Share
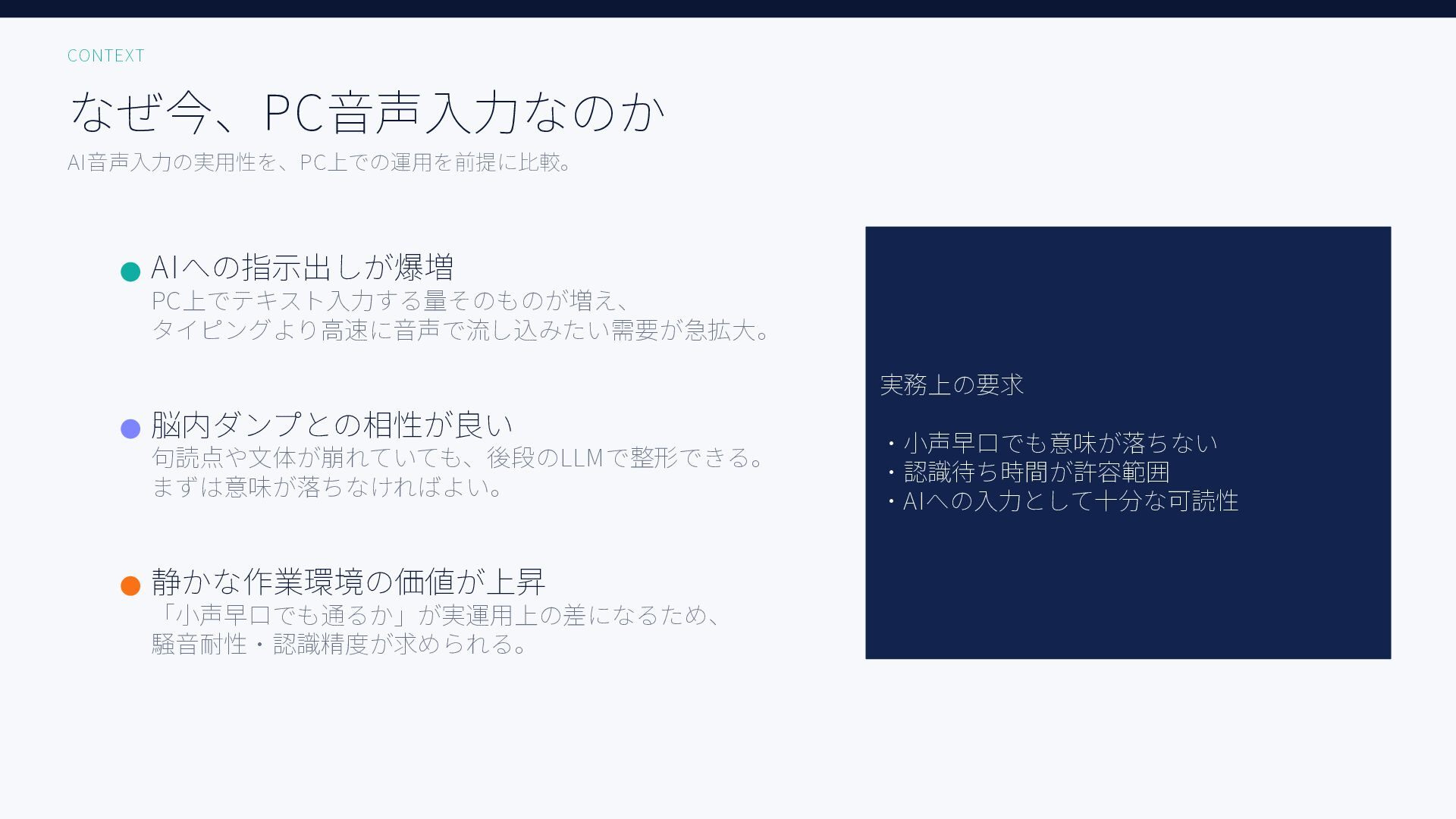
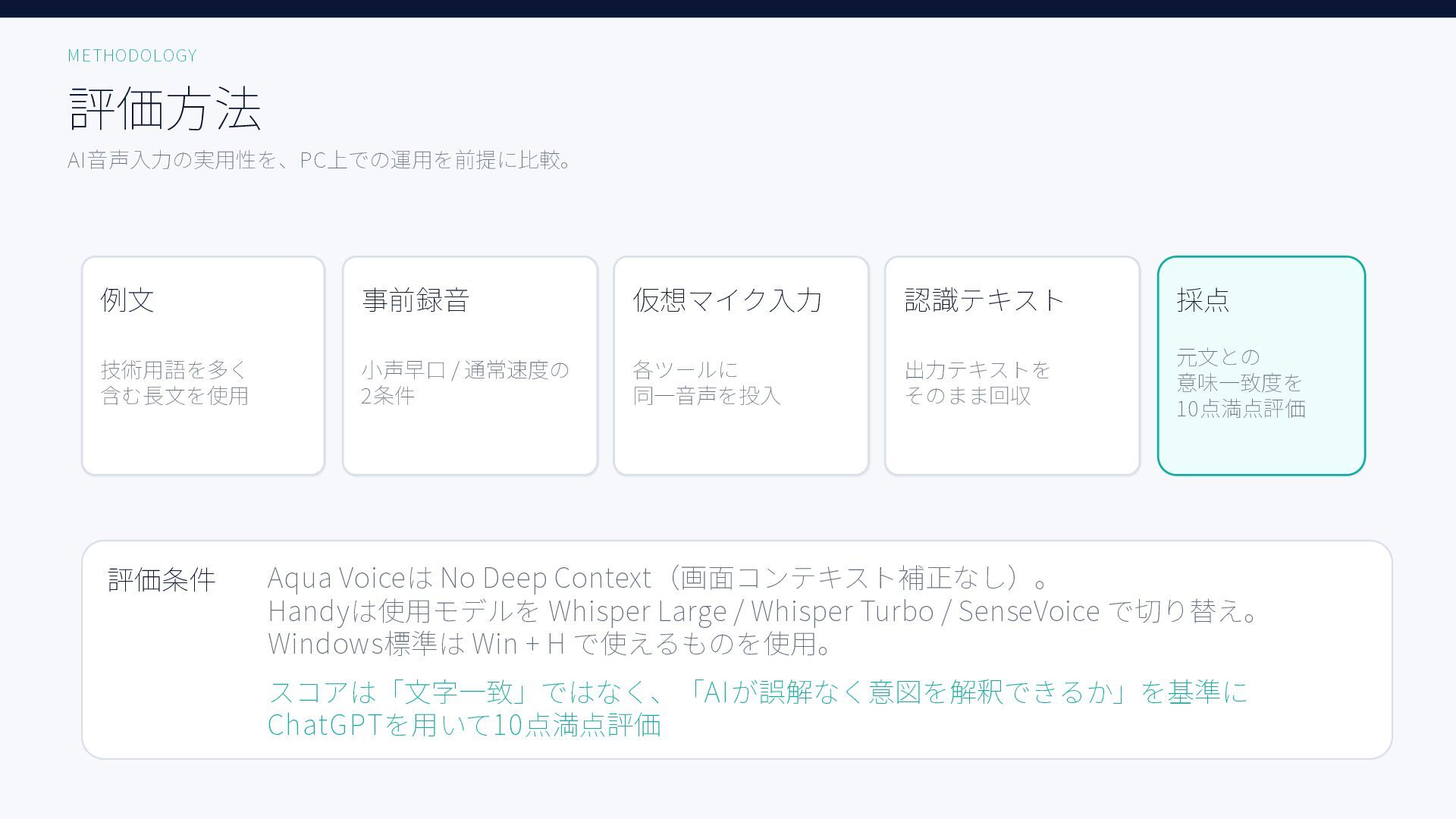
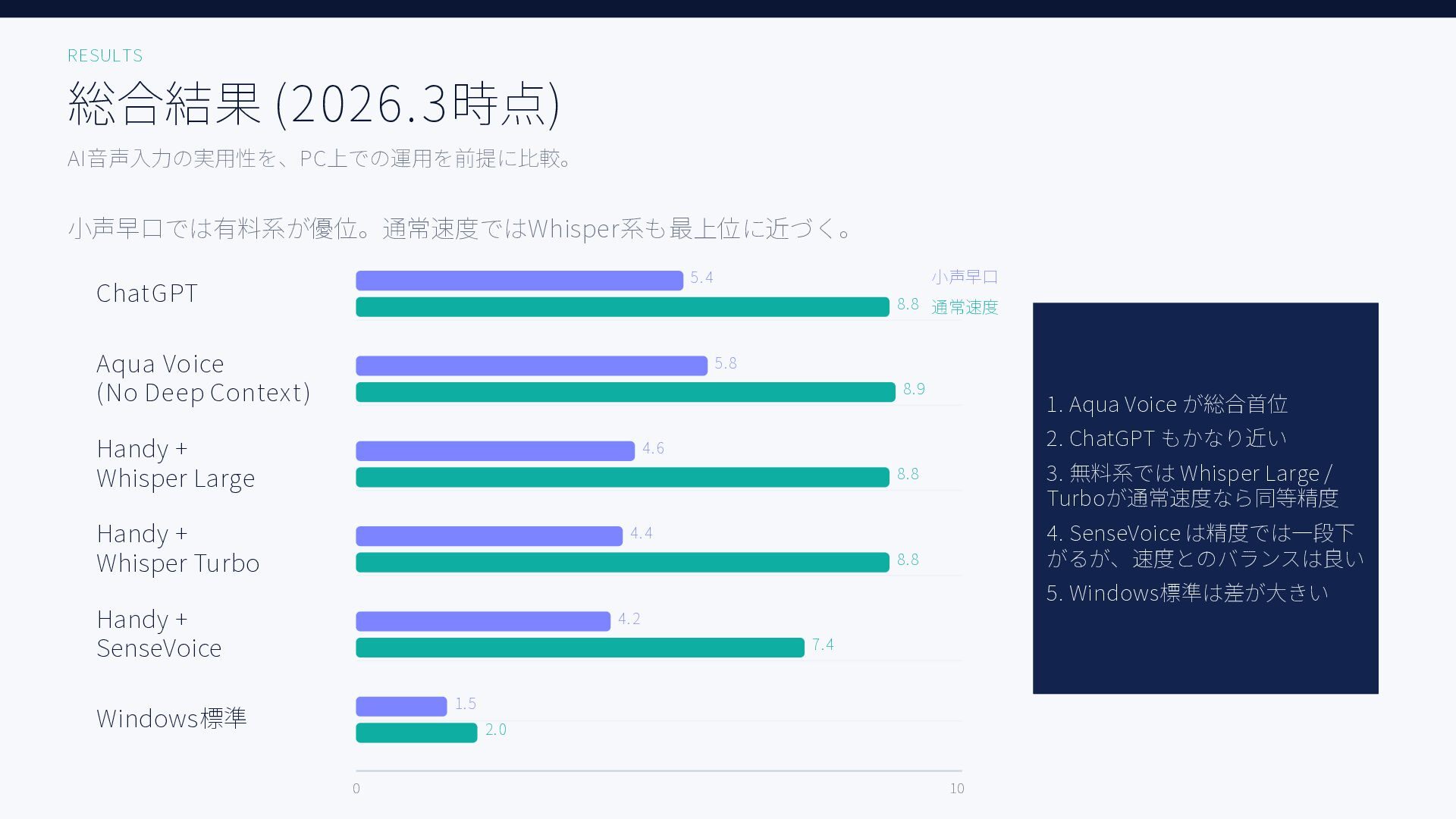
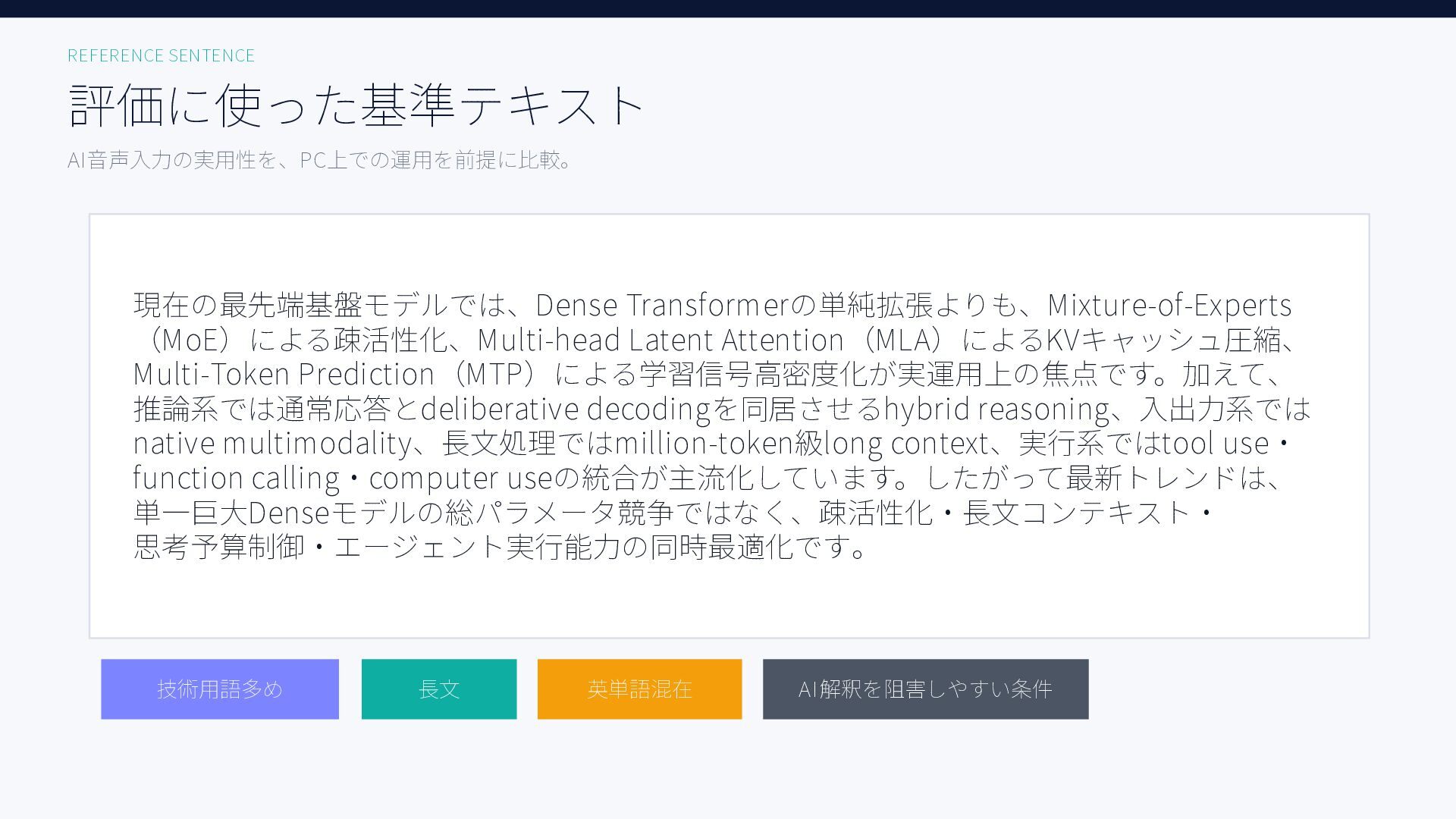
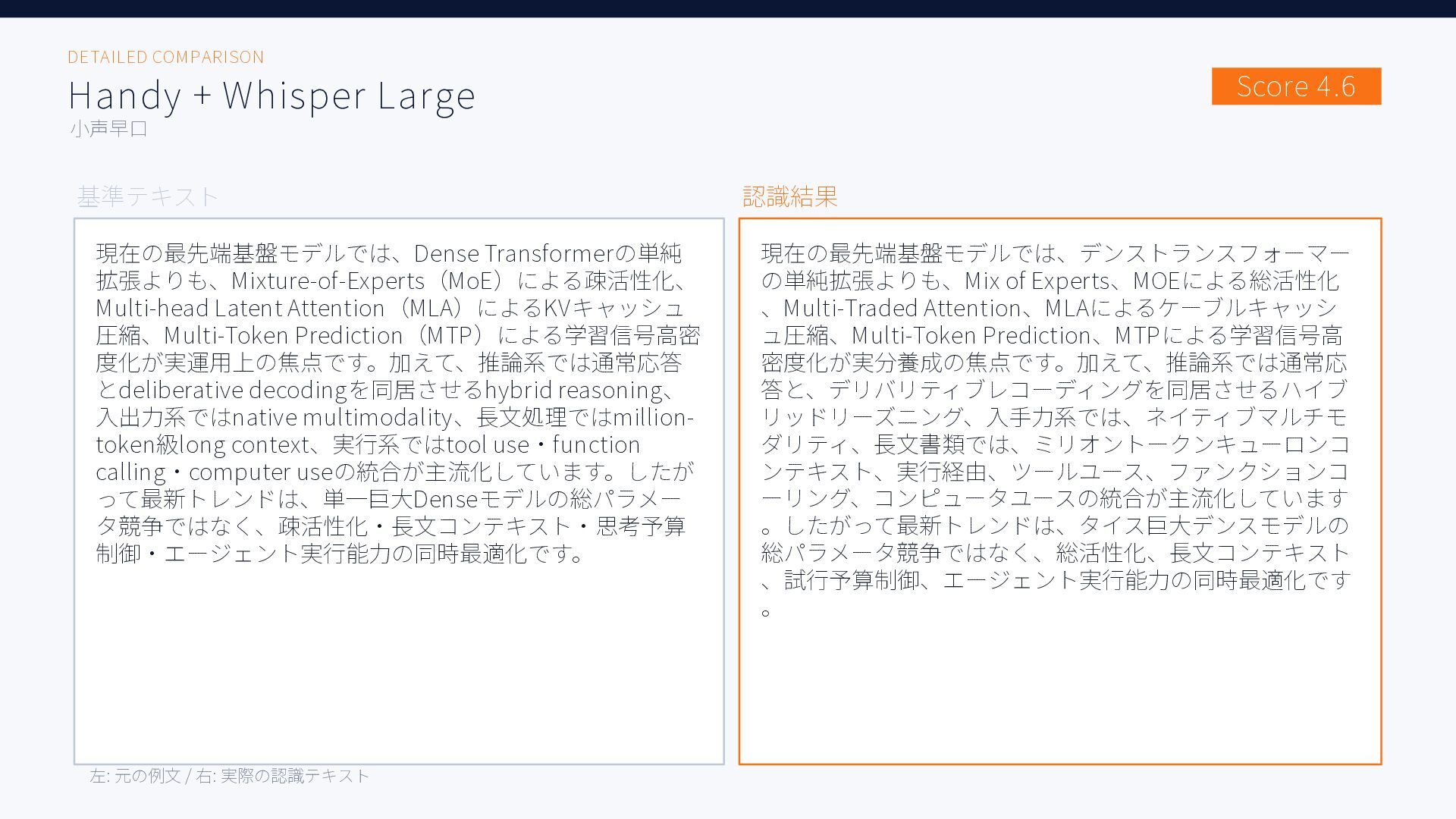
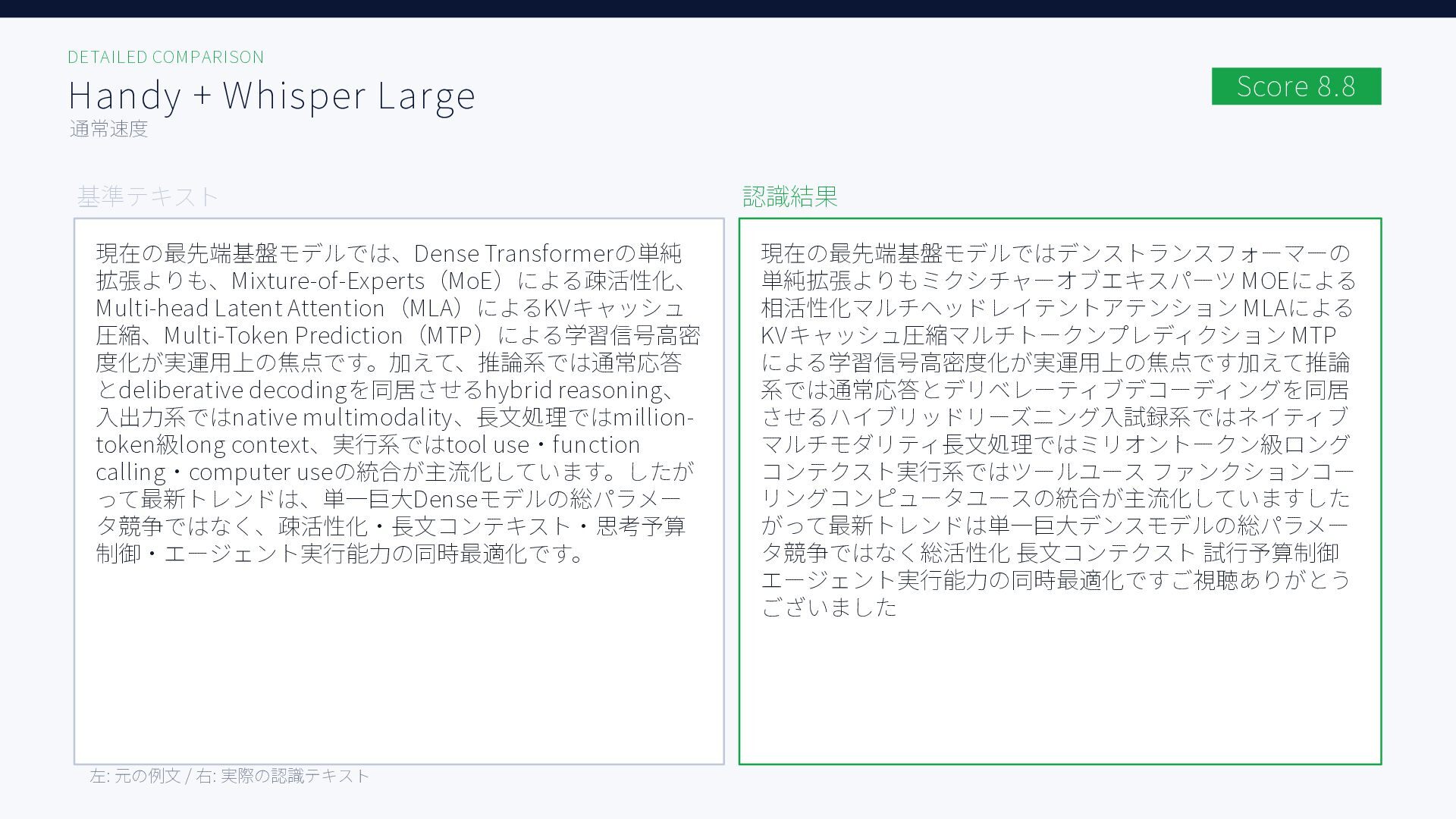
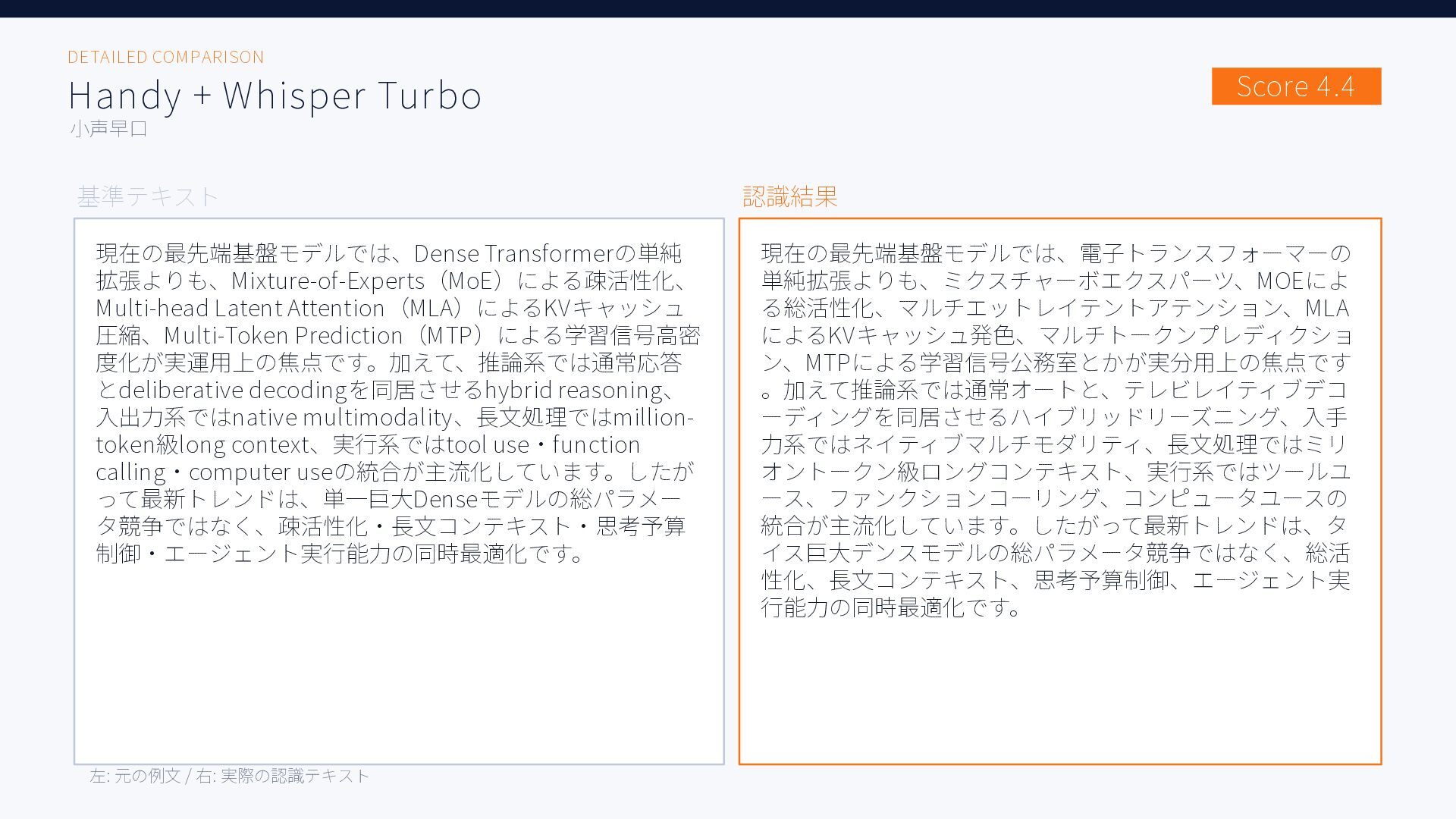
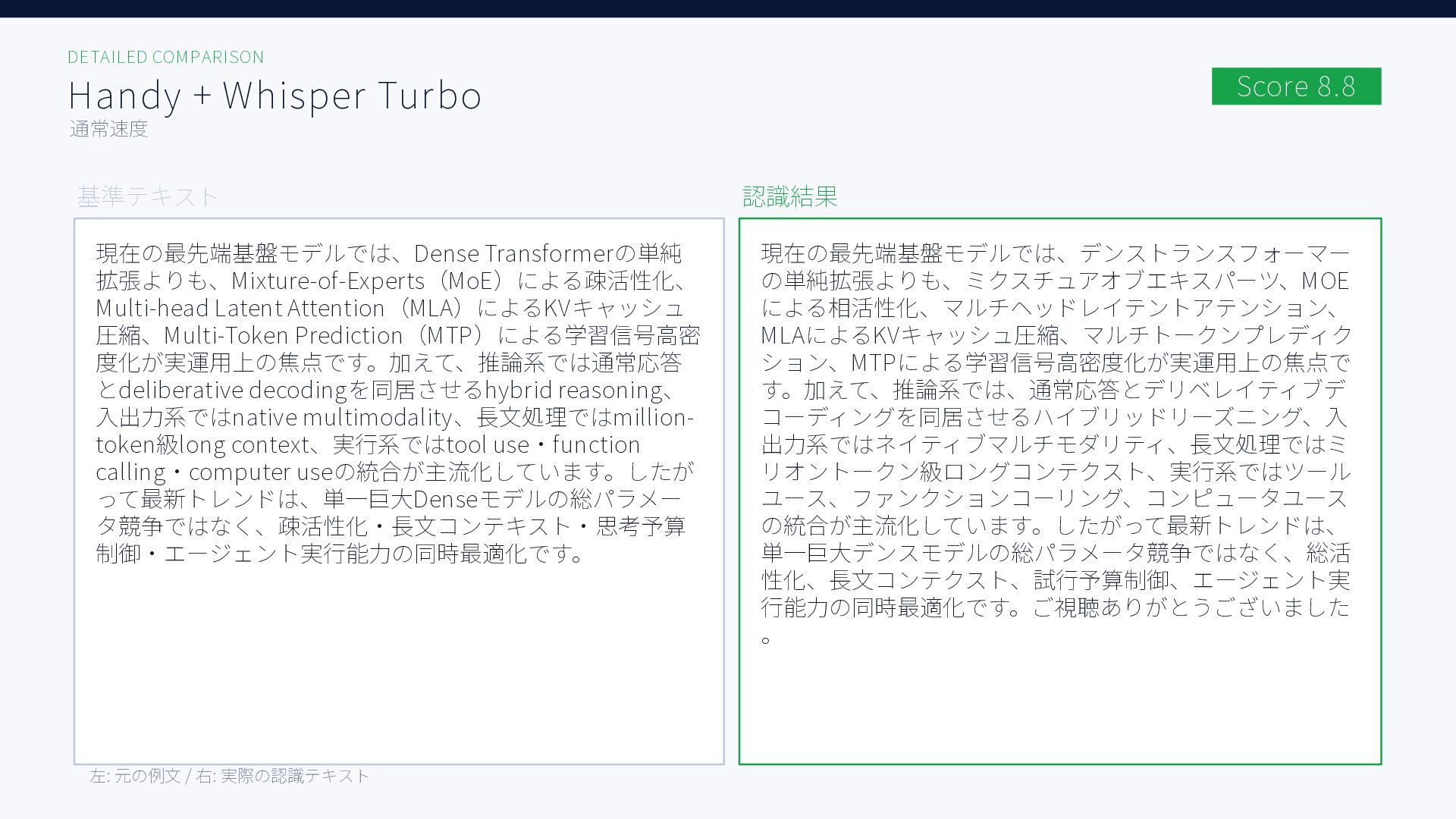
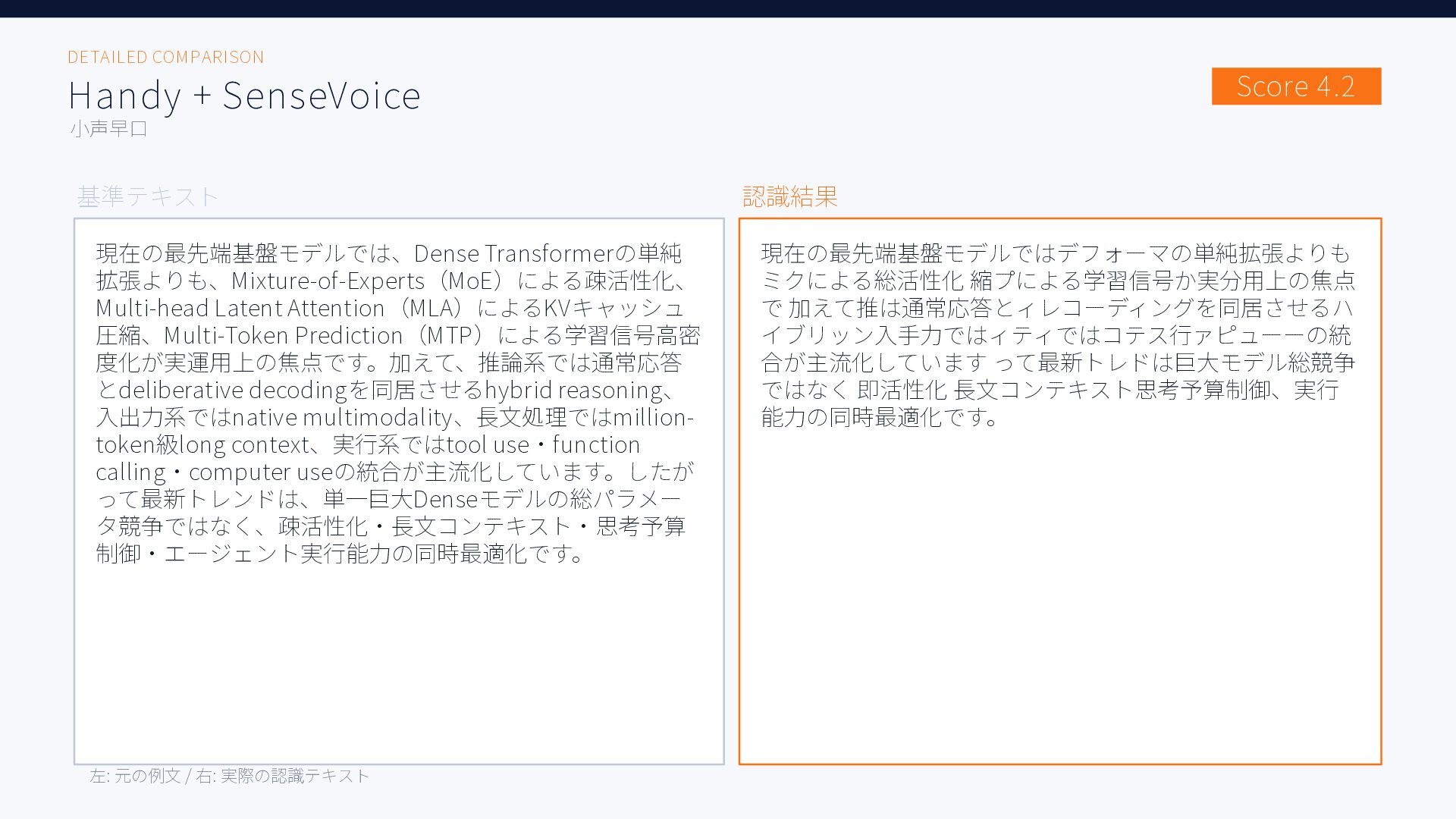
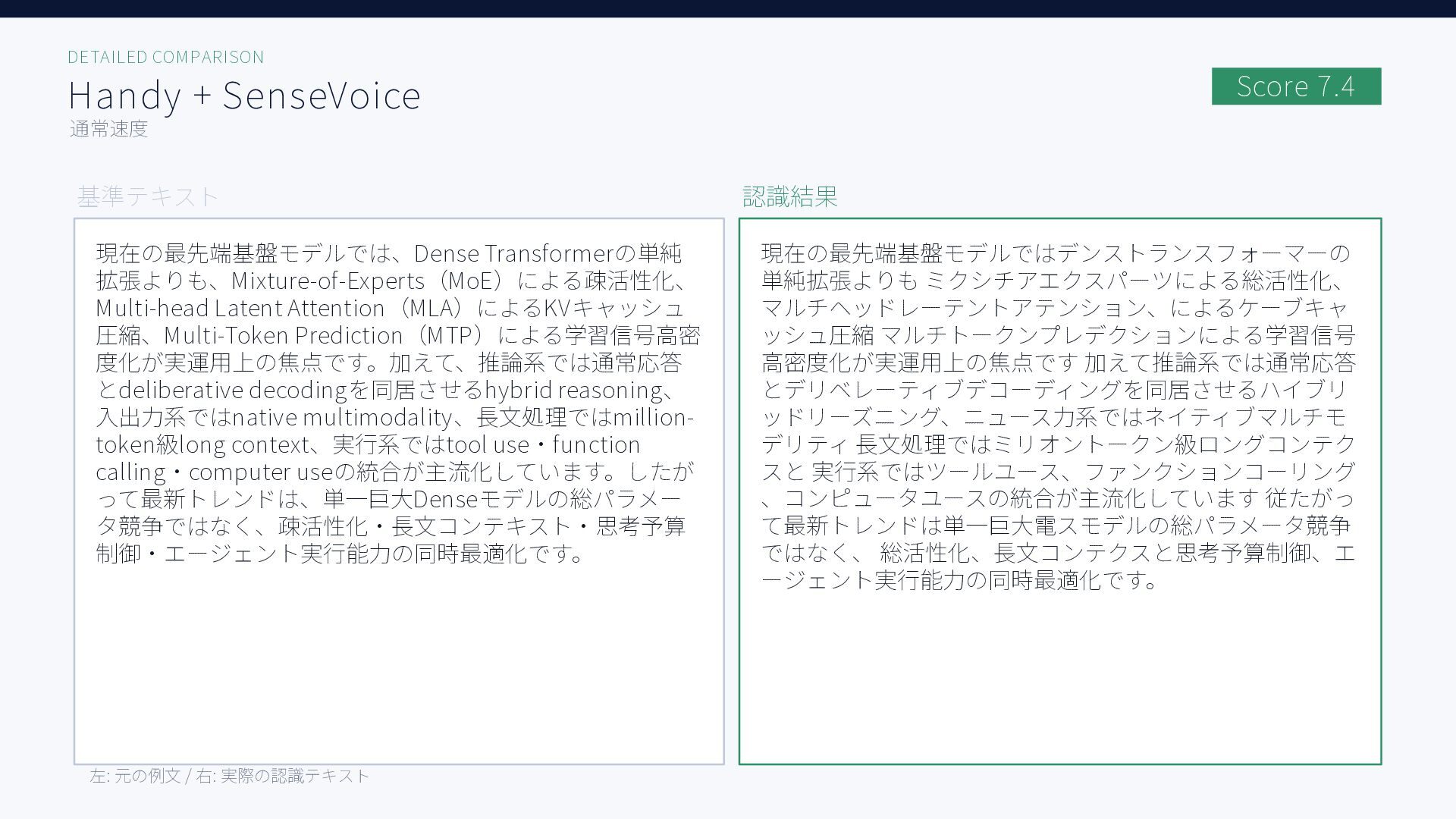
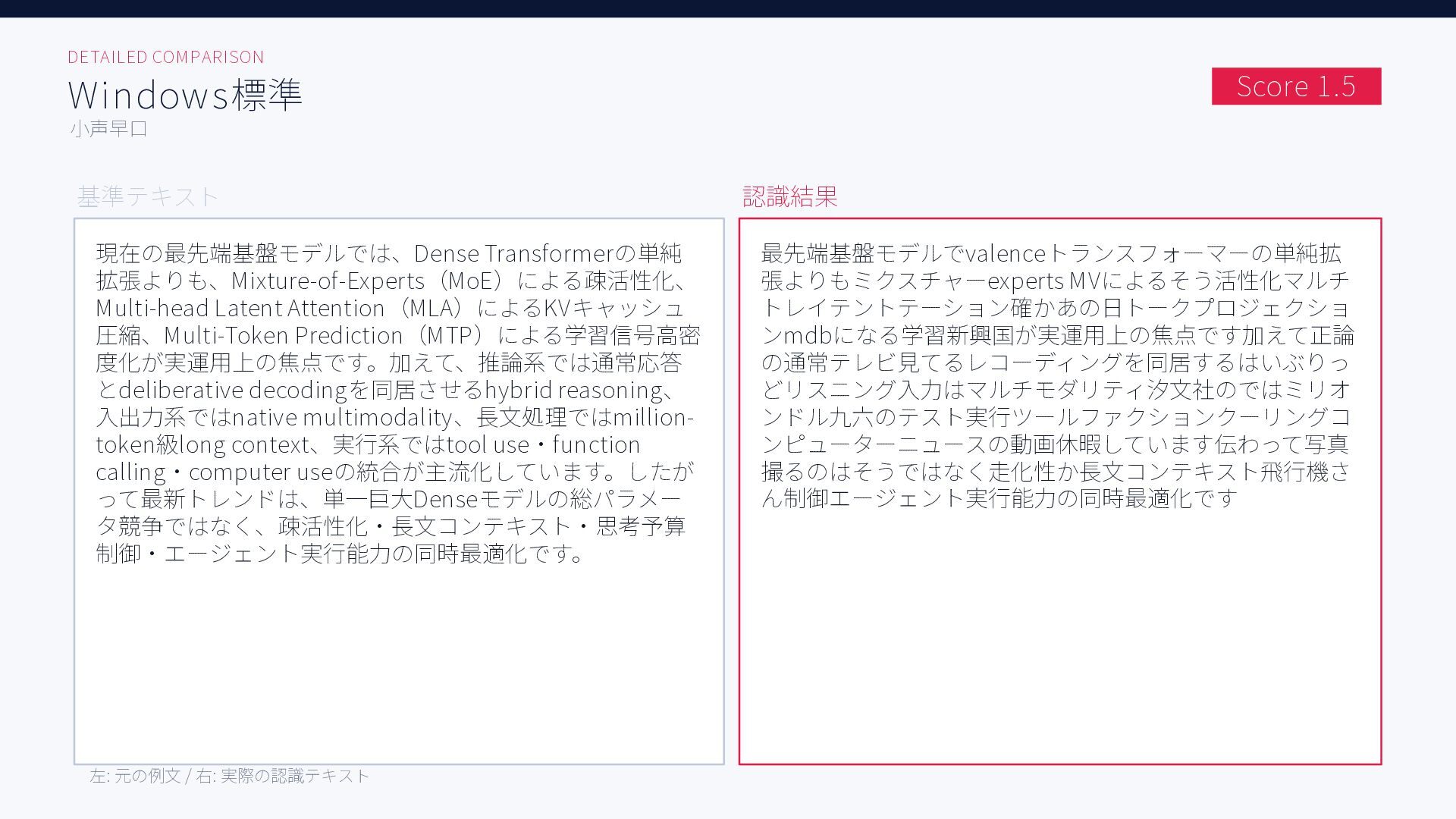
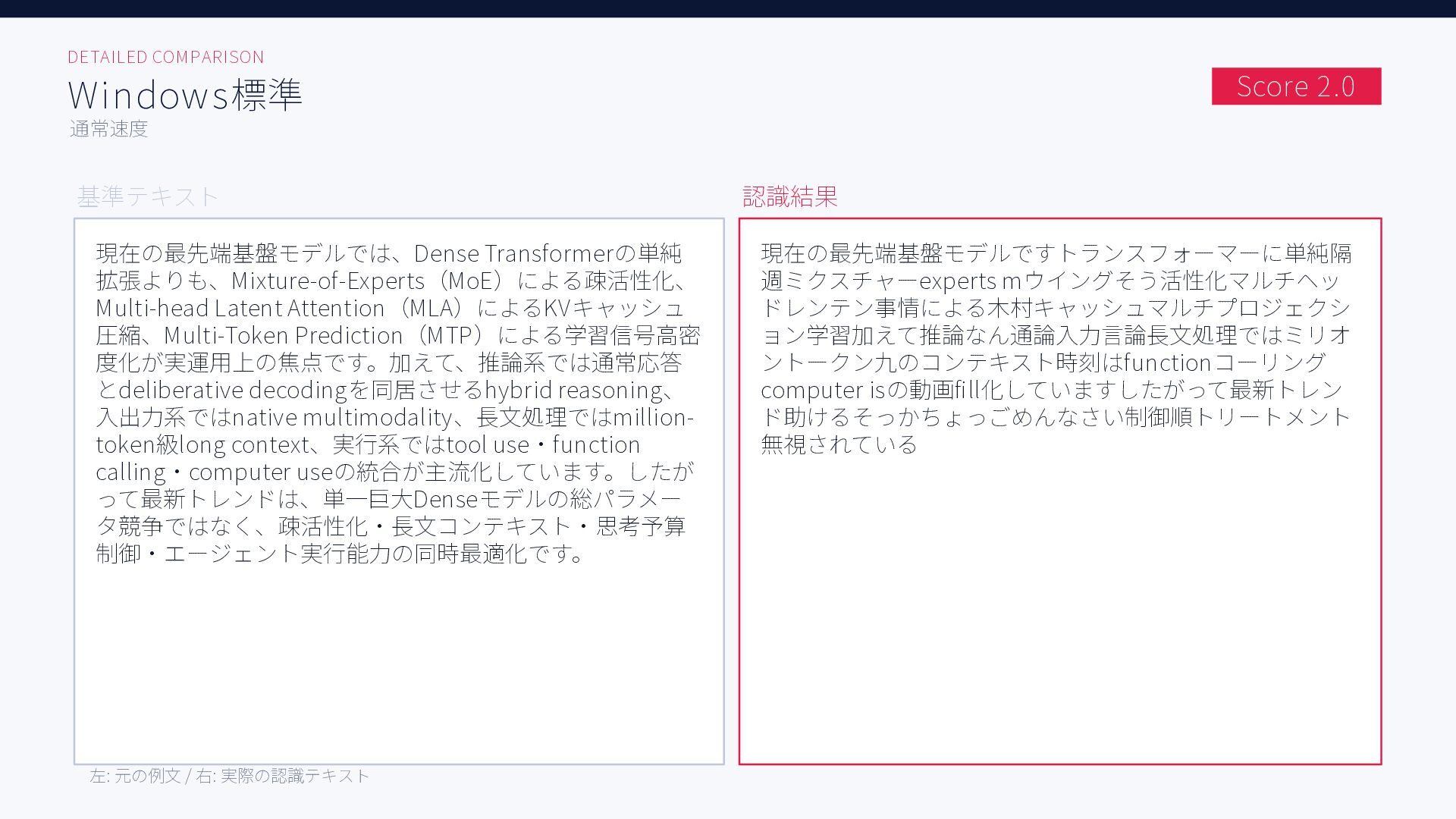
無料ツールを含む6種類のAI音声入力ツール、Aqua Voice / ChatGPT / Handy + Whisper Large, Whisper Turbo, SenseVoice / Windows標準で日本語音声認識精度を比較した結果をまとめた資料です。評価用音声には小声早口な音声と、ある程度ゆっくり話した音声の2種類を用いています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
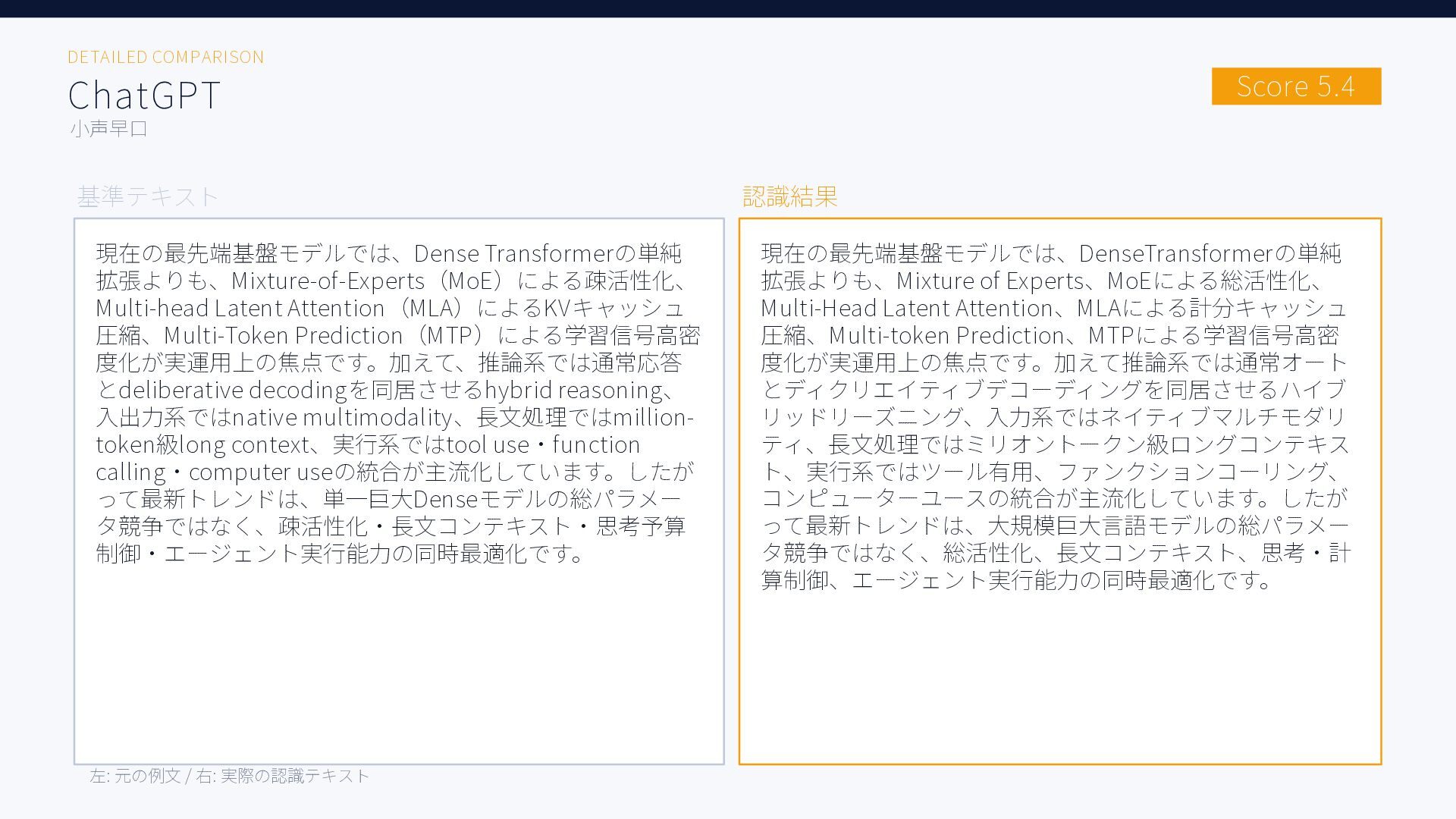{kind=link}
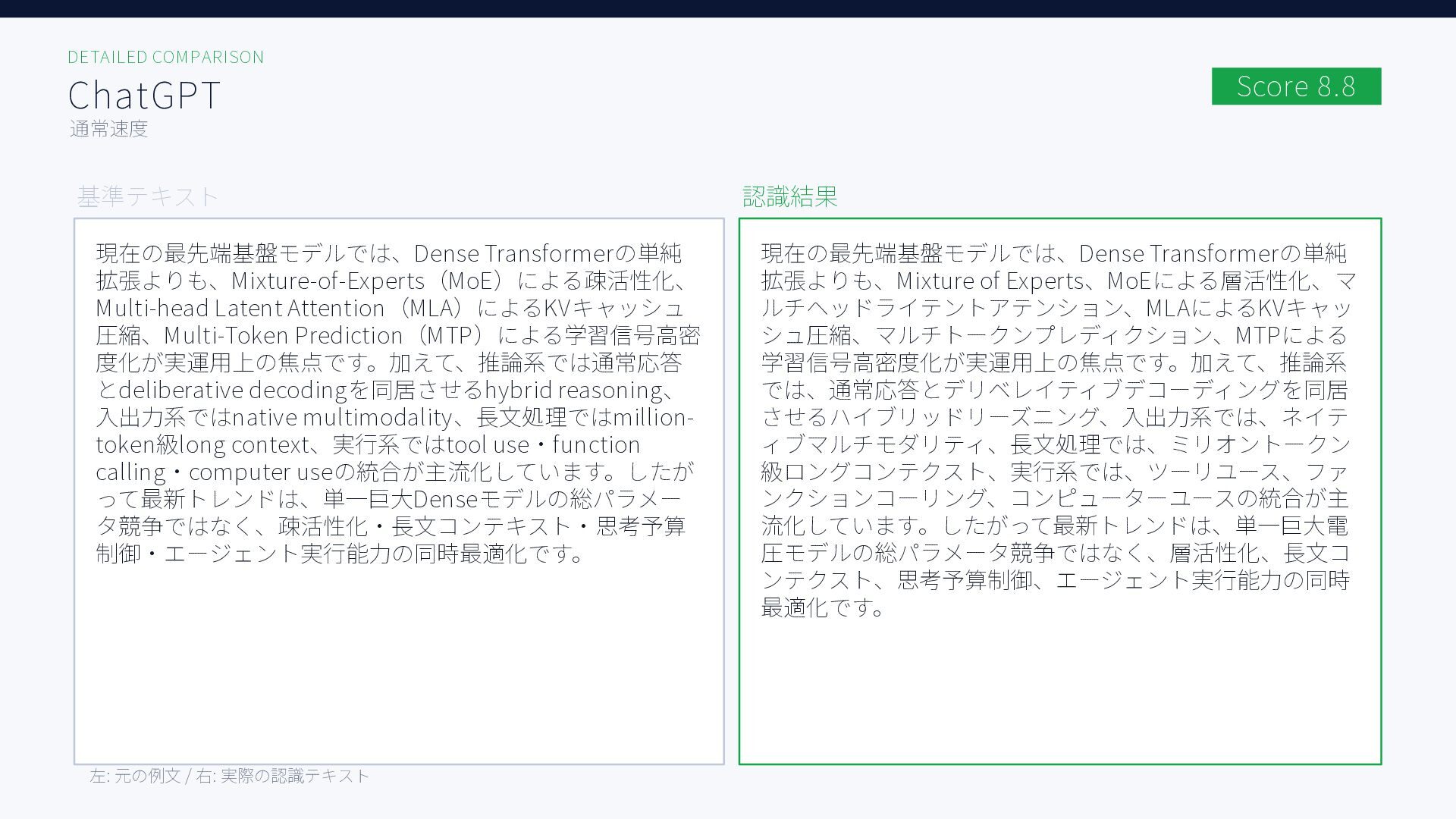{kind=link}
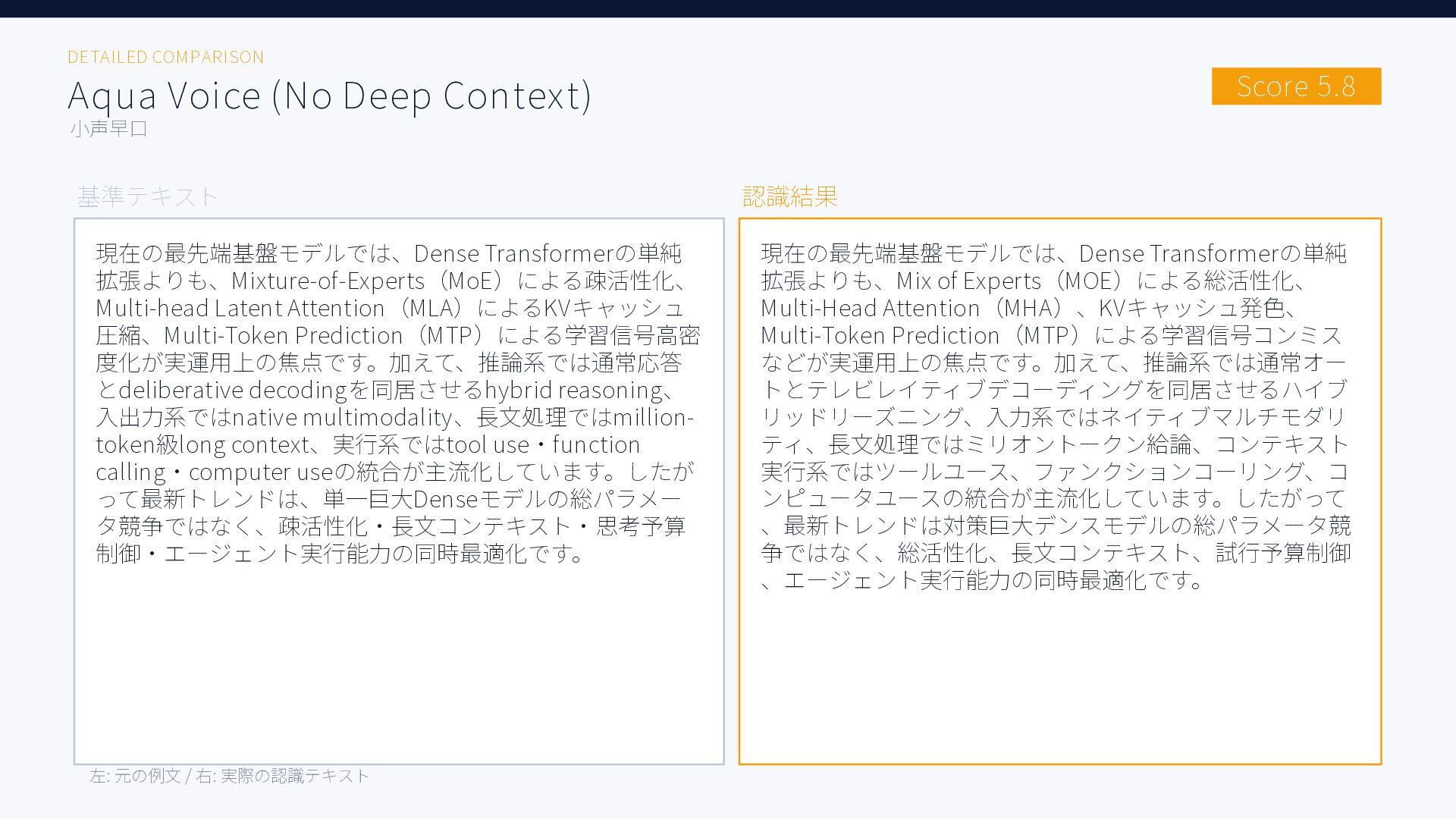{kind=link}
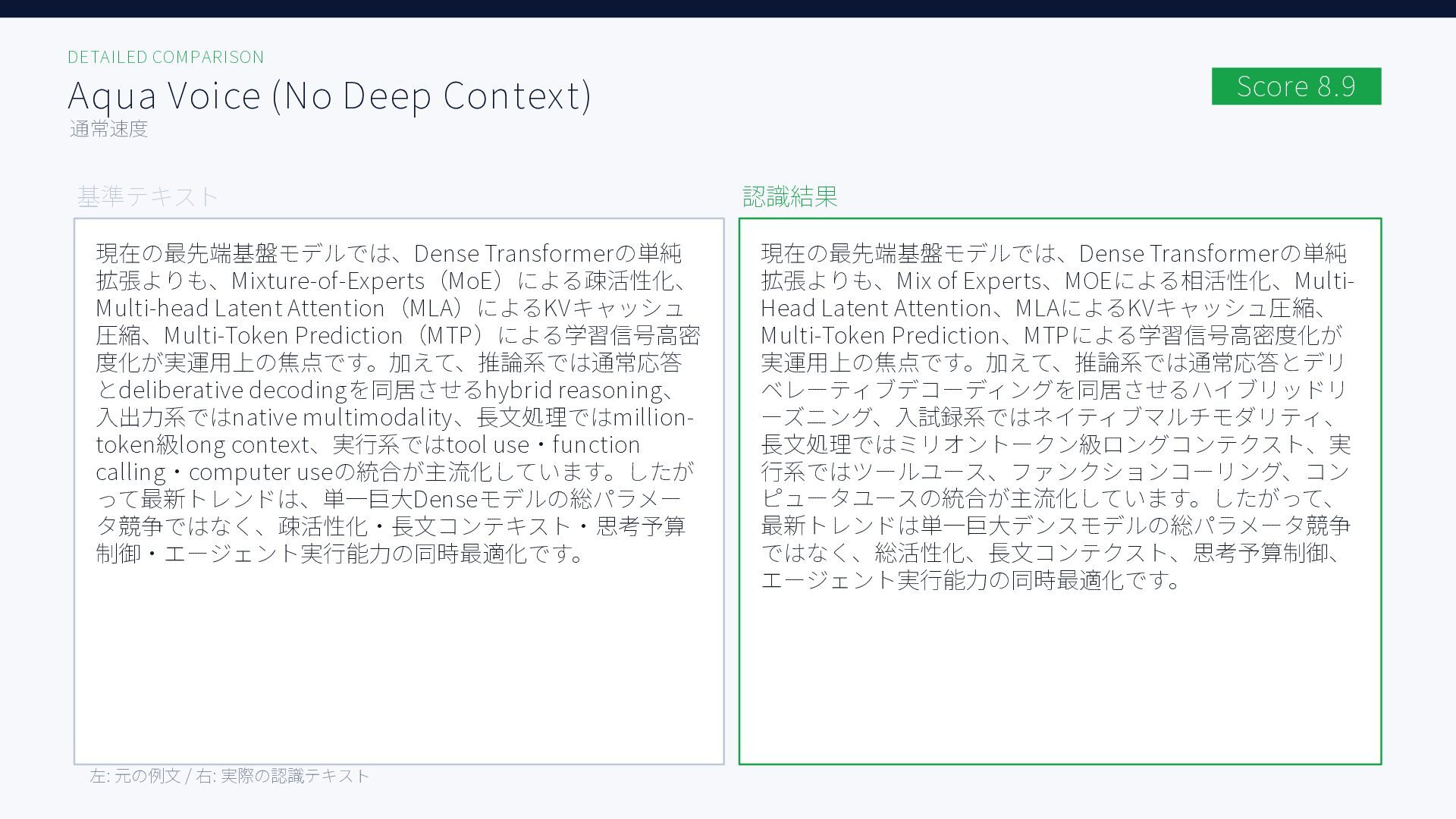{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}