でより高い vector 検索精度が期待できる HyDE 仮説をやってみる タイポの修正による精度向上が報告されている。またはクエリは質問文で投げられる ため、インデックス情報に近い形式に変換することで精度向上が見込める。 Dealing with Typos for BERT-based Passage Retrieval and Ranking - ACL Anthology 単一の質問だけでは解決できない問いに対して、質問を複数に分割する。 検索エンジン側で機能提供されているケースもある。 Measuring and Narrowing the Compositionality Gap in Language Models | OpenReview Step Back 詳細な質問に対して、そのままクエリを投げるのではなく、上位概念に一度変換するクエリを発行する。 例えば「大谷翔平の2023/4/28の第3打席の結果」を直接検索するのではなく、「大谷翔平の2023 年の全打席結果」などと検索する。 [2310.06117] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models (arxiv.org) 文脈追加 質問に関連する知識生成やFAQ(Shot)の付与。 Retrieval-based LM (RAG system) ざっくり理解する - Speaker Deck 検索エンジンの仕組みとマッチング対象データを把握しながら、適切なクエリ生成を狙う。 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
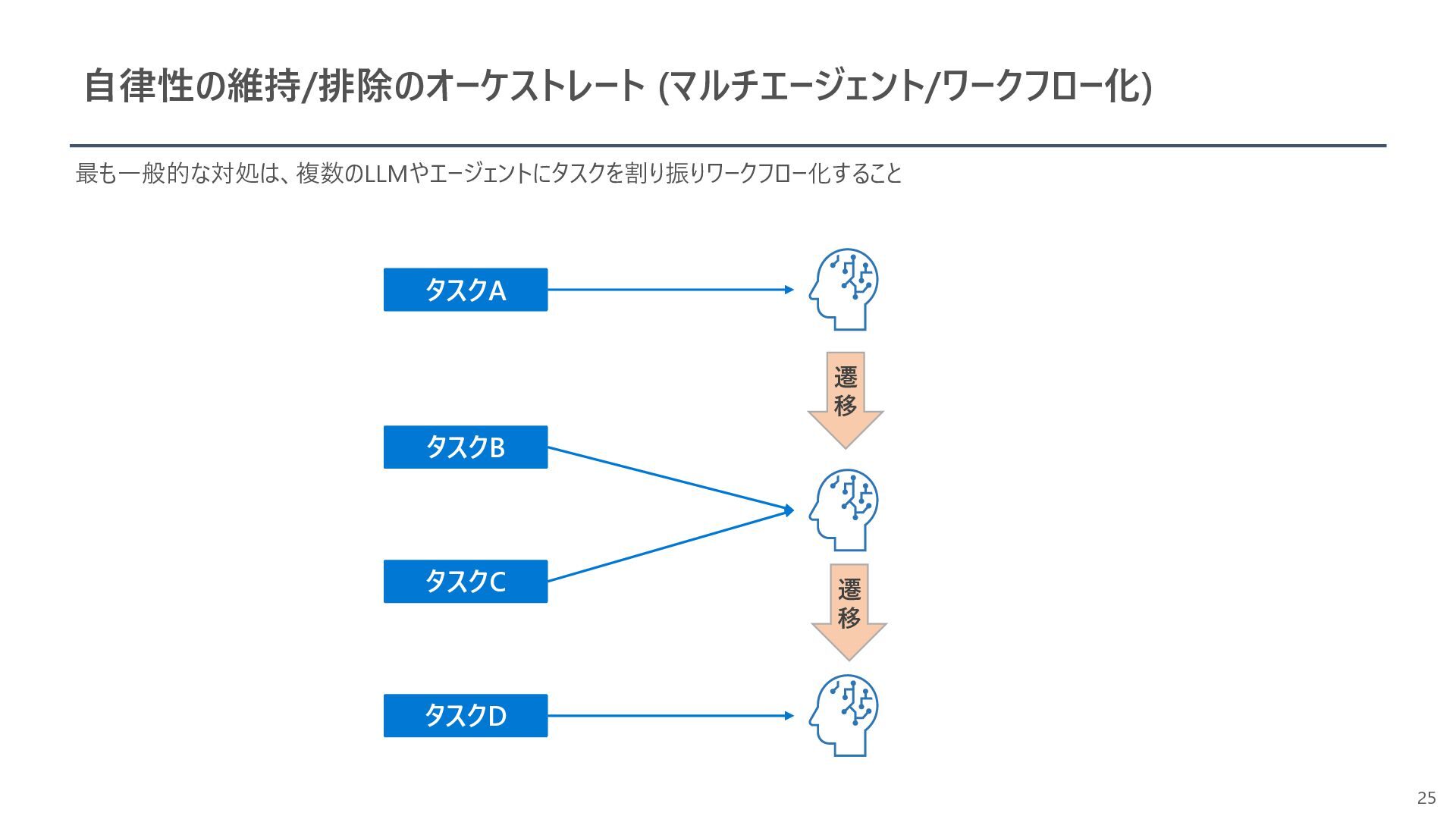{kind=link}
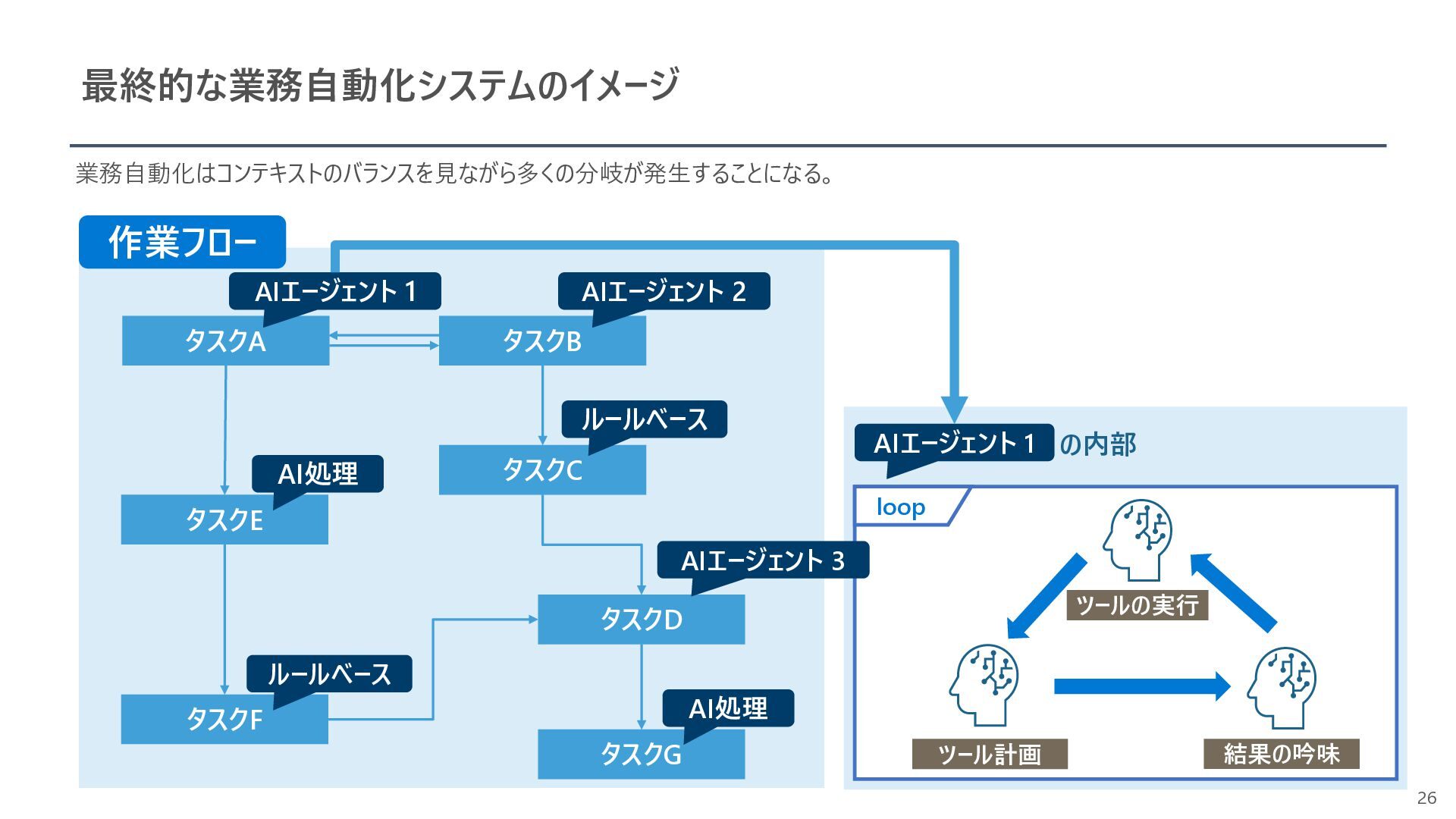{kind=link}
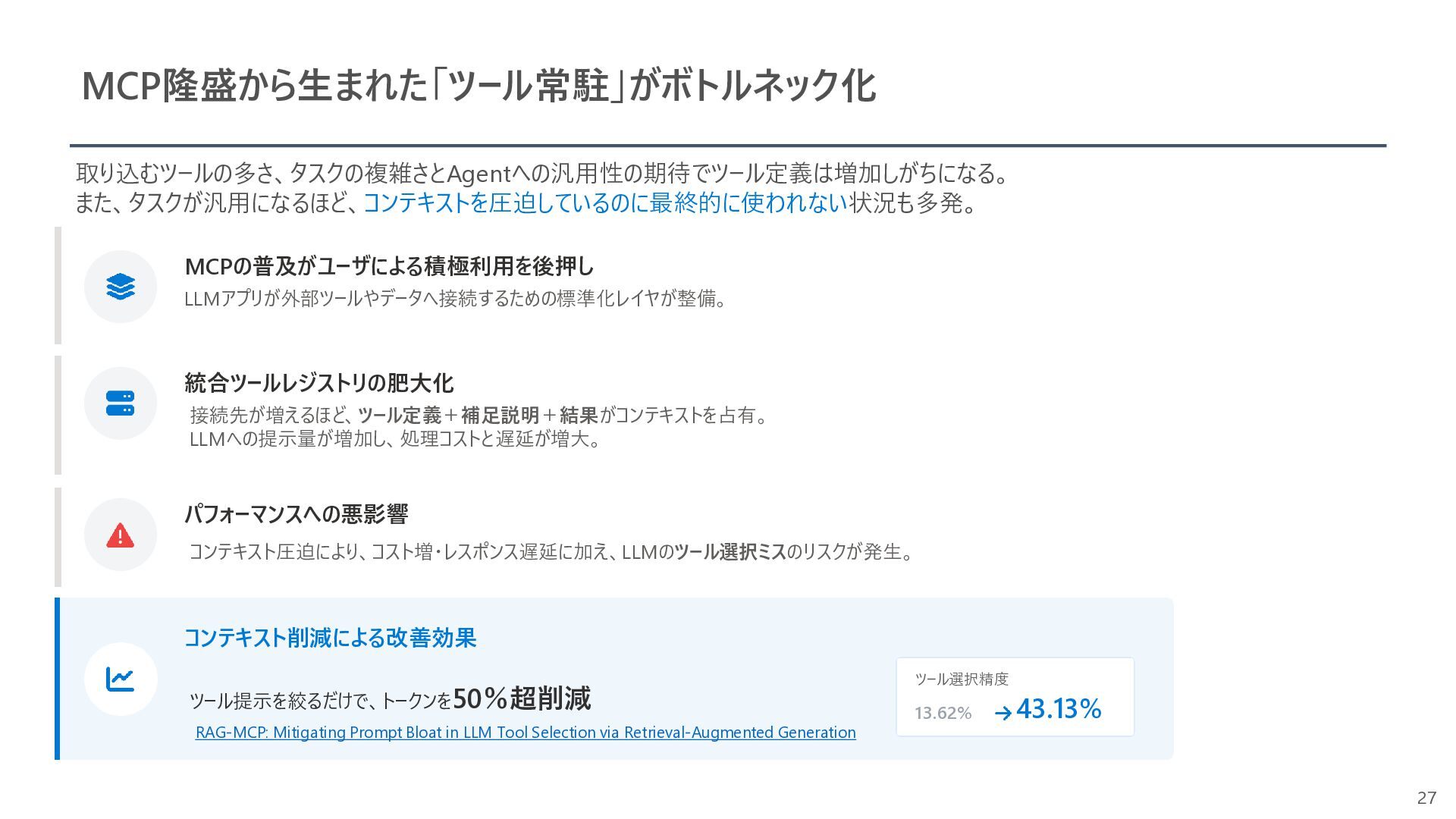{kind=link}
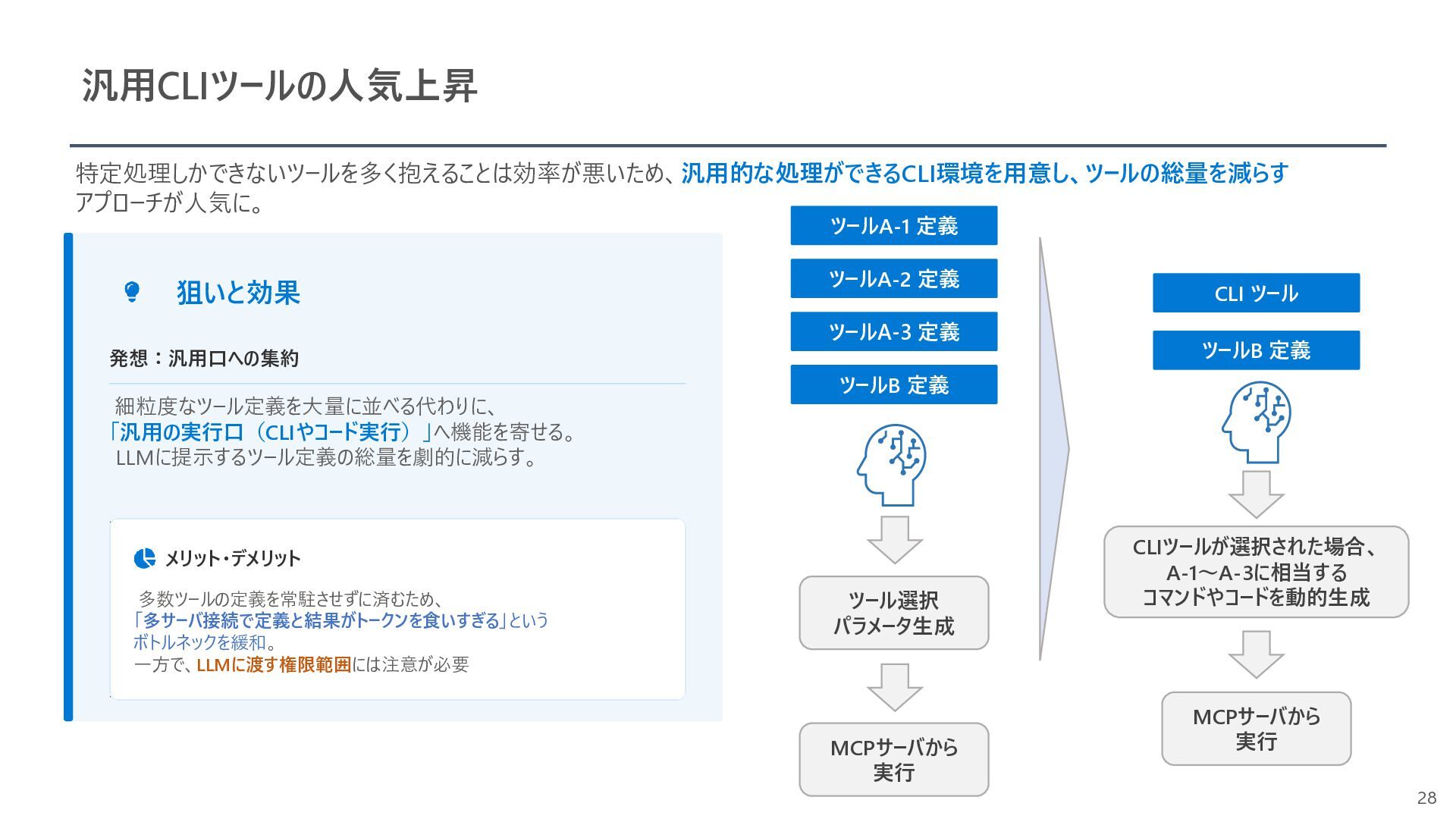{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
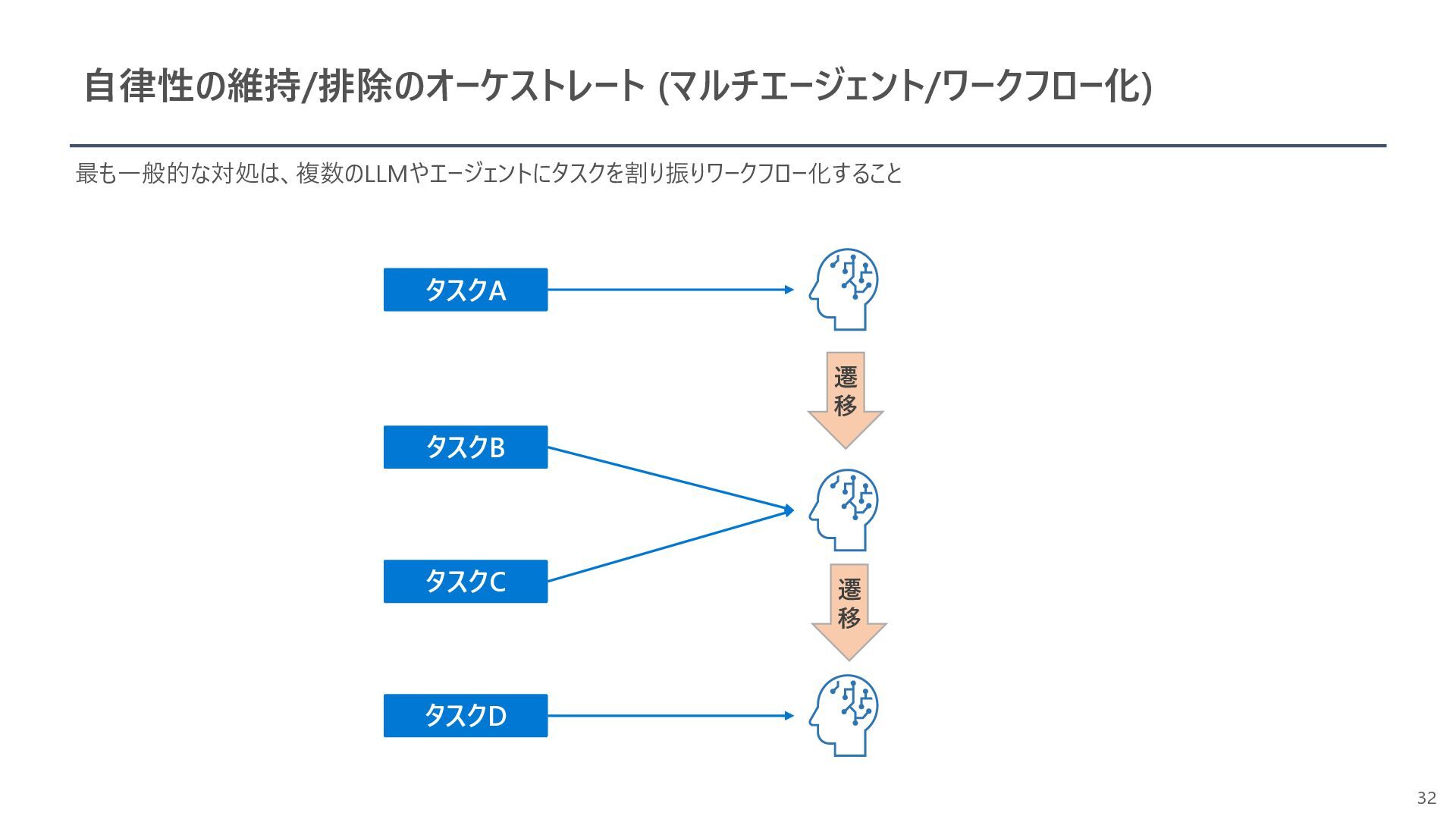{kind=link}
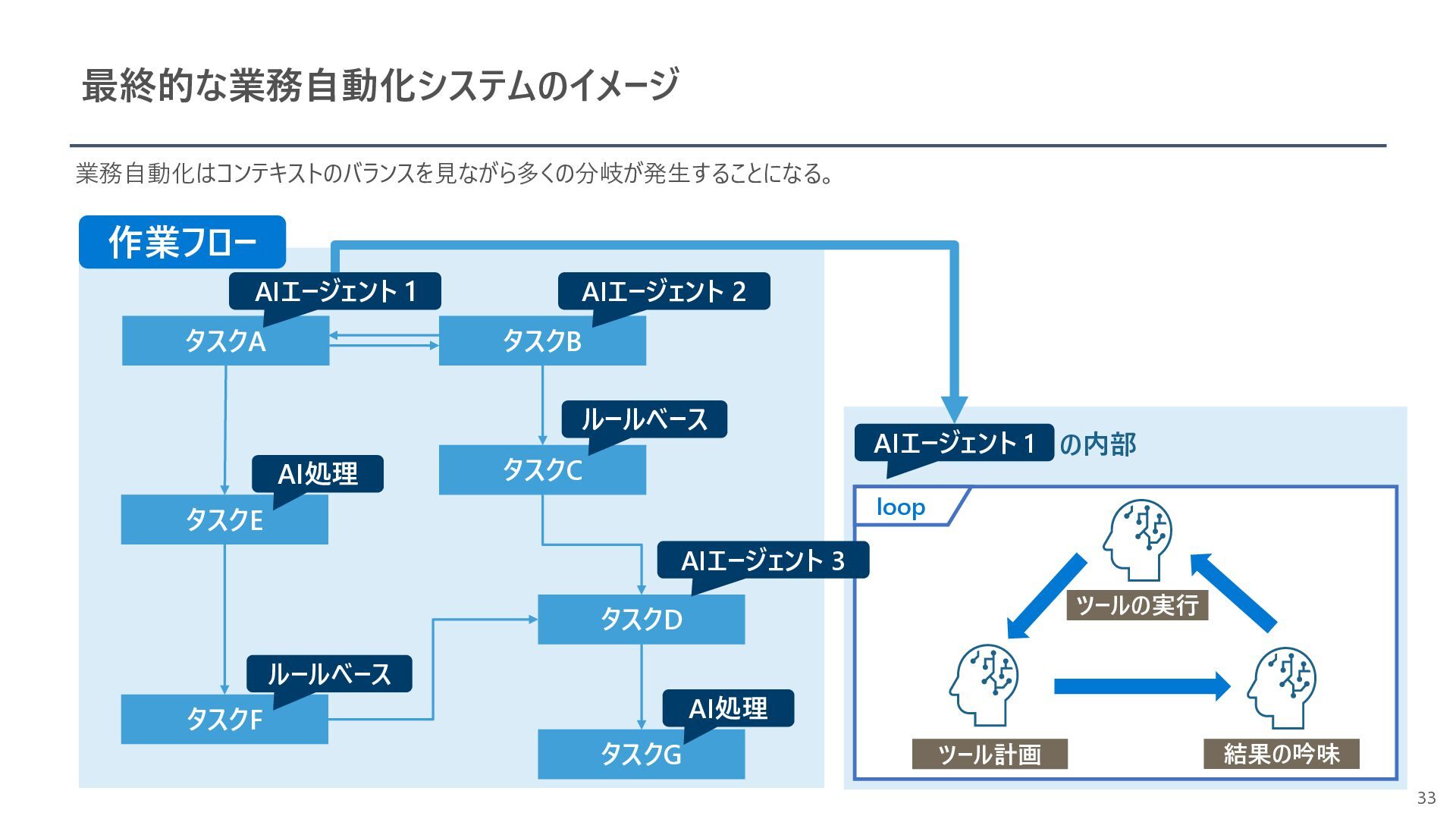{kind=link}
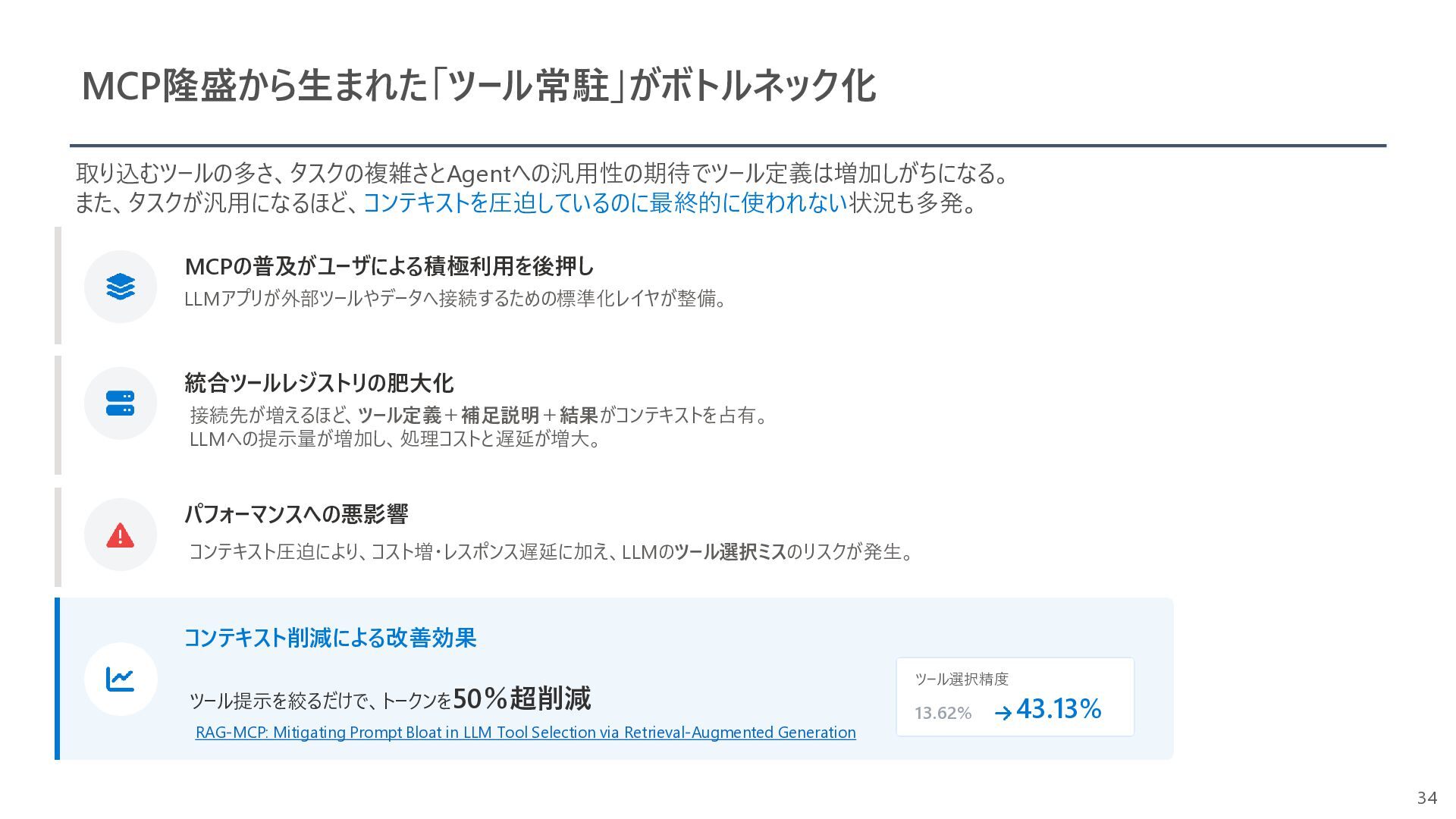{kind=link}
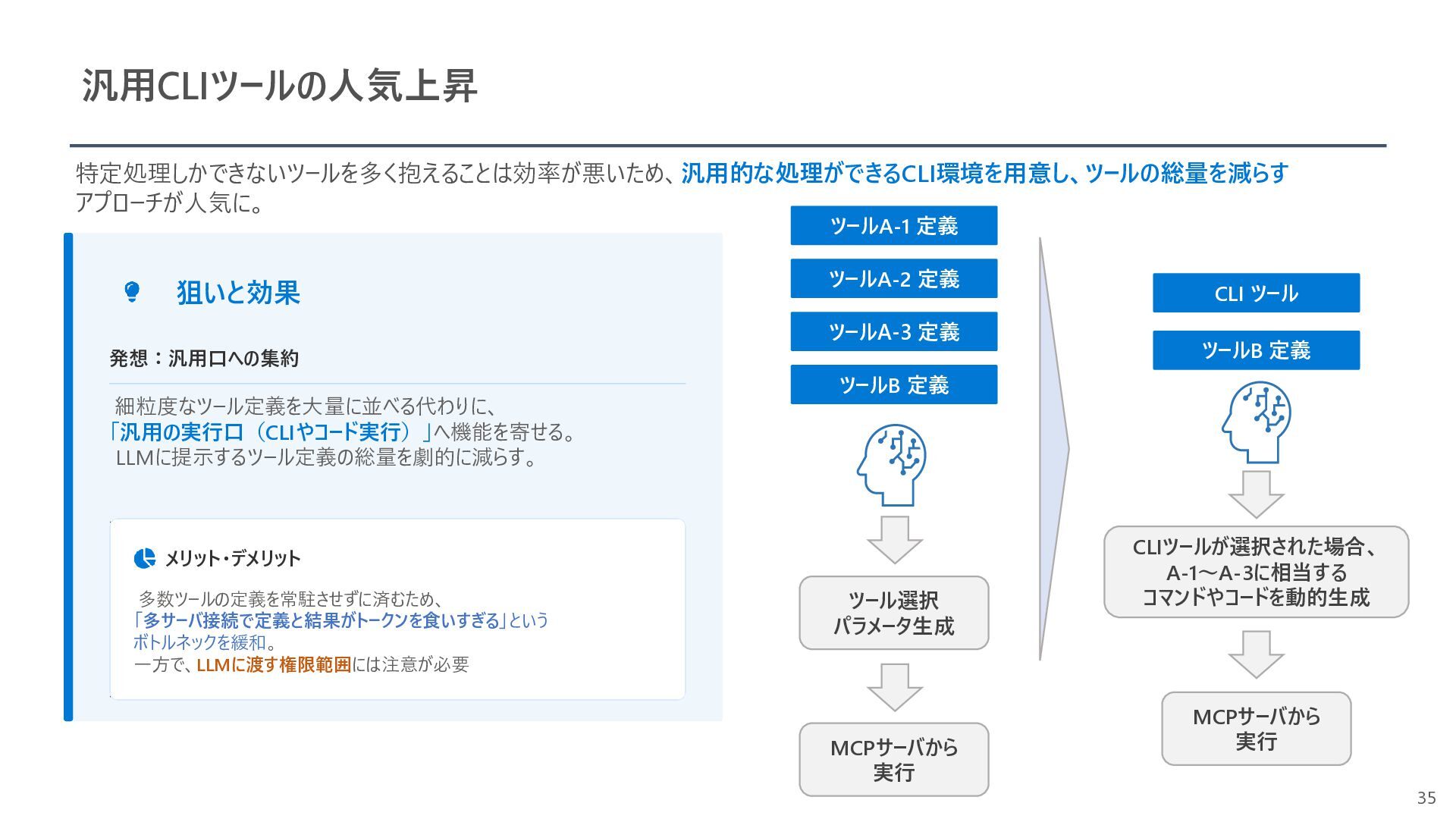{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}