Рассмотрим, чем статически компилируемые языки отличаются от динамически компилируемых, что такое трансляционная семантика, чем трансляция отличается от исполнения и какие странные ограничения статических компиляторов это порождает.
Видео: https://youtu.be/fAZSIAsKarc
{kind=link}
{kind=link}
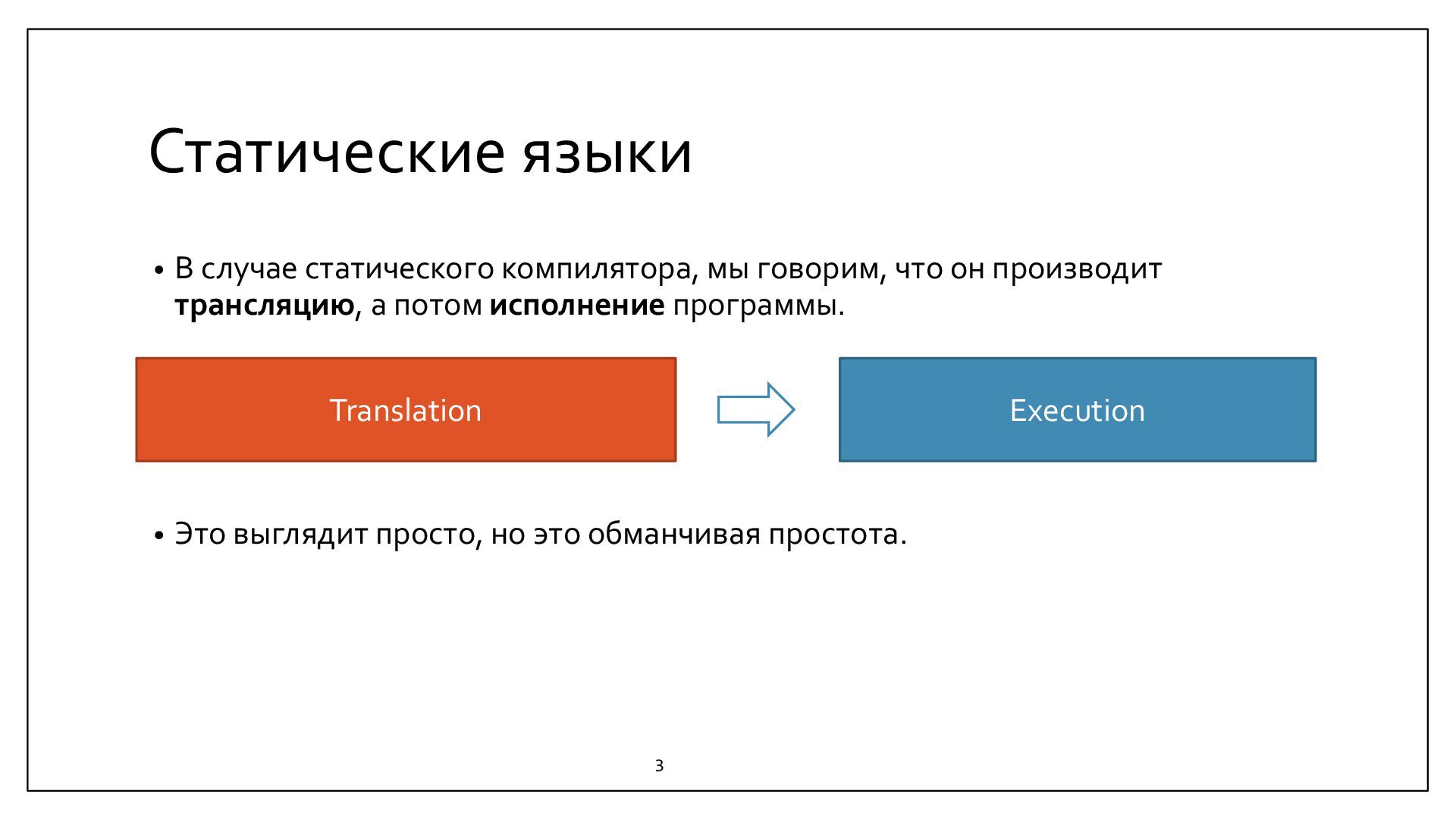{kind=link}
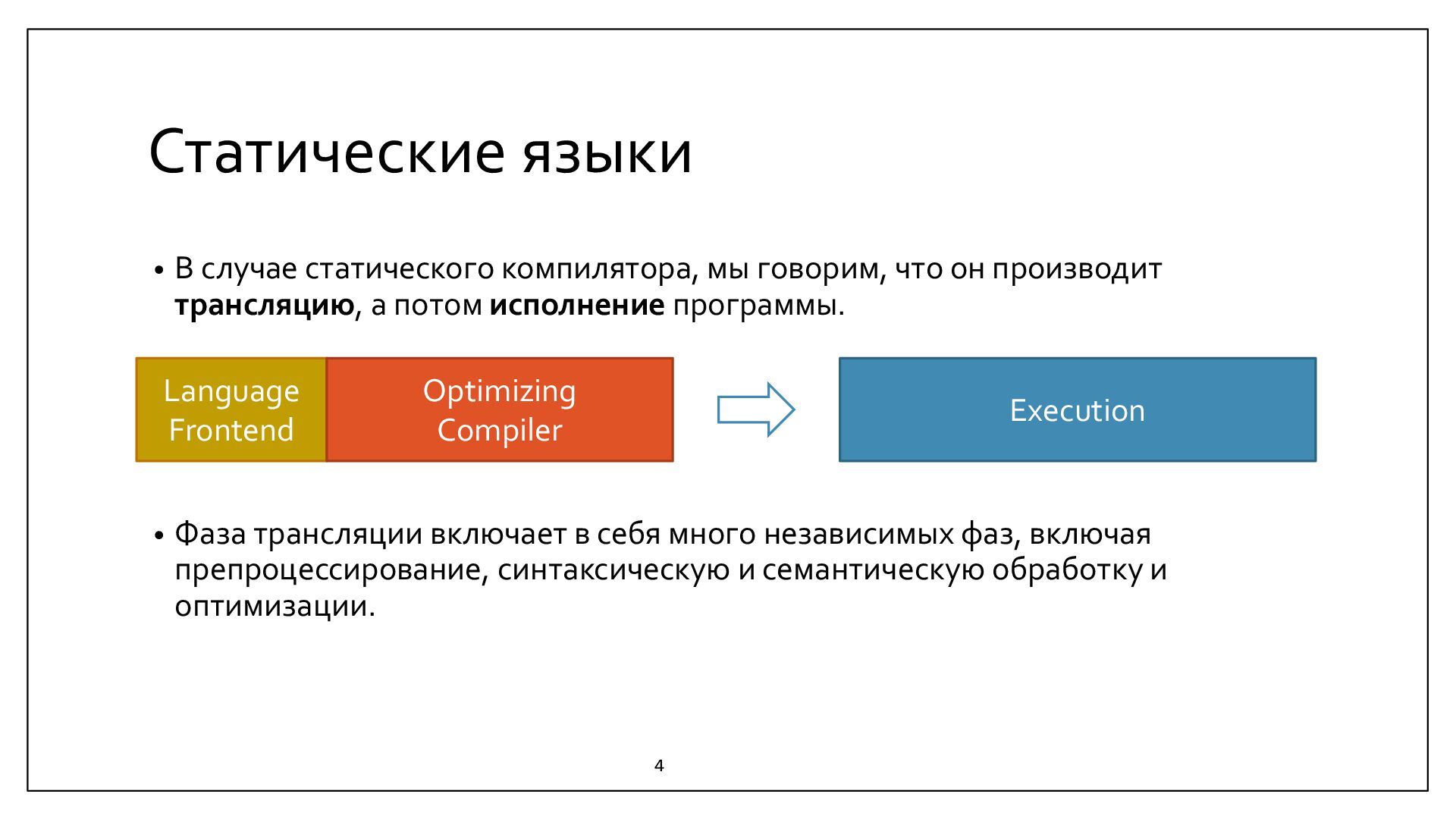{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![As-if rule [intro.abstract] [...] conforming implementations are required to emulate](https://files.speakerdeck.com/presentations/88e4736be9b14a52b455b2a72ab50739/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Undefined behavior • [intro.abstract] A conforming implementation executing a well-formed](https://files.speakerdeck.com/presentations/88e4736be9b14a52b455b2a72ab50739/slide_16.jpg){kind=link}
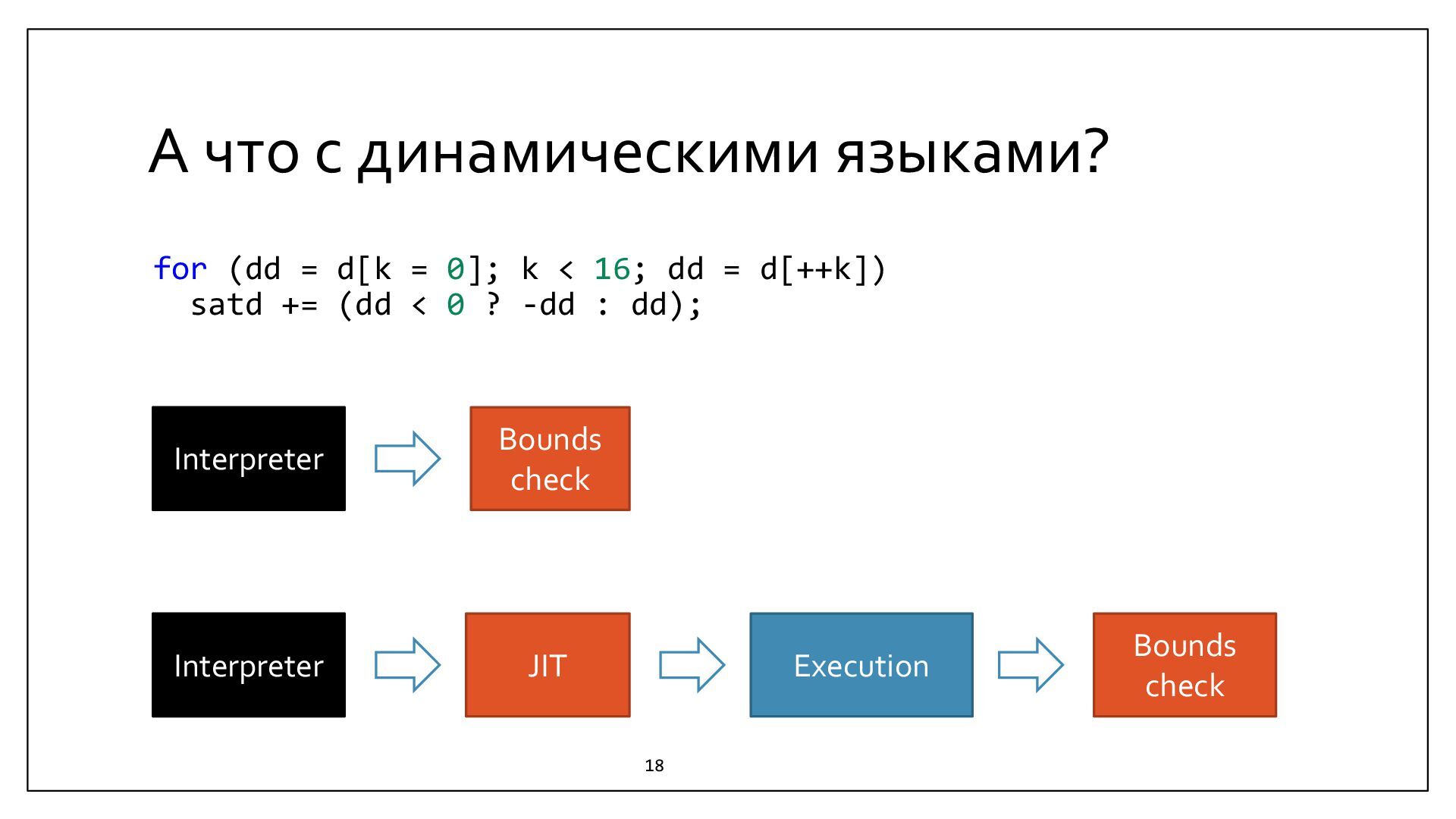{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
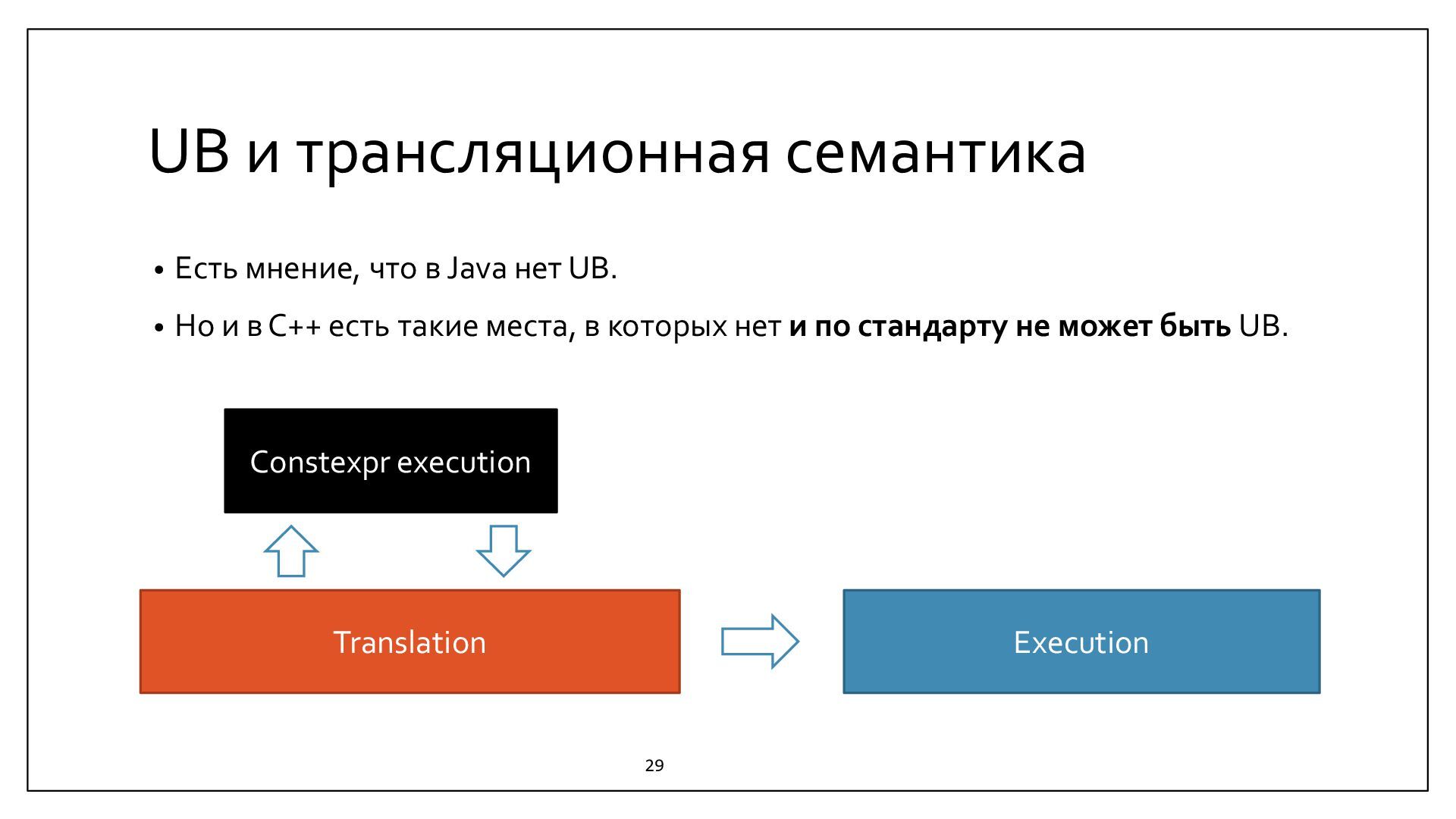{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
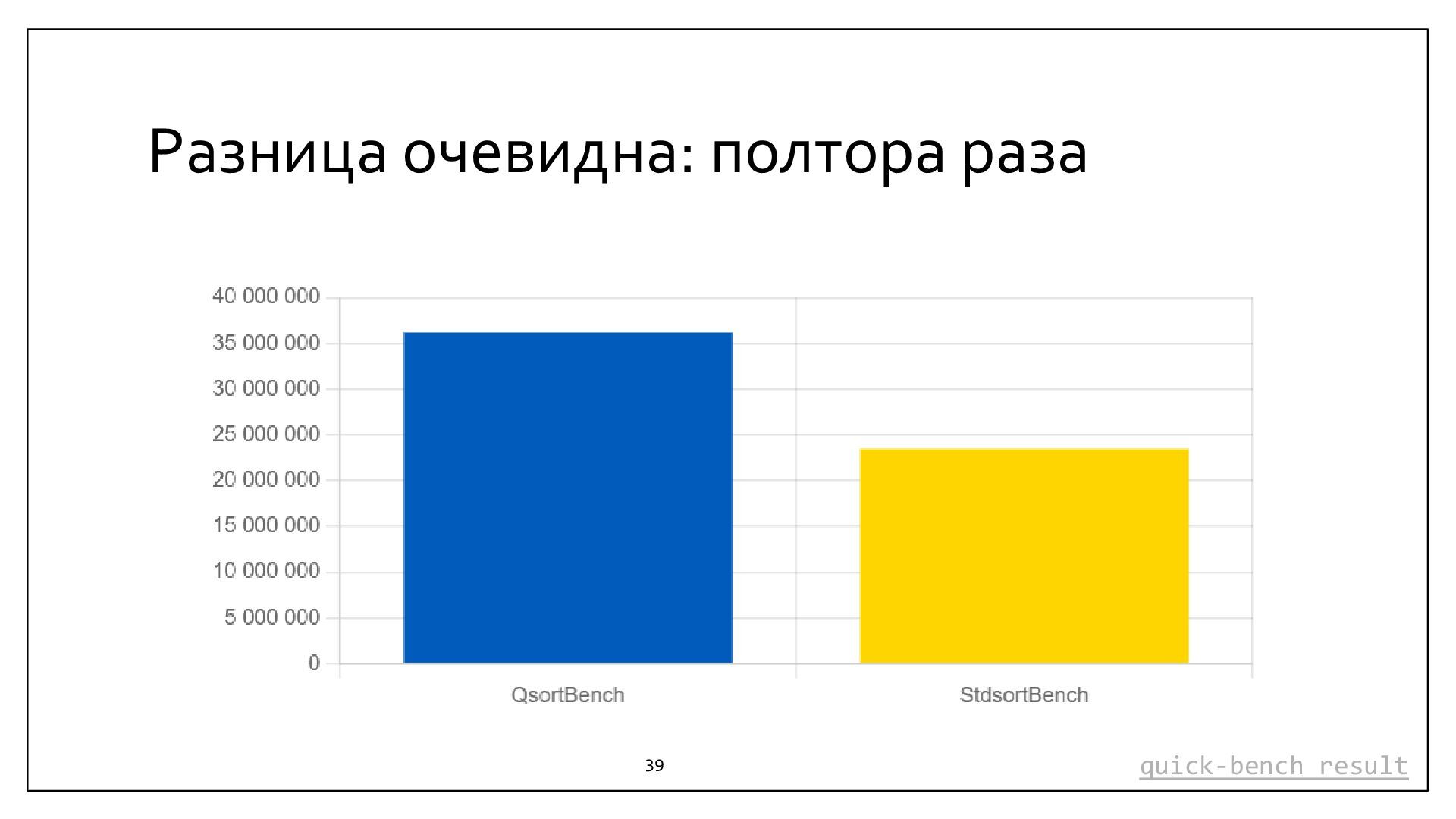{kind=link}
{kind=link}
{kind=link}
{kind=link}
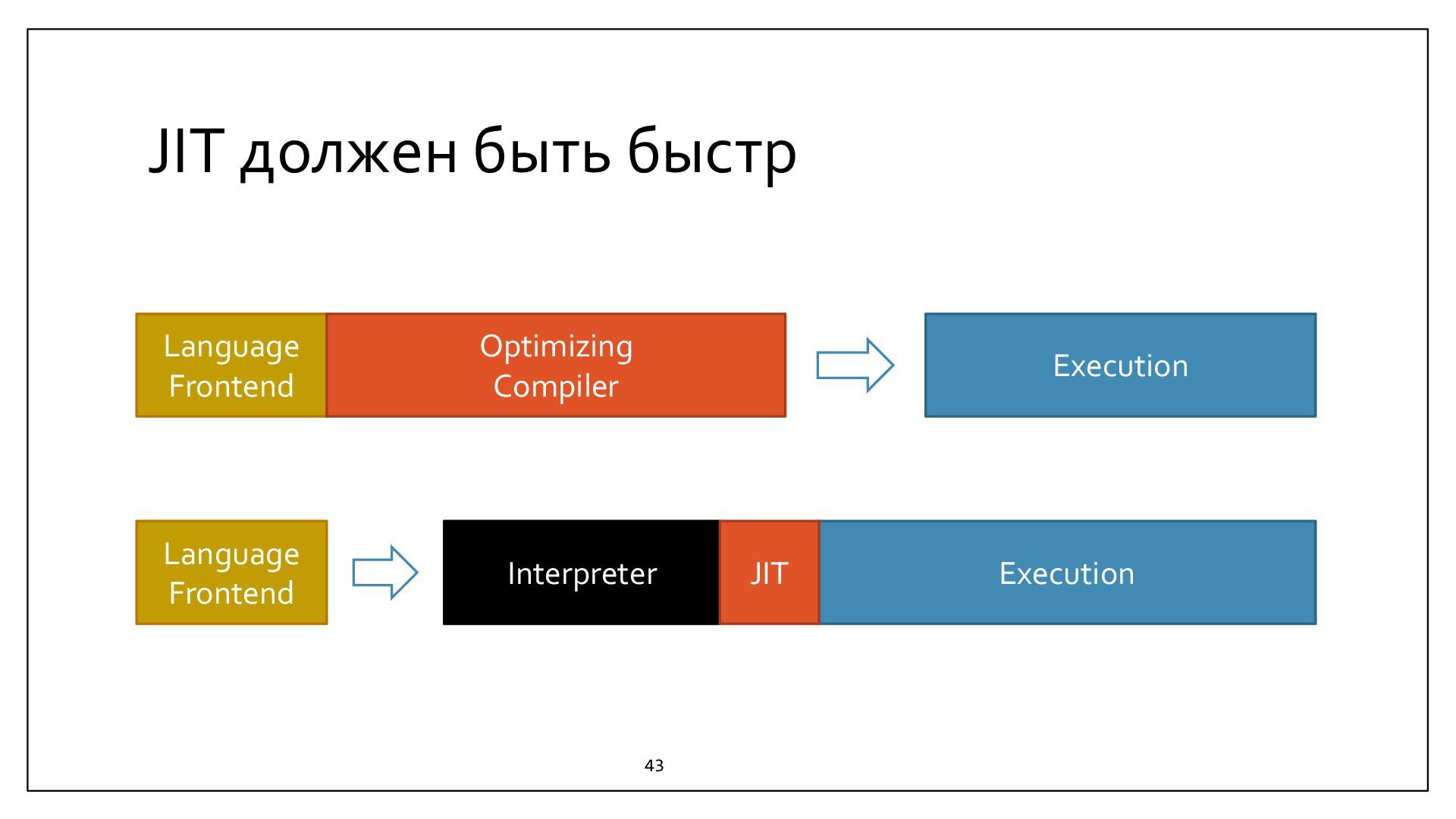{kind=link}
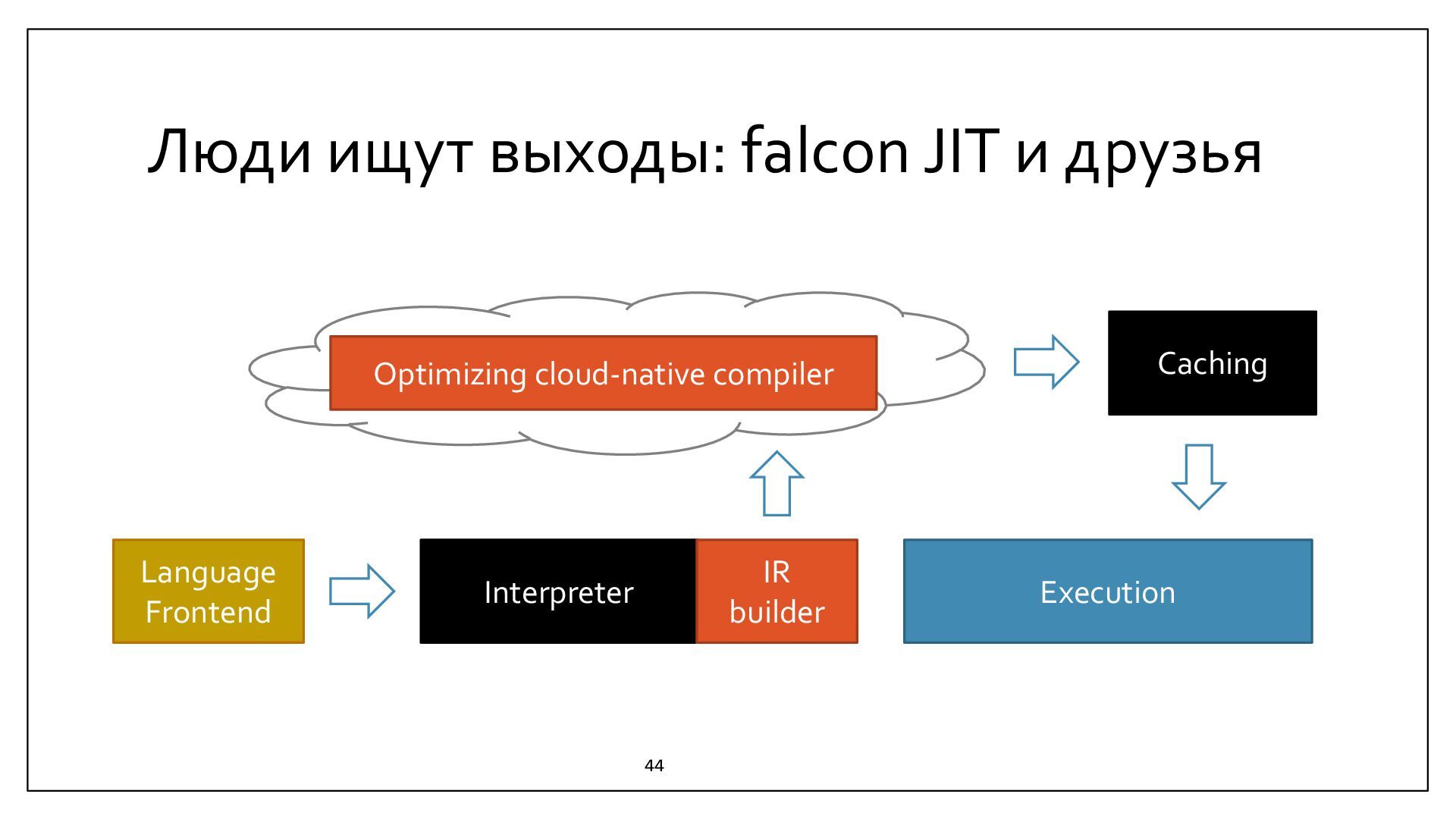{kind=link}
{kind=link}
{kind=link}
{kind=link}
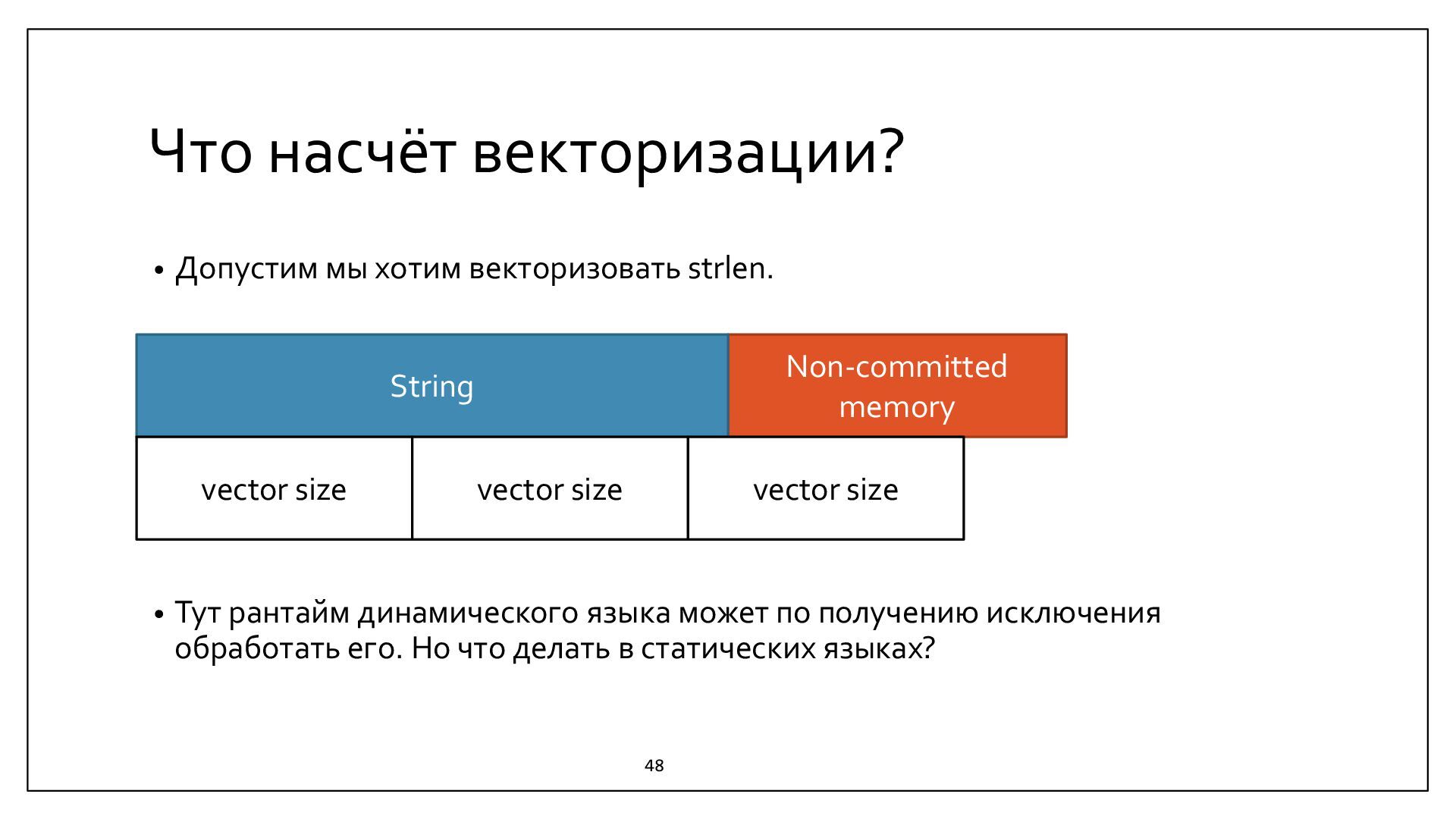{kind=link}
{kind=link}
{kind=link}
{kind=link}
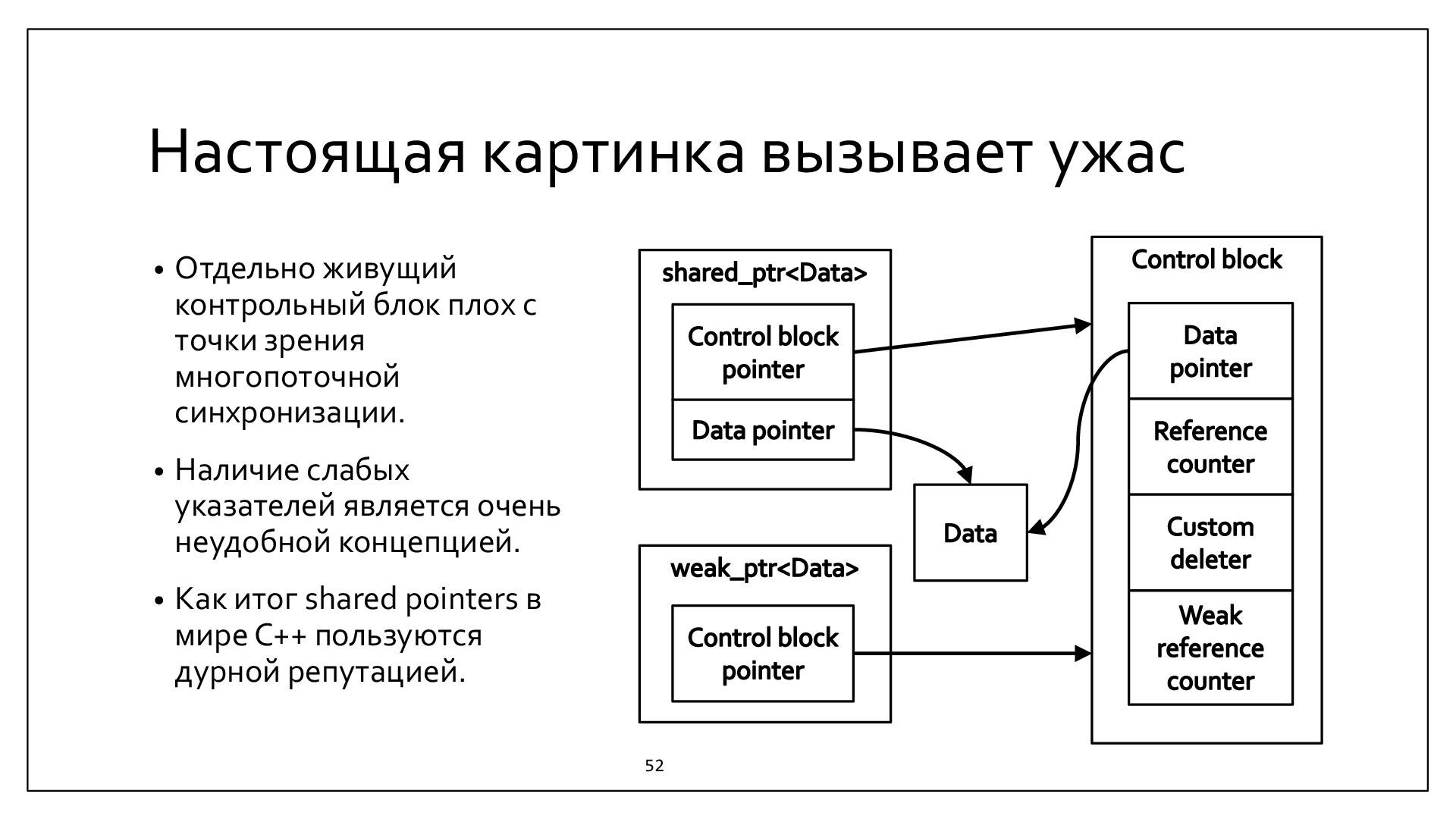{kind=link}