DE PAPINHAS SUPERVISOR DE BRINCADEIRAS PROGRAMADOR @INTELIE MAGO DOS COMPILADORES CO-DIRETOR DE TRETAS CORPORATIVAS MESTRANDO @IME/UERJ CIÊNCIAS COMPUTACIONAIS VICIADO EM COMPETIÇÕES DE PROGRAMAÇÃO
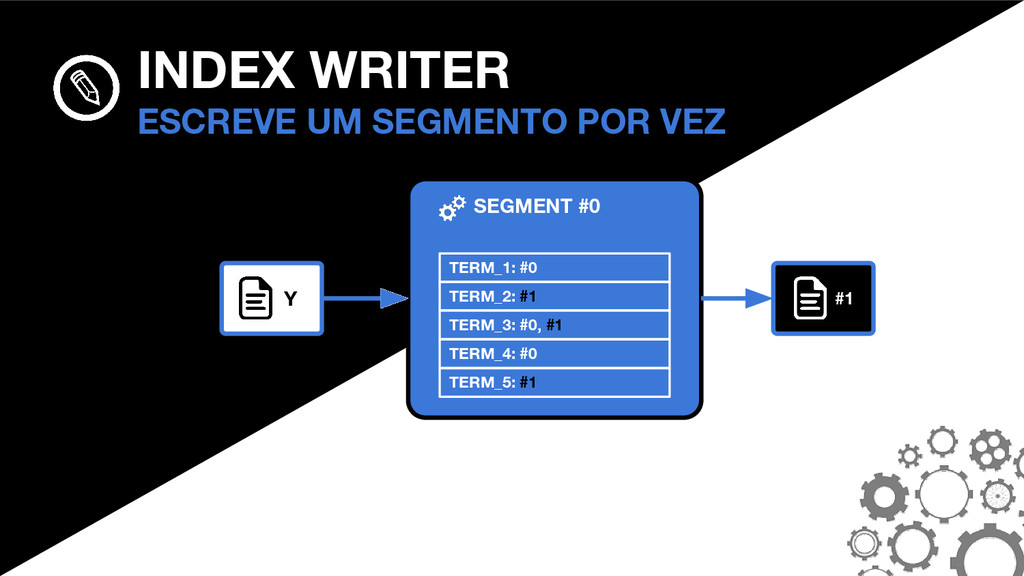
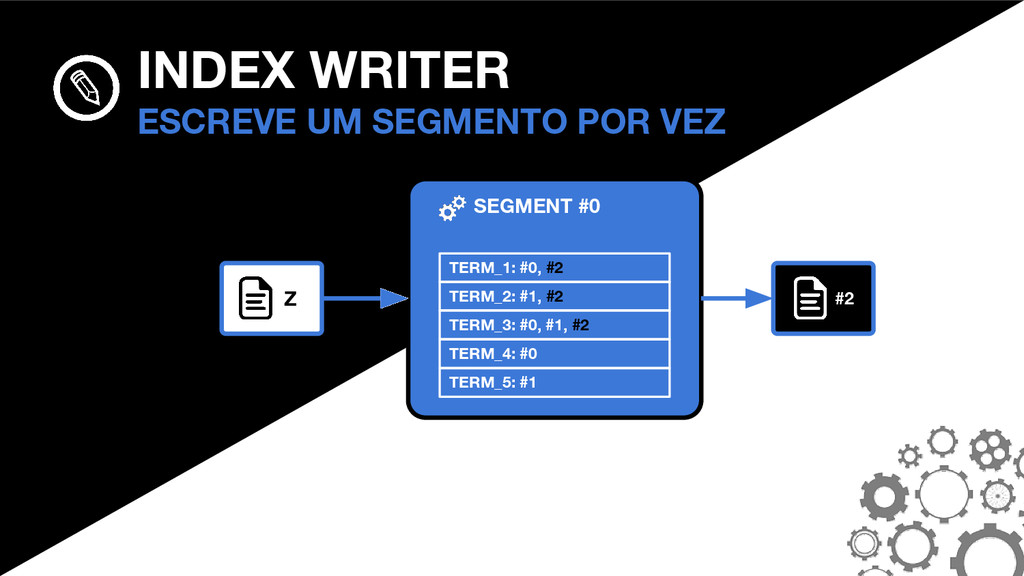
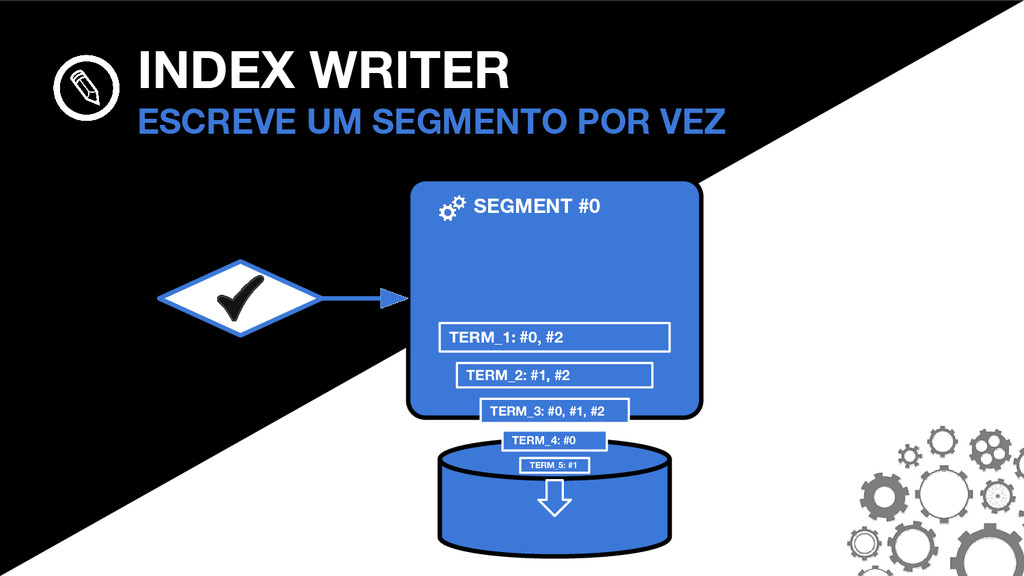
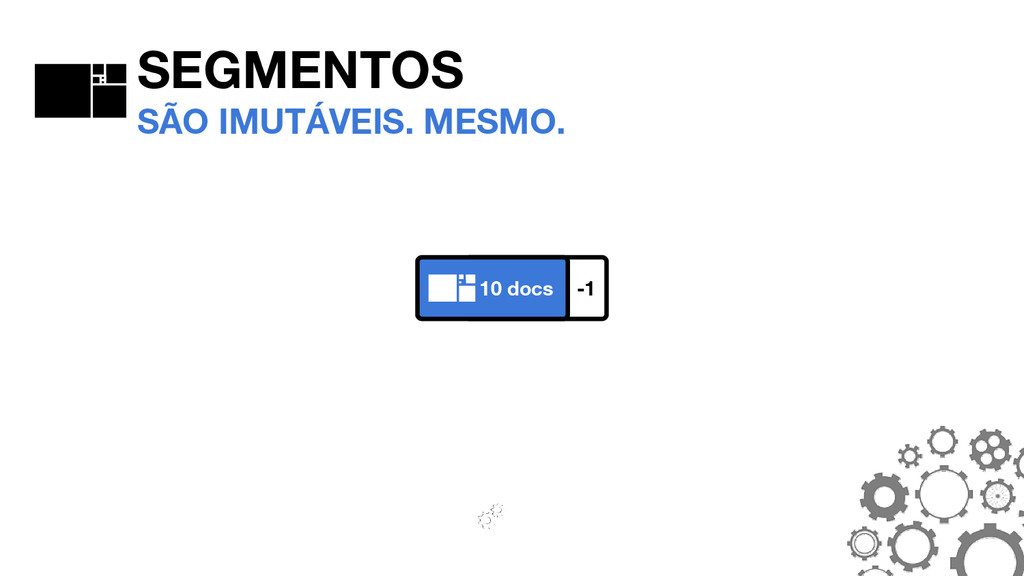
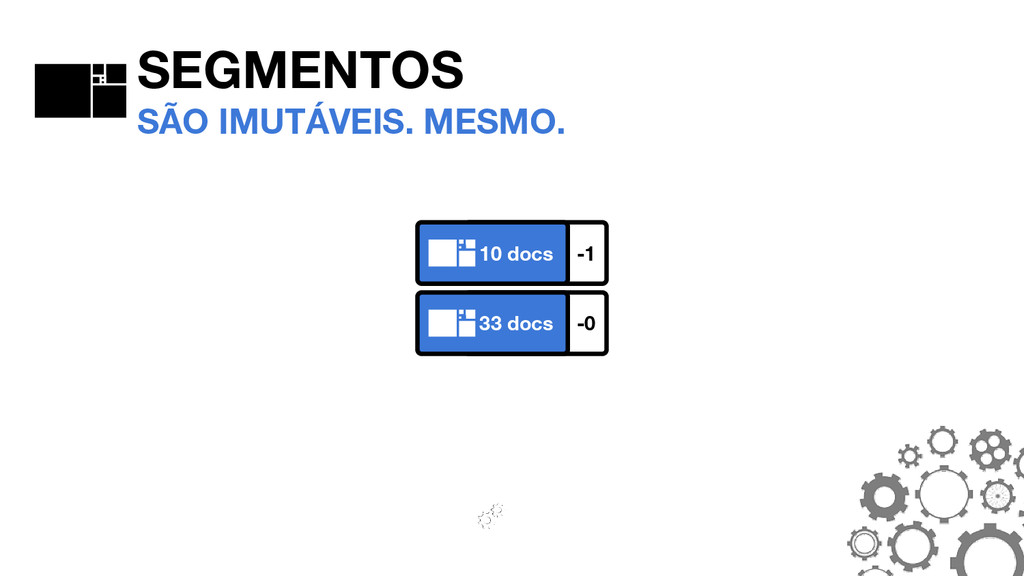
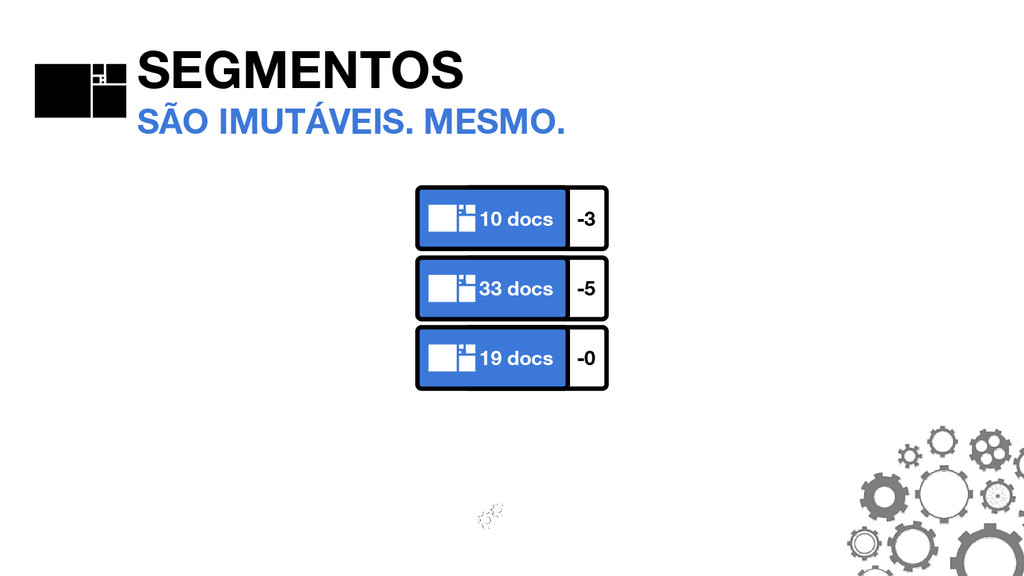
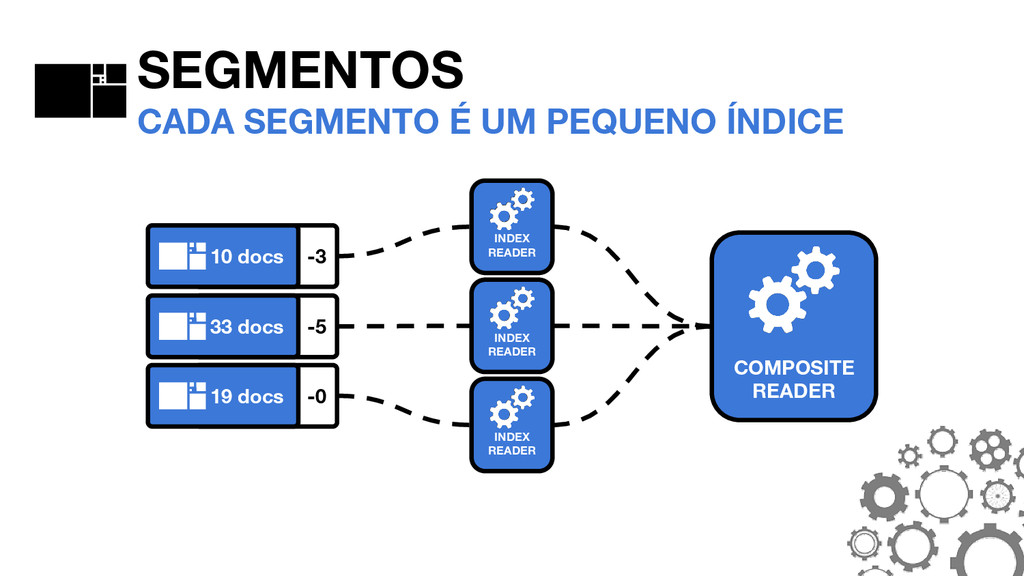
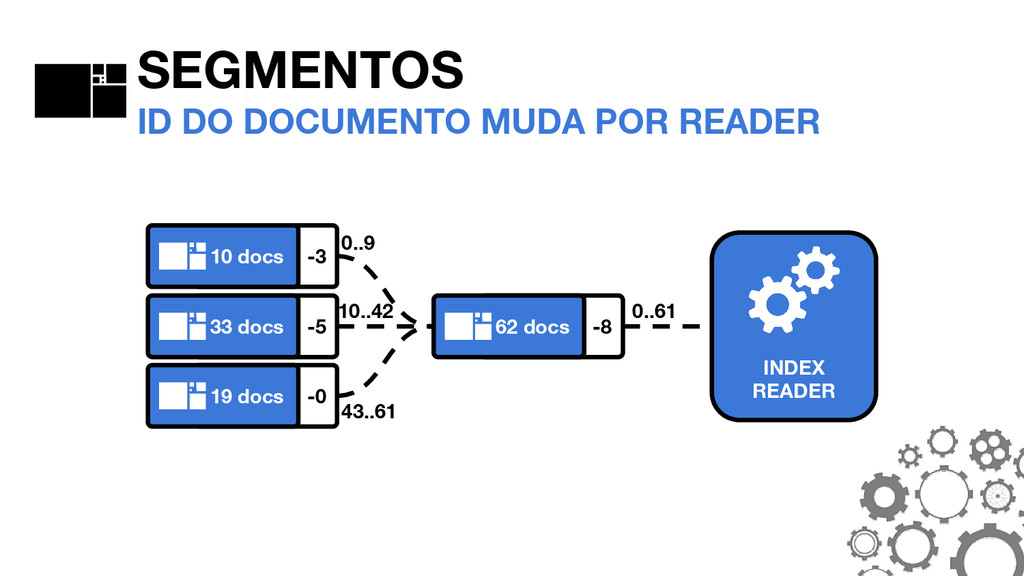
_0. PRX _0. FDT _0. DEL SEGMENTOS A ANATOMIA DO SEGMENTO #0 _0. FNM FNM: FIELD NAMES Mantém informações sobre quais campos existem no segmento, bem como o tipo do campo em cada documento.
_0. TIM _0. TIP _0. PRX _0. FRQ SEGMENTOS A ANATOMIA DO SEGMENTO #0 THE POSTINGS FORMAT São o coração do Lucene. O formato mudou consideravelmente no Lucene 4.0.0.
_0. FDT _0. FNM SEGMENTOS A ANATOMIA DO SEGMENTO #0 _0. TIM _0. TIP TIM E TIP: TERM INDEX Armazenam os termos. O TIP é um “índice do índice” e permite navegar mais rapidamente dentro do TIM.
_0. TIM _0. TIP _0. PRX _0. FRQ SEGMENTOS A ANATOMIA DO SEGMENTO #0 FRQ: FREQUENCIES Armazenam quais documentos contém cada termo, bem como a frequência que os termos aparecem.
_0. DEL _0. FNM _0. FRQ _0. PRX SEGMENTOS A ANATOMIA DO SEGMENTO #0 PRX: POSITIONS Opcional. Armazena as posições em que cada termo aparece nos documentos.
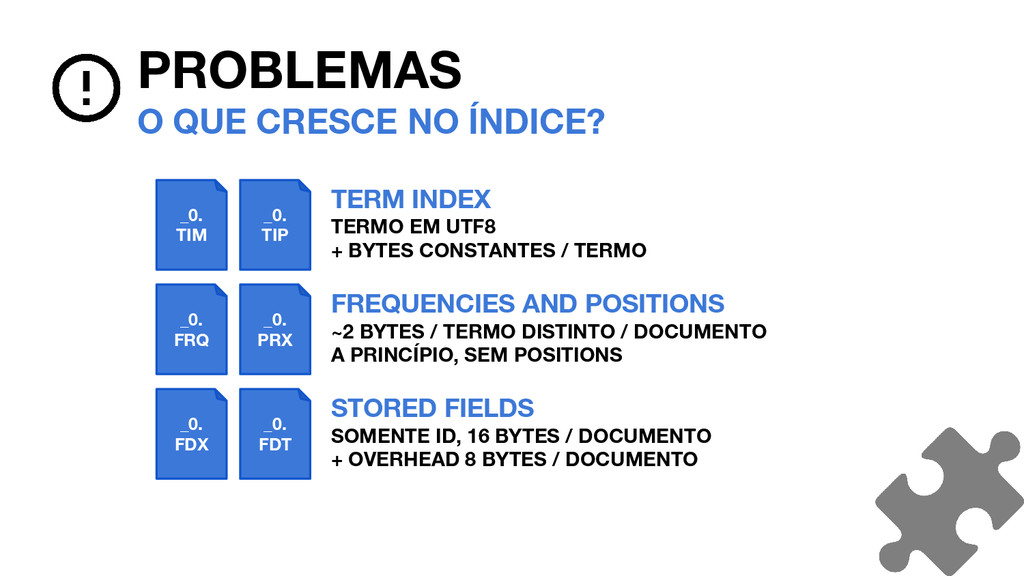
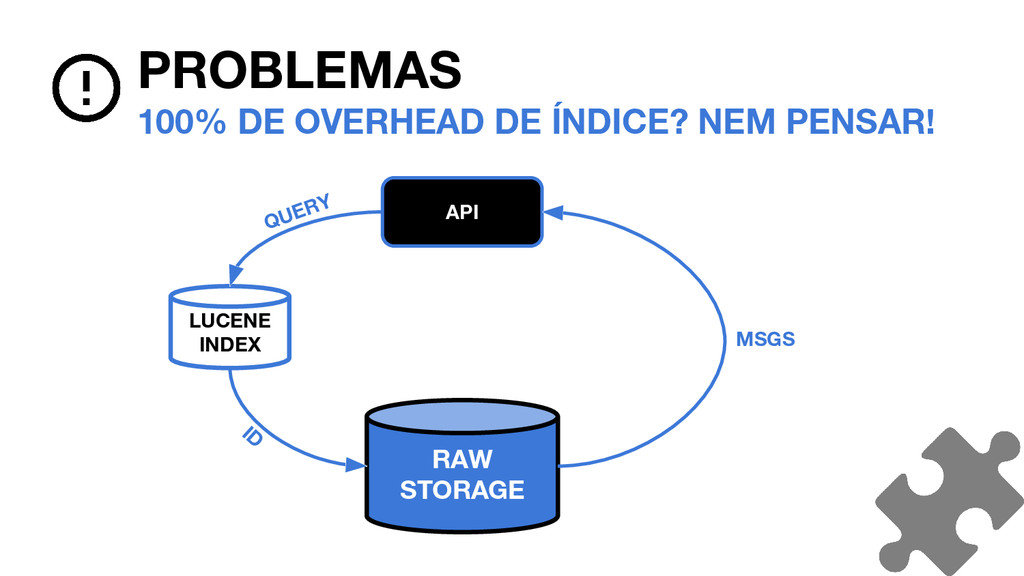
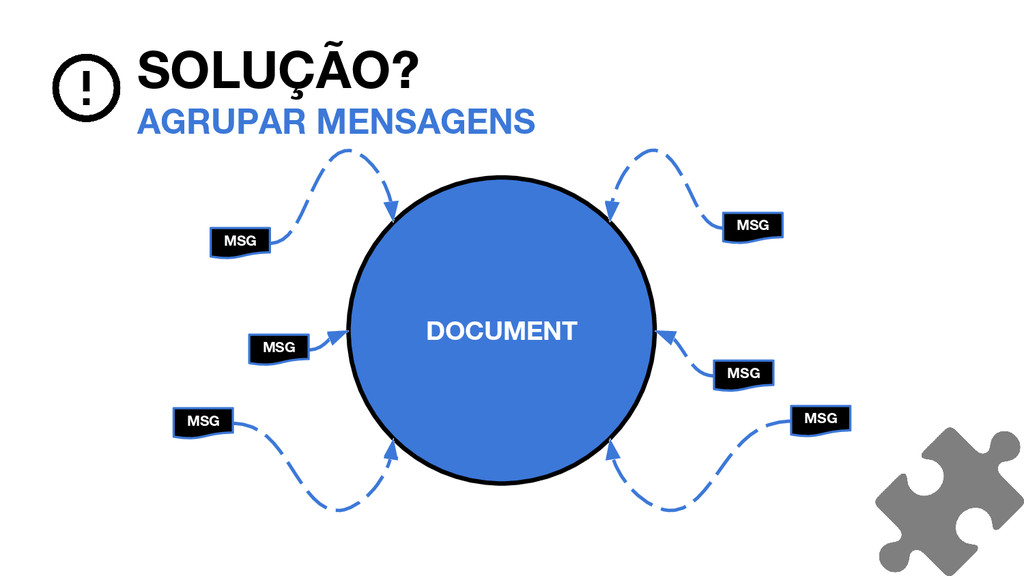
_0. FDT PROBLEMAS O QUE CRESCE NO ÍNDICE? TERM INDEX TERMO EM UTF8 + BYTES CONSTANTES / TERMO FREQUENCIES AND POSITIONS ~2 BYTES / TERMO DISTINTO / DOCUMENTO A PRINCÍPIO, SEM POSITIONS STORED FIELDS SOMENTE ID, 16 BYTES / DOCUMENTO + OVERHEAD 8 BYTES / DOCUMENTO
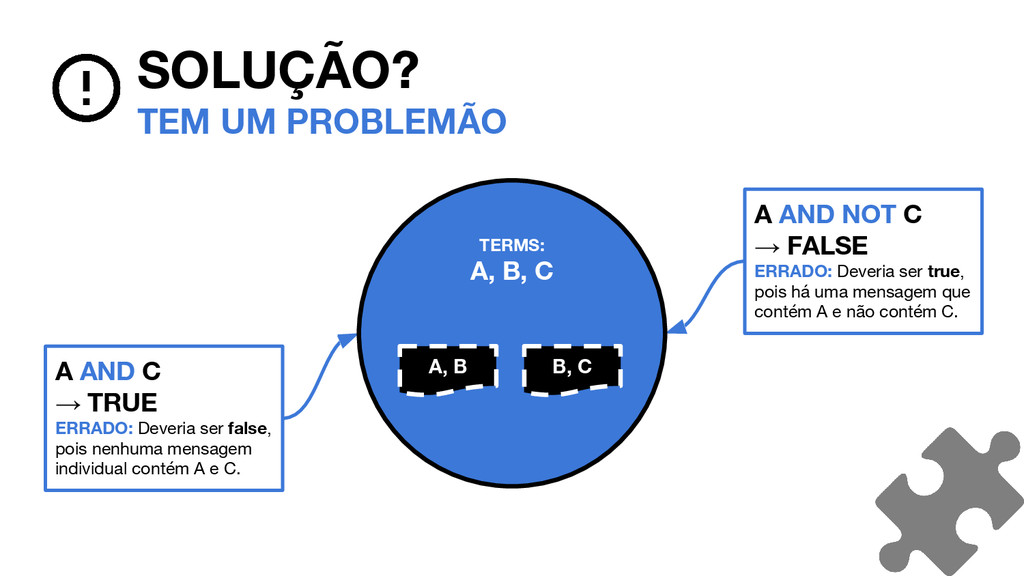
B, C A AND C → TRUE ERRADO: Deveria ser false, pois nenhuma mensagem individual contém A e C. A AND NOT C → FALSE ERRADO: Deveria ser true, pois há uma mensagem que contém A e não contém C.
POR DOCUMENTO ❖ SE < 64 MENSAGENS EM UM MESMO TERMO, USAR POSITIONS. ❖ SE > 64 MENSAGENS, ARMAZENAR UM BITSET COM 128 BYTES NO PAYLOAD (TAMBÉM NO PRX) POIS GERALMENTE CADA POSITION CONSOME 2 BYTES ❖ GARANTE MÁXIMO DE 128 BYTES / TERMO / DOCUMENTO. GERALMENTE MUITO MENOS.
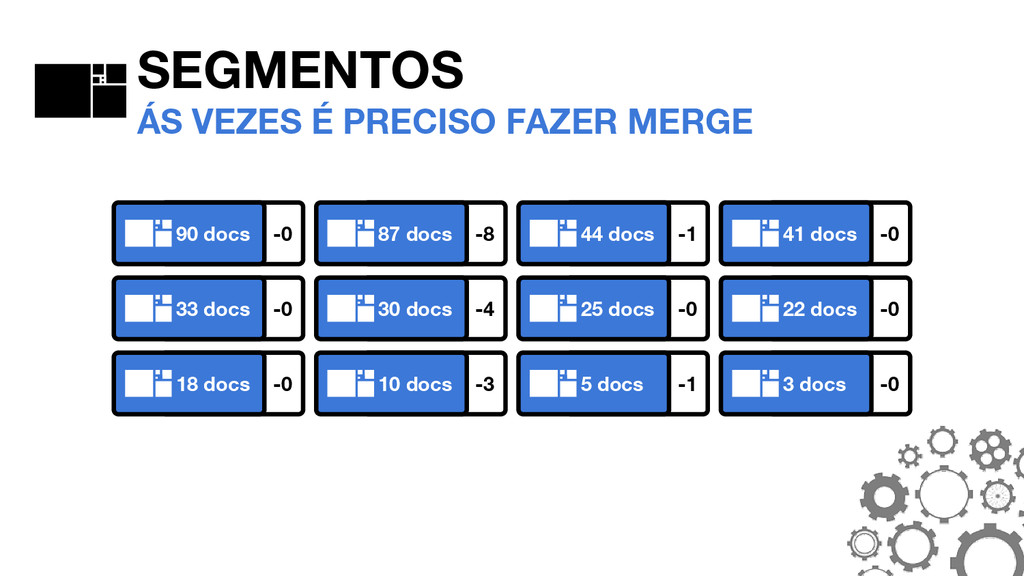
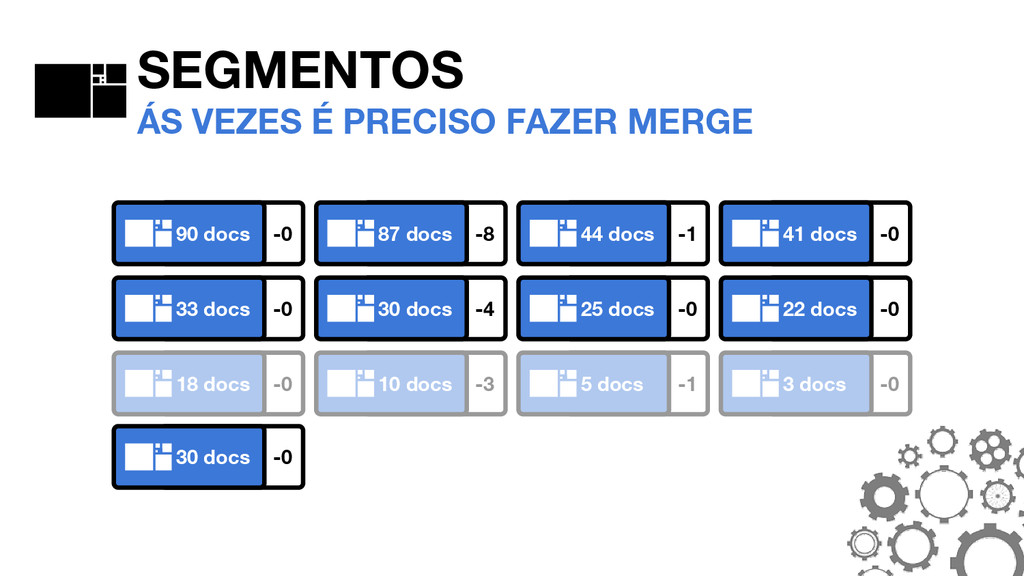
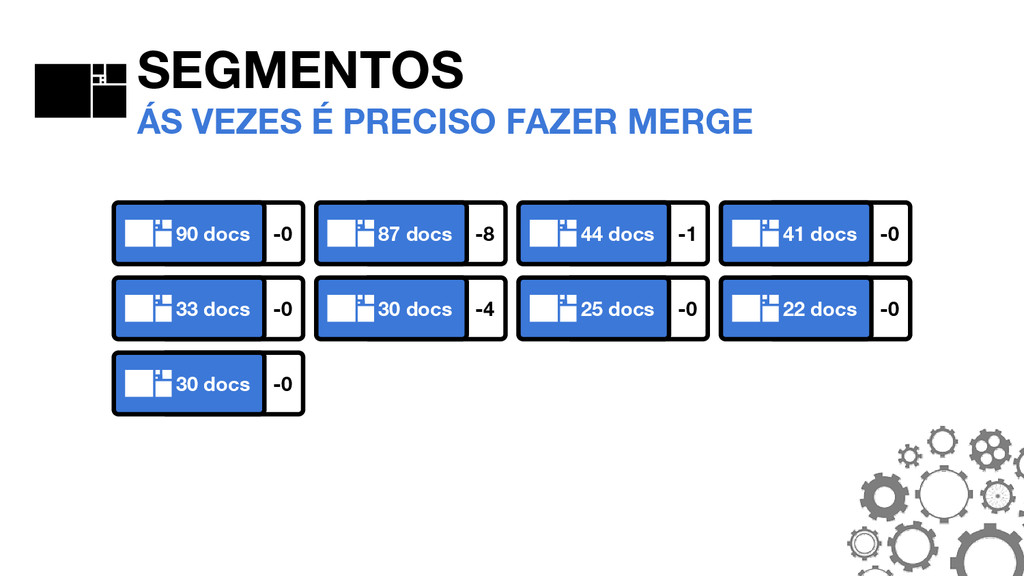
de forma genérica para atender razoavelmente o máximo de casos. Ás vezes, para permitir grandes volumes sem uma infraestrutura colossal, é preciso entender como customizar a ferramenta para suas necessidades.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SUBJECT Important! Don’t let this leak FROM John Doe <[email protected]>](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_14.jpg){kind=link}
![SUBJECT Important! Don’t let this leak FROM John Doe <[email protected]>](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_15.jpg){kind=link}
![SUBJECT important! dont let this leak FROM john doe <[email protected]>](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_16.jpg){kind=link}
![DOCUMENTO RESULTADO: CAMPOS E TERMOS FROM doe, john, [email protected] TO](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
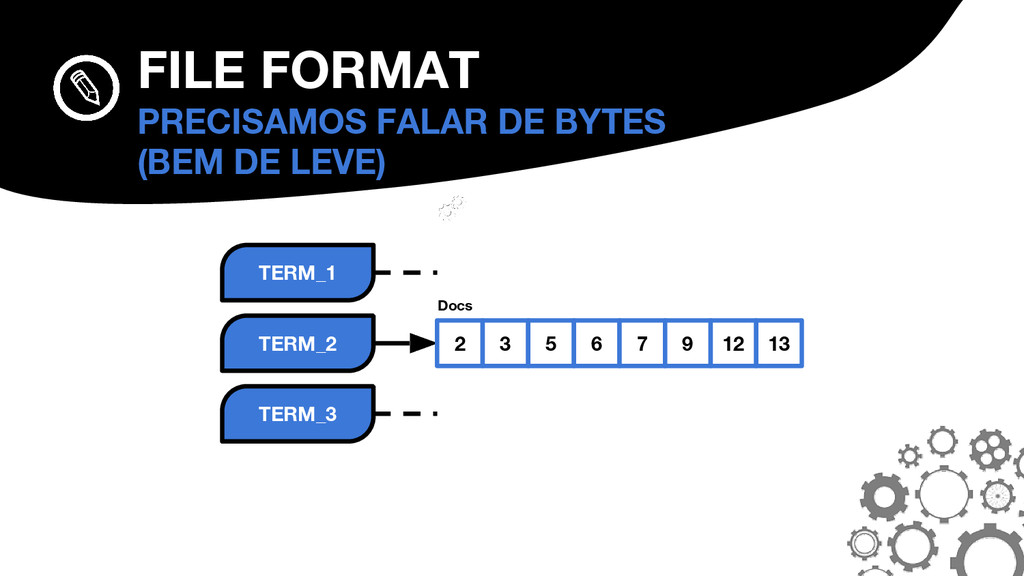{kind=link}
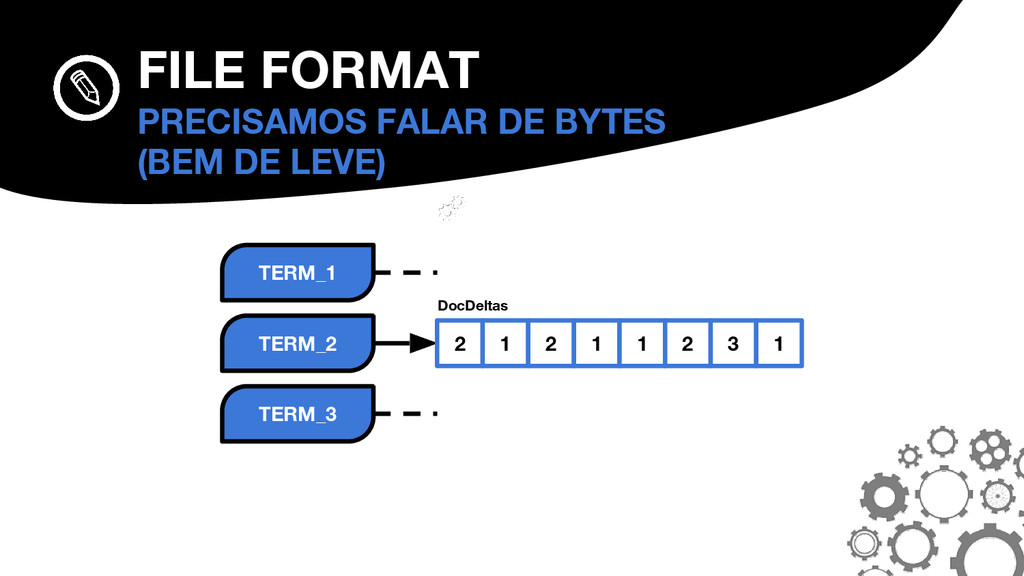{kind=link}
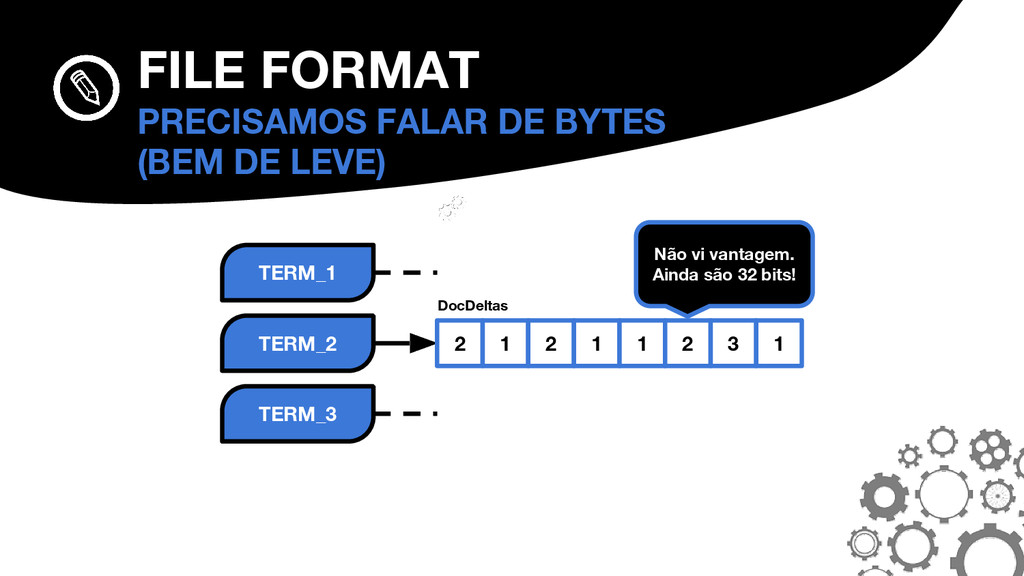{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SOLUÇÃO [2]? ARMAZENAR ÍNDICES USANDO POSITIONS _0. PRX POSITIONS E](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_59.jpg){kind=link}
![DOCUMENT #42 SOLUÇÃO [2]? ARMAZENAR ÍNDICES USANDO POSITIONS A, B,](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_60.jpg){kind=link}
![SOLUÇÃO [2]? ARMAZENAR ÍNDICES USANDO POSITIONS ❖ ATÉ 1024 MENSAGENS](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_61.jpg){kind=link}
![A B SOLUÇÃO [2]? É NECESSÁRIO REIMPLEMENTAR A BUSCA A](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_62.jpg){kind=link}
![SOLUÇÃO [2]? É NECESSÁRIO REIMPLEMENTAR A BUSCA A AND B](https://files.speakerdeck.com/presentations/9ca22027153c401caa3e27237cd17801/slide_63.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}