These are the slides of my talk at vienna.rb:
https://www.meetup.com/en-AU/vienna-rb/events/253616653/
How does TruffleRuby achieves great performance?
How does it understand Ruby code?
The first part of this talk explains how TruffleRuby compiles Ruby code.
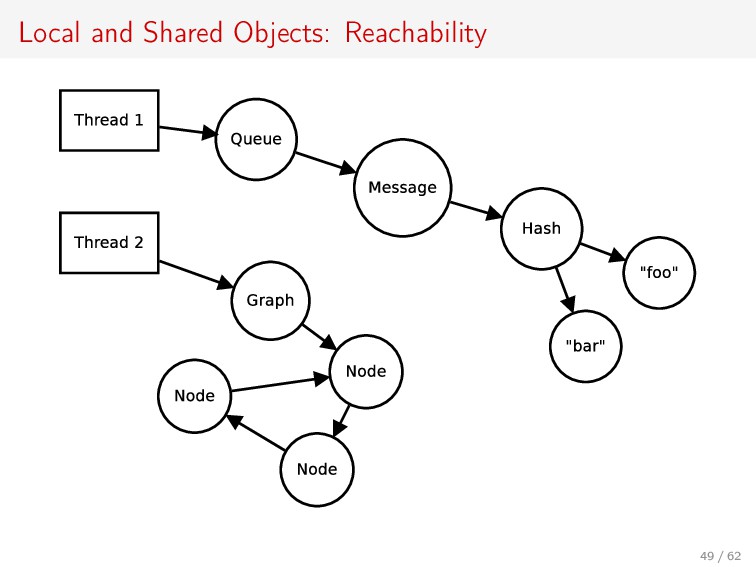
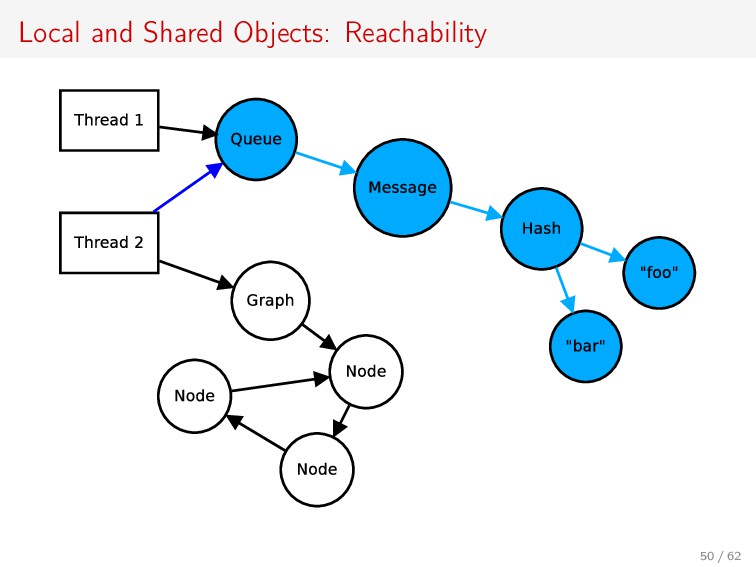
Array and Hash are used in every Ruby program. Yet, current implementations either prevent the use of them in parallel (the global interpreter lock in MRI) or lack thread-safety guarantees (JRuby and Rubinius raise an exception on concurrent Array append).
This talk shows a technique to make Array and Hash thread-safe while enabling parallel access, with no penalty on single-threaded performance. In short, we keep the most important thread-safety guarantees of the global lock while allowing Ruby to scale up to tens of cores!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
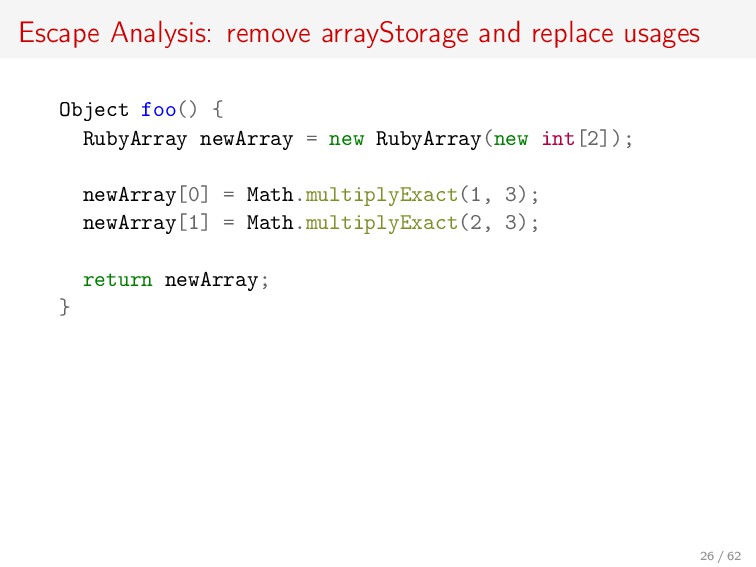
![Escape Analysis: remove array Object foo() { int[] arrayStorage =](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_25.jpg){kind=link}
![Type propagation: arrayStorage is int[] Object foo() { int[] arrayStorage](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_26.jpg){kind=link}
![Loop unrolling Object foo() { int[] arrayStorage = new int[2]](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![TruffleRuby: Partial Evaluation + Graal Compilation def foo [1, 2].map](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_31.jpg){kind=link}
![TruffleRuby: Partial Evaluation + Graal Compilation def foo [1, 2].map](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
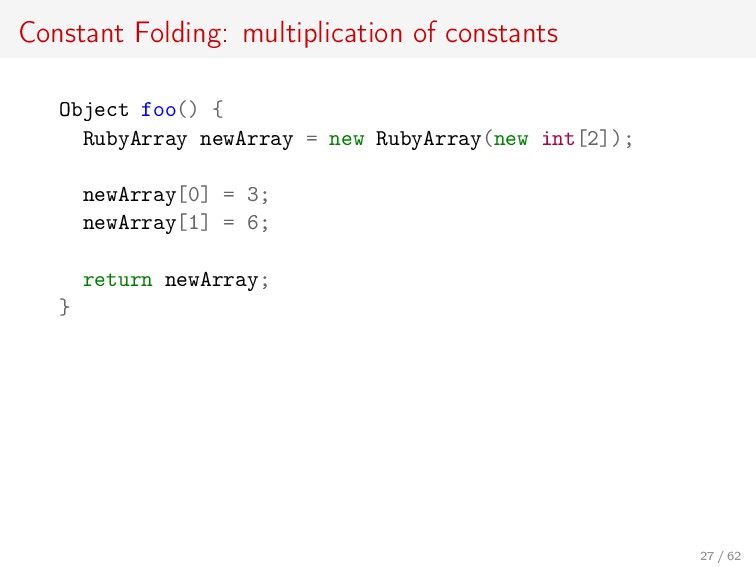
![Clang/GCC: fold FIXNUM_P(3) VALUE foo() { VALUE values[] = {](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appending concurrently array = [] # Create 100 threads 100.times.map](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![A Workaround: using a Mutex array = [] # or](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
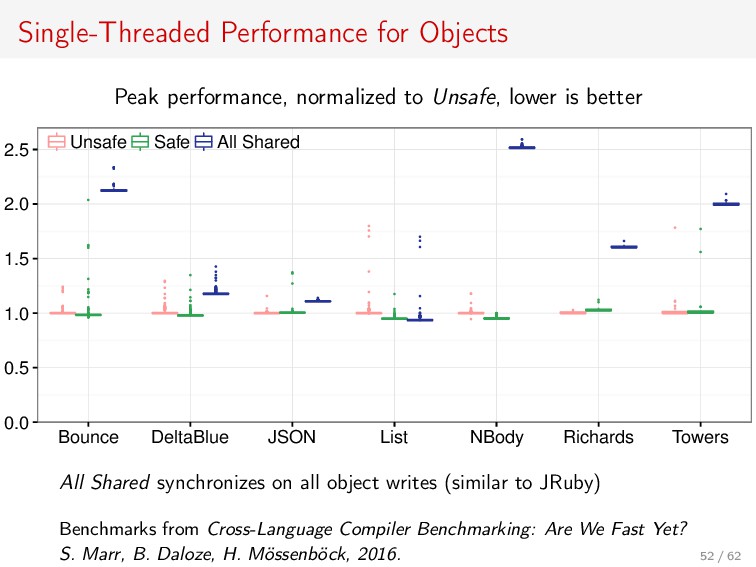{kind=link}
{kind=link}
![Array Storage Strategies empty int[] long[] Object[] double[] store int](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_61.jpg){kind=link}
{kind=link}
![Concurrent Array Strategies SharedFixedStorage Object[] SharedFixedStorage double[] SharedFixedStorage long[] empty](https://files.speakerdeck.com/presentations/eda95ad07a544300bf9d74db701fe1df/slide_63.jpg){kind=link}
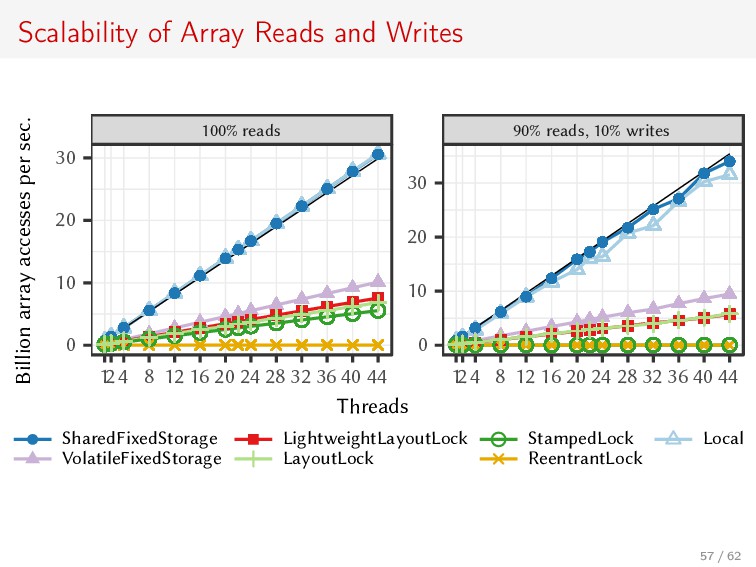{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}