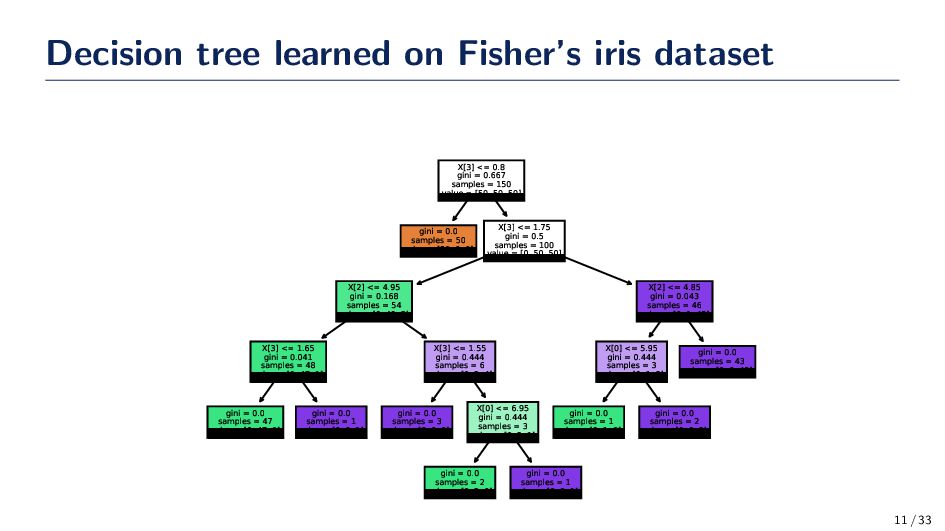
samples = 2 value = [0, 2, 0] gini = 0.0 samples = 1 value = [0, 0, 1] gini = 0.0 samples = 47 value = [0, 47, 0] gini = 0.0 samples = 1 value = [0, 0, 1] gini = 0.0 samples = 3 value = [0, 0, 3] X[0] <= 6.95 gini = 0.444 samples = 3 value = [0, 2, 1] gini = 0.0 samples = 1 value = [0, 1, 0] gini = 0.0 samples = 2 value = [0, 0, 2] X[3] <= 1.65 gini = 0.041 samples = 48 value = [0, 47, 1] X[3] <= 1.55 gini = 0.444 samples = 6 value = [0, 2, 4] X[0] <= 5.95 gini = 0.444 samples = 3 value = [0, 1, 2] gini = 0.0 samples = 43 value = [0, 0, 43] X[2] <= 4.95 gini = 0.168 samples = 54 value = [0, 49, 5] X[2] <= 4.85 gini = 0.043 samples = 46 value = [0, 1, 45] gini = 0.0 samples = 50 value = [50, 0, 0] X[3] <= 1.75 gini = 0.5 samples = 100 value = [0, 50, 50] X[3] <= 0.8 gini = 0.667 samples = 150 value = [50, 50, 50] 11 / 33
![Machine Learning Lectures Decision Trees Gregory Ditzler [email protected] February 24,](https://files.speakerdeck.com/presentations/efca17df409f49bb8ef3eb6eaa8e145c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
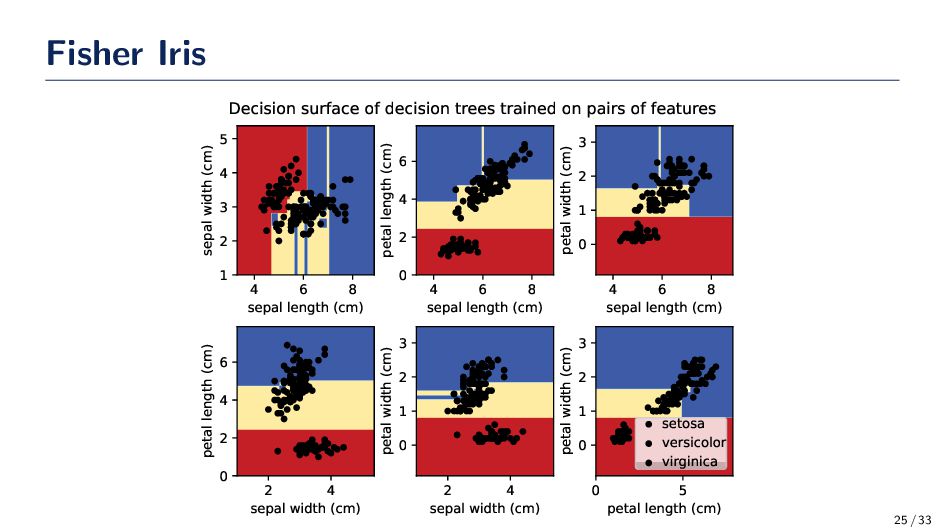{kind=link}
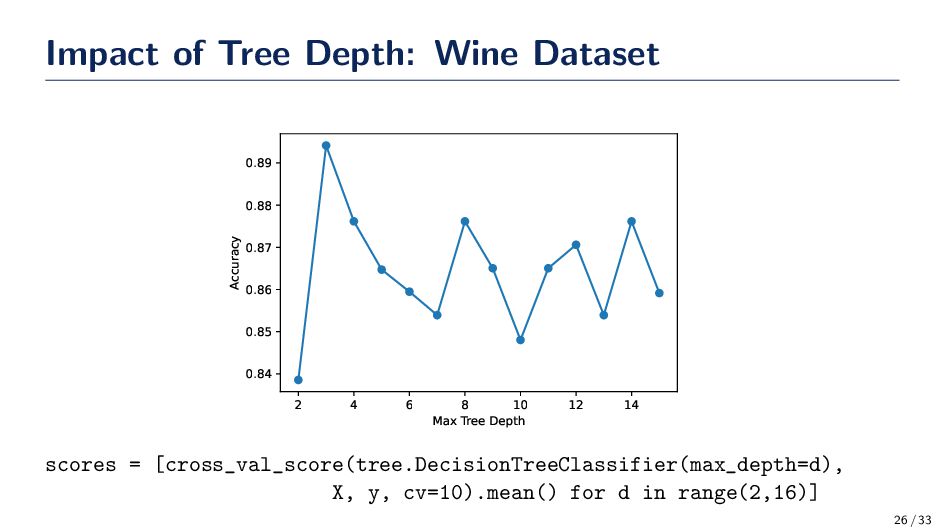{kind=link}
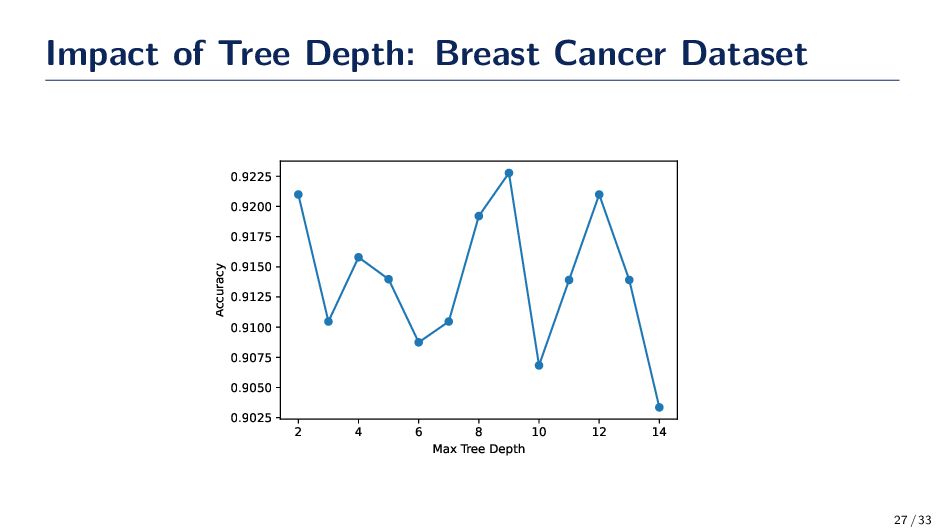{kind=link}
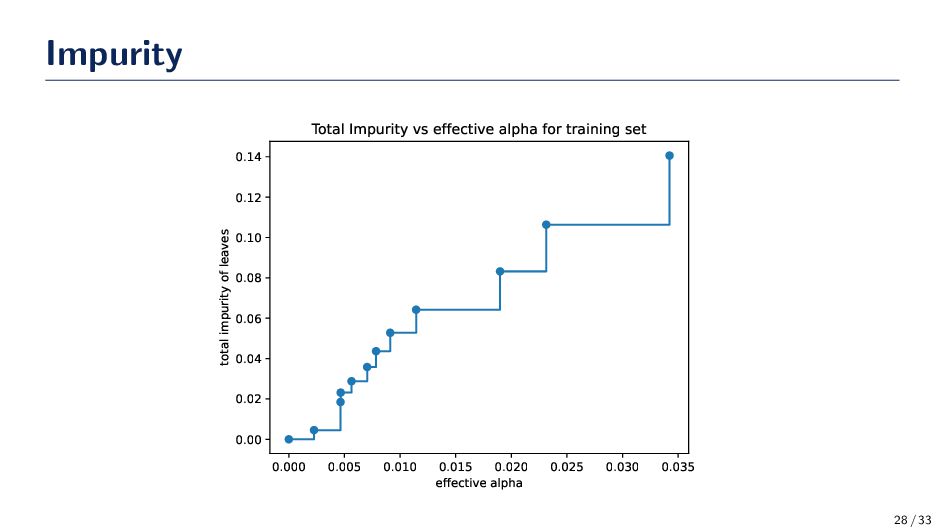{kind=link}
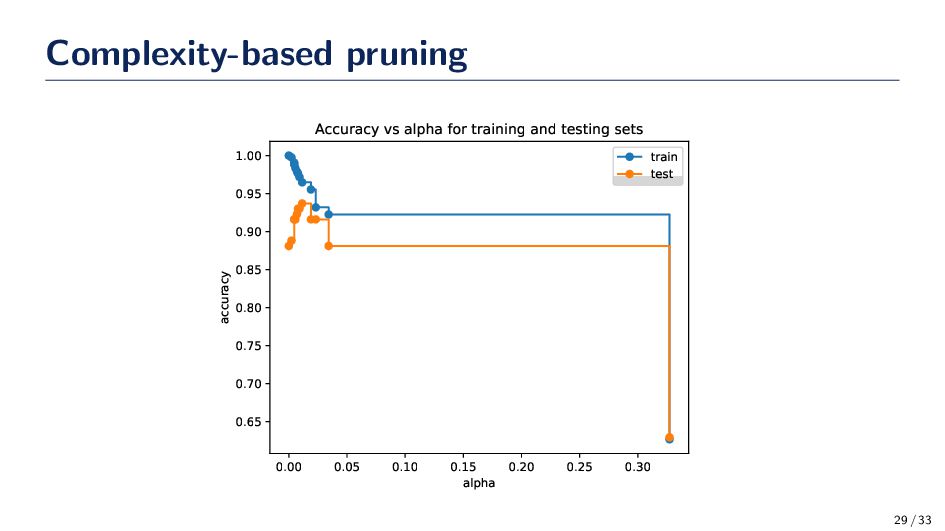{kind=link}
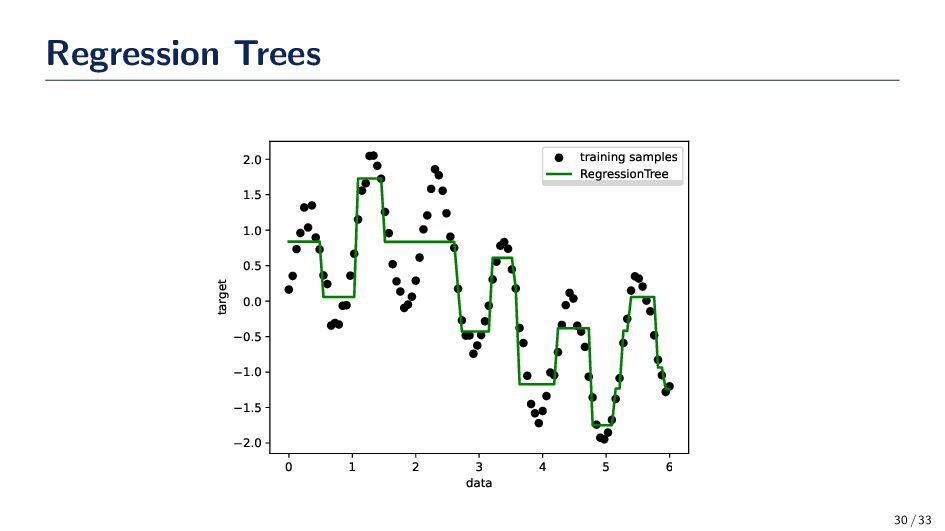{kind=link}
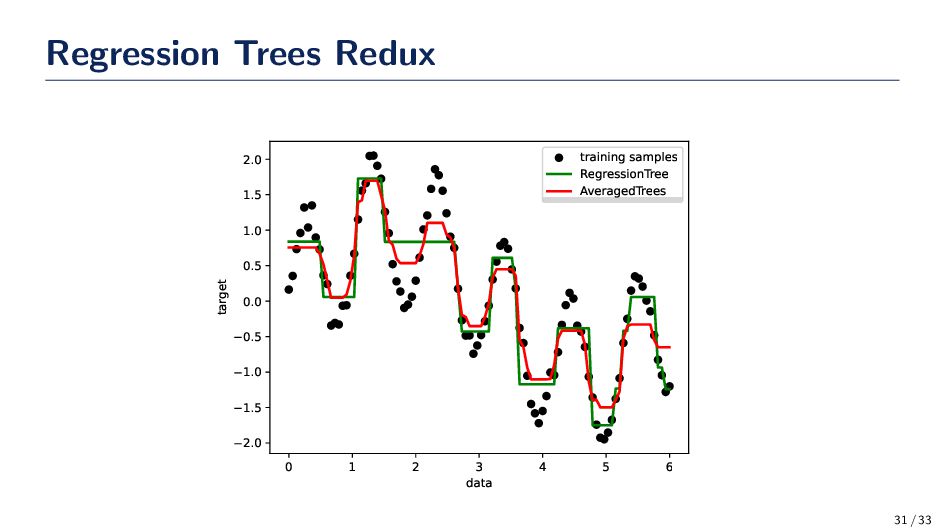{kind=link}
{kind=link}
{kind=link}