Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Djangoアプリケーション運用のリアル〜問題発生から可視化、最適化への道〜 / django...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Kashun Yoshida
October 07, 2023
Programming
280
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Djangoアプリケーション運用のリアル〜問題発生から可視化、最適化への道〜 / django-application-realities
https://djangocongress.jp/
#djangocongress
Kashun Yoshida
October 07, 2023
More Decks by Kashun Yoshida
See All by Kashun Yoshida
サプライチェーン攻撃対策「層を重ねて落ちない壁」を10日間で組み上げた話 #TechLeadConf2026
kashewnuts
1
550
AIとペアプロして処理時間を97%削減した話 #pyconshizu
kashewnuts
1
460
企業がDjangoを使う際に、特にセキュリティで気をつけること
kashewnuts
1
260
Django Ninja による API 開発効率化とリプレースの実践
kashewnuts
1
2.3k
Django NinjaによるAPI開発の効率化とリプレースの実践
kashewnuts
2
1.5k
Djangoアプリケーション 運用のリアル 〜問題発生から可視化、最適化への道〜 #pyconshizu
kashewnuts
2
1.8k
開発環境の垣根を超えるLanguage Server Protocol入門 / Introduction to Language Server Protocol beyond the boundaries of the development environment
kashewnuts
2
4.4k
Django で始める PyCharm 入門
kashewnuts
1
100
Other Decks in Programming
See All in Programming
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
260
AI Engineeringは、AIプロダクトだけのものか? 〜AIがソフトウェアを作る時代の新しい当たり前〜 / No AI in your product. AI Engineering in your development.
rkaga
4
320
React本体のコードリーディング
high_g_engineer
1
120
Android CLI
fornewid
0
200
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
480
改善しないと、タスクが回らない。 “てんこ盛りポジション” を引き継いだ情シスの、入社3ヶ月の業務改善録
krm963
0
240
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
480
php-fpmのプロセスが枯渇した日-調査・対処・そして本当にやるべきだったこと-
shibuchaaaan
0
180
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
570
今さら聞けない .NET CLI
htkym
0
170
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
180
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
160
Featured
See All Featured
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
510
エンジニアに許された特別な時間の終わり
watany
108
250k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Optimising Largest Contentful Paint
csswizardry
37
3.9k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
310
How Software Deployment tools have changed in the past 20 years
geshan
1
34k
Mobile First: as difficult as doing things right
swwweet
225
10k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Transcript
Djangoアプリケーション運用 のリアル 〜問題発生から可視化、最適化への道〜 DjangoCongress JP 2023 @kashew_nuts
お品書き • 会社と登壇者について紹介 • 発表の動機とゴール • アプリケーションを運用している中でのつらみ共有 • つらみをどのように解消できるようにしていったか •
取り組みの結果できるようになったこと • まとめ
Who am I? / お前誰よ • 吉田花春 (Yoshida Kashun) •
@kashew_nuts • BeProud Inc. • Software Developer • 開発環境整備とボルダリングが趣味
What's • Pythonメインで受託開発・研修・自社サービスの運営 • 私は主にconnpassの開発/運営をしています • フルリモートワーキング (5days/week)
発表の動機 • 開発が完了し、リリース後に不具合対応で土日出勤した 経験があった • それ以降も調査するための材料が足りなくて、非常に調 査が時間がかかることがあった • 運用に乗ってからも改善する中で見えることもあった が、まとめたりしていなかった
• 過去の自分や似通った人の導入になればと思った
想定する聞き手 • 現在アプリケーションの開発をしているが、リリースさ れた後の運用について知見を深めたい人 • アプリケーションの運用をもっと楽にしたい人 • 運用時のつらみを共有したい人
アプリケーションを運用する中でのつらみ • ユーザーからシステムエラーが発生したと言われたが、エラー が発生した箇所がわからない • ログが出力されていなくて、何が発生したのか調査できない • ログメッセージが適切でなく、対処方法がわからない • CPUやメモリの使用率が張り付いているが、原因がわからない
• エラー通知が鳴り続けて現場が疲弊する • アラートの調査に時間が取られて、開発の時間が取れない
システムで何が起きて いるか調査できるよう にしたい
つらみをどのように観測していくか 1. エラーやログを取得する 2. APM(Application Performance Monitoring)を活用して ボトルネックを解消する 3. カスタムメトリクスを計装して、問題の原因を把握でき
るようにする
1. エラーやログを取得 する
【現実】ログから判断できない • 例外をキャッチして握りつぶしていて、何が起きている かわからない • アプリ側でログ出力の設定が未整備 • どの操作でAPIが呼ばれているかわからない • DEBUGしか出力しておらず、本番では出力されない
• エラーメッセージから何をしたらいいかわからない
【理想】ログから判断できるようにする • 5W1Hがわかる:特にエラーログ ◦ 「いつ」「どこで」「だれが」「なぜ」「何が起きて」「何をす ればいいのか」 • (例) ◦ 「request_id:
xxx 10:00 INFO 指示書の確定処理が完了」 ◦ 「request_id: yyy 11:00 WARNING 既存システムとの接続に 失敗。〇〇に連絡してください。」
【対策】ログから判断できるようにする 1. INFO、ERROR だけでなくログレベルを使い分ける 1.1. CRITICAL:システム全体や連携システムに影響する重大な問題発生時の情報 1.2. ERROR:プログラム上の処理が中断したり、停止した場合の情報 1.3. WARNING:プログラムの処理は続いているが何か良くないデータや通知の情報
1.4. INFO:プログラムの状況やデータ数など後で挙動を把握しやすくする情報 1.5. DEBUG:ローカル環境で開発するときだけつかう情報 2. APIリクエストのstart/end時にログを出力 2.1. リクエストID, 日時, エンドポイント, ステータスコード 2.2. django-structlogのような構造化ロギングを可能にするライブラリを活用する 3. 5W1Hがわかるようにメッセージ内容を修正する
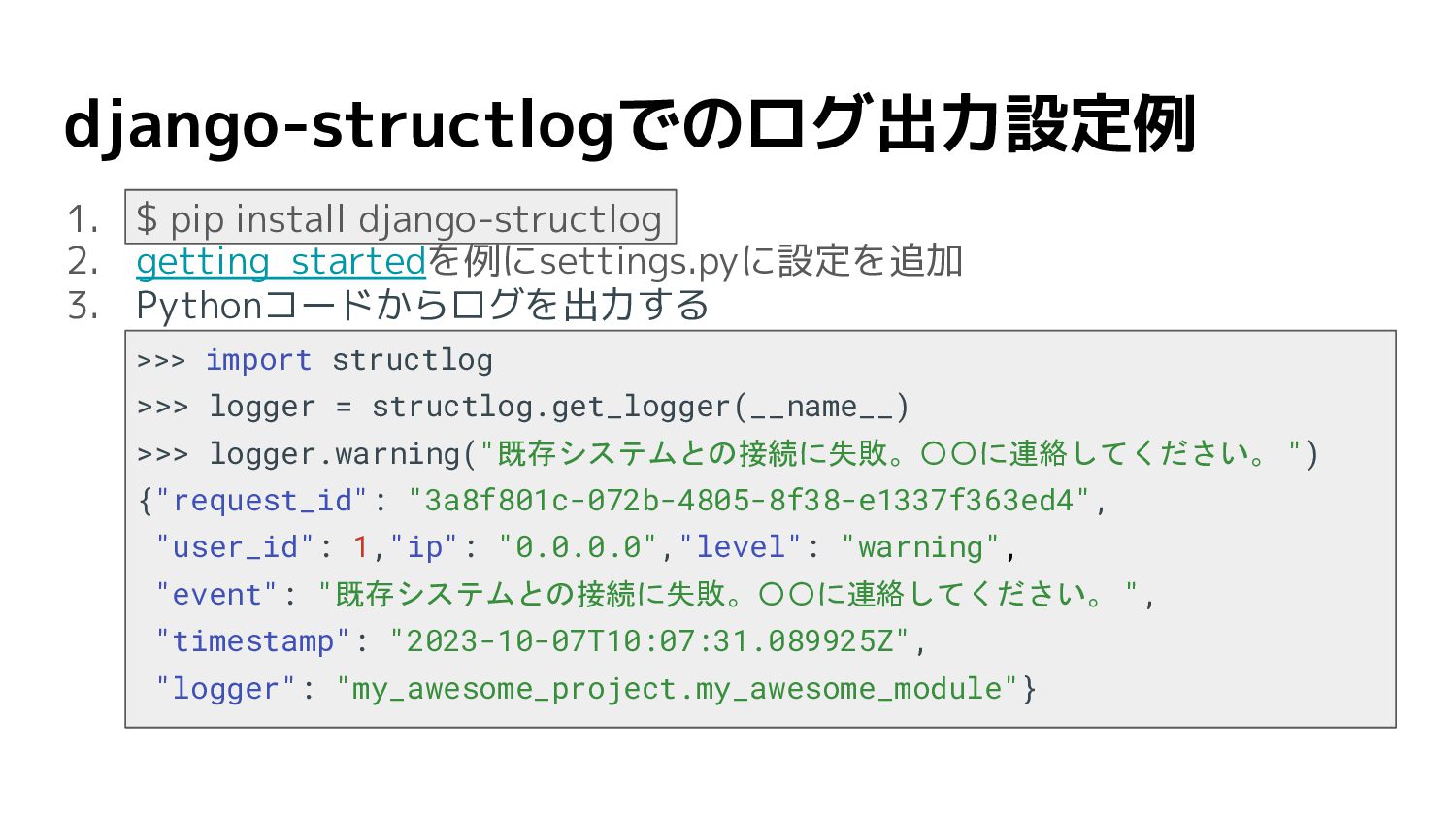
django-structlogでのログ出力設定例 1. $ pip install django-structlog 2. getting_startedを例にsettings.pyに設定を追加 3. Pythonコードからログを出力する
>>> import structlog >>> logger = structlog.get_logger(__name__) >>> logger.warning("既存システムとの接続に失敗。〇〇に連絡してください。 ") {"request_id": "3a8f801c-072b-4805-8f38-e1337f363ed4", "user_id": 1,"ip": "0.0.0.0","level": "warning", "event": "既存システムとの接続に失敗。〇〇に連絡してください。 ", "timestamp": "2023-10-07T10:07:31.089925Z", "logger": "my_awesome_project.my_awesome_module"}
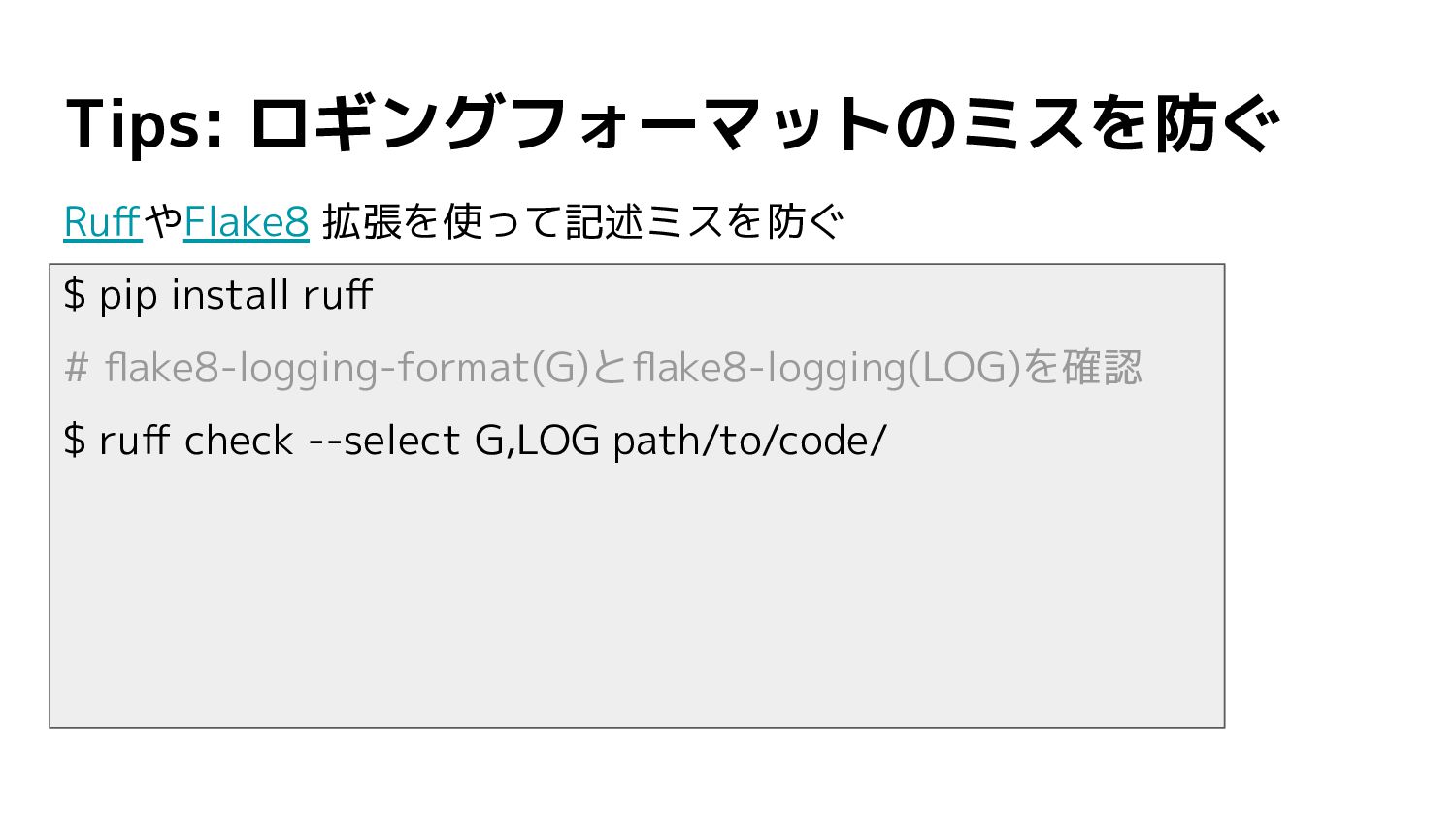
Tips: ロギングフォーマットのミスを防ぐ RuffやFlake8 拡張を使って記述ミスを防ぐ $ pip install ruff # flake8-logging-format(G)とflake8-logging(LOG)を確認
$ ruff check --select G,LOG path/to/code/
【現実】エラー発生時すぐ検知できない • ユーザーからエラーが発生したと連絡がくる • 渡されたエラーログはgrepした1行目の画面キャプチャ ◦ せめてトレースバックください..... • ログだとどんなrequestデータだったのかわからない •
調査にはサーバーにVPNつないでssh接続して、 journalctlコマンドで.... • 調査してる間に別のエラーが....つらい....
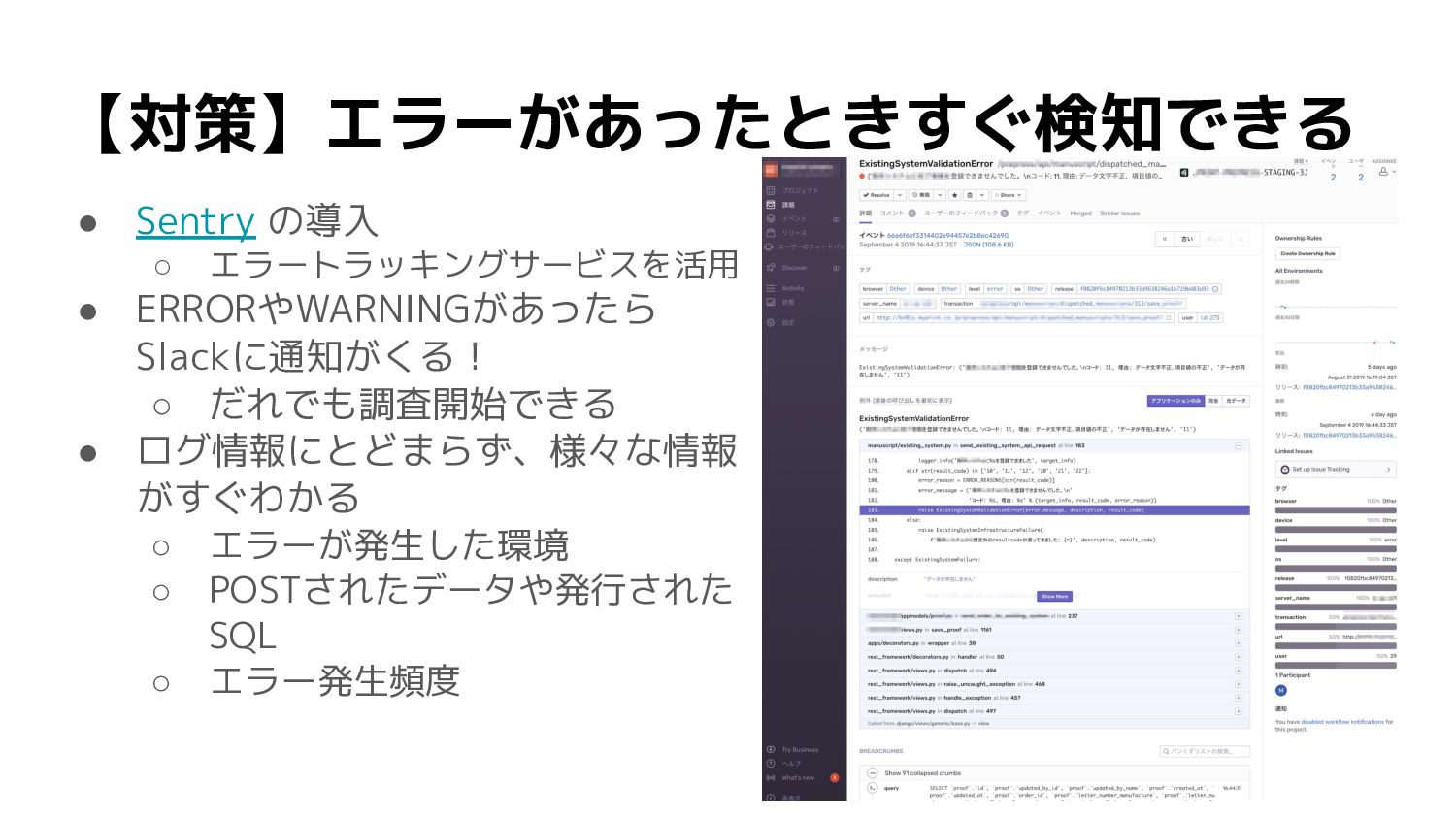
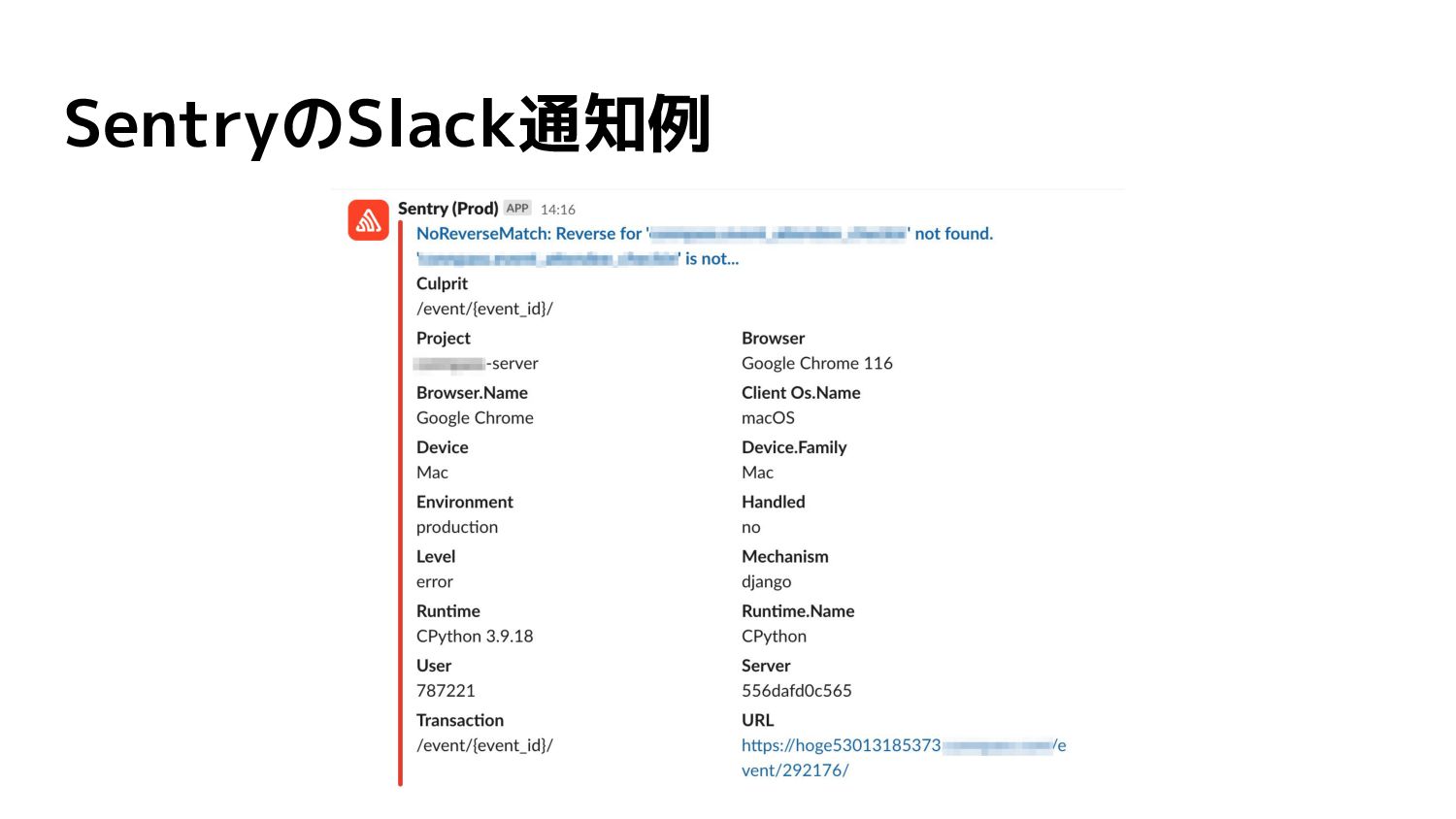
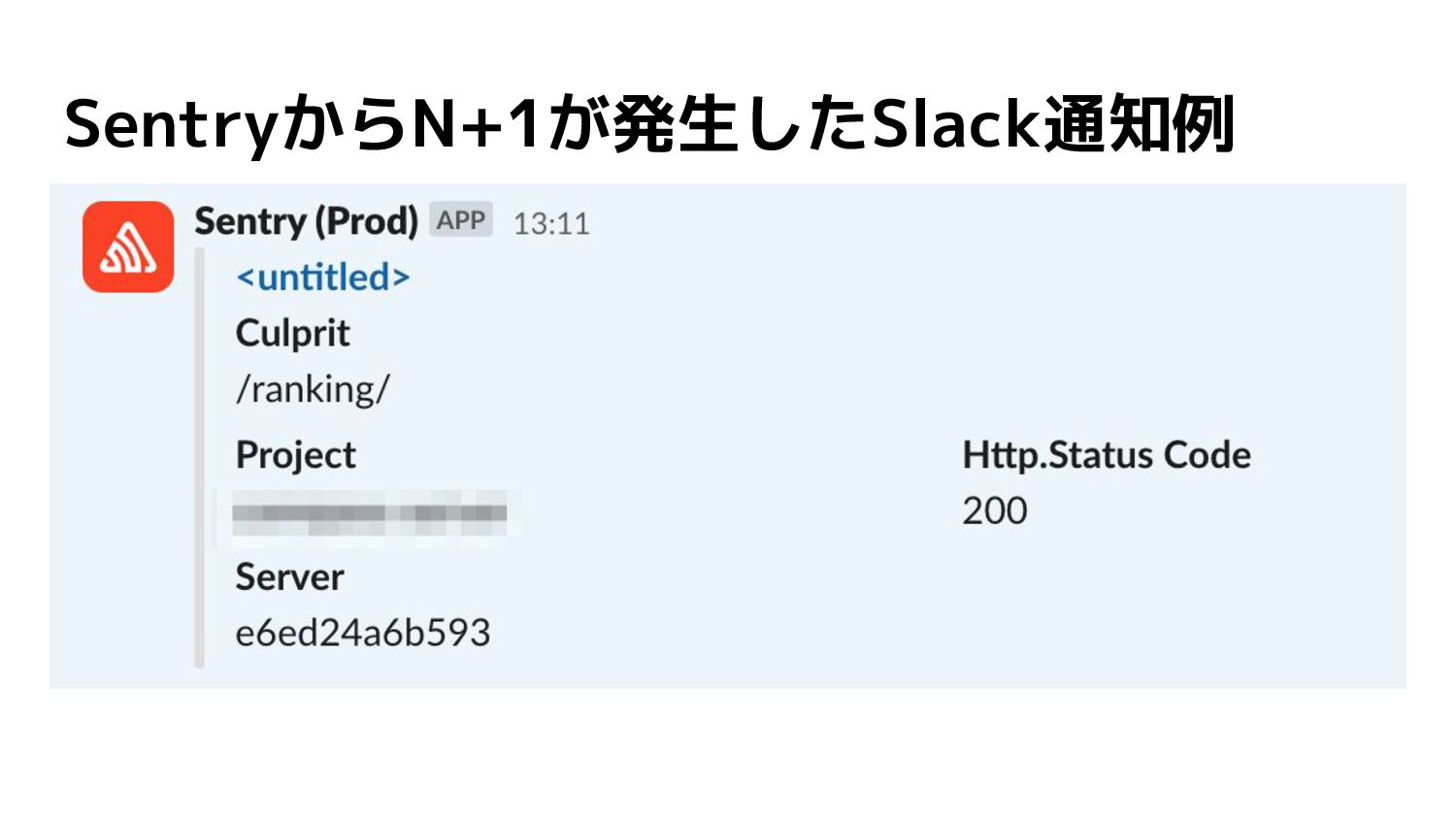
【理想】エラーがあったときすぐ検知できる • ERRORやWARNINGがあったらSlackに通知が届く! ◦ だれでも調査開始できる • 問い合わせが来る前に原因把握と対策の検討まで終わっ てる!
【対策】エラーがあったときすぐ検知できる • Sentry の導入 ◦ エラートラッキングサービスを活用 • ERRORやWARNINGがあったら Slackに通知がくる! ◦
だれでも調査開始できる • ログ情報にとどまらず、様々な情報 がすぐわかる ◦ エラーが発生した環境 ◦ POSTされたデータや発行された SQL ◦ エラー発生頻度
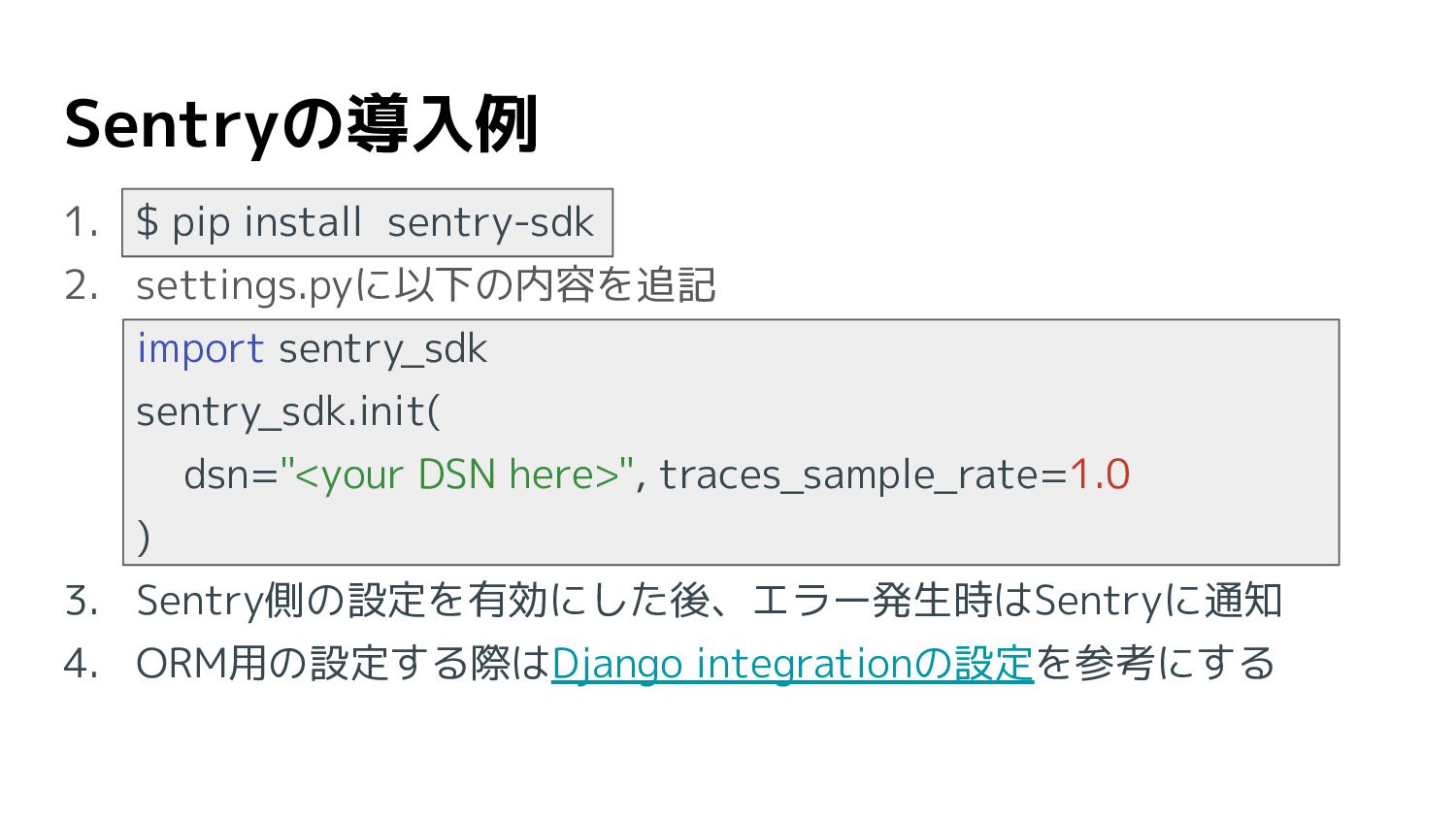
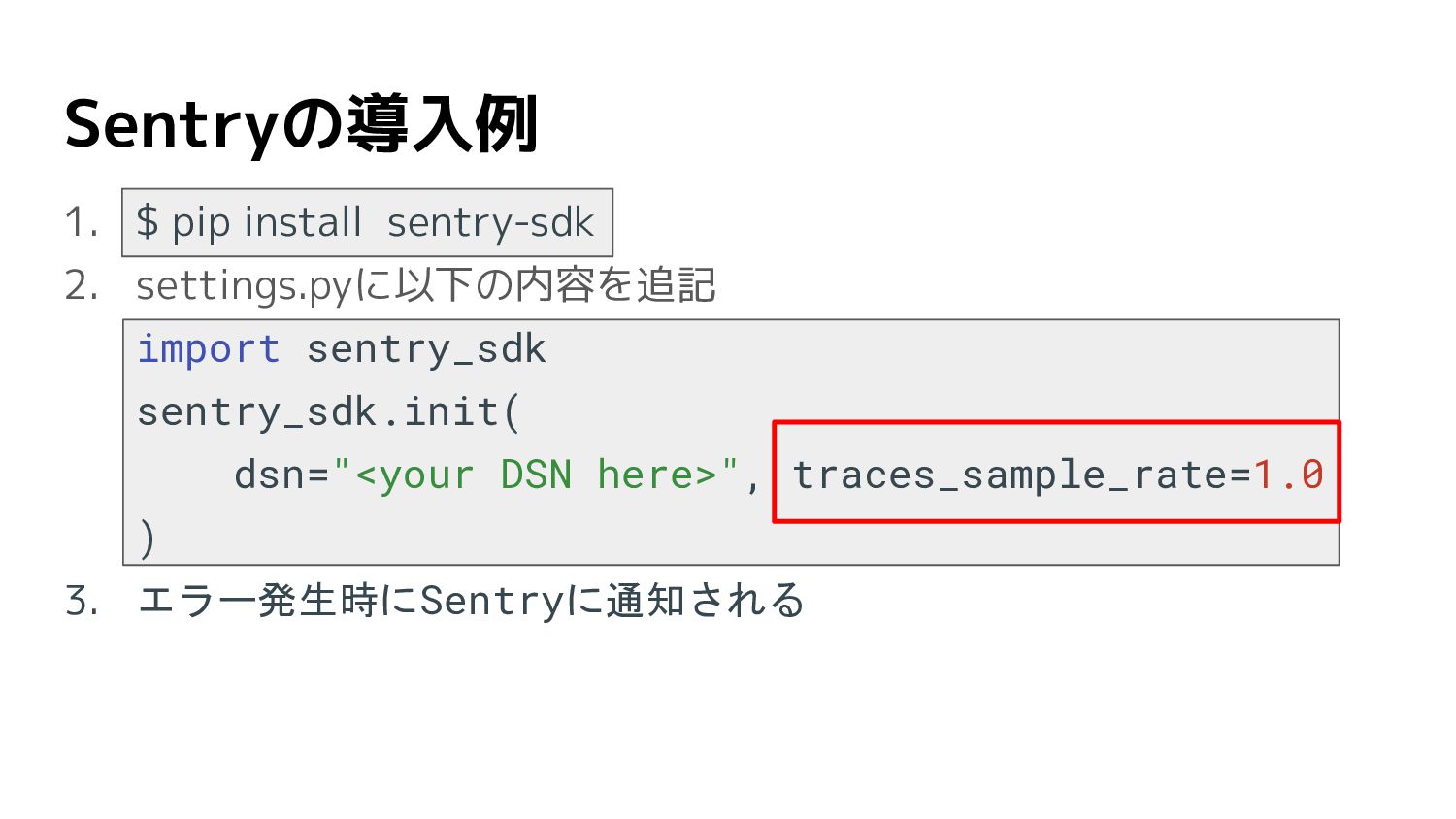
Sentryの導入例 1. $ pip install sentry-sdk 2. settings.pyに以下の内容を追記 import sentry_sdk
sentry_sdk.init( dsn="<your DSN here>", traces_sample_rate=1.0 ) 3. Sentry側の設定を有効にした後、エラー発生時はSentryに通知 4. ORM用の設定する際はDjango integrationの設定を参考にする
SentryでDjango integrationの設定 import sentry_sdk.utils sentry_sdk.utils.MAX_STRING_LENGTH = 2048 # monkey patch
first import sentry_sdk from sentry_sdk.integrations.django import DjangoIntegration from sentry_sdk.integrations.logging import LoggingIntegration # デフォルトでは ERROR 以上しかevent登録されないので、WARNING以上にする sentry_logging = LoggingIntegration(level=logging.INFO, event_level=logging.WARNING) sentry_sdk.init( dsn=SENTRY_DSN, integrations=[sentry_logging, DjangoIntegration()], # Associate users to errors (if using django.contrib.auth) send_default_pii=True, _experiments={'record_sql_params': True} )
SentryのSlack通知例
2. APMを活用して ボトルネックを解消する
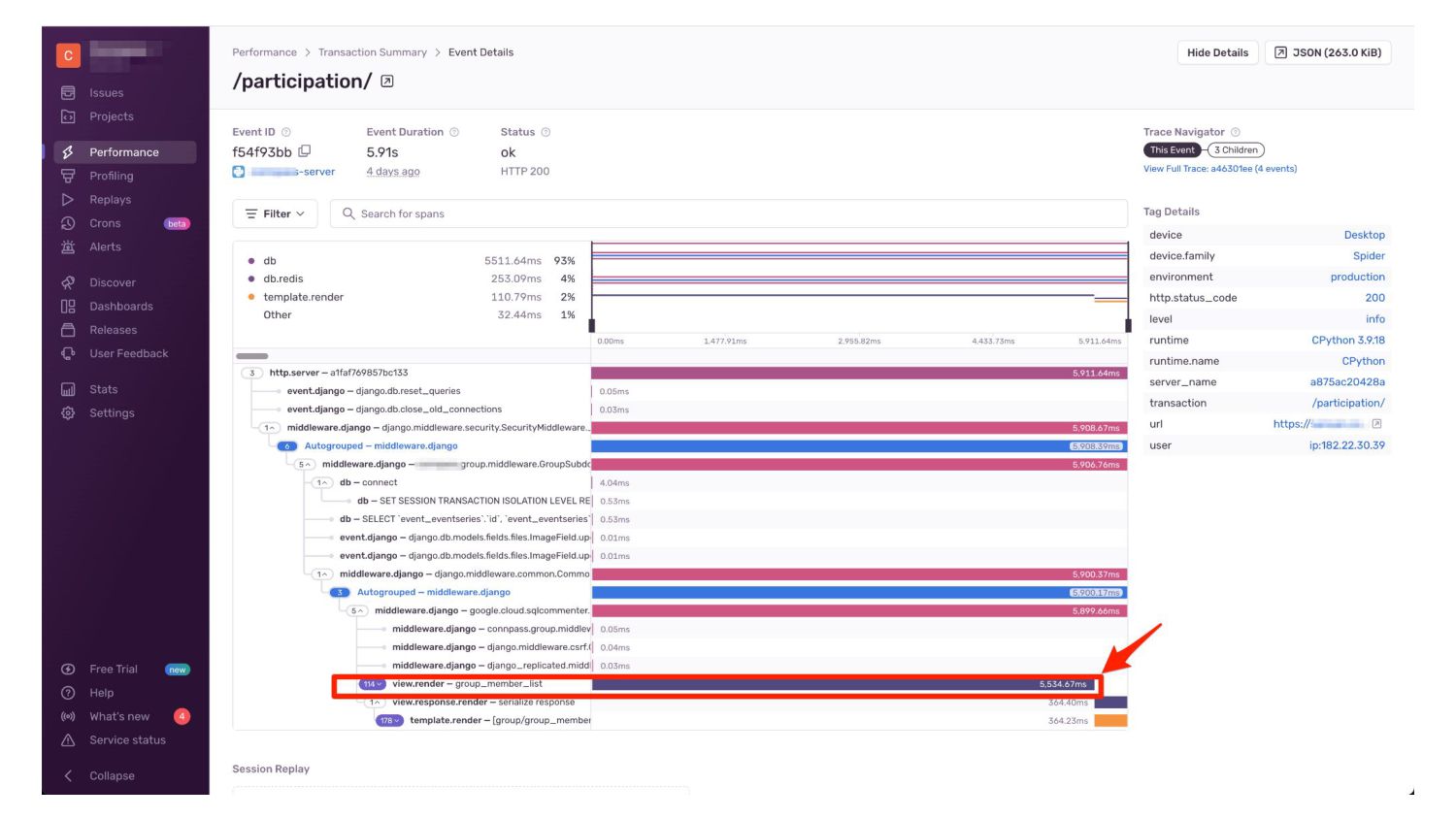
【現実】アプリケーションがなぜか重い • お客さんから画面を開くのが遅いと報告がくる • メトリクスをみると何故かCPU利用率やI/Oが高い • 開発時は問題なかったが、データ量が増えると重い • コードをよく読むとN+1問題のあるコードが散在 •
非同期処理を活用できていなくてボトルネック化 ◦ ex) メール送信、ファイル操作
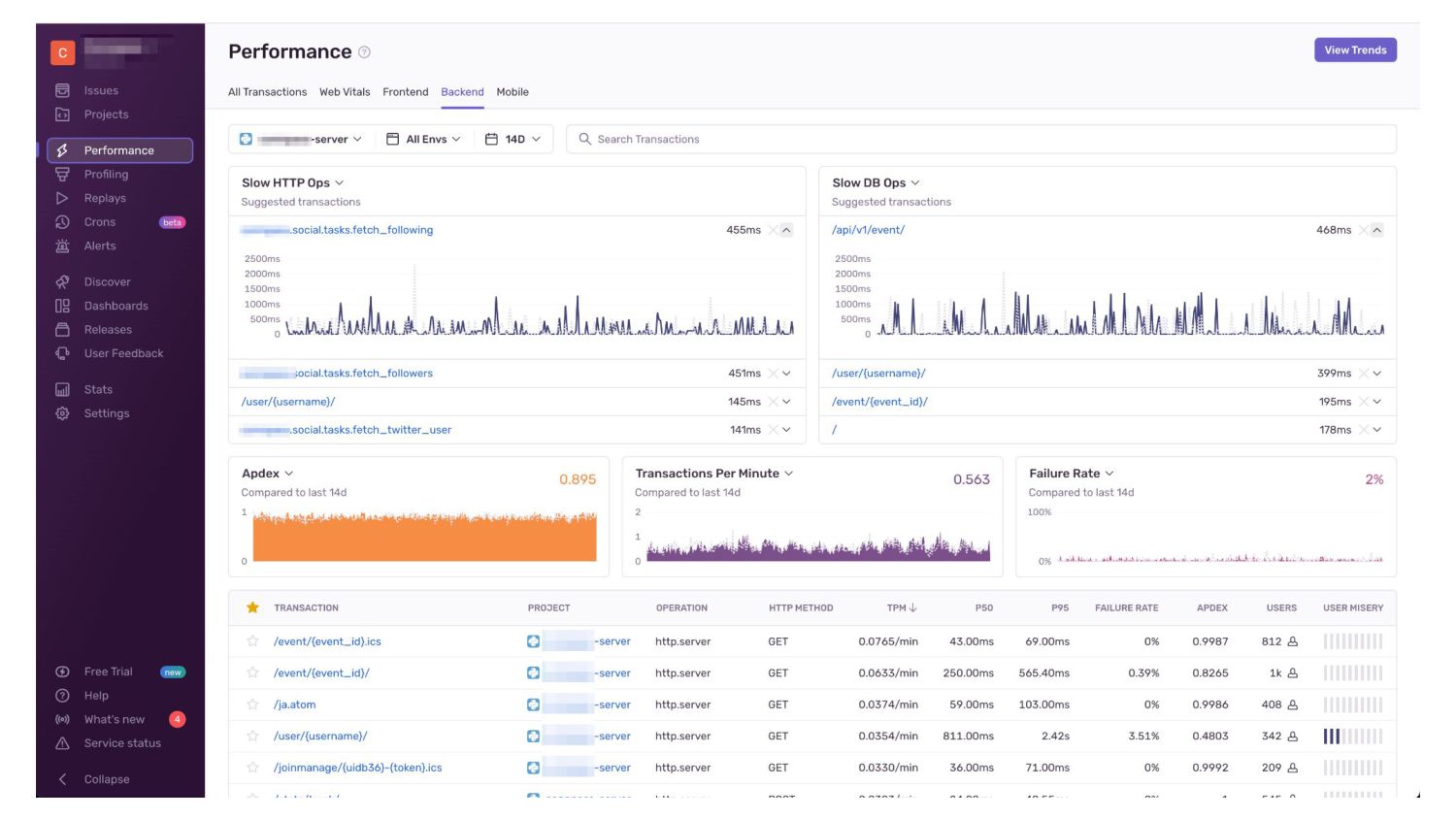
【理想】アプリのどこが重いかがわかる • ツールを活用してAPIや画面のボトルネックが測定できる ◦ スロークエリの発見 ◦ リクエストIDごとに、処理にかかった時間を集計する • パフォーマンスに問題があったらSlackに通知が届く ◦
N+1が発生している箇所がわかる
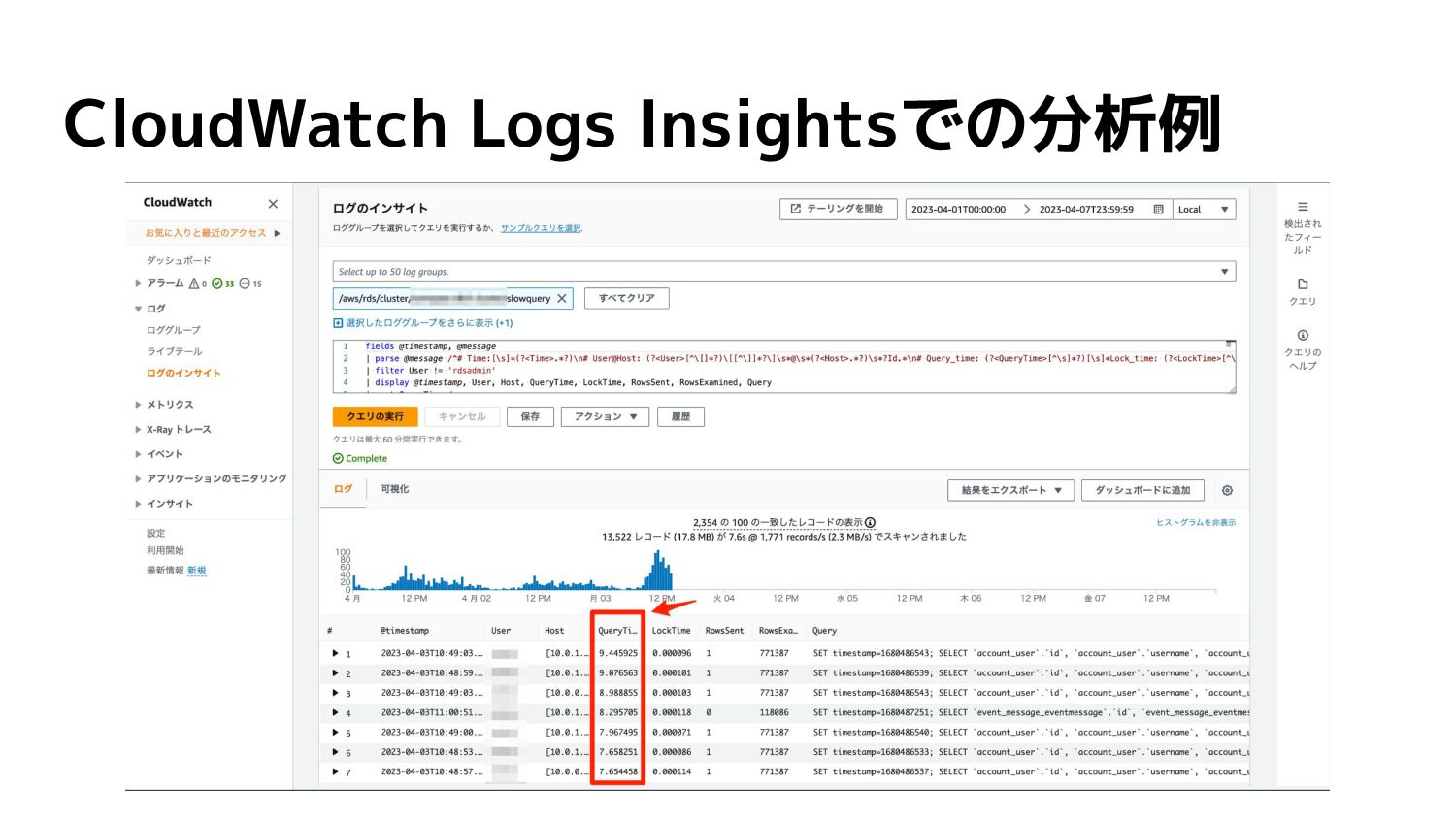
【対策】APMを活用してボトルネック解消 • APM:アプリケーションパフォーマンスモニタリング ◦ SentryのPerformance Monitoring ◦ DatadogのAPM • CloudWatch
Logs Insightsで使ったログデータの分析も 便利 ◦ スロークエリの発見
Sentryの導入例 1. $ pip install sentry-sdk 2. settings.pyに以下の内容を追記 import sentry_sdk
sentry_sdk.init( dsn="<your DSN here>", traces_sample_rate=1.0 ) 3. エラー発生時にSentryに通知される
None
None
SentryからN+1が発生したSlack通知例
CloudWatch Logs Insightsでの分析例
ちょっと休憩
イベントに参加すると聞かれること Q. って人を募集してるんですか?
A. 募集しています!!! We Are Hiring ! Pythonエンジニア https://www.beproud.jp/careers/python/ カジュアル面談 https://onl.tw/LPVc2hd
休憩終わり
3. カスタムメトリクスを 計装し問題の原因を把握
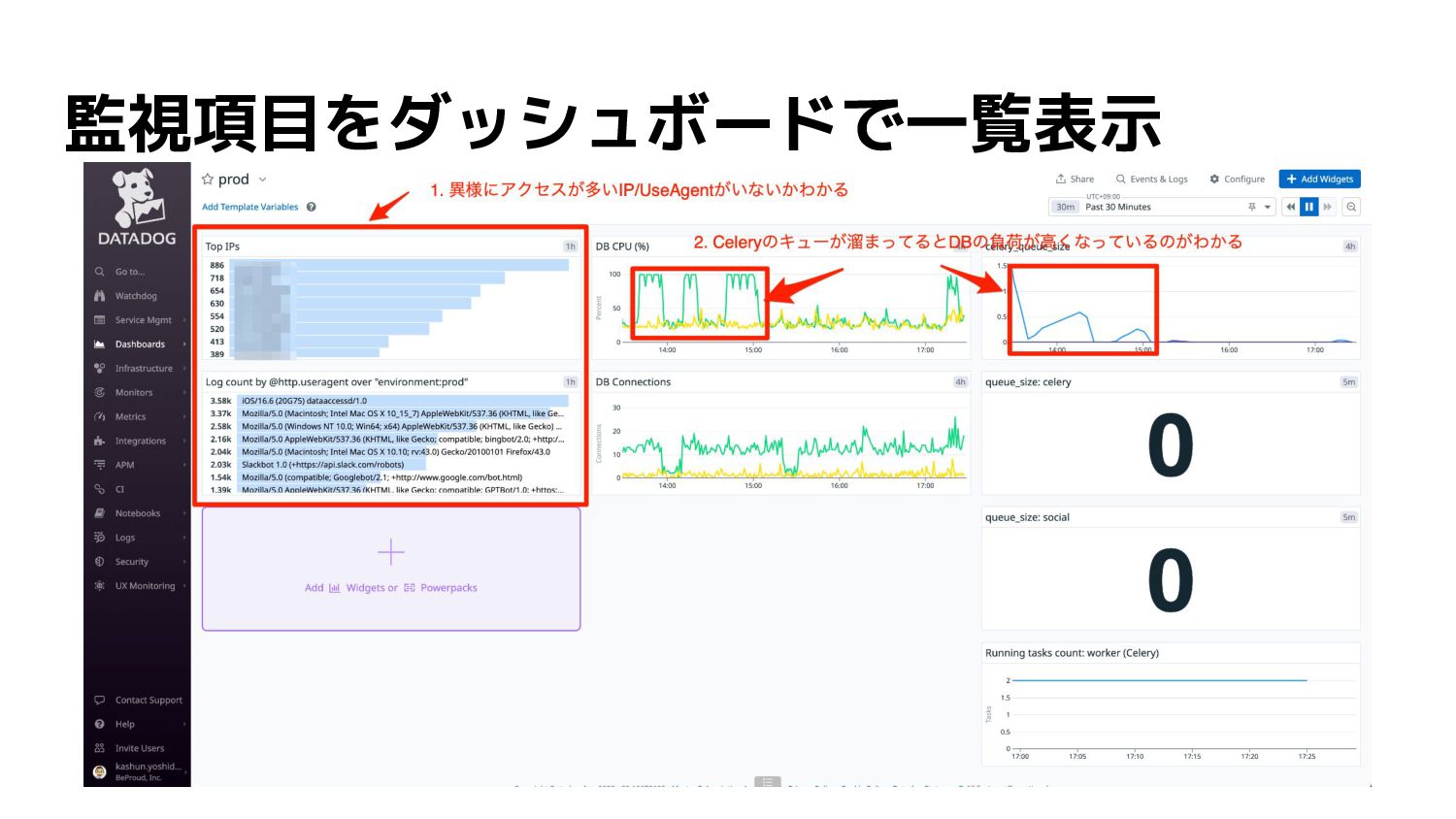
【現実】メトリクスはあるが原因が不明 • メトリクス:システムのパフォーマンスに関するデータ ◦ ex) CPUやメモリ、Diskなどリソース使用状況 • DBの使用率が突然高くなった ◦ 特定IPアドレス/UserAgentからの過度なアクセス
◦ 通知用のCeleryキューが溜まっている
【理想】カスタムメトリクスで把握できる • 取得したログからメトリクスを作成できる • メトリクスはダッシュボードを活用して一覧化 • 各メトリクスの関連性をともなった状況を把握できる • 状況が把握できると、問題解決のために対策を打てる
【対策】Datadogを活用する • ログ分析やAPM、各サービスとのインテグレーション、 カスタムメトリクスなど多種多様な機能を提供するSaaS • ダッシュボードを作成することで対象のメトリクスから どのようにシステムが連携しているかわかる
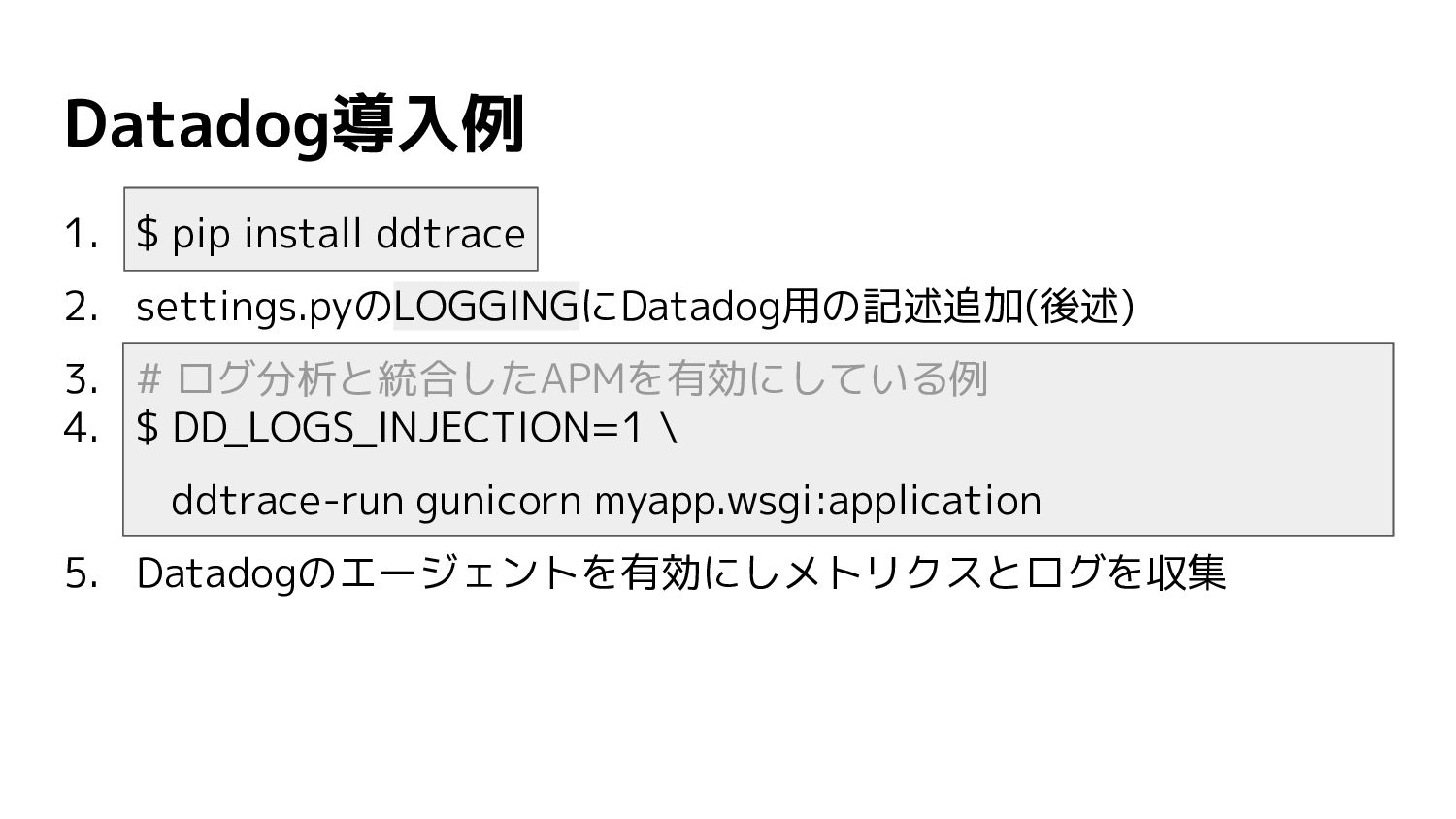
Datadog導入例 1. $ pip install ddtrace 2. settings.pyのLOGGINGにDatadog用の記述追加(後述) 3. #
ログ分析と統合したAPMを有効にしている例 4. $ DD_LOGS_INJECTION=1 \ ddtrace-run gunicorn myapp.wsgi:application 5. Datadogのエージェントを有効にしメトリクスとログを収集
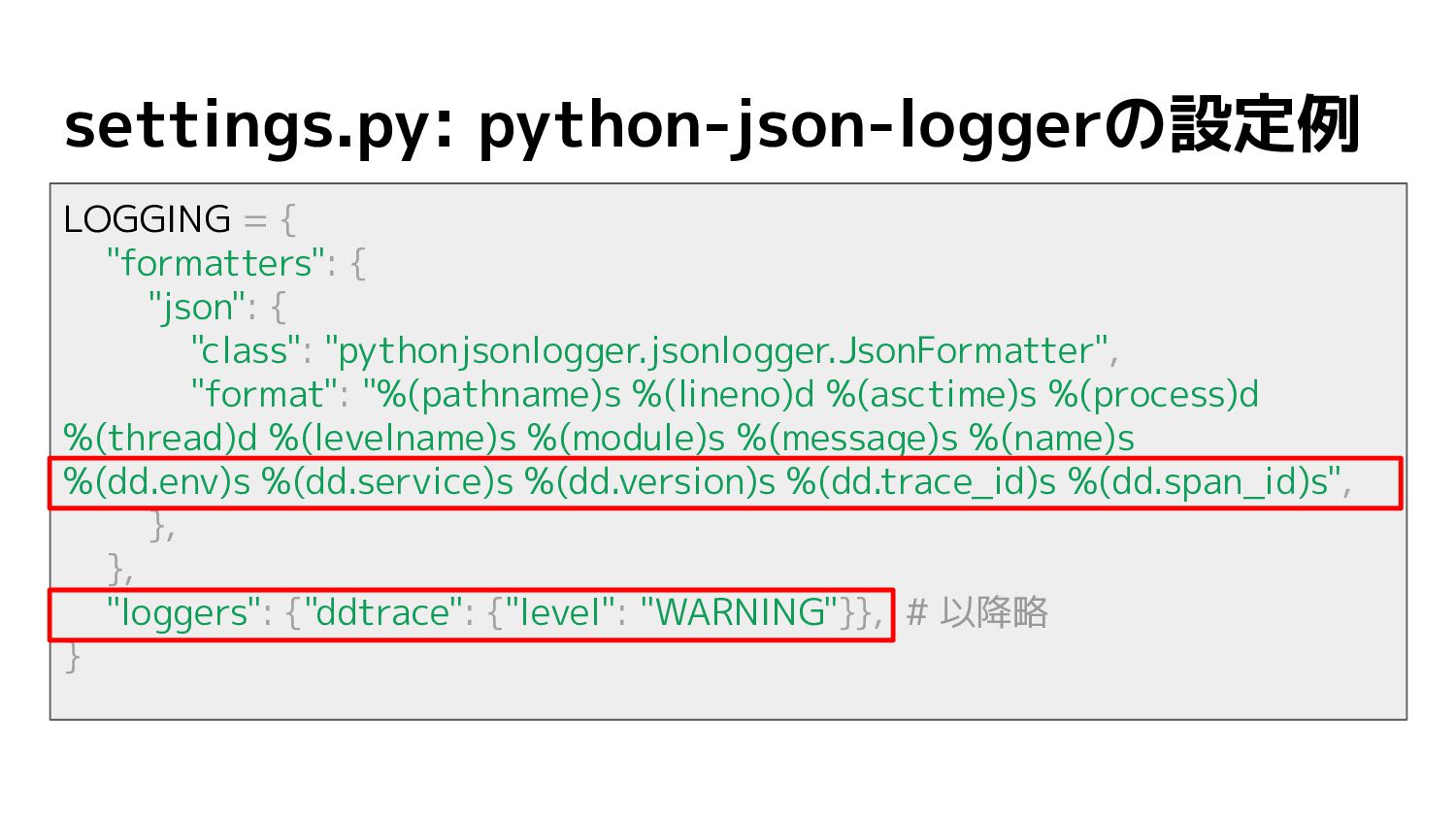
settings.py: python-json-loggerの設定例 LOGGING = { "formatters": { "json": { "class":
"pythonjsonlogger.jsonlogger.JsonFormatter", "format": "%(pathname)s %(lineno)d %(asctime)s %(process)d %(thread)d %(levelname)s %(module)s %(message)s %(name)s %(dd.env)s %(dd.service)s %(dd.version)s %(dd.trace_id)s %(dd.span_id)s", }, }, "loggers": {"ddtrace": {"level": "WARNING"}}, # 以降略 }
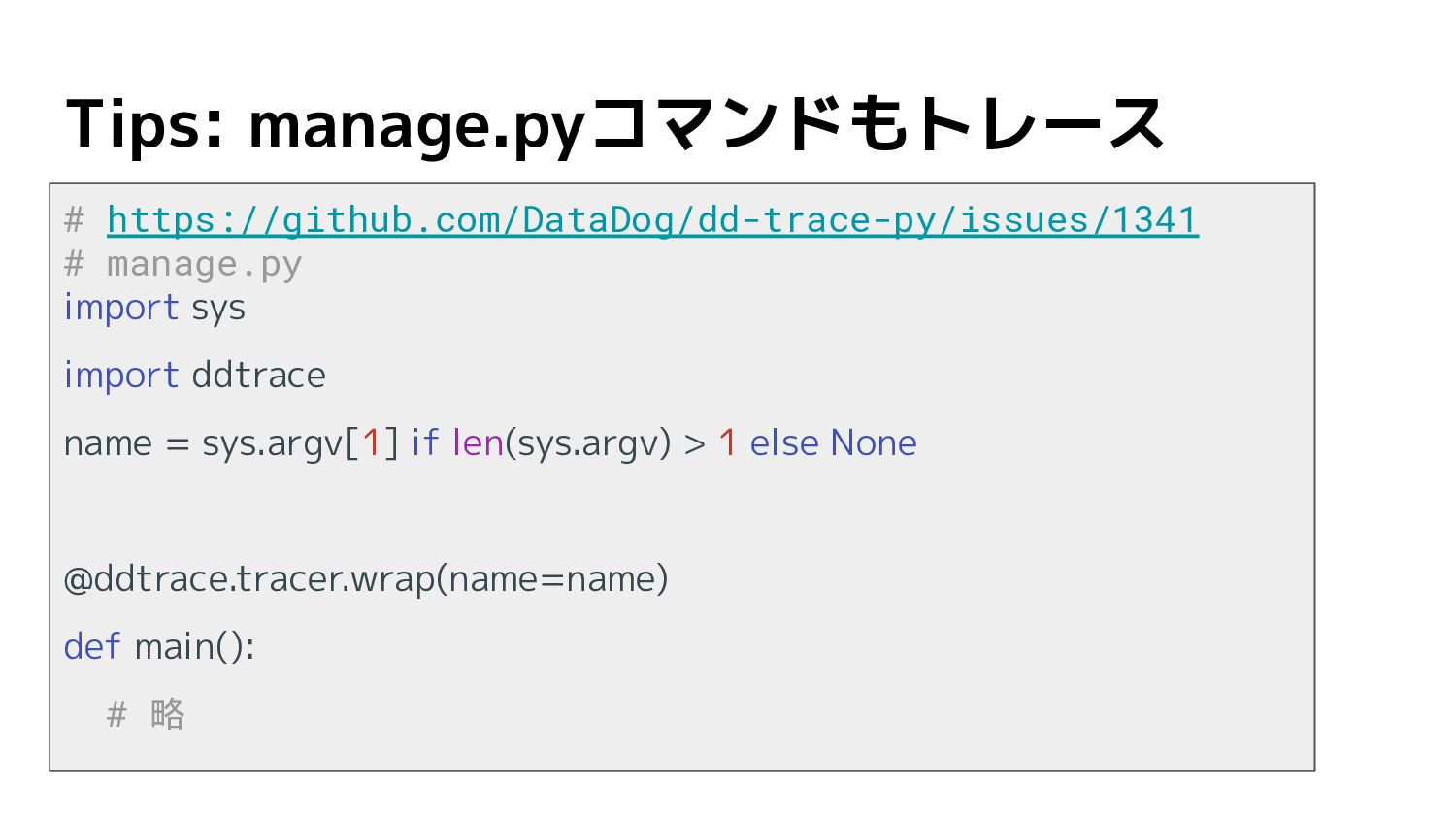
Tips: manage.pyコマンドもトレース # https://github.com/DataDog/dd-trace-py/issues/1341 # manage.py import sys import ddtrace
name = sys.argv[1] if len(sys.argv) > 1 else None @ddtrace.tracer.wrap(name=name) def main(): # 略
監視項目をダッシュボードで一覧表示
取り組みの結果 できるようになったこと
問題を観測し、解消できるようになってきた 1. エラーやログを取得して何が起きているか把握できる ✅ 2. APM(Application Performance Monitoring)を活用して ボトルネックを特定・解消できる ✅
3. カスタムメトリクスを計装し、問題が把握できる ✅
実現できたこと • Sentry: エラートラッキング • Datadog: ログ分析やモニタリング、アラート • Aurora(MySQL): レーテンシー、メモリ低下、コネクション増加
• ElastiCache(Redis):Auroraの項目+SwapUsage • ELB: 5xx response, unhealthy • OpenSearch(ElasticSearch): 死活監視 • Celeryのワーカー数/キュー数 • IPアドレス/UserAgent: アクセス数
可視化できるようになり楽になったこと • メンバー(nonエンジニア)が直接調査できる ◦ 開発者が開発に専念しやすい • ログやAPM、メトリクスなど各機能を横断して閲覧 • 各画面をパーマリンクで開けるのでチームへの共有が楽 •
リソースの負荷が高まったときに何が原因かわかる ◦ 人数が多いイベントの通知のキュー数 ◦ 特定のIPアドレス/UserAgentからの攻撃の発生 ◦ 想定外に実行時間がかかっているSQLの発見
TL;DR • 問題を調査しやすい環境づくりをしていきましょう ◦ これから用意するなら、まずはログから • アプリケーションをよく理解して計測していきましょう ◦ 自分たちのサービスを改善していくのは自分たち •
状況は人それぞれ違うので一歩一歩改善してきましょう ◦ 銀の弾丸はない。ツールは頼りになるが評価し試していく
参考URL • 自走プログラマー • 入門監視 • エキスパートPythonプログラミング 改訂4版 • オブザーバビリティ・エンジニアリング
• Python | Sentry Documentation • Datadog Docs • ddtrace documentation
ご清聴ありがとうございました!! We Are Hiring ! Pythonエンジニア https://www.beproud.jp/careers/python/ カジュアル面談 https://onl.tw/LPVc2hd
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}