Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
戦えるAIエージェントの作り方
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Takuya Akiba
October 31, 2025
Technology
18k
29
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
戦えるAIエージェントの作り方
Takuya Akiba
October 31, 2025
More Decks by Takuya Akiba
See All by Takuya Akiba
KaggleはAIに解けるか? MLE-Benchのいま (2025/08/23; 第4回 関東Kaggler会)
iwiwi
5
3.8k
自然着想型アプローチによる基盤モデルの研究開発 (2025/01/23, 第35回ステアラボ人工知能セミナー)
iwiwi
2
210
Evolutionary Optimization of Model Merging Recipes (2024/04/17, NLPコロキウム)
iwiwi
11
7.5k
LLMの開発は難しい?簡単?Stability AIの現場から (2023/10/11, W&B Fully Connected)
iwiwi
12
10k
Stability AI Japanにおける大規模言語モデルの研究開発
iwiwi
17
12k
Kaggle Traveling Santa 2018 - 4th Place Solution
iwiwi
1
67
Kaggle State Farm Distracted Driver Detection
iwiwi
15
10k
Other Decks in Technology
See All in Technology
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.5k
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
書籍セキュアAPIについて
riiimparm
0
200
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
300
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
960
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
120
人とエージェントが高め合う協業設計
kintotechdev
0
740
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
170
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
210
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
1
270
Featured
See All Featured
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
A Modern Web Designer's Workflow
chriscoyier
698
190k
4 Signs Your Business is Dying
shpigford
187
22k
Producing Creativity
orderedlist
PRO
348
40k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Typedesign – Prime Four
hannesfritz
42
3.1k
Utilizing Notion as your number one productivity tool
mfonobong
4
450
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Music & Morning Musume
bryan
47
7.3k
Transcript
Sakana AI Research Scientist 秋葉 拓哉 戦える AI エージェントの 作り方
W&B Fully Connected 2025 Tokyo
AIエージェント、作るのは簡単? 2 LLMにツールをくっつければエージェントは完成? そうやって出来たエージェントは本当に実用的? 人間の専門家にも匹敵できる 強力で実用的なエージェントを作る決め手は何なのか? 02 03 04 01
専門家と戦えるAIエージェント 推論時スケーリング ドメイン知識の活用 専門家と戦えるAIエージェント 01 02 03
専門家と戦えるAIエージェント 推論時スケーリング ドメイン知識の活用 01 02 03 専門家と戦えるAIエージェント 01
The AI Scientist V2 専門家の査読を通過する論文を執筆するエージェント 5 02 03 04 01
👉 Scores: [3,4,7] 👉 Scores: [3,3,3] 👉 Scores: [6,6,7] 世界初、100%AI生成の論文が査読通過! (ICLR’25 Workshop) sakana.ai/ai-scientist-first-publication/ arxiv.org/abs/2408.06292
ALE-Agent [NeurIPS’25] 専門家並の最適化アルゴリズムを自動設計するエージェント 6 02 03 04 01 sakana.ai/ale-bench-jp/ arxiv.org/abs/2506.09050
7 02 03 04 01 トップ専門家と肩を並べる実力を実プログラミングコンテストで実証! ALE-Agent [NeurIPS’25] 専門家並の最適化アルゴリズムを自動設計するエージェント sakana.ai/ale-bench-jp/
arxiv.org/abs/2506.09050
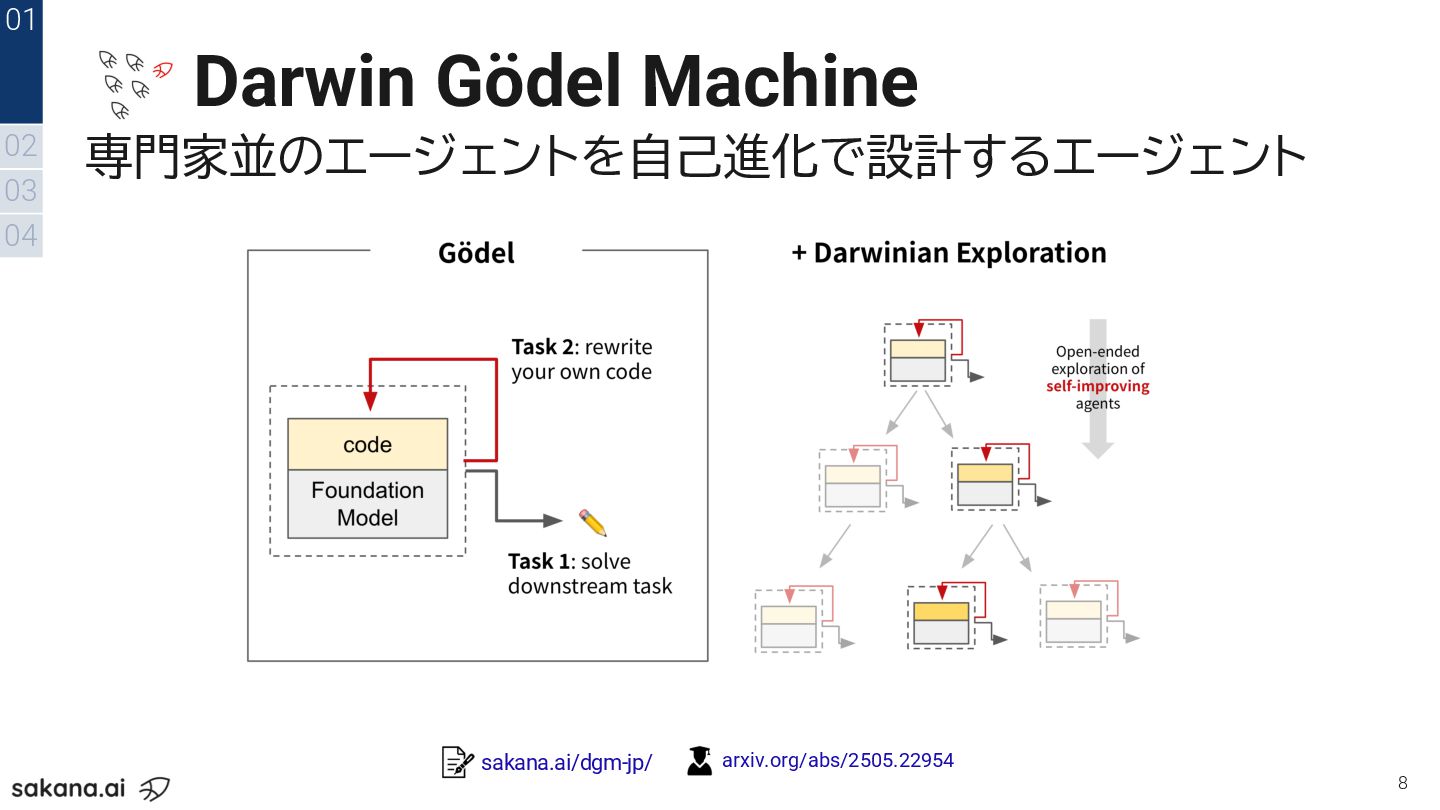
Darwin Gödel Machine 専門家並のエージェントを自己進化で設計するエージェント 8 02 03 04 01 sakana.ai/dgm-jp/ arxiv.org/abs/2505.22954
9 02 03 04 01 専門家が何ヶ月もかけて開発したエージェント 専門家が実装したエージェントに迫る性能に到達! sakana.ai/dgm-jp/ arxiv.org/abs/2505.22954 Darwin Gödel Machine
専門家並のエージェントを自己進化で設計するエージェント
今から話すこと 10 このような、人間の専門家にも匹敵できる 強力で実用的なエージェントを作る決め手は何なのか? 02 03 04 01
専門家と戦えるAIエージェント 推論時スケーリング ドメイン知識の活用 01 02 03 専門家と戦えるAIエージェント 01
専門家と戦えるAIエージェント 推論時スケーリング ドメイン知識の活用 01 02 03 推論時スケーリング 02
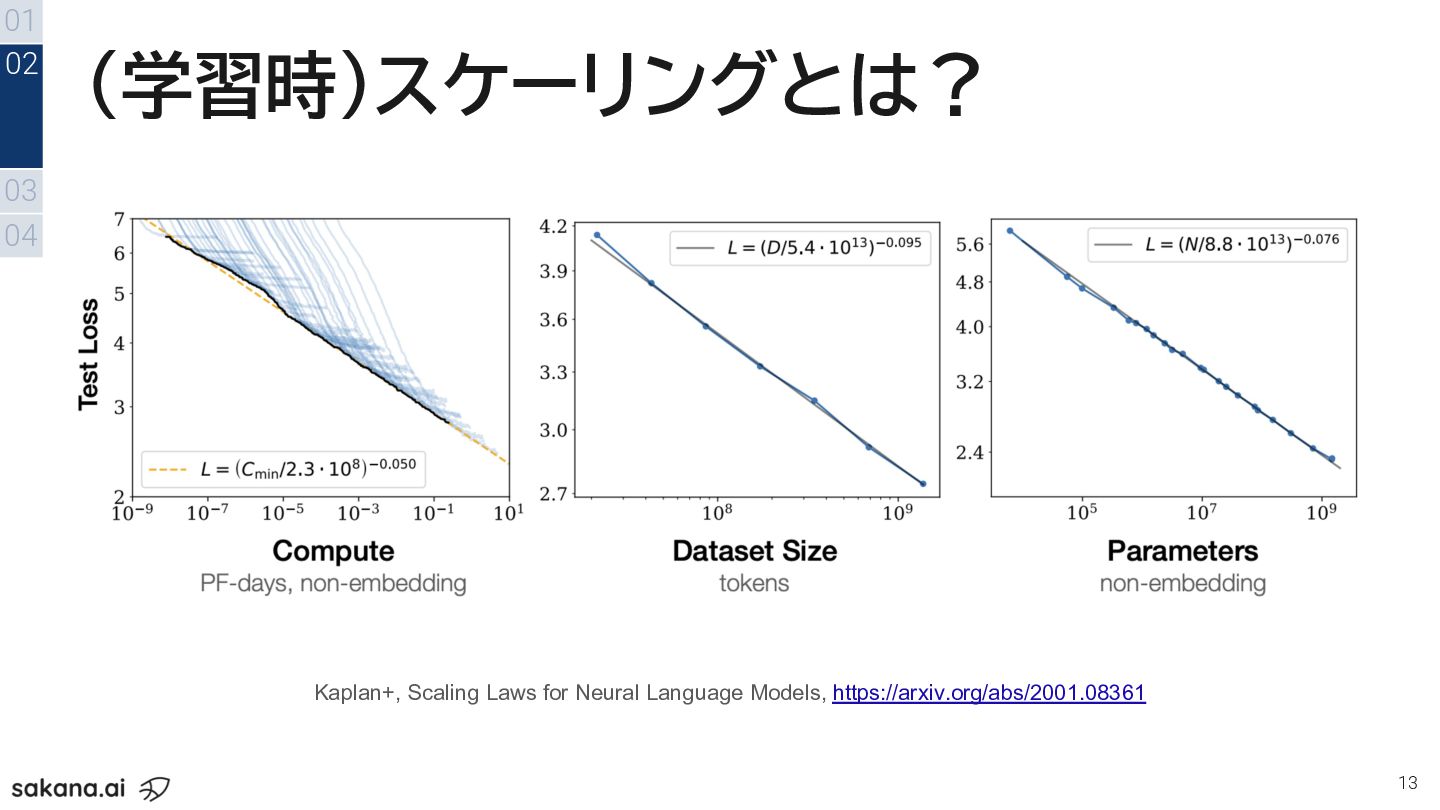
(学習時)スケーリングとは? 13 01 03 04 02 Kaplan+, Scaling Laws for
Neural Language Models, https://arxiv.org/abs/2001.08361
推論時スケーリングとは? 14 (学習時ではなく)推論時にもより多くの計算量を投入する! アプローチ1:LLMが長〜いCoTをする OpenAI o1, DeepSeek R1以降のreasoning model アプローチ2:LLMと丁寧に1つの解答を構築する
Process Reward Modelの利用など アプローチ3:LLMを大量に呼び出し解答を複数作り試行錯誤させる Repeated Sampling, AlphaEvolve/ShinkaEvolve, AB-MCTSなど 01 03 04 02
推論時スケーリングとは? 15 (学習時ではなく)推論時にもより多くの計算量を投入する! アプローチ1:LLMが長〜いCoTをする OpenAI o1, DeepSeek R1以降のreasoning model アプローチ2:LLMと丁寧に1つの解答を構築する
Process Reward Modelの利用など アプローチ3:LLMを大量に呼び出し解答を複数作り試行錯誤させる Repeated Sampling, AlphaEvolve/ShinkaEvolve, AB-MCTSなど 01 03 04 02
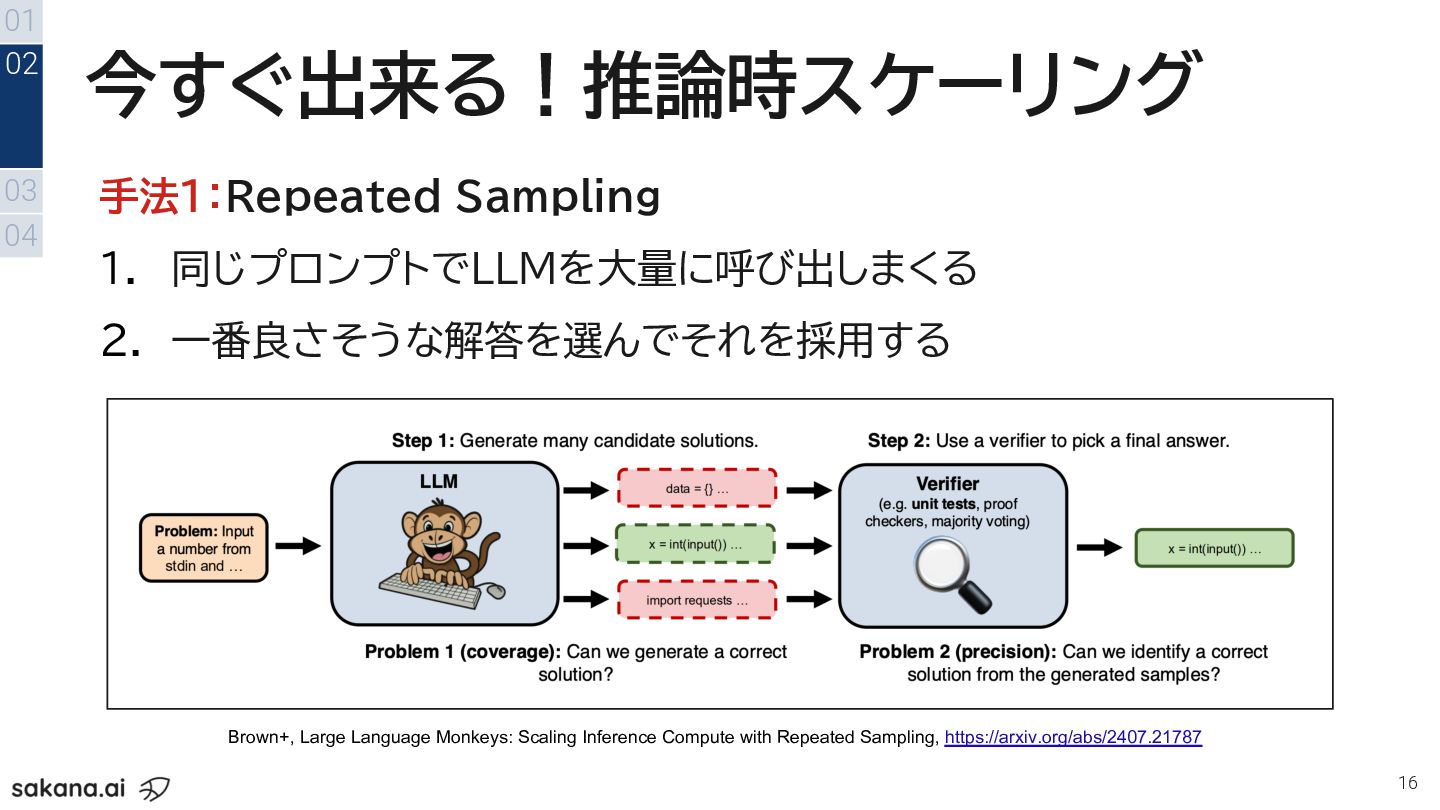
今すぐ出来る!推論時スケーリング 16 手法1:Repeated Sampling 1. 同じプロンプトでLLMを大量に呼び出しまくる 2. 一番良さそうな解答を選んでそれを採用する 01 03
04 02 Brown+, Large Language Monkeys: Scaling Inference Compute with Repeated Sampling, https://arxiv.org/abs/2407.21787
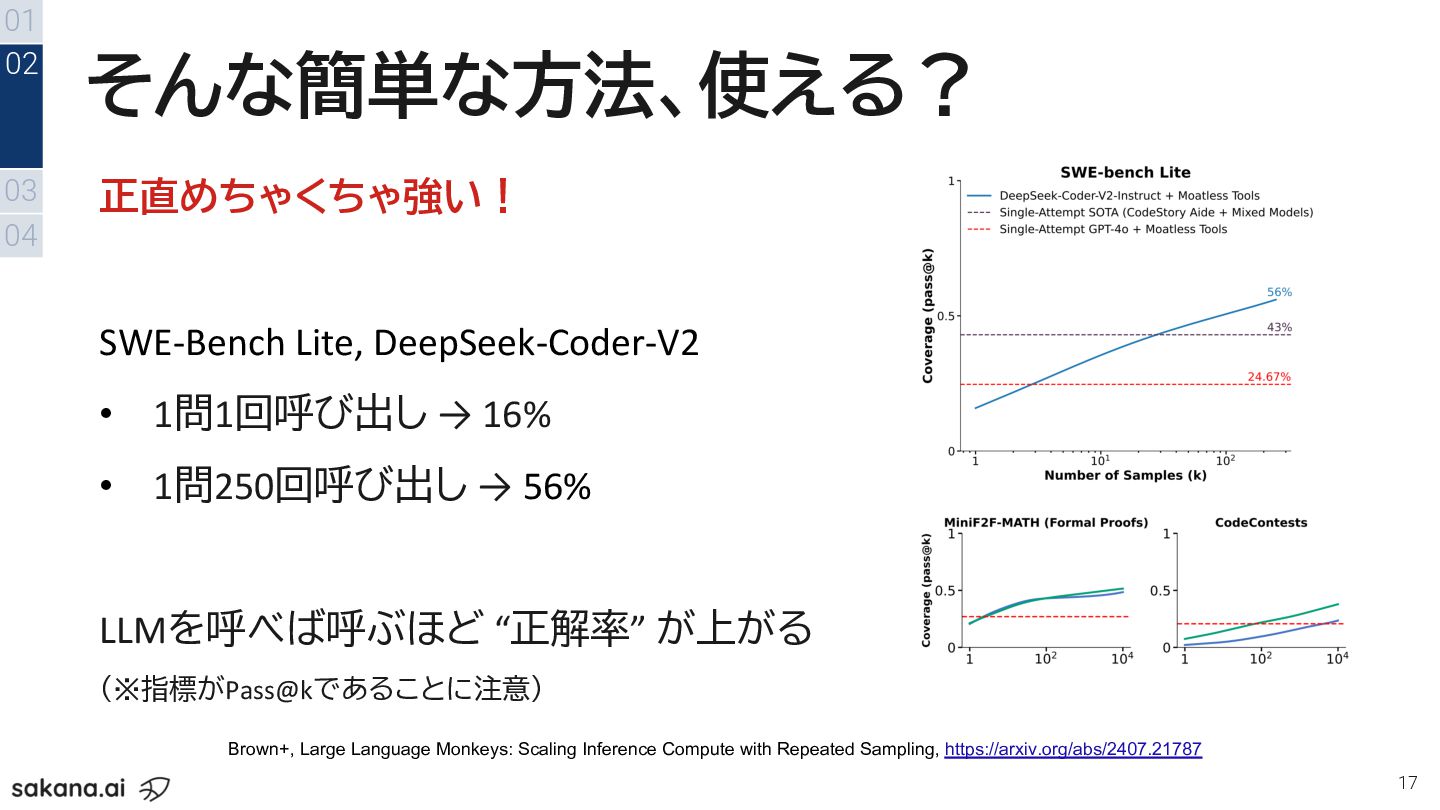
そんな簡単な方法、使える? 17 正直めちゃくちゃ強い! SWE-Bench Lite, DeepSeek-Coder-V2 • 1問1回呼び出し → 16%
• 1問250回呼び出し → 56% LLMを呼べば呼ぶほど “正解率” が上がる (※指標がPass@kであることに注意) 01 03 04 02 Brown+, Large Language Monkeys: Scaling Inference Compute with Repeated Sampling, https://arxiv.org/abs/2407.21787
2024年中旬ぐらいから威力が話題に 18 01 03 04 02 LLMを複数回呼び出し試行錯誤させる事例はあったが、 「思いの外めっちゃ呼んだらめっちゃ強い」って風潮が加熱
……だが意外とかなり前にも事例あり 19 AlphaCode [2022, Science] 1つの問題に最大1,000,000回LLMを呼び出し (後処理をして10個まで減らし、Pass@10を評価) 01 03 04
02 Li+, Competition-Level Code Generation with AlphaCode, https://arxiv.org/abs/2203.07814
AB-MCTS [NeurIPS’25 Spotlight] 20 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412
Repeated Sampling (= “go wide” ) 利点:LLMの出力の多様性を活用 欠点:フィードバックを利用出来ない
AB-MCTS [NeurIPS’25 Spotlight] 21 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412
Repeated Sampling (= “go wide” ) 利点:LLMの出力の多様性を活用 欠点:フィードバックを利用出来ない Sequential Refinement (= “go deep”) 利点:フィードバックを活用できる 欠点:スケールしない つまり、続けても伸びない、間違った方針にハマりがち
AB-MCTS [NeurIPS’25 Spotlight] 22 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412
LLM出力の多様性とフィードバックの両方を適応的に活用できる 推論時スケーリング用のアルゴリズム
AB-MCTS [NeurIPS’25 Spotlight] 23 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412
複数社のLLMを適応的に組み合わせるアルゴリズム的拡張も可 単体LLMよりも高性能
AB-MCTS [NeurIPS’25 Spotlight] 24 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412
複数の実案件で試用中
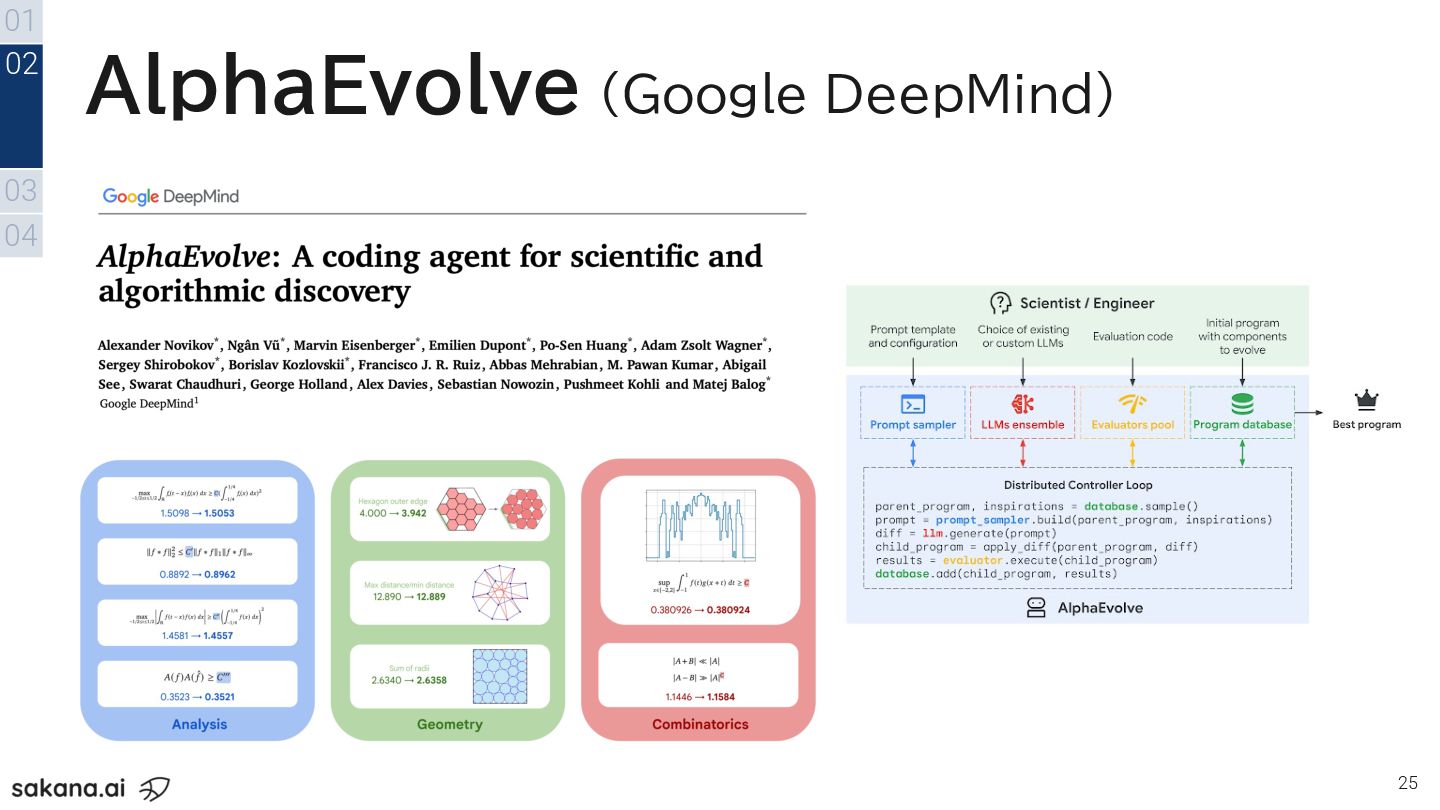
25 01 03 04 02 AlphaEvolve (Google DeepMind)
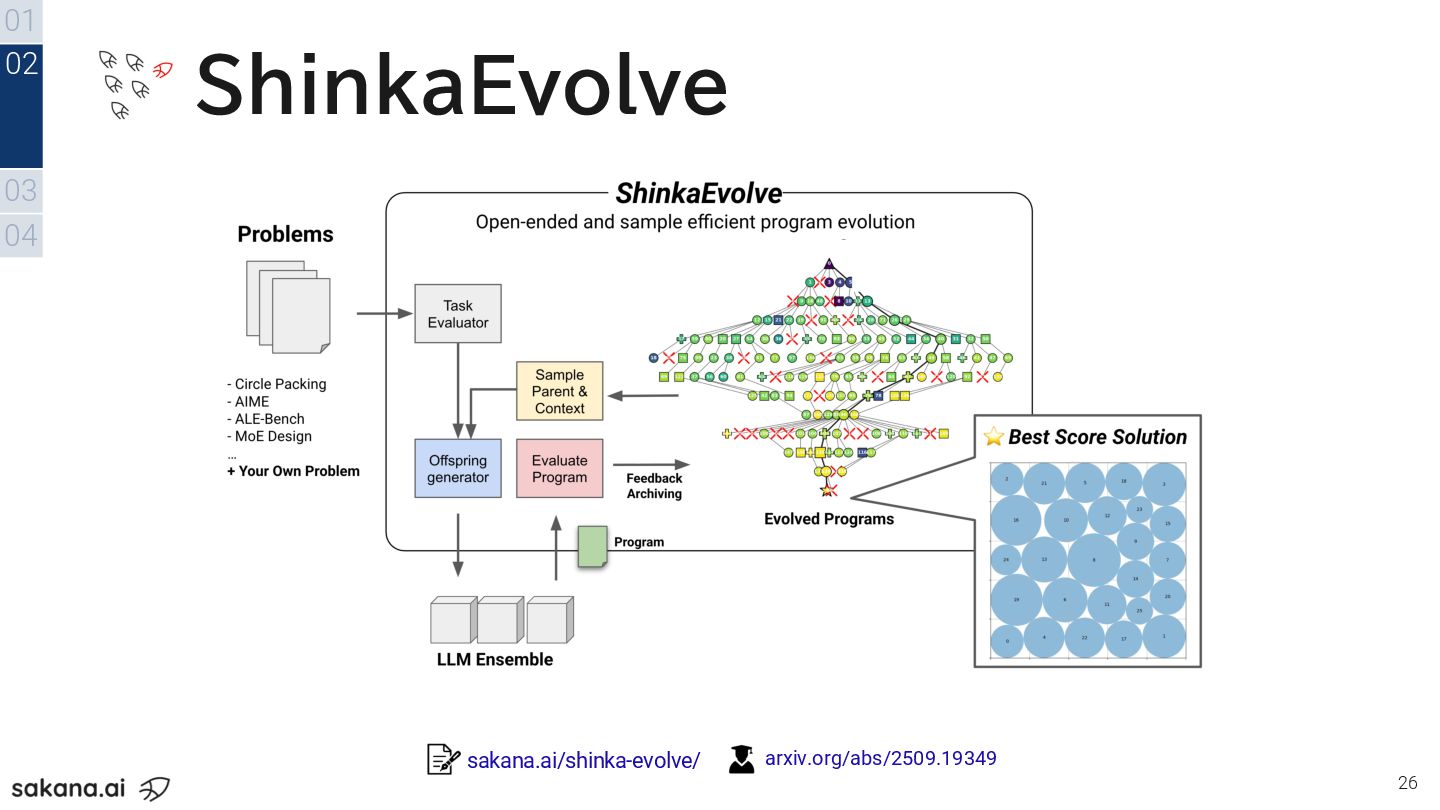
26 01 03 04 02 ShinkaEvolve sakana.ai/shinka-evolve/ arxiv.org/abs/2509.19349
27 01 03 04 02 ShinkaEvolve in Action sakana.ai/icfp-2025/ 国際的プログラミングコンテスト
ICFP-PC 2025 にて ShinkaEvolve が優勝チーム*に貢献 (*: 私を含むチーム)
専門家と戦えるAIエージェント 推論時スケーリング ドメイン知識の活用 01 02 03 推論時スケーリング 02
専門家と戦えるAIエージェント 推論時スケーリング ドメイン知識の活用 01 02 03 ドメイン知識の活用 03
ドメイン知識の活用 30 01 02 04 03 有用な知識や正しい方法が分かっているのであれば、その活用は有効 結局、昔の機械学習と根本的な構造は変わらない 特徴量エンジニアリング、前処理、データにあったNN設計、etc…… ただし方法は変わった
1. プロンプト 31 01 02 04 03 専門的プロンプト追加 知識や方法論のようなドメイン知識をプロンプトに入れる ニッチなタスクに取り組む際に特に効果がある印象
言葉遣いがどうとか頼み方がどうとかは今やどうでもいい、重要な情報を含めよう 何をどう入力するかを考えるところが少し特徴量エンジニアリングに通じる部分がある 推論時スケーリング ALE-Agent のアブレーション分析 ALE-Agent のプロンプト例
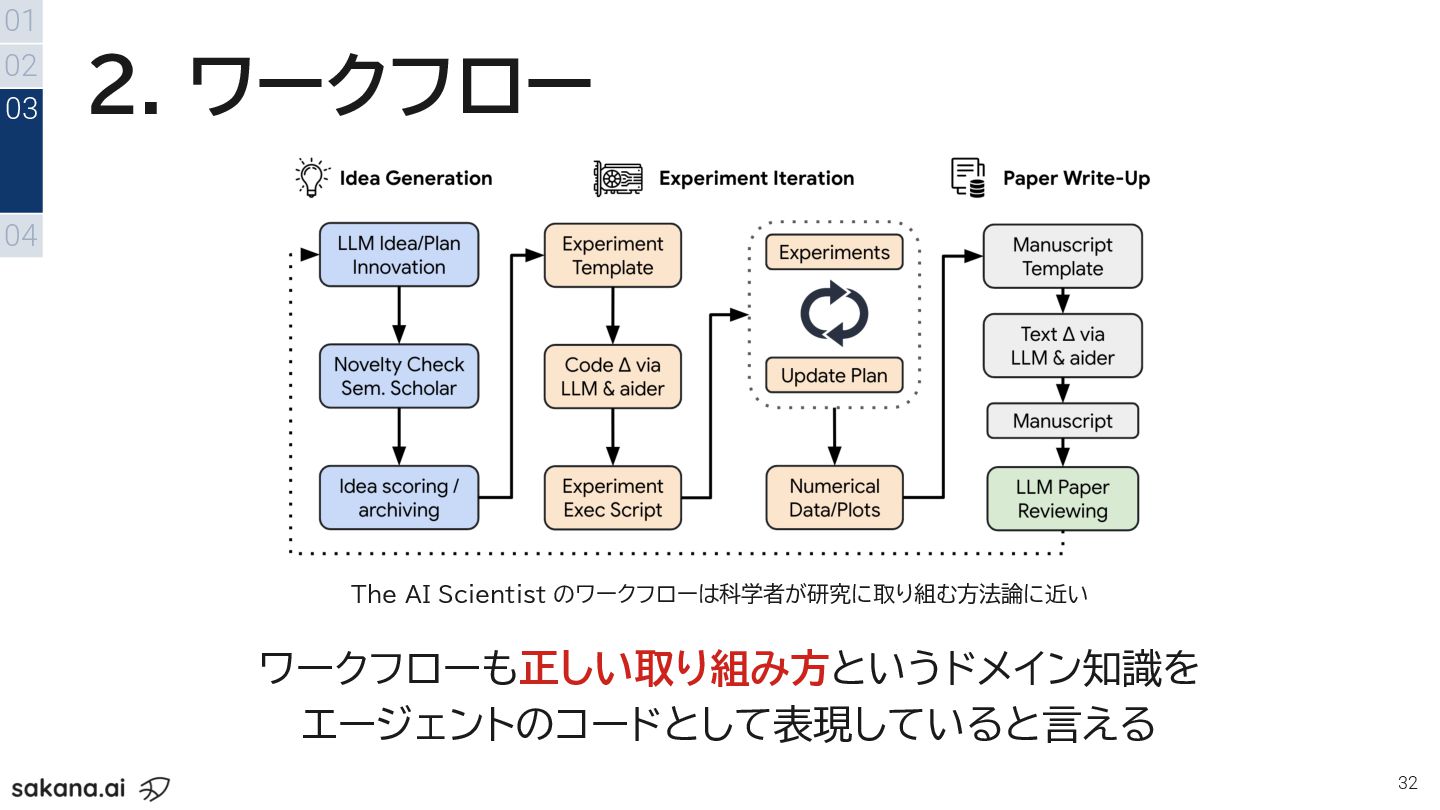
2. ワークフロー 32 01 02 04 03 ワークフローも正しい取り組み方というドメイン知識を エージェントのコードとして表現していると言える The
AI Scientist のワークフローは科学者が研究に取り組む方法論に近い
3. ルーブリック (評価基準) 33 01 02 04 03 実務では解答の評価が難しく、LLM-as-a-Judge に頼ることが多い
ルーブリックにより評価が安定すれば推論時スケーリングも可 ルーブリックの作成にはドメイン知識を活用 PaperBenchでは、扱う論文は20個のみだが、専門家が作成したルーブリックが8,316個含まれる
まとめ 34 専門家にも匹敵できる 強力で実用的なエージェントを作る決め手は何なのか? 1. 専門家と戦えるAIエージェントの事例 2. 推論時スケーリングの主要アプローチと最先端 3. ドメイン知識の活用に関する考え方と展望
01 02 03 04
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ALE-Agent [NeurIPS’25] 専門家並の最適化アルゴリズムを自動設計するエージェント 6 02 03 04 01 sakana.ai/ale-bench-jp/ arxiv.org/abs/2506.09050](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_5.jpg){kind=link}
![7 02 03 04 01 トップ専門家と肩を並べる実力を実プログラミングコンテストで実証! ALE-Agent [NeurIPS’25] 専門家並の最適化アルゴリズムを自動設計するエージェント sakana.ai/ale-bench-jp/](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![……だが意外とかなり前にも事例あり 19 AlphaCode [2022, Science] 1つの問題に最大1,000,000回LLMを呼び出し (後処理をして10個まで減らし、Pass@10を評価) 01 03 04](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_18.jpg){kind=link}
![AB-MCTS [NeurIPS’25 Spotlight] 20 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_19.jpg){kind=link}
![AB-MCTS [NeurIPS’25 Spotlight] 21 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_20.jpg){kind=link}
![AB-MCTS [NeurIPS’25 Spotlight] 22 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_21.jpg){kind=link}
![AB-MCTS [NeurIPS’25 Spotlight] 23 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_22.jpg){kind=link}
![AB-MCTS [NeurIPS’25 Spotlight] 24 01 03 04 02 sakana.ai/ab-mcts-jp/ arxiv.org/abs/2503.04412](https://files.speakerdeck.com/presentations/0dfc61ac79fd461ab585d51da99de524/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}