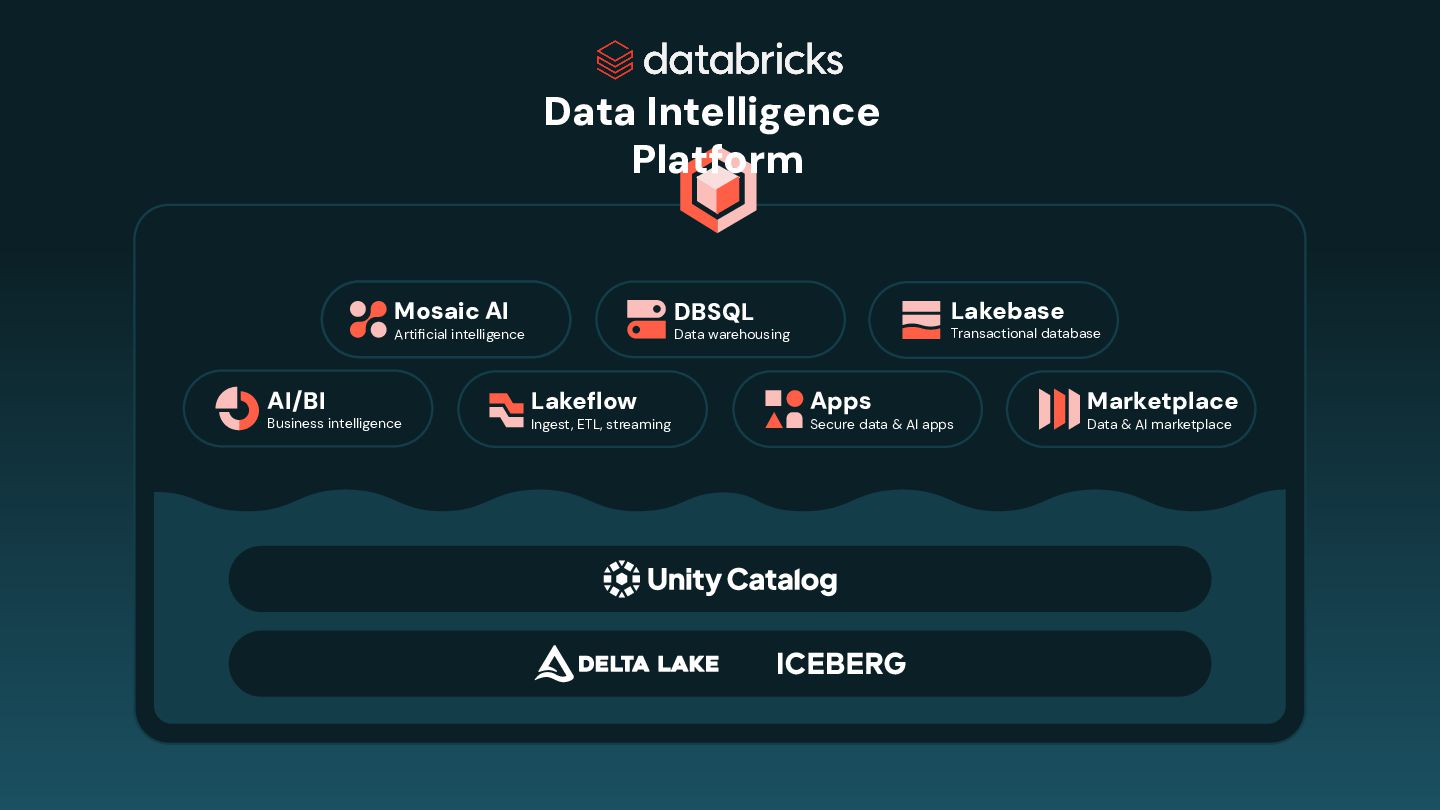
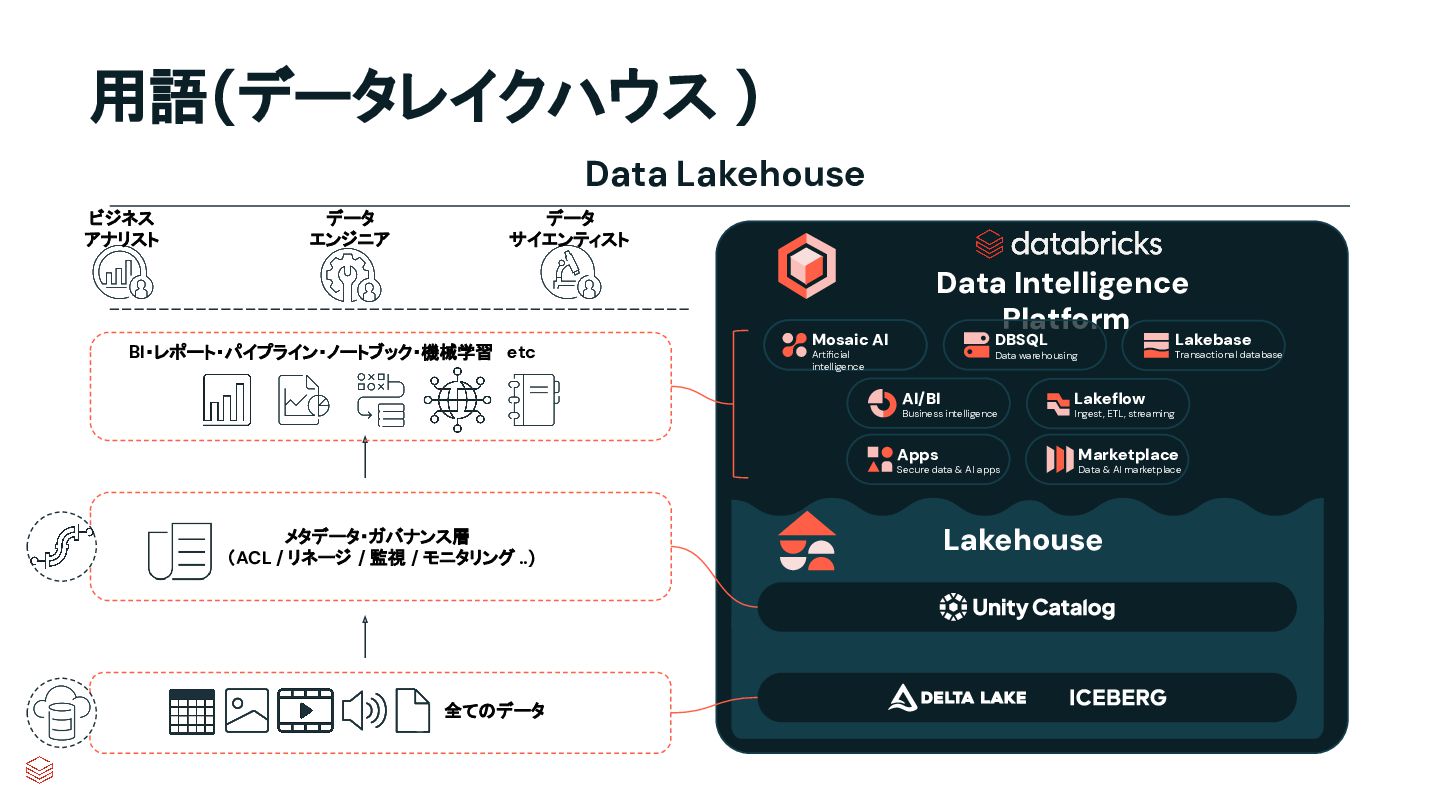
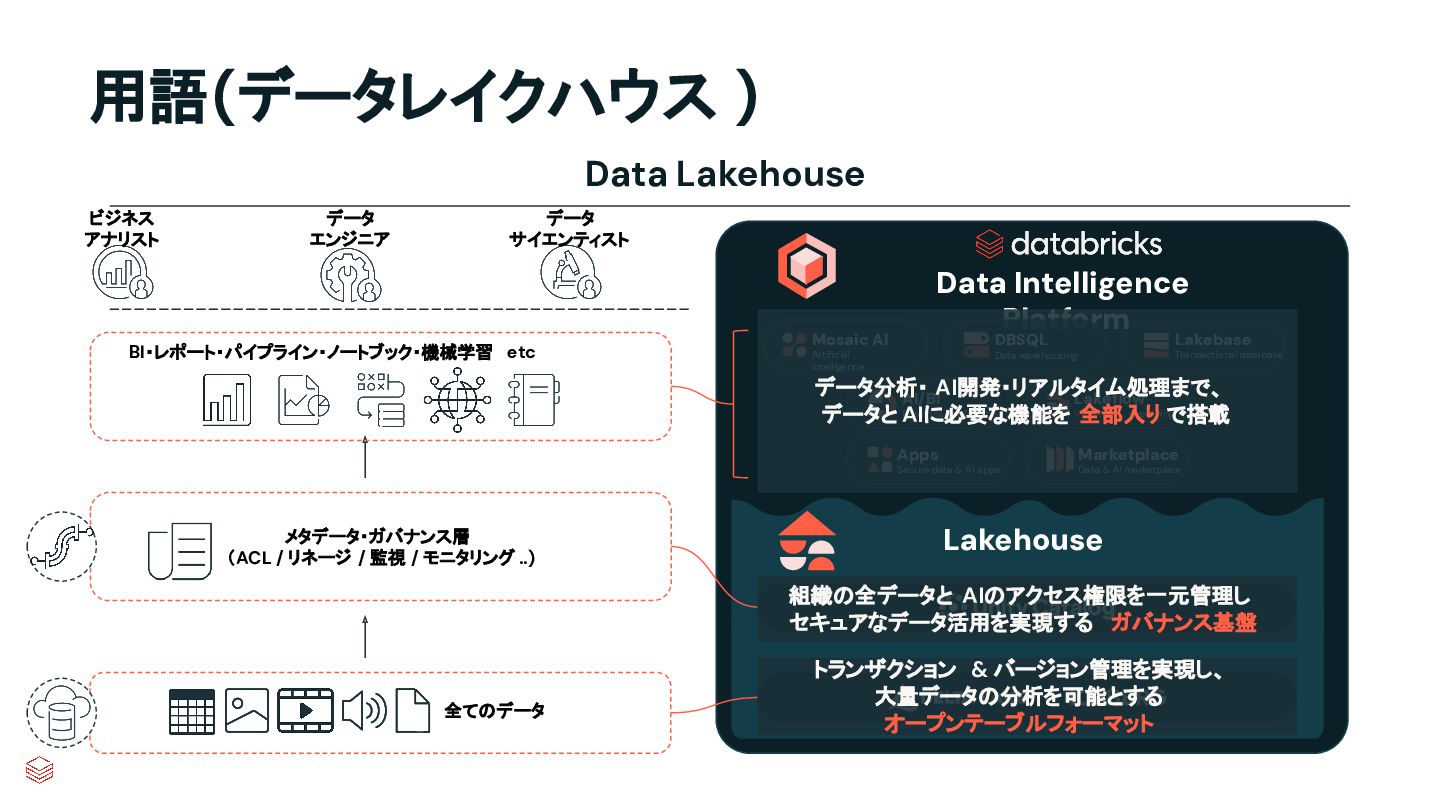
AI marketplace Apps Secure data & AI apps Lakebase Transactional database AI/BI Business intelligence Mosaic AI Artificial intelligence Data Intelligence Platform
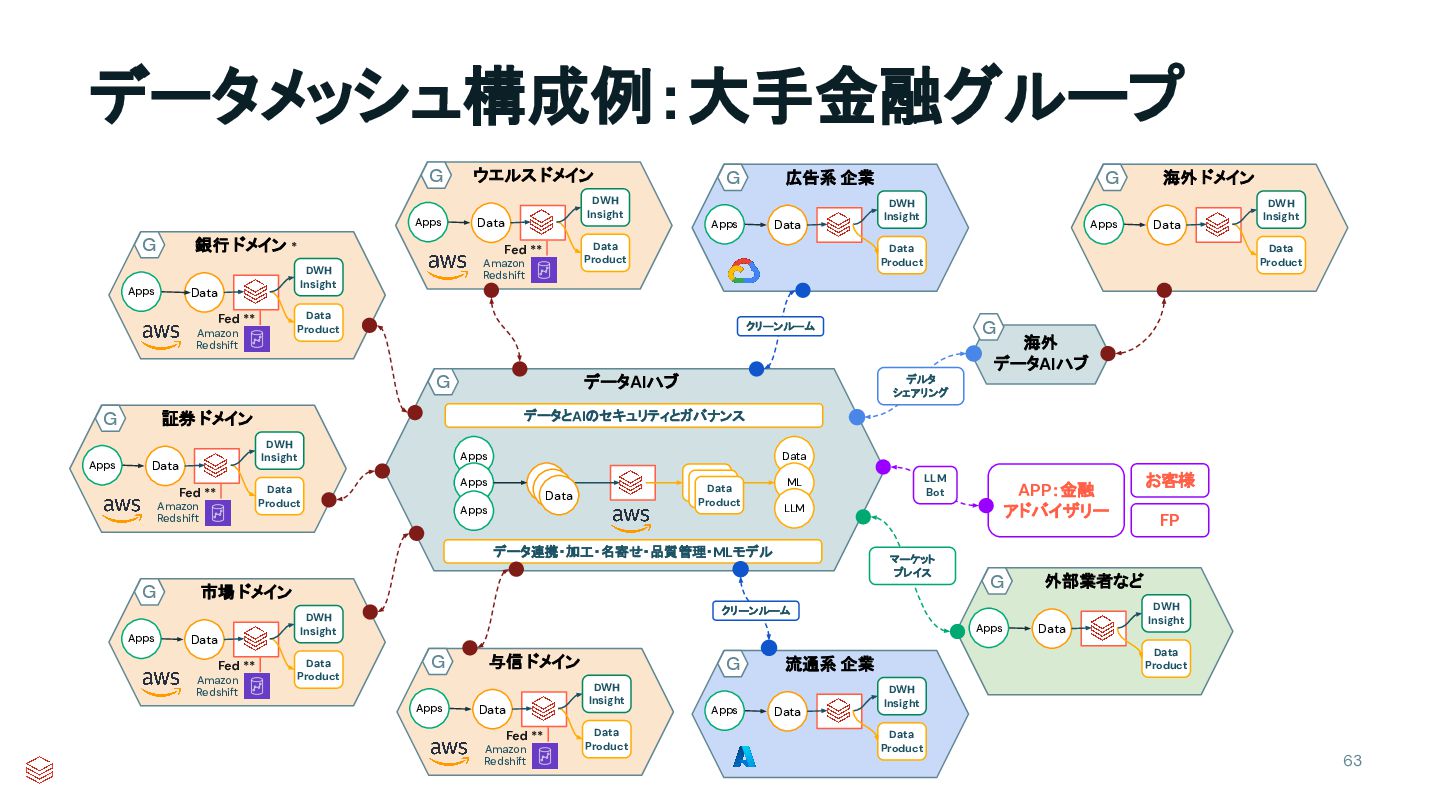
Insight Apps Amazon Redshift Fed ** 流通系 企業 G Data Data Product DWH Insight Apps データとAIのセキュリティとガバナンス データAIハブ G Data Apps Apps Apps Data ML LLM Data Product データ連携・加工・名寄せ・品質管理・MLモデル 証券 ドメイン G Data Data Product DWH Insight Apps Amazon Redshift Fed ** 市場 ドメイン G Data Data Product DWH Insight Apps Amazon Redshift Fed ** ウエルス ドメイン G Data Data Product DWH Insight Apps Amazon Redshift Fed ** 与信 ドメイン G Data Data Product DWH Insight Apps Amazon Redshift Fed ** 広告系 企業 G Data Data Product DWH Insight Apps クリーンルーム クリーンルーム 外部業者など G Data Data Product DWH Insight Apps APP:金融 アドバイザリー お客様 FP 海外 ドメイン G Data Data Product DWH Insight Apps 海外 データAIハブ マーケット プレイス G LLM Bot デルタ シェアリング
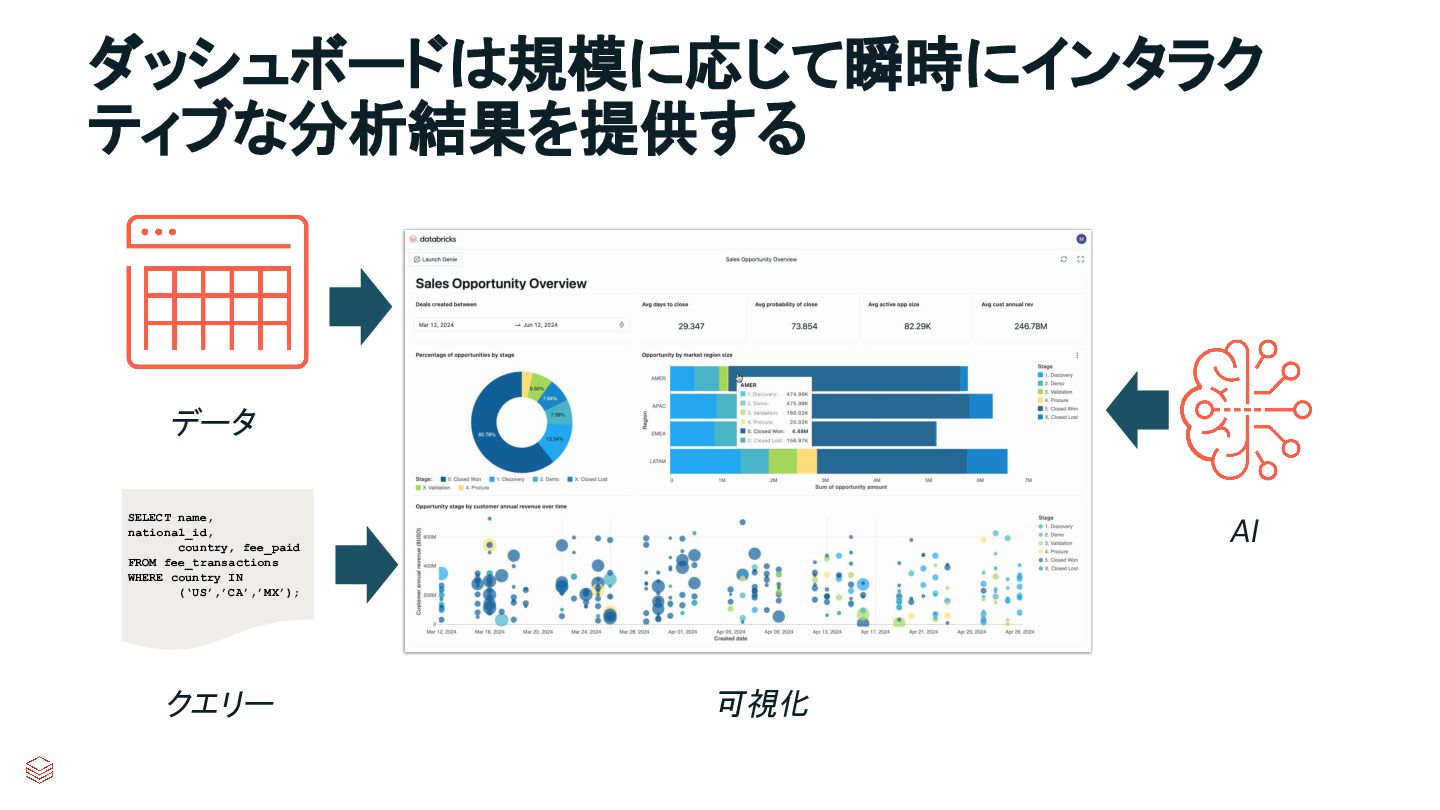
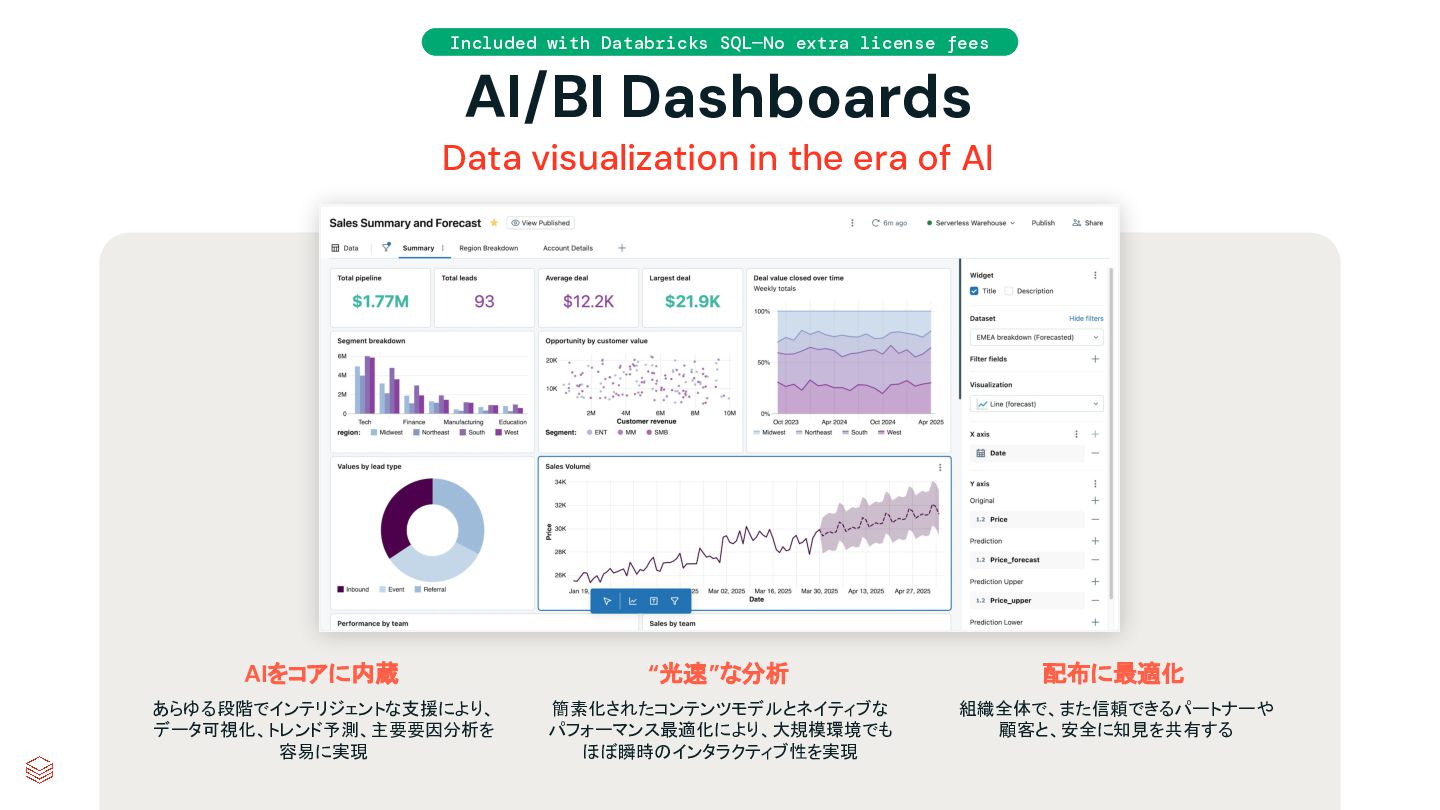
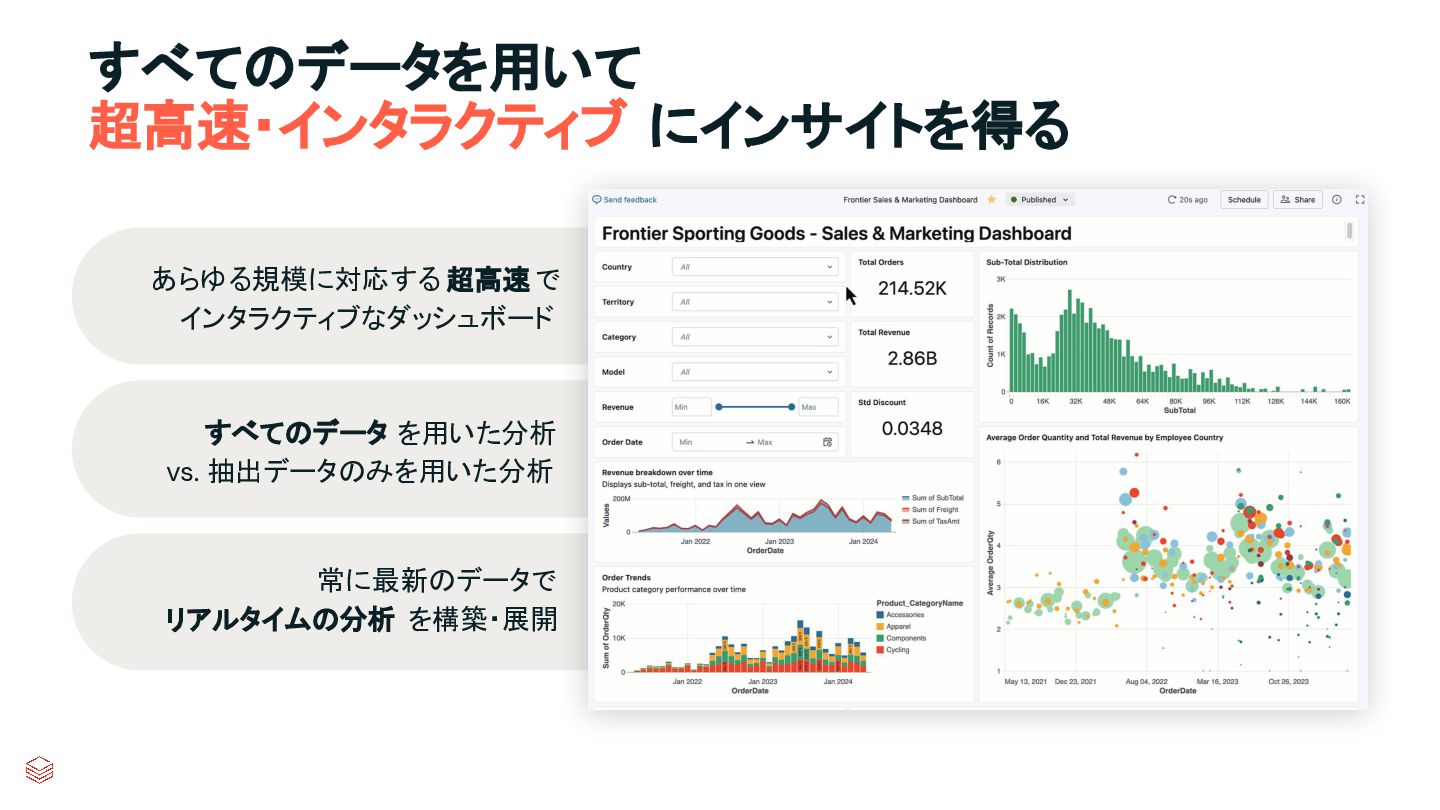
visualization in the era of AI AIをコアに内蔵 あらゆる段階でインテリジェントな支援により、 データ可視化、トレンド予測、主要要因分析を 容易に実現 “光速”な分析 簡素化されたコンテンツモデルとネイティブな パフォーマンス最適化により、大規模環境でも ほぼ瞬時のインタラクティブ性を実現 配布に最適化 組織全体で、また信頼できるパートナーや 顧客と、安全に知見を共有する
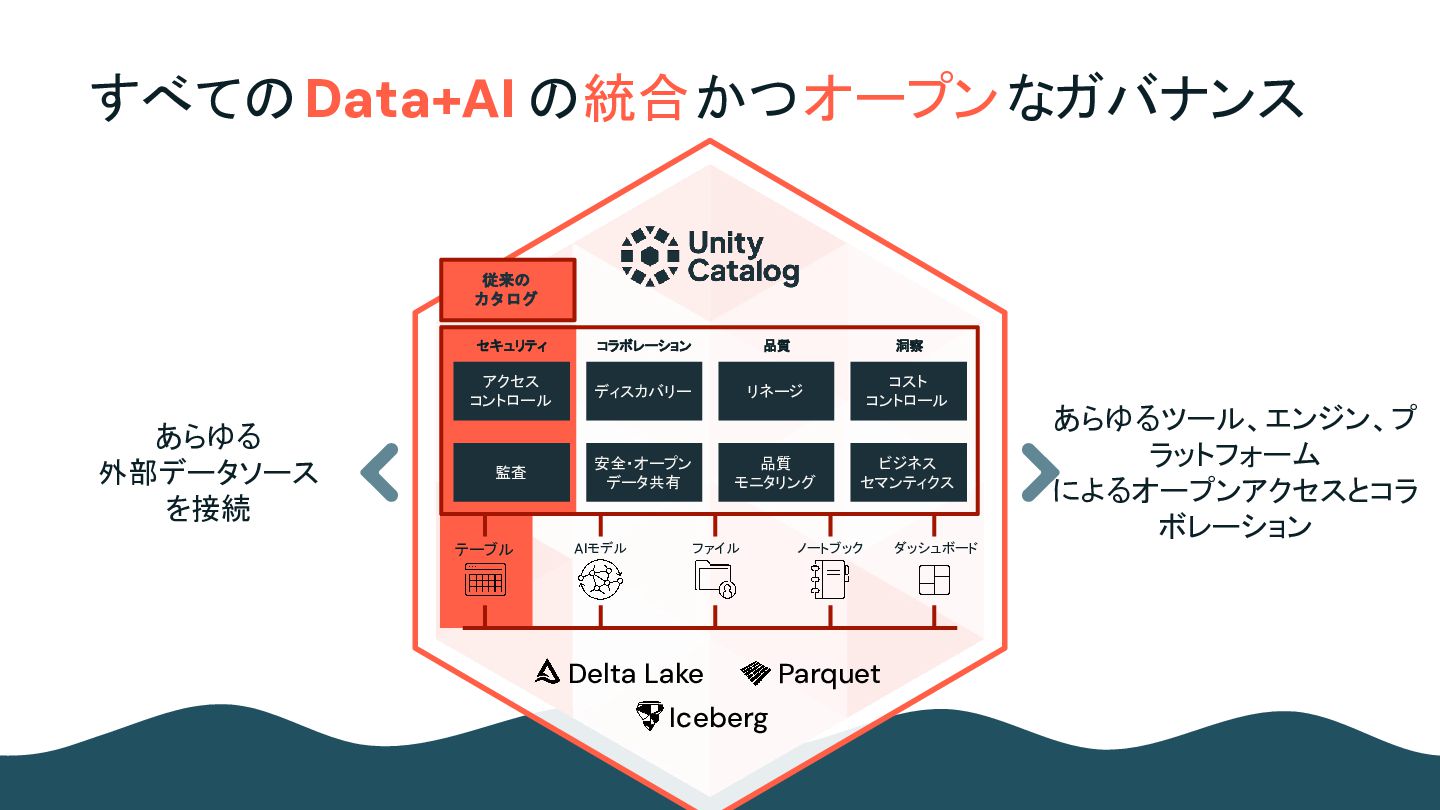
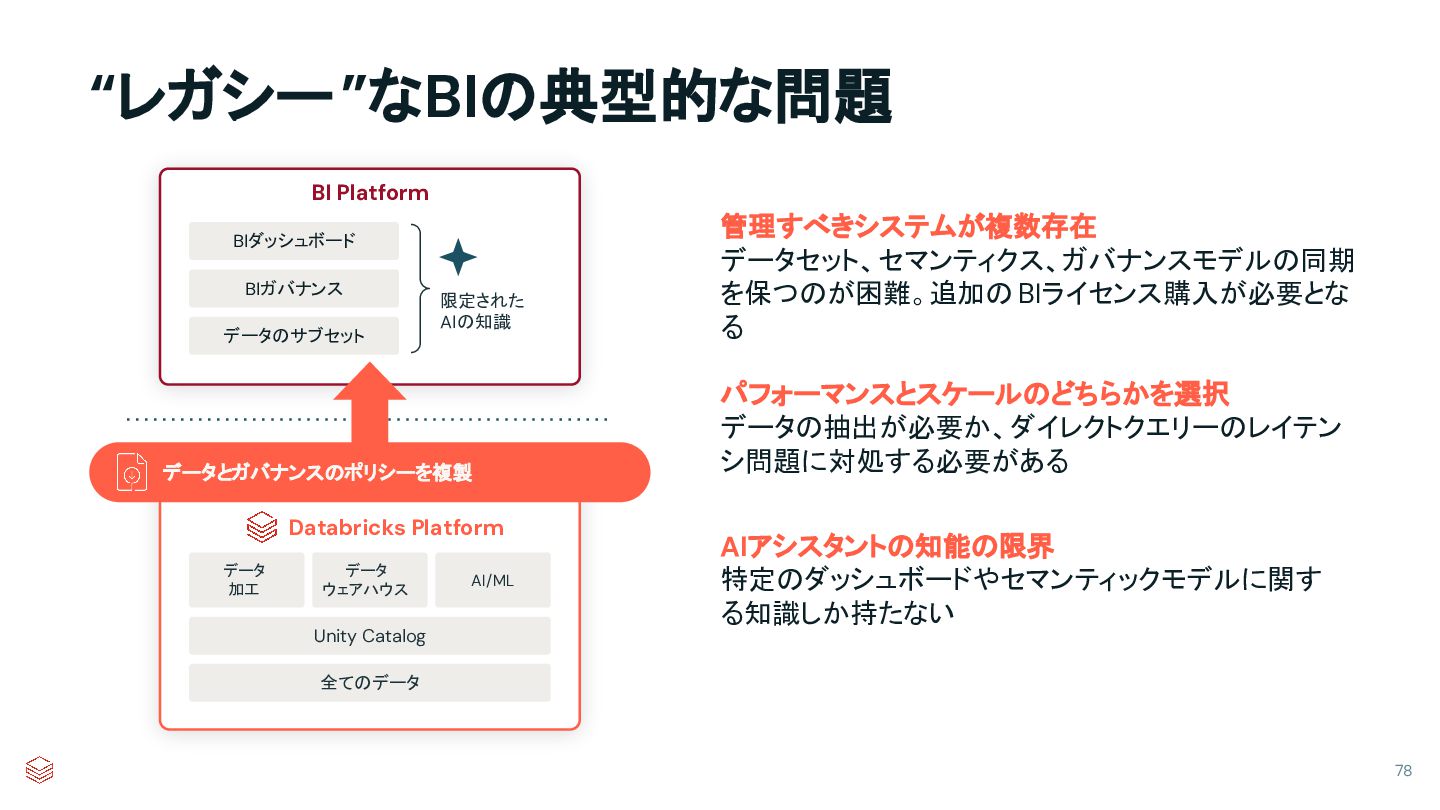
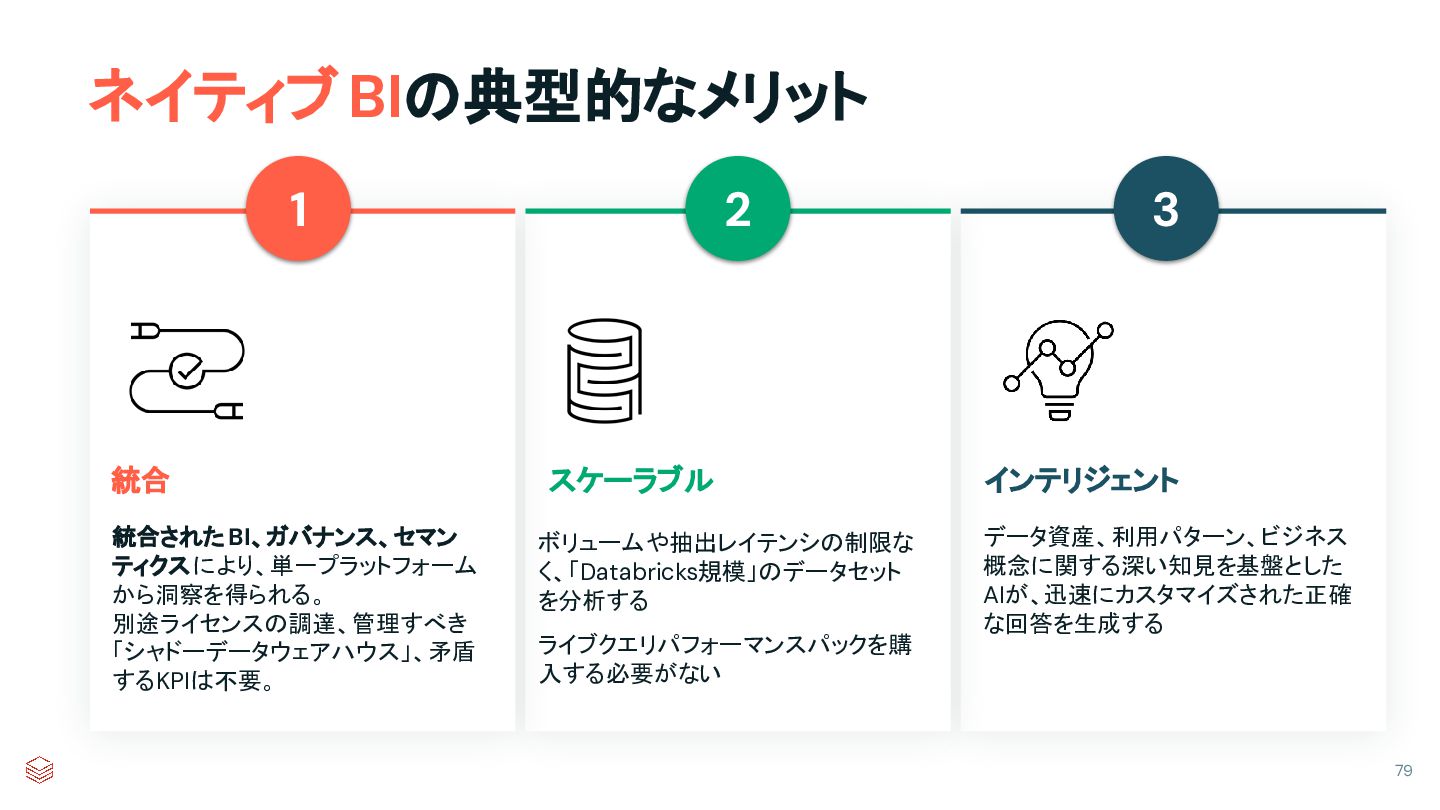
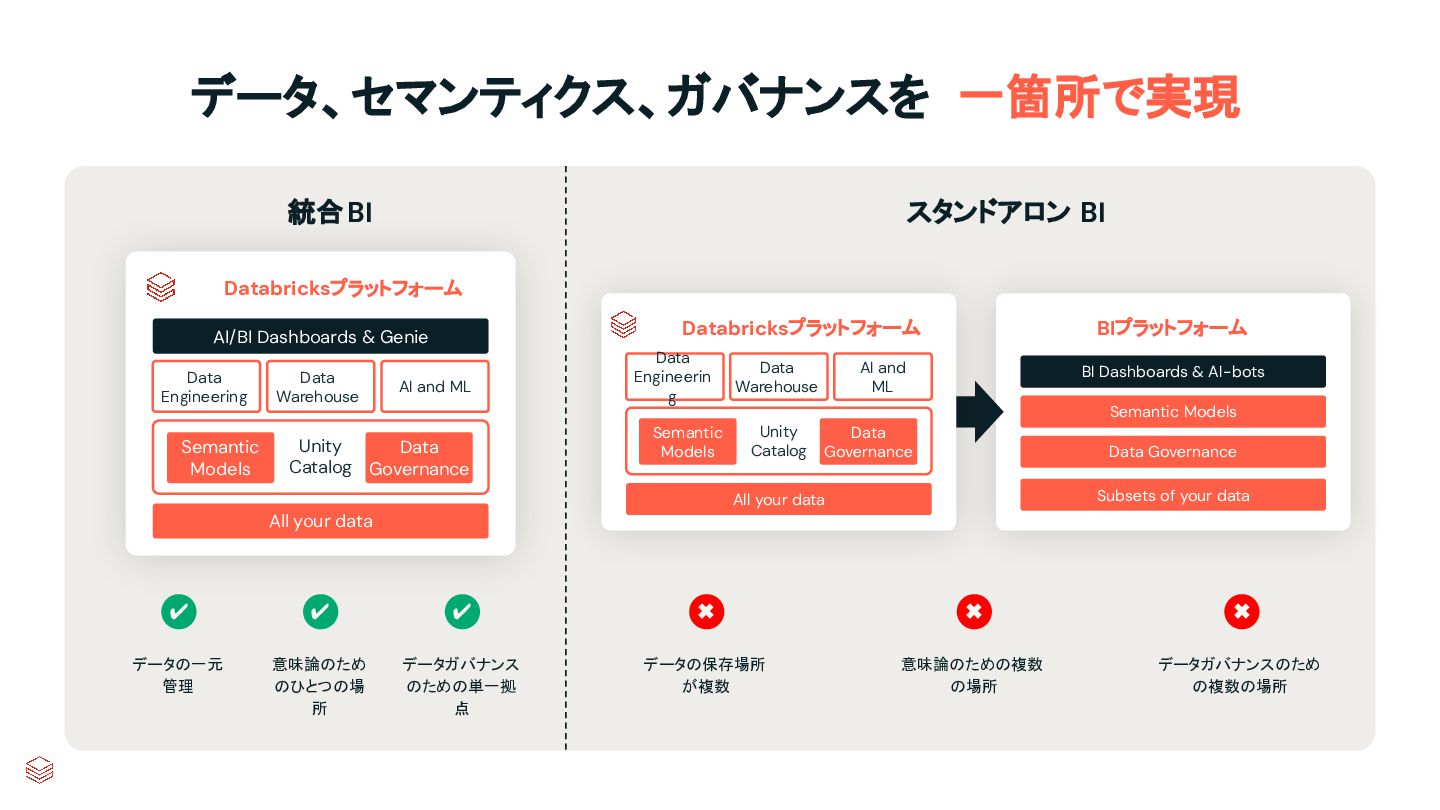
Unity Catalog Data Warehouse AI and ML Data Engineerin g All your data Semantic Models Data Governance Databricksプラットフォーム Unity Catalog Data Warehouse AI and ML Data Engineering All your data Semantic Models Data Governance AI/BI Dashboards & Genie Subsets of your data 統合BI スタンドアロン BI ✔ ✔ ✔ ✖ ✖ ✖ データ、セマンティクス、ガバナンスを 一箇所で実現 データの一元 管理 意味論のため のひとつの場 所 データガバナンス のための単一拠 点 データの保存場所 が複数 意味論のための複数 の場所 データガバナンスのため の複数の場所
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
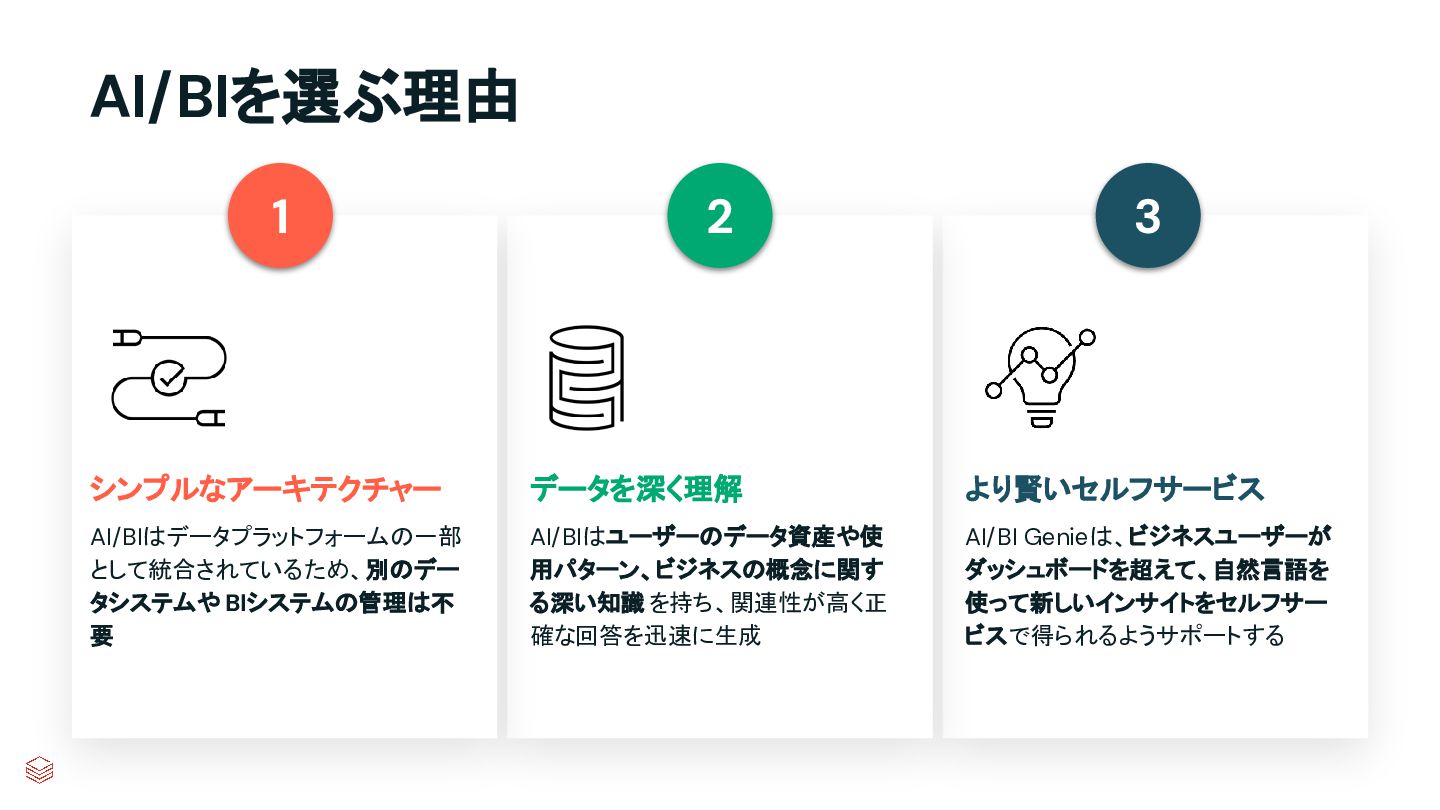{kind=link}
{kind=link}
{kind=link}
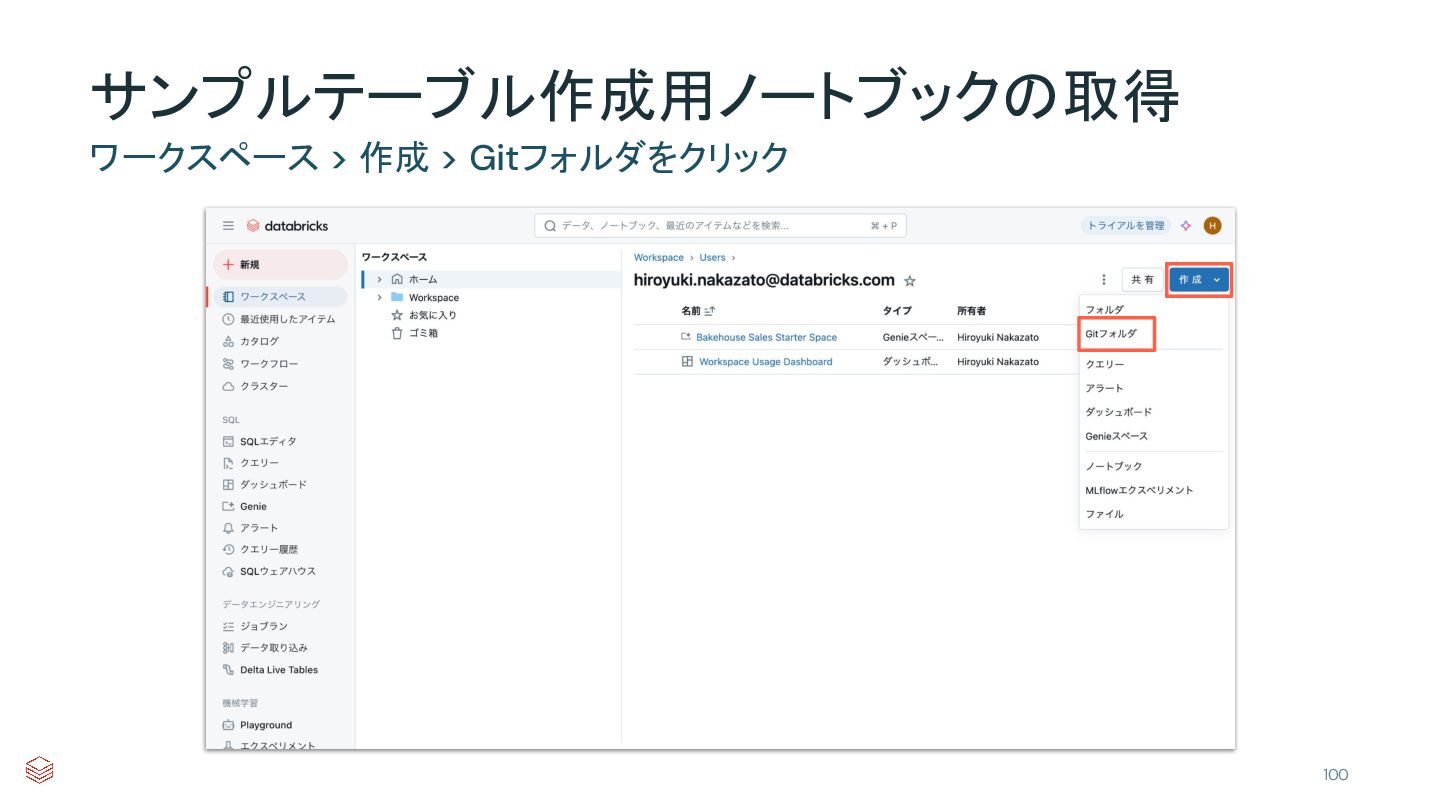{kind=link}
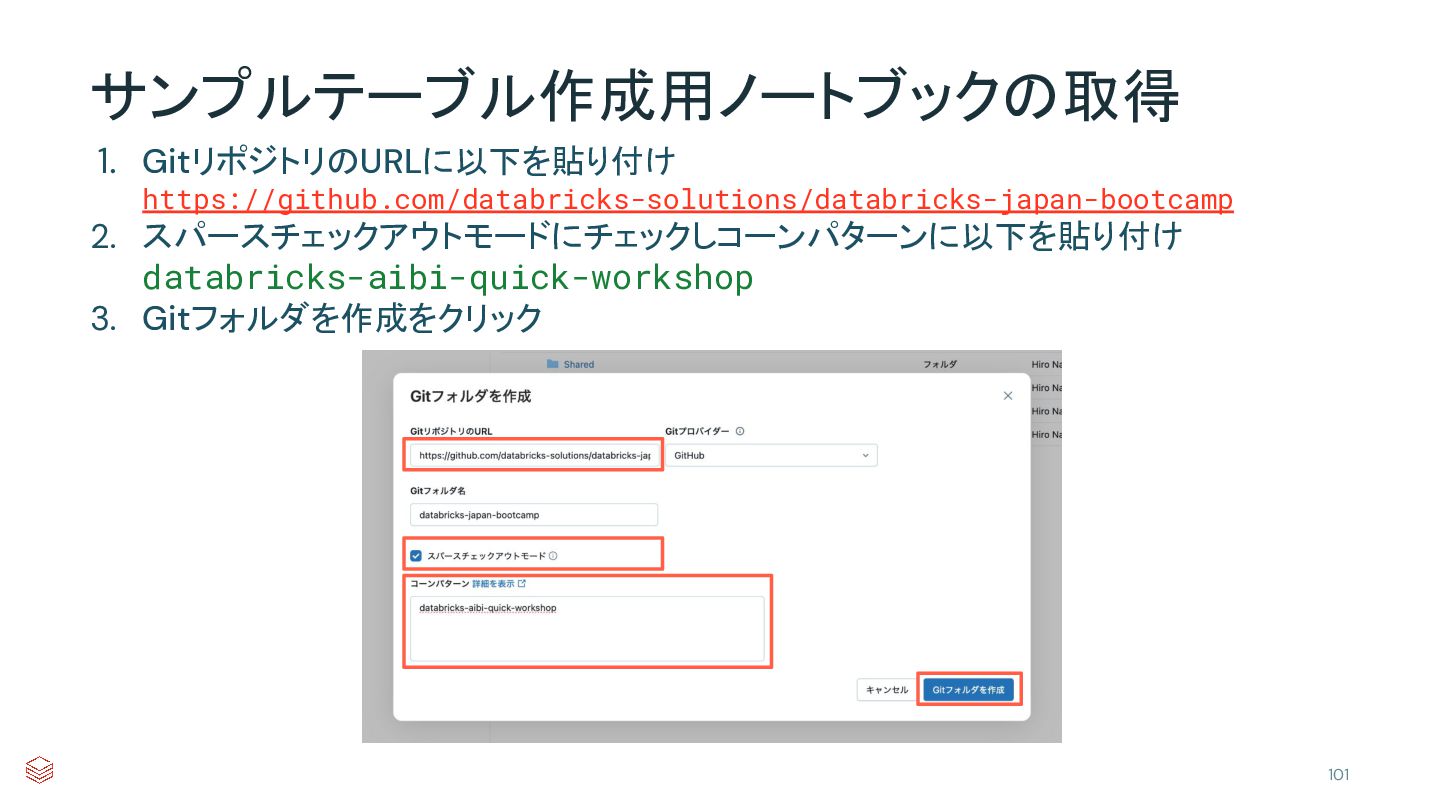{kind=link}
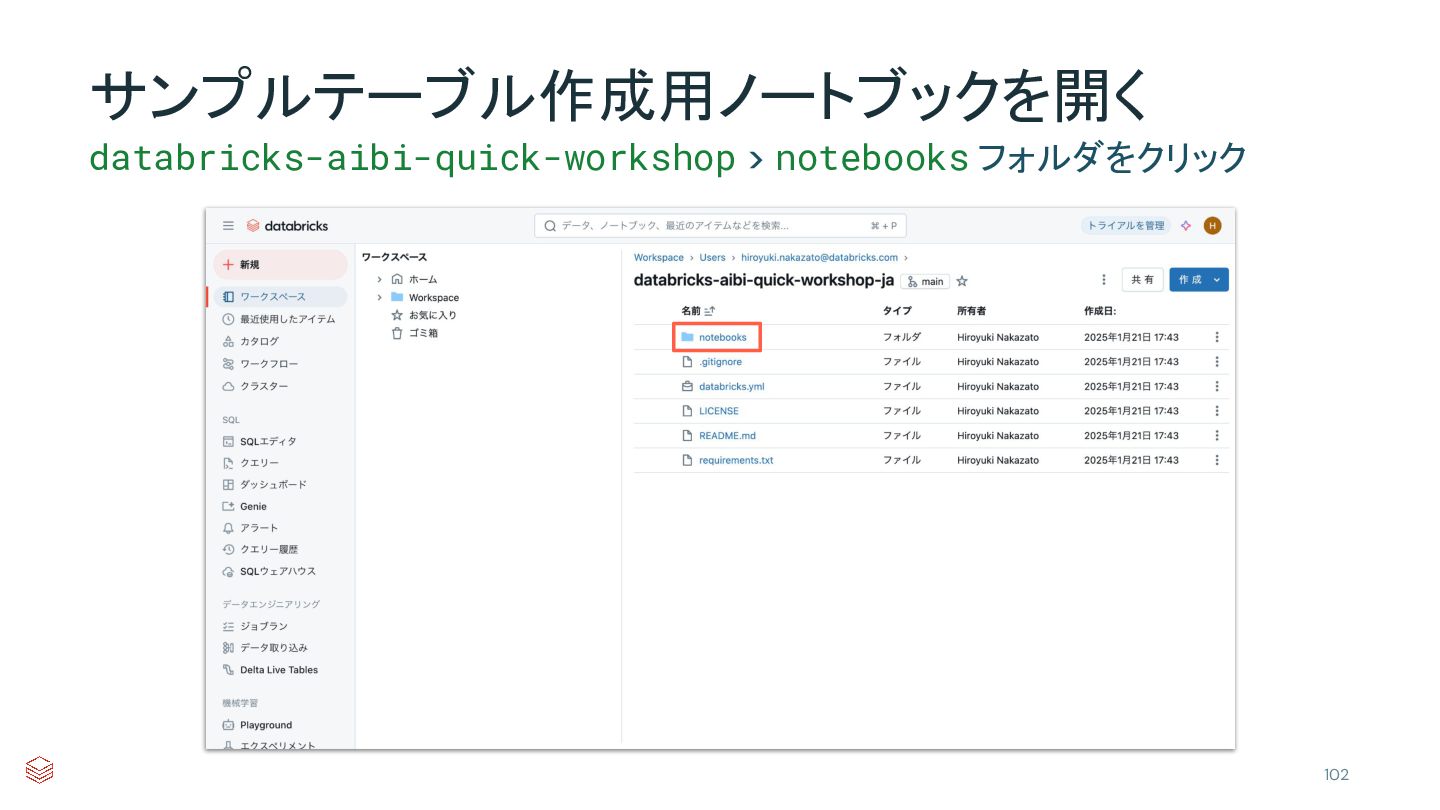{kind=link}
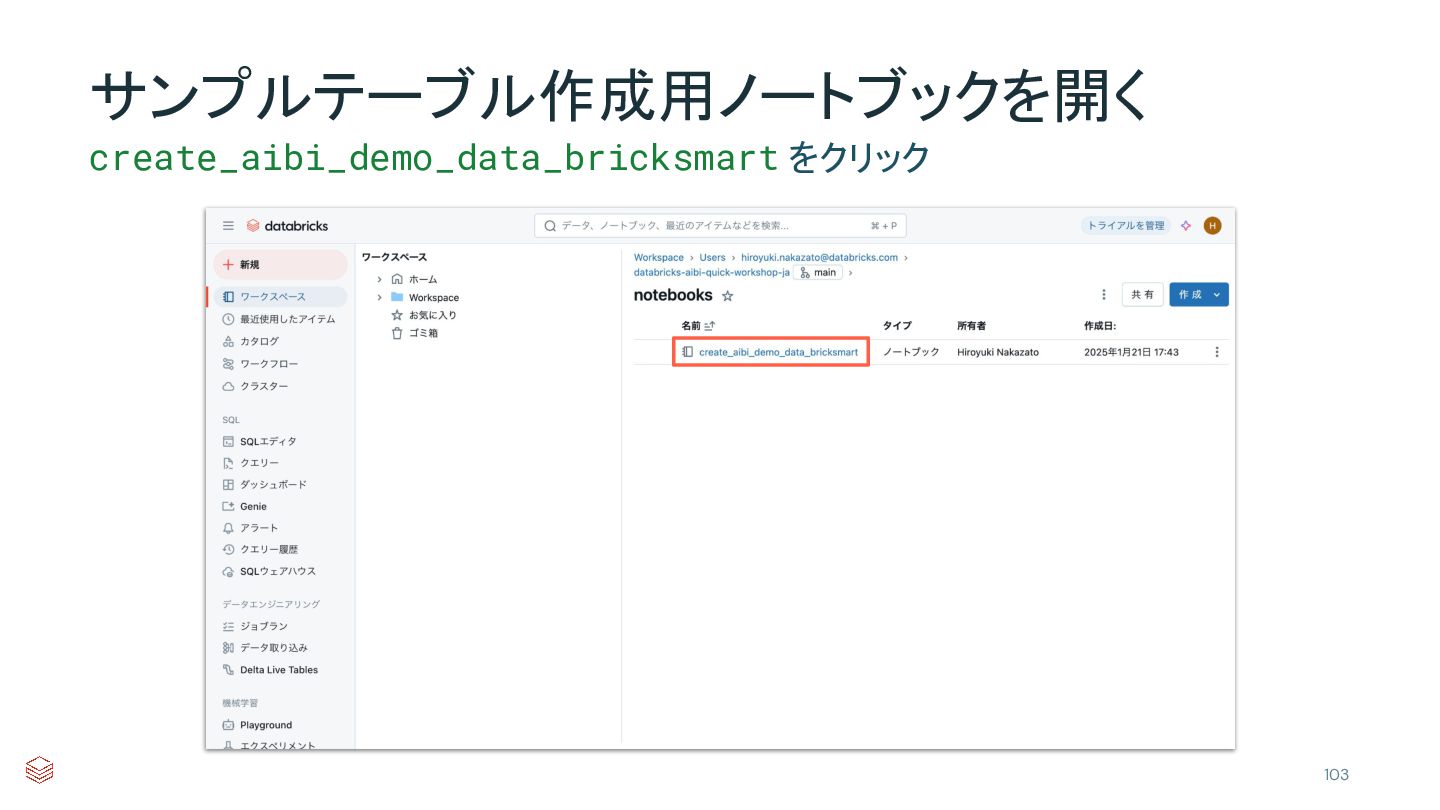{kind=link}
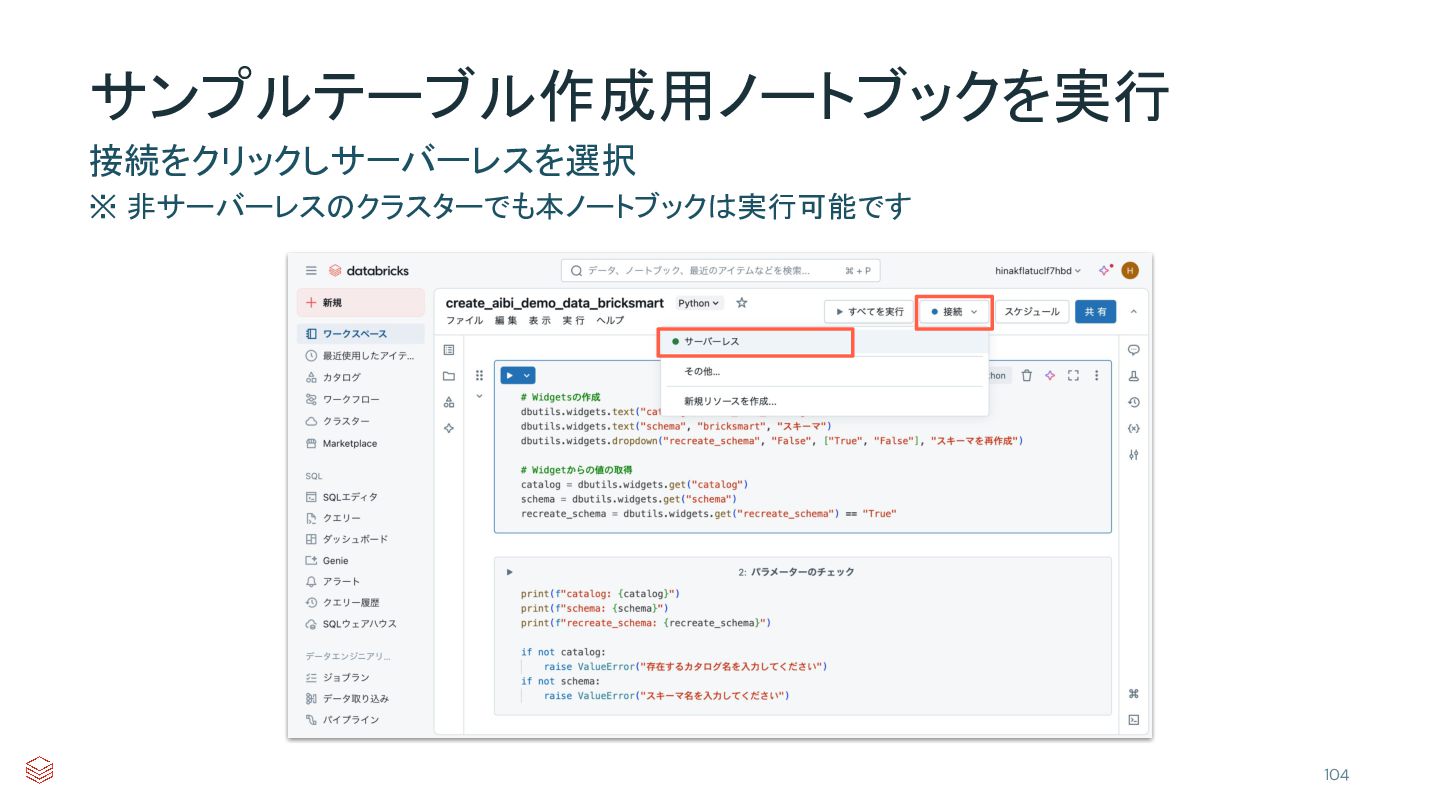{kind=link}
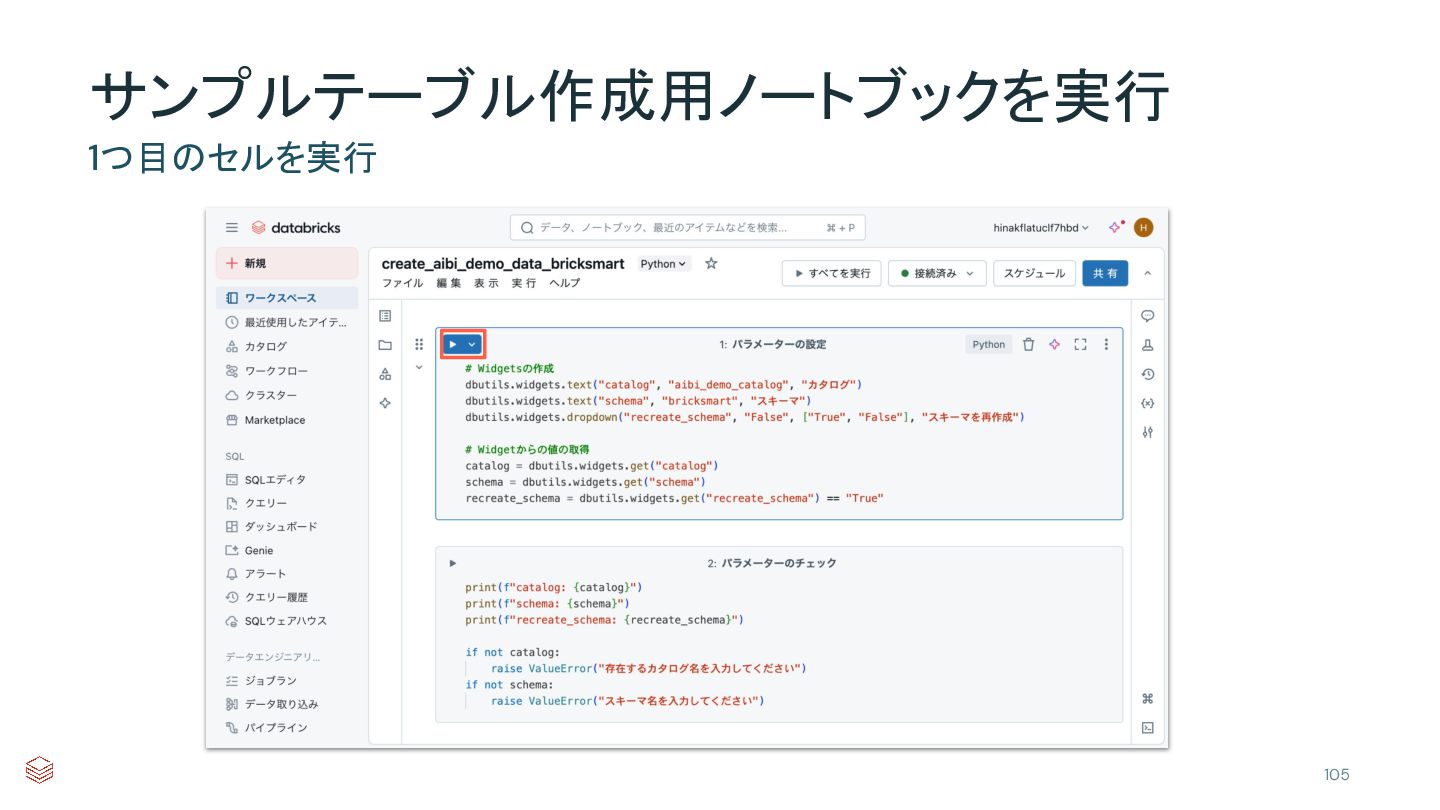{kind=link}
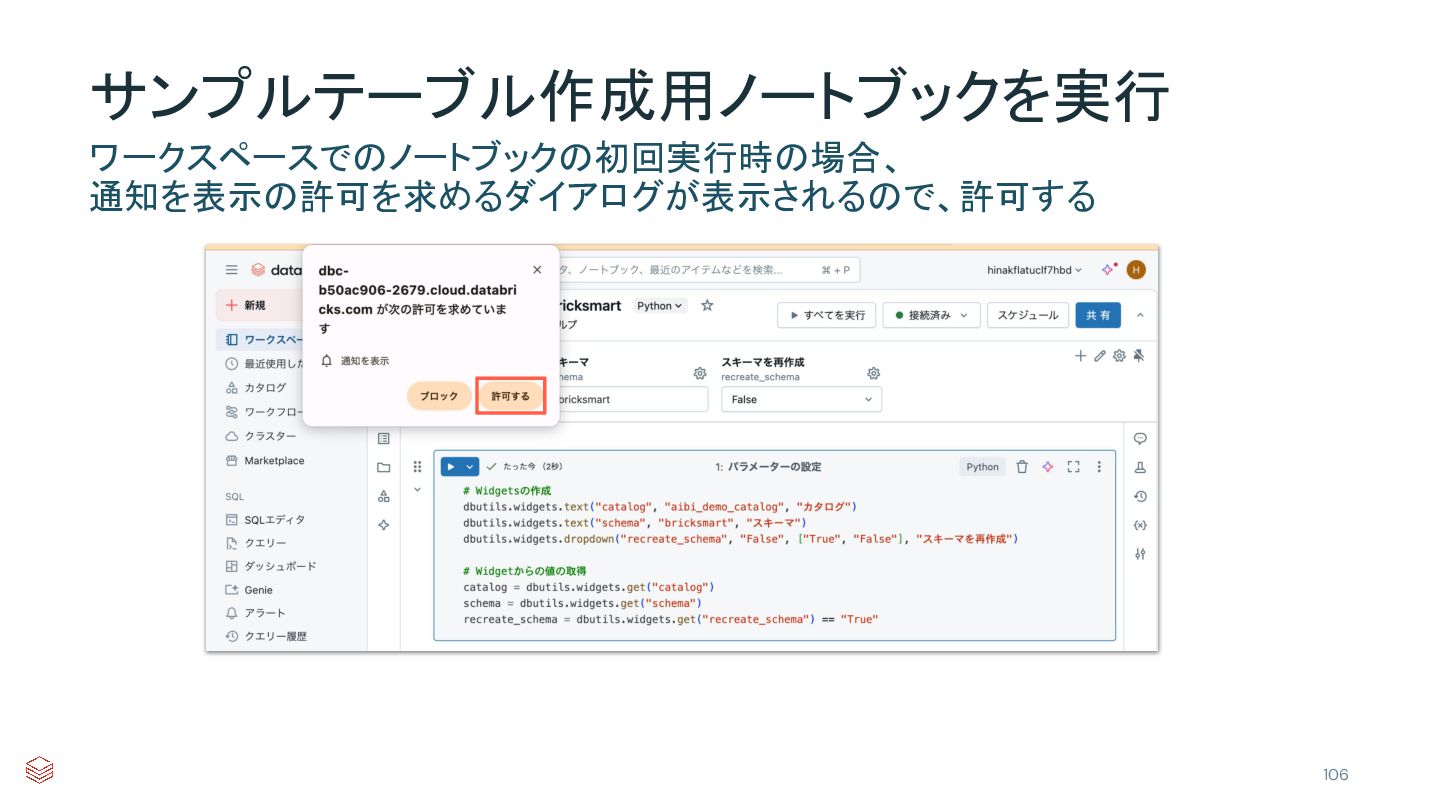{kind=link}
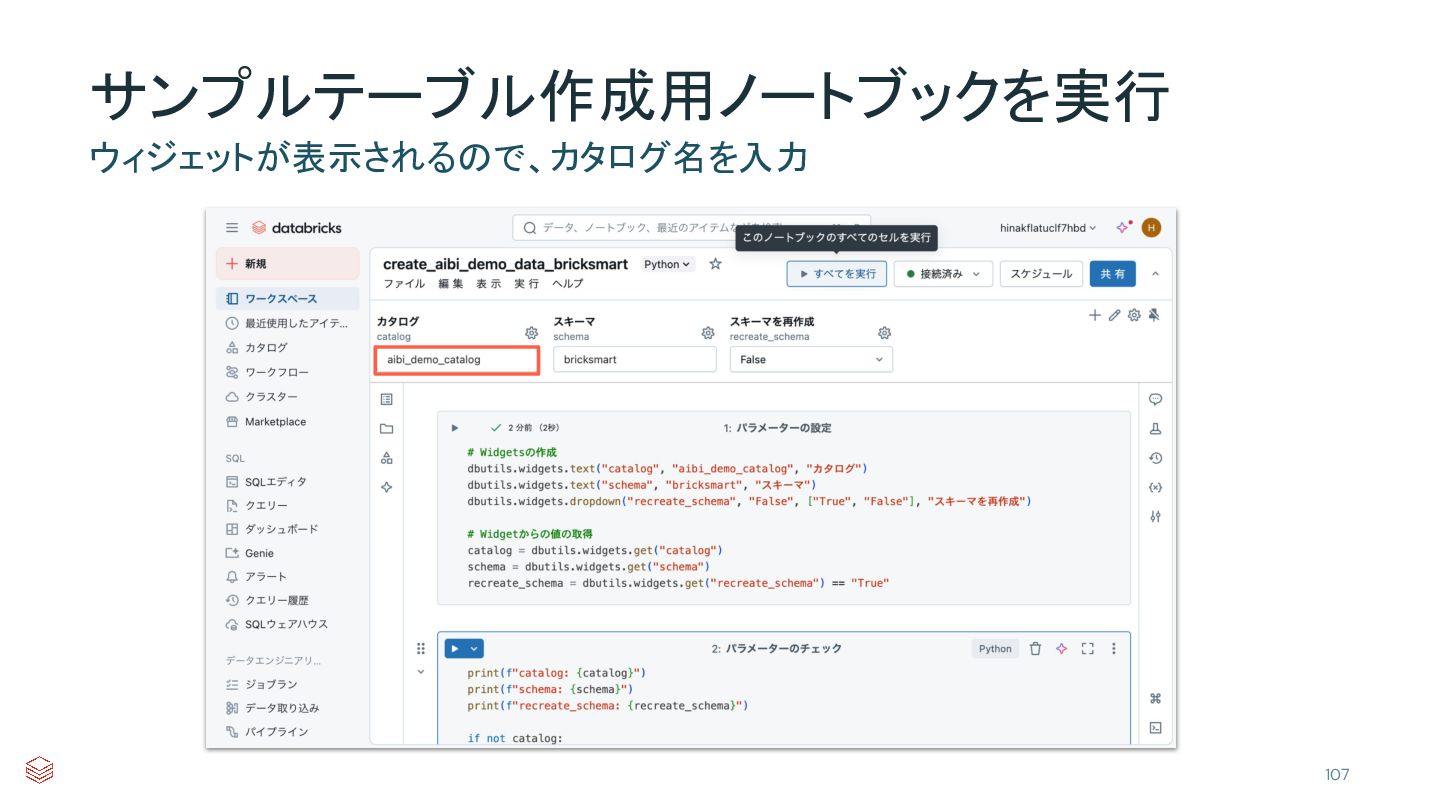{kind=link}
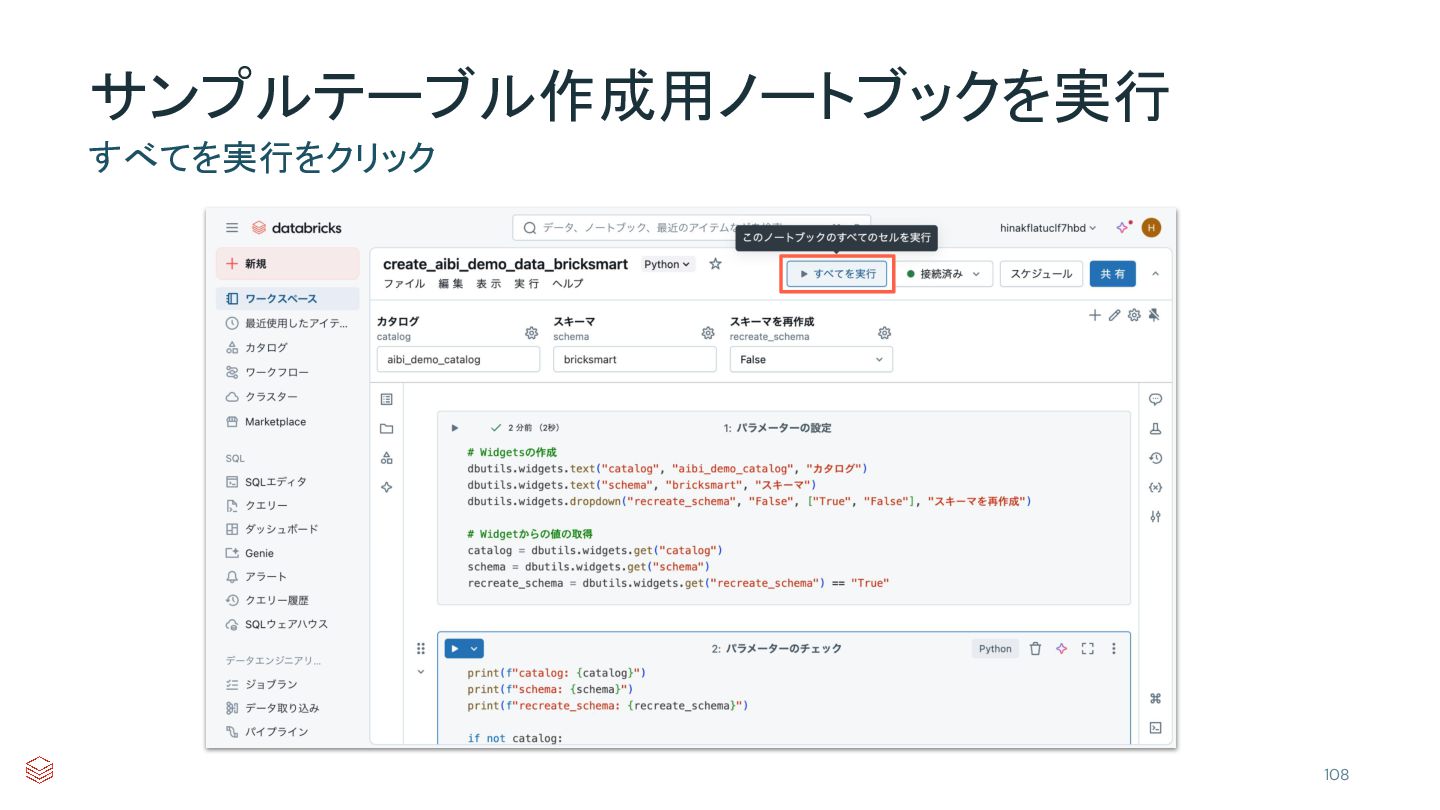{kind=link}
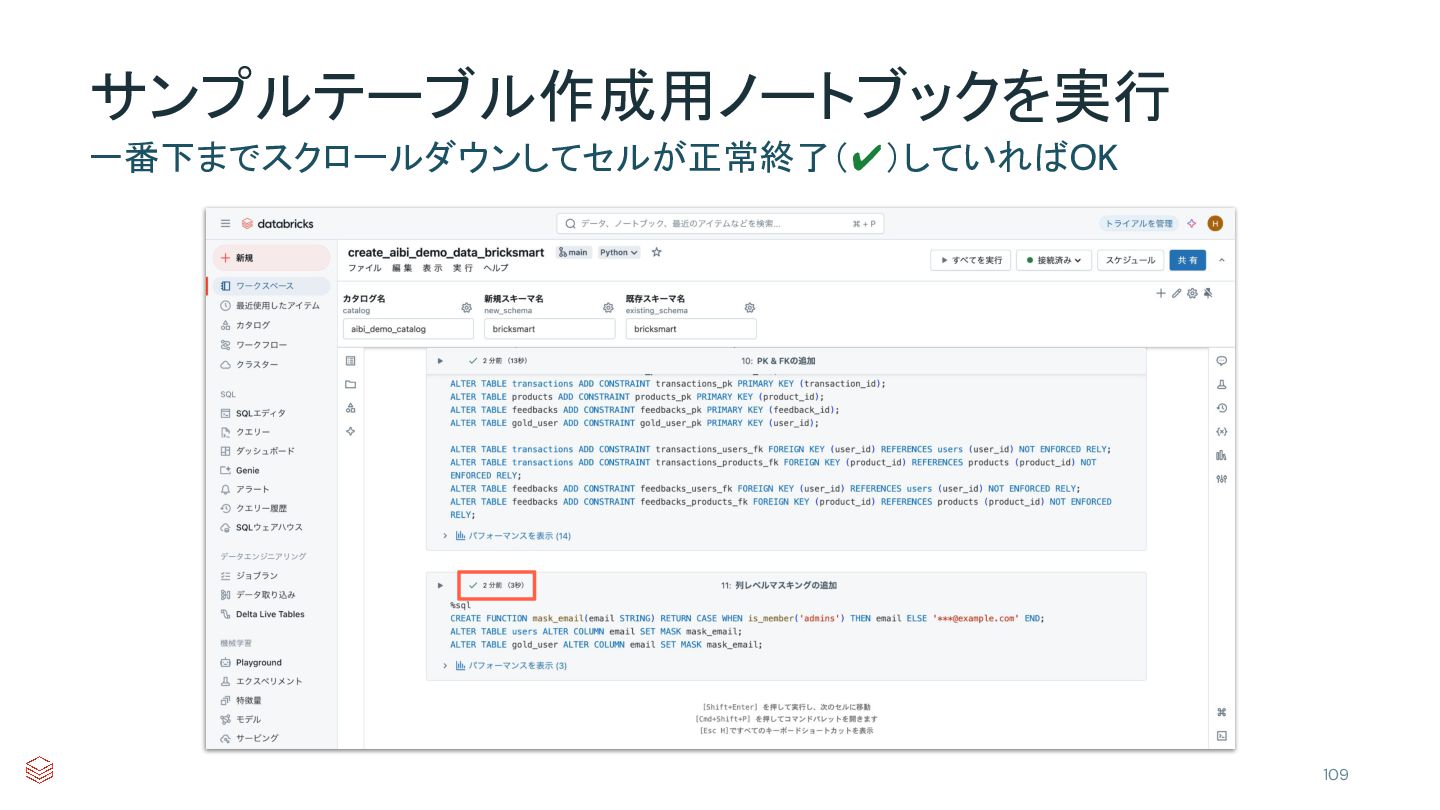{kind=link}
{kind=link}
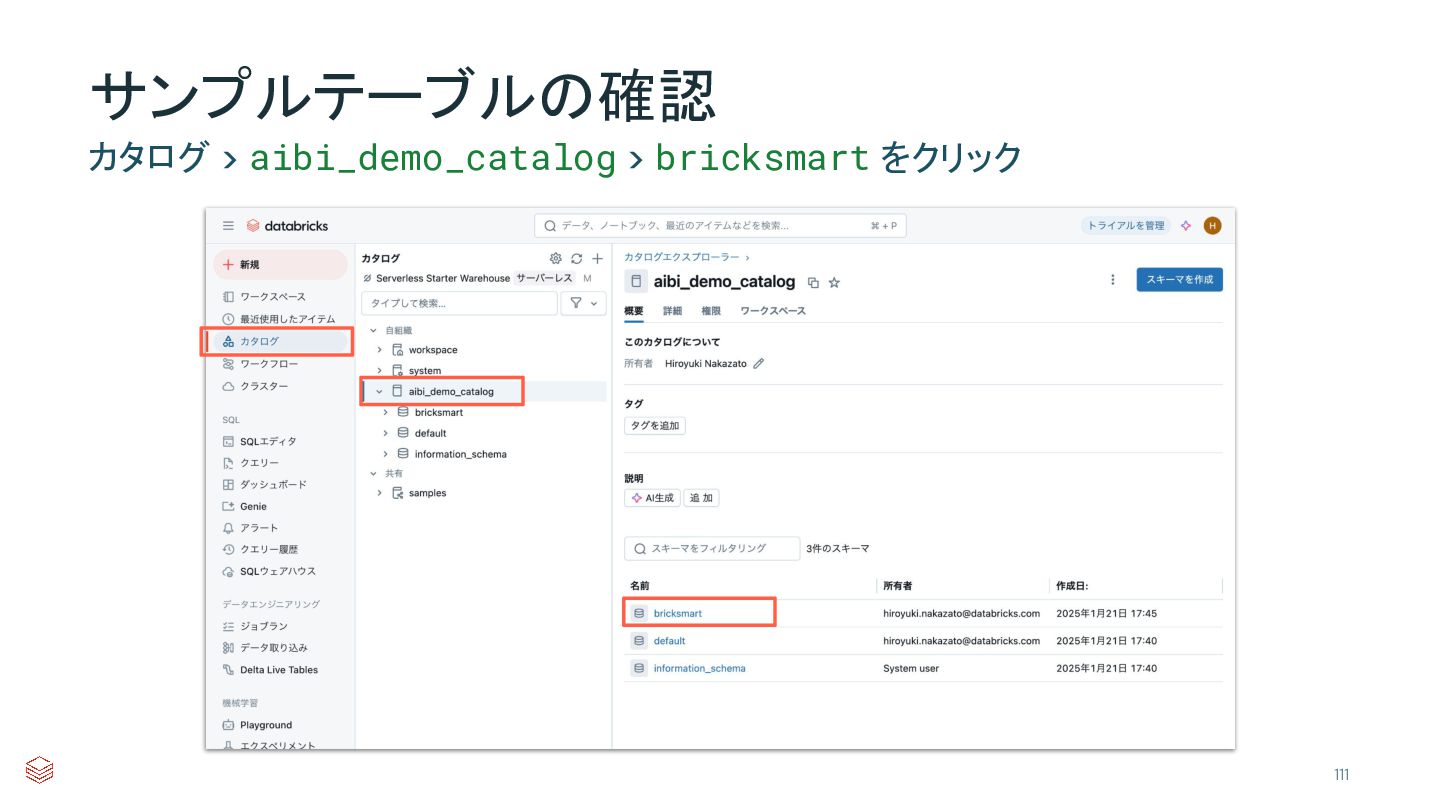{kind=link}
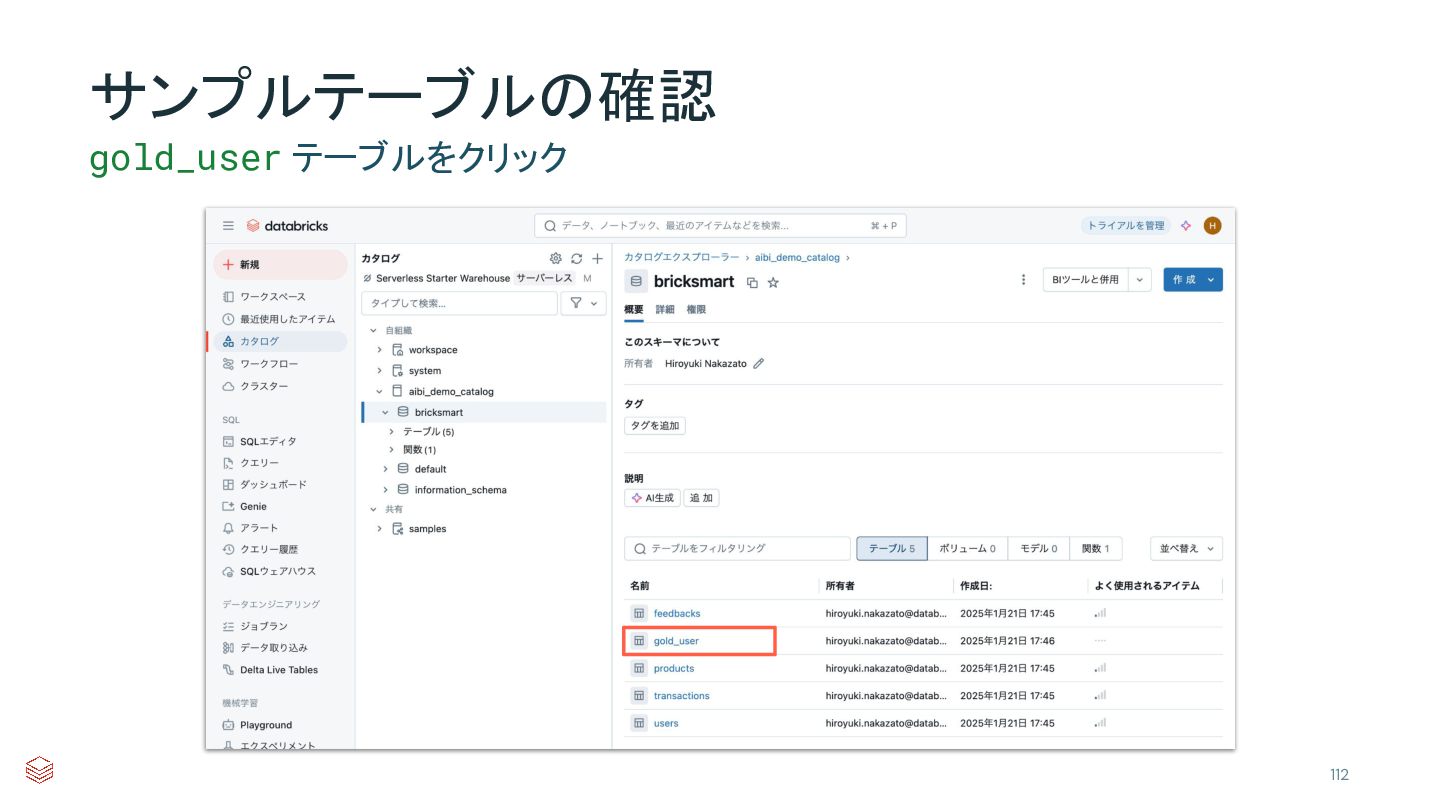{kind=link}
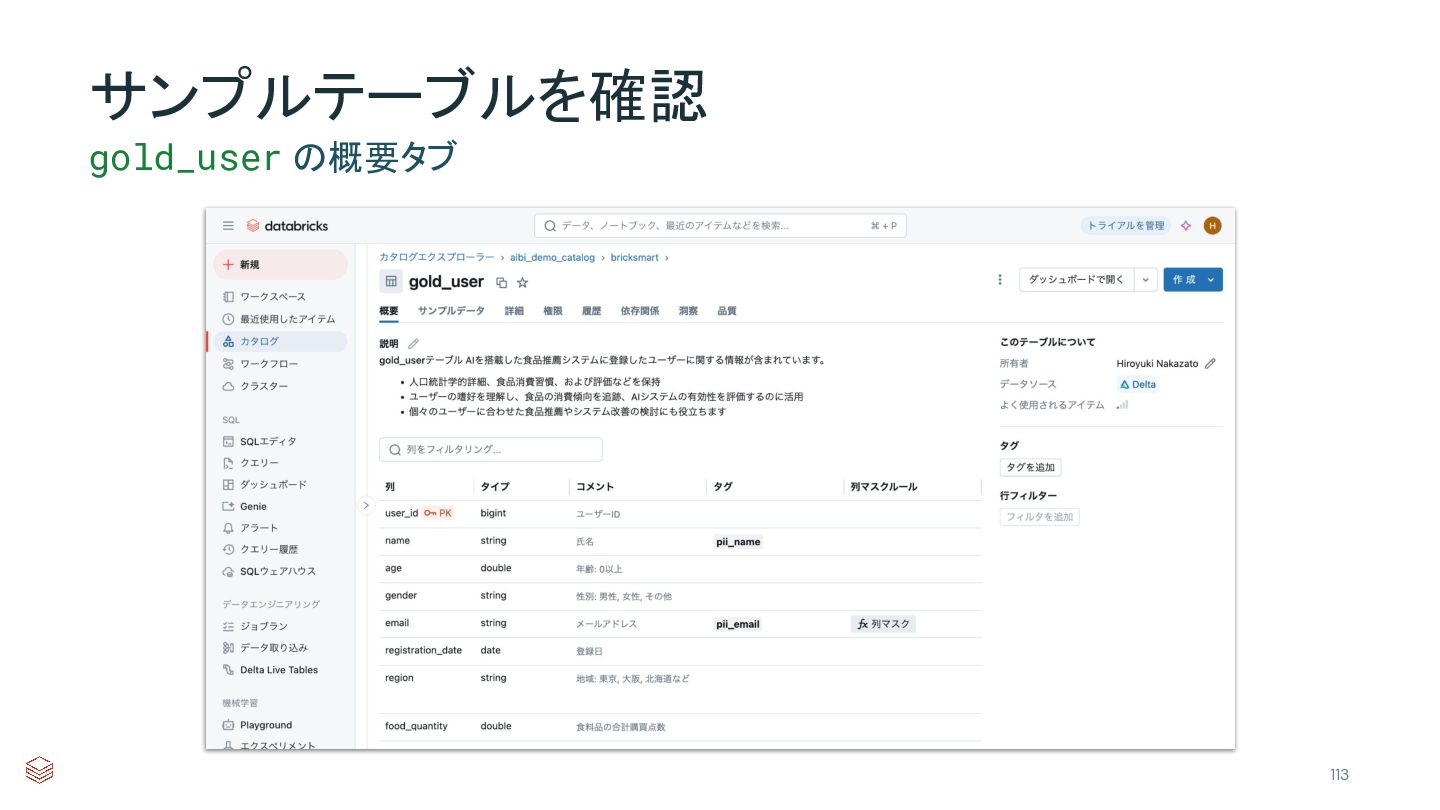{kind=link}
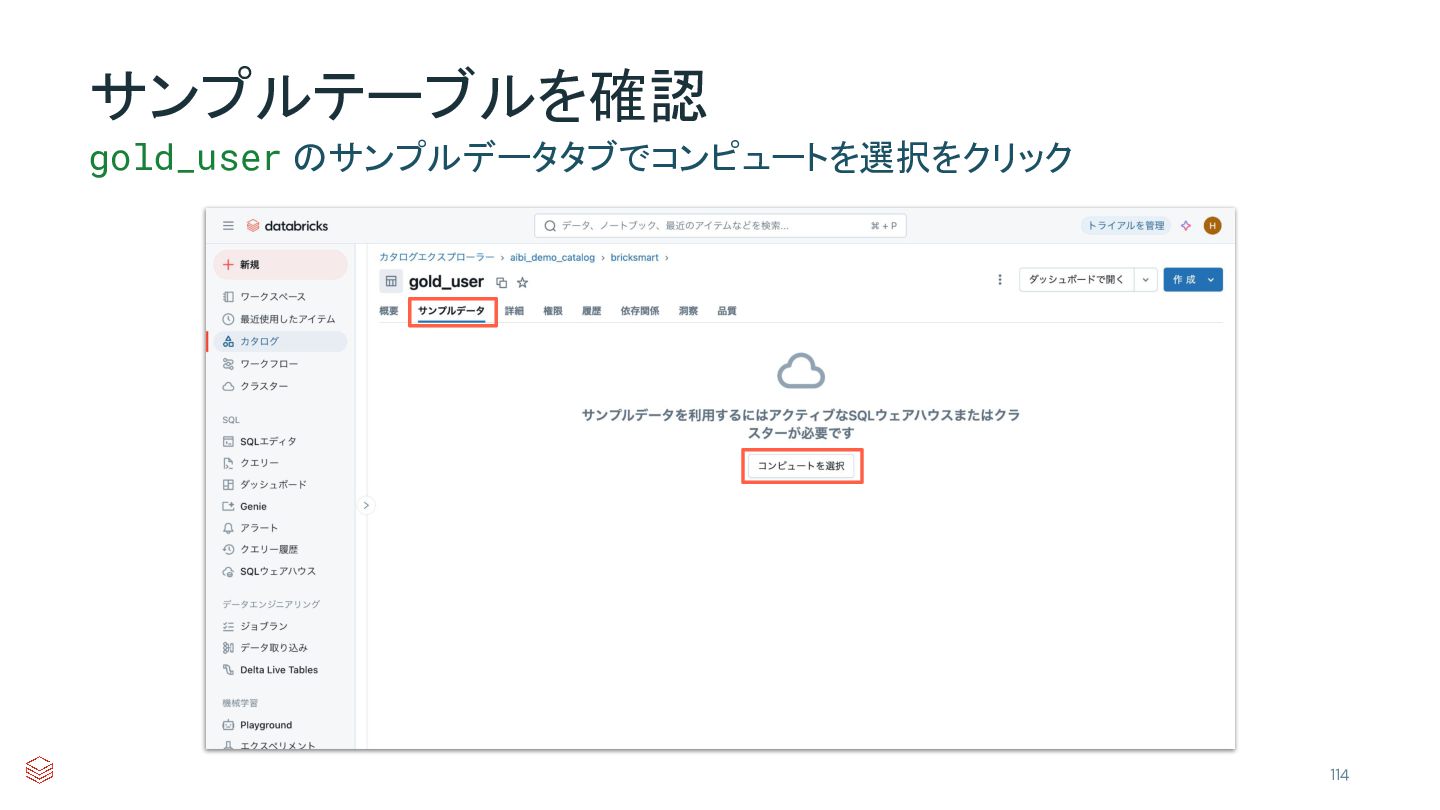{kind=link}
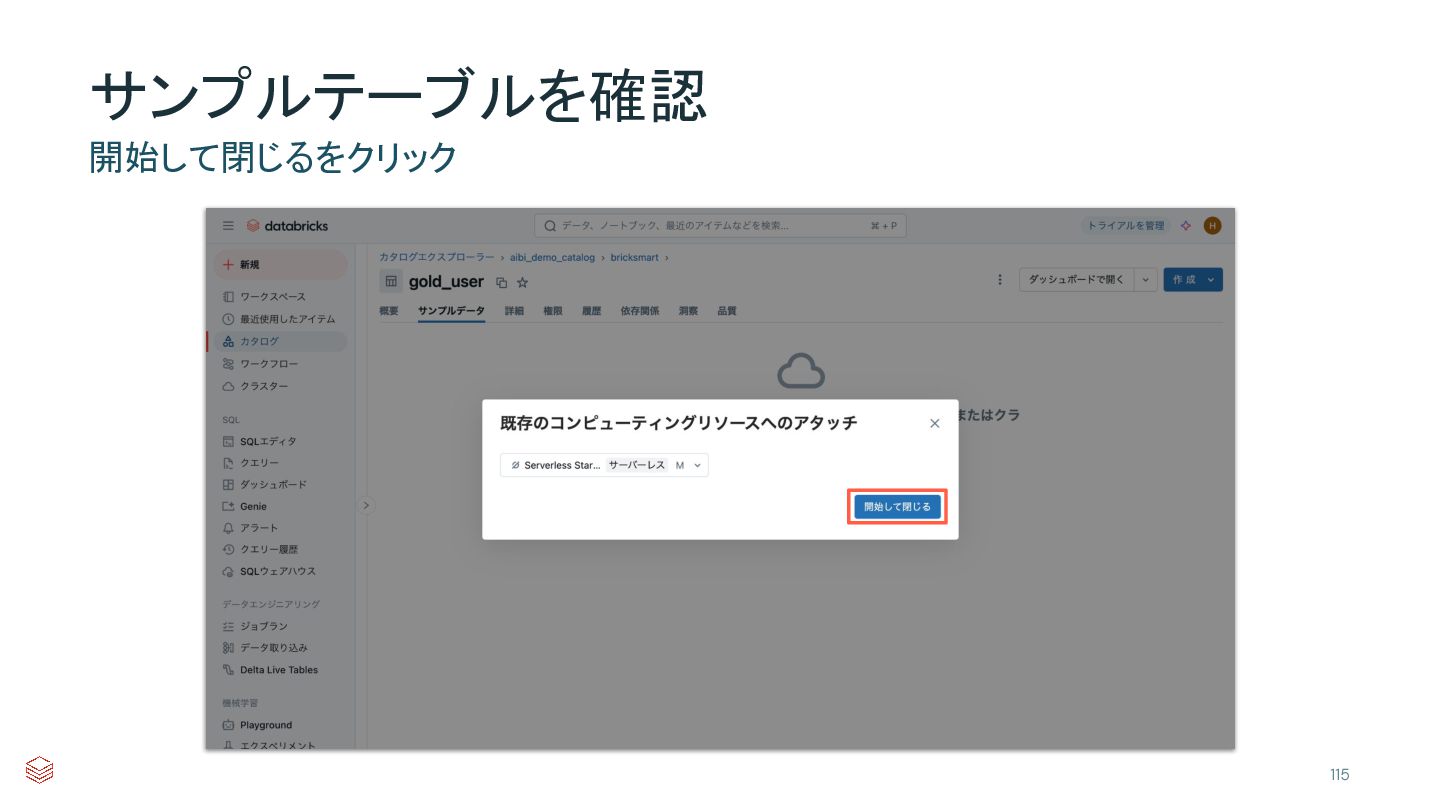{kind=link}
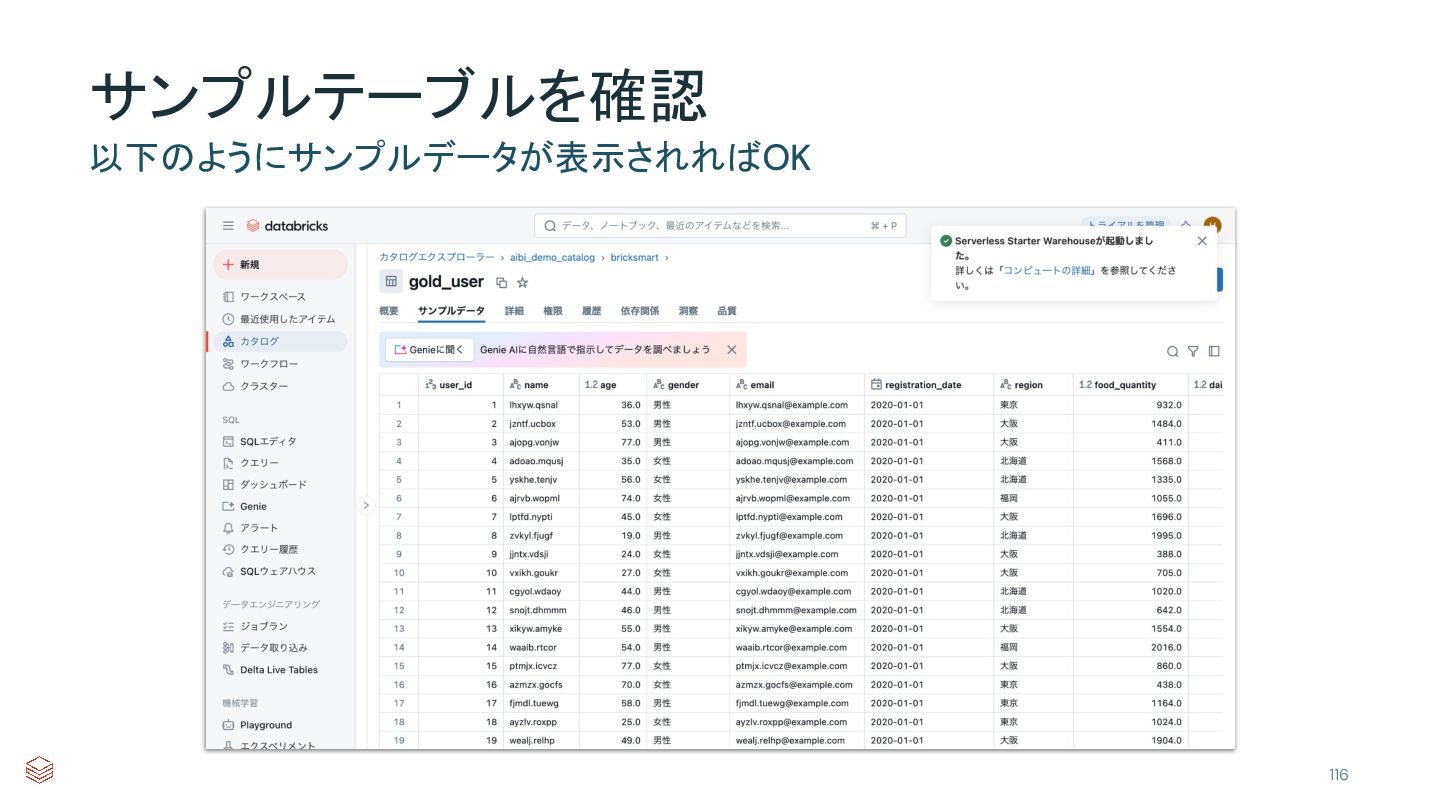{kind=link}
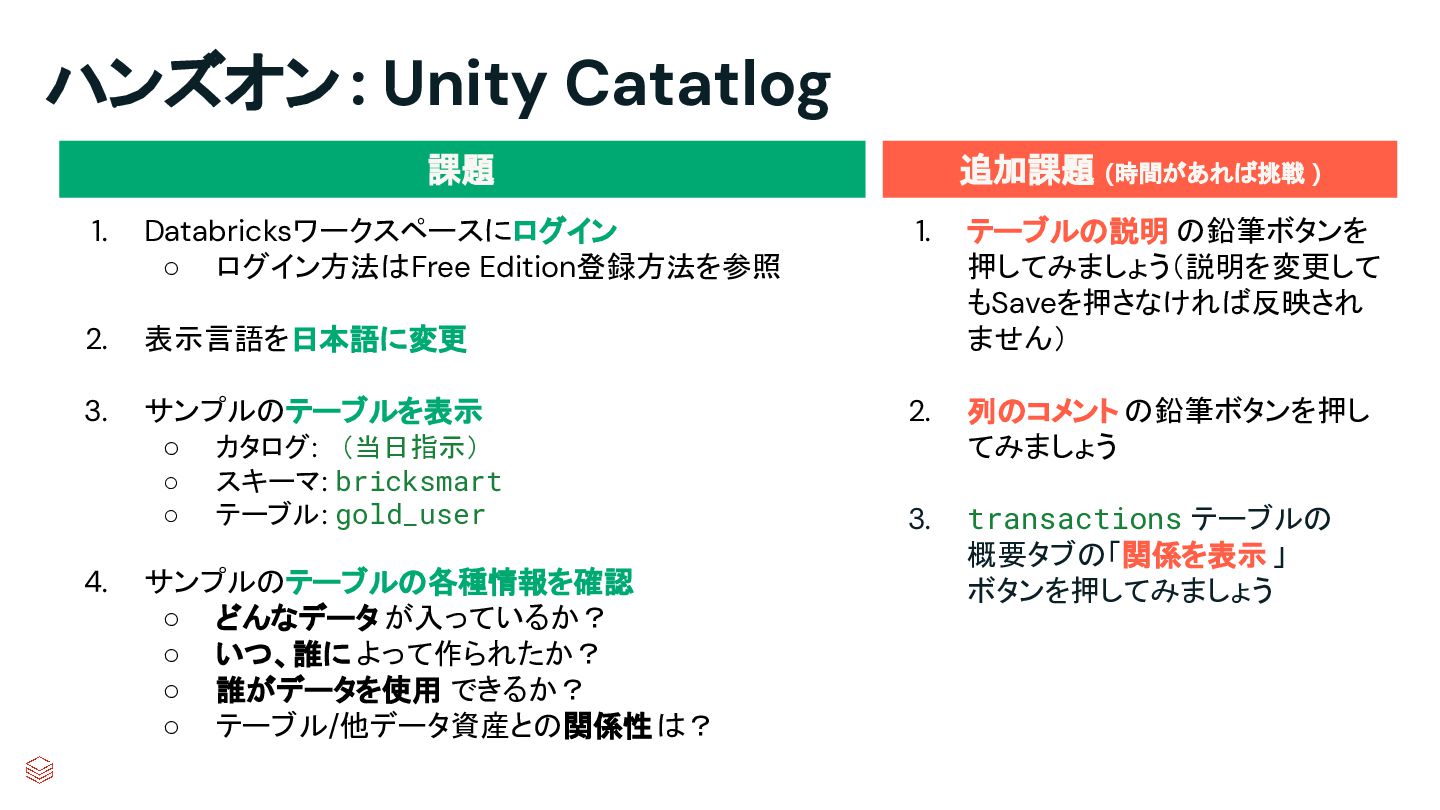{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}