Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Cortex Codeでデータの仕事を全部Agenticにやりきろう!
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
harry
April 07, 2026
Technology
850
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Cortex Codeでデータの仕事を全部Agenticにやりきろう!
AI駆動開発 x Snowflake - Snowflake Night #3
https://snowflakejapan.connpass.com/event/385891/
harry
April 07, 2026
More Decks by harry
See All by harry
組織全員で向き合うAI Readyなデータ利活用
gappy50
6
3.7k
Snowflake Intelligenceにはこうやって立ち向かう!クラシルが考えるAI Readyなデータ基盤と活用のためのDataOps
gappy50
2
2.3k
データエンジニアがクラシルでやりたいことの現在地
gappy50
3
1.4k
dbtを中心にして組織のアジリティとガバナンスのトレードオンを考えてみた
gappy50
3
660
マルチプロダクト、マルチデータ基盤での Looker活用事例 〜BQじゃなくてもLookerはいいぞ〜
gappy50
0
290
クラシルのデータ活用の現在とプロダクトファーストから考えるデータエンジニアのキャリア
gappy50
1
940
プロダクトへ貢献するためのデータ基盤活用事例
gappy50
3
510
1日3億回の行動データを価値に繋げるデータパイプライン構築 〜クラシルにおけるSnowflakeでのニアリアルタイム分析の実現〜
gappy50
1
4.6k
Other Decks in Technology
See All in Technology
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
240
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
100
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
1
220
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
280
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.5k
AI時代の闇と光
tatsuya1970
0
110
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
240
SRE Next 2026 何でも屋からの脱却
bto
0
960
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
560
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
220
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
110
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
310
Featured
See All Featured
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Odyssey Design
rkendrick25
PRO
2
730
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Raft: Consensus for Rubyists
vanstee
141
7.6k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
WCS-LA-2024
lcolladotor
0
710
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Transcript
Cortex Codeで データの仕事を 全部Agenticにやりきろう! harry(@gappy50) / クラシル株式会社
自己紹介 harry (@gappy50) クラシル株式会社 データエンジニア 担当業務 ・ クラシルのデータ基盤新規構築 ・ 現在は全社データ基盤の構築・運用
技術スタック ・ Snowflake / dbt / Lightdash Snowflake Data Superhero ・ 2022-2026(5年連続)
None
None
本日の話: ブログ2本の紹介 + Cortex Code 今日はこの内容を紹介しつつ、同じことがCortex Codeでもできるという話をします https://zenn.dev/dely_jp/articles/claude-code-agent-team-design https://zenn.dev/dely_jp/articles/snowflake-managed-mcp-claude-code-agentic-dataops
ブログで書いたこと
前提: クラシルのデータにはTierがある dbtで管理しているデータモデルに品質の段階(Tier)をつけて運用している Tier 用途 AI利用 期限 Tier 1-2 経営KPI・監査
永続 Tier 3 部門意思決定 永続 Tier 4 アドホック分析 90日で自動削除 Tier 5 個人のSQL試行 30日で自動削除 Tier3以上がAIエージェントで分析可能
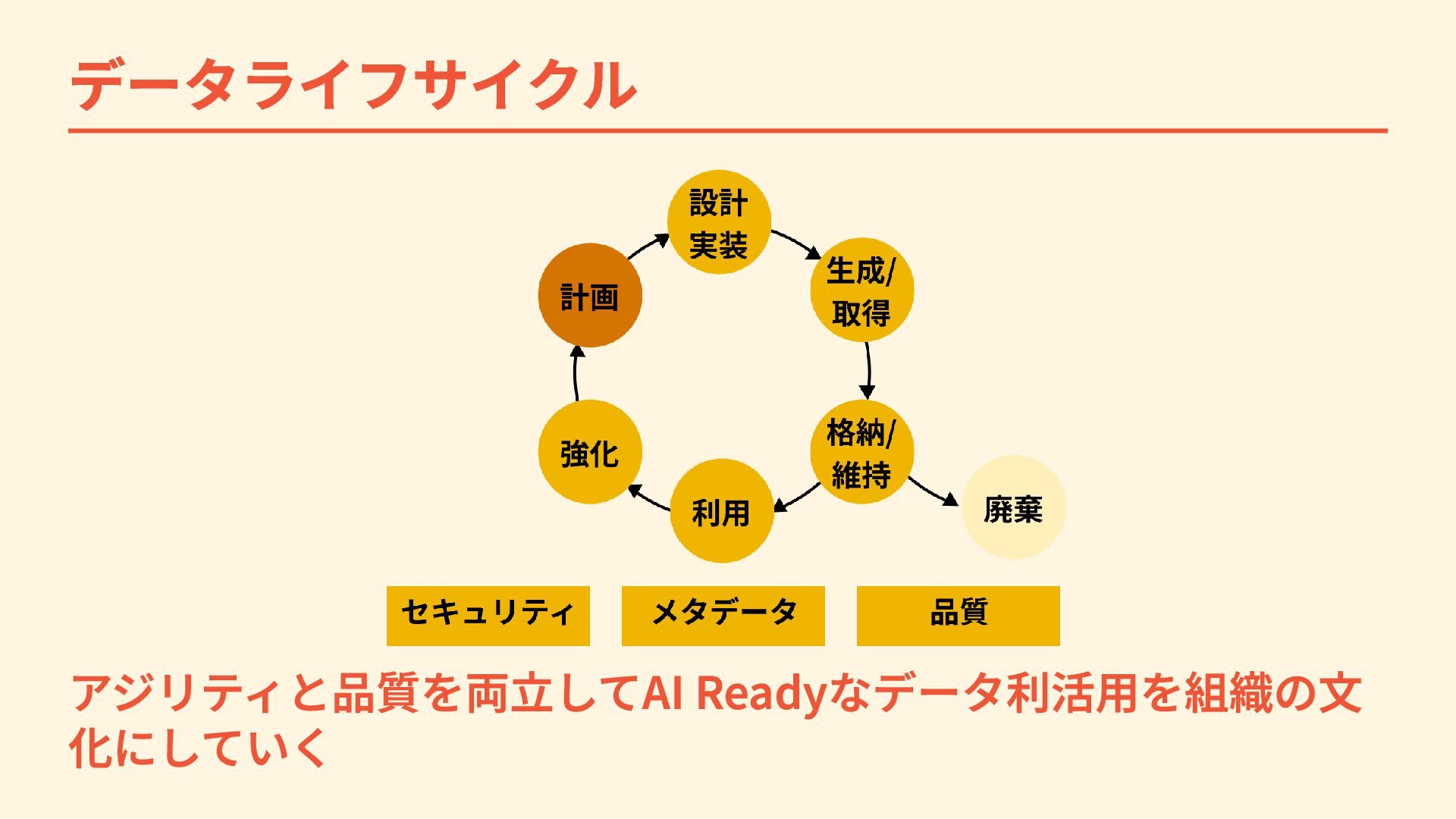
データライフサイクル アジリティと品質を両立してAI Readyなデータ利活用を組織の文 化にしていく
ブログ1本目: Agent Teamsで Tier昇格を自動化
1本目の課題: Tier昇格が回らない Tier4(adhocモデル)をTier3(AI利用可能)に上げるには以下が必要 1. ディメンショナルモデルへの設計変更 2. SQL/YAMLの実装 3. 移行前後の数値が一致するかの検証 4.
メタデータ(カラムの意味や計算ロジック)の整備 これを手動でやると最大2日。2〜3人のデータエンジニアで7ドメインを回しているので、順 番待ちが発生する
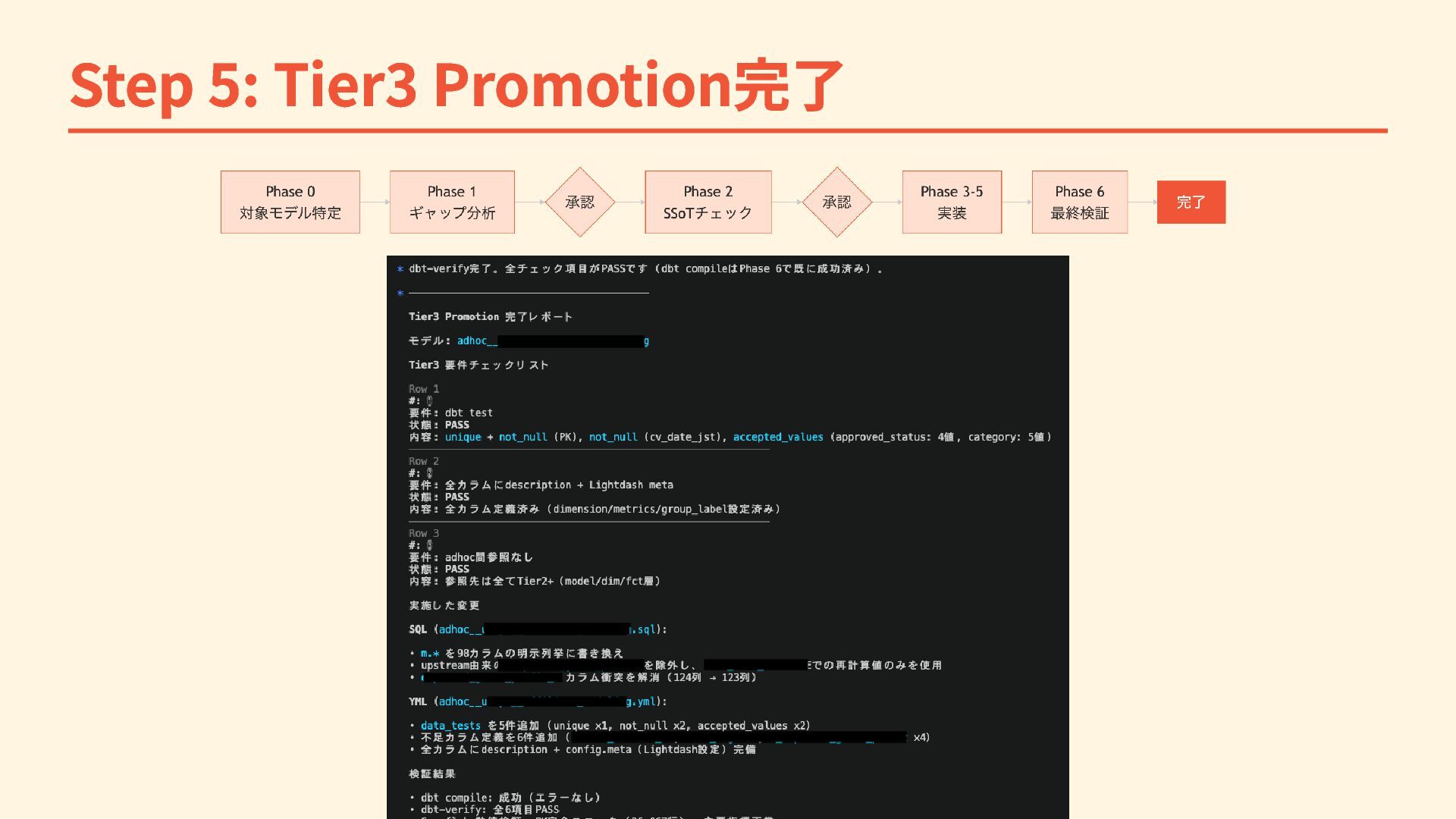
Tier3昇格の3要件 Tier4 -> Tier3に昇格するための品質要件 1. generic testが定義されていること ・ not_null /
unique / accepted_values 等 ・ CIでデータの整合性を自動検証 2. 全カラムにdescriptionが整備されていること ・ カラムの意味・計算ロジックをYAMLに記述 ・ Semantic View生成の入力にもなる 3. 他のadhocモデルへの参照がないこと ・ adhoc間の依存を断ち切り、SSoT(Single Source of Truth)を確立
Tier3昇格フロー(前半)Phase 0〜2
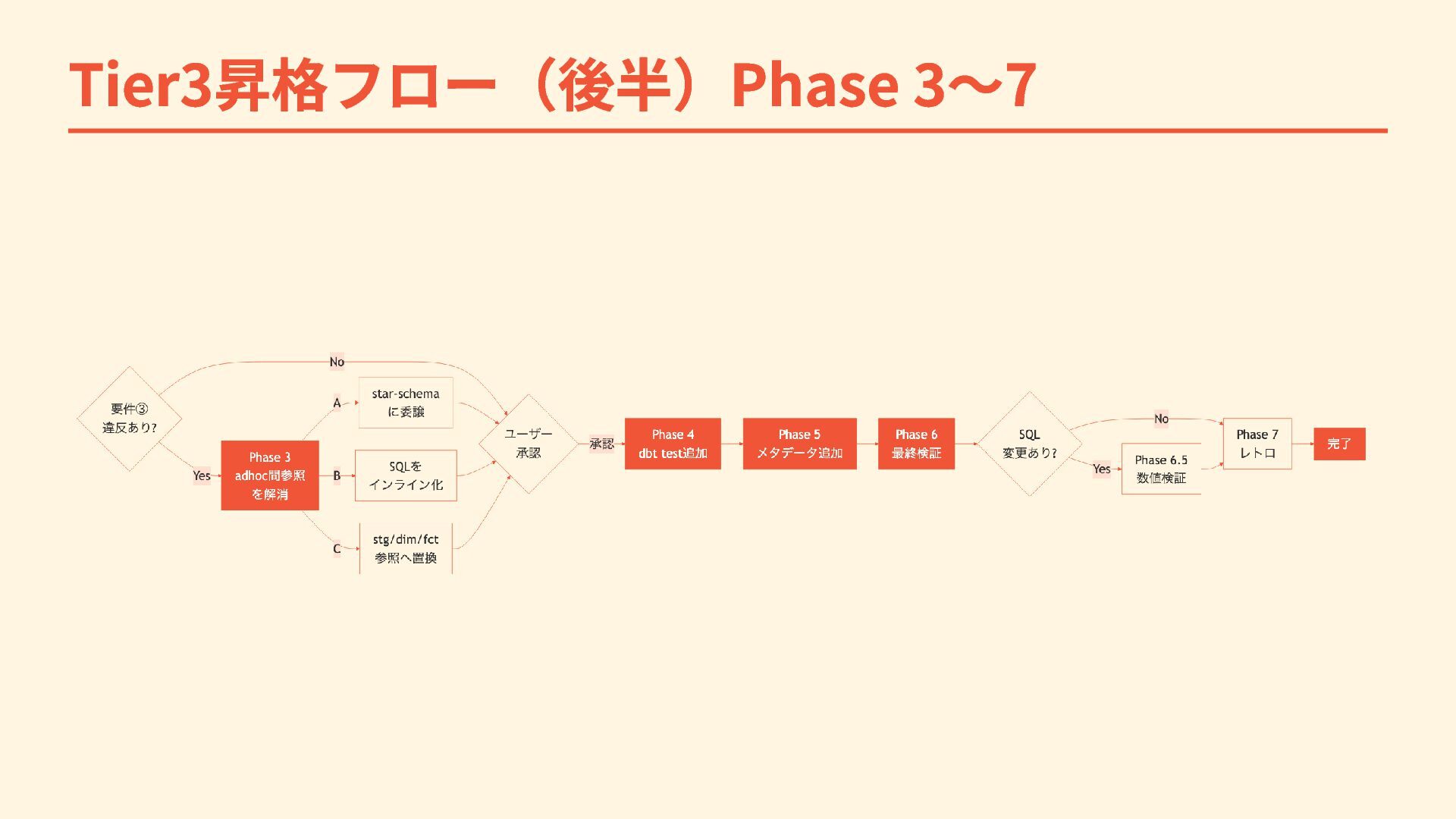
Tier3昇格フロー(後半)Phase 3〜7
1本目の解決: Agent Teamsで分業 4つの役割に分けたエージェントを定義した エージェント やること 権限 data-architect 設計だけ。コードは書かない read-only
dbt-data-modeler 設計に基づいてSQL/YAMLを実装 write migration-tester MCP経由でSnowflakeに接続し数値検証 read-only data-engineer インフラ・パイプライン 全権限 write権限を持つのは実装担当の1体だけ
Claude Code Agent Teamsとは 複数のエージェントに異なる役割・権限・モデルを割り当ててチームとして動かす仕組み なぜ使うか ・ 単一エージェントでは権限の分離ができない(全操作が同一権限で実行される) ・ タスクが複雑になるほどコンテキストが膨らみ、精度が下がる
・ モデルのコスト差が大きい(Opus/Sonnet)ため、全タスクに高コストモデルを使うの は非効率 できること ・ エージェントごとにread-only/writeなど権限を制御 ・ Opus/Sonnetなどモデルを役割に応じて使い分け ・ .claude/agents/ にMarkdownで定義するだけで構成可能 Cortex Codeでもの複数エージェントオーケストレーションがリ リース
ブログ2本目: MCP Serverで Agentic DataOpsを回す
2本目の位置づけ: 1本目の「その先」 1本目はTier昇格(データモデルの品質を上げる作業)の自動化だった 2本目は、品質を上げたデータモデルを使って分析やマネジメントまで含めた一連のサイク ルをAIエージェントで回す話 Snowflake Managed MCP Serverを使って、Claude CodeからSnowflakeに直接接続する
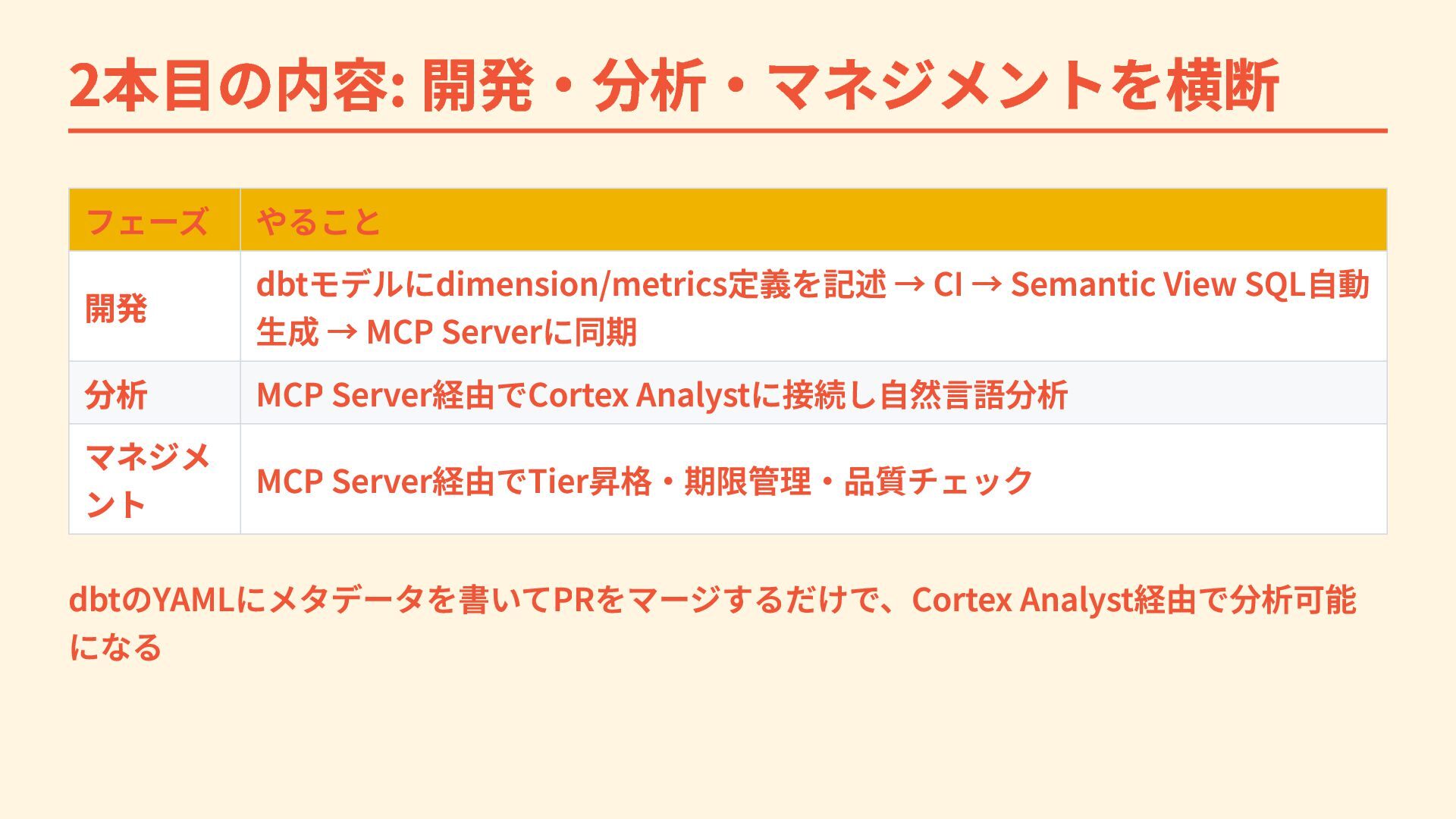
2本目の内容: 開発・分析・マネジメントを横断 フェーズ やること 開発 dbtモデルにdimension/metrics定義を記述 → CI → Semantic
View SQL自動 生成 → MCP Serverに同期 分析 MCP Server経由でCortex Analystに接続し自然言語分析 マネジメ ント MCP Server経由でTier昇格・期限管理・品質チェック dbtのYAMLにメタデータを書いてPRをマージするだけで、Cortex Analyst経由で分析可能 になる
ここまでのまとめ Claude Codeベースでやっていること ・ Agent Teams: 役割分離したエージェントでTier昇格を自動化 ・ MCP Server:
Snowflakeに接続して開発・分析・マネジメントを横断 ・ Semantic View: dbtのメタデータからAI分析可能な定義を自動生成 ・ Skills: エージェントの振る舞いを定義ファイルで管理 MCPやSemantic ViewはSnowflake側の機能なので、エージェント側のツールは入れ替え可 能
同じことが Cortex Code CLIでもできる
Cortex Codeとは Snowflakeが提供するコーディングエージェント 2つの使い方 ・ Snowsight版: SnowflakeのUIからブラウザで利用 ・ CLI版: ローカルシェルで実行。dbt/Airflowをネイティブサポート
クラシルでのCortex Codeの使い分け Cortex Code in Snowsight ・ データエンジニアやPdMがNotebooksで利用しており、かなり威力を発揮できている ・ Snowflake内で完結する作業はCortex
Codeの方が手軽 Claude Code ・ データ分析でグロースに向き合うところでは、メンバーのスキルセット的にClaude Codeに一極集中させた方がいい状態 ・ Snowflake以外のコンテキスト(GitHub、ドキュメント等)もAIに食わせたいケースが 多い
Claude Codeでやったこと -> Cortex Codeでの対 応 機能 Claude Code Cortex
Code エージェントチーム Agent Teams Agent Teams(GA) データ検証 MCP Server経由 ネイティブSQL 自然言語分析 Cortex Analyst via MCP Cortex Analyst直結 スキル定義 .claude/skills/ SKILL.md(同一形式) アクセス制御 OAuth設定が必要 RBAC自動適用 SKILL.mdはClaude CodeとCortex Codeで同一フォーマット(AGENTS.mdも対応) 。スキ ルの相互移植が可能
Cortex Codeの方がシンプルな部分 ・ セットアップ: OAuth/MCP Server構築が不要。ログインすれば使える ・ アクセス制御: SnowflakeのRBACがそのまま効く ・
非エンジニア展開: Snowsight版ならブラウザだけで利用可能 クラシルではデータエンジニア以外も含めてClaude Codeを標準にしている。 Snowflake以外のコンテキストもAIに食わせたいため。 ただしデータの重心を全てSnowflakeに寄せられるなら、Cortex Codeの方がシンプルだし コスト面でも有利な可能性がある
デモ: Tier3昇格の流れ
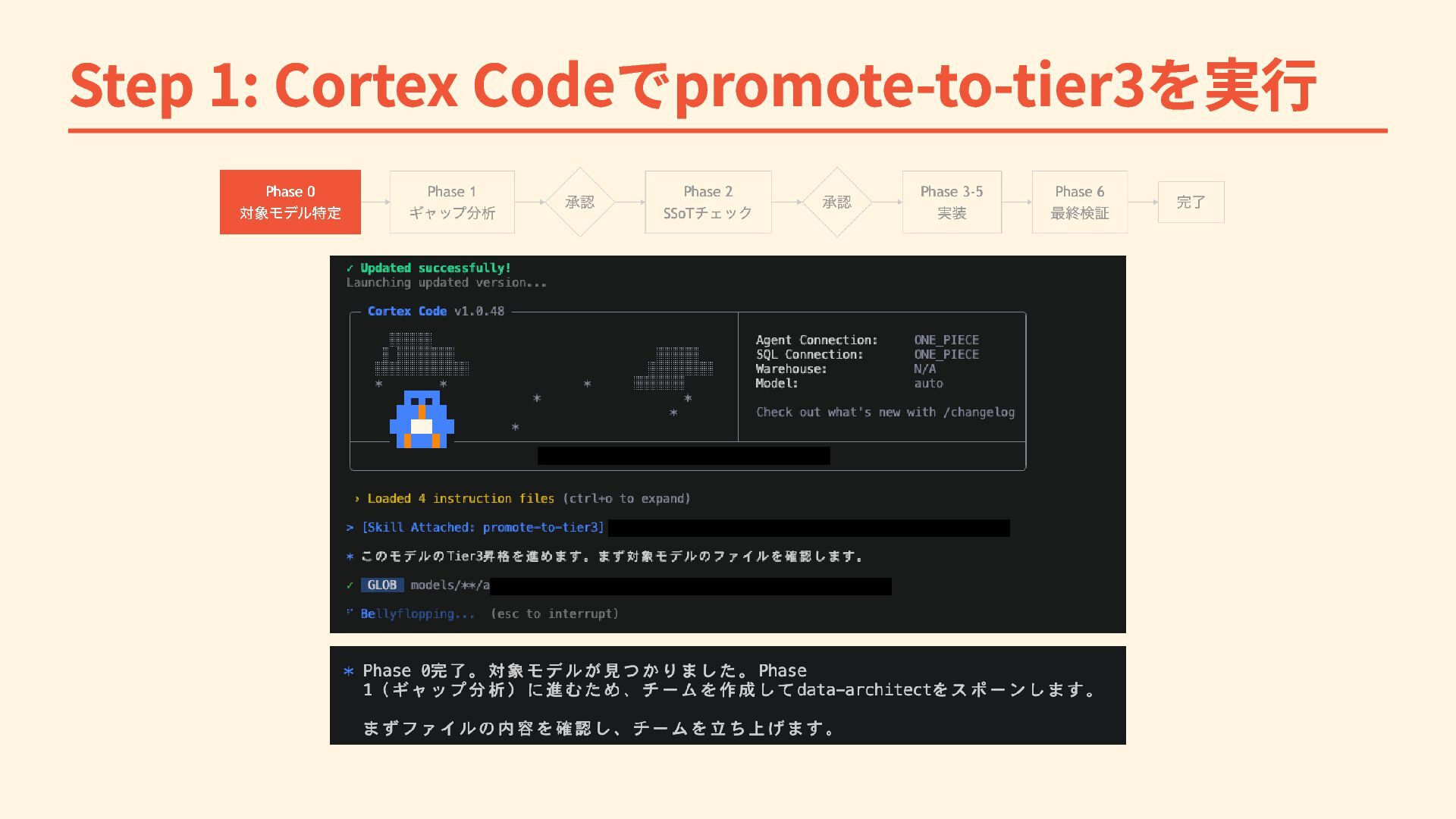
Step 1: Cortex Codeでpromote-to-tier3を実行
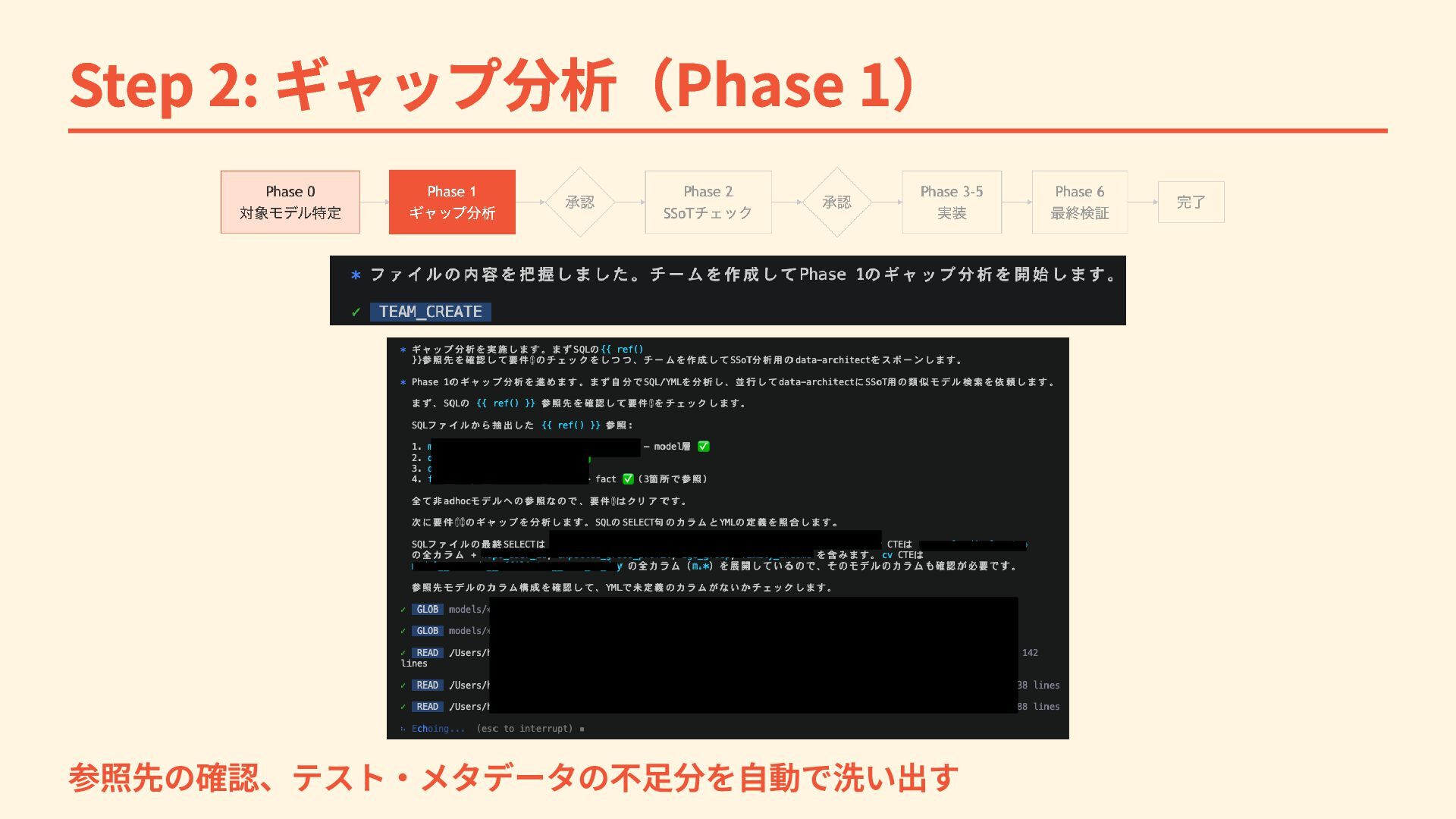
Step 2: ギャップ分析(Phase 1) 参照先の確認、テスト・メタデータの不足分を自動で洗い出す
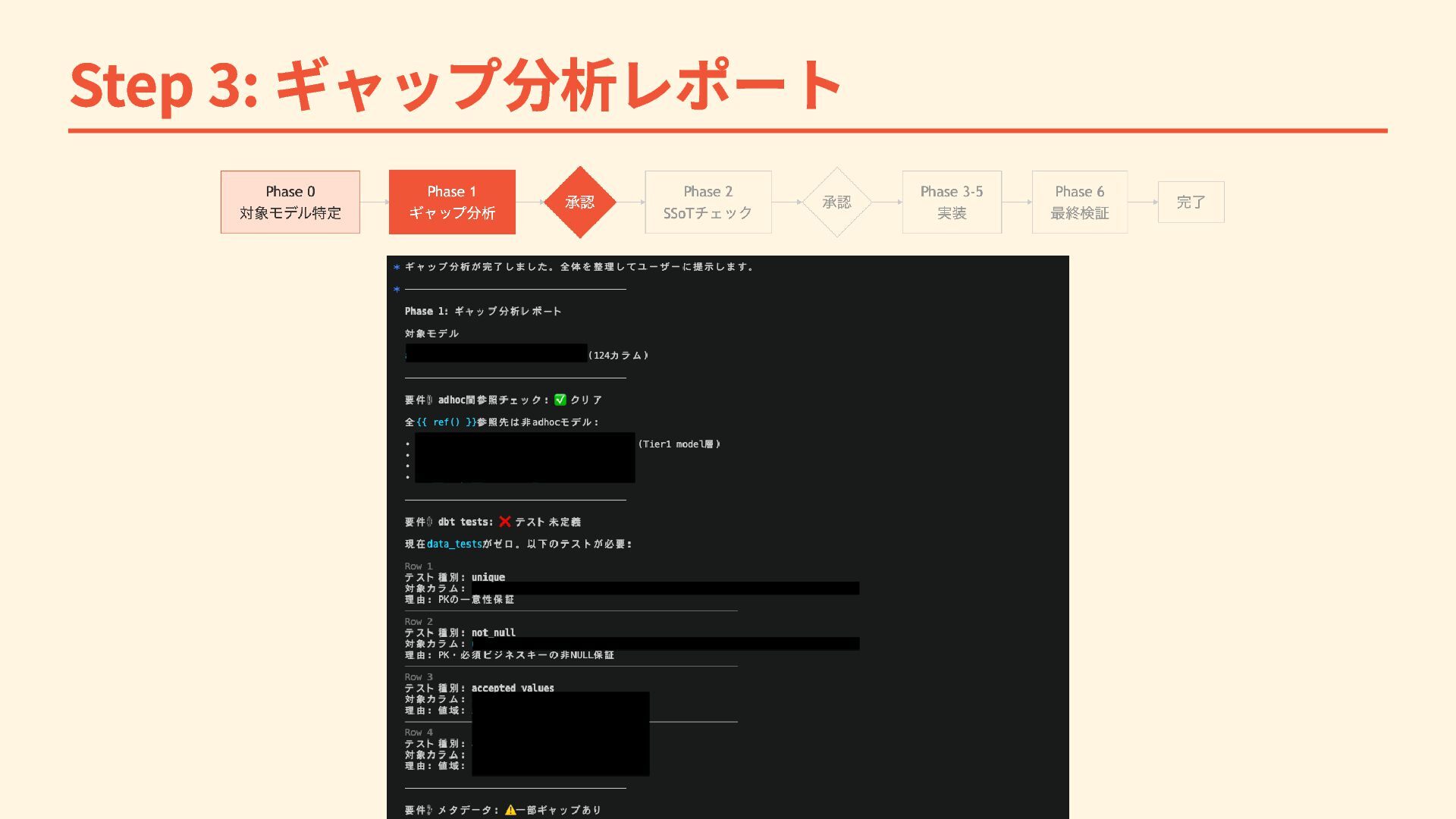
Step 3: ギャップ分析レポート
Step 4: SSoTチェック + ユーザー承認 同一ビジネスイベントの重複モデルがないかを検証。PASSしたモデルにssot_verifiedタグ を付与。ユーザーが承認して次のPhaseへ
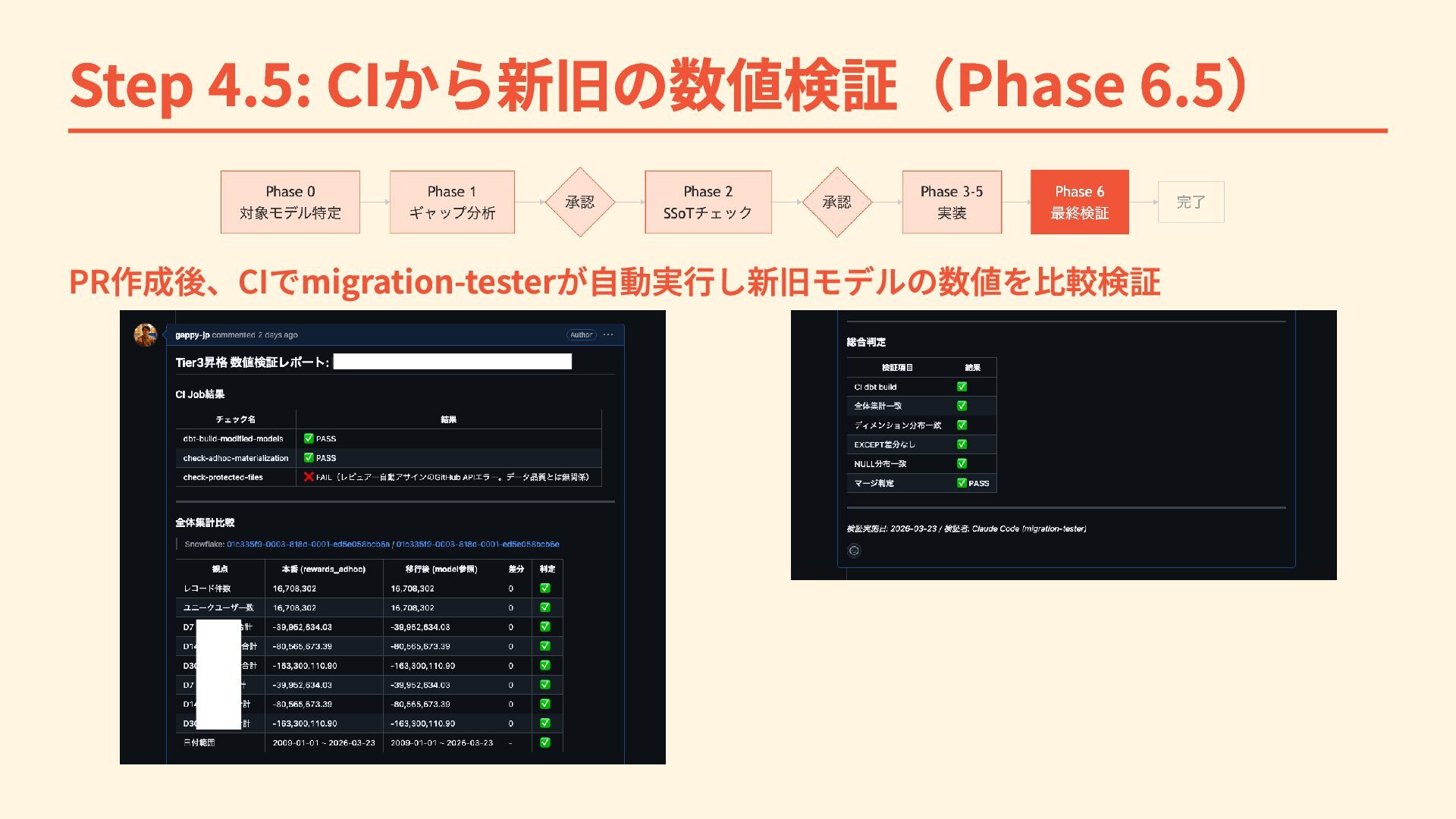
Step 4.5: CIから新旧の数値検証(Phase 6.5) PR作成後、CIでmigration-testerが自動実行し新旧モデルの数値を比較検証
Step 5: Tier3 Promotion完了
Skillsの自己改善ループ
AIに一発で正解を出させるのは難しい どのデータをどう使うのか、品質の判断基準は何か、これらは組織ごとに異なる 自分たちのルールや判断軸をSkillsとして言語化し、AIの振る舞いを制御する「ハーネスエ ンジニアリング」ができると、正解に近づきやすくなる 自分たちのルール -> SKILL.mdに言語化 -> AIがルールに従って実行 ->
結果を確認、ルールを修正 -> SKILL.mdを更新 -> (繰り返し)
クラシルではSkillsの自己改善を実践している 作業完了後にエージェントが振り返りを実行し、改善点をSKILL.mdに書き戻す ・ promote-to-tier3スキルは実際に複数回の改善を経て今の形になった ・ 数値検証に必要なCIの監視ルール、dbtのタグ配置ルール等が振り返りから追加された ・ エージェントが完璧である必要はない。改善が回る仕組みがあればいい Cortex Codeでも同じSKILL.mdフォーマットなので、この改善ループはそのまま適用できる
まとめ
今日話したこと Claude Codeでやったこと ・ Agent TeamsでTier昇格を自動化(手動2日 -> 1-2時間) ・ MCP
Server経由で開発・分析・マネジメントを横断 ・ Semantic Viewの自動パイプライン Cortex Codeでも同じことができる ・ Agent Teams、SKILL.md互換、ネイティブSQL実行 ・ セットアップはCortex Codeの方がシンプル ・ Snowflake中心の組織ならCortex Codeから始めるのもあり
Skillsを活用するとさらに良くなる ・ Cortex Codeにはデータガバナンスやデータエンジニアリング等の組み込みSkillsが用 意されている。まずはそれを使うところから始められる ・ その上で、自分たちの組織のルールや判断軸をSKILL.mdとして言語化すると、AIの出 力が安定する ・ Skillsの自己改善ループも回せると、使うほど精度が上がっていく
Thank you! harry (@gappy50) / クラシル株式会社
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}