Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Scraping: 10 mistakes to avoid @ Breizhcamp 2016
Search
Fabien Vauchelles
March 24, 2016
Science
240
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Scraping: 10 mistakes to avoid @ Breizhcamp 2016
From website, to storage, learn webscraping
#webscraping #tricks
Fabien Vauchelles
March 24, 2016
More Decks by Fabien Vauchelles
See All by Fabien Vauchelles
[StartupCourse/18] Discover Machine Learning
fabienvauchelles
0
92
[StartupCourse/01] Gérer sa carrière @ Polytech Paris Sud 2016
fabienvauchelles
0
69
[StartupCourse/02] Monter Une Startup @ Polytech Paris Sud 2016
fabienvauchelles
0
75
[StartupCourse/03] De l'idée au produit @ Polytech Paris Sud 2016
fabienvauchelles
0
49
Other Decks in Science
See All in Science
やるべきときにMLをやる AIエージェント開発
fufufukakaka
2
1.5k
「念のためのログ保存」を組織全体でやめるためのポリシーと仕組み作り
i2tsuki
4
300
Wet Active Matter
rajeshrinet
0
120
Non-Gaussian, nonlinear causal discovery with hidden variables and application
sshimizu2006
0
160
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
550
AI bij literatuuronderzoek in de wetenschap
voginip
0
220
東北地方における過去20年間の降水量の変化
naokimuroki
1
340
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
810
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
380
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.5k
1. CPC理論の展開と集合的知能モデル(JSAI2026 KS-27 集合的予測符号化と新たな知性の時代)
hayashiyus884
1
300
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
analokmaus
1
600
Featured
See All Featured
Paper Plane
katiecoart
PRO
2
52k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
360
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
Transcript
Fabien VAUCHELLES zelros.com /
[email protected]
/ @fabienv http://bit.ly/breizhscraping (24/03/2016)
FABIEN VAUCHELLES Developer for 16 years CTO of Expert in
data extraction (scraping) Creator of Scrapoxy.io
What is Scraping
“Scraping is to transform human-readable webpage into machine-readable data.” Neo
Why do we do Scraping
EXAMPLES No API ! API with a requests limit Prices
Emails Profiles Train machine learning models Addresses Face recognition
“I used Scraping to create my clients list !” Walter
White
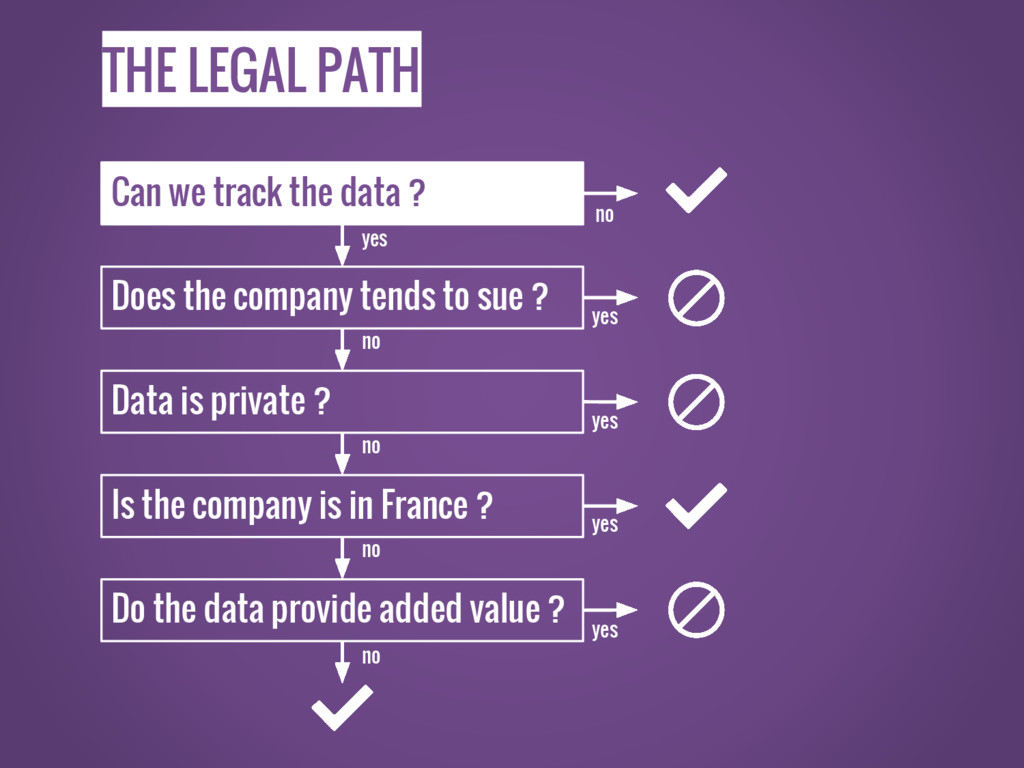
FORGET THE LAW 1.
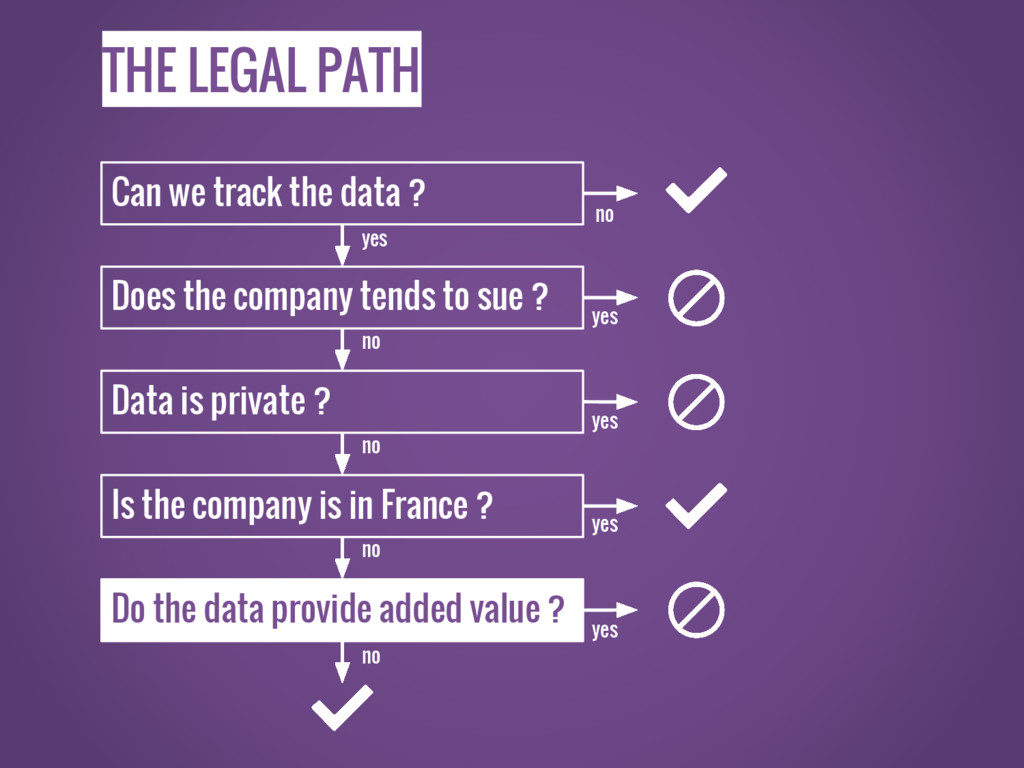
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
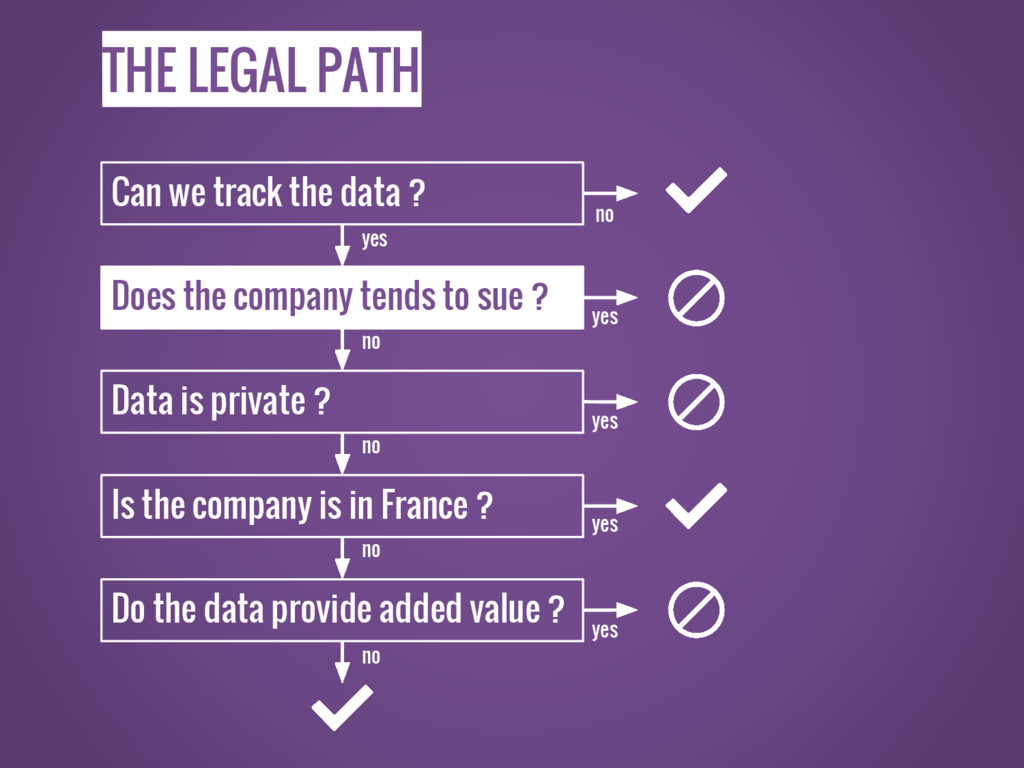
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
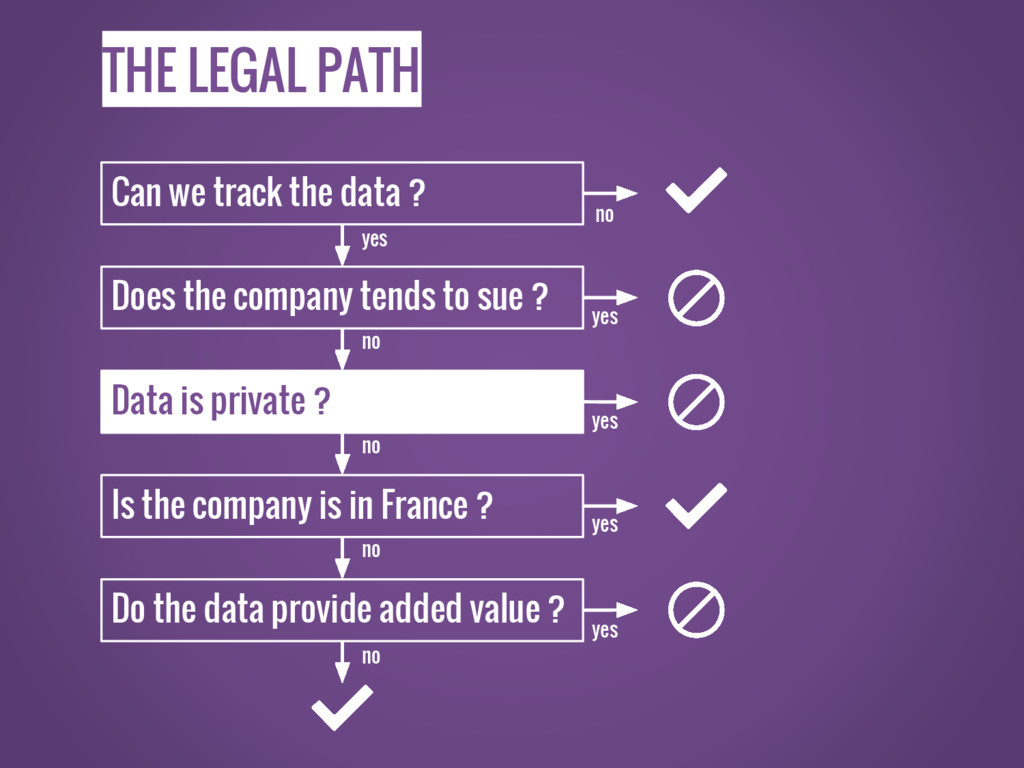
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
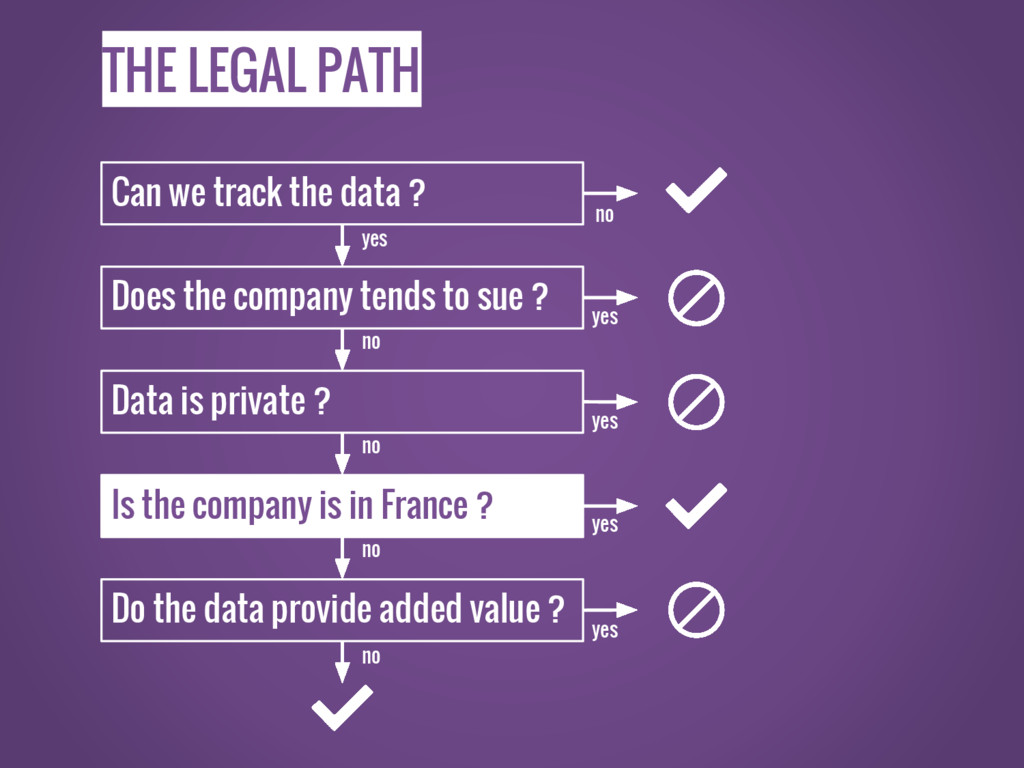
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
RUBBER DUCK E-MARKET LET’S STUDY THE
BUILD YOUR OWN SCRIPT 2.
USE A FRAMEWORK Limit concurrents request by site Limit speed
Change user agent Follow redirects Export results to CSV or JSON etc. Only 15 minutes to extract structured data !
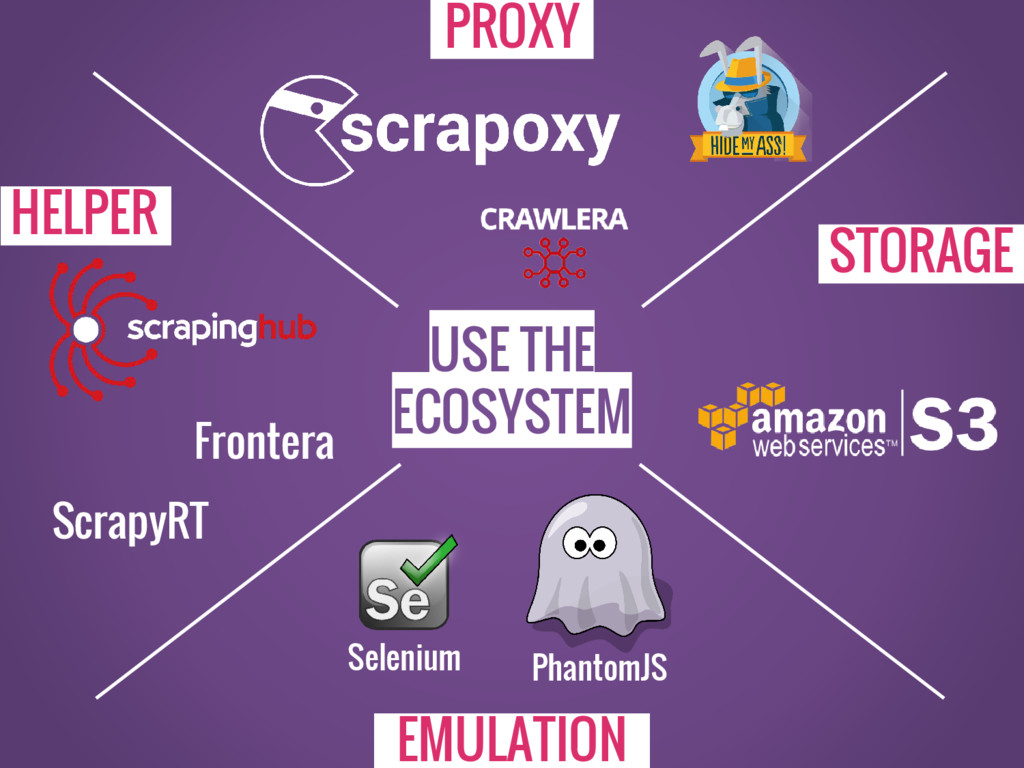
USE THE ECOSYSTEM Frontera ScrapyRT PhantomJS Selenium PROXY EMULATION HELPER
STORAGE
RUSH ON THE FIRST DATA SOURCE 3.
FIND THE EXPORT BUTTON
TAKE TIME TO FIND DATA
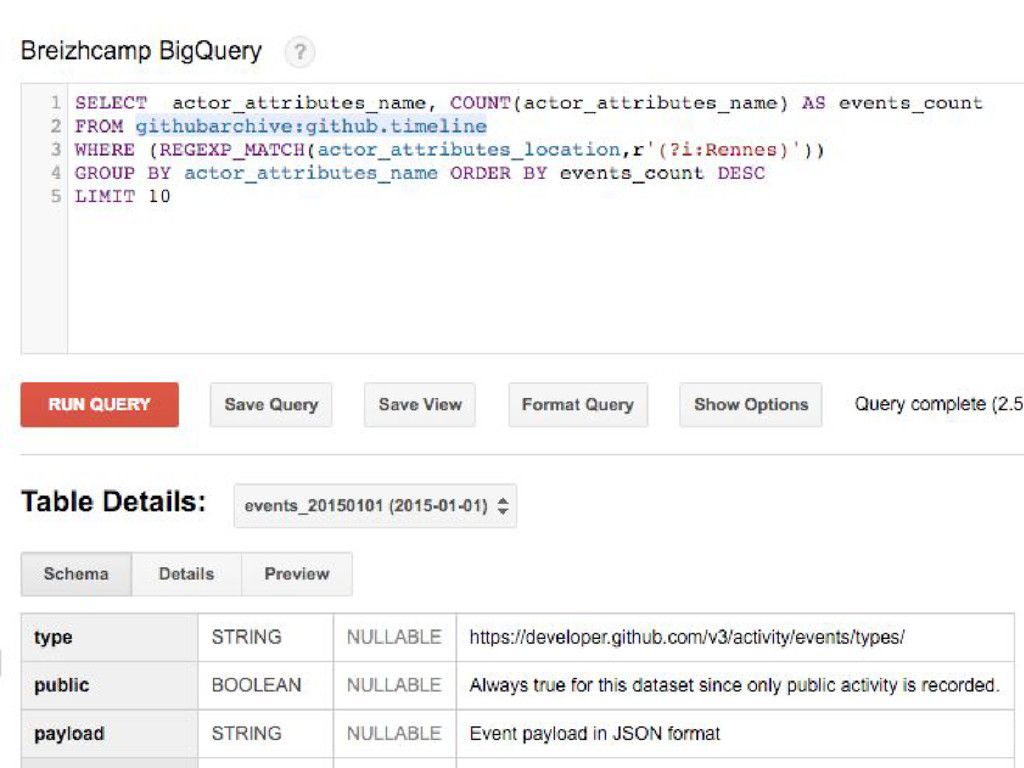
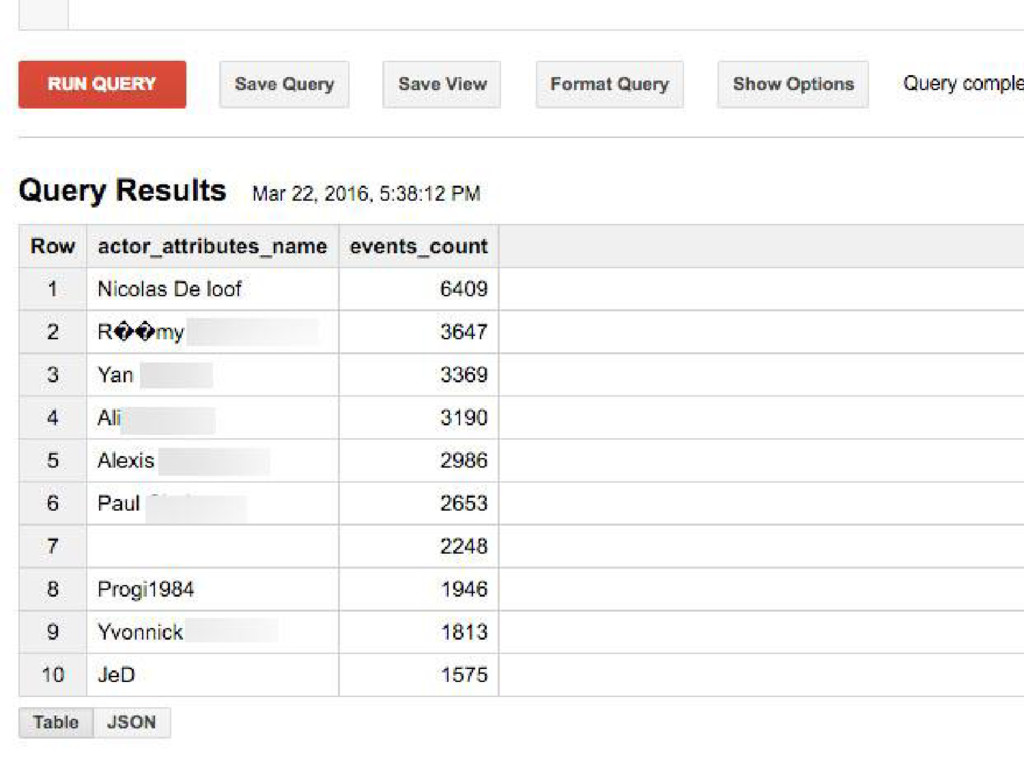
How to find a developer on Rennes
#1. GO TO BREIZHCAMP
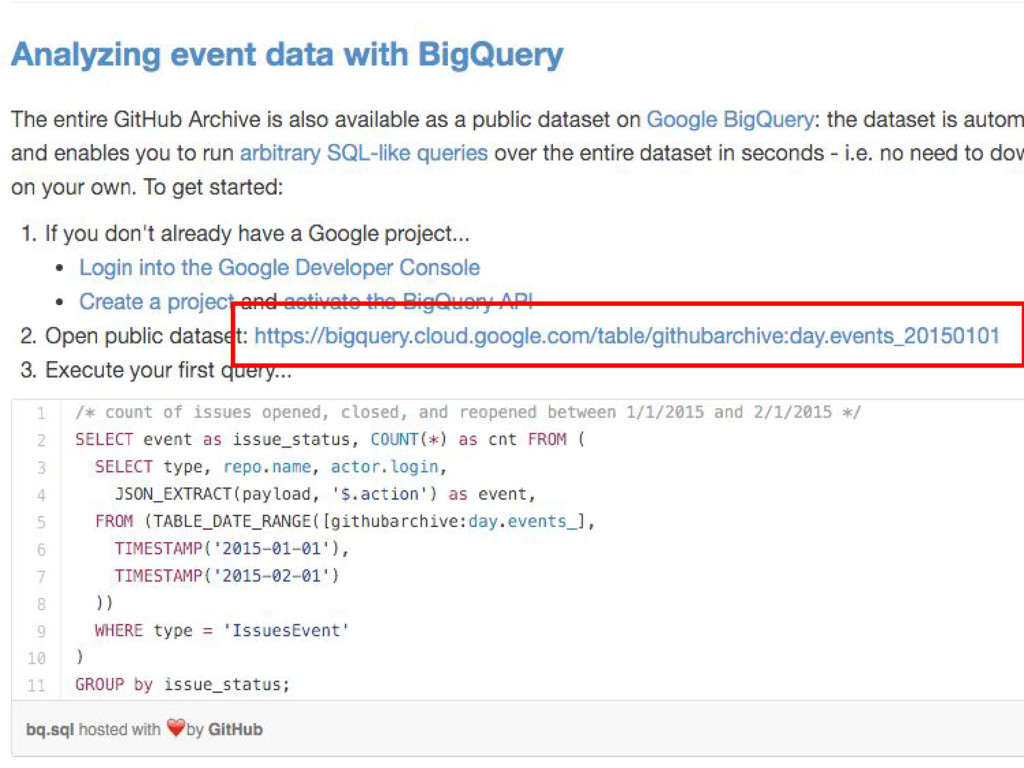
#2. SCRAP GITHUB
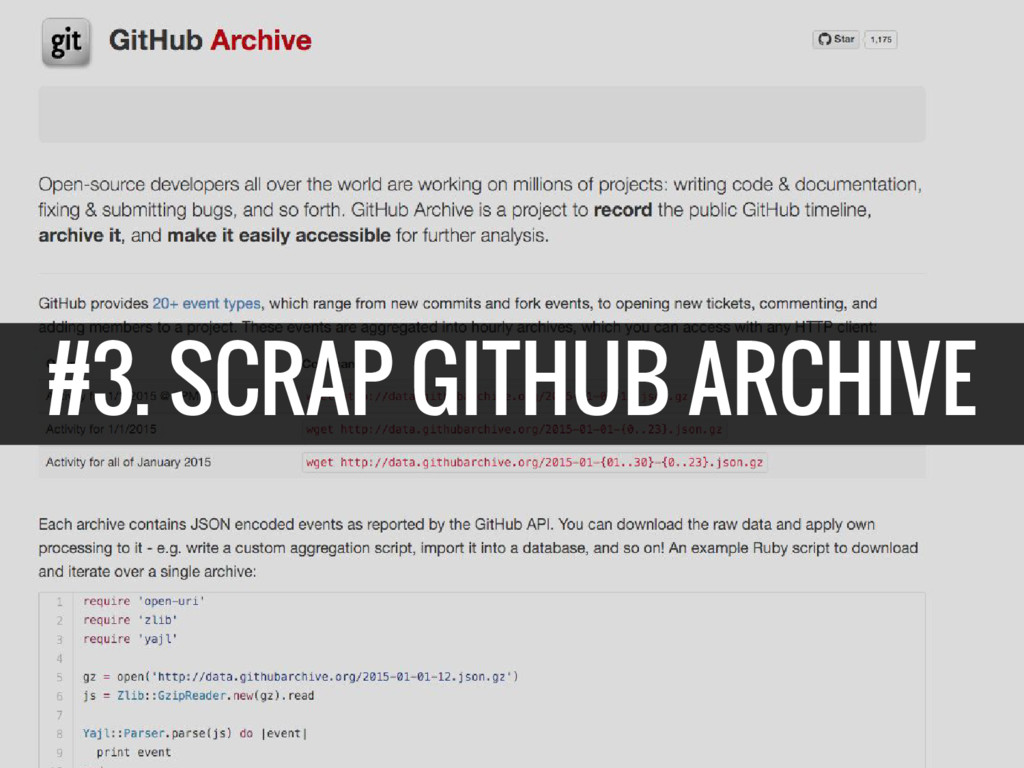
#3. SCRAP GITHUB ARCHIVE
#4. USE GOOGLE BIG QUERY
None
None
None
KEEP THE DEFAULT USER-AGENT 4.
DEFAULT USER-AGENT SCRAPY Scrapy/1.0.3 (+http://scrapy.org) URLLIB2 (Python) Python-urllib/2.1
IDENTIFY AS A DESKTOP BROWSER CHROME Mozilla/5.0 (Macintosh; Intel Mac
OS X 10_11_3)↵ AppleWebKit/537.36 (KHTML, like Gecko)↵ Chrome/50.0.2661.37 Safari/537.36 200 503
SCRAP WITH YOUR DSL ACCESS 5.
BLACKLISTED
What is Blacklisting
TYPE OF BLACKLISTING Change HTTP status (200 -> 503) HTTP
200 but content change (login page) CAPTCHA Longer to respond And many others !
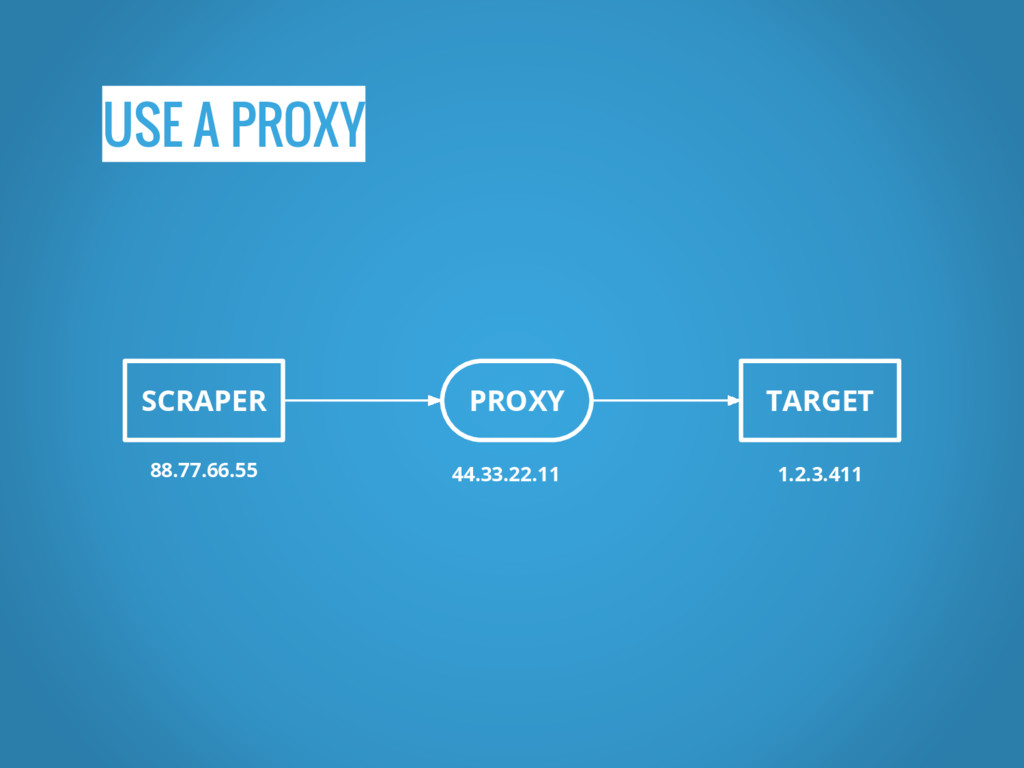
USE A PROXY SCRAPER PROXY TARGET 88.77.66.55 44.33.22.11 1.2.3.411
TYPE OF PROXIES PUBLIC PRIVATE
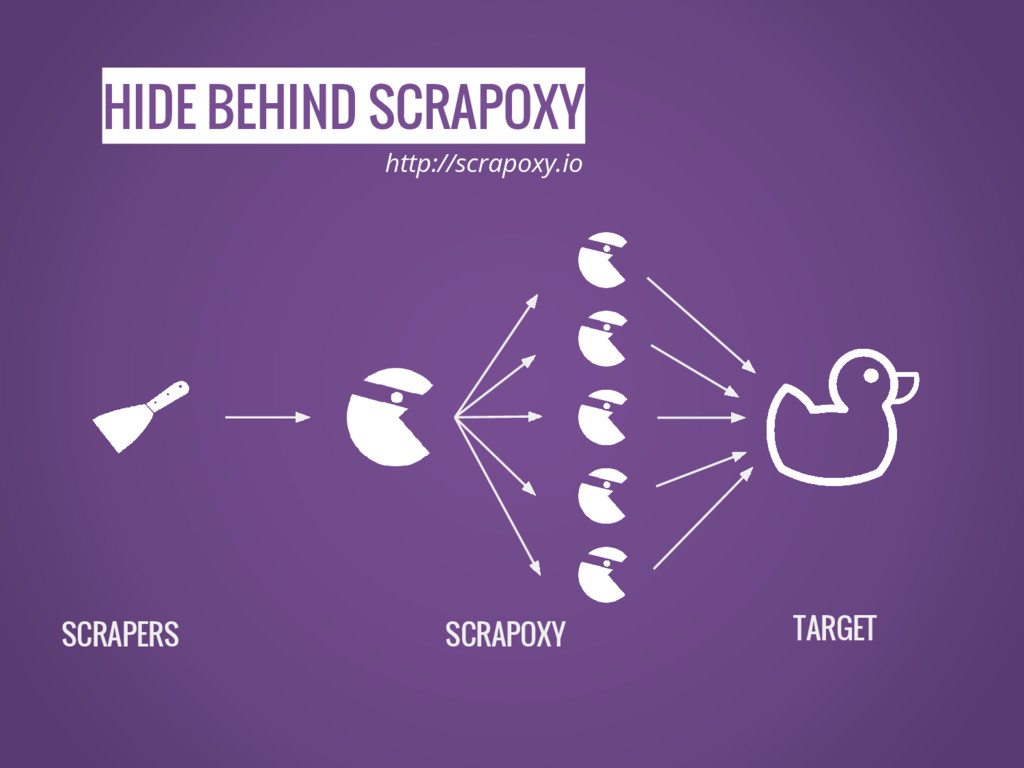
HIDE BEHIND SCRAPOXY SCRAPERS SCRAPOXY TARGET http://scrapoxy.io
TRIGGER ALERTS ON THE REMOTE SITE 6.
STAY OFF THE RADAR
ESTIMATE IP FLOW SCRAPER PROXY TARGET 10 requests / IP
/ minute ✔
ESTIMATE IP FLOW SCRAPER PROXY TARGET 10 requests / IP
/ minute ✔ 20 requests / IP / minute ✔
ESTIMATE IP FLOW SCRAPER PROXY TARGET 10 requests / IP
/ minute ✔ 20 requests / IP / minute ✔ 30 requests / IP / minute X
ESTIMATE IP FLOW The flow is 20 requests / IP
/ minute I want to refresh 200 items every minute I need 200 / 20 = 10 proxies !
MIX UP SCRAPER AND CRAWLER 7.
SCRAPERS ARE NOT CRAWLERS
FOCUS ON ESSENTIAL
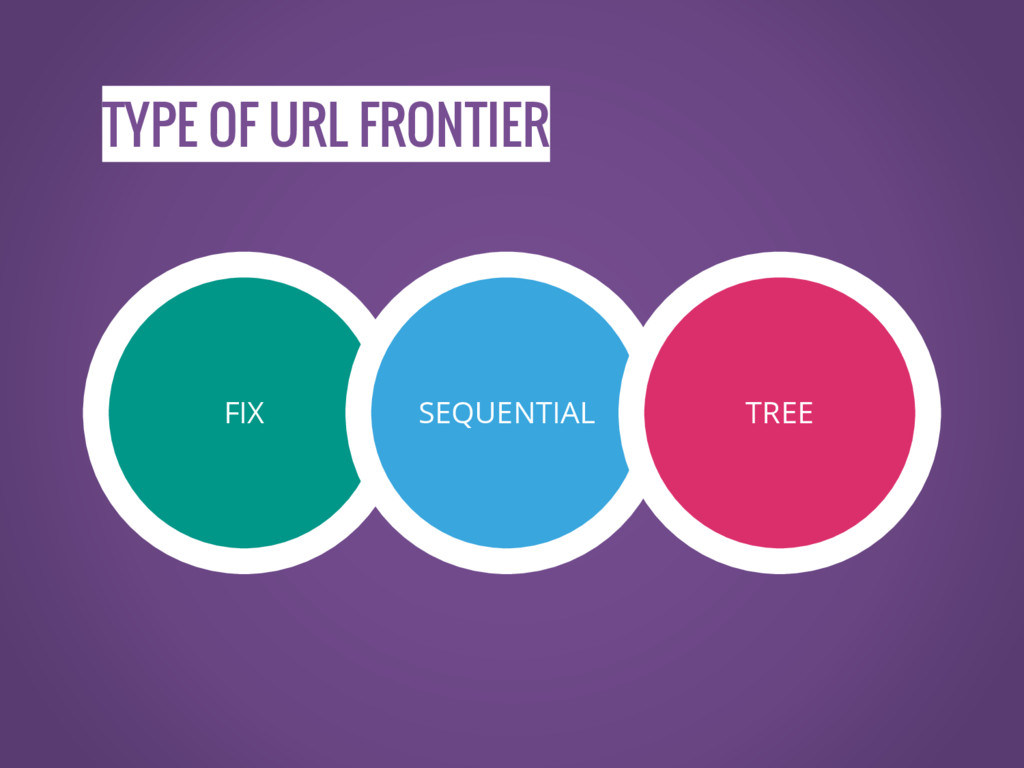
What is the URL frontier
URL frontier is the list of URL to fetch.
TYPE OF URL FRONTIER FIX SEQUENTIAL TREE
STORE ONLY PARSED RESULTS 8.
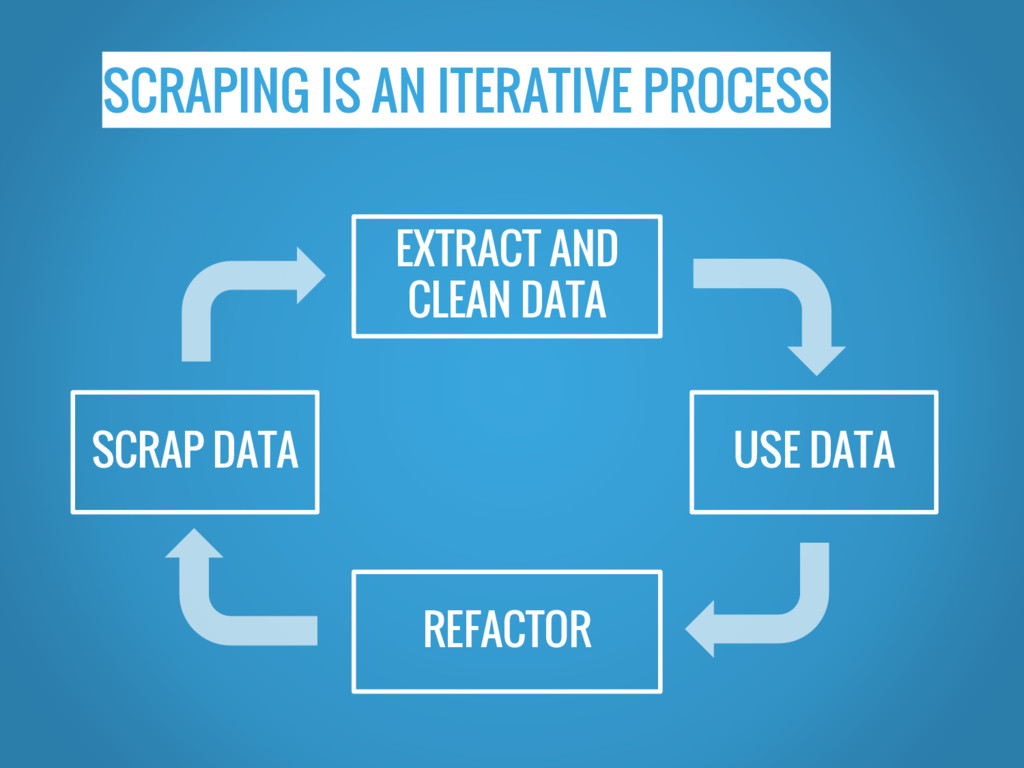
SCRAPING IS AN ITERATIVE PROCESS EXTRACT AND CLEAN DATA SCRAP
DATA USE DATA REFACTOR
SCRAP EVERYTHING... AGAIN ?
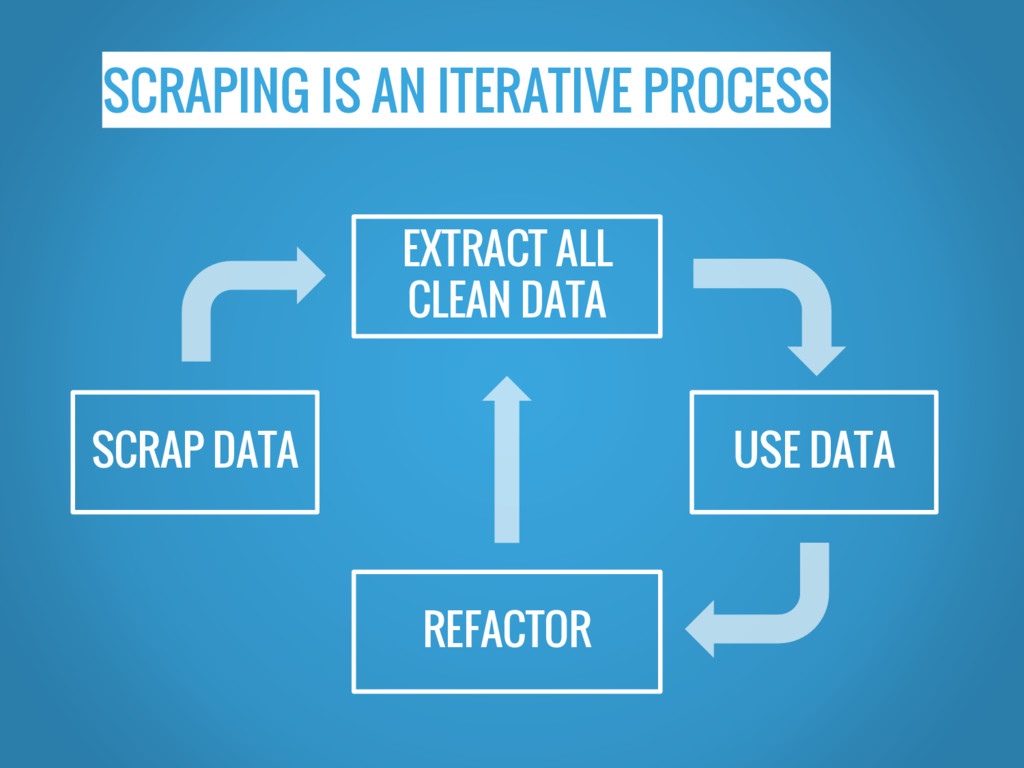
STORE FULL HTML PAGE
SCRAPING IS AN ITERATIVE PROCESS EXTRACT ALL CLEAN DATA SCRAP
DATA USE DATA REFACTOR
STORE WEBPAGE ONE BY ONE 9.
STORAGE CAN’T MANAGE MILLIONS OF SMALL FILES !
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
STORE HTML IN 128 MO ZIPPED FILES
PARSING IS SIMPLE ! 10.
PARSERS There is a lot of parsers ! XPATH CSS
REGEX TAGS TAG CLEANER
2 METHODS TO EXTRACT DATA <div class=”parts> <div class=”part experience”>
<div class=”year”>2014</div> <div class=”title”>Data Engineer</div> </div> </div> How to get the job title ?
#1. BY POSITION <div class=”parts> <div class=”part experience”> <div class=”year”>2014</div>
<div class=”title”>Data Engineer</div> </div> </div> /div/div/div[2] (with XPath parser)
#1. BY POSITION <div class=”parts> <div class=”part experience”> <div class=”year”>2014</div>
<div class=”location”>Paris</div> <div class=”title”>Data Engineer</div> </div> </div> /div/div/div[2] (with XPath parser)
#2. BY FEATURE <div class=”parts> <div class=”part experience”> <div class=”year”>2014</div>
<div class=”title”>Data Engineer</div> </div> </div> .experience .title (with CSS parser)
LET’S RECAP !
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
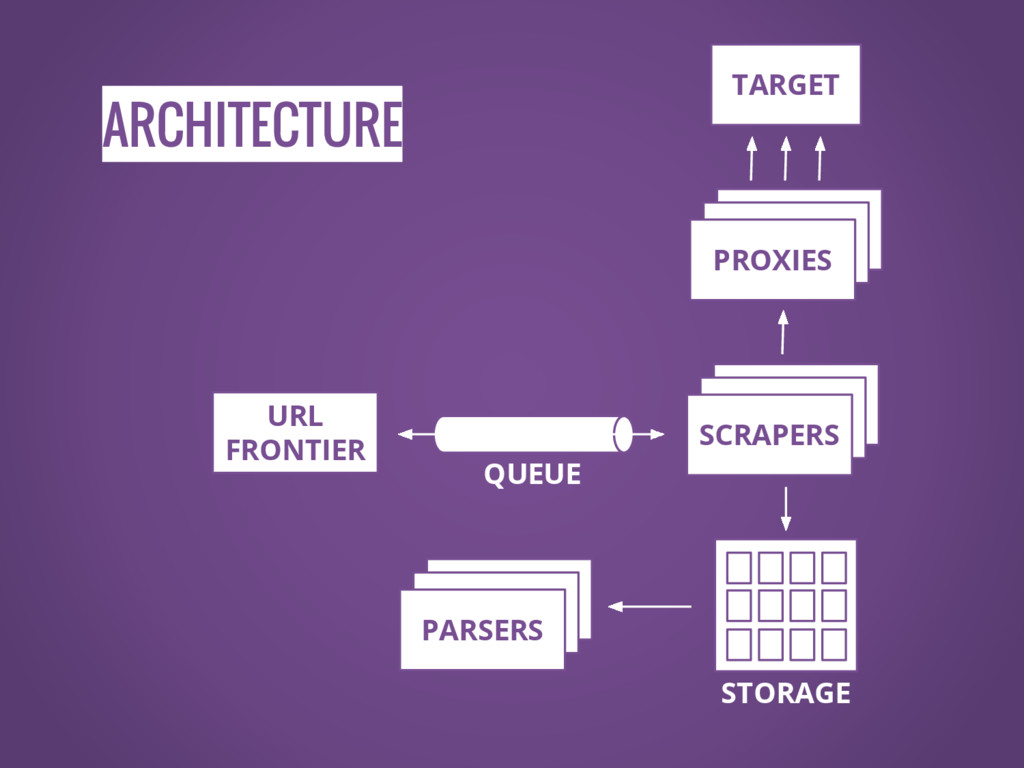
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS
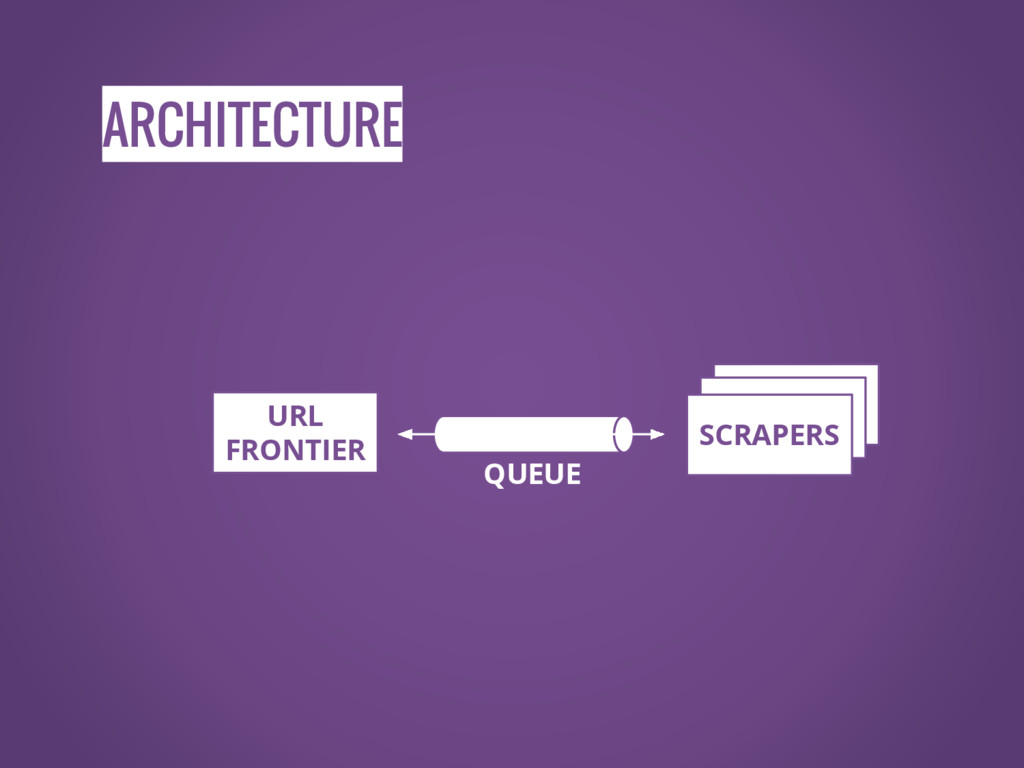
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS URL FRONTIER QUEUE
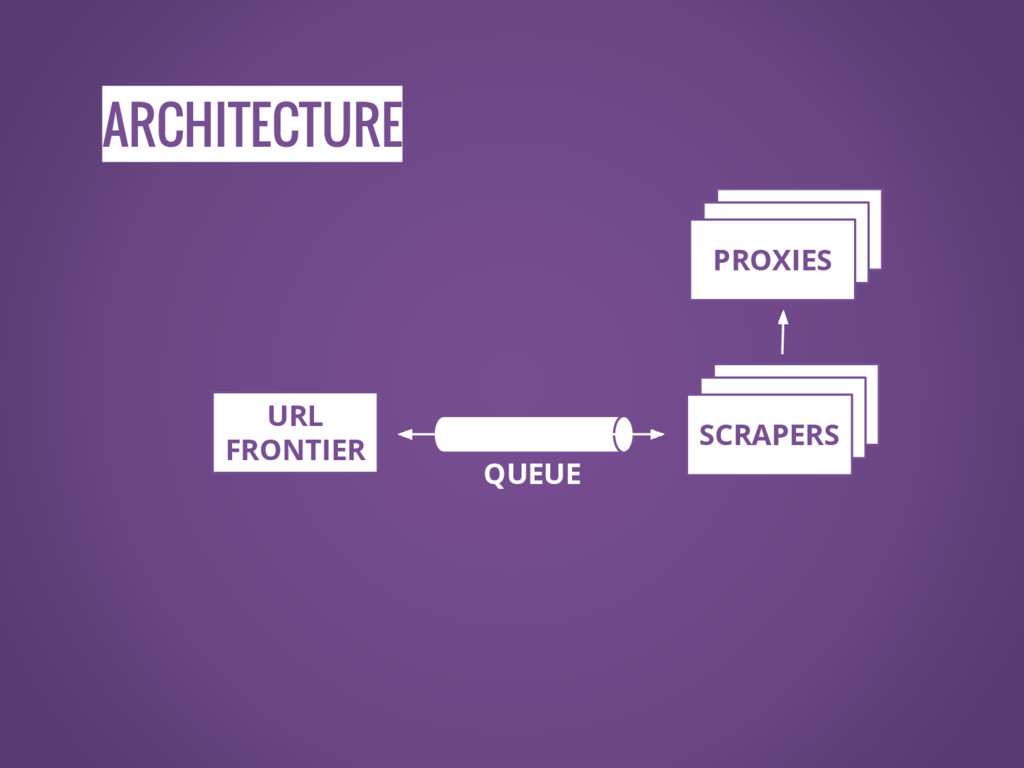
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER QUEUE
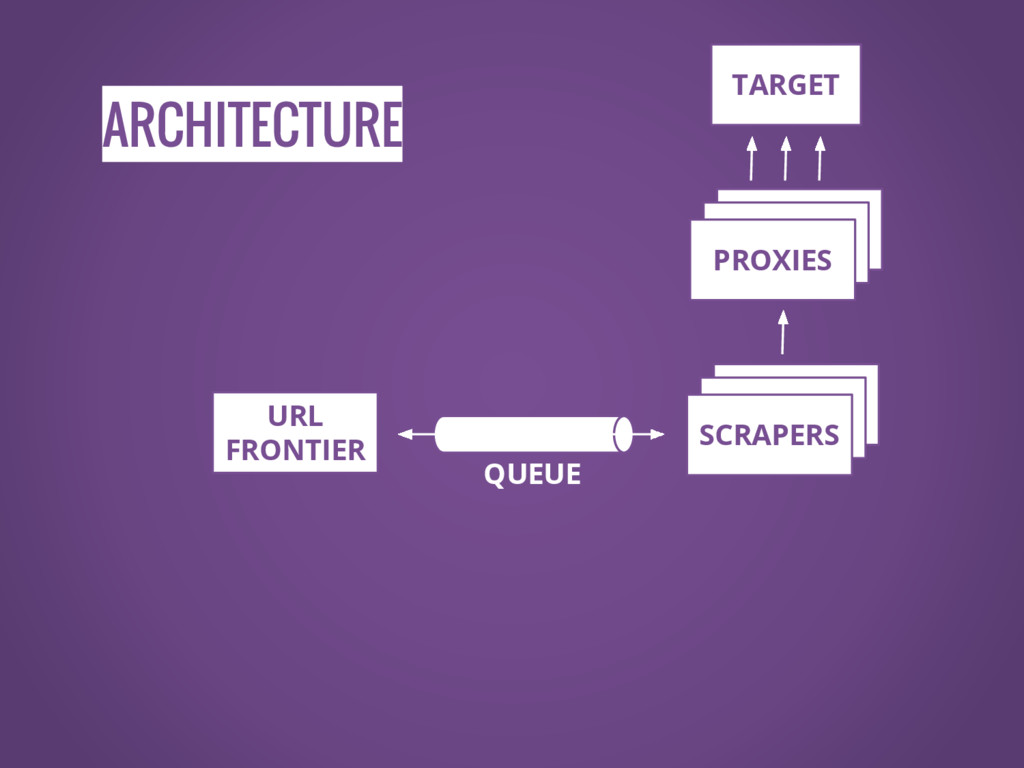
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER TARGET
QUEUE
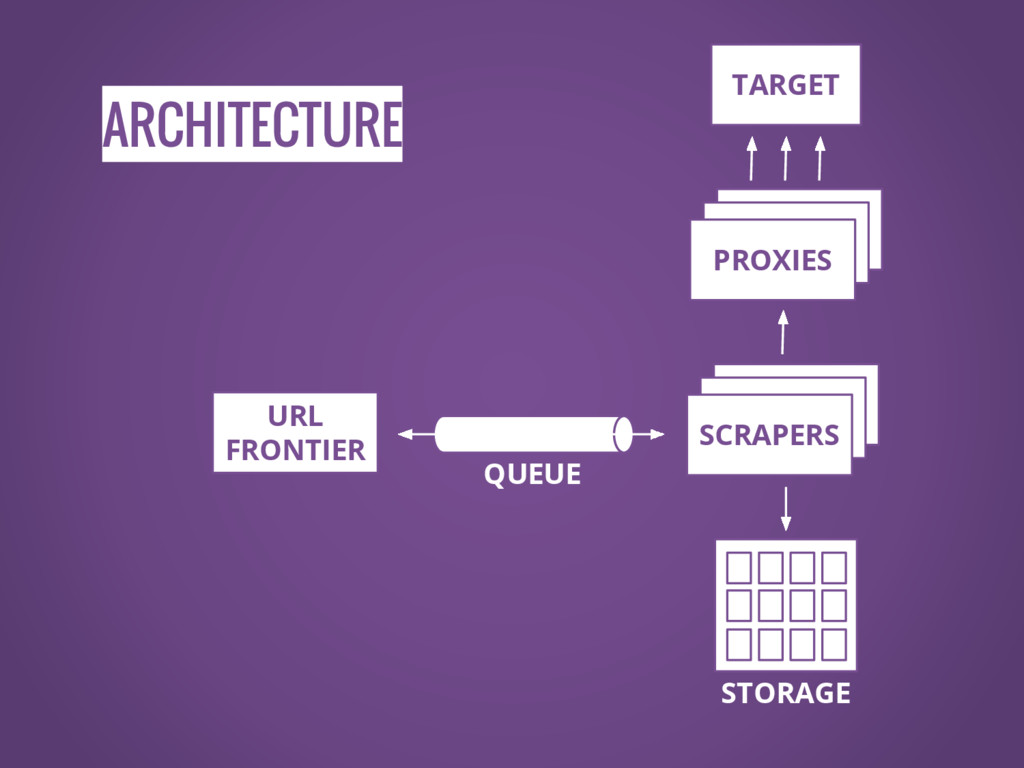
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER STORAGE
TARGET QUEUE
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER SCRAPERS
SCRAPERS PARSERS STORAGE TARGET QUEUE
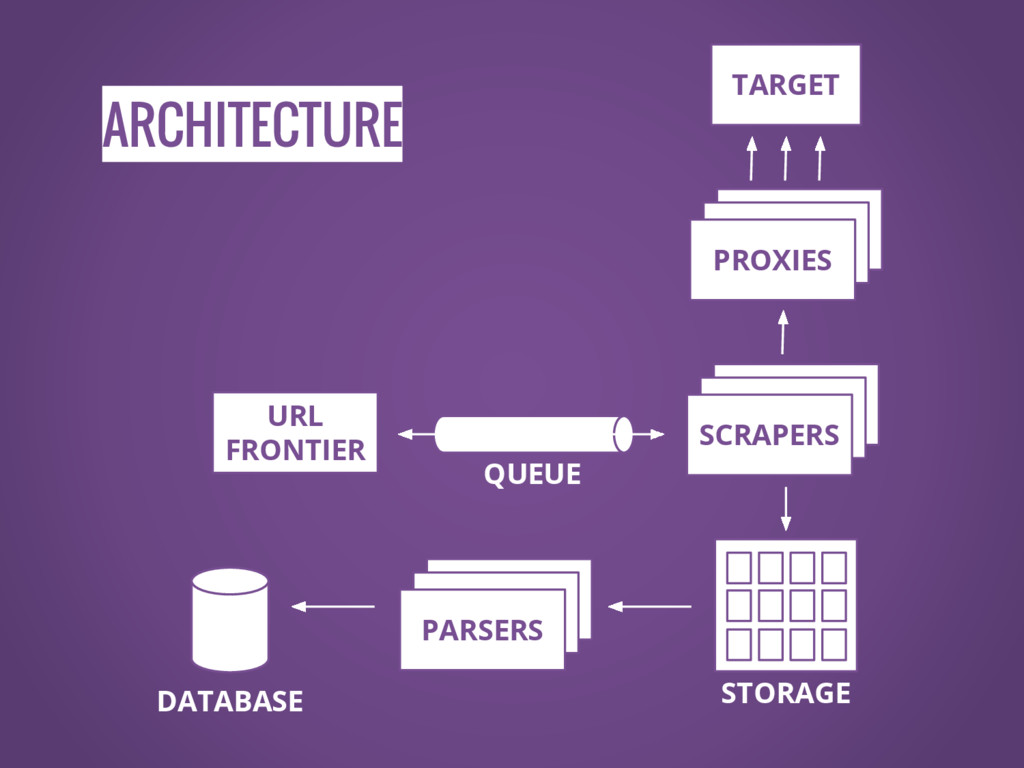
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER SCRAPERS
SCRAPERS PARSERS STORAGE DATABASE TARGET QUEUE
Fabien VAUCHELLES zelros.com /
[email protected]
/ @fabienv http://bit.ly/breizhscraping The best
opensource proxy for Scraping !
![Fabien VAUCHELLES zelros.com / [email protected] / @fabienv http://bit.ly/breizhscraping (24/03/2016)](https://files.speakerdeck.com/presentations/c16f6de99e2e4d3f96c7ed298240bb4a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fabien VAUCHELLES zelros.com / [email protected] / @fabienv http://bit.ly/breizhscraping The best](https://files.speakerdeck.com/presentations/c16f6de99e2e4d3f96c7ed298240bb4a/slide_85.jpg){kind=link}