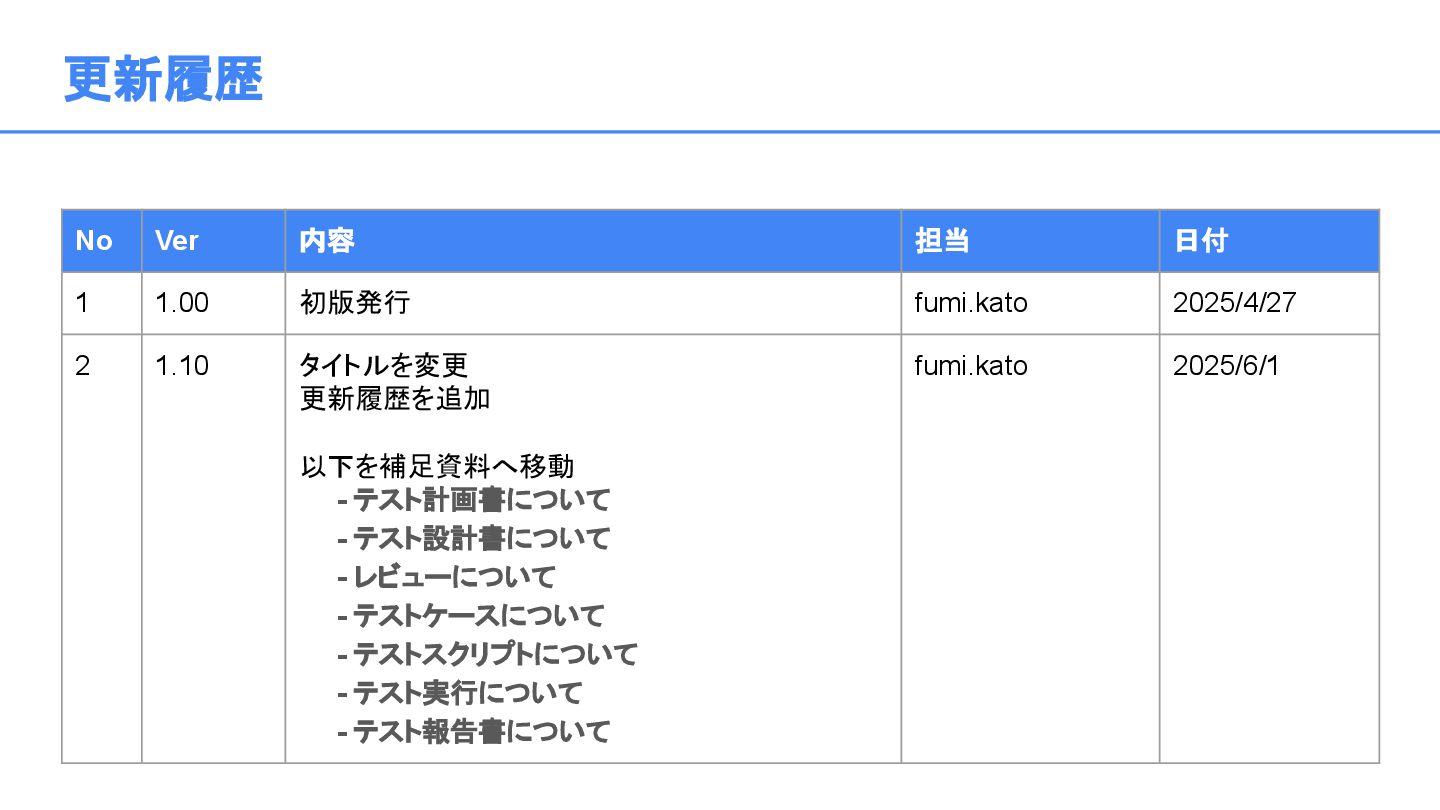
"
[email protected]"]) / 電話番号の空文字および形式不正のテスト引数が準備されている(phoneTestValues = ["12345", "09012345678"]) / 確認のご連絡属性に基づくテスト用パラメータが準備されている(confirmationContactValues = [true, false]) / 依存オブジェクトがテスト対象に注入さ れている(targetInstance.setDependency(mockDepend 前提条件 ステージング環境が構築され、データベースサーバと認証基盤が起動していること。(staging環境構築済み、DBサーバ起動、認証基盤準備完了) / 外部システムとの接続 設定が完了し、ネットワーク設定が適切に行われていること。(外部システム接続設定済み、ネットワーク設定完了) / テスト用のマスタデータ(プラン、商品、ユーザー等)が 登録されていること。(プラン、商品、ユーザー等のマスタデータ登録済み) / モックサーバが設定・起動され、テスト用APIエンドポイントが準備されていること。(モックサーバ 起動済み、テストAPIエンドポイント準備完了) 入力データ テスト対象クラスのインスタンスが生成されている(testInstance = new ConfirmationContactValidator()) / メールアドレス検証用のモックが設定されている (emailValidatorMock = createMock<EmailValidator>()) / 電話番号検証用のモックが設定されている(phoneValidatorMock = createMock<PhoneValidator>()) / "確認 のご連絡"属性に基づく有効なメールアドレスがテスト引数として準備されている(confirmationContact.email = "
[email protected]") / "確認のご連絡"属性に基づく有効 な電話番号がテスト引数として準備されている(confirmationCon ACC Matrix - JSON [{"attr_id": "ATTR-0", "attr_name": "正確性", "comp_id": "COMP-0", "comp_name": "連絡方法選択判定関数", "capability": "連絡方法の条件分岐を正しく判定する", "confidence": 0.95, "actors": ["一般ユーザー"]}, {"attr_id": "ATTR-2", "attr_name": "信頼性", "comp_id": "COMP-1", "comp_name": "入力検証モジュール", "capability": "連絡手段ごとに独立した入力検証を行う", "confidence": 0.9, "actors": ["一般ユーザー"]}, {"attr_id": "ATTR-3", "attr_name": "ユーザービリティ", "comp_id": "COMP-2", "comp_name": "連絡先情報管理", "capability": "誤入力を防止し連絡失敗リスクを低減する", "confidence": 0.8, "actors": ["一般ユーザー"]}] 事後条件 確認のご連絡が「メールでのご連絡」以外の場合、メールアドレスの妥当性チェックはスキップされること / メールアドレスが空でなく正しい形式の場合、連絡方法選択関数が trueを返すこと / メールアドレスが空または形式が不正の場合、連絡方法選択関数がfalseを返すこと / 連絡方法選択関数の判定結果をログに出力すること(対象: application_log, 種類: emit) / 関連するユーザーデータの連絡方法判定結果をDBに更新すること(対象: database, 種類: update) / 判定処理が正常終了した場合、トラン ザクションがコミットされること(対象: transaction, 種類: update) / 判定エラー発生時にエラーログが出力されること(対象: application_log, 種類: emit) 期待結果 連絡方法選択関数が条件の真偽値を独立して正しく判定し戻り値に反映すること(戻り値が条件「確認のご連絡 != 'メールでのご連絡'」または「メールアドレスが空でなく形 式が正しい」の真偽値を正確に反映) / 連絡方法選択関数の戻り値が条件「確認のご連絡 != 'メールでのご連絡'」の真偽値を正しく反映すること(戻り値が確認のご連絡が' メールでのご連絡'でない場合にtrue、それ以外はfalseを返す) / 連絡方法選択関数の戻り値が条件「メールアドレスが空でなくかつ形式が正しい」の真偽値を正しく反映す ること(戻り値がメールアドレスが空でなく形式が正しい場合にtrue、それ以外はfalseを返す) テスト条件の出力サンプル (一部抜粋)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![テスト要件 [workflow] 連絡方法選択判定関数の分岐ロジック等の確認 目的(ビジネス価値) ユーザーからの連絡方法選択に関する条件分岐が正しく機能し、連絡手段毎の入力検証が独立して結果に影響を与えることを保証することで、誤った連絡先情報による連絡 失敗リスクを軽減し、顧客対応品質を向上させる テスト対象フューチャー 連絡方法選択判定関数の条件分岐ロジック(メールアドレス検証関数の入力形式チェック) 範囲IN/範囲OUT 🔳範囲IN](https://files.speakerdeck.com/presentations/5afb1232b98e4e62bd0ea10b76562c5a/slide_79.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(例)機能仕様から生成されるテスト条件 (詳細インサイト ) 入力パラメータ検証 ValidInputCase 内容: 正常系の代表的なテストケース 出力例: 「[email protected]等の標準メール形式での認証成功検証」 InvalidInputCase](https://files.speakerdeck.com/presentations/5afb1232b98e4e62bd0ea10b76562c5a/slide_92.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
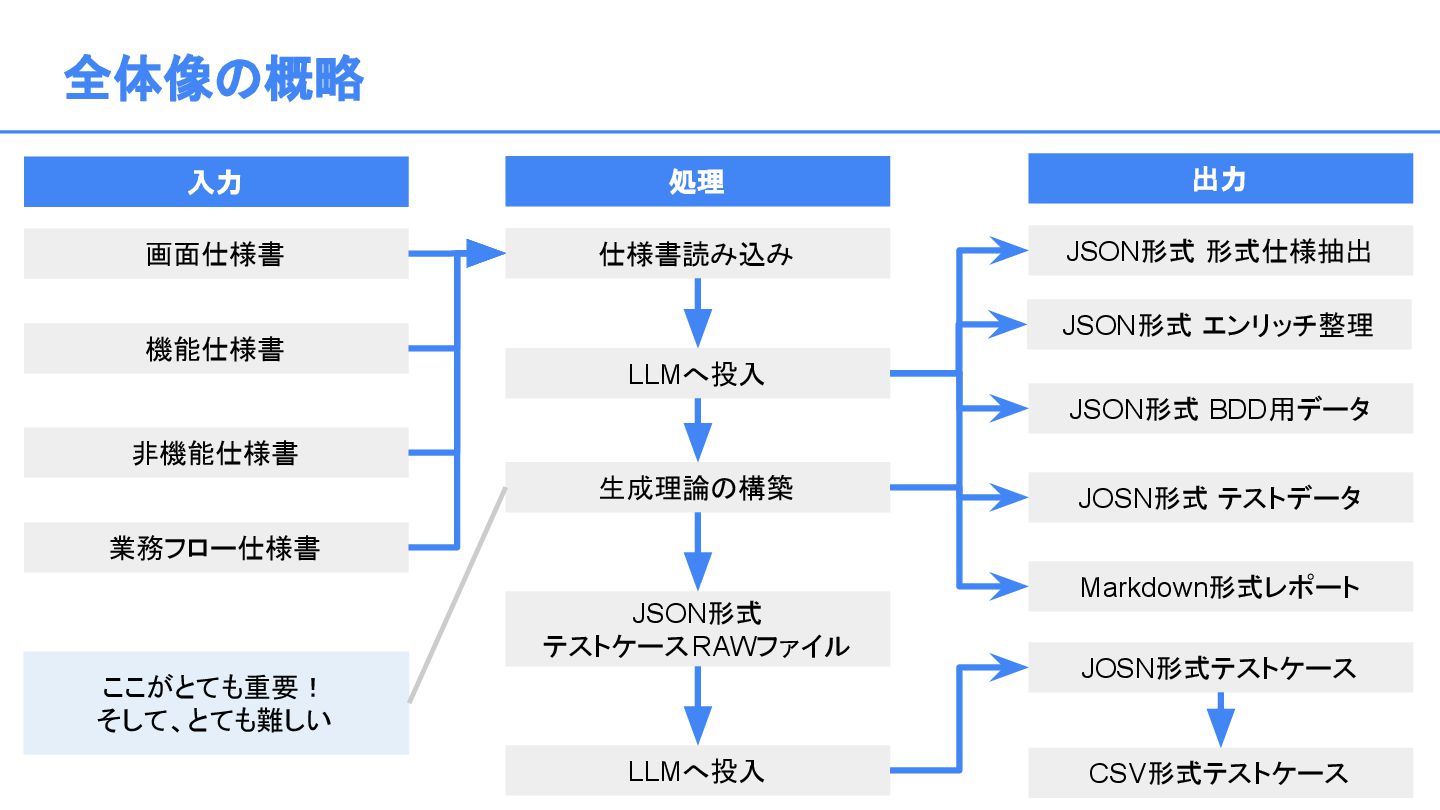{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
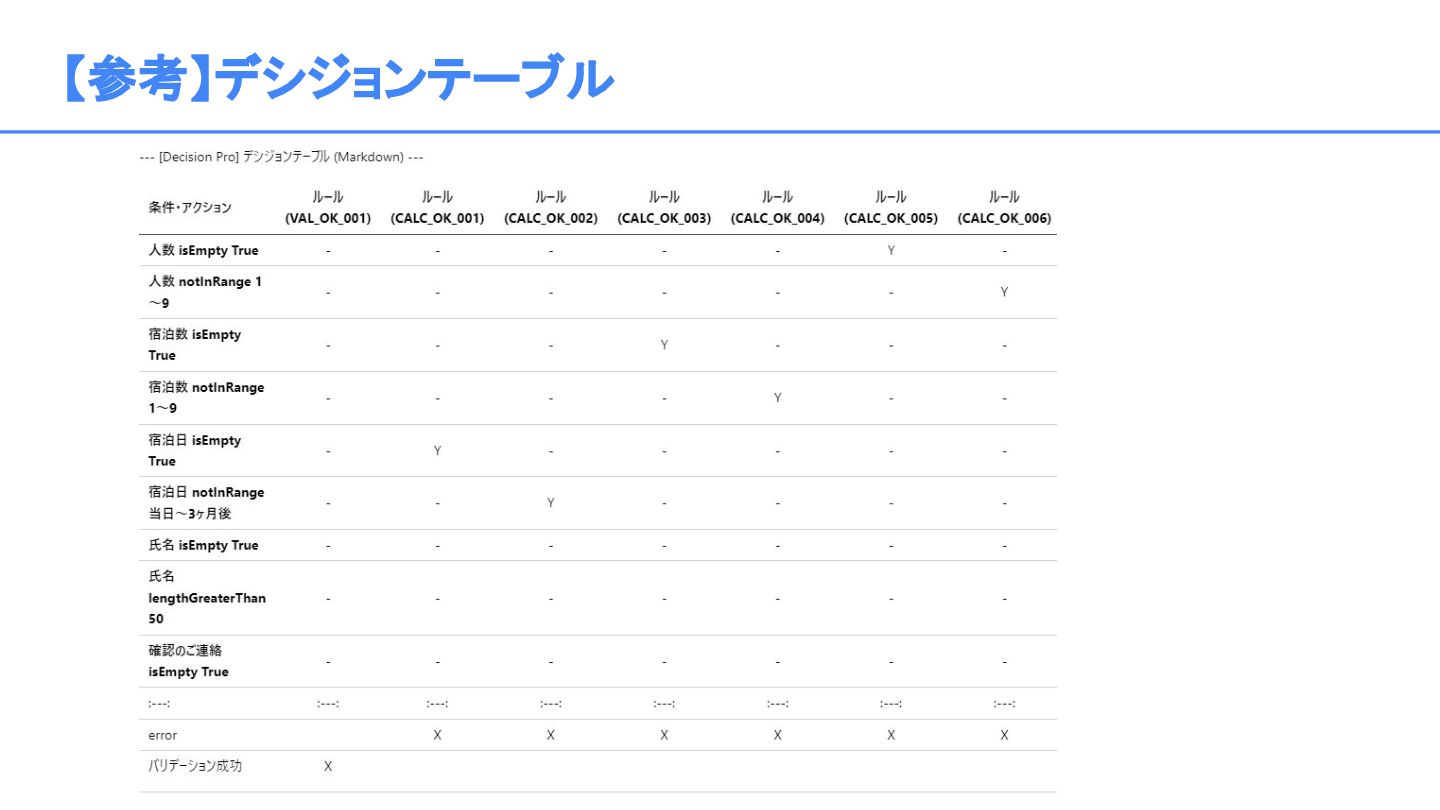{kind=link}