Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第64回コンピュータビジョン勉強会@関東(後編)
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
TSUKAMOTO Kenji
August 20, 2025
Technology
340
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第64回コンピュータビジョン勉強会@関東(後編)
TSUKAMOTO Kenji
August 20, 2025
More Decks by TSUKAMOTO Kenji
See All by TSUKAMOTO Kenji
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
130
第65回コンピュータビジョン勉強会
tsukamotokenji
0
250
DynIBaR (第60回CV勉強会@関東)
tsukamotokenji
0
270
DeepSFM: Structure from Motion Via Deep Bundle Adjustment
tsukamotokenji
2
650
第三回 全日本コンピュータビジョン勉強会(後編)
tsukamotokenji
1
1k
Other Decks in Technology
See All in Technology
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
410
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
120
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
11
7.9k
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
260
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
340
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
3
880
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.2k
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
290
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
370
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
160
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.8k
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
220
Featured
See All Featured
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Documentation Writing (for coders)
carmenintech
77
5.4k
Done Done
chrislema
186
16k
Accessibility Awareness
sabderemane
1
150
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Believing is Seeing
oripsolob
1
170
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
340
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
220
Marketing to machines
jonoalderson
1
5.6k
Between Models and Reality
mayunak
4
370
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Transcript
第64回コンピュータビジョン勉強会@関東(後編) 2025/08/24
発表論文 ロボットが空間理解するためのタスクに対するデータセットの提案 • Github
RobotにおけるTeaching Teaching:ロボットに特定の作業や動きを教え込むプロセス • 特定の動作・作業を行わせるよう設定するため、 人側の作業負荷が大きい • ある程度環境が変わらない状態で動作 → VLMで動作指示をするという流れ
関連研究 • OpenVLA:ロボットが複雑な指示を解釈して実行する。 • GPT-4v for robotics:自然言語の指示から詳細な動作シーケンスを生成 • CoPa:指示から物の把持位置・動作シーケンスを生成 他多数の応用がある
OpenVLA GPT-4v for robotics CoPa
VLMでのタスク指示の課題 タスク:灰色のボウルを車の前に置く VLMは物体認識、シーン分類できるが、物体間の空間的解釈などのタスクは不得意
位置関係の解釈に関する取り組み • SpatialVLMやSpatialRGPT ◦ 物体間の距離や空間関係に関する質問に答えられよう VLMを学習して空間理解の向上 ▪ ネット上の画像・データセットで学習、実空間での利用に差異がある • RoboPointやMolmoなどのPointing
Model ◦ VLMsをシーン内の物体の位置や空きスペースを特定する接地された 2次元座標を生成するように 訓練 ▪ 現実世界の制約の理解に課題:ボウルは車の前におけるサイズなのか? • 位置関係を課題にしたデータセットは現状ない ◦ 汎用的な画像、少ない 3Dスキャンデータ ◦ アノテーション(Question・Answer)が自由形式 ▪ 空間関係は言及されていない
本論文の提案 • Robospatial データセット・パイプライン構築 ◦ 画像:100万、3Dスキャンデータ:5000、空間関係のアノテーション: 300万セット • 空間的指示を異なる視点から解釈するモデルの能力を向上させるため、3つの異 なる参照視点/フレームから提示
◦ Ego-centric Observer’s View(自視点) ◦ Object-centric based on a reference frame(物体視点) ◦ World-centric global world frame (外部視点)
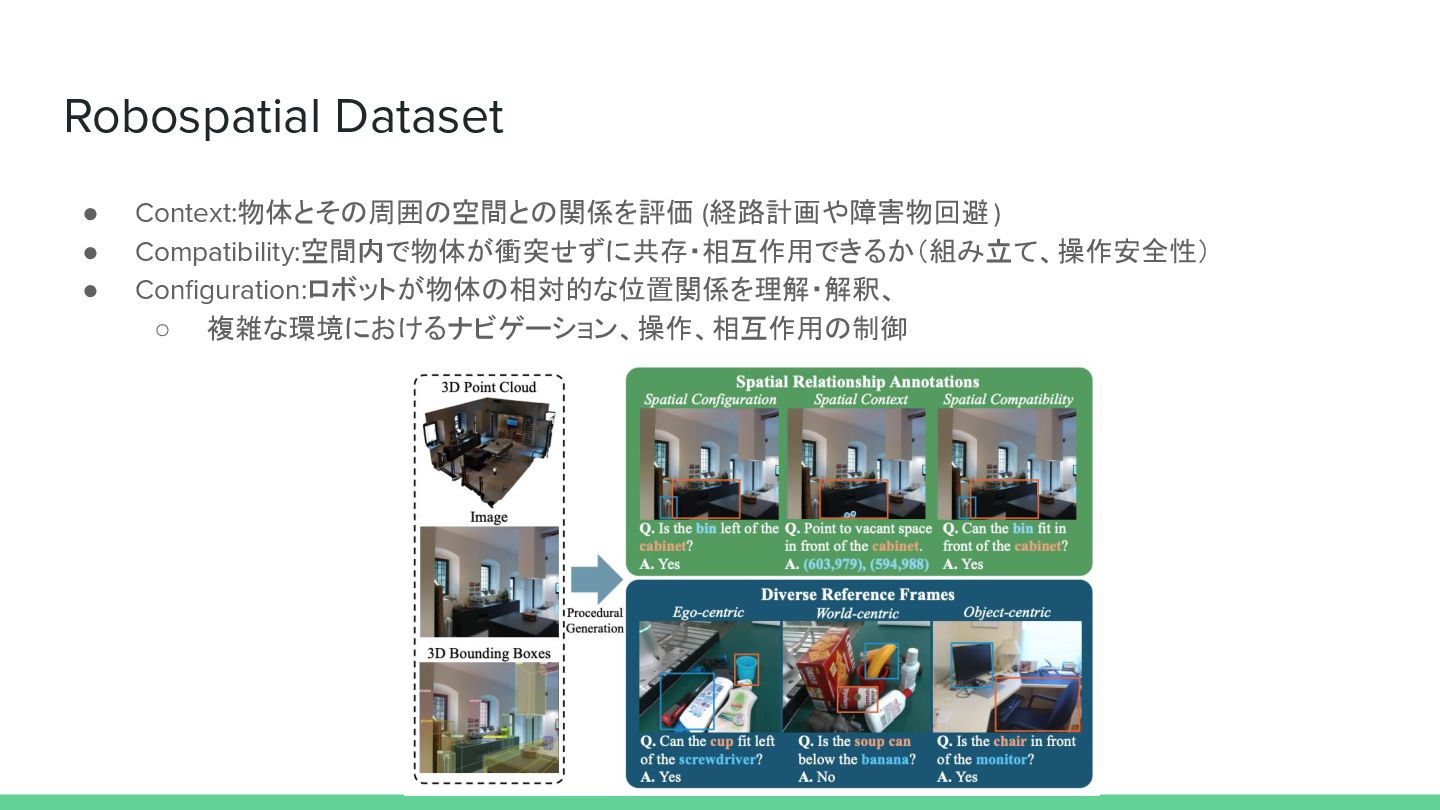
Robospatial Dataset • Context:物体とその周囲の空間との関係を評価 (経路計画や障害物回避 ) • Compatibility:空間内で物体が衝突せずに共存・相互作用できるか(組み立て、操作安全性) • Configuration:ロボットが物体の相対的な位置関係を理解・解釈、
◦ 複雑な環境におけるナビゲーション、操作、相互作用の制御
データ生成 入力:画像、カメラ姿勢(内部・外部パラメータ)、方向つき 3D bbox、アノテーションを含むシーン データセット データ生成のパイプラインは2段階に分けている • 3D Spatial Relation
Extraction • 2D Spatial Point and Region Samping :reference frame label :answer :question :image
3D Spatial Relation Extraction 空間関係は次で定義: • relationの例:in front of (anchor
object) (object frame) • anchor objectの向き(3D bboxと向き)、参照フレームから空間関係の結果を2値 (True/False)でオブジェクトペアの空間関係が成立するか判定 : source image : anchor object : target object or sampled point in free space :参照フレーム
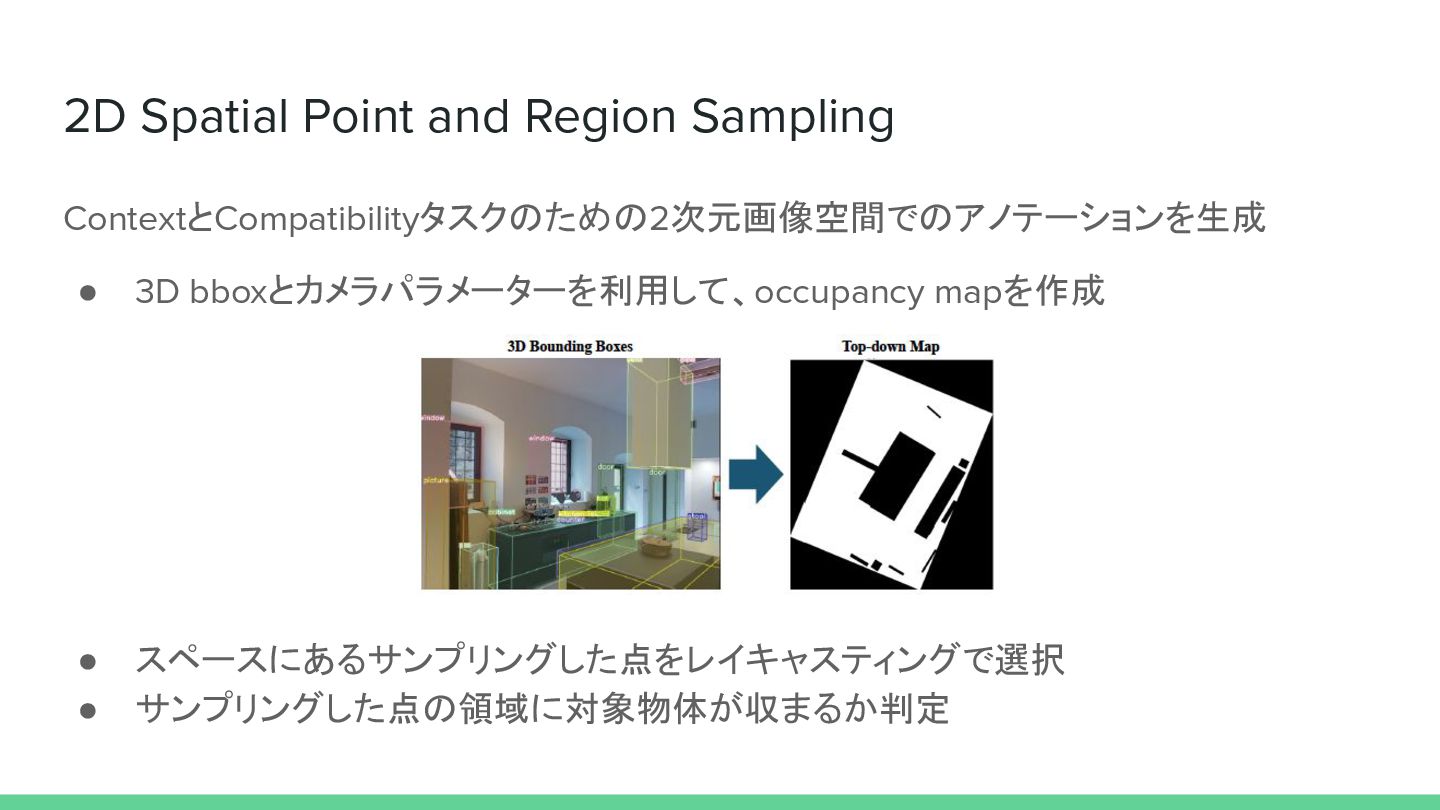
2D Spatial Point and Region Sampling ContextとCompatibilityタスクのための2次元画像空間でのアノテーションを生成 • 3D bboxとカメラパラメーターを利用して、occupancy
mapを作成 • スペースにあるサンプリングした点をレイキャスティングで選択 • サンプリングした点の領域に対象物体が収まるか判定
Question Answer generation Questionの生成 • 空間関係 が抽出されると、対応する質問回答ペア を生成 • 各質問は次の形式: Answerの生成
• Compatibility, Configuration ◦ 二値(True/False)の回答を生成 • Context ◦ 画像空間内の有効な 2次元座標のリストを生成
実験 • データセット ◦ Indoor ▪ ScanNet ▪ Matterort3D ▪
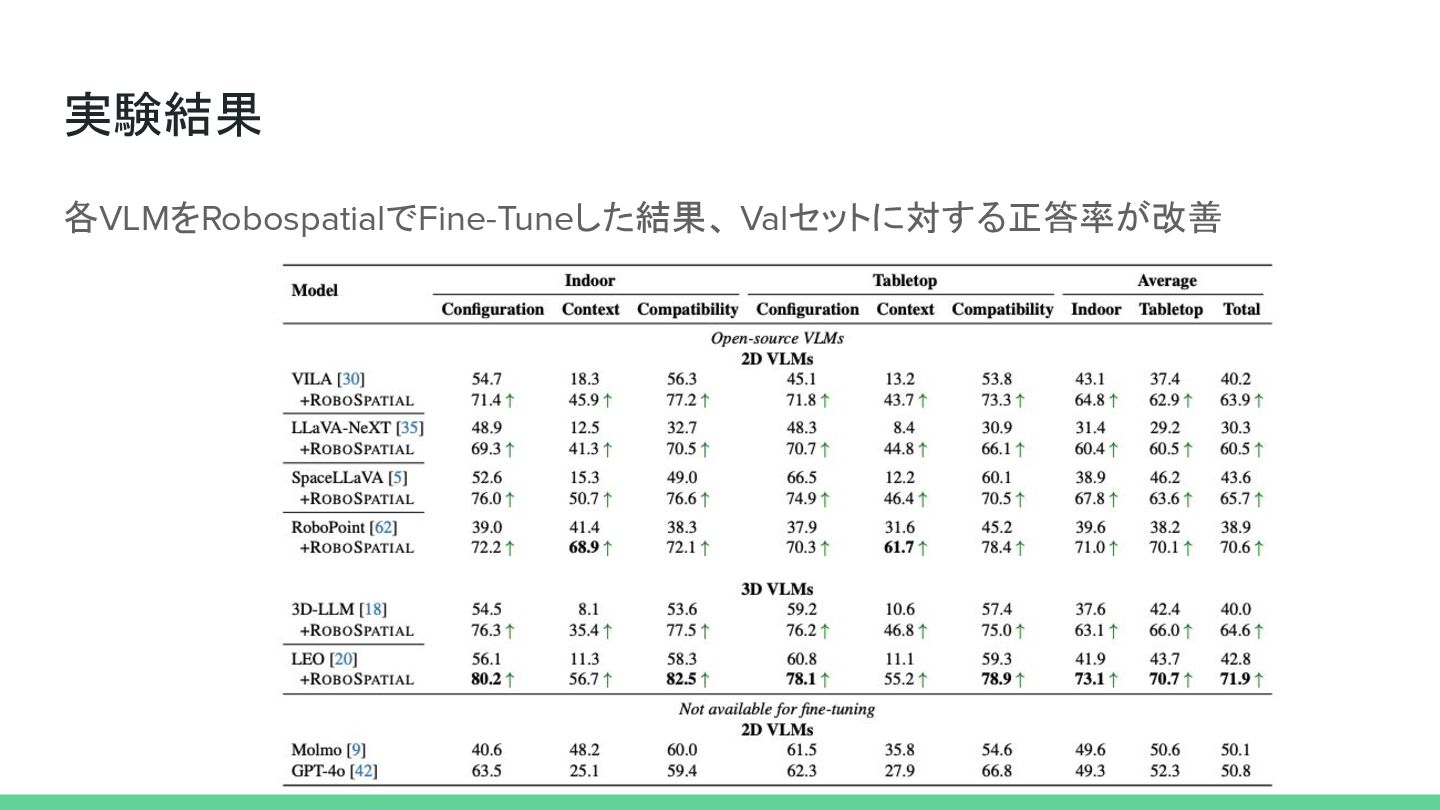
3Rscan ◦ TableTop ▪ HOPE ▪ GraspNet-1B ◦ 3D bboxはEMbodiedScanから検索して使用 • VLM ◦ 2D: VILA-1.5-8B, LLaVA-NeXT-8B, SpaceLLaVA-13Bm Robopoint-13B, GPT-4o, SpatialRGPT ◦ 3D: 3D-LLM(マルチビュー画像から色付き 3D点群を再構築)、LEOを使用 ◦ Molmo、GPT-4o(Fine Tuningなし) • VLMのFine -Tuning ◦ zero-shot, Fine-Tuningの両方でOSSモデルをFine-Tune ◦ 学習コストは不記載
実験結果 各VLMをRobospatialでFine-Tuneした結果、 Valセットに対する正答率が改善
実験結果 各VLMをRobospatialでFine-Tuneした結果、 Valセットに対する正答率・座標指定の精 度が改善
実験結果 Q:ゴミ箱の後ろにある空きスペースをいくつか指定する Q:ポットの左側にある空きスペースを複数指定する Q:椅子はベッドの後ろにある? Q:ランプは棚の上にある?
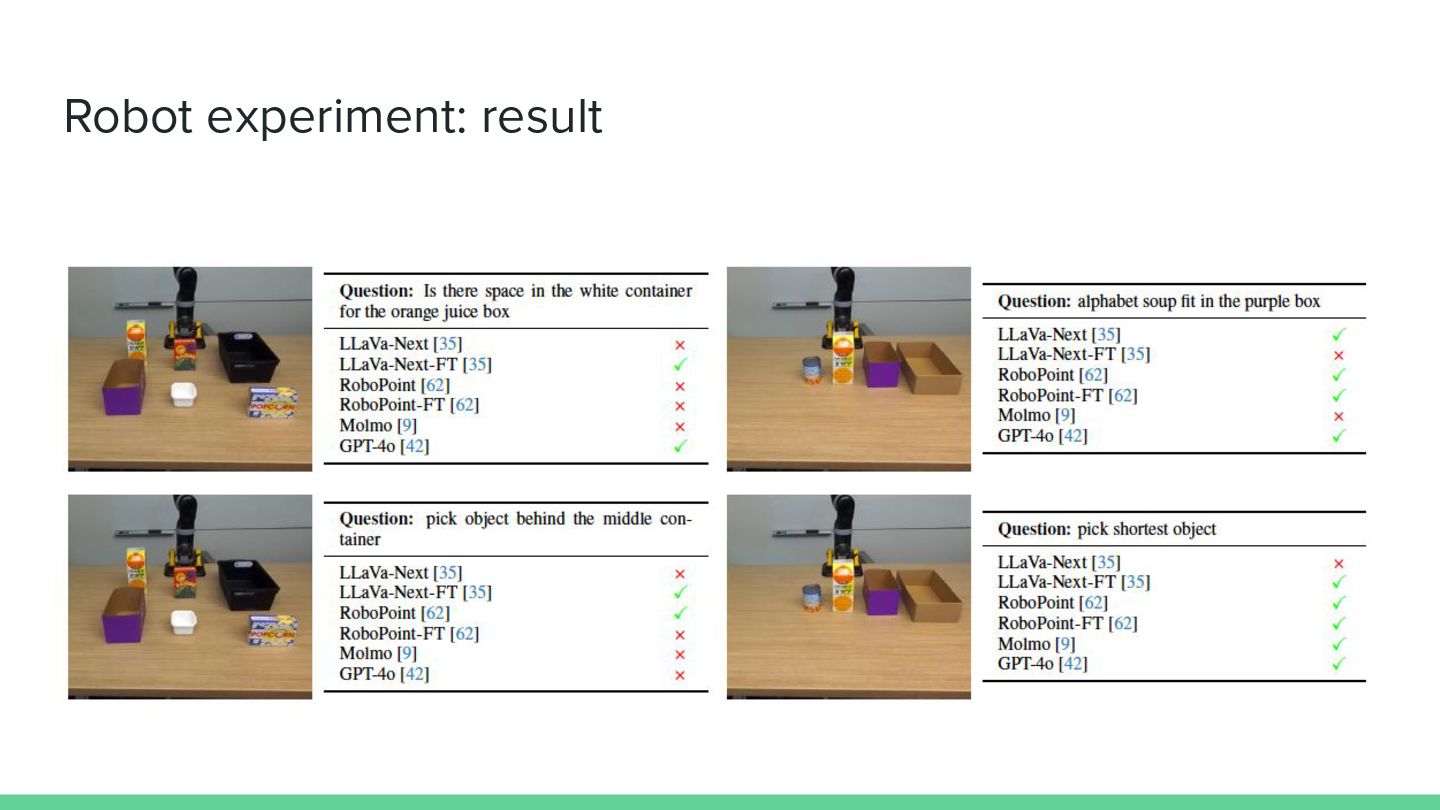
Robot Experiment • テーブルトップ環境でのPick&Placeタスク ◦ Kinova Jacoロボット、RGBDカメラ:ZED2、cuRoboでの動作計画 • 2D VLMはROBOSPATIALで訓練により大きく改善
◦ 数ピクセルの誤差でも 5-10cmズレることもあり、それらに対して改善効果がある
Robot experiment: result
Robot experiment: result Q:2つの物が積み重なったところか ら、最も上にある物を取ってください Q:cheez-itの箱(赤い箱)の上に缶を 置くスペースはありますか? Questionの詳細度、タスクの難易度によっては難しい
考察・まとめ • 考察:データセットによる空間推論が出来るのか? ◦ 「上に、下に」など空間マッピング、「隣に、そばに」など物体間の近接性の理解が向上 ◦ 視点の理解:参照フレームの導入により推論が向上し、物体の幾何・方向と空間言語の関連付け を学習できている ◦ 3D
VLMでは自己座標系、物体座標系で効果がある • まとめ:Robospatialデータセットの提案 ◦ 空間位置関係の理解が必要なタスクへの応用が可能 ▪ 物体の位置関係、参照フレームの違いに対応した推論が可能 ◦ 新たなデータセットに対しても拡張可能
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}