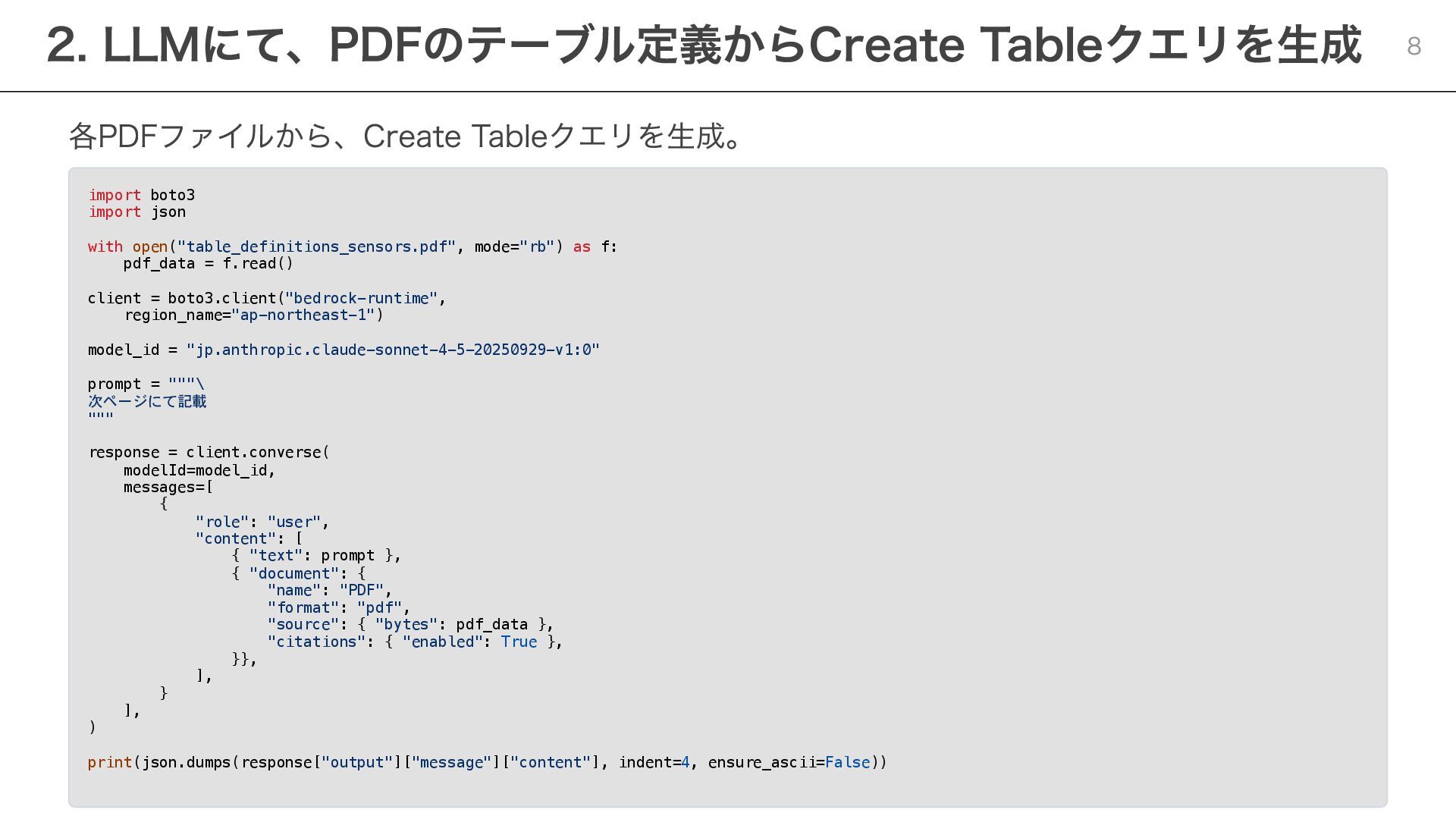
sensor_name VARCHAR NOT NULL, location VARCHAR, is_enabled NUMERIC NOT NULL, latitude DOUBLE PRECISION, longitude DOUBLE PRECISION); -- テーブルコメント COMMENT ON TABLE sensors IS 'センサー情報を管理するテーブル'; -- カラムコメント COMMENT ON COLUMN sensors.sensor_id IS 'センサーの一意識別子 主キー'; COMMENT ON COLUMN sensors.sensor_name IS 'センサーの名称'; COMMENT ON COLUMN sensors.location IS 'センサーの設置場所'; COMMENT ON COLUMN sensors.is_enabled IS 'センサー利用有無 (1: 有効, 2: 無効)'; COMMENT ON COLUMN sensors.latitude IS 'センサー設置緯度 10進数表記'; COMMENT ON COLUMN sensors.longitude IS 'センサー設置経度 10進数表記'; 出力結果例: Amazon Redshift (1) 10
timestamp TIMESTAMP NOT NULL, temperature DOUBLE PRECISION, humidity DOUBLE PRECISION); -- テーブルコメント COMMENT ON TABLE sensor_timelines IS 'センサーから収集された時系列データを管理するテーブル'; -- カラムコメント COMMENT ON COLUMN sensor_timelines.sensor_id IS 'センサーの一意識別子 外部キー (sensors.sensor_id)'; COMMENT ON COLUMN sensor_timelines.timestamp IS 'データ取得時刻 ISO 8601形式 (タイムゾーン付き)'; COMMENT ON COLUMN sensor_timelines.temperature IS '温度 摂氏 (℃)'; COMMENT ON COLUMN sensor_timelines.humidity IS '湿度 パーセント (%)'; 出力結果例: Amazon Redshift (2) 11
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}