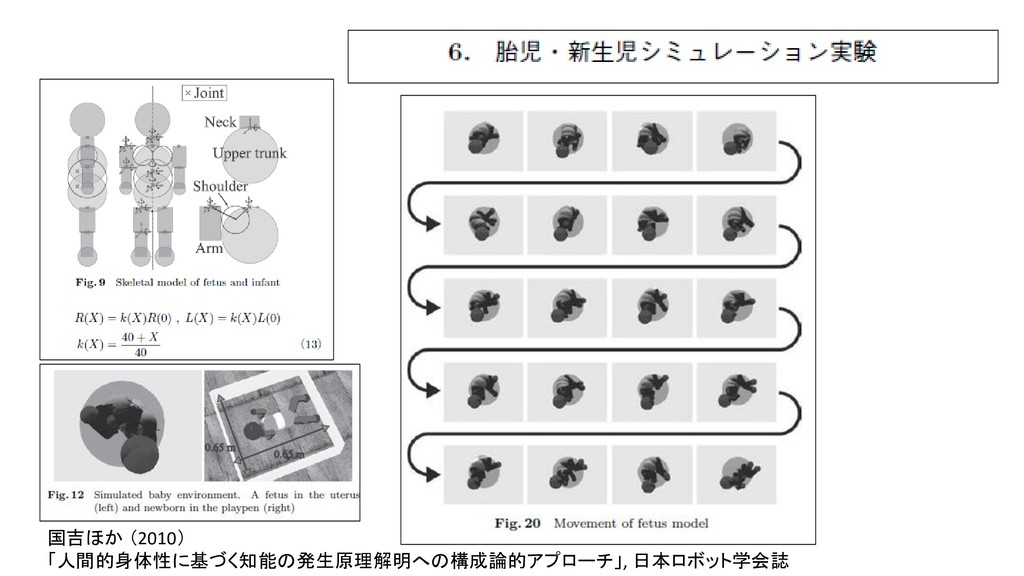{kind=link}
{kind=link}
{kind=link}
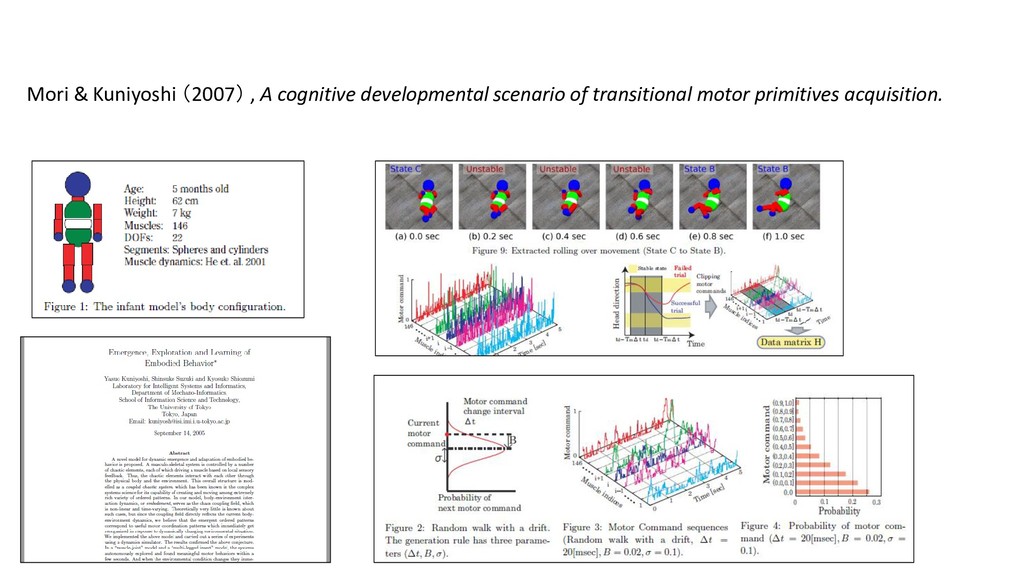{kind=link}
{kind=link}
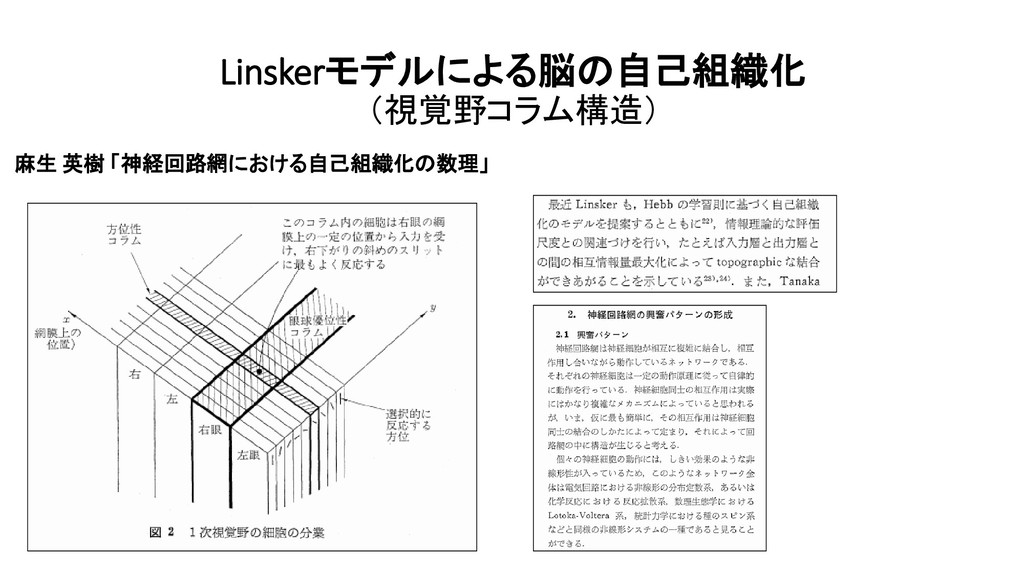
![Linskerモデルによる脳の自己組織化 (視覚野コラム構造) Ralph Linsker [1998] 【 解説 】 浅川 伸一](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_370.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
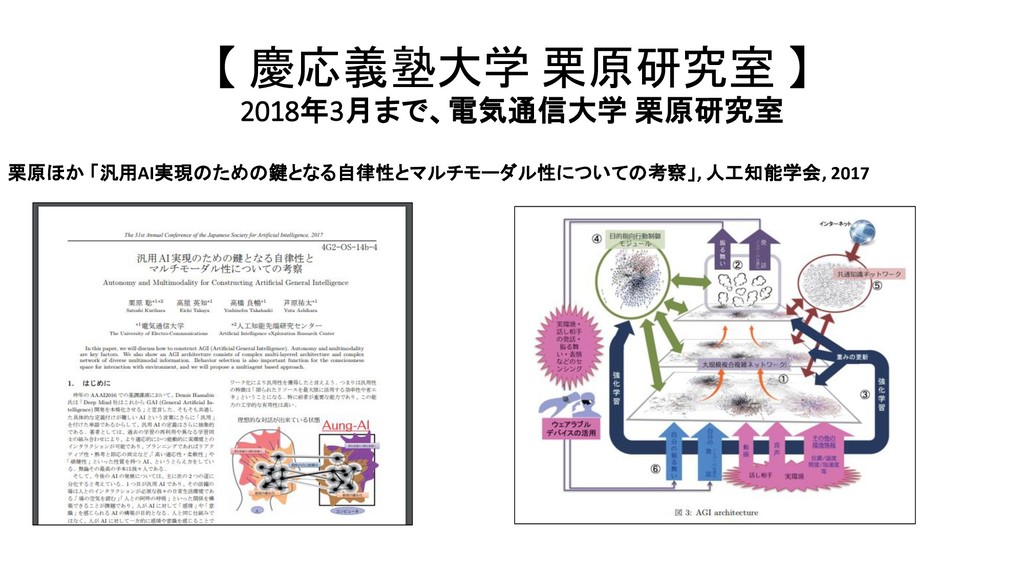{kind=link}
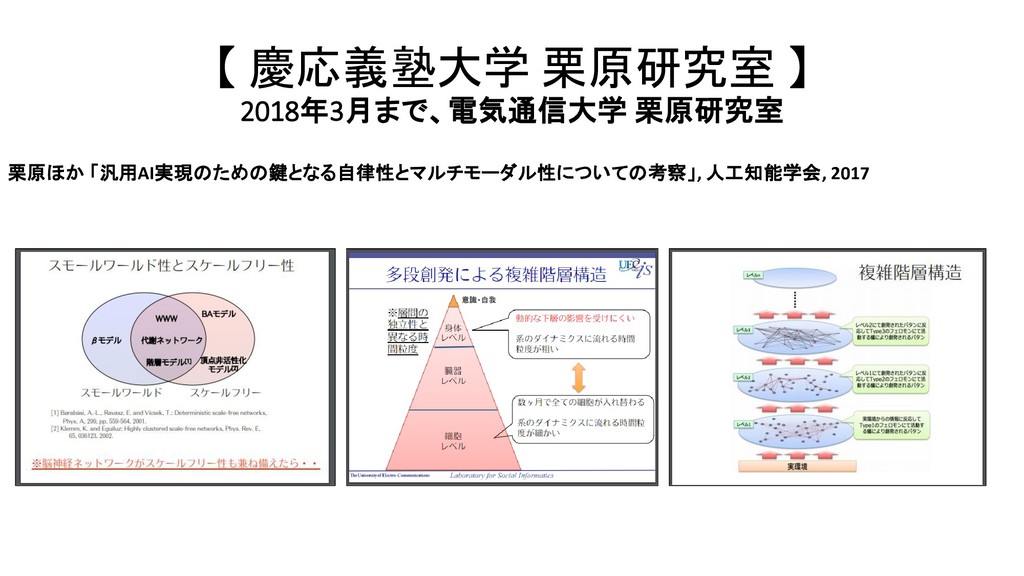{kind=link}
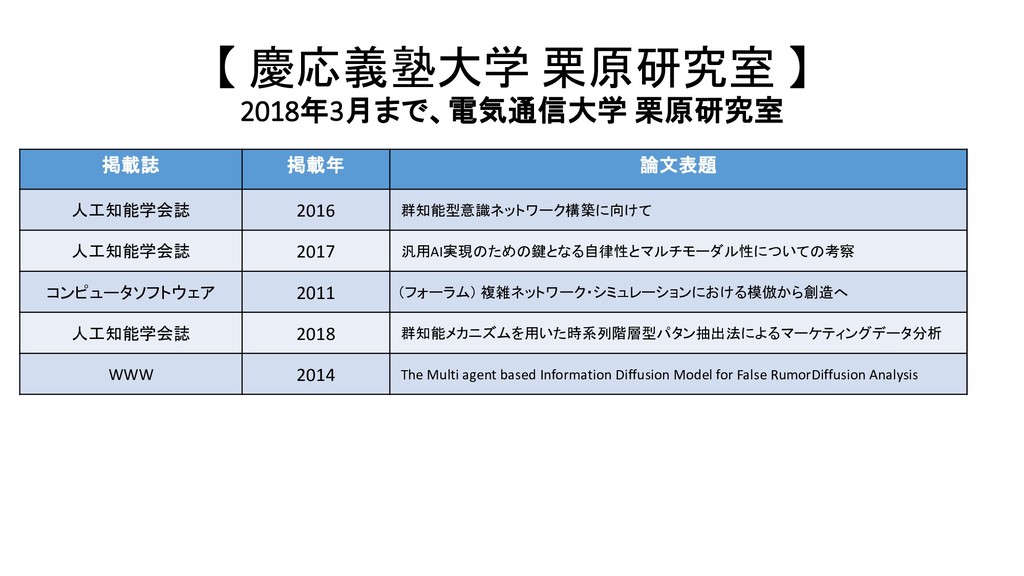{kind=link}
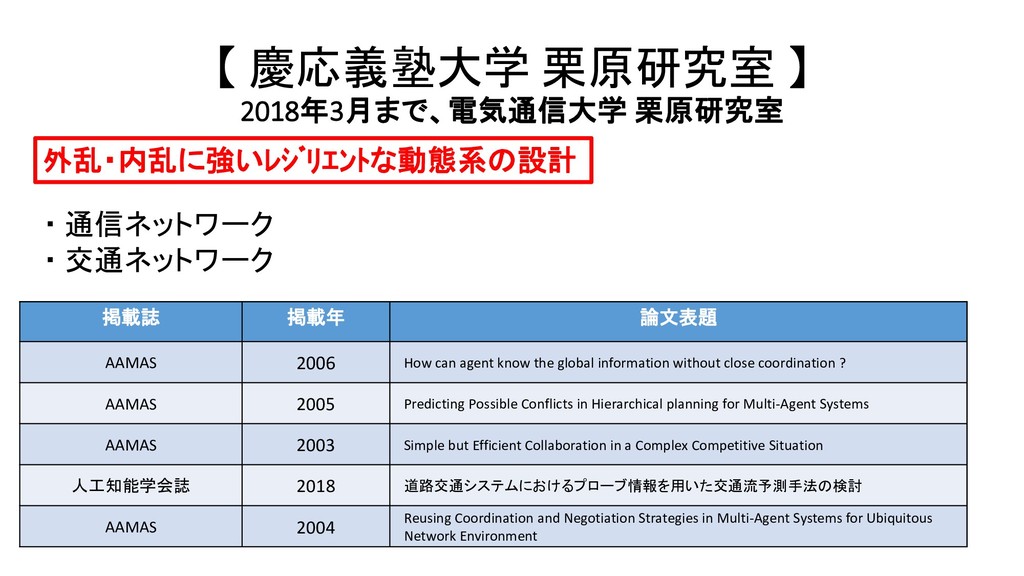{kind=link}
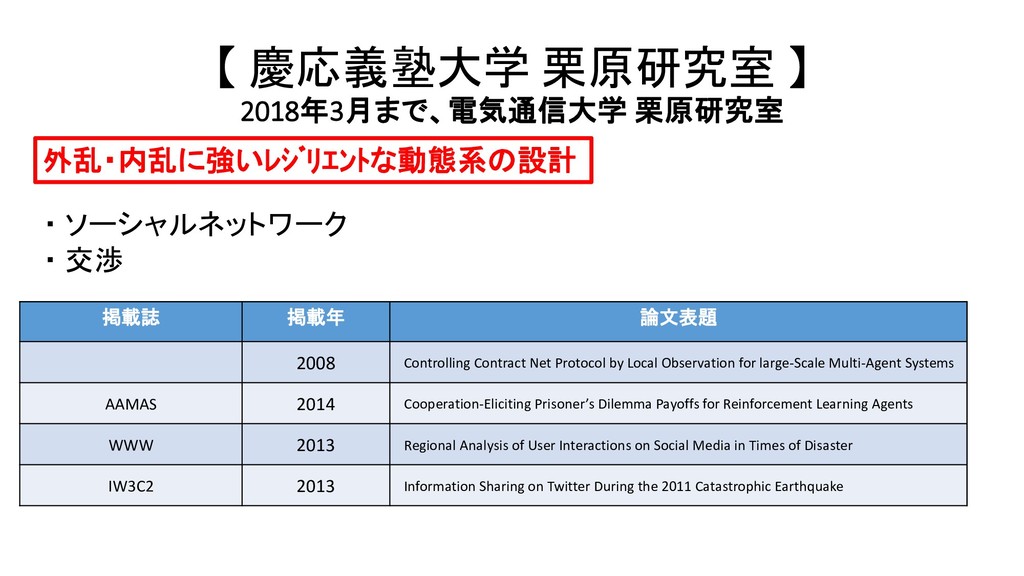{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
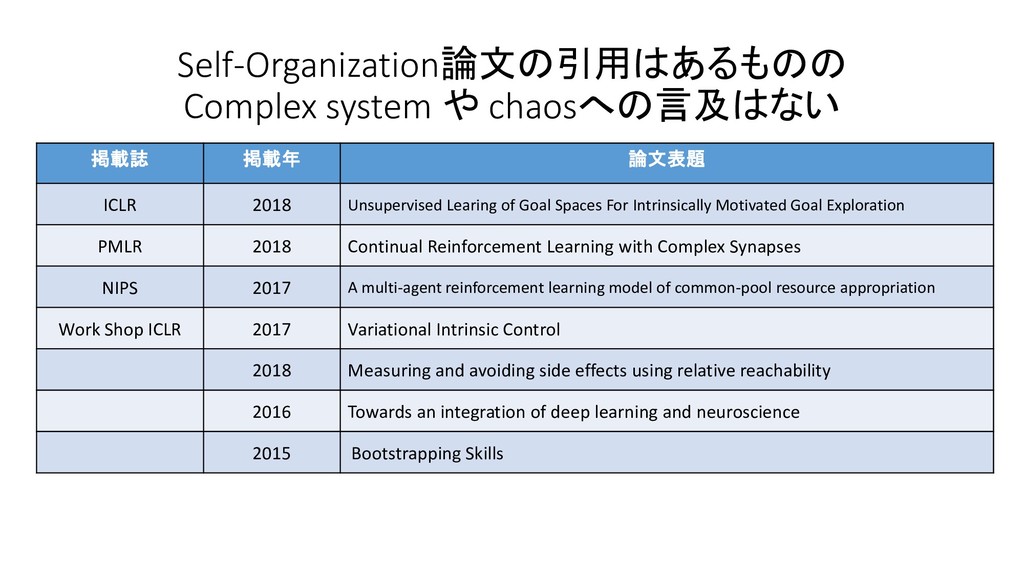{kind=link}
{kind=link}
{kind=link}
{kind=link}
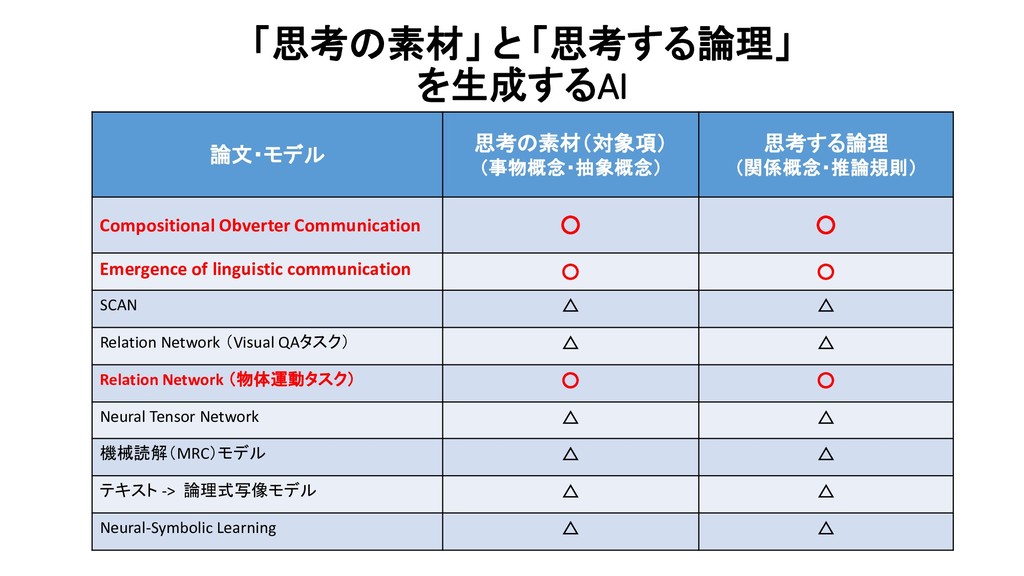{kind=link}
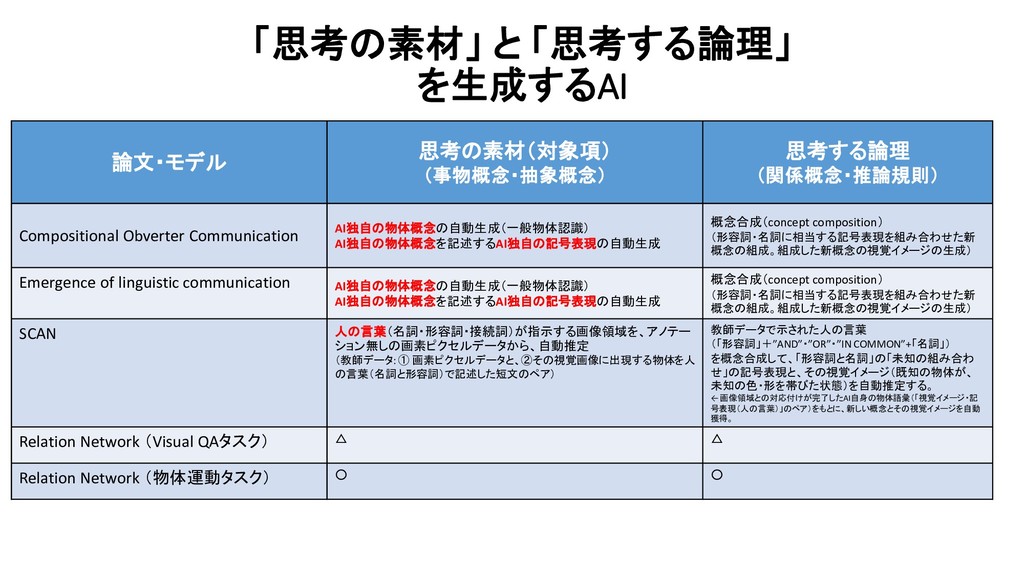{kind=link}
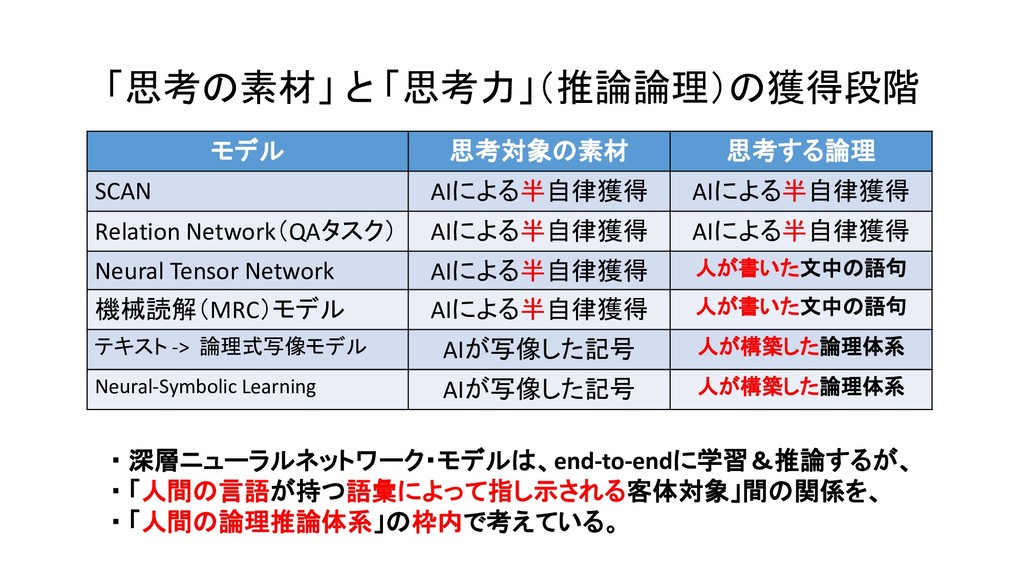
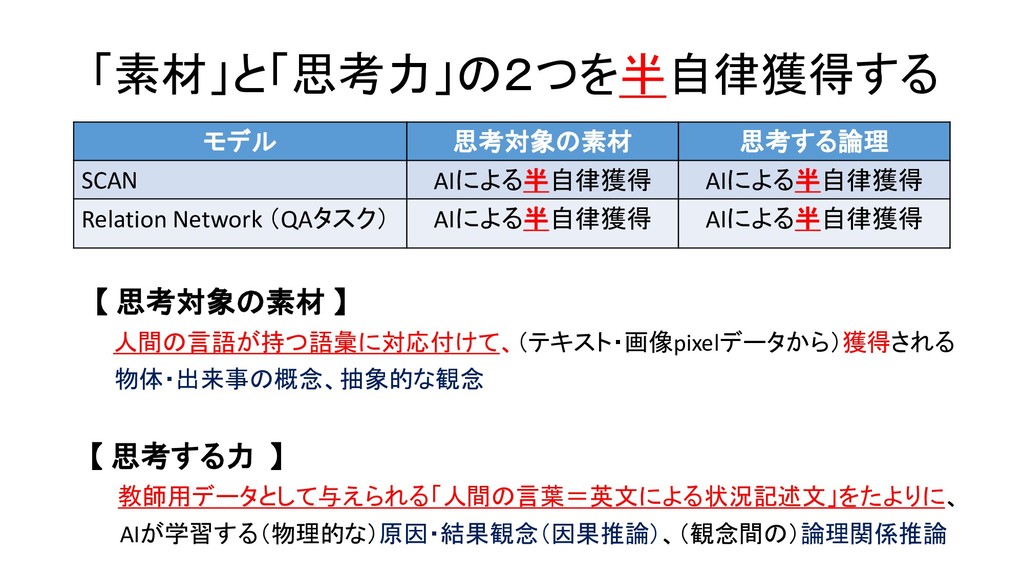
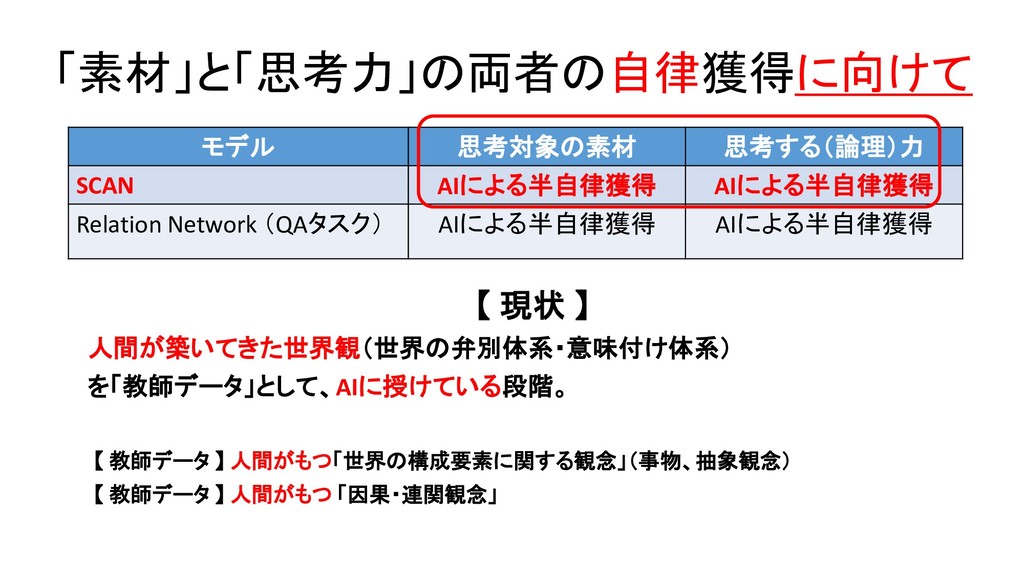
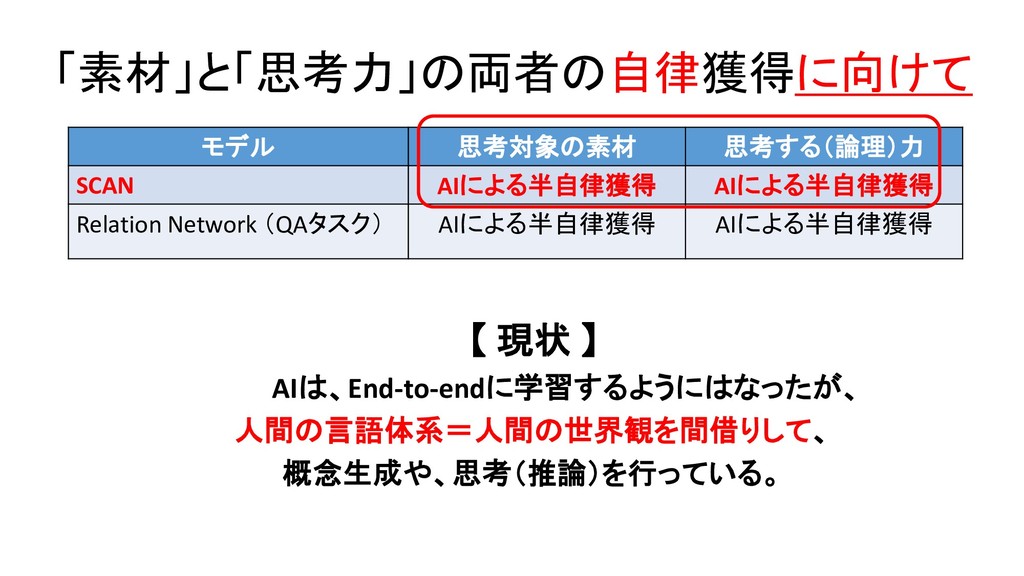
![論文・モデル 思考の素材(対象項) (事物概念・抽象概念) 思考する論理 (関係概念・推論規則) Neural Tensor Network 人が定義した[主語(S)、述語(P)、目的語・補語(O)]のTriple知識 データを学習し、新しいデータを記述するS-P-O記号表現(人の言](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_412.jpg){kind=link}
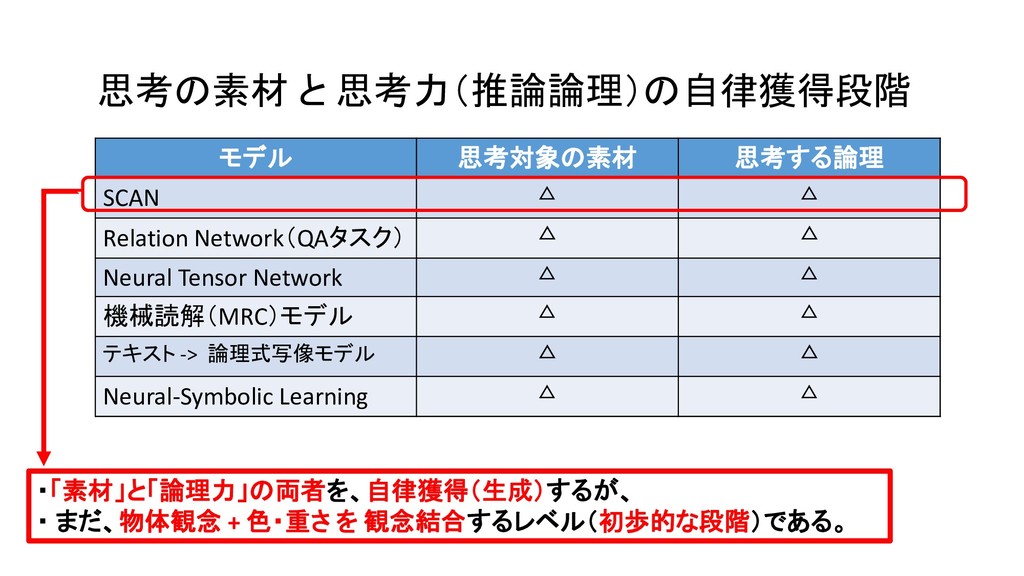{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
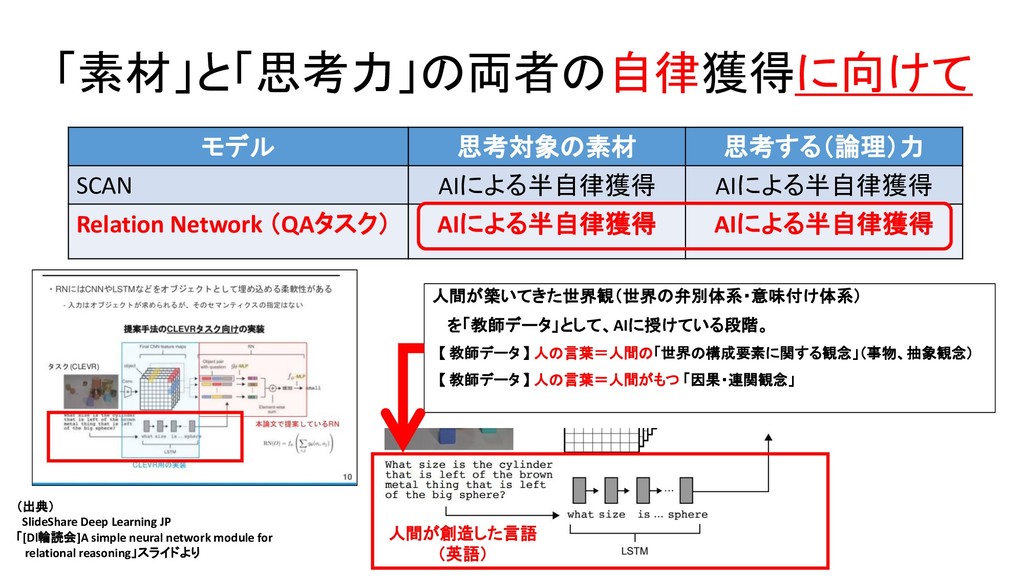{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
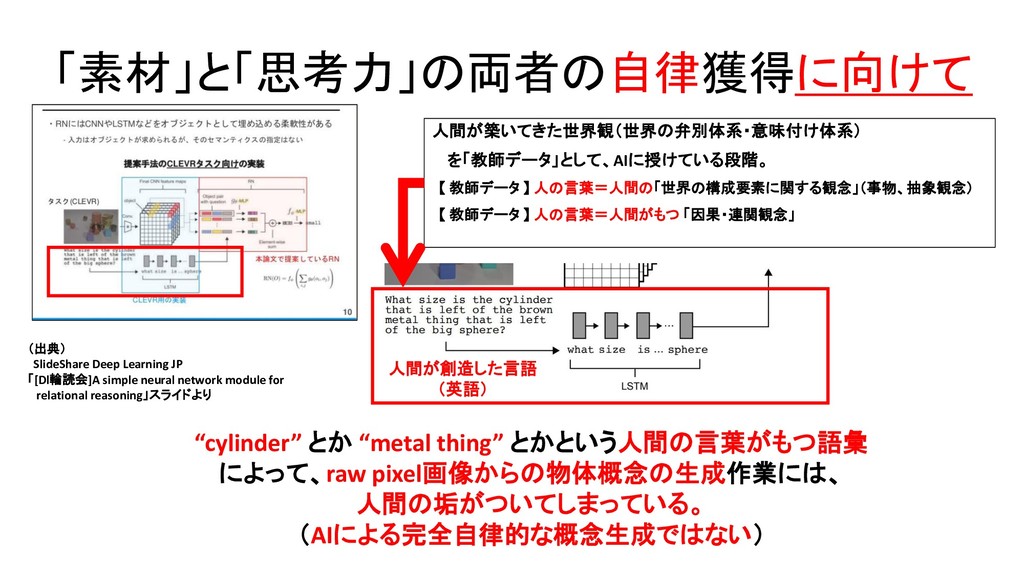
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(出典) SlideShare Deep Learning JP 「[Dl輪読会]A simple neural network module](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_432.jpg){kind=link}
{kind=link}
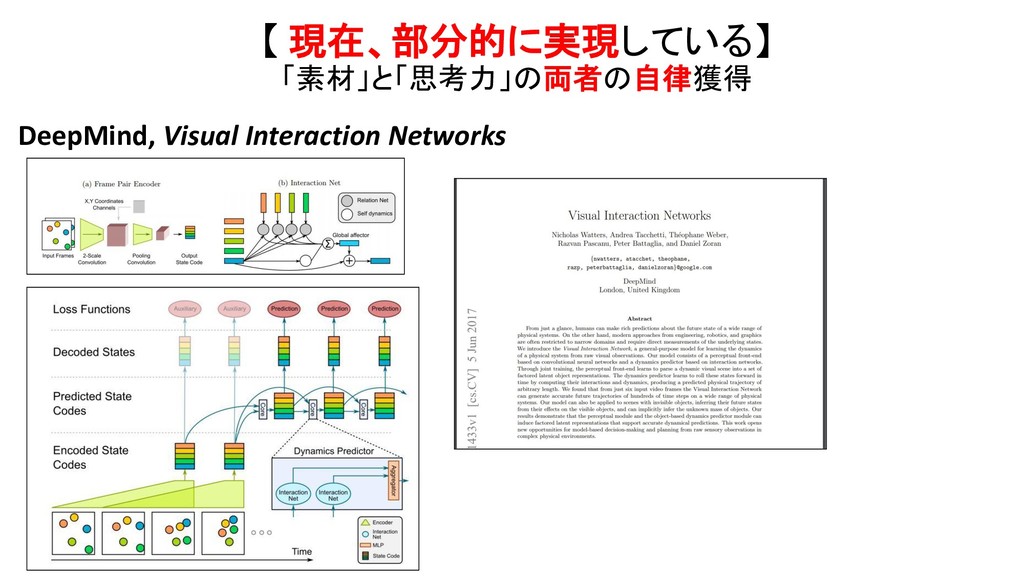{kind=link}
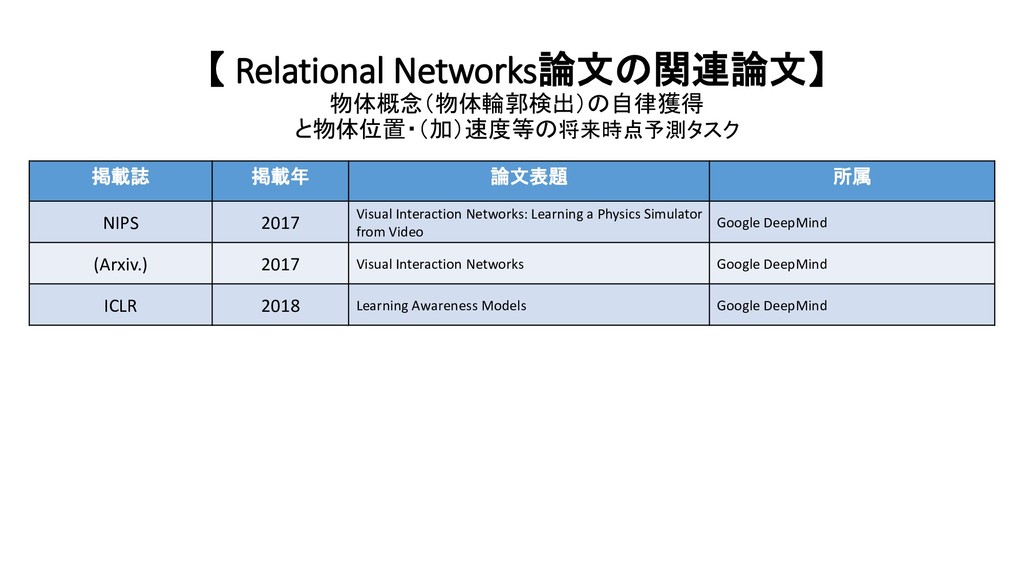{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Linskerモデルによる脳の自己組織化 (視覚野コラム構造) Ralph Linsker [1998] 【 解説 】 浅川 伸一](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_443.jpg){kind=link}
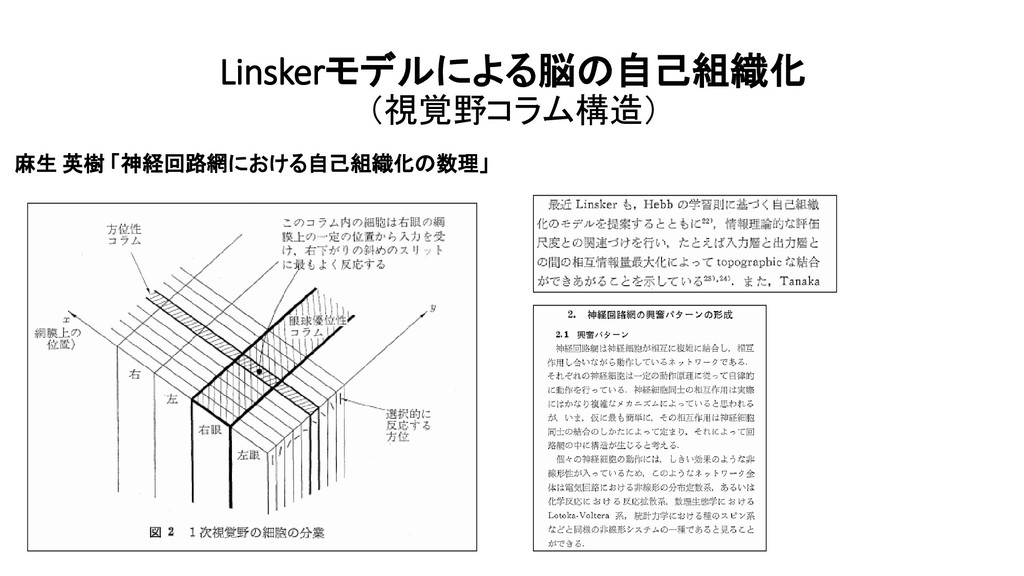{kind=link}
{kind=link}
{kind=link}
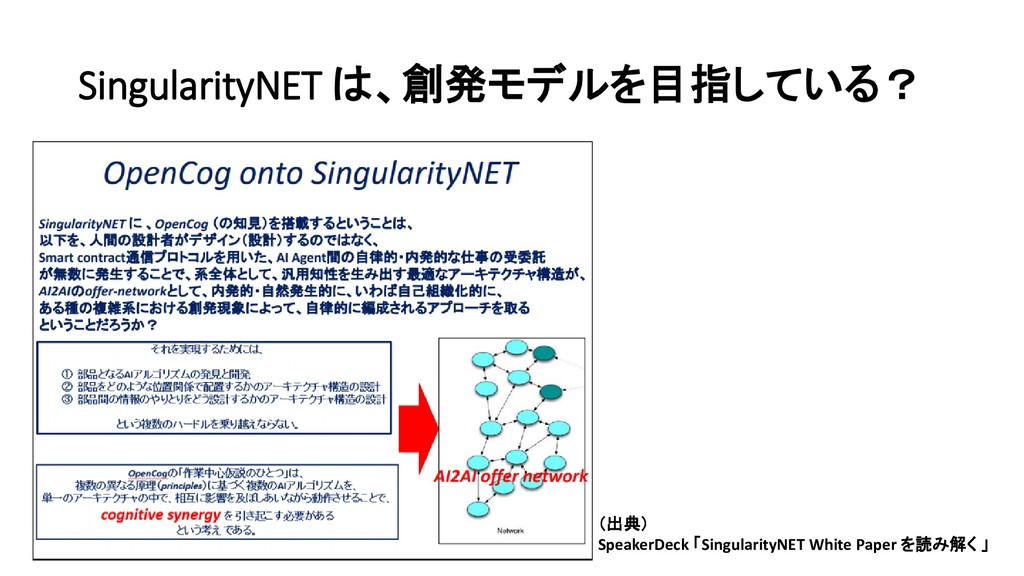{kind=link}
{kind=link}
{kind=link}
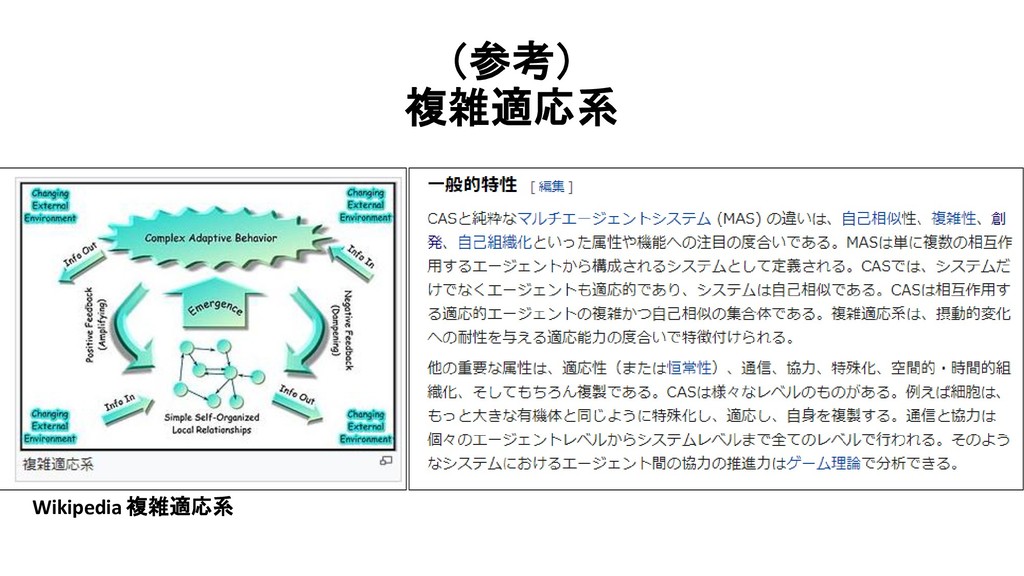{kind=link}
{kind=link}
{kind=link}
![北村[1995]による定義 北村 新三 「創発的機能形成のシステム理論に向けて」, 計測と制御, Vol.37, 1995 「自律的にふるまう個体(要素)間および環境との間の局所的な相互作用 が大域的な秩序をボトムアップ的に発現し、他方、そのように生じた 秩序が個体のふるまいをトップダウン的に拘束するという双方向の動的](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_453.jpg){kind=link}
{kind=link}
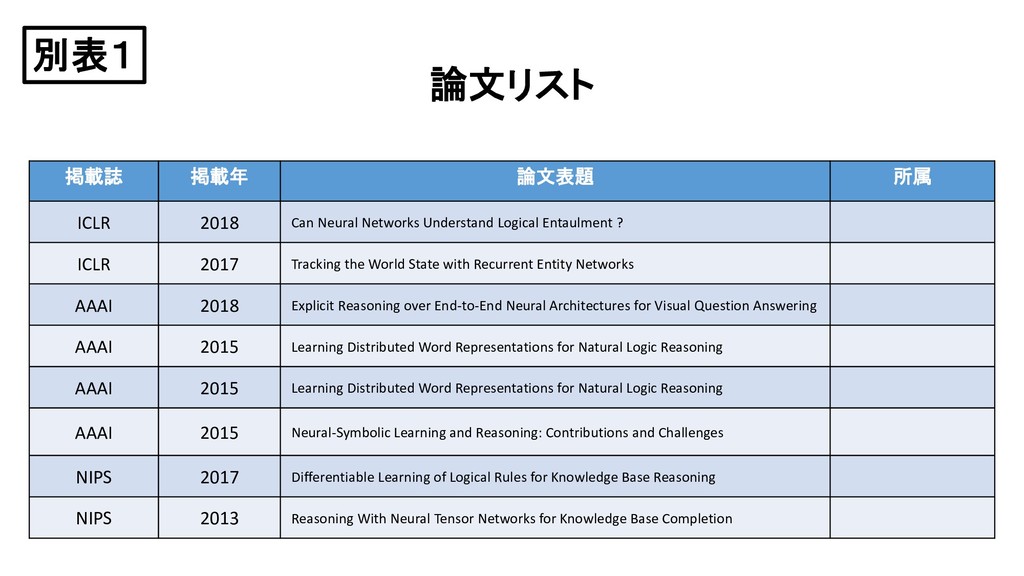{kind=link}
{kind=link}
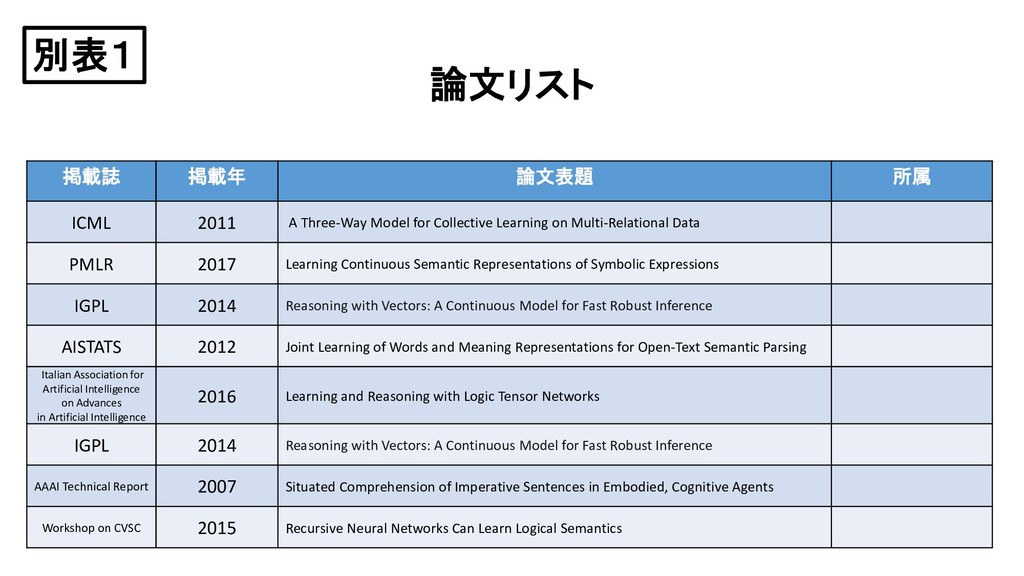{kind=link}
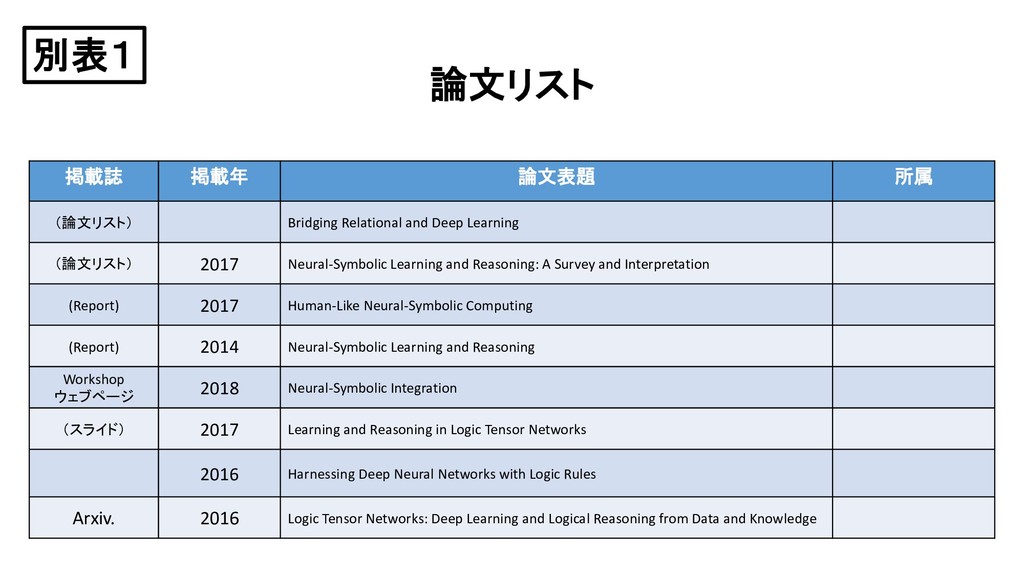{kind=link}
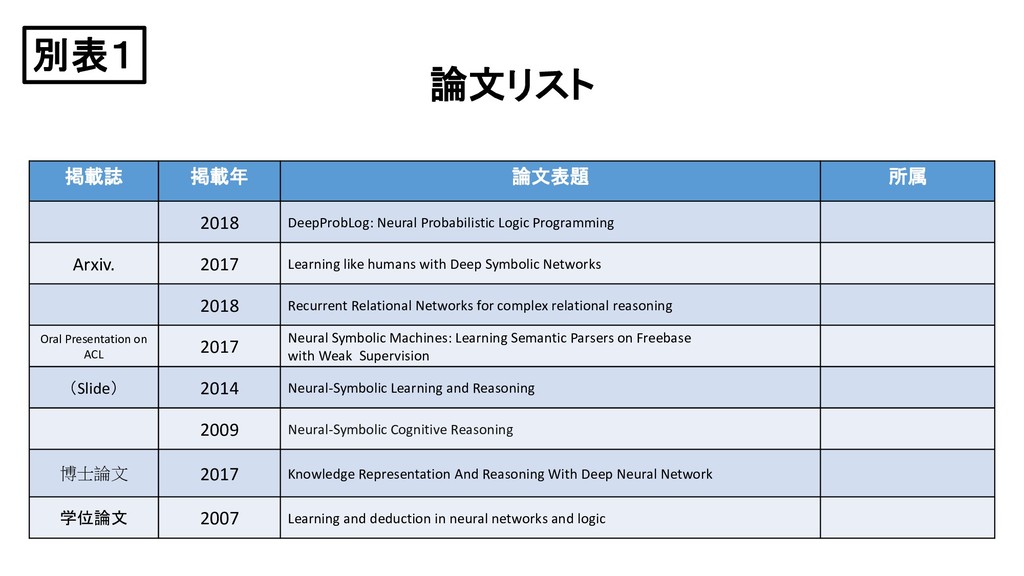{kind=link}
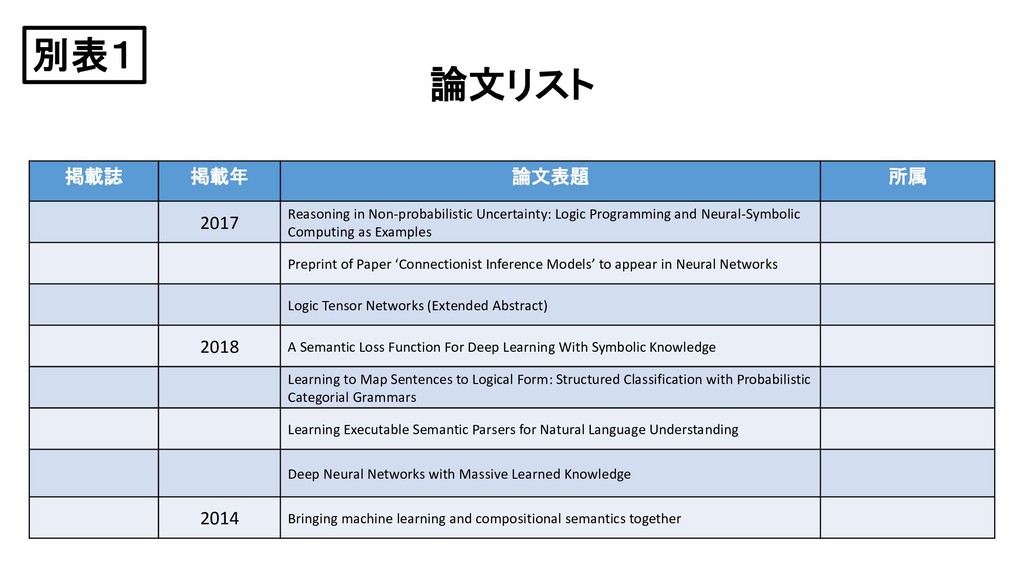{kind=link}
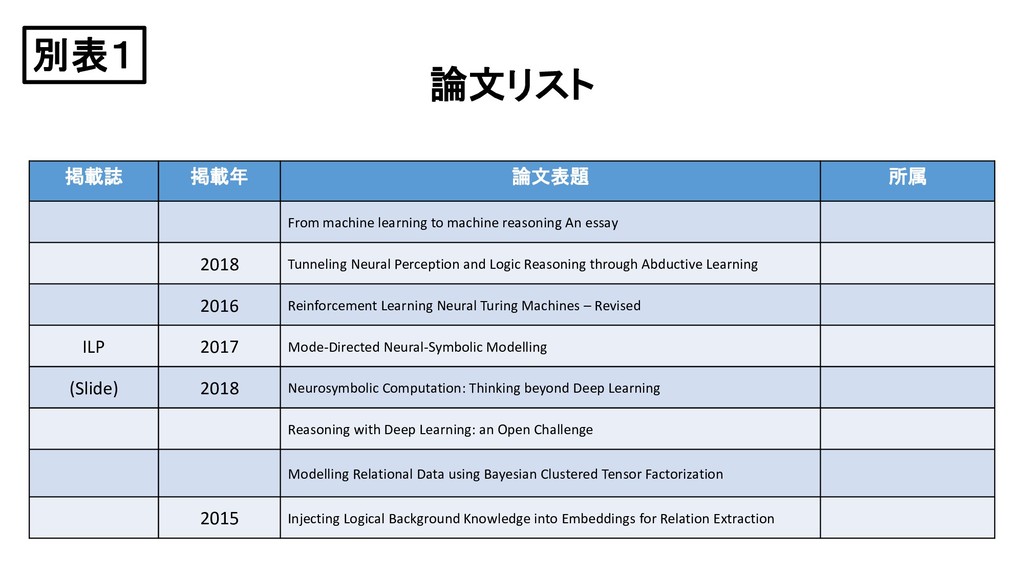{kind=link}
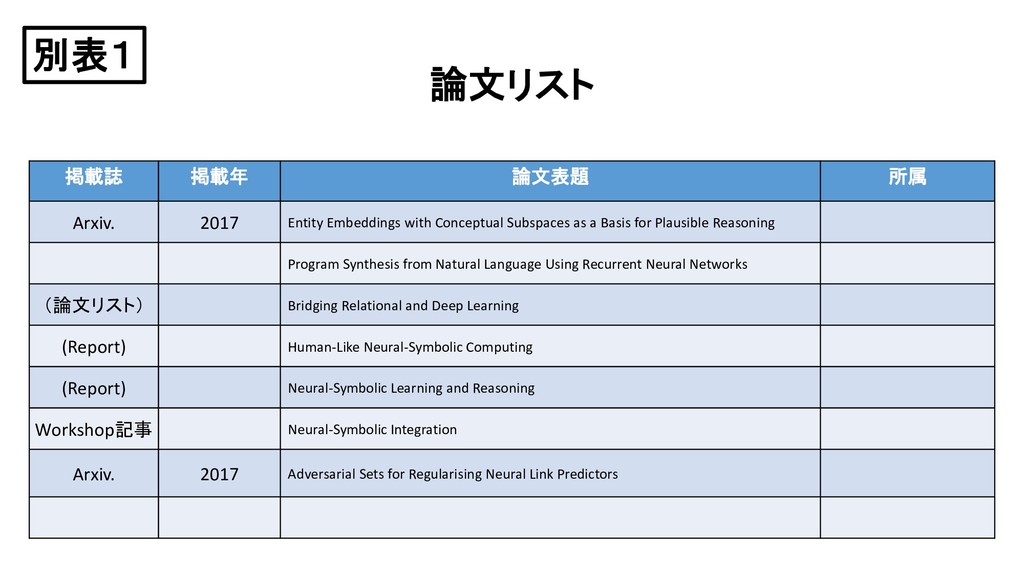{kind=link}
{kind=link}
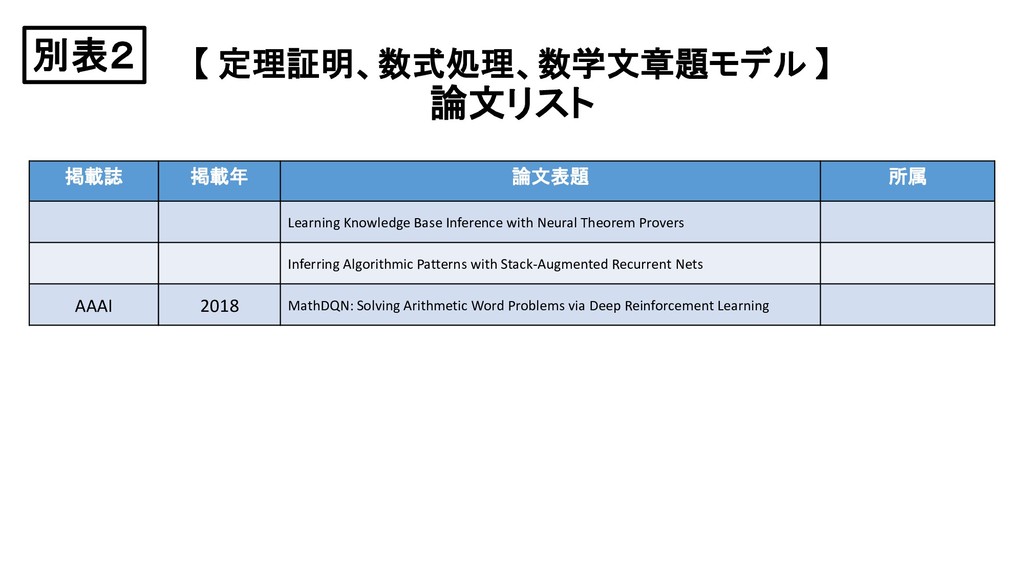{kind=link}
{kind=link}
{kind=link}
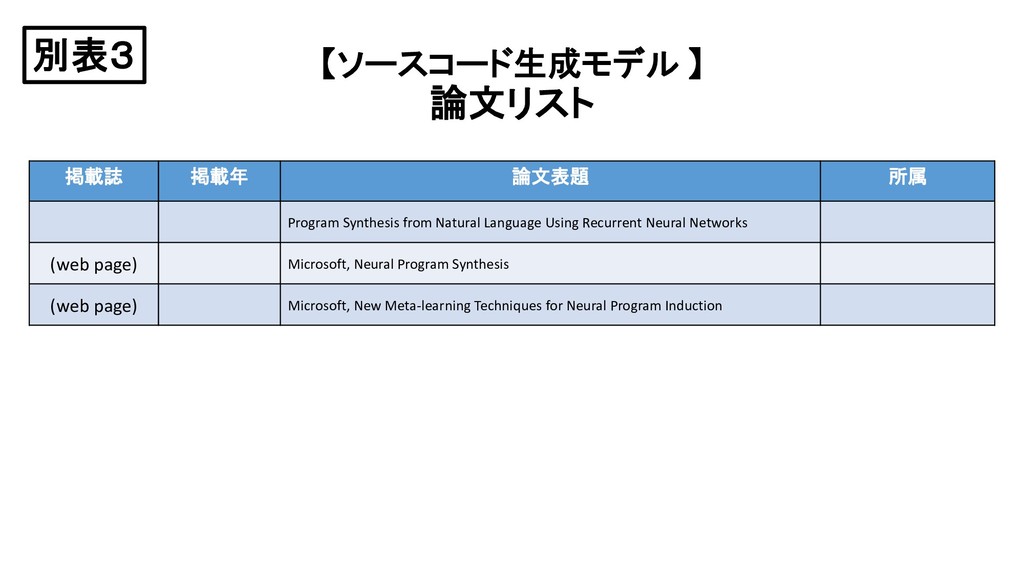{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
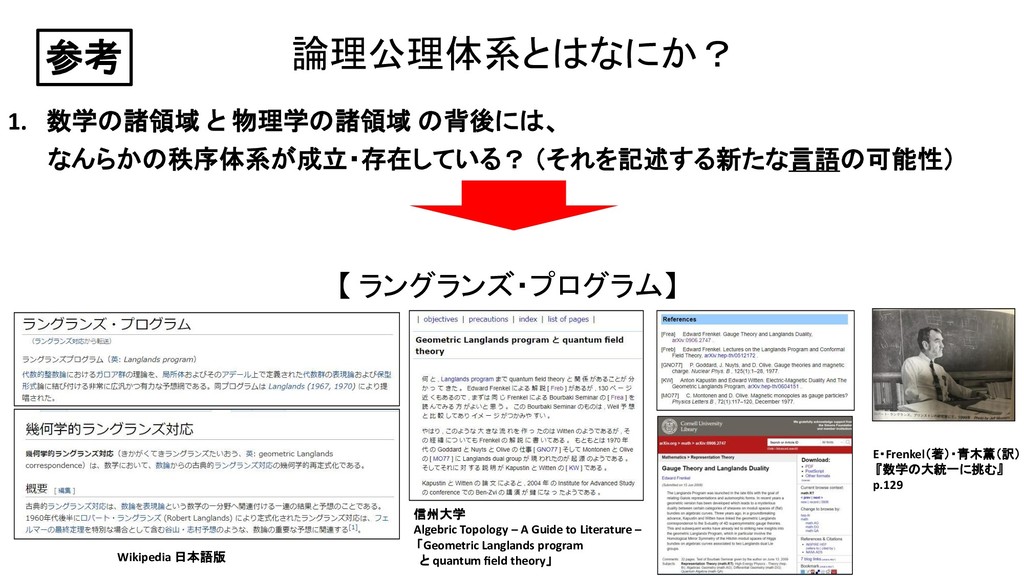{kind=link}
{kind=link}
{kind=link}