이 발표에서는 다국어를 지원하는 Gemma 2 및 RecurrentGemma, PaliGemma 등의 Gemma 패밀리의 기술적 특징 및 다양한 가능성을 다룹니다. 특히 그 중 예시로, 2024년 10월의 Gemma Dev Day Japan 에서 다루어진 Gemma JP가 보여준 소버린 언어 모델 개발에 대해 이야기해 봅니다.
2024년 12월 13일에 열린 Google DevFest Seoul 2024 에서 발표한 자료입니다.
This presentation covers the technical features and various possibilities of the Gemma family, including Gemma 2, RecurrentGemma, and PaliGemma, which support multiple languages. In particular, we will discuss the development of a sovereign language model demonstrated by Gemma JP at Gemma Dev Day Japan in October 2024.
This material was presented at Google DevFest Seoul 2024 on December 13, 2024.
{kind=link}
{kind=link}
{kind=link}
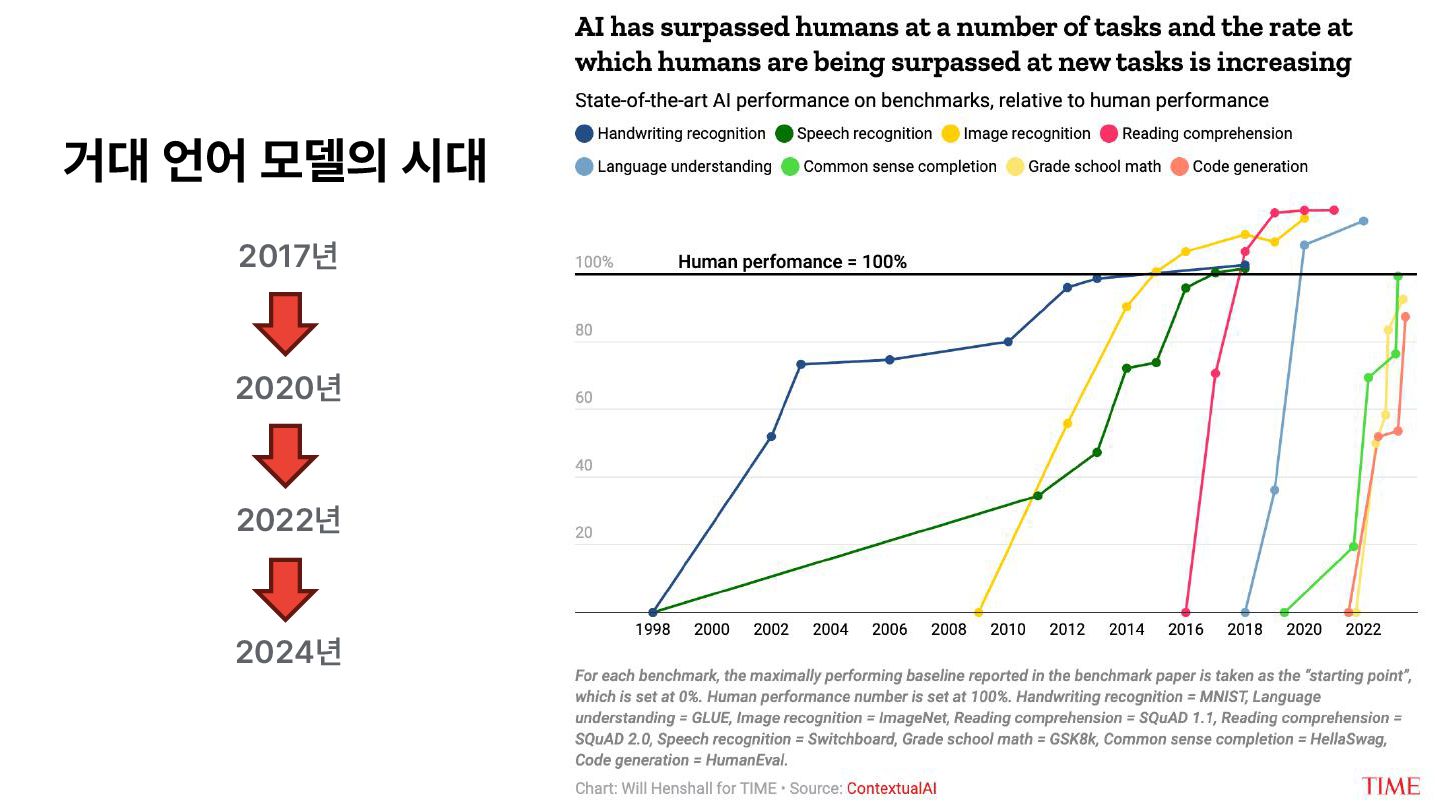{kind=link}
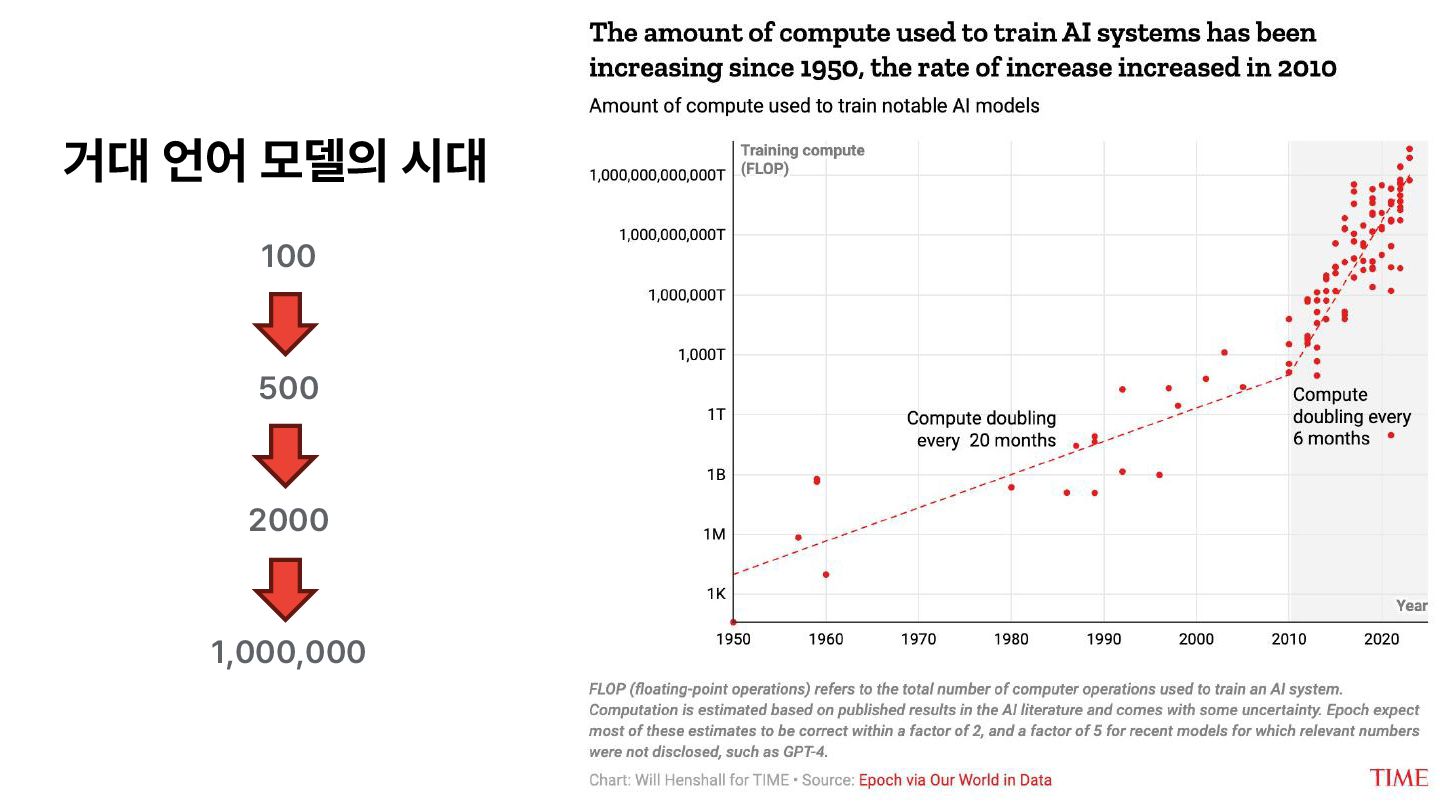{kind=link}
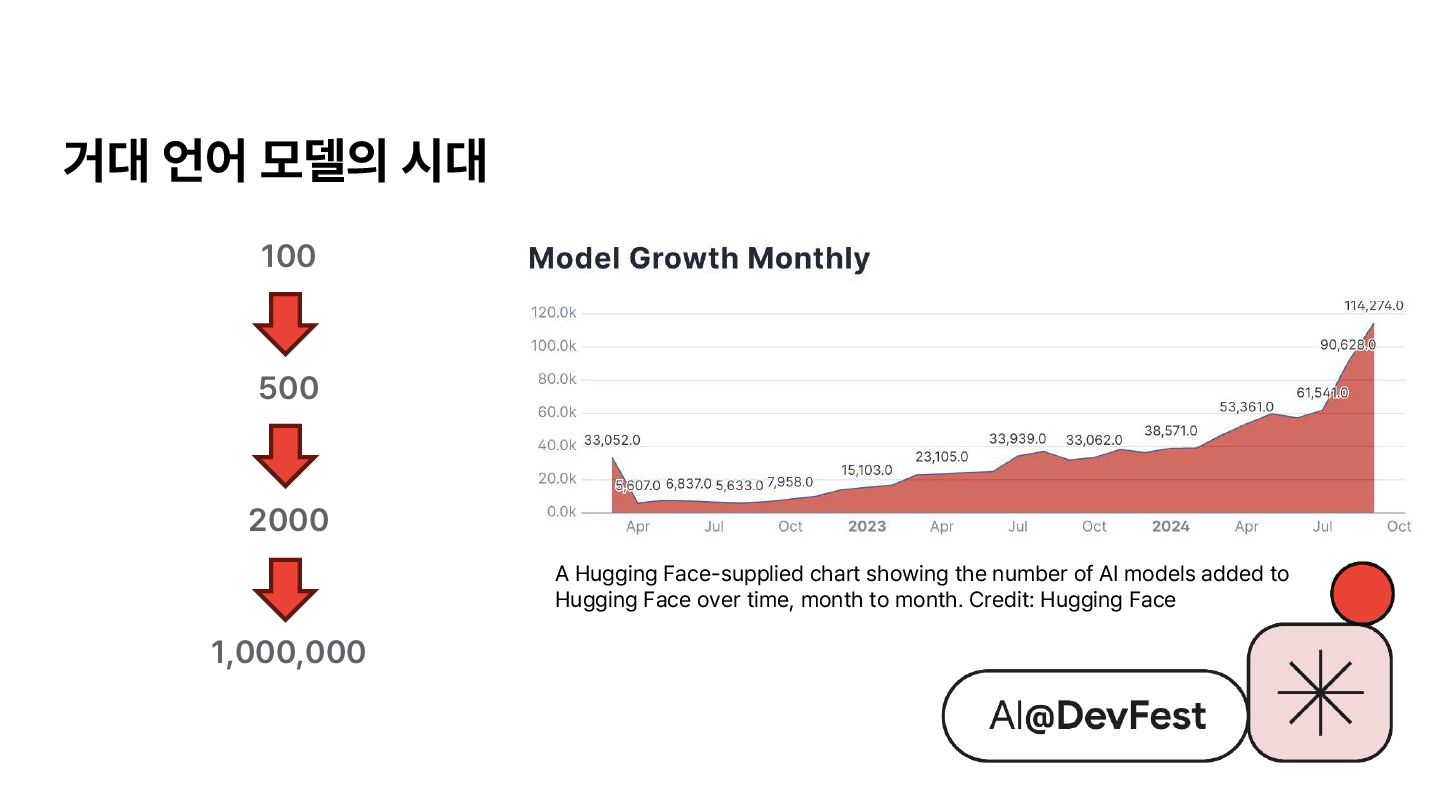{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
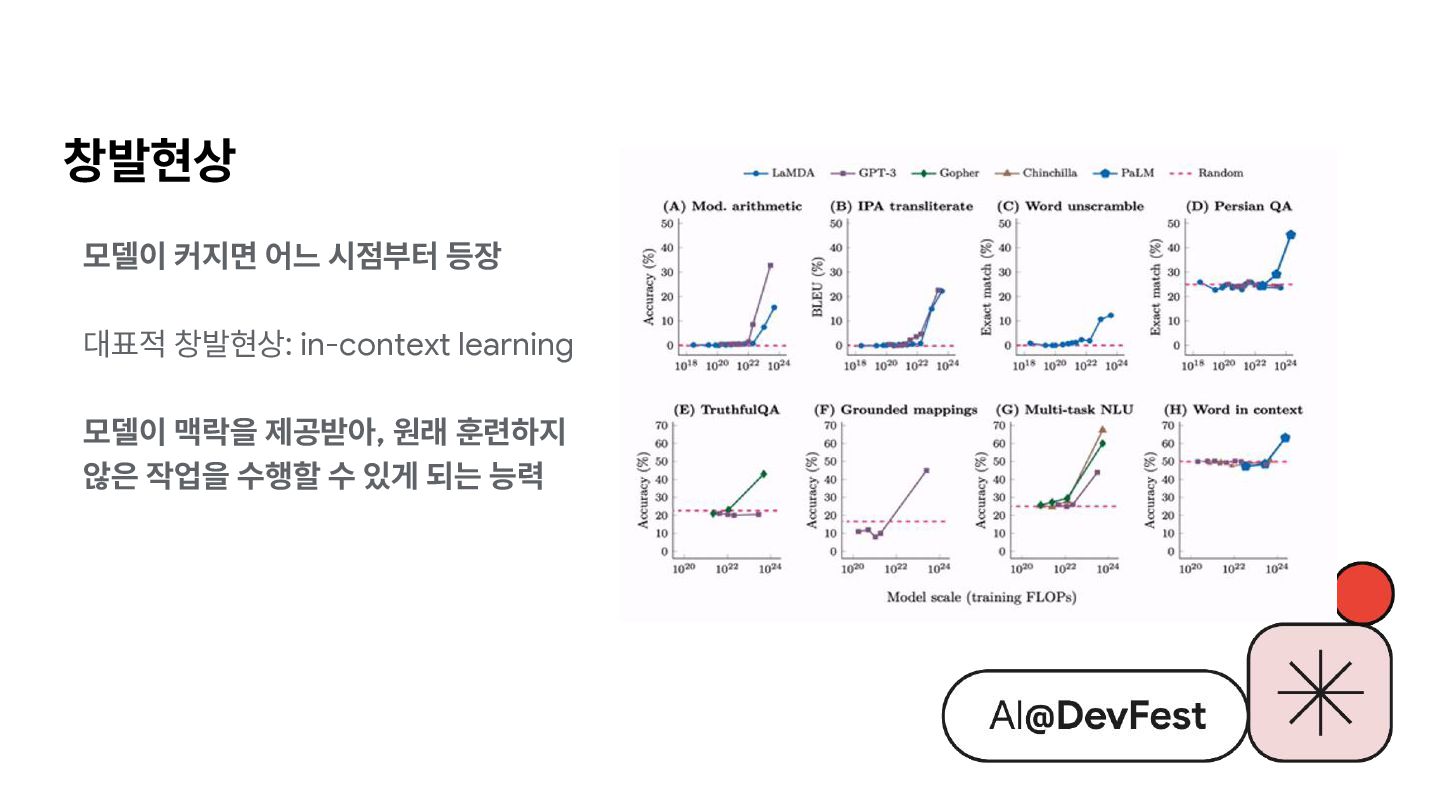{kind=link}
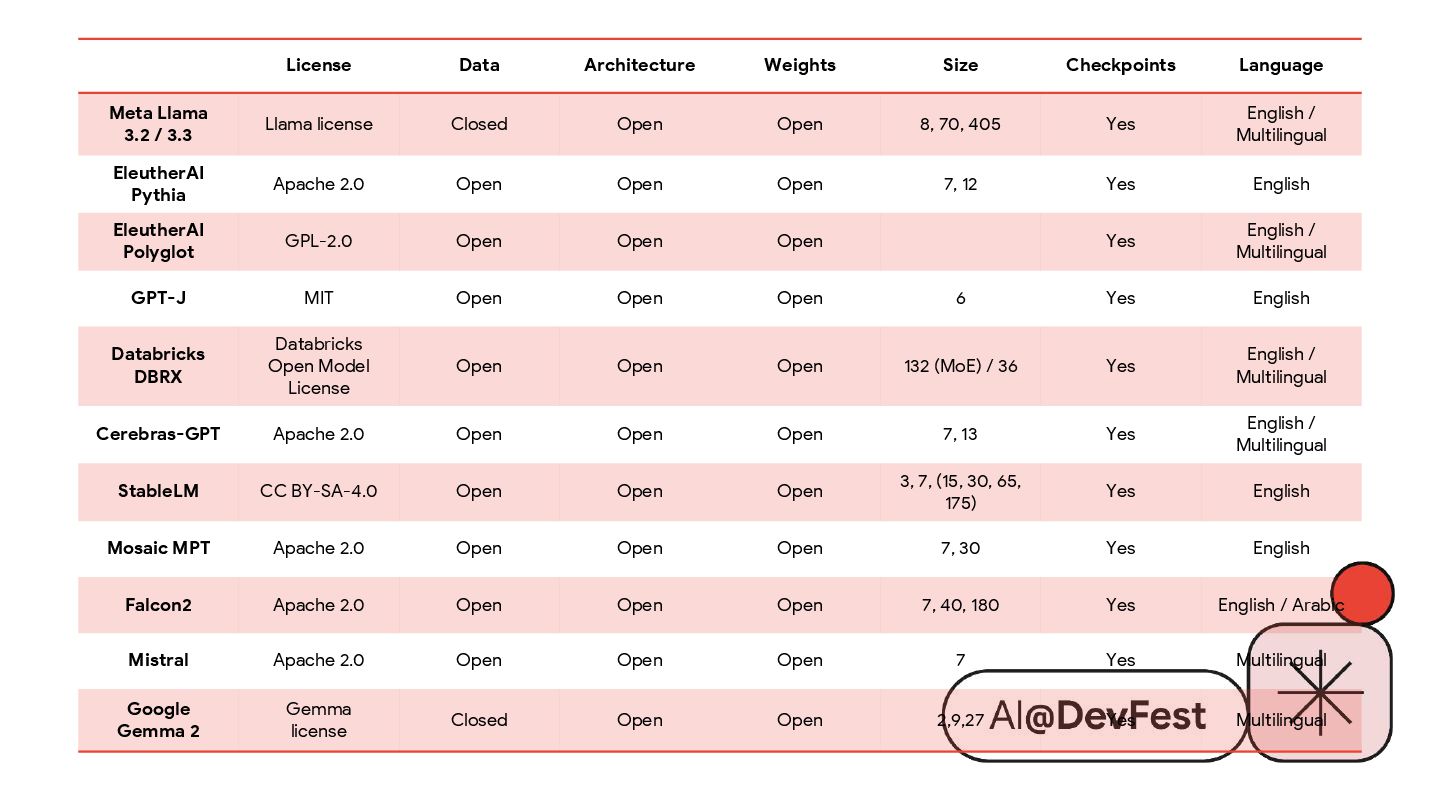{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
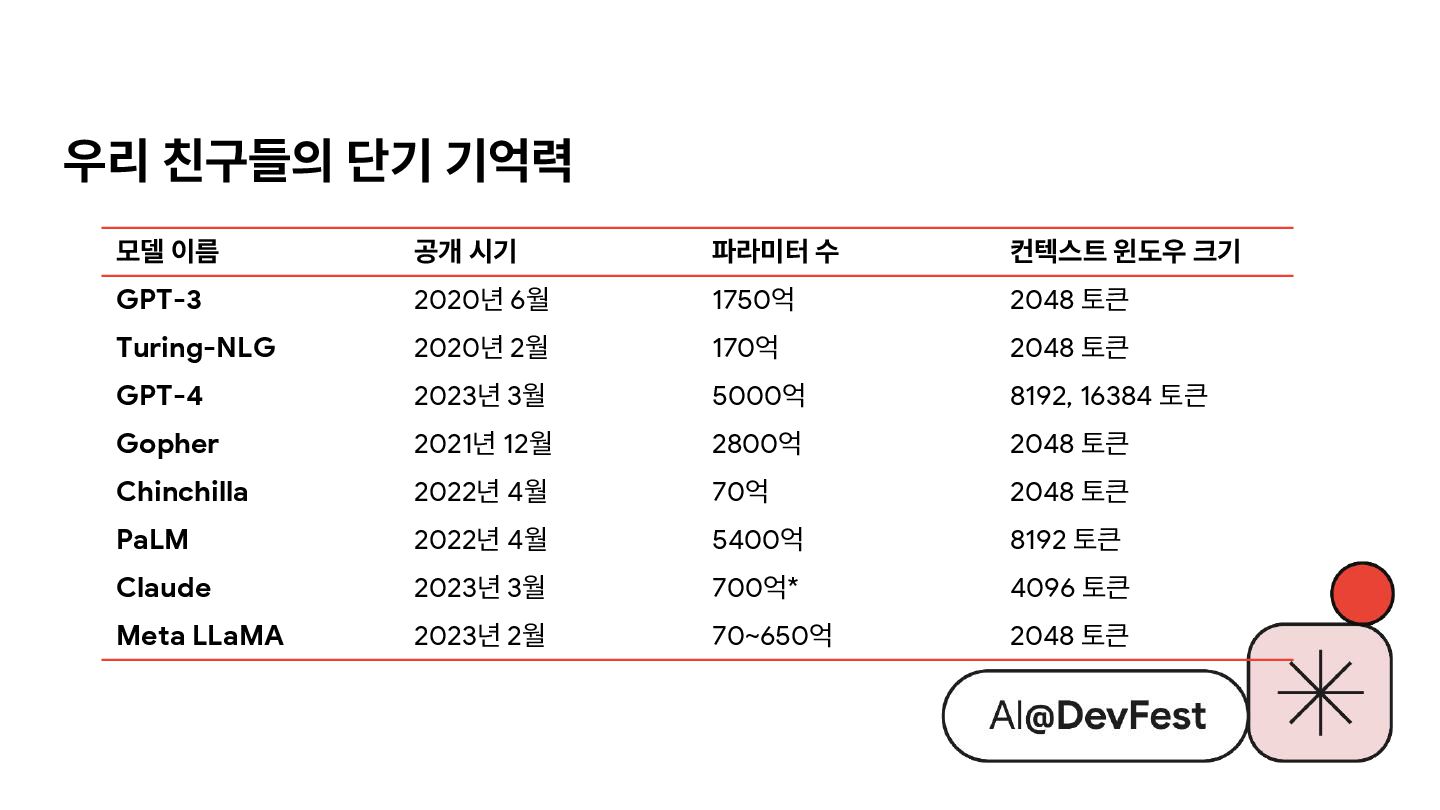{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
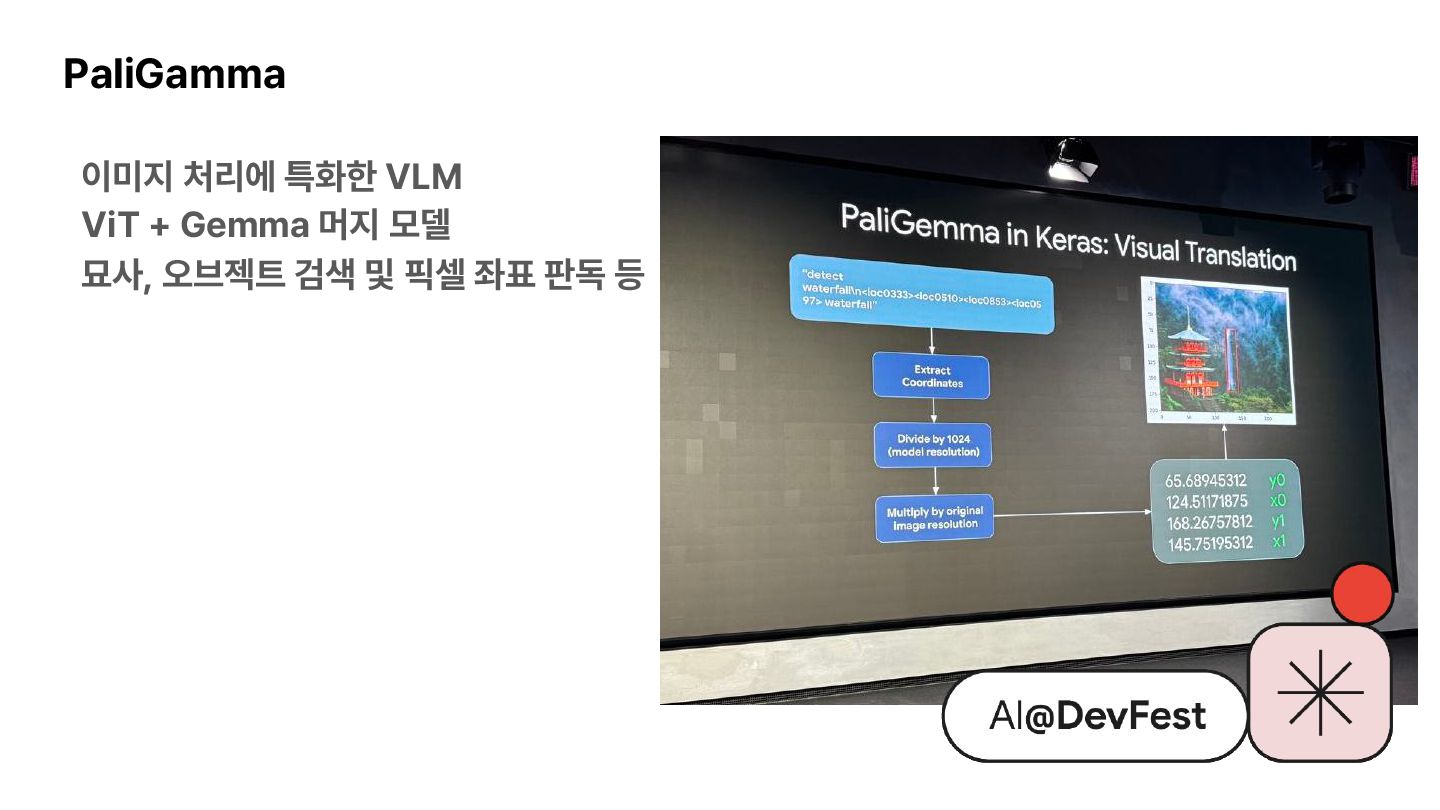{kind=link}
{kind=link}
{kind=link}
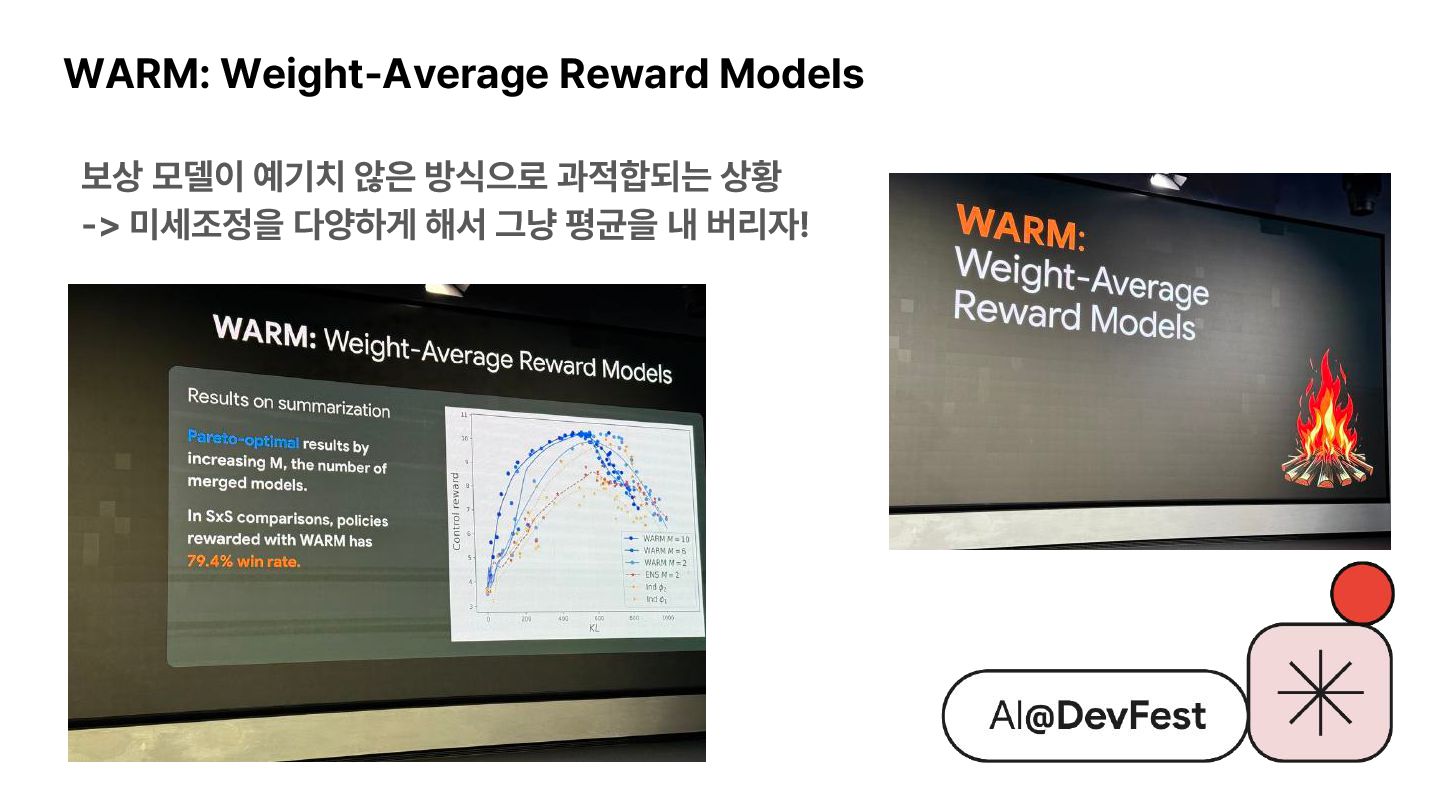{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}