| [.id.S, .address.S, .business_hour.S, .image_url.S, .latitude.N, .longitude.N, .name.S, .website_url.S] | @csv' \ > spots.csv ちょっと工夫して、タグも文字列連結して出力 aws dynamodb scan --table-name niigata_gourmet_spots | \ jq -r '.Items[] | [.id.S, .address.S, .business_hour.S, .image_url.S, .latitude.N, .longitude.N, .name.S, ([.tags.L[].S] | join(",")), .website_url.S] | @csv' \ > spots.csv ヘッダ行が必要な場合は、ヘッダ用の配列を追加しておく。 aws dynamodb scan --table-name niigata_gourmet_spots | \ jq -r '["id","address","business_hour","image_url","latitude","longitude","name","tags","website_url"], (.Items[] | [.id.S, .address.S, .business_hour.S, .image_url.S, .latitude.N, .longitude.N, .name.S, ([.tags.L[].S] | join(",")), .website_url.S]) | @csv' \ > spots.csv jqで応用は効くが、面倒ではある AWS CLIでCSV出力 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![aws dynamodb scan --table-name niigata_gourmet_spots | \ jq -r '.Items[]](https://files.speakerdeck.com/presentations/691fcebdd58840c08aa74d4861b26c73/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
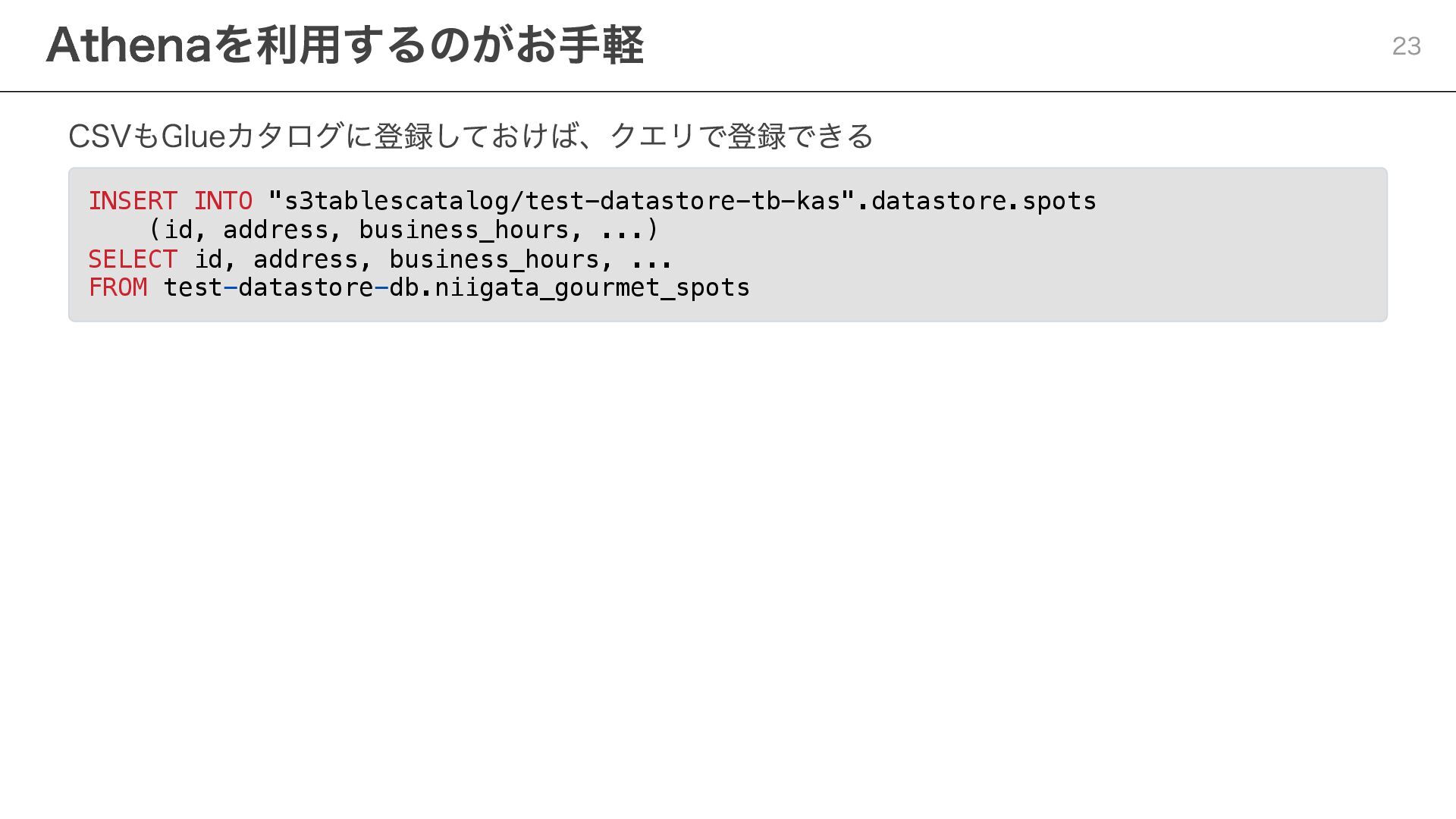{kind=link}
{kind=link}
{kind=link}
{kind=link}
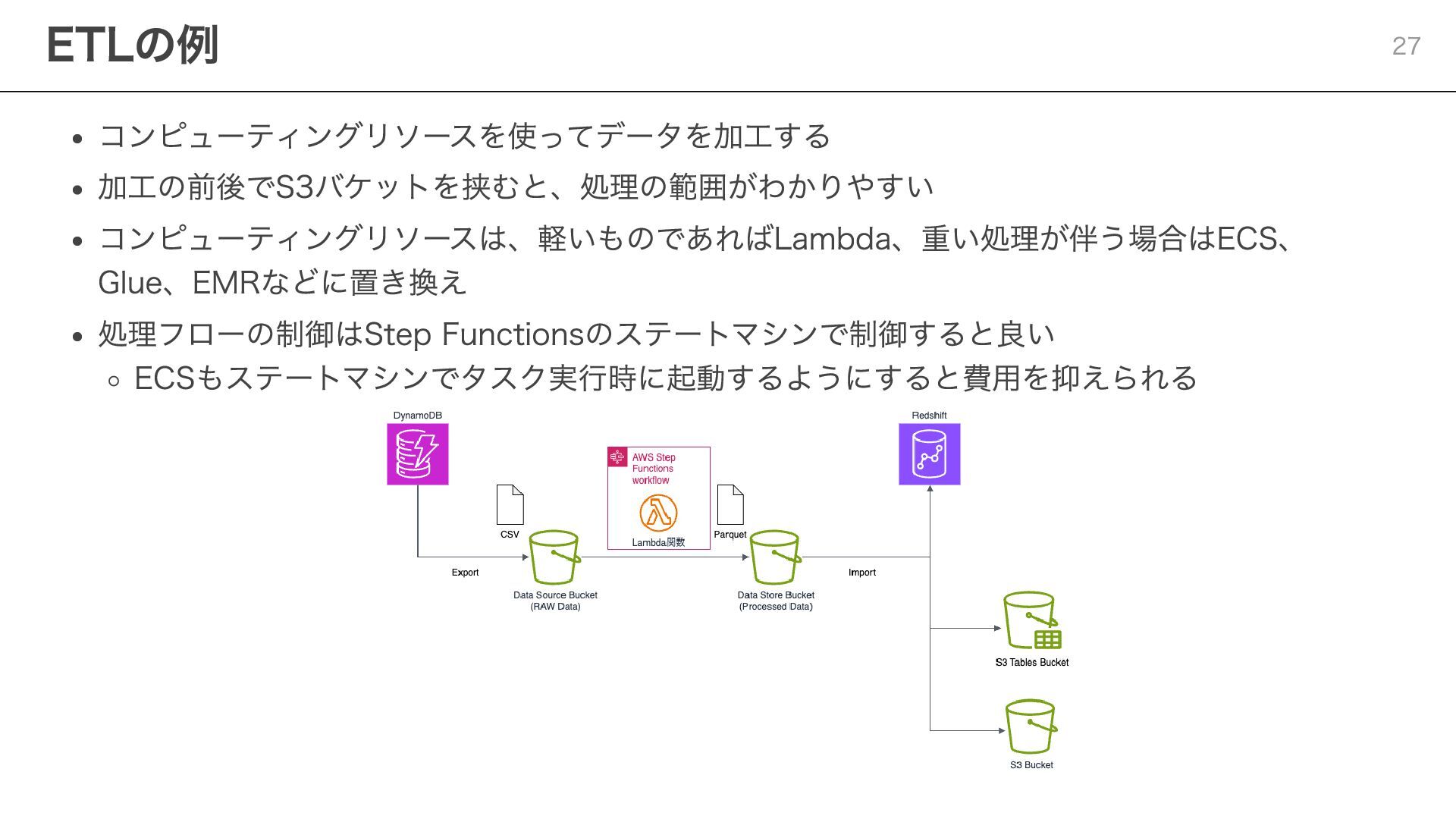{kind=link}
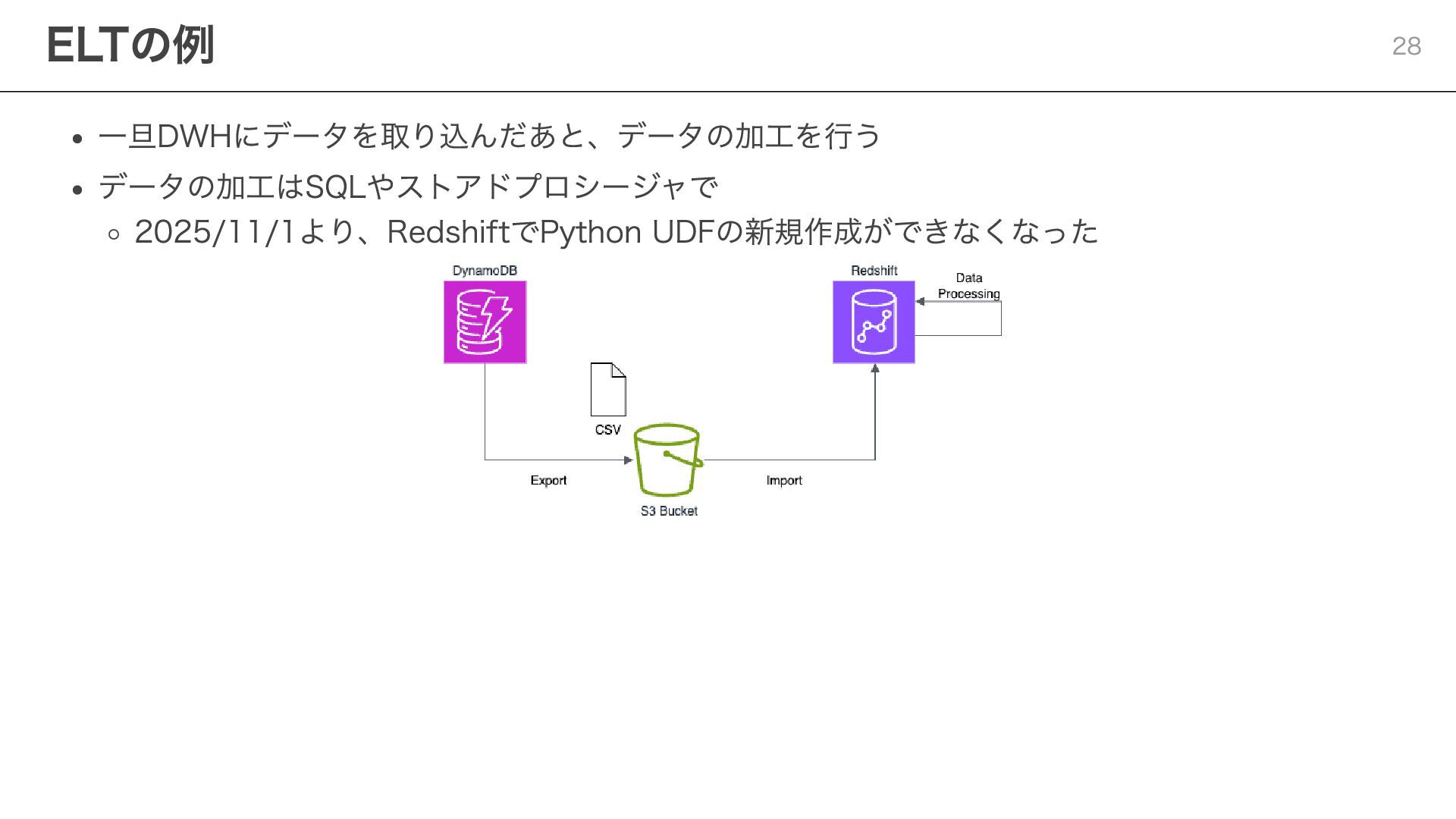{kind=link}
{kind=link}
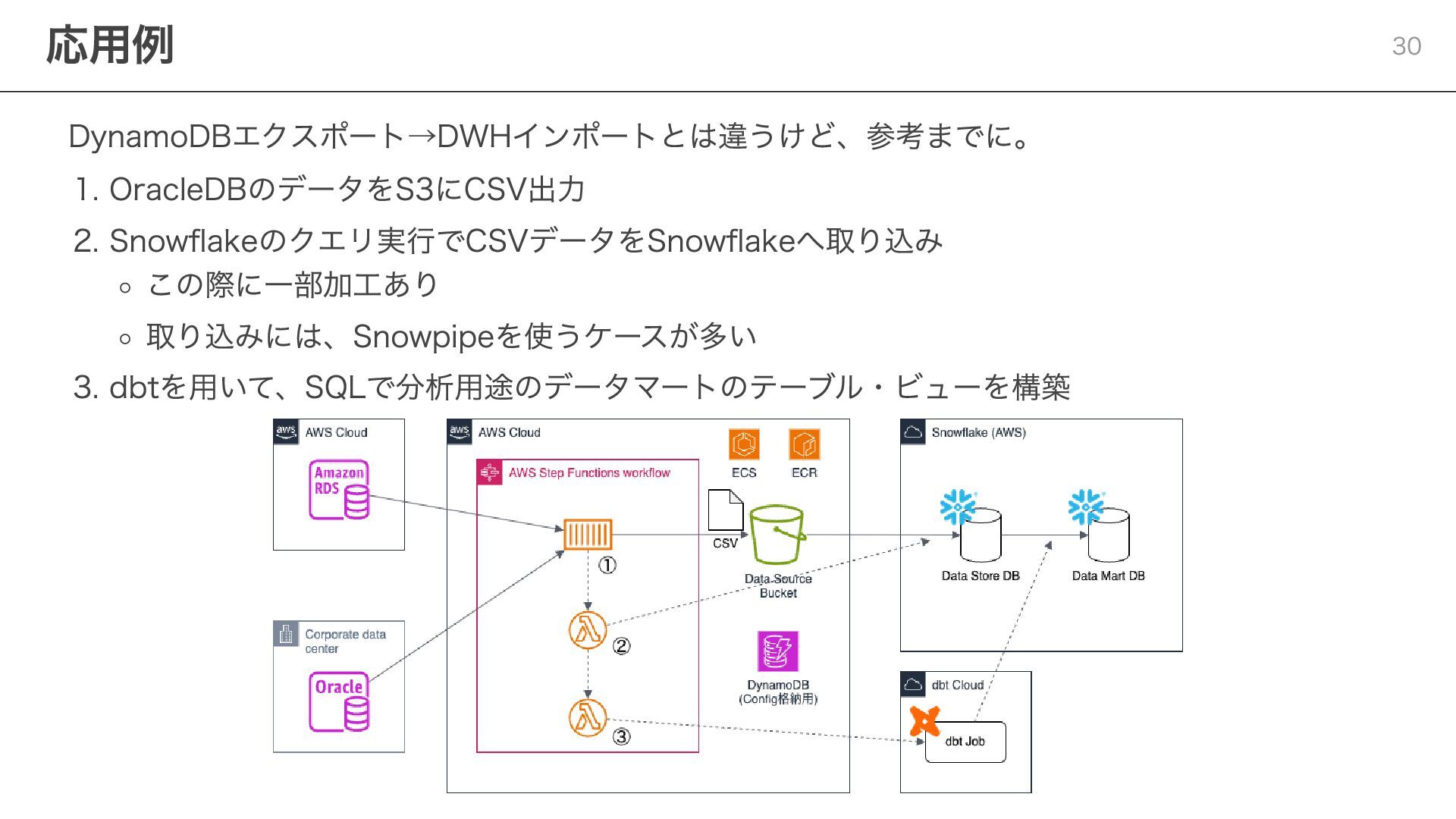{kind=link}
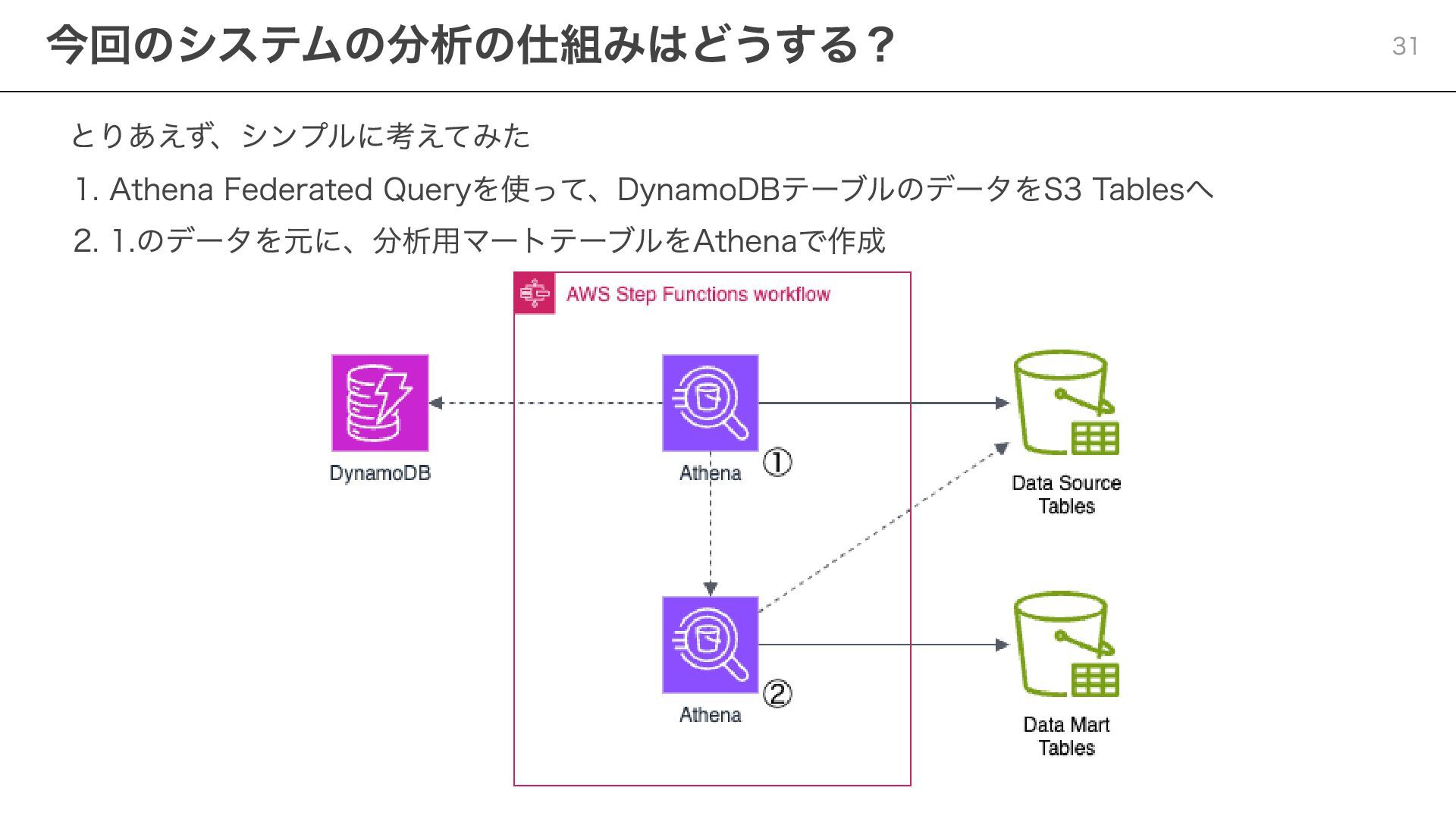{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}