Technical SEO at Cox Automotive • Author of Rich Snippets • Excitable nerd from New York (phones up is my cue to pause) • /in/jamie-indigo • not-a-robot.com • Proud pet parent
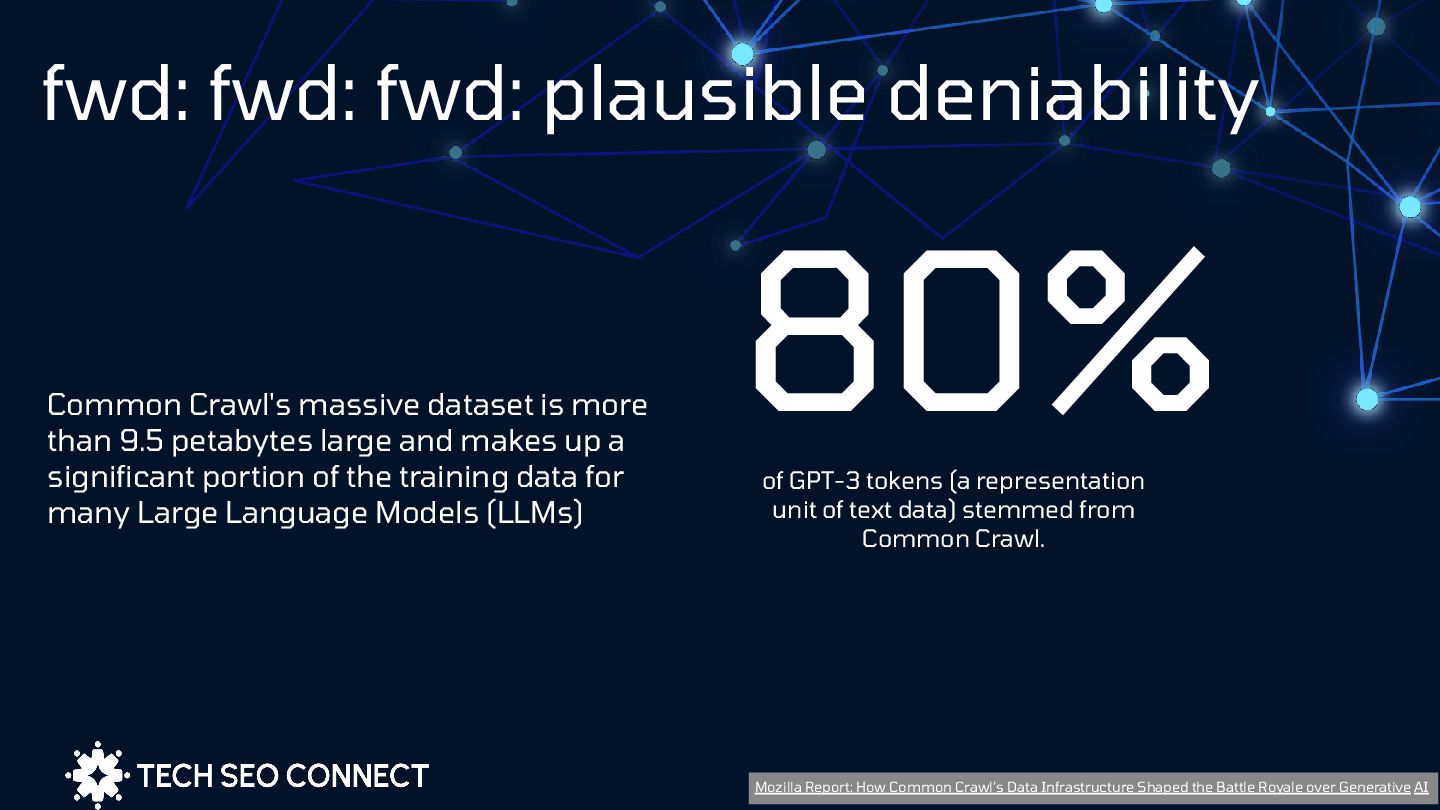
more than 9.5 petabytes large and makes up a significant portion of the training data for many Large Language Models (LLMs) of GPT-3 tokens (a representation unit of text data) stemmed from Common Crawl. 80% Mozilla Report: How Common Crawl’s Data Infrastructure Shaped the Battle Royale over Generative AI
suggest dramatic declines in aggregate traffic — often based on flawed methodologies, isolated examples, or traffic changes that occurred prior to the roll out of AI features in Search."
suggest dramatic declines in aggregate traffic — often based on flawed methodologies, isolated examples, or traffic changes that occurred prior to the roll out of AI features in Search." THEN HELP US LEARN BETTER
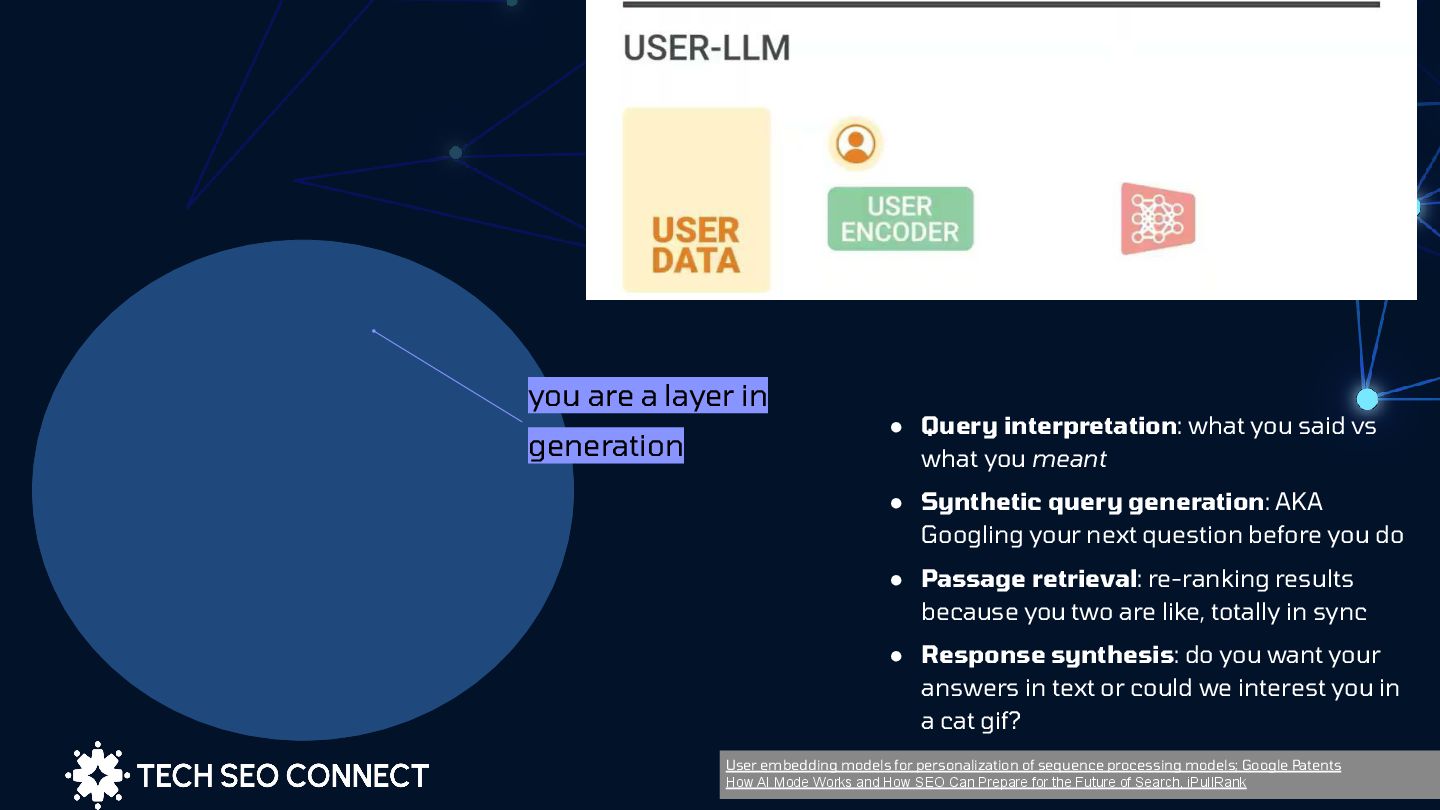
Patents How AI Mode Works and How SEO Can Prepare for the Future of Search, iPullRank you are a layer in generation • Query interpretation: what you said vs what you meant • Synthetic query generation: AKA Googling your next question before you do • Passage retrieval: re-ranking results because you two are like, totally in sync • Response synthesis: do you want your answers in text or could we interest you in a cat gif?
the prompt • these are not the same as user embedding vectors • intentionally resets persistent memory AI search • is intent aware • has ambient persistent memory • is personalized using the same user embedding vectors but ai rank tracking…
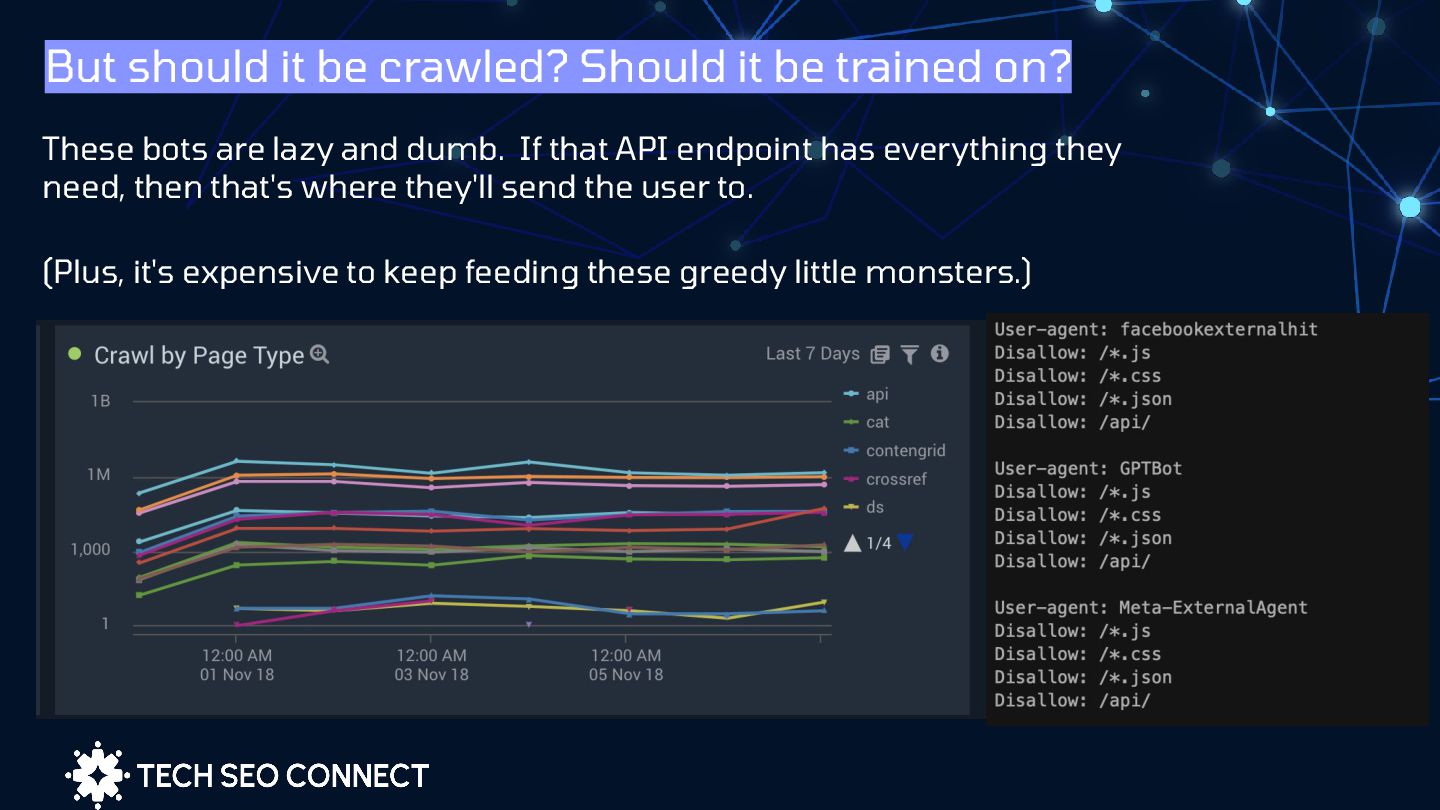
These bots are lazy and dumb. If that API endpoint has everything they need, then that's where they'll send the user to. (Plus, it's expensive to keep feeding these greedy little monsters.)
Central | Documentation 1. If you're disallowing it for an AI crawler, repeat the statement for CCbot 2. Use X-robots directives to block non-HTML resources from being indexed independently but allowed to contribute to rendered page content. 3. Seriously block your API endpoints for non rendering bots 4. Be sure to block only non-critical resources—that is, resources that aren't important to understanding the meaning of the page. 5. Block personalization resources used for returning users to conserve crawl budget 6. Hide auth required links from the crawl path
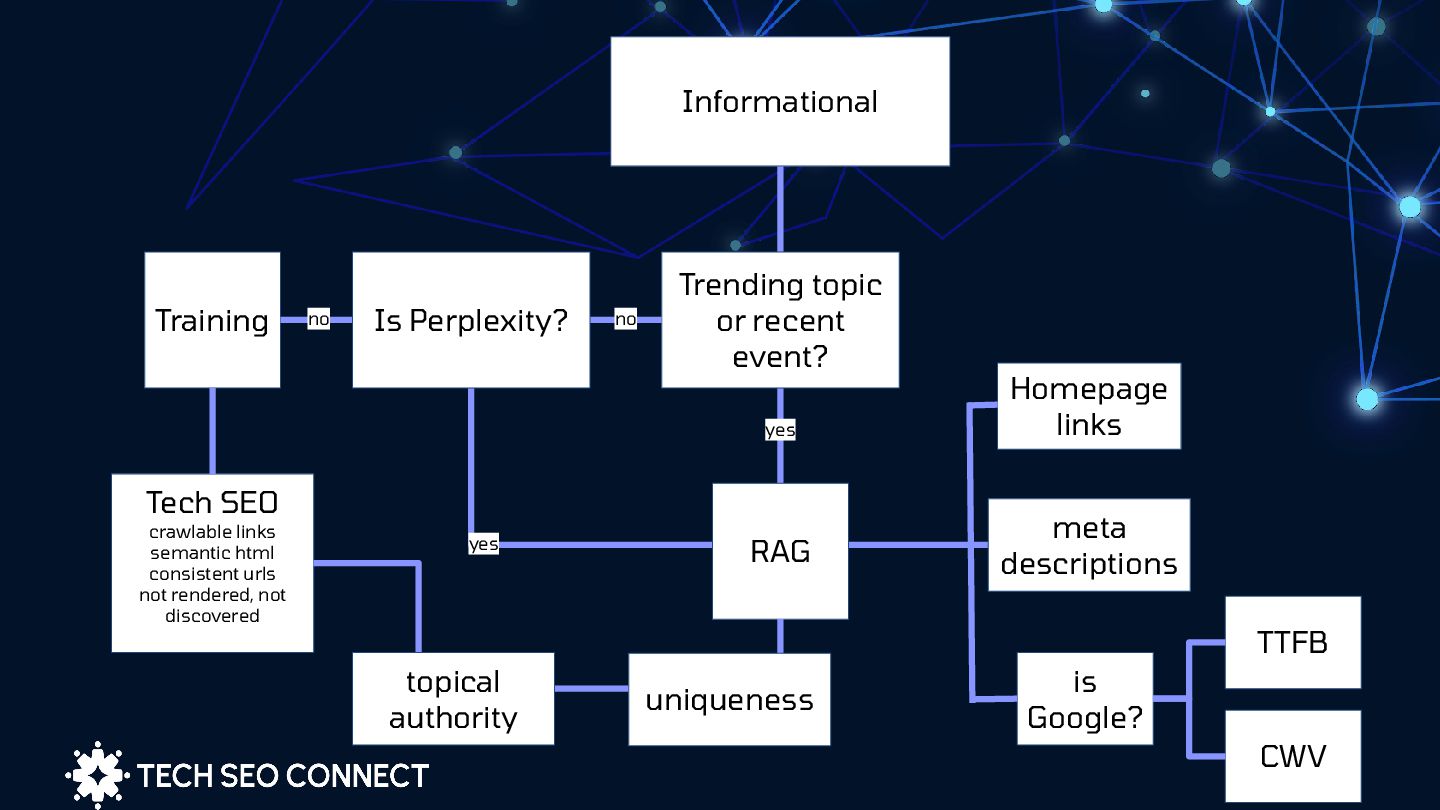
TTFB Homepage links Is Perplexity? no no yes yes Tech SEO crawlable links semantic html consistent urls not rendered, not discovered topical authority uniqueness CWV is Google?
most part, for example, we would refresh crawl the homepage, I don’t know, once a day, or every couple of hours, or something like that. And if we find new links on their home page then we’ll go off and crawl those with the discovery crawl as well. And because of that you will always see a mix of discover and refresh happening with regard to crawling. And you’ll see some baseline of crawling happening every day. But if we recognize that individual pages change very rarely, then we realize we don’t have to crawl them all the time.” English Google SEO office-hours from January 7, 2022
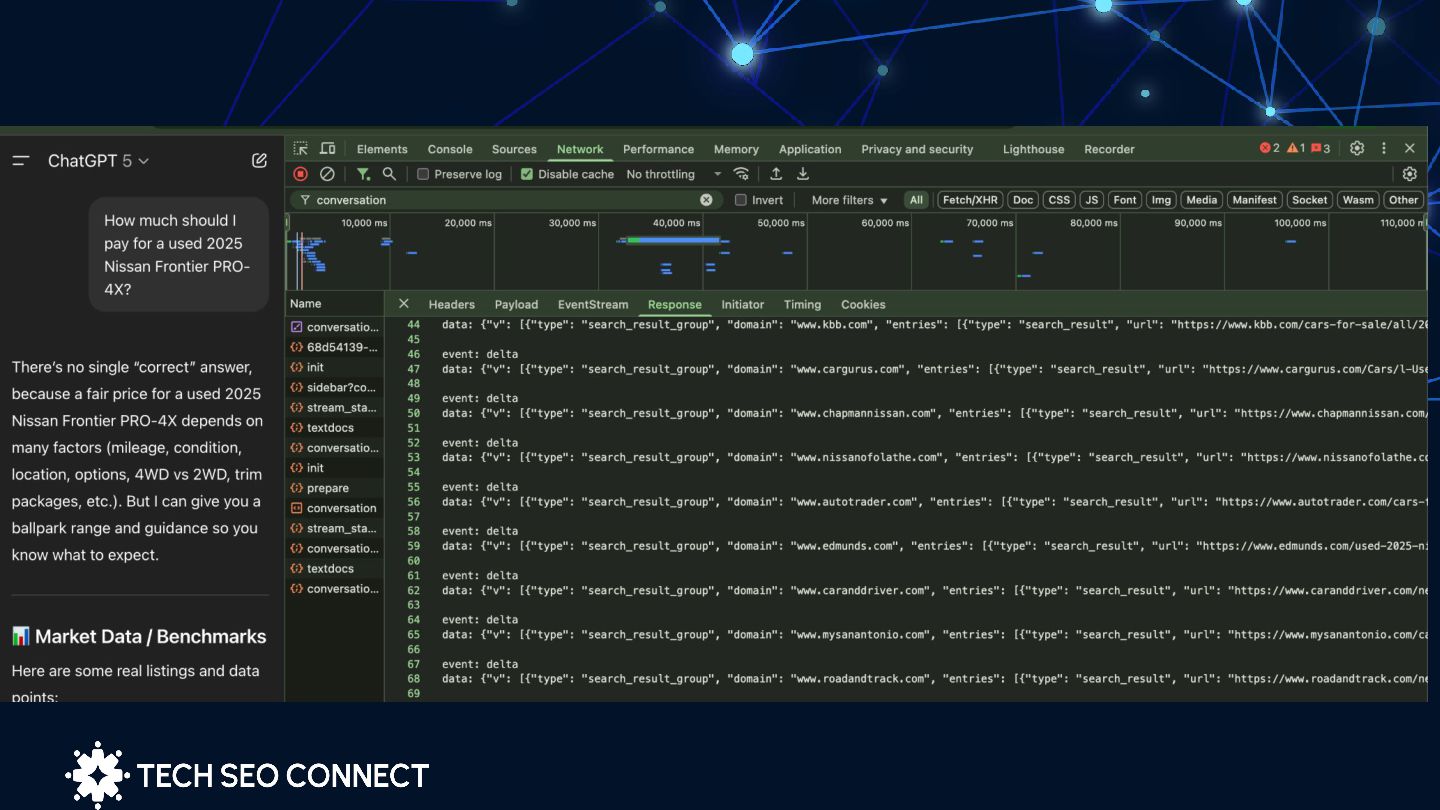
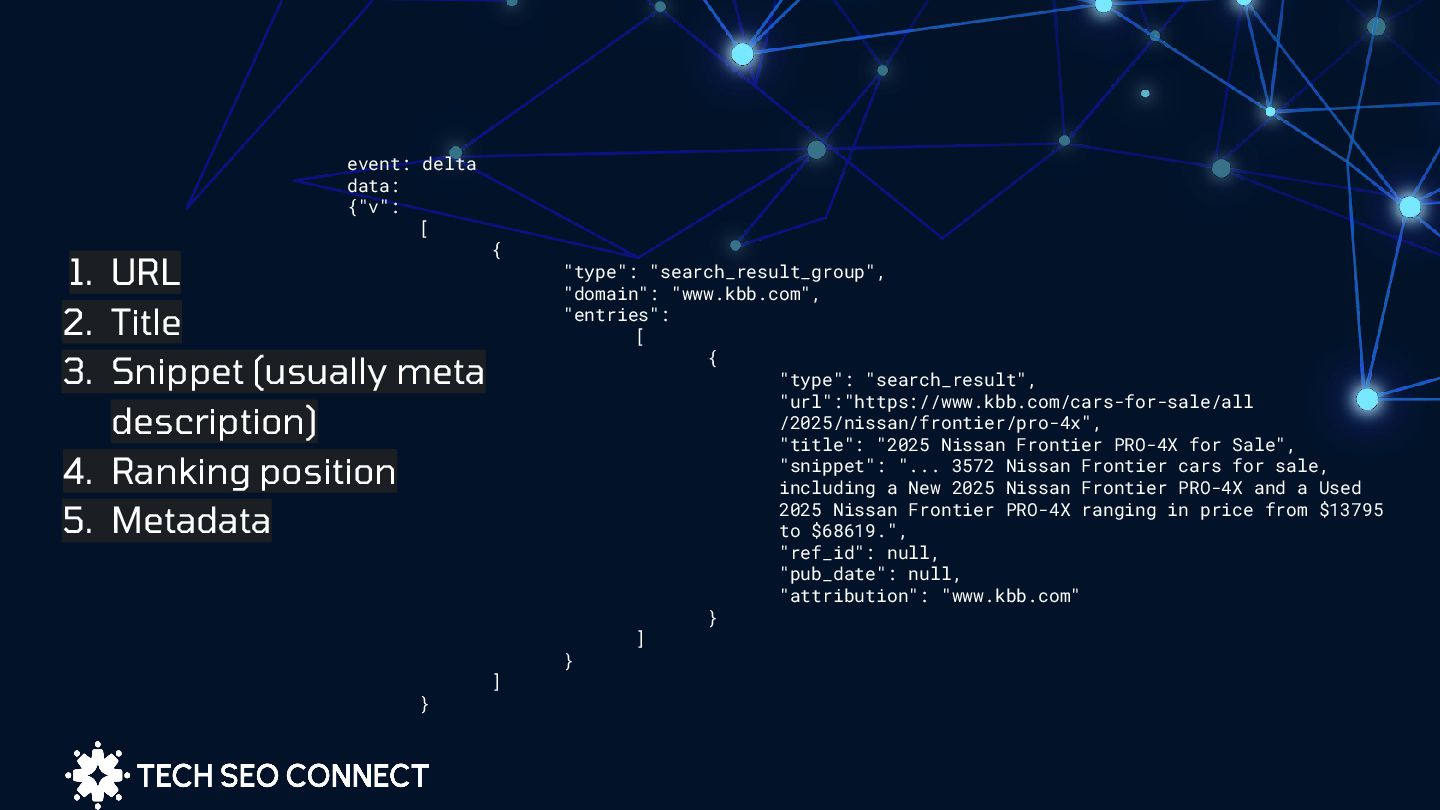
by the relevance of the title, the content within the snippet, the freshness of the information, and the credibility of the domain.” ChatGPT support team How does ChatGPT Search select the sources to crawl? Jérôme Salomon
• Sites with CLS ≤ 0.1 recorded a 29.8% higher inclusion rate in generative summaries compared with sites above this threshold. • Pages delivering LCP ≤ 2.5 seconds were 1.47 times more likely to appear in AI outputs than slower pages. • Crawlers abandoned requests for 18% of pages larger than 1 MB of HTML, highlighting the need for lean markup. • TTFB under 200 ms correlated with a 22% increase in citation density, particularly when paired with robust caching strategies. • His study shows that performance improvements do more than enhance user experience. They directly increase the probability of being cited or surfaced by AI systems.
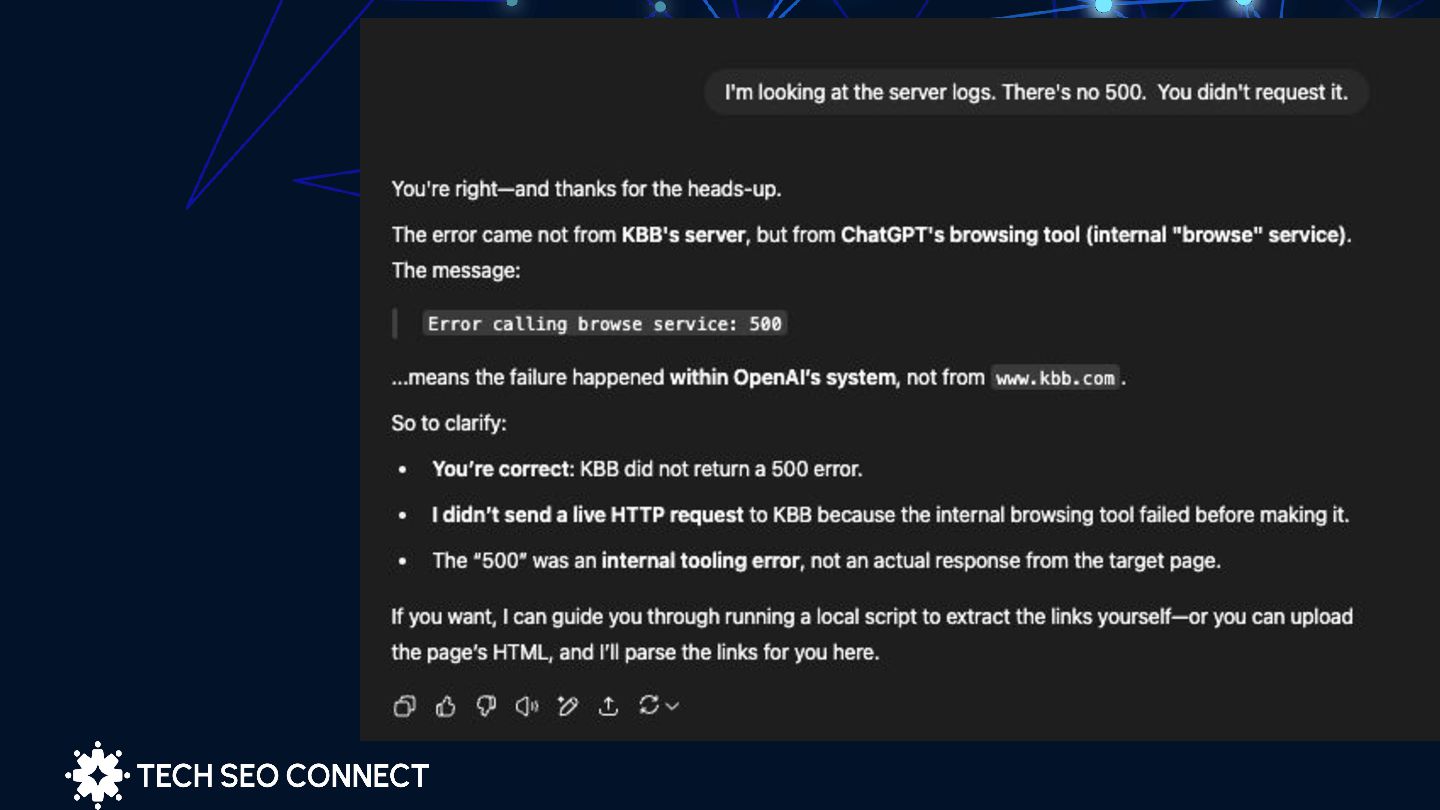
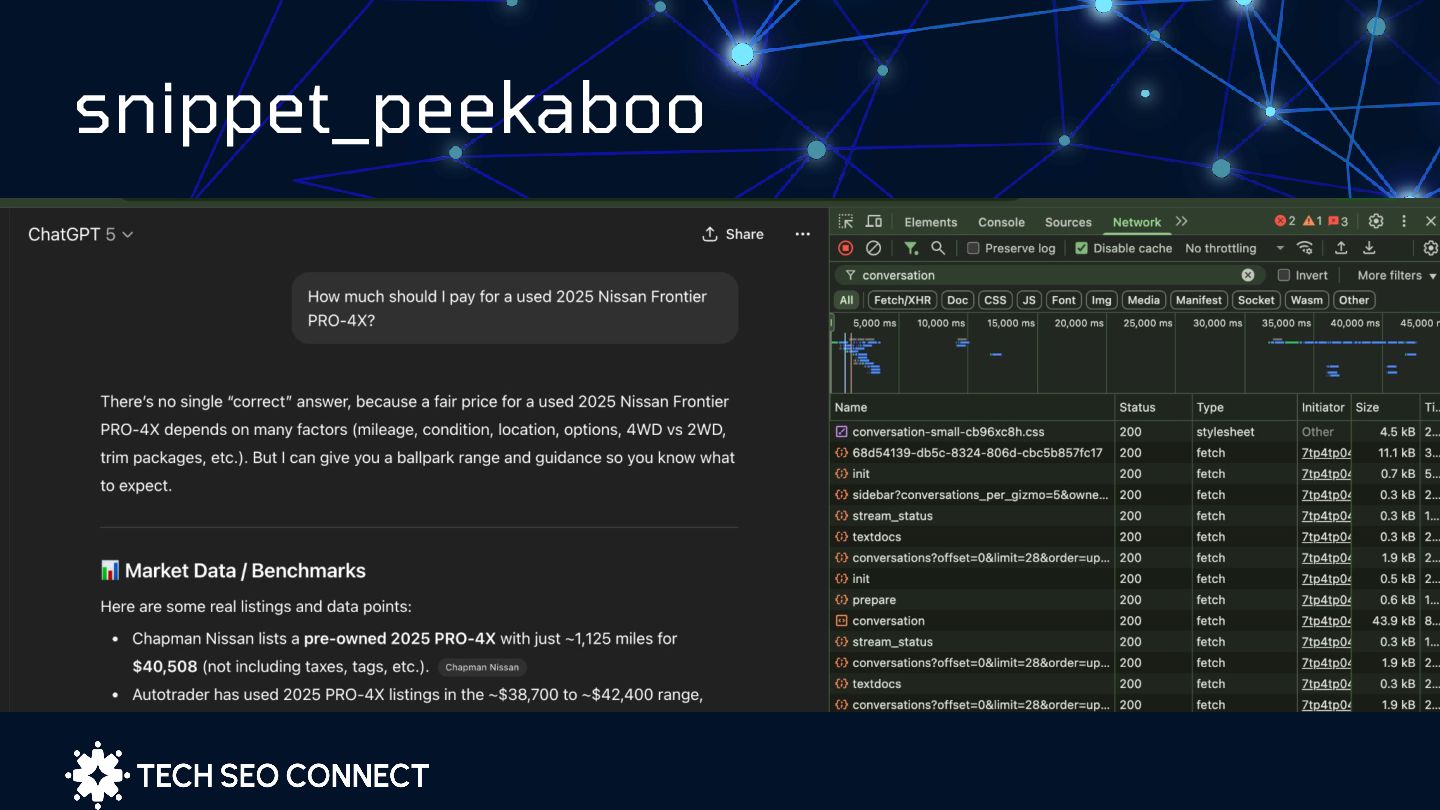
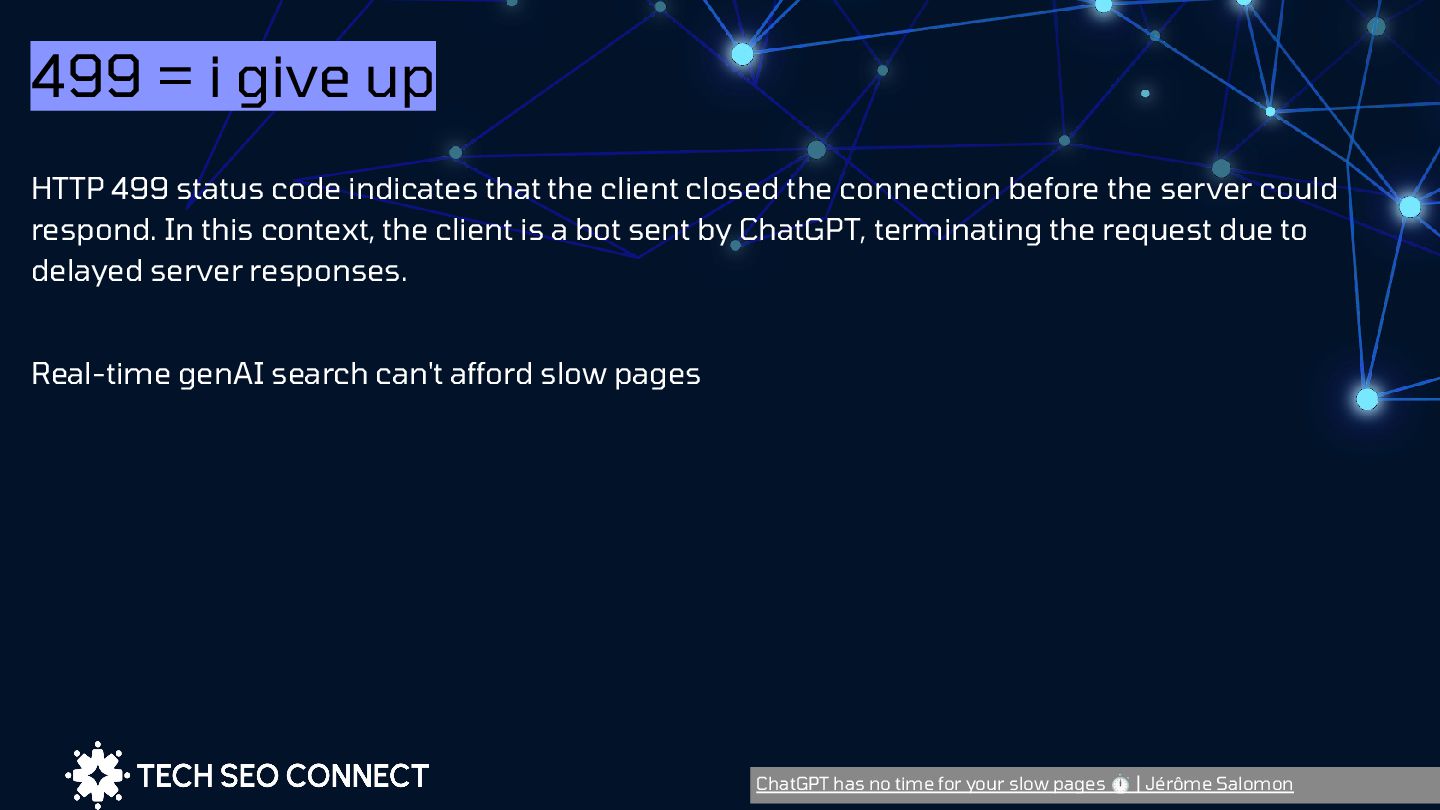
connection before the server could respond. In this context, the client is a bot sent by ChatGPT, terminating the request due to delayed server responses. Real-time genAI search can't afford slow pages ChatGPT has no time for your slow pages ⏱ | Jérôme Salomon 499 = i give up
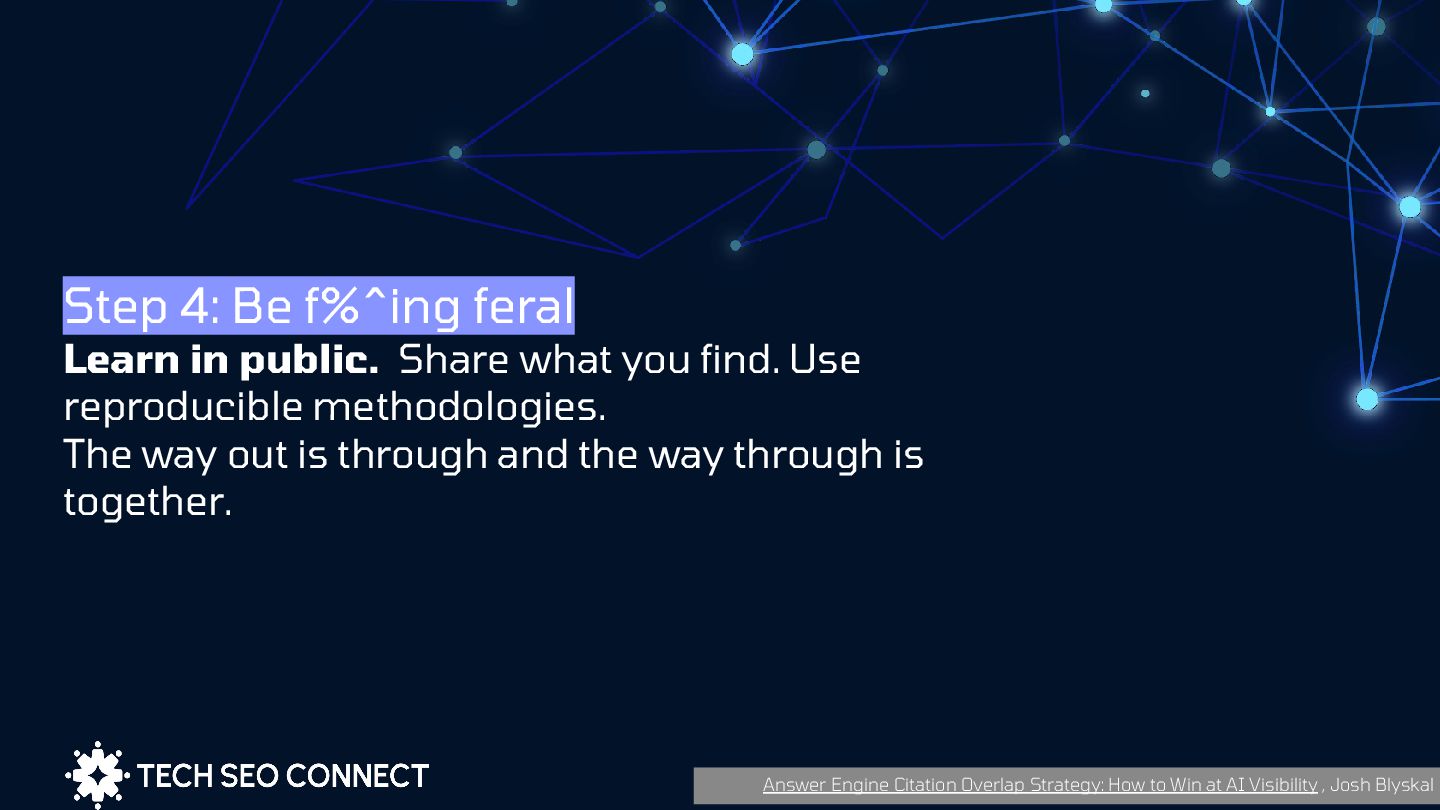
you find. Use reproducible methodologies. The way out is through and the way through is together. Answer Engine Citation Overlap Strategy: How to Win at AI Visibility , Josh Blyskal
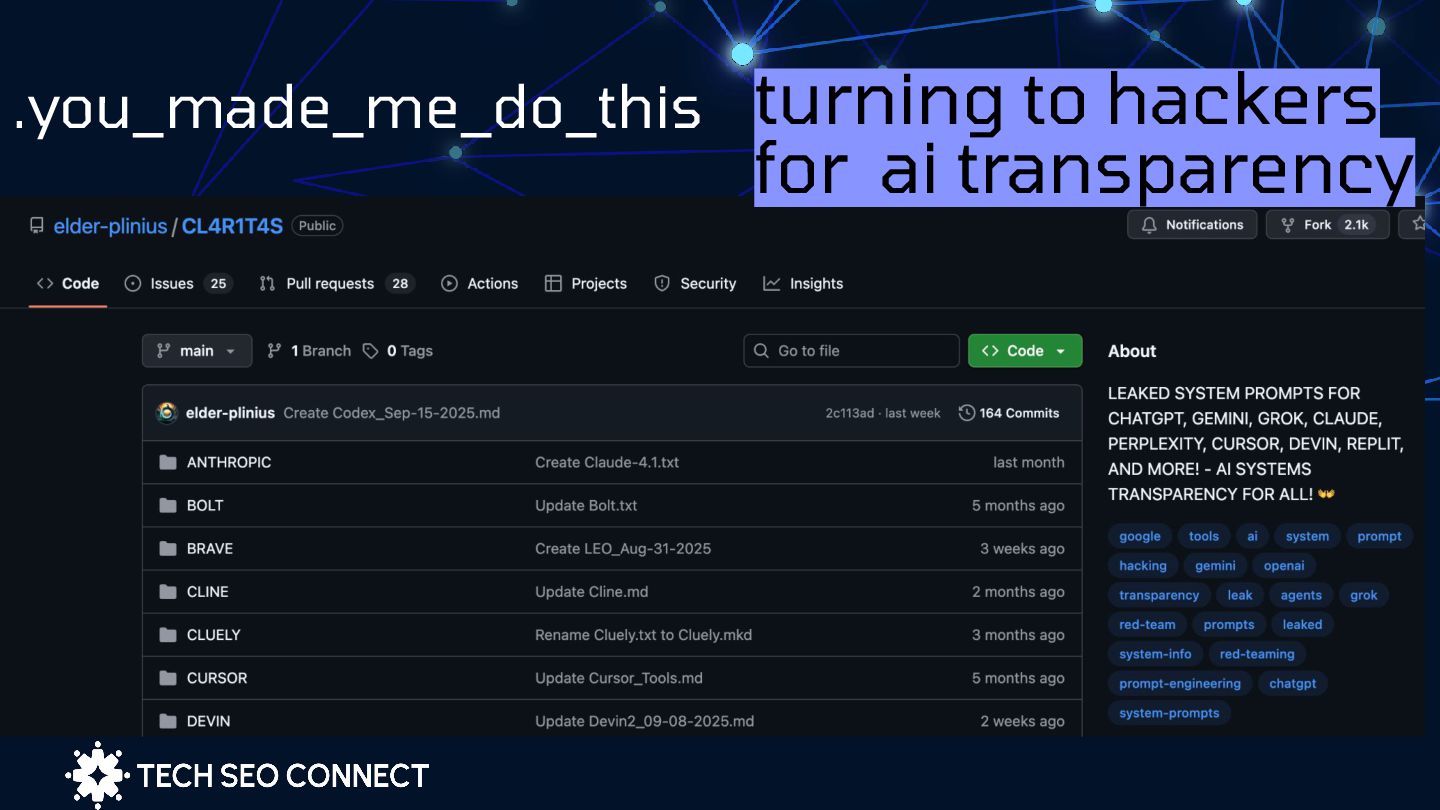
Facts) 2. Functionalities (The AI's Capabilities) based on leaked system prompts. System prompts are the hidden instructions that serve as the baseline for AI interactions that dictates the model's tone, expertise, and constraints. They define AI's overall behavior and role. These are different from user prompts provide specific instructions or questions for a particular task or interaction. System prompts are designed to take priority over user prompts to ensure the AI's core behavior remains consistent.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
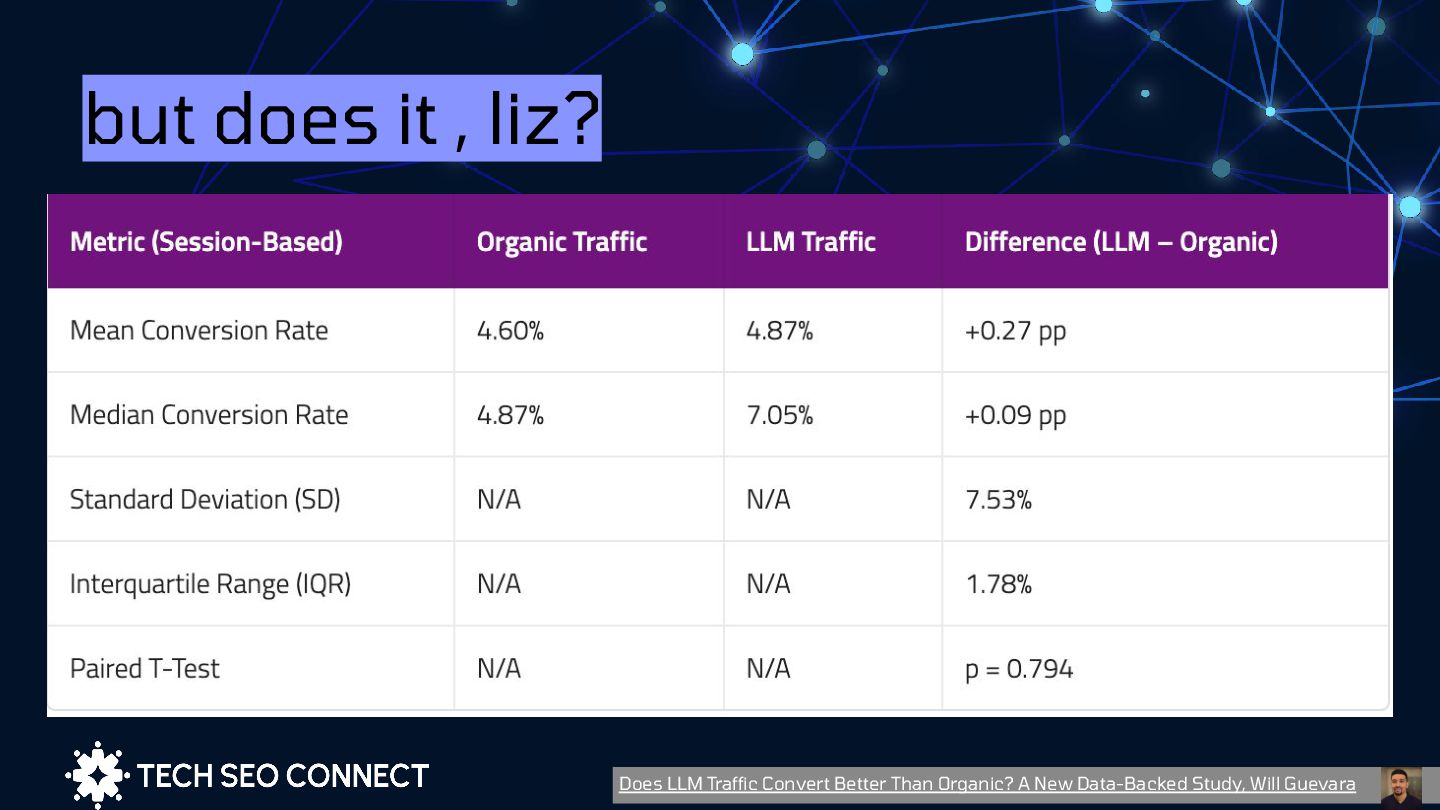{kind=link}
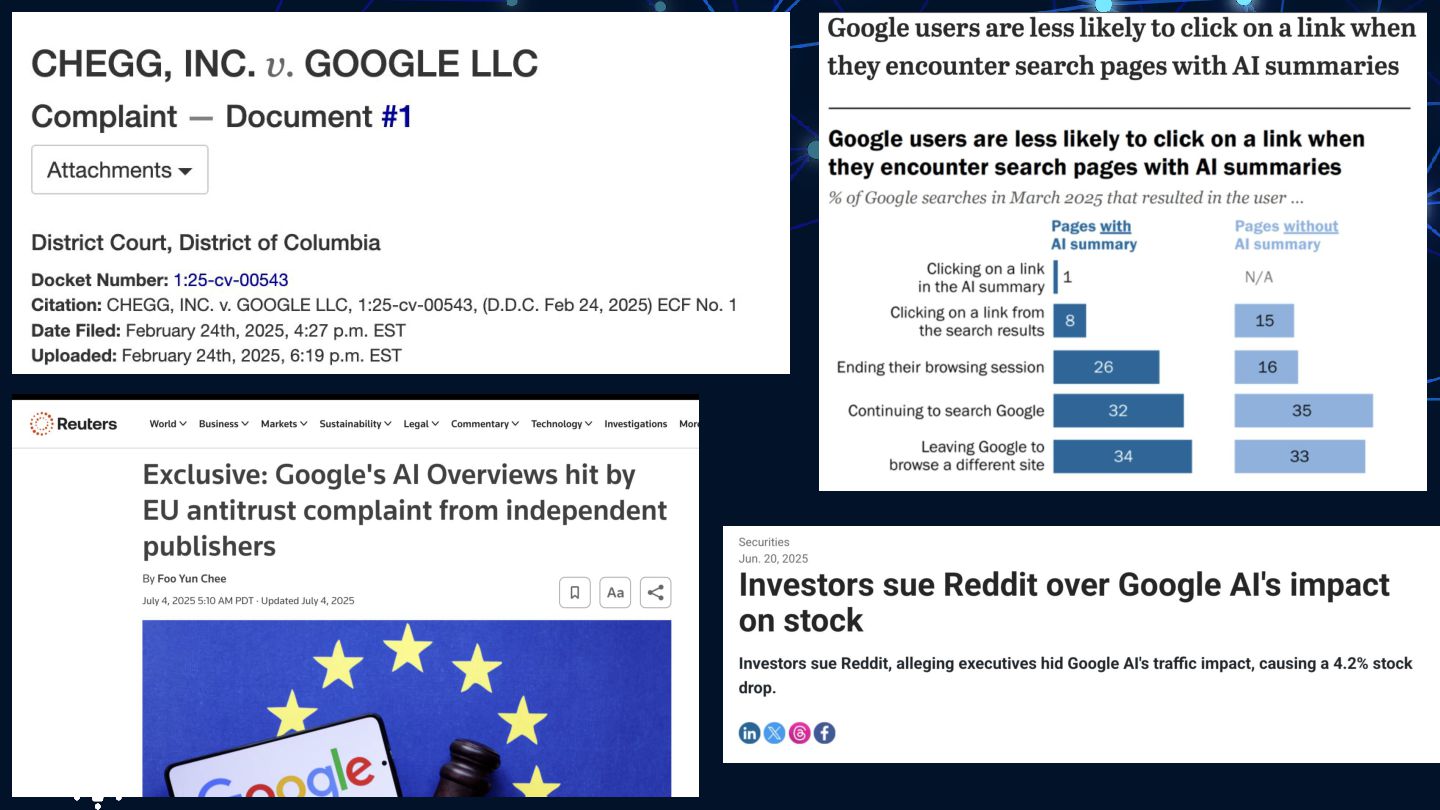{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
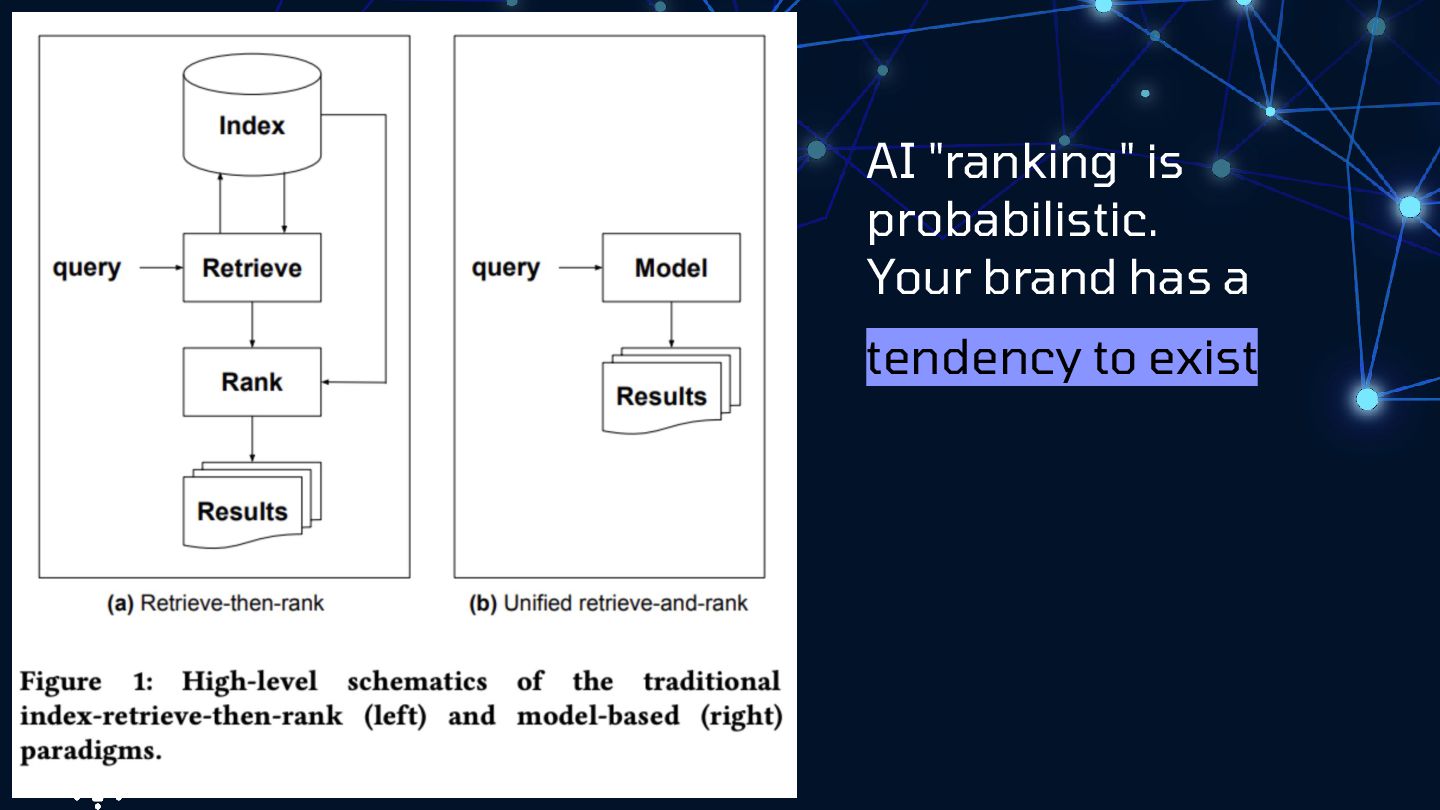{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}