Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Data Ingestion ETL の技術選定の変遷をADRで振り返る / Data Ing...
Search
Shoji Shirotori
July 10, 2024
Technology
2.6k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Data Ingestion ETL の技術選定の変遷をADRで振り返る / Data Ingestion ETL ADRs at DataOps Night#4
DataOps Night#4
https://finatext.connpass.com/event/320643/
Shoji Shirotori
July 10, 2024
More Decks by Shoji Shirotori
See All by Shoji Shirotori
Wantedlyの障害対応文化とインシデントコマンダー / Wantedly Incident Commander
irotoris
5
3k
オンコールよもやま話 / JAWS-UG SRE#7 OnCall Yomoyama
irotoris
1
740
SRE を実践するためのプラットフォームの作り方と技術マネジメント / Building a Platform for SRE
irotoris
3
6.4k
Other Decks in Technology
See All in Technology
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
Making sense of Google’s agentic dev tools
glaforge
1
300
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
270
Type-safe IaC for Dart
coborinai
0
180
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
680
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
760
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
390
kaonavi Tech Night#1
kaonavi
0
140
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
150
GoでCコンパイラを作った話
repunit
0
150
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
0
260
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
5
2.1k
Featured
See All Featured
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
How to build a perfect <img>
jonoalderson
1
5.8k
Mobile First: as difficult as doing things right
swwweet
225
10k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
ラッコキーワード サービス紹介資料
rakko
1
4M
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
Balancing Empowerment & Direction
lara
6
1.2k
Design in an AI World
tapps
1
260
Code Review Best Practice
trishagee
74
20k
Believing is Seeing
oripsolob
1
170
Transcript
© LayerX Inc. Data Ingestion/ETLの技術選定の変遷を ADRで振り返る 2024/07/10 DataOps Night#4 株式会社LayerX
Shoji Shirotori @irotoris
© LayerX Inc. 2 白鳥昇治 ID: @irotoris バクラク事業部 機械学習・データ部 データグループ
DataOpsチーム 入社 v202402.1 Infrastructure, SRE, Data Engineering Redshift / Treasure Data / Netezza / Exadata / BigQuery / Snowflake 自己紹介 自己紹介
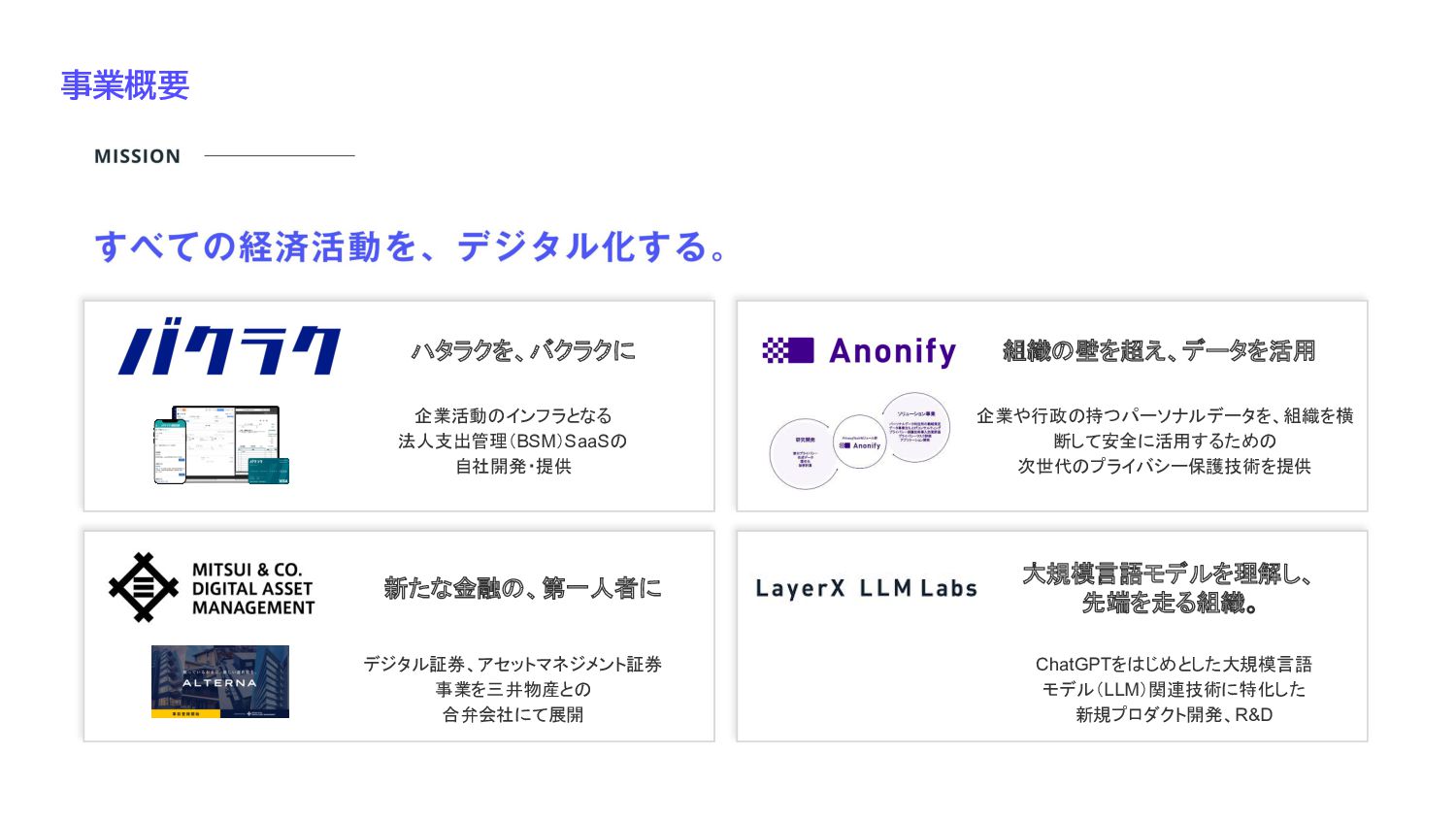
事業概要 ハタラクを、バクラクに 企業活動のインフラとなる 法人支出管理(BSM)SaaSの 自社開発・提供 新たな金融の、第一人者に デジタル証券、アセットマネジメント証券 事業を三井物産との 合弁会社にて展開 組織の壁を超え、データを活用
企業や行政の持つパーソナルデータを、組織を横 断して安全に活用するための 次世代のプライバシー保護技術を提供 大規模言語モデルを理解し、 先端を走る組織。 ChatGPTをはじめとした大規模言語 モデル(LLM)関連技術に特化した 新規プロダクト開発、R&D
バクラクシリーズラインナップ 稟議・支払申請・経費精算 仕訳・支払処理効率化 法人カードの発行・管理 帳票保存・ストレージ 帳票発行 * 経費精算のSlack連携は申請内容の通知のみ ・AIが領収書を5秒でデータ化 ・スマホアプリとSlack連携あり
・領収書の重複申請などミス防止機能 ・AIが請求書を5秒でデータ化 ・仕訳・振込データを自動作成 ・稟議から会計までスムーズに連携 ・年会費無料で何枚でも発行可 ・インボイス制度・電帳法対応 ・すべての決済で1%以上の還元 ・AIが書類を5秒でデータ化 ・あらゆる書類の電子保管に対応 ・電子取引・スキャナ保存に完全対応 ・帳票の一括作成も個別作成も自由自在 ・帳票の作成・稟議・送付・保存を一本化 ・レイアウトや項目のカスタマイズも可能
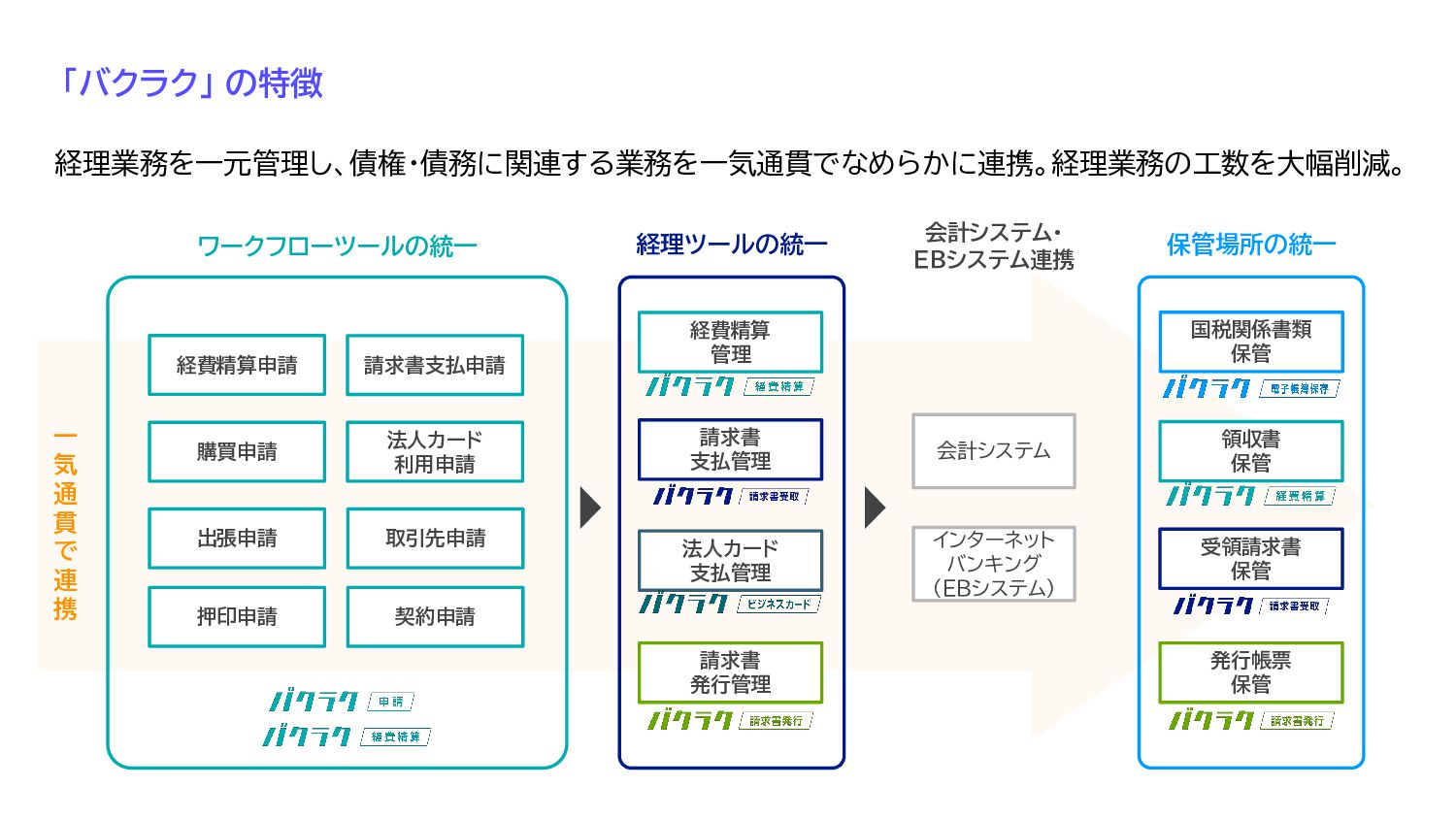
「バクラク」 の特徴 会計システム インターネット バンキング (EBシステム) 法人カード 支払管理 経費精算 管理
請求書 支払管理 ワークフローツールの統一 経理ツールの統一 会計システム・ EBシステム連携 一 気 通 貫 で 連 携 経理業務を一元管理し、債権・債務に関連する業務を一気通貫でなめらかに連携。経理業務の工数を大幅削減。 出張申請 取引先申請 押印申請 契約申請 購買申請 法人カード 利用申請 請求書支払申請 経費精算申請 請求書 発行管理 保管場所の統一 領収書 保管 受領請求書 保管 発行帳票 保管 国税関係書類 保管
© LayerX Inc. 6 こんなこと考えながらデータ基盤で Data Ingestion / ETL の技
術やツール・サービスを選択してるよっていう具体例を話します。 誰かの行動や意思決定の参考になれば幸いです。 今日話すこと
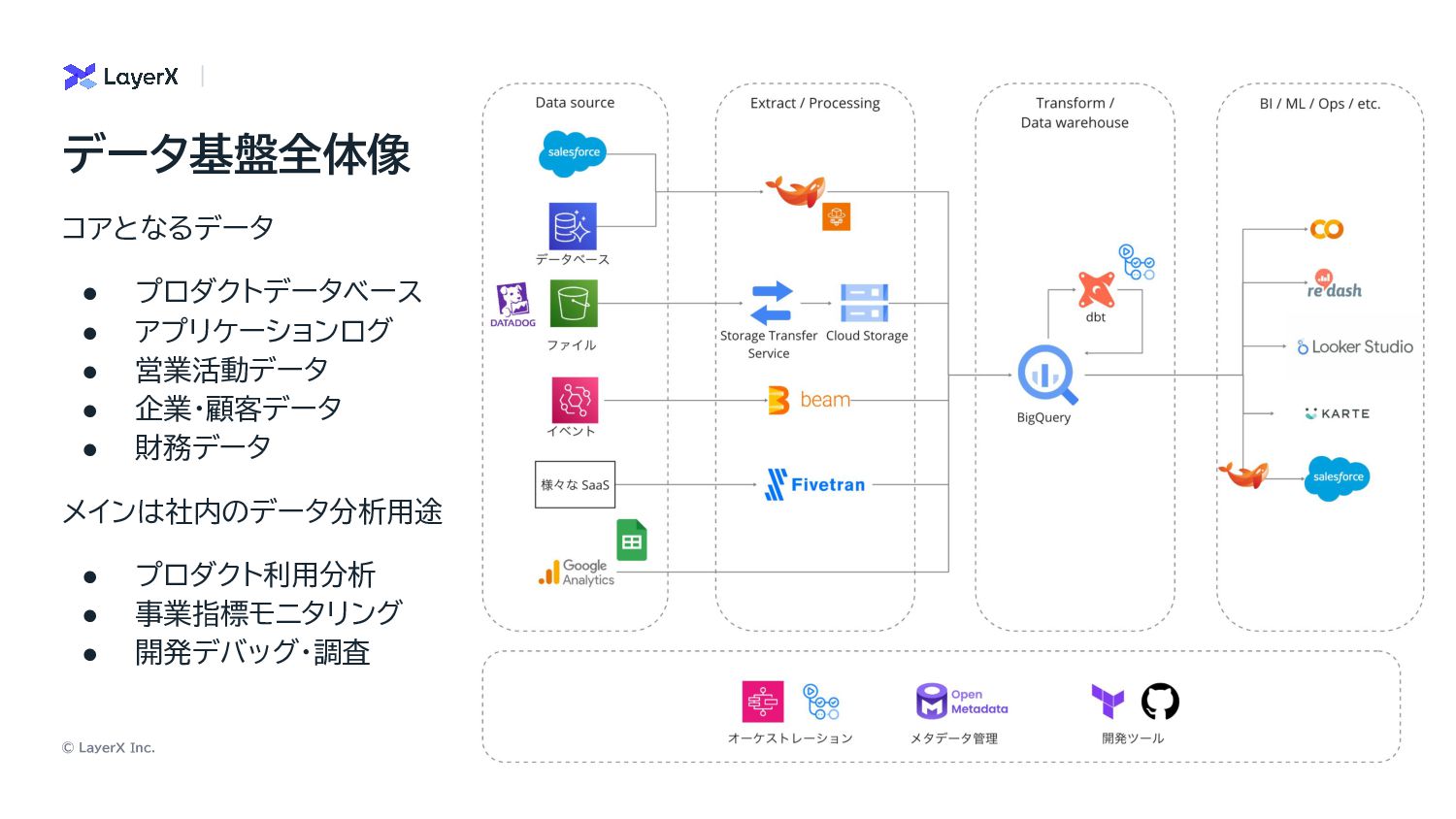
© LayerX Inc. 7 コアとなるデータ • プロダクトデータベース • アプリケーションログ •
営業活動データ • 企業・顧客データ • 財務データ メインは社内のデータ分析用途 • プロダクト利用分析 • 事業指標モニタリング • 開発デバッグ・調査 データ基盤全体像
© LayerX Inc. 8 データ基盤においてデータソースの豊富さと拡張性は、データ分析のリードタイムに直結する。 ➡ 事業においては意思決定の速度を上げ試行回数を増やすことにつながる。 以下を実現するData Ingestion /
ETLの技術選定が重要 • データソースの追加に迅速に応えられる • 追加して流れ出した(必要な)データを止めない Data Ingestion / ETL 技術選定の思想的な話
© LayerX Inc. 9 • Apache Beam on Flink の機運が高まっていた
◦ Amazon EventBridge ➡ BigQuery を Beam で実装した ◦ MySQL の CDC を Debezium + Beam で書こうとしていた ◦ Beam の Plugin で Salesforce が扱えた • 既存 ETL (embulk) 継続運用の悩み ◦ コードの保守、設定追加運用 ◦ Java8、将来的な embulk core v1.1 への対応 • SaaS のデータ取り込みでマネージドなデータ取り込みツールの検証をしていた ◦ Fivetran や Amazon AppFlow など ➡ 結局なにをどう使うといいんだっけ。そうだ、ADR を書こう。 データ基盤 2024年2月頃
© LayerX Inc. 10 • Architecture Decision Record • アーキテクチャに関する意思決定を記録するためのフォーマット
• なぜその技術・設計を用いるのか • 意思決定の背景や選択肢、懸念事項、決定事項が記される ※ 他にも Design Docs というドキュメントもある • 機能や仕組みを実装するために必要な設計情報 • どのような問題を解決するのか、具体的な実装指針 ◦ アーキテクチャ、インターフェース、データモデル、etc. ADR とは
© LayerX Inc. 11 • コアなデータソースは Apache Beam でデータロードを実装することを検討する ◦
コアなデータソースとは…利活用の中心のデータ、量が多いデータ(MySQL, Salesforce) ◦ 実装工数は高いが、信頼性やデータ鮮度を高めるために柔軟な実装が可能なため • データ量が少ない SaaS 系のデータは Fivetran の利用を推奨する ◦ 豊富なコネクタがあり、Beam 実装よりはるかに対応リードタイムが短い ◦ コストは高い(レコード数課金)ため、大量のデータ転送の場合は他の実装を検討する • データソースに付随する機能によってデータロードが簡単に実現・管理できる場合はその機能を使う ◦ 例: Google Analytics の BigQuery 連携 Apache Beam と Fivetran を選択する ADR を書いた
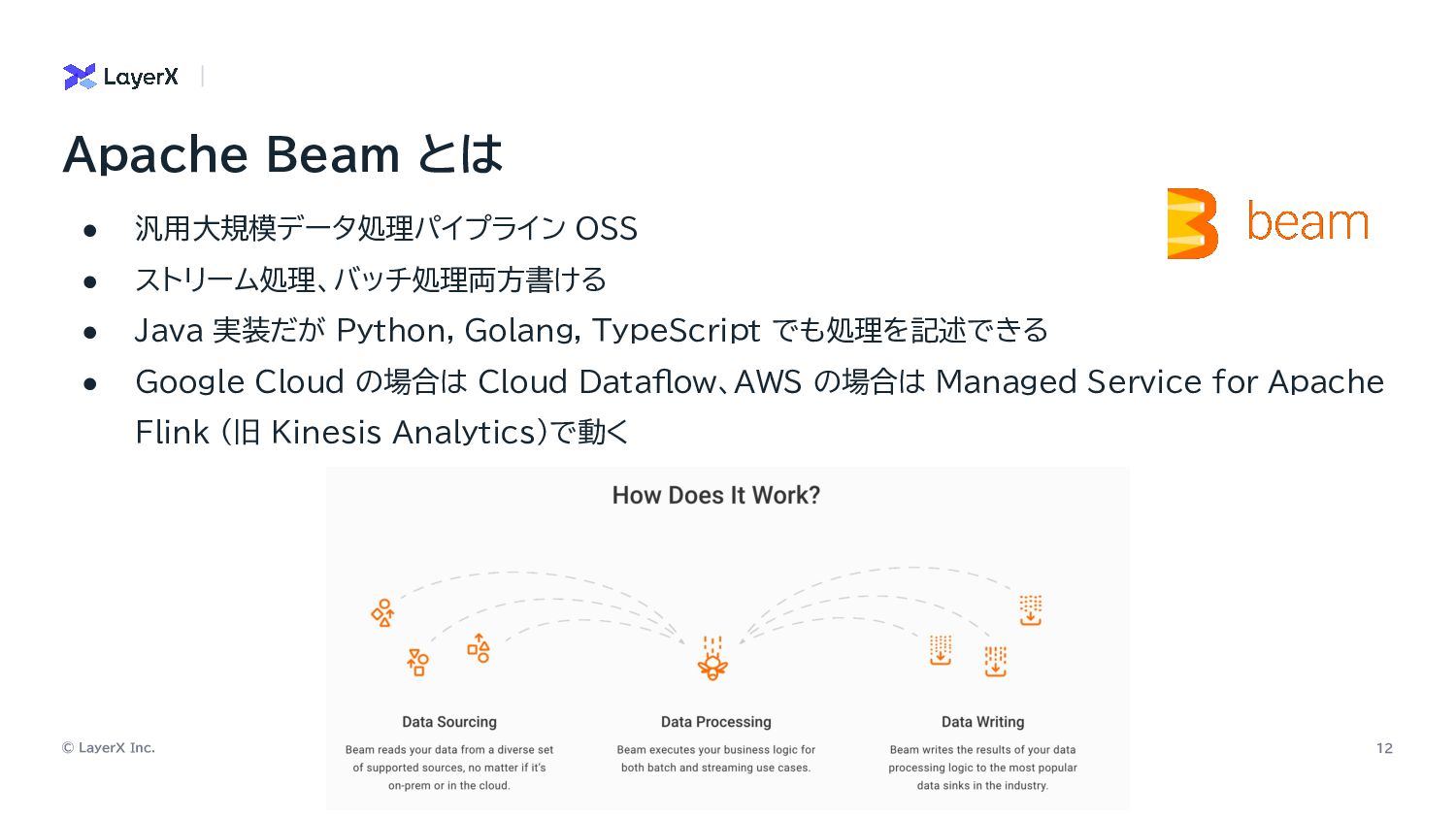
© LayerX Inc. 12 • 汎用大規模データ処理パイプライン OSS • ストリーム処理、バッチ処理両方書ける •
Java 実装だが Python, Golang, TypeScript でも処理を記述できる • Google Cloud の場合は Cloud Dataflow、AWS の場合は Managed Service for Apache Flink (旧 Kinesis Analytics)で動く Apache Beam とは
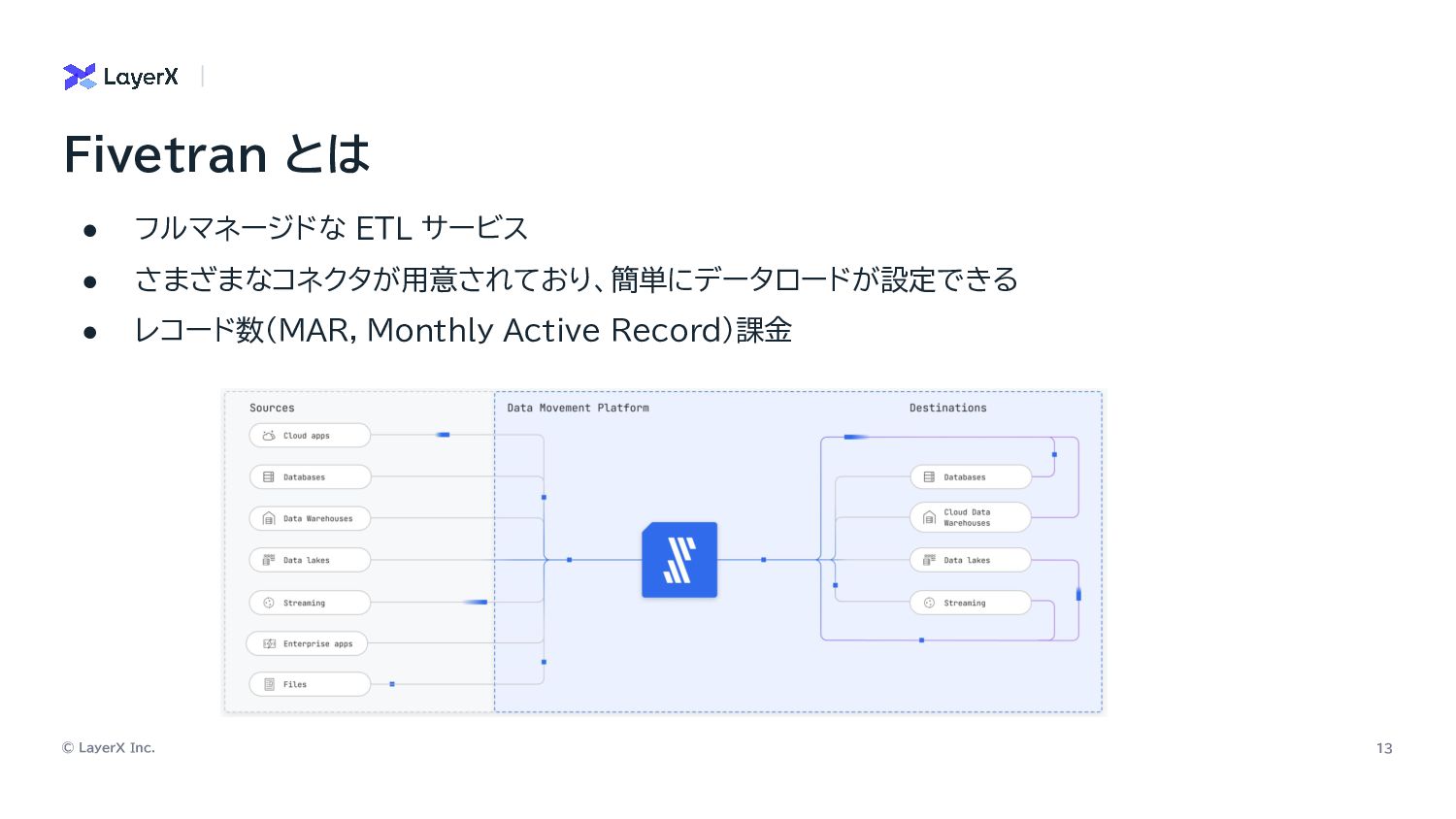
© LayerX Inc. 13 • フルマネージドな ETL サービス • さまざまなコネクタが用意されており、簡単にデータロードが設定できる
• レコード数(MAR, Monthly Active Record)課金 Fivetran とは
© LayerX Inc. 14 Apache Beam の実装(対応データソース)は全然増えなかった 🥺 • 「実装工数は高いが、信頼性やデータ鮮度を高めるために柔軟な実装が可能なため」とは言ったが…
◦ やっぱり実装コストが高かった ◦ 例えば Salesforce のデータ取り込みでやりたいことは「Salesforce のカラム追加・削除でも 失敗しないデータ取り込み」だったが、レコードから型の自動マッピングやスキーマ自動生成処理 を実装するには単純にコード量が多くなってしまった ◦ MySQL の CDC も別件で優先度が上がらず、結局 embulk を置き換えるには至らず Apache Beam やってみた結果
© LayerX Inc. 15 Fivetran はいい感じに使えている 👍 • 本当にシュッと簡単に ETL
が組める ◦ 特に SaaS のデータロードを実装しようとすると、それぞれのサービス仕様や認証、設定を理解 しないといけないが、Fivetran はドキュメントに沿って設定するだけでOK ◦ カラム追加・削除も自動でいいかんじに行われる • データ量課金が高額だが、コネクタごとに無料期間が2週間ある ◦ データ量が多くてコスト的に難しい場合でも、とりあえず Fivetran でデータ持ってきて有用性 の検証、継続的に必要な場合は無料期間のうちに他の方法を検討・実装、みたいな動きができる • データ構造が ER 図で提供されており、データ理解に便利 ◦ データソースによっては Fivetran が分析用の dbt モデルを提供していたりする Fivetran やってみた結果
© LayerX Inc. 16 • こんな感じで技術選定して、開発して運用して、失敗して、また技術選定して…を繰り返している。 ◦ 「データソースの追加に迅速に応える」 「流れ出した(必要な)データは止めない」 を実現するため
• ADR 書くのは振り返りにもなるしいいぞ。 ここまで
© LayerX Inc. 17 • 現在 LayerX ではデータ基盤を Snowflake に載せ替える検証をしている
• Data Ingest / ETL に関して言うと以下が魅力的 (トライアルで検証して総合的に判断はしたが) ◦ プロダクト基盤である AWS から外部への Outbound データ転送量課金が発生しない ◦ S3 にデータを置けば Snowflake から直接参照・ロードができる ◦ マーケットプレイスで様々な App が提供されている • Snowflake のパワーを最大限活かして「全員アナリスト」な環境とデータドリブン文化を醸成する いまやってること
© LayerX Inc. 18 • External Stage (S3) = S3
のファイルを Snowflake からクエリでロー ド(COPY INTO)可能 • Snowpipe = S3 にファイルを置いたら自動的に Snowflake にロードする 仕組み、ログ取り込みがとても簡単 ◦ S3 ➡ Storage Transfer Service ➡ GCS ➡ bq load ➡ BigQuery なイベントドリブンな仕組みが不要に • Snowflalke での MySQL CDC (ニアリアルタイム連携)も探索中 ◦ DMS serverless + Snowpipe でできることは確認したが、高い ◦ 実用的なものが出来たらブログにします Snowflake の Data Ingest / ETL
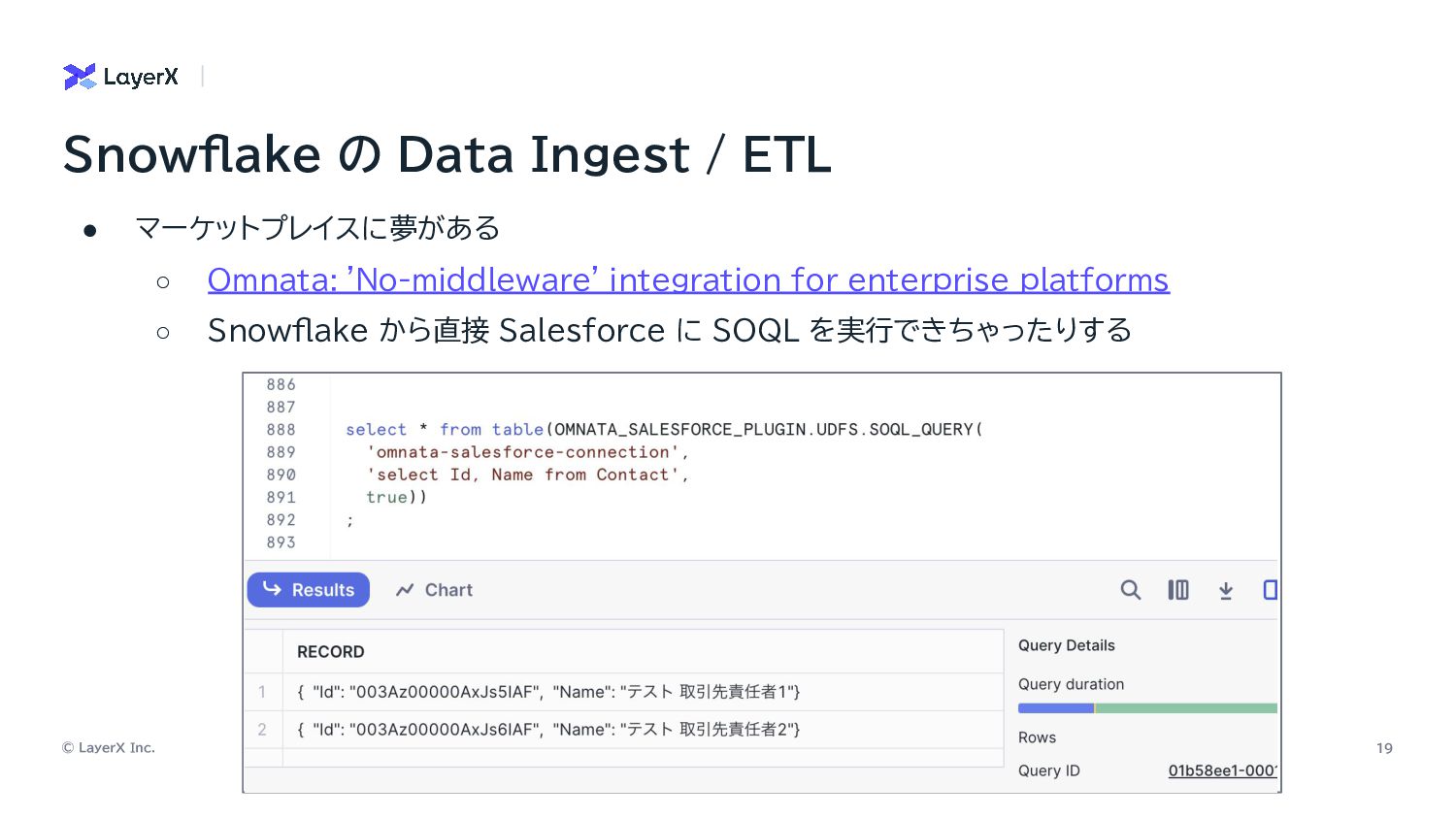
© LayerX Inc. 19 • マーケットプレイスに夢がある ◦ Omnata: 'No-middleware' integration
for enterprise platforms ◦ Snowflake から直接 Salesforce に SOQL を実行できちゃったりする Snowflake の Data Ingest / ETL
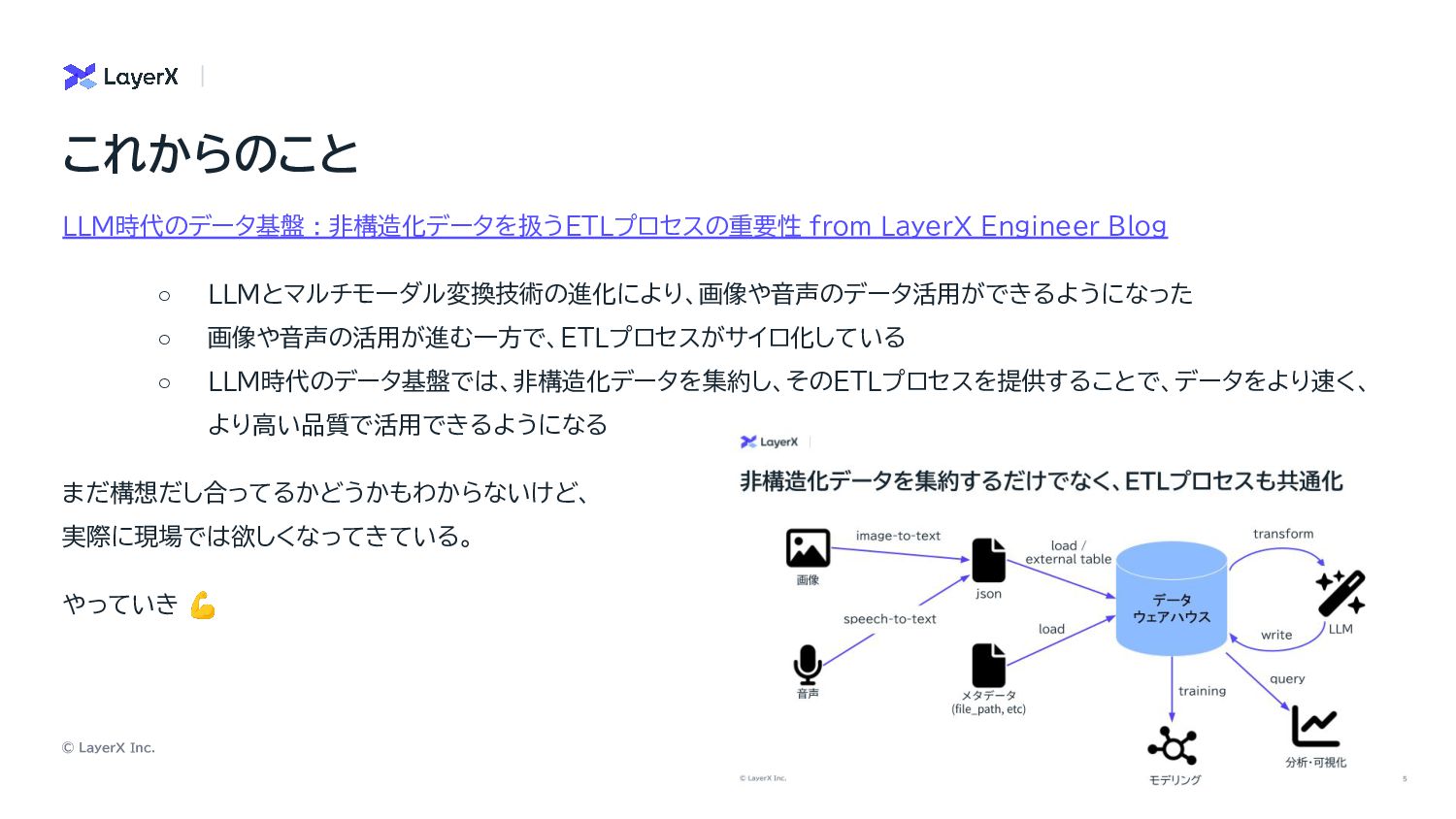
© LayerX Inc. 20 LLM時代のデータ基盤 : 非構造化データを扱うETLプロセスの重要性 from LayerX Engineer
Blog ◦ LLMとマルチモーダル変換技術の進化により、画像や音声のデータ活用ができるようになった ◦ 画像や音声の活用が進む一方で、ETLプロセスがサイロ化している ◦ LLM時代のデータ基盤では、非構造化データを集約し、そのETLプロセスを提供することで、データをより速く、 より高い品質で活用できるようになる まだ構想だし合ってるかどうかもわからないけど、 実際に現場では欲しくなってきている。 やっていき 💪 これからのこと
© LayerX Inc. 21 データ職種全方位積極採用中です!データプラットフォーム開発も DataOps も全然これからなのと、今年 度入ってから急激に事業部でデータ活用が進んでいます!データエンジニアリングで事業を加速させるため に、技術選定においても積極的にチャレンジ・試行錯誤していくフェーズなので、少しでも興味持った方がい らっしゃったらぜひお話ししましょう!
• データエンジニア • アナリティクスエンジニア • データアナリスト • データサイエンティスト これからのこと
Fin.
Q?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}