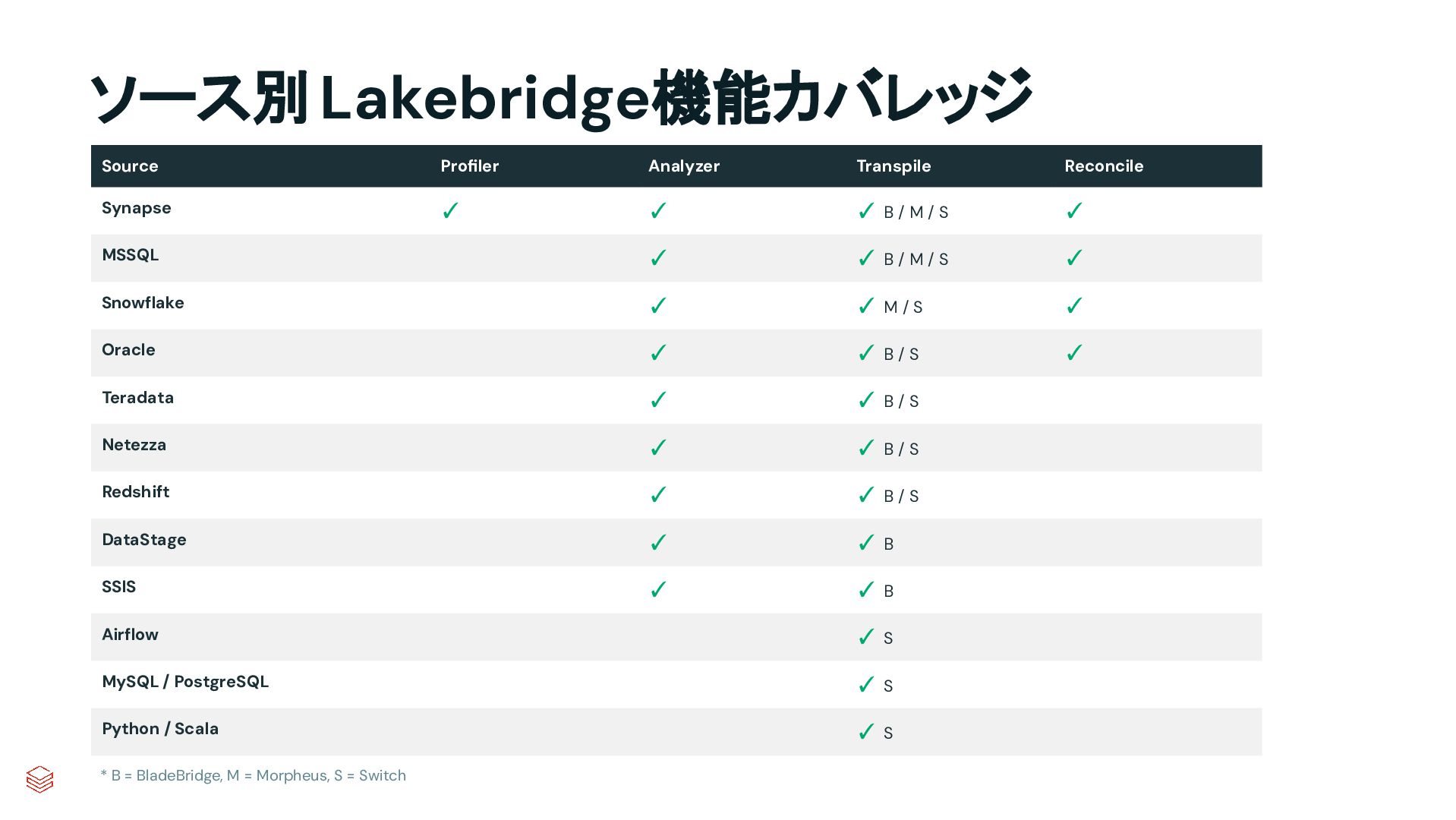
Switch Source Profiler Analyzer Transpile Reconcile Synapse ✓ ✓ ✓ B / M / S ✓ MSSQL ✓ ✓ B / M / S ✓ Snowflake ✓ ✓ M / S ✓ Oracle ✓ ✓ B / S ✓ Teradata ✓ ✓ B / S Netezza ✓ ✓ B / S Redshift ✓ ✓ B / S DataStage ✓ ✓ B SSIS ✓ ✓ B Airflow ✓ S MySQL / PostgreSQL ✓ S Python / Scala ✓ S
code that runs on Databricks according to the following instructions: # Input and Output - Input: A single SQL file containing one or multiple T-SQL statements - Output: Python code with Python comments (in {comment_lang}) explaining the code ${common_python_instructions_and_guidelines} # Additional Instructions 1. Convert SQL queries to spark.sql() format 2. Add clear Python comments explaining the code 3. Use DataFrame operations instead of loops when possible 4. Handle errors using try-except blocks few_shots: - role: user content: | SELECT name, age FROM users WHERE active = 1; - role: assistant content: | # Get names and ages of active users active_users = spark.sql("SELECT name, age FROM users WHERE active = 1") display(active_users)
code that runs on Databricks according to the following instructions: # Input and Output - Input: A single SQL file containing one or multiple T-SQL statements - Output: Python code with Python comments (in {comment_lang}) explaining the code ${common_python_instructions_and_guidelines} # Additional Instructions 1. Convert SQL queries to spark.sql() format 2. Add clear Python comments explaining the code 3. Use DataFrame operations instead of loops when possible 4. Handle errors using try-except blocks few_shots: - role: user content: | SELECT name, age FROM users WHERE active = 1; - role: assistant content: | # Get names and ages of active users active_users = spark.sql("SELECT name, age FROM users WHERE active = 1") display(active_users) system_message (必須) 変換ルール、入力/出力形式、具体的な 指示を定義 few_shots (任意だが推奨 ) 具体的な変換例をいくつか用意することでLLMの 変換精度を向上
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}