Share
2026/06/26 AWS Summit Japan 2026 https://aws.amazon.com/jp/events/summits/japan/
Amazon Redshift zero-ETL 統合を活用した軽量なマルチプロダクトデータ可視化基盤
原 トリ 取締役 CTO
坂井 学 SWE
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
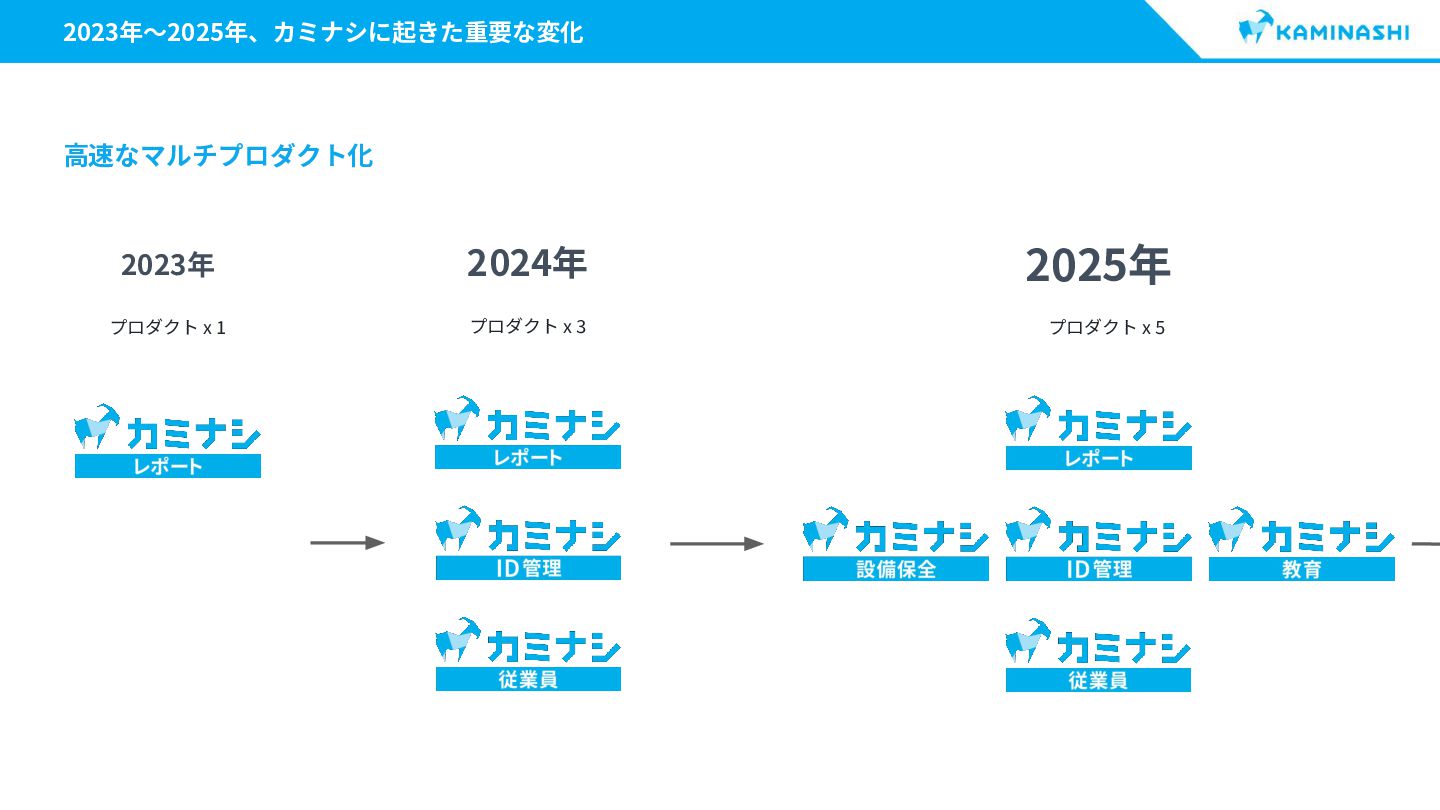{kind=link}
{kind=link}
{kind=link}
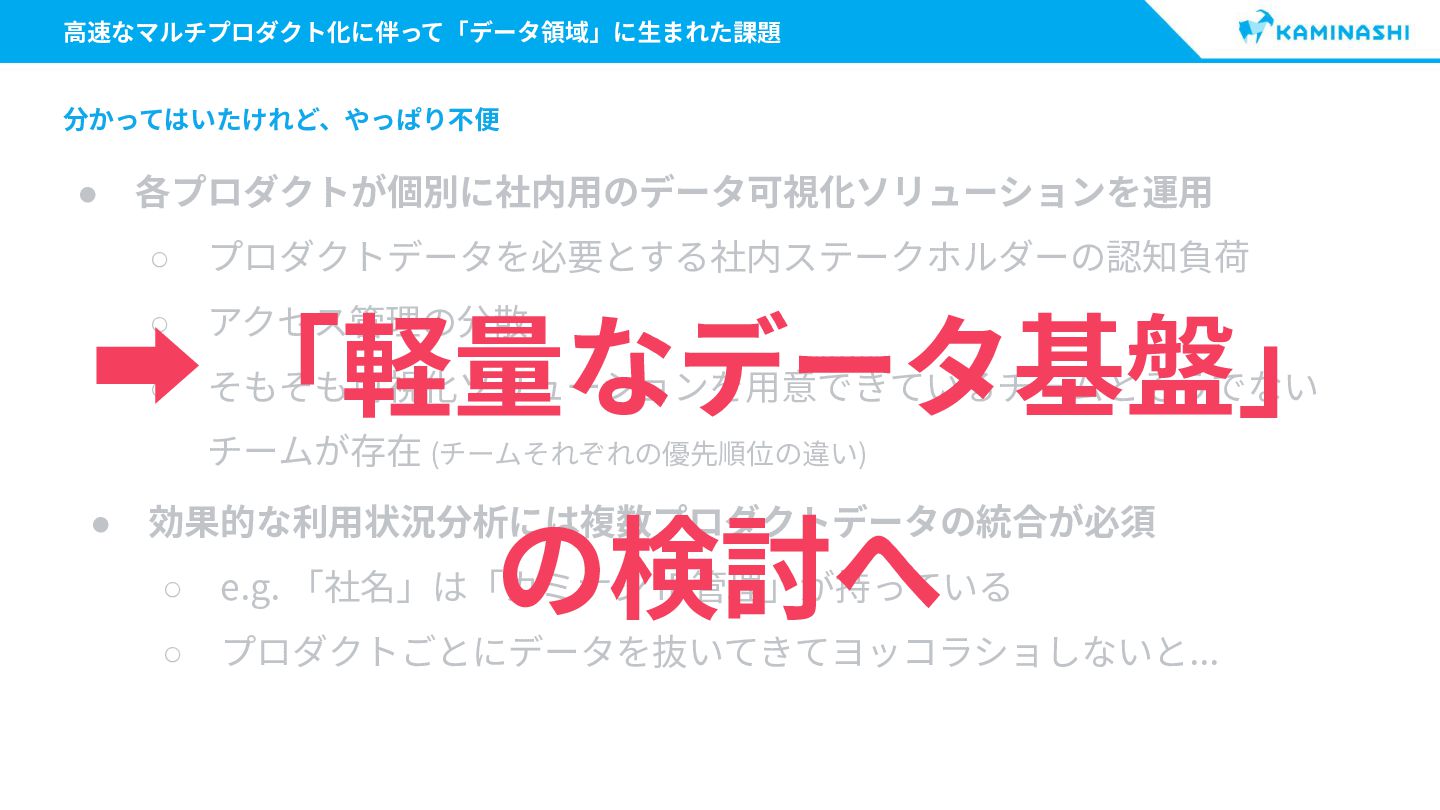{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
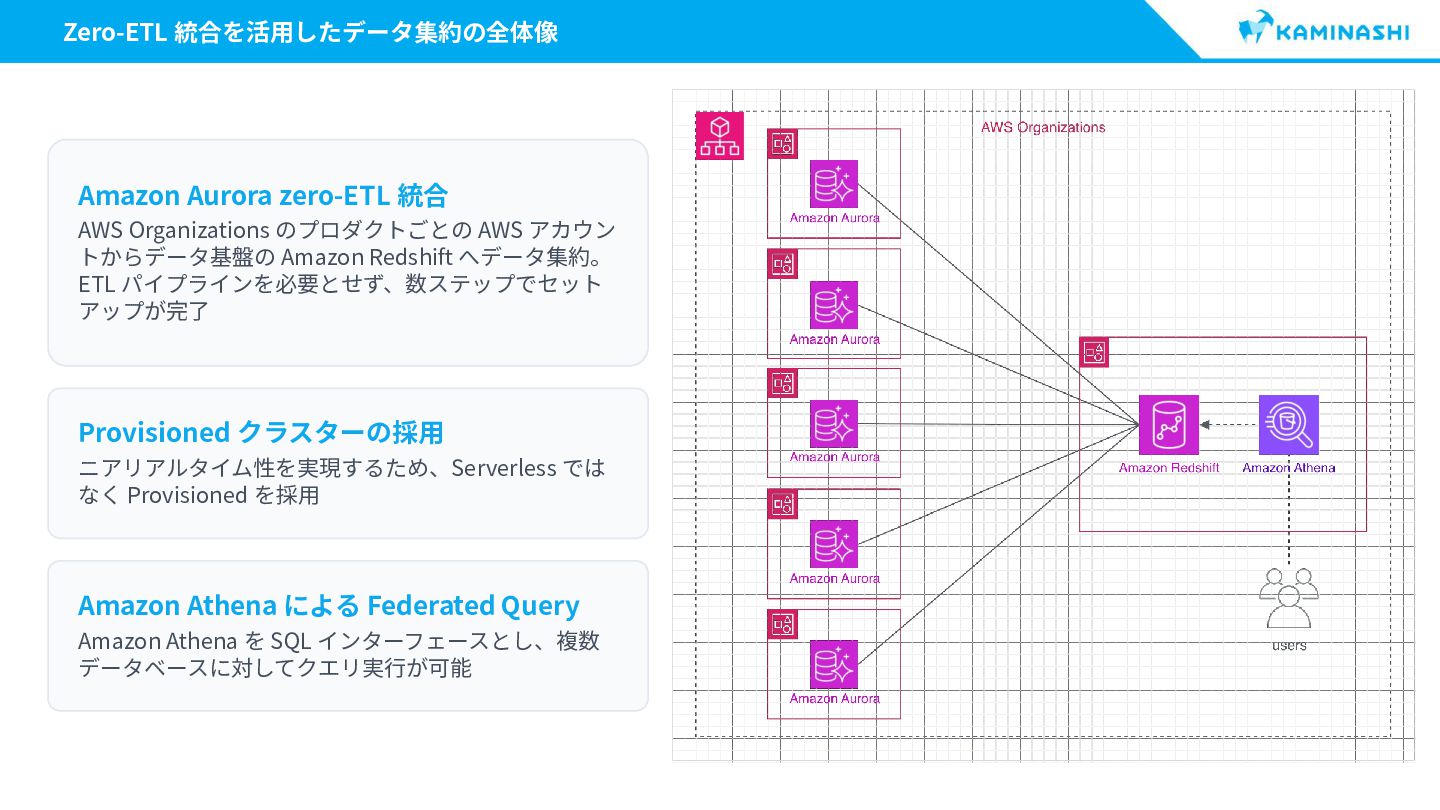{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
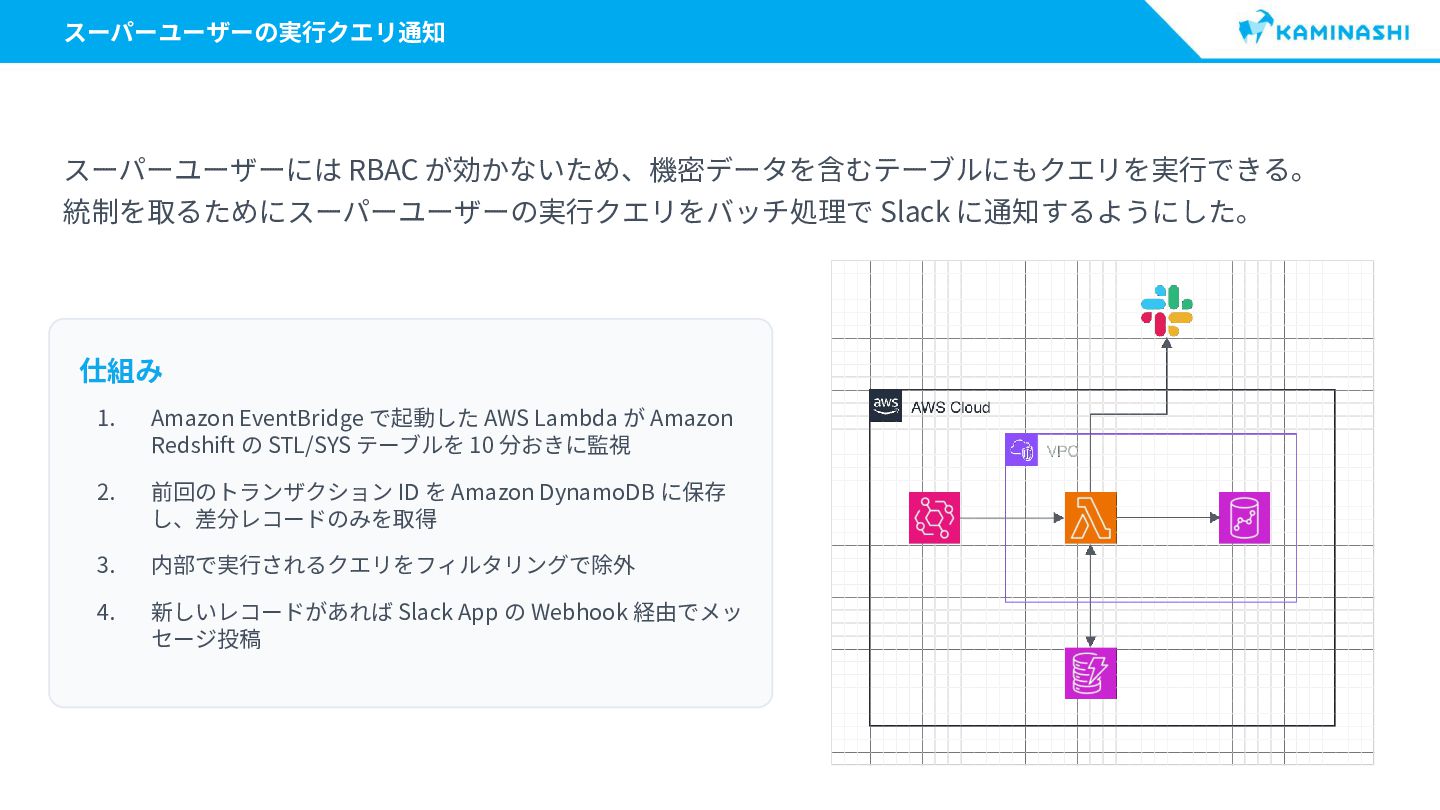{kind=link}
{kind=link}
{kind=link}
{kind=link}
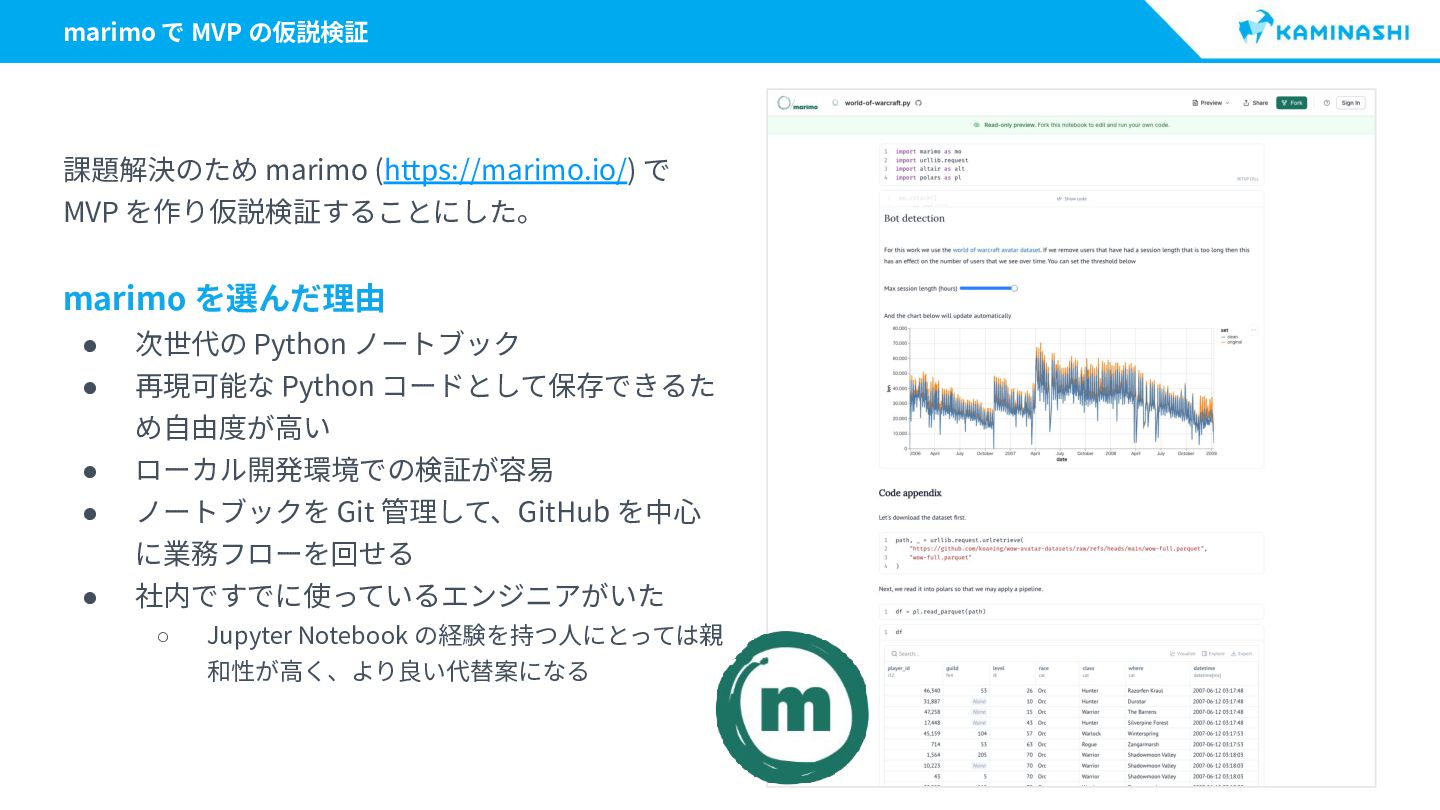{kind=link}
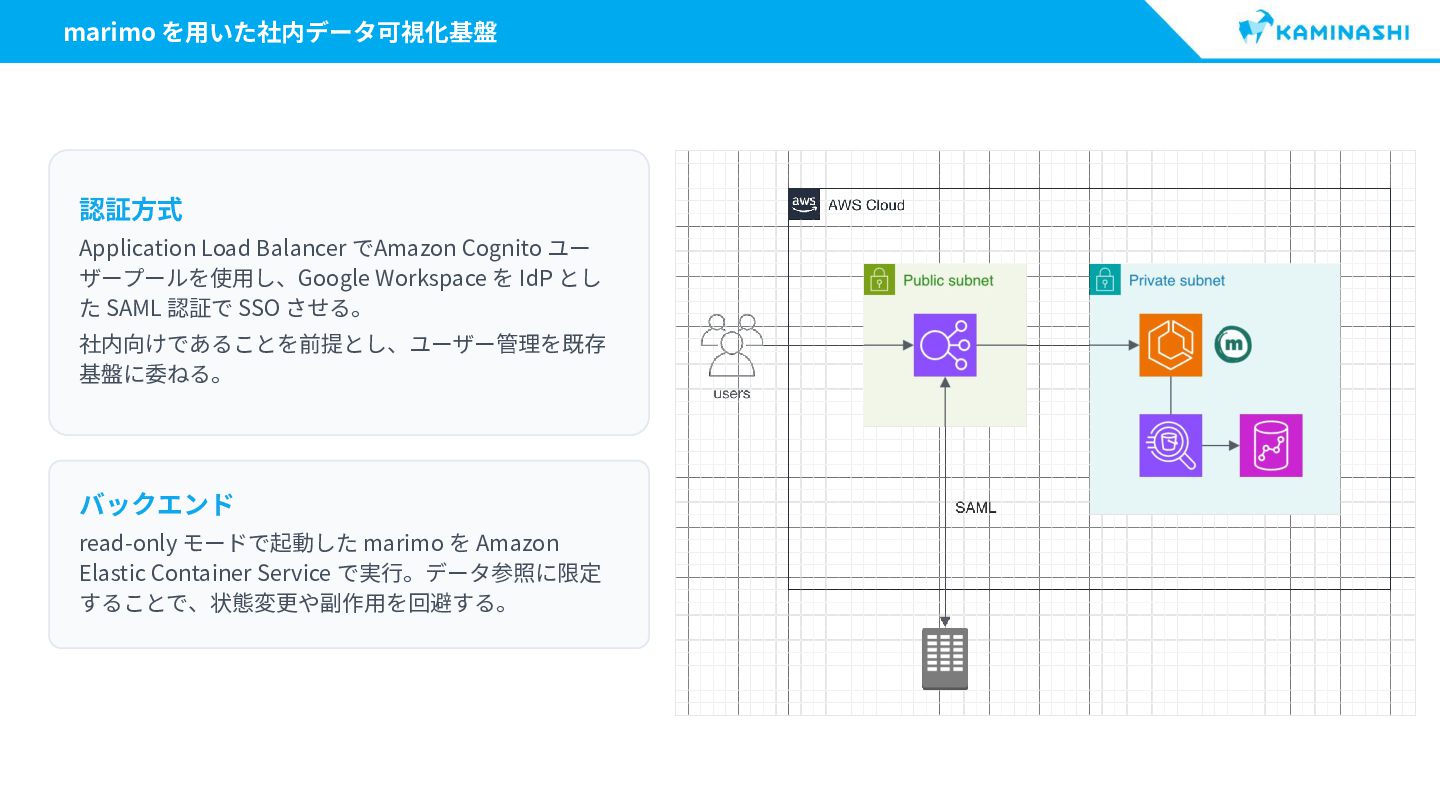{kind=link}
{kind=link}
{kind=link}