con .NET”. Espero poder aportarte los conocimientos mínimos y necesarios para que puedas iniciarte en este apasionante mundo. Jose María Flores Zazo, autor
C# a nivel muy avanzado pero tampoco te será fácil si eres un novato. Lo que vamos a ver es: • Algunas herramientas útiles como BenchmarkDotNet, ConcurrencyVisualizer, Parallel Stacks y Parallel Tasks. • Threading: threads & Thread pool. • Async: − Task, ValueTask, async await, … − Context, executions, fire & forget pattern, deadlocks, awaitable, TaskCompletionSource, Thread Local, … − Aggregations, Parallel.For, Task.WhenAll, cancellation, IAsyncDisposable, … • Concurrencia de bajo nivel. • Herramientas para concurrencia, como locks, lockings, monitor, wait handles, deadlock debugging, … • Estructuras de datos concurrentes. • Y algunas cosas mas. Son temas muy áridos que espero puedas entender con ejemplos sencillos. Pero para comenzar os voy a mostrar una serie de herramientas que nos ayudaran desde el principio. Resumen – De un vistazo
las que se suelen ver cuando vemos las comparativas entre .Net Core 3.1 y .Net6, por ejemplo. En este enlace tienes toda la documentación y una cantidad de ejemplos suficiente como para poder llegar a tener un control de la misma: https://benchmarkdotnet.org/articles/overview.html Y si no, tambien tienes un libro dedicado exclusivamente a esta herramienta: NuGet – Para benchmarking
de línea de aplicación de consola para que puedas ver como funcia a muy alto nivel. Para ello vamos a lanzar el siguiente ejemplo: BenchmarkDotNetSample NuGet –https://www.nuget.org/packages/BenchmarkDotNet
medición coherente debes ejecutar en modo build y no en modo debug: Y obtendrás una cantidad importante de información en la consola, pero nos quedamos con esta: Lo que más te debe importar de todo esto son los decoradores que hacen que los test funcionen y midan lo que tu quieras, esto está todo en la documentación:
mercado, nos ayudará a visualizar la simultaneidad para ver como funciona la aplicación multiproceso. https://docs.microsoft.com/es-es/visualstudio/profiling/concurrency-visualizer?view=vs-2022 En este enlace tienes un artículo básico y el ejemplo ConcurrencyVisualizer. https://jmfloreszazo.com/visualizador-de-concurrencia-para-visual-studio-2022 Extensión – Para Visual Studio 2022
recordatorio de las herramientas que nos proporciona Visual Studio 2022 para poder depurar paralelismo. Seguro que ya lo conocéis pero es bueno pararse 10 minutos para recordar su funcionamiento. Con el ejemplo ParallelStacksTasks, podrás probar según estos pasos: Debug – Parallel
una unidad de ejecución a nivel de sistema operativo. En la Wikipedia tenéis una entrada con una definición formal, la anterior es un resumen mío. La separación de un programa en múltiples tareas, es lo que se conoce como multitarea. Que nos permite usar, por ejemplo, varios programas, ya que el procesador es capaz de gestionar múltiples tareas al mismo tiempo. Esto se traduce en una mejora notable del rendimiento ya que no depende directamente de la velocidad de la CPU. El propósito de los threads es dividir un proceso. Un programa puede estar formado de uno o varios procesos, que a su vez, se dividen en hilos. Los hilos de un proceso comparte comandos, código y acceder al sistema de forma simultanea para completar las tareas lo más rápido posible. A veces me encuentro con una confusión entre hilos y núcleos del procesador. Los hilos y los múltiples núcleos ayudan a que el PC trabaje más rápido, pero son cosas muy diferentes. Los hilos existen a nivel de software mientras que los núcleos son físicos. Los hilos comparten recursos del sistema dentro de un mismo núcleo. Puedes pensar que los hilos son maravillosos, pero tambien tiene alguna desventaja. Como por ejemplo que múltiples hilos pueden interferir entre ellos, sobre todo cuando comparten recursos como cachés. Y por desgracia algunos procesadores limitan el multihilo gestionado por hardware. ¿Qué son los Threads? –¿Qué son los hilos?
posibles opciones: • Una sola CPU • Múltiples CPUs • Hyper-Threading (Intel) y SMT (AMD, simultaneous multithreading) Cada uno de ellos tendrá sus detalles que iremos viendo en esta sección. A nivel hardware no voy a profundizar, no tiene sentido hablar a este nivel, lo importante es que se entienda a un alto nivel y para nuestro día a día de desarrollo. Tambien veremos un ejemplo del funcionamiento de un sola CPU, del funcionamiento del funcionamiento de los hilos.
T2 Core#2 T1 Core#1 Debido a la arquitectura de los microprocesadores, la CPU tiene que organizar los tiempos para que puedan trabajar los cores. Esto se traduce en tiempo perdidos en los cores.
sola CPU? • Nos toca mantener un contexto de hilo (thread context) : − CPU registrada (incluida la IP). − Modo actual (Kernel/Usuario). − Dos pilas (Kernel/Usuario). − La persistencia local del hilo. − Prioridad. − Estado. − …. • Lo pagamos caro con el cambio de contexto, muchos ciclos de reloj y limpieza de cache. • Crear hilos en este caso ya es caro de por si, no tenemos más CPU o Cores que ayuden. • Debemos decidir como deben ejecutarse los hilos: − Al azar o con turnos. − Desarrollar un sistema personalizado. • Y entra en juego el programador de hilos: − Distinto a nivel de SO, Windows distinto a Linux e incluso entre versiones. − A nivel de todo el sistema todos los subprocesos estarán en el mismo grupo de programación. − Es preventivo: activa o desactiva subprocesos de la CPI en cualquier momento. − El proceso se ejecuta durante un período de tiempo llamado quantum. Se ejecuta el máximo establecido. − Puede se reemplazado por un subproceso de mayor prioridad o que este basado en prioridad: siempre se ejecuta al menos uno subproceso.
quantum, pequeña. − Ciclos de reloj muy pequeños. − Más fluido. • Servicios en background: − Variable quantum, más grande. − Ciclos de reloj más grandes. − Baja el coste de hacer cambio de contexto. • Si estas en Windows Server o una VM que necesite trabajos muy largos, la segunda opción sería la adecuada. Hace muchos años en Windows 2000 era muy útil entrar en el registro del sistema y cambiar una serie de valores en las claves, que no voy a mostrar, ya que llevo mucho tiempo desconectado de este tipo de cosas y no se como se comporta esto en los nuevo servidores o en un Windows 10, por ejemplo. Entendiendo la prioridad de los hilos en Windows En .NET tenemos: • ProcessPriorityClass para procesos: idle, below normal, normal (default), above normal, high y realtime. • ThreadPriority para hilos: lowest, below normal, normal (default), above normal, highest.
= ProcessPriorityClass.Hight Thread t = . . .; t.Priority = ThreadPriority.Highest; Como estamos con hilos, veamos algo más sobre como deja de funcionar la prioridad forzada: • Aumentar prioridad, temporalmente. Conocido como Priority Boost: − Un hilo que no se ejecuta durante algún tiempo, evita que se lance aunque tenga establecido el incicio con prioridad. − Un hilo que sea propietario de bloqueos (compartidos o exclusivos), evita que se inicie aunque tenga eventos programados o bloqueado el inicio. − Finalización de I/O, para hilos de I/O o UI, procesado de mensajes de hilos de Windows, por ejemplo. • Y muchas más acciones: − Multimedia: viendo una película y tu programa esta en alta prioridad. − Cuando tienes un juego cargado en memoria y tu programa tiene puesta alta prioridad. − ...
inmediatamente (pero probablemente el hardware lo gestionará). • Running: ejecutándose en la CPU (hasta que el quantum lo diga). • Waiting: esperando a la ejecución (esperando por algo, fue suspendido, …). • Standby, Terminanted, Inizialized, Stopped, … ya lo iremos viendo. Aquí tenéis un ejemplo que muestra los estados: ThreadStatesSample. Ready Running Waiting postponed Quatum ended preemption Hardware thread assigned Postponed ended
son los que proporciona el sistema operativo. • Hilos no administrados, ejecutan codigo no administrado: − Obviamente nativo. − Incluido codigo de runtime de .NET (como puede ser GC, Garbage Collection). − No se suspenden durante el GC. • Hilos administrados, ejecutan código de .NET como los de nuestra aplicación C#: − En su mayoría siguen siendo hilos nativos. − Hilos administrados que llama a codigo no administrado (Invokes), sigue siendo administrados. − Mantienen un contexto mayor que los hilos nativos . • Hilos especiales: − Hilo de finalización. − Hilos de GC. − Hilos de debugger. Primer plano vs segundo plano: • La aplicación espera hasta que los hilos en segundo plano finalicen. • Cuando una aplicación existe, todos los hilos de segundo plano forzosamente se detienen: − Cuidado con la limpieza, Dispose se ignorará y los bloques Finally tambien. − Cuidado con los cálculos, se perderán… − Solución: ¿dejamos que un hilo de primer plano espere a los del segundo?. − Y sí… los ThreadPools utilizan hilos de segundo plano. Antes hemos visto la teoría general –Ahora nos toca ver que ocurre en .Net
new Thread(…); // Solo gestionada, aun no hay nativo t.IsBackground = true; // Configura el hilo de segundo plano t.Start(arg); // Nativo asignado e iniciado t.join(); // El hilo actual espera a que el hilo termine (bloqueo) Podemos usar la rutina con un solo parámetro o no: public delegate void ThreadStart(); public Thread (System.Threading.ThreadStart start); public delegate void ParametrizedThreadStart(object obj); public Thread (System.Threading.ThreadStart start);
usado cientos de veces para parar un rato la ejecución en algún tipo de pruebas. Aun así vamos a ver como funciona. Para ello lo primero es bajar esta aplicación y probar la resolución del reloj de tu sistema: ClockRes v2.1 Despegada esta duda, vamos a ver algunas características de Thread.Sleep: • El sistema operativo no programará la ejecución del hilo actual durante le tiempo especificado… − Debes ponerlo en esperar con WaitSleepJoin. − O retomarlo usando un temporizador cambiando el estado a Ready. • El sistema operativo no programará la ejecución del hilo actual durante le tiempo especificado… − Ya que el tiempo es limitado para la ejecución, por defecto 15,6ms aproximadamente. − O por qué algunos programas como (SQL Sever o Chrome) son capaces de modificarlo. • Obviamente esto impacta en la programación de los hilos.
ejecutas esto va a dejar la CPU bloqueada al 100% en el proceso: while (!condición) { . . . Tu Código . . . }; Pero podemos dejar algunos espacios para que se procesen otros hilos: while (!condición) { . . . Agregar código que te permita ir a otros procesos . . . }; Aquí tienes algunas opciones o combinaciones de ellas que tambien nos ayudan: Thread.Sleep(0); // 0ms Thread.Sleep(100); // 100ms Thread.Yield(); // ns, selected time by SO Thread.SpinWait(10); // ? Yield, cede la ejecución a otro subproceso mientras que Sleep suspende el proceso durante un tiempo. Y SpinWait lo que hace es que espere un número definido de iteraciones definidas en el parámetros. Ahora lo vermeos mejor.
contexto a cambiar de subproceso limitándolo en realidad a la resolución de tiempo que marcas en SO. Usar: Thread.Sleep(0); Lo que estas haciendo es marcar al subproceso como Ready, con el funcionamiento ya conocido en la teoría. Usar: Thread.Yield(); Es muy rápido y gestiona bien los subprocesos Ready, pero solo lo que están en la misma CPU. Esta instrucción es una buena instrucción para diagnosticar tu programa ya que puede romper o arreglar tu programa. Usar: Thread.SpinWait(10); Llama X veces a una instrucción especial de la CPU para ejecutar la espera. X normalmente son iteraciones del ciclo del la CPU.
ThreadAbortException: Thread.Abort; ¡En .NET5 en adelante ya no está soportado! Ver información. Lanza una excepción ThreadInterruptedException, incluso cuando estas en WaitSleepJoin (sí, ya que el hilo esta en la memoria con su correspondiente contexto): Thread.Interrupt Aquí tienes un ejemplo. Thread Cancelaciones En el blog ya puse un ejemplo de .NET, ver artículo. Revísalo para tener más contexto de esto.
de resetear un evento con las siguientes instrucciones: • AutoResetEvent, manda una señal al hilo para que lo cierre (resetea). • ManualResetEvent/ManualResetEventSlim, son señales para cerrar muchos hilos. La señal se comparte entre diferentes hilos: var autoEvent = new AutoResetEvent(false); autoEvent.WaitOne(); // Uno o más eventos esperan que la señal se active autoEvent.Set(); // Una vez terminado el trabajo se deben asignar las señales autoEvent.Close(); // o autoEvent.Dispose() no te olvides de limpiar.
–¿Qué son los grupos de subprocesos/hilos/threads? Un grupo de subprocesos (thread pool) es un patrón de diseño de software que se usa para lograr concurrencia en la ejecución. A menudo, tambien llamado modelo de trabajadores replicados (replicated worker). Un grupo de subprocesos mantiene varios subprocesos en espera de que el programa supervisor asigne tareas para su ejecución simultánea. Al mantener un conjunto de subprocesos, el modelo aumenta en rendimiento y evita la latencia en la ejecución debido a la frecuente creación y destrucción de subprocesos de corta duración. La cantidad de subprocesos disponible se ajusta según los recursos del hardware y en una cola de tareas paralelas. Task Queue Thread Pool Completed Tasks
• Que los pools pueden ser de dos tipos: − Worker Threads, que ejecutan elementos de trabajo vía callbacks, callbacks de timer, y esperan a registros de callbacks. − Subproceso de I/O. • Que usan hilos de background. • Es un grupo único de todo el proceso. • Internamente mucho servicios lo usan como WCF, ASP.NET, temporizadores, PLINQ, patrón asíncrono basado en eventos (EAP, event-bases asynchronous pattern) e incluso el JIT a varios niveles. • Tiene un mecanismo de auto-balanceo, tratando de mantener una buena cantidad de subprocesos. • No tiene soporte prioritario de los elementos de trabajo, es decir, nos toca escribirlo nosotros mismos. • Restablece las propiedades de subprocesos devuelto al grupo. Como cualquier otra librería de .Net los ThreadPool tienen sus definiciones y vamos a ver las más habituales: • Siendo la más utilizada: ThreadPool.QueueUserWorkItem • En menor medida: ThreadPool.GetAviableThreads, ThreadPool.GetMaxThreads, ThreadPool.SetMaxThreads, ThreadPool.GetMinThreads, ThreadPool.SetMinThreads • Y casi nunca, por su grado de complejidad: ThreadPool.RegisterWaitForSingleObject, ThreadPool.BindHandle, ThreadPool.UnsafeQueueNativeOverlapped, ThreadPool.UnsafeQueueUserWorkItem, …
de trabajo en una cola (delegado) para que lo ejecute en algún momento de los subprocesos de trabajo del ThreadPool: • No garantiza que se ejecutará inmediatamente. • No hay una forma directa de esperarlo u obtener un resultado (fire & forget). • Tiene algunas peculiaridades que veremos poco a poco. El siguiente ejemplo muestra como lo usamos y con un manejador de excepciones, si no, no se podrá manejar y el programa aunque se sigue rompiendo puedes hacer algo antes de cerrar: ThreadPoolQueueUserWorkItemSample Cuando un ThreadPool se termina: • Recuerda que son subprocesos en background. • .Net no esperará a que termine el trabajo, incluidos aquellos que estan en la cola. • Es conveniente cooperar y usar CancellationToken.IsCancellationRequested. Logicamente si queremos asegurarnos que se procesa hasta el final considera: usa un mecanismo de hilos separados con algo de sincronización. Y otra es la que veremos a continuación.
background ya que usar IsBackground resetea el hilo y obviamente te juntas con otras dos situaciones: • El hilo principal de la aplicación puede finalizar antes que los subprocesos se iniciaran. Por tanto es recomendable usar ThreadPool.PendingWorkItemCount en otro hilo de background. Se complica por momentos. • Y si un evento esta encolado, el DoSomeWork podría terminar antes de establecer IsBackgroud. Por tanto necesitas un mecanismo de programación o sincronización. Otro problema más. Ahora es cuando llegamos a un punto importante: La administración del pool.
Un pool comienza un número de hilos por defectos. • Después necesitará crear o eliminar algunos de esos hilos: − Intentará mantener el numero de hilos bajo, modificando la carga de trabajo y evitando crear nuevos hilos tanto tiempo como le sea posible. − Si tiene poco hilos y varios hilos estan en espera, significa un gasto de CPU innecesario. − Si tiene muchos hilos y esta continuamente cambiado de contexto se esta tirando a la basura proceso de la CPU. • Esto nos lleva a preguntarnos ¿cual es el ratio correcto para la carga de trabajo?, un thread pool mantiene un mínimo y un máximo de hilos. Máximo número de hilos: • Es un valor real cuantitativo. • No podrá crear más de los indicados. • Si se excede del número el mecanismo que aplica es encolarlos y usarlos cuando tenga hilos disponibles. Mínimo número de hilos: • En realidad no es un mínimo, ya que puede ser el valor 0. • Si existen menos hilo que el mínimo: se crean inmediatamente para alcanzar ese valor. • Si tenemos más hilos que el mínimo, irá creando hilos a intervalos pequeños.
realiza mediante un fichero, por ejemplo [appname].runtimeconfig.json o el fichero de proyecto, en el siguiente enlace podrás ampliar toda la información: JSON { "runtimeOptions": { "configProperties": { "System.Threading.ThreadPool.MinThreads": 4 } } } Proyect: <Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <ThreadPoolMinThreads>4</ThreadPoolMinThreads> </PropertyGroup> </Project> Desde programación tambien se puede: ThreadPool.SetMinThread, ThreadPool.SetMaxThreads, …
para que espere a la clase WaitHandle mediante un tiempo en ms. Aquí tenéis un ejemplo. Por ejemplo: ThreadPool.RegisterWaitForSingleObject espera a un handle en vez de bloquear todo el hilo con .WaitOne(). Colas Una carga de trabajo se lanzará a de estas dos colas: • Global task queue: − Si el elemento se encola desde un sitio que no es un hilo al thread pool. − Si se usa ThreadPool.QueueUserWorkItem o ThreadPool.UnsafeQueueUserWorkItem. − Si se usa TaskCreationOption.PreferFairness con la ocpión Task.Factory.StarNew. − Si se llama a Task.Yield en el subproceso por defecto. • Tareas locales encoladas por cada worker thread: • Si un elemento a sido encolado de un thread pool thread. Esto nos lleva a desencolar: se desencola usando LIFO para colas locales (si creas colas locales dentro de otro hilo usa FIFO) y la colas globales usa FIFO.
producir un deadlock, en este artículo lo explican muy bien: .NET ThreadPool starvation, and how queuing makes it worse En resumen: 1. llega una ráfaga constante de peticiones. 2. el pool de hilos se queda sin recursos. 3. se ponen en cola 5 ítems por segundo en la cola global (debido a la ráfaga). 4. cada uno de esos elementos pone en cola un elemento más en la cola local y espera. 5. cuando se crea un nuevo hilo (debido a la inanición, starvation), mira en su cola local pero está vacía, ya que se acaba de crear la cola global, que crece constantemente. 6. el encolado a la cola global (5/seg) es más rápido que el crecimiento del threadpool (0,5/seg) por lo que nunca recuperamos las tareas en cola localmente que no se procesan ya que los hilos recientemente creados están cogiendo tareas de la cola global. Así que los hilos de los workers se quedan bloqueados esperando... La solución: • En el punto 3 cambia la cola a local. • Cuando se crea un nuevo hilo (debido al starvation), mira su cola loca, pero esta vacia por qué se acaba de crear en la global, al no poner nada en esa cola. • Y ahora nunca esperan de forma asincróna.
un I/O (he asumido que conocéis Input/Ouput, Entrada/Salida o E/S). • Si se puede se completa inmediatamente o devuelve un código de estado indicando que la I/O esta pendiente. • Asigna un puerto de finalización I/O, para poder observar el resultado: − Puede representar muchas operaciones de I/O simultaneas en curso . − Uno o varios hilos pueden esperar a IOCP (Input/Output completion port). − Se ejecuta un callback con la información. • En los ThreadPool de .NET: − Uno o varios IOCP pueden estar observando cambios. − Se marca la tarea como completada. − Y a continuación se encola al SincronizationContext o al ThreadPool. • Las operaciones IOCP bloquean, en realidad se bloquea el IOCP a si mismo: − Un hilo puede manejar un gran numero de notificaciones IOCP. IOCP Queued Thread Queued Thread Queued Thread Worker Thread Worker Thread Notificación de finalización Queued Thread Cola de worker inactivos preparados para ser activados
workerThreads = 0; var completionPortThreads = 0; ThreadPool.GetAvailableThreads(out workerThreads, out completionPortThreads); ThreadPool.GetMinThreads(out int workerThreads, out int completionPortThreads); ThreadPool.GetMaxThreads(out int workerThreads, out int completionPortThreads); Con: dotnet-counters La documentación aquí: ir al enlace. Pero os dejo un ejemplo para hacerlo lo más simple posible con una WebAPI: PerfomanceCounterSample. Arranca la web api y que salga swagger y ahora entra en la línea de comandos del CLI para ver si tenemos esta herramienta, si no, sigue estos pasos de aquí para instalarla.
herramientas más importantes: dotnet dump collect –p <PID> Y aquí la documentación de esta herramienta de volcado. Ejecutas: dotnet dump analyze .\dump_20220714_133404.dmp
puntos importantes muy por encima. Estos puntos que a continuación os numero, deberá profundizarlos por tu cuenta: • Queue Starvation (por defecto a 0). • ThreadPool_DebugBreakOnWorkerStarvation , rompe en el depurador si el ThreadPool detecta trabajo • ThreadPool_DisableStarvationDetection, desactiva la función de ThreadPool que obliga a los nuevos hilos a ser añadidos cuando los workitems estan corriendo mucho tiempo (por defecto 0). • ThreadPool_EnableWorkerTracking , habilita el seguimiento extra de cuántos hilos de trabajo simultáneos hay (por defecto 0). • ThreadPool_ForceMaxWorkerThreads, anula la configuración MaxThreads para el pool de trabajadores ThreadPool (por defecto 0). • ThreadPool_ForceMinWorkerThreads, anula la configuración de MinThreads para el pool de trabajadores ThreadPool (por defecto 0). • ThreadPool_UnfairSemaphoreSpinLimit, número máximo de cambios por procesador de un trabajador. • threadpoolThreadpoolTickCountAdjustment, ajuste interno que se utilizado sólo en la compilación de depuración del tiempo de ejecución • HillClimbing, un grupo de ajustes para el algoritmo Hill Climbing. • ThreadPool_EnabledWorkerTracking, es el más importante de todos ya que nos da trazas, pero es muy costoso.
que incluye varios datos informativos de seguridad (impersonación, información establecida por el thread) no se captura en las llamadas (en la Queue) por tanto, no se puede usar cuando se invoca un callback en el thread pool. Pero es muy rápido. ThreadPool.UnsafeQueueNativeOverLapped() Pone en cola una operación de I/O superpuesta para su ejecución (en el pool de hilos IOCP). ThreadPool.UnsafeRegisterWaitForSingleObject() Version no segura de RegisterWaitForSingleObject, por lo tanto no se captura el execution context.
para este curso, pero no para devs de .Net Framework) ThreadPool.QueueUserWorkItem no proporciona una manera fácil de pasar más de un parámetro tipado y recibir el resultado de un hilo después de que haya terminado de ejecutarse. El delegado asíncrono resuelve esta limitación, permitiendo pasar cualquier número de argumentos tipificados en ambas direcciones. Además, las excepciones no manejadas en los delegados asíncronos se vuelven a lanzar en el hilo original (o más exactamente, en el hilo que comprende BeginInvoke / EndInvoke), no necesitan un handling explícito. En el ejemplo AsyncchronousDelegatesSample, podéis ver que no esta soportado por .NET6:
Framework 4.8, ya podéis probarlo: Patrones que ya han quedado obsoletos En este enlace de Microsoft tienes varios patrones que podrás investigar por tu cuenta: TAP, EAP y APM.
mis consejos: Mi primer consejo es que leas toda la documentación relacionada con Parallel Programming de Microsoft. Lo que debes leer en segundo lugar es: Procedimientos recomendados para el subproceso administrado de Microsoft. En tercer lugar toca ver los: Procedimientos recomendados de rendimiento de ASP.NET Core. El cuarto lugar revisar la: Biblioteca de procesamiento paralelo basado en tareas (TPL). Y por último te recomiendo la lectura de: Concurrency in C# Cookbook. Y entrar en el blog: https://blog.stephencleary.com/ del autor. Todos los anteriores enlaces proporcionan una serie de buenas prácticas y recomendaciones por parte de Microsoft, que sería volver a repetirlo aquí, por eso os mando directamente a la fuente original. Como ves es un tema tedioso que necesita muchas horas de estudio. 1ª regla de threading es no hacer threading – Y evita dolores de cabeza
Kestrel es un servidor web Kestrel. Es un servidor web que se incluye y habilita de forma predeterminada en las plantillas de un proyecto .NET. Créditos de la imagen: Microsoft. Ver documento. Establece una asincronía de I/O basada inicialmente en la librería LIBUV (de Node.JS) créditos de la imagen: docs.libuv.org
podrás ver que tiene que ver que os cuente esto de aquí: los ThreadPools y los IOCP. En la primera versión.NET Core Microsoft uso LIBVU, pero luego añadió una capa llamada Kestrel. En ese momento Node.JS y ASP.NET compartían el mismo servidor HTTP. Desde la evolución de .NET y su crecimiento, se han implementado muchas mas funcionalidades, hasta el punto que Microsoft a construido su propios servidor HTTP basado en .NET Sockets y a eliminado LIBVU que era una dependencia que ni poseían ni la controlaban. Ahora Kestrel, es un servidor HTTP con todas las funcionalidades para ejecutar .NET. El IIS actúa como proxy inverso que reenvía el trafico a Kestrel y gestiona el proceso Kestrel de Kestrel. En Linux, normalmente se utiliza NGINX como proxy inverso para Kestrel. Os voy a dar una pincelada de algún parámetro que podemos cambiar en la configuración de Kestrel. Lo primero es anular un poco el WebHostBuilder para configurar Kestrel, solo podrás a partir de ASP.NET Core 3.0. Es decir que el servidor web de Kestrel está configurado para el constructor de hosts. Desde la versión ASP.NET Core 5 LIBUV esta obsoleto. No recibe actualizaciones y cualquer llamada a UseLibuv debes cambiarla por el socker predeterminado de Kestrel.
publicas una aplicación web en Azure una Web Apps en Windows, por tanto, continuas usando IIS para hospedar la aplicación. Sigues teniendo ese proxy inverso para ejecutar tu aplicación en el servidor HTTP Kestrel. Lo que os voy a contar a continuación aun tiene mucha vigencia y es muy importante que conozcáis que ocurre con nuestra aplicación de .NET. Si queremos que el pool de thread de IIS nos de un alto rendimiento para altas cargas de trabajo tenemos que saber que IIS puede sufrir el anterior mencionado Thread Pool Starvation (Teoría y Práctica / ThreadPools en .Net (8/14) ) y tambien es posible que sufra un thread pool exhaustion (agotamiento de los subprocesos). Lo primero que debes saber que existe una diferencia entre el ThreadPool de IIS y el ThreadPool de .NET (de aplicación). Para ello vamos a ver el ThreadPool de IIS: IIS mantiene un ThreadPool que elimina rápidamente las solicitudes de la cola de la aplicación y las lleva a procesar con el worker de IIS. Ya hemos aprendido que los thread estan limitados en cuanto a crecimiento y creación. Por tanto si todos los subproceso de IIS estan ocupados, este ThreadPool puede llegar a agotarse, por tanto puede provocar problemas de rendimiento. Veamos esquemáticamente como funciona IIS y como navega la información.
Driver: handler TCP connection, TLS/SSL Channels, Request validations, Windows Authentication, Kernel request listener, Kernel Cache TCPIP.SYS IIS WAS Config. IIS Worker w3wp.exe IIS Worker w3wp.exe IIS Worker Process (DefaultAppPool = Worker 1) w3wp.exe IIS Thread Pool A continuación puedes ver los componentes: • Cliente que lanza y recibe request. • HTTPS.SYS + TCPIP.SYS donde se asienta IIS. • IIS con los posibles workers, por defecto es 1. • Y los procesos.
inicia por primera vez, intentará crear la cantidad mínima de subprocesos IIS en el grupo de subprocesos de IIS. Y: • Recibe las solicitudes de la cola al grupo de aplicaciones. • Configura el contexto. • Ejecuta la pipeline de la aplicación ASP.NET. • Y va vaciando para emitir la respuesta. Nada nuevo, el funcionamiento se extrapola con lo anteriormente conocido de colas, en resumen: existe un ThreadPool por encima de nuestro ThreadPool de Aplicación. Para un trabajo de una sola solicitud se puede procesar en un hilo de IIS e ignora los conmutadores asíncronos. De nuevo mismo funcionamiento que el estudiado con las CPUs. Pero lo habitual es que las solicitudes casi siempre se mueven a un grupo de subproceso de la aplicación. Los hilos de aplicación se procesan en subprocesos del CLR, de ASP.NET, etc. Por tanto IIS realiza un procesado mínimo y casi nunca se bloquean.
tendrá lugar en subproceso de IIS. Lo recalco: La request empieza en un hilo de IIS. Se mueve al hilo de ASP.NET tan pronto como el módulo ASP.NET esté cargado. Y la mayoría de las veces permanece en el hilo de APS.NET hasta su finalización.
procesamiento en comparación con la aplicación, en la mayoría de las ocasiones. Los subprocesos de IIS casi nunca se bloquean en las aplicaciones actúales. Debido a que las operaciones de bloqueo de subprocesos o de ejecución prolongada ocurren dentro del código de la aplicación, bloquean el subproceso de la aplicación en su lugar, no el subproceso de IIS. Por tanto, es común que experimentemos bloqueos debido a la inanición (Starvation) del grupo de proceso del CLR, esto no tiene nada que ver con IIS. Una vez contado eso, existen casos muy específicos que el ThreadPool de IIS se puede agotar, es decir, que experimentemos que se agote un ThreadPool o encontrarnos con problemas de rendimiento que perjudican el funcionamiento de la aplicación. Esto se hace primero: monitorizando el IIS.
así iréis directo a donde buscar. Agotamiento e Inanición del ThreadPool de IIS. Los subprocesos de IIS son los responsables de eliminar las solicitudes de la cola del grupo de aplicaciones, es decir, que veremos una cola de aplicaciones en constante crecimiento. Los contadores que nos permiten observarlo son: • HTTP Service Request Queues\Current Queue Size • HTTP Service Request Queue\Rejection Rate Performance Rule • IIS Worker Process Thread Count. Es posible que tengas inanición o agotamiento si: • Si tienes una cola de aplicación distinta de cero. • Si El numero de thread activos en el “Active Thread Count” es mayor que cero. Si el numero es mayor que 0 lo primero es que puede ocurrir es que existan bloqueos y si es muy grande que sea inanición. Y si el valor es mayor que el máximo lo que tenemos es un agotamiento (caso muy poco probable). Ahora una vez visto los síntomas toca un trabajo muy complejo en el código para localizar que hace que indirectamente afecte a la cola.
que sobrecargan la CPU. b) Bloqueos de subprocesos debido a la inanición de la aplicación. c) Bloqueo de subprocesos debido a archivos lentos o alta latencia de red. Como se soluciona, alguna pista: a) Optimizar el código, agregar más CPU (y probablemente más memoria), más nodos. b) Los 503 suelen solucionarse con reinicios, pero esto no es la solución: usar herramientas de diagnóstico de memoria y similares. c) Mover archivos de una unidad de red lo más cerca del servidor IIS. Revisar la calidad de la red, reducir los tamaños, … Una última nota: ya sabemos como funciona el cambio de contexto para evitar los problemas de cambios de contexto IIS lo que hace es que solo permite 1 subproceso por núcleo del procesado, esto no da RPS más altos, si no más bajos ya que se gasta mucho tiempo en el cambio de contexto (más adelante tengo un ejemplo con Async y Sync de una API de .NET donde se evidencia esto).
se aprecie como funciona queue y hill-climbing. ThreadPoolWithBenchmarks Este ejemplos muestra la diferencia entre usar un método con Thread y otro con ThreadPool.
aplicación empresarial es la escalabilidad, es decir, escalar para reducir el tiempo que tardarnos en servir una petición, aumentar el número de peticiones que un servidor puede procesar, y aumentar el número de usuarios que una aplicación puede atender simultáneamente sin aumentar el tiempo de carga. El uso adecuado de programación asíncrona y paralelismo puede hacer que las métricas mejores y lo mejor de todo es que C# tiene una sintaxis simplificada gracias al TPL (Task Parallel Library) o async-await, con la que podemos escribir un código muy claro y mantenible. En esta sección aunque parezca que vuelvo a recordar conceptos anteriormente descritos, quiero que te lo tomes como afianzar conceptos para que: • Quede clara la jerga que se utiliza en este tipo de desarrollo. • Desmitificar los thread, lazy initialization o ThreadPools. • Entender que son los semáforos y el SemaphoreSlim. • Introducir Task y paralelismos. Otros aspectos como async-await o colecciones concurrentes para paralelismo lo iremos viendo en siguientes secciones. A veces tienes que volver a gatear… – Asentar conocimientos
otros documentos, verá que me gusta dejar la jerga clara para que todo el mundo hable sobre la misma definición. En esta ocasión no lo he puesto la principio, lo pongo aquí por qué tiene más sentido en esta sección. Los tecnicismo a veces son duros y por eso voy a preparar una analogía para que puedas entender las cosas con algo real, es más yo hace años programé software para este sector del ejemplo. Imagina que estas en la cola de un restaurante de comida rápida esperando para hacer tu pedido, y mientras estas en la cola, respondes a un correo electrónico del trabajo o hablas por MS Teams. Después, tras pedir la comida y mientras esperas a recogerla, hablas por teléfono con un cliente. En el restaurante (de comida rápida), tenemos muchos mostradores donde se toman pedidos, y la comida es preparada por los operarios mientras se hacen y toman pedidos. Es decir, se hacen pedidos en cada uno de los mostradores. Los operarios estan trabajando paralelamente preparando comida mientras se hacen pedidos. Como te han dado un ticket con el número de pedido, dependiendo de tiempo de preparación, un pedido puede ser entregado antes que el tuyo al mostrador de recogidas. Usaremos alguno de los términos del ejemplo ya que mantienen el mismo concepto y la definición es igual.
mismo tiempo; en nuestro ejemplo: es cuando respondemos a un correo mientras hacemos cola para pedir en el restaurante, o que los operarios de cocina estén con varios platos al mismo tiempo, uno iniciándolo, otros a medias y otro finalizándolo. En aplicaciones la concurrencia implica que varios hilos comparta un núcleo y, en función de su tiempo, ejecuten tareas y realicen cambios de contexto. Paralelismo Se realizan múltiples tareas de forma independiente al mismo tiempo; en nuestro ejemplo: es cuando varios pedidos se realizan desde distintos mostradores. En aplicaciones el paralelismo sería múltiples hilos/tareas que se ejecutan al mismo tiempo en una CPU multinúcleo. Sin embargo en una de un solo núcleo tambien se puede hacer a través de hyper-threading, normalmente es una división lógica del núcleo en más de un núcleo, con una CPU de 4 núcleos en un hyper-threading se dividen en 2 y por tanto tenemos 8 núcleos (cores). El siguiente ejemplo puedes revisarlo para ver su funcionamiento: ParallelSample.
técnica que se basa en la ejecución de tareas de forma asíncrona en lugar de bloquear el hilo actual mientras esperan. En el ejemplo: consiste en esperar a que llamen por tu número de ticket para que te acerques al mostrador a recoger tu pedido mientras operarios de cocina estan trabajando en tu comida. Pero mientras esperas, te alejas del mostrador de pedidos, permitiendo así que otras personas recojan su comida. Esta es la forma en como se ejecuta la asincronía y como libera recursos mientras esperas a una tarea (como por ejemplo I/O, acceso a datos de una base de datos). Lo importante de la asincrónica es que las tareas se ejecuten paralelamente o concurrentemente gracias a un framework y liberar a los desarrolladores de este trabajo para centrarse en la lógica de negocio. El siguiente ejemplo: BasicAsycTest ponemos en práctica algo sencillo. Multithreading Es una forma de lograr concurrencia donde los nuevos hilos se crean muralmente y se ejecutan de forma concurrente, como el ThreadPool del CLR (que ya hemos visto). En un sistema con multiprocesador/multinúcleo, el mulithreading ayuda a conseguir paralelismo al ejecutar hilos en diferentes núcleos.
es la unidad más pequeña de un sistemas operativo y ejecuta instrucciones en el procesador. Un proceso es un contenedor de ejecución más grande y el hilo dentro del proceso es la unidad más pequeña de tiempo del procesador que ejecuta instrucciones. La clave para recordar es que siempre que tu código necesite ser ejecutado en un proceso, debe ser asignado a un hilo. Cada procesador sólo puede ejecutar una instrucción a la vez; es por qué, es un sistema de un solo núcleo, en un momento dado, sólo se esta ejecutado un hilo. Existe algoritmos que gestionan el tiempo de procesado del hilo. Un hilo puede tener una pila (que lleva la cuenta del historia del ejecuciones), registros que almacenan variables, contadores, etc. para ser ejecutadas. Una aplicación típica de .Net Core tiene un solo hilo cuando se inicia y puede añadir creándolos manualmente, ya hemos visto como hacerlo, aunque lo recordaremos tambien aquí, ya que es necesario que la base este muy afianzada antes de llegar a la sección 3.
instancias de System.Threading.Thread y pasando un método delegado. Por ejemplo: Thread loadFileFromDisk = new Thread(LoadFileFromDisk); void LoadFileFromDisk(object? obj) { Thread.Sleep(1000); Console.WriteLine(“File loaded from file"); } loadFileFromDisk.Start(); Thread fetchDataFromAPI = new Thread(FetchDataFromAPI); void FetchDataFromAPI(object? obj) { Thread.Sleep(1000); Console.WriteLine(“Data requested from API"); } fetchDataFromAPI.Start(); Console.ReadLine(); Podemos ver que los métodos LoadFileFromDisk y FetchDataFromAPI se ejecutan cada uno en un nuevo hilo. Recordar en el cambio de contexto y las CPU/Nucleos, esto tiene un coste, no siempre es mejor los hilos.
sus ventajas para tener control sobre como se ejecutan, tambien tiene sus inconvenientes: • La gestión del ciclo de vida de los hilos, como la creación, reciclaje y cambio de contexto. • Implementación de conceptos como tracking/reporting para la ejecución de hilos. Además, de la cancelación que es compleja y es limitada. • El manejo de excepciones, que si no se hace adecuadamente, puedes bloquear la aplicación. • La depuración, las pruebas y el mantenimiento del código puede ser a veces complejo y, a veces, pueden provocar problemas de rendimiento si no se gestionan correctamente. Y aquí es donde entra en juego los ThreadPools del CLR (Common Language Runtime) que vamos a ver ahora. ThreadPool Los hilos pueden ser creados haciendo uso de los pools de hilos gestionados .Net, conocido como CLR ThreadPool. El ThreadPool de CLR es un conjunto de hilos de trabajo que se cargan en la aplicación junto el CLR y se encargan del ciclo de vida de los hilos, incluyendo el reciclado de hilos, la creación y el cambio de contexto. El ThreadPool del CLR puede ser consumidos por varias API de System.Threading.ThreadPool. En concreto, para programar una operación en un hilo, existe el método (que ya hemos visto) QueueUserWorkItem, toma un delegado del método que necesita se programado. Continuando con el ejemplo anterior, podríamos poner: ThreadPool.QueueUserWorkItem(FetchDataFromAPI);
QueueUserThreadPool, lo que hace es usar colas, por tanto cualquier código que se ejecute se pondrá en una cola y luego se retirará de ella, es decir, se asigna un work thread con FIFO. ThreadPool esta diseñado con una cola global. Cuando se crea un nuevo hilo en el ThreadPool, éste mantiene su propia cola local que comprueba la cola global y retira el elemento de trabajo de una manera FIFO; sin embargo, si el código se ejecuta en ese hilo crea otro hilo, es decir, éste se crea en la cola local y no en la cola global. El orden de ejecución de las operaciones de la cola local del worker thread es siempre LIFO, y la razón de esto es que el elemento de trabajo creado más ranciamente puede estar aun caliente en caché y por lo tanto puede ser ejecutado recientemente. Además, podemos decir que en cualquier momento, habrá n+1 colas en el ThreadPool, donde n es el número de hilos de ThreadPools, es decir, n colas locales y 1 se refiere a la cola global. Una representación de alto nivel de ThreadPool: Cola Local Cola Local Cola Local Cola Global Worker Thread Worker Thread Worker Thread
otras propiedades/métodos disponibles, como ha os he mencionado, pero recapitulemos estas que son las más importantes: • SetMinThreads: se utiliza para establecer el mínimo de hilos de trabajo y de I/O asíncronos que tendrá ThreadPool cuando se inicie el programa. • SetMaxThreads: se utiliza para establecer el máximo de hilos de trabajo y de I/O asíncronos que tendrá ThreadPool, después del cual, las nuevas peticiones se ponen en cola. Por ejemplo usar QueueUserWorkItem, tiene limitaciones, que servirán para que veas siempre los pros y contras cuando estudies la librería: • No podemos obtener una respuesta de un worker programado en el ThreadPool, por eso el delegado es void. • No es fácil seguir el progreso del trabajo de un hilo programado en el ThreadPool. • No está pensado para larga duración. • Los ThreadPools son de background, y la diferencia que existe con los de primer plano, es que si se cierra el de primer plano, no espera a que se terminen los de background. Debes ser consciente de la limitaciones de cada elemento del API de System.Threading.ThreadPool, por tanto lo mejor es usar la librería TPL, que es la opción con el enfoque más sencilla y no tiene las limitaciones anteriores que nos permitirá que nuestra aplicación sea escalable. Esta librería la veremos más adelante.
perezosa, este patrón de creación de objectos hace que se aplace la creación hasta que sea usada por primera vez. Se basa en la premisa de que mientras la propiedades de una clase no se utilicen, no existe ninguna ventaja en inicializar el objeto. Por tanto, esto retrasa la creación de un objeto y, en última instancia, reduce la hulla de memoria de la aplicación, mejorando el rendimiento. Un ejemplo, que ya habrás usando cientos de veces, es el objeto de la conexión de una base de datos. Este patrón es buena opción para clases que contienen muchos datos y cuya creación es potencialmente costosa. Por ejemplo, una clase que carga todos los productos de una plataforma de comercio electrónico puede ser inicializado sólo cuando sea necesario listar los productos. Una implementación típica de una clase de este tipo, restringe la inicialización de propiedades en los constructores y tiene uno o más métodos que rellenan las propiedades de la clase:
object loadProducts; public ProductsFile(string fileName) { this.fileName = fileName; } public object GetFile() { if (loadFile == null) { loadFile = File.ReadAllJson(fileName); } return loadProducts; } } Es una clase que carga un fichero JSON de todos nuestros catalogo de productos (imaginaros que es para una importación a otro sistema), no tiene sentido cargar todo el listado hasta que alguien diga que debe hacer un GetFile. Este patrón solo carga información cuando es necesaria. No es nuevo, es un patrón típico que se usa para caché, llamado cache-aside, en el que cargamos un objeto en caché cuando se accede la primera vez. Pero en hilos tenemos un reto: si llamo muchas veces a GetFile puedo bloquear por tanto necesitamos sincronizar
deja su System.Lazy para gestionar esta implementación, cuya principal ventaja es que es segura con los hilos, aun así, si quieres programarte la tuya la tarea es cuantiosa. Esta clase nos proporciona constructores para implementar este patrón. Y aquí os presento la forma más comunes de usar, tambien puedes usarlo via propiedades: public class ProductsFile { string fileName; public object LoadProducts { get; set;}; public ProductsFile(string fileName) { this.fileName = fileName; this.ProductsFile = $"YOUR_CODE"; } } Lazy< ProductsFile > productsFile = new Lazy< ProductsFile >(() => new ProductsFile(“test.json")); var json = ProductsFile.Value.LoadProducts; En general este patron tambien se usa para singleton, pero eso ya es otra historia. En resumen quería que vierais que usamos cosas sin saberlo, aquí toda la información.
paralelismo necesitamos tener mucho cuidado con las variables compartidas. Si tenemos el siguiente ejemplo: dos usuarios intentan comprar un producto y solo queda un artículo disponible, ambos añaden el artículo a la cesta y el primero usuario hace el pedido, mientras se procesa en la pasarela de pagos el segundo intenta lanzar su pedido. En este caso el segundo no debería poder comprarlo si estuviera sincronizado. Además si falla el pago, el segundo debería poder hacer la compra (si no guardamos un tiempo el producto). Por tanto, lo que estoy intentado explicar es que la cantidad debe ser bloqueada mientras se procesa el primer pedido y ser liberado cuando tenga un ok o un KO. Tendremos la sección crítica lugar donde se leen y escriben las variables usadas por múltiples hilos, es decir, variables globales que se usan en toda la aplicación y que se modifican en lugares diferentes en momentos diferentes o al mismo tiempo. En multihilo, un solo thread podrá entrar y modificar esos valores de esta sección crítica. Si en nuestra aplicación no estemos este tipo de variables (sección) podremos considerarla como thread-safe. Por tanto siempre es aconsejable no usarlas. Pero como seguro que en algún momento lo necesitas, existe una sección llamada non-thread-safe conocidas como primitivas de sincronización o construcciones de sincronización que son: • Construcciones de bloqueo: permiten a un hilo entrar en la sección crítica para proteger el acceso a recursos compartidos, y que lo demás hilos esperen hasta que sea liberado el bloqueo del que la bloqueo. • Construcciones de señalización: permiten que un hilo entre en la sección crítica señalando la disponibilidad de recursos, un productor bloquea y el consumidor espero la señal para hacer su trabajo.
básica que permite lograr la sincronización en código multithread donde cualquier variable del bloque de bloqueo puede ser accedida por un solo hilo. En los bloqueos, el que adquiere el bloqueo tendrá que liberarlo, y hasta entonces, cualquier otro hilo que intente entrar en el bloqueo pasa a un estado de espera. object locker = new object(); lock (locker) { //Your code } El hilo que sea el primero en ejecutar este código adquirirá el bloqueo y lo liberará tras la finalización del bloque de código. Los bloqueos tambien pueden adquirirse usando Monitor.Enter y Monitor.Exit, es más, internamente C# los locks los transforma a monitor. Unos detalles que tienes que tener en cuenta sobre locks: • Debe ser usados en el tipo de referencia debido a su afinidad con el hilo. • Son muy costosos en términos de rendimiento, ya que pausan los hilos y añaden retraso. • Una buena práctica que te evitará problemas, es usar un double-check cuando adquieras un bloqueo, lo habitual es una implementación similar a singleton.
problemas: • Es necesario bloquear los datos/objetos compartidos dondequiera que se estén modificando. Es muy fácil obviar las secciones críticas de la aplicación, ya que la sección crítica es más bien un término lógico. Los compiladores no lo marcan si no hay bloqueos alrededor de un sección crítica. • Si no se manejan correctamente, se puede llegar a un punto muerto. • La escalabilidad es un problema, ya que sólo un hilo puede acceder a un bloqueo a la vez, mientras que los demás hilos deben esperar. Nota: Existe un concepto importante llamado atomicidad. Una operación es atómica si y solo si no hay ninguna forma de leer o escribir el estado intermedio de una variable. Es decir, si el valor de un entero se modifica y pasa de 2 a 4, cualquier hilo que lea ese valor entero verá 2 o 4; ninguno de los hilos verá el estado intermedio del hilo en el que el entero se actualiza parcialmente, es decir pasa de 2 a 3, por ejemplo. Garantizar la atomicidad es causa directa de hilos seguros. Utiliza colecciones concurrentes, que veremos más adelante, en lugar de bloqueos, ya que las colecciones manejan internamente el bloqueo de las secciones críticas.
a semáforos): Son blóquenos no exclusivos que soportan sincronización que permite que varios hilos puedan entrar en la sección crítica. Sin embargo, la diferencia con bloqueos exclusivos, es que un semáforo se usa en situaciones en la que es necesario restringir el acceso a un conjunto de recursos, por ejemplo, un grupo de conexión de base de datos que permite un número fijo de conexiones. En nuestro ejemplo si existen 2 artículos solo 2 usuarios o 1 usuario podrán añadir esos 2 artículos y si un tercer usuario quiere añadir un artículo quedará a la espera de liberar 1 por parte de los otros compradores. Tenemos un API en System.Threading.Semaphore que nos permite: • Pasar el numero inicial de peticiones activas. • El número total de peticiones concurrentes permitidas. Por ejemplo: var s = new Semaphore(0, 10); 0 significa que ninguna petición ha adquirido el recurso compartido y como máximo se permiten 10 peticiones concurrentes.
y para liberar a Release(). La opción ligera, suele basarse en un concepto llamado spinning. Cada vez que un recurso necesita bloquear un recurso compartido, en lugar del bloquear el recurso inmediatamente , SemaphoreSlim utiliza un pequeño bucle que se ejecuta durante unos microsegundos para no tener que pasar por el proceso costoso de bloqueo, cambio de contexto y transición al kernel (los semáforos usan el kernel de Windows para bloquear un recurso). Finalmente, SemaphoreSlim vuelve a bloquear si el recurso compartido todavía necesita ser bloqueado. Es casi igual que el anterior semáforo: var s = new SemaphoreSlim(0, 10); Cosas a tener en cuenta: • Un semáforo se utiliza para acceder a un conjunto de recursos, los semáforos no tienen afinidad con los hilos, y cualquier hilo puede liberar un recurso. • Se pueden usar Semaphore con nombre, que se pueden utilizar para bloquear recursos entre procesos; sin embargo SemaphoreSlim no puede. • La diferencia enter una y otra es que SemaphoreSlim es soporta métodos asíncronos y cancelación, por tanto se puede usar con async-await (que veremos en la sección 3).
Lock/Monitor Bloqueo Para bloquear sección crítica por un solo hilo. Cualquier variable de la aplicación. Mutex Bloqueo Para bloquear sección crítica por un solo hilo en el proceso o entre procesos. Solo la instancia de un proceso necesita permiso, entre varios mutex de la aplicación. Semaphore SemaphoreSlim Bloqueo Para bloquear el pool de recurso en una aplicación a través de un proceso o entre procesos Pool de una conexión de una base de datos. AutoResetEvent Señalización Permite que un recurso sea accedido por un hilo a través de una señal. Se suele usar para recursos que son accesibles bajo una condición en un hilo. https://docs.microsoft.com/es- es/dotnet/api/system.threading.autore setevent?view=net-6.0 ManualResetEvent ManualResetEvenSlim Señalización Permite desbloquear todos los hilos en espera mediante esta señal. https://docs.microsoft.com/es- es/dotnet/api/system.threading.manu alresetevent?view=net-6.0 Volatile Bloqueo Bloqueo que garantiza que usa la memoria para escribir y modificar. Es muy útil para multi-cores. https://docs.microsoft.com/en- us/dotnet/api/system.threading.volatil e?view=net-6.0
nuestras aplicaciones escalen y respondan mejor, por lo que implementar aplicaciones de este tipo no debería ser un sobresfuerzo. Aunque Thread y ThreadPool ayudan, añaden mucho sobresfuerzo y limitaciones. Por eso Microsoft a creado herramienta que nos ayudan en este tipo de desarrollo. Y aquí es donde profundizamos en modos de programación Task y TPL. La idea de la programación asíncrona es que ninguno de los hilos debe estar esperando en una operación, el framework debe tener la capacidad de envolver una operación en alguna abstracción y luego reanudarla una vez que la operación se ha completado sin bloquear ningún hilo. Esa abstracción es Task, que se expone vía Sytem.Threading.Task y nos ayuda con codigo asíncrono en .Net. Task simplifica mucho cualquier operación, ya sean recuperar datos de una base de datos, lectura de un archivo o cualquier tarea intensiva de CPU, y simplifica la ejecución en un hilo separado si es necesario. Estas son las características más importantes: • Task admite genéricos Task<T>. • Task se encarga de programar los hilos en los ThreadPools, particionar aplicaciones y programar más de un hilo en un ThreadPool, abstrayendo complejidad. • Soporta CancellationsToken via IProgress. Task & TPL – Ahora sí, ya hemos llegado a las Task tras este resumen de conocimientos
la aplicación que llama, incluso en jerarquías multihilo (padre/hijo). • Y las más importante es que Task soporta async-await, que ayuda a reanudar el procesamiento de la aplicación/método llamador una vez que la tarea se ejecuta. TPL es un grupo de APIs de System.Threading.Task y System.Threading, que proporciona formas de crear y gestionar tareas. Las tareas se puede crear cuando llamamos a System.Threading.Task y pasando un bloque de código que debe ser ejecutado en la tarea. Formas de crear tareas: var t = new Task(() => FetchDataFromAPI(https://test.com/test)); t.Start(); Ó var t = new Task.Run(() => FetchDataFromAPI(https://test.com/test)); Ó var t = new Task.Factory.StartNet(() => FetchDataFromAPI(https://test.com/test)); Los métodos que tenemos de obtener la información de una API mediante FetchDataFromAPI se ejecutan en un hilo de ThreadPool y res referenciado mediante el objeto t, que es devuelto a quien llama para continuar con la operaciones. Como esta tarea se ejecuta de forma asíncrona en el ThreadPool y el ThradPool son de background, la aplicación no esperará a FetchDataFromAPI. El TPL exponer un método Wait() que espera a finalizar la tarea, como un t.Wait().
FetchDataFromAPI(https://test.com/test)); t.wait(); void FetchDataFromAPI(string apiURL) { Thread.Sleep(2000); Console.WriteLine(“Returned API data"); } Tambien podemos usar delegados: var t = new Task.Factory.StartNet(delegate {FetchDataFromAPI(https://test.com/test);}); Con genéricos: var t = new Task.Factory.StartNet<string>(() => FetchDataFromAPI(https://test.com/test)); t.wait(); Console.WriteLine(t.result); Esto métodos aceptan, algunso de ellos, parámetros opcionales muy importantes: • Cancelación con CancellationToken. • Controlar su comportamiento con TaskCreationOptions. • Colas de tareas con TaskScheduler.
FetchDataFromAPI("YOUR_API"), TaskCreationOptions.LongRunning); Aunque esto no garantiza una salida rápida, si no más bien da una pista al desarrollador par aunque lo optimice. Por ejemplo, podemos partir esa tarea en cosas más pequeñas. Tas admite la espera de múltiples tareas al mismo tiempo creando y pasando todas la tareas como parámetrso a los siguientes métodos: • WaitAll, espera a finalizar todas la tareas y bloquea el hilo. No recomendado. • WhenAll, espera a que se completen las tareas sin bloquear. Normalmente usado con async-await. Recomendado. • WaitAny, espera la finalización de una de las tareas y bloquea el hilo hasta ese momento. No recomendado. • WhenAny, espera a que finalice una tarea sin bloquear hilo. Usando normalmente con async-await. Recomendado. Las tareas a diferencia de los hilos, tienen un amplo soporte y gestión de excepciones. Veámoslo. El manejo de excepciones en la tareas es tan simple como escribir un bloque Try envolviendo la tarea y luego las excepciones, que normalmente se envuelven en AggregateException. Try { var t = new Task.Factory.StartNet(() => FetchDataFromAPI("YOUR_API")); t.wait(); } catch (AggregateException ex) { console.WriteLine(ex.InnerException.Message); }
una sola tarea, sin embargo cuando tengamos más de una, será una colección de InnerException. Además como tiene un Handle, que podemos suscribiré al catch y el callback nos dará la información de la excepción. Aquí tienes un ejemplo más completo. Las cancelaciones de las tareas, son de dos tipos: • CancellationTokenSource, clase que crea el token de cancelación y admite cancelación vía Cancel. • CancellationToken, estructura que escucha una cancelación y se activa si una tarea se cancela. cts = new CancellationTokenSource(); CancellationToken token = cts.Token; Task dataFromAPI = Task.Factory.StartNew(()=> FetchDataFromAPI(new List<string> { "https://test.test/test", }), token); cts.Cancel(); En ASP.NET que tenemos tareas asíncronas en GetAsync y PostAsync, podemos usarlo, ver este ejemplo. Cuando realizamos aplicaciones, seguro que tendrás muchas tareas, por tanto se construye una jerarquía de tareas y por tanto una dependencia. Esto funciona muy parecido a las promesas de JavaScript y permite encadenar tareas. Por ejemplo:
.ContinueWith(b => Task3(b.Result)) .ContinueWith(c => Console.WriteLine(c.Result)); Console.ReadLine(); En ASP.NET que tenemos tareas asíncronas en GetAsync y PostAsync, podemos usarlo, ver este ejemplo. Aquí puedes ver como funciona ContinueWith y demás métodos relacionados. Otro aspecto que hemos hablado mucho es del contexto de sincronización: SynchronizationContext y que volvemos a ver brevemente. Es una clase abstracta disponible en System.Threading que ayuda en la comunicación entre hilos. Por ejemplo, la actualización de un elemento de la interfaz de usuario desde una tarea paralela requiere que el hilo se reincorpore al hilo de la UI y reanude la ejecución. SynchronizationContext proporciona esta abstracción principalmente a través del método Post de esta clase, que acepta un delegado para ejecutar en una etapa posterior. En el ejemplo anterior, si necesito actualizar un elemento de la UI, necesito coger SynchronizationContext del hilo UI, llamar a su método Post, y pasar los datos necesarios para actualizar el elemento de la interfaz de usuario. Como SynchronizationContext es una clase abstracta, hay varios tipos derivados de ella.
Cuando creamos una tarea programada en un hilo de ThreadPool, ¿quién lo hace?. Pues System.Threading.Task.TaskScheduler que esta disponible en el TPL para poner en cola y ejecutar delegados de tareas en el ThreadPool. Expone una por defecto que es ThreadPoolTaskScheduler; para GUI suele utilizar SynchronizationContextScheduler para que las tareas puedan volver y actualizar los elementos de la interfaz de usuario. TaskScheduler y SynchronizationContext. Juegan un papel importante en async-await, y ayudan a depurar rápidamente cualquier problema relacionado con un punto muerto. Al final ya nos queda solamente Paralelismo para terminar esta sección. Que consiste en dividir una colección en múltiples tareas que se ejecutan en paralelo. Con TPL tenemos paralelismo en For y ForEach gracias a la sobrecargas que tienen. var numbers = Enumerable.Range(1, 100).ToList(); Parallel.For(numbers.First(), numbers.Last(), x => DoSomeWork(x)); Parallel.ForEach(numbers, x => DoSomeWork(x)); Alguna de las ventajas de usar paralelismo como los anteriores son: • Se pueden cancelar los bucles ParallelStateOptions.Break. • Se pueden parar gracias a ParallelStateOptions.Stop. Esto nos da mucho juego con los datos, que veremos mucho más adelante.
Cuando creamos una tarea programada en un hilo de ThreadPool, ¿quién lo hace?. Pues System.Threading.Task.TaskScheduler que esta disponible en el TPL para poner en cola y ejecutar delegados de tareas en el ThreadPool. Expone una por defecto que es ThreadPoolTaskScheduler; para GUI suele utilizar SynchronizationContextScheduler para que las tareas puedan volver y actualizar los elementos de la interfaz de usuario. TaskScheduler y SynchronizationContext. Juegan un papel importante en async-await, y ayudan a depurar rápidamente cualquier problema relacionado con un punto muerto. Al final ya nos queda solamente Paralelismo para terminar esta sección. Que consiste en dividir una colección en múltiples tareas que se ejecutan en paralelo. Con TPL tenemos paralelismo en For y ForEach gracias a la sobrecargas que tienen. var numbers = Enumerable.Range(1, 100).ToList(); Parallel.For(numbers.First(), numbers.Last(), x => DoSomeWork(x)); Parallel.ForEach(numbers, x => DoSomeWork(x)); Alguna de las ventajas de usar paralelismo como los anteriores son: • Se pueden cancelar los bucles ParallelStateOptions.Break. • Se pueden parar gracias a ParallelStateOptions.Stop. Esto nos da mucho juego con los datos, que veremos mucho más adelante. Además de PLINQ.
async Task<int> SomeMethodAsync() { return 0; } public async Task<int> SomeMethodAsync() { return await OtherMethodAsync(); } Y ¿qué hemos visto? Pues como crear métodos asíncronos. El primer método es síncrono, el segundo NO es asíncrono aunque pongamos la sentencia async, ya que realmente la asincronía la da el await. Por tanto el tercer método sí es asíncrono. Ya sabéis identificar código asíncrono: public async Task SomeMethodAsync() { await OtherMethodAsync(); OtherMethod(); } Ejemplo – Con un pequeño ejemplo nos sumergimos
paso a paso como se ejecuta el código en este ejemplo: async task DoProcessAsync() { … int x = await DoOtherProcessAsync(); … } async task<int> DoOtherProcessAsync() { … int y = await stream.ReadAsync(buff); … return y; } Cola del ThreadPool 1 2 3 4 5 6 7 8
ejecuta DoProcessAsync, y las instrucciones correspondientes hasta llegar a una función que vea con await. 2. Se encola en el ThreadPool DoOtherProcessAsync para ejecutarla. 3. La función principal DoProcessAsync se encola en el ThreadPool 4. Se desencola DoOtherProcessAsync para que se pueda ejecutar la función. 5. Se va ejecutando la parte síncrona de la función hasta que: • Si ve una await como en nuestro caso, ocurre lo siguiente: que coloca el proceso en el ThreadPool, salta a la función que quieres llamar con await y volvemos a empezar. • Si no lo hubiera la función se ejecutaría hasta el final y devolvería la información a la función que lo llama. 6. Si estamos en el caso de que dentro de la función DoOtherProcessAsync tenemos que llamar a una función asíncrona con el await, pues es el mismo proceso que hemos visto antes. 7. En caso de haber terminado la función asíncrona del paso anterior o si todo fuera síncrono, retornamos el valor correspondiente. 8. Continua el proceso en la función DoProcessAsync. En todo este proceso simplificado tienes que tener en cuenta que debes aplicar el valor de quantum que habíamos visto en anteriores explicaciones. Y tambien tenemos que tener en cuenta que para esta gestión el procesador usa de algoritmos de máquina de estados. En resumen estamos dejando que el ThreadPool que gestione el trabajo para logra que no se bloquee ningún proceso.
una tarea: • La primera vez, si la tarea subyacente aun no se ha completado, realmente espera a la finalización de la tarea. • En usos posteriores, como el resultado ya es conocido, estamos en un proceso síncrono. Task task = SleepAsync(5000); await task; // La tarea tardará x ms para ejecutarse await task; // La tarea es inmediata ya no existe una promesa Se puede poner un retraso, pero no siempre es útil, aun así la siguientes veces continua siendo más rápido que la primera: Task task = SleepAsync(5000); await task; // La tarea tardará x ms para ejecutarse await task; // La tarea es inmediata ya no existe una promesa static async Task SleepAsync (int delayMS) { await Task.Delay(delayMs); } Aclaraciones – Sobre awaiting
• Una tarea continua siendo una promesa. • Una tarea se puede esperar (await) para obtener un resultado asíncrono ( si es necesario). async Task DoSomeAsync() { await DoAsync(); DoOther(); } Conceptualmente es: async Task DoSomeAsync() { Task t = DoAsync(); //Inicia la operación en background y retorna una promesa await t; //espera a que la promesa DoOther(); } Como veis no es ninguna magia, si anidamos await con otro await podemos extrapolar el ejemplo anterior y verlo de forma más conceptual.
síncrono, estos ejemplos nos ayudarán: public int DoSome () // Claramente es un método síncrono { return 0; } Sin embargo aunque pongamos asíncrono, realmente es síncrono, mucho cuidado con este caso, ya que estamos usando memoria para crear una máquina de estados que nunca se usará, es un desarrollo ineficiente: public Task<int> DoSomeAsync () { return 0; } Y esto sí es realmente un método asíncrono: public Task<int> DoSomeAsync () { return await DoOtherAsync(); }
. . . } async Task<int> CalculateAsync(int arg) { . . . } ¿Cual es la diferencia?, ¿Cuál es mejor? Depende, ambos son awaitables, pero tienen un significado diferente. A esto se le llama async eliding (asincronía por omisión). Veamos que es. Entremos en el siguiente ejemplo donde tenemos unos benchmark: asyncelidingtest Más aclaraciones – Cosas que a veces creemos que sabemos y no es así
El resultado del rendimiento es llamativo como para pensárnoslo en entornos de alta disponibilidad. Pero esto no quiere decir que debamos quitarlo. El rendimiento mejora al no crear máquinas de estado, en eso radica la ganancia. Esta optimización implica cambios en: • Cómo deben manejarse las excepciones. • Y la forma en la que se liberan recursos, el dispose. Maquina de estados: Await en Task<T> obtiene la finalización de la promesa, desenvolvemos Task<T> para obtener el resultado. Lo que está ocurriendo es que se comprueba si la operación ya está completada (para dar el resultado inmediatamente); si no, activa una máquina de estados asíncrona que pone en marcha un MoveNext que programa una continuación en el contexto de sincronización y, si es nulo ese contexto, en el TaskScheduler actual.
2.B await SleepAsyncOne(); //Case 2.C SleepAsynTwo(); //Case 2.A _ = SleepAsynTwo(); //Case 2.B await SleepAsynTwo(); //Case 2.C static async Task SleepAsyncOne() { await Task.Delay(100); throw new NullReferenceException(); } static async Task<Task> SleepAsynTwo() { await Task.Delay(100); return Task.FromException(new NullReferenceException()); } Vamos a explicarlo con el ejemplo anterior, para ello ve comentado las líneas una a una y ejecuta el código:
nada, se ejecuta el código y continua, el error nunca se muestra, el programa principal termina. • Caso 1.B (recuerda resto comentado): No devuelve nada, se ejecuta el código y continua, el error nunca se muestra, el programa principal termina. • Caso 1.C (recuerda resto comentado): Await hace que el código espere a que se ejecute, por tanto el error salta y se rompe la aplicación. • Caso 2.A (recuerda resto comentado): No devuelve nada, se ejecuta el código y continua, el error nunca se muestra, el programa principal termina. • Caso 2.B (recuerda resto comentado): No devuelve nada, se ejecuta el código y continua, el error nunca se muestra, el programa principal termina. • Caso 2.C (recuerda resto comentado): Await hace que el código espere a que se ejecute, por tanto el error salta pero se envía con un Task.FromException que devuelve el código al hilo principal. No lo estamos rompiendo como el 1.C. En resumen tenemos 2 tipos de situaciones en las excepciones: - Error por el uso. Por ejemplo cuando pasamos un null o hacemos una división por cero. Un uso incorrecto de la programación. Son errores en tiempo de compilación. Siempre se dan hasta que se arreglan. - Error por la ejecución. Aquellos que se dan de forma intermitente, por ejemplo a veces no esta el fichero que debemos cargar o no tiene derecho de ejecución algún tipo de usuario. Se dan en tiempo de ejecución, más complicados de encontrar por que no se dan siempre.
cuenta como debemos gestionar los errores en la asincronía o bien se rompe la aplicación o bien se realizan reintentos, por ejemplo. Por tanto mi consejo es: • Lanzar errores por uso directamente en los método de asincronía, en lugar de envolverlos y subirlos, ya que al subirlos tenemos más posibilidades de ignorarlos. Tambien evitamos sobrecargar la máquina de estados, por tanto menos IOPs. • Envolver los errores por la ejecución en una Task. Esto nos permite operar sobre el y gestionarlos ya que casi siempre debíamos esperar un resultado de esa tarea. Por tanto: async Task DoSomeProcessAsync() { Task t = DoAsync(); // Para cuando queramos usar errores de uso await t; // Para cuando queremos usar errores de ejecución DoOtherProcess(); }
CancellationTokens, esto nos permite cancelar operaciones de larga duración. No es habitual que cancelemos tareas y por tanto es interesante poder reutilizar los CancellationTokenSource, el objeto que genera CancellationToken. Hasta la versión 6 no había seguridad de poder hacer esto ya que no sabíamos si todavía se hacía referencia a ese token. En .NET 6 se amplía CancellationTokenSource con TryReset, veamos el siguiente ejemplo:
{ _cancellationTokenSource.Cancel(); } public async Task DoSomeAwesomeWork() { if (!_cancellationTokenSource.TryReset()) { _cancellationTokenSource = new CancellationTokenSource(); } var data = await FetchData(_cancellationTokenSource.Token); } public async Task<someObject> FetchData(CancellationToken token) { token.ThrowIfCancellationRequested(); var client = new HttpClient(); var response = await client.GetAsync("[YOUR_API]", token).ConfigureAwait(false); return await response.Content.ReadAsStringAsync(token).ConfigureAwait(false); } Una vez cancelado el token, no se podrá reciclar y TryReset no dará un false. En el ejemplo anterior, si hemos realizado un CancelAction y luego hacemos nuestro DoSomeAwesomeWork, si no existe un token, instanciamos uno nuevo. Por tanto, mientras no se cancele el token, podremos realizar un FetchData, pero si lo hubiéramos cancelado, no podríamos traernos nada de la API a la que llamamos.
método asíncrono que pueda ejecutarse de forma síncrona. Lo vemos en ejemplo: ValueTaskVsTaskTest Este ejemplo usa una caché de memoria, si el valor no esta en la caché se ejecutará un método asíncrono en caso contrario es proceso es todo síncrono. Aquí esta la explicación mucho más clara a la primera frase. Ahora seguro que se entiende mejor. Cuando ejecutemos los benchmark, vamos a ver que realmente es más rápido:
similares. Pero vamos a responder a ciertas preguntas que se os puede pasar por la cabeza: • ¿merece la pena andar revisando en una refactorización esto?, en una aplicación de baja demanda no, pero como en cloud todo cuesta mucho dinero, aunque sea de baja demanda, es un ahorro económico, extrapola esto a un sistema de alta demanda, no hablamos de cientos de euro, si no de cientos de euros. • ¿a que se debe esta mejora? como veis el tiempo es muy similar, pero lo que importa es la memoria. Task se aloja en la memoria mientras que ValueTask si no lo necesita (como nuestro ejemplo) aloja 0 bytes en memoria. Si esto no termina de convenceros, aun tenemos más. Task es muy flexible y tiene muchos veneficios: • Nos permite hacer await muchas veces y por cualquier tipo de consumidor. • Concurrencia, sin problemas. • Puedes hacer un tipo de caché de resultados asíncronos. • Puedes bloquear la espera hasta que se complete uno. • Puedes usar: WhenAll, WhenAny, …
necesitan: var result = await SomeProcessAsync() Pregúntate si todo el proceso va a ser 100% asíncrono si no es así, tienes un claro indició de ValueTask. Creo que más claro que el ejemplo anterior no vas a encontrar. Y para terminar: Task aloja memoria debido a que es un tipo por referencia y eso quiere decir que el Garbage Collector (GB) una vez completada la tarea debe hacer limpieza de recursos y objetos asignados a la tarea. A más tareas más trabajo del GB. Por tanto, usar un tipo por valor (ValueTask) nos permitirá mejorar el rendimiento de nuestra aplicación por ese pequeño ahorro con el GB. Estos enlaces podrán ayudarte con algo más de información: • Understanding the Whys, Whats, and Whens of ValueTask • ValueTask en la documentation de Microsoft
2 carpetas, jmeter y postman. El test de JMeter es muy sencillo: Como se puede observar, el throughput (request/segundo) es mayor en asincronía, no va 1 a 1 como en síncrono. Esto nos da unas mejores tiempo Min/Max debido a que hace un mejor uso del procesador. No es que funcione más rápido. El equipo es el mismo, los ejemplos se han realizado sobre la misma VM, en mi caso no he usado Azure Load Testing, tendría que desplegarla en un App Service y me he ahorrado todo eso. Por tanto la frase que resalté tiempo atrás demuestra el por qué de la asincronía… pero recordar, es await quien nos la da.
de 100, por ejemplo. Exporta a json el resultado y usa Excel para sacar medias. O bien a simple vista: Aunque aquí nos quedamos cortos con Excel por que no podríamos ver el throughput, que es quien hace el trabajo con los hilos en el Kerstel (revisar secciones anteriores donde lo explico).
{ _cancellationTokenSource.Cancel(); } public async Task DoSomeAwesomeWork() { if (!_cancellationTokenSource.TryReset()) { _cancellationTokenSource = new CancellationTokenSource(); } var data = await FetchData(_cancellationTokenSource.Token); } public async Task<someObject> FetchData(CancellationToken token) { token.ThrowIfCancellationRequested(); var client = new HttpClient(); var response = await client.GetAsync("[YOUR_API]", token).ConfigureAwait(false); return await response.Content.ReadAsStringAsync(token).ConfigureAwait(false); } Una vez cancelado el token, no se podrá reciclar y TryReset nos dará un false. En el ejemplo anterior, si hemos realizado un CancelAction y luego hacemos nuestro DoSomeAwesomeWork, si no existe un token, instanciamos uno nuevo. Por tanto, mientras no se cancele el token, podremos realizar un FetchData, pero si lo hubiéramos cancelado, no podríamos traernos nada de la API a la que llamamos con FetchData. Deadlock – Literalmente es el punto muerto, pero ya veremos si la traducción es adecuada
potencia que nos da usar siempre cancelaciones de token. Supongamos un sistema de alta demanda como puede ser el buscador de Google. Habrás visto que según vas escribiendo va lanzando consultas al buscador va haciendo llamadas al API de Google. Esto mejora la experiencia de usuario pero si no se hace bien, saturas el servidor de peticiones que deben terminar de ejecutarse cada vez que pones un carácter nuevo en la caja de texto. ¿Qué hace Google o qué debería hacer tu aplicación para no dejar llamadas muertas en el servidor? Muy sencillo cancelar con el token cada llamada para que el servidor mate ese proceso y no ocupe proceso, es decir, cada vez que escribes una letra nueva si tu petición aun esta siendo procesada en el servidor, previamente deberías mandar una cancelación de la request anterior. Quizá tu aplicación no lo necesite y quizás pienses que poner cancelación por todo y para todo, ya que debes propagarlo, es un incordio; pero si estas en sistemas de alta demanda, cualquier ms o cualquier optimización de este tipo es obligatorio. Ahora entiendes que dejar peticiones sin cancelar, hacen que el servidor continue procesando a pesar de que ese request no lo vas a necesitar nunca.
este artículo, o este otro, … Podrás encontrar muchos más. Esto viene relacionado con el contexto de la aplicación: SynchronizationContext, que usaré de pretexto para explicar ambos términos. En un artículo muy famoso llamado: “Async and Await” de Stephen Cleary, que es de 2012 recomienda su uso, pero es muy peligroso por dos razones: principiantes y riesgo de mantenimiento. Principiantes Es un mal consejo ya que la sincronización es un tema complejo. Si le dices que use ConfigureAwait(false) siempre a menos que lo necesite su contexto, te preguntará qué “significa necesitarlo”, por tanto, esta pregunta indica que si no lo sabes, no debes usarlo, pero como no lo sabrán terminará por usarlo siempre… He visto hacer un refactor indicado por un arquitecto jefe pidiendo que se ponga obligatoriamente (esto en 2019, cuando ya se conocía la problemática), este señor introdujo un posible problema a futuro ya que es una magia negra que hace que puedas perder horas y horas intentado ver un problema por haber introducido esto indiscriminadamente. Existen personas con las que no se puede discutir… Mi consejo es no usarlo a menos que sepas que es lo que hace y que el contexto no lo necesitas para nada. ConfigureAwait(false) – Seguro que ya has leído algo al respecto
es un tema complejo, sobre todo dependiendo a que métodos se llaman posteriormente. Puede ser que no lo necesites ahora, pero y ¿en lo siguientes?. Es un riesgo que no debes correr al meterlo en todas partes. Para concluir: Lee este artículo sobre un FAQ de ConfigureAwait. Y yo en mi código no me preocupo donde ponerlo o, simplemente lo ignoro… aunque se que poniéndolo podría obtener una mejora en el rendimiento, pero dudo que sea notable tanto como para justificar el riesgo. Pero como todo en la vida, existen excepciones y esta es cuando escribas librerías que usaran otras aplicaciones, tal y como señala el anterior FAQ, usa siempre ConfigureAwait(false): • Una librería no debería tener contexto de aplicación y si no lo pones y alguien lo usa podrías generar un Deadlock. • Y que debes usarlo en la librería en todos los sitios… El artículo de Stephen esta obsoleto y en stackoverflow reconoce que se debe cambiar… por tanto no estoy siendo un arrogante sin cabeza.
y SynchronizationContext Ejecuta lo que toca en el mismo hilo sin hacer una planificación (scheduling) La tarea esta completada? Capturado por el contexto de sincronización? Haces una planificación (schedule) para que continue vía SynchronizationContext Planificas la continuación en TaskSchedler Si Si No No
que se ejecuten, se asocian a un TaskScheduler que tiene el método QueueTask para que sea posteriormente invocado mediante ExecuteTask. Dispone de tres métodos importantes: • TaskScheduler.Default, que es solamente un pool de hilos. • TaskScheduler.Current, que es un getter proporcionado por el planificador inicial de tareas. • TaskScheduler. FromCurrentSynchronizationContext, que crea un nuevo planificador de tareas para que sea capturado por SynchronizationContext.Current. Además contiene a otros dos planificadores: CurrentScheduler (que es un reader) y ExclusiveSheduler (que es un writer). Solamente uno puede ejecutarse, es decir, no son concurrentes. Esto nos plantea varios escenarios: • Bloqueos entre escritura/lectura. • Limites en las concurrencias. Y si quieres profundizar más, en este ejemplo podemos crear un limitador de subprocesos para una aplicación. TaskScheduler – Planificador de tareas
en algún momento te interesará llamar con TrySetResult o TrySetExcepcion para completar la tarea. Uno de los escenarios que te interesará saber su utilidad es cuando una operación externa asíncrona deseamos encapsulara. Como es un tema muy complejo lo mejor es ir a la fuente que es el artículo: The Nature of TaskCompletionSource y The Danger of TaskCompletionSource Class. TaskCompletionSource – Útil en diversos escenarios
Contexto de seguridad. • Para asincronía del código, para Task.Run, ThreadPool.Queue, … • Para Async/Await. Por ejemplo si un Await no se completa, lo captura el ExcutionContext y lo restaura cuando lo necesite. Y ¿qué diferencia existe entre ExecutionContext (ec) y SyncronizationContext (sc)? • EC es un concepto más amplio que SC. • EC se usa para las máquinas de asincronía, es muy raro que se pueda modificar y es requerido por la infraestructura de .NET. • SC está integrado en las tareas (Task), permite un control detallado, lo usa .ConfigureAwait() por tanto permite personalizaciones sobre el flujo. • EC ya no captura flujo de el SC desde la versión .NET Core 3.1, esto es bueno ya que permite optimizar el código en el backend sin depender del EC. ExecutionContext – Planificador de tareas
mismo que esto: var awaitable = obj.SomeMethodAsync(); var awaiter = awaitable.GetAwaiter(); if (!awaiter.IsCompleted) { } int i = awaiter.GetResult(); Por tanto podemos usar await a todo aquello que tenga un GetAwaiter. Awaitables – Task y Task<T> son awaitables
un orden en una serie de llamadas a funciones y esperas que el resultado de una venga para la otra. Cuando estas mezclando cosas asíncronas y síncronas suele ser un gran problema, por ejemplo esperas que el orden de una secuencia será 1, 2, 3, 4, 5 y 6, pero no espera que sea 1,3,4,2,5 y 6. Esto es un gran problema cuando manejas este tipo de funciones. Si comienzas a poner .GetResult o .GetAwaiter al final estarás generando bloqueos entre funciones. Muchas veces al final se convierte todo a síncrono y te olvida de este problema, pero generas otro como es el escalado en grandes entornos o entornos de alta demanda. Otras tantas veces lo que se hace es envolver (wrap), pero es un tema muy peligroso que deberías descartarlo, siempre en favor a Async-Await. Para ello lo mejor es leas este artículo de Microsoft, que nos muestra como hacer tareas secuenciales o bien ejecutar tareas en paralelo para que al final el proceso sea como esperamos. Un pequeño stop – Lo normal es que a veces el trabajo se solape
código similar a esto: BackgroundOperationAsync(); ... public async void BackgroundOperationAsync() { var result = await CallDependencyAsync(); DoSomething(result); } Pero es una muy mala opción: Ya que los métodos vacíos asíncronos bloquean el proceso si se lanza una excepción. Simplemente no puedes captúralo. Un método de este tipo, usa el SynchronizationContext para enviar las excepciones allí y como suele ser null, no puede manejarlo. Además, tampoco puedes hacer unit testing. Ejecutar y olvidar – Ejecuto y me pongo a otra cosa
es envolverlo con: Task.Run(BackgroundOperationAsync); ... public async Task BackgroundOperationAsync() { var result = await CallDependencyAsync(); DoSomething(result); } Solo es una buena opción para retrocompatibilidad para event handles, pero no lo uses para nada más. Si quieres ampliar más, aquí te dejo un artículo.
(2nd Ed) − Concurrency in .NET: Modern patterns of concurrent and parallel programming − Pro .NET 4 Parallel Programming in C# − C# 7 and .NET Core 2.0 High Performance − Concurrency in C# Cookbook, 2nd Edition (recomiendo su lectura) − Pro .NET Benchmarking: The Art of Performance Measurement − High-Performance Programming in C# and .NET Videos: − Hands-On Parallel Programming with C# 8 and .NET Core 3.0 − Async Expert (curso que me a aportado muchos conocimientos y consolidado otros) En parte tienen culpa… – Además te servirán como base para ampliar conocimientos
− https://mvolo.com/ − https://blog.stephencleary.com/ Nota: Algunas de las imágenes estan basadas en esta bibliografía así como alguno de los puntos tratados. Si encuentra alguna similitud con alguna de las obras anteriores y no lo ves correcto, avísame y tratamos de arreglar este libro gratuito y sin ningún tipo de lucro.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
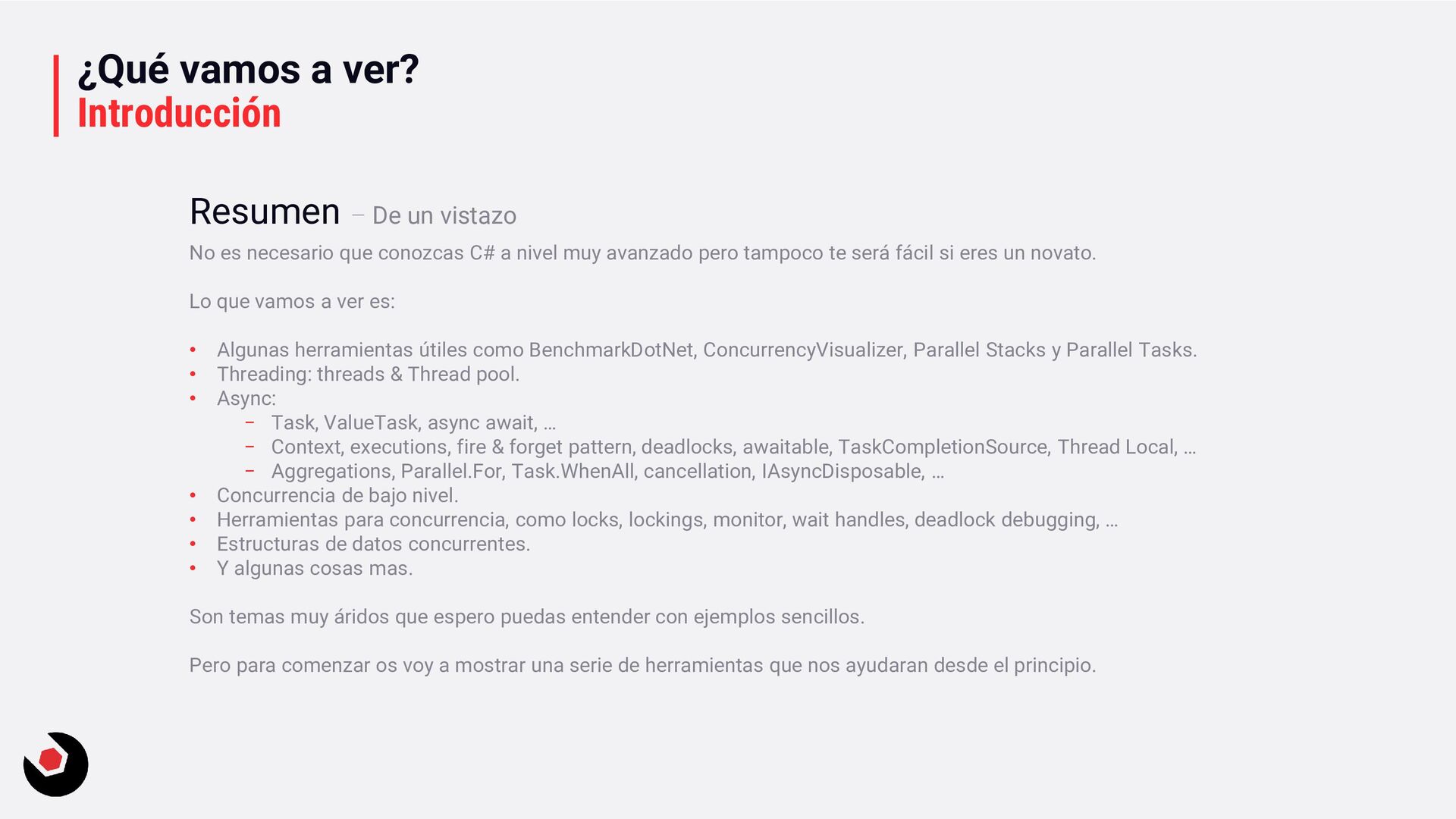{kind=link}
{kind=link}
{kind=link}
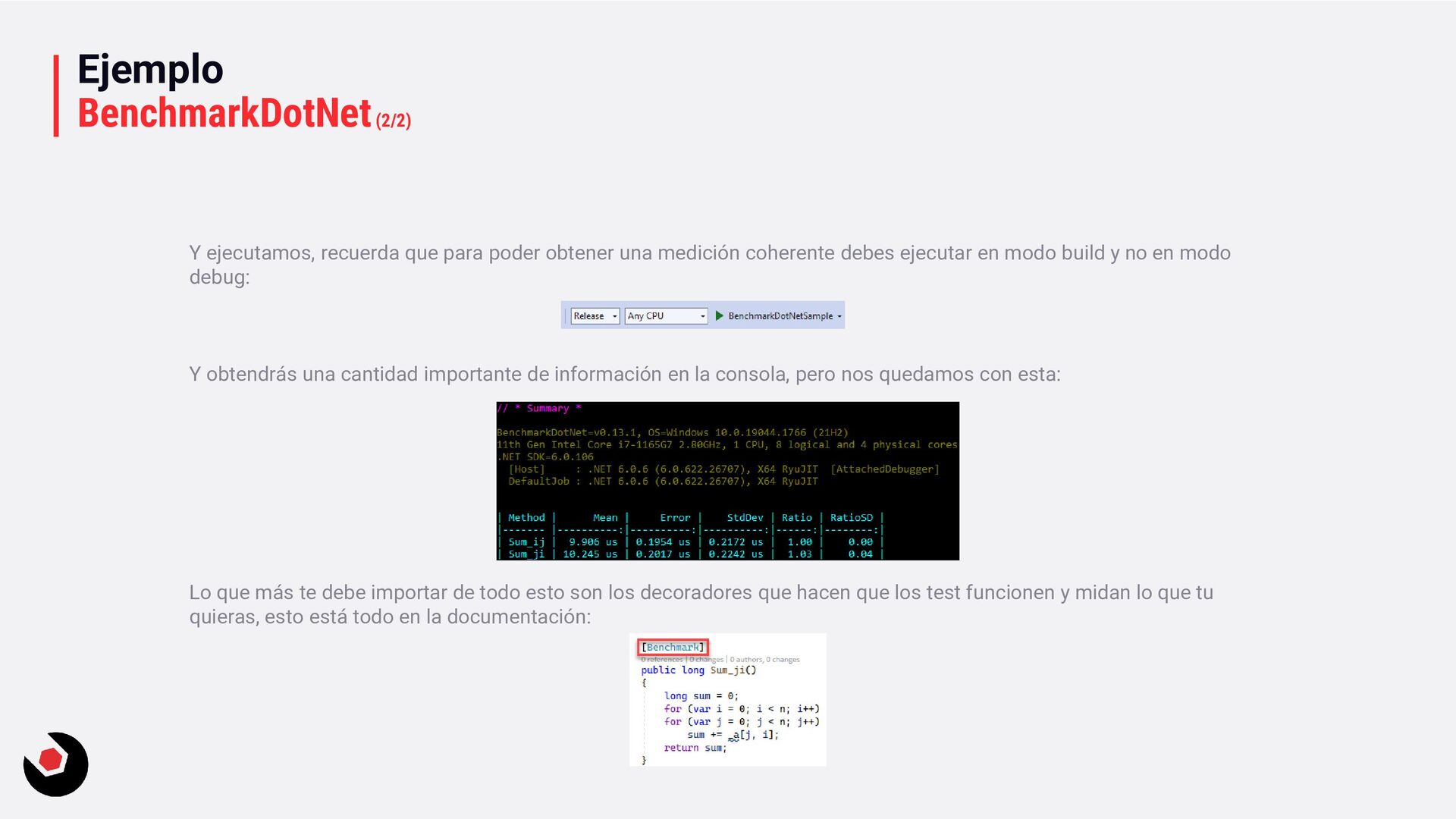{kind=link}
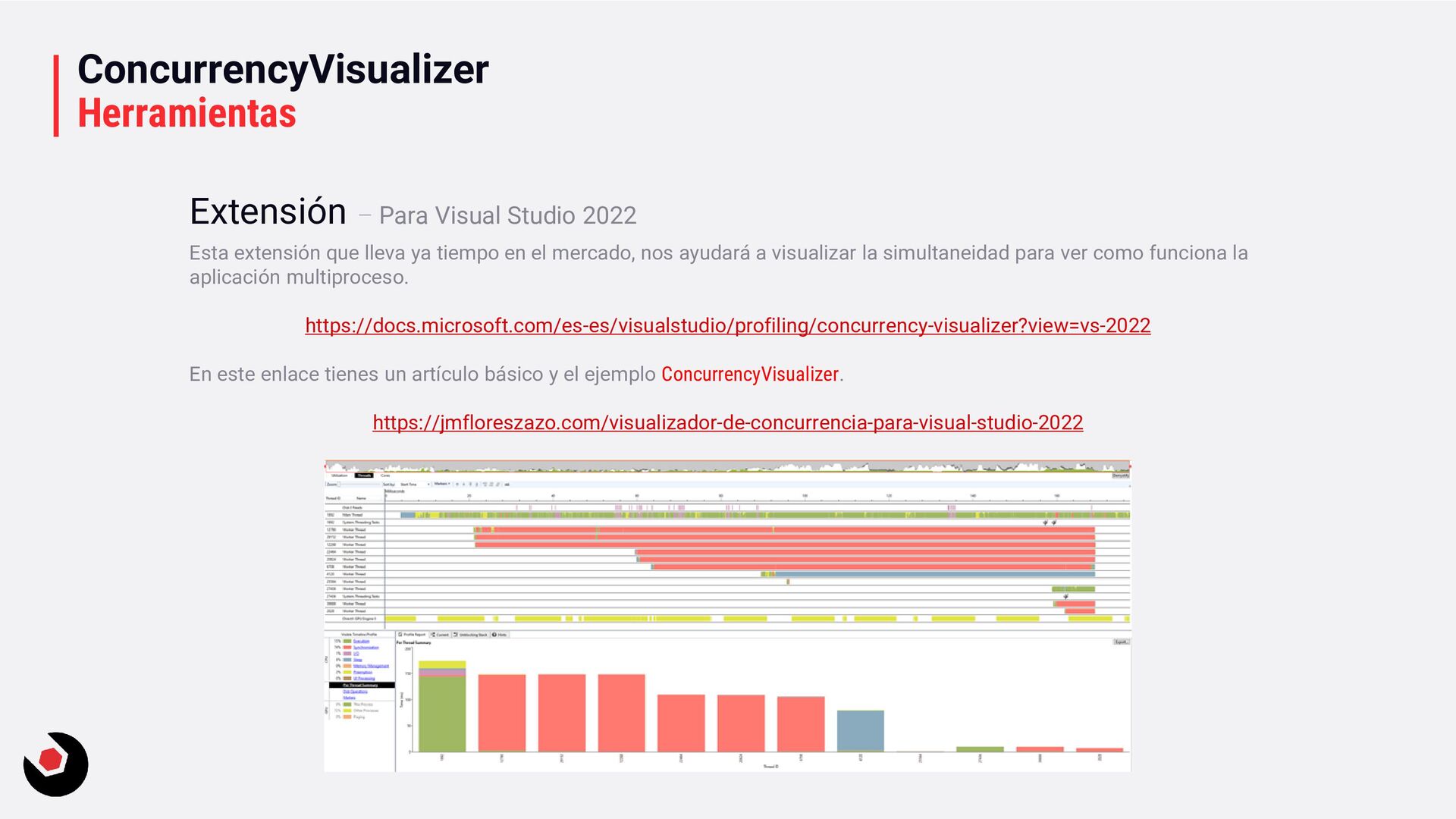{kind=link}
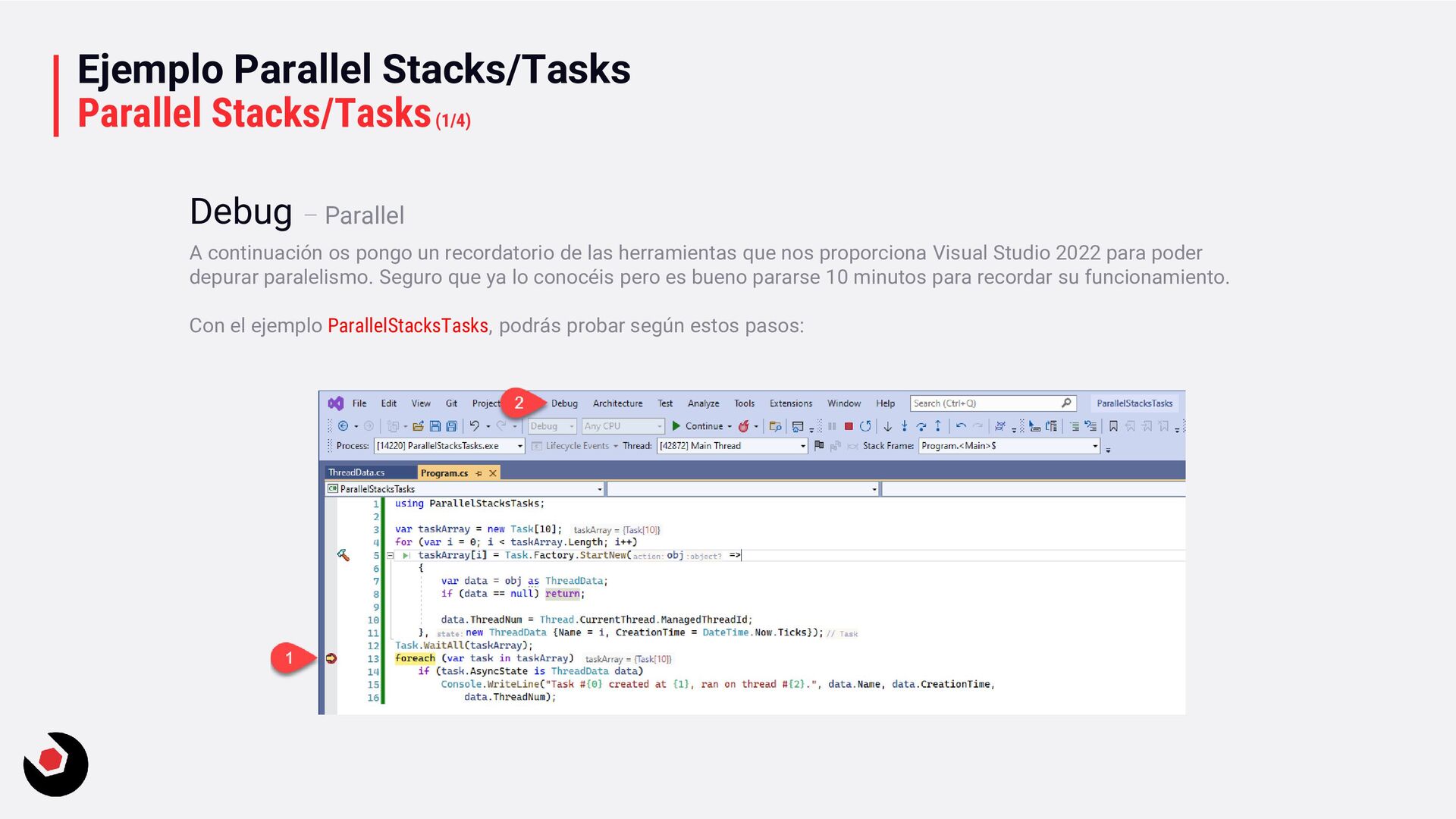{kind=link}
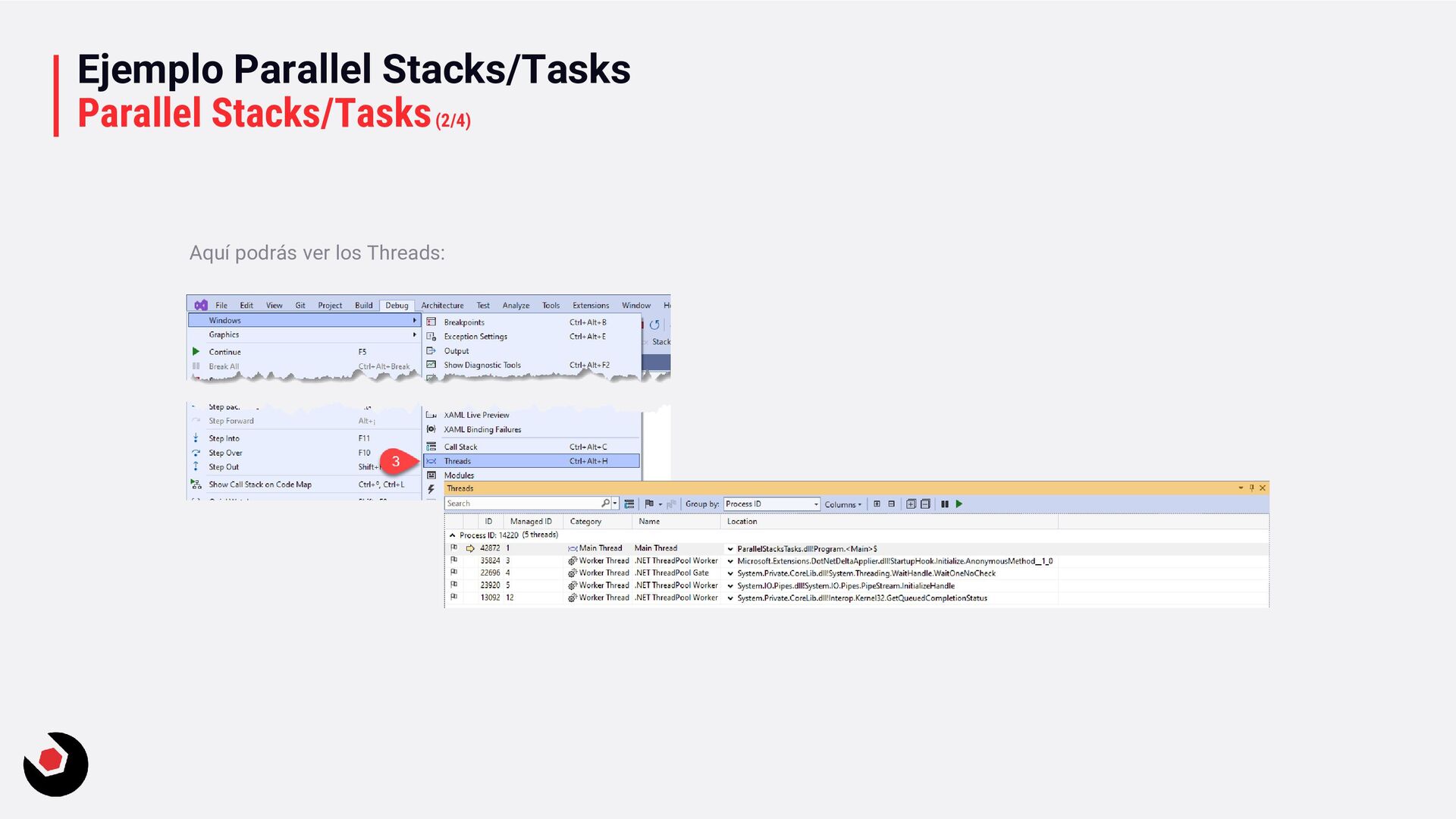{kind=link}
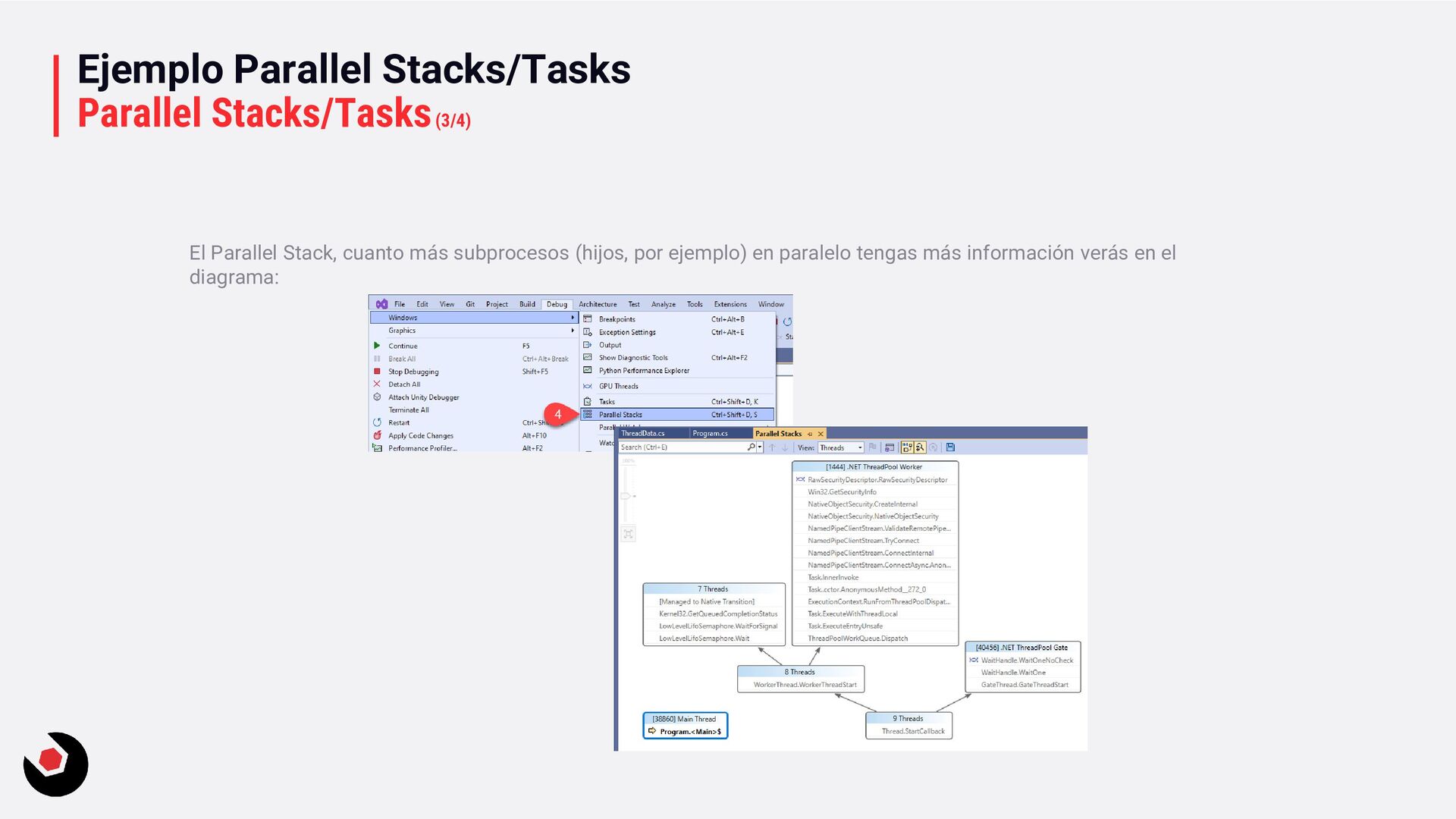{kind=link}
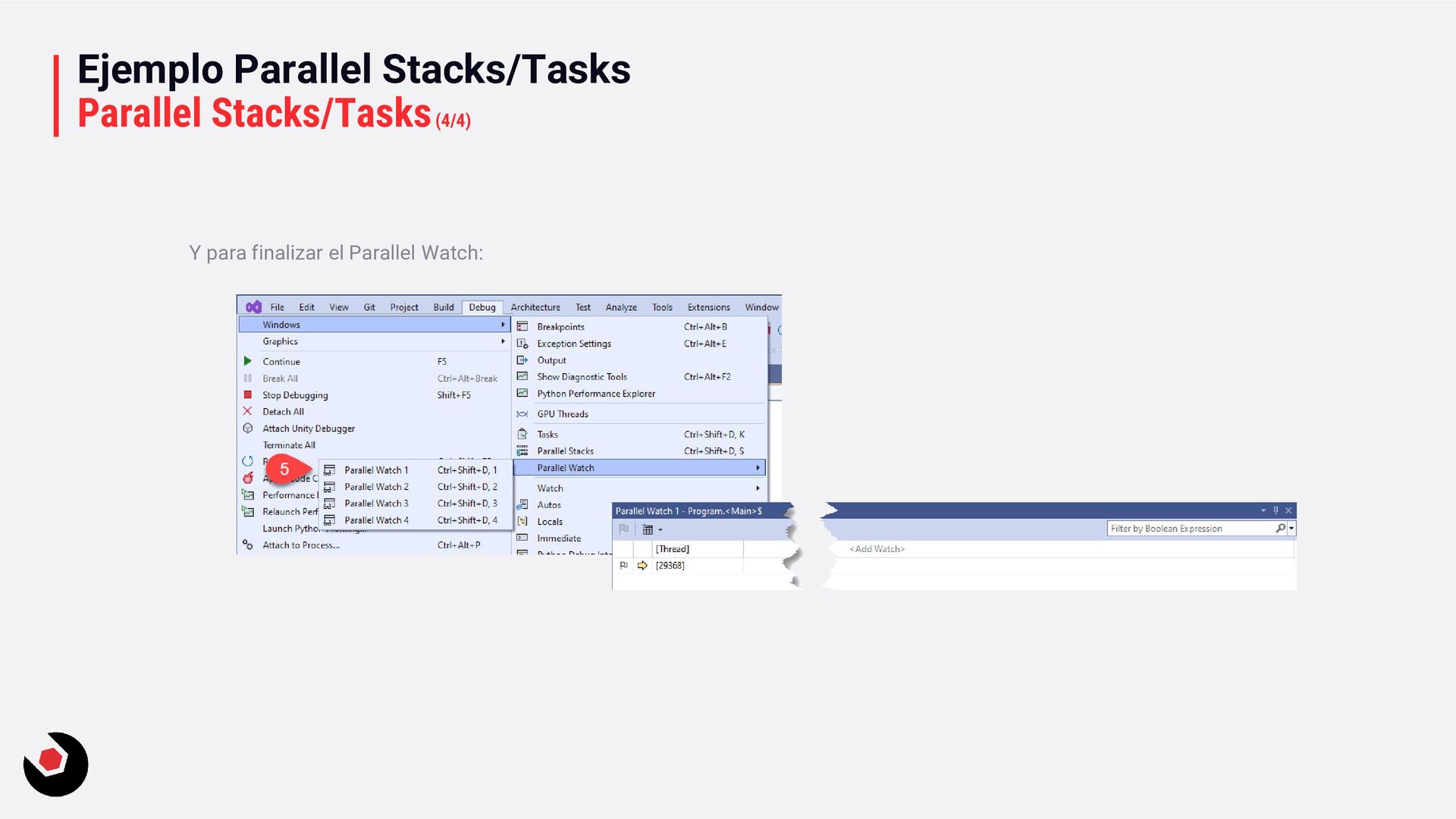{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
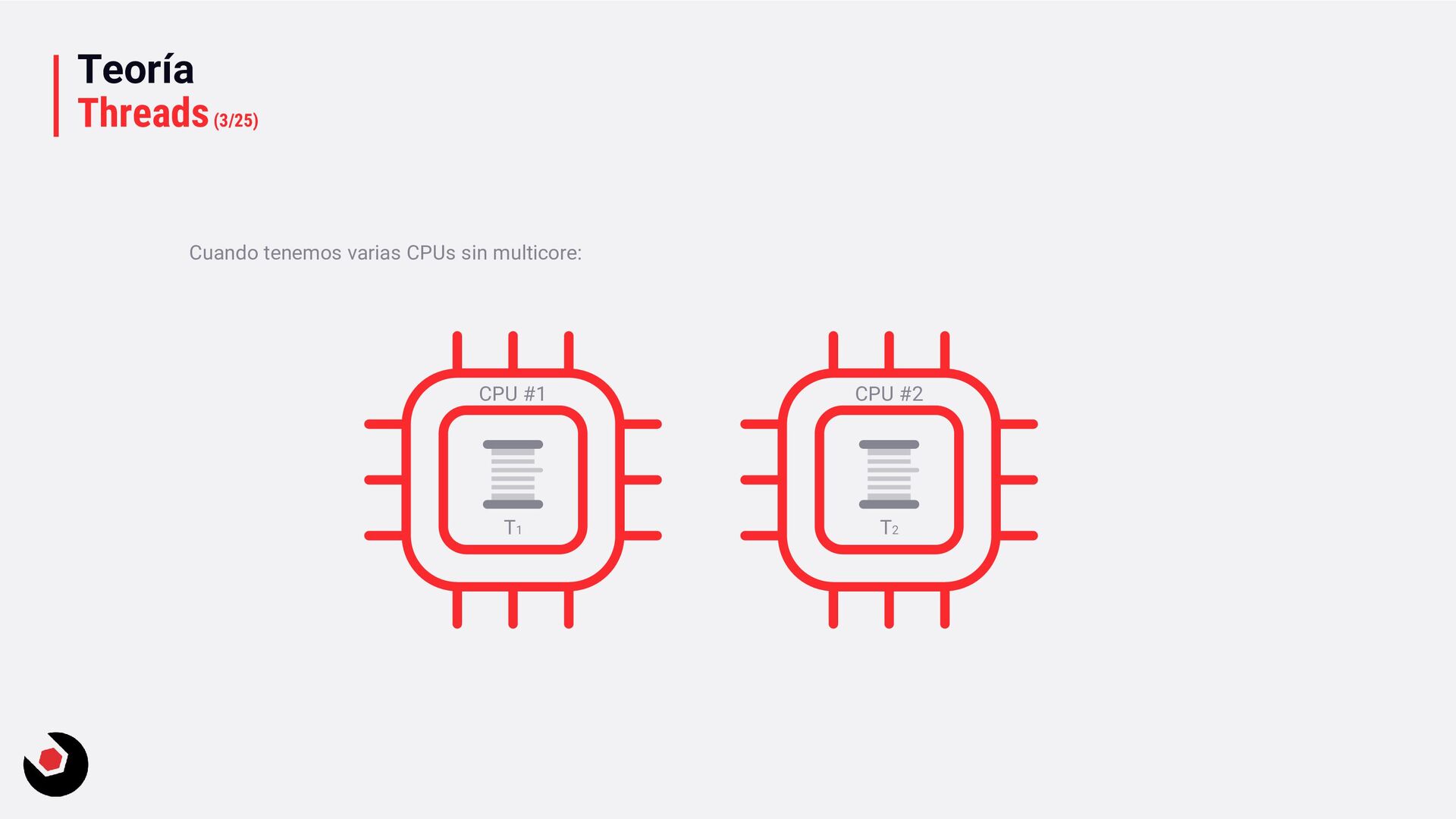{kind=link}
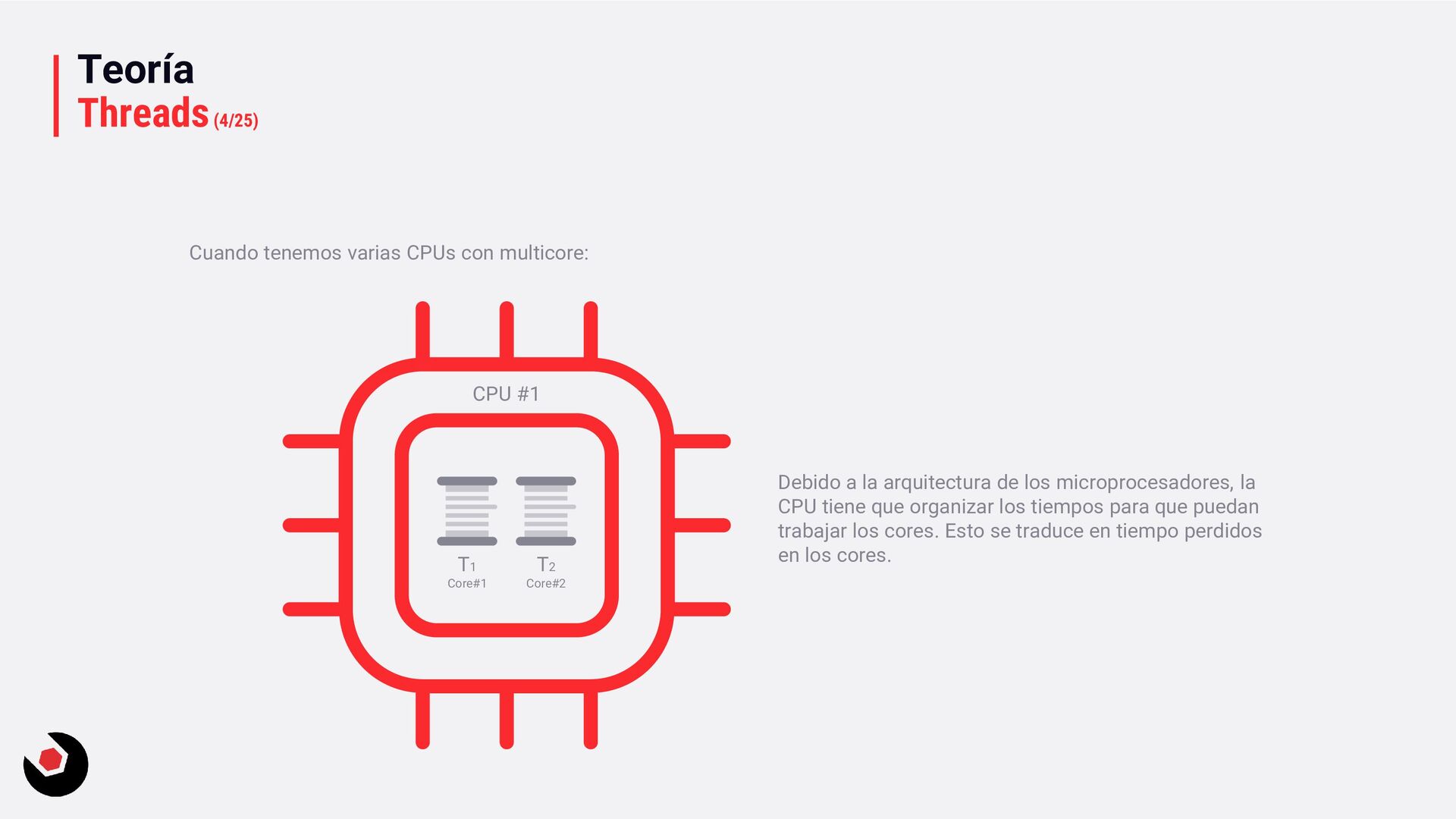{kind=link}
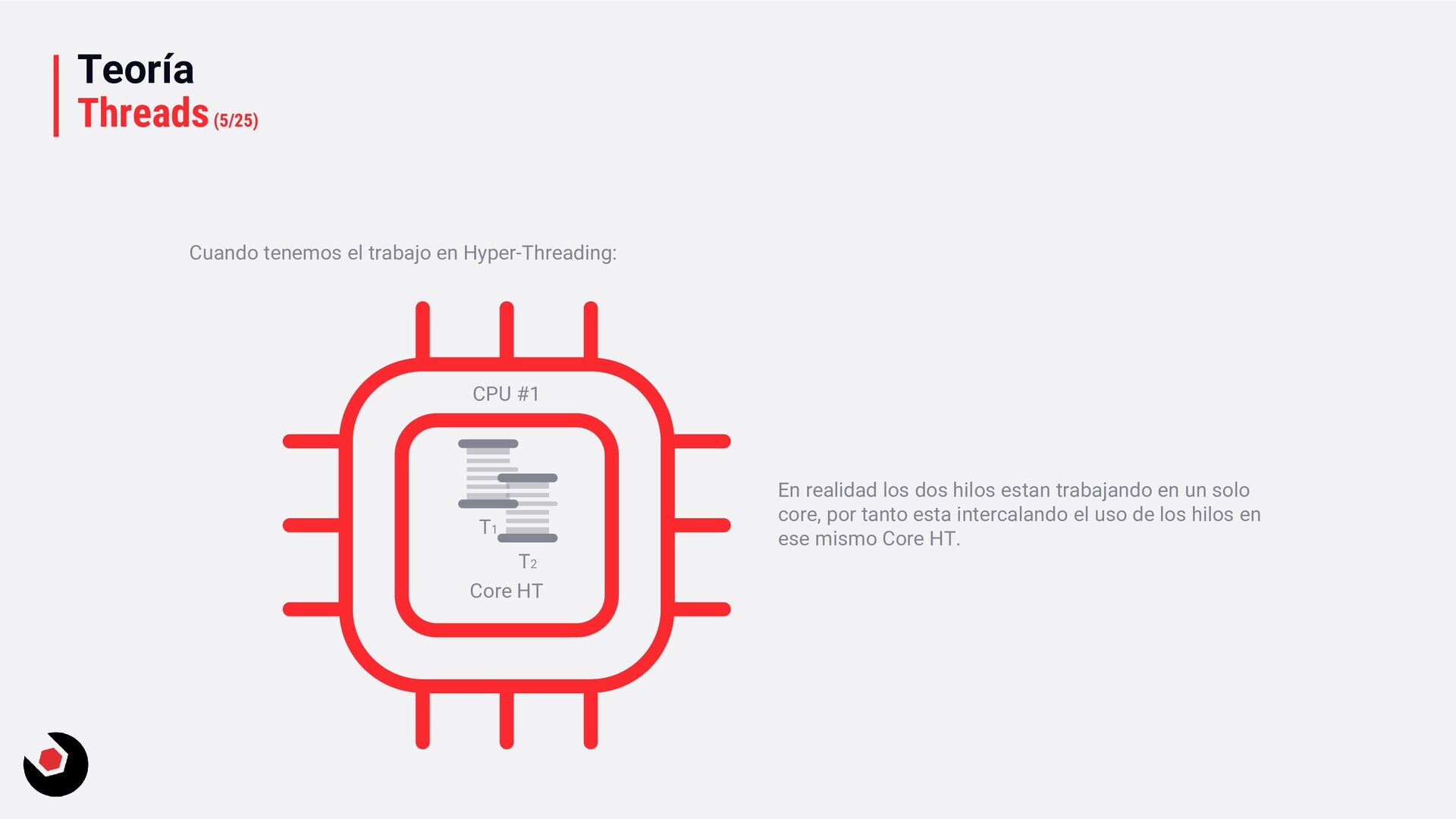{kind=link}
{kind=link}
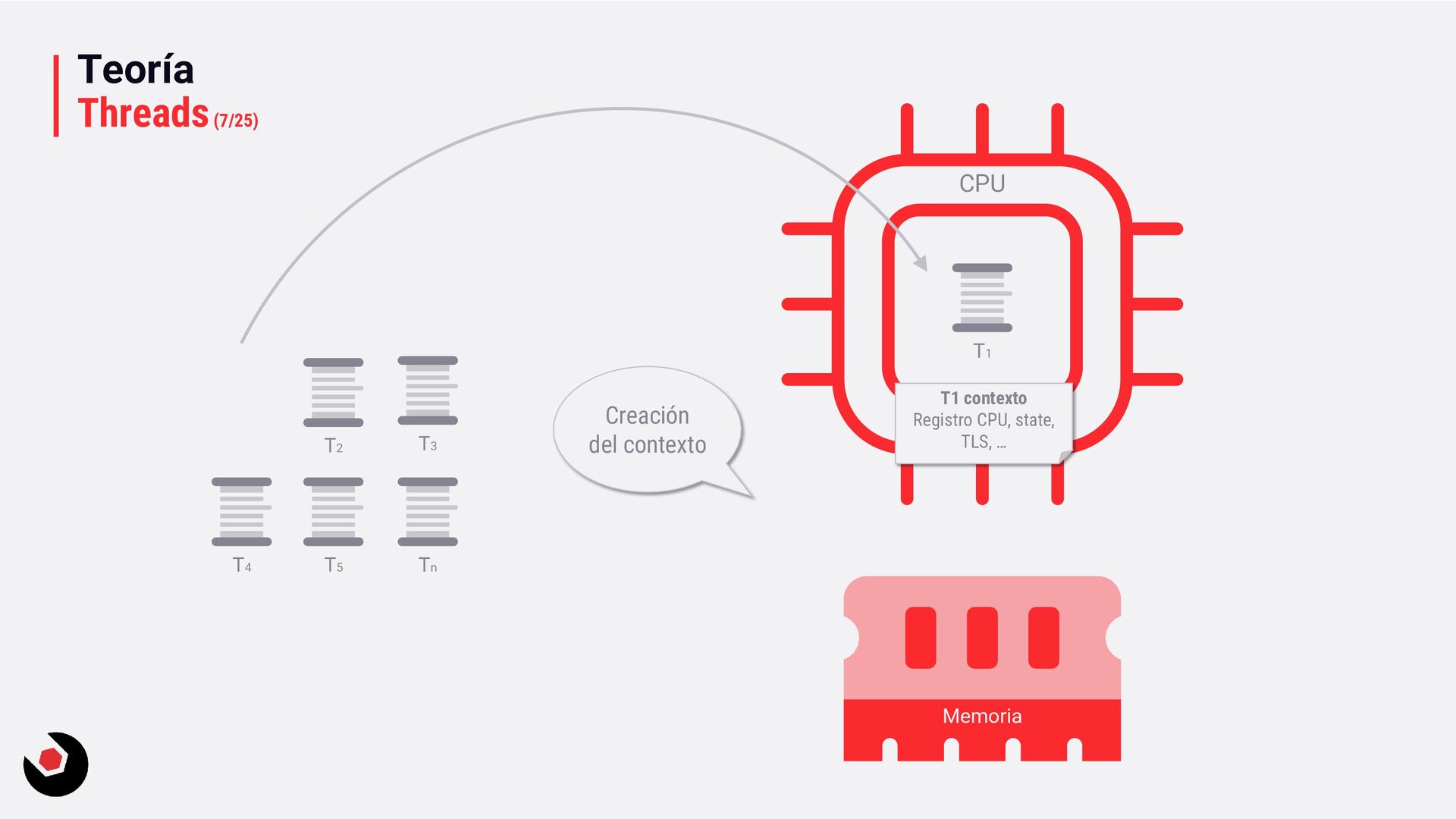{kind=link}
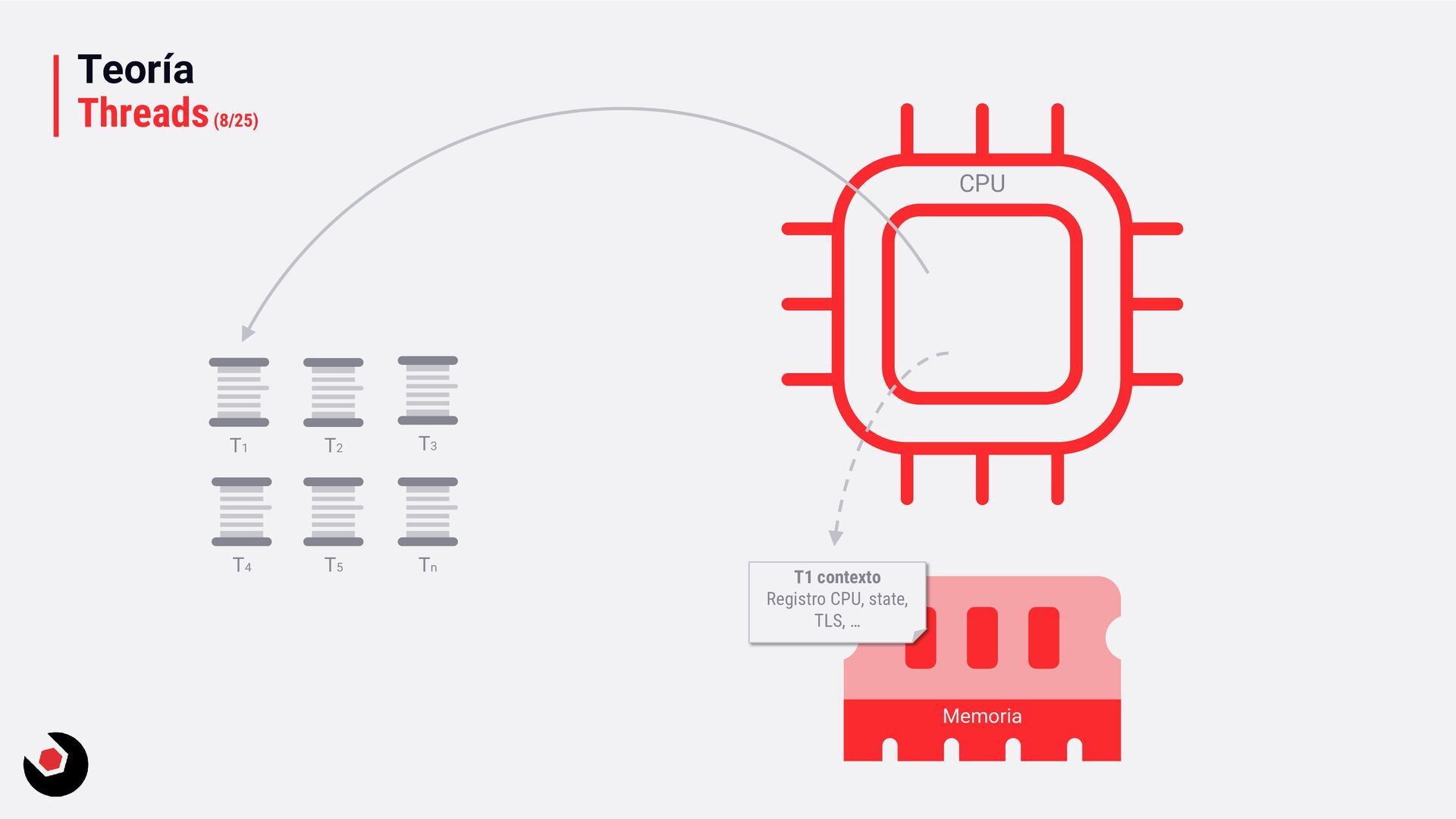{kind=link}
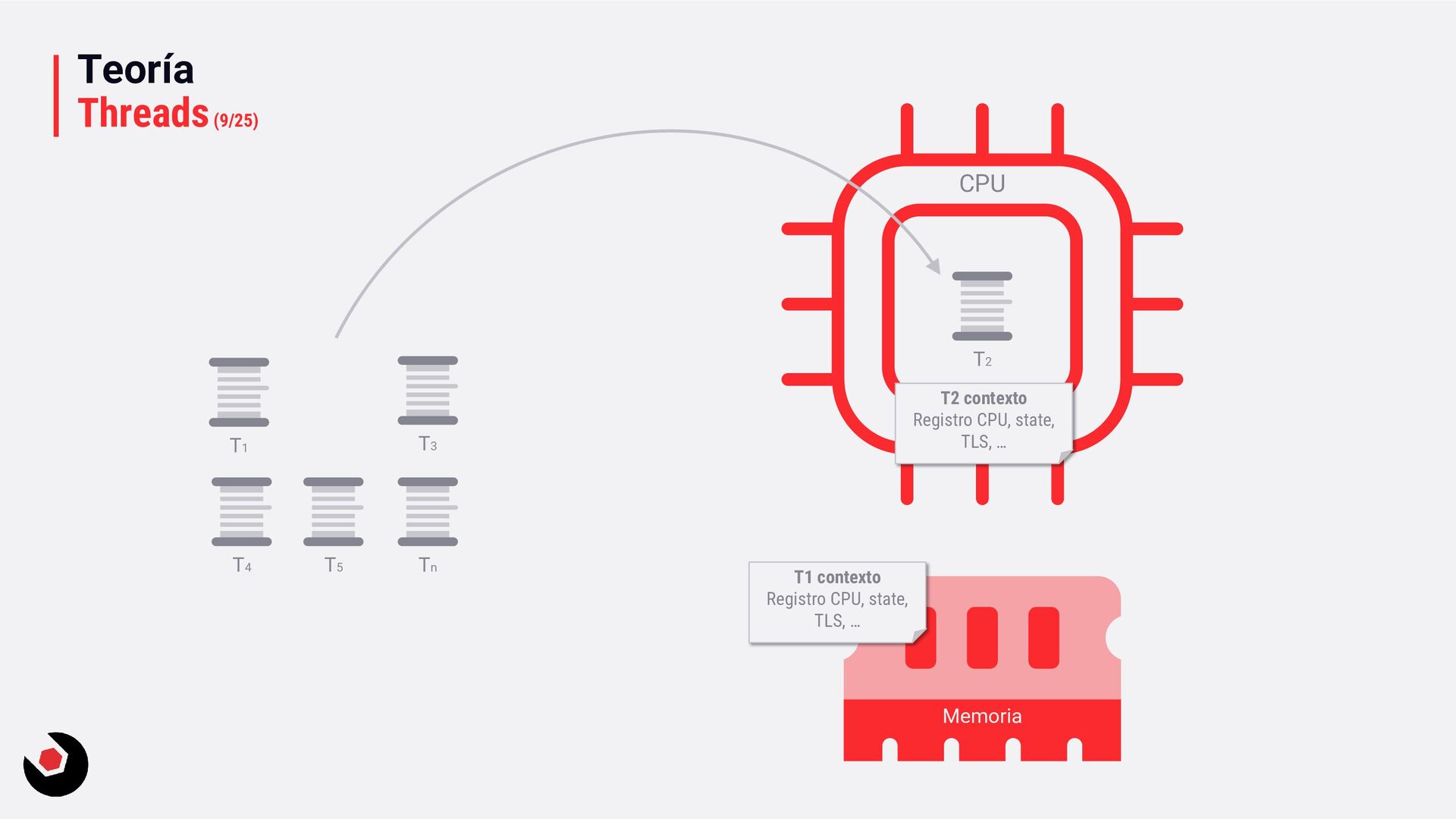{kind=link}
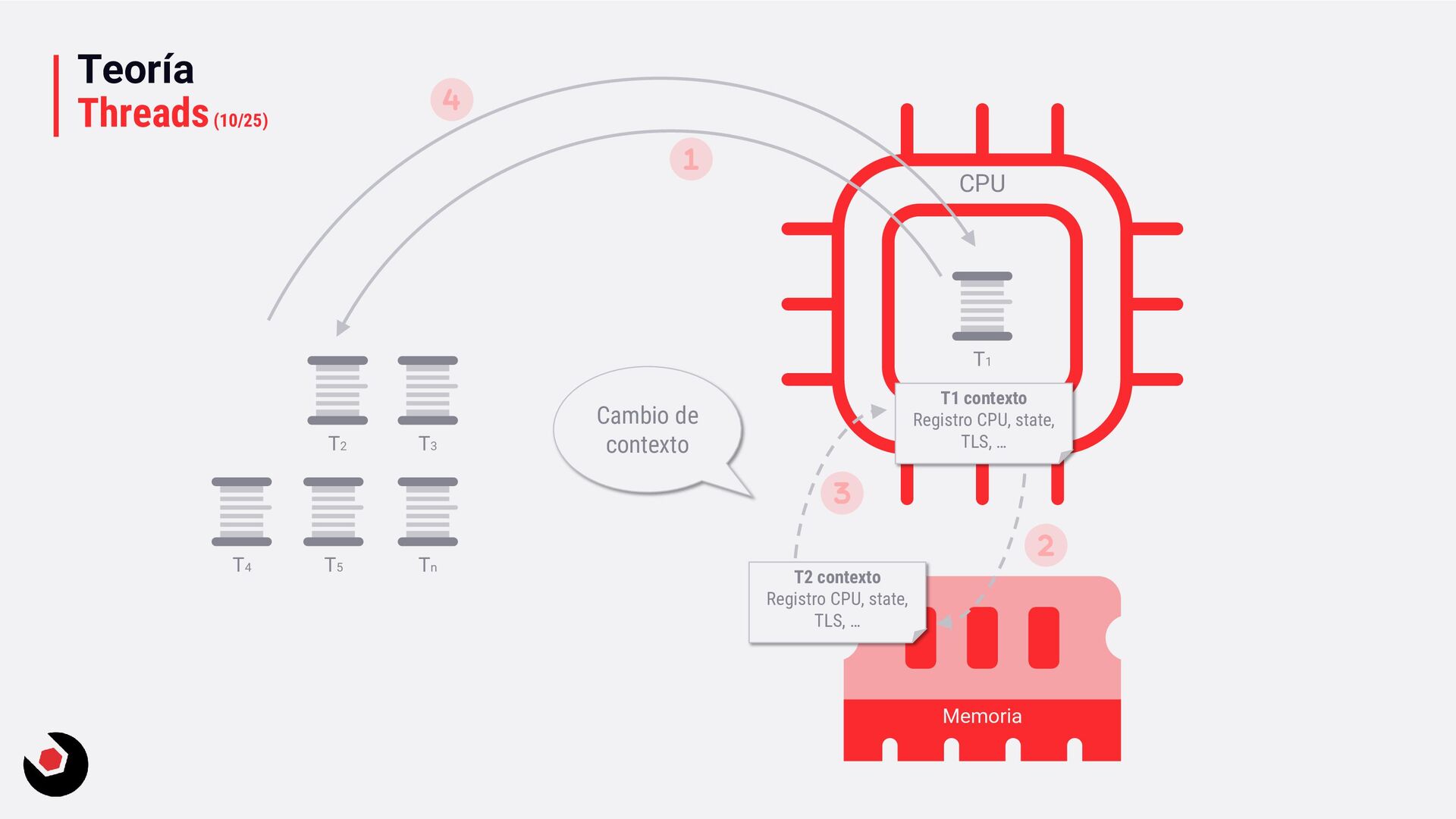{kind=link}
{kind=link}
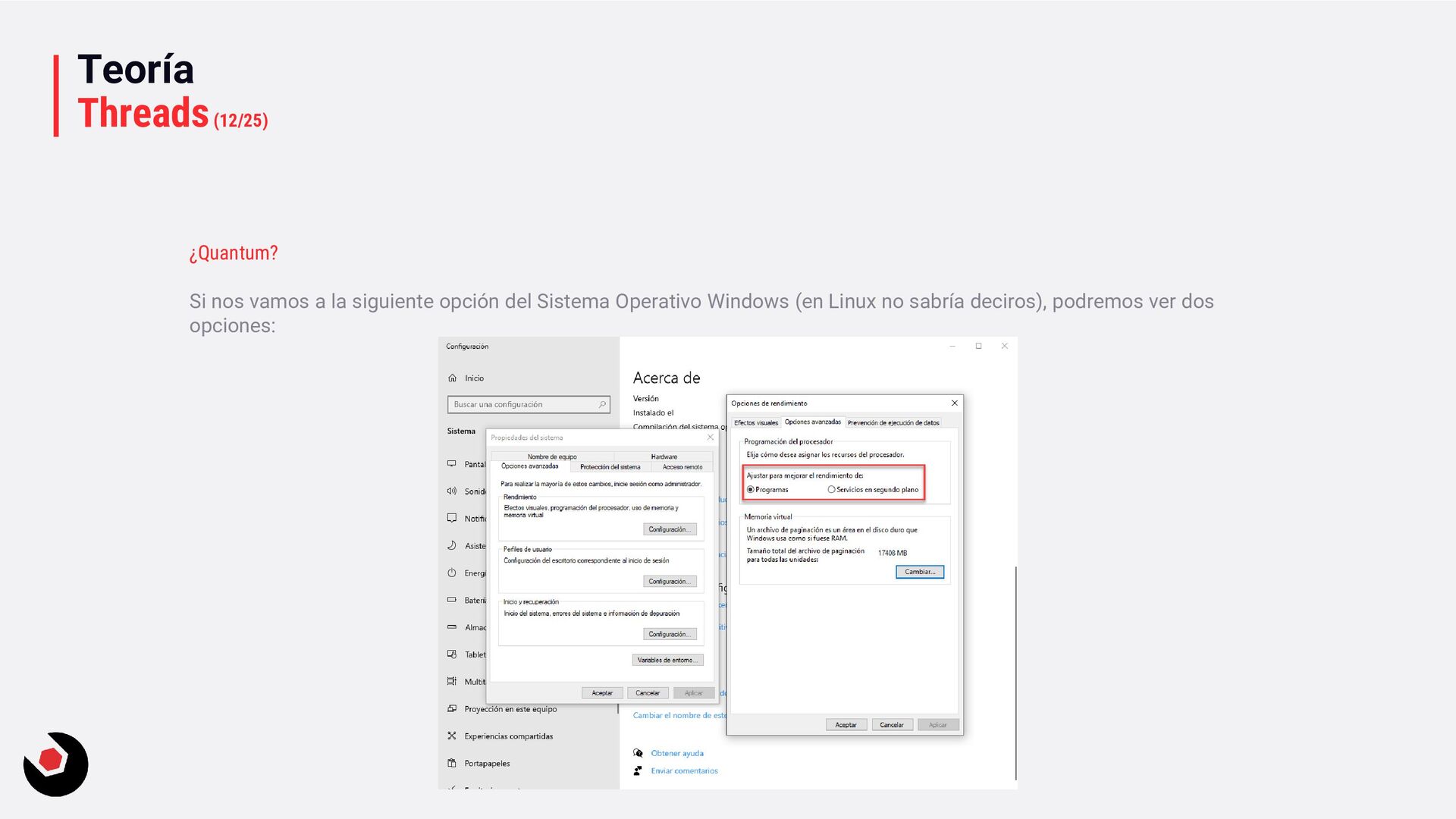{kind=link}
{kind=link}
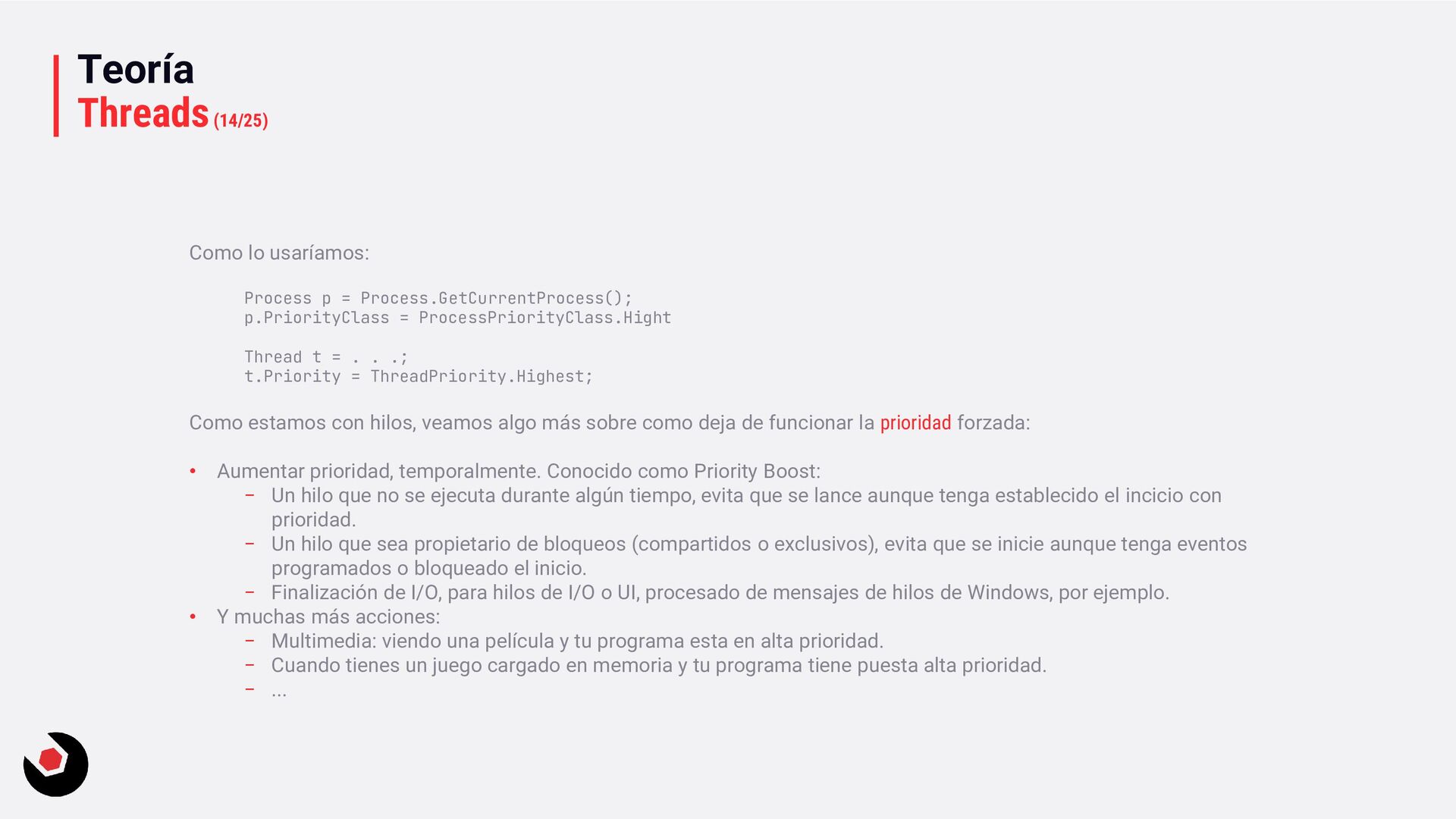{kind=link}
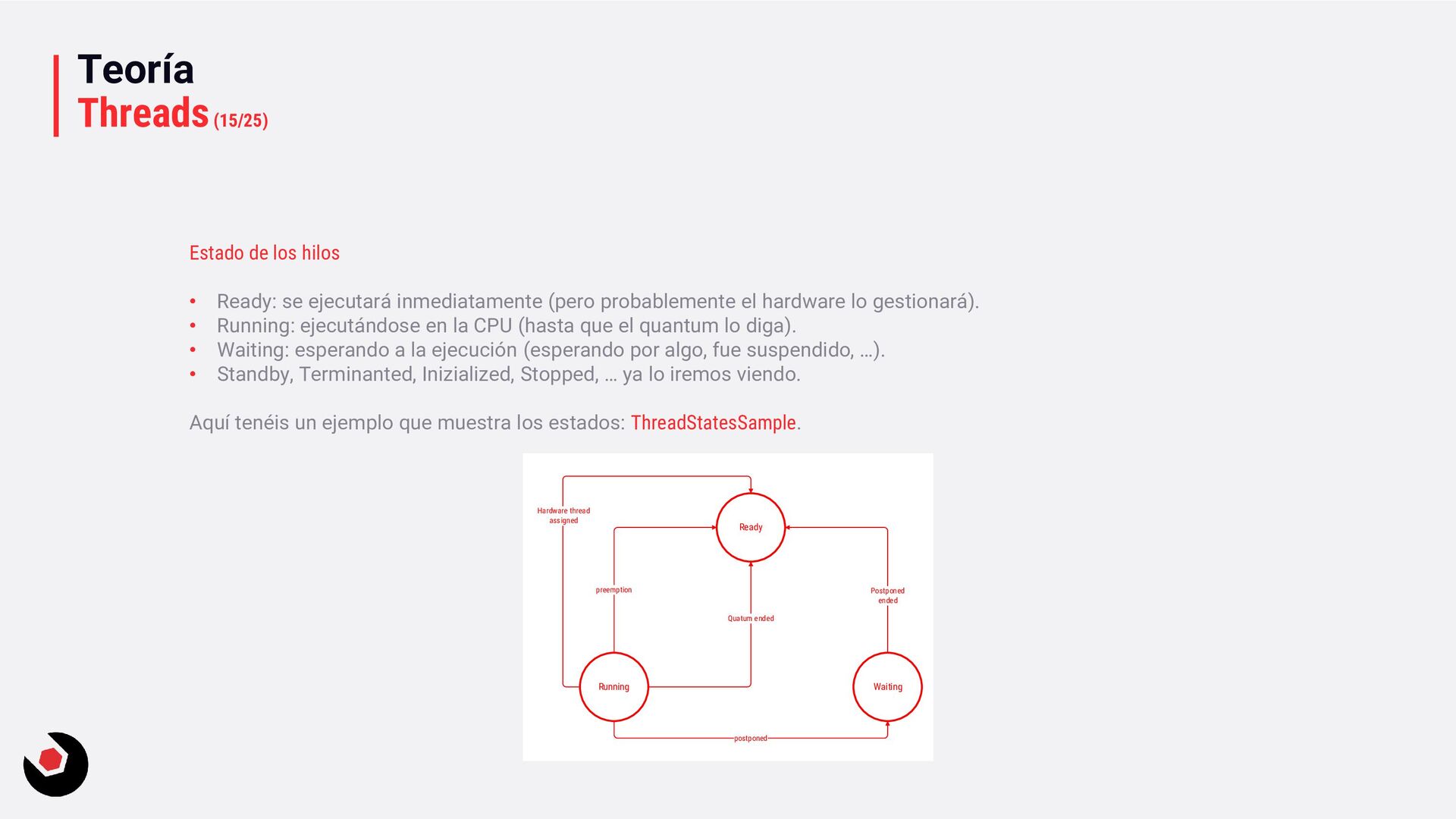{kind=link}
{kind=link}
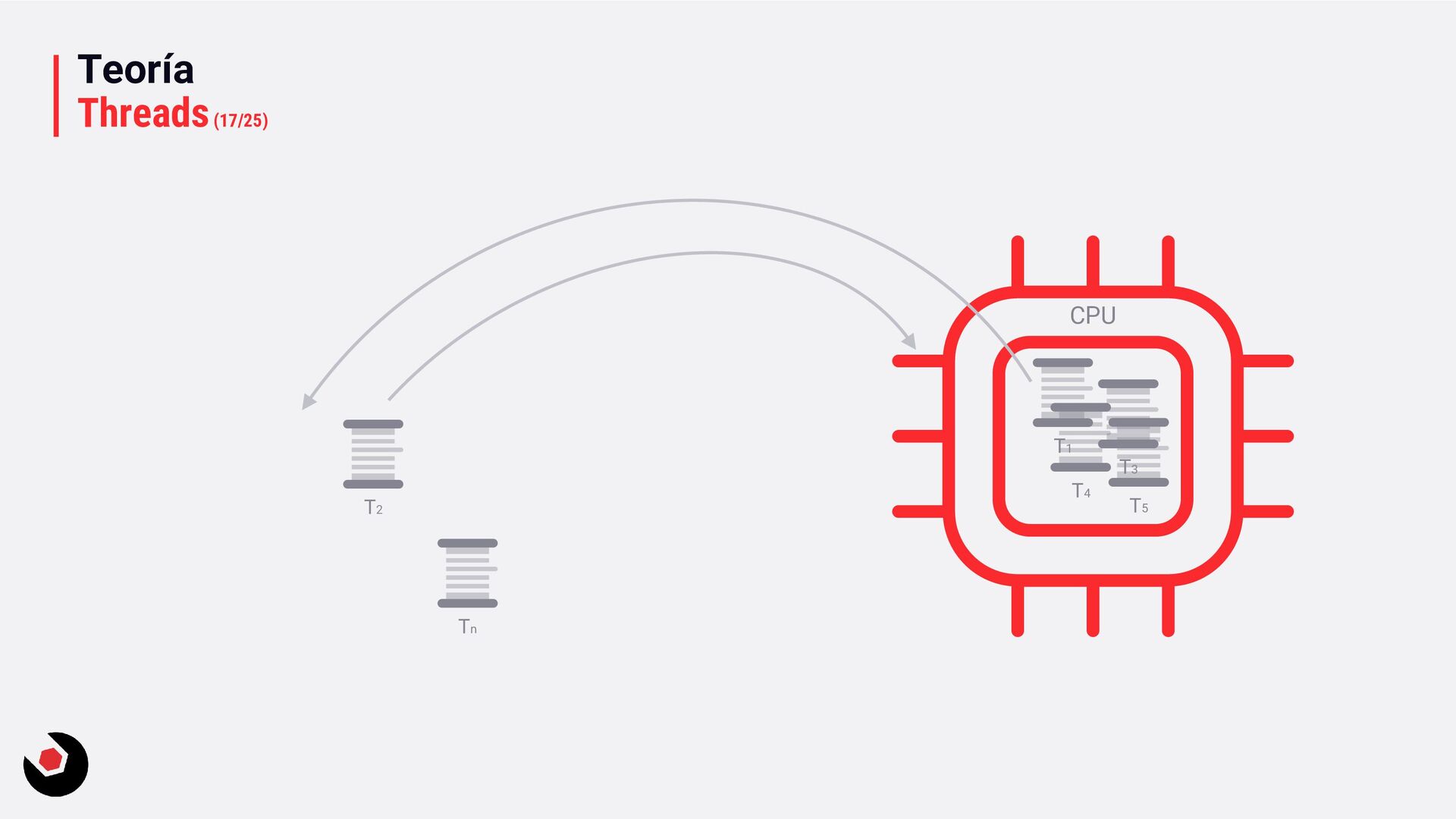{kind=link}
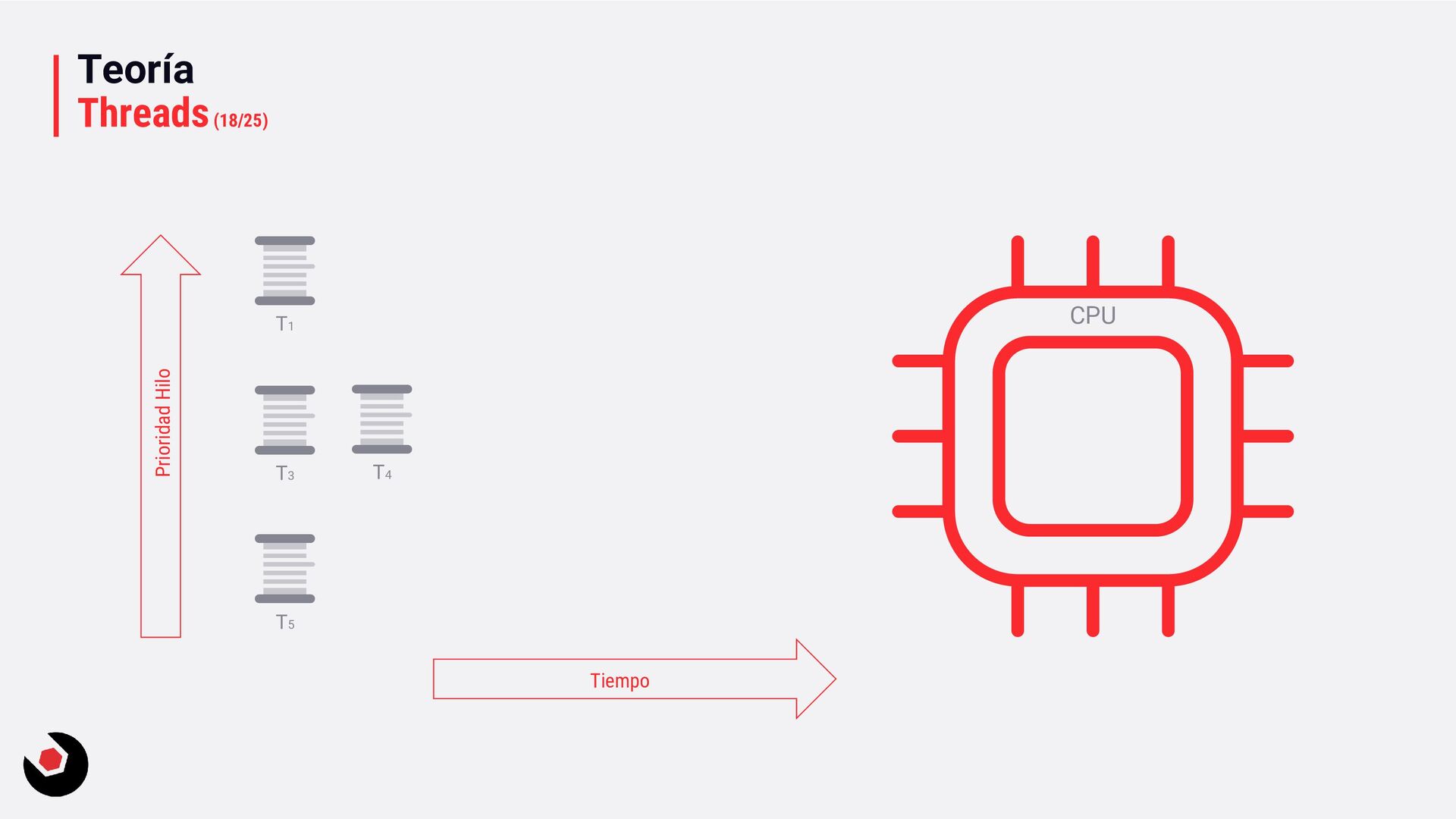{kind=link}
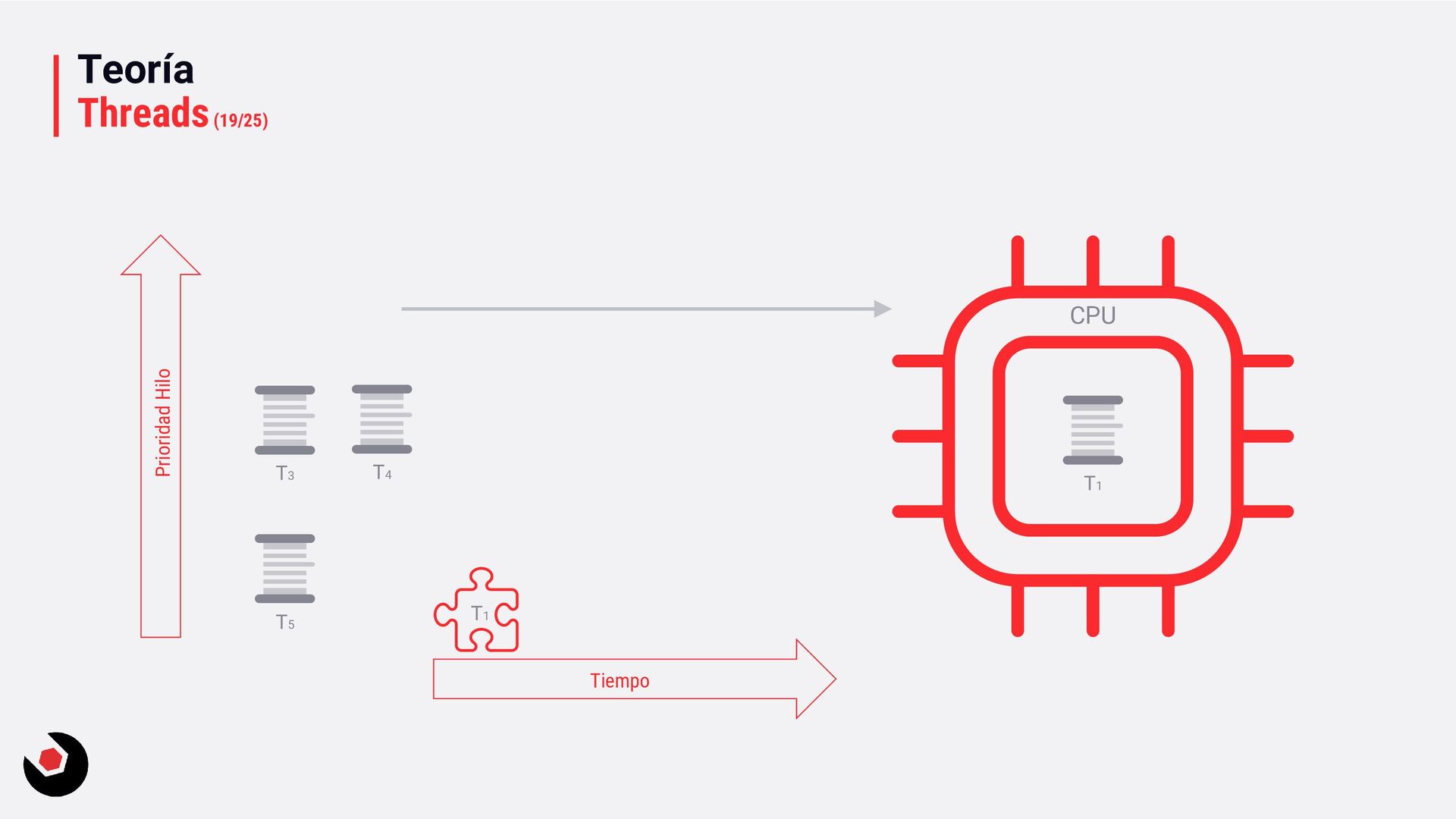{kind=link}
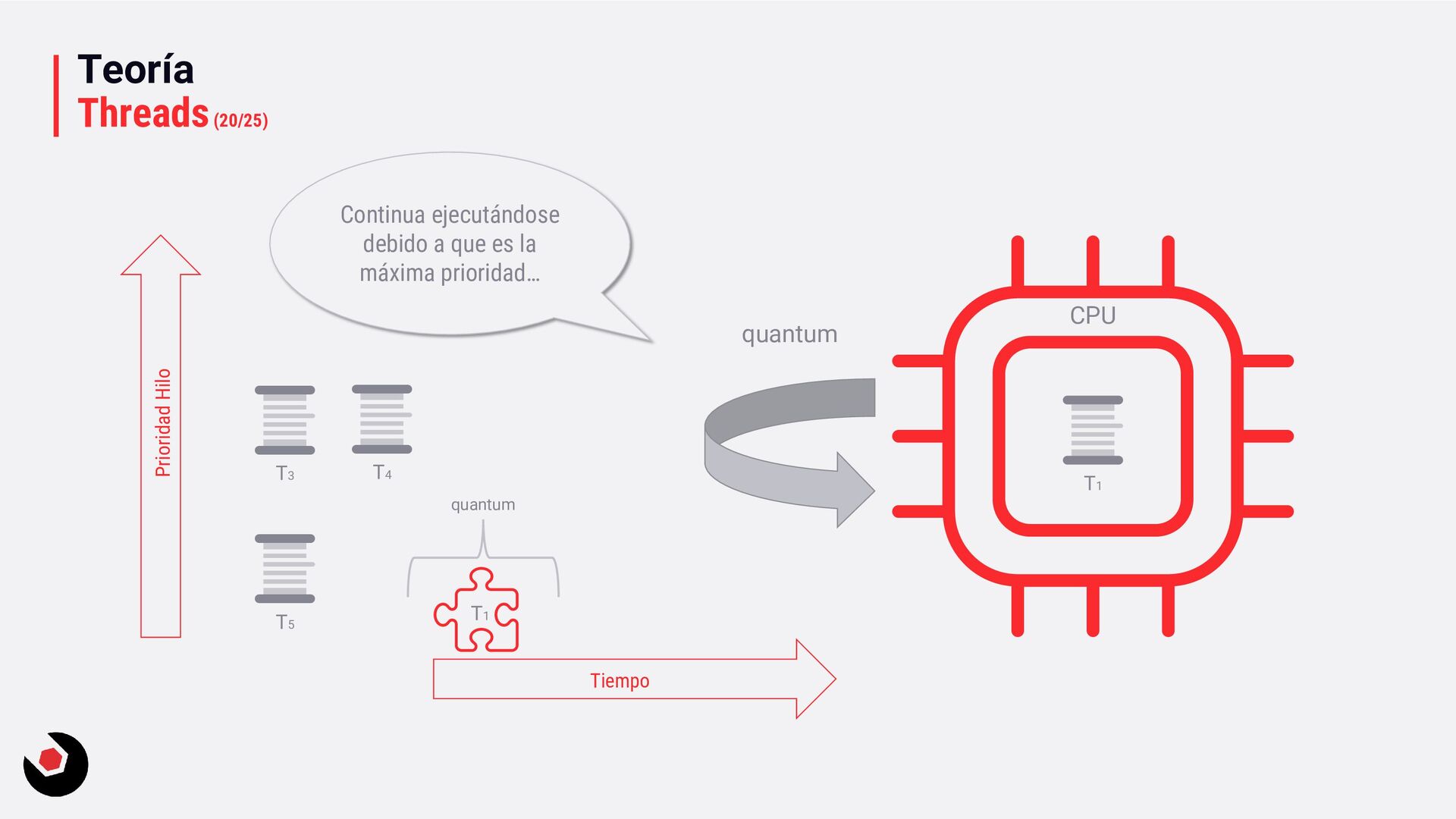{kind=link}
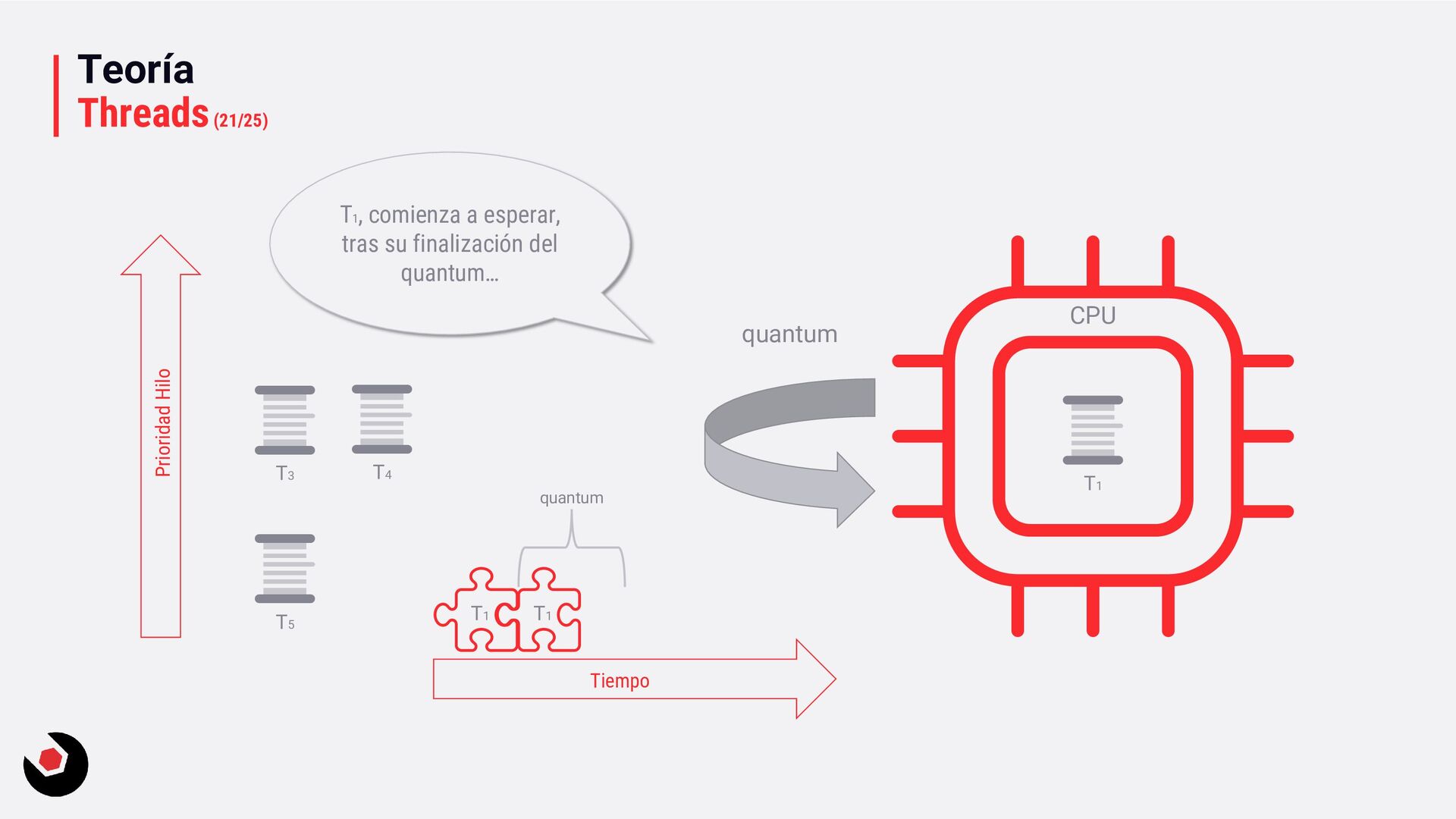{kind=link}
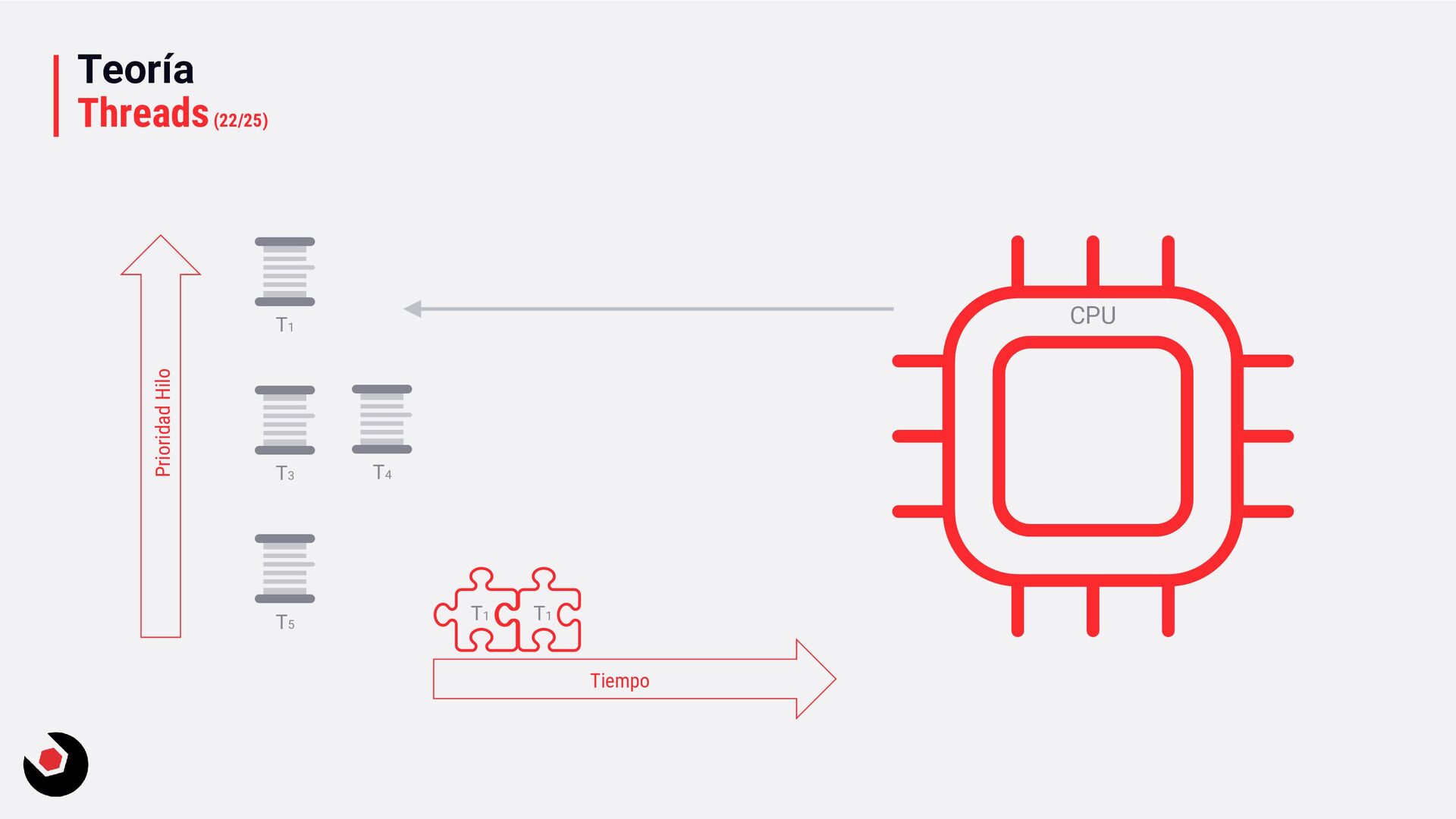{kind=link}
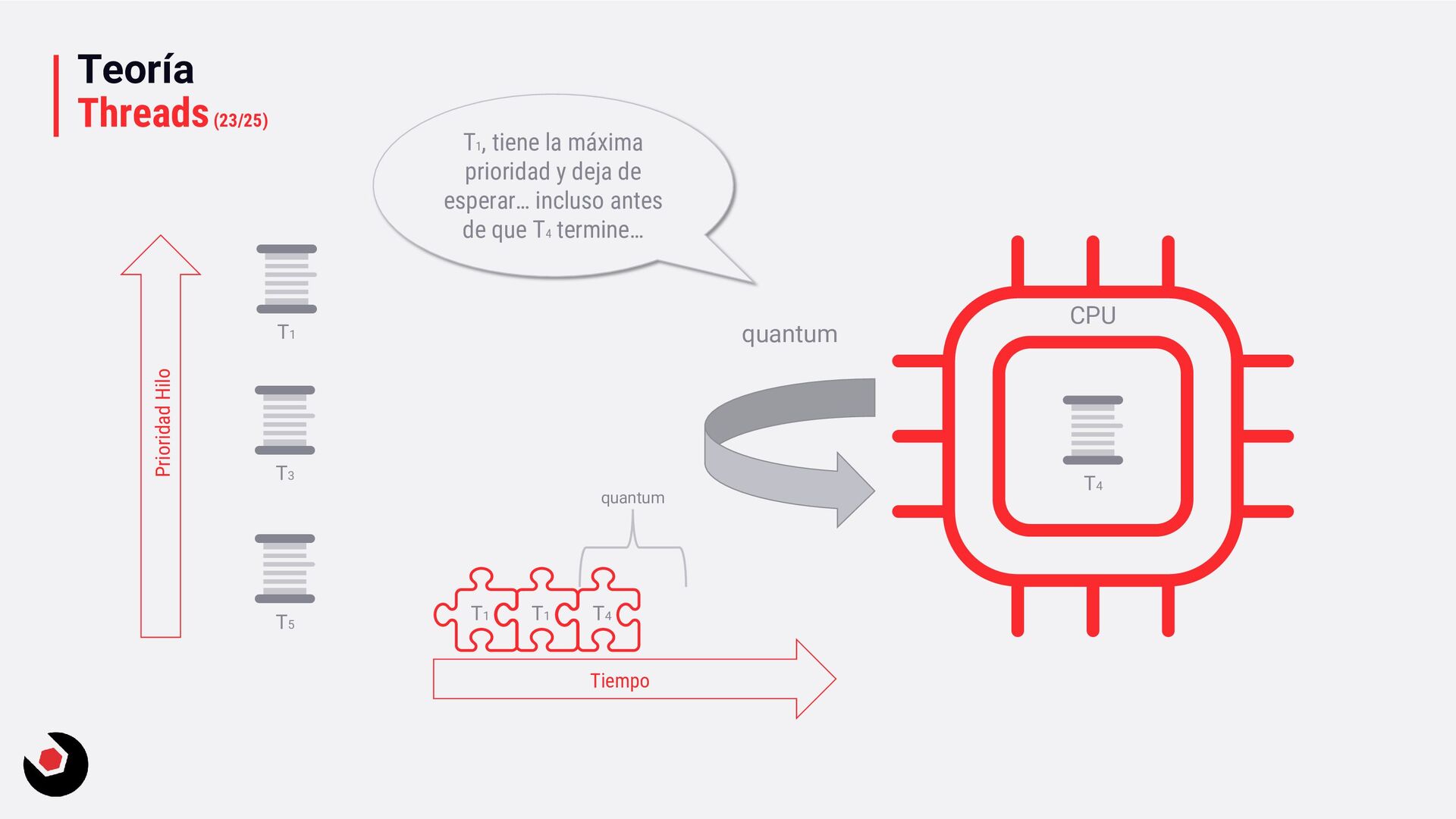{kind=link}
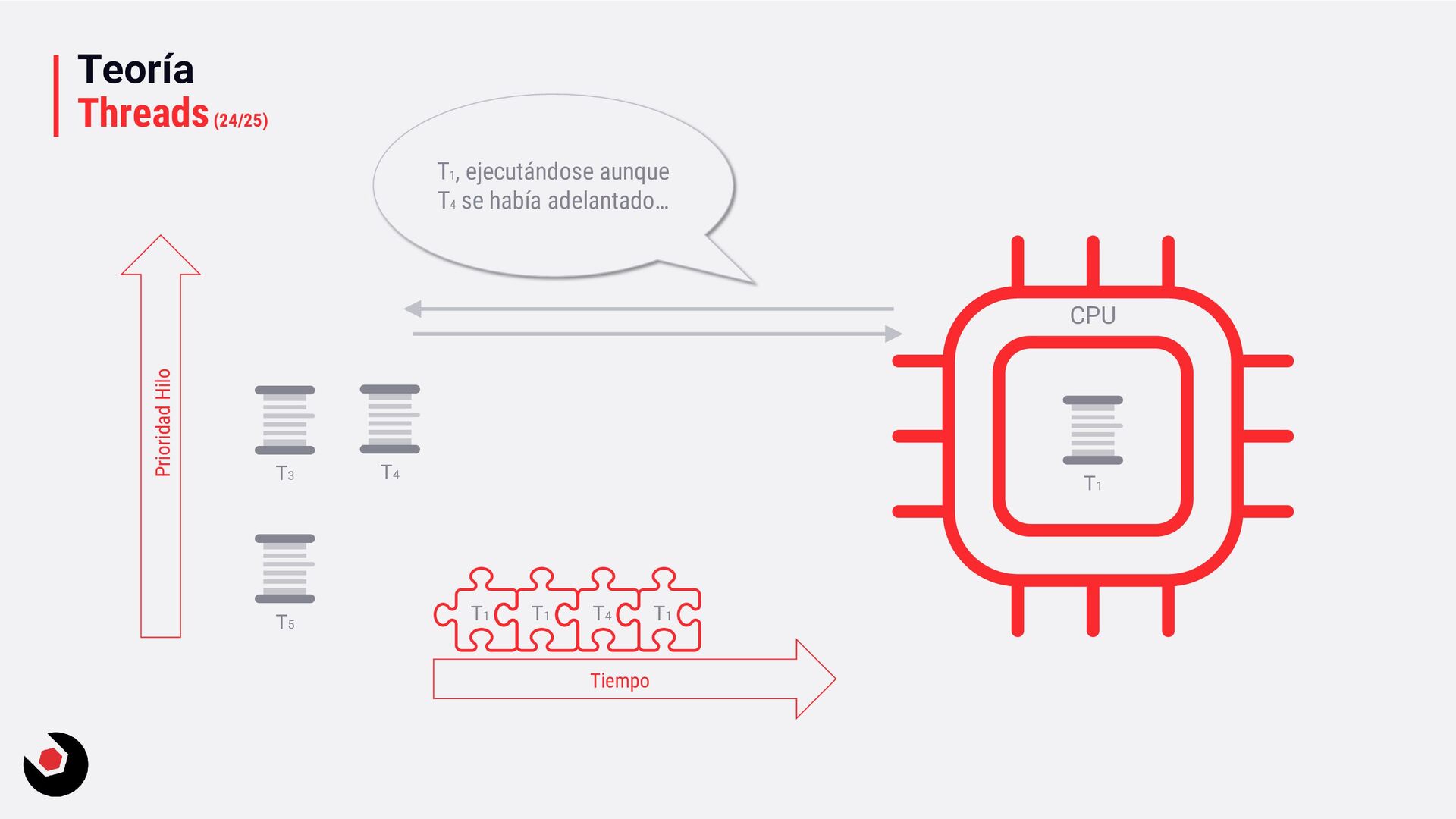{kind=link}
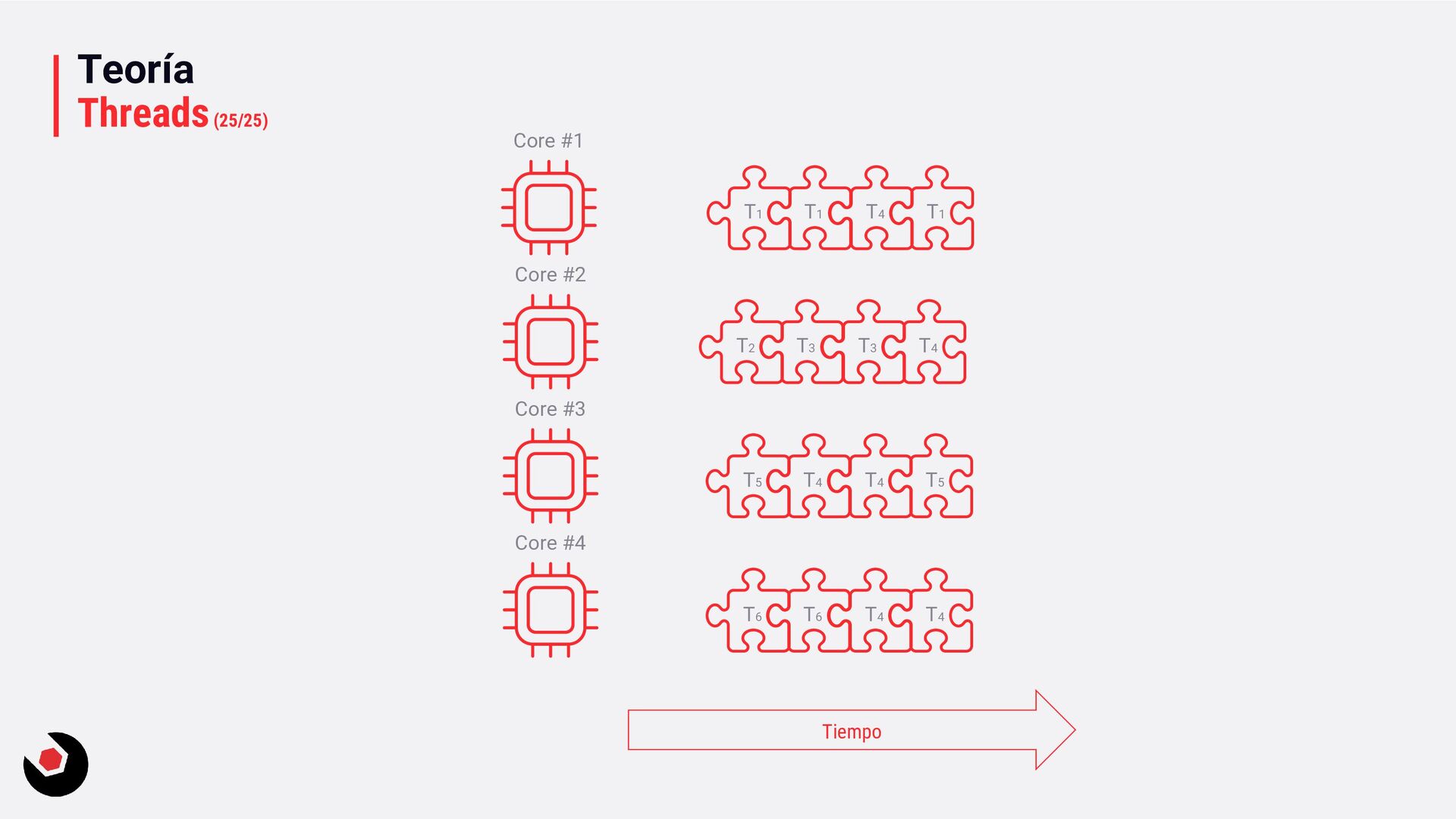{kind=link}
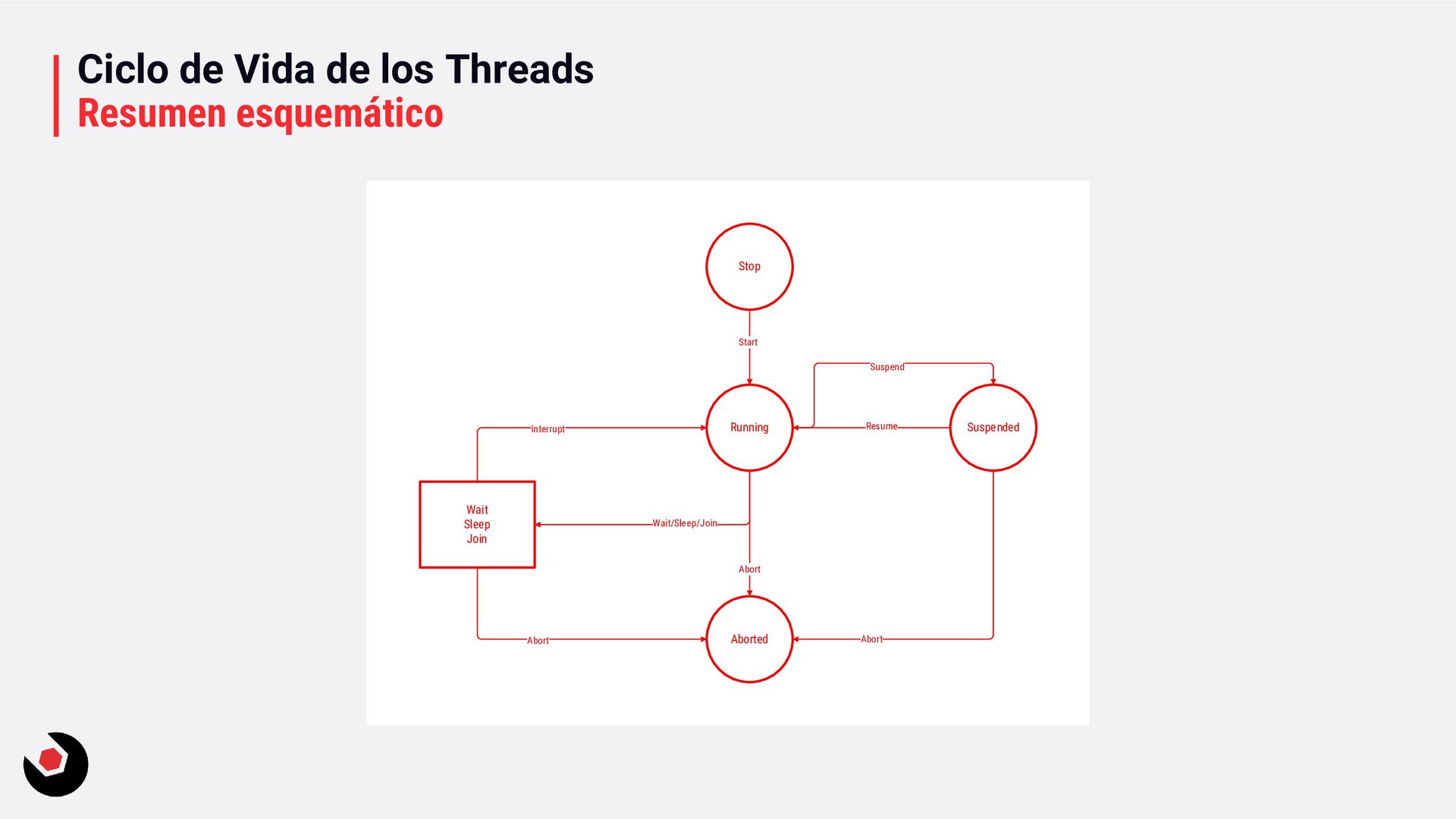{kind=link}
{kind=link}
{kind=link}
{kind=link}
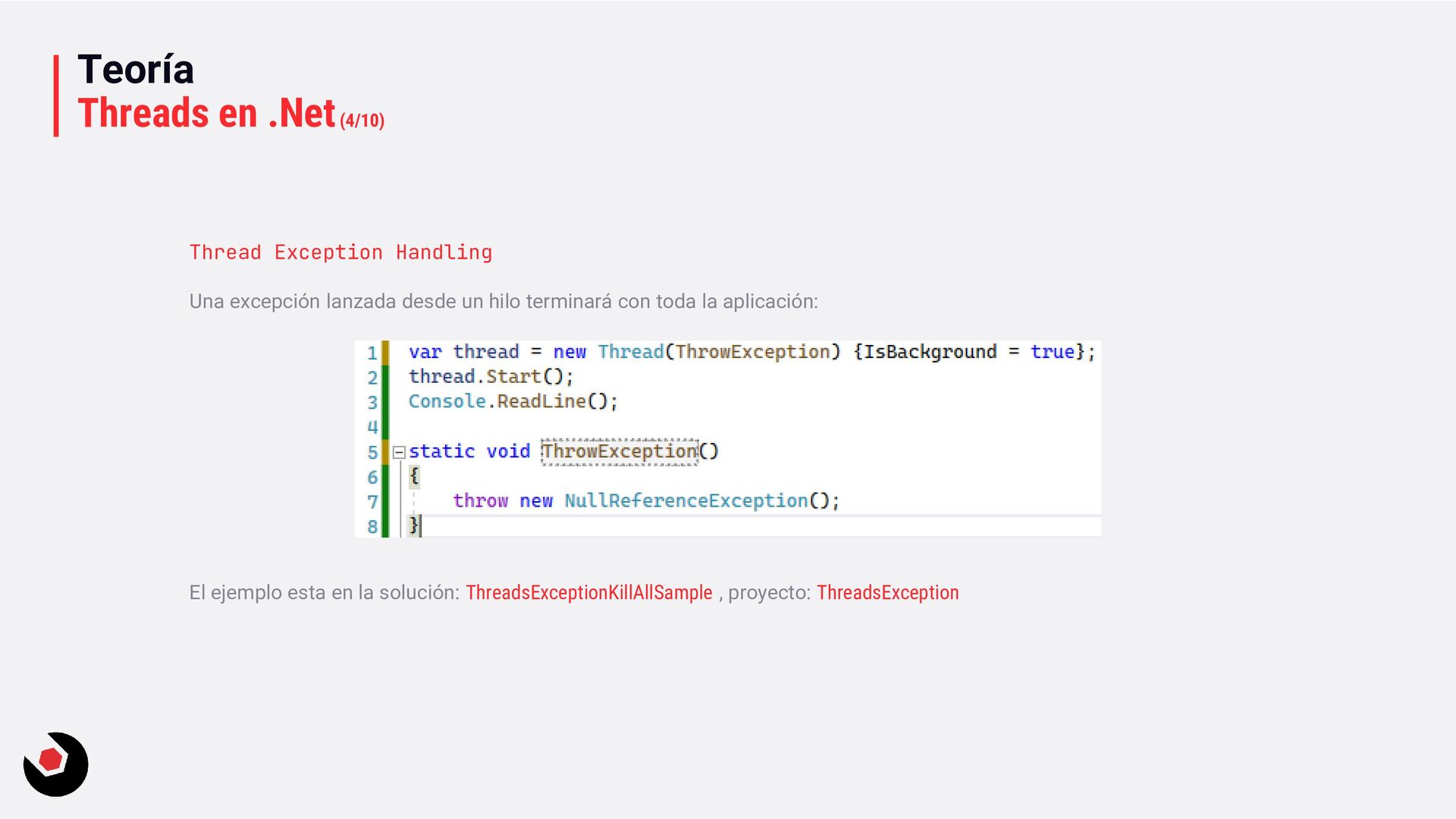{kind=link}
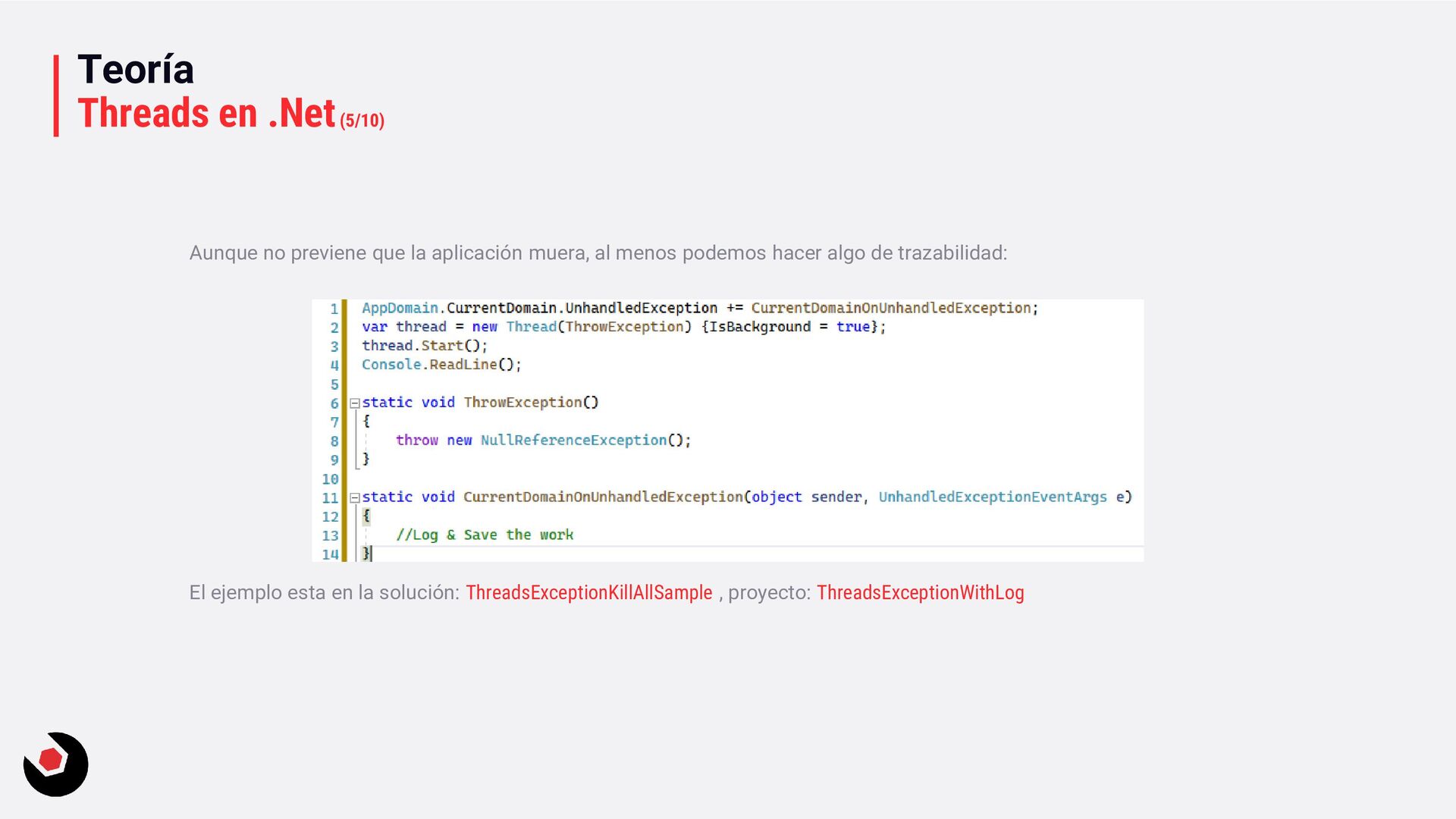{kind=link}
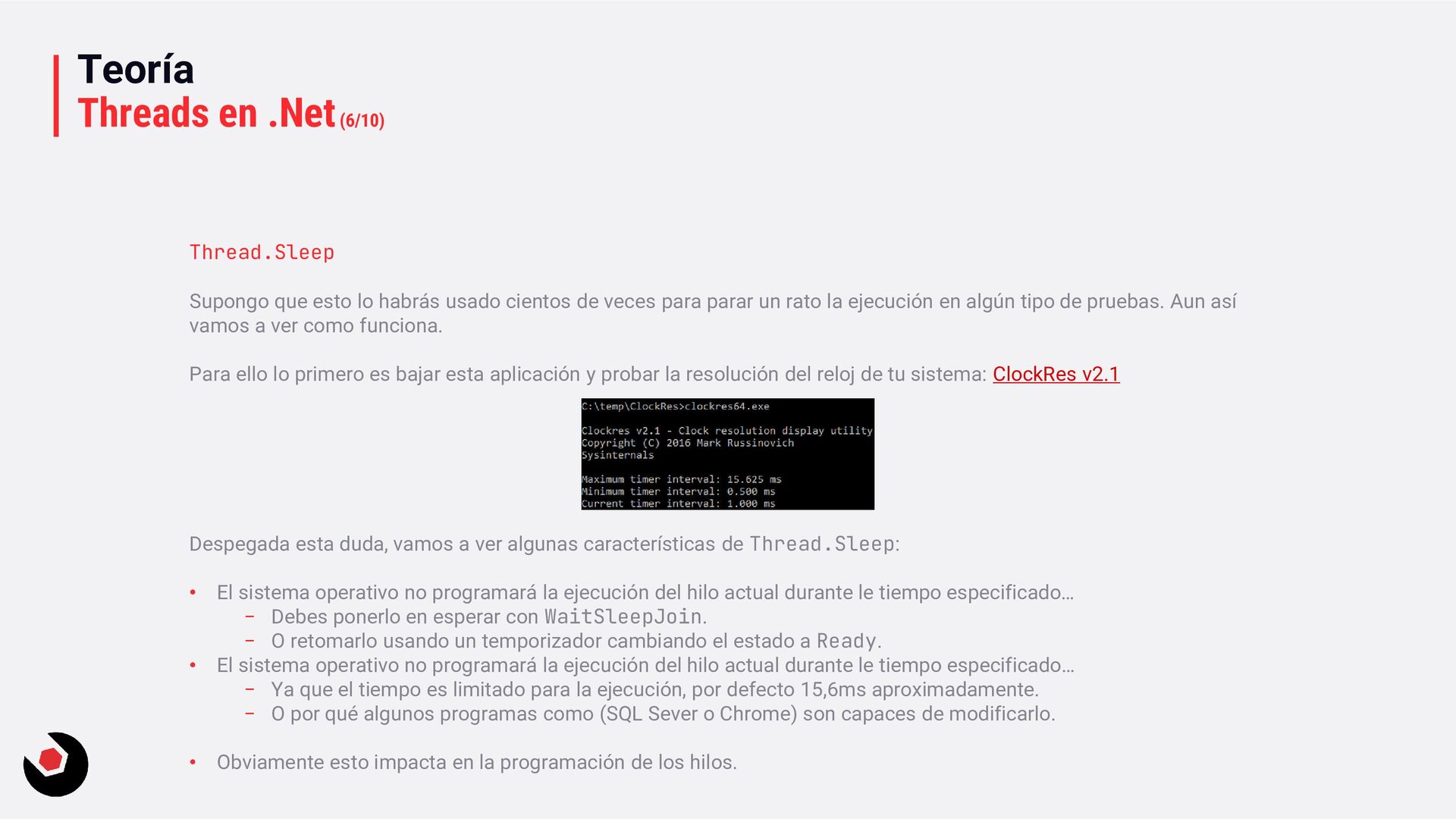{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
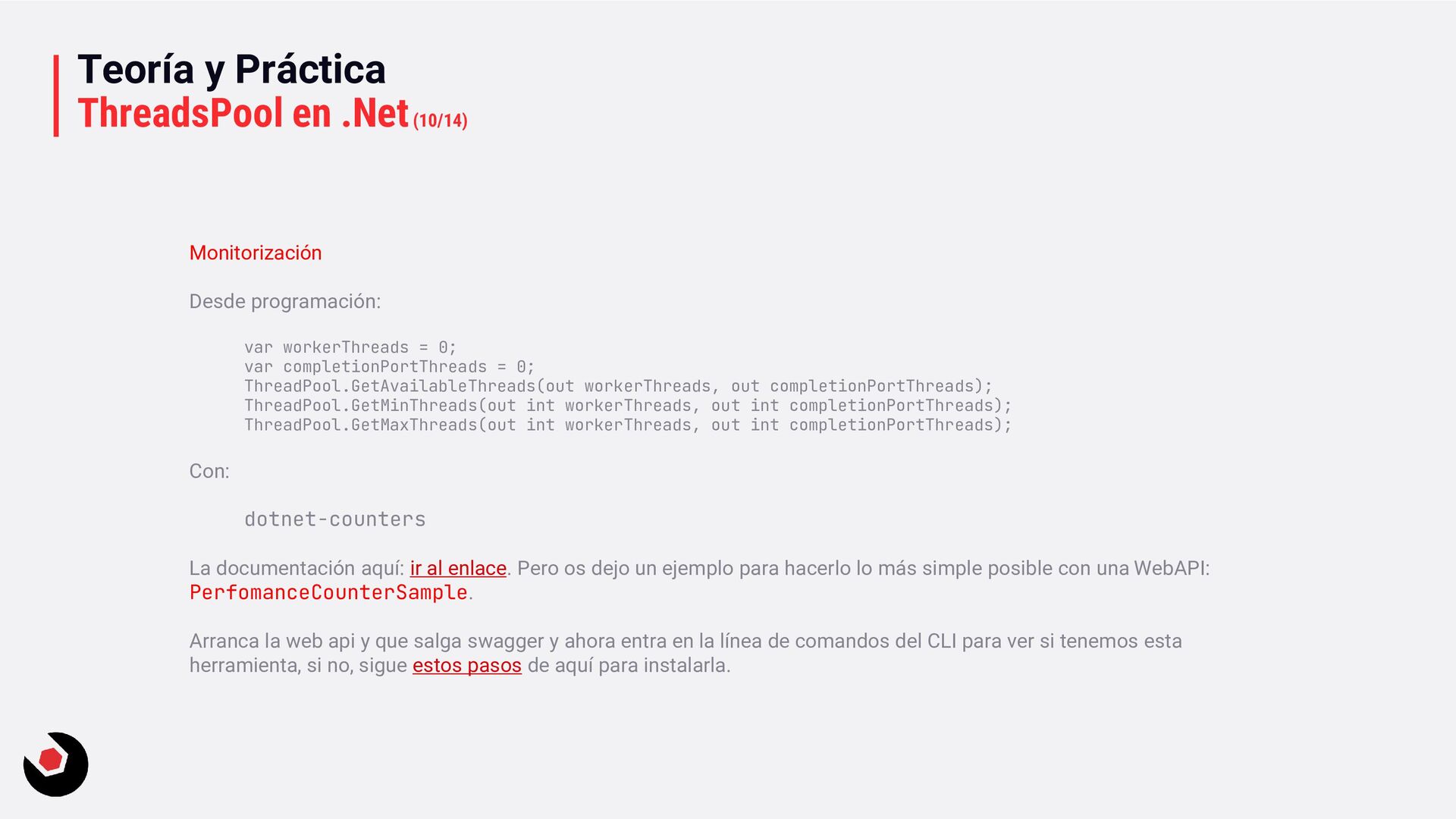{kind=link}
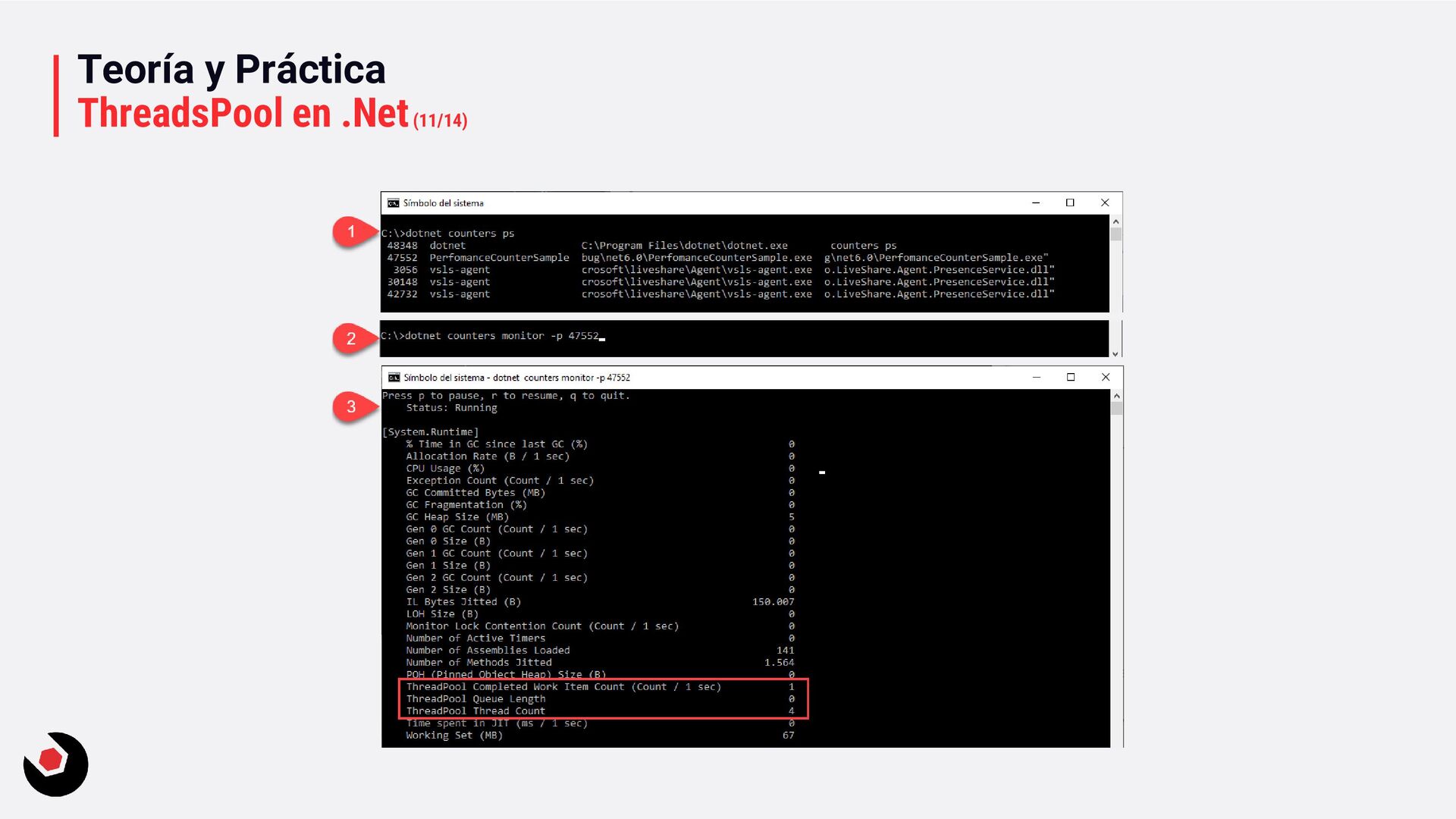{kind=link}
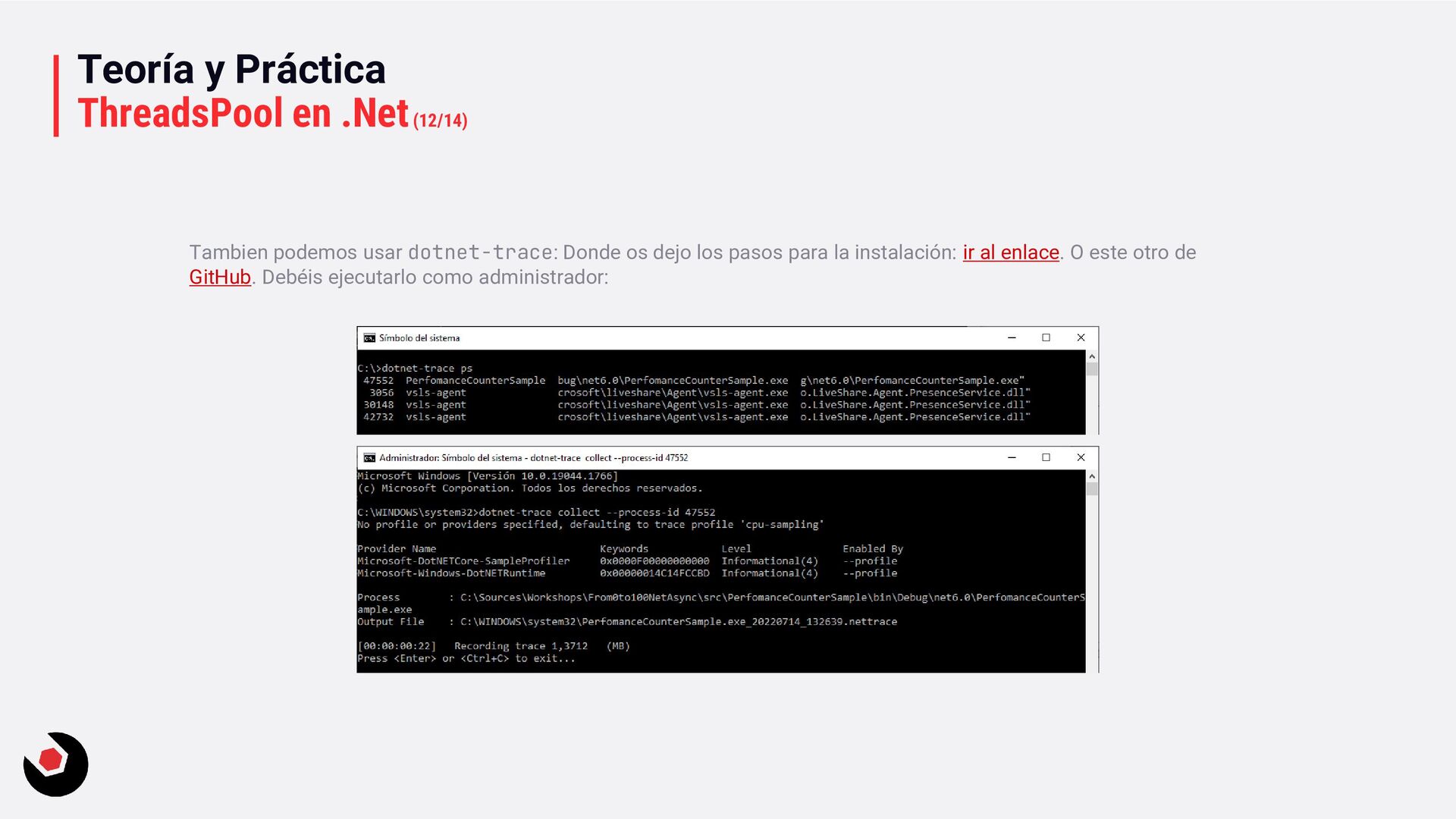{kind=link}
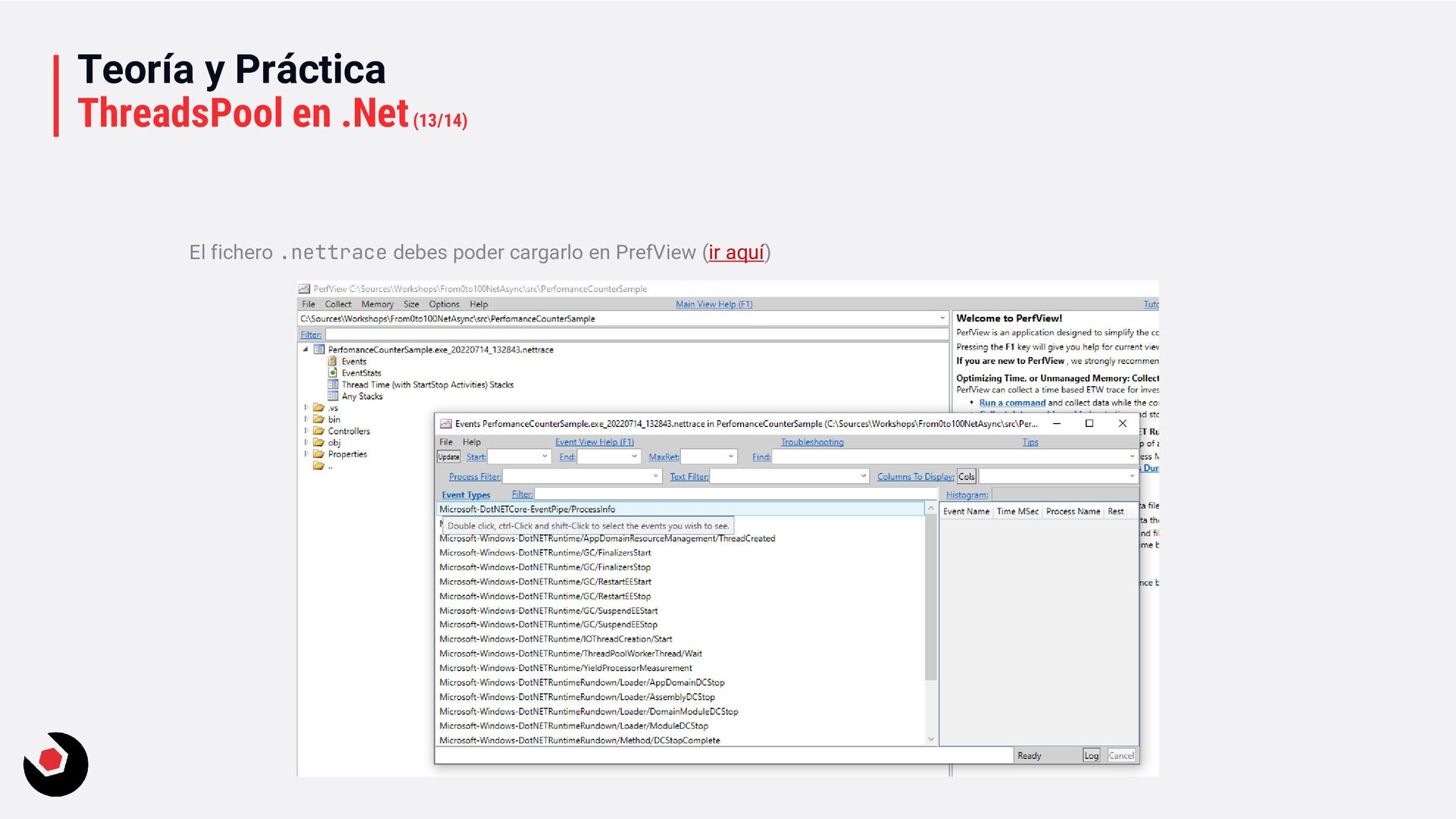{kind=link}
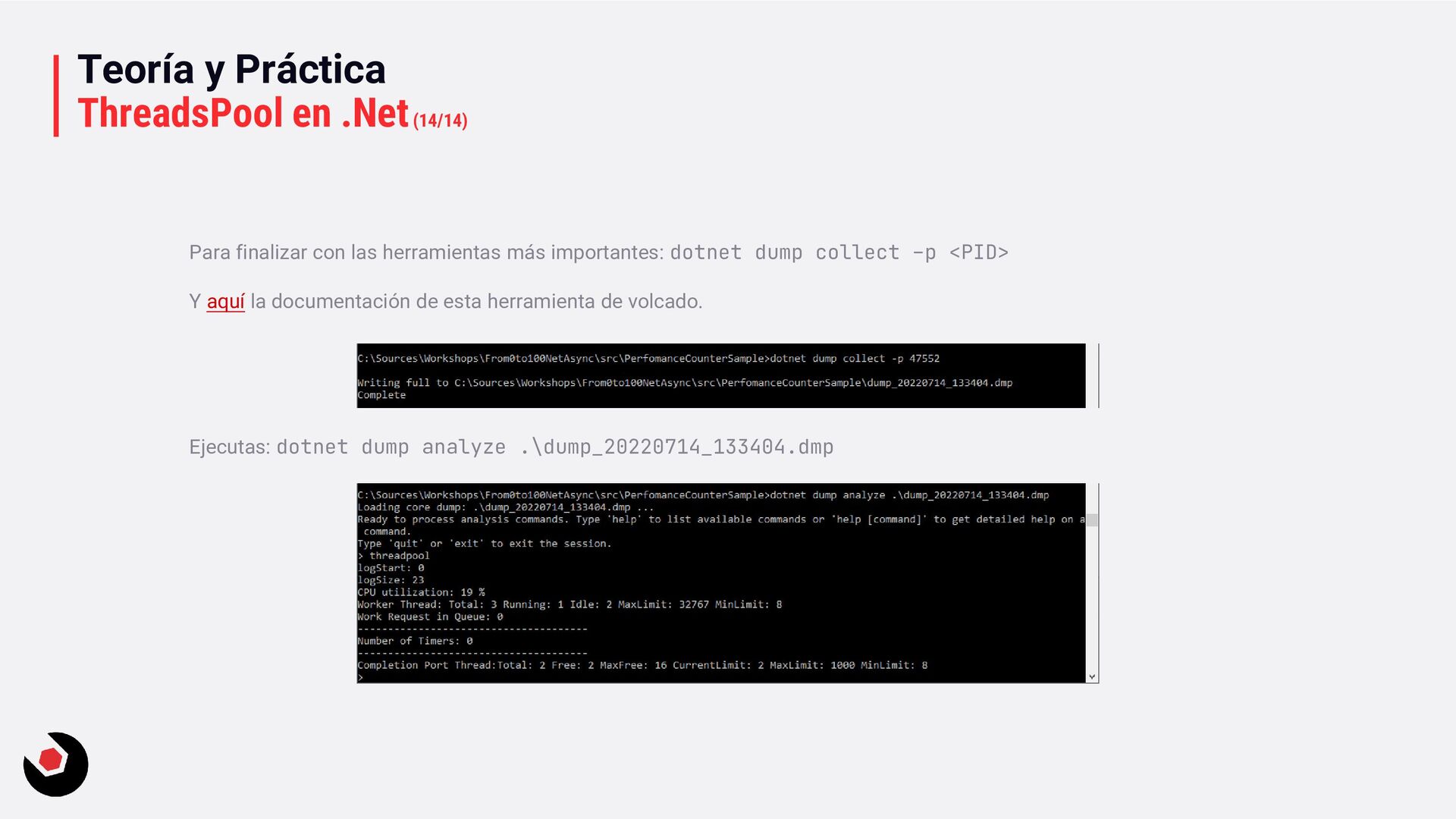{kind=link}
{kind=link}
{kind=link}
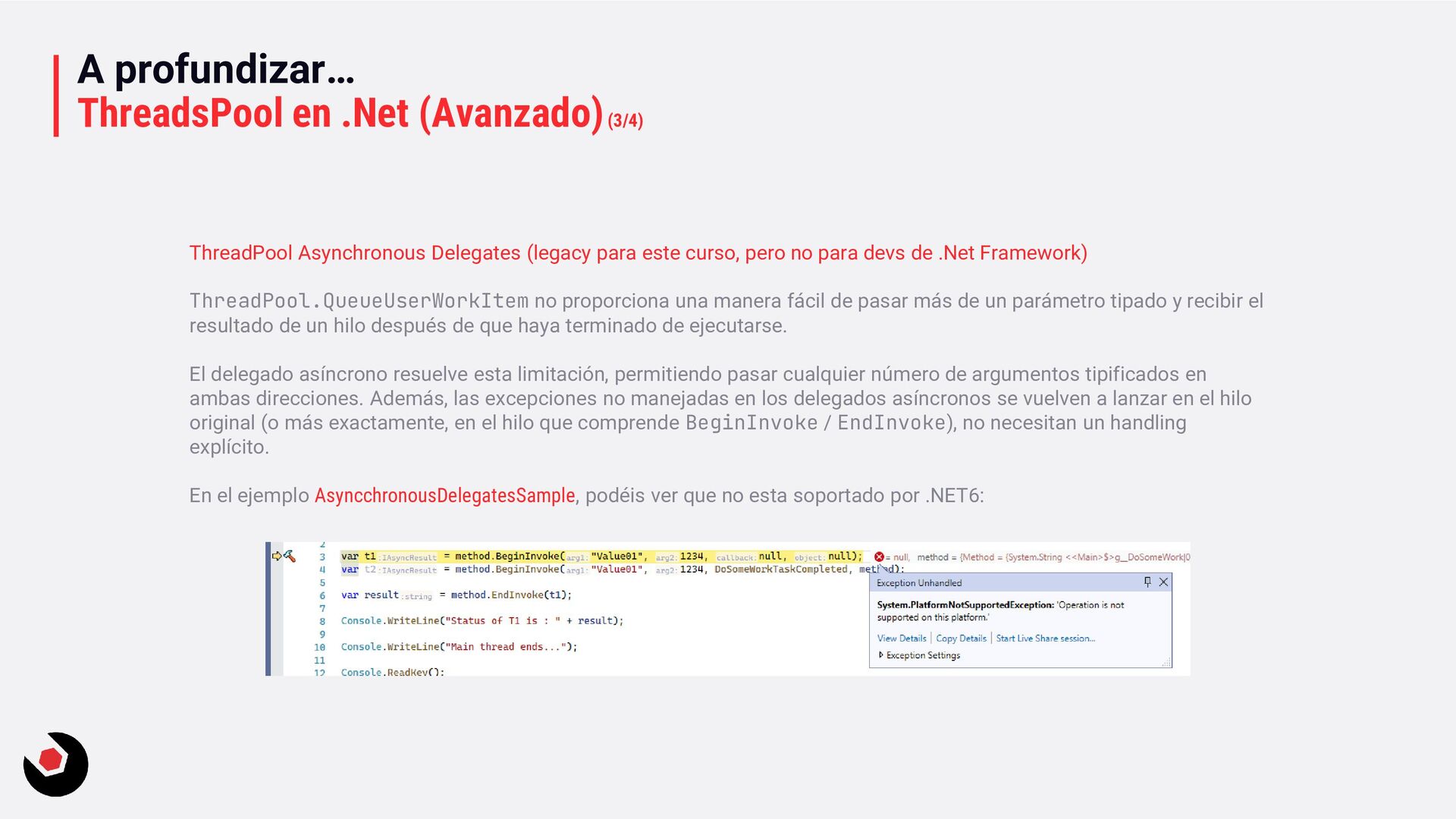{kind=link}
{kind=link}
{kind=link}
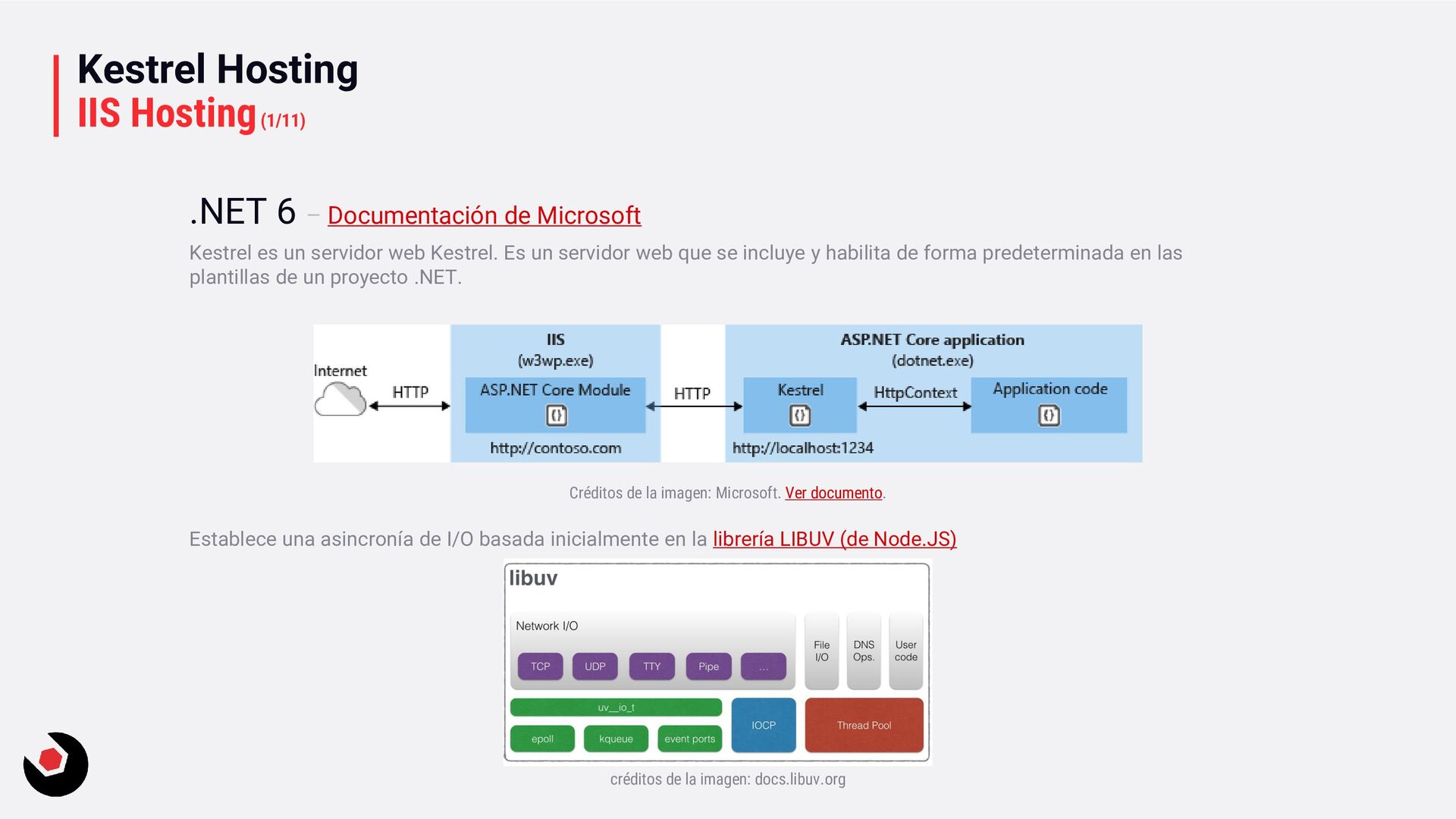{kind=link}
{kind=link}
![Kestrel Hosting IIS Hosting(3/11) En el fichero appsettings.[environment].json: { "Kestrel":](https://files.speakerdeck.com/presentations/477470d562724bf89363f79673e3a407/slide_76.jpg){kind=link}
{kind=link}
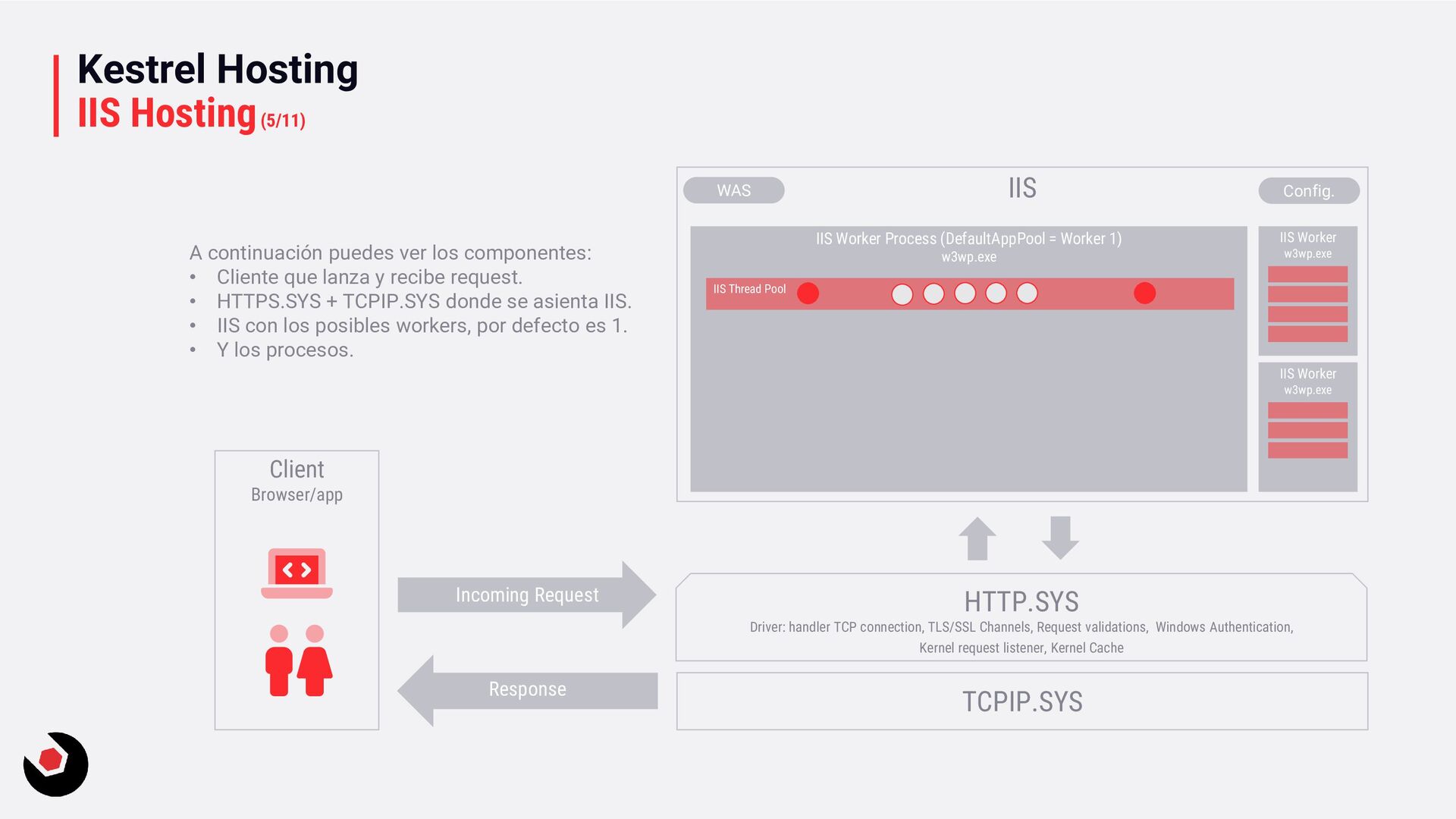{kind=link}
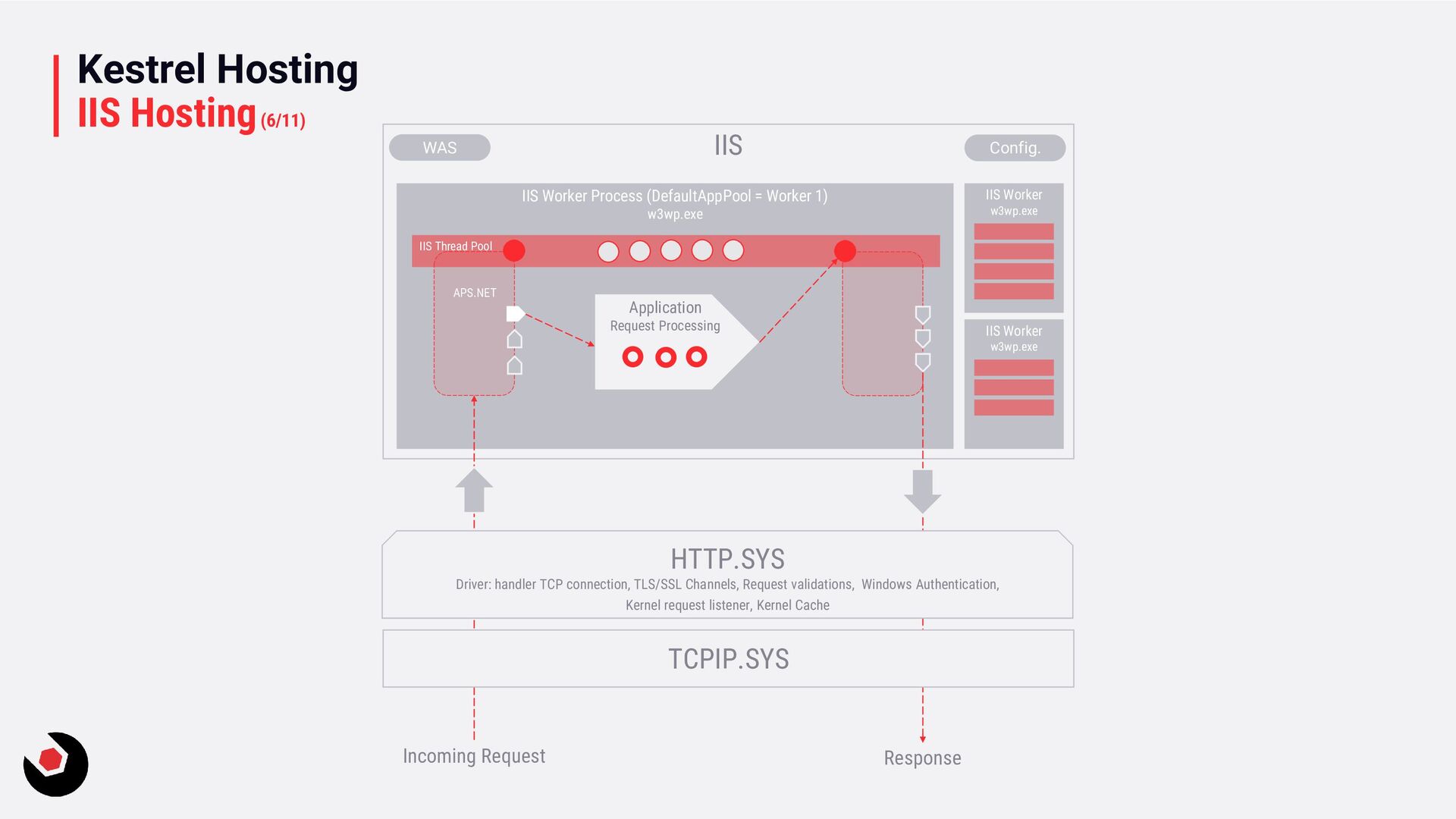{kind=link}
{kind=link}
{kind=link}
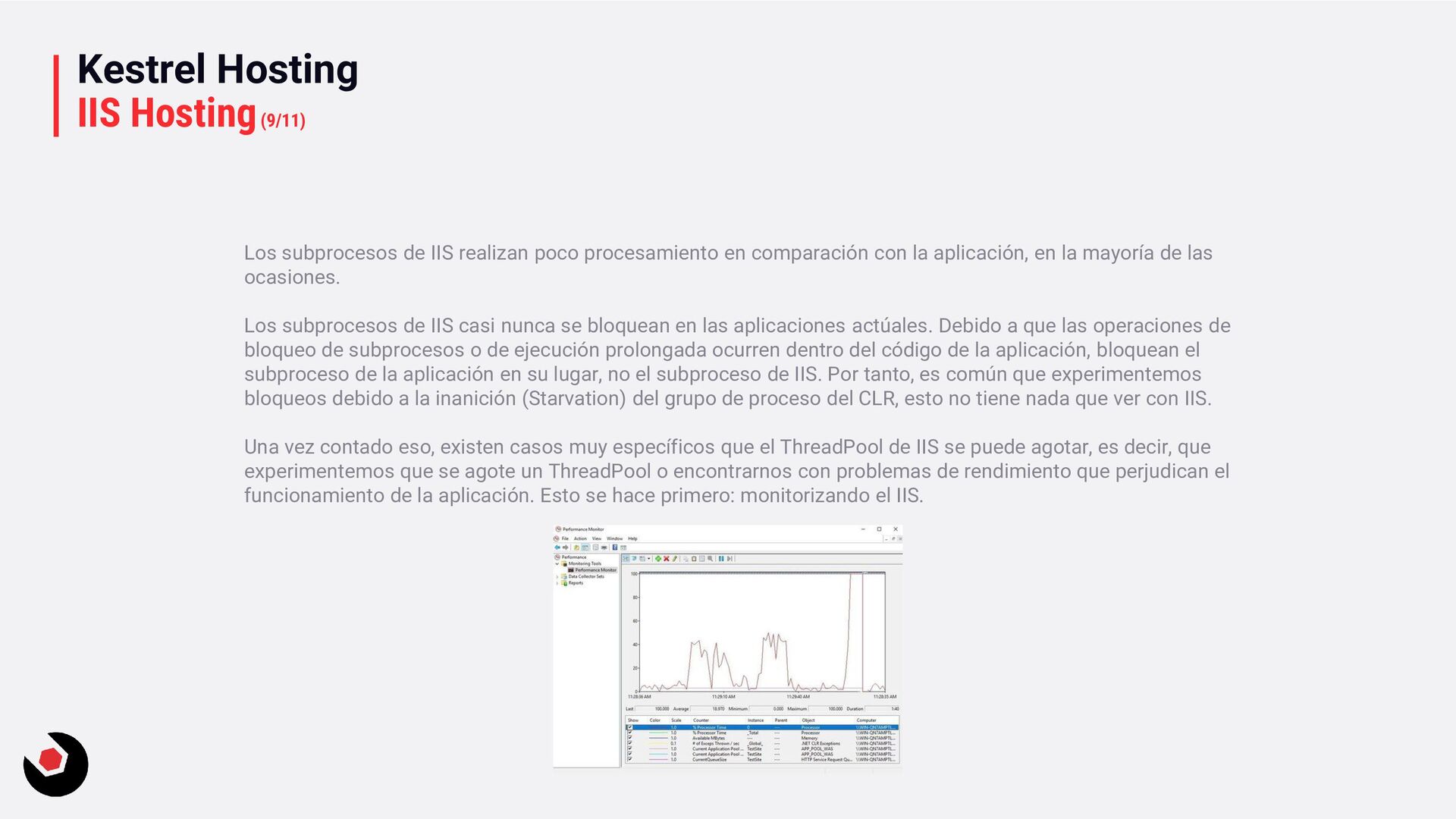{kind=link}
{kind=link}
{kind=link}
{kind=link}
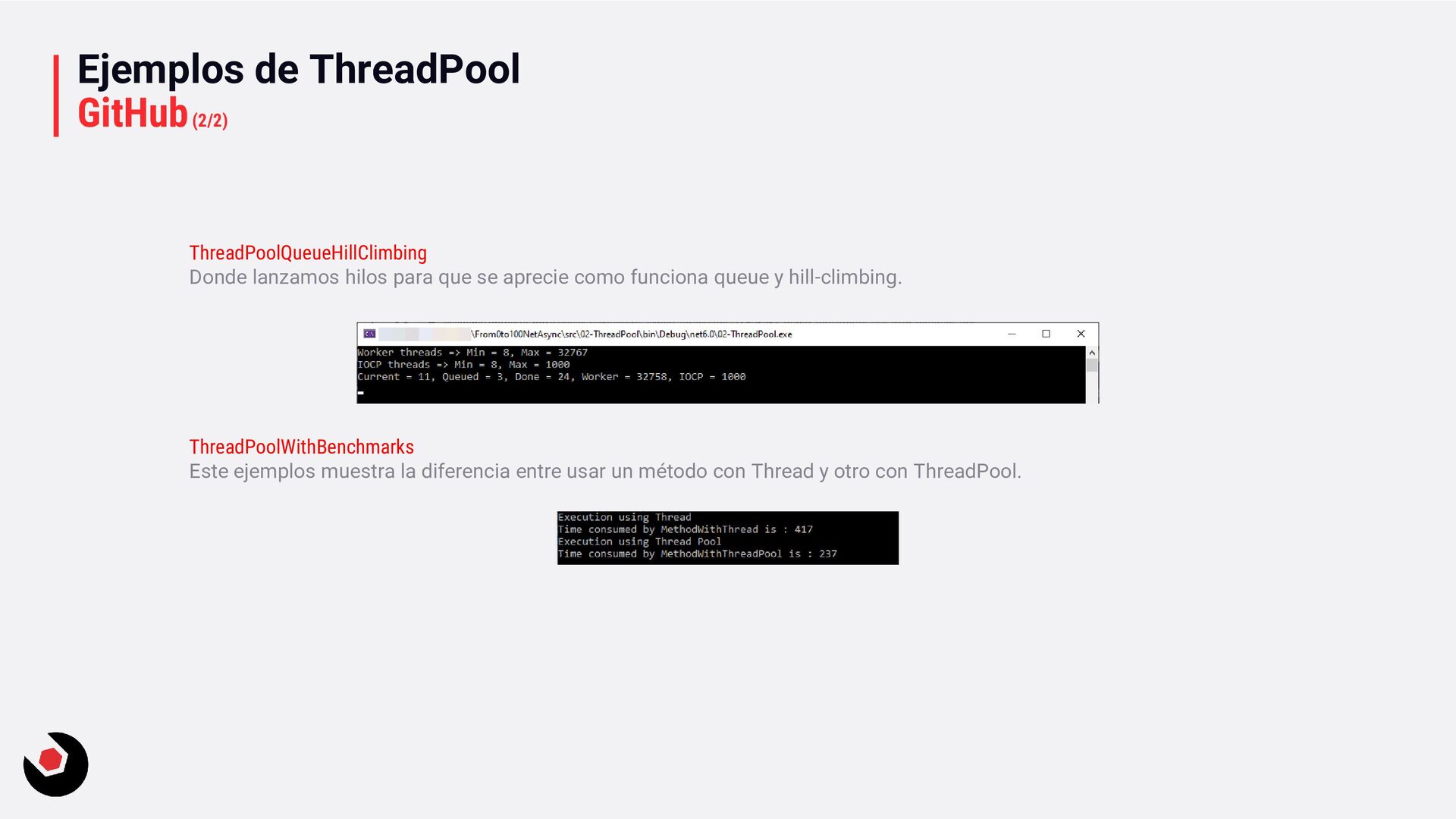{kind=link}
{kind=link}
{kind=link}
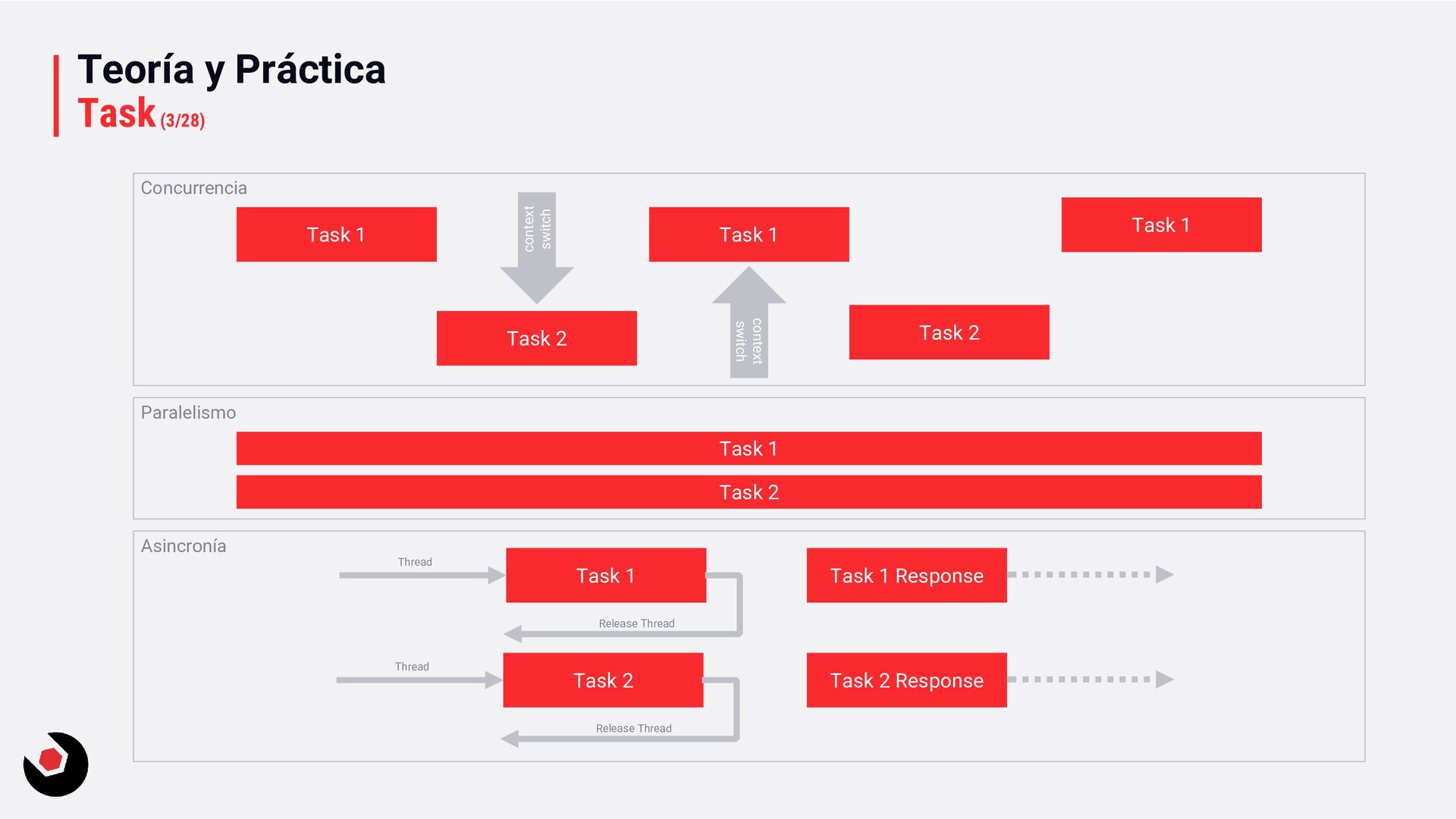{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
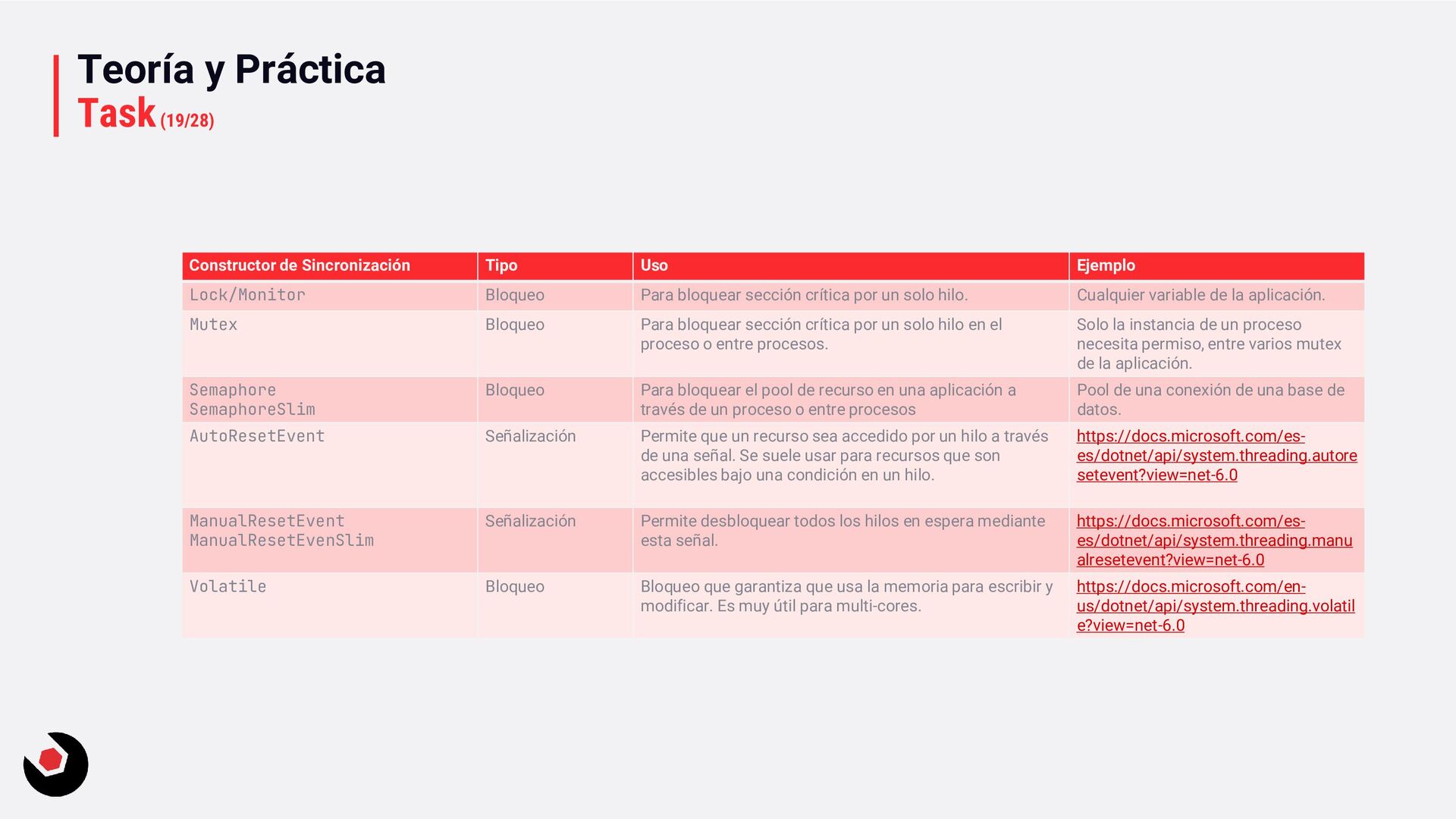{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
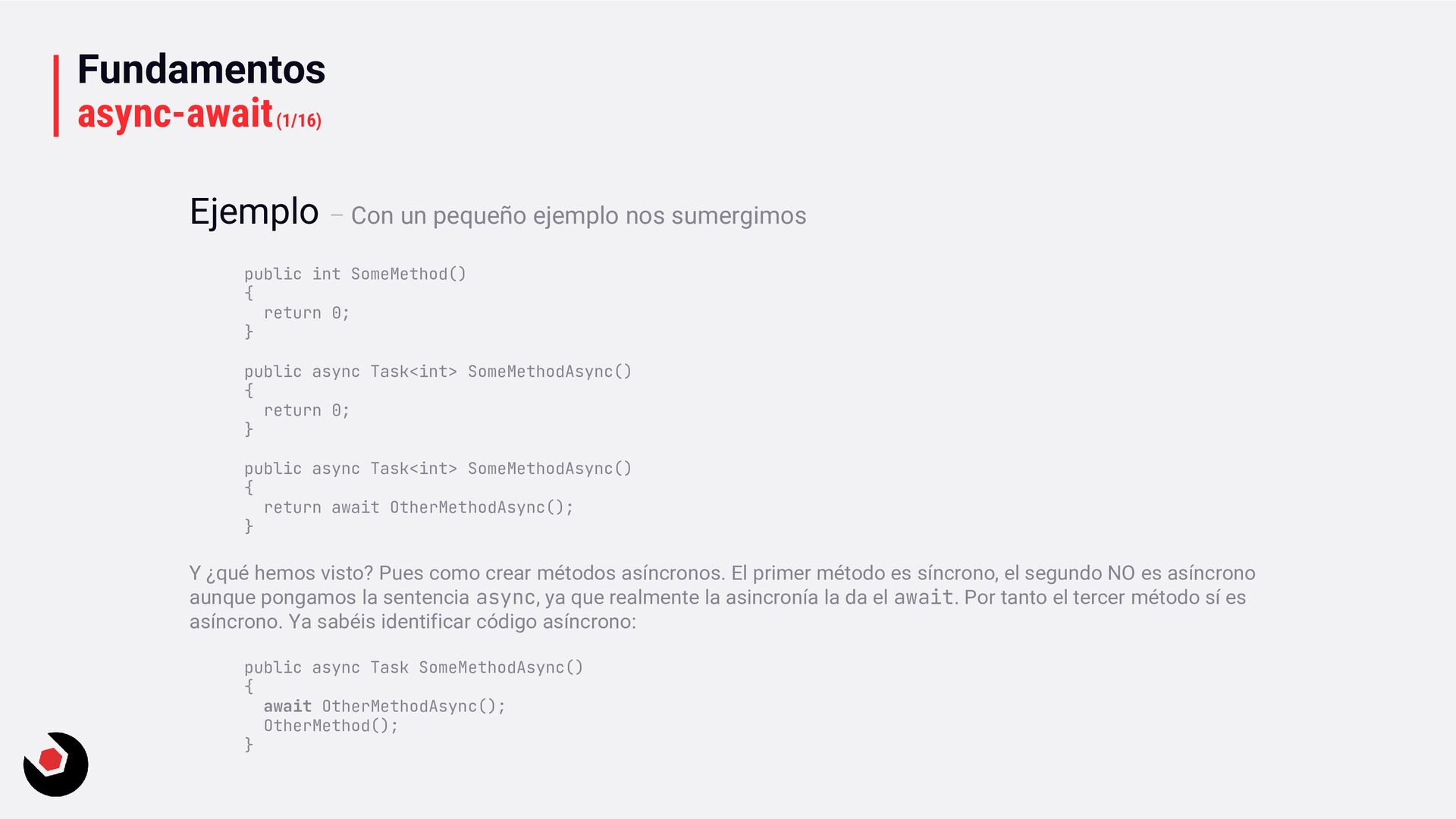{kind=link}
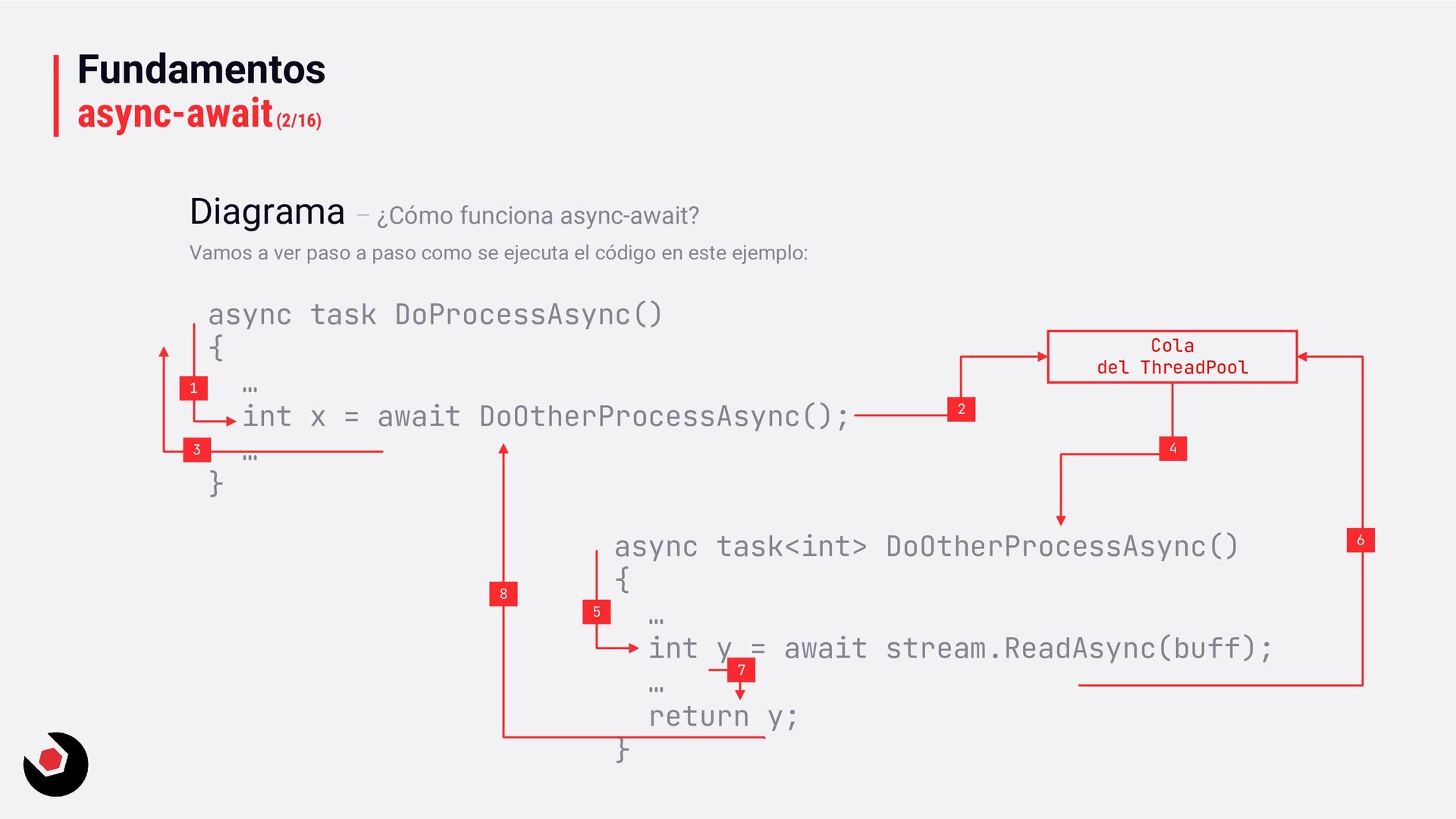{kind=link}
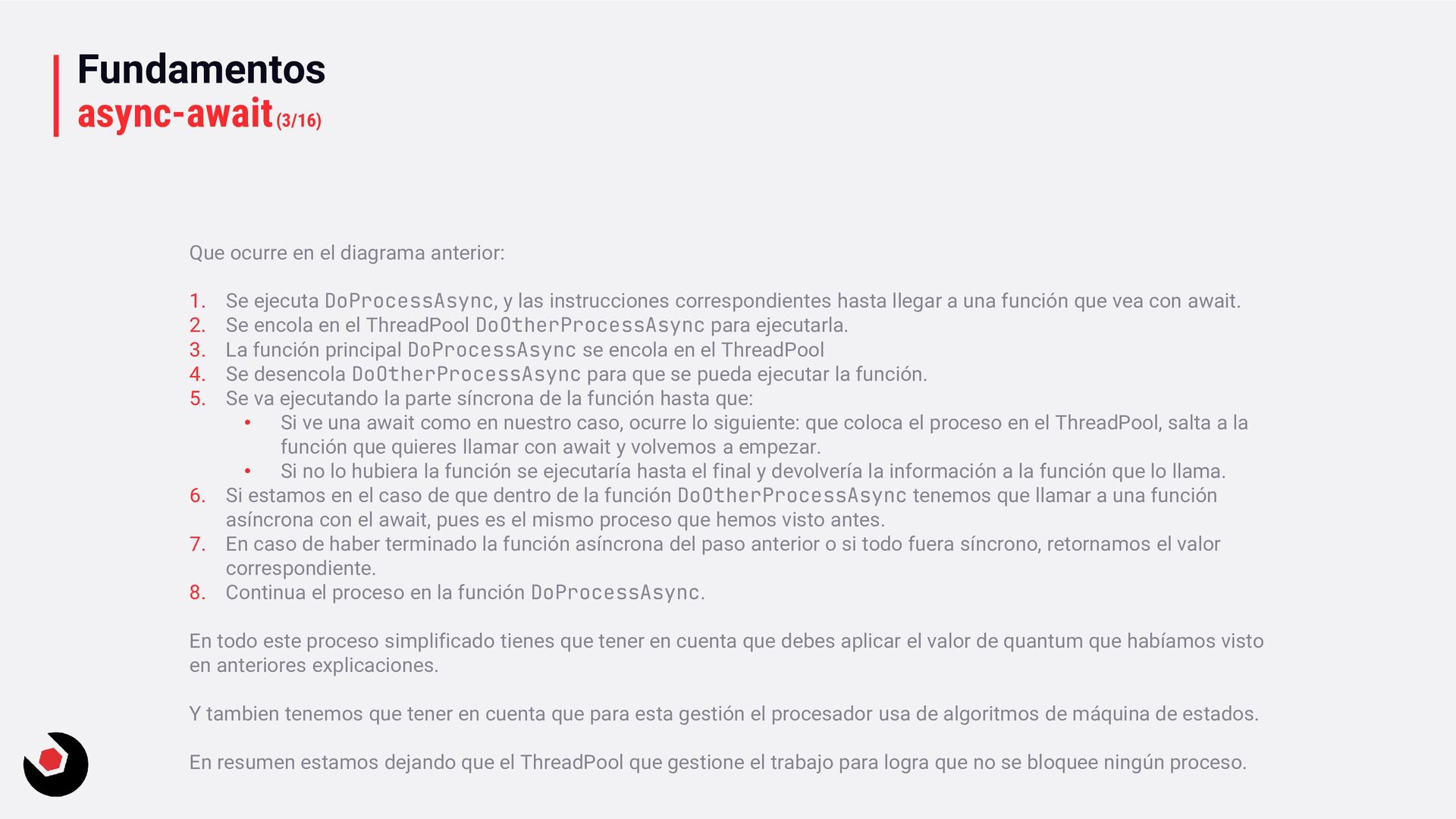{kind=link}
{kind=link}
{kind=link}
{kind=link}
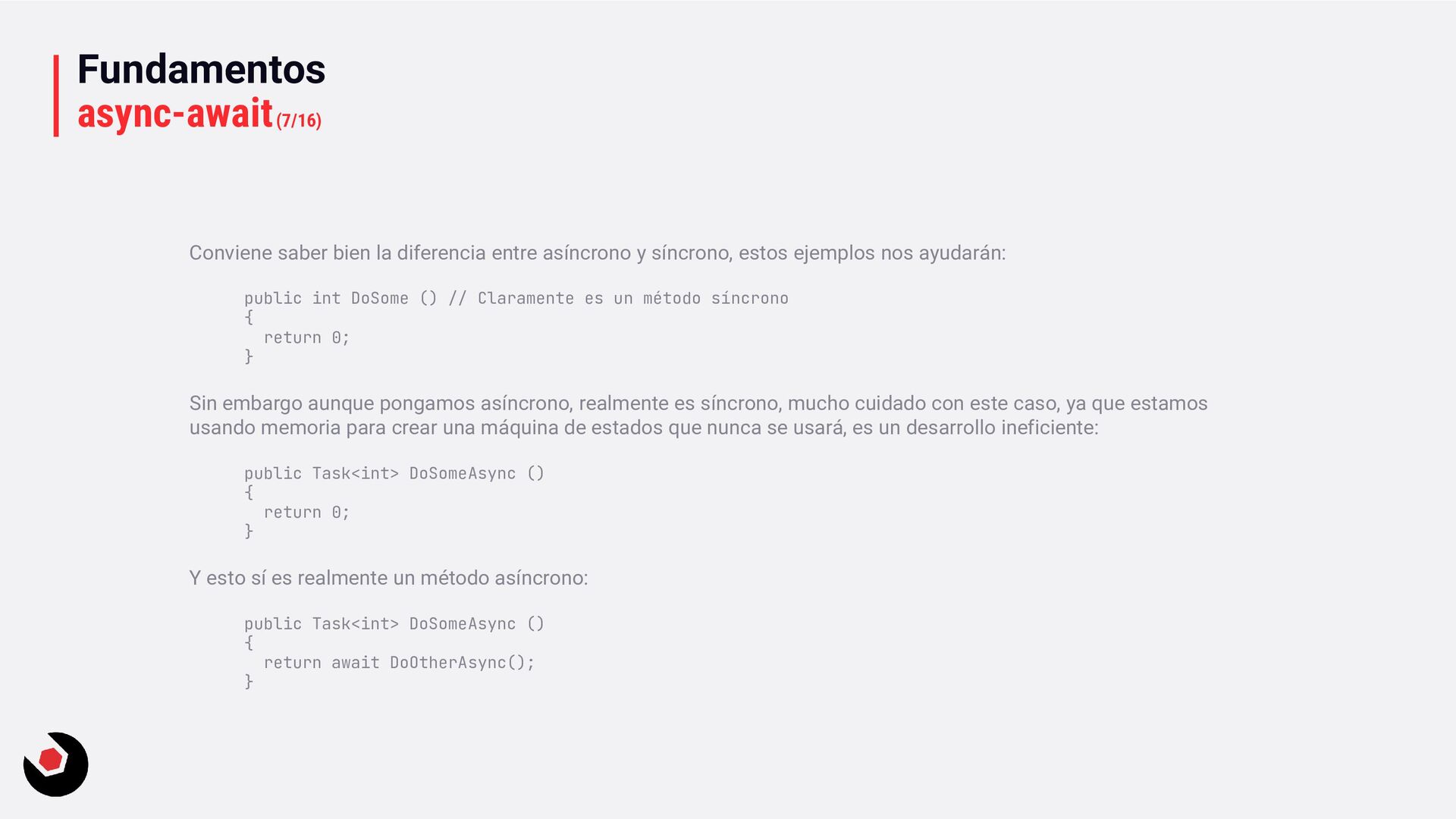{kind=link}
{kind=link}
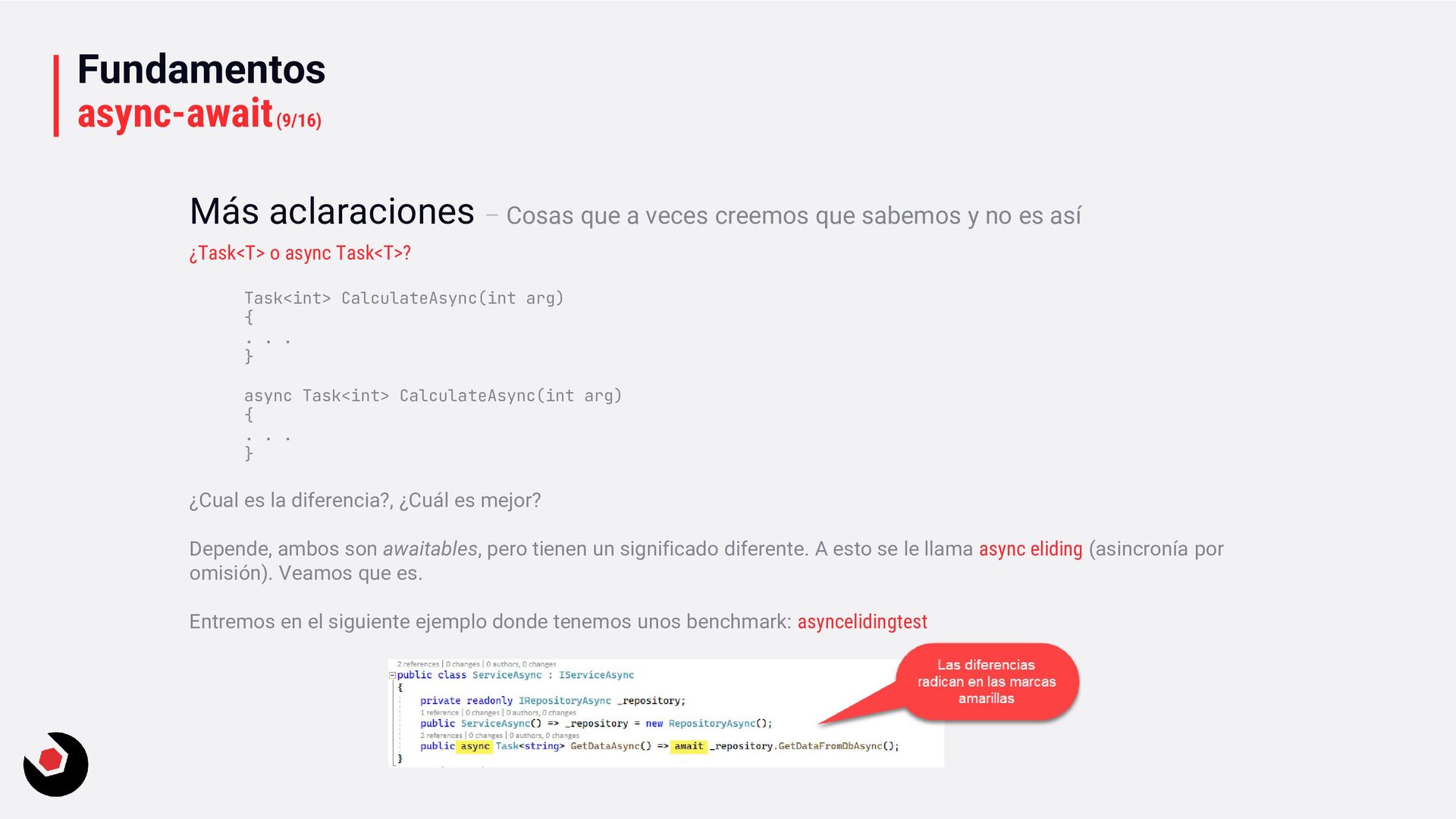{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
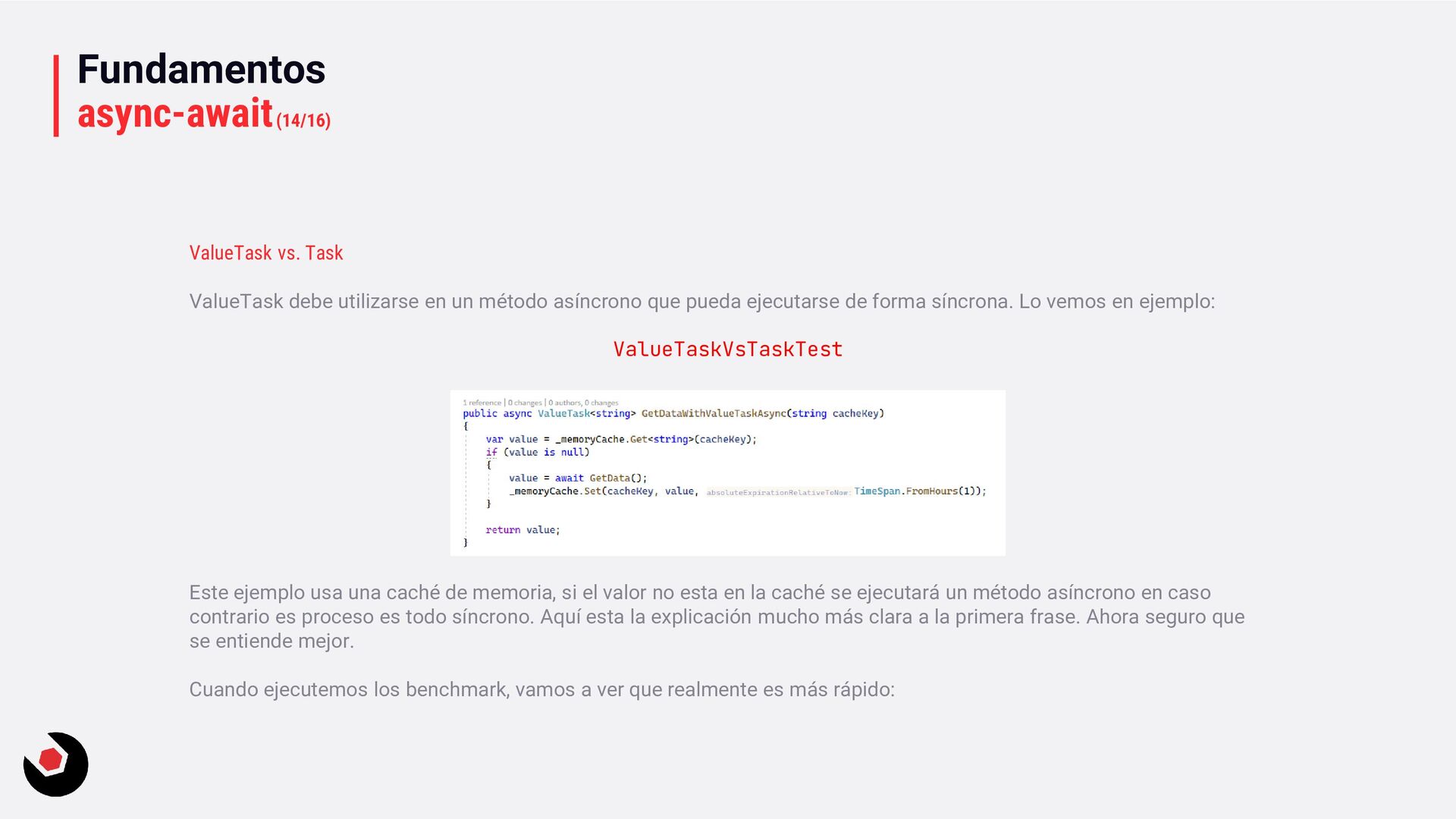{kind=link}
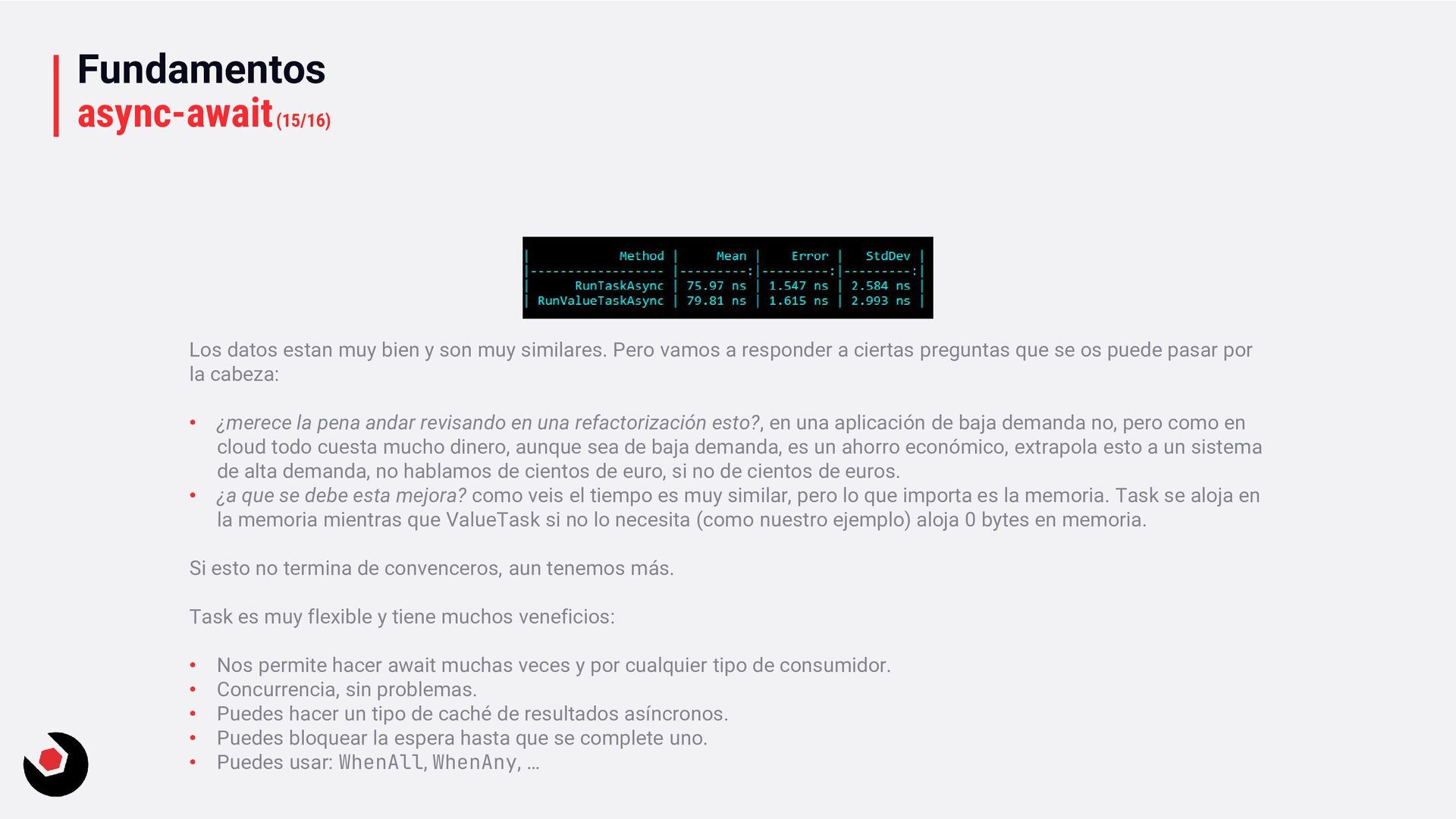{kind=link}
{kind=link}
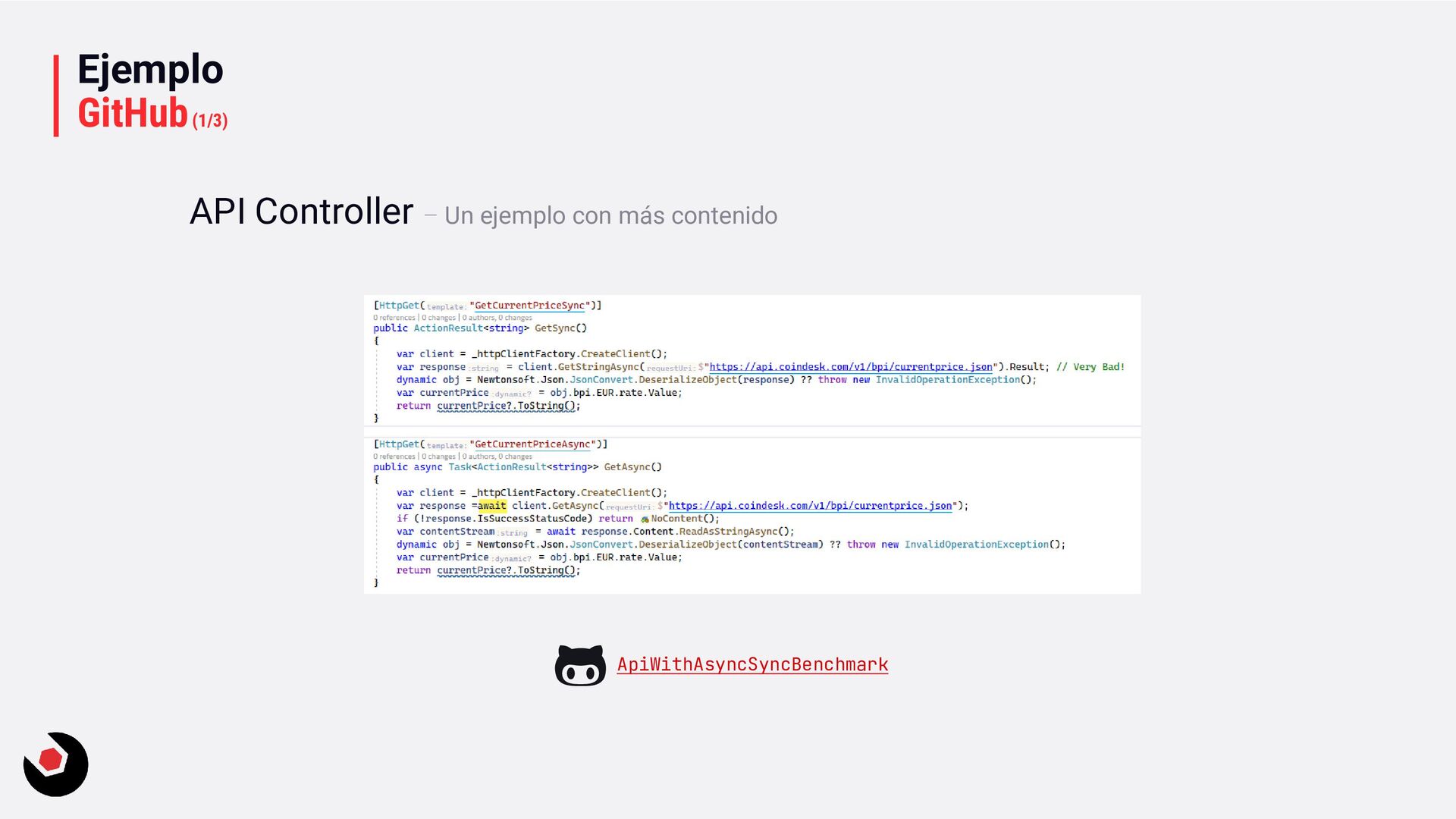{kind=link}
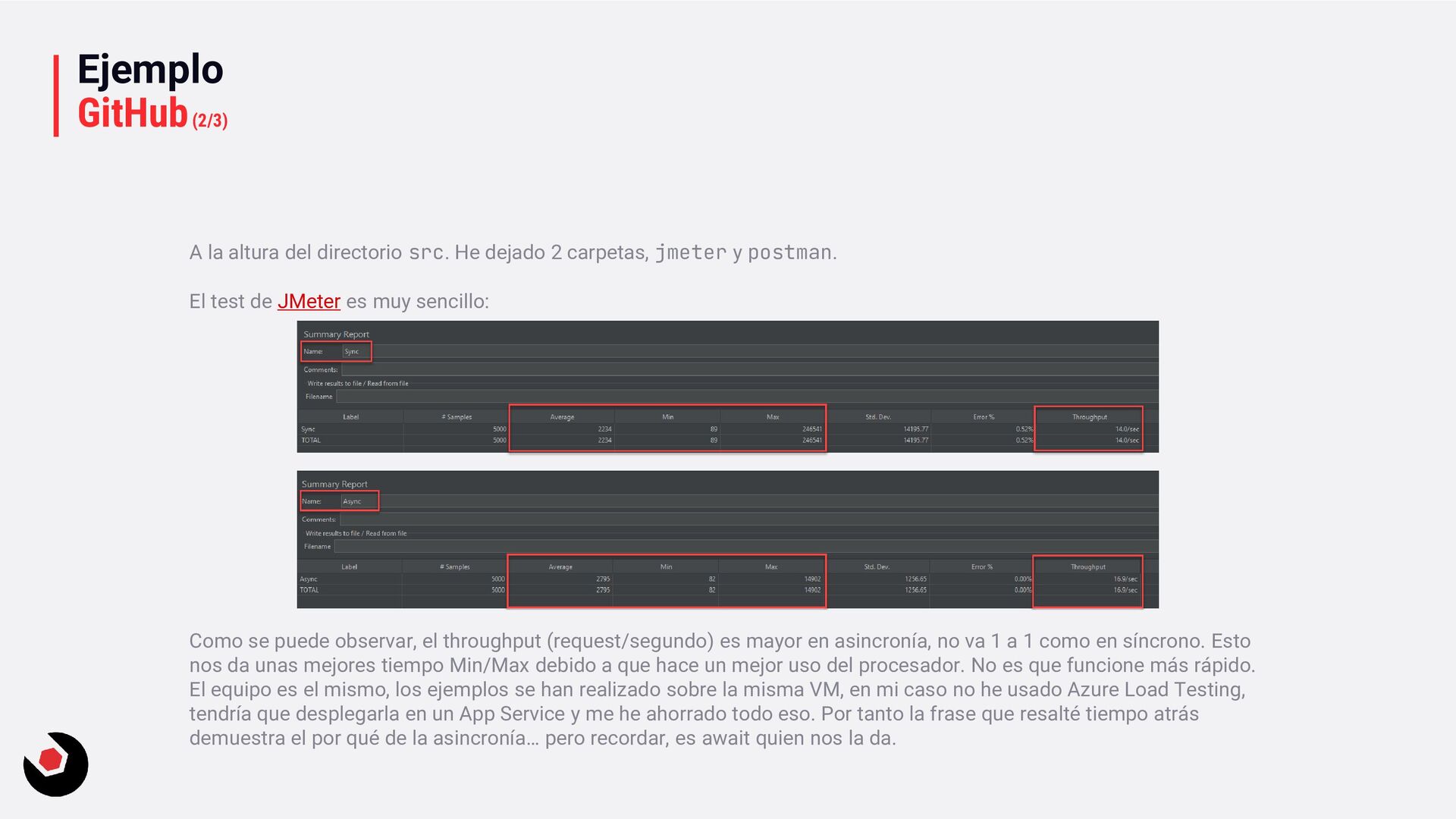{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
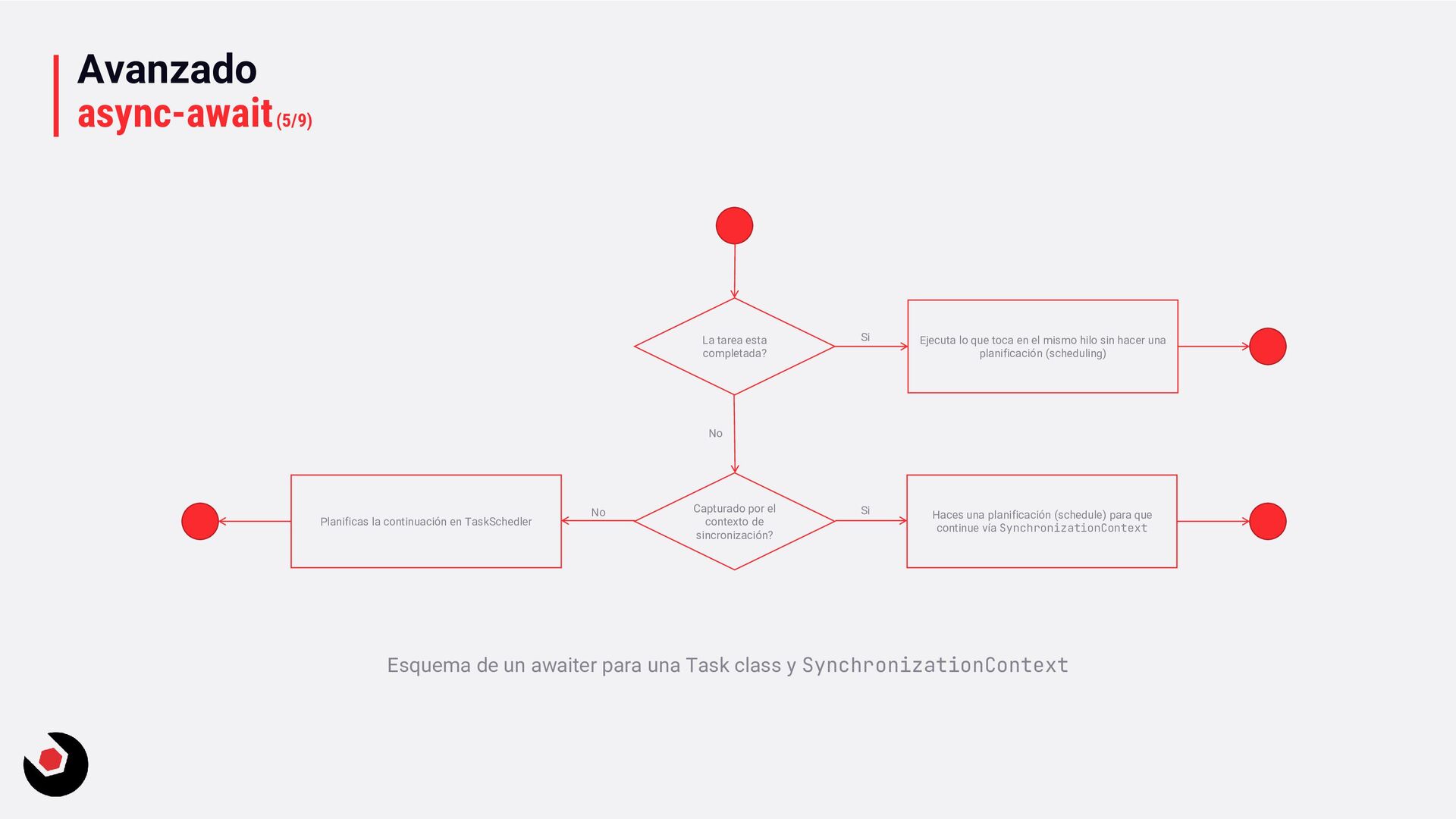{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}