◦ Charge by # of tokens ◦ No control or ownership ◦ Risk of rate limit ◦ Risk of data privacy ◦ Risk of instability ◦ Open-weight: the trained parameters are released publicly ◦ Run locally ◦ Set up a server for API access ◦ Can be retrained / fine-tuned ◦ More cost-effective ◦ No vendor lock-in ◦ Gemini, GPT, Claude, … ◦ Gemma, Deepseek, Llama, …
High-throughput? Real-time performance? Mobile or edge? • Multi modality? • Multi linguality? • Reasoning capabilities? • Agentic behaviour? • Process long documents? A lot of different documents? • Domain-specific knowledge? • Access to recent knowledge? • Commercial license?
Anthropic. The current date is {{currentDateTime}}. (...) Claude cares about people’s wellbeing and avoids encouraging or facilitating self-destructive behaviors such as addiction, disordered or unhealthy approaches to eating or exercise (…) Claude never starts its response by saying a question or idea or observation was good, great, fascinating, profound, excellent, or any other positive adjective. It skips the flattery and responds directly. Claude is now being connected with a person.
the NN ◦ Smaller but faster ◦ Note that Ollama runs a quantized model by default! • Distillation ◦ Reduce the number of parameters in the neural network ◦ Train smaller model ("student") with outputs of larger model ("teacher") ◦ TinyBert: 96.8% of BERT’s performance, but 7.5x smaller and 9.4x faster • Look at options from the original provider as well as other users on HF https://smcleod.net/
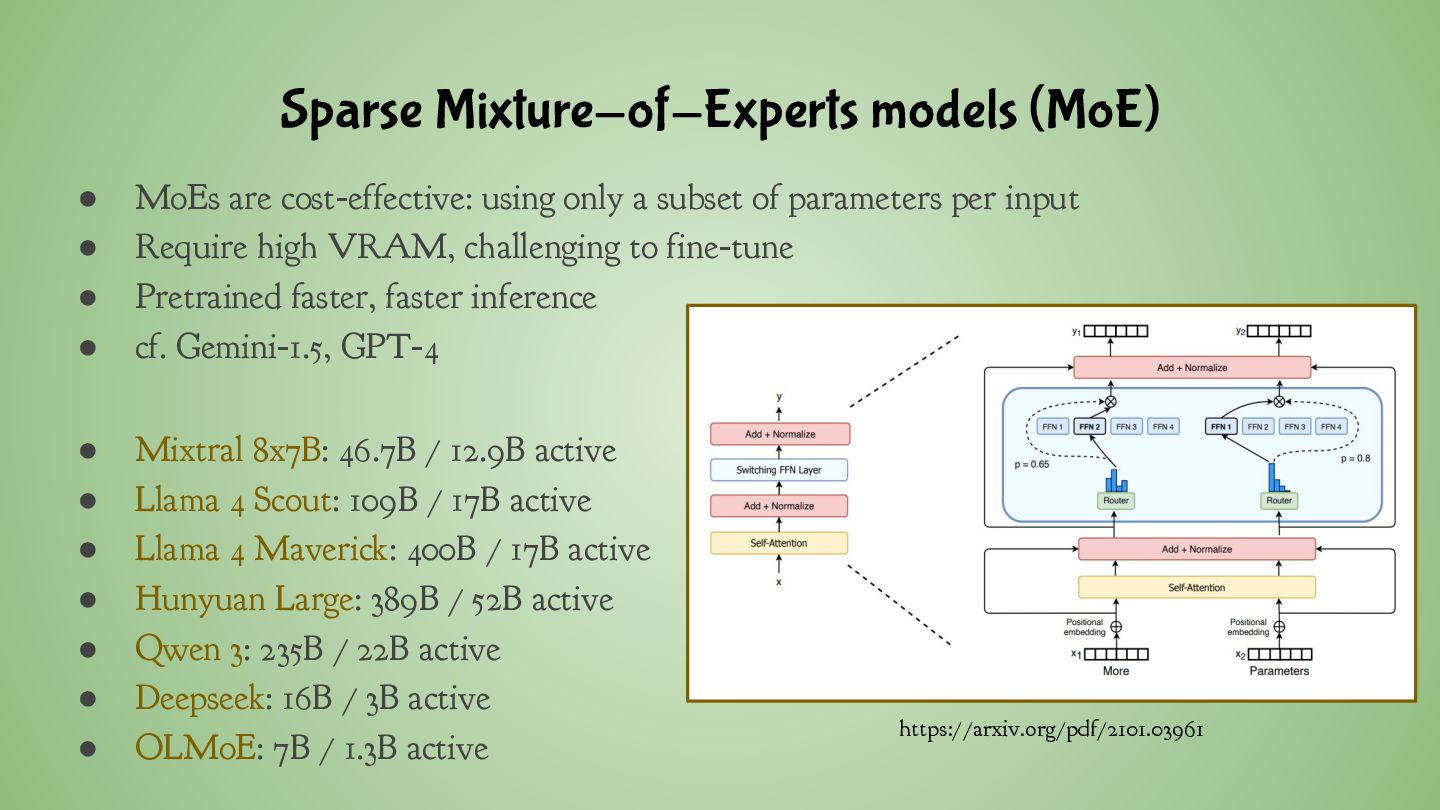
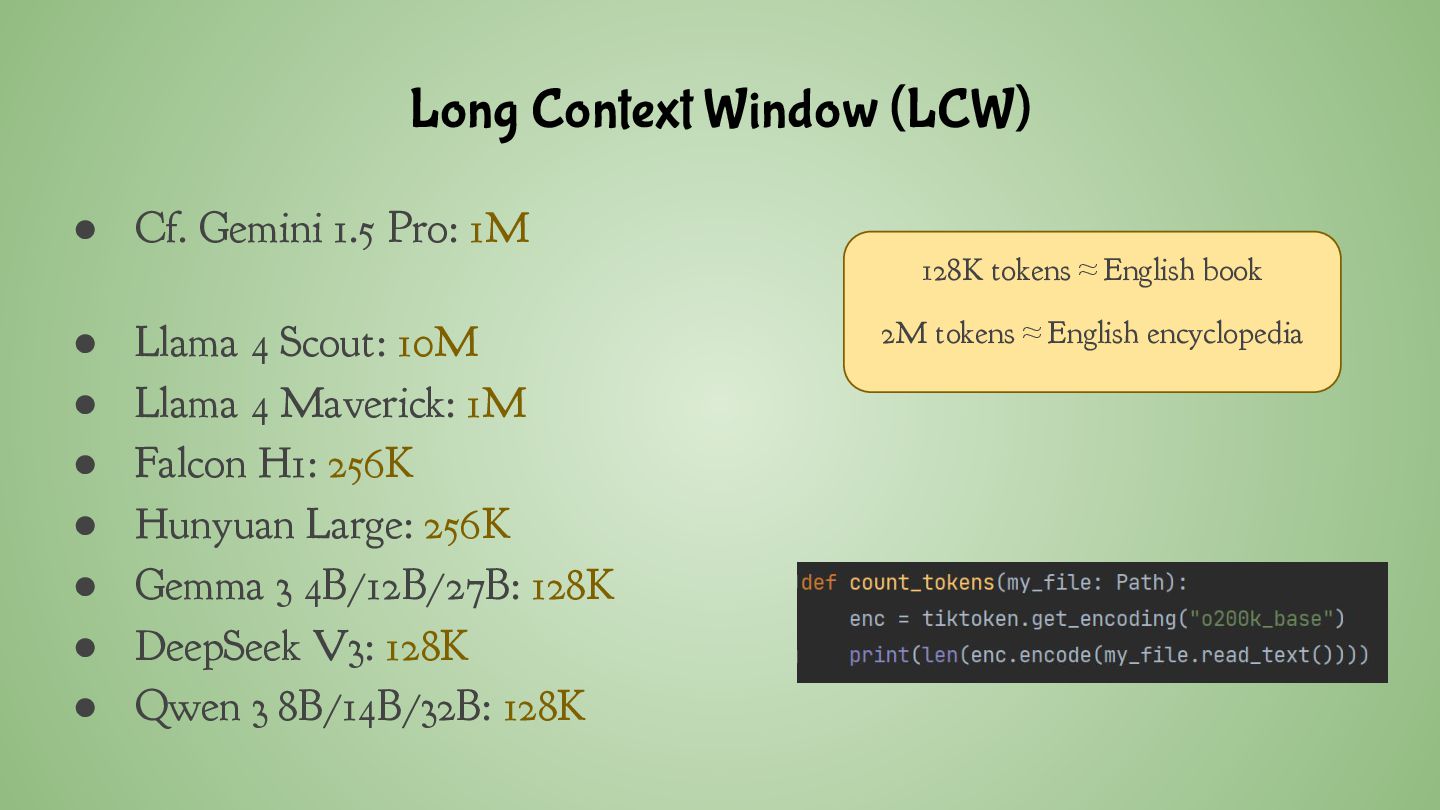
Mamba ◦ Uses less memory ◦ More efficient for long sequences ◦ Summarization and chatting with long documents • Use-cases for Transformers ◦ Accurately capture complex relations ◦ Deep contextual understanding, code generation, Math • Mamba/Transformer hybrid architectures: ◦ Hunyuan Turbo S / T1 (also MoE) ◦ Falcon-H1
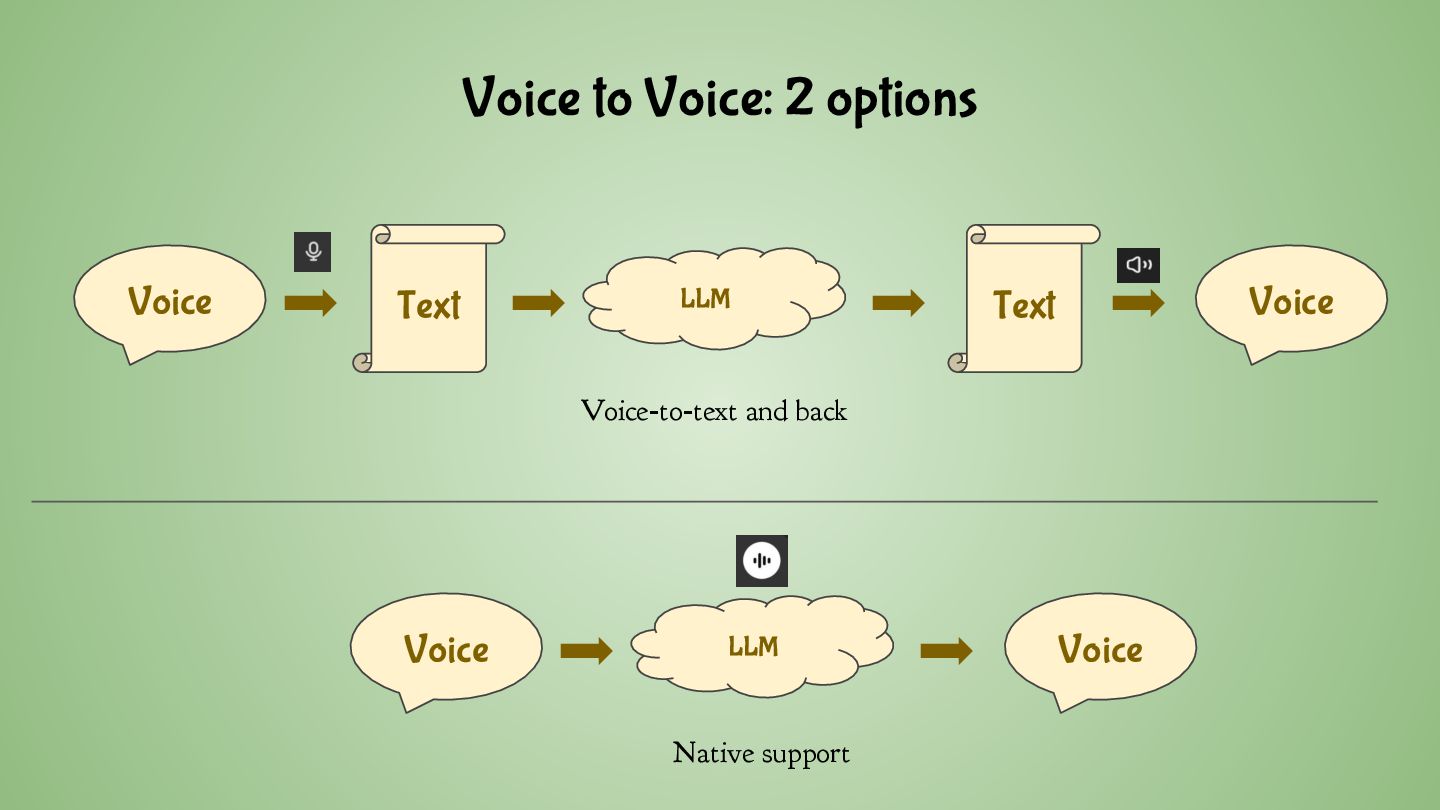
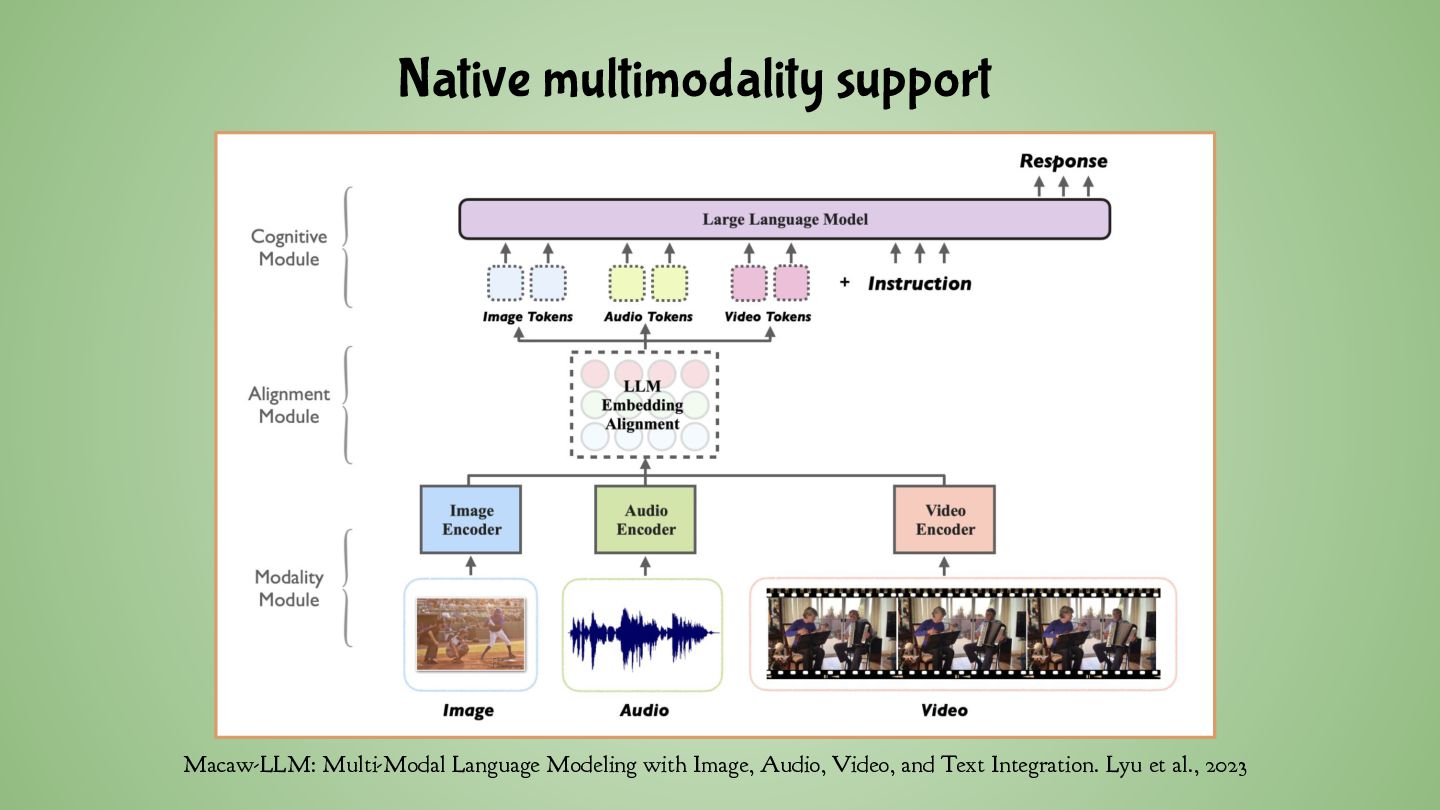
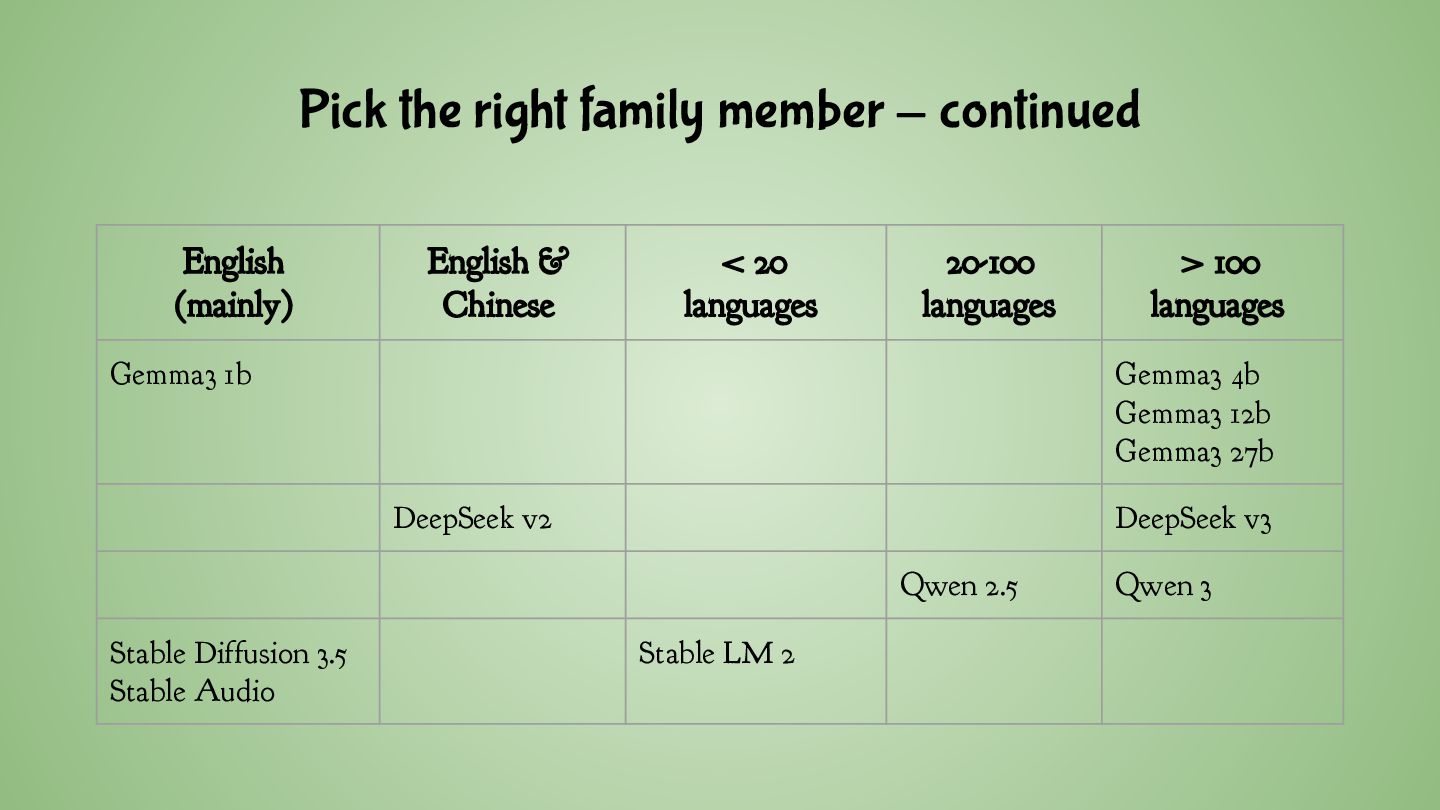
only does text-to-text ◦ 4B, 12B and 27B also allow processing of input images • DeepSeek ◦ Normal models only do text-to-text ◦ There’s also a DeepSeek VL and multi-modal “Janus” • SLP-RL: SIMS-Llama3.2-3B ◦ A fine-tuned Llama 3.2 3B with extended vocabulary ◦ 500 speech tokens to support voice-to-voice • For image/audio/video generation, you typically want specialised models ◦ e.g. Stable Diffusion, Stable Audio, Flux 1.1 Pro, HiDream-I1, ...
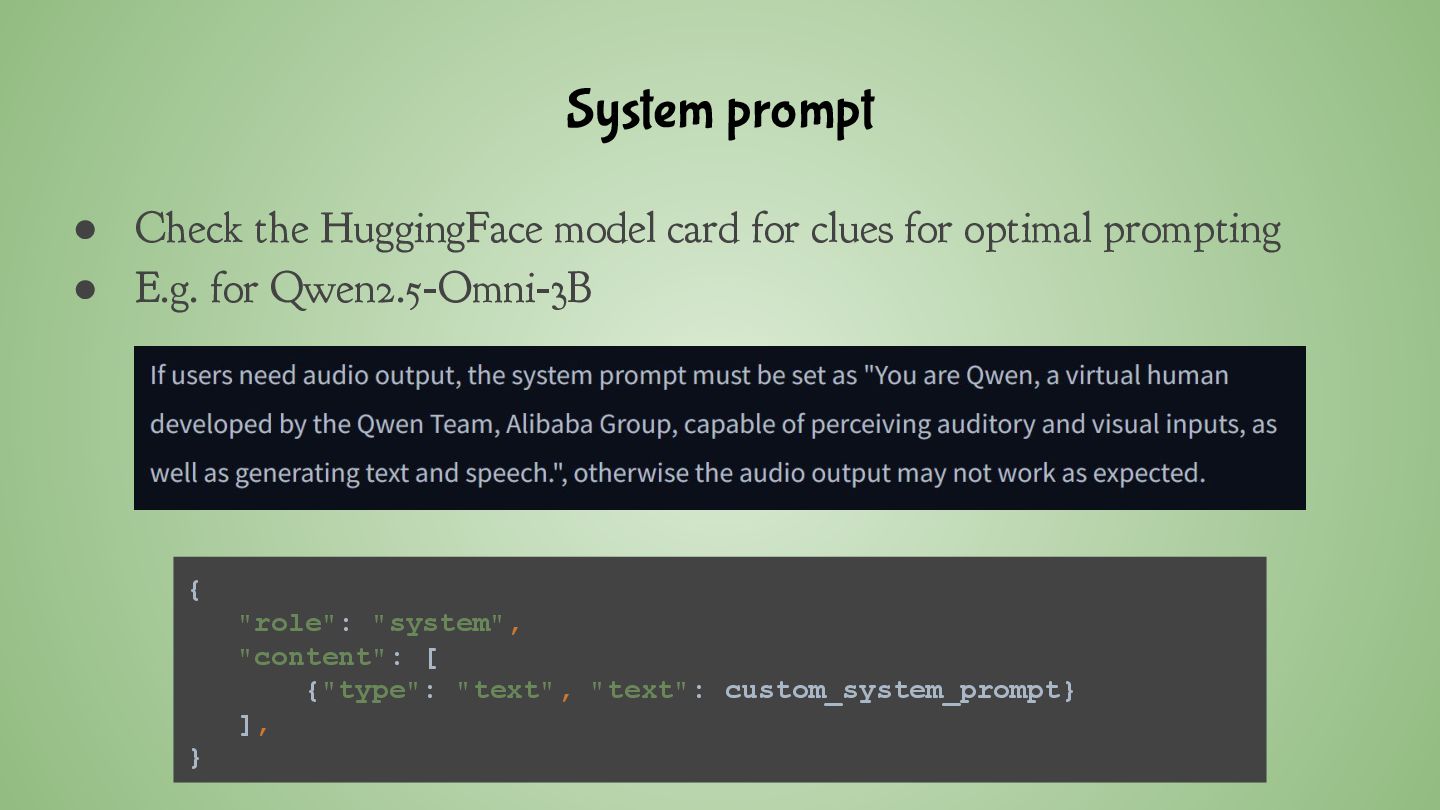
audio outputs ◦ If audio is not necessary, you can disable it ◦ This saves about 2GB of GPU memory! model = Qwen2_5OmniForConditionalGeneration.from_pretrained( "Qwen/Qwen2.5-Omni-3B", torch_dtype="auto", device_map="auto" ) model.disable_talker()
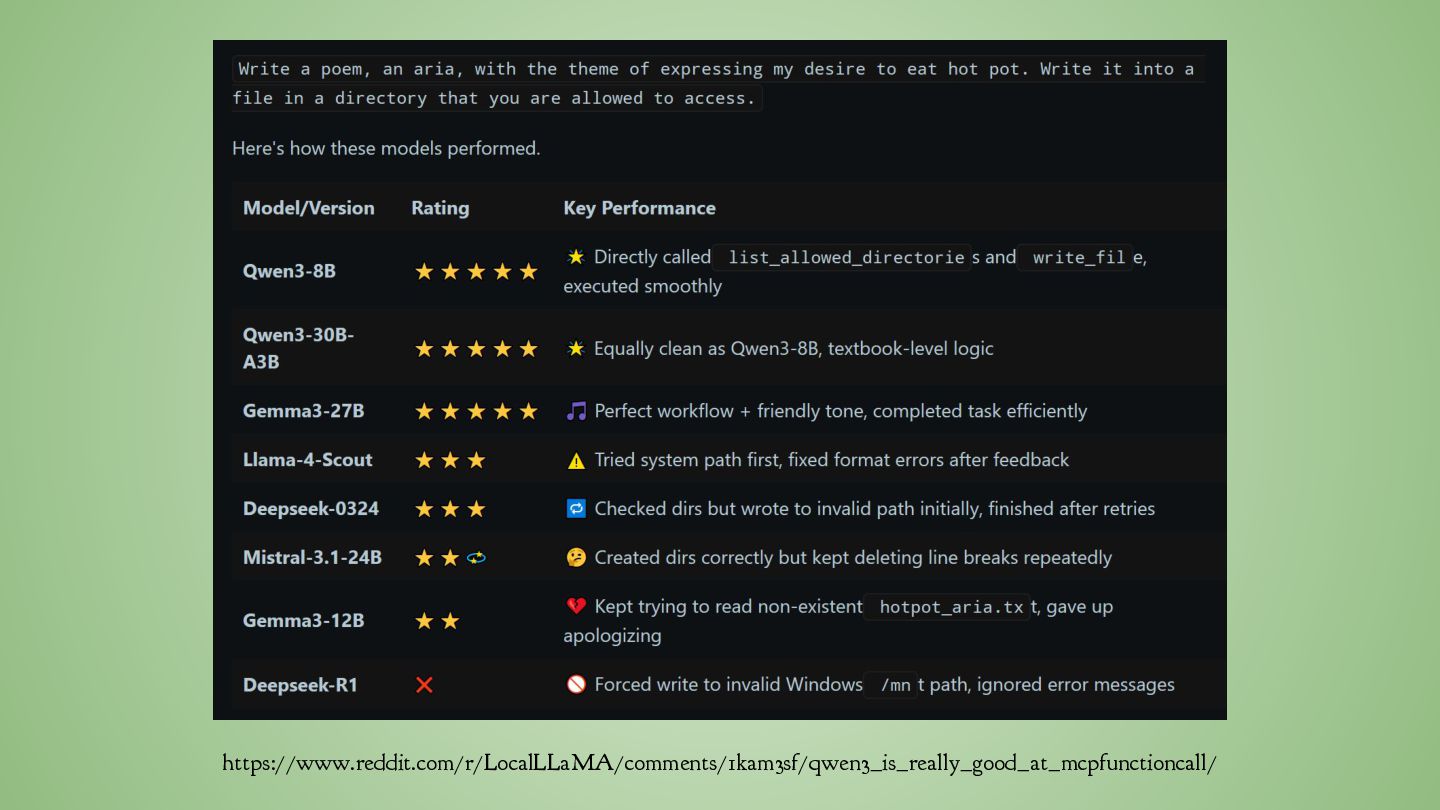
for Code & Math problems • Usually not necessary for simple information extraction such as NER • Qwen 3 • DeepSeek R1 and Deepseek V3 • Llama 3.1 and subsequent Llama releases • Magistral Small
via “fast thinking” for general conversation • Analytical reasoning via “slow thinking” for math problems & logical reasoning • Hunyuan Turbo S • Qwen 3: ◦ Thinking can be enabled/disabled on demand ◦ Custom accuracy/speed trade-off
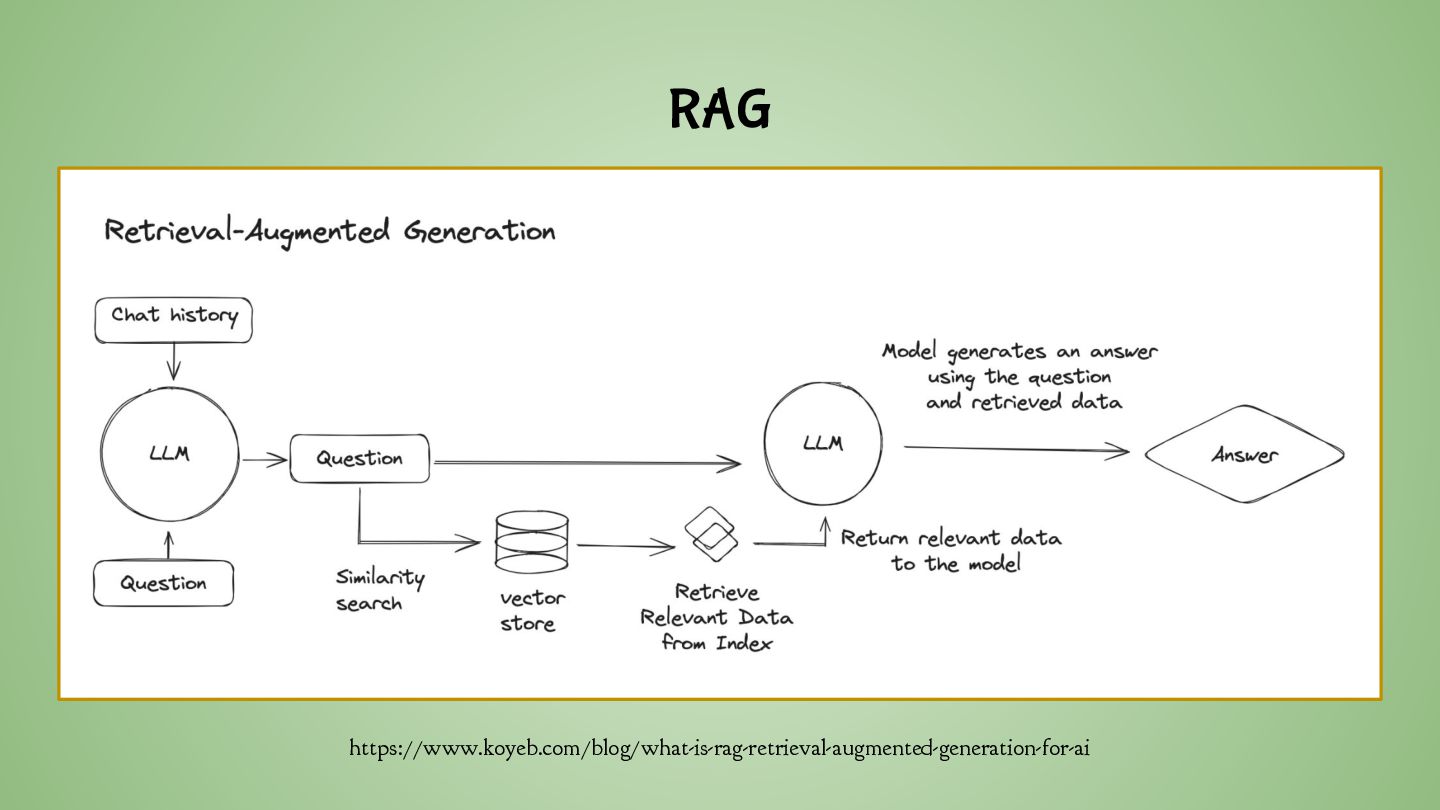
become diluted ◦ Can be computationally expensive ◦ Summarization ◦ Document analysis ◦ Deep understanding of a single document ◦ Process and integrate information from multiple sources ◦ Adds a pre-processing step to build the vector database ◦ Open-domain QA
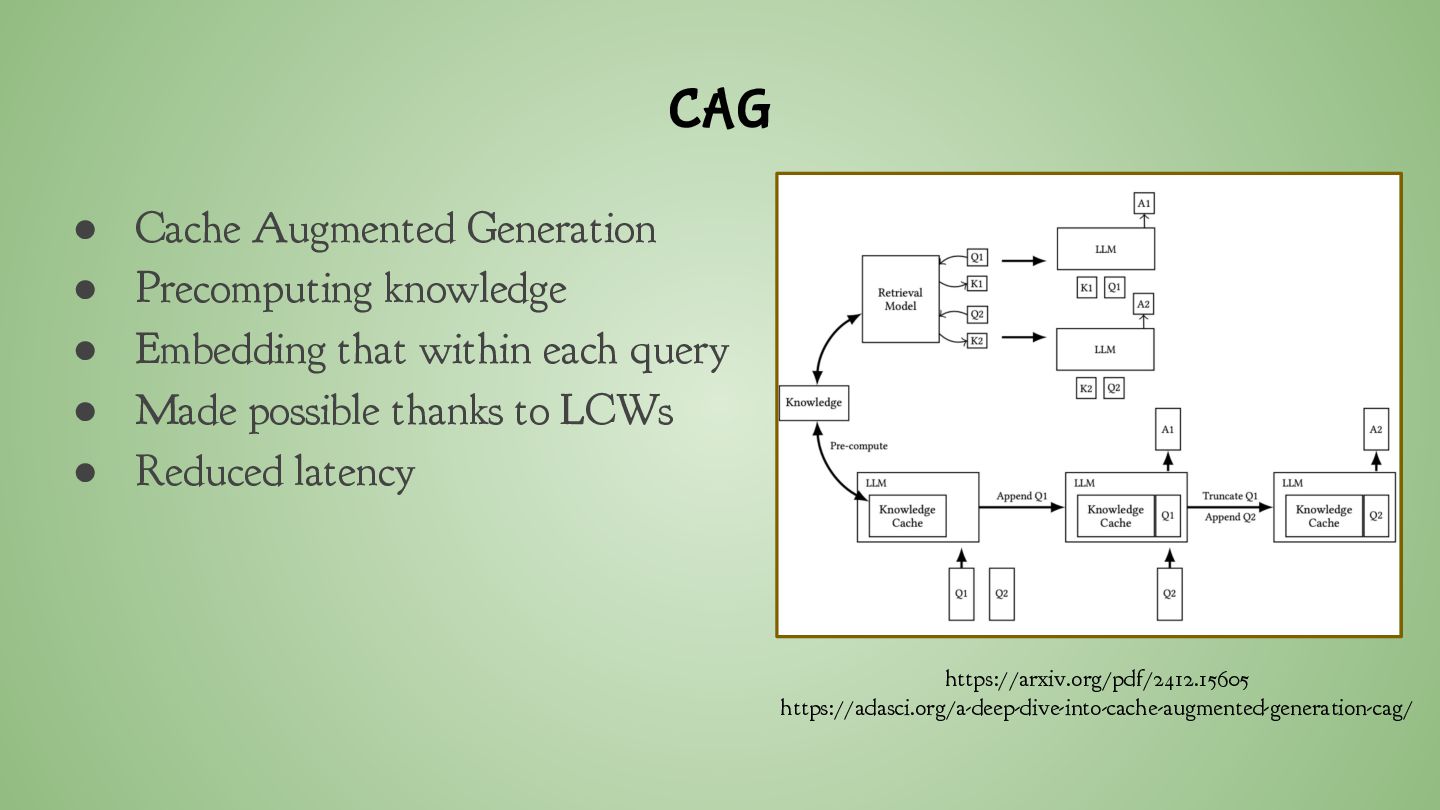
that within each query • Made possible thanks to LCWs • Reduced latency https://arxiv.org/pdf/2412.15605 https://adasci.org/a-deep-dive-into-cache-augmented-generation-cag/
Llama Materials or any output or results of the Llama Materials to improve any other large language model" • You need a specific license for Llama if you have >700M active users • Stability AI’s license is free, unless for businesses with >$1M revenue • Mistral also has proprietary models (Mistral Medium 3, Ministral 3B)
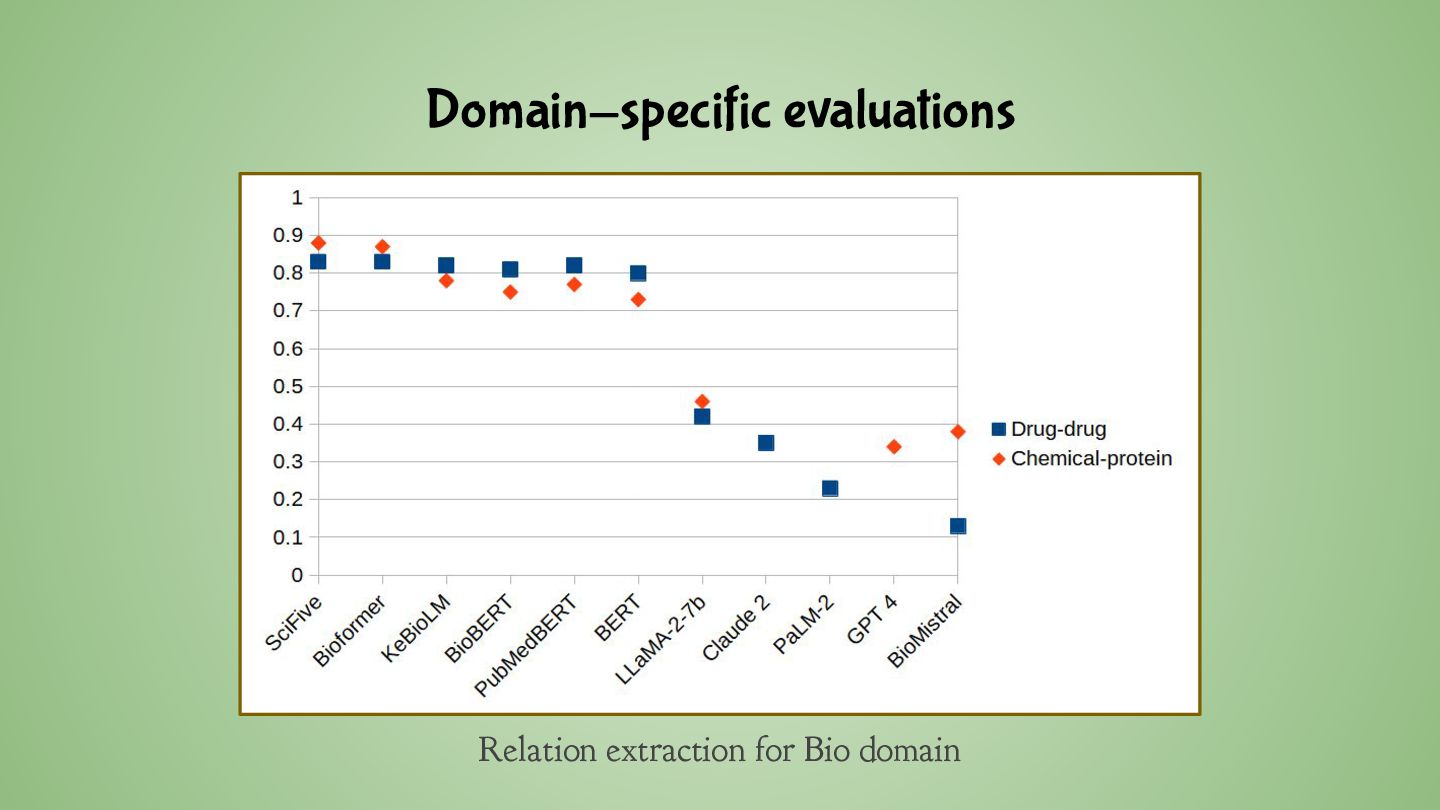
kind of data has been trained on • Example: StableLM Base Alpha ◦ Published under a commercial license ◦ Partially fine-tuned on data prohibiting commercial usage • This is especially problematic with image generation models • As a commercial user, are you at risk? • Do you want to be better safe than sorry?
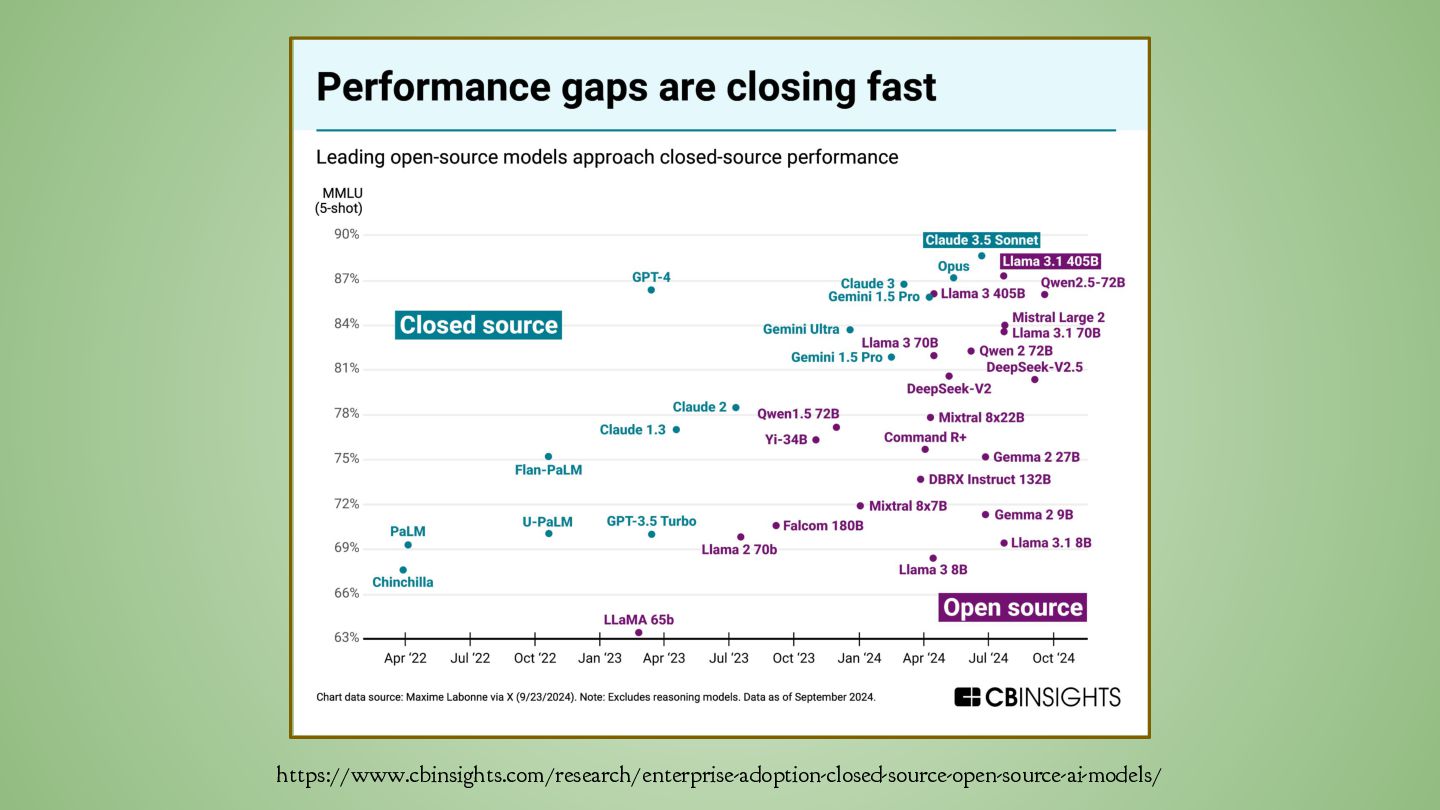
Artificial Intelligence (Seattle) • Open and accessible training data • Dolma dataset by Ai2 (3T tokens) ◦ Includes Common Crawl ◦ ODC-BY (commercial) license • Open-source training code • Reproducible training recipes • Transparent evaluations • OLMo 2 model: 1B, 7B, 13B, 32B • OLMoE model: 7B, 1B active
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}