Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
マクロからミクロへMMMとアップリフトモデルによる広告効果測定
Search
The Japan DataScientist Society
PRO
July 31, 2025
Video
3.2k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
マクロからミクロへMMMとアップリフトモデルによる広告効果測定
※webセミナーの講演資料(2025年7月30日)
※その他概要はこちら→
https://techplay.jp/event/983194
The Japan DataScientist Society
PRO
July 31, 2025
Video
More Decks by The Japan DataScientist Society
See All by The Japan DataScientist Society
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
530
データサイエンティスト養成講座オンライン2026
datascientistsociety
PRO
0
1.4k
生成AIを授業の相棒にするデータサイエンス入門(「デジタル✕探究」イノベーターズフォーラム テクニカルセッション講演資料)
datascientistsociety
PRO
0
350
データサイエンティストの業務変化
datascientistsociety
PRO
0
480
データサイエンティストをめぐる環境の違い2025年版〈一般ビジネスパーソン調査の国際比較〉
datascientistsociety
PRO
0
1.5k
次代のデータサイエンティストへ~スキルチェックリスト、タスクリスト更新~
datascientistsociety
PRO
3
47k
DSお仕事図鑑
datascientistsociety
PRO
1
4.8k
生成AIと学ぶPythonデータ分析再入門-Pythonによるクラスタリング・可視化をサクサク実施-
datascientistsociety
PRO
4
2.2k
学生向けアンケート<データサイエンティストについて>
datascientistsociety
PRO
0
19k
Featured
See All Featured
We Are The Robots
honzajavorek
0
290
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
56
3.4k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
AI: The stuff that nobody shows you
jnunemaker
PRO
9
850
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
The browser strikes back
jonoalderson
0
1.4k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
590
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.6k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Transcript
マクロからミクロへ MMMとアップリフトモデルによる 広告効果測定 株式会社ジンズ データサイエンス部 松本 健
JINSのご紹介 •ビジネスの内容 • メガネ・サングラスの企画、製造、販売を一貫して行う アイウエアカンパニー • 全国および海外の店舗、そしてオンラインストアを通じて、 定番からトレンドのアイウエアを手頃な価格で提供 •私たちのビジョン:Magnify Life
- まだ見ぬ、ひかりを • 私たちは、まだ誰も知らない可能性にひかりを当て、世界中の 人々の生き方そのものを豊かに拡げることを目指している • このビジョンを実現するため、データとテクノロジーの活用を 経営の重要な柱の一つと位置づけている 2
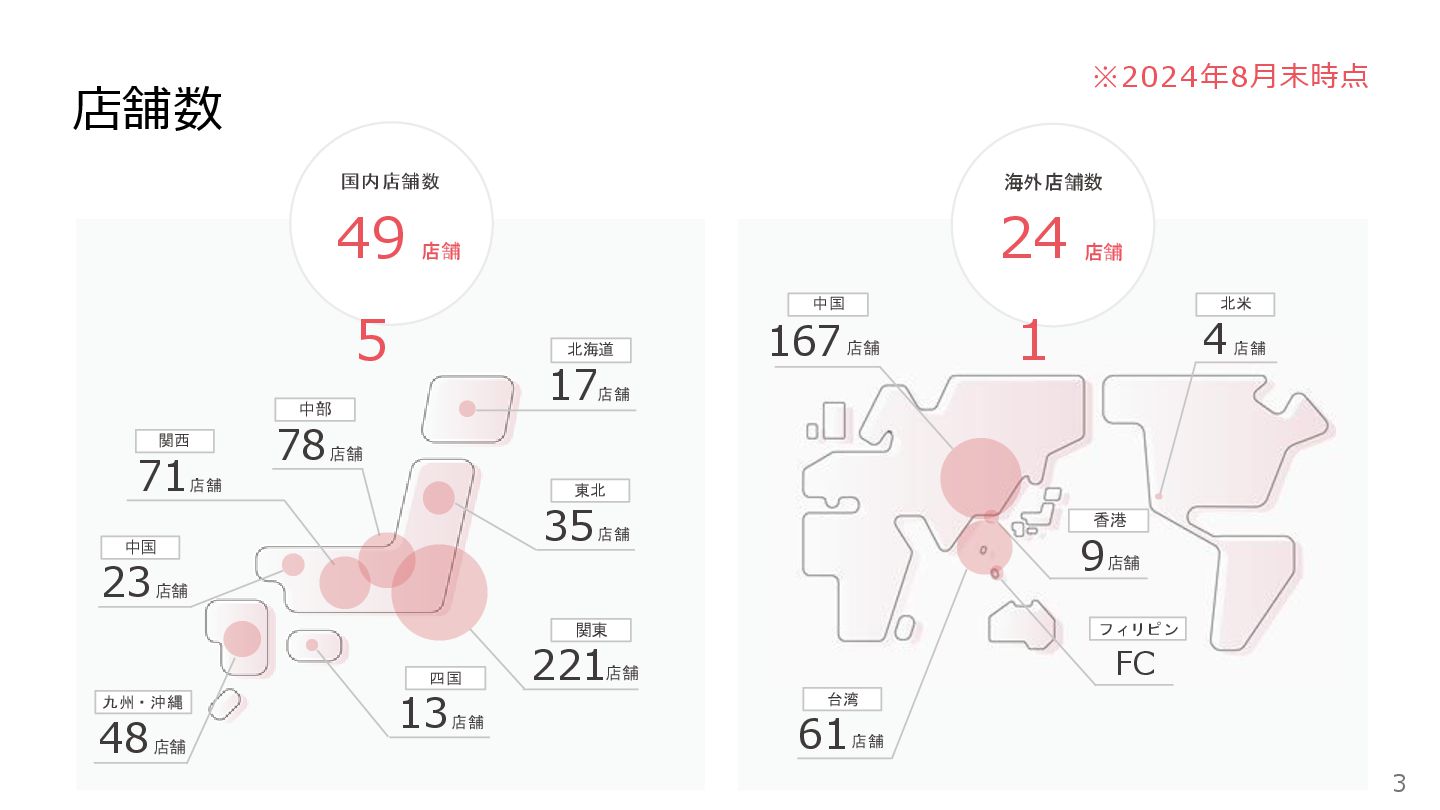
北海道 店舗 17 東北 店舗 35 関東 店舗 221 中部
店舗 78 関西 店舗 71 中国 店舗 23 四国 店舗 13 九州・沖縄 店舗 48 中国 店舗 167 北米 店舗 4 フィリピン FC 香港 店舗 9 台湾 店舗 61 49 5 店舗 国内店舗数 24 1 店舗 海外店舗数 店舗数 3 ※2024年8月末時点
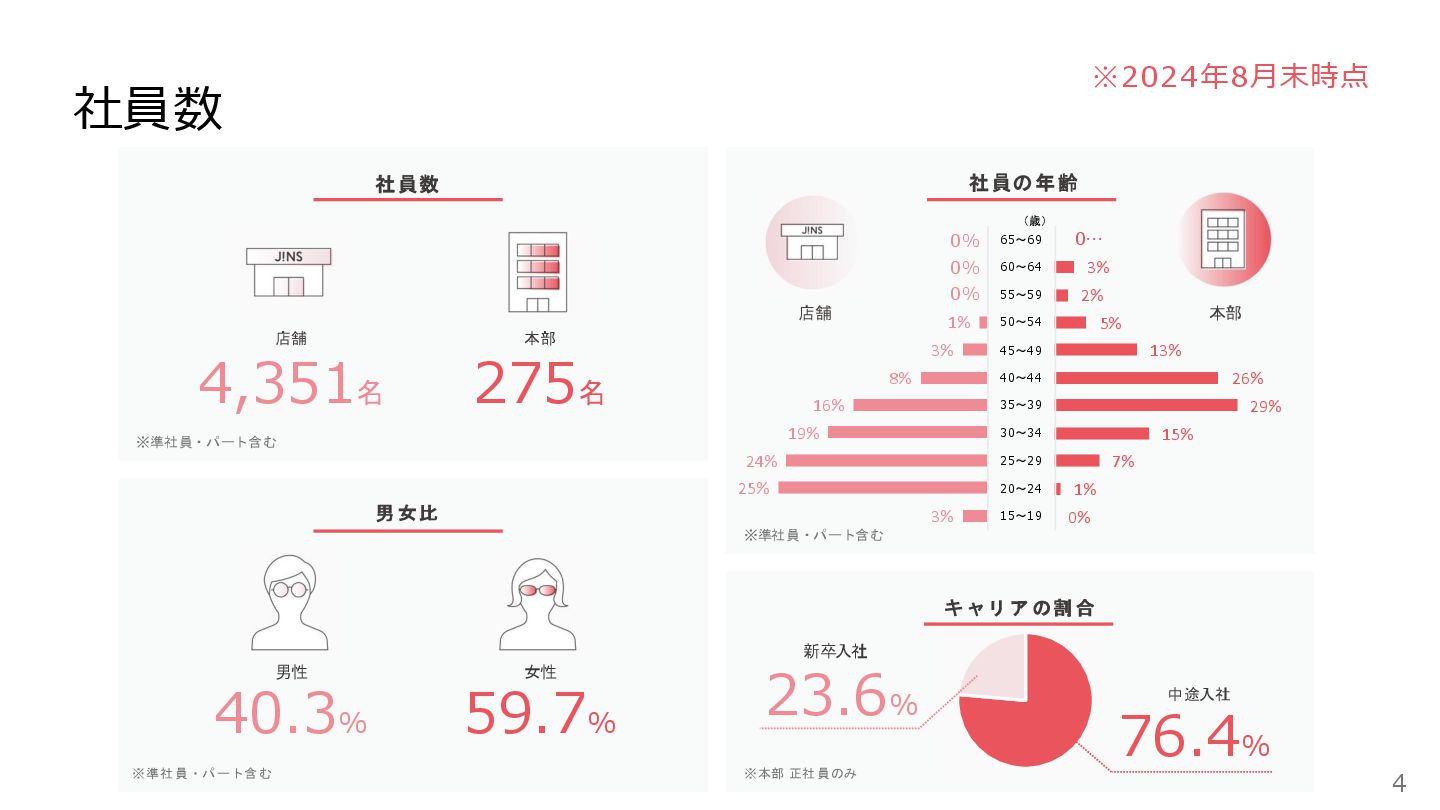
社員数 店舗 本部 275名 4,351名 40.3% 男性 女性 65〜69 60〜64
55〜59 50〜54 45〜49 40〜44 35〜39 30〜34 25〜29 20〜24 15〜19 男 女比 キ ャリ ア の割 合 (歳) ※準社員・パート含む ※準社員・パート含む ※準社員・パート含む ※本部 正社員のみ 中途入社 76.4% 23.6% 新卒入社 社 員の年齢 社 員数 本部 店舗 59.7% 0% 1% 7% 15% 29% 26% 13% 5% 2% 3% 0… 3% 25% 24% 19% 16% 8% 3% 1% 0% 0% 0% 4 ※2024年8月末時点
2025年春 JINS360°が大ヒット 5 レンズとテンプルをつなぐ部分が360°可動する独自開発機構を搭載 JINSでもっとも壊れにくいメガネ 日経MJ 2024年ヒット番付にも選出
発表の流れ Part 1: 本当に重要なものを測定する Part 2: 最強の手法とその限界:ランダム化比較試験 Part 3: マクロな視点:マーケティング・ミックス・モデリング
Part 4: ミクロな視点:アップリフトモデリング Part 5: まとめと質疑応答 6
Part 1: 本当に重要なものを測定する 7
マーケティング活動(大規模なキャンペーン) - クーポン配布の効果 - テレビCM 本当に売上を伸ばしていることを どう証明すればよいのか? 8
広告効果ってどうやって測定すれば良いだろうか? 9
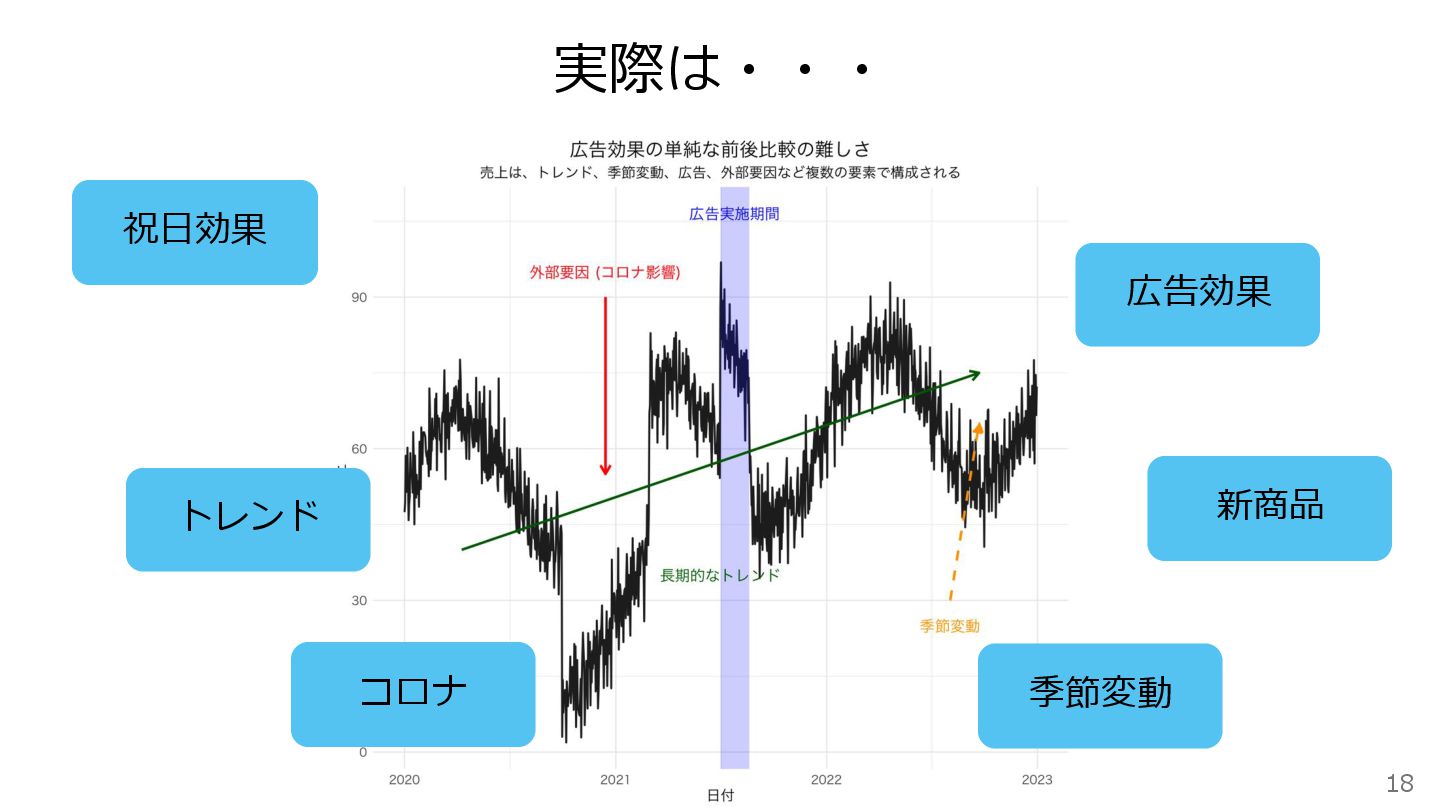
測定の難しさ 単純な前後比較だけでは不十分 売上は、トレンド や季節変動 、祝日の効果 、 新商品の発売 、コロナ禍など 広告以外に、外部のイベントや 同時期に起こる多くの要因に影響される
10
11 2つの強力なデータサイエンス手法を紹介 1. マクロなアプローチ マーケティング・ミックス・モデリング(MMM) TVCMなど集計された時系列データに対して効果を計算する 2. ミクロなアプローチ アップリフトモデリング 顧客ごとの異質性を考慮し
顧客ごとにクーポンやポイントの効果を計算する
Part 2: 最強の手法とその限界: ランダム化比較試験 12
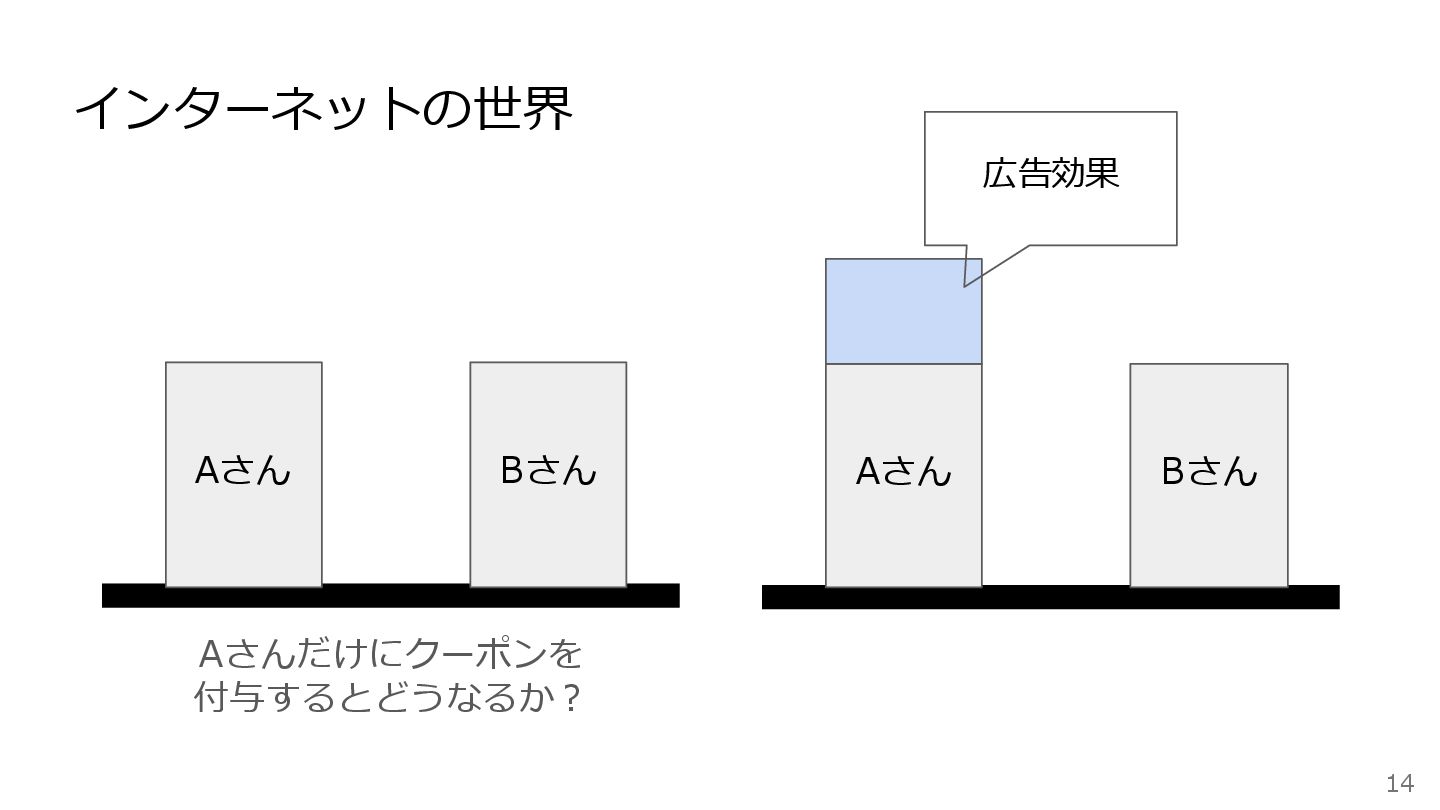
最強な手法は、 ランダム化比較試験 (RCT;Randomized controlled trial) 13
Aさん Bさん Aさんだけにクーポンを 付与するとどうなるか? Aさん Bさん 広告効果 インターネットの世界 14
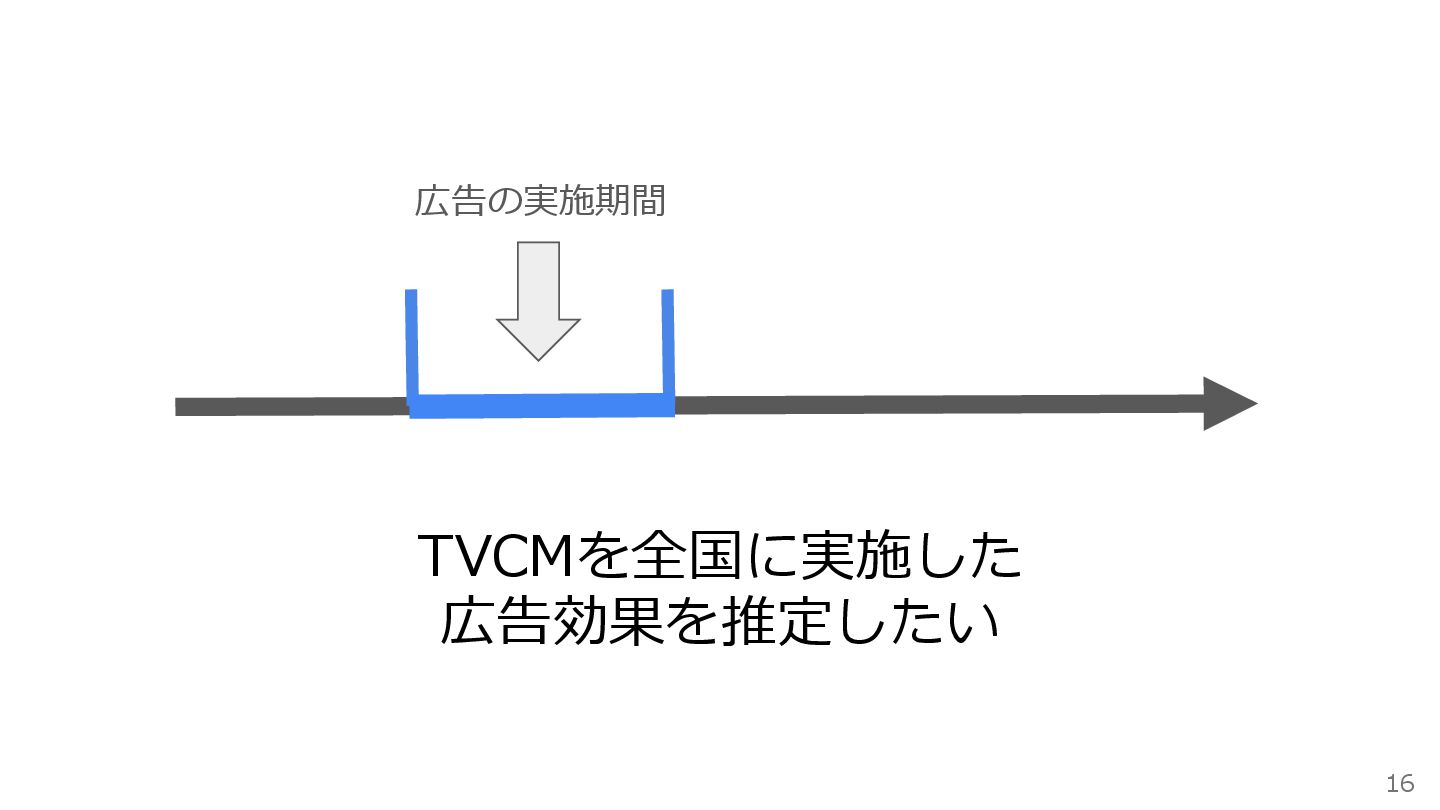
しかし TVCMなどのマス広告は ランダム化比較試験が難しい 15
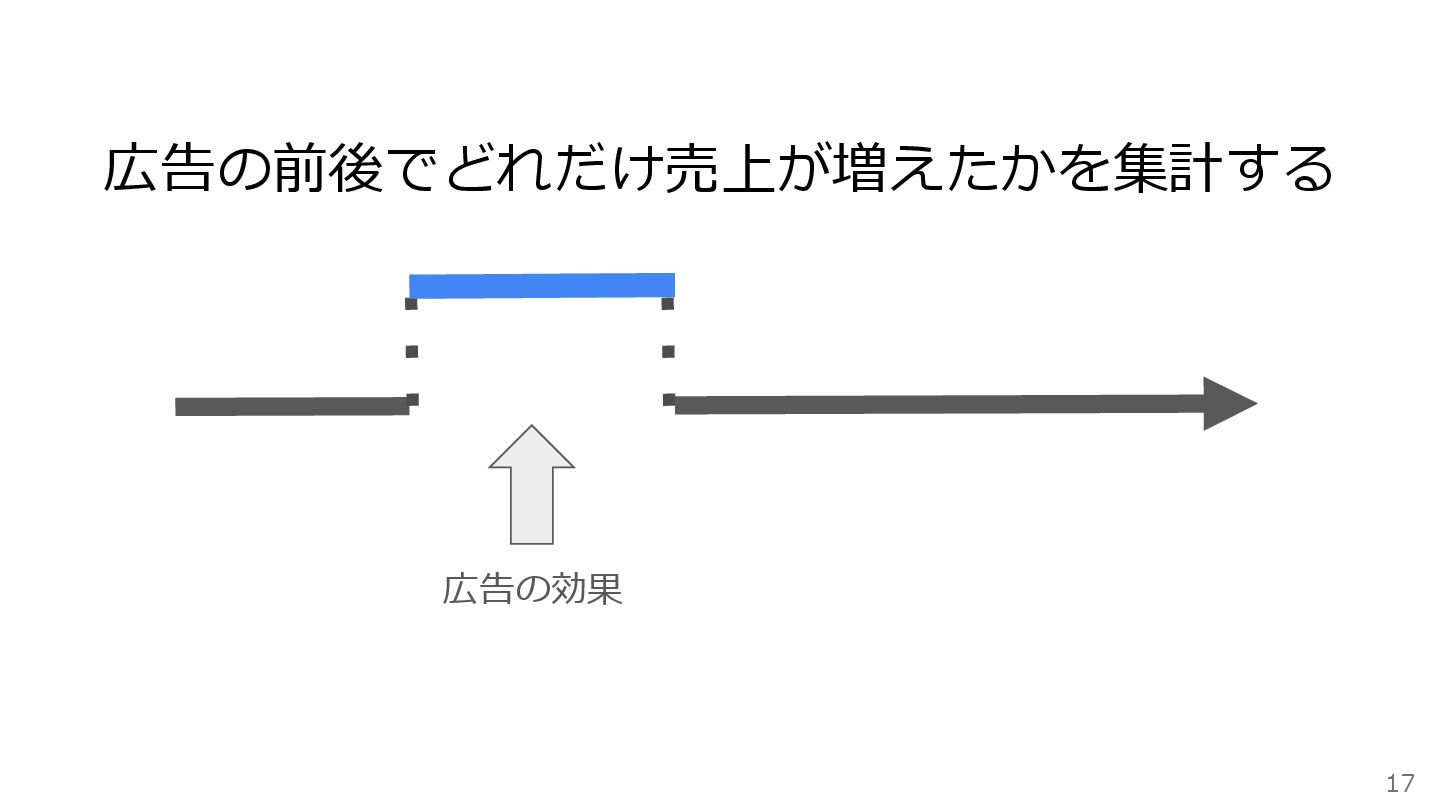
広告の実施期間 TVCMを全国に実施した 広告効果を推定したい 16
広告の前後でどれだけ売上が増えたかを集計する 広告の効果 17
実際は・・・ トレンド 季節変動 祝日効果 広告効果 コロナ 新商品 18
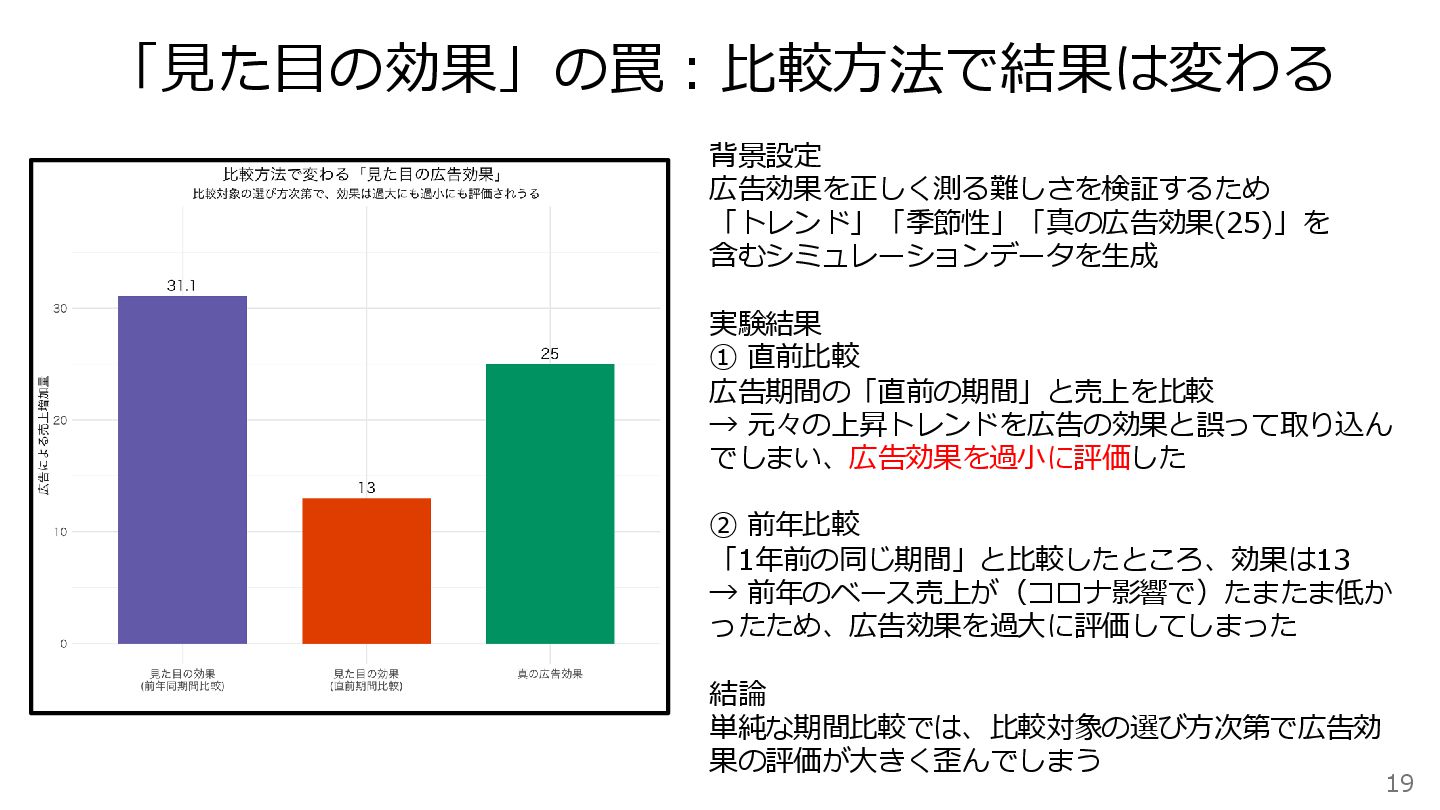
「見た目の効果」の罠:比較方法で結果は変わる 背景設定 広告効果を正しく測る難しさを検証するため 「トレンド」「季節性」「真の広告効果(25)」を 含むシミュレーションデータを生成 実験結果 ① 直前比較 広告期間の「直前の期間」と売上を比較 →
元々の上昇トレンドを広告の効果と誤って取り込ん でしまい、広告効果を過小に評価した ② 前年比較 「1年前の同じ期間」と比較したところ、効果は13 → 前年のベース売上が(コロナ影響で)たまたま低か ったため、広告効果を過大に評価してしまった 結論 単純な期間比較では、比較対象の選び方次第で広告効 果の評価が大きく歪んでしまう 19
Part 3: マクロな視点: マーケティング・ミックス・モデリング 20
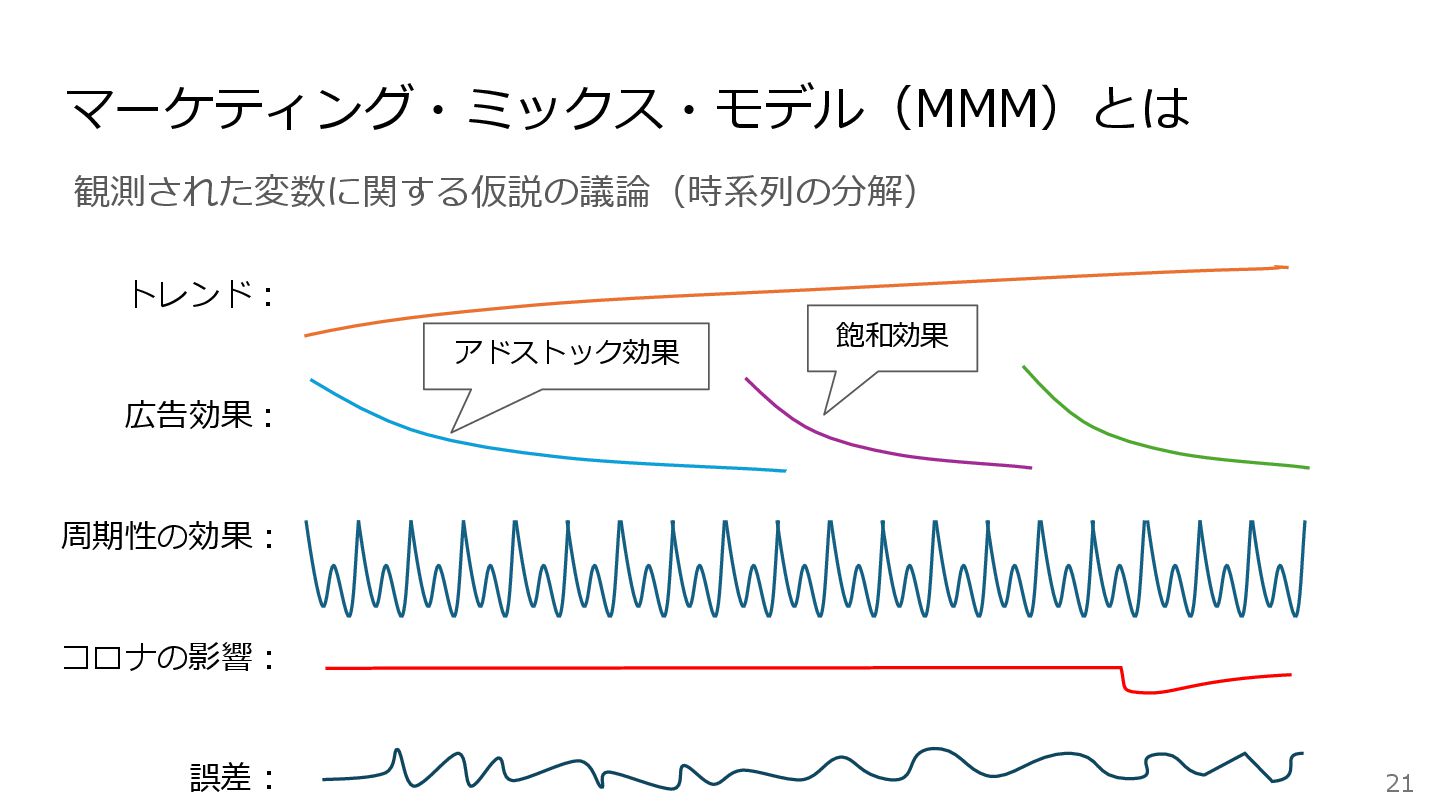
マーケティング・ミックス・モデル(MMM)とは 観測された変数に関する仮説の議論(時系列の分解) 21 トレンド: 広告効果: 周期性の効果: 誤差: コロナの影響: アドストック効果 飽和効果
マーケティング・ミックス・モデル(MMM)とは 売上のようなビジネスの成果を、様々な要因に分解する統計的手法 各マーケティングチャネルの貢献度を理解することができる 主要なモデル構成要素 時系列データ = ベース売上 + マーケティング効果 +
その他の要因(誤差) ベース売上: トレンド や周期性(季節性)、 マーケティング活動がない場合の売上 22
マーケティング・ミックス・モデル(MMM)とは 売上のようなビジネスの成果を、様々な要因に分解する統計的手法 各マーケティングチャネルの貢献度を理解することができる 主要なモデル構成要素 時系列データ = ベース売上 + マーケティング効果 +
その他の要因(誤差) マーケティング効果: 広告効果をモデル化する 1. アドストック効果(残存効果) 2. 飽和効果 23
マーケティング・ミックス・モデル(MMM)とは 売上のようなビジネスの成果を、様々な要因に分解する統計的手法 各マーケティングチャネルの貢献度を理解することができる 主要なモデル構成要素 時系列データ = ベース売上 + マーケティング効果 +
その他の要因(誤差) その他の要因 1. 祝日効果 2. コロナの影響 3. 天気 4. 誤差など 24
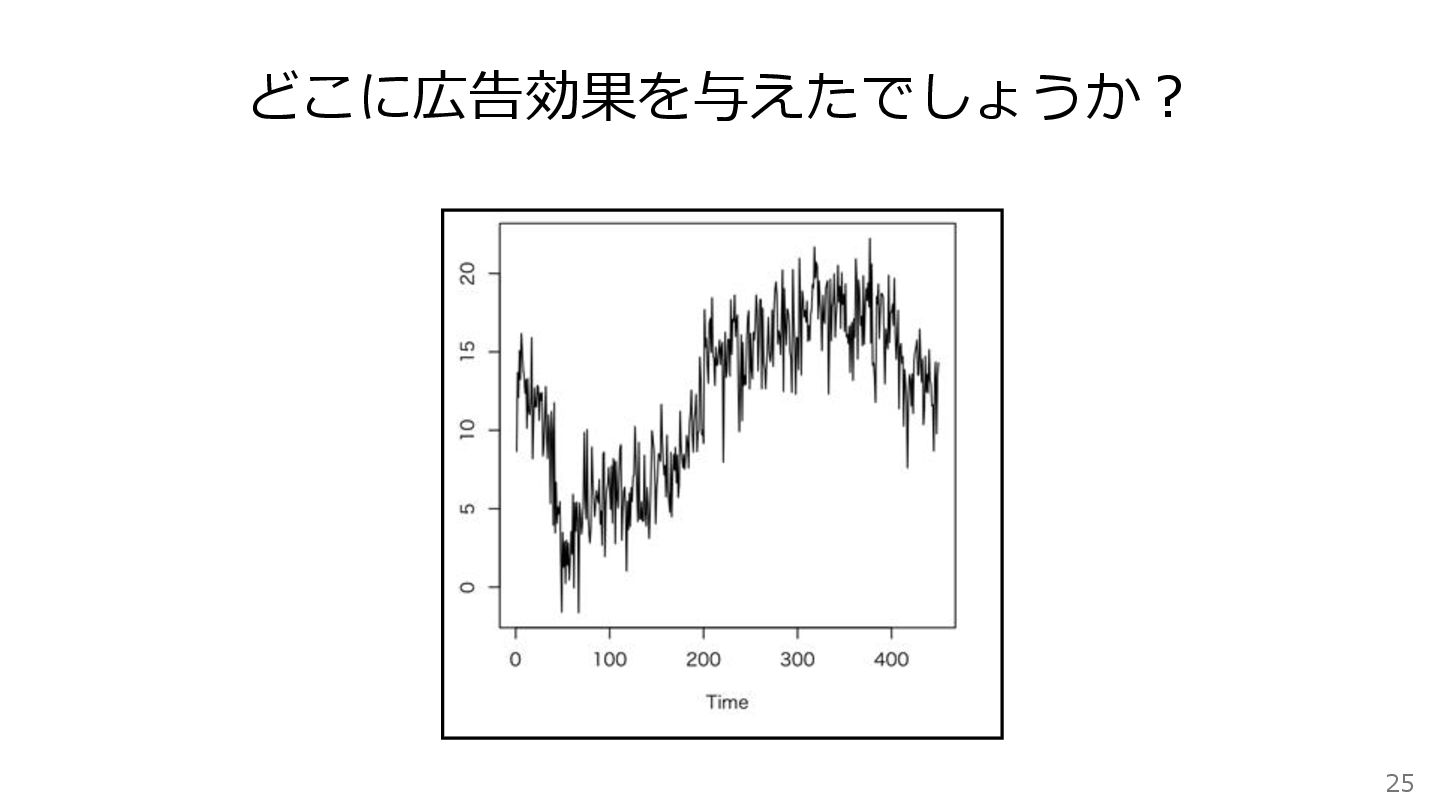
25 どこに広告効果を与えたでしょうか?
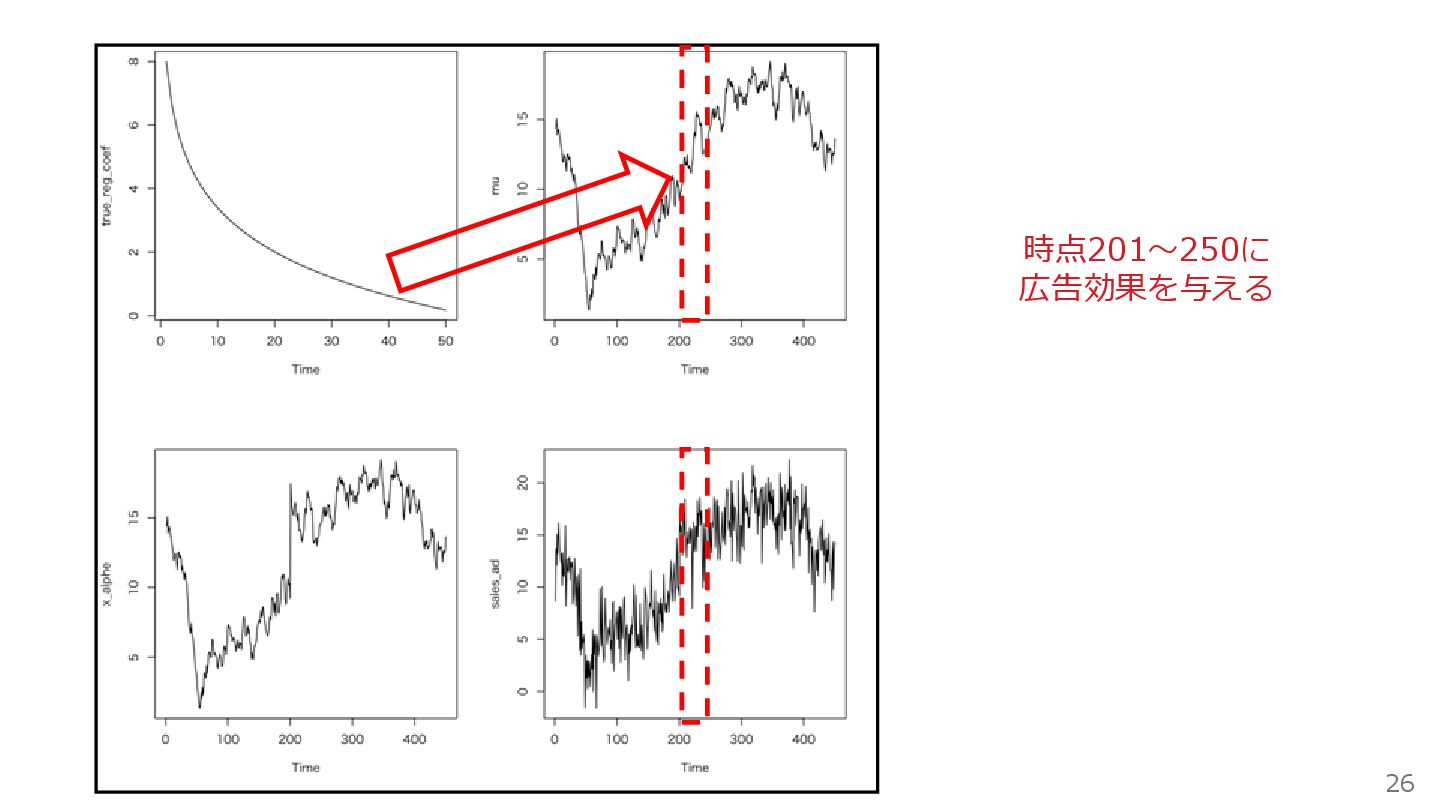
26 時点201〜250に 広告効果を与える
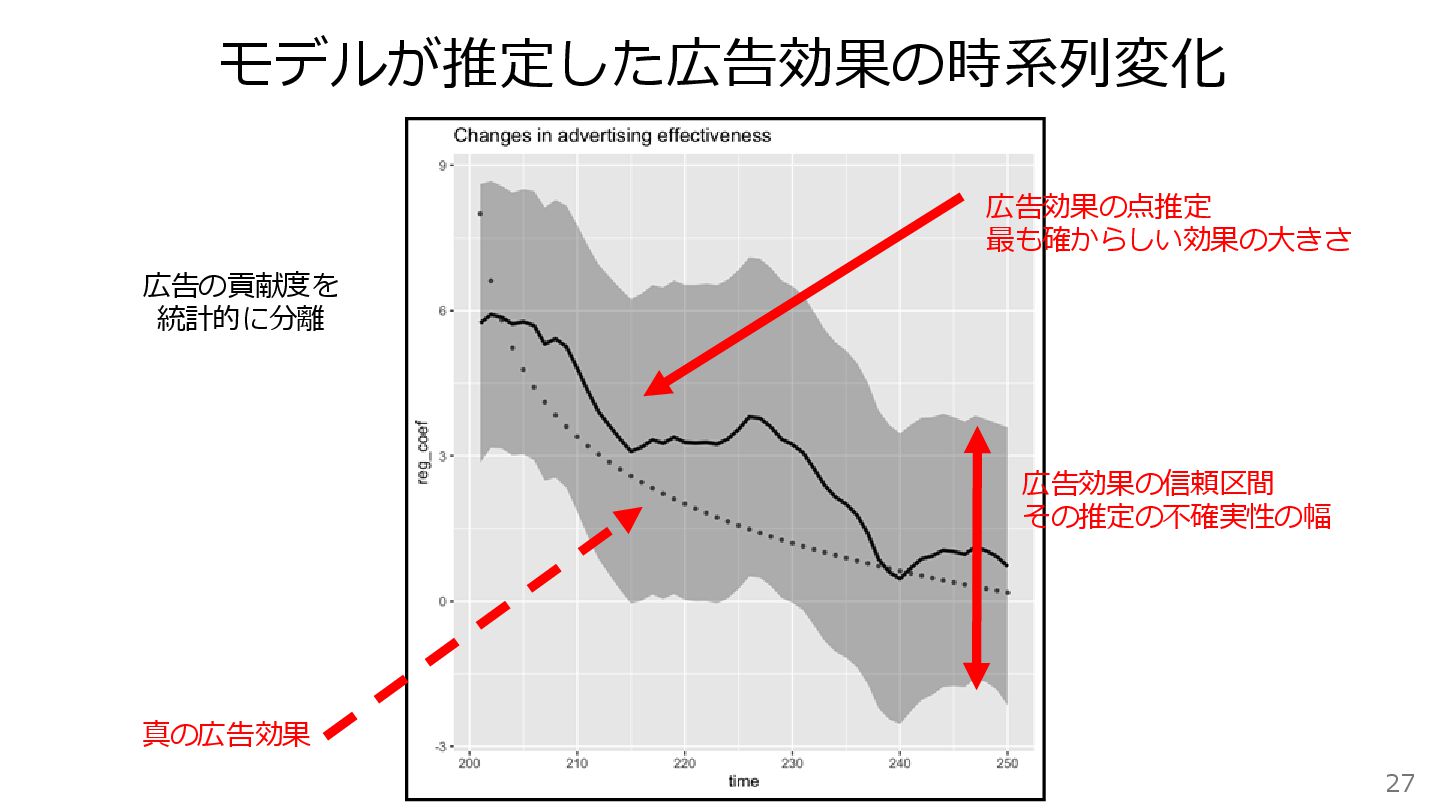
27 広告効果の信頼区間 その推定の不確実性の幅 真の広告効果 広告効果の点推定 最も確からしい効果の大きさ モデルが推定した広告効果の時系列変化 広告の貢献度を 統計的に分離
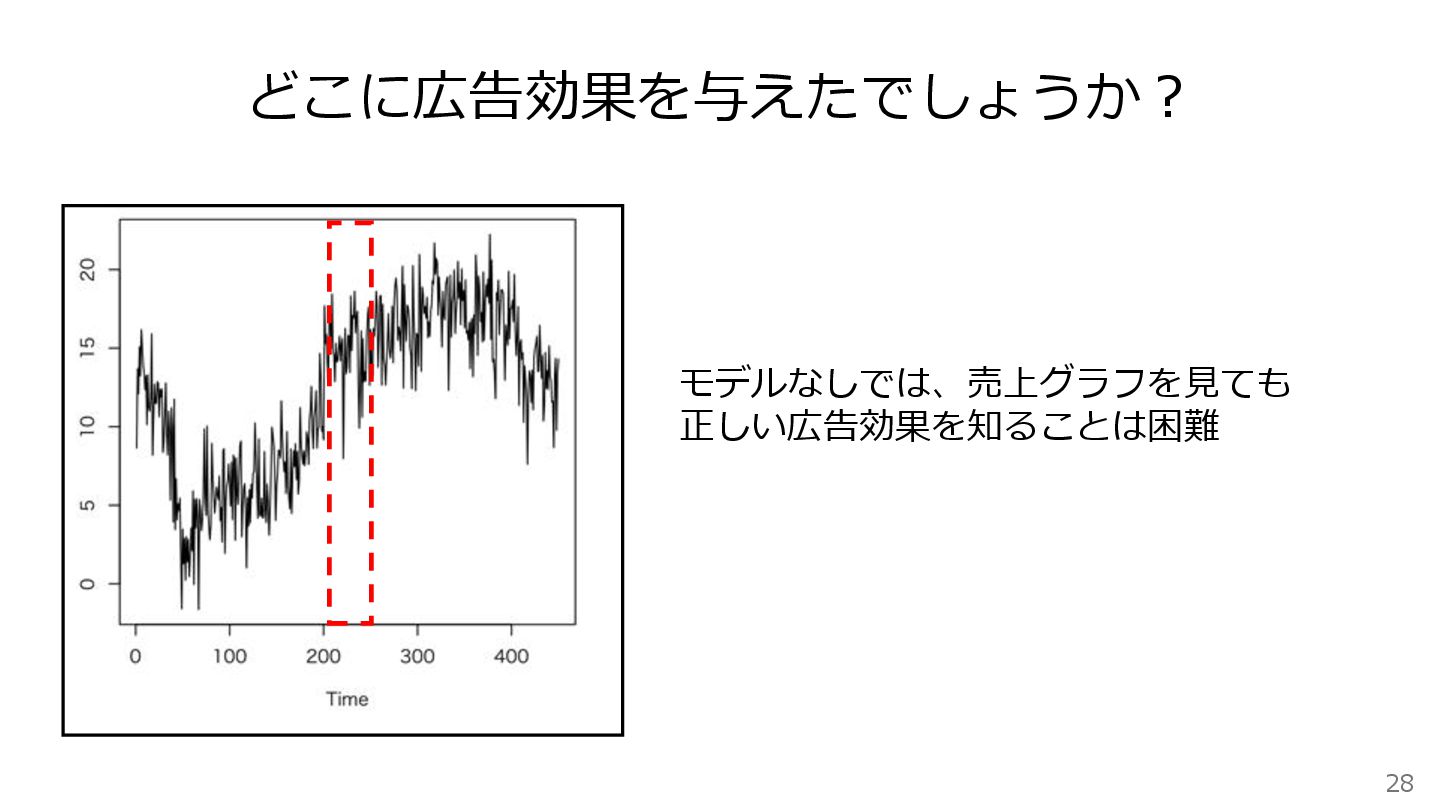
28 どこに広告効果を与えたでしょうか? モデルなしでは、売上グラフを見ても 正しい広告効果を知ることは困難
エリアABテストとは何か 29 TVCMを施策を実施するグループ(TG)と TVCMを実施しないコントロールグループ(CTL)を 地理的に分けて設定し、TVCMの効果を分析 → エリアABテストを利用することで 精度が向上することが期待される
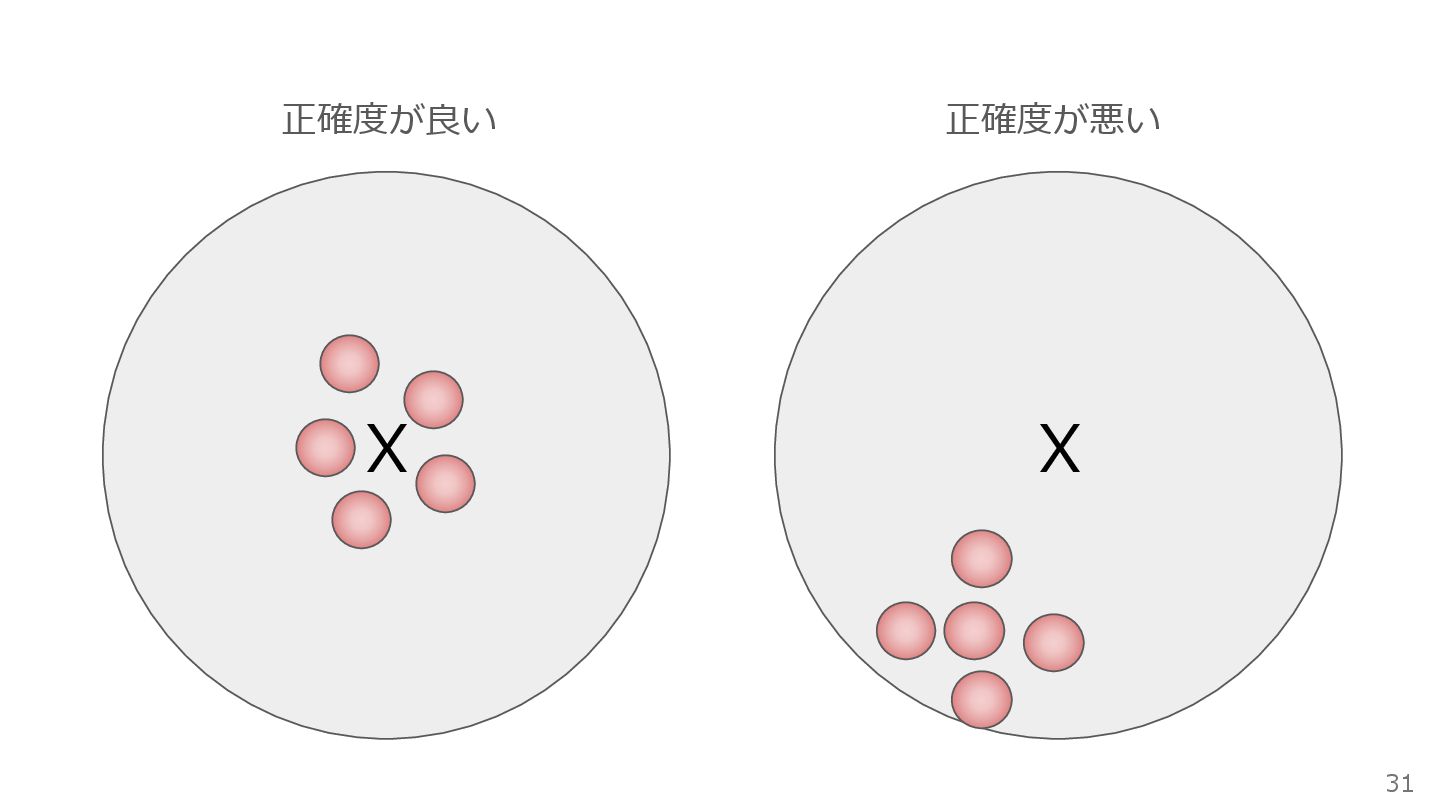
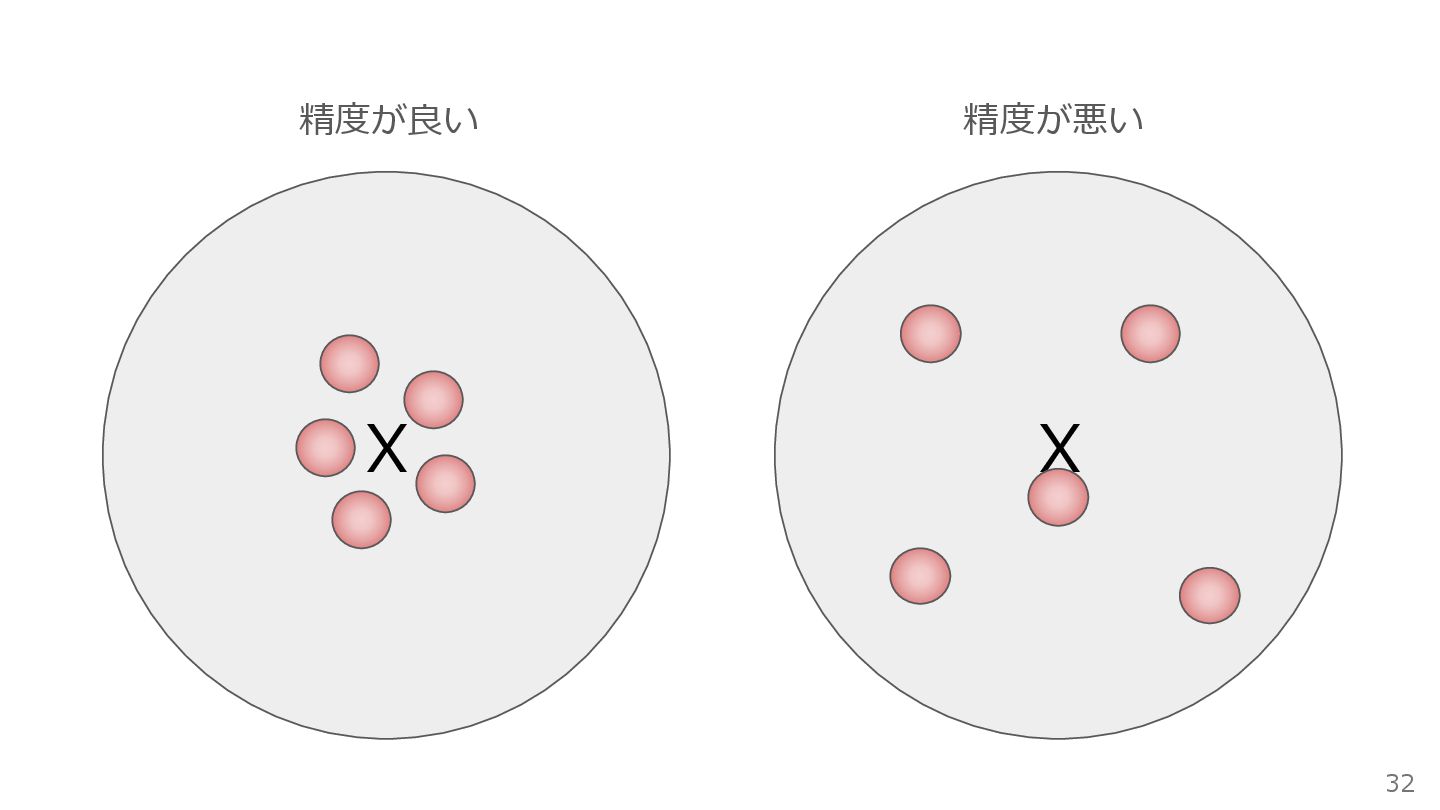
精度!? 30
X X 正確度が良い 正確度が悪い 31
X X 精度が良い 精度が悪い 32
エリアABテストのシミュレーション実験 33 実験1:TGのみ 実験2:TGとCTL 実験1と実験2を100回繰り返す 広告効果:真のパラメータ 平均 2.00(中心の位置) 分散 1.00(ばらつき)
平均値は、実験1と実験2では差がない 分散は、実験2の方が小さい 平均のシミュレーション結果 分散のシミュレーション結果 分散の推定 分散の分散 実験1 1.00 0.0051 実験2 1.00 0.0021 平均の推定 平均の分散 実験1 2.01 0.14 実験2 1.99 0.05
エリアABテストが広告効果の推定精度を向上させる理由 34 シナリオA:エリアテストなし(全国一斉CM) シナリオB:エリアテストあり
エリアABテストが広告効果の推定精度を向上させる理由 35 推定された係数 𝛽 の分散の公式は、以下のように表される
エリアABテストが広告効果の推定精度を向上させる理由 36 エリアABテストなしの問題点 このモデルでは、広告効果を推定する変数は、多くの場合、他の要因と強い相関がある • クリスマスキャンペーンを考えると、「クリスマス時期である」という季節要因と完全に連動する • 夏のキャンペーンなら、気温や休日のトレンドと連動する モデルは「売上の増加が、広告によるものなのか、たまたま重なった季節トレンドによるものなのか」を 正確に区別できず、推定が不安定になる
エリアABテストが広告効果の推定精度を向上させる理由 37 エリアABテストありの優位性 • 全国共通のトレンドや季節性は、広告実施エリアと非実施エリアの両方に同じように影響する • 広告が実施されていないコントロール群のデータを使って、これらの共通要因の影響を正確に学習 し、その効果(γ)を分離することができる • その結果、広告効果を示す交互作用項と、共通要因との間の相関は大幅に低下する
エリアABテストは、広告効果と全国共通のトレンドや季節性といった交絡因子(Confounders)との 間の多重共線性を軽減させる効果がある 結果、モデルは広告の純粋な効果をクリーンに分離できるようになり、広告効果パラメータの推定量の 分散が減少し、推定の精度が数学的に向上する
エリアABテストによるMMMの課題 38 エリアABテストと呼ばれる準実験的なアプローチを用いることで、 モデルの「精度」を大幅に向上させることが期待できる コンセプト: TVCMを放映するエリア(TG)と、放映しないエリア(CTL)を地理的に 設定する 利点: シミュレーション実験が示すように、CTLを設けることで、広告効果の推定値の 分散が小さくなる(=精度が向上する)
これにより、結果に対する信頼性が高まる 課題:適切なコントロールエリアの設計が意外と難しい
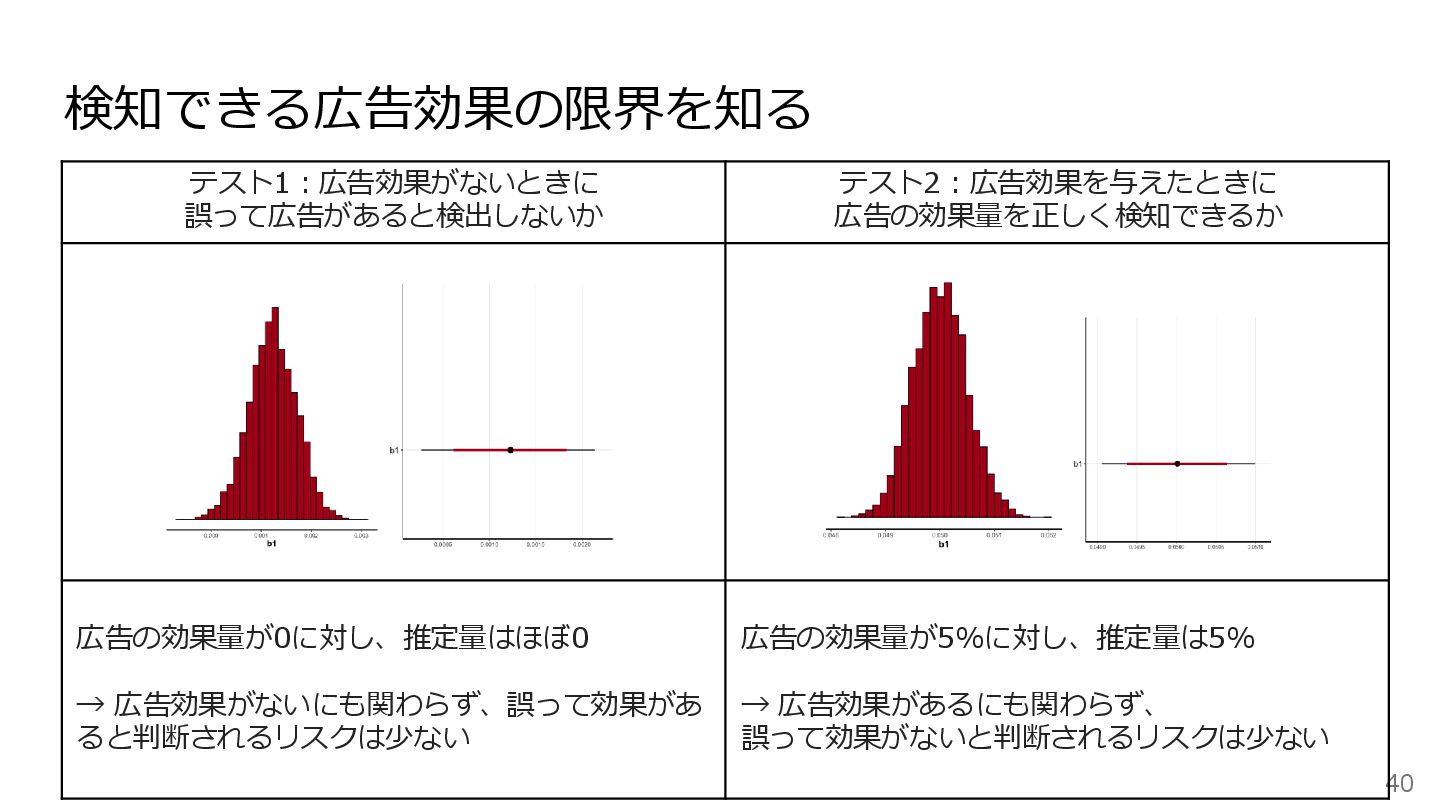
検知できる広告効果の限界を知る 39 1. テスト1:広告効果がないときに、誤って広告があると検出しないか ノイズを与えないデータ(TV CMの効果がないデータ)に対し、仮想の広 告期間を与えた場合に、広告効果がほぼ0であることを確認する 2. テスト2:広告効果を与えたときに、広告の効果量を正しく検知できるか 1%,
2%, 3%, ..., x%のノイズを仮想の広告期間に与え検知できることを 確認する(推定可能な広告効果の限界値を知る) (例)事前のテストで検知できるリフトが5%程度必要だと分かった → 想定される施策効果が1%程度である場合、モデルを作成してもノイズとみ なされるリスクが高い
検知できる広告効果の限界を知る 40 テスト1:広告効果がないときに 誤って広告があると検出しないか テスト2:広告効果を与えたときに 広告の効果量を正しく検知できるか 広告の効果量が0に対し、推定量はほぼ0 → 広告効果がないにも関わらず、誤って効果があ ると判断されるリスクは少ない
広告の効果量が5%に対し、推定量は5% → 広告効果があるにも関わらず、 誤って効果がないと判断されるリスクは少ない
Part 4: ミクロな視点: アップリフトモデリング 41
42 MMMはTVCMキャンペーンが 「全体としてどれだけ」売上に貢献したか を教えてくれる しかし、「誰に」アプローチすべきかは教えてくれない
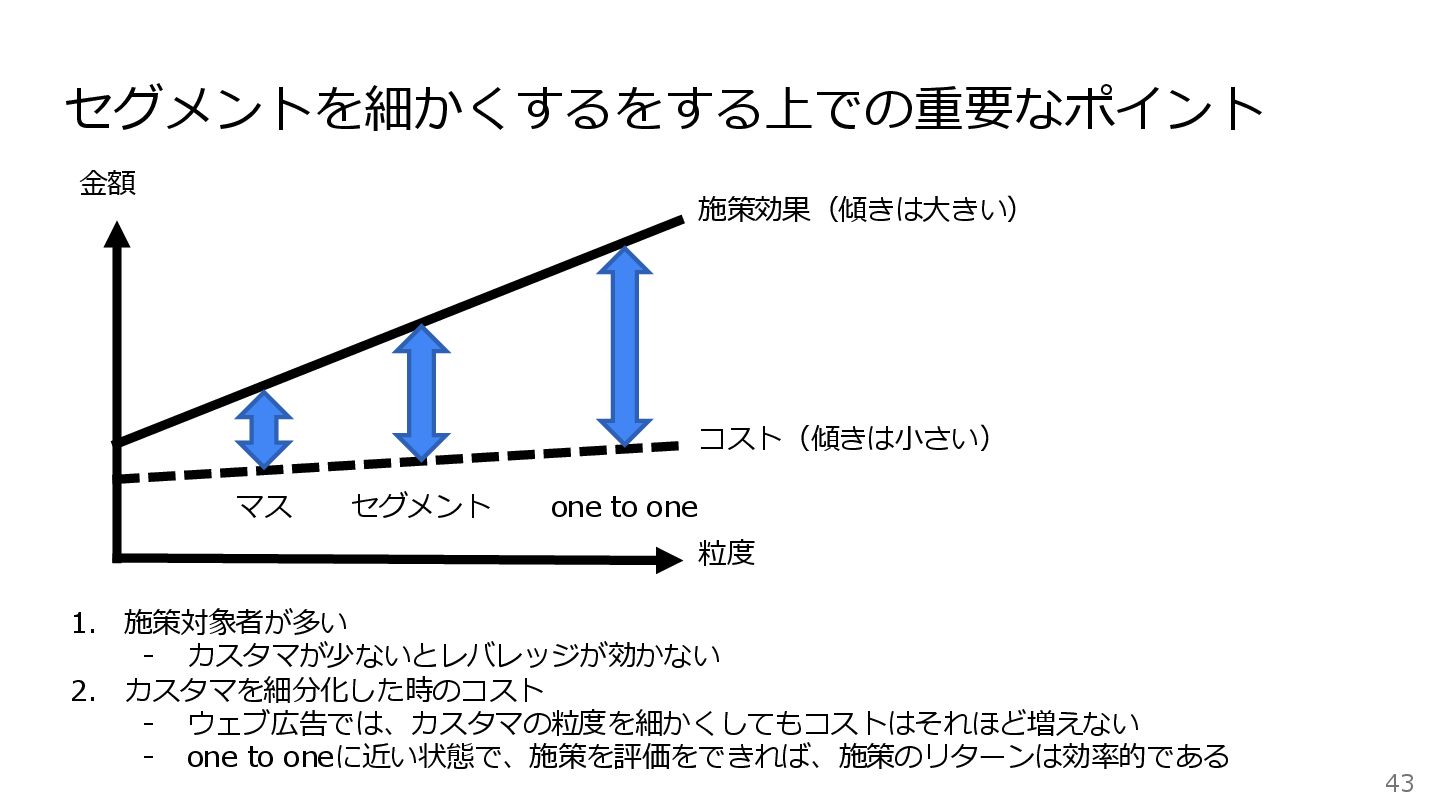
粒度 金額 コスト(傾きは小さい) 施策効果(傾きは大きい) マス one to one セグメント 43
セグメントを細かくするをする上での重要なポイント 1. 施策対象者が多い - カスタマが少ないとレバレッジが効かない 2. カスタマを細分化した時のコスト - ウェブ広告では、カスタマの粒度を細かくしてもコストはそれほど増えない - one to oneに近い状態で、施策を評価をできれば、施策のリターンは効率的である
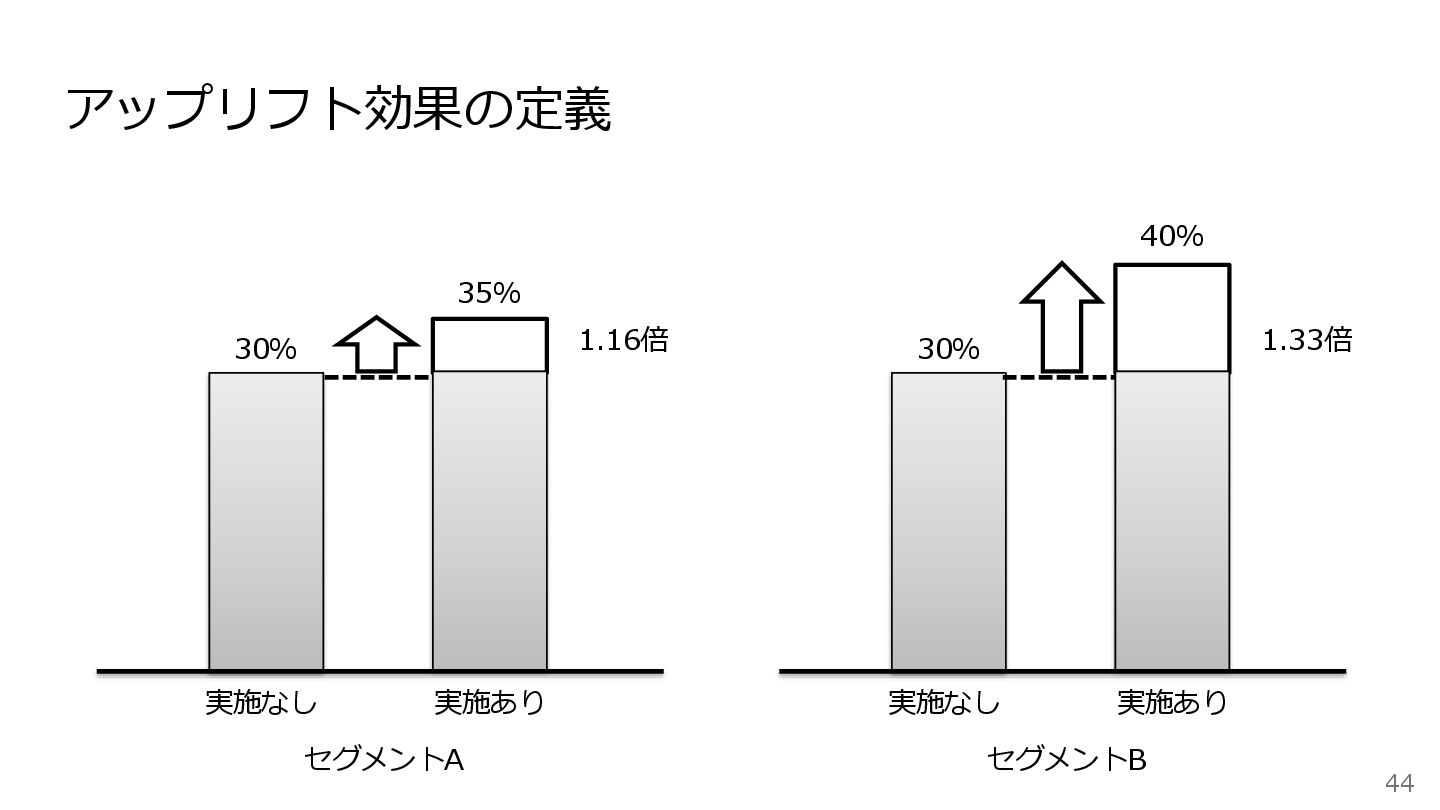
44 アップリフト効果の定義 実施なし 実施あり セグメントA 30% 35% 1.16倍 実施なし 実施あり
セグメントB 30% 40% 1.33倍
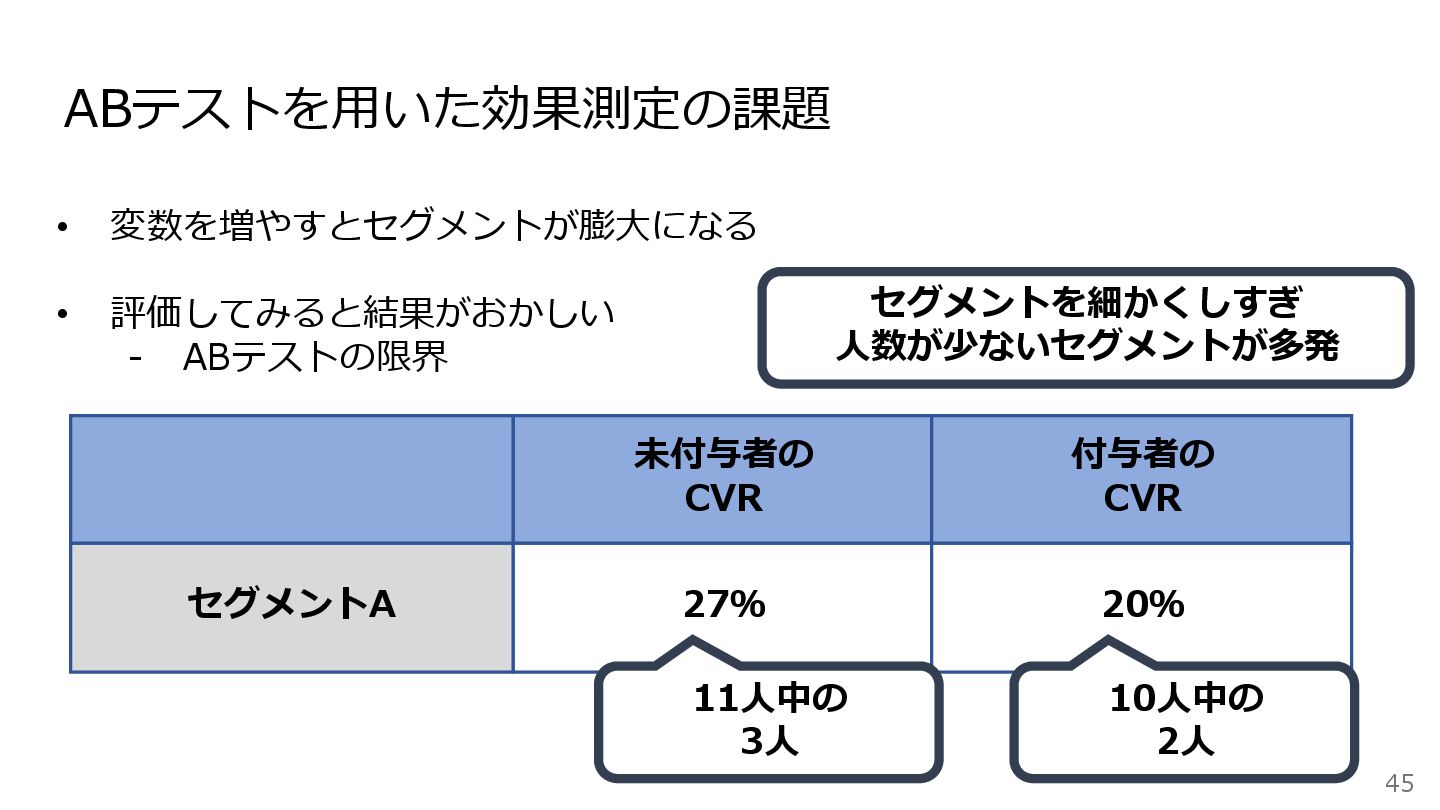
45 ABテストを用いた効果測定の課題 • 変数を増やすとセグメントが膨大になる • 評価してみると結果がおかしい - ABテストの限界 27% 20%
セグメントA 未付与者の CVR 付与者の CVR セグメントを細かくしすぎ 人数が少ないセグメントが多発 10人中の 2人 11人中の 3人
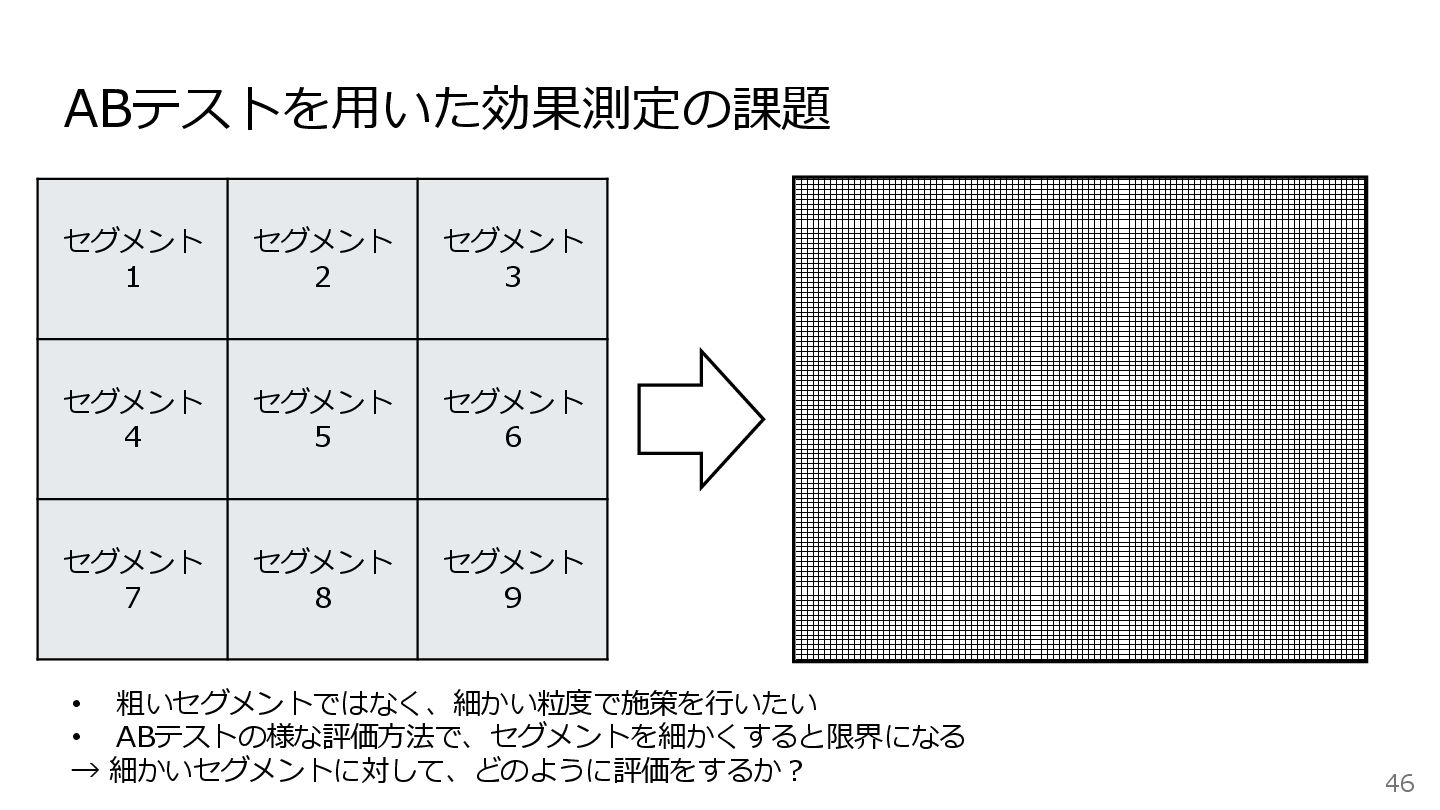
ABテストを用いた効果測定の課題 46 • 粗いセグメントではなく、細かい粒度で施策を行いたい • ABテストの様な評価方法で、セグメントを細かくすると限界になる → 細かいセグメントに対して、どのように評価をするか? セグメント 1
セグメント 2 セグメント 3 セグメント 4 セグメント 5 セグメント 6 セグメント 7 セグメント 8 セグメント 9
アップリフトモデリングの紹介 47 重要な4つのセグメント概念 説得可能層(The Persuadables) 施策を受け取った場合に購入確率が上昇する層 この層をターゲットにする 無関心層(The Sure Things)
施策の有無にかかわらず購入する層 クーポンコストの無駄になる 離反層(The Lost Causes) 施策の有無にかかわらず購入しない層 クーポンコストの無駄になる 迷惑層(The Sleeping Dogs) 施策を受け取ると、むしろ購入しなくなる層 しつこい広告でブランドが嫌いになる → こんな人って本当に存在する?
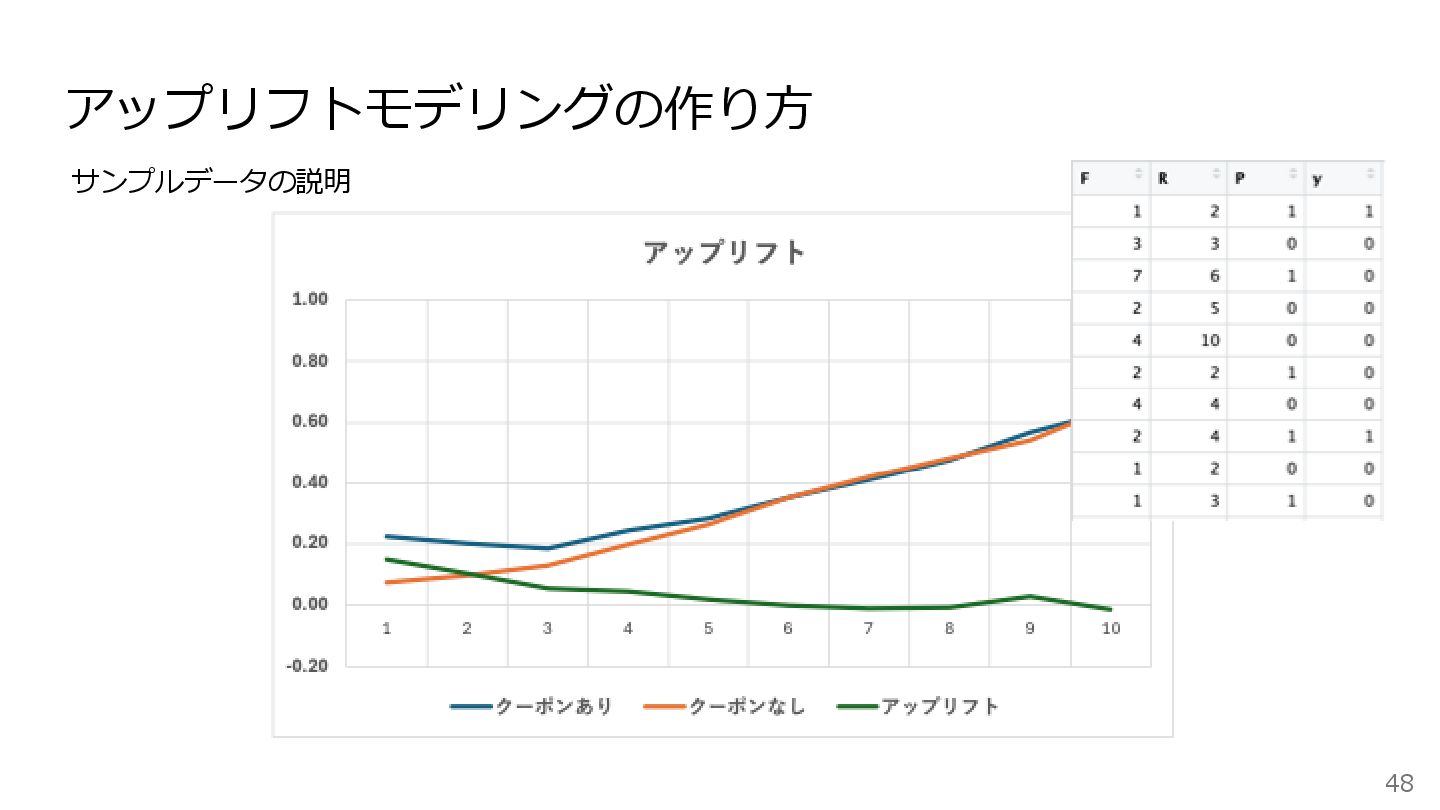
アップリフトモデリングの作り方 48 サンプルデータの説明
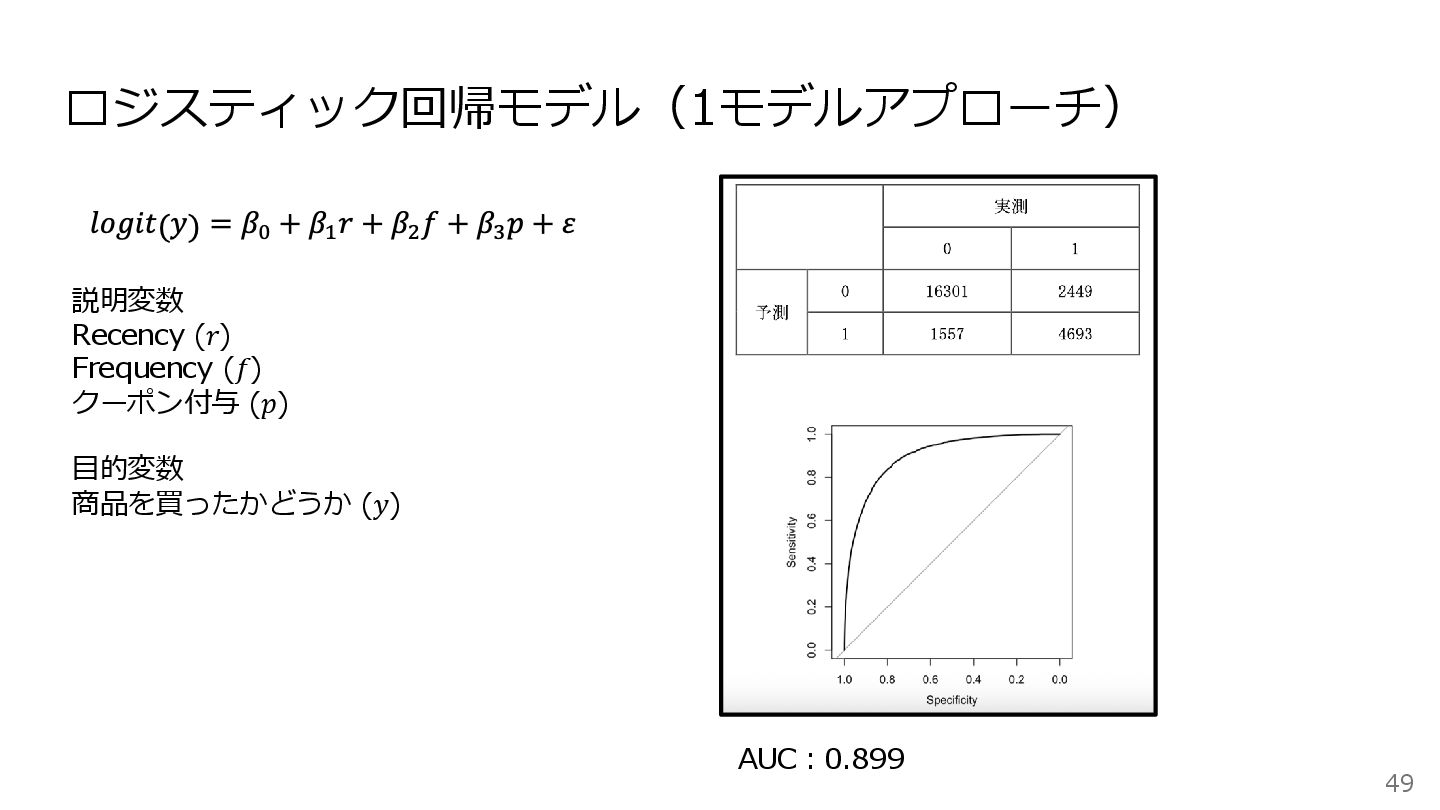
ロジスティック回帰モデル(1モデルアプローチ) 49 説明変数 Recency (𝑟) Frequency (𝑓) クーポン付与 (𝑝) 目的変数
商品を買ったかどうか (𝑦) AUC:0.899
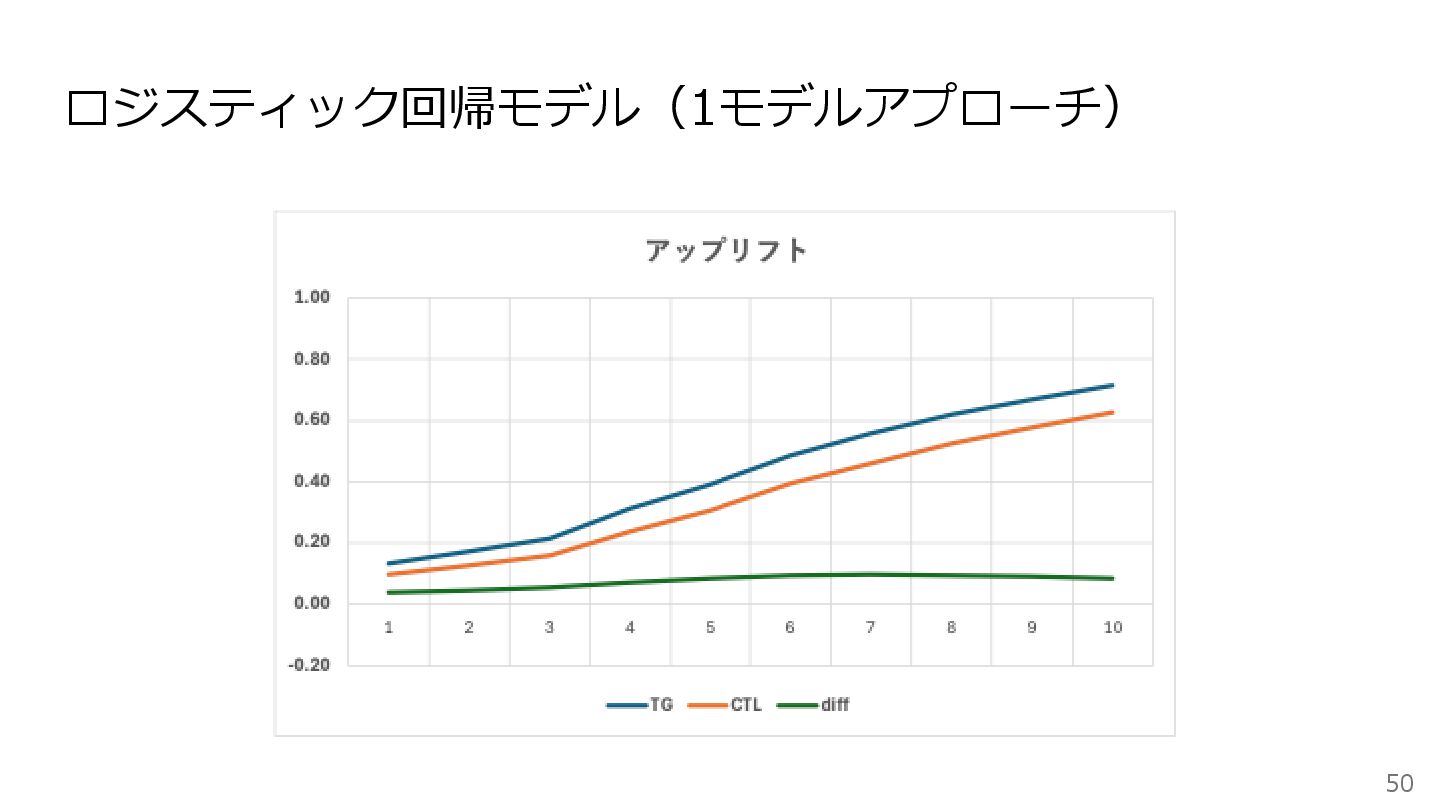
ロジスティック回帰モデル(1モデルアプローチ) 50
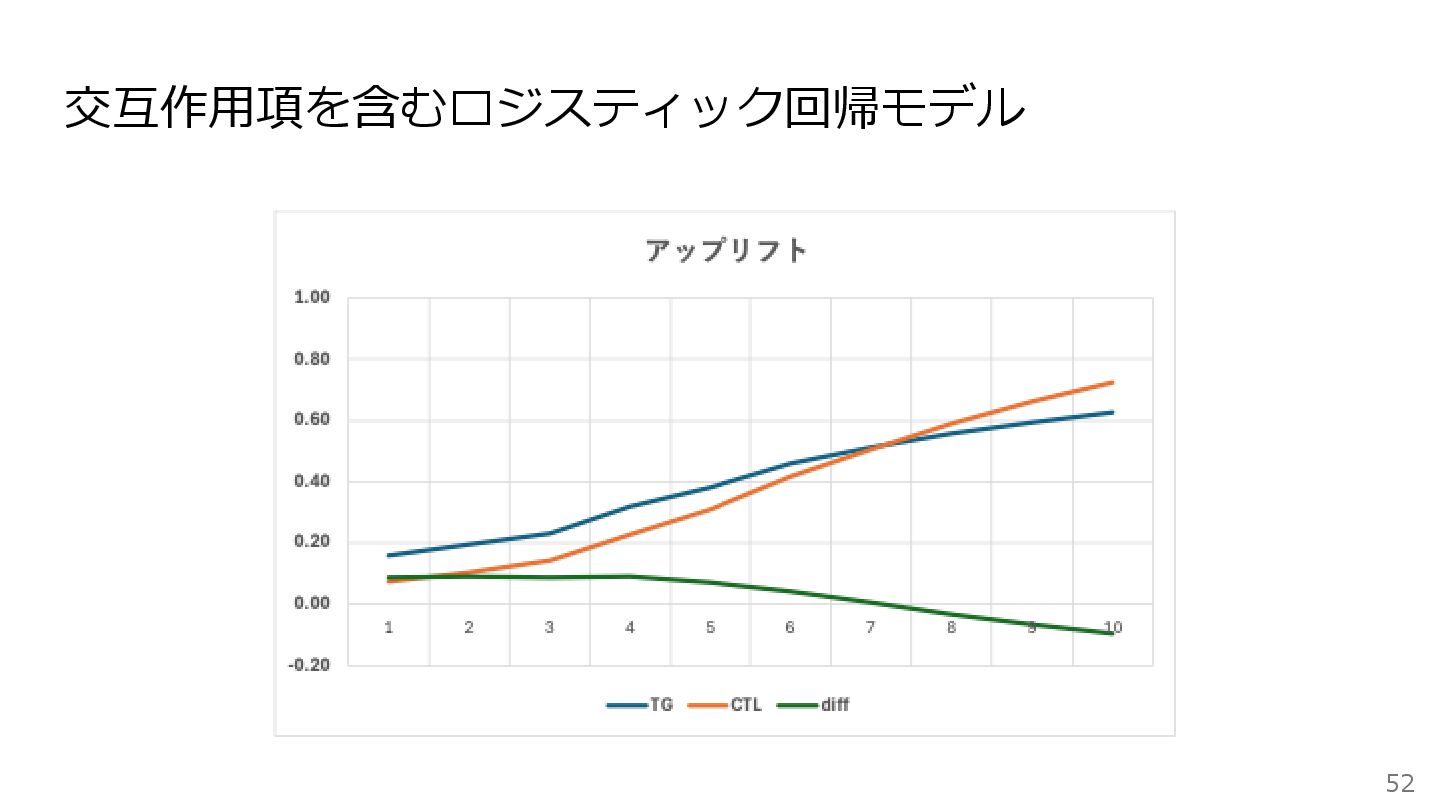
交互作用項を含むロジスティック回帰モデル 51 単純なロジスティック回帰モデルは、クーポン効果の異質性を表現することができなかった → 交互作用項を含むモデルを作れば良いのではないかという発想になる クーポン効果として、全員一律の効果ではなく、 Frequency や Recency によってクーポンの効果(クーポン感度)が
異なるという工夫を入れている
交互作用項を含むロジスティック回帰モデル 52
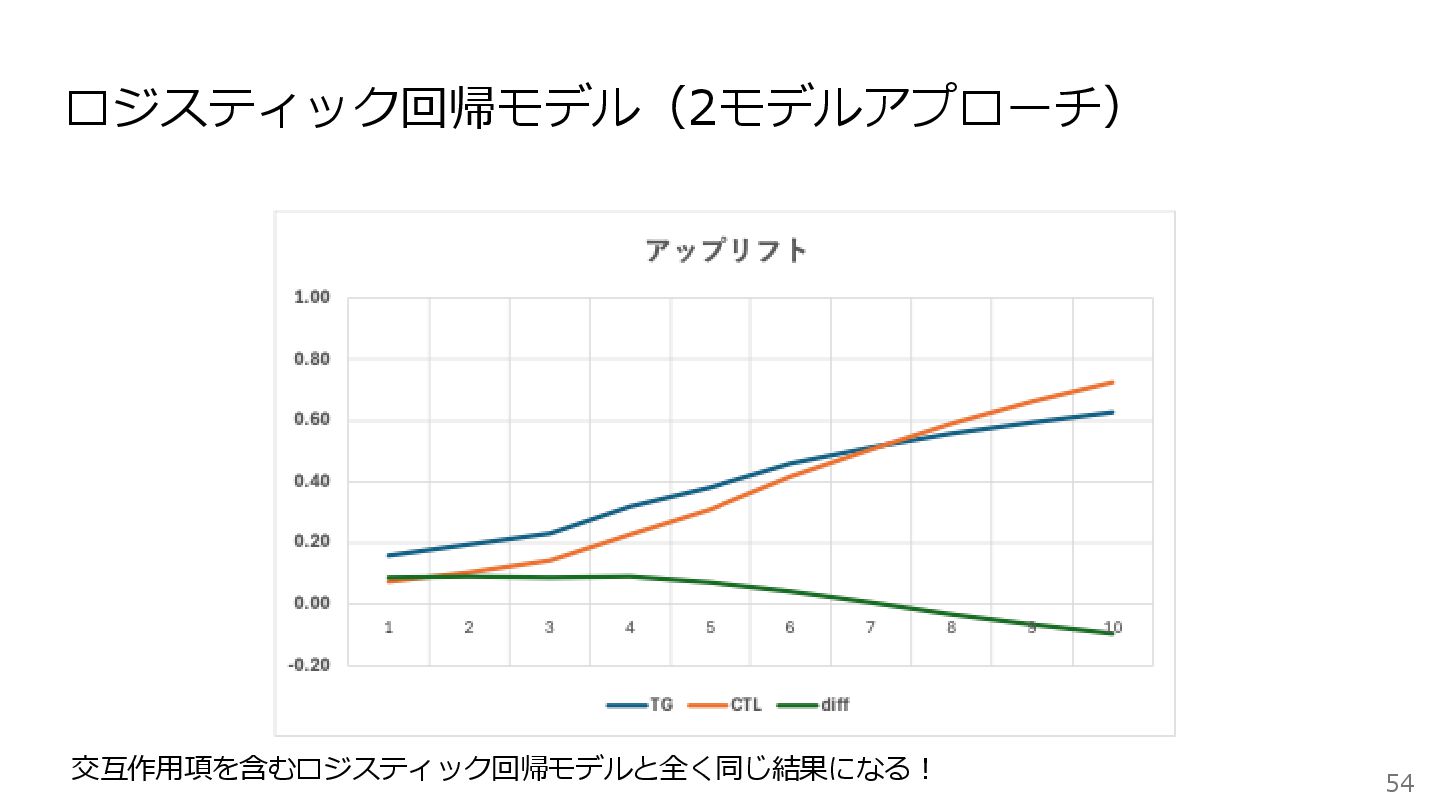
ロジスティック回帰モデル(2モデルアプローチ) 53 ステップ1:ロジスティック回帰を TG グループと CTL グループに対して それぞれモデル作成を作成する ステップ2:[ TG
グループの予測確率 - CTL グループの予測確率 ]を行い、 その差分をアップリフトスコア、つまり、クーポン付与の効果と考える
ロジスティック回帰モデル(2モデルアプローチ) 54 交互作用項を含むロジスティック回帰モデルと全く同じ結果になる!
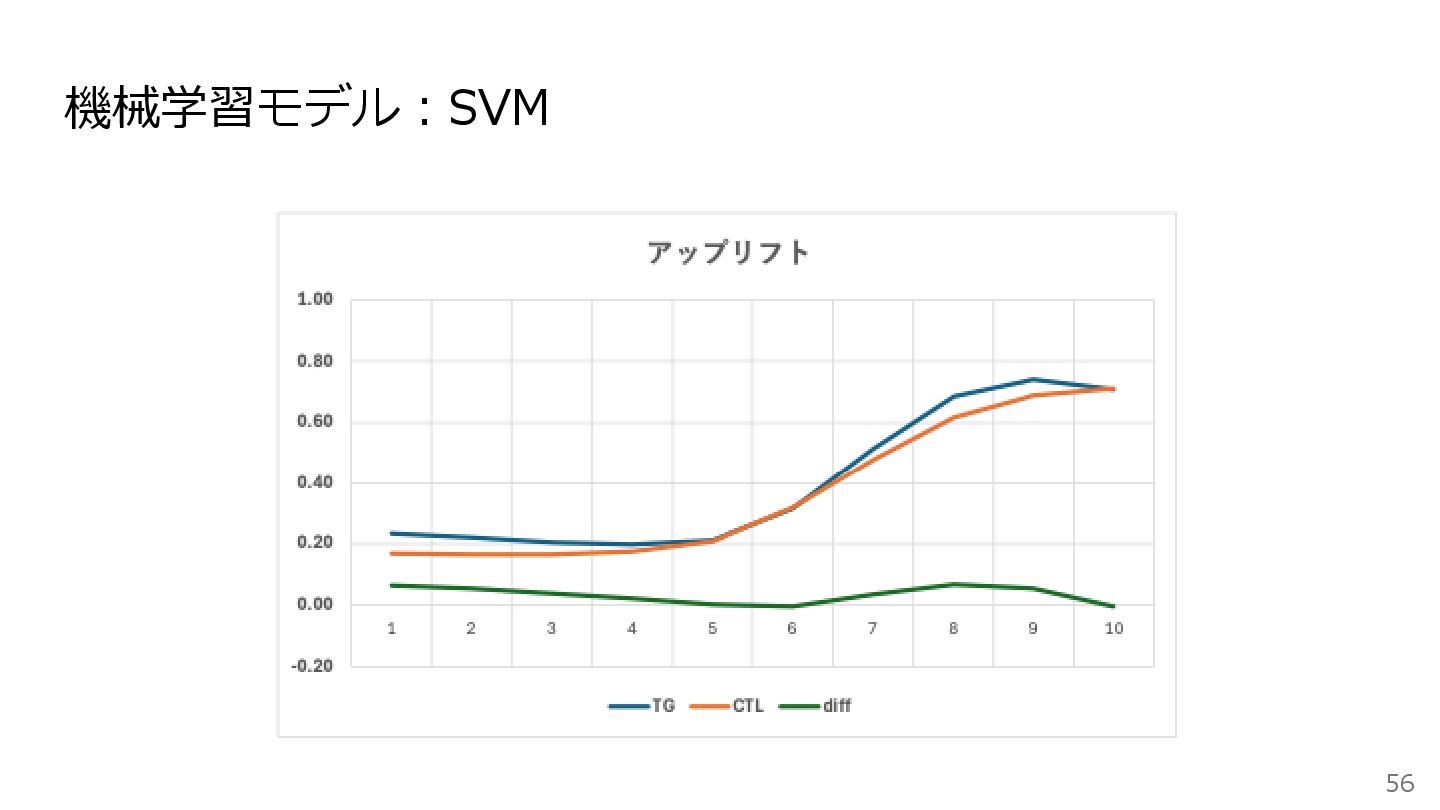
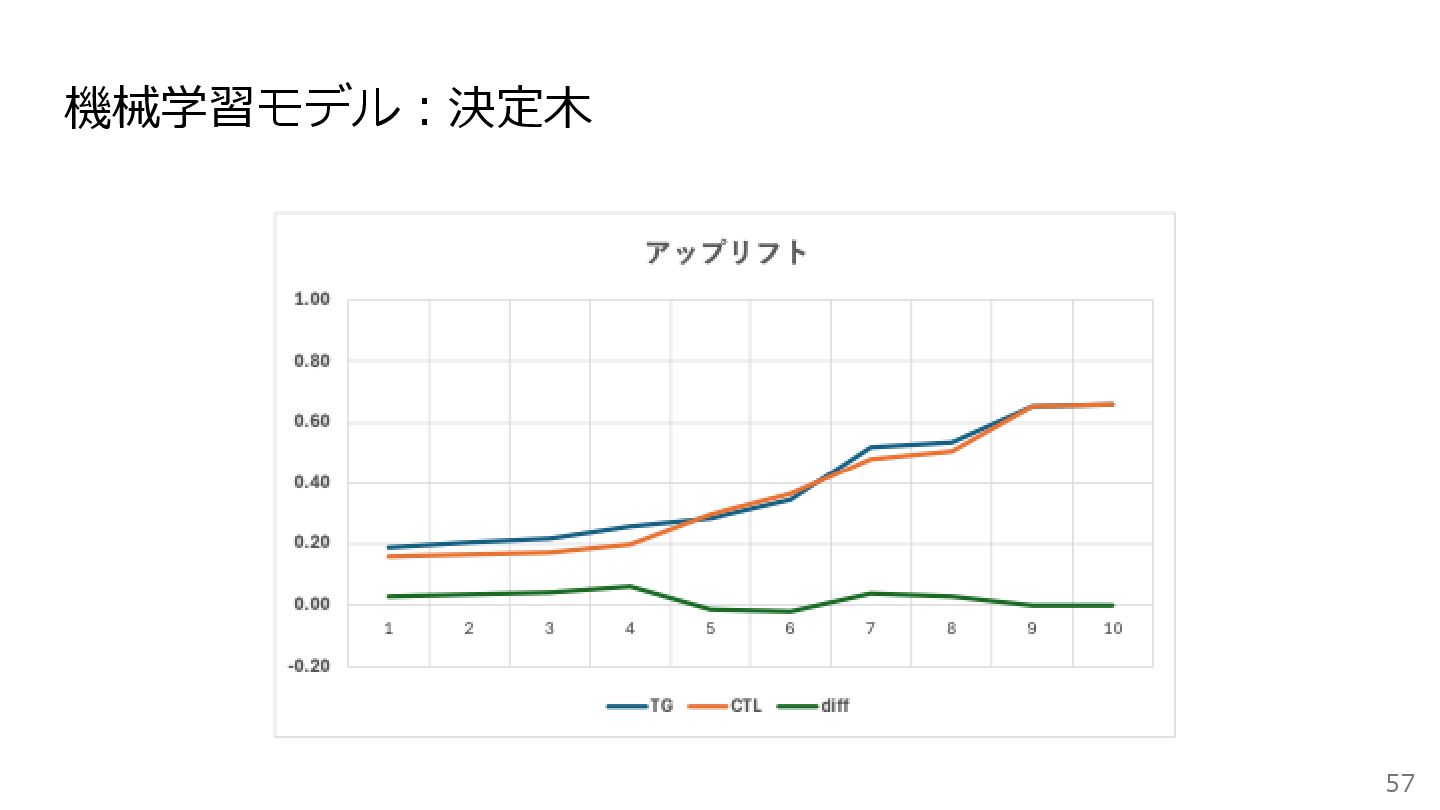
機械学習モデル:SVMと決定木 55 • サポートベクターマシン (SVM) 顧客を分類する境界線を見つけるのが得意なモデル 特に、顧客の特徴量が多い場合に力を発揮する • 決定木 「もしAがYseで、かつBがNoなら…」のように、条件分岐を繰り返して顧客を分類するモデル
結果が非常に分かりやすく、「説得可能層」がどのような顧客かを図で理解しやすいのが特徴 長所と短所 長所 • 顧客の属性と施策効果の間の、複雑で非線形な関係を捉えることができる • 一般的に、ロジスティック回帰よりも高い予測精度が期待できる 短所 • モデルがブラックボックスになりがちで、なぜそうなったかを説明するのが難しい • モデルがデータに過学習しやすく、未知のデータに対する精度が落ちることがある
機械学習モデル:SVM 56
機械学習モデル:決定木 57
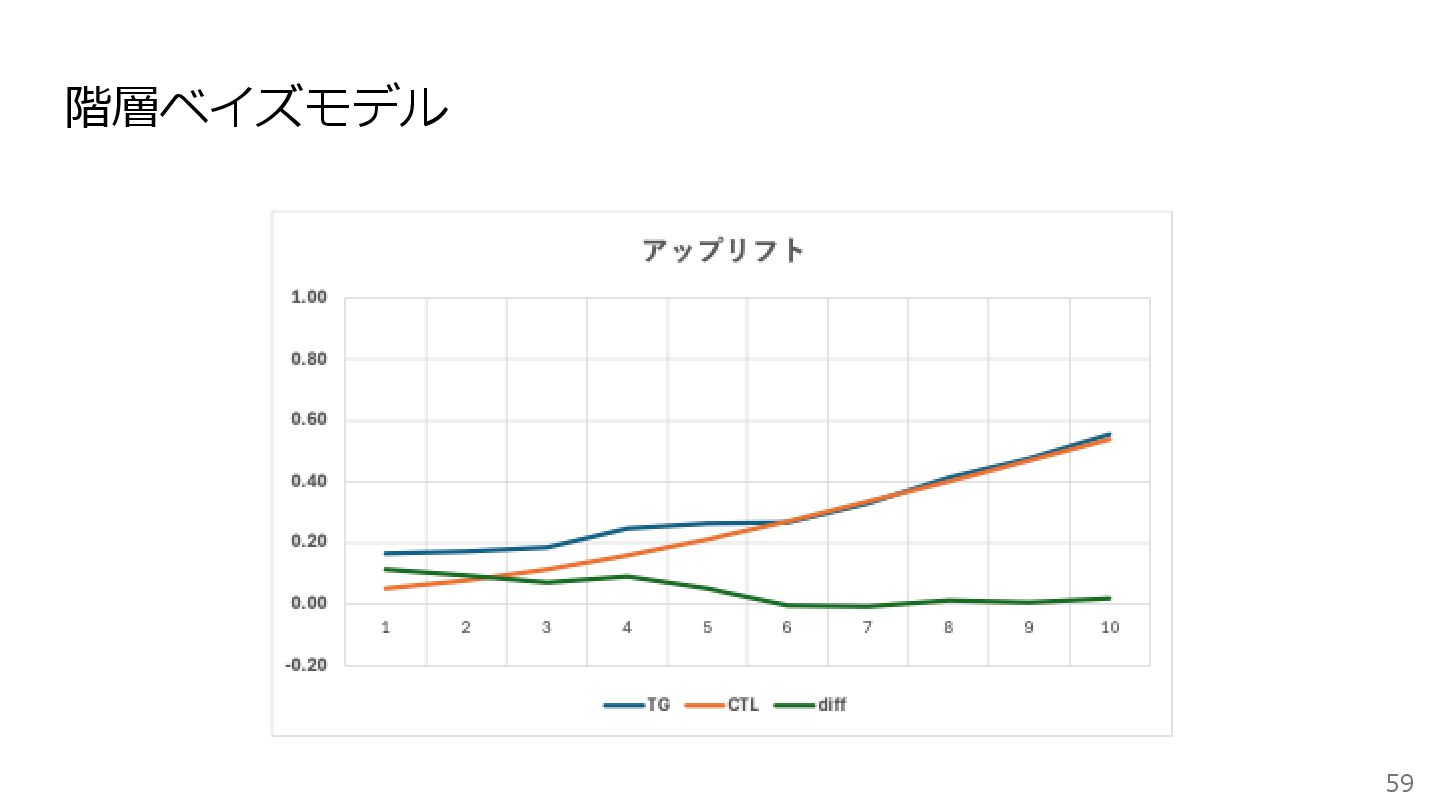
階層ベイズモデル 58 ロジスティック回帰モデル 階層ベイズモデル 𝛽3 が平均的なクーポン効果であり、 𝛽3i は顧客ごとのクーポン効果を表現している
階層ベイズモデル 59
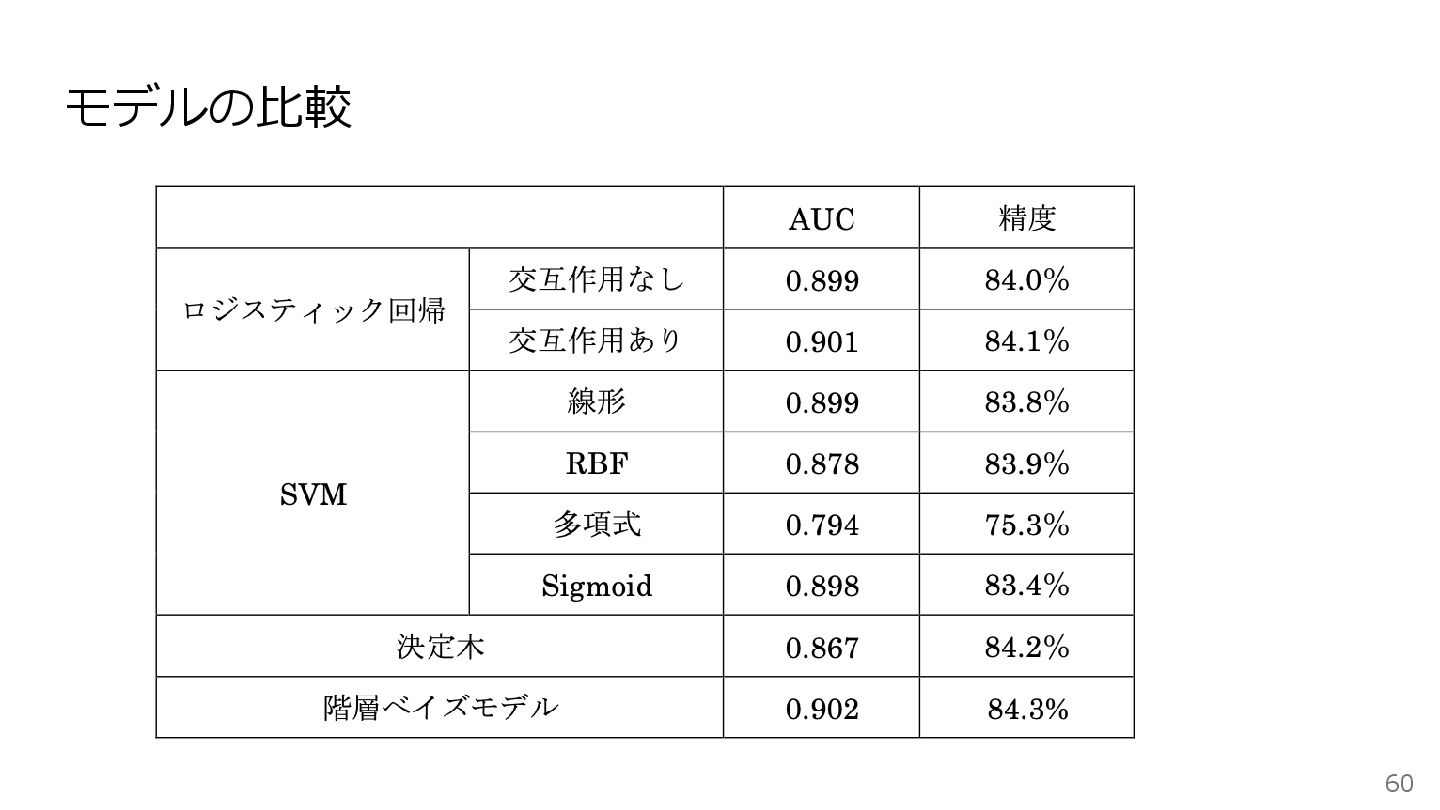
モデルの比較 60
モデルの比較 61 • アップリフトモデルとして機械学習を用いるケースが多い • 実際に、モデルの予測能力だけで評価すれば、機械学習の精度は高いことが多い • 機械学習によって作られたモデルは、構造が複雑になっているため、なぜそういった予 測になるのか理由を説明することが難しい •
機械学習を用いれば誰が購入予約をするかを精度高く予測することができるが、なぜそ の人が購入するのかは明らかにできない • たまたま施策効果が大きそうに見えていた顧客にクーポンを付与してしまい、 実際に は効果がほとんどなく、巨額の損失を生じさせるといったリスクもある
AIは、100%ではない 仮に90%だとすると 10%は間違える 62
データサイエンスが支える企業の成長 63 • アップリフトモデルのような施策は、直接的な利益貢献が期待できる一方、 その効果は一過性(1-shot)になりがち • 企業の持続的な成長のためには、顧客との長期的な関係を築くCX戦略(顧客 体験)が不可欠 • データサイエンスの役割は、この両方を支えることにある
短期利益と長期的成長の両輪を回す 64 短期的な利益貢献 長期的な企業成長 施策の最適化(1-shotの積み重ね) 顧客体験(CX)の向上 個別のマーケティング施策の効果を最大化 し、直接的な利益を生み出す 顧客との良好な関係を築き、LTVを高める ことで、持続的な成長の土台を作る
<具体例> • アップリフトモデリング • 広告効果測定(MMM) • 価格最適化 即効性があるが、効果は限定的・一過性 <具体例> • 顧客理解の深化 • ロイヤルティプログラムの分析 • ブランド価値の測定 効果の発現に時間がかかるが、 企業の根幹を支える
Part 5: まとめと質疑応答 65
まとめ 66 • 広告効果を測定するための2つの補完的なフレームワーク • MMMとアップリフトモデルの比較 - MMM 予算配分(例:テレビ vs
デジタル)の意思決定に役立つ - アップリフトモデル 個々のユーザーに広告を表示すべきかどうかの判断に役立つ
67 各分析アプローチの長所と短所 分析アプローチ メリット(長所) デメリット(短所) 前後比較・昨対比較 ・手軽さ: 計算が非常に簡単で、 誰でもすぐに結果を出せる。 ・直感的:
理解しやすい。 ・信頼性が極めて低い: トレンド、 季節性、競合など、あらゆるバ イアスの影響を受ける。 ・誤った意思決定: 見かけ上の効 果に騙され、判断を誤るリスク が非常に高い。 ランダム化比較試験 (RCT) ・最も信頼性が高い: 因果関係を 特定するゴールドスタンダード。 ・結果が明快: 施策の純粋な効果 をバイアスなく測定できる。 ・実施コストが高い: 特にマス広 告での実施は困難または不可能。 ・限定的: 特定の期間・クリエイ ティブの効果しか検証できない。 アップリフトモデル ・個人レベルの示唆: 「誰に効く か」を特定し、次の施策のROI を最大化できる。 ・顧客体験の向上: 迷惑層へのア プローチを避け、離反を防ぐ。 ・RCTデータが必須: モデル構 築のために、個人単位のRCTが 必要。 ・モデルの複雑性: 構築や解釈に 専門的な知識を要する。
68 各分析アプローチの長所と短所 分析アプローチ メリット(長所) デメリット(短所) エリアABテストMMM ・高い信頼性: RCTに近く、マス 広告の効果を高い精度で測定で きる。
・交絡因子の排除: 全国共通のト レンド等の影響を自然に排除で きる。 ・コントロールエリア選定の難 しさ: DIDの前提(平行トレンド 仮定)を満たす、売上傾向が酷 似したエリアを見つけるのが非 常に難しい。 ・実施の制約: 広告を放映しない エリアの確保が必要。 ・コスト: 通常のMMMより分 析・準備のコストがかかる。 MMM (通常の観察データ) ・網羅性: 複数のマーケティング 施策の効果を同時に評価できる。 ・比較的安価: 既存のデータのみ で分析が可能。 ・モデル依存: 交絡因子を全てモ デルで調整する必要があり、見 落としのリスクがある。 ・精度限界: あくまで統計的な調 整であり、RCTほどの信頼性は ない。
69 仲間を募集しています:JINSで新しい価値を創造しませんか? データとテクノロジーでアイウエアの未来を創る仲間を募集中! 本日お話ししたような、挑戦的で面白い課題に溢れています。 問い合わせ:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![69 仲間を募集しています:JINSで新しい価値を創造しませんか? データとテクノロジーでアイウエアの未来を創る仲間を募集中! 本日お話ししたような、挑戦的で面白い課題に溢れています。 問い合わせ:[email protected]](https://files.speakerdeck.com/presentations/c6f423bdcb48462a83d5773a1ddfc16b/slide_68.jpg){kind=link}