Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
baseballrによるMLBデータの抽出と階層ベイズモデルによる打率の推定 / TokyoR118
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
森下光之助
June 21, 2025
Science
960
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
baseballrによるMLBデータの抽出と階層ベイズモデルによる打率の推定 / TokyoR118
第118回R勉強会@東京(#TokyoR)の発表資料です。
https://tokyor.connpass.com/event/357734/
森下光之助
June 21, 2025
More Decks by 森下光之助
See All by 森下光之助
『ビジネス課題を解決する技術』を出版しました / CA DATA Night #7
dropout009
1
88
tidymodelsによるtidyな生存時間解析 / Japan.R2024
dropout009
2
1.4k
データ不足に数理モデルで立ち向かう / Japan.R 2023
dropout009
12
6.3k
回帰分析ではlm()ではなくestimatr::lm_robust()を使おう / TokyoR100
dropout009
67
11k
Counterfactual Explanationsで機械学習モデルを解釈する / TokyoR99
dropout009
3
3.2k
『機械学習を解釈する技術』の紹介 / Devsumi2022
dropout009
4
4.1k
シンプルな数理モデルでビジネス課題を解決する / Japan.R 2021
dropout009
2
7.1k
テレビCMのユニークリーチを最適化する / PyData.Tokyo24
dropout009
0
1.9k
Accumulated Local Effects(ALE)で機械学習モデルを解釈する / TokyoR95
dropout009
3
10k
Other Decks in Science
See All in Science
Utiliser Bitcoin sans Internet
rlifchitz
0
310
データベース15: ビッグデータ時代のデータベース
trycycle
PRO
1
520
第67回コンピュータビジョン勉強会論文紹介「RoboWheel: A Data Engine from Real-World Human Demonstrations for Cross-Embodiment Robotic Learning」
x_ttyszk
0
130
20260410_SystemsThinking
takusamar
1
130
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.6k
AkarengaLT vol.40
hashimoto_kei
0
120
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
120
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
analokmaus
1
620
生成AIが科学とRAにもたらしていること:メタサイエンスの視点から
rmaruy
0
110
Sstニューロンによる睡眠不足と回復の制御:データ駆動型トランスクリプトーム解析
tagtag
PRO
0
110
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
240
AIを用いた PID制御で部屋 の温度制御をしてみた
nearme_tech
PRO
0
190
Featured
See All Featured
Rails Girls Zürich Keynote
gr2m
96
14k
Fireside Chat
paigeccino
42
4k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
240
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
190
Are puppies a ranking factor?
jonoalderson
1
3.7k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
420
The SEO identity crisis: Don't let AI make you average
varn
0
520
HDC tutorial
michielstock
2
760
Automating Front-end Workflow
addyosmani
1370
210k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Transcript
baseballerによるMLBデータの抽出と 階層ベイズモデルによる打率の推定 森下光之助 (@dropout009) Tokyo.R 118 2025/06/21
森下光之助 (@dropout009) ドカベン、H2、ONE OUTS、リトルバスターズ、 サンキューピッチなど数多の文献から野球を独 学 「スクイズの時の小フライはいかなる場合でもイ ンフィールドフライにはならない」「代打バースと 早口で言うとおはようございますに聞こえる」 「大谷翔平はおむすびのおいしい国に生まれた」
など、広く深いドメイン知識を持つ 自己紹介 2
1. baseballrパッケージによるMLBデータの抽出 2. 階層ベイズモデルによる打率の推定 3. まとめ 目次 3
シーズンの途中までの成績から、選手のシーズン終了時点の打率を予測する という問題に取り組む (他に追加情報がないなら)単純にシーズン途中の打率でそのまま予測する しかないように思える 実際は、シーズン途中の打率は打数が少なく安定していないので、シーズン 終了時点の打率をうまく予測できない この問題を克服するために、階層ベイズモデルで打率を推定する。各選手の 打率を予測する際に、他の選手の情報を利用することで、打率の予測精度を 向上させることを狙う 本日お話する内容
4
打率は、打数に対する安打数の割合 打率(BA) = 安打数(H) ÷ 打数(AB) ここで、打数(AB)とは、打席数(PA)から四死球と犠打を引いた数 ちなみに、打率ってなんだっけ? 5
baseballrによるMLBデータの抽出 6
Rの野球分析パッケージ FanGraphs.com、Baseball-Reference.com、 baseballsavant.mlb.comからデータを取得 データ取得と指標計算の二つの主要機能を提供 baseballrとは 7
データ取得 MLB打者・投手の日次成績データ 特定日時点でのリーグ順位 Statcastのピッチデータ Baseball Referenceの過去データ 指標計算 wOBA(weighted On-Base Average)
FIP(Fielding Independent Pitching) チーム一貫性の指標 baseballrの主な機能 8
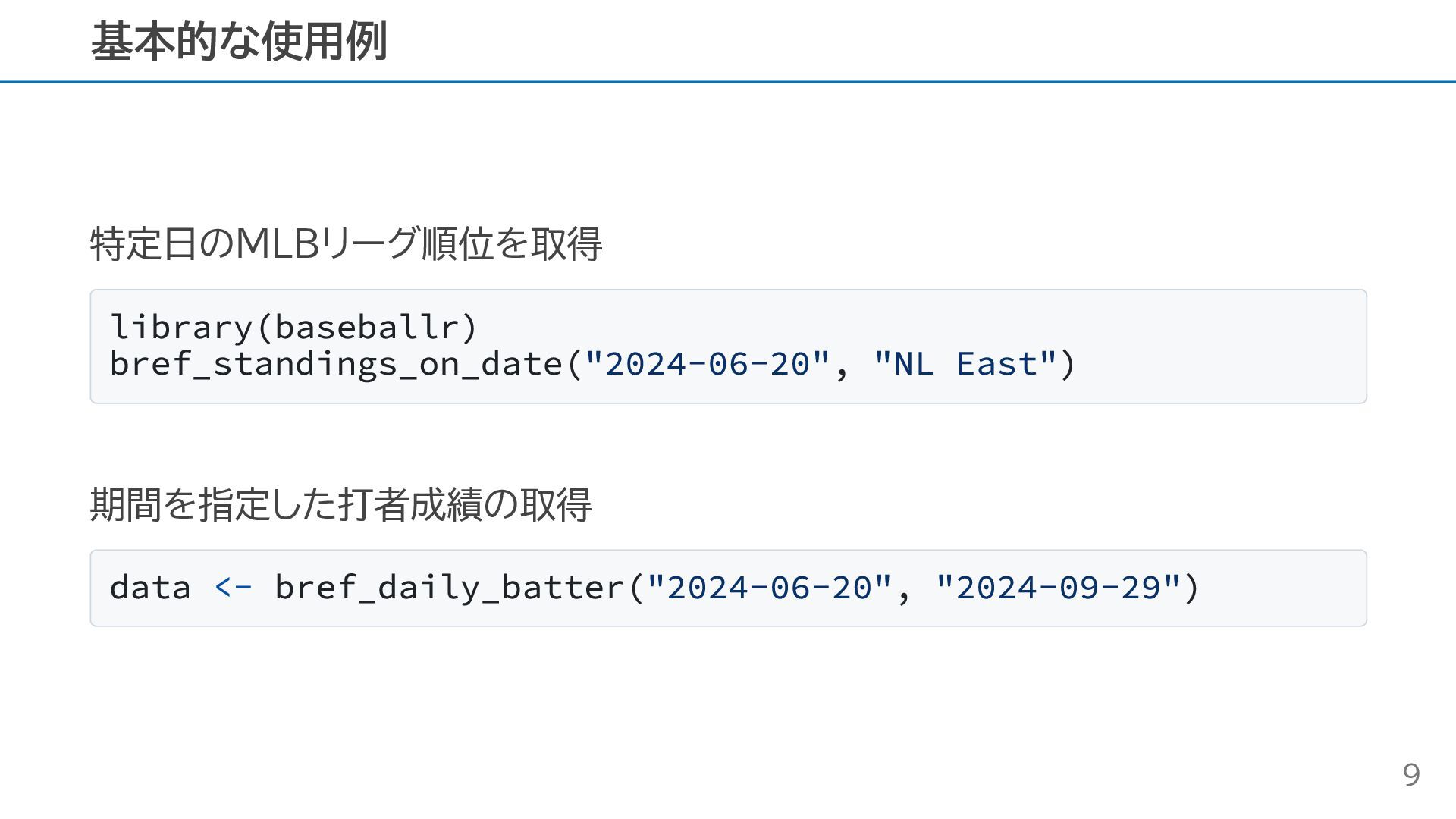
特定日のMLBリーグ順位を取得 library(baseballr) bref_standings_on_date("2024-06-20", "NL East") 期間を指定した打者成績の取得 data <- bref_daily_batter("2024-06-20", "2024-09-29")
基本的な使用例 9
シーズンの初期と最終時点の打撃成績を取得 start_date <- "2024-03-20" # シーズン開始 mid_date <- "2024-04-30" #
シーズンの途中までのデータ抽出用 end_date <- "2024-09-29" # シーズン終了 # 初期時点のデータ抽出 df_initial <- baseballr::bref_daily_batter( t1 = start_date, t2 = mid_date ) # 最終時点のデータ抽出 df_total <- baseballr::bref_daily_batter( t1 = start_date, t2 = end_date ) データの取得 10
ここで、 PA は打席数、 AB は打数、 H は安打数、 BA は打率 df
<- df_total |> # 初期時点と最終時点のデータを結合 select(Name, PA, AB, H, BA) |> filter(PA >= 502) |> # 規定打席以上の選手に限定 inner_join( df_initial |> select(Name, PA, AB, H, BA), by = c("Name"), suffix = c("_tot", "_ini") ) |> mutate(BA_mean = mean(BA_ini)) df # A tibble: 128 × 10 Name PA_tot AB_tot H_tot BA_tot PA_ini AB_ini H_ini BA_ini BA_mean <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 Jarren Duran 732 668 190 0.284 142 127 34 0.268 0.257 2 Shohei Ohtani 731 636 197 0.31 149 131 44 0.336 0.257 3 Gunnar Henderson 719 630 177 0.281 132 117 34 0.291 0.257 4 Marcus Semien 718 650 154 0.237 135 124 32 0.258 0.257 5 Juan Soto 713 576 166 0.288 144 117 38 0.325 0.257 分析用データの作成と確認 11
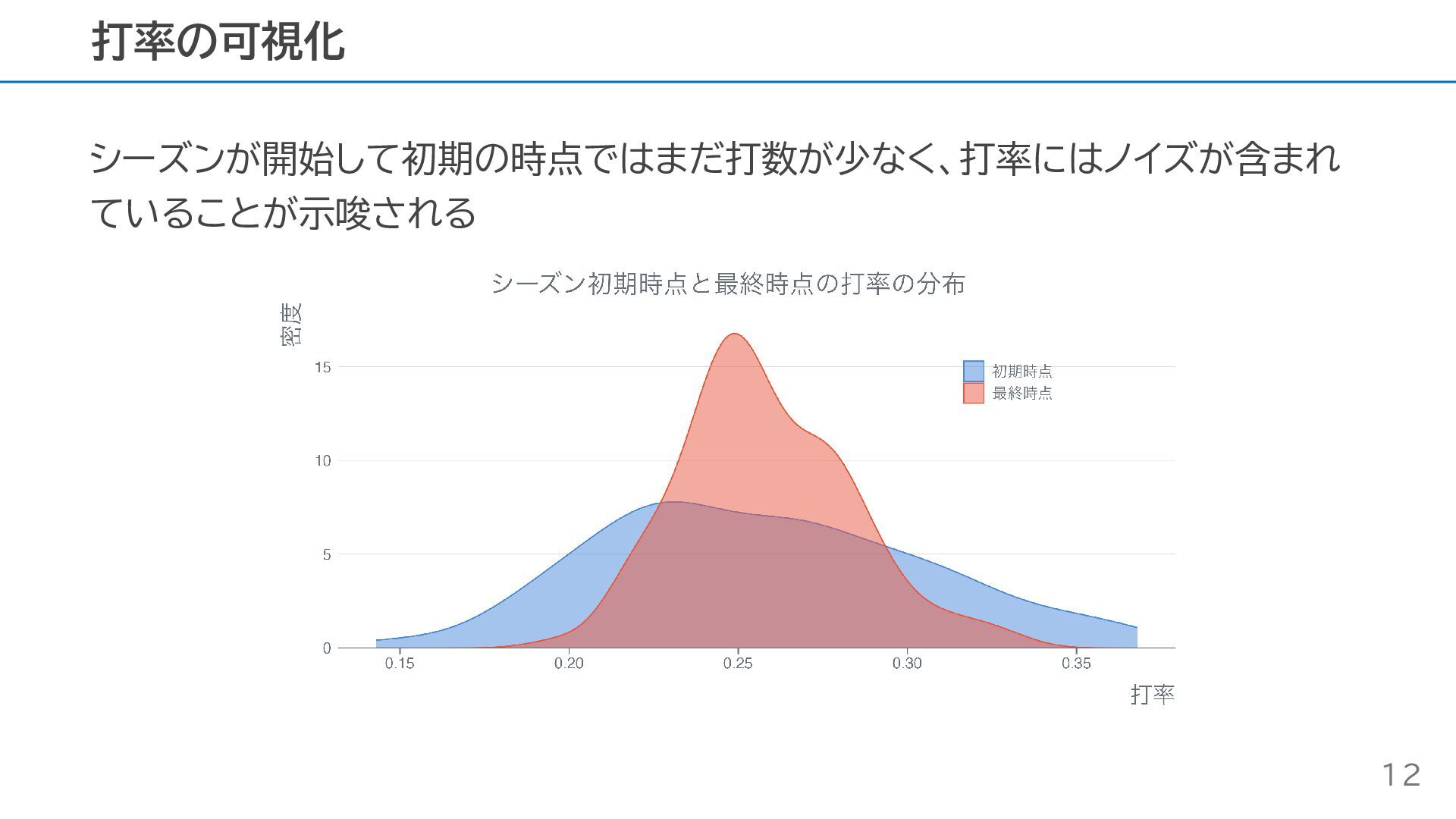
シーズンが開始して初期の時点ではまだ打数が少なく、打率にはノイズが含まれ ていることが示唆される 打率の可視化 12
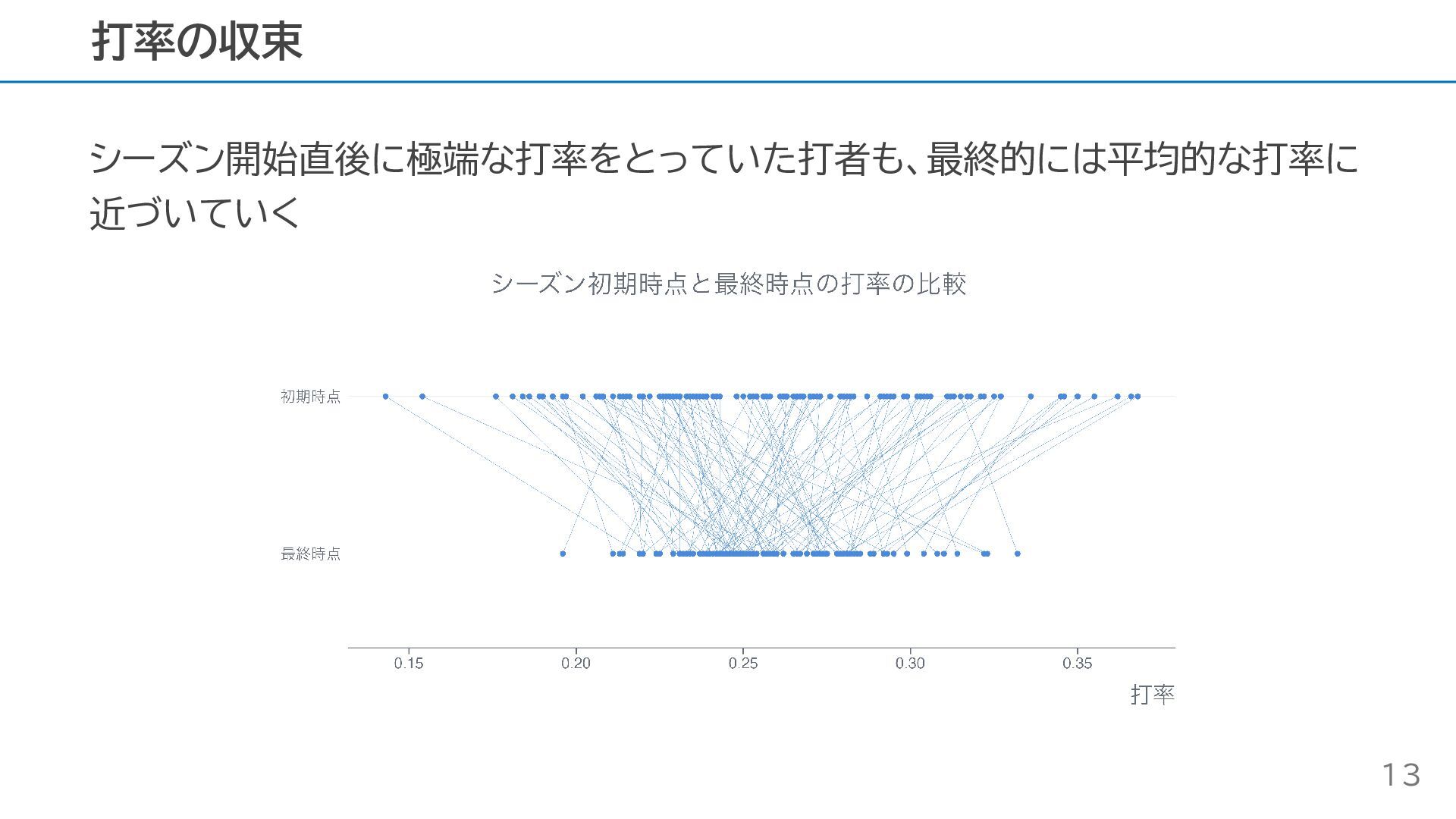
シーズン開始直後に極端な打率をとっていた打者も、最終的には平均的な打率に 近づいていく 打率の収束 13
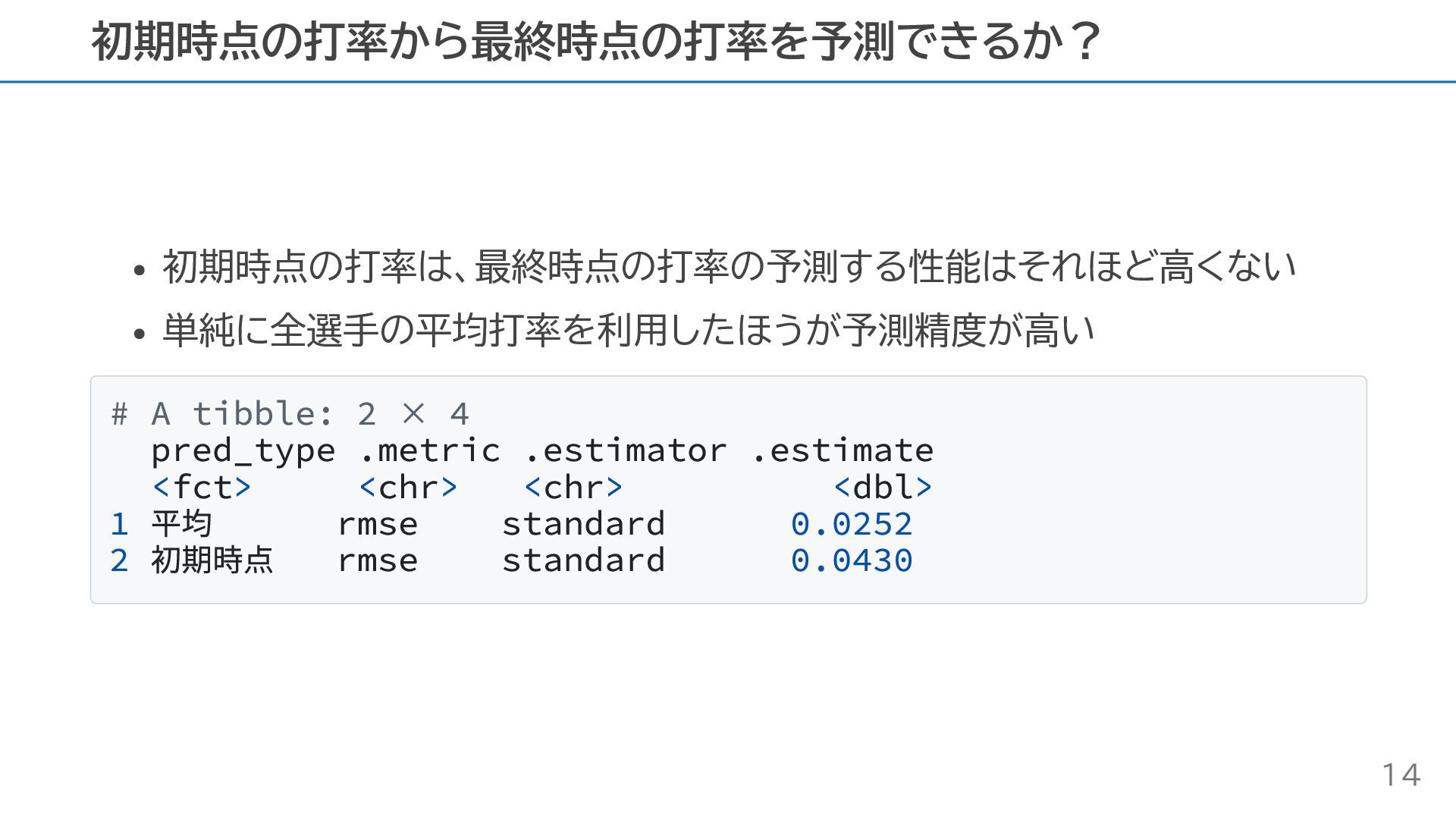
初期時点の打率は、最終時点の打率の予測する性能はそれほど高くない 単純に全選手の平均打率を利用したほうが予測精度が高い # A tibble: 2 × 4 pred_type .metric
.estimator .estimate <fct> <chr> <chr> <dbl> 1 平均 rmse standard 0.0252 2 初期時点 rmse standard 0.0430 初期時点の打率から最終時点の打率を予測できるか? 14
予測精度が悪いのは、シーズンの初期時点では各選手の打数がまだ少なく、 推定に誤差が多く含まれていることが原因 このように、各選手の打数が少なく情報が不足している場合は、他の選手の 打撃成績を間接的に利用することが効果的 たとえば、初期時点で打率4割の選手がいても、最終時点では全体平均の2 割5分7厘に近い打率になると予測したほうが妥当性が高いと思われる このようなモデリング手法として、階層ベイズモデルが知られている データの情報不足を補う 15
階層ベイズモデルによる打率の推定 16
階層ベイズに入る前に、まずは通常のベイズで打率を推定する方法を考える 個人 の安打数 は、試行回数が打数 で、成功率が打率 の二項分布に従うと考えられる 打率は0から1の間の値をとる確率変数なので、無情報事前分布として区間 の一様分布を利用する
H i θ i ∼ Binomial(AB , θ ) i i ∼ Uniform(0, 1) 打率の推定をベイズで考えると… i = 1, … , n H i AB i θ i [0, 1] 17
前述のモデルをStanで記述すると以下のようになる data { int<lower=0> N; int<lower=0> AB[N]; int<lower=0> H[N]; }
parameters { vector<lower=0, upper=1>[N] theta; } model { H ~ binomial(AB, theta); theta ~ uniform(0, 1); } Stanコード 18
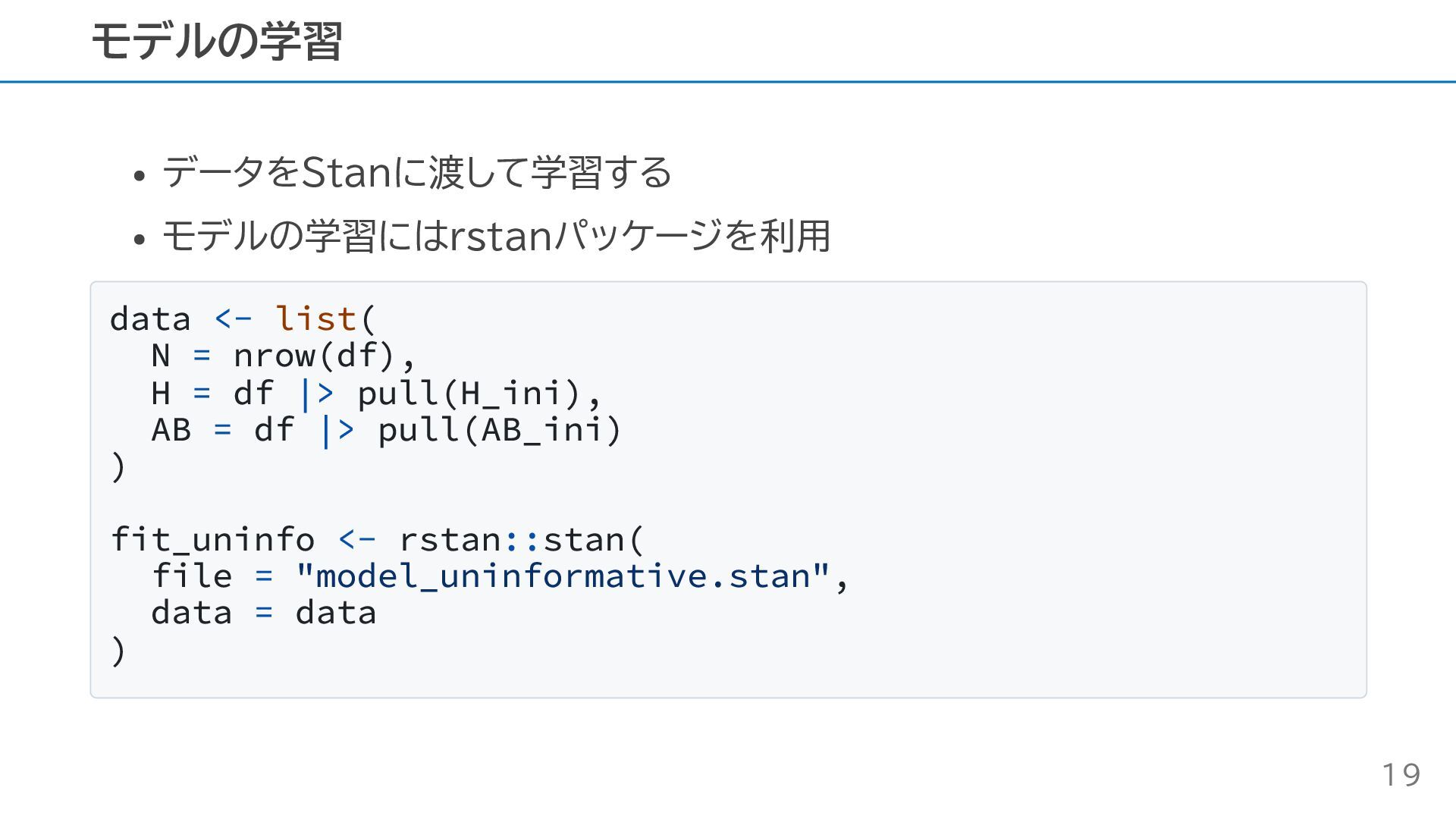
データをStanに渡して学習する モデルの学習にはrstanパッケージを利用 data <- list( N = nrow(df), H =
df |> pull(H_ini), AB = df |> pull(AB_ini) ) fit_uninfo <- rstan::stan( file = "model_uninformative.stan", data = data ) モデルの学習 19
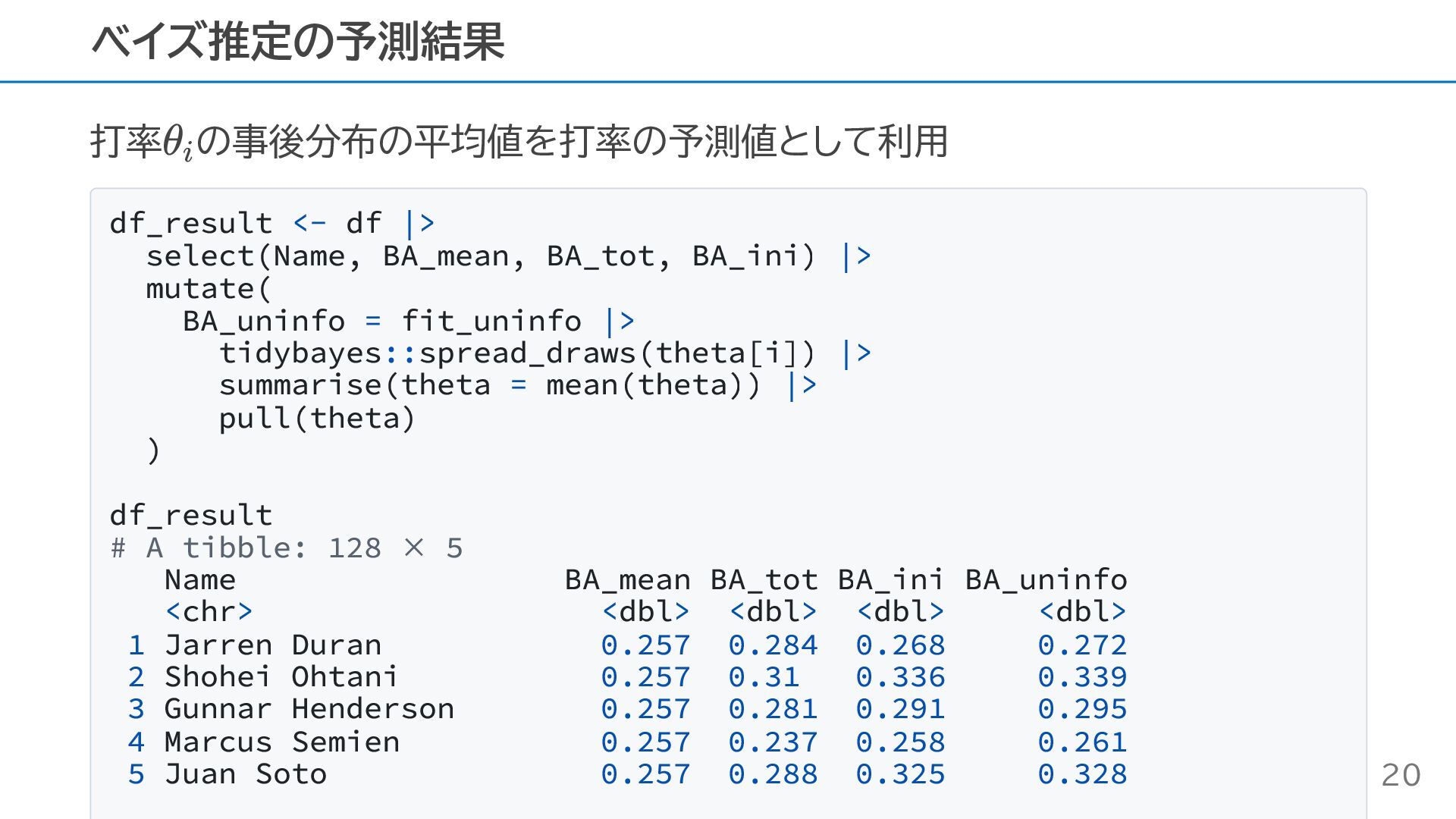
打率 の事後分布の平均値を打率の予測値として利用 df_result <- df |> select(Name, BA_mean, BA_tot, BA_ini)
|> mutate( BA_uninfo = fit_uninfo |> tidybayes::spread_draws(theta[i]) |> summarise(theta = mean(theta)) |> pull(theta) ) df_result # A tibble: 128 × 5 Name BA_mean BA_tot BA_ini BA_uninfo <chr> <dbl> <dbl> <dbl> <dbl> 1 Jarren Duran 0.257 0.284 0.268 0.272 2 Shohei Ohtani 0.257 0.31 0.336 0.339 3 Gunnar Henderson 0.257 0.281 0.291 0.295 4 Marcus Semien 0.257 0.237 0.258 0.261 5 Juan Soto 0.257 0.288 0.325 0.328 ベイズ推定の予測結果 θ i 20
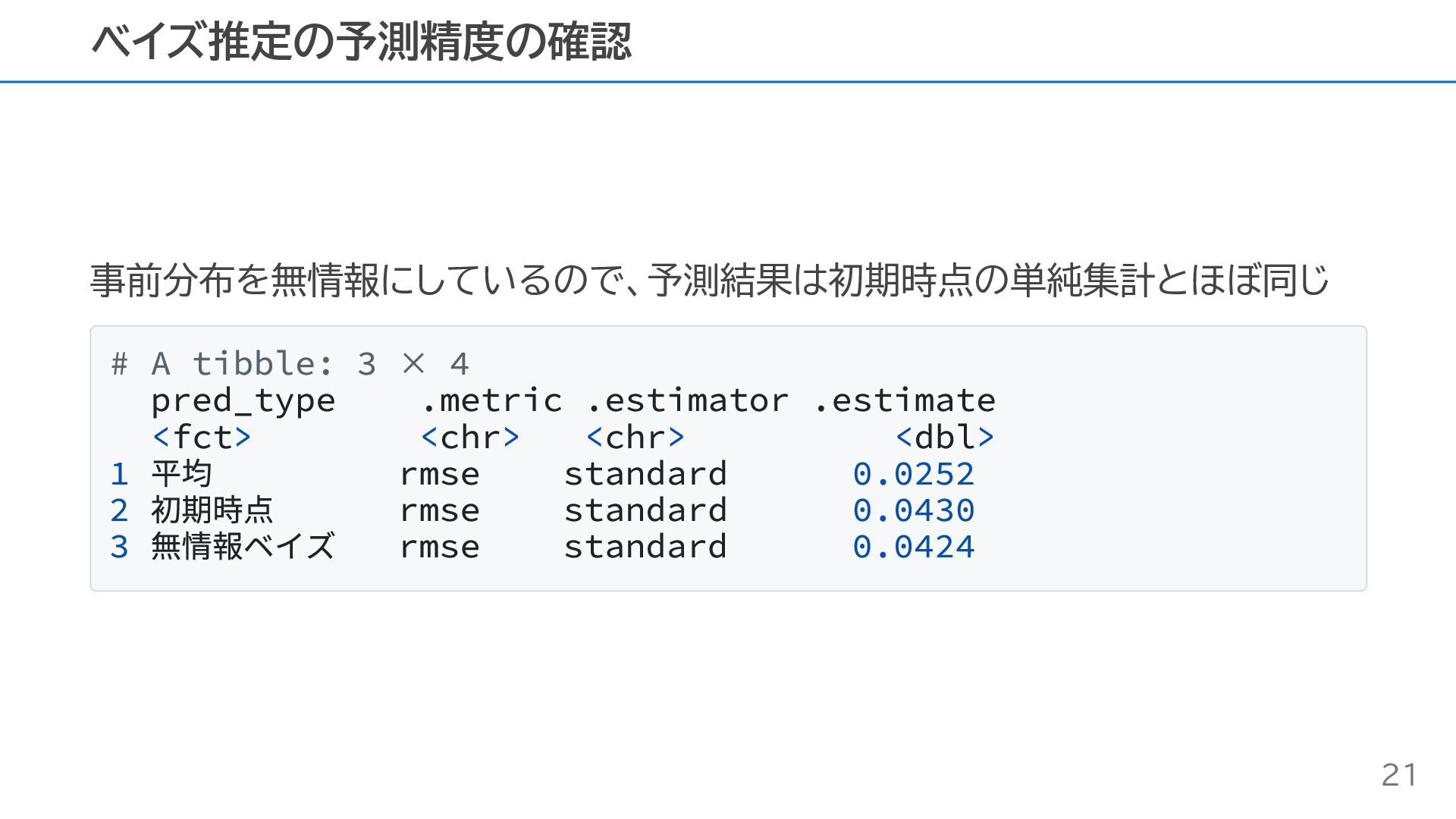
事前分布を無情報にしているので、予測結果は初期時点の単純集計とほぼ同じ # A tibble: 3 × 4 pred_type .metric .estimator
.estimate <fct> <chr> <chr> <dbl> 1 平均 rmse standard 0.0252 2 初期時点 rmse standard 0.0430 3 無情報ベイズ rmse standard 0.0424 ベイズ推定の予測精度の確認 21
各選手の打率 が、選手全体に共通する一つの分布から生成されていると 考え、他の選手の情報を間接的に利用する 具体的には、各選手の打率 が、共通の平均 と精度 を持つベータ分布に 従うと仮定
H i θ i μ ν ∼ Binomial(AB , θ ) i i ∼ Beta(μν, (1 − μ)ν) ∼ Beta(a, b) ∼ Exponential(c) は全選手の平均打率、 は打率のばらつきの小ささ(精度)を表すパラメー タ。これらにも事前分布を設定し、データから と も同時に推定する 階層ベイズモデルを構築 θ i θ i μ ν μ ν μ ν 22
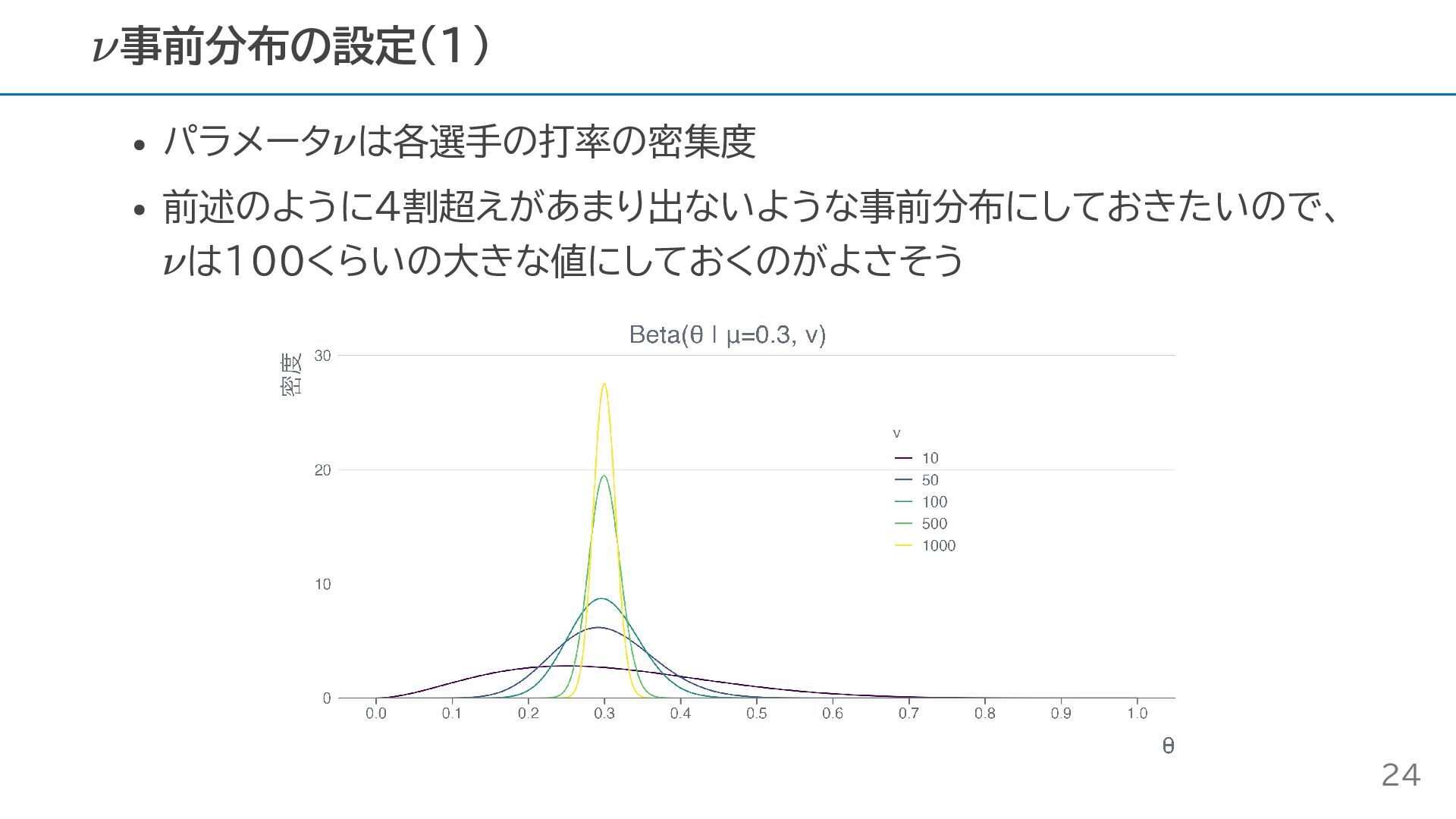
パラメータ は全選手の打率の平均 も確率なので、その事前分布もベータ分布で設定する 4割打者は漫画の中にしかいないというドメイン知識を活かして、打率の平 均は3割程度になると予想する 全選手の打率の平均は選手数が十分多いので弱い事前分布でも問題なく推 定できそう なので、 を事前分布として設定する 事前分布の設定
μ μ μ Beta(3, 7) 23
パラメータ は各選手の打率の密集度 前述のように4割超えがあまり出ないような事前分布にしておきたいので、 は100くらいの大きな値にしておくのがよさそう 事前分布の設定(1) ν ν ν 24
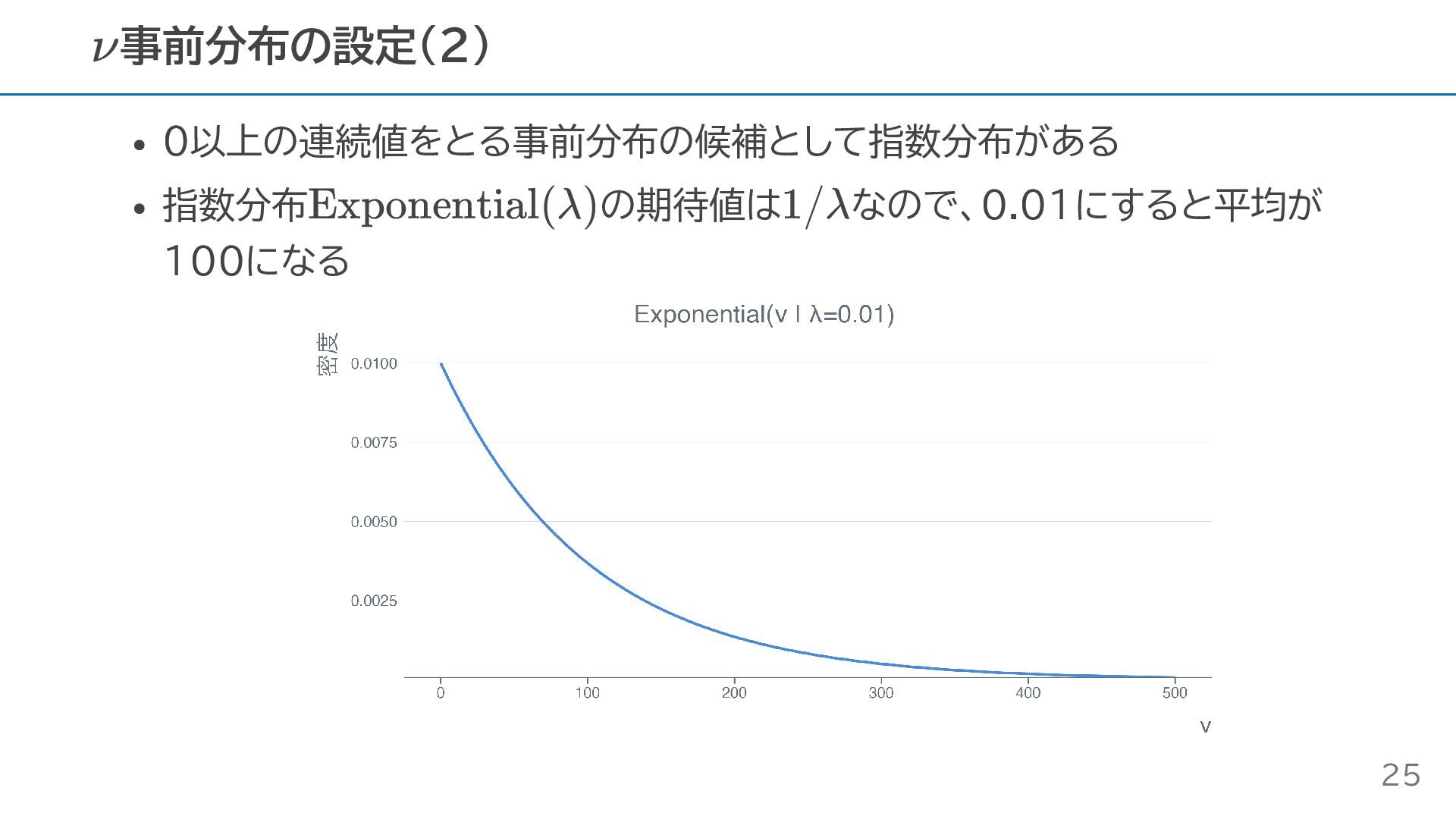
0以上の連続値をとる事前分布の候補として指数分布がある 指数分布 の期待値は なので、0.01にすると平均が 100になる 事前分布の設定(2) ν Exponential(λ) 1/λ 25
data { int<lower=0> N; int<lower=0> AB[N]; int<lower=0> H[N]; } parameters
{ real<lower=0, upper=1> mu; real<lower=0, upper=10> nu; vector<lower=0, upper=1>[N] theta; } model { H ~ binomial(AB, theta); // nuはスケール調整されているため、100倍して元のスケールに戻して使用 theta ~ beta(100 * mu * nu, 100 * (1 - mu) * nu); mu ~ beta(3, 7); nu ~ exponential(1); } Stanコード 26
df_result <- df_result |> mutate( BA_hier = fit_hier |> tidybayes::spread_draws(theta[i])
|> summarise(theta = mean(theta)) |> pull(theta) ) df_result # A tibble: 128 × 6 Name BA_mean BA_tot BA_ini BA_uninfo BA_hier <chr> <dbl> <dbl> <dbl> <dbl> <dbl> 1 Jarren Duran 0.257 0.284 0.268 0.272 0.261 2 Shohei Ohtani 0.257 0.31 0.336 0.339 0.284 3 Gunnar Henderson 0.257 0.281 0.291 0.295 0.268 4 Marcus Semien 0.257 0.237 0.258 0.261 0.258 5 Juan Soto 0.257 0.288 0.325 0.328 0.278 階層ベイズモデルの予測結果 27
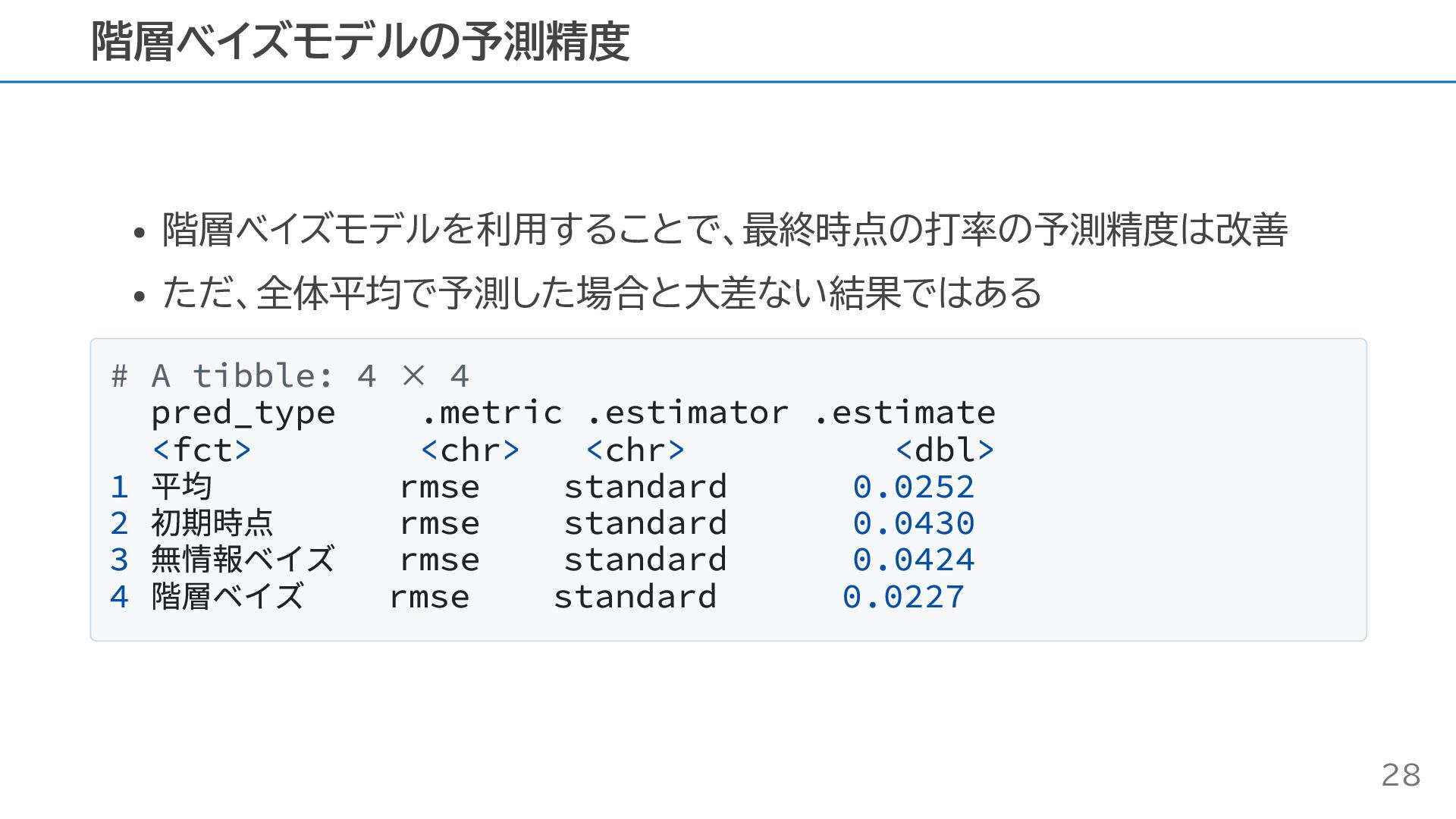
階層ベイズモデルを利用することで、最終時点の打率の予測精度は改善 ただ、全体平均で予測した場合と大差ない結果ではある # A tibble: 4 × 4 pred_type .metric
.estimator .estimate <fct> <chr> <chr> <dbl> 1 平均 rmse standard 0.0252 2 初期時点 rmse standard 0.0430 3 無情報ベイズ rmse standard 0.0424 4 階層ベイズ rmse standard 0.0227 階層ベイズモデルの予測精度 28
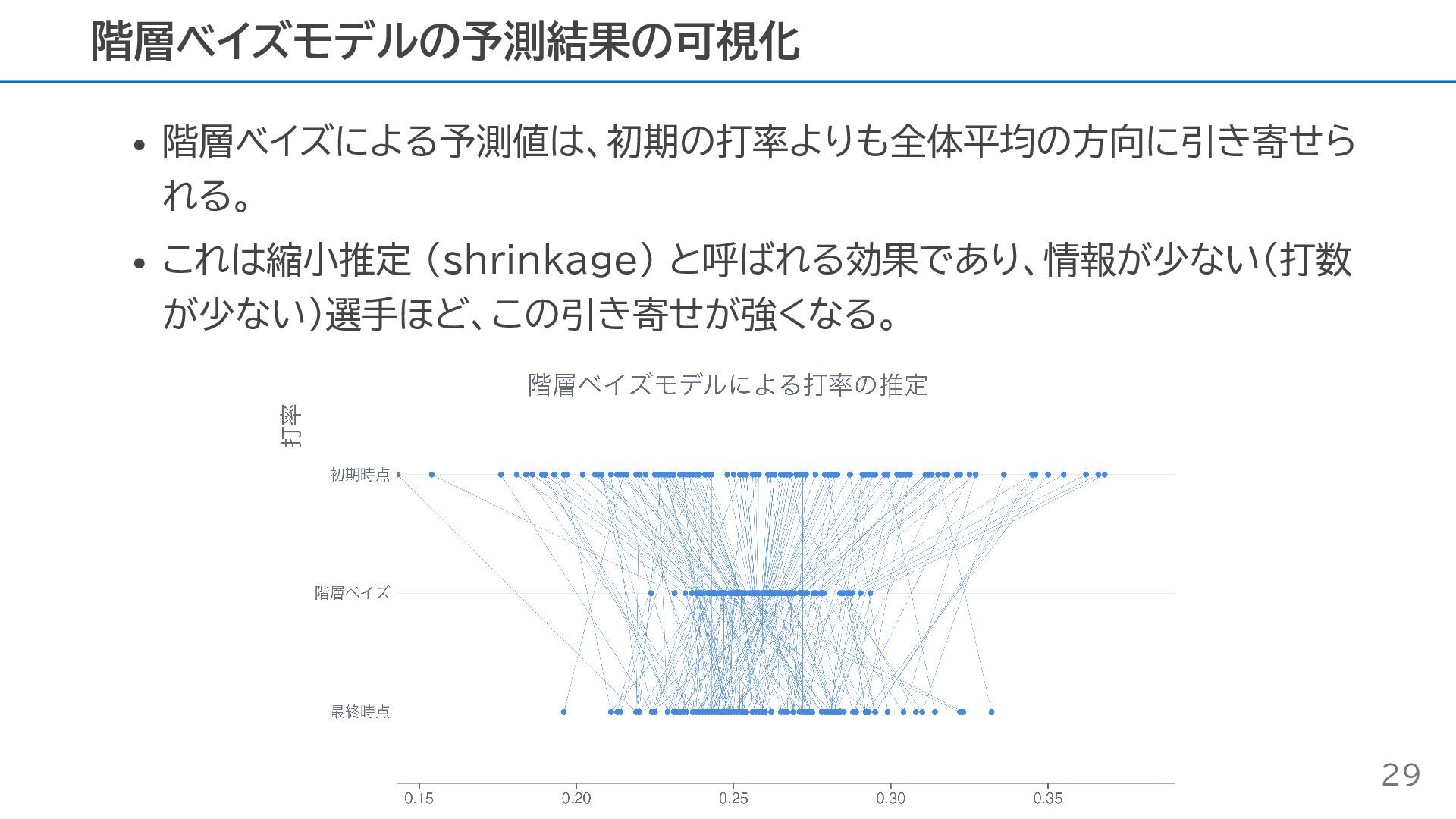
階層ベイズによる予測値は、初期の打率よりも全体平均の方向に引き寄せら れる。 これは縮小推定 (shrinkage) と呼ばれる効果であり、情報が少ない(打数 が少ない)選手ほど、この引き寄せが強くなる。 階層ベイズモデルの予測結果の可視化 29
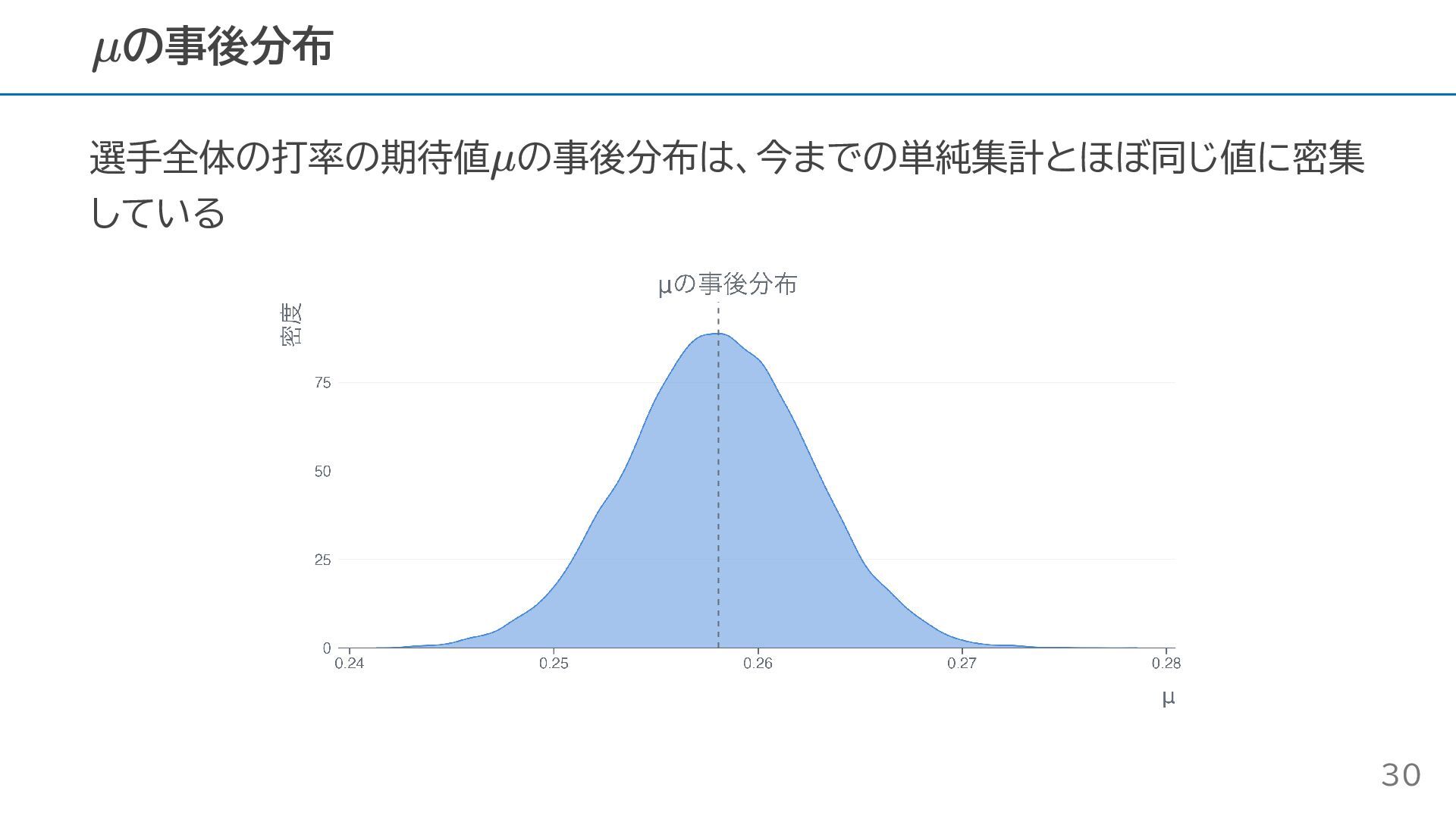
選手全体の打率の期待値 の事後分布は、今までの単純集計とほぼ同じ値に密集 している の事後分布 μ μ 30
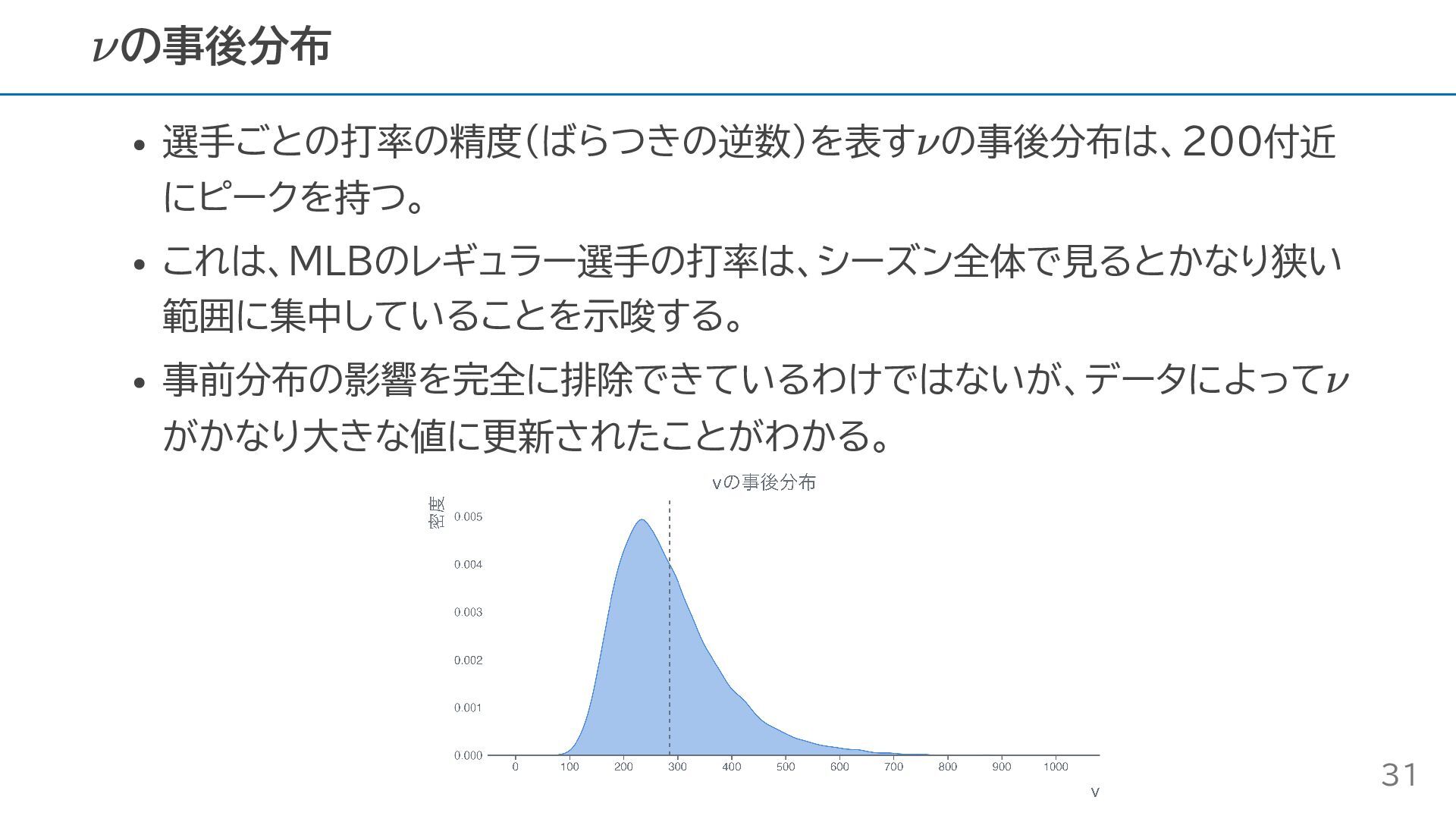
選手ごとの打率の精度(ばらつきの逆数)を表す の事後分布は、200付近 にピークを持つ。 これは、MLBのレギュラー選手の打率は、シーズン全体で見るとかなり狭い 範囲に集中していることを示唆する。 事前分布の影響を完全に排除できているわけではないが、データによって がかなり大きな値に更新されたことがわかる。 の事後分布 ν ν
ν 31
まとめ 32
baseballrでMLBの打撃成績データを取得し、シーズン途中成績からシー ズン最終打率を予測する問題に取り組んだ シーズン途中の打率は情報量が少なく不安定なため、そのままでは予測精度 は高くない そこで、全選手の情報を活用する階層ベイズモデルを構築。これにより、予測 精度を改善できることを確認した(でも、予測精度がすごく高いわけではな かった) 階層ベイズモデルの縮小推定の効果により、特に打数が少なく成績が極端な 選手に対しても、より妥当な予測値を与えることが可能となる まとめ
33
本分析では事後分布の平均値を予測値として利用したが、ベイズ推定の大き な利点は予測の不確実性を定量化できる点にある 各選手の予測打率の95%信用区間などを算出・可視化することで、予測の 確からしさを評価できる たとえば、打数が少ない選手ほど信用区間は広くなり、「まだ情報不足 で真の打率は不明確である」ことを表現可能 議論(1)予測の不確実性の評価 34
構築したモデルがデータをどの程度うまく説明できているか、事後予測チェ ックなどで検証することが望ましい モデルから生成したシミュレーションデータと実データを比較し、分布が大き く異なる場合はモデルの改善を検討する 議論(2)モデルの妥当性チェック 35
今回は全選手が同じ分布に従うと仮定したが、より精緻な予測のためには選 手個人の特徴量を活用することが考えられる 前年の成績、年齢、打席の左右などの共変量をモデルに導入することで、よ り選手の実力に応じた予測が可能となる 議論(3)モデルの拡張 36
精度パラメータ が大きな値に推定されたことは、「MLBレギュラー選手の 真の打率は、非常に狭い範囲に密集している」というデータからの知見と解 釈できる 事前分布の選択が結果に与える影響(感度分析)も重要な論点。異なる事前 分布を試し、結果の頑健性を示すことも考えられる 議論(4)パラメータの解釈と事前分布 ν 37
補足:本塁打数のモデリング 38
資料を作ってしまってから、大谷翔平の本塁打数を予測しよう、みたいなテ ーマのほうが面白かったと思った せっかくなので、モデリングを考えてみたい。基本的には、打率と似たモデリ ングになると思う HR i θ
i ∼ Binomial(PA , θ ) i i ∼ Beta(μν, (1 − μ)ν) ここで、 は打席数(打数ABではない)、 は本塁打数、 は本塁打率 本塁打数のモデリング PA i HR i θ i 39
本塁打数は「数」なので、「率」よりも予測が難しい。シーズン終了時点の打席 数 も予測対象になる シーズン途中の試合数 として、打席数 は に比例すると仮定する 試合数に対する打席数の分布はカウントデータなので、ポアソン分布を仮定 するして学習。 PA
∼ i Poisson(Gλ ) i ここで、 は1試合あたりの平均的な打席数。打順や出場試合数が異なるの で、選手ごとに推定 予測のときは、シーズン終了時点の試合数は162試合と決まっているので、 これを利用して で予測 打席数のモデリング PA i G PA i G λ i G = 162 40
1試合あたりの打席数はデータから学習するので、事前分布をおく 平均的には4打席くらいまわると思われるので、ガンマ分布の期待値 が4く らいになるように超事前分布を置く PA i λ
i α ϕ ∼ Poisson(Gλ ) i ∼ Gamma(α, α/ϕ) ∼ Gamma(a, b) ∼ Gamma(c, d) の事前分布 λ ϕ 41
『ビジネス課題を解決する技術』を執筆しました 数理最適化、数理モデル、そしてデータを統 合的に活用してビジネス課題を解決する方 法を解説しています データサイエンスを使ってビジネス価値を生 み出したいすべての人に届いてほしいで す! 発売日:2025/06/27 宣伝 42
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![前述のモデルをStanで記述すると以下のようになる data { int<lower=0> N; int<lower=0> AB[N]; int<lower=0> H[N]; }](https://files.speakerdeck.com/presentations/e288d6abc27a46a6909fd5c81f7ada3b/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data { int<lower=0> N; int<lower=0> AB[N]; int<lower=0> H[N]; } parameters](https://files.speakerdeck.com/presentations/e288d6abc27a46a6909fd5c81f7ada3b/slide_25.jpg){kind=link}
![df_result <- df_result |> mutate( BA_hier = fit_hier |> tidybayes::spread_draws(theta[i])](https://files.speakerdeck.com/presentations/e288d6abc27a46a6909fd5c81f7ada3b/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}