2025년 4월 30일 kt cloud summit에서 발표한 발표자료입니다.
상단의 Video 버튼 및 하단에 발표 영상이 있습니다.
# 초록
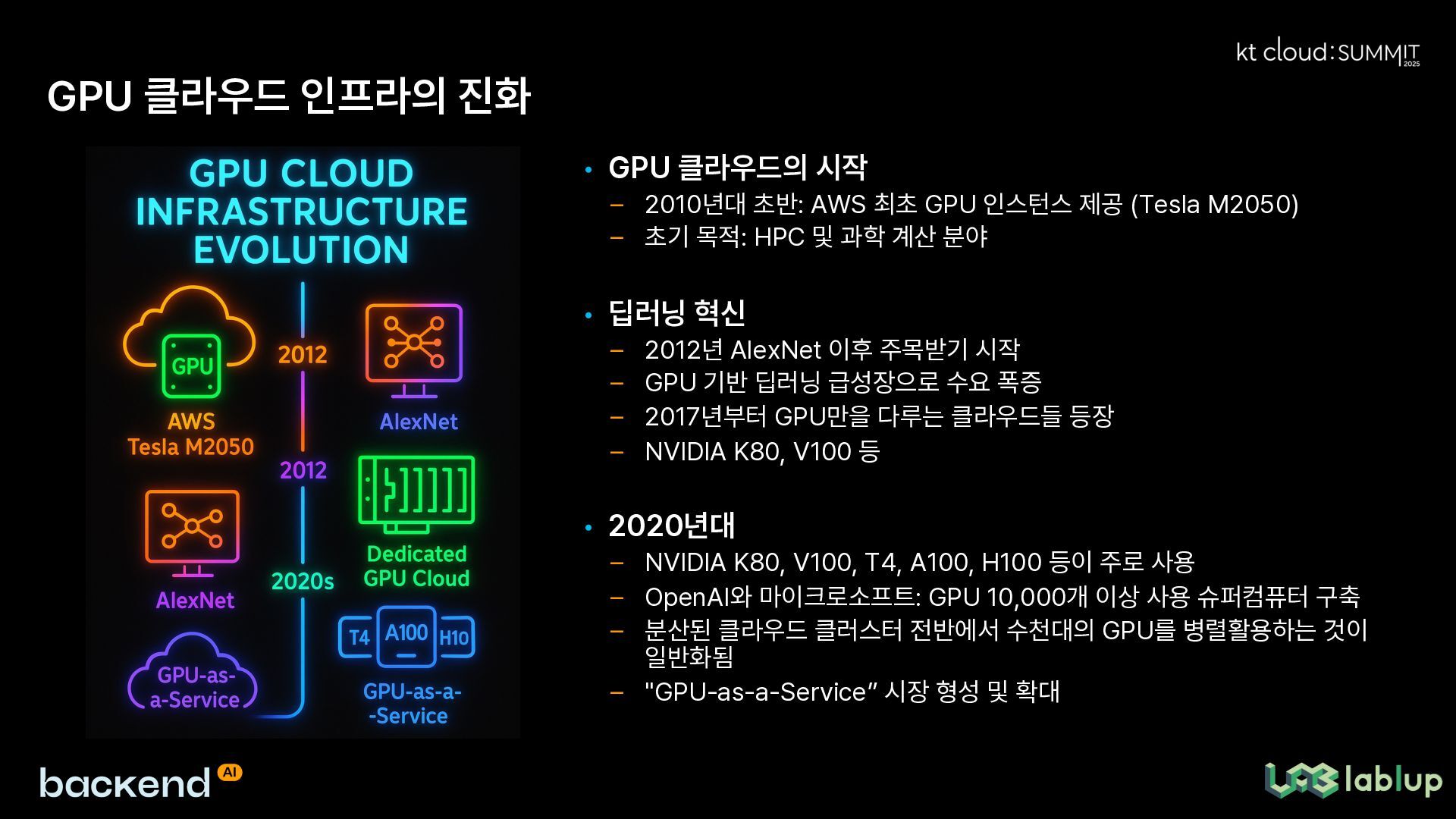
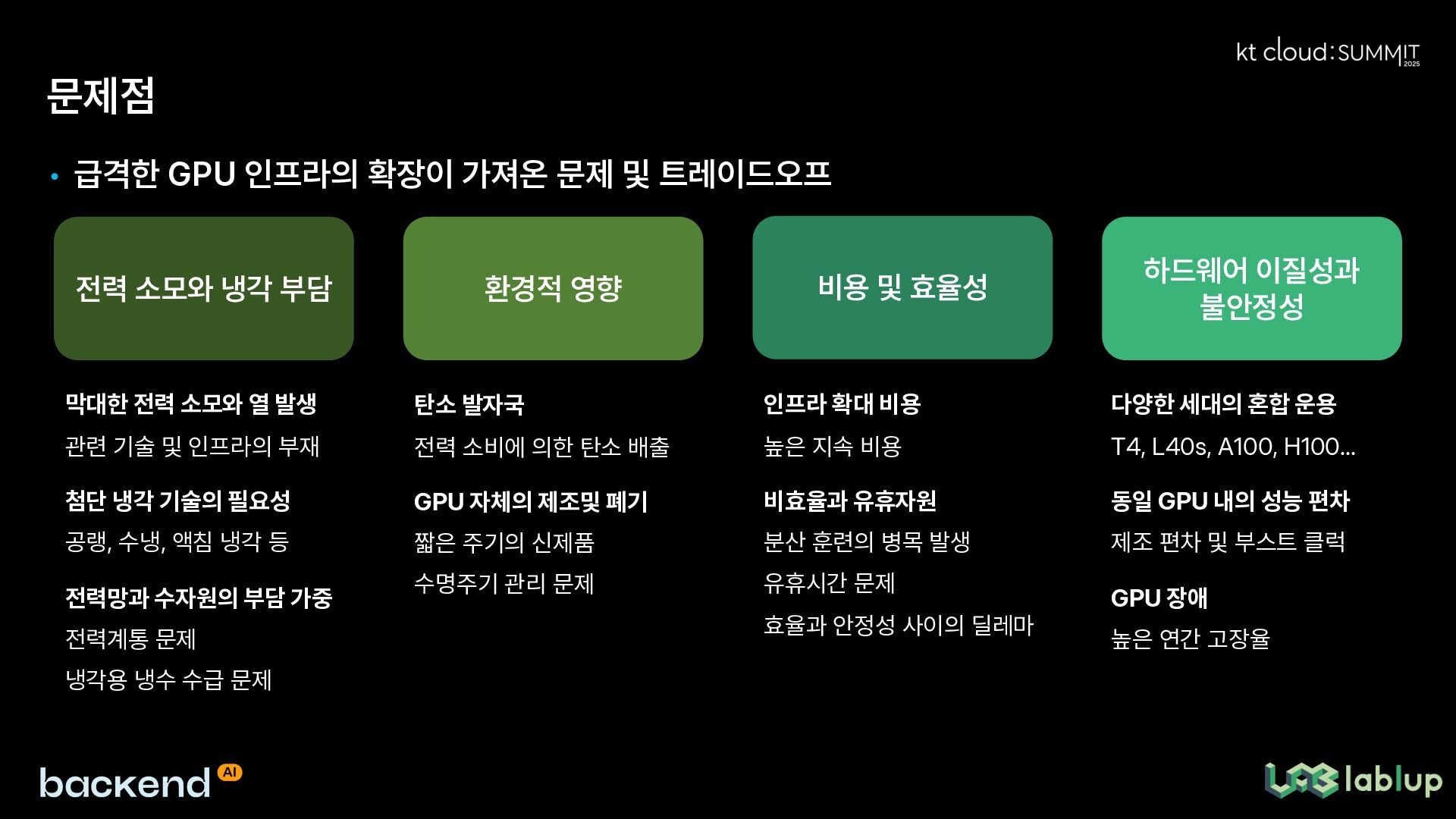
본 발표는 급속도로 성장하는 GPU 클라우드 인프라 환경에서의 AI 운영 과제와 해결책을 포괄적으로 다룹니다. 2010년대 초반 과학 계산 중심이었던 GPU 클라우드가 딥러닝 혁신 이후 AI 붐과 함께 급성장하면서 발생하는 다양한 문제점들을 분석합니다. 특히 대규모 GPU 클러스터에서 발생하는 전력 및 냉각 문제, 환경적 영향, 비용과 효율성 트레이드오프, 하드웨어 편차와 불안정성, 장애와 작업 중단, 스케줄링 불확실성, 멀티테넌시 및 격리 이슈 등을 심도 있게 조명합니다.
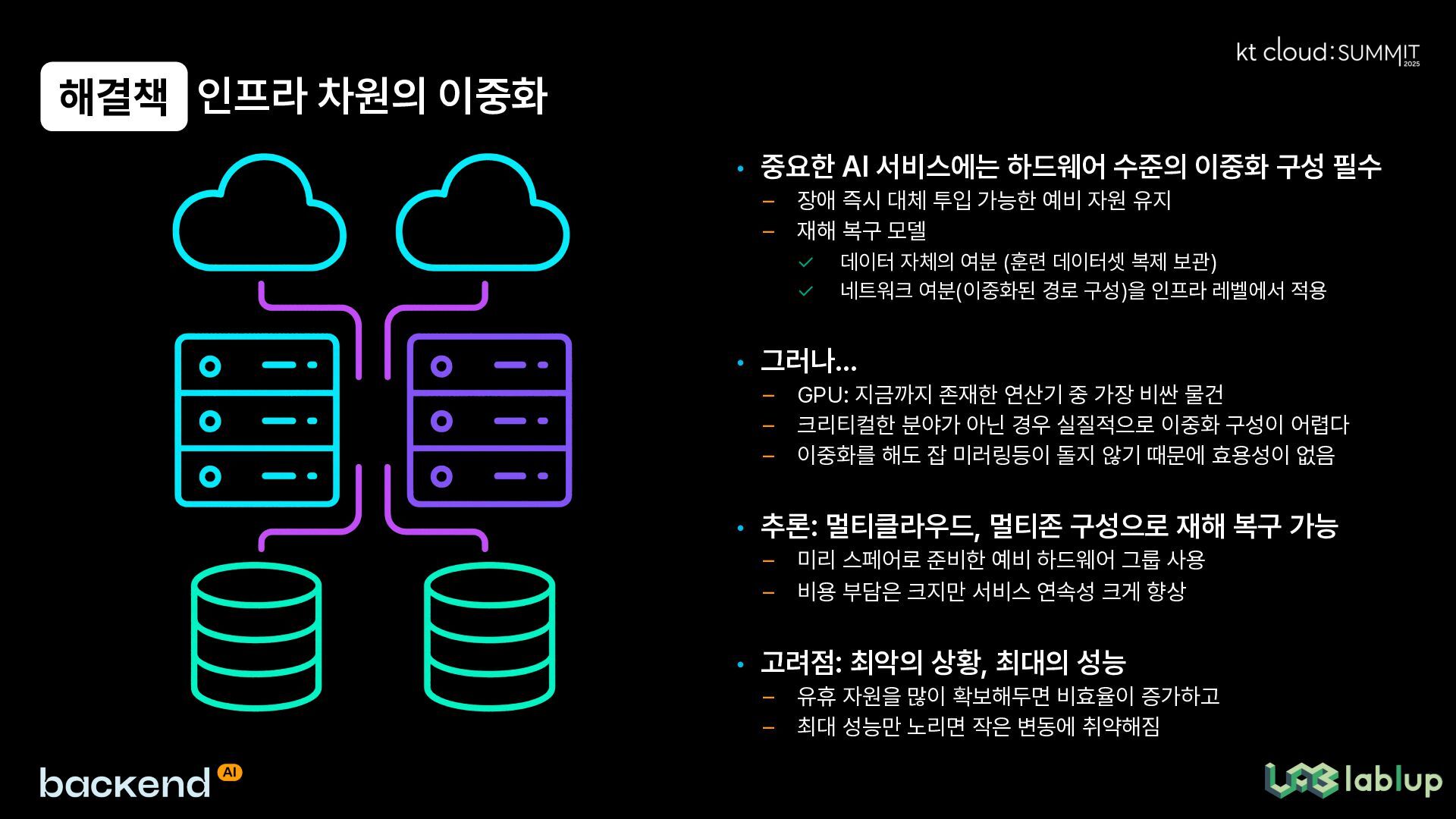
이러한 도전에 대응하기 위한 회복탄력적 AI 운영 전략으로 자동 장애 탐지 및 처리, 탄력적 훈련 방법론, 체크포인트 및 빠른 복구 메커니즘, 동적 자원 재배치, 인프라 차원의 이중화, 내결함성 미들웨어 등의 해결책을 제시합니다. 특히 Backend.AI 사례를 통해 GPU 분할 가상화, 동적 스케줄링 및 장애 처리, Continuum 하이브리드 프록시와 같은 실제 구현 전략과 그 효과를 공유합니다.
본 발표를 통해 급변하는 AI 인프라 환경에서 효율성과 회복탄력성을 동시에 달성할 수 있는 통합적 접근법을 제시해봄과 동시에, 경험을 통해 얻은 신뢰성 있고 지속가능한 AI 운영을 위한 통찰을 공유합니다.
# Abstract
This presentation comprehensively addresses the challenges and solutions in AI operations within rapidly growing GPU cloud infrastructure environments. It analyzes various issues that arise as GPU cloud infrastructure, which was initially focused on scientific computing in the early 2010s, experiences explosive growth alongside the AI boom following deep learning innovations. In particular, it thoroughly examines power and cooling problems, environmental impacts, cost and efficiency trade-offs, hardware variations and instabilities, failures and work interruptions, scheduling uncertainties, and multi-tenancy and isolation issues that occur in large-scale GPU clusters.
As resilient AI operation strategies to respond to these challenges, the presentation offers solutions including automatic failure detection and handling, elastic training methodologies, checkpoint and rapid recovery mechanisms, dynamic resource reallocation, infrastructure-level redundancy, and fault-tolerant middleware. Specifically, through Backend.AI case studies, it shares actual implementation strategies and their effects, such as GPU partitioning virtualization, dynamic scheduling and failure handling, and Continuum hybrid proxy.
Through this presentation, we propose an integrated approach that can simultaneously achieve efficiency and resilience in a rapidly changing AI infrastructure environment, while sharing insights for reliable and sustainable AI operations gained through our experience.
This presentation was delivered at the KT Cloud Summit on April 30, 2025.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![감사합니다. 신정규 [email protected] facebook/Jeongkyu.shin](https://files.speakerdeck.com/presentations/3e39c09022e140689723bdadef8702a2/slide_24.jpg){kind=link}
{kind=link}