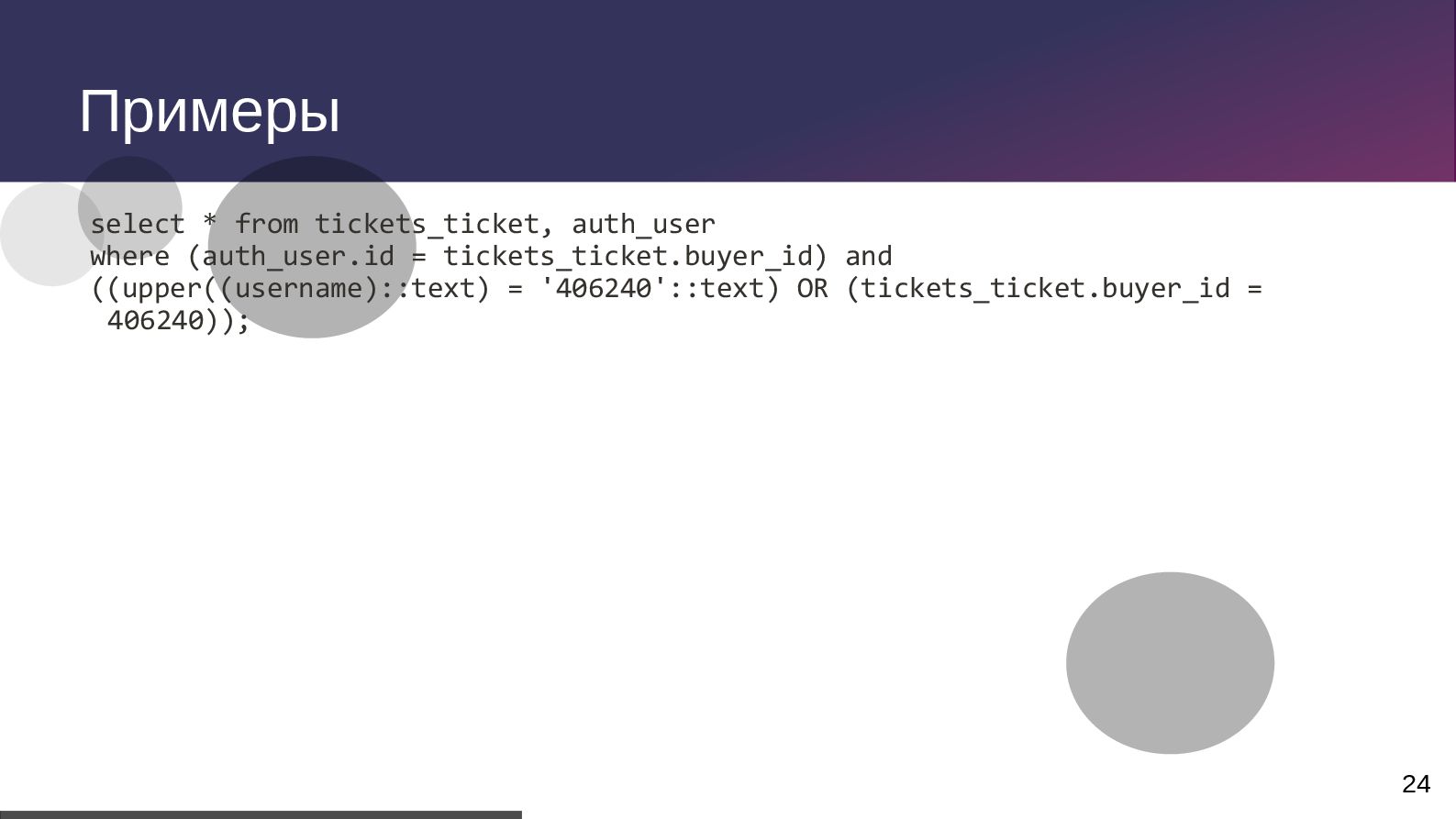
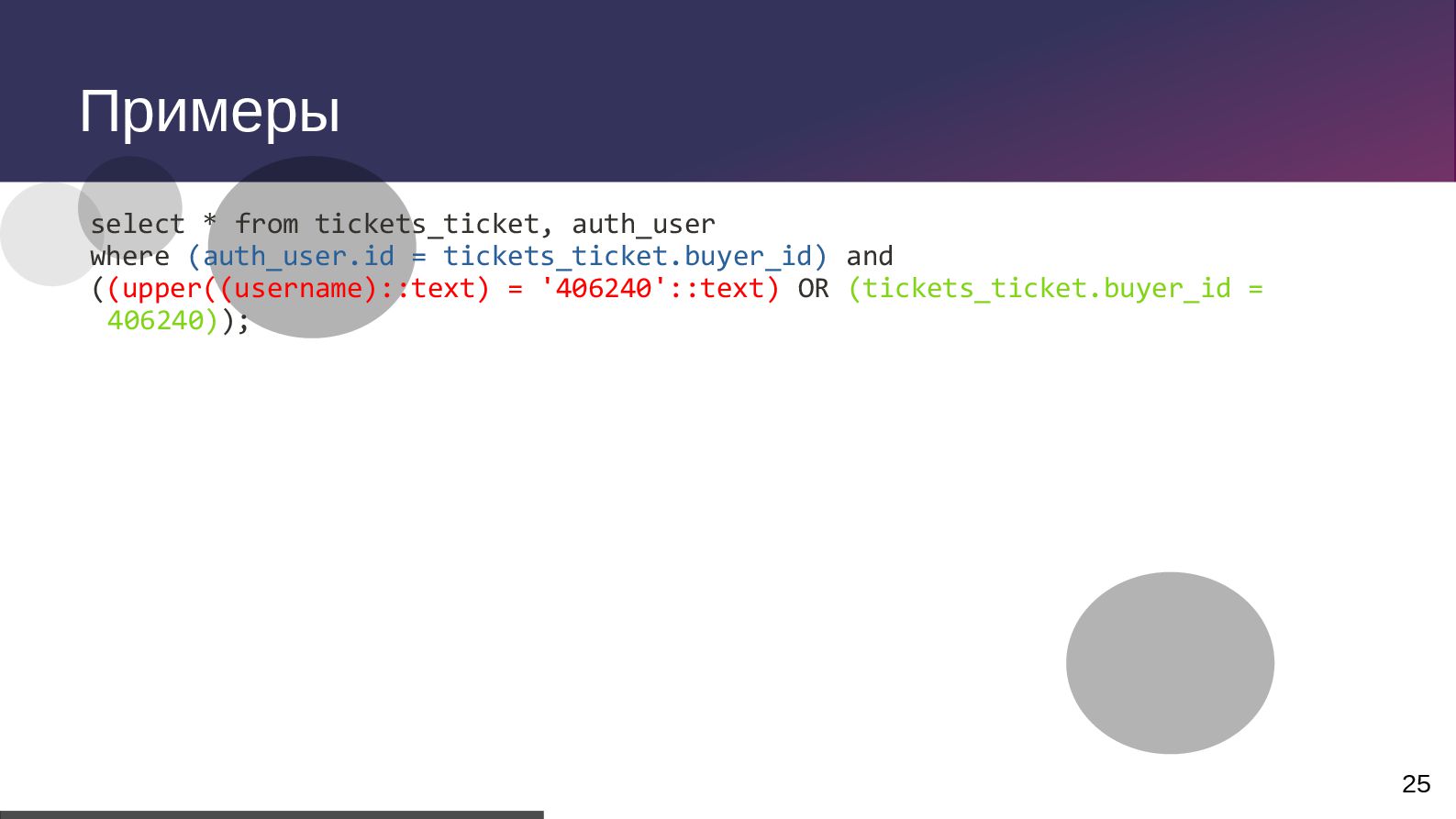
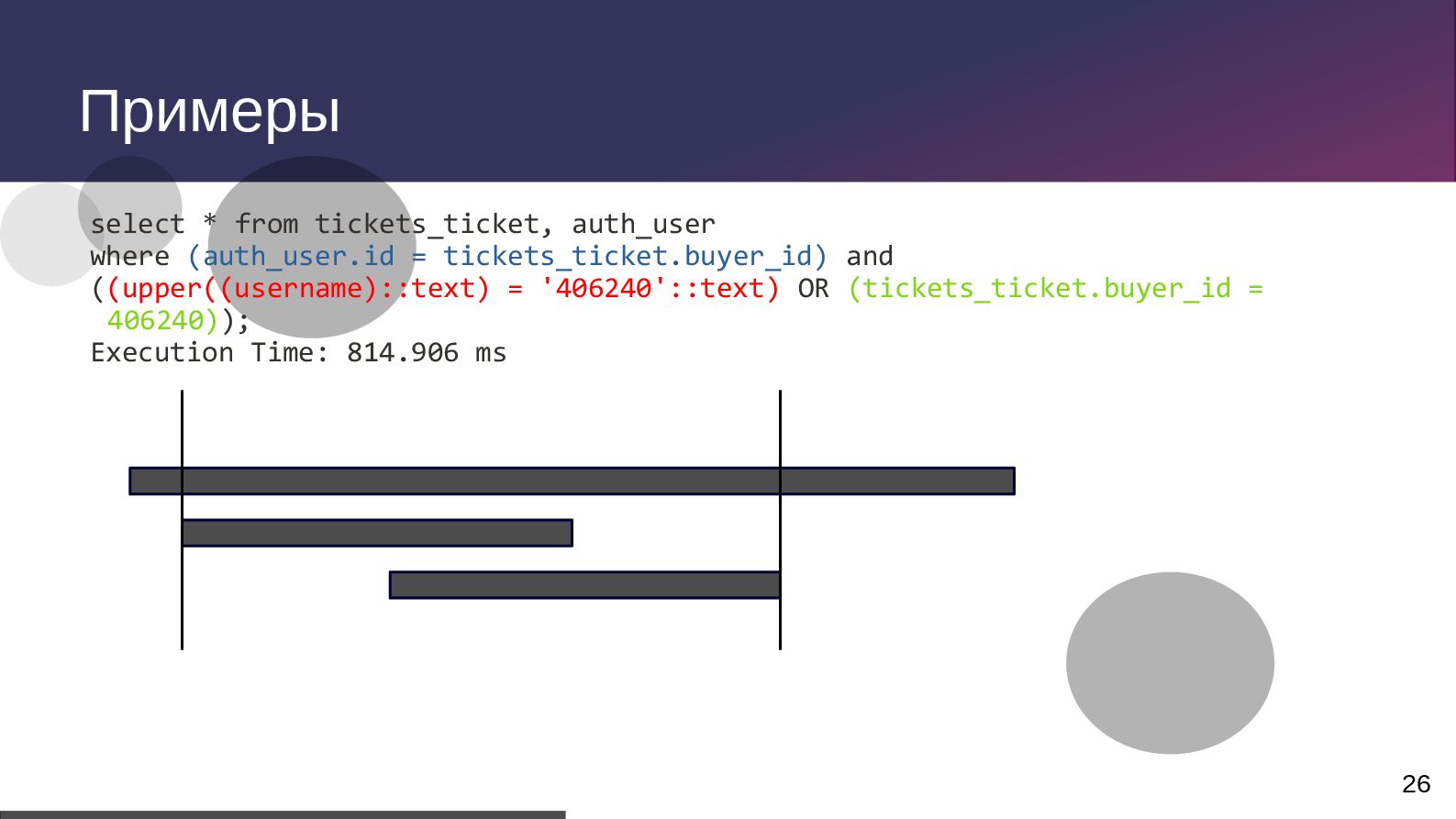
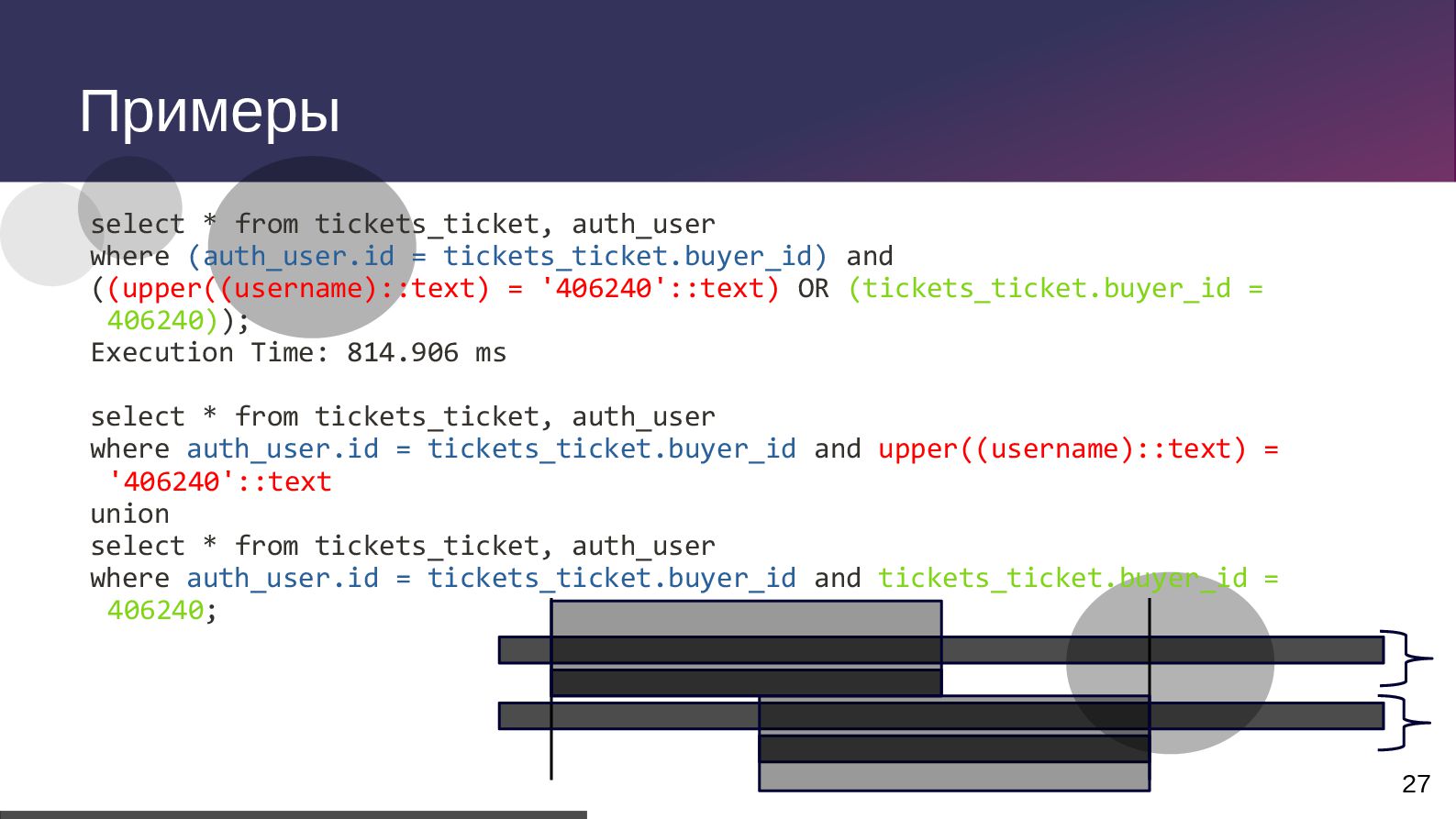
txid:0] [SELECT] LOG: duration: 100.494 ms execute S_17: select totetransp0_.id as id1_1_, totetransp0_.created as created2_1_, totetransp0_.modified as modified3_1_, totetransp0_.version as version4_1_, totetransp0_.active_date as active_d5_1_, totetransp0_.complete_status as complete6_1_, totetransp0_.current_location_id as current15_1_, totetransp0_.destination_location_id as destina16_1_, totetransp0_.error_reason as error_re7_1_, totetransp0_.finished_date as finished8_1_, totetransp0_.forcedfinish as forcedfi9_1_, totetransp0_.number as number10_1_, totetransp0_.original_destination_location_id as origina17_1_, totetransp0_.source_location_id as source_18_1_, totetransp0_.status as status11_1_, totetransp0_.tote_number as tote_nu12_1_, totetransp0_.transport_batch_number as transpo13_1_, totetransp0_.type as type14_1_ from tote_transport_order totetransp0_ where totetransp0_.tote_number=$1 and (totetransp0_.status in ($2 , $3 , $4 , $5 , $6)) order by totetransp0_.modified desc limit $7 2024-09-29 00:00:00.686 MSK 105770 user@db_name from 10.13.19.81 [vxid:53/174763983 txid:0] [SELECT] DETAIL: parameters: $1 = 'T00000005212', $2 = 'CREATED', $3 = 'ACTIVE', $4 = 'FINISHED', $5 = 'CANCELLED', $6 = 'ERROR', $7 = '1'
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
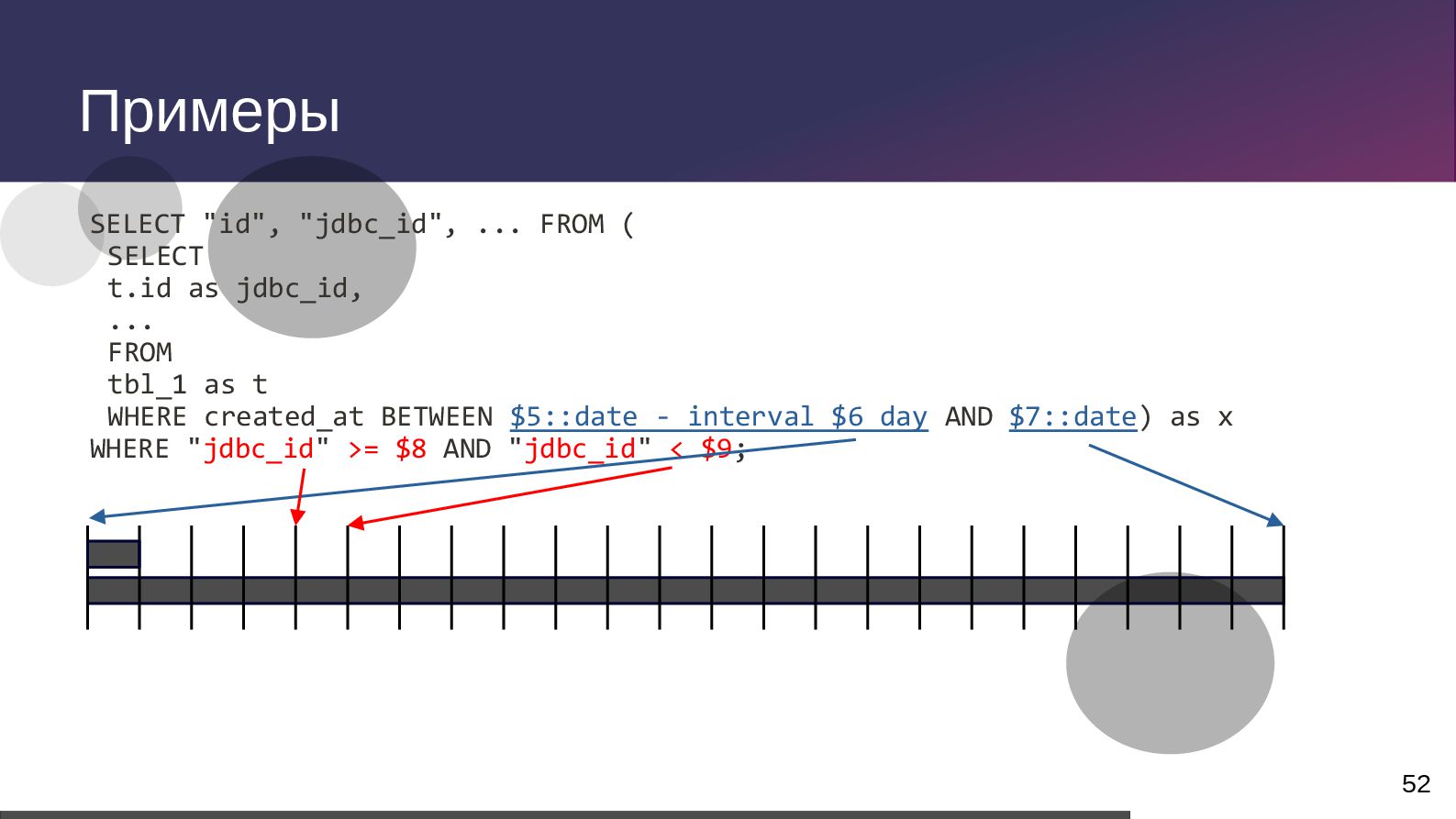{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
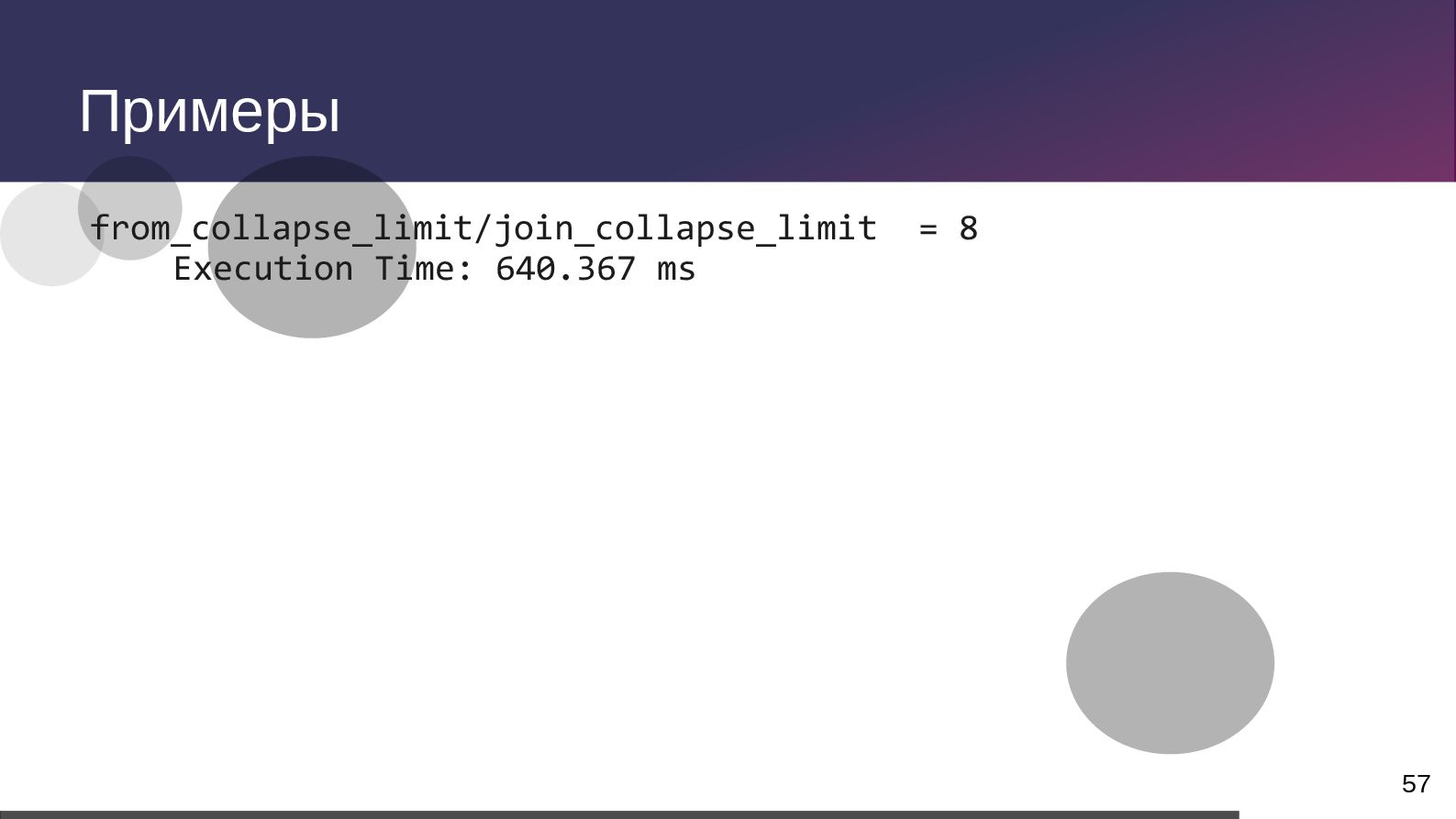{kind=link}
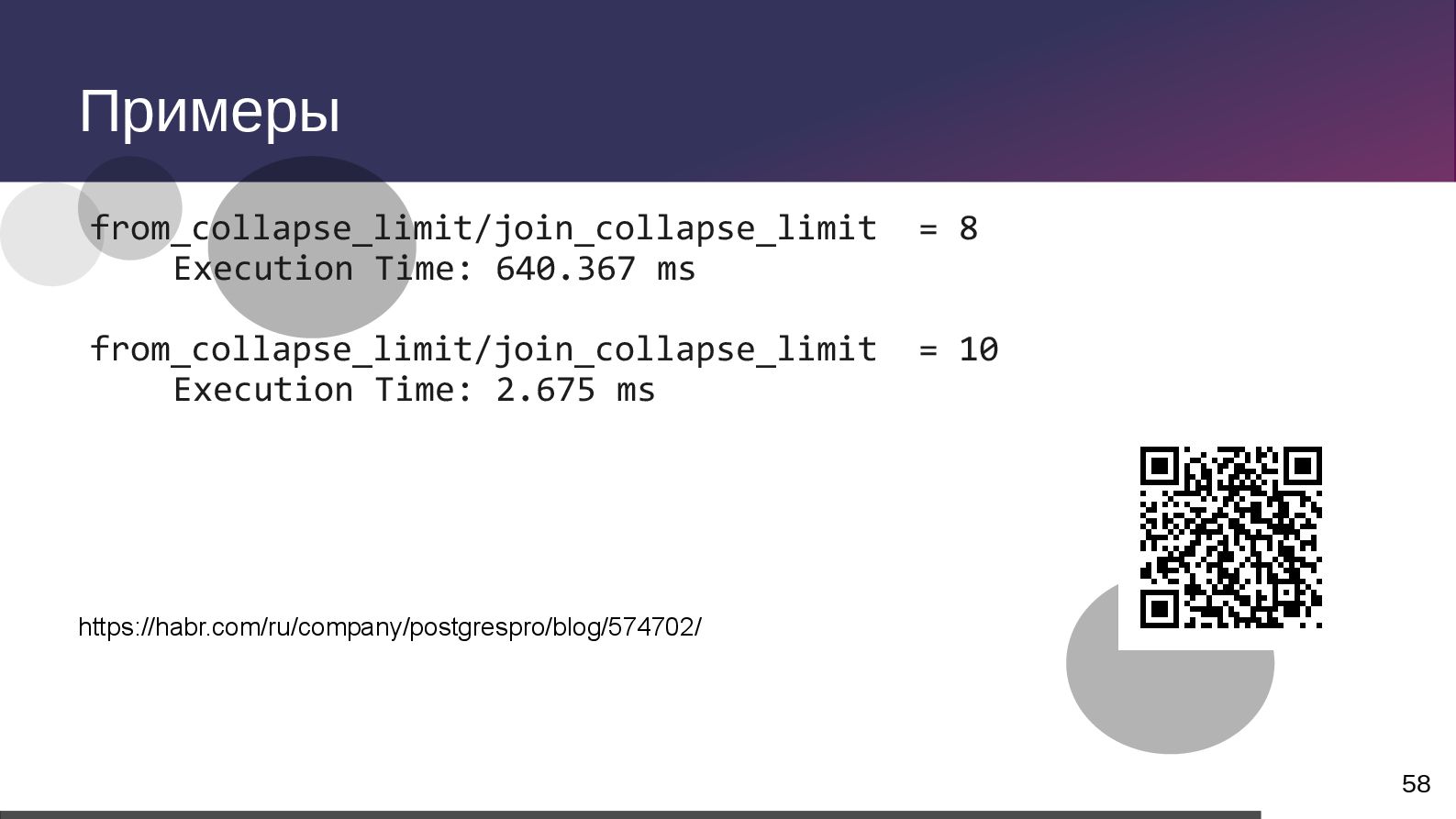{kind=link}
{kind=link}
{kind=link}
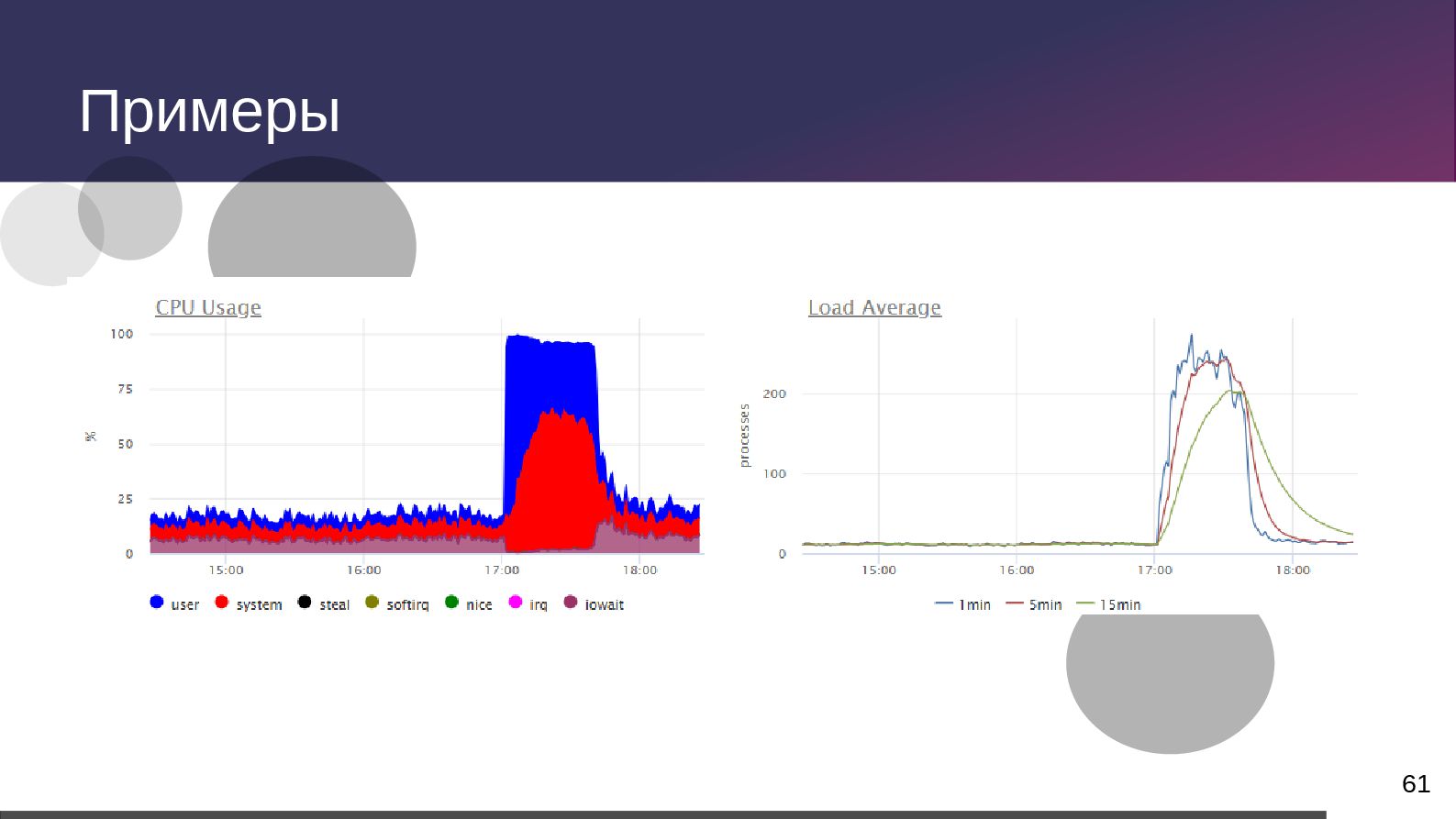{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![67 DBA Team Александр Никитин E-mail: [email protected] tg: @anikitindba Бонус:](https://files.speakerdeck.com/presentations/c702efe405de4ac8bce87918a8d04ec8/slide_66.jpg){kind=link}