Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
(CVPR2026) Back to Basics: Let Denoising Genera...
Search
Shumpei Takezaki
June 09, 2026
Science
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
https://arxiv.org/abs/2511.13720
Shumpei Takezaki
June 09, 2026
More Decks by Shumpei Takezaki
See All by Shumpei Takezaki
(IJCNN2026) Cell Instance Segmentation via Multi-Task Image-to-Image Schrödinger Bridge
shumpei777
0
17
(IJCNN2026) SCoRe: Clean Image Generation from Diffusion Models Trained on Noisy Images
shumpei777
0
25
(Preprint) Diffusion Transformers with Representation Autoencoders
shumpei777
1
1.3k
(Blog post) Diffusion is spectral autoregression
shumpei777
3
1.3k
(Preprint) Diffusion Classifiers Understand Compositionality, but Conditions Apply
shumpei777
1
650
(ICLR2021) Score-Based Generative Modeling through Stochastic Differential Equations
shumpei777
1
690
(ICLR2023) Improving Deep Regression with Ordinal Entropy
shumpei777
0
52
(NeurIPS2024) Guiding a Diffusion Model with a Bad Version of Itself
shumpei777
0
46
(ICML2023) I2SB: Image-to-Image Schrödinger Bridge
shumpei777
0
67
Other Decks in Science
See All in Science
フィードフォワードニューラルネットワークを用いた記号入出力制御系に対する制御器設計 / Controller Design for Augmented Systems with Symbolic Inputs and Outputs Using Feedforward Neural Network
konakalab
0
160
データベース05: SQL(2/3) 結合質問
trycycle
PRO
0
1.2k
なぜエネルギーは保存する? 〜自由落下でわかる“対称性”とネーターの定理〜
syotasasaki593876
0
210
データベース03: 関係データモデル
trycycle
PRO
1
610
20260410_SystemsThinking
takusamar
1
120
Testing the Longevity Bottleneck Hypothesis
chinson03
0
370
不動産業界における業界特化のデータ整備とAI活用 ─Vertical DataとVertical AI─
estie
1
810
プロジェクト「Azayaka」のSARの数式とジオメトリ
syuchimu
0
380
あなたに水耕栽培を愛していないとは言わせない
mutsumix
1
360
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
130
[NLP2026 参加報告会] AI for Science まとめ / NLP2026
lychee1223
0
1.9k
Kritische evaluatie van GenAI-output voor literatuuronderzoek
voginip
0
190
Featured
See All Featured
Accessibility Awareness
sabderemane
1
160
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
BBQ
matthewcrist
89
10k
RailsConf 2023
tenderlove
30
1.5k
The agentic SEO stack - context over prompts
schlessera
0
850
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Amusing Abliteration
ianozsvald
1
230
Building Adaptive Systems
keathley
44
3.1k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Transcript
拡散モデルには画像を予測させよ 2026.06.09 Shumpei Takezaki
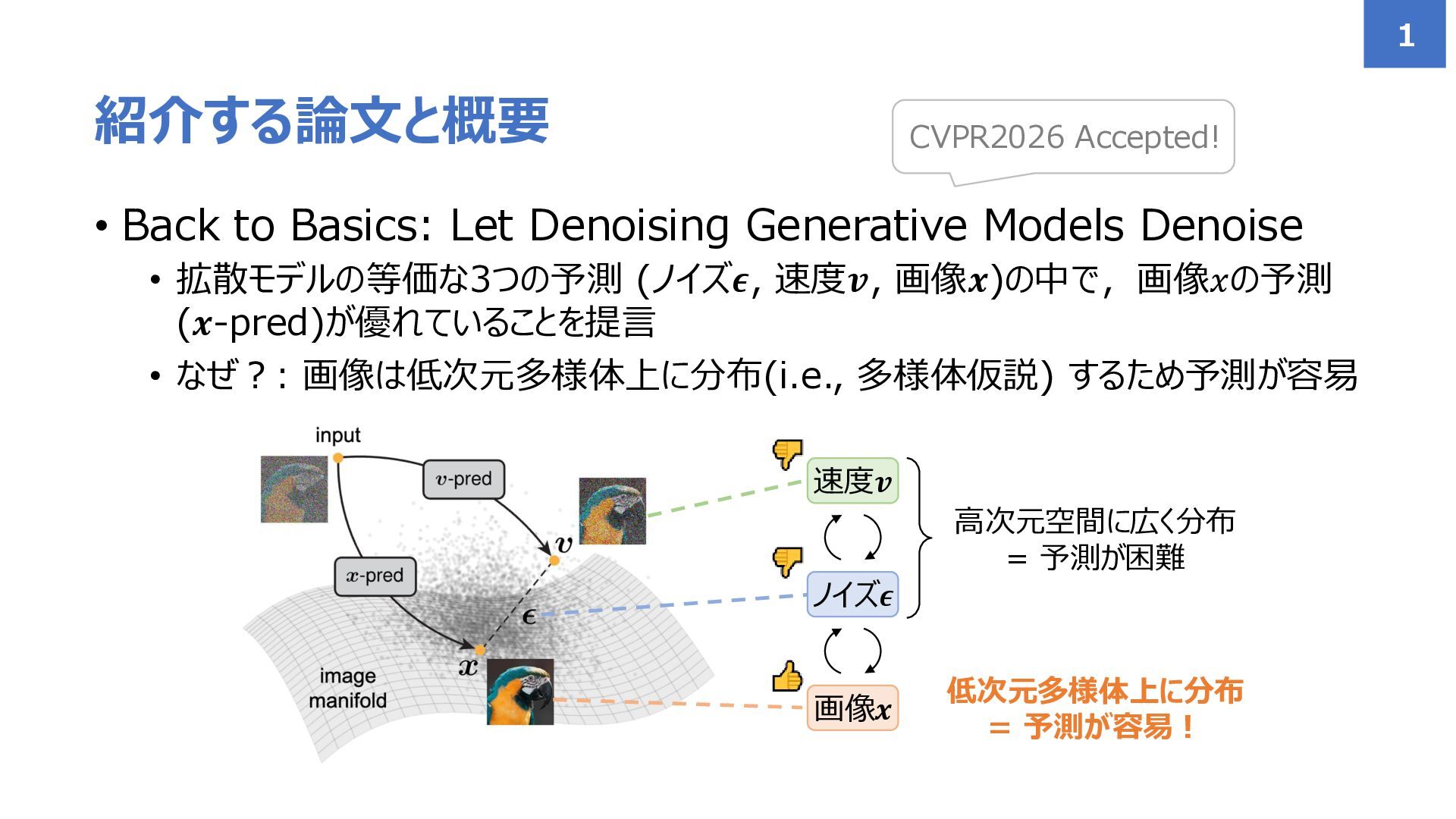
• Back to Basics: Let Denoising Generative Models Denoise •
拡散モデルの等価な3つの予測 (ノイズ𝝐, 速度𝒗, 画像𝒙)の中で,画像𝑥の予測 (𝒙-pred)が優れていることを提言 • なぜ?: 画像は低次元多様体上に分布(i.e., 多様体仮説) するため予測が容易 紹介する論文と概要 1 CVPR2026 Accepted! 画像𝒙 ノイズ𝝐 速度𝒗 高次元空間に広く分布 = 予測が困難 低次元多様体上に分布 = 予測が容易!
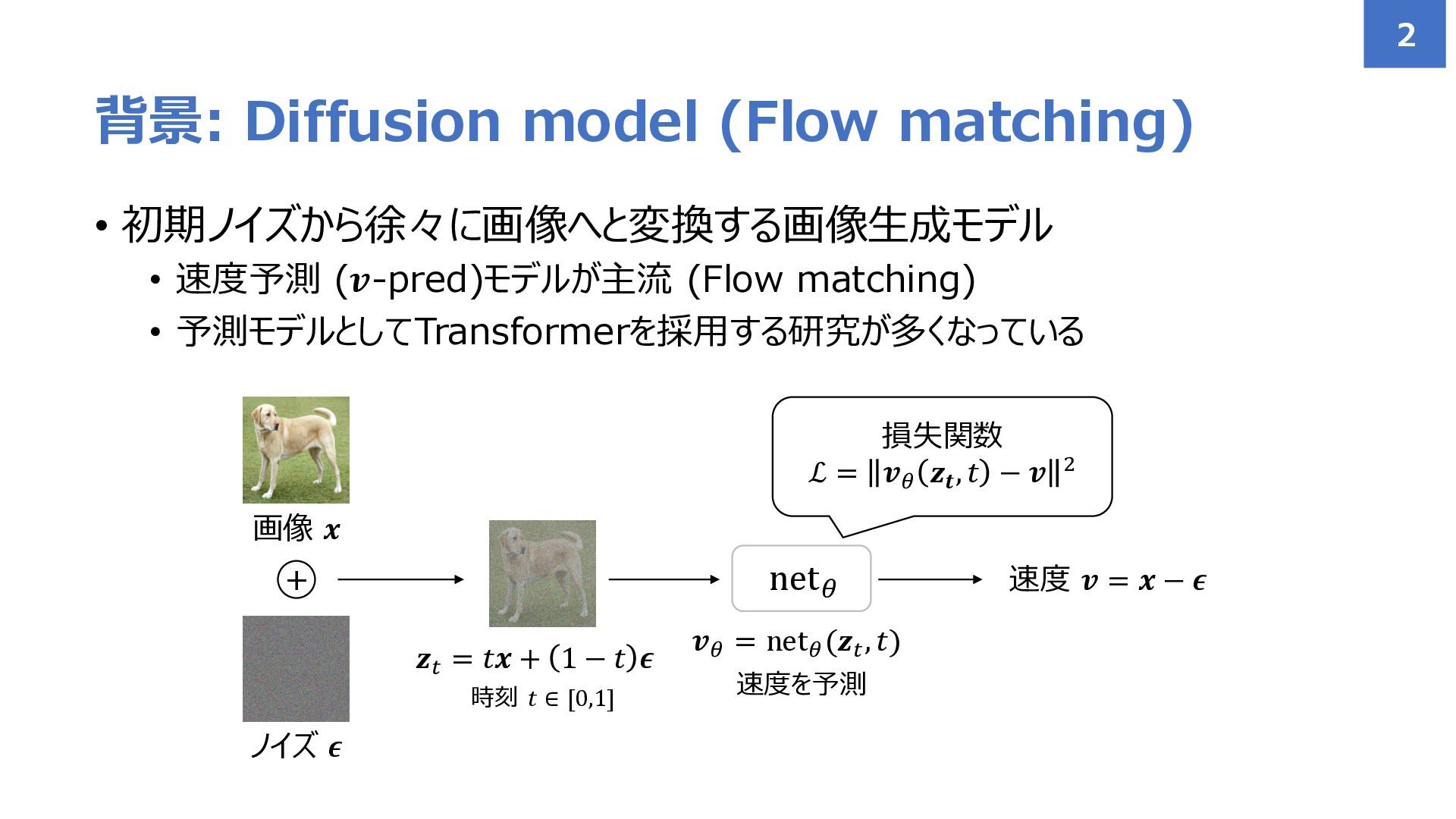
• 初期ノイズから徐々に画像へと変換する画像生成モデル • 速度予測 (𝒗-pred)モデルが主流 (Flow matching) • 予測モデルとしてTransformerを採用する研究が多くなっている 背景:
Diffusion model (Flow matching) 2 画像 𝒙 ノイズ 𝝐 net𝜃 𝒛𝑡 = 𝑡𝒙 + 1 − 𝑡 𝝐 時刻 𝑡 ∈ [0,1] + 速度 𝒗 = 𝒙 − 𝝐 損失関数 ℒ = 𝒗𝜃 𝒛𝒕 , 𝑡 − 𝒗 2 𝒗𝜃 = net𝜃 (𝒛𝑡 , 𝑡) 速度を予測
• 画像𝒙, ノイズ𝝐, 速度𝒗 は互いに等価で交換可能 事前知識: Diffusion modelにおける等価な予測 3 画像
𝒙 ノイズ 𝝐 速度 𝒗 net𝜃 例) 𝒙-pred 𝒛𝑡 = 𝑡𝒙 + 1 − 𝑡 𝝐 𝒙𝜃 𝒙𝜃 = net𝜃 𝝐𝜃 = (𝒛𝑡 − 𝑡𝒙𝜃 )/(1 − 𝑡) 𝒗𝜃 = (𝒙𝜃 − 𝒛𝑡 )/(1 − 𝑡) 𝒙, 𝝐, 𝒗の関係より 𝒙𝜃 , 𝒛𝑡 , 𝑡から導出可能!
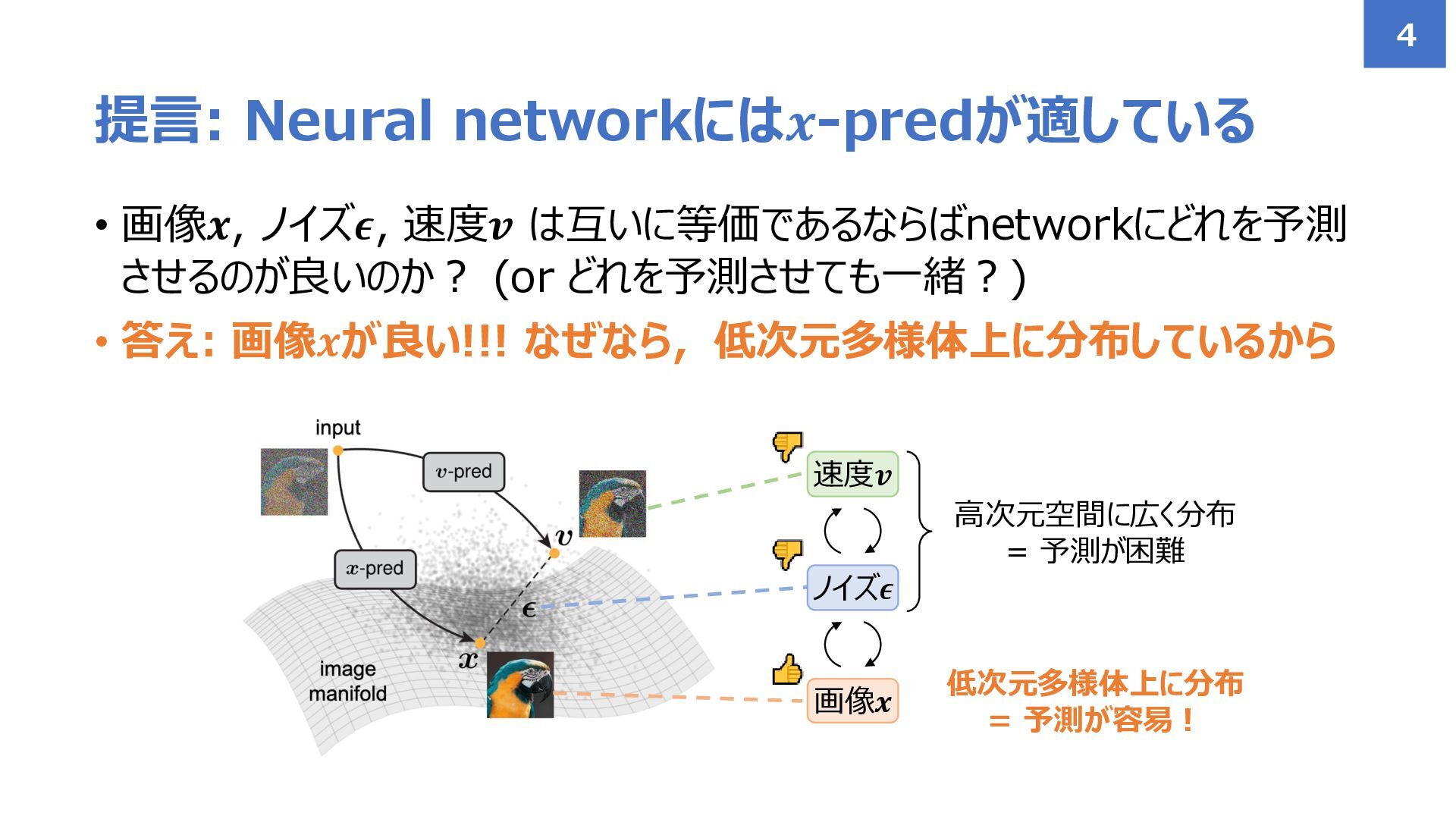
• 画像𝒙, ノイズ𝝐, 速度𝒗 は互いに等価であるならばnetworkにどれを予測 させるのが良いのか? (or どれを予測させても一緒?) • 答え:
画像𝒙が良い!!! なぜなら,低次元多様体上に分布しているから 提言: Neural networkには𝒙-predが適している 4 画像𝒙 ノイズ𝝐 速度𝒗 高次元空間に広く分布 = 予測が困難 低次元多様体上に分布 = 予測が容易!
• Transformerが𝒙-predを行うDiffusion model • 𝒙-pred → 𝒗-pred に変換するだけ.損失や推論は𝒗-predモデルのまま 提案手法: Just
image Transformer (JiT) 5 𝒛𝑡 𝒙𝜃 net𝜃 𝒙-pred Transformer 𝒙-pred → 𝒗-pred 学習 推論
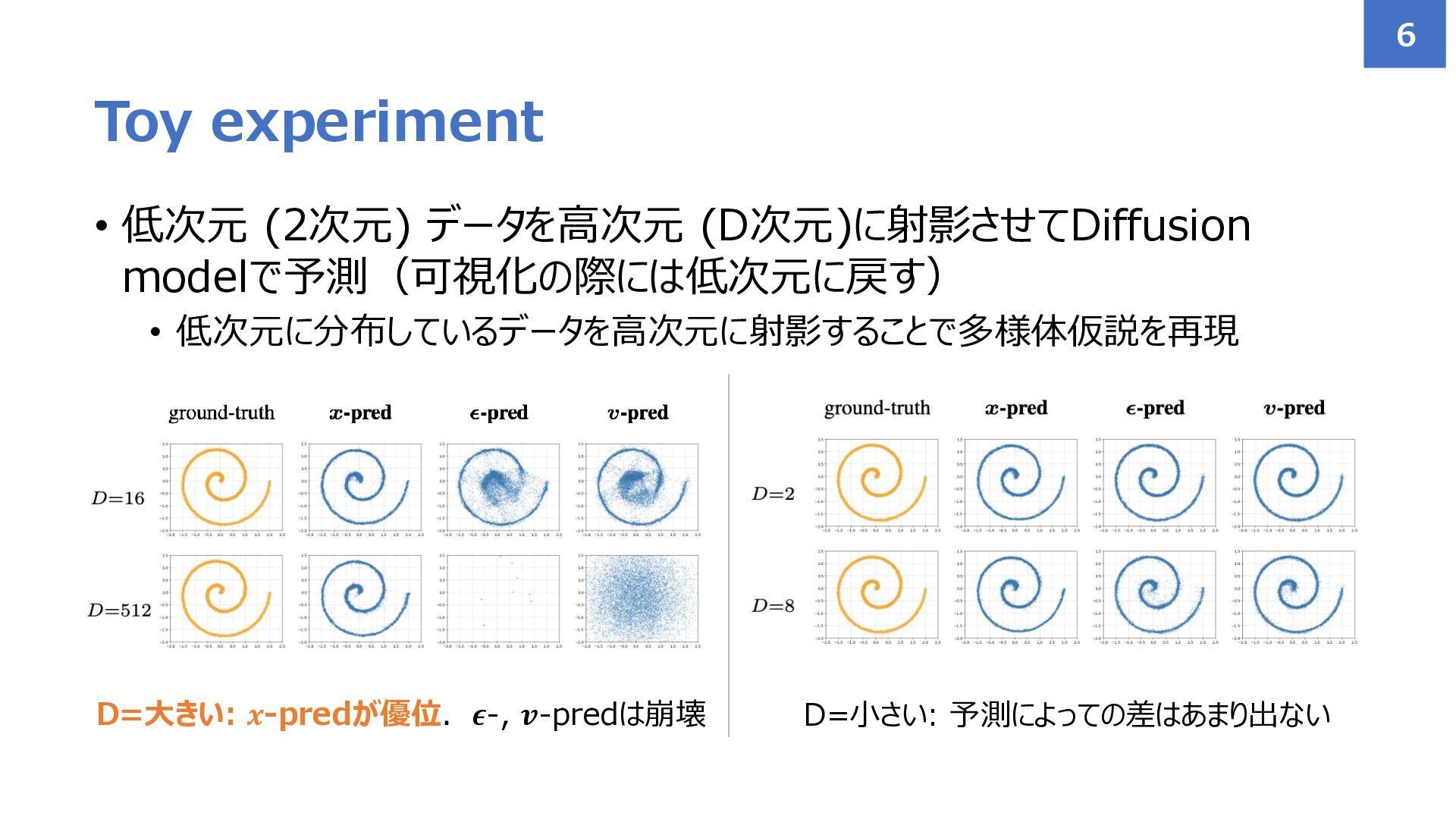
• 低次元 (2次元) データを高次元 (D次元)に射影させてDiffusion modelで予測(可視化の際には低次元に戻す) • 低次元に分布しているデータを高次元に射影することで多様体仮説を再現 Toy experiment
6 D=小さい: 予測によっての差はあまり出ない D=大きい: 𝒙-predが優位.𝝐-, 𝒗-predは崩壊
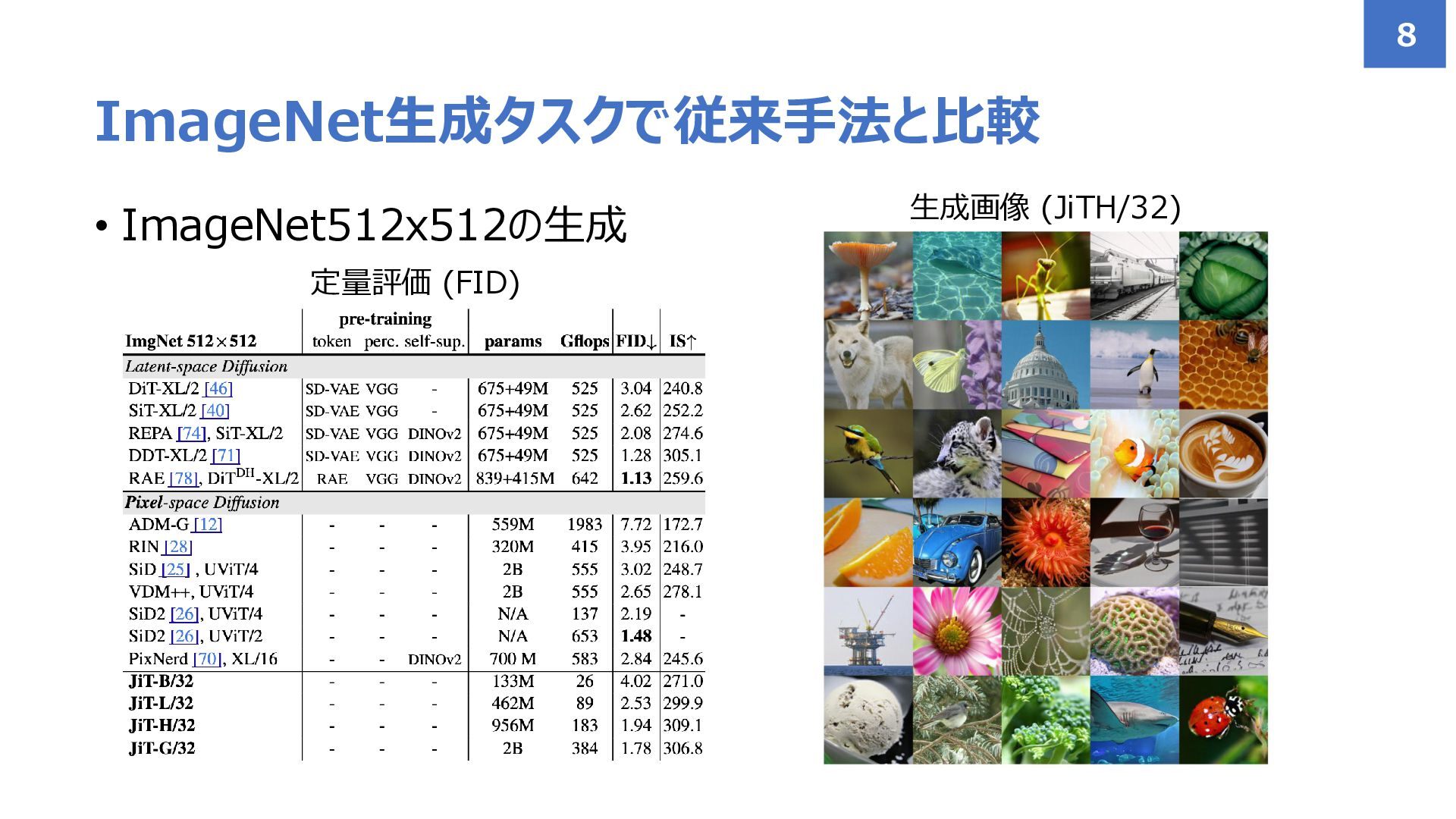
• ImageNet256x256 (左図): 𝒙-predが優位 • ImageNet64x64 (右図): 𝒙-, 𝝐-, 𝒗-predであまり差がない
• データの次元が比較的低いため,複雑な分布を予測するだけのモデル容量が確保 てきている ImageNet生成タスクで𝒙-predを検証 7 FIDで評価 𝒙-predが優位 予測によっての差はあまり出ない
• ImageNet512x512の生成 ImageNet生成タスクで従来手法と比較 8 生成画像 (JiTH/32) 定量評価 (FID)
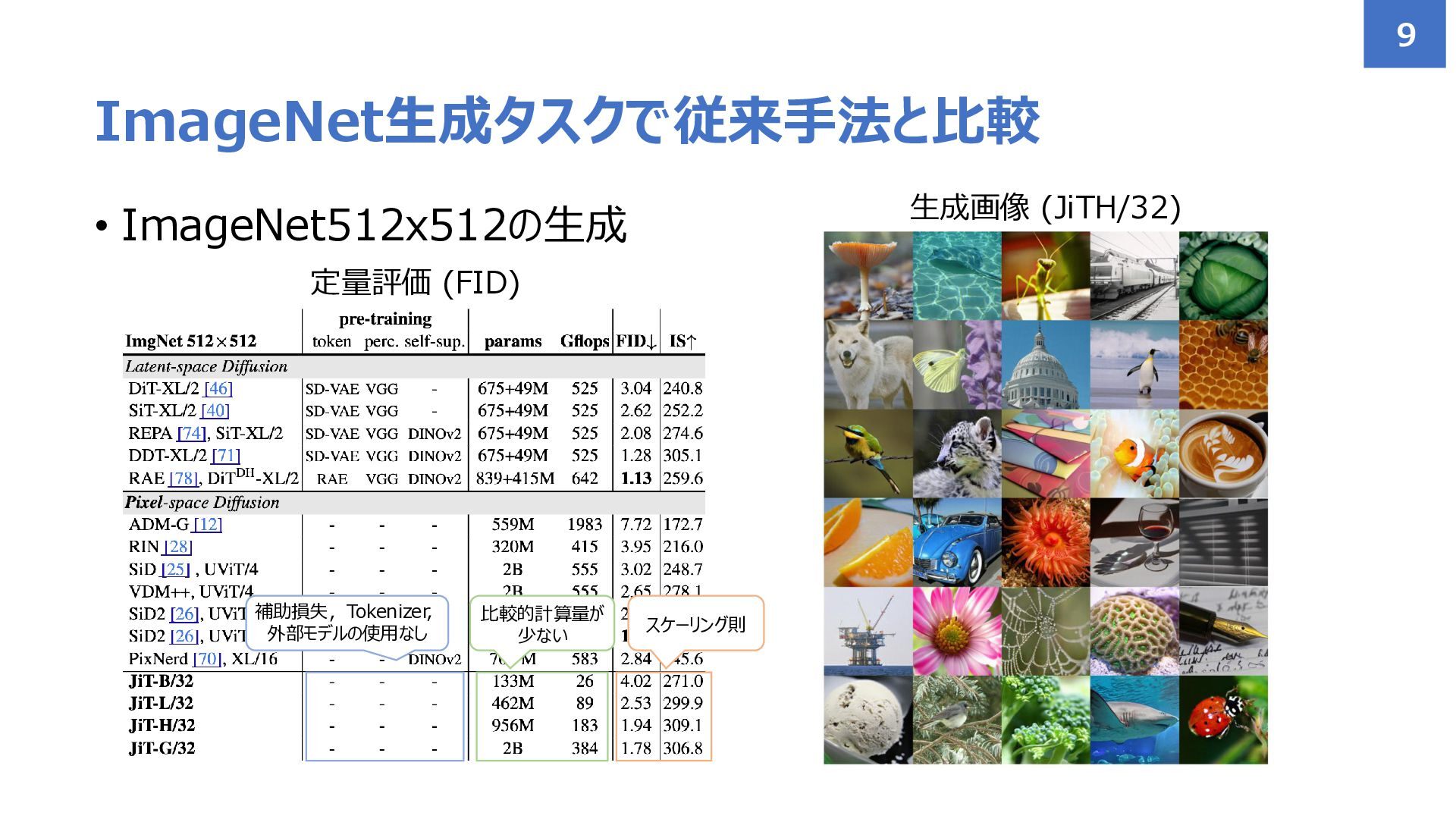
• ImageNet512x512の生成 ImageNet生成タスクで従来手法と比較 9 生成画像 (JiTH/32) 定量評価 (FID) 補助損失,Tokenizer, 外部モデルの使用なし
比較的計算量が 少ない スケーリング則
• 𝒙-pred は画像空間 (Pixel space)以外でも効果を発揮! • 多様体仮説が成り立つようなデータなら適用可能なはず • これからも応用先は増え続けると予想 画像空間以外で𝒙-predを適用した研究
10 WavFlow (Waveform space) JLT (Latent space) Funning Fu, et al., “JLT: Clean-Latent Prediction in Latent Diffusion Transformers”, arxiv preprint, arxiv:2605.27102, 2026 Feiyan Zhou, et al., “WavFlow: Audio Generation in Waveform Space”, arxiv preprint, arxiv:2605.18749, 2026
• まとめ • 拡散モデルの等価な3つの予測 (ノイズ𝝐, 速度𝒗, 画像𝒙)の中で,画像𝑥の予測 (𝒙-pred)が優れていることを提言 • 画像は低次元多様体上に分布(i.e.,
多様体仮説) するため予測が容易であるこ とがその要因 • Latent space, Waveform spaceでも機能することが報告 • 感想 • シンプルな提言 (拡散モデルで何を予測するのか?)かつインパクトのある結果 • 美しい まとめ 11
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}